
IBM Data Engine for Hadoop and Spark - POWER System Edition ver1 March 2016
35
IBM Data Engine for Hadoop and Spark – Power Systems Edition An IBM System Reference Guide Version 1.0 March 9, 2016 POL03246USEN-00 Page 1 of 35 © Copyright IBM Corporation 2016
-
Upload
anand-haridass -
Category
Engineering
-
view
485 -
download
3
Transcript of IBM Data Engine for Hadoop and Spark - POWER System Edition ver1 March 2016

IBM Data Engine for Hadoop and Spark– Power Systems Edition
An IBM System Reference Guide
Version 1.0
March 9, 2016
POL03246USEN-00
Page 1 of 35© Copyright IBM Corporation 2016

Table of contents
Document history....................................................................................................... 3Revision history........................................................................................................................................ 3
Introduction............................................................................................................... 3
Business problem and business value......................................................................... 3Business problem.................................................................................................................................... 3Business value......................................................................................................................................... 4
Requirements............................................................................................................ 5Functional requirements........................................................................................................................... 5Non-functional requirements.................................................................................................................... 5
Architectural overview................................................................................................ 6
Component model...................................................................................................... 8Software options...................................................................................................................................... 9Advantages of BigInsights Enterprise Management...............................................................................11
Operational model.................................................................................................... 13IBM POWER8 server............................................................................................................................. 13System management node....................................................................................................................13Analytics node: Hadoop Management Node..........................................................................................14Analytics node: Hadoop Data Node.......................................................................................................14Analytics node: Spark Worker Node......................................................................................................14Network connections.............................................................................................................................. 15
Deployment considerations....................................................................................... 16Configuration.......................................................................................................................................... 18
System management node..............................................................................................19Analytics node: Hadoop management node....................................................................19Analytics node: Hadoop data node..................................................................................20Analytics node: Spark worker node..................................................................................21Networks.......................................................................................................................... 22
Predefined configurations......................................................................................................................24Sizing the system................................................................................................................................... 28
Resources............................................................................................................... 30References............................................................................................................................................. 30Installation scripts.................................................................................................................................. 30Configurator guide................................................................................................................................. 30
Notices.................................................................................................................... 31
Trademarks............................................................................................................. 34
POL03246USEN-00
Page 2 of 35© Copyright IBM Corporation 2016

Document history
Revision historyRevision Number
RevisionDate
Summary of Changes Changes marked
1 03/09/2016 First version of this document.
IntroductionThis document describes the IBM® Data Engine for Hadoop and Spark (IDEHS) - Power Systems™
Edition, an IBM® integrated solution. This solution features a technical-computing architecture that supports
running Big Data-related workloads more easily and with higher performance. It includes the servers, network switches, and software needed to run MapReduce and Spark-based workloads. The information
in this document is intended for:
• Architects in an IT or business organization who are responsible for deploying and operating a
cluster for Big Data-related workloads.
• Technical users who are looking for easy-to-deploy and easy-to-use High Performance Computing
(HPC) or technical computing clusters that increase the performance and capabilities of
MapReduce and Spark-based Big Data workloads.
• ISV Architects and Business Partners who are using the solution described in this document as a
base to create customized solutions and reference architectures.
Business problem and business value
Business problem
Every day 2.5 quintillion bytes of data is created. The growth in data is so large that 90% of the data in the
world today was created in the last two years. This data comes in many forms and from many sources,
such as sensors used to gather climate information, posts to social media sites, digital pictures and videos,
purchase transaction records, cell phone GPS signals, and many other diverse sources. Businesses that
can harvest and analyze this data to gain insight about their business and customers and make data
driven decisions have an advantage over their peers and competition.
Big Data is more than a challenge; it is an opportunity to find insight in new and emerging types of data
and to answer questions that, in the past, were beyond reach. The IBM Data Engine for Hadoop and Spark
provides a platform that allows new insights to be discovered in an optimized MapReduce and Spark
analytics environment.
POL03246USEN-00
Page 3 of 35© Copyright IBM Corporation 2016

Business value
The IBM Data Engine for Hadoop and Spark - Power Systems Edition provides an expertly-designed,
tightly-integrated solution for running analytics workloads. The first set of application patterns supported by
this solution are MapReduce and Spark, with additional workloads that will be added in the future. This
architecture defines the following:
• Complete cluster – A comprehensive, tightly-integrated cluster that is designed for ease of
procurement, deployment, and operation. It includes all required components for Big Data
applications, including servers, network, operating system, management software, Hadoop® and
Spark compatible software, and runtime libraries.
• Scale out architecture – Designed with a traditional Hadoop architecture, each data node in the
system includes locally-attached disks that are used to create the HDFS or Spectrum Scale file
system for the cluster. Data is replicated three times between different nodes to protect against
data loss. Compute capacity and file system capacity are scaled together by adding additional
data nodes.
• Open software with optional value-added components – The Open Data Platform initiative (ODPi)
is a shared industry effort promoting & advancing the state of Apache Hadoop® and Big Data
technologies. The ODPi Core is a set of common open source software components including
Apache Hadoop® and Apache® Ambari. IBM Open Platform (IOP) with Apache Hadoop is the
freely available distribution of the ODPi Core components used in this solution. IBM BigInsights™
Data Scientist, IBM BigInsights™ Analyst, and IBM BigInsights™ Enterprise Management are
optional value-added software packages that integrate with IBM Open Platform and provide
additional benefits for a variety of analytics workloads. The optional value-added packages provide
capabilities including using SQL and R as query languages, advanced machine learning, rich text
analytics, and streaming data analysis. The combination of IBM Open Platform and the BigInsights
value-added packages provides an open and comprehensive solution for Hadoop and Spark
workloads.
• Open hardware with POWER8 processors – IBM OpenPOWER S812LC servers with POWER8
processors provide high performance in a cost effective server design. POWER8 processors
provide exceptional computing power for analytics workloads with 8 threads per core, 8 MB of L3
cache per core, and a total max peak memory bandwidth of 170 GB/s.
• Ease of deployment – The full solution is assembled and installed at an IBM delivery center before
delivery with all of the included software preloaded. On-site services personnel integrate the
solution into the customer data center. The solution includes Platform Cluster Manager Advanced
Edition to simplify deployment and monitoring of the cluster.
POL03246USEN-00
Page 4 of 35© Copyright IBM Corporation 2016

Requirements
The following functional requirements provide a high-level overview of the desired characteristics of the
solution architecture.
Functional requirementsDomain experts require technical computing or Hadoop® and Spark® clusters that can be quickly deployed without deep computer engineering skills. These clusters require the following attributes:
• The system is configured with an easy-to-use web management interface, which allows the
system administrator to control all elements of the cluster.
• The cluster is integrated easily into an existing Ethernet and storage infrastructure. As part of the
system configuration, the cluster manager looks for Lightweight Directory Access Protocol (LDAP).
• The cluster is optimized for general Big Data applications and has a built-in web interface that
allows the users to manage workloads.
• Access to the cluster for job submission is provided by a web interface. However, remote terminal
access to the analytics nodes through Secure Shell (SSH) can be configured, if desired.
Non-functional requirements
In addition to the functional attributes, the cluster architecture requires the following non-functional attributes:
• The hardware and software must be deployable by a competent UNIX administrator with cluster
deployment experience.
• The cluster must be capable of being installed and configured at an IBM solution delivery center
before delivery. During delivery, the cluster is assembled on the customer site and cluster
operation is verified. Optionally, the installation and configuration steps can be performed on-site
instead of at a solution delivery center.
• The system management node of the cluster is shipped preinstalled with an operating system,
management software, and runtime libraries.
• All of the compute nodes are deployed by Platform Cluster Manager to ensure that they all have
the appropriate software configuration.
• The cluster is high-density (requires a small amount of floor space) and is also optimized for power
and cooling.
• An average Linux® administrator can operate and maintain the cluster without acquiring specific
cluster and workload management skills.
• The cluster is usable by end users without extensive training and is no more difficult to use than
their own workstations.
POL03246USEN-00
Page 5 of 35© Copyright IBM Corporation 2016

• The latest technology is used for the compute servers to ensure the best performance or the best
price/performance ratio.
• The solution is orderable by contacting your IBM Sales Representative.
Architectural overviewFrom an infrastructure design perspective, a cluster that supports Big Data-related workloads has two key
aspects: the Hadoop Distributed File System (HDFS) and a MapReduce engine. By default, this solution
implements the HDFS and MapReduce environment using IBM Open Platform with Hadoop. In the future,
you will be able to order this solution with BigInsights Enterprise Management, which provides an
enhanced HDFS file system and MapReduce engine by using IBM Spectrum Scale and IBM Platform
Symphony, respectively.
This solution has four server roles: system management node, Hadoop management node, Hadoop data
node and Spark worker node.
Type of node Role
System management node This node is the primary provisioning and monitoring node for the
cluster. The Platform Cluster Manager console that is used to
deploy and monitor all of the analytics nodes runs on the system
management node.
Analytic node:
Hadoop management node
These nodes encompass daemons that are related to managing
the cluster and coordinating the distributed environment.
Analytic node:
Hadoop data node
These nodes encompass daemons that are related to storing
data and accomplishing work within the distributed environment.
The major difference between these two types of analytic nodes
are in hardware and corresponding software configurations.Analytic node:
Spark worker node
The number of each type of node that is required within a Big Data cluster depends on the client
requirements. Such requirements might include the size of a cluster, the size of the user data, the data
compression ratio, workload characteristics, and data ingestion.
HDFS is the standard distributed file system provided by Apache™ Hadoop® in which Hadoop stores data.
HDFS provides a distributed file system that spans all of the nodes within a Hadoop cluster, linking the file
systems on many local nodes to make one big file system with a single namespace. In this solution, HDFS
services are provided by IBM Open Platform with Hadoop by default. As a value-added option that is
included with BigInsights Enterprise Management, IBM Spectrum Scale provides a fully compatible HDFS
API. However, it also enhances HDFS by supplying a fully posix-compliant distributed file system, in
addition to allowing HDFS style access.
POL03246USEN-00
Page 6 of 35© Copyright IBM Corporation 2016
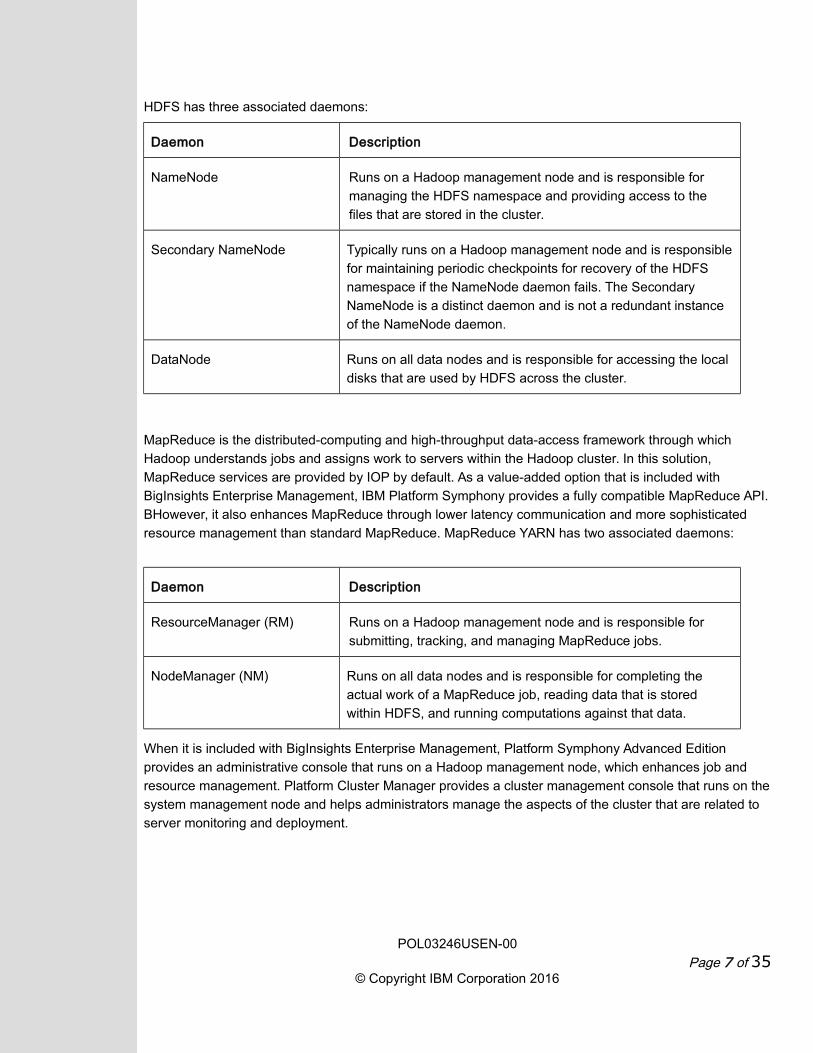
HDFS has three associated daemons:
Daemon Description
NameNode Runs on a Hadoop management node and is responsible for
managing the HDFS namespace and providing access to the
files that are stored in the cluster.
Secondary NameNode Typically runs on a Hadoop management node and is responsible
for maintaining periodic checkpoints for recovery of the HDFS
namespace if the NameNode daemon fails. The Secondary
NameNode is a distinct daemon and is not a redundant instance
of the NameNode daemon.
DataNode Runs on all data nodes and is responsible for accessing the local
disks that are used by HDFS across the cluster.
MapReduce is the distributed-computing and high-throughput data-access framework through which
Hadoop understands jobs and assigns work to servers within the Hadoop cluster. In this solution,
MapReduce services are provided by IOP by default. As a value-added option that is included with
BigInsights Enterprise Management, IBM Platform Symphony provides a fully compatible MapReduce API.
BHowever, it also enhances MapReduce through lower latency communication and more sophisticated
resource management than standard MapReduce. MapReduce YARN has two associated daemons:
Daemon Description
ResourceManager (RM) Runs on a Hadoop management node and is responsible for
submitting, tracking, and managing MapReduce jobs.
NodeManager (NM) Runs on all data nodes and is responsible for completing the
actual work of a MapReduce job, reading data that is stored
within HDFS, and running computations against that data.
When it is included with BigInsights Enterprise Management, Platform Symphony Advanced Edition
provides an administrative console that runs on a Hadoop management node, which enhances job and
resource management. Platform Cluster Manager provides a cluster management console that runs on the
system management node and helps administrators manage the aspects of the cluster that are related to
server monitoring and deployment.
POL03246USEN-00
Page 7 of 35© Copyright IBM Corporation 2016

Component model
Figure 1 illustrates the component model for this solution architecture.
Figure 1: Solution architecture component model
Regarding networking, this solution specifies three networks for a MapReduce implementation: a data
network, a management network, and a service network. All 1Gb Ethernet networking for the management
and service network is provided by Lenovo RackSwitch™ switches. The high speed data network is
implemented using 10Gb RackSwitch Ethernet switches. For more information about networking, see the
Networks section.
To facilitate easy sizing, this solution is offered in two preconfigured sample sizes:
Configuration size Description
Starter configuration Consists of a minimum of one Hadoop management
node, three Hadoop data or Spark worker nodes,
and one system management node in a single rack.
This is intended for starter/proof-of-concept usage.
Landing Zone configuration The default configuration includes six Hadoop
management nodes, seven Hadoop data or Spark
worker nodes, one system management node, and a
redundant data network in a single rack.
Note: The number of Hadoop management nodes that are required varies depending on cluster size and
workload. For multi-rack configurations, a select combination of these racks is needed. For the required
number of management nodes and network switches, in single-rack or multi-rack configurations, see the
Configuration section.
POL03246USEN-00
Page 8 of 35© Copyright IBM Corporation 2016

Software options
The base software components that will be installed and configured in this solution are listed in Table 1.
Name Mode Description
RHEL v7.2 ppc64le Required RedHat Enterprise Linux v7.2 for Power (LittleEndian)
Platform Cluster Manager Advanced Edition
Required
IBM Open Platform with Apache Hadoop
Default
IBM BigInsights Enterprise Management
Selectable (future release)
Includes IBM Spectrum Scale and IBM Platform Symphony
IBM BigInsights Data Scientist Selectable
IBM BigInsights Analyst Selectable
Table 1: Software list
This solution provides a variety of software combinations. Each combination is composed of a set of
software feature codes. The supported software feature codes are listed in Table 2.
Feature Code Feature Name Default Min Max
EHLF IBM Open Platform with Apache Hadoop Indicator 1 0 1
EHJQ IBM BigInsights Enterprise Management, andIBM Open Platform with Apache Hadoop Indicator(Will be enabled in a future release.)
0 0 0
EHJR IBM BigInsights Data Scientist Indicator 0 0 1
EHJS IBM BigInsights Analyst Indicator 0 0 1
Table 2: Software feature codes
The following software combination feature matrix is supported:
1. EHLF only
• This is the default installation, which uses HDFS in IOP as the file system.
2. EHLF + EHJS
• Install IOP, using HDFS as file system, as well as the BigInsights value-added modules which
include BigInsights Analyst.
3. EHJQ + EHJS
POL03246USEN-00
Page 9 of 35© Copyright IBM Corporation 2016

• Install IOP using Spectrum Scale as the file system and Platform Symphony as the resource
manager and MapReduce engine. Spectrum Scale and Platform Symphony are both installed
as part of the BigInsights Enterprise Management package.
• Install BigInsights value-added modules which include BigInsights Analyst.
4. EHJQ + EHJR
• Install IOP using Spectrum Scale as the file system and Platform Symphony as the resource
manager and MapReduce engine. Spectrum Scale and Platform Symphony are both installed
as part of the BigInsights Enterprise Management package.
• Install BigInsights value-added modules which include BigInsights Data Scientist.
5. OS only install
• Provision the node so that the RHEL v7.2 ppc64le operating system is installed and
networking is configured. No additional software needs to be installed.
6. EHLF + EHJR
• Install IOP, using HDFS as file system, as well as the BigInsights value-added modules which
include BigInsights Data Scientist.
POL03246USEN-00
Page 10 of 35© Copyright IBM Corporation 2016

Advantages of BigInsights Enterprise Management
BigInsights Enterprise Management consists of two software products: Spectrum Scale and Platform
Symphony. In the future, it can be ordered by requesting the EHJQ feature code. If BigInsights Enterprise
Management is ordered, it will be installed and configured as the replacement for the HDFS file system
and MapReduce in IOP.
As the replacement for the HDFS file system in IOP, Spectrum Scale includes several enterprise features
that provide distinct advantages. Some of these features are especially useful for managing and running a
Big Data and Analytics cluster.
✔ Full POSIX compliance
• Support for a wide range of traditional applications
• Support for common UNIX utilities to manage content in the file system, such as copy, delete,
move and so on.
• Allows HDFS data to be stored and accessed from the same file system as all other POSIX
compliant applications
✔ High performance support for MapReduce applications and other traditional applications
• Supports striping data across disks to speed up MapReduce split IO
• Includes an optimized cache mechanism which increases the throughput of random read
• Supports concurrent reads and writes by multiple programs
✔ Hierarchical storage management
• Allows sufficient use of disk drives with different performance characteristics, such as the
mixture of SSD and HDD.
✔ Data replication
• Supports cluster-to-cluster replication over a wide area network, which provides capability of
some kinds of disaster recovery.
✔ Snapshot
As the replacement for the MapReduce engine in IOP, Platform Symphony also provides some distinct
advantages.
Platform Symphony is capable of running distributed application services on a scalable, shared,
heterogeneous grid. This low-latency scheduling solution supports sophisticated workload management
capabilities beyond those of standard Hadoop MapReduce.
POL03246USEN-00
Page 11 of 35© Copyright IBM Corporation 2016

Platform Symphony can orchestrate distributed services on a shared grid in response to dynamically
changing workloads. This component combines a service-oriented application middleware (SOAM)
framework, a low-latency task scheduler, and a scalable grid management infrastructure. This design
ensures application reliability while also ensuring low-latency and high-throughput communication between
clients and compute services.
Hadoop has limited prioritization features, whereas Platform Symphony has thousands of priority levels
and multiple options that you can configure to manage resource sharing. This sophisticated resource
sharing allows you to prioritize for interactive workloads that are not possible in a traditional MapReduce
environment. For example, with Platform Symphony, you can start multiple Hadoop jobs and associate
those jobs with the same consumer. Within that consumer, jobs can share resources based on individual
priorities.
For example, consider a 100 slot cluster where you start job "A" with a priority of 100. Job "A" starts, and
consumes all slots if enough map tasks exist. You then start job "B" while job "A" is running, and give job
"B" a priority of 900, which is nine times greater than the priority of job "A". Platform Symphony
automatically rebalances the cluster to give 90 slots to job "B" and 10 slots to job "A", so that resources
are distributed in a prioritized manner that is transparent to the jobs.
The scheduling framework of Platform Symphony is optimized for MapReduce workloads that are
compatible with Hadoop and Spark. When choosing Platform Symphony, it transparently improves
performance for a variety of big data workloads, at a lower cost.
POL03246USEN-00
Page 12 of 35© Copyright IBM Corporation 2016

Operational modelThe software components that are described in the previous section are implemented on the following hardware components. Each of the components shown is described in detail in the subsequent sections.
IBM POWER8 server
IBM Power Systems™ are the ultimate systems for today's compute and data-intensive workloads. Linux is a robust and uniquely extensible operating system that is built on open source innovation. The IBM POWER8™ server is the perfect combination of IBM Power Systems and Linux for resolving Big Data challenges.
The IBM Power Systems servers provide the performance of Power at an x86 price point. It is a high-performance, efficient server that is ideal for running multiple, industry standard Linux workloads that deliver superior economy.
The IBM Power Systems servers use the POWER8 chip, which has up to 8~10 cores per socket. With SMT8 technology, the POWER8 chip has eight threads per core (four times more than Intel) for running parallel Java workloads, which takes maximum advantage of the processing capability. The POWER8 chiphas very high memory and I/O bandwidth, which is critical for a BigData system to achieve superior performance. The POWER8 architecture also offers better reliability, availability, and serviceability than x86 servers.
The IBM Power System S812LC server is based on POWER8 architecture. It is a high-efficiency, single socket, 2U rack server and supports a maximum of 1 TB of memory.
The IBM Power System S812LC server is used to fulfill all logical server roles within the cluster: System Management Node, Hadoop Management Node, Hadoop Data Node and Spark worker node.
System management node
The system management node (SMN) hosts the Platform Cluster Manager Advanced Edition software that
controls cluster deployment and management operations. The system management node is pre-installed
with Platform Cluster Manager Advanced Edition software and will contain other software packages that
are required for deploying and configuring the rest of the cluster.
The software that comes installed on the system management node includes:
• Operating system (OS): Red Hat® Enterprise Linux® (RHEL) Server
• Operating system repository: RHEL repository for deploying the cluster nodes, including all
required device drivers
• Cluster management and monitoring software: IBM Platform Cluster Manager Advanced Edition
(PCM AE)
• Web interface for cluster administrators and end users: IBM Platform Cluster Manager Advanced
Edition
POL03246USEN-00
Page 13 of 35© Copyright IBM Corporation 2016

All of the software is stored on the system management node and scripts are provided to configure the
rest of the system. The system management node is configured appropriately to be able to provide all of
its intended functions. The system management node configuration is limited to ensure that each possible
variation has been well-validated.
Analytics node: Hadoop Management Node
Hadoop management nodes (MNs) manage the Hadoop service components in each analytics node. The
management services for all software components are typically distributed between three and six Hadoop
management nodes.
The software that is to be installed on Hadoop management nodes includes:
• Operating system (OS): Red Hat® Enterprise Linux® (RHEL) Server
• Hadoop runtime environment: IBM Open Platform for Hadoop (IOP), IBM BigInsights Enterprise
Management, which includes IBM Platform™ Symphony and Spectrum Scale, IBM BigInsights
value-added services: Analyst and Data Scientist.
After the cluster is deployed, these nodes provide the following functions:
• A MapReduce engine for workload management, provided by IOP or IBM Platform™ Symphony.
• A web interface that enables users to access the cluster and run their applications, which are
provided by IOP or IBM Platform™ Symphony.
The Hadoop management node is the base of a clustered system that uses the architecture that is defined
in this document and is supported in minimal and high-availability (HA) configurations. The Hadoop
management node is configured appropriately to be able to provide all of its intended functions. The
management node configuration is limited to ensure that each possible variation has been well-validated.
Analytics node: Hadoop Data Node
Data nodes run the HDFS DataNode service and the YARN NodeManager. They are configured for data-
intensive Hadoop applications. Data nodes have some local disks for the OS, the application, and runtime
libraries. They have many more local disks for the HDFS or Spectrum Scale.
Analytics node: Spark Worker Node
Spark worker nodes runs HDFS and the YARN NodeManager. They are configured for memory-intensive
Spark applications. Spark worker nodes have some local disks for the OS, the application, and runtime
libraries. They have many more local disks for the HDFS or Spectrum Scale. Optionally, additional local
SSDs can be used as cache spaces for Spark tasks.
POL03246USEN-00
Page 14 of 35© Copyright IBM Corporation 2016

Network connections
There are three distinct networks included in the architecture of this solution, each serving a specific role:
(1) Service network: This network is connected to the BMC on each IBM Power Systems server and
switches management ports. It allows the management software to manage and monitor the
hardware on a 1-Gigabit Ethernet interconnect without requiring the node operating system to be
up. Typical hardware-level management functions include power-cycling the node, hardware
status monitoring, firmware configuration, and hardware console access.
(2) Management network: This network is used for provisioning the operating system, deploying
software components and applications, monitoring, and workload management. It uses a 1-Gigabit
Ethernet interconnect.
(3) Data network: This high-performance network is used for accessing data in the cluster file system,
communicating between analytics applications, and moving data into and out of the cluster. The
data network uses 10-Gigabit Ethernet high-speed interconnects.
POL03246USEN-00
Page 15 of 35© Copyright IBM Corporation 2016

Deployment considerationsThe solution is optimized for general Big Data applications, and users are able to take advantage of the
performance and capability that the cluster delivers with minimal training.
Figure 2 shows the software stack in this cluster.
Figure 2: Software stack
In this software stack:
• Platform Cluster Manager (PCM) provides hardware management and monitoring functions
and a web console.
• IBM Open Platform for Hadoop (IOP) provides standard Hadoop service and its management
console. Components of IOP are shown in dark green boxes in figure 3.
• BigInsights Enterprise Management provides alternative Hadoop service components and its
management console.
POL03246USEN-00
Page 16 of 35© Copyright IBM Corporation 2016

◦ Platform Symphony provides the MapReduce engine functions and job-related web console,
which are packaged with IBM BigInsights Enterprise Management.
◦ Spectrum Scale provides the HDFS functions for the solution and is packaged with IBM
BigInsights Enterprise Management.
• BigInsights Analytist and Data Scientist provides value added services from IBM, such as
BigSQL, BigSheets, BigR, and so on.
POL03246USEN-00
Page 17 of 35© Copyright IBM Corporation 2016

Configuration
IBM provides predefined configurations for this solution. If these recommended configurations do not fit
your requirements, please contact IBM for assistance.
A typical supported configuration consists of the following components:
Rack and power supply
System management node:
IBM Power System S812LC
8 x 3.32GHz cores
32 GB memory (default), maximum memory is 1 TB
2 x 1 TB 3.5" SATA hard disk drives (HDDs)
1 x Shiner-S Ethernet adapter with 2 x 10-Gigabit ports and 2 x 1-Gigabit ports.
Hadoop management node:
IBM Power System S812LC
10 x 2.92GHz cores
128 GB Memory (default), maximum memory is 1 TB
2 x 1 TB 3.5" SATA hard disk drives (HDDs)
1 x Shiner-S Ethernet adapter with 2 x 10-Gigabit ports and 2 x 1-Gigabit ports.
Hadoop Data node:
IBM Power System S812LC
10 x 2.92GHz cores
128 GB Memory (default), maximum memory is 1 TB
2 x 1 TB 3.5" SATA hard disk drives (HDDs)
12 x 6 TB 3.5" SATA hard disk drivers (HDDs)
1 x Shiner-S Ethernet adapter with 2 x 10-Gigabit ports and 2 x 1-Gigabit ports.
1 x PMC-Sierra 71605E RAID adapter, over 530K IOPs, up to 6.6GB/s reads and 5.7 GB/s writes.
Spark worker node:
IBM Power System S812LC
10 x 2.92GHz cores
256 GB Memory (default), maximum memory is 1 TB
2 x 1 TB 3.5" SATA hard disk drives (HDDs)
10 x 6 TB 3.5" SATA hard disk drivers (HDDs)
POL03246USEN-00
Page 18 of 35© Copyright IBM Corporation 2016

2 x 960 GB SSD
1 x Shiner-S Ethernet adapter with 2 x 10-Gigabit ports and 2 x 1-Gigabit ports.
1 x PMC-Sierra 71605E RAID adapter, over 530K IOPs, up to 6.6GB/s reads and 5.7 GB/s writes.
Network router:
Lenovo RackSwitch G8052: 48 x 1-Gigabit and 4 x 10-Gigabit Ethernet top-of-rack switch for
management and service network
Lenovo RackSwitch G8264: 48 x 10-Gigabit and 4 x 40-Gigabit Ethernet top-of-rack switch for
data network
Lenovo RackSwitch G8124: 24 x 10-Gigabit Ethernet top-of-rack switch for data network, for
smaller configurations withouht scaling request.
Software:
IBM Platform Cluster Manager Advanced Edition
IBM Open Platform for Hadoop (IOP)
IBM BigInsights Enterprise Management, which includes
IBM Spectrum Scale
IBM Platform Symphony Advanced Edition
IBM BigInsights Data Scientist
IBM BigInsights Analytist
System management node
The system management node is an IBM Power Systems S812LC server. One system management node
is sufficient for a cluster of up to 128 analytics nodes.
Analytics node: Hadoop management node
In this solution, Hadoop management nodes run on IBM Power Systems S812LC servers. Hadoop
management nodes encompass the following services:
• HDFS NameNode
• HDFS Secondary NameNode
• YARN ResourceManager
• Symphony Service-Oriented Application Middleware (SOAM) workload management services,
such as Session Director (SD), Repository Service (RS) and Service Session Manager (SSM)
• Symphony Enterprise Grid Orchestrator (EGO) services, such as VEM Kernel Daemon (VEMKD)
and EGO Service Controller (EGOSC)
POL03246USEN-00
Page 19 of 35© Copyright IBM Corporation 2016

• Symphony Platform Management Console (PMC)
• Symphony Reports
• Amabari server
• HBase master
• BigSQL server
• Hive server
• Other services including Zookeeper, Oozie, and so on.
IBM Spectrum Scale is a distributed file system that is supported by this solution as an alternative to
HDFS. Because Spectrum Scale uses different methods than HDFS to manage metadata, it does not have
a centralized NameNode and does not require a Secondary NameNode.
Symphony SOAM is composed of workload management services and workload execution services.
Workload execution services are required on all data nodes. Workload management services are usually
installed on a limited number of management nodes. By default, a minimum of three management nodes
are recommended for Landing zone configuration if HA is not used. When considering cluster scaling,
more management nodes can be added so that there are more SSM daemons to respond simultaneously
to user jobs.
Symphony PMC is the centralized web interface for viewing, monitoring, and managing MapReduce jobs
and the MapReduce running environment.
Symphony Reports provides the reporting functions by collecting historical data into a database and
generating reports in graphical or tabular formats.
For a production cluster, a minimum of three Hadoop management nodes are required. If high availability
is desired, six Hadoop management nodes are required. A single Hadoop management node is only
recommended for small, non-production clusters.
For a cluster with multiple racks and multiple management nodes, consult with the IBM Service team for
more information about scaling.
Analytics node: Hadoop data node
In this solution, the third type of analytics node is the data node. Data nodes run on IBM Power Systems
S812LC servers, with one data node logical partition using all of the resources of a single server. Data
nodes encompass the following services:
• HDFS DataNode
• YARN NodeManager
• HBase RegionServer
• Spectrum Scale NSD Servers
• Symphony SOAM execution management services, such as Session Instance Manager (SIM) and
Service Instance (SI)
POL03246USEN-00
Page 20 of 35© Copyright IBM Corporation 2016

• Symphony EGO services, such as Load Information Manager (LIM) and Process Execution
Manager (PEM)
• Other services for IOP and BigInsights.
IBM Spectrum Scale is the POSIX compatible distributed file system for this solution. It provides the HDFS
access API for Hadoop services and workloads. The data nodes host Spectrum Scale NSD servers, which
are used for storage for the file system. A file placement optimization (FPO) configuration is used to allow
data locality while still maintaining the distributed, fault-tolerant nature that is inherent to a Spectrum Scale
file system.
Symphony SOA execution management services are installed on all data nodes to support running and
managing the MapReduce workloads that are scheduled by upper-level SOA workload management
services.
Symphony EGO services are installed on all data nodes to collect computational resource information and
to help the Symphony SOA workload management service to schedule jobs more quickly and efficiently.
There are also other services for IOP and BigInsights that can be installed in data nodes, depending on
the application requirements for the Big Data cluster. For example, if some analytic workloads require
HBase, the region server for HBase needs to be installed, configured, and run on all data nodes.
Analytics node: Spark worker node
Spark worker nodes run the same services as Hadoop data nodes, but these services are configured to
utilize the extra memory and SSDs for Spark workloads.
POL03246USEN-00
Page 21 of 35© Copyright IBM Corporation 2016

Networks
This solution specifies three networks as described in the "Network connections" section.
Network Description
Data network The data network is a high-performance cluster data interconnect among data
nodes that is used for accessing data, moving data between nodes within the
cluster, and ingesting data into the file system.
This solution uses 10 Gb Ethernet for the data network.
Note: The data network is very important to the performance of Big Data
application workloads.
Management
network
The management network is a 1 Gb Ethernet network that is used for in-band OS
administration. In-band administrative services that run on the host operating
system, such as Secure Shell (SSH) or Virtual Network Computing (VNC), allow for
the administration of cluster nodes. It is required that the management and service
network traffic be segregated by using separate VLANs and subnets for the
management and service networks. The management and service networks are
typically implemented using separate VLANs within a single switch or set of
switches.
Service
network
The service network is a 1 Gb Ethernet network that is used for out-of-band
management of the IBM Power Systems servers and out-of-band management of
network switches. The service network connects the BMC on the IBM Power
Systems server and the system management node. This allows for hardware-level
management of the Power Systems servers such as power control, node
deployment, firmware updates and monitoring. Out-of-band hardware management
of network switches is performed by using the management interfaces of these
devices. This allows for hardware setup, firmware updates and monitoring of these
devices. The service network is segregated from the management network by
using a private subnet and an isolated VLAN. The management and service
networks are typically implemented using separate VLANs within a single switch or
set of switches.
POL03246USEN-00
Page 22 of 35© Copyright IBM Corporation 2016

Figure 3 shows the networks that are used in this solution.
Figure 3: An example cluster network
Table 3 shows the IBM rack switches that are used in this reference architecture.
Switch model Switch description
Lenovo RackSwitch
G8052
1 GbE top-of-rack switch for the management and service networks. The
connections that are needed for the service network VLAN are one physical
link to the system management node, one physical link to the BMC of each
server for out-of-band hardware management, and one physical link to each
network switch for out-of-band switch management. The connections that
are needed for the management network VLAN are one physical link to the
system management node and one physical link for each analytics node.
Lenovo RackSwitch
G8264 / G8124
10 GbE top-of-rack switch for the data network. The connections that are
needed for the data network are one or two physical links for the system
management node, and one or two physical links for each analytics node. In
general, the G8124 switch is only used for small clusters that do not have
scaling requests. The G8264 switch is recommended for the future growth.
Table 3: Rack switches
POL03246USEN-00
Page 23 of 35© Copyright IBM Corporation 2016

Note: Core switches will not be included in the default configuration because customers usually have their
own core switch network deployed already. Also, to avoid a single point of failure, use redundant core
switches.
POL03246USEN-00
Page 24 of 35© Copyright IBM Corporation 2016

Predefined configurations
There are two predefined configurations for this solution: Starter and Landing Zone.
Figure 4 shows the predefined Starter configuration with Hadoop data nodes.
Figure 4: Small configuration with Hadoop data nodes
POL03246USEN-00
Page 25 of 35© Copyright IBM Corporation 2016

Figure 5 shows the predefined Starter configuration with Spark worker nodes.
Figure 5: Starter configuration with Spark worker nodes.
POL03246USEN-00
Page 26 of 35© Copyright IBM Corporation 2016

Figure 6 shows the Landing Zone predefined configuration with Hadoop data nodes.
Figure 6: Landing Zone configuration with Hadoop data nodes.
POL03246USEN-00
Page 27 of 35© Copyright IBM Corporation 2016

Figure 7 shows the Landing Zone predefined configuration with Spark worker nodes.
Figure 7: Landing Zone configuration with Spark worker nodes.
POL03246USEN-00
Page 28 of 35© Copyright IBM Corporation 2016

Sizing the system
With the data provided in the previous “Predefined Configurations” section, one can easily size the system
based on some rules.
The starter configuration has only one MN and a non-redundant 10 GB data network. If the system is
targeted to be a cluster, which is small initially and required to growth in future, and if it is mainly used for
Proof of Concept, development, testing, or evaluation, then the Starter configuration is recommended. This
configuration starts from minimal one SMN, one MN, three DN. It can grow to one full rack with one SMN,
one MN and 17 DN. With the amount of CPU, memory and raw disk capacity provided in this document,
one can also estimate the system capability and capacity to match the workload requirements.
The landing zone configuration starts with a minimum of one SMN, six MN and seven DN. It provides
redundancy at the network, software and hardware level. It can be scaled easily by adding the extended
rack of Landing zone configuration. If the system was targeted for production or other high available
workloads, the Landing zone configuration is recommended with very good cost per GB, features and
performance. With the amount of CPU, memory and raw disk capacity provided in this document, one can
also estimate the system capability and capacity to match the workload requirements. If the estimated
cluster size is more than two racks, contact IBM for help with planing the network and services.
When estimating disk space within a Hadoop cluster, consider the following points:
● For improved fault tolerance and improved performance, HDFS replicates data blocks across
multiple cluster data nodes. By default, HDFS maintains three replicas. In this solution, we use this
default setting.
● With the MapReduce process, shuffle/sort data is passed from Mappers to Reducers by writing the
data to the data node’s local file system. If the MapReduce job requires more than the available
shuffle file space, the job will terminate. As a rule of thumb, reserve 25 percent of the total disk
space for the local file system as shuffle file space.
● The actual space that is required for shuffle/sort data is workload-dependent. In the unusual
situation where the 25 percent rule of thumb is insufficient, available space on the OS drives can
be used to provide more shuffle/sort space.
● The compression ratio is an important consideration in estimating disk space. Within Hadoop, the
user data and the shuffle/sort data can be compressed. If the client’s data compression ratio is not
available, assume a compression ratio of 2.5.
Assuming that the default replicas are maintained by HDFS, the total cluster data space and the required
number of data nodes can be estimated by using the following equations:
POL03246USEN-00
Page 29 of 35© Copyright IBM Corporation 2016

Total Data Disk Space = (User Raw Data, Uncompressed) / 0.75 x (number of replicas) / (compression
ratio)
Total Required Data Nodes = (Total Data Disk Space) / (Data Space per Server)
When estimating disk space, also consider future growth requirements.
This solution provides two kinds of data nodes, Hadoop Data Node and Spark Worker Node. The total
number of disk space in the cluster increases linearly when you increase the number of specific data
nodes. Table 4 shows the disk space which each kind of a data node can provide.
Data Node Type Raw disk space (TB) Effective disk space (TB)
Hadoop Data Node 72 54
Spark Worker Node 60 45
• Hadoop Data Node with default configuration: 12 x 6T data HDDs
• Spark Worker Node with default configuration: 10 x 6T data HDDs
• Use default three repolicas
• Reserve 25% of the raw disk space as shuffle file space. So, effective disk space for each node is
75% of the raw disk space.
Table 4: Disk space per node
POL03246USEN-00
Page 30 of 35© Copyright IBM Corporation 2016

Resources
References IBM Power Systems: http://www.ibm.com/systems/power/hardware/linux.html
IBM Power System S812LC Data Sheet: http://www.ibm.com/common/ssi/cgi-bin/ssialias?
subtype=SP&infotype=PM&htmlfid=POD03109USEN#
Lenovo RackSwitch: http://www.ibm.com/systems/networking/switches/rack.html
IBM BigInsights: http://www.ibm.com/software/data/infosphere/biginsights/
Open Data Platform initiative: http://www.odpi.org/
IBM Platform Computing: http://www. ibm.com/platformcomputing
Installation scripts
Installation scripts and a guide are available to help you install and bring up the system. To access these,
go to:
http://www.ibm.com/support/fixcentral/
and enter the following in the Search Fix Central box:
IDEHS_Inst_1.0
Configurator guide
To aid in ordering these solutions, your IBM Sales Representative has access to sample configuration filesto use as a starting point for both the hardware and software order.
POL03246USEN-00
Page 31 of 35© Copyright IBM Corporation 2016

NoticesThis information was developed for products and services that are offered in the USA.
IBM may not offer the products, services, or features discussed in this document in other countries.
Consult your local IBM representative for information on the products and services currently available in
your area. Any reference to an IBM product, program, or service is not intended to state or imply that only
that IBM product, program, or service may be used. Any functionally equivalent product, program, or
service that does not infringe any IBM intellectual property right may be used instead. However, it is the
user's responsibility to evaluate and verify the operation of any non-IBM product, program, or service.
IBM may have patents or pending patent applications covering subject matter described in this document.
The furnishing of this document does not grant you any license to these patents. You can send license
inquiries, in writing, to:
IBM Director of LicensingIBM CorporationNorth Castle Drive, MD-NC119Armonk, NY 10504-1785United States of America
For license inquiries regarding double-byte character set (DBCS) information, contact the IBM Intellectual
Property Department in your country or send inquiries, in writing, to:
Intellectual Property LicensingLegal and Intellectual Property LawIBM Japan Ltd.19-21, Nihonbashi-Hakozakicho, Chuo-kuTokyo 103-8510, Japan
The following paragraph does not apply to the United Kingdom or any other country where such
provisions are inconsistent with local law: INTERNATIONAL BUSINESS MACHINES CORPORATION
PROVIDES THIS PUBLICATION "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR
IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF NON-INFRINGEMENT,
MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE. Some states do not allow disclaimer
of express or implied warranties in certain transactions, therefore, this statement may not apply to you.
This information could include technical inaccuracies or typographical errors. Changes are periodically
made to the information herein; these changes will be incorporated in new editions of the publication. IBM
may make improvements and/or changes in the product(s) and/or the program(s) described in this
publication at any time without notice.
Any references in this information to non-IBM websites are provided for convenience only and do not in
any manner serve as an endorsement of those websites. The materials at those websites are not part of
the materials for this IBM product and use of those websites is at your own risk.
IBM may use or distribute any of the information you supply in any way it believes appropriate without
incurring any obligation to you.
POL03246USEN-00
Page 32 of 35© Copyright IBM Corporation 2016

The licensed program described in this document and all licensed material available for it are provided by
IBM under terms of the IBM Customer Agreement, IBM International Program License Agreement or any
equivalent agreement between us.
Any performance data contained herein was determined in a controlled environment. Therefore, the results
obtained in other operating environments may vary significantly. Some measurements may have been
made on development-level systems and there is no guarantee that these measurements will be the same
on generally available systems. Furthermore, some measurements may have been estimated through
extrapolation. Actual results may vary. Users of this document should verify the applicable data for their
specific environment.
Information concerning non-IBM products was obtained from the suppliers of those products, their
published announcements or other publicly available sources. IBM has not tested those products and
cannot confirm the accuracy of performance, compatibility or any other claims related to non-IBM
products. Questions on the capabilities of non-IBM products should be addressed to the suppliers of those
products.
All statements regarding IBM's future direction or intent are subject to change or withdrawal without notice,
and represent goals and objectives only.
All IBM prices shown are IBM's suggested retail prices, are current and are subject to change without
notice. Dealer prices may vary.
This information is for planning purposes only. The information herein is subject to change before the
products described become available.
This information contains examples of data and reports used in daily business operations. To illustrate
them as completely as possible, the examples include the names of individuals, companies, brands, and
products. All of these names are fictitious and any similarity to the names and addresses used by an
actual business enterprise is entirely coincidental.
COPYRIGHT LICENSE:
This information contains sample application programs in source language, which illustrate programming
techniques on various operating platforms. You may copy, modify, and distribute these sample programs in
any form without payment to IBM, for the purposes of developing, using, marketing or distributing
application programs conforming to the application programming interface for the operating platform for
which the sample programs are written. These examples have not been thoroughly tested under all
conditions. IBM, therefore, cannot guarantee or imply reliability, serviceability, or function of these
programs. The sample programs are provided "AS IS", without warranty of any kind. IBM shall not be liable
for any damages arising out of your use of the sample programs.
Each copy or any portion of these sample programs or any derivative work, must include a copyright
notice as follows:
Portions of this code are derived from IBM Corp. Sample Programs.
© Copyright IBM Corp. 2015. All rights reserved.
Trademarks
POL03246USEN-00
Page 33 of 35© Copyright IBM Corporation 2016

IBM, the IBM logo, and ibm.com are trademarks or registered trademarks of International Business
Machines Corp., registered in many jurisdictions worldwide. Other product and service names might be
trademarks of IBM or other companies. A current list of IBM trademarks is available on the web at
www.ibm.com/legal/copytrade.shtml.
Terms and conditions for product documentation
Permissions for the use of these publications are granted subject to the following terms and conditions.
Applicability
These terms and conditions are in addition to any terms of use for the IBM website.
Personal use
You may reproduce these publications for your personal, noncommercial use provided that all proprietary
notices are preserved. You may not distribute, display or make derivative work of these publications, or
any portion thereof, without the express consent of IBM.
Commercial use
You may reproduce, distribute and display these publications solely within your enterprise provided that all
proprietary notices are preserved. You may not make derivative works of these publications, or reproduce,
distribute or display these publications or any portion thereof outside your enterprise, without the express
consent of IBM.
Rights
Except as expressly granted in this permission, no other permissions, licenses or rights are granted, either
express or implied, to the publications or any information, data, software or other intellectual property
contained therein.
IBM reserves the right to withdraw the permissions granted herein whenever, in its discretion, the use of
the publications is detrimental to its interest or, as determined by IBM, the above instructions are not being
properly followed.
You may not download, export or re-export this information except in full compliance with all applicable
laws and regulations, including all United States export laws and regulations.
IBM MAKES NO GUARANTEE ABOUT THE CONTENT OF THESE PUBLICATIONS. THE
PUBLICATIONS ARE PROVIDED "AS-IS" AND WITHOUT WARRANTY OF ANY KIND, EITHER
EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO IMPLIED WARRANTIES OF
MERCHANTABILITY, NON-INFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
POL03246USEN-00
Page 34 of 35© Copyright IBM Corporation 2016

TrademarksIBM, the IBM logo, and ibm.com are trademarks of International Business Machines Corp., registered in many jurisdictions worldwide. Other product and service names might be trademarks of IBM or other companies. A current list of IBM trademarks is available on the web at "Copyright and trademark information" at www.ibm.com/legal/copytrade.shtml.
Intel, Intel Inside (logos), MMX, and Pentium are trademarks of Intel Corporation or its subsidiaries in the United States, other countries, or both.
UNIX is a registered trademark of The Open Group in the United States and other countries.
Linux is a registered trademark of Linus Torvalds in the United States, other countries, or both.
Other company, product, or service names may be trademarks or service marks of others.
POL03246USEN-00
Page 35 of 35© Copyright IBM Corporation 2016


















