
การวางแผนผสู บืทอด และ การพฒันาเสน ทางอาชพี (Career ... · Division Mgr. Asst. Division Mgr. Section
Upload
eugene-houstonCategory
view
226download
0
http://www.webarchiv.cz
WebArchive – Archive of the Czech WebWebArchive – Archive of the Czech Web
Mgr. Jan HUTAŘMgr. Jan HUTAŘ

http://www.webarchiv.cz
Why we started with WebArchiv?Why we started with WebArchiv?
amount of documents published on the Internet is growing dramatically – average lifespan is 40 days --> if the documents are not archived a part of the national cultural heritage would disappear forever
need to save and keep accessible the documents on the CZ web
about 90% documents on the web exist only in electronic form
trend around the world (Australia, Sweden, Internet Archive … etc.)
NK ČR is suppose to do it – it is deposit library main mission of the NK is to collect, catalog, permanently
preserve documents published in the territory and make them available to the general public

http://www.webarchiv.cz
The beginningThe beginning
launched in 2000 – till 2002 – grant project R&D „Registration, preservation and access of national electronic resources in the Internet“ by Ministry of Culture
cooperation with Moravian Library Brno and Institute of Computer Science at the Masaryk University Brno
they are our „IT department“ ;-) only grants money
we are still going on!

http://www.webarchiv.cz
Main AimsMain Aims
to implement best solution in the field of archiving of the national web, i.e. bohemical online-born documents
prepare tools, methods and conditions for collecting, archiving and preserving web resources
to provide long-term access to them large-scale automated harvesting of the entire national web
and selective archiving are being carried out, including thematic „event-based“ collections
to solve current legal issues (the legal deposit legislation, CA) Legal Deposit Act doesn‘t cover online-born documents and according to the Copyright Act, it is not possible to make archived data available to public.
set selection criteria for selective approach / harvest to establish conditions for cooperation between libraries
and publishers of electronic documents

http://www.webarchiv.cz
Workflows Prague:
Resource selection Cataloguing for the National Bibliography (MARC21) Providing Dublin Core metadata for interested publishers Making archive access agreements with publishers
Brno: Running WebArchiv hardware Software localization, maintenance and development Pre-harvesting resource analysis Harvesting, indexing, access
Results so far: 4 harvesting rounds of .cz domain (2001, 2002, 2004, 2006) 5 event-oriented harvests several times per year – harvests of sites under agreements 5.4 TB archive with 136 million files

http://www.webarchiv.cz
Selection Criteria
The amount of documents on the Internet is quite big – for selective approach we need to find the ones with „research value“
For acquisition (harvesting) 2 approaches:
1. selective approach - only selected documents are harvested and archived – according to selec. criteria
2. complete harvest – of the entire national domain for example .cz. We need only to set harvester…
approaches are different in different countries trend is to do both (Australia, Denmark)

http://www.webarchiv.cz
Criteria –selective approachCriteria –selective approach
to set selection criteria was very difficult we coordinated "Web Cultural HeritageWeb Cultural Heritage„ project (in
the frame of EU Culture 2000 program)EU Culture 2000 program)
Content Resource type Original form Access Format Domain National aspect

http://www.webarchiv.cz
Criteria –selective approachCriteria –selective approach
1. Contents
Web resources of art or research value, news stories and feature articles and resources as outputs of government and other offices. Promotion material of an individual or a corporation is omitted.
2. Resource Type
Serials, monographs, conference proceedings, research and other reports, academic works etc.
3. Original form
Only resources originally published in the web – it means they have no traditional/printed copy
4. Access
Only freely accessed resources are collected

http://www.webarchiv.cz
Criteria –selective approachCriteria –selective approach
5. Format
Resources available in formats that are interpreted by common web browsers without necessity of installing plug-ins are collected.
6. Domain
Resources accessible at servers under the top level domain .cz and at servers under the other domains …
7. National aspect
Resources according to „authors nationality“, „national language“, „country or nation as a subject“

http://www.webarchiv.cz
What we have done…What we have done… continuous testing of:
SW tools applications for harvesting, archiving, indexing and
accessing of the web pages only open source SW effort / push to change legislation international cooperation (activities in R&D within IIPC –
even before we become a member)
we have opened part of our archive for public (since autumn 2005)
the whole archive archive should be open right now (only local access)

http://www.webarchiv.cz
Harvest of the .cz domainHarvest of the .cz domain 2001 first try of the whole domain harvest of the .cz
domain, 1 PC + tape robot, cz2001 includes over 3 mil. of unique URLs (107 GB) – not completed
2002 harvest interrupted - lack of space on data storage and floods. cz2002 includes 315,5 GB, from 10 263 855 URLs harvested over 10 mil. docs
in 2003 no harvest 2004 March- October, from 32 149 396 URLs harvested
32,5 million files = 1,2 TB september 2006 2nd harvest of .cz by Heritrix. Stoped –
no data storage space. Limits: max. 5000 docs/server, max. file size 100 MB
all harvest executed by the NEDLIB harvester, deep 25-50 links from 2004 new harvester HERITRIXHERITRIX

http://www.webarchiv.cz
Registrované domény v .cz
0
50000
100000
150000
200000
250000
300000
IX.99
XII.99III.00VI.00IX.00
XII.00III.01VI.01IX.01
XII.01III.02VI.02IX.02
XII.02III.03VI.03IX.03
XII.03III.04VI.04IX.04
XII.04III.05VI.05IX.05
XII.05III.06VI.06IX.06
http://www.webarchiv.cz
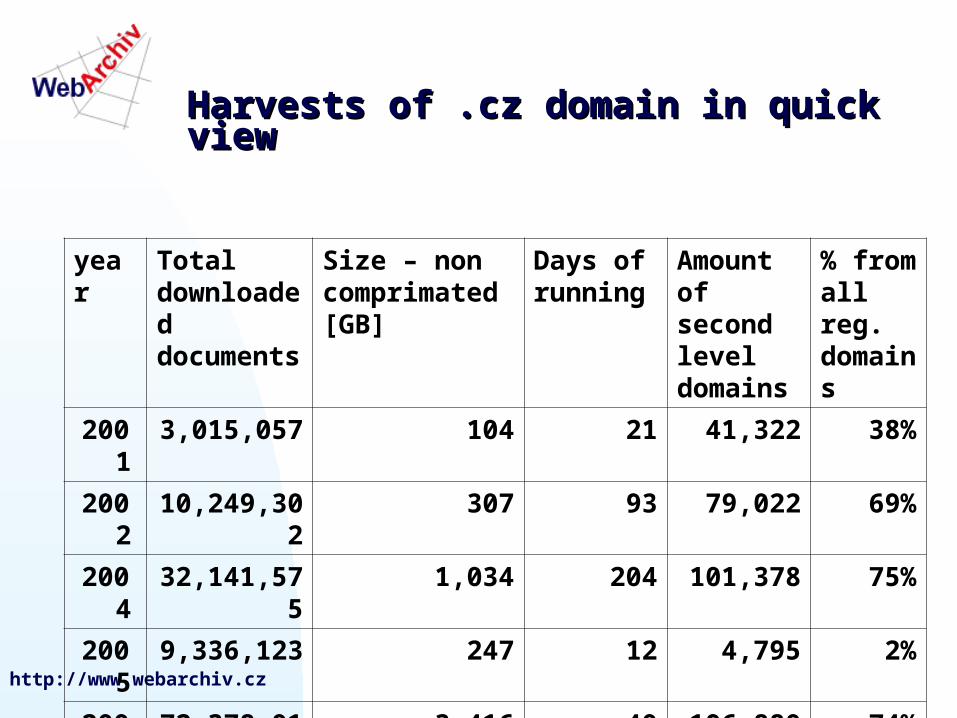
Harvests of .cz domain in quick Harvests of .cz domain in quick viewview
year Total downloaded documents
Size – non comprimated [GB]
Days of running
Amount of second level domains
% from all reg. domains
2001 3,015,057 104 21 41,322 38%
2002 10,249,302 307 93 79,022 69%
2004 32,141,575 1,034 204 101,378 75%
2005 9,336,123 247 12 4,795 2%
2006 72,378,019 3,416 40 196,880 74%

http://www.webarchiv.cz
Present state of the projectPresent state of the project 4-6 times/year is 4-6 times/year is harvested collection of selected
resources (agreement with NK), about 350 servers. increase is around 10GB of data for each harvest it is still rising
harvest of „small“ amounts of data is successful analysis of the domain .cz was done servers
„suspicious“ from unrelevancy were rejected (mail, mysql apod.) as well as duplicates – number of URLs decreased from 540 to 378 thousands
BUTBUT … from 2004 we were not able to keep running the
harvest of the whole .cz domain. – problem of Heritrix with memory using new release solved this issue

http://www.webarchiv.cz
Present state of the projectPresent state of the project
main standards are used (MARC21, DC, ISSN and URN) selected docs are catalogued in an ALEPH library system which
supports Z39.50 and OAI-PMH protocols selected resources (with agreements) at least 4 times a year at present we have in WebArchivWebArchiv saved cca 5,5 TB of data
(uncompressed) ≈ 158 milions of documents
in the end of 2007 all data will be moved on the new data repository
in 2008 archive of the project should become a part of prepared project of „National Digital Library“ at National Library (together with Kramerius and Manuscriptorium)

http://www.webarchiv.cz
Software changesSoftware changes 2004 development and support of NEDLIB harvester was
canceled – we replaced it by Heritrix 2004-2005 consecutive change over to SW developed by
IIPC (International Internet Preservation Consortium) archival file format nedlib replaced by ARCARC format (used
by Heritrix) warc format in near future – then wayback

http://www.webarchiv.cz
Harvester Heritrix – advantagesHarvester Heritrix – advantages
system modularity, extensibility, continual development (v.1.8), very good and fast support from Internet Archive developers
open source codes and modularity allow cooperation of third party on its development – good for us ;-)
2 parts – framework and add on modules Framework – basic control over harvests, user
interface, process managemenst, harvest settings modules – used for specific harvest implementation,
set up each harvest step by step

http://www.webarchiv.cz
Harvester Heritrix - problemsHarvester Heritrix - problems
not possible to leave the whole process of harvesting without the control of experts
trap detection extraction of links from websites (Java) memory problems (whole domain harvest) - solved incremental harvest and changes detection

http://www.webarchiv.cz
SW for accessSW for access
from IIPC (IA) fulltext document indexing - NutchWAXNutchWAX,
extension/superstructure over search engine NutchNutch WERAWERA (successor of NWA tools) – user interface for
accessing documents on the web – it can deal with Czech diacritics (accents etc. – display it, search by it, sort)
ARCWaybackARCWayback make index over whole archive, it allows access into archive by URL and time
Wayback Wayback for only restricted on-site access from within the library is possible to all files in the archive

http://www.webarchiv.cz
Nutch a NutchWAX Nutch a NutchWAX Nutch open source search engine, by IAsearch engine, by IA comes from Apache Lucene architecture
Nutch is able to: download and work up millions of sites in a month, manage
and control their index and search in this index 1000times/second
NutchWAX superstructure over SE Nutch made for indexing of
documents archived by Heritrix set of indexing and query plug-in, which add some needed
metadata to index

http://www.webarchiv.cz
WERA - WERA - WEb aRchive AccessWEb aRchive Access
cooperation between IIPC, Internet Archive and NWA use some parts from NWA very easy navigation, nice user interface (time line with
documents version in time) search hits in URL form are displayed very digestedly,
each hit has link to the timeline to get differ. version of the same URL
possibility to search by URL address (like Wayback M.) archived docs and WERA are linked by NutchWAX index

http://www.webarchiv.cz
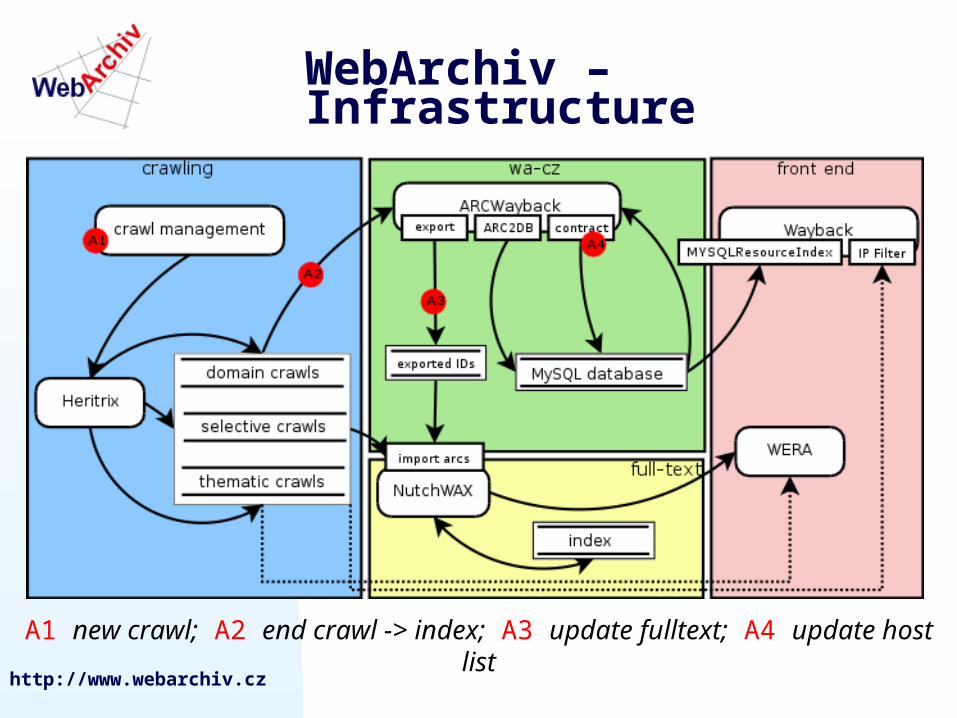
How does it work actually?How does it work actually?
harvest of docs – by the Heritrix crawler, docs are saved to data storage in ARC format
to make archived docs accessible we have to make index + interface, which display seach hits
1. making of the fulltext index over the collection of selected resources v- for searching by the words- NutchWAX
2. making of global index to provide access of the whole archive - ARCWayback
displaying of docs from archive - WERA and Wayback
http://www.webarchiv.cz
WebArchiv – Infrastructure
A1 new crawl; A2 end crawl -> index; A3 update fulltext; A4 update host list

http://www.webarchiv.cz
WERA - WERA - ukázkaukázka

http://www.webarchiv.cz
Our futureOur future
main aimmain aim – finish 2006 harvest, >> keep in processing the whole .cz domain harvest every year
go on with selective collection and increase the amount of resources in it
provide legal access to the whole archive – localy-according to the new CA (searching by URL and by the time of harvest
implemantation of incremental harvest (changes identification in repeatedly harvested docs)
Harvesting of bohemical resourcs outside the .cz domain - some language recognition tool
Adaptive incremental harvesting

http://www.webarchiv.cz
Our futureOur future Identification of duplicate (or rather very similar)
documents Incremental indexing - adding of new docs into already
made index, not to make new one everytime Fulltext indexing of the whole archive Selective harvesting on demand Permanent linking into the archive Access limitations set by the new copyright law OAI-PMH implementation on top of the registration
database Building METS structures on top of the archive integration of the archive into the proposed NDL 2007/08
http://www.webarchiv.cz
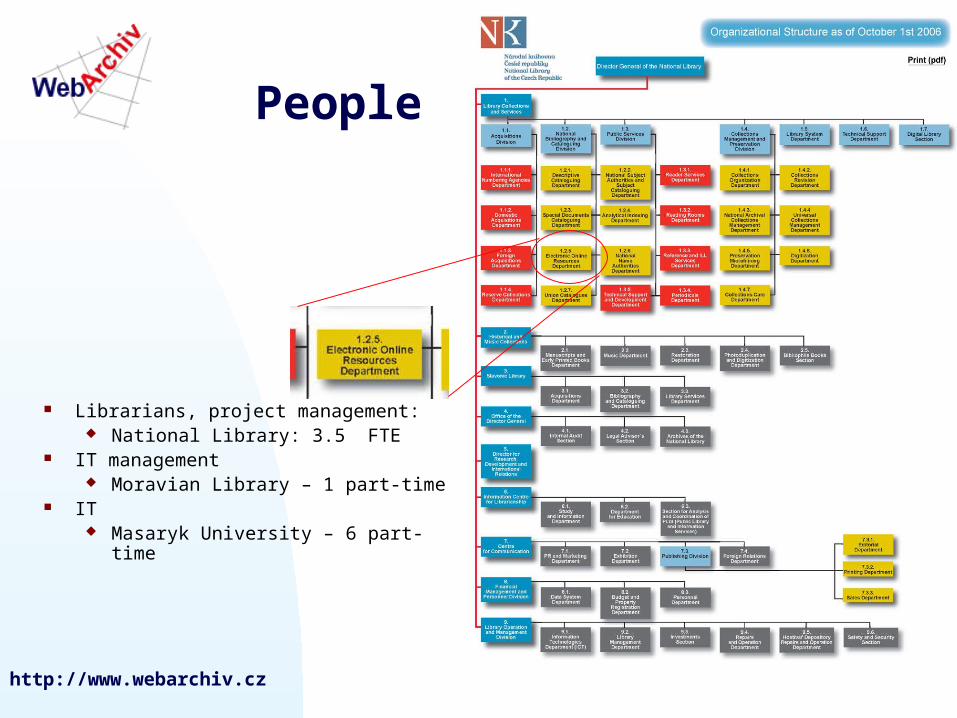
People
Librarians, project management: National Library: 3.5 FTE
IT management Moravian Library – 1 part-time
IT Masaryk University – 6 part-
time

http://www.webarchiv.cz
Useful links – in english;-)Useful links – in english;-) WebArchiv homepagehttp://en.webarchiv.cz/
Petr ŽabičkaDigital Cultural Heritage and the Cooperation of National Memory Institutes
Archiving the Czech Web: Issues and Challenges
this presentationhttp://www.webarchiv.cz/files/dokumenty/konference/hutarENG.ppt
Petr ŽABIČKA: WebArchiv, Czech Web Archive http://www.webarchiv.cz/files/dokumenty/konference/iipc.ppt


















