
HUG France - Apache Drill
30
1 ©MapR Technologies - Confidential Apache Drill
-
Upload
mapr-technologies -
Category
Technology
-
view
1.101 -
download
2
description
Talk at Hug FR on December 4, 2012 about the new Apache Drill project. Notably, this talk includes an introduction to the converging specification for the logical plan in Drill.
Transcript of HUG France - Apache Drill

1©MapR Technologies - Confidential
Apache Drill

2©MapR Technologies - Confidential
My Background
Academia, Startups– Aptex, MusicMatch, ID Analytics, Veoh– Big data since before big
Open source– since the dark ages before the internet–Mahout, Zookeeper, Drill– bought the beer at first HUG
MapR Founding member of Apache Drill

3©MapR Technologies - Confidential
MapR Technologies
The open enterprise-grade distribution for Hadoop– Easy, dependable and fast– Open source with standards-based extensions
MapR is deployed at 1000’s of companies– From small Internet startups to the world’s largest enterprises
MapR customers analyze massive amounts of data:– Hundreds of billions of events daily– 90% of the world’s Internet population monthly– $1 trillion in retail purchases annually
MapR has partnered with Google to provide Hadoop on Google Compute Engine

4©MapR Technologies - Confidential
Agenda
What?– What exactly does Drill do?
Why?– Why do we need Apache Drill?
Who?– Who is doing this?
How?– How does Drill work inside?
Conclusion– How can you help?– Where can you find out more?

5©MapR Technologies - Confidential
Apache Drill Overview
Drill overview– Low latency interactive queries – Standard ANSI SQL support
Open-Source– 100’s involved across US and Europe – Community consensus on API, functionality
PMC expects first version late this quarter– Several components already developed

6©MapR Technologies - Confidential
Big Data Processing – Hadoop
Batch processing
Query runtime Minutes to hours
Data volume TBs to PBs
Programming model
MapReduce
Users Developers
Google project MapReduce
Open source project
Hadoop MapReduce

7©MapR Technologies - Confidential
Big Data Processing – Hadoop and Storm
Batch processing Stream processing
Query runtime Minutes to hours Never-ending
Data volume TBs to PBs Continuous stream
Programming model
MapReduce DAG (pre-programmed)
Users Developers Developers
Google project MapReduce
Open source project
Hadoop MapReduce
Storm or Apache S4

8©MapR Technologies - Confidential
Big Data Processing – The missing part
Batch processing Interactive analysis Stream processing
Query runtime Minutes to hours Never-ending
Data volume TBs to PBs Continuous stream
Programming model
MapReduce DAG (pre-programmed)
Users Developers Developers
Google project MapReduce
Open source project
Hadoop MapReduce
Storm and S4

9©MapR Technologies - Confidential
Big Data Processing – The missing part
Batch processing Interactive analysis Stream processing
Query runtime Minutes to hours Milliseconds to minutes
Never-ending
Data volume TBs to PBs GBs to PBs Continuous stream
Programming model
MapReduce Queries(ad hoc)
DAG (pre-programmed)
Users Developers Analysts and developers
Developers
Google project MapReduce
Open source project
Hadoop MapReduce
Storm and S4

10©MapR Technologies - Confidential
Big Data Processing
Batch processing Interactive analysis Stream processing
Query runtime Minutes to hours Milliseconds to minutes
Never-ending
Data volume TBs to PBs GBs to PBs Continuous stream
Programming model
MapReduce Queries DAG
Users Developers Analysts and developers
Developers
Google project MapReduce Dremel
Open source project
Hadoop MapReduce
Storm and S4

11©MapR Technologies - Confidential
Big Data Processing
Batch processing Interactive analysis Stream processing
Query runtime Minutes to hours Milliseconds to minutes
Never-ending
Data volume TBs to PBs GBs to PBs Continuous stream
Programming model
MapReduce Queries DAG
Users Developers Analysts and developers
Developers
Google project MapReduce Dremel
Open source project
Hadoop MapReduce
Storm and S4
Introducing Apache Drill

12©MapR Technologies - Confidential
Latency Matters
Ad-hoc analysis with interactive tools
Real-time dashboards
Event/trend detection and analysis– Network intrusions– Fraud– Failures

13©MapR Technologies - Confidential
Nested Query Languages
DrQL– SQL-like query language for nested data– Compatible with Google BigQuery/Dremel• BigQuery applications should work with Drill
– Designed to support efficient column-based processing• No record assembly during query processing
Mongo Query Language– {$query: {x: 3, y: "abc"}, $orderby: {x: 1}}
Other languages/programming models can plug in

14©MapR Technologies - Confidential
Nested Data Model
The data model in Dremel is Protocol Buffers– Nested– Schema
Apache Drill is designed to support multiple data models– Schema: Protocol Buffers, Apache Avro, …– Schema-less: JSON, BSON, …
Flat records are supported as a special case of nested data– CSV, TSV, …
{ "name": "Srivas", "gender": "Male", "followers": 100}{ "name": "Raina", "gender": "Female", "followers": 200, "zip": "94305"}
enum Gender { MALE, FEMALE}
record User { string name; Gender gender; long followers;}
Avro IDL JSON

15©MapR Technologies - Confidential
Extensibility
Nested query languages– Pluggable model– DrQL– Mongo Query Language– Cascading
Distributed execution engine– Extensible model (eg, Dryad)– Low-latency– Fault tolerant
Nested data formats– Pluggable model– Column-based (ColumnIO/Dremel, Trevni, RCFile) and row-based (RecordIO, Avro, JSON, CSV)– Schema (Protocol Buffers, Avro, CSV) and schema-less (JSON, BSON)
Scalable data sources– Pluggable model– Hadoop– HBase

16©MapR Technologies - Confidential
Design Principles
Flexible• Pluggable query languages• Extensible execution engine• Pluggable data formats
• Column-based and row-based• Schema and schema-less
• Pluggable data sources
Easy• Unzip and run• Zero configuration• Reverse DNS not needed• IP addresses can change• Clear and concise log messages
Dependable• No SPOF• Instant recovery from crashes
Fast• C/C++ core with Java support
• Google C++ style guide• Min latency and max throughput
(limited only by hardware)

17©MapR Technologies - Confidential
Apache DRill

18©MapR Technologies - Confidential
Architecture
Only the execution engine knows the physical attributes of the cluster– # nodes, hardware, file locations, …
Public interfaces enable extensibility– Developers can build parsers for new query languages– Developers can provide an execution plan directly
Each level of the plan has a human readable representation– Facilitates debugging and unit testing

19©MapR Technologies - Confidential
Execution Engine Layers
Drill execution engine has two layers– Operator layer is serialization-aware• Processes individual records
– Execution layer is not serialization-aware• Processes batches of records (blobs)• Responsible for communication, dependencies and fault tolerance

20©MapR Technologies - Confidential
DrQL Example
SELECT DocId AS Id, COUNT(Name.Language.Code) WITHIN Name AS Cnt, Name.Url + ',' + Name.Language.Code AS StrFROM tWHERE REGEXP(Name.Url, '^http') AND DocId < 20;
* Example from the Dremel paper
21©MapR Technologies - Confidential
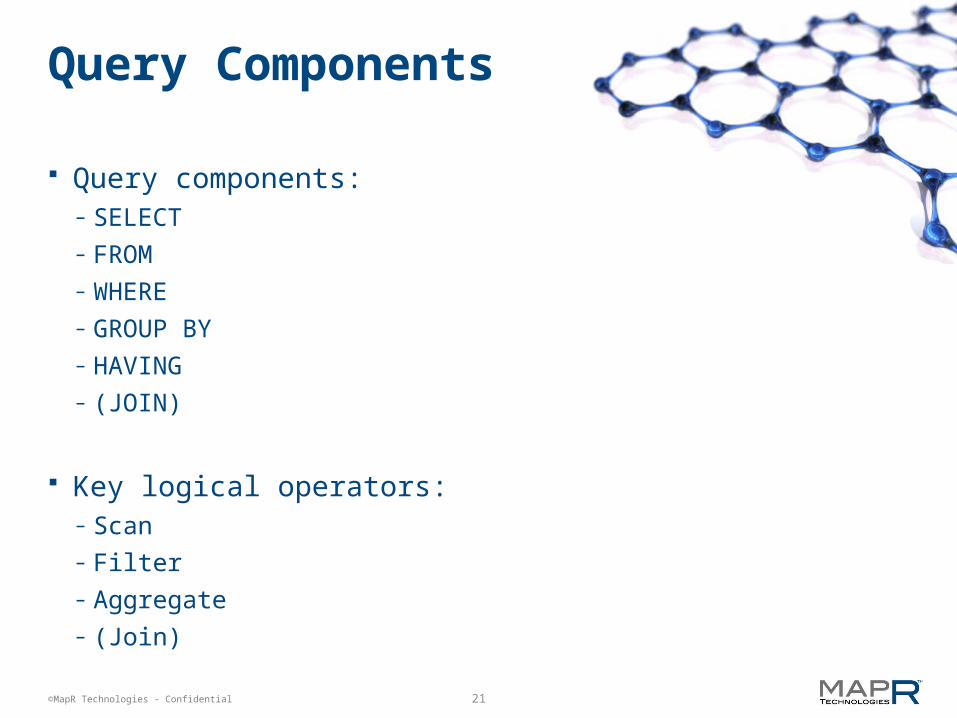
Query Components
Query components:– SELECT– FROM– WHERE– GROUP BY– HAVING– (JOIN)
Key logical operators:– Scan– Filter– Aggregate– (Join)

22©MapR Technologies - Confidential
Logical Plan
23©MapR Technologies - Confidential
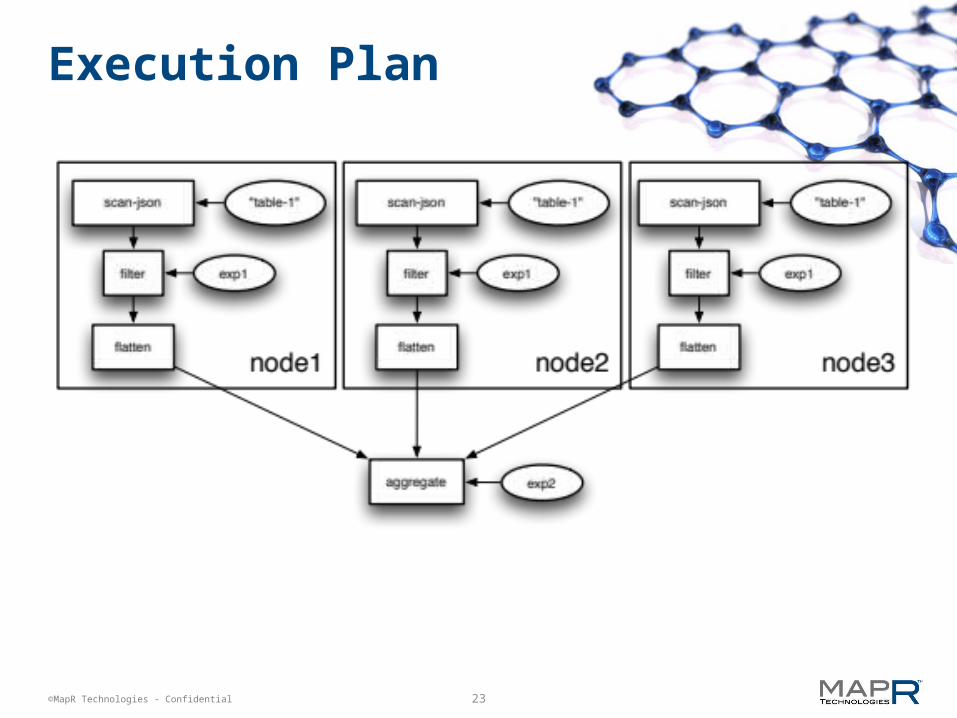
Execution Plan

24©MapR Technologies - Confidential
{op: "sequence", do: [ {op: "scan", source: "table-1.json" selection: "*" }, {op: "filter", expr: <expr> }, {op: "flatten", expr: <expr>, drop: "false" }, {op: "aggregate", type: repeat, keys: [<name>,...], aggregations: [ {ref: <name>, expr: <aggexpr> },... ] } ]}
Logical Plan Syntax

25©MapR Technologies - Confidential
Representing a DAG
{ @id: 19, op: "aggregate", input: 18, type: <simple|running|repeat>, keys: [<name>,...], aggregations: [ {ref: <name>, expr: <aggexpr> },... ]}

26©MapR Technologies - Confidential
Multiple Inputs
{ @id: 25, op: "cogroup", groupings: [
{ref: 23, expr: “id”}, {ref: 24, expr: “id”} ]}

27©MapR Technologies - Confidential
Scan Operators
Scan with schema Scan without schema
Operator output
Protocol Buffers JSON-like (MessagePack)
Supported data formats
ColumnIO (column-based protobuf/Dremel)RecordIO (row-based protobuf)CSV
JSONHBase
SELECT … FROM …
ColumnIO(proto URI, data URI)RecordIO(proto URI, data URI)
Json(data URI)HBase(table name)
• Drill supports multiple data formats by having per-format scan operators• Queries involving multiple data formats/sources are supported
• Fields and predicates can be pushed down into the scan operator
• Scan operators may have adaptive side-effects (database cracking)• Produce ColumnIO from RecordIO• Google PowerDrill stores materialized expressions with the data

28©MapR Technologies - Confidential
Design Principles
Flexible• Pluggable query languages• Extensible execution engine• Pluggable data formats
• Column-based and row-based• Schema and schema-less
• Pluggable data sources
Easy• Unzip and run• Zero configuration• Reverse DNS not needed• IP addresses can change• Clear and concise log messages
Dependable• No SPOF• Instant recovery from crashes
Fast• C/C++ core with Java support
• Google C++ style guide• Min latency and max throughput
(limited only by hardware)

29©MapR Technologies - Confidential
Hadoop Integration
Hadoop data sources– Hadoop FileSystem API (HDFS/MapR-FS)– HBase
Hadoop data formats– Apache Avro– RCFile
MapReduce-based tools to create column-based formats Table registry in HCatalog Run long-running services in YARN

30©MapR Technologies - Confidential
Get Involved!
Download these slides– http://www.mapr.com/company/events/hug-france-12-04-2012
Join the project– [email protected] – #apachedrill
Contact me:– [email protected]– [email protected]
– [email protected]– @ted_dunning
Join MapR– [email protected]


















