IBM SPSS & Apache Spark - Meetupfiles.meetup.com/7770922/SPSS and Spark.pdf · IBM SPSS & Apache...
27
1 © 2016 IBM Corporation Meetup Big Data Developers - Madrid IBM SPSS & Apache Spark Making Big Data analytics easier and more accessible [email protected] @foreswearer
Transcript of IBM SPSS & Apache Spark - Meetupfiles.meetup.com/7770922/SPSS and Spark.pdf · IBM SPSS & Apache...

1 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
IBM SPSS & Apache Spark
Making Big Data analytics easier and more accessible
[email protected] @foreswearer

2 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
Modeler y Spark. Integration
� Infrastructure overview– Spark, Hadoop & IBM– Example architecture
– New with SPSS Modeler 18 (March 15, 2016)
� IBM new capabilities: SPSS y Spark out of the box and via Analytic Server
� Functionality demonstration of Spark– Spark basic model– Monitor Spark jobs
– Creating custom modeler with SPSS
� Conversation / Debate / Discussion� Apendix –IBM development communities y and online resources

3 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
INFRASTRUCTURE OVERVIEW
Part One

4 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
Analytics at Scale: Performance Matters
In-DatabaseIn-Database
� Reduce data movement: SQL pushback� Optimize performance: in-database adapters� Increase analytic flexibility: in-database mining
� Optimized for Big Data environments� Reduce network traffic� Improved processing speed
ParallelParallel
IBM BigInsightsfor Apache Hadoop

5 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
Distributed analysis on modern data sources
� Comprehensive statistics and datamining on Hadoop based systems
� Data focused architecture assures scalability and performance– The processing happens where data resides– Exploits Spark to run analytics faster & make users more productive
� Provides extensible framework for augmenting analytics– Provides access to Python libraries & Spark MLlib algorithms– Efficiently deploys R models into distributed systems
Abstracts analysts from complexities of distributed big
data systems
6 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
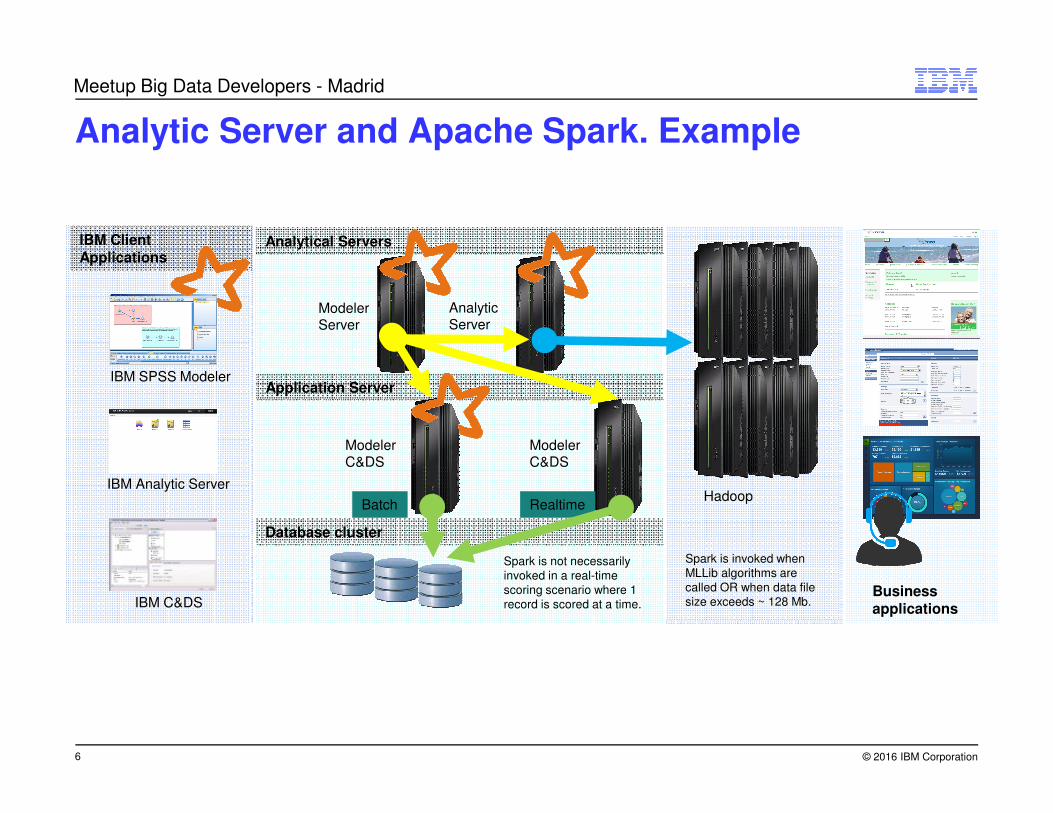
Analytic Server and Apache Spark. Example
IBM SPSS Modeler
IBM Analytic Server
IBM C&DS
ModelerServer
ModelerC&DS
AnalyticServer
ModelerC&DS
Application Server
Analytical Servers
Database cluster
IBM ClientApplications
Batch RealtimeHadoop
Businessapplications
Spark is invoked when MLLib algorithms are called OR when data file size exceeds ~ 128 Mb.
Spark is not necessarily invoked in a real-time scoring scenario where 1 record is scored at a time.

7 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
SPARK INTEGRATION IN SPSS
Part Two

8 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
IBM SPSS Modeler
� Discover key insights, patterns & trends in data to optimize decisions� Predictive Analytics workbench
– Easy to use / visual
– Comprehensive set of algorithms
– Structured & unstructured data
– Supports data mining process– Outstanding performance
& scalability
– Reproducible process
delivering high productivity, quick time-to-solution
& high ROI
Brings repeatability to ongoing decision making
9 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
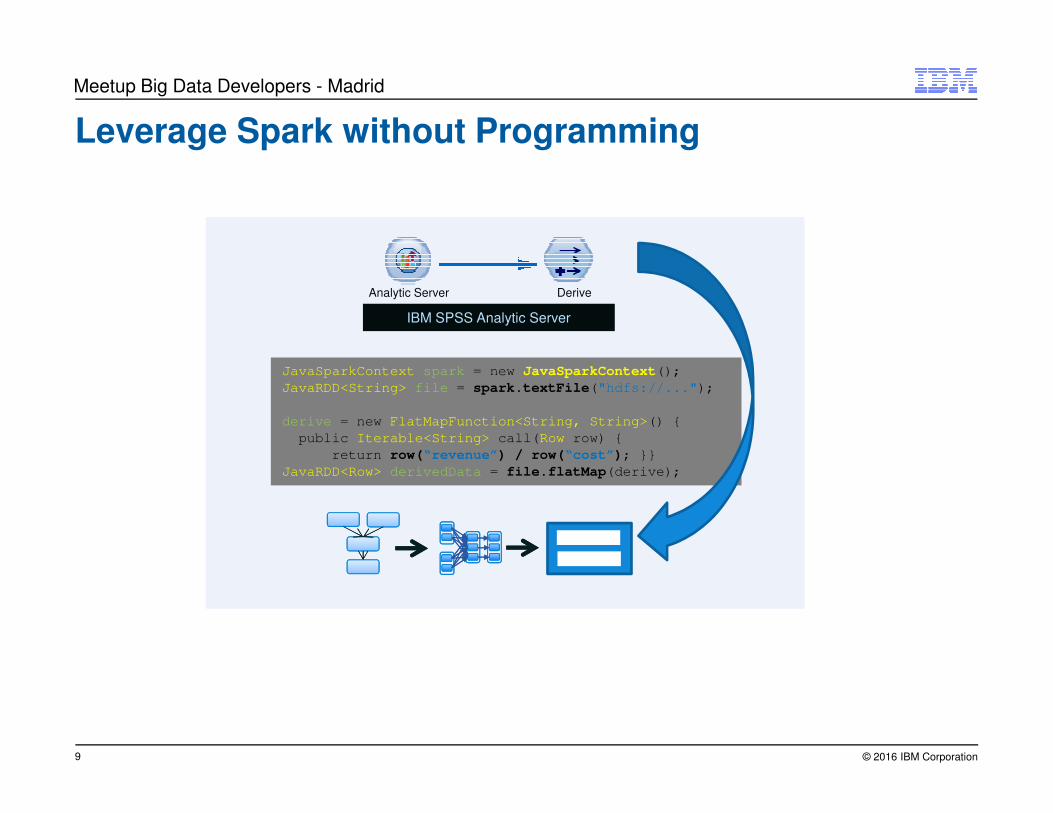
JavaSparkContext spark = new JavaSparkContext();
JavaRDD<String> file = spark.textFile("hdfs://...");
derive = new FlatMapFunction<String, String>() {
public Iterable<String> call(Row row) {
return row(“revenue”) / row(“cost”); }}
JavaRDD<Row> derivedData = file.flatMap(derive);
Task Threads
Block Manager
Leverage Spark without Programming
IBM SPSS Analytic Server
Analytic Server Derive
10 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
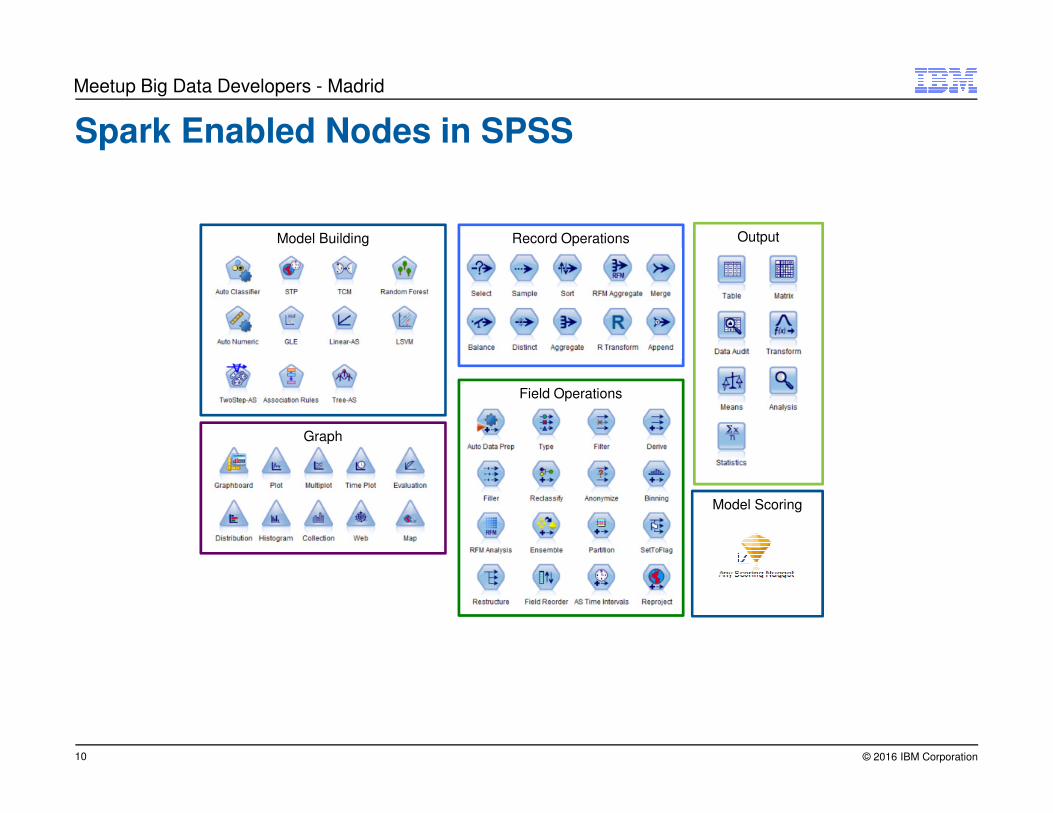
Spark Enabled Nodes in SPSS
Model Building Record Operations
Field Operations
Graph
Output
Model Scoring
11 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
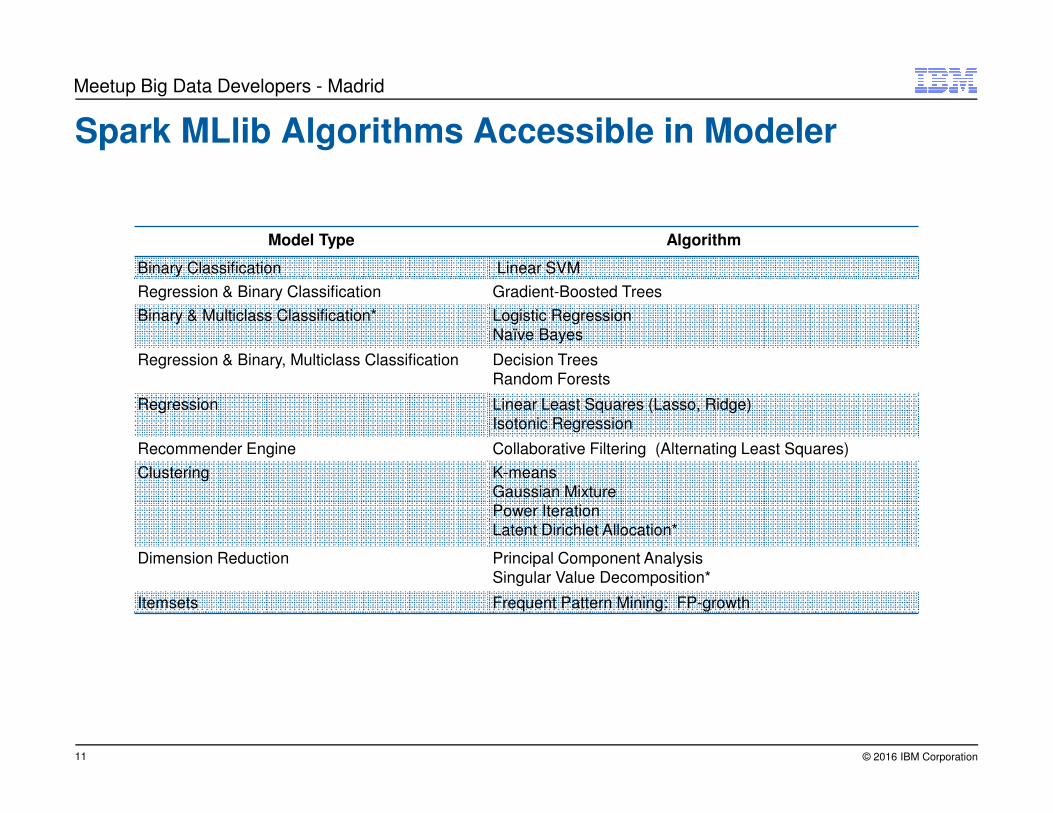
Spark MLlib Algorithms Accessible in Modeler
Model Type Algorithm
Binary Classification Linear SVM
Regression & Binary Classification Gradient-Boosted Trees
Binary & Multiclass Classification* Logistic Regression
Naïve Bayes
Regression & Binary, Multiclass Classification Decision TreesRandom Forests
Regression Linear Least Squares (Lasso, Ridge)Isotonic Regression
Recommender Engine Collaborative Filtering (Alternating Least Squares)
Clustering K-meansGaussian MixturePower IterationLatent Dirichlet Allocation*
Dimension Reduction Principal Component AnalysisSingular Value Decomposition*
Itemsets Frequent Pattern Mining: FP-growth

12 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
Spark MLlib Algorithms Accessible in Modeler
Spark MLlib SPSS Modeler'AS Node
Linear SVM LSVM
Logistic Regression GLE
Random Forests Random Trees
LASSO & Ridge Regression GLE
There is some overlap between Spark MLlib algorithms and native SPSS Modeler Nodes:

13 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
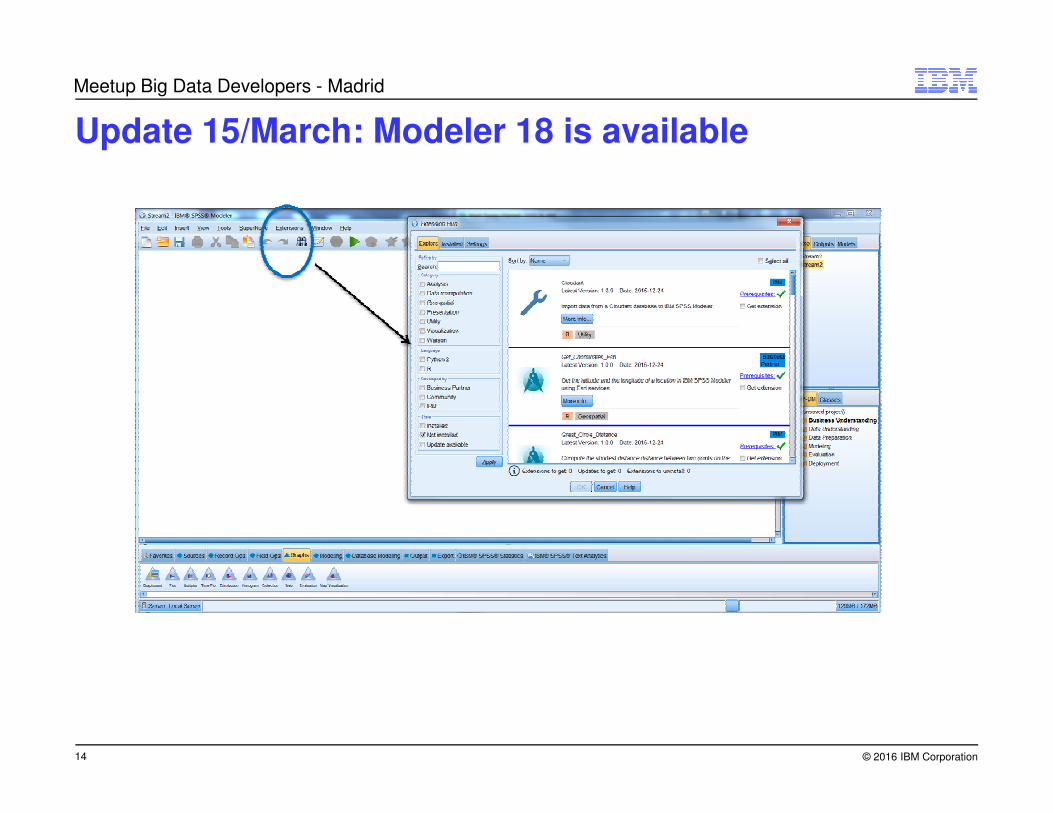
Update 15/March: Modeler 18 is available
In version 18, these algorithms are now available in Modeler with any type of data, i.e. there is no need to connect Modeler to an Analytic
ServerThe algorithms include:
• Random Trees – a popular method in the data science
community that involves taking a C&R Tree model with bagging and then only consider a sampling with replacement of variables
for each split of the tree
• Tree-AS which is based on CHAID• GLE – which incorporates a number of regression methods
• Linear-AS which performs linear regression
• Linear Support Vector Machines• Two-Step-AS clustering
14 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
Update 15/March: Modeler 18 is available
15 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
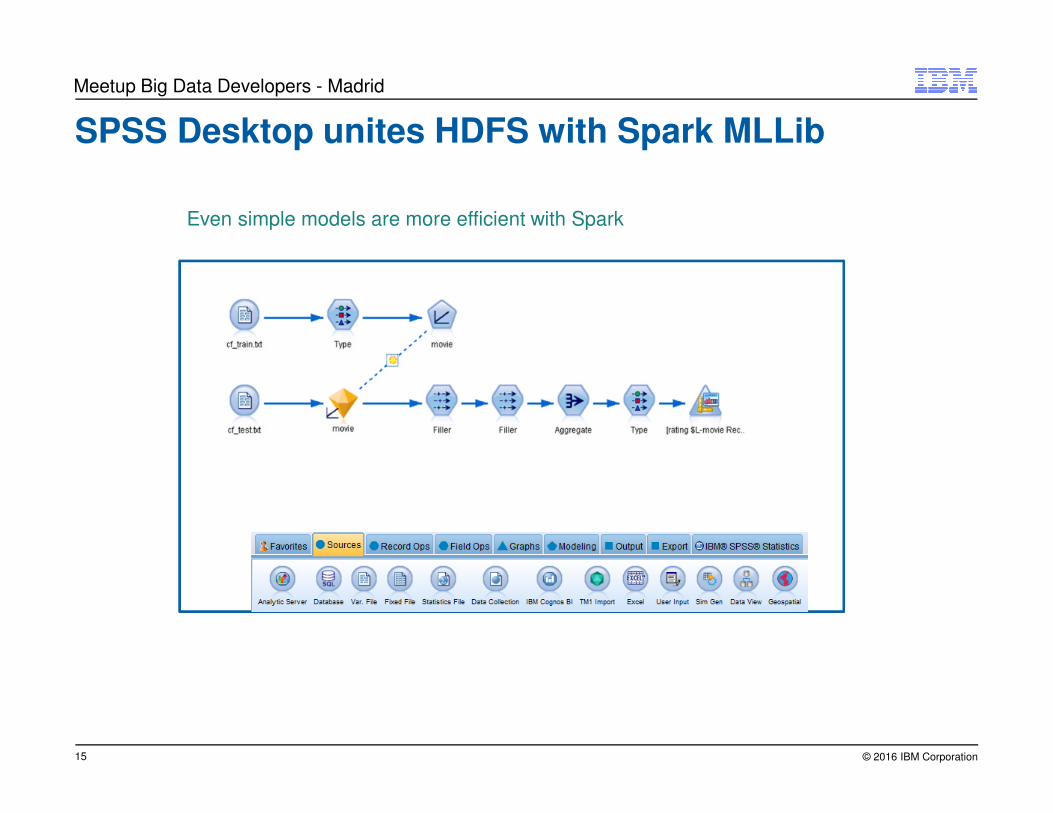
SPSS Desktop unites HDFS with Spark MLLib
Even simple models are more efficient with Spark
16 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
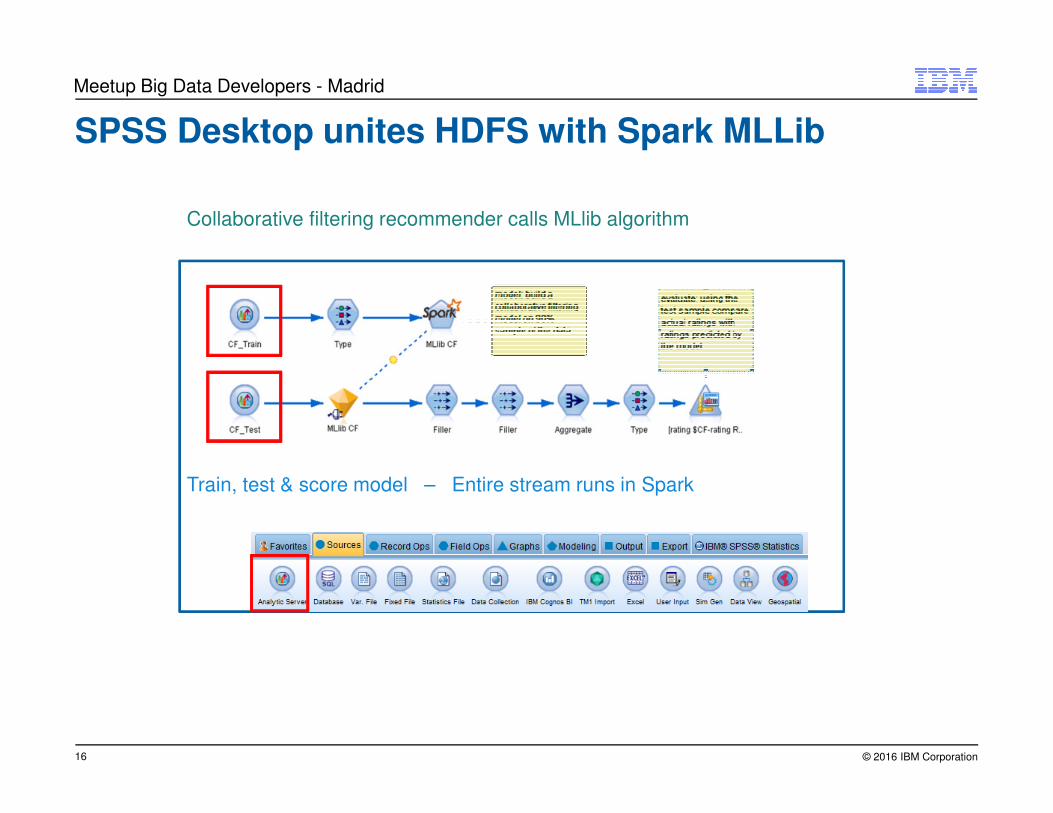
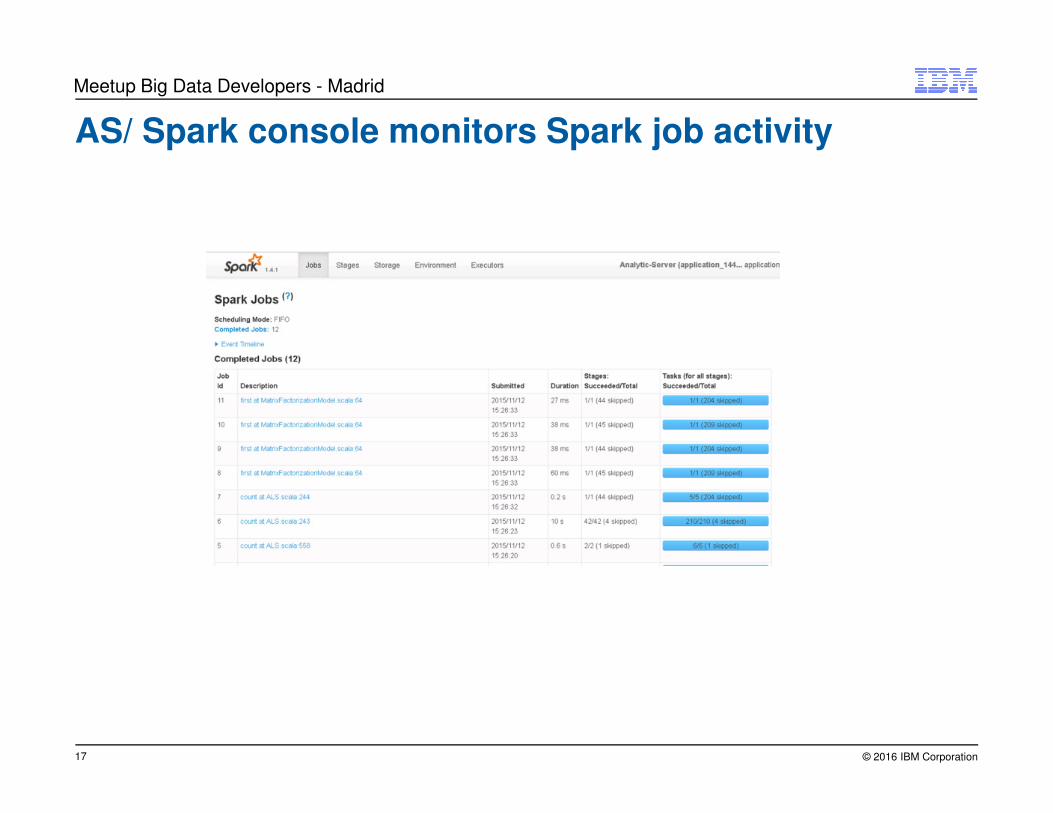
Collaborative filtering recommender calls MLlib algorithm
Train, test & score model – Entire stream runs in Spark
SPSS Desktop unites HDFS with Spark MLLib
17 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
AS/ Spark console monitors Spark job activity
18 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
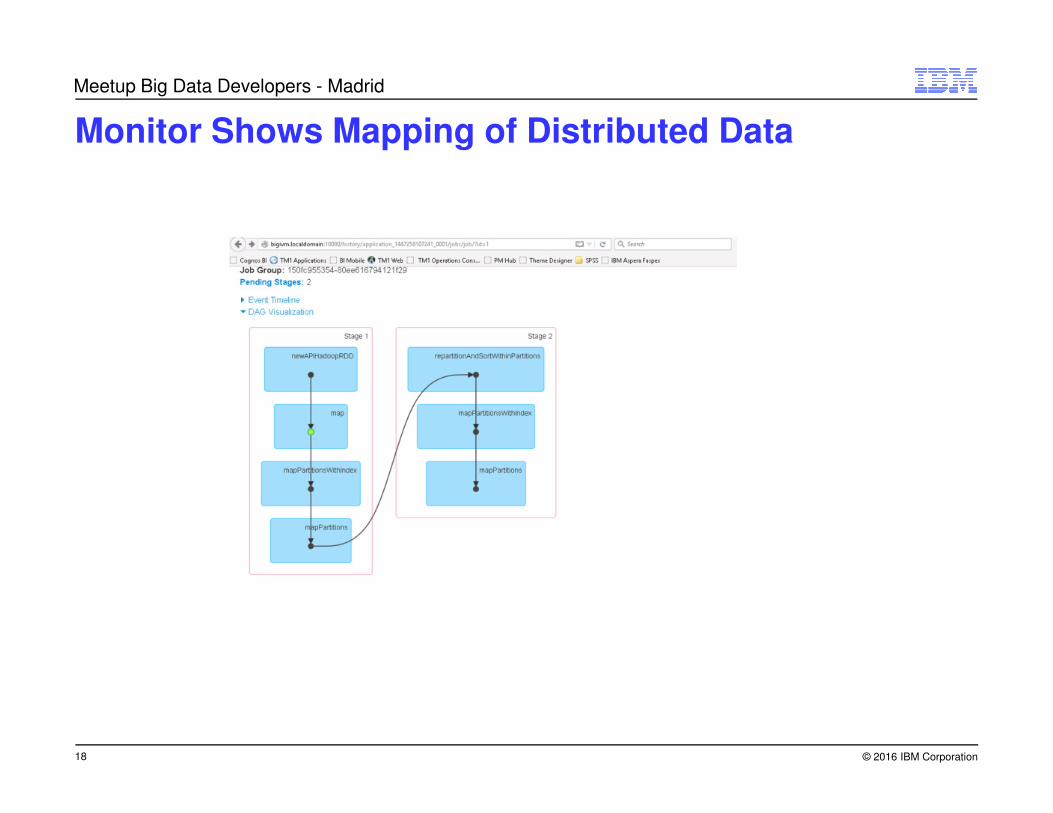
Monitor Shows Mapping of Distributed Data

19 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
CUSTOM MODELS USING
PYSPARK
Part 3
20 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
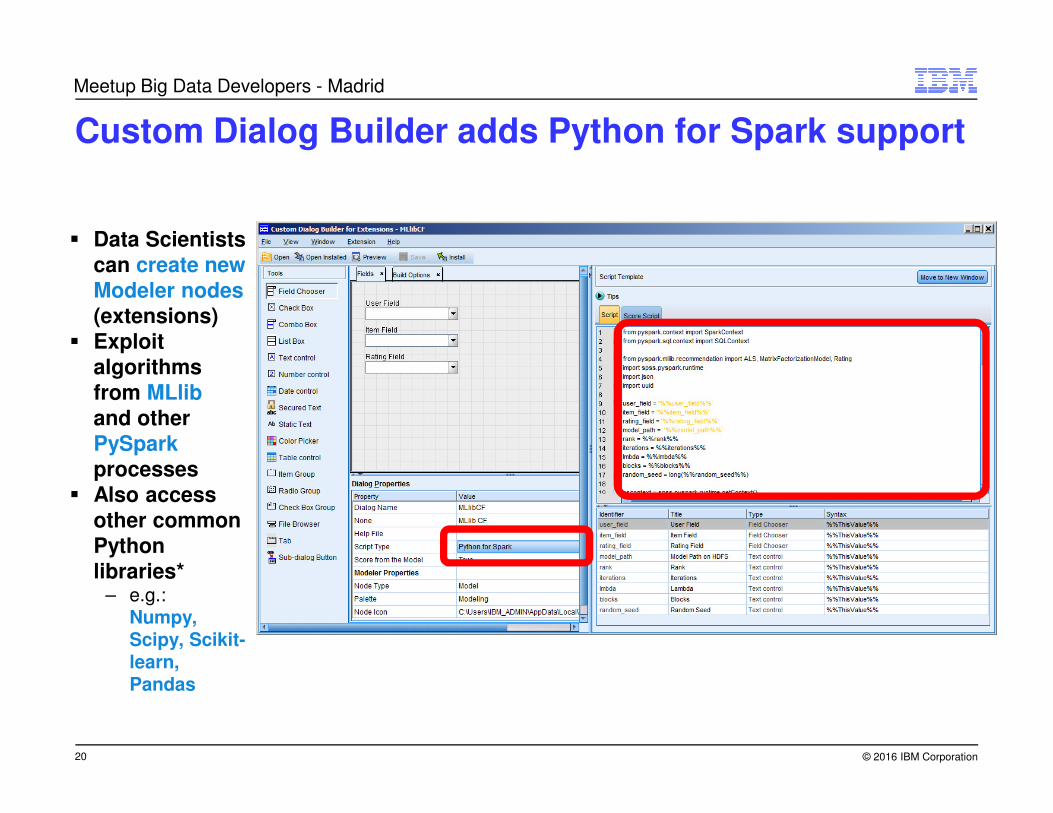
Custom Dialog Builder adds Python for Spark support
� Data Scientists
can create new
Modeler nodes
(extensions)
� Exploit
algorithms
from MLlib
and other
PySpark
processes
� Also access
other common
Python
libraries*– e.g.:
Numpy, Scipy, Scikit-learn, Pandas
21 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
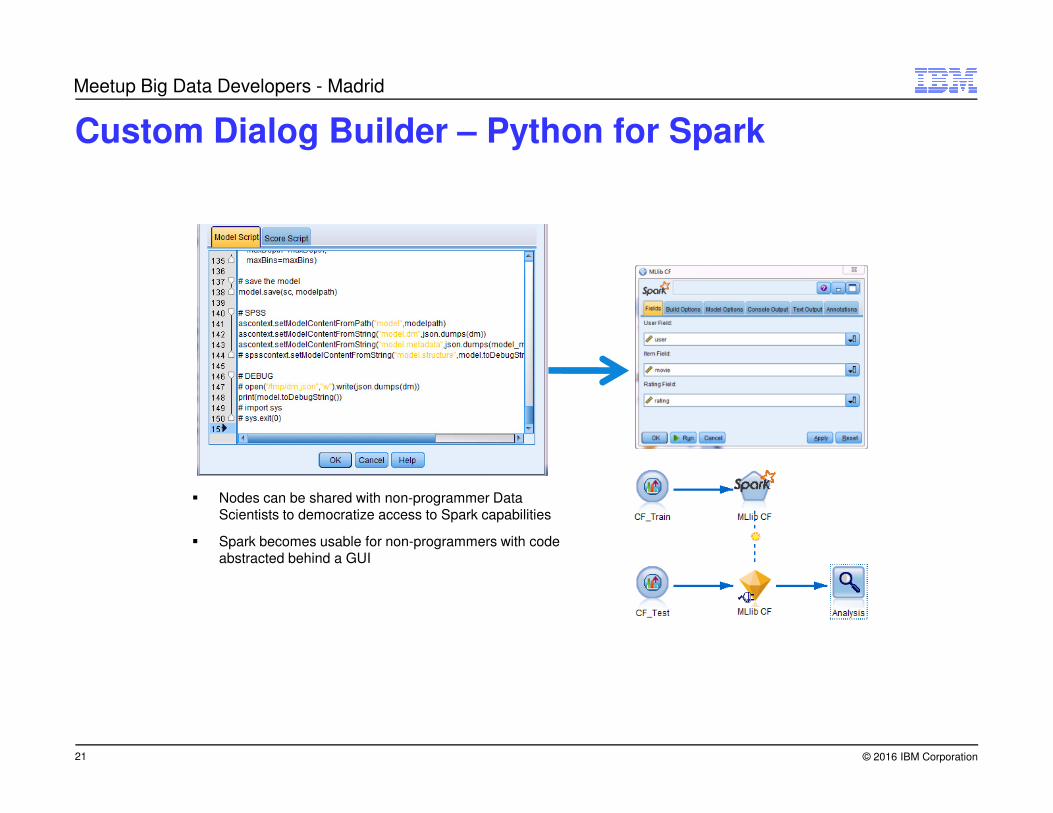
Custom Dialog Builder – Python for Spark
� Nodes can be shared with non-programmer Data Scientists to democratize access to Spark capabilities
� Spark becomes usable for non-programmers with code abstracted behind a GUI

22 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
DISCUSSION

23 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
APPENDIX
24 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
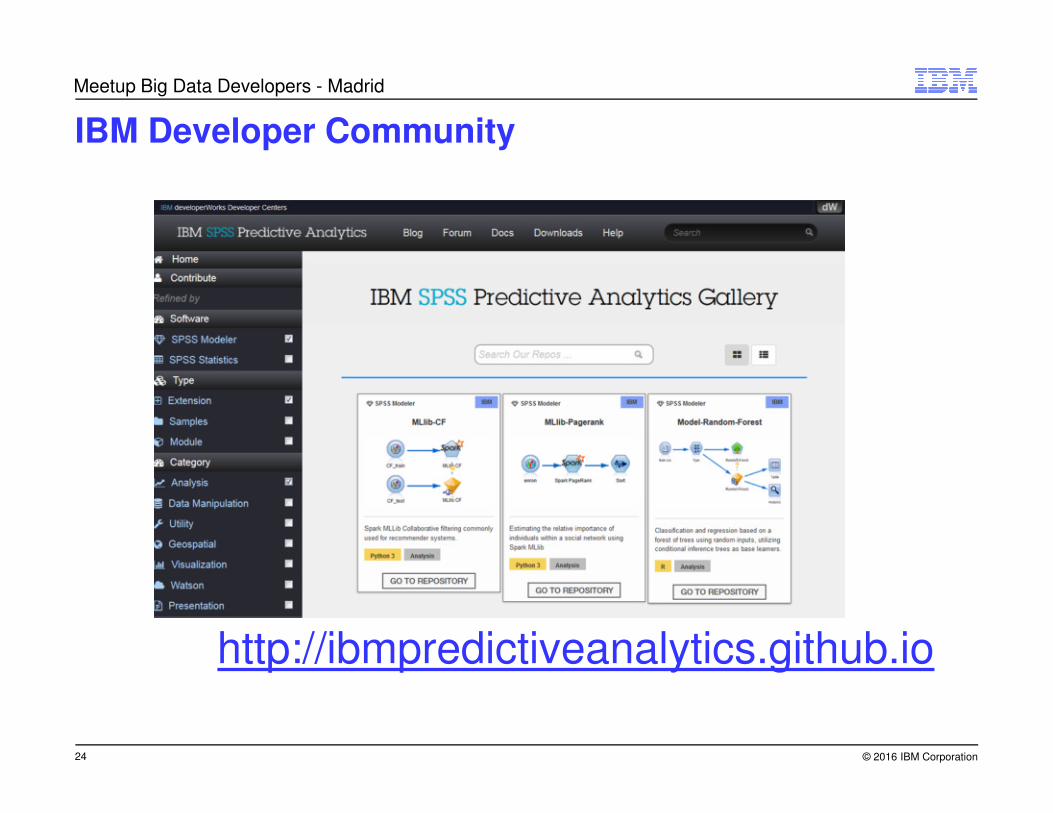
IBM Developer Community
http://ibmpredictiveanalytics.github.io
25 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
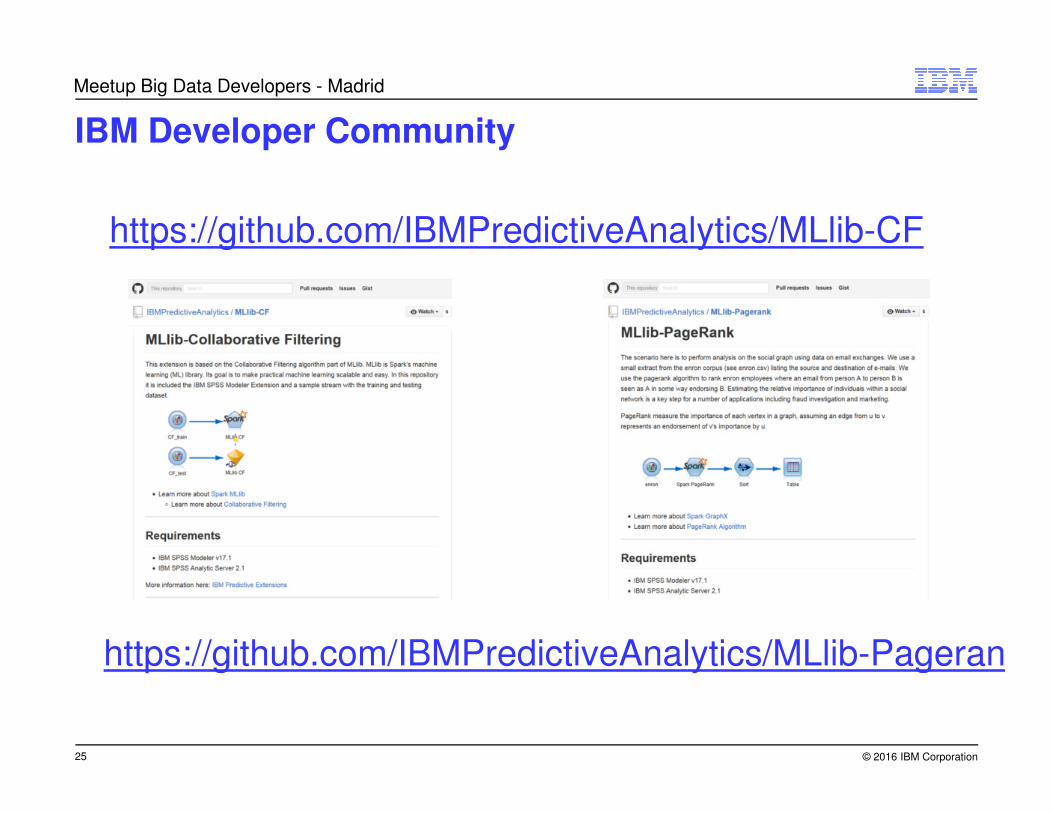
IBM Developer Community
https://github.com/IBMPredictiveAnalytics/MLlib-CF
https://github.com/IBMPredictiveAnalytics/MLlib-Pagerank
26 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
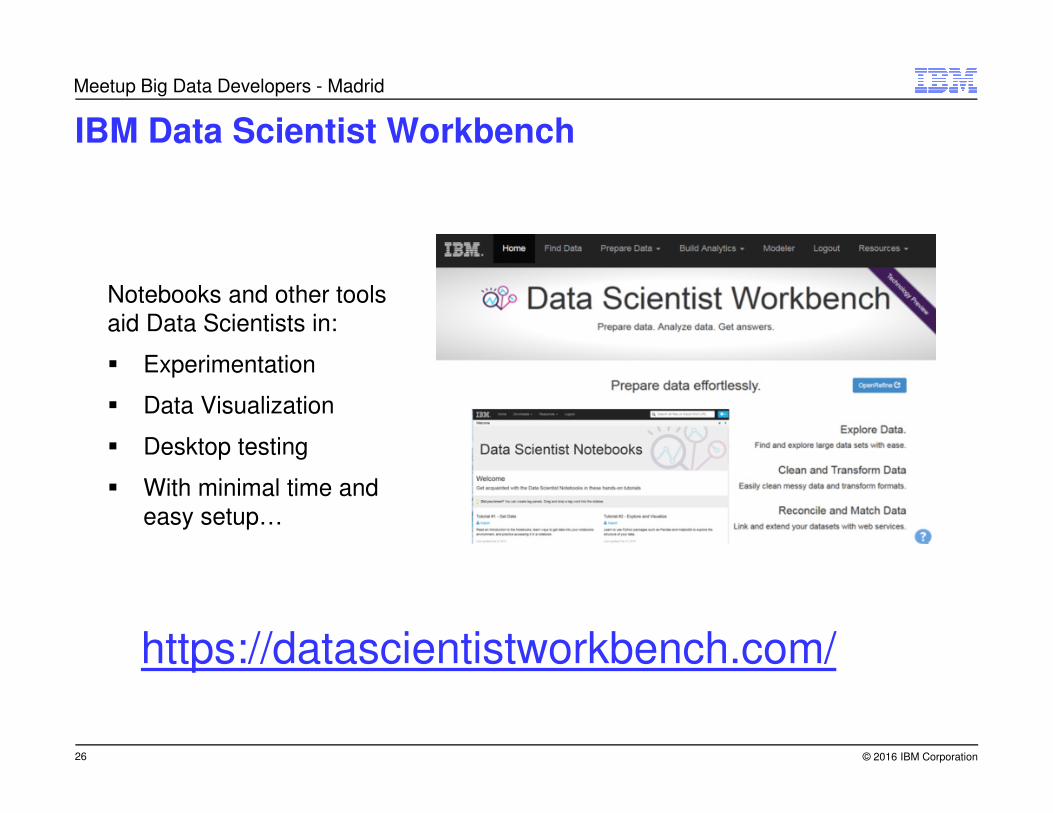
IBM Data Scientist Workbench
Notebooks and other tools aid Data Scientists in:
� Experimentation
� Data Visualization
� Desktop testing
� With minimal time and
easy setup…
https://datascientistworkbench.com/

27 © 2016 IBM Corporation
Meetup Big Data Developers - Madrid
IBM AnalyticsZone
Developer-focused environment for exploration and testing
Downloads and trial
versions
Visualization tools
Extensions
Industry-specific
examples
www.analyticszone.com