
IBM Cloud Professional Certification Program · IBM Cloud Professional Certification Program Study...
78
IBM Cloud Professional Certification Program Study Guide Series Exam C5050-300 - Foundations of IBM DevOps V1
Transcript of IBM Cloud Professional Certification Program · IBM Cloud Professional Certification Program Study...

IBM Cloud Professional Certification Program Study Guide Series Exam C5050-300 - Foundations of IBM DevOps V1

PURPOSE OF EXAM OBJECTIVES ................................................. - 3 -
HIGH-LEVEL EXAM OBJECTIVES .................................................. - 4 -
DETAILED EXAM OBJECTIVES ...................................................... - 6 -
Section 1 - DevOps Principles ................................................................................ - 6 - Section 2 - Adopting DevOps ............................................................................... - 34 - Section 3 - IBM DevOps Reference Architecture & Methods ............................... - 50 - Section 4 - Open Source, Open Standard & Other Open Components ............... - 64 - Section 5 - IBM Solutions for DevOps .................................................................. - 70 -
NEXT STEPS .................................................................................. - 78 -

Purpose of Exam Objectives
When an exam is being developed, the Subject Matter Experts work together to define the role the certified individual will fill. They define all of the tasks and knowledge that an individual would need to have in order to successfully implement the product. This creates the foundation for the objectives and measurement criteria, which are the basis for the certification exam. The Cloud certification item writers use these objectives to develop the questions that they write and which will appear on the exam. It is recommended that you review these objectives. Do you know how to complete the task in the objective? Do you know why that task needs to be done? Do you know what will happen if you do it incorrectly? If you are not familiar with a task, then go through the objective and perform that task in your own environment. Read more information on the task. If there is an objective on a task there is about a 95% chance that you WILL see a question about it on the actual exam. After you have reviewed the objectives and completed your own research, then take the assessment exam. While the assessment exam will not tell you which question you answered incorrectly, it will tell you how you did by section. This will give you a good indication as to whether you are ready to take the actual exam or if you need to further review the materials. Note: This is the high-level list of objectives. As you review these objectives, click for a more detailed level of how to perform the task.

High-level Exam Objectives
Section 1 - DevOps Principles
1.1 Summarize different development approaches
1.2 Explain and identify delivery pipelines
1.3 Explain lean principles
1.4 Explain DevOps practices
1.5 Describe Collaborative Development
1.6 Describe Continuous Integration
1.7 Advantages to Continuous integration
1.8 Describe Continuous Delivery
1.9 Describe Continuous Deployment
1.10 Describe Continuous Availability / Service Management / Monitoring
1.11 Describe Continuous Security / Security for DevOps
1.12 Explain Shift-Left Test /Continuous Test
1.13 Explain Shift Left Ops
1.14 Explain Multi-speed IT
1.15 Explain Continuous Feedback
1.16 Explain the implications of the “12 Factor app” design principles for DevOps
1.17 ITIL and DevOps
Section 2 - Adopting DevOps
2.1 Describe business and IT drivers of DevOps
2.2 Explain the barriers to adoption of DevOps
2.3 Explain how to build a roadmap for DevOps adoption
2.4 Explain how to adopt DevOps in Multi-speed IT environment
2.5 Explain other continuous improvement approaches
2.6 Illustrate the cultural & organizational differences when transforming from traditional to DevOps processes
2.7 Planning & Organization
2.8 Performance & Culture
2.9 Measure
2.10 Explain the benefits of Design Thinking for DevOps process adoption
Section 3 - IBM DevOps Reference Architecture & Methods
3.1 Describe IBM DevOps Reference Architecture pattern
3.2 Explain the IBM point of view on DevOps
3.3 Explain DevOps for Microservices
3.4 Explain DevOps for Cloud Native
3.5 Explain DevOps for Cloud Ready
3.6 Explain Cloud Service Management Operations
3.7 Describe the IBM Bluemix Garage Method
3.8 Define and identify the common components of a DevOps Tool chain
3.9 Describe the key architectural decisions made to adopt DevOps
Section 4 - Open Source, Open Standard & Other Open Components
4.1 Identify tools for Build & Deploy
4.2 Identify tools for Collaboration & Notification
4.3 Identify other common tools and their uses
4.4 Describe common container technology
4.5 Explain the applicability of open standards for DevOps
Section 5 - IBM Solutions for DevOps
5.1 Describe the IBM solutions for the THINK phase in DevOps
5.2 Describe the IBM solutions for the CODE phase in DevOps
5.3 Describe the IBM solutions for the DELIVER phase in DevOps
5.4 Describe the IBM solutions for the RUN phase in DevOps
5.5 Describe the IBM solutions for the MANAGE phase in DevOps
5.6 Describe the IBM solutions for the LEARN phase in DevOps
5.7 Describe the IBM solutions for the CULTURE phase in DevOps
5.8 Describe the IBM solutions for Security in DevOps
5.9 Describe the IBM solutions for transformation and connectivity in DevOps

Detailed Exam Objectives
Section 1 - DevOps Principles
DevOps Principles This section focusses upon the core principles, definitions and practices of DevOps that recognised across the industry, and are vendor and solution agnostic. Essentially, this is about the WHAT is DevOps? It will cover the end to end process of DevOps, the common methods and terminology that a DevOps practitioner will regularly encounter during a DevOps solution implementation. Define DevOps DevOps is an approach that promotes closer collaboration between lines of business, development and IT operations. It is an enterprise capability that enables the continuous delivery, continuous deployment and continuous monitoring of applications. It reduces the time needed to address customer feedback. Development, testing, operations and lines of business were often siloed in the past. DevOps brings them together to improve agility. DevOps started as a culture and set of practices to support collaboration and communication across development and operations, and to apply automation to key phases of the software delivery process. It has been popularized by successful new companies developing business models and related applications empowered by the cloud (cloud-native applications). More recently, large, established enterprises have recognized the need to deliver innovation faster to stay relevant and capitalize on industry disruption, while also improving operational metrics for application quality and cost. DevOps and cloud have emerged as essential parts of their IT strategy as they improve core competency in continuous delivery of software-driven innovation. https://www.ibm.com/cloud-computing/learn-more/what-is-devops/ https://www-01.ibm.com/common/ssi/cgi-bin/ssialias?subtype=WH&infotype=SA&htmlfid=RAW14389USEN&attachment=RAW14389USEN.PDF https://en.wikipedia.org/wiki/DevOps 1.1. Summarize different development approaches 1.1.1. Define the different development approaches
In any enterprise you will see a number of development approaches, and often more than one including ,but not limited to: 1.1.1.1. Traditional waterfall 1.1.1.2. V-Model 1.1.1.3. Incremental 1.1.1.4. Agile 1.1.1.5. SAFe® 1.1.1.6. Disciplined Agile Delivery
1.1.2. Briefly describe traditional waterfall In a waterfall process all the requirements need to be defined in detail and signed off before design can start. Then the design has to be agreed before development can start. Next low level design, code and unit test complete (sometimes known as DCUT) needs to be shown before independent testing

can start, and finally release into production only happens when testing is complete. In practice very often these phases overlap, but the feedback loop between the phases is minimal.
1.1.3. Briefly describe the V-Model V- model means Verification and Validation model. Just like the waterfall model, the V-Shaped life cycle is a sequential path of execution of processes. Each phase must be completed before the next phase begins. Testing of the product is planned in parallel with a corresponding phase of development in V-model.
1.1.4. Briefly describe incremental method
In incremental model requirements are identified up front and then divided into various builds or iterations. Each iteration passes through the requirements, design, implementation and testing phases in a mini-waterfall way. A working version of software is produced during the first iteration, so you have working software early on during the software life cycle. Each subsequent release of the module adds function to the previous release. The process continues till the complete system is achieved.
1.1.5. Briefly describe agile development Agile development is typically defined by the 12 principles outlined in the Agile Manifesto below 1.1.5.1. The highest priority is to satisfy the customer through early and
continuous delivery of valuable software. 1.1.5.2. Welcome changing requirements, even late in development. Agile
processes harness change for the customer’s competitive advantage. 1.1.5.3. Deliver working software frequently, from a couple of weeks to a
couple of months, with a preference to the shorter timescale.

1.1.5.4. Business people and developers must work together daily throughout the project.
1.1.5.5. Build projects around motivated individuals. Give them the environment and support they need, and trust them to get the job done.
1.1.5.6. The most efficient and effective method of conveying information to and within a development team is face‐ to‐ face conversation.
1.1.5.7. Working software is the primary measure of progress. 1.1.5.8. Agile processes promote sustainable development. The sponsors,
developers, and users should be able to maintain a constant pace indefinitely.
1.1.5.9. Continuous attention to technical excellence and good design enhances agility.
1.1.5.10. Simplicity — the art of maximizing the amount of work not done — is essential.
1.1.5.11. The best architectures, requirements, and designs emerge from self‐ organizing teams.
1.1.5.12. At regular intervals, the team reflects on how to become more effective and then tunes and adjusts its behavior accordingly.
The Agile Manifesto and the principles behind it are published at www.agilemanifesto.org.
1.1.6. Briefly describe Scaled Agile Framework® (SAFe®) SAFe provides comprehensive guidance for achieving the benefits of Lean-Agile development at enterprise scale. It is designed to help enterprises deliver value continuously and more efficiently on a regular and predictable schedule, making them more Agile in the marketplace and more competitive in their industry. Many of the largest organizations in the world have adopted SAFe, and the adoption rate is accelerating. The Scaled Agile Framework® (SAFe®) is a freely revealed knowledge base of proven, integrated patterns for enterprise-scale Lean-Agile development. It is scalable and modular, allowing each organization to apply it in a way that provides better business outcomes and happier, more engaged employees.
1.1.7. Briefly describe Disciplined Agile Delivery (DAD) Disciplined Agile Delivery (DAD) is a process framework that encompasses the entire solution life cycle, acting like a hybrid of the best practices from many agile approaches. DAD sees the solution from initiation of the project through construction to the point of releasing the solution into production. The project is carved into phases with lightweight milestones to ensure that the project is focused on the right things at the right time, such as initial visioning, architectural modelling, risk management, and deployment planning. This differs from methods such as Scrum and XP, which focus on the construction aspects of the life cycle while details about how to perform initiation and release activities, or even how they fit into the overall life cycle, are typically missing. For more information on this topic, see Disciplined Agile Delivery: A Practitioner’s Guide to Agile Software Delivery in the Enterprise, by Scott W. Ambler and Mark Lines (IBM Press, 2012).

http://istqbexamcertification.com/what-is-v-model-advantages-disadvantages-and-when-to-use-it/ http://www.scaledagileframework.com/ http://www.disciplinedagiledelivery.com/introduction-to-dad/ https://www.ibm.com/ibm/devops/us/en/resources/dummiesbooks/
1.2. Explain and identify delivery pipelines
A delivery pipeline is so-named because it allows code to flow through a consistent, automated sequence of stages where each stage in the sequence tests the code from a different perspective. Each successive stage becomes more production-like in its testing and provides more confidence in the code as it progresses through the pipeline. While each stage is either building or testing the code, the stage must have the necessary automation to not only run the test but also to provision, deploy, set up, and configure the testing and staging environments. The code should progress through each stage automatically. The goal is to strive for unattended automation that eliminates or minimizes human intervention. There are many different terms and views on DevOps but there is consensus that an end to end DevOps process will cover capabilities that support;
Planning – covering the capabilities needed to turn business needs into requirements and organise the resources to deliver upon the plan.
Development – creating the application / service or artefact.
Source Code Management – controlling the source code, integrating changes and managing the different versions.
Build – combining the source code into binaries that can run in the target environment.
Package Repository – storing all the components and dependencies into a managed repository where the deployment team can build the target environment / application.
Deployment – the process of instantiating the application (and environment if necessary) to support the running application.
Testing – deploying the application to test environments supporting the verifying of the application that it meets its needs and expectations by performing a variety of increasing levels of testing.
Staging – deploying the application pre-production environment where final checks, security, data loads, and operational processes are verified prior to production deployment.
Production – where the application runs and responds to functional and non-functional needs.
Management – the operational processes that are performed on the application to ensure the service is maintained and the application is in good health.
Development SCM Build Package Repo Deploy Testing Staging Production Feedback Planning Manage

Feedback – the process to capture feedback from users, operation, business and other stakeholders that is returned to the development organisation for consideration in a future release.
Note: IBM organises these different capabilities into phases called THINK, CODE, DELIVER, RUN, MANAGE and LEARN defined within the IBM Bluemix Garage Method (See section 3.7). A typical continuous delivery pipeline will include the following capabilities: environment provisioning; build automation and continuous integration; test automation; and deployment automation.
1.2.1. Benefits of an Automated Delivery Pipeline
1.2.1.1. By providing automation, a pipeline removes the need for expensive and error-prone manual tasks.
1.2.1.2. New team members can get started and become productive faster because they don't need to learn a complex development and test environment.
1.2.1.3. Teams can detect any code that is not fit for delivery and then reject the code and provide feedback as early as possible.
1.2.1.4. A pipeline provides visibility into and confidence in the code as it progresses through successive stages where the testing becomes more like production.
1.2.2. Environment Provisioning The deployment pipeline is supported by platform provisioning and system configuration management, which allow teams to create, maintain and tear down complete environments automatically or at the push of a button. Automated platform provisioning ensures that your candidate applications are deployed to, and tests carried out against, correctly configured and reproducible environments. It also facilitates horizontal scalability and allows the business to try out new products in a sandbox environment at any time.
1.2.3. Build Automation and continuous integration The pipeline starts with building binaries to create the deliverables that will be eventually go to test and deployment stages. New features implemented by the developers are continuously integrated into a central code base, built and unit tested. This is also the first direct feedback opportunity for the development team regarding the robustness of their application code.
1.2.4. Test Automation As the name implies, the new version of an application is rigorously tested to ensure that it meets all desired system qualities. It is important that all relevant aspects (functionality, security, performance, compliance, etc…) are verified through testing. The stage often involves both automated and manual activities.
1.2.5. Deployment Automation A deployment occurs every time the application is installed in an environment for testing, and, most critically, when the application is rolled out to production. Since the preceding stages have verified the overall quality of the system, this should be a low-risk step. Additionally, to mitigate risk, the deployment can be staged, with the new version being initially released to a subset of the production environment and monitored before being completely rolled out.

The deployment is fully automated, allowing for the reliable delivery of new functionality to users within minutes instead of hours or days.
https://devops.com/continuous-delivery-pipeline/ https://www.ibm.com/devops/method/content/deliver/practice_delivery_pipeline/ https://www.ibm.com/devops/method/experience/culture/dibbe_edwards_devops_build_a_delivery_pipeline/
1.3. Explain lean principles
Critical factors for success in DevOps are well aligned with many of the lean principles. The factors include the following:
• Eliminate waste • Build quality in • Create knowledge • Defer commitment • Develop fast • Respect the people • Optimize the whole
Consider a team‐based example: Lean and agile thinking guides teams to
deliver in smaller increments and get early feedback. Thus, teams reduce cycle time by focusing only on those activities that maximize value based on feedback. Wasted effort is identified and eliminated, enabling teams to spend
time on value‐add activities, such as innovation and quality improvements. Now
consider scaling that process across the enterprise.By applying lean and agile
principles across the teams, the organization can align to focus on what matters — getting ideas into production quickly so customers can use them and provide feedback.
1.3.1. Principle 1: Eliminate waste “Waste is anything that interferes with giving customers what they value at the time and place where it will provide the most value. Anything we do that does not add customer value is waste, and any delay that keeps customers from getting value when they want it is also waste.” Waste found in a lot of development organizations includes: 1.3.1.1. Unnecessary overhead
o Internal paperwork o Red tape and change control
1.3.1.2. Unnecessary and late re-work o Delivery delays o Wait time o Defects
1.3.1.3. Building the Wrong Things o Extra features, not requested by the product owner o Complexity
1.3.2. Principle 2: Build Quality In “The job of tests, and the people that develop and runs tests, is to prevent defects, not to find them. A quality assurance organization should champion processes that build quality into the code from the start rather than test quality in later. This is not to say that verification is unnecessary. Final verification is a good idea. It’s just that finding defects should be the exception, not the rule,

during verification. If verification routinely triggers test-and-fix cycles, then the development process is defective. In software development, it should mean that we use test-driven development and continuous integration to be sure the code behaves exactly as intended at that point in time.”
1.3.3. Principle 3: Create Knowledge It is important to have a development process that encourages systematic learning throughout the development cycle, but we also need to systematically improve that development process. “Sometimes in the search for “standard” processes we have locked our processes up in documentation that makes it difficult for development teams to continually improve their own processes. A lean organization knows that it must constantly improve its processes because in a complex environment there will always be problems. Every abnormality should trigger a search for the root cause, experiments to find the best way to remedy the problem, and a change in process to keep it from resurfacing. Process improvement efforts should be the responsibility of development teams, and every team should set aside time to work on process improvement on a regular basis.”
1.3.4. Principle 4: Defer Commitment “Many people like to get tough decisions out of the way, to address risks head-on, to reduce the number of unknowns. However, in the face of uncertainty especially when it is accompanied by complexity, the more successful approach is to tackle tough problems by experimenting with various solutions, leaving critical options open until a decision must be made. In fact, many of the best software design strategies are specifically aimed at leaving options open so that irreversible decisions can be made as late as possible.” If plans are commitments, then we are committing to decisions made when we were the most ignorant. Measuring conformance to plan is measuring the wrong thing. Three tenants for deferring commitment: 1.3.4.1. First decide when the decision will be made – when is the last
responsible moment 1.3.4.2. Don’t make the decision until that time - you have the most
information you can get 1.3.4.3. Don’t make the decision before that time – you may commit yourself
to something that is not optimal 1.3.5. Principle 5: Deliver Fast
To reduce cycle time you need to: 1.3.5.1. Even out the arrival of work 1.3.5.2. Minimize the number of things in process 1.3.5.3. Minimize the size of things in process 1.3.5.4. Establish a regular cadence 1.3.5.5. Limit work to capacity 1.3.5.6. Use pull scheduling
1.3.6. Principle 6: Respect People Your people are your greatest asset. They have bright ideas. Celebrate the wild ducks and encourage their innovation. There is no such thing as “one best way”. “There is no process that cannot be improved. Processes should be improved by the work team doing the job. They need the time and the

empowerment to tackle their problems, one at a time, biggest bottleneck first. It is a never ending continuous improvement process.”
1.3.7. Principle 7: Optimize the whole A lean organization identifies bottlenecks across the entire value stream. It is easy to optimize in silos, but harder to manage bottlenecks when there are delays in handoff of responsibilities. If you break a value stream into silos and optimize them separately, experience has shown that the overall system will almost certainly be sub-optimized. Finding metrics that measures the entire lifecycle that is ‘Measure UP’ will enable a value stream optimization.
https://www.infoq.com/resource/articles/poppendieck-implementing-lean/en/resources/poppendieck_ch02.pdf
1.4. Explain DevOps practices 1.4.1. Summarize the classification of practices
The practices used in a DevOps implementation can be loosely categorized as: 1.4.1.1. Collaboration practices 1.4.1.2. Delivery practices 1.4.1.3. Leadership practices
1.4.2. Describe the Collaborative practices Collaborative practices aim at creating an environment in which DevOps teams can respond rapidly to customer’s demands, deal effectively with changing situations, and convert new knowledge gained through shared experiences which require constant interactions and exchanges between team members.
1.4.3. Practices 1.4.3.1. Issues Bull's Eye - one of several visual management systems that
can be used in Agile, providing clear cues that make it obvious that something needs to be discussed.
1.4.3.2. Mood Marbles - can provide team members with a way to anonymously display their mood each day.
1.4.3.3. Planning Poker - planning poker is a crowd-based technique for estimating the amount of effort or relative size of a story.
1.4.3.4. Retrospectives - A Retrospective is an event for the team to discuss what went well, what did not go well and to define improvement for the upcoming period, iteration, release, meeting and workshop. Use a Retrospective work item type, to ensure that this event occurs and to track the team's comments and plans. It is a key technique to help in continuous team/end user alignment.
1.4.3.5. Showcase - used to demonstrate the completed iteration features to the product owner and stakeholders, solicit their feedback and present a discussion opportunity for course correction.
1.4.3.6. Social Contract - a team-designed agreement for a aspirational set of values, behaviors and social norms. It is a vision for how it would be to work in an incredibly safe and powerful team.
1.4.3.7. Stand-Ups - a great technique to get everyone in your team up to speed, to facilitate brainstorm discussions and to enable collaboration.

1.4.3.8. Story Cards - a technique to capture user requirements in small chunks so the team can understand, design, and build the solution within the time constraint of a single iteration.
1.4.4. Describe the Delivery practices This section includes a set of practices within the Delivery capabilities. DevOps practitioners should choose those that will address their highest priority bottleneck.
1.4.5. Practices 1.4.5.1. AB Testing - two versions of code are executed and experimented
simultaneously to define which one is successful based on pre-set criteria.
1.4.5.2. Application Technical Debt Management - application technical debt is the future cost of not making improvements to your application code which, over time, will result in higher maintenance expenses, increased labor, limited functionality and reduced quality.
1.4.5.3. Automated Data and Database Object Migration - leverages automation to migrate data and database objects from existing systems to new systems.
1.4.5.4. Automated Deployment - allows for application teams to automatically, reliably and securely deploy entire application runtime environments from development to production.
1.4.5.5. Automated Rollbacks - the ability to automatically “revert” or “fallback” to the previous version of the release.
1.4.5.6. Automated SoD - Separation of Duties (SoD) is defined as ensuring no single person can introduce fraudulent or malicious code or data without detection.
1.4.5.7. Behavior Driven Development - a development methodology where the acceptance criteria are in the form of an executable test prior to coding and testing.
1.4.5.8. Blue/Green Deployment - consists of having two production instances but only one is live at any point in time.
1.4.5.9. Infrastructure as Code - configuration and script management as code leverages scripts to automate the configuration of the infrastructure for creating environments and managing deployments.
1.4.5.10. Continuous Build and Integration - continuous build is about assembling multiple components as a system. Continuous integration is about integrating continuous builds.
1.4.5.11. Deployment Certification - deployment certification is the techniques that support automated deployment while satisfying the restriction criteria.
1.4.5.12. Design Application to be Testable - the ability to automate testing at the appropriate levels of testing is heavily dependent on the design of the application.
1.4.5.13. Feature Decoupling from Release - feature decoupling enables you to deploy an application with some features hidden, which can be exposed later without re-releasing the application.
1.4.5.14. Refactoring - Changing an existing body of code to improve its internal structure

1.4.5.15. Software Configuration Management - the task of tracking and controlling changes in the software. Practices include revision control and the establishment of baselines.
1.4.5.16. Test Automation Strategy - a test automation strategy considers where automation is appropriate and what tools are right for the project.
1.4.5.17. Test Driven Development - a core agile and DevOps practice which is a complement to development methods where test cases are key to the development process.
1.4.5.18. Test Environments under Change Control - resemble the production environment and ensure changes are tracked and continue to reflect the production environment.
1.4.5.19. Test Suites as part of Continuous Integration - incorporates automated testing as an integral part of the Continuous Integration process.
1.4.5.20. Test Virtualization - the "virtualization" of components or interfaces so that they can be managed and accessed in a virtualized test environment.
1.4.5.21. Version Control - a system that records changes so that you can recall specific versions.
1.4.6. Describe the Leadership practices
Agile practices that ultimately change behaviour: 1.4.7. Practices
1.4.7.1. Backlog Refinement - Agile teams use backlog refinement to ensure that the product backlog is current and complete.
1.4.7.2. Burn-Down and Burn-Up charts - these are two alternate ways of depicting the rate of progress a team is making.
1.4.7.3. Engaging the Product owner - the vision, product goals and link to the customer provided by the Product Owner help the team achieve a successful outcome through clarity of purpose.
1.4.7.4. Estimation and Story Points - this practice involves whole teams collaborate to agree on the relative size of user stories.
1.4.7.5. Iteration Planning - Agile teams collaborating to select, understand, estimate and commit the work to be done in the upcoming iteration.
1.4.7.6. Kaizen & Continuous Improvement - Kaizen always seeks accelerating improvement and reducing waste (muda) where the work takes place (gemba).
1.4.7.7. Kanban - a concept born out of lean manufacturing which agile teams use as a key component of continuous improvement.
1.4.7.8. Release Planning - the activity where epics and features are discussed and understood, decomposed into smaller stories; which are then estimated in story points.
1.4.7.9. User Story, Acceptance Criteria and Definition of Done - User story is defined as a user need, Acceptance Criteria is the set of requirements pertinent to one user story, Definition of Done is a set of criteria that is common across multiple related user stories.
1.4.7.10. Wall of Work - makes the flow of knowledge work visible so the team can see the work waiting to be done, what's being worked on and what's finished.

1.4.7.11. Whole Team - includes the Product Owner, Project Manager, Iteration Manager, developers, the needed analysts and subject matter experts.
1.5. Describe Collaborative Development
Software delivery efforts in an enterprise involve large numbers of cross-functional teams, including lines-of-business owners, business analysts, enterprise and software architects, developers, QA practitioners, operations personnel, security specialists, suppliers, and partners. Practitioners from these teams work on multiple platforms and may be spread across multiple locations. Collaborative development enables these practitioners to work together by providing a common set of practices and a common platform they can use to create and deliver software.
https://www.ibm.com/ibm/devops/us/en/resources/dummiesbooks/
1.6. Describe Continuous Integration
Continuous Integration is the process that monitors the source code management tool for any changes introduced to the mainline, changes then automatically triggers a build and the associated automated build acceptance testing. This is required to ensure the code maintains a certain level of stability and all changes are being integrated often to find code conflicts early. Continuous Integration requires that every time someone commits changes to Source Control Management (SCM), the entire applications is built and a compressive set of automated test run against the new build. If the build fails, rapid feedback is provided to the developer, they are able apply to fix the problem immediately. The goal is that the software is in a working state at all times. Continuous Integration was developed to solve the problem of long lived branching in the SCM environment which makes merging of those branched more complex the longer they remained branched. When long lived branches are merged, the integration challenges often required substantial amounts of rework to get them back into a deployable state. Continuous Integration was designed to solve these problems by making merging a part of a developer’s daily work. Continuous Integration is a practice that requires commitment from the team and the discipline to check-in small incremental code changes frequently to mainline with the agreement that if the build fails, the developer immediately fixes the issues.
1.7. Advantages to Continuous integration: 1.7.1. Teams that use Continuous Integration effectively are able to delivery code
much faster and with fewer bugs. 1.7.2. Bugs caught early in the delivery process provide significant cost and time
savings. 1.8. Describe Continuous Delivery

Continuous Delivery is the ability to get changes of all types—including new features, configuration changes, bug fixes and experiments—into production, or into the hands of users, as safely and quickly as is sustainable. Our goal is to make deployments—whether of a large-scale distributed system, a complex production environment, an embedded system, or an application, on Premise or cloud based—predictable, routine affairs that can be performed on demand. Continuous delivery requires that code changes constantly flow from development all the way through to production. To continuously deliver in a consistent and reliable way, a team must break down the software delivery process into delivery stages and automate the movement of the code through the stages to create a delivery pipeline. We achieve all this by ensuring our code is always in a deployable state, even in the face of teams of thousands of developers making changes on a daily basis.
https://continuousdelivery.com/
1.9. Describe Continuous Deployment
Continuous deployment is the release of code to production as quickly and frequently as possible through the process of automation that is consistent across build, test and production.
1.9.1. Describe the differences between Continuous Delivery and Continuous Deployment 1.9.1.1. Continuous delivery is a series of practices designed to ensure that
code can be rapidly and safely deployed to production delivering every change to a production-like environment and ensuring business applications and services function as expected through rigorous automated testing. Since every change is delivered to a staging environment using complete automation, you can have confidence the application can be deployed to production with a push of a button when required
1.9.1.2. Continuous deployment is the next step of continuous delivery. For every change that passes the automated tests it is deployed to production automatically. The business needs dictate whether continuous deployment is viable as it is not an IT limitation. For example, there may be regulatory requirements that prevent an automatic push to Production upon completion of testing.

https://sdarchitect.blog/2013/10/16/understanding-devops-part-6-continuous-deployment/ https://www.ibm.com/devops/method/content/deliver/practice_automated_deployment/ http://www-01.ibm.com/common/ssi/cgi-bin/ssialias?subtype=BK&infotype=PM&appname=SWGE_RA_VF_USEN&htmlfid=RAM14026USEN&attachment=RAM14026USEN.PDF
1.10. Describe Continuous Availability / Service Management / Monitoring 1.10.1. Describe Continuous Availability (CA)
Continuous availability is the ability to transparently withstand component failures, to introduce changes non-disruptively, and to withstand catastrophes transparently or nearly transparently. Clouds simplify the implementation of continuous availability with dynamic scaling.
1.10.2. Describe IT Service Management (ITSM) IT Service Management refers to all activities that are performed by an organization to plan, design, deliver, operate, and control IT and cloud services that are offered to customers. This includes incident and problem management to respond to outages, and change, release, and configuration management to assure seamless deployment and release of new versions.
1.10.3. Define incident management Restores normal service operation as quickly as possible and minimizes the adverse effect on business operations, ensuring that the best possible levels of service quality and availability are maintained. Capabilities include event correlation, monitoring, log monitoring, collaboration, notification, dashboard, and runbooks.
1.10.4. Define problem management Resolves the root causes of incidents to minimize the adverse impact of incidents caused by errors, and to prevent the recurrence of incidents related to these errors. Capabilities include root cause analysis, incident analysis, and aspects of incident management.
1.10.5. Define change & configuration management Change management ensures that standardized methods and procedures are used for efficient handling of all changes. Capabilities include backlog, develop, test, approve, and change.
1.10.6. Define change management Configuration management focuses on maintaining the information required to deliver a service, including relationships. Capabilities include request configuration, topology, and approve configuration.
1.10.7. Explain what is the ITSM toolchain The ITSM toolchain is the collection of products and solutions that support operations tasks. The complete toolchain is usually split into a number of independent yet overlapping toolchains, each of which may support a different operations management domain and be used by different roles.
1.10.8. Explain the difference between the use a ITSM toolchain in a traditional environment versus a cloud-oriented environment In a traditional environment the customer owns (or is responsible for) much of the infrastructure. In a PaaS cloud environment, the customer is not responsible for, and does not have access to, the underlying infrastructure of the system, so functions such as asset management no longer apply.

Typically, cloud based SLAs and expectations are higher than for traditional applications and the downtime budget (i.e. how much downtime can occur and still achieve SLAs) is much smaller. This forces a higher level of efficiency, cooperation, and responsibility of the incident participants. There is no full hand-over of the responsibility, rather there is a breaking down of silos in what is commonly called "ChatOps".
1.10.9. Describe Toolchain Capabilities 1.10.9.1. Explain what performance monitoring is (metrics)
Performance monitoring is the collection and processing of quantitative information. This may include information about quantities, rates, percentages and anything else in the environment that may be measured. The term "4 golden signals" refers to Latency, Traffic, Errors and Saturation measurement.
1.10.9.2. Explain what user experience / synthetic transaction monitoring is User experience monitoring is monitoring parameters that are explicitly correlated with human interaction of the application. For example, measuring the latency of an application opening a web-site is user experience monitoring. Measuring the latency for a message to be delivered from one backend application to another is not. Synthetic transactions are transactions that are generated in a controlled manner (either by a scheduler or a robot) and are used to check the status of the application without needing a human to interact with it.
1.10.9.3. Explain log monitoring Logs are streams of aggregated, time-ordered events collected from all the running processes and backing services of the application. The logs may contain errors or information which can be used to diagnose another error detected elsewhere.
1.10.9.4. Explain event monitoring Monitoring systems are designed to trigger events when a change condition occurs. This may be the simple crossing of a threshold, a specific event or log message being detected, a state change of a component or may be more complex such as a trigger that waits for a percentage of transactions to fail or compares values over time.
1.10.9.5. Explain event correlation The purpose of the event correlation engine is to make sure that only the most important and business-affecting events are forwarded as actionable incidents. Event correlation occurs when a number of events are sent to the Event Management engine and it finds a connection between them. For example, if the monitoring components of the tool chain detect that the latency of multiple users performing a query is high, then then events will be de-deduplicated and only one incident will be presented to the 1st responders. Also, the event correlation engine may attach other events to the incident (for example, if it received an event regarding the performance of the database of the application)
1.10.9.6. Explain event enrichment Event enrichment is the process of adding meta-data to an event in order to improve the process of solving the issue. Examples of

enrichment include finding the overall service or customer affected by the event, the name of the owner or even something as simple as translating an IP address to a domain name.
1.10.9.7. Explain collaboration / ChatOps ChatOps is a collaboration model that connects people, tools, process, and automation into a transparent workflow. This flow connects the work needed, the work happening, and the work done in a persistent location staffed by the people, bots, and related tools. The transparency tightens the feedback loop, improves information sharing, and enhances team collaboration.
1.10.9.8. Explain Runbooks A runbook is a set of routine procedures that are a response to a given incident and remediation. The refinement of the runbook may include a completely automated solution triggered by the toolchain that resolves the incident or a runbook could be a "how-to" document that contains manual instructions for the 1st responder to follow.
Continuous Availability: http://www.redbooks.ibm.com/abstracts/redp5109.html?Open http://www.redbooks.ibm.com/redpapers/pdfs/redp5090.pdf ITSM/CSMO: https://developer.ibm.com/architecture/gallery/incidentManagement/walkthrough https://developer.ibm.com/architecture/serviceManagement SRE & ChatOps: http://shop.oreilly.com/product/0636920041528.do / Site Reliability Engineering: How Google Runs Production Systems https://blogs.atlassian.com/2016/01/what-is-chatops-adoption-guide/ 1.11. Describe Continuous Security / Security for DevOps 1.11.1. What is Continuous Security?
Adoption of DevOps practices introduces complications for implementing and auditing standardized security controls, presenting issues such as constantly changing assets, continuous deployment and a breakdown in the traditional segregation of duties. Yet DevOps tools and philosophies can also provide advantages, providing opportunity for integration of security automation as part of the development and deployment of applications and giving Security early input into design and implementation
DevOps by design blurs lines between developer and operator of an application, which can lead to questions regarding segregation of duties if proper checkpoints aren’t introduced to limit a particular developer’s end-to-end control over the system. Even with these challenges, the DevOps movement has several major advantages in improving software security. The DevOps focus on fast deployment, continual improvement, and automation naturally forces collaboration with security teams; without this collaboration, a potential deployment barrier exists in the form of last-minute manual audits and reviews.

Secure by design development strategies are maturing at the same time that DevOps projects are emerging. A secure by design development strategy as exemplified by the IBM secure engineering framework can be applied to DevOps projects.
These frameworks cover multiple prospective recognizing that vulnerabilities can be introduced from multiple entry points including: 1.11.1.1. From the Supplier chain, these could be from either external or
internal suppliers 1.11.1.2. Insider attacks, individuals that have access to development
artefacts, deployment artefacts, or to the systems that do the deployments and manage configurations
1.11.1.3. Errors or mistakes made by the development project, 1.11.1.4. Weakness in the design, code or integrations.
1.11.2. Recognizing these entry points, security standards and risk compliance frameworks must include at minimum the following: 1.11.2.1. the concept of physical security, to ensure the security of the
premises 1.11.2.2. they must include security of the delivery pipeline itself, and 1.11.2.3. Include security of the deliverable.
1.11.3. Securing the delivery pipeline can be broken down further into the following sub categories: 1.11.3.1. Implementing secure engineering principals, the application
architecture must be built with secure as a fore thought to minimize threat models and attack patterns. Developers must understand and implement secure development practices, both whitebox and blackbox code scanning needs to be included. The developer workstation should be able to support whitebox static code scans, these security code scans need to be included as automation when the application enters the Build or Continuous Integration stage. A remediation process in important here to ensure that security fixes are prioritized by the development team. Further automated Blackbox penetration testing needs to be run regularly to simulate hackers hitting the web page. These penetration test should run not only in QA, but against productions as well to ensure no security flaws have been inserted into production.
1.11.3.2. A patch management strategy is also an important capability to be
include as it ensure that know vulnerabilities in the OS or middleware environments are patch and current.
1.11.3.3. The framework should include content to ensure that secure development platform and tooling are deployed, ensuring no one can tamper with or have access to Software Configuration/Version Management system, or security of the build and deployment environments, such that once a build and the associated unit test and security scans are complete, the build artefact is placed into a tamper proof repository.
1.11.3.4. Framework includes the need for separation of duties to ensure only those that are authorized to execute a task are in fact able to, but not authorized are unable to have access to run the task. Thus

making sure we have a well-integrated access control system is key. Also need to ensure scripts that are run to install, configure or deploy aspects of the environment are secure and void from introducing vulnerabilities. Improper access can result in information being altered, destroyed, misappropriated, or can result in misuse of your systems to attack others.
The cultural and technical practices that comprise the DevOps shift have both advantages and disadvantages when implementing a security based controls infrastructure. In a regulated environment, DevOps teams will need to involve security early in the process to ensure a smooth deployment for new features; the opportunity for greater collaboration with security teams can only be a positive step.
Sources: https://devops.com/automated-security-testing-continuous-delivery-pipeline/ Continuous Security: Implementing the Critical Controls in a DevOps Environment
1.12. Explain Shift-Left Test /Continuous Test 1.12.1. Shift Left Test
Shift left testing is an approach to software testing and system testing in which testing is performed earlier in the lifecycle (i.e., moved left on the project timeline).
The goal is to increase quality, shorten long test cycles, and reduce the possibility of unpredictable results at the end of the development cycle—or still worse, in production.
Advantages: 1.12.1.1. Shift Left practices help to avoid rework, delays and churn that can
occur when major defects are discovered late in the testing cycle. 1.12.1.2. By proactively testing high-risk integrations early and frequently,
delivery teams can isolate the most disruptive, significant defects sooner for faster remediation.
1.12.1.3. By shifting integration testing and feedback left—that is, closer to the beginning of the delivery pipeline—technical risk and the possibility of market failure are reduced
1.12.1.4. Shift left testing finds problems earlier where they are much less expensive to fix. Multiple studies have determined that it’s exponentially more expensive to fix a defect found once it has been released.
Enablers for Shift-left testing include pair programming, test driven development, automated integration testing. Additionally if any of the dependent application components aren’t available to test, virtual services can mimic the real components’ behavior until they’re ready.

1.12.2. Continuous Test
Continuous Test means automated testing earlier and continuously across the life cycle. The goal is to reduce costs and shortened testing cycles and achieved continuous feedback on quality. In a DevOps continuous delivery environment, the first principle is that no code is delivered without automated tests. Determining where to invest in test automation requires a strategy. Consider the test automation pyramid:
Here, the largest numbers of tests are unit and API tests. Test-driven development ensures that the team creates unit tests and has a robust framework that makes them easy to write, deliver, and run. Adopting behavior-driven development (BDD) creates a robust, maintainable test automation framework for customer acceptance tests using the API or Service layer. In fact, the combination of developers implementing BDD scenarios, in conjunction with their code delivery, tends to ensure the testability of the API or Service layer. This helps teams achieve the desired structure of the pyramid. Typically, these tests are run in a deployed test environment and include integration tests, which are sometimes called "system" tests. Finally, there is GUI test automation. This is typically the hardest to write and maintain. As a best practice, if the GUI tests can simply verify that everything is "hooked up," meaning that values entered though the UI are passed correctly to the APIs that were robustly tested independently, then this layer

can indeed be even smaller than represented in the pyramid above. The smaller the top portion of the pyramid, the better. Across all layers of testing, it is important to take into consideration how the tests will run automatically. For unit tests, there are many industry standard frameworks that run with the continuous integration build. For API or service and GUI tests, setting up the production-like test environment is automated with the same deployment automation used for delivering to production. These test environments require deploying test tools, test scripts, and possibly test data, into the test environments to allow the tests to run unattended. When implementing a test automation framework, introducing dependencies increases the complexity of automatically running the tests, and so this is to be avoided. Steps to establishing a continuous testing strategy: 1.12.2.1. Store the test automation code base in version control repository. 1.12.2.2. Automation suite must be integrated with the build deployment tool
to enable centralized execution and reporting. 1.12.2.3. To enable faster feedback at each checkpoint, there is a need to
classify the automation suite in multiple layers of tests. The most common types of these tests are: o Unit tests: run automatically by the developers as code is
developed o Health check: this is an automated check to verify that services
are up after deployment. o Smoke tests: this most critical set of automated tests ensures
that system features are operational and no blocking defects occur.
o Full scale regression test: the goal is to keep feedback time as short as possible through parallel execution of automated tests through multiple threads or machines.
o Intelligent regression: if the execution time for overall regression test is significantly high, continuous test setup becomes less effective due to longer feedback cycles. In such a scenario, full regression execution can be shifted to overnight or during the weekend depending on its alignment with recurring build frequencies.
1.12.2.4. Existing automation tests and migrating tests may need to be simplified.
1.12.2.5. To effectively use available resources and establish the ability to run the load tests on-demand without wasting time and resources, organisations should consider building a cloud infrastructure.
1.12.2.6. The results of these tests should be provided as feedback to the developers and as quality controls to determine if the code should progress to higher level environments.
http://www.devopsonline.co.uk/jumpstarting-devops-with-continuous-testing/ https://www.ibm.com/devops/method/content/code/practice_automated_testing/ https://www.ibm.com/developerworks/community/blogs/rqtm/entry/what_is_shift_left_testing?lang=en

1.13. Explain Shift Left Ops In the DevOps delivery pipeline, Shift Left Ops involves integrating the Operations functions as part of the overall DevOps team. “If you build it, you run it” is a mantra of many DevOps teams. Environment provisioning, configuration, deployment, go-live, management, and monitoring are all responsibilities of the DevOps team.
Goal : The build process can include the tasks like compilation, automated unit tests, static code analysis, data operations etc. Most of the time build process generates deployable or executable package.
A goal of the DevOps movement is to engage everyone who is involved in the process of building, deploying, testing, and releasing software working and collaborating together. This enables organizations to use the exact same binaries and the same processes for deploying into every environment. Differences between environments should be captured as configuration detail.
1.13.1. These different organizations will include: 1.13.1.1. Development 1.13.1.2. Deployment 1.13.1.3. QA and Testing 1.13.1.4. Operations 1.13.1.5. Support 1.13.1.6. Security 1.13.1.7. Database Administration 1.13.1.8. Network Administration
1.13.2. Advantages : 1.13.2.1. Shift Left Ops enables DevOps teams to deploy to all stages
including production with confidence and understanding of all details for successful delivery.
1.13.2.2. By getting all teams working together, an organization is able to understand the complexities of deploying applications and work out how to automate these application deployments in a seamless and reliable, repeatable manner.
1.13.3. Understand ‘Build to manage’ Build to Manage is a new approach to operations which specifies the practice of activities developers can do in order to instrument the application, or provide manageability aspects as part of an application The “Build to Manage” approach includes the following aspects: 1.13.3.1. HealthCheck API - endpoint to a RESTful (micro) service allows a
quick, standardized method to validate the status of a component and all its dependencies. As a microservice component has a relatively small and clearly defined scope, the component owner/developer will be well positioned to understand all the dependencies and how to best validate their availability.
1.13.3.2. Log Format and Catalog - It is important that the log entries are readable to humans. Avoid using complex encoding that would require lookups to make event information intelligible. At the same time, systems should also be able to parse logfiles easily and rapidly. The way to do this is to generate a unique identifier on

every log entry type. Reading and parsing a variety of log entries and a multitude of logfiles of a distributed environment can be made easier by prepending unique identifiers (UID) to each log line.
1.13.3.3. Deployment correlation - It is important that the delivery pipeline has the ability to register the deployment event with relevant information with a deployment marker tool. A deployment marker for a deployment artifact is typically an empty file with the same name as the artifact with the file suffix indicating the state of the application's deployment. These files mark the status of an application within the deployment directory.
1.13.3.4. Distributed Tracing- Distributed Tracing is a technique where a unique Transaction ID is passed through the call chain of each transaction in a distributed application topology, such as micro services based topologies. Try to pass the id you generated on an entry point to each subsystem that is used to finish the job. Ideally this should be done transparently, via wrapper functions and http headers where possible. o Advanced Latency analysis - Attaching timing information to
the transaction enables an in depth, end-to-end analysis of the total time it takes for the topology to process a single transaction, with the ability to drill down to find bottle-necks within the system.
o Log correlation - You should create unique identifiers for transactions that involve processing across many threads and/or processes. The initiator of the transaction should create the ID, and it should be passed to every component that performs work for the transaction. This ID should be logged by each component when logging information about the transaction. This makes it much easier to trace a specific transaction when many transactions are being processed concurrently
o Topology view / Service Maps - Correlating the captured transaction id together with application/service identification and other meta data makes it possible to build out a topology view, or dependency map of all the services in the topology.
1.13.3.5. Topology Information – o Deployment Descriptors for Container In Docker, the docker-
compose.yml file defines services, networks and volumes. See https://docs.docker.com/compose/compose-file/ for a reference of the file structure. Below you find the key sections relevant to dependencies.
o Deployment Descriptor in XML - Security and dependencies can also be added to .xml files.
o Enhancing Deployment Descriptor - The information in deployment descriptors can be paired with additional information, such as information about SLAs / SLOs or tenants. Another example would be version information or linkage to feature requests or defects.
1.13.3.6. Event Format and Catalog - In addition to monitoring and logs, applications may also emit alerts. Although many applications in

the cloud use logs as the sole way of generating alerts, there may be reasons why organizations want to continue using the direct way of alerting.
1.13.3.7. Test Cases and Scripts - Automated unit and integration tests can validate server-side and client-side features independently using an API contract. Tools can mimic user actions in functional test to validate important inter-system workflows. Ideally these tests would be the same tests used in development functional testing.
1.13.3.8. Runbooks - Runbook Automation is an effective way to optimized the error budget: Runbooks codify the individual steps to be executed, allowing an automated execution of these steps. Further, the execution of these runbooks could be triggered automatically, reducing the wait time until actions are initiated.
1.13.3.9. First Failure Data Capture- is to automatically collect the data as soon as the application detects an error. This is what we call First Failure Data Capture (FFDC). The FFDC feature instantly collects information about events and conditions that might lead up to a failure. The captured data in these files can be used to analyze a problem. Code will be instrumented to dump valuable information in a crash situation.
https://www.ibm.com/ibm/devops/us/en/solutions/ https://www.ibm.com/devops/method/category/manage
1.14. Explain Multi-speed IT
In today's world, teams must develop new applications as fast as possible and reduce the cost of hosting applications by delivering on the cloud. To make that happen, teams often must integrate new applications with traditional applications. In that situation, it's likely that at least two teams are involved in the project: the cloud application team and the traditional application team. If those teams deliver new function at different speeds, they are practicing multi-speed IT.

Bimodal is the practice of managing two separate but coherent styles of work: one focused on predictability; the other on exploration. Mode 1 is optimized for areas that are more predictable and well-understood. It focuses on exploiting what is known, while renovating the legacy environment into a state that is fit for a digital world. Mode 2 is exploratory, experimenting to solve new problems and optimized for areas of uncertainty. These initiatives often begin with a hypothesis that is tested and adapted during a process involving short iterations, potentially adopting a minimum viable product (MVP) approach. Both modes are essential to create substantial value and drive significant organizational change, and neither is static. Combining a more predictable evolution of products and technologies (Mode 1) with the new and innovative (Mode 2) is the essence of an enterprise bimodal capability. Both play an essential role in the digital transformation. Bimodal IT is also sometimes referred to as ‘2-Speed IT’. This view is being referred to in the industry as “bi-modal IT” and is actually more of a continuum than a clear-cut two modes model. Hence, the term is evolving now to “Multi-speed IT.” This is the IBM view which represents a more pragmatic view of what is happening in the market. (You will never find a customer who is implementing just Mode 1 or Mode2, but instead will have a range of different speeds). https://devops.com/devops-agility-multi-speed-it/ http://www.gartner.com/it-glossary/bimodal/

https://developer.ibm.com/architecture/pdfs/IBMCloud-AC-DEvOpsMultiSpeedIT-35.pdf https://www.ibm.com/devops/method/content/culture/practice_multispeed_it/ https://www.ibm.com/developerworks/community/blogs/gcuomo/entry/two_speed_integration_by_ibm?lang=en https://www.ibm.com/devops/method/content/tracks/hybrid_track_overview https://devops.com/devops-agility-multi-speed-it/
1.15. Explain Continuous Feedback
Organizations are realizing the benefit of a DevOps approach with people, process, and technology as a way to drive software delivery speed and, ultimately, business results.
But it is paramount for teams involved with DevOps to understand what they need to deliver and to understand the people to whom they are delivering too? Despite great advancements in delivery, quality service still begins with communicating with and understanding the needs of users, including not just product owners and all stakeholders, but also developers, test engineers and operations.
Feedback loops are a key enabler for modern delivery. In order to link customers to DevOps, you need to focus on user delivery needs by amplifying and shortening your feedback loops. Almost every implemented DevOps process should aim for accelerated response times and continuous release based on user requests and usage behavior.
"Feedback loops galore will fuel your data-driven decisions and offer entirely new levels of precision and rapid adjustment. Traditionally, hand-offs waste a lot of time. If you want to accelerate your feedback loops, eliminate as many hand-offs as possible to help development flow throughout your system.
The goal of Continuous Feedback is that is happens at every stage of the delivery pipeline. Every stakeholder provides feedback to the stakeholders to their left in the pipeline - testers to developers, developers to architects/designers/analysts, analysts to the business, etc.
In DevOps, the dev and test team members work closely with operations, often as a unified, multi-skilled team set on carrying out common, customer-related goals. By knowing their users, developers can build products on top of a loosely coupled architecture, making sure to reduce complexity and enhance delivery flexibility. Along with making it easier to understand customers' needs, flexibility can help the team deliver the smallest amount of functionality that produces value in the most efficient manner. With their new position in the delivery process, developers have an enhanced responsibility to users and depend on user feedback to constantly deliver value.
Test engineers, as the first end users of new features, should be able to see the whole picture. Similar to product owners, testers should directly interact with users, which allows them to qualitatively assess a feature's value and
https://www.ibm.com/developerworks/community/blogs/gcuomo/entry/two_speed_integration_by_ibm?lang=en

readiness. Knowing users in person helps testers work with product owners in order to build user focus groups, which can help run a controlled UAT.
Your operations team must understand user behaviour and business needs. Simply knowing that the system should be up and running 24x7 is not enough. Operations should know, understand, and take part in building service-level agreements with users. By doing so, they can plan, implement, build, and maintain their environment according to user expectations.
Continuously capturing and responding to feedback is key to rapidly and repeatedly turning innovative ideas into highly relevant and desirable products and services. It is based on delivery as well as customer feedback in order to make improvements.
1.16. Explain the implications of the “12 Factor app” design principles for
DevOps 1.16.1. List the "12 Factor app" principles
1.16.1.1. Codebase - One codebase tracked in revision control, many deploys.
1.16.1.2. Dependencies - Explicitly declare and isolate dependencies. 1.16.1.3. Config - Store config in the environment. 1.16.1.4. Backing Services - Treat backing services as attached resources. 1.16.1.5. Build, release, run - Strictly separate build and run stages. 1.16.1.6. Processes - Execute the app as one or more stateless processes. 1.16.1.7. Port binding - Export services via port binding. 1.16.1.8. Concurrency - Scale out via the process model. 1.16.1.9. Disposability - Maximize robustness with fast startup and graceful
shutdown. 1.16.1.10. Dev/prod parity - Keep development, staging, and production as
similar as possible. 1.16.1.11. Logs - Treat logs as event streams. 1.16.1.12. Admin processes - Run admin/management tasks as one-off
processes 1.16.2. Explain the benefits of 12 factor app development in cloud
The 12 factors of app development are a methodology for building apps that have a clean contract with underlying operating system, enable continuous deployment with maximum agility, significant scale up capability, and are independent of programming languages and back end services. It leverages the modern cloud platforms principles with emphasis on agility.
1.16.3. Explain the meaning of anti-fragile development Especially in cloud architectures, there is a high level of volatility and change in the application environment. Instead of building robust applications that are highly resistant to the expected changes but vulnerable to unexpected changes ("black swans"), DevOps prefers designing anti-fragile solutions that will accept and "embrace change". An antifragile system evolves its identity in order to improve itself. It does not simply resist external stimuli that cause issues, it uses them as learning experiences for continuous improvement (i.e. via continuous feedback). It then follows that to implement anti-fragile development you should periodically induce failures in the

systems to test resilience and validate correct responses (both by the application and the human processes supporting it)
1.16.4. Explain "Simian Army" The "Simian Army" is a gold standard for antifragility developed and used by Netflix. According to Netflix: “They are services (Monkeys) in the cloud for generating various kinds of failures, detecting abnormal conditions, and testing our ability to survive them. The goal is to keep our cloud safe, secure, and highly available." The various monkeys each attempt to disrupt the applications and cloud environment. Making sure that the monkeys fail validates that the systems will survive unplanned disruptions. https://12factor.net/ http://www.sciencedirect.com/science/article/pii/S1877050916302290 https://github.com/Netflix/SimianArmy/wiki
1.17. ITIL and DevOps 1.17.1. What is ITIL?
The Information Technology Infrastructure Library (ITIL) is a framework of best practice approaches intended to facilitate the delivery of high quality IT services. It outlines an extensive set of management procedures that are intended to support businesses in achieving value for money and quality in IT operations. These procedures are supplier independent and have been developed to provide guidance across the breadth of the IT infrastructure.
The Information Technology Infrastructure Library (ITIL) defines the organisational structure and skill requirements of an information technology organisation and a set of standard operational management procedures and practices to allow the organisation to manage an IT operation and associated infrastructure.
The 'library' itself continues to evolve, with version three, known as ITIL v3, being the current release. This comprises five distinct volumes: 1.17.1.1. ITIL Service Strategy 1.17.1.2. ITIL Service Design 1.17.1.3. ITIL Service Transition 1.17.1.4. ITIL Service Operation 1.17.1.5. ITIL Continual Service Improvement.
These five volumes map the entire ITIL Service Lifecycle, beginning with the identification of customer needs and drivers of IT requirements, through to the design and implementation of the service and finally, the monitoring and improvement phase of the service.
The service strategy stage of the ITIL service lifecycle is crucial for defining an IT service strategy that operates effectively within its business context. Valuable on its own, ITIL Service Strategy will give even greater benefits when used as part of the fully integrated approach described by the other core publications within the ITIL lifecycle suite.

The ITIL service design stage of the ITIL service management framework offers a step-by-step approach to planning focusing on quality and efficiency, leading to robust IT services that will stand the test of time. Understanding IT practices, processes and their governing policies will lead to excellence in IT service design and describes an approach to ensure the most relevant IT services are introduced into fully supported environments, meeting an organization's current and future business needs.
The ITIL service transition stage of the ITIL service management framework offers guidance to introduce new and changed services, ensuring that the value identified in the service strategy is maintained and controlling risks to smooth operations. Additionally, it describes practices for managing service change, and helping departments and businesses to transition efficiently, from one state to another.
The ITIL service operation stage of the ITIL framework highlights best-practice for delivering IT to meet agreed service levels for both business users and customers. ITIL Service Operation also includes the day-to-day management of technology needed to deliver and support services. It reduces the risk of service outages, and ensures that authorized levels of access are consistently available.
ITIL continual service improvement should be an integral part of every stage of the ITIL service management framework. ITIL Continual Service Improvement provides best-practice guidance for introducing a cycle of service management improvements, and a structured approach for assessing and measuring services.
1.17.2. ITIL and DevOps together
IT Infrastructure Library (ITIL) or IT Service Management (ITSM) are codifications of the business processes that underpin IT operations. They describe many of the capabilities needed for IT operations to support a DevOps-style work stream.
Agile, and continuous integration and release, are the outputs of development, which are the inputs into IT operations. To accommodate the faster release cadence associated with DevOps, many areas of the ITIL processes require automation, specifically around the change, configuration, and release processes. The goal of DevOps is not just to increase the rate of change. It can also successfully deploy features into production without causing chaos and disruption of other services, while quickly detecting and correcting incidents when they occur. This brings in the ITIL disciplines of service design and incident and problem management.
Continuous improvement is a key tenant of DevOps and this dovetails nicely with the ITIL continuous service improvement.
The intersection of Devops and ITIL® by Global Knowledge https://www.globalknowledge.net/mea-shared-content/documents/645372/1077294/1077301
InfoQ: ITIL vs DevOps: Different Viewpoints. https://www.infoq.com/news/2015/06/itil-vs-devops The ITSM Review: Trust me: The DevOps Movement fits perfectly with ITSM. http://www.theitsmreview.com/2014/03/trust-devops-movement-fits-perfectly-itsm/ ITIL® Vs. DevOps! 25 Influential Experts Share Their Insights (Is ITIL® Agile Enough?) https://purplegriffon.com/blog/is-itil-agile-enough

Section 2 - Adopting DevOps
2.1. Describe business and IT drivers of DevOps As an approach that promotes closer collaboration among line of business, development and IT operations, DevOps has an impact across the business. For line of business executives and CIOs, a key concern is the capability of DevOps to enable business transformation through faster development of innovative software that meets emerging business needs—or even creates those needs in the market. For senior application development executives, the primary concern is about improving operational metrics around cost, risk, quality, productivity and speed in the development cycle. DevOps practitioners want to work on great applications, focus on delivering value, eliminating waste and automating grunt work, and make release party weekends a thing of the past. IBM defines DevOps as an “essential enterprise capability for the continuous delivery of software-driven innovation that enables organizations to seize market opportunities and reduce time to customer feedback”.
2.1.1. Business drivers
Reduce time from idea to production capability. Ability to test and fail quickly, pivot, and introduce new capabilities.
Position capabilities for flexible and rapid growth, scaling capabilities to demand. Delivery of services without human intervention. Quickly respond to customer feedback, increasing customer satisfaction, and client retention / reduced churn. Protecting and improving the brand image. To correct the present misalignment of people and goals by fostering closer links between developers and the business.
2.1.2. IT drivers
To accelerate and remove error from the delivery of changes by introducing automation throughout the development cycle.
To improve insight into the real value of applications by using customer feedback to drive optimization. Improve the quality of products or services delivered, uptime of available services, minimize disruptions or outages, reduce MTTR, reduce defects, predict and prevent outages.
https://www.ibm.com/cloud-computing/learn-more/what-is-devops/ https://www-01.ibm.com/common/ssi/cgi-bin/ssialias?subtype=WH&infotype=SA&htmlfid=RAW14389USEN&attachment=RAW14389USEN.PDF https://en.wikipedia.org/wiki/DevOps
2.2. Explain the barriers to adoption of DevOps 2.2.1. Identify common bottlenecks to the adoption of DevOps
2.2.1.1. Cultural / process bottlenecks

2.2.1.1.1. No DevOps vision or strategy has been defined 2.2.1.1.2. Different delivery organizations responsible for different
deliverables (outsourcing, multiple silos, contractual conflicts, etc.)
2.2.1.1.3. Lack of executive buy-in 2.2.1.1.4. Lack of collaboration between Bus, Dev and Ops 2.2.1.1.5. No DevOps vocabulary is in place 2.2.1.1.6. No coordination of the delivery environment elements (e.g.
a DevOps Center of Excellence (COE)) 2.2.1.1.7. No or limited DevOps specific metrics in place 2.2.1.1.8. Governance when applying DevOps 2.2.1.1.9. Resistance to change (inertia, political change, comfort
zone, authority and power, preserving the status quo) 2.2.1.1.10. Existing development practices
2.2.1.2. Skills and knowledge bottlenecks 2.2.1.2.1. Inconsistent understanding of Agile, Lean and DevOps
principles 2.2.1.2.2. Lack of understanding how to applying DevOps in a
regulated environment 2.2.1.2.3. Lack of understanding how to adopt DevOps in a multi-
speed IT environment 2.2.1.3. Environmental bottlenecks
2.2.1.3.1. Lack of flexible environment provisioning required by DevOps teams
2.2.1.3.2. Deployments are largely manual (and error prone) 2.2.1.3.3. No integrated tools architecture in place 2.2.1.3.4. Missing or inconsistent mechanisms for getting feedback
2.2.1.4. Testing bottlenecks 2.2.1.4.1. Test data management 2.2.1.4.2. Testing is not performed early (shift-left testing) using
capabilities such as service virtualization 2.2.1.4.3. Insufficient and inconsistent test automation
2.2.2. Explain how Cultural/process bottleneck can be overcome
Note this section does not say organizational bottlenecks – very often an organizational change is NOT required – a change in the culture of the organization is what is needed. DevOps adoption is usually impossible unless management has bought in and at least some of the engineers are willing to change the way they work. As organizations mature their DevOps adoption they must seek to embrace a culture which; 2.2.2.1. Is open, honest and transparent. 2.2.2.2. Encourages collaboration. 2.2.2.3. Promotes innovation, accountability and responsibility. 2.2.2.4. Builds and rewards trust across organizational boundaries. 2.2.2.5. Enhances visibility of change and risk. For DevOps to be truly successful, the entire organization must adopt its philosophy.
2.2.3. Explain how skills and knowledge bottleneck can be overcome

Whole team education is key to success. When everyone is convinced of the benefits of DevOps and everyone has a common understanding of the DevOps terminology, principles and practices then many of the barriers to adoption can be overcome. This education does not only apply to the practitioners. Educating sponsors, stakeholders, executives and, perhaps most importantly, middle managers is key.
https://www.virtualizationpractice.com/barriers-devops-adoption-23650/ https://www-03.ibm.com/support/techdocs/atsmastr.nsf/5cb5ed706d254a8186256c71006d2e0a/0aa752f8a7c021ba86257f3f00751ed8/$FILE/Addressing%20Barriers%20to%20Agile%20Adoption%20-%20Final.pdf http://searchcio.techtarget.com/feature/DevOps-model-a-profile-in-CIO-leadership-change-management http://www.computerweekly.com/feature/Overcoming-the-business-and-technology-barriers-to-DevOps-adoption https://www.devopsguys.com/2013/03/13/continuous-delivery-adoption-barriers/
2.3. Explain how to build a roadmap for DevOps adoption 2.3.1. Define the methods to create a roadmap
2.3.1.1. In order to create a roadmap for DevOps adoption it is necessary to understand the following: 2.3.1.1.1. Understand the transformation goals from both a business
and IT perspective 2.3.1.1.2. Assess where you are today and in particular what are the
greatest challenges or, from a lean perspective, greatest bottleneck the organization is facing to achieve the goals
2.3.1.1.3. Decide and prioritize which problems to fix or situations to improve
2.3.1.1.4. Create a roadmap for the change including quick wins for momentum and buy-in
2.3.1.2. There are a number of ways to discover those bottlenecks including: 2.3.1.2.1. Value stream mapping 2.3.1.2.2. Maturity models 2.3.1.2.3. Assessments and interviews
2.3.1.3. The top 3 to 5 prioritized bottlenecks can be used as input to describe an adoption roadmap that includes relevant DevOps capabilities, such as: 2.3.1.3.1. process improvement 2.3.1.3.2. automation with tools 2.3.1.3.3. cultural/organizational changes
2.3.2. Describe value stream mapping
A value stream mapping workshop, with participation from line of business, development, QA, operations and production support, enables the participants to gain a common understanding of the current DevOps landscape. The group will discuss topics including:
2.3.2.1. Business and IT goals for transformation

2.3.2.2. Current transformation initiatives 2.3.2.3. Existing practices and bottlenecks in the DevOps pipeline with focus
on: 2.3.2.3.1. Methodology 2.3.2.3.2. Requirements gathering and management 2.3.2.3.3. Development, test, operations and productions support
activities 2.3.2.3.4. Environments and tools 2.3.2.3.5. Repositories 2.3.2.3.6. Roles 2.3.2.3.7. Metrics 2.3.2.3.8. Culture including executive support
2.3.2.4. All bottlenecks are categorized into themes 2.3.2.5. Themes are prioritized 2.3.2.6. Feasibility of fixing bottlenecks discussed 2.3.2.7. First draft of an improvement roadmap is drawn up
2.3.3. Describe maturity models
There are a number of maturity models (see references below) that teams can use to assess their current capabilities and use as a discussion tool for future improvements. There is no one generally accepted DevOps maturity model, but they all follow the basic principle of a left to right mapping of the DevOps process and practices, bottom-to-top increasing level of capability / tooling / outcome. The maturity model is then used to assess current ‘as is’ position today, and desired future state or the ‘to-be’ vision. The gap between the current and future provide the adoption roadmap, and the capabilities to be acquired provide the detail in the roadmap.
Typical DevOps maturity models are assessing the maturity of the different practices including: Build management and continuous integration, environment and deployment, release and compliance management, testing, collaboration, reporting, etc.
A recommended practice for using maturity models is for the team to meet to agree on the current level of maturity for each practice and then to decide what would be their target level. Once the delta is understood a roadmap can be built to reach the target level.
2.3.4. Assessments and Interviews
Assessing current state can also be achieved by interviews, either individually or in groups, with representatives from the various software engineering disciplines (requirements management, development, test, operations etc.). The facilitator then gathers the inputs from the interviews to suggest a roadmap for improvement.
Demonstration of DevOps Innovation and Optimization workshop: https://www.youtube.com/watch?v=U9SnBeKIO0I

DevOps Adoption Framework for multi-day assessments: https://jazz.net/devops_adoption_framework/devops.publish.devops_practices.base-ibm/guidances/guidelines/adopting_devops_13A460AB.html
DevOps Assessment on Bluemix: http://devopsassessment.mybluemix.net/#/
DevOps Assessment and Planning workshop: http://www-01.ibm.com/software/rational/services/devops/
DevOps Handbook: How To Create World-Class Agility, Reliability, & Security in Technology Organizations: http://itrevolution.com/devops-handbook
DevOps Guys cd maturity model: https://www.devopsguys.com/wp-content/uploads/2013/02/cdmaturitymodel.png
Forrester Report commissioned by ThoughtWorks: http://info.thoughtworks.com/rs/thoughtworks2/images/Continuous%20Delivery%20_%20A%20Maturity%20Assessment%20ModelFINAL.pdf
Wikipedia – Value Stream Mapping: https://en.wikipedia.org/wiki/Value_stream_mapping
IBM DevOps adoption model inc maturity assessment: https://www.ibm.com/developerworks/library/d-adoption-paths/
IBM’s Continuous Delivery Maturity Model : https://developer.ibm.com/urbancode/docs/continuous-delivery-maturity-model/
2.4. Explain how to adopt DevOps in Multi-speed IT environment 2.4.1. Define the keys to a Multi Speed IT adoption
2.4.1.1. Tracking and managing dependencies When a multi-speed IT project is being planned, each team manages its overall project separately. However, planning must also occur across teams to identify dependencies and time frame expectations. Each team manages its ranked backlog. When new work is added to the cloud team's backlog that requires either a new or changed API on the traditional system, the cloud team must communicate that requirement to the traditional application team. The traditional application team must determine when to deliver the dependency so that the cloud team can position the item in the backlog and ensure that the dependency will be available when needed. To track their work, the teams use a work-item tracking system.
2.4.1.2. Project-level daily standups
Communication is key to ensuring that a hybrid application can come together in production. Each team runs its own daily stand-up meeting, and the results of those meetings are brought to a project standup meeting. The project-level standup meeting addresses the same questions as the individual team meetings:
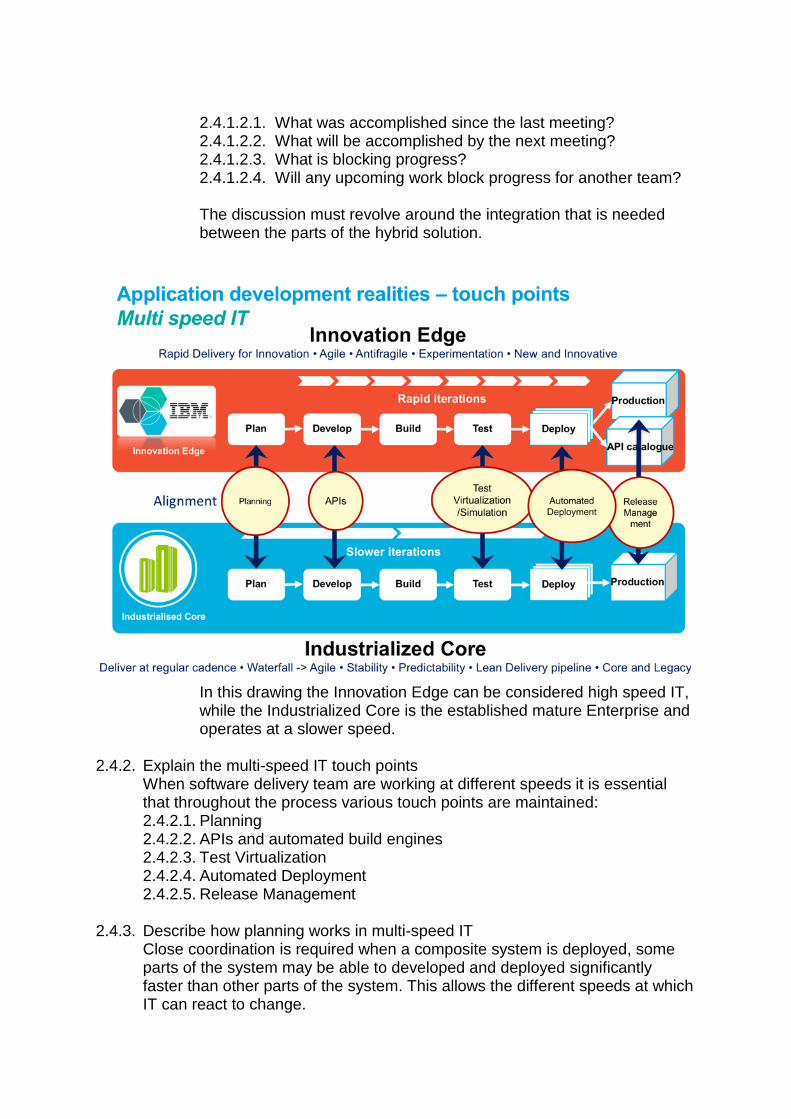
2.4.1.2.1. What was accomplished since the last meeting? 2.4.1.2.2. What will be accomplished by the next meeting? 2.4.1.2.3. What is blocking progress? 2.4.1.2.4. Will any upcoming work block progress for another team?
The discussion must revolve around the integration that is needed between the parts of the hybrid solution.
In this drawing the Innovation Edge can be considered high speed IT, while the Industrialized Core is the established mature Enterprise and operates at a slower speed.
2.4.2. Explain the multi-speed IT touch points
When software delivery team are working at different speeds it is essential that throughout the process various touch points are maintained: 2.4.2.1. Planning 2.4.2.2. APIs and automated build engines 2.4.2.3. Test Virtualization 2.4.2.4. Automated Deployment 2.4.2.5. Release Management
2.4.3. Describe how planning works in multi-speed IT
Close coordination is required when a composite system is deployed, some parts of the system may be able to developed and deployed significantly faster than other parts of the system. This allows the different speeds at which IT can react to change.

2.4.3.1. Joint activities will include;
2.4.3.1.1. Track work and team progress 2.4.3.1.2. Create defects 2.4.3.1.3. See what's incoming 2.4.3.1.4. Maintain project backlog 2.4.3.1.5. Plan work for future sprints and releases.
Decide on Repository for sharing, storing source code, and versioning code drops, managing tests and defects.
If one part of the organization is using a waterfall method and the other an agile/iterative method then this planning activity become even more essential.
If the agile team has dependencies of the waterfall team then they can ask the waterfall team, ‘Please develop the code by the x date. We will then be able to use that code in our next iteration. We realise you won’t have thoroughly tested the code as you are waterfall, but we can test our interface to that code for you and provide you with feedback.’
If the waterfall team has dependencies on an agile team, then from the agile team’s point of view the waterfall team is just another stakeholder. The product owner can prioritise the work and provide tested code to the waterfall team to use.
2.4.4. Describe how APIs and automated build engines can help with multi-speed IT
Decoupling the various aspects of the application can enable multi-speed IT. Securely invoke and integrate code with APIs to and from other systems. Core system APIs are securely accessed through a secure gateway. APIs provided to external users are made available and managed through the API management services.
A build engine consumes source code, database scripts, property files, and build scripts in a version control system to maintain a complete history of every change made to the application. It ensures that when a library is changed, the dependent applications are rebuilt and dependency problems are connected for route cause analysis.
2.4.5. Describe how Service Virtualization and Integration testing can help with
multi-speed IT Integrated test suite to define test plans, test scripts, and manage test results. Automate testing of application components. Shift-left testing to enable developers to do more integration tests with the help of service virtualization.
Test automation tooling can significantly reduce test cycle times, moving integration testing earlier in the development lifecycle and drastically improving application quality. Test scripts are automatically invoked as part of the deployment process.

Build, scan, test, integrate, and package apps before deploying.
2.4.6. Describe how automated deployment can help with multi-speed IT
Automates builds and deployments to the cloud or local systems. Ensures local and cloud based code stay synchronised. Also ensures code and configuration tested in development environment is consistent with code and configurations being tested in the test environments and ultimately released into production.
Deployment engines orchestrate the deployment of builds to environments, configure the environment, trigger the automated tests, and return results.
Stage gates are configured in the release management system that define when a build can progress between environments and be closer to final production deployment.
2.4.7. Describe how release management can help with multi-speed IT
Release management tools help handle the growing number and complexity of releases, helping to plan, execute, and track a release through every stage of the delivery lifecycle. It results in reduced errors, while making large releases faster and more agile.
DevOps and Agility for Multi-Speed IT https://devops.com/devops-agility-multi-speed-it/ DevOps reference architecture for Multi-speed IT https://developer.ibm.com/architecture/pdfs/IBMCloud-AC-DEvOpsMultiSpeedIT-35.pdf
2.5. Explain other continuous improvement approaches 2.5.1. Plan-Do-Study-Act / PDSA Cycle
The PDSA Cycle (Plan-Do-Study-Act) is a systematic series of steps for gaining valuable learning and knowledge for the continual improvement of a product or process. Also known as the Deming Wheel, or Deming Cycle. The cycle begins with the Plan step. This involves identifying a goal or purpose, formulating a theory, defining success metrics and putting a plan into action. These activities are followed by the Do step, in which the components of the plan are implemented, such as making a product. Next comes the Study step, where outcomes are monitored to test the validity of the plan for signs of progress and success, or problems and areas for improvement. The Act step closes the cycle, integrating the learning generated by the entire process, which can be used to adjust the goal, change methods or even reformulate a theory altogether. These four steps are repeated over and over as part of a never-ending cycle of continual improvement.
2.5.2. Six Sigma Six Sigma projects are built on a DMAIC framework of five phases: Define, Measure, Analyse, Improve, Control. These phases each contain a set of tools and techniques that guide the problem solver through the improvement process from start to finish.
2.5.3. Lean Six Sigma

Lean Six Sigma is a set of tools and techniques that help improve processes; reduce waste; increase quality; and enhance your customer’s experience. Lean Six Sigma takes the principles of Lean and Six Sigma and integrates them to form a “magnificent seven” set of principles: 2.5.3.1. Focus on the customer. 2.5.3.2. Identify and understand how the work gets done. 2.5.3.3. Manage, improve and smooth the process flow. 2.5.3.4. Remove non-value-add steps and waste. 2.5.3.5. Manage by fact and reduce variation. 2.5.3.6. Involve and equip the people in the process. 2.5.3.7. Undertake improvement activity in a systematic way.
2.5.4. Lean Startup Similar to the concepts of lean manufacturing, the lean startup methodology seeks to eliminate wasteful practices and increase value-producing practices during the product development phase so that startups can have a better chance of success without requiring large amounts of outside funding, elaborate business plans, or the perfect product. Customer feedback during product development is integral to the lean startup process, and ensures that the producer does not invest time designing features or services that consumers do not want. This is done primarily through two processes, using key performance indicators and a continuous deployment process. The key concepts in lean startup are;
2.5.4.1. Minimum viable product - MVP is the "version of a new product
which allows a team to collect the maximum amount of validated learning about customers with the least effort".
2.5.4.2. Continuous deployment (only for software development) - is a process "whereby all code that is written for an application is immediately deployed into production," which results in a reduction of cycle times.
2.5.4.3. Split testing - A split or A/B test is an experiment in which "different versions of a product are offered to customers at the same time." The goal of a split test is to observe differences in behaviour between the two groups and to measure the impact of each version on an actionable metric.
2.5.4.4. Actionable metrics - Actionable metrics can lead to informed business decisions and subsequent action.
2.5.4.5. Pivot - A pivot is a "structured course correction designed to test a new fundamental hypothesis about the product, strategy, and engine of growth."
2.5.4.6. Innovation accounting - This topic focuses on how entrepreneurs can maintain accountability and maximize outcomes by measuring progress, planning milestones, and prioritizing.
2.5.4.7. Build–Measure–Learn - The Build–Measure–Learn loop emphasizes speed as a critical ingredient to product development. A team or company's effectiveness is determined by its ability to ideate, quickly build a minimum viable product of that idea, measure its effectiveness in the market, and learn from that experiment.
2.5.5. Kaizen

Kaizen (Continuous Improvement) create a culture of continuous improvement where all employees are actively engaged in improving the company. Nurture this culture by organizing events focused on improving specific areas of the company. Kaizen is a strategy where employees at all levels of a company work together proactively to achieve regular, incremental improvements to the manufacturing process. In a sense, it combines the collective talents within a company to create a powerful engine for improvement.
2.5.6. Scrum Scrum is a process framework, within which you can employ various processes and techniques, that has been used to manage complex product development. The Scrum framework consists of Scrum Teams and their associated roles, events, artefacts, and rules.
2.5.7. Squads, Tribes, Chapters and Guilds. 2.5.7.1. A squad (scrum team) is a very small team that own a certain part of
functionality end to end. It will have a dedicated product owner who will feed them user stories to build. This is the pretty standard set up for any organisation doing scrum. These squads sit together and have one long term mission. They have all the skills and tools needed to design, develop, test and release to production, being an autonomous, self-organising team who are experts in their product area. They are kind of like mini start-ups.
2.5.7.2. Squads are grouped together in what they call Tribes. These are a collection of squads within the same business area, for example there could be a tribe focusing on mobile. The squads within a tribe sit in the same area, and there are usually 100 or less per tribe.
2.5.7.3. Chapters are a group or team members working within a special area. So, for example a squad might be made up of front office developers, back office developers, database administrator and testers. So, a chapter could be a ‘front office chapter’, where front office developers get together and exchange ideas, get help on challenges and discuss new technologies.
2.5.7.4. Finally, there is the concept of a guild. A guild is a community of members with shared interests. These are a group of people across the organization who want to share knowledge, tools code and practices.
2.6. Illustrate the cultural & organizational differences when transforming
from traditional to DevOps processes A DevOps culture is characterized by a high degree of collaboration across roles, focus on business instead of departmental objectives, trust, and high value placed on learning through experimentation.
Building a culture isn’t like adopting a process or a tool. It requires (for lack of a better term) social engineering of teams of people, each with unique predispositions, experiences, and biases. This diversity can make culture-building challenging and difficult.
Typical measurements reward operations teams for uptime and stability, and reward developers for new features delivered, but they pit these groups against each other. Operations knows that the best protection for production is to

accept no changes, for example, and Development has little incentive to focus on quality. Replace these measurements with shared responsibility for delivering new capabilities quickly and safely. The leaders of the organization should further encourage collaboration by improving visibility.
A DevOps organization understands this value equation. They focus on the processes that add value, organize themselves around those actions and do the best to minimize the risk. Traditional IT gets it too – at least conceptually. However, they treat all stages in the SDLC with equal importance or worse emphasize the wrong stage(s).
In general, when comparing DevOps organizations to traditional IT, DevOps will have policies and practices that differ from those of traditional IT along the following eight key dimensions:
2.7. Planning & Organization 2.7.1. Batch Sizes: Go from Big to Micro
Traditional IT has a bias for going big and for good reason. First, most development shops grew out of the waterfall method which by its inherent nature takes a lot of time. Second, since releases are costly and disruptive, operations allow developers only a few windows a year to release software. And third, its simply not sexy – doing big is how you get promoted. As a result, development organizations maximize productivity, by planning big projects, that involve a lot of code, bundled (hastily at times) into a release, and jammed into production.
A DevOps organization takes the opposite point of view and believe that small is beautiful. They understand that large batch sizes are inherently complex, risky (since there are so many moving parts), and hard to coordinate. Small batches sizes, on the other hand, are simple, easy to understand and test

rigorously, and less risky. If things go wrong the impact is minimal and it is much easier and faster to fix. In other words, by going small organizations are able to perform more frequent releases and become more responsive to the customer.
2.7.2. Organization: From Skill Centric Silos to Dedicated Cells Traditional IT is organized around skill centric silos. For the most part silos work, they band like skills together, drive greater utilization, and benefit from economies of scale. However, where these “cost optimized” silos break down is at the hand offs. In a typical IT environment, a new feature has to go through at least 3 – 4 silos before the customer gets it. It is not uncommon for an idea / code to spend 80% of its time waiting or ping-ponging back and forth between silos. A DevOps organization also operates in a silo but at a different cross section. Here teams are arranged in “cells”, consisting of dedicated cross functional teams, and focused on only one application. By creating this self-sufficient cell that consists of developers, testers, business analysts, and operators, an idea can move from one stage to another without hand offs, promotes cross-training / understanding (key to collaboration), focuses the team on the end goal, and encourages the “shift left” thinking. As for utilization and scale benefits, the rules for response states that for every ¼ reduction in cycle time, productivity will improve 2x, and operating costs by 20%.
2.7.3. Scheduling: Centralize to Decentralize & Continuous Efficient scheduling is at the heart of a Traditional IT organization. Since resources are pooled, projects are usually clamouring for access to SMEs and / or infrastructure. To get around this, enterprises have invested in sophisticated scheduling planning systems. And while these systems are quite sensitive, they are inherently inaccurate, take up to much time to manage, and in some cases become the very bottleneck that they are trying to alleviate. In a DevOps organization scheduling is pushed to the local cell level. The combination of smaller batch sizes, dedicated teams, and automated processes makes scheduling more simple to operate. How? First, forecasting is limited to the very near future (2 – 3 weeks) where the teams have better insight. Second, there is no fighting for people’s time since it is a dedicated team. Third, there is no waiting for infrastructure since it has already been defined and automatically provisioned. And fourth, it eliminates time consuming loop backs to management for escalations and decisions.
2.8. Performance & Culture 2.8.1. Release: Turn a High Risk Event to a Non Event
In a Traditional IT organization, releasing software into production is a high risk proposition. It is fraught with issues, escalations, and constant fire-fighting. The process is tightly managed, governed from the highest levels, and requires participation from all parts of the organization. It is not uncommon for IT to set up war rooms staffed 24×7 for weeks before and after the release. DevOps organizations, on the other hand, make the release of software into a non-event much as possible. They reduce risk by daily integrating code into the trunk, automating testing, ensuring all environments are in sync, reducing

batch sizes (as mentioned above) etc. In other words, they only promote code from one stage to another after they are confident that it will work in production. Thus eliminating all the hoopla about release windows and they are able to move new functionality into production at a much faster clip.
2.8.2. Information: Focus is on Dissemination vs. Actionable Both types of organizations generate and share a ton of data. The difference lies in how the teams uses data. In Traditional IT, information is generated by specialists (e.g. operations team), bundled together with other data into a massive report, goes through management approval, is then shared with other managers, who then send it out their specialist (testers, developers etc.). In most cases the report goes unread, simply because there is too much data, not timely enough, and / or not the right data. In other words, information is shared but poorly consumed, and rarely used to take any actions. Within a DevOps organization, it’s the team cell that gather and creates the data. Since the data is to be consumed locally they only collect the data (also automated) that the team deems is necessary. And since the data is processed within the team, it eliminates the time lag of creating lengthy reports, manager approvals, and queue time (sitting in some ones email box). As a result, the team is quickly able to read and react to the data – resulting in faster feedback time.
2.8.3. Culture: Do Not Fail vs. Fail Early Traditional IT is fundamentally a risk averse organization. A CIO’s first priority is to do no harm to the business. It is the reason why IT invests in so much red tape, processes, approvals etc. All focused on preventing failure. And yet despite all these investments, IT has a terrible track record – 30% of new projects are delivered late, 50% of all new enhancements are rolled back due to quality issues, and 40% of the delay is caused by infrastructure issues. A DevOps organization is risk averse too but they also understand that failure is inevitable. So instead of trying to eliminate failure they prefer to choose when and how they fail. They prefer to fail small, fail early, and recover fast. And they have built their structure and process around it. Again the building blocks we have referred to in this article – from test driven development, daily integration, done mean deployable, small batch sizes, cell structure, automation etc. all reinforce this mindset.
2.9. Measure 2.9.1. Metric: Cost & Capacity to Cost, Capacity, & Flow
Silos work for Traditional IT because they are directly tied to its measurement model – cost and capacity. IT is measured on how much can it get done (capacity) for the least amount of money (cost). It is no wonder that cutting cost, while trying to keep capacity constant, has been all the rage in IT over the last two decades. It’s one of the reasons why outsourcing became so popular.
And while this model works great for stable legacy applications, the newer “system of engagement” applications require an additional metric – the element of time. DevOps organization understand this paradigm shift and have added “flow” as an additional metric. Flow forces an organization to take a look at its end to end cycle time, identify areas of waste, calculate true

productive time, quantify quality, and focus on activities that add the most value.
2.9.2. Definition of Done: “I did my job” vs. “it’s ready to deploy”
Another source of measurement difference is in how the two types of organizations define done. In Traditional IT, done is defined as the specialist doing “just” their part and handing it off. In essence, their done is more focused on meeting the hand off deadline vs. making sure what is done is deployable. This varying definition leads to some bad habits such as sub-par work, quality loss, finger pointing, and an overall sub-optimized process.
To get way from the finger pointing mentality is another reason why a DevOps organization prefers to create a dedicated cross functional team. With every member of the various parts of IT represented in this “cell” structure and all of them being held accountable for one and only one thing, they all end up having just one definition of done – bring quality software to market.
https://www.ibm.com/developerworks/community/blogs/invisiblethread/entry/comparing_devops_to_traditional_it_eight_key_differences?lang=en
2.10. Explain the benefits of Design Thinking for DevOps process adoption 2.10.1. Design Thinking Definition
A framework of thinking about problems that leverages the collective expertise of multi-disciplinary teams, encouraging discovery and understanding (empathy) from the needs of the customer’s perspective that encourages design, test and iterate.
Key Benefits: 2.10.1.1. Drives innovation at speed and scale to achieve continuous
reinvention and feedback to ensure product/solution viability is uncovered before too many resources are spent on any one idea
2.10.1.2. Innovates thinking and creative problem solving leveraging multi-disciplinary teams
2.10.1.3. Focuses on important outcomes and user experience rather than perceived or imagined needs
2.10.1.4. Ensures final outcomes meet objectives and customer expectation matching what is technologically feasible with customer requirements and viable business outcomes
2.10.1.5. Enables knowledge sharing through feedback and collaboration so that the DevOps team and the customer have the same definition of the objectives and milestones.
2.10.2. How does Design Thinking benefit DevOps?
With the convergence of Development and Operations into DevOps, activities need to be focused and closely coupled as the team shares in the responsibility for quality development (DEV) and quality of service (OPS) that connect directly back to the users. The DevOps teams need to quickly learn what works and what doesn’t work which means there needs to be a tighter feedback loop which is the heart of Design Thinking.

Design Thinking benefits DevOps through user-centered leadership practices that focus and align the teams on outcomes that matter to the users we are developing for. These practices are broken down into three areas: Outcomes for Users, The Loop, and Radical Collaboration.
Outcome for Users: Focuses on empathy for users exploring and understanding their requirements to deliver a great experience and avoids pitfalls. This helps DevOps teams get aligned, stay align and stay in touch with user requirements through the concept of Hills, Playbacks and Sponsor Users
Hills keep teams aligned (stakeholders, sponsors, developers/testers, operations, etc.). Hills are statements of intent written as meaningful user outcomes that become a hypothesis or fully framed objective helping developers to explore ideas without losing sight of the goal. A hypothesis should be directly tied to:
“Who”, a specific class of users or group of users that the solution will ultimately provide value to,
“What”, that ties to a specific action or enablement, and
“Wow” which defines a measurable market differentiator or metric so you know you are delivering value and have completed the task. (Recommend no more than three (3) Hills at a given time)
Playbacks align the team (Developers, Operations, Stakeholders and Sponsor Users) across time. They are basically demos that bring the all members of the team into the loop in a safe space to exchange feedback and ideas around the end-to-end user experience that is being developed. Playbacks are powerful as they help developers ensure they are focusing on a common view of what is to be accomplished and reveal misalignment as well as measure progress against the Hill you are trying to solve for.
Sponsor Users align developers with real-world users that contribute to the expertise of the team making sure the DevOps team stays in touch with the real-user needs throughout the project building the right hypothesis. This group, brought in early in the process, should consist of a small number of clients or target customers that bring domain expertise to the development teams providing a better understanding of what developers need to solve for ensuring refinement of the hypothesis and design.
The Loop (Continuous Learning): emphasizes continuous learning throughout the development process.
Observe (set aside assumptions and understand the user’s perspective;
Reflect (synthesize what you’ve learned, be able to articulate this and develop a plan;
Make (turn what you’ve learned into reality). Using the concept of a loop, creates continuous feedback that is focused on user outcomes as you do continuous incremental delivery. Having a better understanding on what kind of data is needed gives us the most confidence

to test the hypothesis and based on the data acquired to either: adopt the change, make a mid-course correction or disprove the hypothesis which means you probably didn’t understand your users and need to pivot in a different direction. Design Thinking encourages test early, fail fast so you aren’t wasting effort or losing time as it causes reflection by the team to take into account what has been learned based on the data and feedback gathered.
Radical Collaboration: is grounded on the idea of collaboration between disciplines that share responsibility for user outcomes. To be most effective, everyone on the team should share in ownership. Collaboration is all about understanding and bringing together the right mix of disciplines i.e. Design engineers, operations, testers, support, product management, possibly inside sales or marketing and a small group of customers so you gain insight and involvement sharing in the outcomes you are trying to achieve. To ensure success, it’s recommended to utilize a tool chain of collaboration tools in which all stakeholders can share work-in-progress with other disciplines. Some tools already mentioned: Hills to make sure you are continuing to focus on tasks and “take the hill”. Playbacks to ensure you come back to the user’s view of the outcome, reflecting on what has been done and obtaining feedback.
http://www.ibm.com/design/thinking https://en.wikipedia.org/wiki/Design_thinking

Section 3 - IBM DevOps Reference Architecture & Methods
3.1. Describe IBM DevOps Reference Architecture pattern The IBM Cloud Reference Architectures present vendor-agnostic and open patterns on how to construct cloud workload solutions, using IBM’s best practice gained from thousands of client engagements. The advantages of using reference architecture patterns are that;
They are proven in the real world, reducing technical risk.
They are full solution patterns covering all of the important components required.
They accelerate delivery, as the thinking has been already done.
They drive real business outcomes versus a technical feasibility exercise.
They support open standards, mixing components from different vendors.
They map to real products and solutions, so can be quickly instantiated.
The IBM DevOps reference architecture pattern describes the components and relationships required to implement a full end to end DevOps process and supporting tooling. It brings together the seven phases that an application will go through on its DevOps lifecycle, together with the components required to instantiate the solution. The seven phases are described in the Bluemix Garage Method.
The DevOps reference architecture does not state how the application (or payload) of the DevOps process should be constructed, as those components are described in their own reference pattern. For instance, it does not state how applications should be coded or which languages should be used, but does describe the set of best practices that an application will go through during its lifecycle in a DevOps process.

The steps that flow through the DevOps reference architecture are as follows; 3.1.1. Collaborative development - Collaboration tools enable a culture of
innovation. Developers, designers, operations teams, and managers must communicate constantly. Development and operations tools must be integrated to post updates and alerts as new builds are completed and deployed and as performance is monitored. The team can discuss the alerts as a group in the context of the tool.
3.1.2. Track & Plan - As the team brainstorms ideas, responds to feedback and metrics, and fixes defects, team members create work items and rank them in the backlog. The team works on items from the top of the backlog, delivering to production as they complete work.
3.1.3. Edit code - Developers write source code in a code editor to implement the architecture. They construct, change, and correct applications by using various coding models and tools.
3.1.4. Source control - Developers manage the versions and configuration of assets, merge changes, and manage the integration of changes. The source control tool that a team uses should support social coding.
3.1.5. Build, test, and continuous integration - Developers compile, package, and prepare software assets. They need tools that can assess the quality of the code that is being delivered to source control. Those assessments are done before delivery, are associated with automated build systems, and include practices such as code reviews, unit tests, code quality scans, and security scans.

3.1.6. Artifact management - Binary files and other output from the build are sent to and managed in a build artifact repository.
3.1.7. Release management - The release is scheduled. The team needs tools that support release communication and managing, preparing, and deploying releases.
3.1.8. Deployment orchestration - The team coordinates the manual and automated processes that are required for the solution to operate effectively. The team must strive towards continuous delivery with zero downtime. A/B deployments can help to gauge the effectiveness of new changes.
3.1.9. Runtime and containers - Depending on the application requirements, some or all of the application stack must be considered, including middleware, the operating system, and virtual machines.
3.1.10. Application - The team must understand the application and the options for the application’s runtime environment, security, management, and release requirements.
3.1.11. Security - The team must ensure that all aspects of the application and its supporting infrastructure are secured.
3.1.12. Monitoring and metrics - The team plans, configures, monitors, defines criteria, and reports on application availability and performance. Predictive analytics can indicate problems before they occur.
3.1.13. Alert notifications - The right people on the team or systems are notified when issues occur.
3.1.14. IT service management - The team manages the process for responding to operations incidents, and delivers the changes to fix any incidents.
3.1.15. Usage analytics - The team uses analytics to learn how users interact with the application and measure success through metrics.
3.1.16. Application consumers - When users interact with the application, they can provide feedback on their requirements and how the application is meeting them, which is captured by analytics as well.
3.1.17. DevOps engineers - DevOps engineers manage the entire application lifecycle while they respond to feedback and analytics from the running application.
3.1.18. Transformation and connectivity - The enterprise network is protected by a firewall and must be accessed through transformation and connectivity services and secure messaging services.
3.1.19. Enterprise user directory - The security team uses the user directory throughout the flow. The directory contains information about the user accounts for the enterprise.
https://developer.ibm.com/architecture/devOps https://developer.ibm.com/architecture/devOps
3.2. Explain the IBM point of view on DevOps
For many DevOps is purely the bringing together of Development and Operations to speed up IT delivery. However, at IBM we take a much broader point of view:
3.2.1. DevOps covers the end-to-end software delivery lifecycle including an
expanded set of stakeholders such as business owners and end users, and practices such as design thinking and user analytics.

3.2.2. DevOps adoption is expanding in large organizations as they enable existing IT applications for cloud (cloud-enabled applications). New methods enable organizations to success-fully implement DevOps as they move to cloud.
3.2.3. Hybrid cloud architecture is becoming the norm for both cloud-enabled and cloud-native applications. Hybrid cloud provides flexibility in deployment, enabling organizations to choose the right platform to run their workloads.
3.2.4. DevOps solutions can vary as teams across large organizations have different goals, processes, culture and tools.
3.2.5. In cases where disparate teams work together on common business objectives, DevOps helps organizations respond to the challenges of multi-speed IT (a.k.a. two-speed IT, or bimodal IT) in combination with methods such as Scaled Agile Framework environment (SAFe) to facilitate collaboration.
3.2.6. Continuous delivery and Continuous Availability is the desired future-state achieved with the application of a DevOps approach.
https://www-01.ibm.com/common/ssi/cgi-bin/ssialias?subtype=WH&infotype=SA&htmlfid=RAW14389USEN&attachment=RAW14389USEN.PDF
3.3. Explain DevOps for Microservices
Microservices architecture is an alternative approach to structuring applications. An application is broken into smaller, completely independent components, enabling them to have greater agility, scalability, and availability. The microservices architectural style can be seen as an evolution of the SOA (Services Oriented Architecture) architectural style.
When you look at the implications of this, you see that five simple rules drive the implementation of applications built using the microservices architecture. They are:
3.3.1. Break large monoliths down into many small services A single network-
accessible service is the smallest deployable unit for a microservices application. Each service should run in its own process. This rule is sometimes stated as “one service per container”, where “container” could mean a Docker container or any other lightweight deployment mechanism such as a Cloud Foundry runtime.
3.3.2. Optimize services for a single function –In a microservices approach, there should be one and only one business function per service. This makes each service smaller and simpler to write and maintain.
3.3.3. Communicate via REST API and message brokers – A rule for microservices is to avoid the tight coupling introduced by implicit communication through a database – all communication from service to service must be through the service API
3.3.4. Apply Per-service CI/CD -- When building a large application comprised of many services, you soon realize that different services evolve at different rates. Letting each service have its own unique Continuous Integration/Continuous Delivery pipeline allows that evolution to proceed at is own natural pace – unlike in the monolithic approach where different aspects

of the system were forced to all be released at the speed of the slowest-moving part of the system.
3.3.5. Apply Per-service HA/clustering decisions – The reality is that in a large system, not all services need to scale and can be deployed in a minimum number of servers to conserve resources. Others require scaling up to very large numbers.
One monolith is easier to monitor and manage than multiple microservices, so you’d better get good at Microservices DevOps. Microservices require a mature delivery capability. Continuous integration, deployment, and fully automated tests are a must. Build and deployment chains need significant changes to provide the right separation of concerns for a microservices environment. Follow a Microservices DevOps approach that allows you to isolate each Microservice as much as possible, while being able to easily and quickly identify and resolve issues with the Microservices. Applying unique CI/CD pipelines to each Microservice will allow you to build and deploy each Microservice individually. However, having a common approach allows you to set guidelines on how microservices interrelate and interact with each other.
Redbook - http://www.redbooks.ibm.com/redbooks.nsf/RedbookAbstracts/sg248275.html Paper - Intro to Microservices - https://www.ibm.com/developerworks/cloud/library/cl-bluemix-microservices-in-action-part-1-trs/ paper - refactoring to Microservices - https://www.ibm.com/developerworks/cloud/library/cl-refactor-microservices-bluemix-trs-1/
3.4. Explain DevOps for Cloud Native
A cloud native application is a program that is designed specifically for a cloud computing architecture.
3.4.1. CNAs are designed to take advantage of cloud computing frameworks, which
are composed of loosely-coupled cloud services. That means that developers must break down tasks into separate services that can run on several servers in different locations. Because the infrastructure that supports a native cloud app does not run locally, CNAs must be planned with redundancy in mind so the application can withstand equipment failure and be able to re-map IP addresses automatically should hardware fail. The characterisitics they have are;
3.4.1.1. Stateless and self-contained 3.4.1.2. Fine-grained (<100 lines of code) 3.4.1.3. Designed to be anti-fragile 3.4.1.4. Typically follow a micro-services approach, asynchronous messaging 3.4.1.5. Dynamically changed (hours / days) 3.4.1.6. Operationally automated and independent 3.4.1.7. Scaled horizontally (spin up more services) 3.4.1.8. NFRs driven by application design

3.4.1.9. Key metrics: Agility, Performance, Speed of change, MTTR 3.4.2. The specific impacts of these characterisitics mean that the DevOps process
will be; 3.4.2.1. Faster moving, with a higher number of deployments than cloud-ready
or traditional applications. 3.4.2.2. The infrastructure elements are delegated to the cloud service
providers, and therefore do not need to be managed as part of the deployment automation – they are assumed to be there.
3.4.2.3. Inherently, they contain more components, as the individual sizes will be smaller, supporting greater agility.
3.4.2.4. Dependency management (and release management) becomes a greater concern as code / application / runtime dependencies may span across many components, libraries, and locations.
3.4.2.5. Control and organisation is now distributed, so there is no single one ‘central command’, which requires greater level of cross-slio communication and collaboration.
3.4.2.6. Many of the non-functional charateristics are now delivered by the application layer, and must be planned in the test programmes by the application developers.
3.4.2.7. Operational processes need to be highly automated – see ‘Build to Manage’.
3.4.2.8. There is a role change, with a shift in responsibilities from traditional operations to new combined teams of DevOps.
Another concept which may occur in the context of DevOps for Cloud Native applications is NoOps, (Forrester coined the term NoOps) which they define as "the goal of completely automating the deployment, monitoring and management of applications and the infrastructure on which they run."
3.5. Explain DevOps for Cloud Ready 3.5.1. Cloud Ready applications describe a set of applications that can run in a
cloud infrastructure but are limited in their ability to take advantage of the cloud. They work, but they are not optimized for the cloud environment. Typically, they have modular components (SOA) allowing decoupling of application and infrastructure, components can be scaled separately, and can be deployed as standard images or patterns, benefiting from automation. The typical characterisitics of cloud ready applications are; 3.5.1.1. Stateful and highly inter-dependent 3.5.1.2. Monolithic structures (Millions lines of code) 3.5.1.3. Designed for resilience (instead of agility) 3.5.1.4. Tightly coupled architecture, synchronous communication 3.5.1.5. Difficult to change (months / years) 3.5.1.6. Operationally intensive and needy 3.5.1.7. Scaled vertically (add more capacity) 3.5.1.8. NFRs driven by infrastructure 3.5.1.9. Key metrics: Availability, Cost, Uptime, MTBF
3.5.2. The specific impacts of these characterisitics mean that the DevOps process will be;

3.5.2.1. Slower moving with release/code deployments every few weeks or months.
3.5.2.2. Tighter dependencies between the application layers and the infrastructure layers.
3.5.2.3. Require ‘Orchestration tools’ to coordinate the changes required in the environment, application and infrastructure that constitute the new release.
3.5.2.4. Use Pattern tools to automate the deployment of environments combing IaaS and PaaS capabilities into a full solution stack where the application release can be deployed repeatably.
3.5.2.5. Clear roles and responsibilities often integrated into a centralized support and operations organization.
3.5.2.6. There is a stronger focus upon service management and ensuring the applications are operated to a high level of service and availability. Therefore strong service management needs to be factored into the DevOps process.
3.6. Explain Cloud Service Management Operations
Cloud based applications need to be available at all times and must meet the demands of business. Cloud service management and operations refers to all of the activities—organized in persona, processes, and tools—that are performed by an organization to plan, design, deliver, operate, and control IT and cloud services that are offered to customers. Incident management, problem management, change management, configuration management, and operations are sub-domains of the service management architecture.
3.6.1. Business Drivers for CSMO:
3.6.1.1. Assure availability and performance of applications running on the IBM Cloud platform, given the target SLA of 99.99% availability for applications.
3.6.1.2. Establish and maintain consistency of the application’s performance and its functional and physical attributes with its requirements, design, and operational information.
3.6.1.3. Manage and control operational risks and threats. 3.6.2. Functional Requirements:
3.6.2.1. Visibility to the availability and performance of applications and services. Ability to rapidly perform problem determination and restore the service.
3.6.2.2. Effectively manage change, mitigate new threats from more interconnected services and infrastructures, and ensure compliance.
3.6.2.3. Orchestrate service delivery across dynamic cloud, ensure service quality, and enable continuous delivery of new capabilities at the speed of business.
3.6.3. Non-Functional Requirements: 3.6.3.1. Availability and performance: Support the need for highest availability
by proactive monitoring and rapid restoration of services. 3.6.3.2. Collaboration: Enable close collaboration between application and
cloud infrastructure, and between business, development, and operations.

3.6.3.3. Scalability: Ability to scale management and operations together with the business needs.
3.6.4. CSMO Components
3.6.4.1. Incident management Restores normal service operation as quickly as possible and minimizes the adverse effect on business operations, ensuring that the best possible levels of service quality and availability are maintained. Capabilities include event correlation, monitoring, log monitoring, collaboration, notification, dashboard, and runbooks.
3.6.4.2. Problem management Resolves the root causes of incidents to minimize the adverse impact of incidents caused by errors, and to prevent the recurrence of incidents related to these errors. Capabilities include root cause analysis, incident analysis, and aspects of incident management.
3.6.4.3. Change management Ensures that standardized methods and procedures are used for efficient handling of all changes in development, test and production. Capabilities include backlog, develop, test, approve, and change.
3.6.4.4. Configuration management Focuses on maintaining the information required to deliver a service, including relationships. Capabilities include request configuration, topology, and approve configuration.
3.6.4.5. Operations Includes processes to recommend best practice for requirements analysis, planning, design, deployment, and ongoing operations

management and technical support of cloud-based applications. Capabilities include runbook, dashboard, and collaboration.
https://www.ibm.com/developerworks/library/d-implement-itil-devops/ https://devops.com/devops-and-itil-its-not-your-mothers-itsm/ https://developer.ibm.com/architecture/serviceManagement https://developer.ibm.com/architecture/gallery/incidentManagement/ https://developer.ibm.com/architecture/gallery/incidentManagement/ https://developer.ibm.com/architecture/serviceManagement
3.7. Describe the IBM Bluemix Garage Method
IBM Bluemix® Garage Method breaks down DevOps into everything that development, testing and operations teams need. It brings together best practices on Design Thinking, Lean Startup, agile development, DevOps and cloud to help clients deliver innovative new applications more quickly. It includes how-to guides on culture, as well as best practices, tools, self-guided or hands-on training—even sample code and architectures. IBM’s method for DevOps can help turn client’s organizations from a slow, siloed collection of teams to a self-managing, solution-oriented, bottleneck-free, go-fast team.
3.7.1. Components of the Bluemix Garage Method
The Garage Method’s practices, architectures, tracks, and toolchains are fundamental to transforming the entire product lifecycle. 3.7.1.1. Practices. Each practice defines an overall business transformation
goal and presents achievable activities that clients and their teams can do to reach that goal.
3.7.1.2. Architectures. Architectures provide a structure that can be used to integrate cloud services into the applications and solutions. Each architecture includes specific implementations that can be used and customized.
3.7.1.3. Tracks. A track represents a guided path through the practices, architectures, toolchains, and tools that are used to develop a solution. The track that clients choose to follow depends on the business and transformation goals with details based on the type of product that is being built.
3.7.1.4. Toolchains. A toolchain is a set of tool integrations that supports development, deployment, and operations tasks. The collective power of a toolchain is greater than the sum of its individual tool integrations. The tools in the method are used by teams at IBM and IBM clients on their transformation journeys.
3.7.2. Phases of the Bluemix Garage Method
The method is divided into seven phases. Each phase includes a set of practices and tools to helps clients achieve the business and technical transformation goals. 3.7.2.1. Culture. Transform the organization by combining business,
technology, and process innovations that help create teams that quickly learn from market experiences. Some of the key principles include; 3.7.2.1.1. Building diverse teams

3.7.2.1.2. Define organizational roles 3.7.2.1.3. Work in autonomous co-located squads 3.7.2.1.4. Adopt agile principles.
3.7.2.2. Think. Incrementally deliver differential and disruptive solutions by using IBM Design Thinking and related design practices. Some of the key principles include; 3.7.2.2.1. Use IBM Design Thinking 3.7.2.2.2. Define a minimum viable product 3.7.2.2.3. Hold playbacks 3.7.2.2.4. Plan iterations using rank ordered backlog
3.7.2.3. Code. Adopt development practices to build cloud-native applications, release incremental function, gather feedback, and measure results. Some of the key principles include; 3.7.2.3.1. Hold daily standup meetings 3.7.2.3.2. Program in pairs and use test-driven development (TDD) 3.7.2.3.3. Continuously integrate 3.7.2.3.4. Automate testing
3.7.2.4. Deliver. Accelerate time-to-market by using continuous integration, continuous deployment, and automating repeatable and transparent processes. Some of the key principles include; 3.7.2.4.1. Deliver continuously using a pipeline 3.7.2.4.2. Automate Deployments
3.7.2.5. Run. Run solutions on a cloud platform by using Cloud Foundry, containers, or VMs. Run on a public cloud, a dedicated cloud, a private cloud, or in a hybrid environment. Auto-scale resources and manage them across worldwide data centers. Some of the key principles include; 3.7.2.5.1. Build a high availability infrastructure 3.7.2.5.2. Dark Launch and Feature Toggles 3.7.2.5.3. Auto-scaling
3.7.2.6. Manage. Ensure operational excellence with continuous application monitoring, high availability, and fast recovery practices that expedite problem identification and resolution. Some of the key principles include; 3.7.2.6.1. Automate monitoring 3.7.2.6.2. Enable fast recovery 3.7.2.6.3. Be resilient 3.7.2.6.4. Automate operations
3.7.2.7. Learn. Continuously experiment by testing hypotheses, using clear measurements to inform decisions, and driving findings into the backlog so that the team can pivot. Some of the key principles include; 3.7.2.7.1. Run A/B tests 3.7.2.7.2. Drive development with hypotheses 3.7.2.7.3. Use analytics tools
https://www.ibm.com/devops/method https://www.ibm.com/devops/method/files/Garage_Method_Field_Guide_Nov2016.pdf
3.8. Define and identify the common components of a DevOps Tool chain

A toolchain is a set of tool integrations that supports development, deployment, and operations tasks. The collective power of a toolchain is greater than the sum of its individual tool integrations. The tools in the method are used by teams at IBM and IBM clients on their transformation journeys.
3.8.1. Toolchain Components Examples: 3.8.1.1. Lifecycle management 3.8.1.2. Code repository 3.8.1.3. Building 3.8.1.4. Continuous Integration & deployment 3.8.1.5. Automation & Orchestration 3.8.1.6. Provisioning Platforms 3.8.1.7. Monitoring & Alerting 3.8.1.8. Reporting & Notification
https://www.ibm.com/devops/method/category/tools https://www.ibm.com/blogs/bluemix/2016/08/master-continuous-integration-delivery-ibm-devops-toolchain/ https://en.wikipedia.org/wiki/DevOps_toolchain http://linoxide.com/linux-how-to/best-known-devops-tools/
3.9. Describe the key architectural decisions made to adopt DevOps
There are a number of significant architectural decisions that need to be taken early during the instantiation of the DevOps solution. In broad terms, they cover;
3.9.1. What will be built in the DevOps process? Consider that if you were building a car, the process (skills, sequence, tooling, dependencies, scale, investment etc.) would be considerably different to that required for building a ship. Therefore, the ‘payload’ going through the DevOps process has a fundamental impact upon how the process is defined, implemented and optimized. What is the application, service or product that will be built in the DevOps process? Options might include; 3.9.1.1. Cloud Native application 3.9.1.2. Cloud Ready application 3.9.1.3. Monolithic application 3.9.1.4. Hybrid application 3.9.1.5. Mobile application 3.9.1.6. Micro-services 3.9.1.7. API / Integration 3.9.1.8. Internet of Things 3.9.1.9. Big Data & Analytics
3.9.2. What tooling will be used in the end to end DevOps process? Again using the ship and car analogy, the tooling used to construct the payload is usually optimized for its construction. Such tooling has dependencies which must be managed, and integrated into the overall process. What toolchain will be used to construct the artefacts and manage the DevOps process? Options might include; 3.9.2.1. Requirements and lifecycle management 3.9.2.2. Integrated development environment 3.9.2.3. Source control management

3.9.2.4. Build / Artefact repository 3.9.2.5. Continuous integration tool 3.9.2.6. Service virtualization 3.9.2.7. Deployment automation 3.9.2.8. Orchestration 3.9.2.9. Service management 3.9.2.10. Defects management 3.9.2.11. Test automation 3.9.2.12. Test data management
3.9.3. Where the tooling will be deployed? For cloud based solutions, we have the choice to use tooling which can be in a variety of locations from on-premises, in a private cloud, in a public cloud or even as a service. Options might include; 3.9.3.1. On-premises 3.9.3.2. Off-premises 3.9.3.3. Hybrid Cloud 3.9.3.4. Traditional IT 3.9.3.5. Number of test / staging environments
3.9.4. How and where the end solution will be deployed? Similarly to where the toolchains and delivery pipeline are located, the location of where (and their specific characteristics) the end product will be deployed needs to factored into the DevOps process. The reason for this is to ensure that the development, test and staging environments match as closely as possible where the artefact will run in the production environments. Options to consider include; 3.9.4.1. On-premises 3.9.4.2. Off-premises 3.9.4.3. Hybrid Cloud 3.9.4.4. Traditional IT 3.9.4.5. Deployment automation 3.9.4.6. Orchestration 3.9.4.7. Security
3.9.5. Describe the concepts of Software Defined Environments Software Defined Environment (SDE) virtualizes the entire computing infrastructure; compute, storage and network resources abstracting the application service design and delivery away from the details of the underlying hosting technologies. Driving SDE is the ability to obtain economies of scale to enable workloads (that define infrastructure requirements and configurations) to adapt dynamically to demand extending across multiple environments.
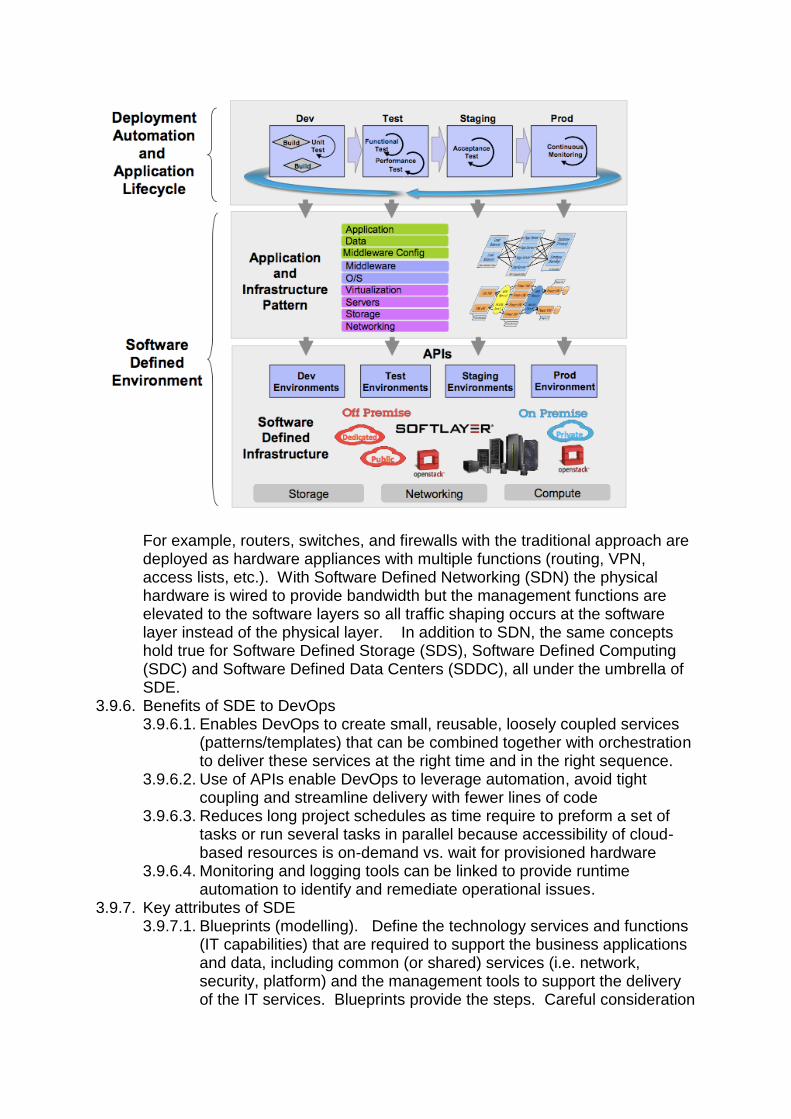
For example, routers, switches, and firewalls with the traditional approach are deployed as hardware appliances with multiple functions (routing, VPN, access lists, etc.). With Software Defined Networking (SDN) the physical hardware is wired to provide bandwidth but the management functions are elevated to the software layers so all traffic shaping occurs at the software layer instead of the physical layer. In addition to SDN, the same concepts hold true for Software Defined Storage (SDS), Software Defined Computing (SDC) and Software Defined Data Centers (SDDC), all under the umbrella of SDE.
3.9.6. Benefits of SDE to DevOps 3.9.6.1. Enables DevOps to create small, reusable, loosely coupled services
(patterns/templates) that can be combined together with orchestration to deliver these services at the right time and in the right sequence.
3.9.6.2. Use of APIs enable DevOps to leverage automation, avoid tight coupling and streamline delivery with fewer lines of code
3.9.6.3. Reduces long project schedules as time require to preform a set of tasks or run several tasks in parallel because accessibility of cloud-based resources is on-demand vs. wait for provisioned hardware
3.9.6.4. Monitoring and logging tools can be linked to provide runtime automation to identify and remediate operational issues.
3.9.7. Key attributes of SDE 3.9.7.1. Blueprints (modelling). Define the technology services and functions
(IT capabilities) that are required to support the business applications and data, including common (or shared) services (i.e. network, security, platform) and the management tools to support the delivery of the IT services. Blueprints provide the steps. Careful consideration

should be given to each step as too many steps create complexity and may not be necessary to the design.
3.9.7.2. Orchestration. The central process control to deploy multiple components based on templates. (Orchestration Engines: OpenStack HEAT, IBM Cloud Orchestration) It should include: 3.9.7.2.1. Event based processing with the ability to audit where the
workflows are at any point in time 3.9.7.2.2. Coordinate asynchronously between services and
correlate messages being exchanged. Gather information and use that information exchanged.
3.9.7.2.3. Supports parallel processing 3.9.7.2.4. Transaction able to be rolled back. If a service fails, it
needs to be able to “undo” what has already been done up to the point of the failure.
3.9.7.2.5. Manage long running business transactions. For example, when a service is requested, the orchestration engine needs to make a call to operational support or business to obtain “human” approval to proceed to deliver the service so it needs to know where to pick up after receiving the approval
3.9.7.3. Patterns/Templates 3.9.7.3.1. Patterns/Templates should be small reusable loosely
coupled services that when combined together deliver a service. (i.e. host instances, IP Address, volumes, databases, install & configure applications, SSH key pairs, etc.)
3.9.7.3.2. Reusable components reduce time to deliver new applications, testing and remediation throughout the delivery cycle as a developer may only need to design one component leveraging others that already exist (i.e. operating system build, database build)
3.9.7.3.3. Pattern Technologies: OpenStack Heat Orchestration Templates (HOT); UrbanCode Deploy with Patterns; IBM Cloud Manager with OpenStack
http://www.redbooks.ibm.com/redbooks/pdfs/sg248238.pdf

Section 4 - Open Source, Open Standard & Other Open Components
Most clients will have a variety of tools that support development and operational infrastructure, and are unlikely to have a full end to end stack from a single vendor. This section will focus upon the Open source, open standards, and defacto-common components and solutions that a DevOps architect or practitioner will encounter, and should understand in order to implement a full stack DevOps solution. 4.1. Identify tools for Build & Deploy
The proliferation of open source technologies has facilitated a major change in development processes facilitating DevOps adoption. There are a plethora of open source solutions commonly in use throughout the DevOps toolchain.
4.1.1. Common Build tools. 4.1.1.1. Ant- Apache Ant is a software tool for automating software build
processes, which originated from the Apache Tomcat project in early 2000. It was a replacement for the unix make build tool, and was created due to a number of problems with the unix make.
4.1.1.2. Buildr- Apache Builder is a build system for Java-based applications, including support for Scala, Groovy and a growing number of JVM languages and tools.
4.1.1.3. Git- is a version control system (VCS) that is used for software development and other version control tasks. As a distributed revision control system it is aimed at speed, data integrity, and support for distributed, non-linear workflows.
4.1.1.4. Gradle- is an open source build automation system that builds upon the concepts of Apache Ant and Apache Maven and introduces a Groovy-based domain-specific language (DSL) instead of the XML form used by Apache Maven of declaring the project configuration
4.1.1.5. Jenkins- Jenkins is an open source automation server written in Java.
4.1.1.6. Make- GNU Make is a tool which controls the generation of executables and other non-source files of a program from the program's source files.
4.1.1.7. Maven- Maven is a build automation tool used primarily for Java projects
4.1.1.8. Tweaker- Tweaker is an open-source, extendible software development build automation platform to consolidate the creation, management, and execution of scripts and custom utilities under a single location, intermix any languages (scripted or compiled) to perform tasks, allow common user interaction dialogs from all languages, and enable tasks to be executed from remote clients.
4.1.2. Common Deploy tools. 4.1.2.1. Ansible- Ansible is a free-software platform for configuring and
managing computers which combines multi-node software deployment, ad hoc task execution, and configuration management. It manages nodes over SSH or over PowerShell.
4.1.2.2. Chef- Chef is both the name of a company and the name of a configuration management tool written in Ruby and Erlang. It uses a pure-Ruby, domain-specific language (DSL) for writing system

configuration "recipes". Chef is used to streamline the task of configuring and maintaining a company's servers
4.1.2.3. Docker- Docker is an open-source project that automates the deployment of Linux applications inside software containers.
4.1.2.4. Packer- Packer is an open source tool for creating identical machine images for multiple platforms from a single source configuration.
4.1.2.5. Puppet- Puppet is an open-source configuration management tool. It runs on many Unix-like systems as well as on Microsoft Windows, and includes its own declarative language to describe system configuration.
4.1.2.6. Jenkins- Jenkins is an open source automation server written in Java.
4.1.2.7. Salt- Salt is a Python-based open-source configuration management software and remote execution engine. Supporting the "Infrastructure as Code" approach to deployment and cloud management.
4.1.2.8. Vagrant- Vagrant is an open-source software product for building and maintaining portable virtual development environments.
https://xebialabs.com/the-ultimate-devops-tool-chest/build/ https://devops.com/9-open-source-devops-tools-love/ http://techbeacon.com/open-source-tools-put-ops-devops
4.2. Identify tools for Collaboration & Notification
The proliferation of opensource technologies has facilitated a major change in development processes facilitating DevOps adoption. There are a plethora of opensource solutions commonly in use throughout the DevOps toolchain.
4.2.1. Common Collaboration tools.
4.2.1.1. Collabtive- Collabtive is a web-based project management software published as free software. It provides an open source alternative to proprietary tools like Basecamp, Asana and Trello.
4.2.1.2. Glip- Glip is an online team messaging platform launched in October 2013. Built as a conversation based collaboration solution, users have access to proprietary productivity tools which are integrated into team, group and individual chat streams.
4.2.1.3. Hipchat- HipChat is a Web service for internal/private chat and instant messaging. As well as one-on-one and group/topic chat, it also features cloud-based file storage, video calling, searchable message-history and inline-image viewing.
4.2.1.4. Rocket.chat- Rocket.Chat is a Web ChatServer, developed in JavaScript, using the Meteor fullstack framework.
4.2.1.5. Slack- Slack is a cloud-based team collaboration tool co-founded by Stewart Butterfield, Eric Costello, Cal Henderson, and Serguei Mourachov.
4.2.2. Common Notification tools. 4.2.2.1. ELK (Elasticsearch, LogStash, Kibana)- Logstash is an open source
tool for collecting, parsing, and storing logs for future use. Kibana 3 is a web interface that can be used to search and view the logs that Logstash has indexed. Both of these tools are based on

Elasticsearch. Elasticsearch, Logstash, and Kibana, when used together is known as an ELK stack
4.2.2.2. Graphite- Graphite, a free open-source software (FOSS) tool that monitors and graphs the performance of computer systems. Graphite was developed by Orbitz and released as open source software in 2008.
4.2.2.3. Monit- Monit is a utility for managing and monitoring processes, programs, files, directories and filesystems on a Unix system. Monit conducts automatic maintenance and repair and can execute meaningful causal actions in error situations.
4.2.2.4. Nagios- Nagios, now known as Nagios Core, is a free and open source computer-software application that monitors systems, networks and infrastructure. Nagios offers monitoring and alerting services for servers, switches, applications and services.
http://www.informationweek.com/devops/10-tools-for-effective-devops-collaboration/d/d-id/1327395 https://www.blazemeter.com/blog/top-10-monitoring-tools-every-devops-needs
4.3. Identify other common tools and their uses 4.3.1. IBM Bluemix Availability Monitoring Bluemix Availability Monitoring helps
DevOps teams ensure their applications are always available and meeting user expectations for response time as they roll out continuous updates. The service, which is tightly integrated into the DevOps toolchain, runs synthetic tests from locations around the world, around the clock to proactively detect and fix performance issues before they impact users.
4.3.2. IBM Bluemix Globalization Pipeline IBM Globalization Pipeline is a DevOps integrated application translation management service that you can use to rapidly translate and release cloud and mobile applications to your global customers. Access IBM Globalization Pipeline capabilities through its dashboard, RESTful API, or integrate it seamlessly into your application's Delivery Pipeline.
4.3.3. BlazeMeter Platform for load and performance testing enabling Dev and QA teams to run scalable and continuous testing for website, mobile, api and software.
4.3.4. New Relic Performance management solution enabling developers to diagnose and fix application performance problems in real time.
4.3.5. Hiptest Cloud based test management designed for agile and DevOps teams. Integration with Jira, Trello, CI tools and many test frameworks
https://console.ng.bluemix.net/catalog/services/availability-monitoring/ https://console.ng.bluemix.net/catalog/services/globalization-pipeline/ https://www.blazemeter.com/ https://newrelic.com/ https://hiptest.net/ https://xebialabs.com/periodic-table-of-devops-tools/
4.4. Describe common container technology 4.4.1. Describe Containers

Definition – A standard way to package an application, dependencies & configurations so that it can be moved between environments and run without changes. Containers work by isolating the differences between applications inside the container so it will always run the same, regardless of the environment. Why are containers relevant to DevOps: 4.4.1.1. Speed time to market, accelerating development and continuous
delivery as they are lightweight and promote portability and consistency of application images regardless of where they are run.
4.4.1.2. Increases application development efficiency by enabling continuous integration and continuous delivery of compostable services. Reduces time spent in setup of environments and issues encountered inherit with differences between environments.
4.4.1.3. Improve deployment efficiency as it allows higher density of compute resources utilization (CPU, Memory, Storage). Lightweight containers can run on a single machine sharing the same OS kernel while images are layered file systems sharing common files to make efficient use of resources.
4.4.1.4. Docker containers can be integrated into various infrastructure (AWS, ,Google, IBM Bluemix, OpenStack, HPE Helion Stackato, VMware vSphere, Cloud Foundry (Diego), OpenShift, etc.)
4.4.2. Docker Container Definitions & Attributes 4.4.2.1. Docker Layer: A layer is a change to an existing image (intermediate
changes). Because layers are intermediate images, if a change is made to a Docker file, only the layer that was changed and the ones after that will be re-built. Referred to as layer caching.
4.4.2.2. Dockerfile: Text document containing required commands to build docker image
4.4.2.3. Docker Image: filesystem and parameters referenced at runtime that is read only. Image can consist of one or more layers. Docker uses copy-on-write (union) file systems to combine layers into a single image using Docker build command
4.4.2.4. Docker Container: self-contained running instance built from one or more docker images. As Docker Images are read-only in a running container, there is a thin R/W layer on top of the underlying stack referred to as the “container layer”. All writes to the container that add new, modify or delete data are stored in this writeable layer. Since each container has it’s own R/W layer, multiple containers can share access to the same underlying image. 4.4.2.4.1. Containers are stateless 4.4.2.4.2. Each container has it’s own namespace isolating the
application’s view of the operating system and uses resource isolation (CPU, memory, block, I/O, network).
4.4.2.4.3. Containers are supported on UNIX (multiple versions) and Windows (2016)
4.4.2.5. Container Security 4.4.2.5.1. By default run in isolated views preventing access to
devices or system calls outside of the container. External privileges, system capabilities or device can be added to container at run time. IBM Bluemix does not allow

privileged commands. If required, must create container using container technology (i.e. Docker) on VM in an IBM Cloud Data Center (formerly
4.4.3. Explain the differences between VMs vs. Containers
Virtual machines involve a hypervisor providing an abstraction of the system hardware permitting multiple virtual machines to run on a given system, each containing its own guest operating system (OS). 4.4.3.1. Advantages for VMs
4.4.3.1.1. Hypervisor based virtualization (emulates the underlying physical hardware and creates virtual hardware instances and operating systems)
4.4.3.1.2. Provides a high level of isolation and security that has been hardened and proven over time
4.4.3.1.3. VMotion (enabling migration of running virtual machines from one physical server to another with zero downtime providing continuous service availability)
4.4.3.2. Disadvantages for VMs; 4.4.3.2.1. Performance overhead due to emulation of the hardware in
the hypervisor; 4.4.3.2.2. Multiple copies of the operating system are present as
each guest hosts its own OS reducing the number of VMs that a given system can share.
4.4.3.2.3. Initialization of a VM’s application and software stack takes longer time and consumes additional resources during initialization of the hypervisor.
4.4.3.2.4. Containers virtualize the operating system rather than the system hardware as all containers on a given system use the same host OS kernel. Each container isolates a set of processes and resources such as memory, CPU, disk.
4.4.3.3. Advantages for Containers; 4.4.3.3.1. No separate copy of the operating system within the
container resulting in a host being able to host a larger number of containers
4.4.3.3.2. Only the application, binaries and libraries required to run the application are required.
4.4.3.3.3. Stopping & starting containers is relatively fast as there is no operating system to initialize making it lightweight.
4.4.3.3.4. Lightweight nature of containers provides faster startup/download time as base layers are “cached”.
4.4.3.3.5. Can be run in parallel in separate containers distributing incoming requests across all instances using a load balancer.
4.4.3.3.6. Ready-prepared software stacks avoiding the need for developer to build & configure the stack from scratch (i.e. programming language runtimes such as Java, PHP, Node.js, Ruby, etc.)
4.4.3.4. Disadvantages for Containers; 4.4.3.4.1. Security isolation technology is not as strong for containers
as VMs which is a more mature technology as containers

rely primarily on the kernel features to isolate and control resources.
https://www.ibm.com/blogs/bluemix/2015/06/ibm-containers-a-bluemix-runtime-leveraging-docker-technology/ https://docs.docker.com/ https://docs.docker.com/engine/userguide/storagedriver/imagesandcontainers/ https://www.ibm.com/blogs/bluemix/2015/07/containers-for-agility-and-quality/ http://kubernetes.io/docs/whatisk8s/ https://docs.docker.com/swarm/overview/
4.5. Explain the applicability of open standards for DevOps 4.5.1. Explain the applicability of open standards for DevOps
DevOps drives improvements in the development and delivery of IT systems. Collaboration, transparency, and modularity are key objectives of DevOps methodology. The adoption of open standards supports these objectives in both the development of internal systems and the integration with externally developed systems.
4.5.2. Why use open standards? The adoption of open standards supports the goals of interoperability, reduced risk, and flexibility in IT service development. This is particularly import in a multi-speed IT environment where common DevOps processes are applied across a diverse range of tool designed to support specific application development. Examples of open standards relevant to DevOps 4.5.2.1. OCI – Open Container Initiative: An open standards project defining
specifications for container management. 4.5.2.2. OSLC - Open Services for Lifecycle Collaboration: An open
standards project defining specifications for tool integration. 4.5.2.3. TOSCA - OASIS Topology and Orchestration Specification for Cloud
Applications: An open standard templating language used in cloud orchestration.
4.5.2.4. Open Stack Foundation: An open source project developing a software platform primarily used to implement Infrastructure-as-a-service.
4.5.2.5. Open Power Foundation: An open source project supporting systems development using Power microprocessors.
4.5.2.6. OpenDaylight: An open source project with the goal of accelerating open standards based software-defined networking (SDN) and network function virtualization (NFV).
4.5.2.7. Cloud Foundry: An open source project developing a software platform used to implement platform-as-a-service.

Section 5 - IBM Solutions for DevOps
This section exclusively focuses upon the IBM solutions that IBM provides to help clients implement DevOps processes and solutions. Whilst most clients will not implement an all IBM solution stack, it is important to understand the specific solutions that should be considered during each of the phases of a DevOps process.
5.1. Describe the IBM solutions for the THINK phase in DevOps The Think phase in the Bluemix Garage method helps clients incrementally deliver differential and disruptive solutions by using IBM Design Thinking and related design phases. When you create a new service, product or a new iteration, you must conceptualize, design, refine and prioritize features that will delight your customers. To do this effectively, you’ll bring together business leaders, sales, designers, development, product management, and customers. IBM solutions that support the DevOps THINK include;
5.1.1. Rational Team Concert – is an agile lifecycle management solution, helping teams collaborate for faster software delivery. 5.1.1.1. Enhances team collaboration with integrated features including
work-item, build and software configuration management. 5.1.1.2. Provides high visibility into project activities and team progress
with multilevel dashboards and reporting features. 5.1.1.3. Facilitates planning and execution of agile or formal projects with
planning tools and templates, including a new Scaled Agile Framework (SAFe) template that is available in the latest version of Rational Team Concert.
5.1.1.4. Helps improve productivity with advanced source control for geographically distributed teams.
5.1.2. IBM Bluemix® DevOps Services (Track and Plan) – Helps clients to create user stories, tasks, and defects to describe and track project work, and use agile planning tools for the product backlog, releases, and sprints.
https://www.ibm.com/devops/method/category/think https://www.ibm.com/devops/method/content/architecture/architecture_devops
5.2. Describe the IBM solutions for the CODE phase in DevOps
The Code phase in the Bluemix Garage method helps clients adopt development practices to build traditional, cloud ready and cloud-native applications, release incremental function, gather feedback, and measure results. IBM solutions that support the DevOps CODE include;
5.2.1. Web IDE - The Eclipse Orion Web IDE is a browser-based development environment integrated into Bluemix, where developers can develop for the web. They can develop in JavaScript, HTML, and CSS with the help of content assist, code completion, and error checking.
5.2.2. Github (hosted on Bluemix) - Git is a distributed version-control system. With Git, developers can track changes to code and other content and collaborate on it with the team in an agile way. Git is fast because its repos are stored

locally instead of on a remote computer. Some people consider Git to be the defacto standard of version control.
5.2.3. IBM Rational Application Developer(and IBM Rational Developer for System z)- Helps developers design, develop, test, analyze, and deploy multi-tier, multi-channel Java, Java EE, portal, web and Web 2.0, OSGi, Web Services, REST services, SOA, mobile web, and hybrid mobile, and IBM Bluemix applications.
5.2.4. IBM Rational Test Workbench- IBM® Rational® Test Workbench provides software testing tools supporting a DevOps approach: API testing, functional UI testing, performance testing and service virtualization. To achieve DevOps or continuous delivery, software testing teams must automate regression testing to reduce the risk of deploying poor quality software into production. Effective test automation should include application programming interface (API) testing, user interface testing and overall system testing. Rational Test Workbench helps clients automate and run these tests earlier and more frequently to discover errors sooner—when they are less costly to fix.
5.2.5. IBM UrbanCode Build - IBM® UrbanCode™ Build is a continuous integration and build management server optimized for the enterprise. Designed for teams that provide build management as a service to other groups, UrbanCode Build provides scalable configuration and management of build infrastructures with seamless integration in to development, testing and release tooling. This extensible, customizable build solution provides a wide range of plugins for most common tools and easily works within a customized framework.
https://www.ibm.com/devops/method/category/code https://www.ibm.com/devops/method/content/architecture/architecture_devops
5.3. Describe the IBM solutions for the DELIVER phase in DevOps
The deliver phase in the Bluemix Garage method helps clients accelerate time-to-market by using continuous integration, continuous deployment, and automating repeatable and transparent processes. IBM solutions that support the DevOps DELIVER include;
5.3.1. IBM Bluemix® DevOps Services (Delivery Pipeline) - Use Delivery Pipeline to automate builds and deployments, test execution, configure build scripts, and automate execution of unit tests. Automatically build and deploy application to IBM's cloud platform, Bluemix.Build jobs compile and package app source code from Git or Jazz source control management (SCM) repositories. The build jobs produce deployable artifacts, such as WAR files or Docker containers for IBM Containers. Additionally, clients can run unit tests within the build automatically. Each time the source code changes, a build is triggered.
5.3.2. IBM UrbanCode Release - IBM® UrbanCode™ Release manages the release of complex interdependent applications, infrastructure changes and simultaneous deployments of multiple applications. This software enables clients to plan, execute and track a release through every stage of the lifecycle model. IBM UrbanCode Release helps to reduce errors while making large releases faster and more agile.

5.3.3. IBM UrbanCode Build - IBM® UrbanCode™ Build is a continuous integration and build management server optimized for the enterprise. Designed for teams that provide build management as a service to other groups, UrbanCode Build provides scalable configuration and management of build infrastructures with seamless integration in to development, testing and release tooling.
5.3.4. IBM UrbanCode Deploy- UCD orchestrates and automates application deployments, middleware configurations and database changes to on-premises or cloud-based development, test and production environments. Allows teams to deploy as often as needed—on demand or on schedule, with security-rich, self-service release management. Whether its deployed on-premises or as-a-service, IBM UrbanCode Deploy helps clients accelerate time to market, drive down deployment costs, reduce risks and achieve continuous delivery.
5.3.5. IBM Active Deploy– Active deploy is a Bluemix service to allow developers to deploy new versions of code to production without any downtime in their application access.
5.3.6. IBM Cloud Orchestrator - IBM Cloud Orchestrator is a cloud management platform for automating provisioning of cloud services using policy-based tools. It enables clients to configure, provision, deploy development environments, integrate service management—and add management, monitoring, back-up and security—in minutes. All from a single, self-service interface.
https://www.ibm.com/devops/method/category/deliver https://www.ibm.com/devops/method/content/architecture/architecture_devops
5.4. Describe the IBM solutions for the RUN phase in DevOps
The run phase in the Bluemix Garage Method describes how clients run solutions on a cloud platform by using Cloud Foundry, containers, or VMs. Run on a public cloud, a dedicated cloud, a private cloud, or in a hybrid environment. Auto-scale resources and manage them across worldwide data centers. IBM solutions that support the DevOps RUN include;
5.4.1. IBM Bluemix® runtimes (Node.js, Java, Liberty, OpenWhisk and more) - Developers use runtimes to get apps up and running quickly, with no need to set up and manage VMs and operating systems. Runtimes in IBM® Bluemix® are based on Cloud Foundry, which means that community buildpacks or tooling plug-ins for Cloud Foundry also work with Bluemix. The runtimes currently included in Bluemix are; Java Liberty, NodeJs, Go, Ruby, Python, XPages, and also a variety of community build packs.
5.4.2. IBM Containers - IBM Containers run Docker containers in a hosted cloud environment on IBM Bluemix®. Containers are virtual software objects that include all of the elements that an app needs to run. A container has the benefits of resource isolation and allocation, but is more portable and efficient than, for example, a virtual machine.
5.4.3. IBM Cloud Platform is comprised of a number of key offerings; 5.4.3.1. IBM Bluemix - IBM® Bluemix® is IBM's cloud computing platform that
combines platform as a service (PaaS) with infrastructure as a service

(IaaS). Additionally, Bluemix has a rich catalog of cloud services that can be easily integrated with PaaS and IaaS to build business applications rapidly.
5.4.3.2. IBM Cloud Data Centres – (formerly known as SoftLayer) IBM Cloud Data Centres are the largest provider of dedicated hosting in the world. Combining "bare metal" servers and Infrastructure-as-a-Service virtual servers on a pay-per-use basis, built on extensive hardware and network infrastructure across over 40+ global data centres. All of this can be managed remotely through a cloud environment.
5.4.3.3. Bare Metal Servers - bare metal servers provide the raw horsepower required for processor-intensive and disk I/O-intensive workloads. These servers come with the most complete package of standard features and services.
5.4.3.4. IBM Bluemix Local - IBM Bluemix Local System simplifies and automates application environment deployments so apps can be deployed in minutes, not months. This hybrid cloud application platform runs either, or both, cloud-native and cloud-enabled enterprise apps on the same system in the client’s private cloud. Using pre-built, customizable patterns, you can rapidly deploy application environments with just a few clicks.
5.4.3.5. IBM Bluemix Private Cloud–(formerly known as IBM Bluebox) is IBM’s local private cloud solution powered by non-proprietary OpenStack Private Cloud as a Service (PCaaS). Its key features are; On premises, Streamlined, rapid deployment, Complete configuration management, Hybrid capabilities, and of course powered by OpenStack.
5.4.4. IBM Cloud for VMware Solutions 5.4.4.1. VMware Cloud Foundation - use VMware Cloud Foundation to
implement and deploy a VMware environment in just a few minutes using the advanced automation developed through the partnership between IBM and VMware, allowing consistent deployment the unified software-defined VMware platform to the cloud.
5.4.4.2. VMware vCenter Server on IBM Cloud provides the automated deployment of the underlying vSphere virtualization technology and vCenter Server management layer needed to build a flexible and customizable VMware solution that fits the client’s workloads.
5.4.5. IBM PureApplication - is a hybrid cloud application platform for deploying application environments quickly and repeatedly for both on-premises and off-premises cloud landscapes. App deployment normally requires scripting and configuring the tasks to deploy and manage an application, its environment and the underlying infrastructure. IBM PureApplication simplifies and automates these tasks and processes to accelerate application delivery, lower costs and reduce errors.
5.4.6. IBM Auto-Scaling for Bluemix– allows developers to create rules and policies for automatically increasing and decreasing the resources allocated to running application in Bluemix, thereby providing auto-scaling for the application.
https://www.ibm.com/devops/method/category/run https://www.ibm.com/devops/method/content/architecture/architecture_devops

5.5. Describe the IBM solutions for the MANAGE phase in DevOps
The manage phase in the Bluemix Garage Method describes how client ensure operational excellence with continuous application monitoring, high availability, and fast recovery phases that expedite problem identification and resolution.
IBM solutions that support the DevOps MANAGE include;
5.5.1. IBM Application Performance Management - IBM application performance
management solutions help clients manage the performance and availability of their applications. These solutions can identify bottlenecks and quickly detect the root cause of service to application performance problems.
5.5.2. IBM IT Operations Analytics - IT operations analytics involves collecting IT data from different sources, examining that data in a broader context, and proactively identifying problems in advance of their occurrence. ITOA allows clients to extract insight from key operational data types, such as log files, performance metrics, events and trouble tickets, in order to ; Proactively avoid outages; Achieve faster mean time to repair (MTTR) ; and realize cost savings through greater operational efficiency.
5.5.3. IBM Alert Notification - Use Alert Notification to get notifications of application or service issues before they affect the users. Filter the alerts that you want to be notified of and route them to authorized users.
5.5.4. IBM Bluemix® Availability Monitoring- Bluemix Availability Monitoring helps DevOps teams ensure their applications are always available and meeting user expectations for response time as they roll out continuous updates. The service, which is tightly integrated into the DevOps toolchain, runs synthetic tests from locations around the world, around the clock to proactively detect and fix performance issues before they impact users.
5.5.5. IBM Monitoring and Analytics for Bluemix – provides Health and Availability of clients applications; Performance Monitoring of application runtimes; Log Analytics to quickly find errors in application logs; and Alerting and Notification support to send events if application problems occur.
5.5.6. IBM Runbook Automation - Use Runbook Automation to build and execute runbooks that can help IT staff to solve common operational problems. IBM Runbooks Automation can automate procedures that do not require human interaction, thereby increasing the efficiency of IT operations processes. Operators can spend more time innovating and are freed from performing time-consuming manual tasks.
5.5.7. IBM Control Desk - IBM® Control Desk unified IT asset and service management software provides a common control center for managing business processes for both digital and physical assets. It enables control, governance and compliance to applications, endpoints and assets to protect critical data and prevent outages.
https://www.ibm.com/devops/method/category/manage https://www.ibm.com/devops/method/content/architecture/architecture_devops

5.6. Describe the IBM solutions for the LEARN phase in DevOps The learn phase in the Bluemix Garage Method helps clients continuously experiment by testing hypotheses, using clear measurements to inform decisions, and driving findings into the backlog so that you can pivot.
IBM solutions that support the DevOps LEARN include;
5.6.1. IBM Tealeaf CX - IBM® Tealeaf® CX uses customer experience
management solutions to capture and manage visitor interactions on websites in cloud and on-premises environments. It provides extensive visibility into customers’ online experiences and insight into customer behaviours within web and mobile browsers. The Tealeaf CX platform can be used throughout an organization to support a range of functions, including e-commerce, marketing, development and design, customer service and compliance administration.
5.6.2. IBM Digital Analytics - IBM® Digital Analytics (formerly Core metrics Web Analytics), is a platform for near real-time digital analytics, data monitoring and comparative benchmarking. It analyses and reports on visitors' digital journeys—across marketing touchpoints and channels—to provide customer insights that help marketers deliver more personalized, relevant and effective marketing. The IBM Digital Analytics platform has options to analyse multiple sites, offline customer behaviour, ad relevancy, impression attribution and social media channels.
5.6.3. IBM Mobile Quality Assurance- Mobile Quality Assurance enables mobile beta management, mobile app testing, user validation, and streamlined quality feedback with sentiment analysis, over-the-air build distribution, automated crash reporting, in-app bug reporting and user feedback.
https://www.ibm.com/devops/method/category/learn https://www.ibm.com/devops/method/content/architecture/architecture_devops
5.7. Describe the IBM solutions for the CULTURE phase in DevOps
The culture phase in Bluemix Garage Method focusses upon transforming your organization by combining business, technology, and process innovations that help you create teams that quickly learn from market experiences.
Collaboration tools enable a culture of innovation. Developers, designers, operations teams, and managers must communicate constantly. Development and operations tools must be integrated to post updates and alerts as new builds are completed and deployed and as performance is monitored. The team can discuss the alerts as a group in the context of the tool.
IBM solutions that support the DevOps culture include;
5.7.1. IBM Connections - IBM® Connections™ is a business social network
platform that helps teams collaborate and get work done. Connections allows organizations to engage the right people, accelerate innovation and deliver results. Using this business social network, they can confidently share knowledge beyond traditional organizational boundaries. Connections can

help them improve decision-making, increase productivity and accelerate time to market on a platform that is delivered on premises or as software as a service on IBM Cloud.
5.7.2. IBM Verse - IBM® Verse is a email hosting solution that enables users to access their business communications from a laptop or desktop browser or from a mobile device. The email and business messaging experience is based on an innovative user-centric design, including social analytics and advanced search capabilities. IBM Verse helps users quickly find and focus on what content is most important, empowering them to build stronger working relationships while optimizing business results.
https://www.ibm.com/devops/method/category/culture https://www.ibm.com/devops/method/content/architecture/architecture_devops
5.8. Describe the IBM solutions for Security in DevOps
The team must ensure that all aspects of the application and its supporting infrastructure are secured. IBM solutions that support the security in DevOps include;
5.8.1. IBM Access Trail - The Access Trail service enables developers and
operators to view, search, and export API access logs for IBM cloud runtime and services. They can then use the information to improve solution visibility, consider security improvements, and comply with regulatory audit requirements.
5.8.2. IBM Application Security on Cloud - IBM Application Security on Cloud helps secure organization's applications by detecting dozens of today's most pervasive published security vulnerabilities. As such, it helps to eliminate vulnerabilities from applications before they are placed into production and deployed. Convenient, detailed reporting permits developers to effectively address vulnerabilities that are found, enabling application users to benefit from a more secure experience.
5.8.3. IBM Single Sign On - Implement user authentication for web and mobile apps quickly, using simple policy-based configurations.
5.8.4. IBM Key Protect - A cloud based security service to provide key life cycle management (key creation, usage, deletion) for encryption keys used in IBM Cloud services or customer built applications, with "root of trust" backed by a Hardware Security Module (HSM).
5.8.5. IBM Security QRadar - IBM® QRadar® SIEM consolidates log events and network flow data from thousands of devices, endpoints and applications distributed throughout a network. It normalizes and correlates raw data to identify security offenses, and uses an advanced Sense Analytics engine to baseline normal behaviour, detect anomalies, uncover advanced threats, and remove false positives. As an option, this software incorporates IBM X-Force® Threat Intelligence which supplies a list of potentially malicious IP addresses including malware hosts, spam sources and other threats. IBM QRadar SIEM can also correlate system vulnerabilities with event and network data, helping to prioritize security incidents.

https://www.ibm.com/devops/method/content/architecture/architecture_devops
5.9. Describe the IBM solutions for transformation and connectivity in DevOps
The enterprise network is protected by a firewall and must be accessed through transformation and connectivity services and secure messaging services.
IBM solutions that support the transformation and connectivity in DevOps include;
5.9.1. IBM API Connect - IBM API Connect is a comprehensive end-to-end API
lifecycle solution that enables the automated creation of APIs, simple discovery of systems of records, self-service access for internal and third party developers and built-in security and governance. Using automated, model-driven tools, create new APIs and microservices based on Node.js and Java runtimes—all managed from a single unified console. Ensure secure & controlled access to the APIs using a rich set of enforced policies. Drive innovation and engage with the developer community through the self-service developer portal. IBM API Connect provides streamlined control across the API lifecycle and also enables businesses to gain deep insights around API consumption from its built-in analytics.
5.9.2. IBM Secure Gateway - The Secure Gateway Service brings Hybrid Integration capability to a clients Bluemix environment. It provides secure connectivity from Bluemix to other applications and data sources running on premises or in other clouds. A remote client is provided to enable secure connectivity.
5.9.3. IBM z/OS Connect - Create efficient and scalable RESTful APIs for mobile and cloud applications. IBM® z/OS® Connect Enterprise Edition (EE) allows clients to expose applications and data through an API management platform. https://www.ibm.com/devops/method/content/architecture/architecture_devops

Next Steps
1. Take the Foundations of IBM DevOps V1 assessment test.
2. If you pass the assessment exam, visit pearsonvue.com/ibm to schedule your
testing sessions.
3. If you failed the assessment exam, review how you did by section. Focus attention on the sections where you need improvement. Keep in mind that you can take the assessment exam as many times as you would like, however, you will still receive the same questions only in a different order.


















