
Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006 1 Topics in...
60
1 Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006 Topics in Reliable Distributed Systems 048961 Winter 2005-2006 Dr. Idit Keidar
-
date post
21-Dec-2015 -
Category
Documents
-
view
213 -
download
0
Transcript of Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006 1 Topics in...

1Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Topics in Reliable Distributed Systems
048961 Winter 2005-2006
Dr. Idit Keidar

2Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Course Overview
• Graduate level• Format: reading group & seminar• Discussion and evaluation of research
papers• Prerequisite: an introductory course on
distributed computing– Consensus, Byzantine agreement, etc.– Please see me if you didn’t take one

3Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
So What Are Those “Hot” Topics
• Peer-to-peer systems– Content distribution (BitTorrent)– Overlay networks
• Fault-tolerant distributed systems– Byzantine fault-tolerance– Availability and quorums– Consensus and state-machine replication

4Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Requirements and Grading
• Reading the papers (one a week)
• 10 short paper summaries – 20%
• Participating in class discussions – 10%
• Presenting one of the papers – 70%– Please select a paper within the next 2 weeks– Bibliography:
http://www.ee.technion.ac.il/people/idish/048961/bib.html

5Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Reading The Papers
• This is a reading group.• This means that you should read each paper before it is
being discussed. • Read the entire paper and be familiar with all its content.
– Most will be conference papers.
• You don’t need to understand everything, check previous work, or memorize details.
• Hand in a short summary of the paper (unless you are presenting it) by e-mail to me the night before the lecture.– Any time before 8:00am the morning of the lecture is considered
part of the night before.

6Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Paper Summaries
• Total of ½ a page to 1 page long (no more!!). • One paragraph overview
– What question is the paper is trying to answer?– What are the main results?
• One subjective paragraph on your experience– What did you learn?– What questions remain unanswered?– What didn’t you understand?
• Short discussion of the paper’s strengths and weaknesses.

7Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Evaluating Strengths and Weaknesses, Examples
• Is the paper answering the “right” question?– Does it make reasonable assumptions?
• How novel is the solution?• Is the solution technically sound?• How well is the solution evaluated?• Expected impact. (Hard to guess).• Writing level: is the paper clearly written?
Is it self-contained?

8Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Paper Presentations
• Fully understand the paper, be familiar with previous work, and compare the paper with other similar work.
• The presentation should include:– Summary and evaluation.– Background and comparison with other work.– List of topics to discuss in class.
• It is highly recommended to discuss the presentation with me beforehand.
9Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Contact Me
• Idit Keidar <idish@ee>– Please send me e-mail with 048961 in the subject,
and I’ll add you to the course mailing list. – Warning: Technion spam filter may block email from
company addresses.
• Let me know in the coming two weeks what you would like to present.– See bibliography on course web page:
http://www.ee.technion.ac.il/people/idish/048961/
• Schedule will be posted on the course web page.

10Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Introduction to Peer-to-Peer (P2P) Lookup Systems

11Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Sources
• Looking up Data in P2P Systems– Balakrishnan et al.
• Chord: A Scalable Peer-to-peer Lookup Service for Internet Applications– Stoica et al.
• SkipNet: A Scalable Overlay Network with Practical Locality Properties– Harvey, Jones, Saroiu, Theimer, Wolman
Microsoft Research

12Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
What Does Peer-to-Peer Mean?
Characterization from CFP of IPTPS 2004: – decentralized, – self-organizing – distributed systems, – in which all or most communication is
symmetric.

13Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Typical Characteristics
• Lots of nodes (e.g., millions).• Dynamic: frequent join, leave, failure.• Little or no infrastructure.
– No central server.
• Communication possible between every pair of nodes (cf. the Internet).
• All nodes are “peers” – have same role; don’t have lots of resources.

14Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
The Main Challenge
To design and implement a robust and scalable distributed system
composed of inexpensive, individually unreliable
computers in unrelated administrative domains.
“Looking up Data in P2P Systems”, Balakrishnan et al., CACM Feb 2003.

15Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
It All Started with Lookup
• Goal: Make billions of objects available to millions of concurrent users– e.g., music files, movies, software updates
• Need a mechanism to keep track of them– map files to their locations
• First There was Napster– centralized server/database – pros and cons?

16Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Traditional Scalability Solution
• Hierarchy– tree overlay: organize nodes into a spanning
tree; communicate on links of the tree– structured lookup: know where to forward the
query next– e.g., DNS.
• Pros and cons?

17Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Overlay Networks
• A virtual structure imposed over the physical network (e.g., the Internet)– over the Internet, there is a (IP level) unicast
channel between every pair of hosts– an overlay uses a fixed subset of these– nodes that have the capability to communicate
directly with each other do not use it
• What is this good for?

18Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Symmetric Lookup Algorithms
• All nodes were created equal
• No hierarchy– overlay not a tree
• So how does the search go?– depends….

19Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Searching in Overlay Networks Take I: Gnutella
• Build a decentralized unstructured overlay– each node has several neighbors;– holds several keys in its local database
• When asked to find a key X– check local database if X is known– if yes, return, if not, ask your neighbors
• What is the communication pattern?

20Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
How Come It Works?
• Search is fast– what people care about
• People don’t care so much about wasting bandwidth– may change as ISPs start charging for bandwidth
• Scalability is limited – normally no more than ~40,000 peers
• Files are replicated many times so flooding with a small TTL usually finds the file– even if there are multiple connected components

21Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Take II: FastTrack, KaZaA, eDonkey
• Improve scalability by re-introducing a hierarchy– though not a tree– super-peers have more resources, more
neighbors, know more keys– search goes through super-peers
• Pros and Cons?

22Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Structured Lookup Overlays
• Many recent academic systems – – CAN, Chord , D2B, Kademlia, Koorde, Pastry,
Tapestry, Viceroy, …• OverNet based on the Kademlia algorithm• Symmetric, no hierarchy• Decentralized self management• Structured overlay – data stored in a defined place,
search goes on a defined path• Implement Distributed Hash Table (DHT)
abstraction

23Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Distributed Hash Tables (DHTs)
• Nodes store table entries
• Good abstraction for lookup? Why?
• Requirements for an application being able to use DHTs?– data identified with unique keys– nodes can (agree to) store keys for each other
• location of object or actual object.

24Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
The DHT Service Interface
lookup( key )
returns the location of the node currently responsible for this key
key usually numeric (in some range)

25Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Using the DHT Interface
• How do you publish a file?
• How do you find a file?

26Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
What Does a DHT Implementation Need to Do?
• Map keys to nodes– needs to be dynamic as nodes join and leave– how does this affect the service interface?
• Route a request to the appropriate node– routing on the overlay
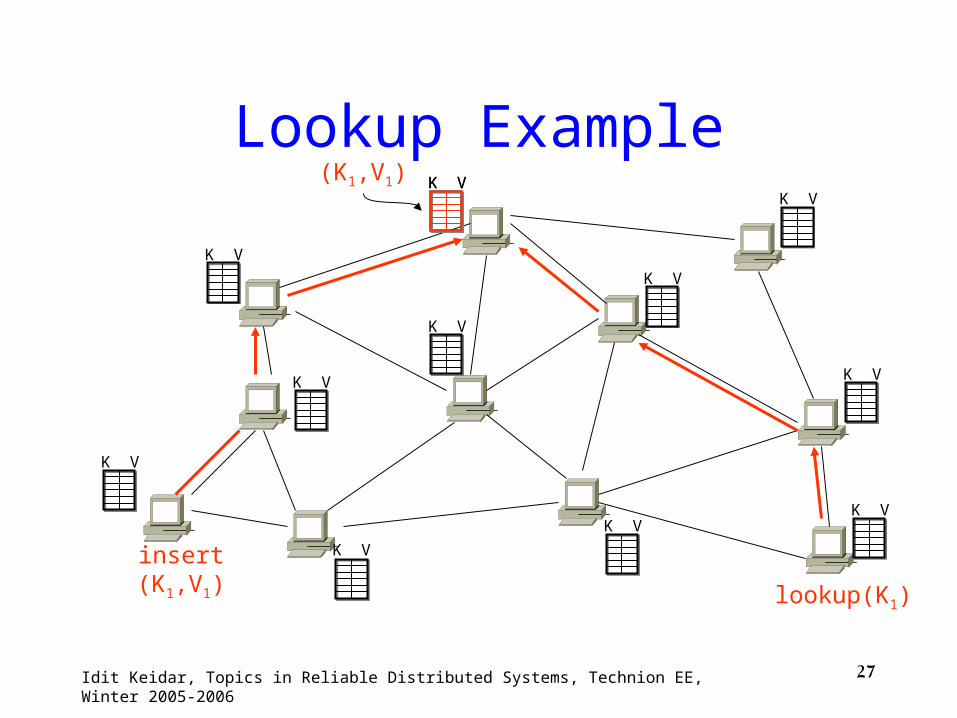
27Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Lookup Example
K V
K V
K V
K V
K V
K V
K V
K V
K V
K V
K V
insert(K1,V1)
K V(K1,V1)
lookup(K1)

28Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Mapping Keys to Nodes
• Goal: load balancing– why?
• Typical approach: – give an m-bit identifier to each node and each
key (e.g., using SHA-1 on the key, IP address)– map key to node whose id is “close” to the key
(need distance function). – how is load balancing achieved?

29Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Routing Issues
• Each node must be able to forward each lookup query to a node closer to the destination
• Maintain routing tables adaptively– each node knows some other nodes– must adapt to changes (joins, leaves, failures)– goals?

30Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Handling Join/Leave
• When a node joins it needs to assume responsibility for some keys – ask the application to move these keys to it– how many keys will need to be moved?
• When a nodes fails or leaves, its keys have to be moved to others– what else is needed in order to implement this?

31Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Chord
Stoica, Morris, Karger, Kaashoek, and Balakrishnan

32Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Chord Logical Structure
• m-bit ID space (2m IDs), usually m=160.• Think of nodes as organized in a logical ring
according to their IDs.N1
N8
N10
N14
N21
N30N38
N42
N48
N51N56

33Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Consistent Hashing: Assigning Keys to Nodes
• Key k is assigned to first node whose ID equals or follows k – successor(k)
N1
N8
N10
N14
N21
N30N38
N42
N48
N51N56
K54

34Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Moving Keys upon Join/Leave
• When a node joins, it becomes responsible for some keys previously assigned to its successor – local change– assuming load is balanced, how many keys
should move?
• And what happens when a node leaves?

35Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Simple Routing Solutions
• Each node knows only its successor. – routing around the circle
• Each node knows all other nodes– O(1) routing– cost?
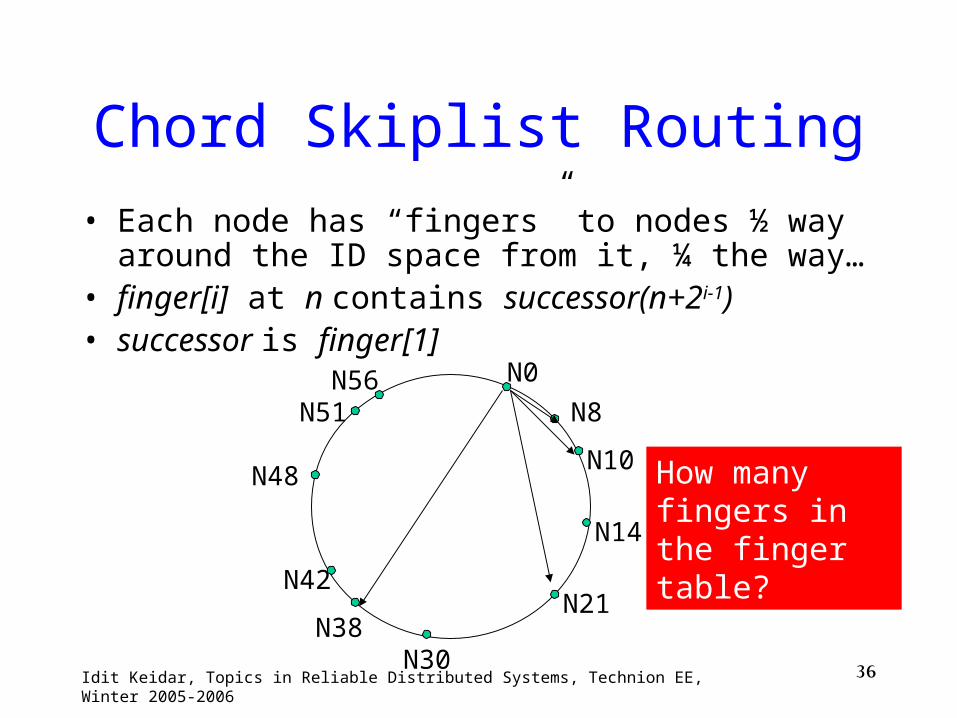
36Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Chord Skiplist Routing
• Each node has “fingers” to nodes ½ way around the ID space from it, ¼ the way…
• finger[i] at n contains successor(n+2i-1)• successor is finger[1]
N0
N8
N10
N14
N21
N30N38
N42
N48
N51N56
How many fingers in the finger table?

37Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Chord Data Structures (At Each Node)
• Finger table
• First finger is successor
• Predecessor

38Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Forwarding Queries
• Query for key k is forwarded to finger with highest ID not exceeding k
K54 Lookup( K54 )N0
N8
N10
N14
N21
N30N38
N42
N48
N51N56

39Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
How long does it take?
Remote Procedure Call (RPC)

40Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Routing Time
• Node n looks up a key stored at node p• p is in n’s ith interval
p ((n+2i-1)mod 2m, (n+2i)mod 2m]
• n contacts f=finger[i]– RPC closest_preceding_node
• f is at least 2i-1 away from n• p is at most 2i-1 away from f• The distance is halved

41Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Joining Chord
• Goals?• Steps:
– Find your successor– Initialize finger table and predecessor– Notify other nodes that need to change their
finger table and predecessor pointer• O(log2n)
– Learn the keys that you are responsible for; notify others that you assume control over them

42Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Join Algorithm: Take II
• Observation: for correctness, successors suffice – fingers only needed for performance
• Upon join, update successor only• Periodically,
– check that successors and predecessors are consistent
– fix fingers

43Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Failure Handling
• Periodically fixing fingers • List of r successors instead of one successor• Periodically probing predecessors:

44Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
The Model?
• Failures can be accurately detected!• Properties hold as long as failure is bounded:
– If we use a successor list of length r = (logN) in a network that is initially stable, and then every node fails with probability 1/2, then with high probability find successor returns the closest living successor to the query key.
– In a network that is initially stable, if every node then fails with probability 1/2, then the expected time to execute find successor is O(logN).

45Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
What About Moving Keys?
• Left up to the application
• Solution: keep soft state, refreshed periodically– every refresh operation performs lookup(key)
before storing the key in the right place
• How can we increase reliability for the time between failure and refresh?

46Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Summary: DHT Advantages
• Peer-to-peer: no centralized control or infrastructure
• Scalability: O(log N) routing, routing tables, join time
• Load-balancing
• Overlay robustness

47Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
DHT Disadvantages
• No control where data is stored
• In practice, organizations want:– Content Locality – explicitly place data where
we want (inside the organization)– Path Locality – guarantee that local traffic (a
user in the organization looks for a file of the organization) remains local
• No prefix search

48Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
SkipNet: A Scalable Overlay Network with Practical Locality
PropertiesHarvey, Jones, Saroiu, Theimer, Wolman
Microsoft Research

49Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
SkipNet Content Locality
• Place files at nodes according to names
• Name ID space (DNS-like)– for files and nodes– node name = reverse DNS name of the host
(com.microsoft.host1)– file names have same prefix
• Problem?

50Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Constrained Load-Balancing
• Data uniformly distributed in designated subset of nodes – e.g., inside organization

51Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
SkipNet’s Two Name Spaces
Name ID Space
Numerical ID Space
com.microsoft.host1
h(com.microsoft.host1)
non-uniform
uniform

52Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Skip Lists - Reminder
• In-memory dictionary data structure.– Sorted linked list with a subset of nodes having
additional links to skip over many list elements
• Perfect (deterministic) skip list:– Search: O (log N), N – number of nodes in the list.– Insertion/deletion: expensive/awkward
• Probabilistic skip list:– Search, Insert, Delete: O (log N) w.h.p.

53Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Skip List: Good for Us?
• The Good: – Sorted list: path locality for name-based search– O(log N) search with skip pointers– Up to log(N) skip pointers: O(log N) instertion
• The Bad:– Lookup starts from root only– Unequal load

54Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
SkipNet Global ViewRing000
Ring001
Ring010
Ring011
Ring100
Ring101
Ring110
Ring111
A
D M O
T
Z X V
A
M
T
X
D O
Z V
A T
M
X
O
Z
D
V
A T
M
X Z
O D
V
Ring 00 Ring 01 Ring 10 Ring 11
Ring 0 Ring 1
Root Ring Level L = 0
L = 1
L = 2
L = 3
The full SkipNet routing infrastructure for an 8 node system, including the ring labels.

55Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
SkipNet Structure
• Skip Graph = Distributed Skip List– Every node belongs to rings at all levels – Search can start at any node– Use doubly linked lists at each level to account for
absence of head and tail nodes.
• Perfect vs. Probabilistic – Perfect : Pointers at level h point to nodes that are
exactly 2h nodes to the left and right.– Probabilistic : A node in level h probabilistically
determines which ring it belongs to.

56Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Routing By Name ID
• Routing in Skip Graph = Search in Skip Lists • Simple Rule:
– Forward the message to node that is closest to destination, without going too far.
• Route either clockwise/counterclockwise• Terminates when messages arrives at a node
whose name ID is closest to destination. • Number of hops is O(log N) w.h.p.

57Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Routing By Numeric ID
• Numeric id’s random, no ring sorted by them– We can’t route top-down!
• Bottom-up routing– Begin at level h= 0.– Find a node whose numeric ID matches the
destination numeric ID in the first digit.– Move to a ring in level h+1, where nodes share
h+1 digits with destination numeric ID.

58Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Example: Routing by Numeric ID
– Hash(“Foo.c”) = 101
Level: L = 0
L = 1
L = 2Ring 00Ring 00 Ring 01Ring 01 Ring 10Ring 10 Ring 11Ring 11
RingRing000000RingRing000000
Ring001Ring001
Ring010Ring010
Ring011Ring011
Ring100Ring100
Ring101Ring101
Ring110Ring110
Ring111Ring111
Root RingRoot RingD M O
TVXZ
Ring 0Ring 0
M
T
X
Ring 1Ring 1D
Z V
O
OZA T
M
X
D
V
A TM
X
DV Z
O L = 3
Foo.c
A
A

59Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
Routing by Numeric ID
• The same routing tables are used for routing by nameID and numericID
• The number of message hops is O(log N) whp• What sequential data structure does this search
resemble?

60Idit Keidar, Topics in Reliable Distributed Systems, Technion EE, Winter 2005-2006
More P2P Issues Later in the Course
• Multi-dimensional keyword search
• Unstructured search
• Content distribution – BitTorrent, incentives– Coding, overlays


















