
HPCMPUG2011 cray tutorial
294
-
Upload
jeff-larkin -
Category
Technology
-
view
2.520 -
download
7
description
Maximizing Application Performance
on the Cray XE6
Transcript of HPCMPUG2011 cray tutorial


Review of XT6 Architecture
AMD Opteron
Cray Networks
Lustre Basics
Programming Environment
PGI Compiler Basics
The Cray Compiler Environment
Cray Scientific Libraries
Cray Message Passing Toolkit
Cray Performance Analysis Tools
ATP
CCM
Optimizations
CPU
Communication
I/OJune 20, 2011 22011 HPCMP User Group © Cray Inc.

AMD CPU Architecture
Cray Architecture
Lustre Filesystem Basics
June 20, 2011 32011 HPCMP User Group © Cray Inc.

June 20, 2011 42011 HPCMP User Group © Cray Inc.

2003 2005 2007 2008 2009 2010
AMD Opteron™
AMD Opteron™
“Barcelona” “Shanghai” “Istanbul” “Magny-Cours”
Mfg. Process
130nm SOI 90nm SOI 65nm SOI 45nm SOI 45nm SOI 45nm SOI
CPU Core
K8 K8 Greyhound Greyhound+ Greyhound+ Greyhound+
L2/L3 1MB/0 1MB/0 512kB/2MB 512kB/6MB 512kB/6MB 512kB/12MB
HyperTransport™Technology
3x 1.6GT/.s 3x 1.6GT/.s 3x 2GT/s 3x 4.0GT/s 3x 4.8GT/s 4x 6.4GT/s
Memory 2x DDR1 300 2x DDR1 400 2x DDR2 667 2x DDR2 800 2x DDR2 800 4x DDR3 1333
June 20, 2011 52011 HPCMP User Group © Cray Inc.

12 cores
1.7-2.2Ghz
105.6Gflops
8 cores
1.8-2.4Ghz
76.8Gflops
Power (ACP)
80Watts
Stream
27.5GB/s
Cache
12x 64KB L1
12x 512KB L2
12MB L3
1
3
4 10
5 8
6
7
9 12
2 11
June 20, 2011 62011 HPCMP User Group © Cray Inc.

ME
MO
RY
CO
NT
RO
LL
ER
HT
Lin
k
HT
Lin
k
ME
MO
RY
CO
NT
RO
LL
ER
HT
Lin
k
HT
Lin
kH
T L
ink
HT
Lin
k
HT
Lin
k
HT
Lin
k
L3 cache
L2 cache L2 cache
L2 cacheL2 cache
L2 cache L2 cache L2 cache
L2 cache L2 cache
L2 cache
L2 cache L2 cache
Core 0
Core 1
Core 2
Core 3
Core 4
Core 5
Core 6
Core 7
Core 8
Core 9
Core 10
Core 11
June 20, 2011 72011 HPCMP User Group © Cray Inc.

A cache line is 64B
Unique L1 and L2 cache attached to each core
L1 cache is 64 kbytes
L2 cache is 512 kbytes
L3 Cache is shared between 6 cores
Cache is a “victim cache”
All loads go to L1 immediately and get evicted down the caches
Hardware prefetcher detects forward and backward strides through memory
Each core can perform a 128b add and 128b multiply per clock cycle
This requires SSE, packed instructions
“Stride-one vectorization”
6 cores share a “flat” memory
Non-uniform-memory-access (NUMA) beyond a nodeJune 20, 2011 82011 HPCMP User Group © Cray Inc.

Processor Frequency Peak (Gflops)
Bandwidth (GB/sec)
Balance(bytes/flop
)
Istanbul (XT5)
2.6 62.4 12.8 0.21
MC-8
2.0 64 42.6 0.67
2.3 73.6 42.6 0.58
2.4 76.8 42.6 0.55
MC-12
1.9 91.2 42.6 0.47
2.1 100.8 42.6 0.42
2.2 105.6 42.6 0.40
9June 20, 20112011 HPCMP User Group © Cray Inc.

Gemini (XE-series)
June 20, 2011 102011 HPCMP User Group © Cray Inc.

Microkernel on Compute PEs, full featured Linux on Service PEs.
Service PEs specialize by function
Software Architecture eliminates OS “Jitter”
Software Architecture enables reproducible run times
Large machines boot in under 30 minutes, including filesystem
Service Partition
Specialized
Linux nodes
Compute PE
Login PE
Network PE
System PE
I/O PE
June 20, 2011 112011 HPCMP User Group © Cray Inc.

Boot RAID
XE6System
ExternalLogin Server
10 GbE
IB QDR
June 20, 2011 132011 HPCMP User Group © Cray Inc.

6.4 GB/sec direct connect
HyperTransport
CraySeaStar2+
Interconnect
83.5 GB/sec direct connect memory
Characteristics
Number of Cores
16 or 24 (MC)32 (IL)
Peak PerformanceMC-8 (2.4)
153 Gflops/sec
Peak Performance MC-12 (2.2)
211 Gflops/sec
Memory Size 32 or 64 GB per node
Memory Bandwidth
83.5 GB/sec
14June 20, 20112011 HPCMP User Group © Cray Inc.
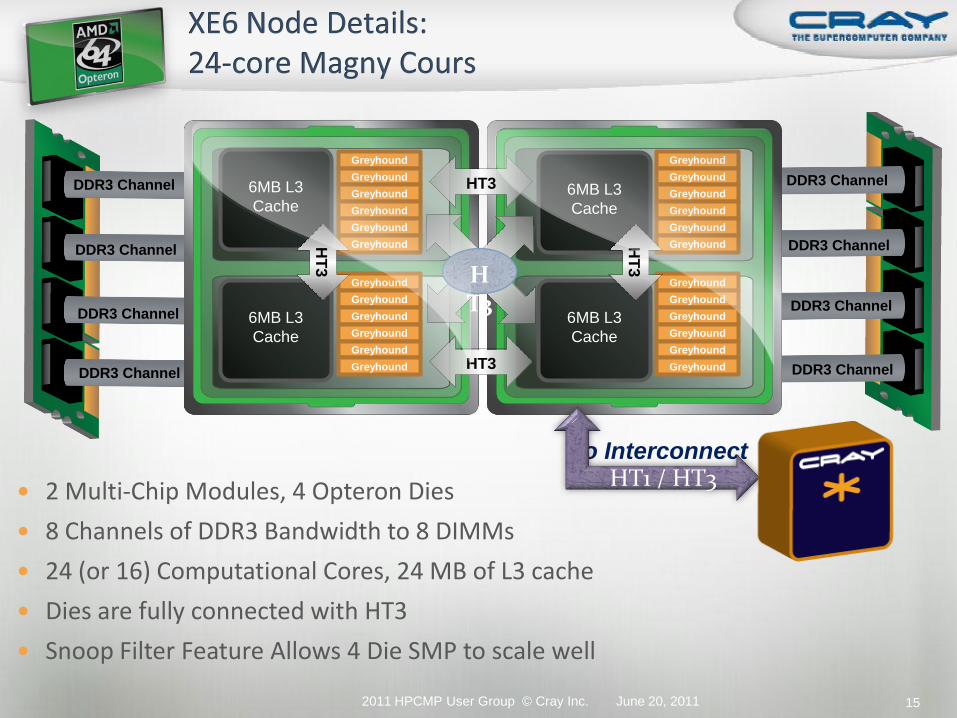
DDR3 Channel
DDR3 Channel
DDR3 Channel
DDR3 Channel
DDR3 Channel
DDR3 Channel
DDR3 Channel
DDR3 Channel
6MB L3
Cache
Greyhound
Greyhound
Greyhound
Greyhound
Greyhound
Greyhound
6MB L3
Cache
Greyhound
Greyhound
Greyhound
Greyhound
Greyhound
Greyhound
6MB L3
Cache
Greyhound
Greyhound
Greyhound
Greyhound
Greyhound
Greyhound
6MB L3
Cache
Greyhound
Greyhound
Greyhound
Greyhound
Greyhound
GreyhoundHT
3
HT
3
2 Multi-Chip Modules, 4 Opteron Dies
8 Channels of DDR3 Bandwidth to 8 DIMMs
24 (or 16) Computational Cores, 24 MB of L3 cache
Dies are fully connected with HT3
Snoop Filter Feature Allows 4 Die SMP to scale well
To Interconnect
HT3
HT3
HT3
HT1 / HT3
15June 20, 20112011 HPCMP User Group © Cray Inc.

Without snoop filter, a streams test
shows 25MB/sec out of a possible
51.2 GB/sec or 48% of peak
bandwidth
16June 20, 20112011 HPCMP User Group © Cray Inc.
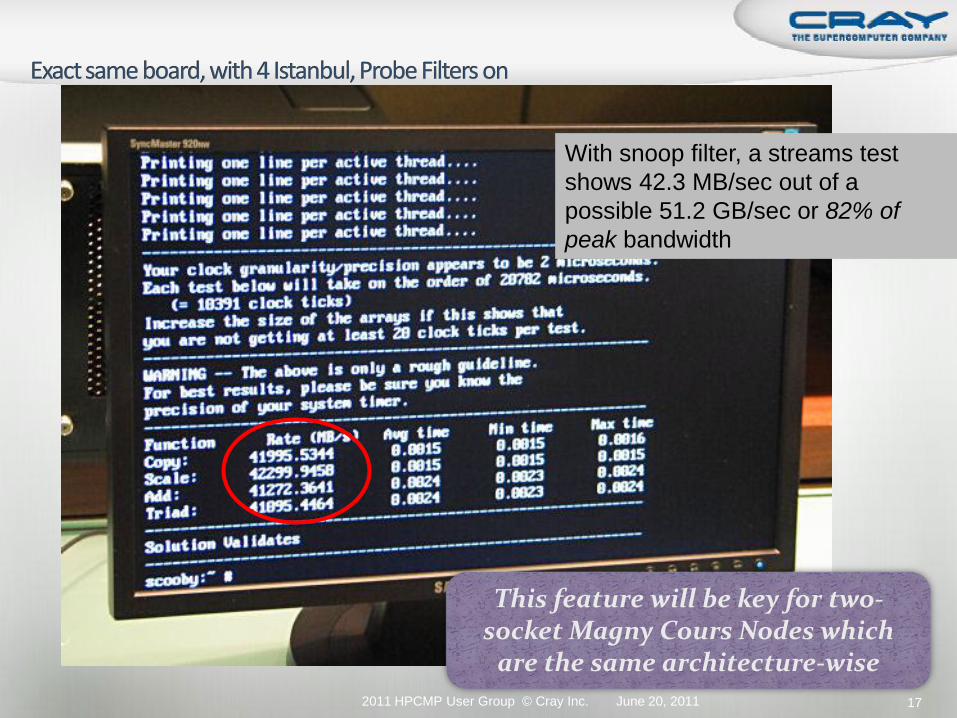
This feature will be key for two-socket Magny Cours Nodes which
are the same architecture-wise
With snoop filter, a streams test
shows 42.3 MB/sec out of a
possible 51.2 GB/sec or 82% of
peak bandwidth
17June 20, 20112011 HPCMP User Group © Cray Inc.

New compute blade with 8 AMD Magny Cours processors
Plug-compatible with XT5 cabinets and backplanes
Upgradeable to AMD’s “Interlagos” series
XE6 systems ship with the current SIO blade
18June 20, 20112011 HPCMP User Group © Cray Inc.

19June 20, 20112011 HPCMP User Group © Cray Inc.

Supports 2 Nodes per ASIC
168 GB/sec routing capacity
Scales to over 100,000 network endpoints
Link Level Reliability and Adaptive Routing
Advanced Resiliency Features
Provides global address space
Advanced NIC designed to efficiently support
MPI
One-sided MPI
Shmem
UPC, Coarray FORTRAN
LO
Processor
Gemini
Hyper
Transport
3
NIC 0
Hyper
Transport
3
NIC 1Netlink
BlockSB
48-Port
YARC Router
20June 20, 20112011 HPCMP User Group © Cray Inc.

10 12X Gemini
Channels
(Each Gemini
acts like two
nodes on the 3D
Torus)
Cray Baker Node Characteristics
Number of Cores
16 or 24
Peak Performance
140 or 210 Gflops/s
Memory Size 32 or 64 GB per node
Memory Bandwidth
85 GB/sec
High Radix
YARC Router
with adaptive
Routing
168 GB/sec
capacity
21June 20, 20112011 HPCMP User Group © Cray Inc.

Module with
SeaStar
Module with
Gemini
Y
X
Z
22June 20, 20112011 HPCMP User Group © Cray Inc.

FMA (Fast Memory Access) Mechanism for most MPI transfers Supports tens of millions of MPI requests per second
BTE (Block Transfer Engine) Supports asynchronous block transfers between local and remote memory,
in either direction For use for large MPI transfers that happen in the background
HT
3 C
av
e
vc0
vc1
vc1
vc0
LB Ring
LB
LM
NL
FMA
CQ
NPT
RMTnet req
H
A
R
B
net
rsp
ht p
ireq
ht treq p
ht irsp
ht np
ireq
ht np req
ht np reqnet req
ht p req O
R
B
RAT
NAT
BTE
net
req
net
rsp
ht treq np
ht trsp net
req
net
req
net
req
net
req
net
reqnet req
ht p req
ht p req
ht p req net rsp
CLM
AMOnet rsp headers
T
A
R
B
net req
net rsp
S
S
I
D
Ro
ute
r T
ile
s
23June 20, 20112011 HPCMP User Group © Cray Inc.

Two Gemini ASICs are packaged on a pin-compatible mezzanine card
Topology is a 3-D torus
Each lane of the torus is composed of 4 Gemini router “tiles”
Systems with SeaStarinterconnects can be upgraded by swapping this card
100% of the 48 router tiles on each Gemini chip are used
24June 20, 20112011 HPCMP User Group © Cray Inc.

June 20, 2011 282011 HPCMP User Group © Cray Inc.

Name Architecture Processor Network # Cores Memory/Core
Jade XT-4 AMDBudapest (2.1 Ghz)
Seastar 2.1 8584 2GB DDR2-800
Einstein XT-5 AMD Shanghai (2.4 Ghz)
Seastar 2.1 12827 2GB (some nodes have 4GB/core) DDR2-800
MRAP XT-5 AMD Barcelona (2.3 Ghz)
Seastar 2.1 10400 4GB DDR2-800
Garnet XE-6 Magny Cours 8 core 2.4 Ghz
Gemini 1.0 20160 2GB DDR3-1333
Raptor XE-6 Magny Cours 8 core 2.4 Ghz
Gemini 1.0 43712 2GB DDR3-1333
Chugach XE-6 Magny Cours 8 core 2.3 Ghz
Gemini 1.0 11648 2GB DDR3 -1333
June 20, 2011 292011 HPCMP User Group © Cray Inc.

June 20, 2011 302011 HPCMP User Group © Cray Inc.

June 20, 20112011 HPCMP User Group © Cray Inc. 31

June 20, 2011 322011 HPCMP User Group © Cray Inc.

2011 HPCMP User Group © Cray Inc.
Hig
h V
elo
city A
irflow
Hig
h V
elo
city A
irflow
Lo
w V
elo
city A
irflo
w
Lo
w V
elo
city A
irflo
w
Lo
w V
elo
city A
irflo
wJune 20, 2011 33

Hot air stream passes through evaporator, rejects heat to R134a via liquid-vapor phase change
(evaporation).
R134a absorbs energy only in the presence of heated air.
Phase change is 10x more efficient than pure water
cooling.
Liquid/Vapor Mixture out
Liquid in
Cool air is released into the computer room
June 20, 201134
2011 HPCMP User Group © Cray Inc.
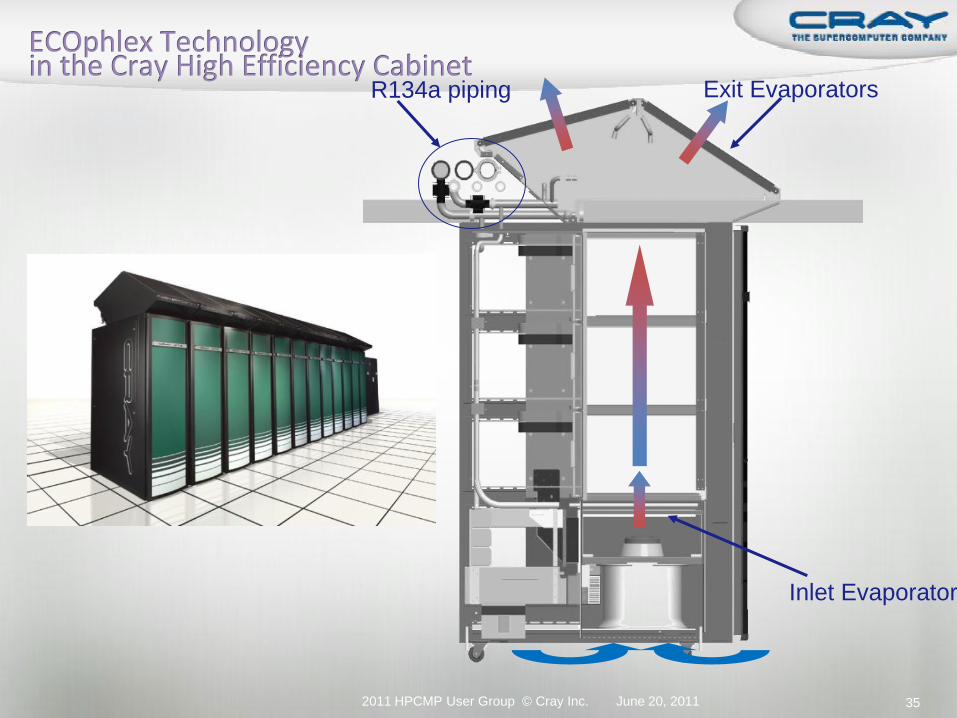
R134a piping Exit Evaporators
Inlet Evaporator
35June 20, 20112011 HPCMP User Group © Cray Inc.

June 20, 2011 362011 HPCMP User Group © Cray Inc.

Term Meaning Purpose
MDS Metadata Server Manages all file metadata for filesystem. 1 per FS
OST Object Storage Target The basic “chunk” of data written to disk. Max 160 per file.
OSS Object Storage Server Communicates with disks, manages 1 or more OSTs. 1 or more per FS
Stripe Size Size of chunks. Controls the size of file chunks stored to OSTs. Can’t be changed once file is written.
Stripe Count Number of OSTs used per file.
Controls parallelism of file. Can’t be changed once file is writte.
June 20, 20112011 HPCMP User Group © Cray Inc. 37

2011 HPCMP User Group © Cray Inc.June 20, 2011 38

2011 HPCMP User Group © Cray Inc.June 20, 2011 39

32 MB per OST (32 MB – 5 GB) and 32 MB Transfer Size Unable to take advantage of file system parallelism
Access to multiple disks adds overhead which hurts performance
Lustre
0
20
40
60
80
100
120
1 2 4 16 32 64 128 160
Wri
te (
MB
/s)
Stripe Count
Single WriterWrite Performance
1 MB Stripe
32 MB Stripe
40 2011 HPCMP User Group © Cray Inc.June 20, 2011

Lustre
0
20
40
60
80
100
120
140
1 2 4 8 16 32 64 128
Wri
te (
MB
/s)
Stripe Size (MB)
Single Writer Transfer vs. Stripe Size
32 MB Transfer
8 MB Transfer
1 MB Transfer
Single OST, 256 MB File Size Performance can be limited by the process (transfer size) or file system
(stripe size)
41 2011 HPCMP User Group © Cray Inc.June 20, 2011

Use the lfs command, libLUT, or MPIIO hints to adjust your stripe count and possibly size
lfs setstripe -c -1 -s 4M <file or directory> (160 OSTs, 4MB stripe)
lfs setstripe -c 1 -s 16M <file or directory> (1 OST, 16M stripe)
export MPICH_MPIIO_HINTS=‘*: striping_factor=160’
Files inherit striping information from the parent directory, this cannot be changed once the file is written
Set the striping before copying in files
June 20, 2011 422011 HPCMP User Group © Cray Inc.

Available Compilers
Cray Scientific Libraries
Cray Message Passing Toolkit
June 20, 2011 432011 HPCMP User Group © Cray Inc.

Cray XT/XE Supercomputers come with compiler wrappers to simplify building parallel applications (similar the mpicc/mpif90)
Fortran Compiler: ftn
C Compiler: cc
C++ Compiler: CC
Using these wrappers ensures that your code is built for the compute nodes and linked against important libraries
Cray MPT (MPI, Shmem, etc.)
Cray LibSci (BLAS, LAPACK, etc.)
…
Choosing the underlying compiler is via the PrgEnv-* modules, do not call the PGI, Cray, etc. compilers directly.
Always load the appropriate xtpe-<arch> module for your machine
Enables proper compiler target
Links optimized math libraries
June 20, 2011 442011 HPCMP User Group © Cray Inc.

PGI – Very good Fortran and C, pretty good C++
Good vectorization
Good functional correctness with optimization enabled
Good manual and automatic prefetch capabilities
Very interested in the Linux HPC market, although that is not their only focus
Excellent working relationship with Cray, good bug responsiveness
Pathscale – Good Fortran, C, possibly good C++
Outstanding scalar optimization for loops that do not vectorize
Fortran front end uses an older version of the CCE Fortran front end
OpenMP uses a non-pthreads approach
Scalar benefits will not get as much mileage with longer vectors
Intel – Good Fortran, excellent C and C++ (if you ignore vectorization)
Automatic vectorization capabilities are modest, compared to PGI and CCE
Use of inline assembly is encouraged
Focus is more on best speed for scalar, non-scaling apps
Tuned for Intel architectures, but actually works well for some applications on AMD
…from Cray’s Perspective
45June 20, 20112011 HPCMP User Group © Cray Inc.

GNU so-so Fortran, outstanding C and C++ (if you ignore vectorization)
Obviously, the best for gcc compatability
Scalar optimizer was recently rewritten and is very good
Vectorization capabilities focus mostly on inline assembly
Note the last three releases have been incompatible with each other (4.3, 4.4, and 4.5) and required recompilation of Fortran modules
CCE – Outstanding Fortran, very good C, and okay C++
Very good vectorization
Very good Fortran language support; only real choice for Coarrays
C support is quite good, with UPC support
Very good scalar optimization and automatic parallelization
Clean implementation of OpenMP 3.0, with tasks
Sole delivery focus is on Linux-based Cray hardware systems
Best bug turnaround time (if it isn’t, let us know!)
Cleanest integration with other Cray tools (performance tools, debuggers, upcoming productivity tools)
No inline assembly support
46
…from Cray’s Perspective
June 20, 20112011 HPCMP User Group © Cray Inc.
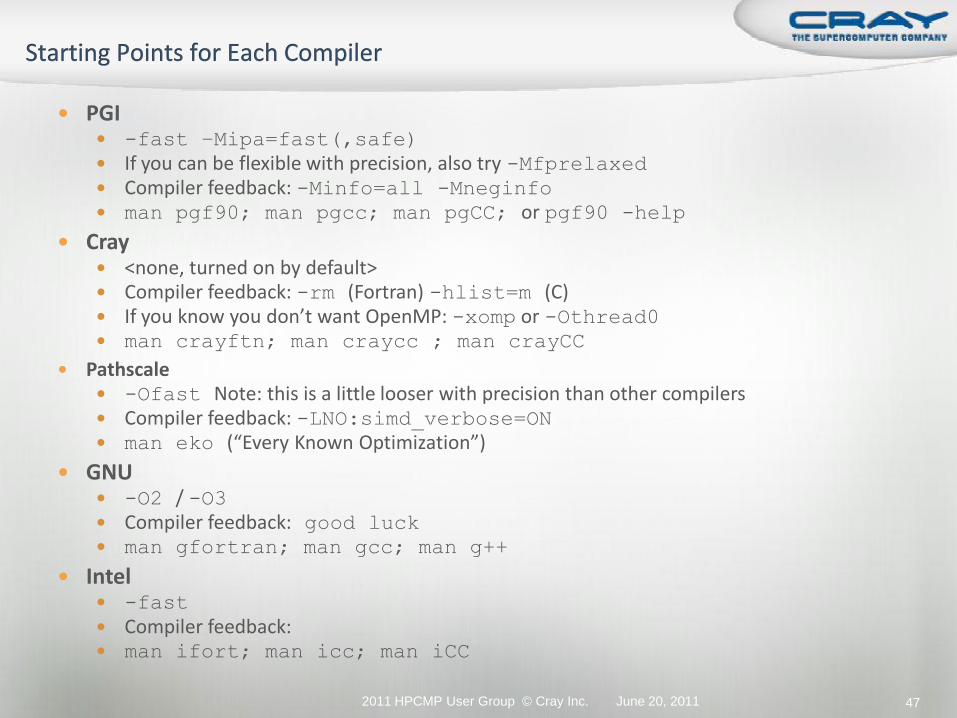
PGI -fast –Mipa=fast(,safe)
If you can be flexible with precision, also try -Mfprelaxed Compiler feedback: -Minfo=all -Mneginfo man pgf90; man pgcc; man pgCC; or pgf90 -help
Cray <none, turned on by default> Compiler feedback: -rm (Fortran) -hlist=m (C) If you know you don’t want OpenMP: -xomp or -Othread0 man crayftn; man craycc ; man crayCC
Pathscale -Ofast Note: this is a little looser with precision than other compilers Compiler feedback: -LNO:simd_verbose=ON man eko (“Every Known Optimization”)
GNU -O2 / -O3 Compiler feedback: good luck
man gfortran; man gcc; man g++
Intel -fast
Compiler feedback: man ifort; man icc; man iCC
47June 20, 20112011 HPCMP User Group © Cray Inc.

June 20, 2011 482011 HPCMP User Group © Cray Inc.

Traditional (scalar) optimizations are controlled via -O# compiler flags
Default: -O2
More aggressive optimizations (including vectorization) are enabled with the -fast or -fastsse metaflags
These translate to: -O2 -Munroll=c:1 -Mnoframe -Mlre
–Mautoinline -Mvect=sse -Mscalarsse
-Mcache_align -Mflushz –Mpre
Interprocedural analysis allows the compiler to perform whole-program optimizations. This is enabled with –Mipa=fast
See man pgf90, man pgcc, or man pgCC for more information about compiler options.
June 20, 2011 492011 HPCMP User Group © Cray Inc.

Compiler feedback is enabled with -Minfo and -Mneginfo
This can provide valuable information about what optimizations were or were not done and why.
To debug an optimized code, the -gopt flag will insert debugging information without disabling optimizations
It’s possible to disable optimizations included with -fast if you believe one is causing problems
For example: -fast -Mnolre enables -fast and then disables loop redundant optimizations
To get more information about any compiler flag, add -help with the flag in question
pgf90 -help -fast will give more information about the -fast flag
OpenMP is enabled with the -mp flag
June 20, 2011 502011 HPCMP User Group © Cray Inc.

Some compiler options may effect both performance and accuracy. Lower
accuracy is often higher performance, but it’s also able to enforce accuracy.
-Kieee: All FP math strictly conforms to IEEE 754 (off by default)
-Ktrap: Turns on processor trapping of FP exceptions
-Mdaz: Treat all denormalized numbers as zero
-Mflushz: Set SSE to flush-to-zero (on with -fast)
-Mfprelaxed: Allow the compiler to use relaxed (reduced) precision to speed up some floating point optimizations
Some other compilers turn this on by default, PGI chooses to favor accuracy to speed by default.
June 20, 2011 512011 HPCMP User Group © Cray Inc.

June 20, 2011 522011 HPCMP User Group © Cray Inc.

Cray has a long tradition of high performance compilers on Cray platforms (Traditional vector, T3E, X1, X2)
Vectorization
Parallelization
Code transformation
More…
Investigated leveraging an open source compiler called LLVM
First release December 2008
June 20, 2011 532011 HPCMP User Group © Cray Inc.

X86 Code
Generator
Cray X2 Code
Generator
Fortran Front End
Interprocedural Analysis
Optimization and
Parallelization
C and C++ Source
Object File
Co
mp
iler
C & C++ Front End
Fortran Source C and C++ Front End
supplied by Edison Design
Group, with Cray-developed
code for extensions and
interface support
X86 Code Generation from
Open Source LLVM, with
additional Cray-developed
optimizations and interface
support
Cray Inc. Compiler
Technology
June 20, 2011 542011 HPCMP User Group © Cray Inc.

Standard conforming languages and programming models Fortran 2003 UPC & CoArray Fortran
Fully optimized and integrated into the compiler
No preprocessor involved
Target the network appropriately:
GASNet with Portals
DMAPP with Gemini & Aries
Ability and motivation to provide high-quality support for custom Cray network hardware
Cray technology focused on scientific applications Takes advantage of Cray’s extensive knowledge of automatic
vectorization Takes advantage of Cray’s extensive knowledge of automatic
shared memory parallelization Supplements, rather than replaces, the available compiler
choices June 20, 2011 552011 HPCMP User Group © Cray Inc.

Make sure it is available
module avail PrgEnv-cray
To access the Cray compiler
module load PrgEnv-cray
To target the various chip
module load xtpe-[barcelona,shanghi,mc8]
Once you have loaded the module “cc” and “ftn” are the Cray compilers
Recommend just using default options
Use –rm (fortran) and –hlist=m (C) to find out what happened
man crayftn
June 20, 2011 562011 HPCMP User Group © Cray Inc.

Excellent Vectorization Vectorize more loops than other compilers
OpenMP 3.0 Task and Nesting
PGAS: Functional UPC and CAF available today
C++ Support
Automatic Parallelization Modernized version of Cray X1 streaming capability
Interacts with OMP directives
Cache optimizations Automatic Blocking
Automatic Management of what stays in cache
Prefetching, Interchange, Fusion, and much more…
June 20, 2011 572011 HPCMP User Group © Cray Inc.

Loop Based Optimizations Vectorization OpenMP
Autothreading
Interchange Pattern Matching Cache blocking/ non-temporal / prefetching
Fortran 2003 Standard; working on 2008
PGAS (UPC and Co-Array Fortran) Some performance optimizations available in 7.1
Optimization Feedback: Loopmark
Focus
June 20, 2011 582011 HPCMP User Group © Cray Inc.

Cray compiler supports a full and growing set of directives and pragmas
!dir$ concurrent
!dir$ ivdep
!dir$ interchange
!dir$ unroll
!dir$ loop_info [max_trips] [cache_na] ... Many more
!dir$ blockable
man directives
man loop_infoJune 20, 2011 592011 HPCMP User Group © Cray Inc.

Compiler can generate an filename.lst file. Contains annotated listing of your source code with letter indicating important
optimizations
%%% L o o p m a r k L e g e n d %%%
Primary Loop Type Modifiers
------- ---- ---- ---------
a - vector atomic memory operation
A - Pattern matched b - blocked
C - Collapsed f - fused
D - Deleted i - interchanged
E - Cloned m - streamed but not partitioned
I - Inlined p - conditional, partial and/or computed
M - Multithreaded r - unrolled
P - Parallel/Tasked s - shortloop
V - Vectorized t - array syntax temp used
W - Unwound w - unwound
June 20, 2011 602011 HPCMP User Group © Cray Inc.

• ftn –rm … or cc –hlist=m …
29. b-------< do i3=2,n3-1
30. b b-----< do i2=2,n2-1
31. b b Vr--< do i1=1,n1
32. b b Vr u1(i1) = u(i1,i2-1,i3) + u(i1,i2+1,i3)
33. b b Vr > + u(i1,i2,i3-1) + u(i1,i2,i3+1)
34. b b Vr u2(i1) = u(i1,i2-1,i3-1) + u(i1,i2+1,i3-1)
35. b b Vr > + u(i1,i2-1,i3+1) + u(i1,i2+1,i3+1)
36. b b Vr--> enddo
37. b b Vr--< do i1=2,n1-1
38. b b Vr r(i1,i2,i3) = v(i1,i2,i3)
39. b b Vr > - a(0) * u(i1,i2,i3)
40. b b Vr > - a(2) * ( u2(i1) + u1(i1-1) + u1(i1+1) )
41. b b Vr > - a(3) * ( u2(i1-1) + u2(i1+1) )
42. b b Vr--> enddo
43. b b-----> enddo
44. b-------> enddo
June 20, 2011 612011 HPCMP User Group © Cray Inc.

ftn-6289 ftn: VECTOR File = resid.f, Line = 29
A loop starting at line 29 was not vectorized because a recurrence was found on "U1" between lines 32 and 38.
ftn-6049 ftn: SCALAR File = resid.f, Line = 29
A loop starting at line 29 was blocked with block size 4.
ftn-6289 ftn: VECTOR File = resid.f, Line = 30
A loop starting at line 30 was not vectorized because a recurrence was found on "U1" between lines 32 and 38.
ftn-6049 ftn: SCALAR File = resid.f, Line = 30
A loop starting at line 30 was blocked with block size 4.
ftn-6005 ftn: SCALAR File = resid.f, Line = 31
A loop starting at line 31 was unrolled 4 times.
ftn-6204 ftn: VECTOR File = resid.f, Line = 31
A loop starting at line 31 was vectorized.
ftn-6005 ftn: SCALAR File = resid.f, Line = 37
A loop starting at line 37 was unrolled 4 times.
ftn-6204 ftn: VECTOR File = resid.f, Line = 37
A loop starting at line 37 was vectorized.June 20, 2011 622011 HPCMP User Group © Cray Inc.

-hbyteswapio
Link time option
Applies to all unformatted fortran IO
Assign command
With the PrgEnv-cray module loaded do this:
setenv FILENV assign.txt
assign -N swap_endian g:su
assign -N swap_endian g:du
Can use assign to be more precise
June 20, 2011 632011 HPCMP User Group © Cray Inc.

OpenMP is ON by default Optimizations controlled by –Othread#
To shut off use –Othread0 or –xomp or –hnoomp
Autothreading is NOT on by default; -hautothread to turn on
Modernized version of Cray X1 streaming capability
Interacts with OMP directives
If you do not want to use OpenMP and have OMP directives in the code, make sure to make a run with OpenMP shut
off at compile time
June 20, 2011 642011 HPCMP User Group © Cray Inc.

June 20, 2011 652011 HPCMP User Group © Cray Inc.

Cray have historically played a role in scientific library development
BLAS3 were largely designed for Crays
Standard libraries were tuned for Cray vector processors (later COTS)
Cray have always tuned standard libraries for Cray interconnect
In the 90s, Cray provided many non-standard libraries
Sparse direct, sparse iterative
These days the goal is to remain portable (standard APIs) whilst providing more performance
Advanced features, tuning knobs, environment variables
66June 20, 20112011 HPCMP User Group © Cray Inc.

69
FFT
CRAFFT
FFTW
P-CRAFFT
Dense
BLAS
LAPACK
ScaLAPACK
IRT
CASE
Sparse
CASK
PETSc
Trilinos
IRT – Iterative Refinement Toolkit
CASK – Cray Adaptive Sparse Kernels
CRAFFT – Cray Adaptive FFT
CASE – Cray Adaptive Simple EigensolverJune 20, 20112011 HPCMP User Group © Cray Inc.

There are many libsci libraries on the systems
One for each of
Compiler (intel, cray, gnu, pathscale, pgi )
Single thread, multiple thread
Target (istanbul, mc12 )
Best way to use libsci is to ignore all of this
Load the xtpe-module (some sites set this by default)
E.g. module load xtpe-shanghai / xtpe-istanbul / xtpe-mc8
Cray’s drivers will link the library automatically
PETSc, Trilinos, fftw, acml all have their own module
Tip : make sure you have the correct library loaded e.g. –Wl, -ydgemm_
70June 20, 20112011 HPCMP User Group © Cray Inc.

Perhaps you want to link another library such as ACML
This can be done. If the library is provided by Cray, then load the module. The link will be performed with the libraries in the correct order.
If the library is not provided by Cray and has no module, add it to the link line.
Items you add to the explicit link will be in the correct place
Note, to get explicit BLAS from ACML but scalapack from libsci
Load acml module. Explicit calls to BLAS in code resolve from ACML
BLAS calls from the scalapack code will be resolved from libsci (no way around this)
71June 20, 20112011 HPCMP User Group © Cray Inc.

Threading capabilities in previous libsci versions were poor Used PTHREADS (more explicit affinity etc) Required explicit linking to a _mp version of libsci Was a source of concern for some applications that need
hybrid performance and interoperability with openMP
LibSci 10.4.2 February 2010 OpenMP-aware LibSci Allows calling of BLAS inside or outside parallel region Single library supported (there is still a single thread lib)
Usage – load the xtpe module for your system (mc12)
GOTO_NUM_THREADS outmoded – use OMP_NUM_THREADS
June 20, 2011 722011 HPCMP User Group © Cray Inc.

Allows seamless calling of the BLAS within or without a parallel region
e.g. OMP_NUM_THREADS = 12
call dgemm(…) threaded dgemm is used with 12 threads!$OMP PARALLEL DO do
call dgemm(…) single thread dgemm is usedend do
Some users are requesting a further layer of parallelism here (see later)
73June 20, 20112011 HPCMP User Group © Cray Inc.

0
20
40
60
80
100
120G
FL
OP
s
Dimension (square)
Libsci DGEMM efficiency
1thread
3threads
6threads
9threads
12threads
June 20, 2011 742011 HPCMP User Group © Cray Inc.

75
0
20
40
60
80
100
120
140
1 2 4 8 12 16 20 24
GF
LO
PS
Number of threads
Libsci-10.5.2 performance on 2 x MC12 2.0 GHz(Cray XE6)
K=64
K=128
K=200
K=228
K=256
K=300
K=400
K=500
K=600
K=700
K=800
June 20, 20112011 HPCMP User Group © Cray Inc.

All BLAS libraries are optimized for rank-k update
However, a huge % of dgemm usage is not from solvers but explicit calls
E.g. DCA++ matrices are of this form
How can we very easily provide an optimization for these types of matrices?
76
=
=
*
*
June 20, 20112011 HPCMP User Group © Cray Inc.

Cray BLAS existed on every Cray machine between Cray-2 and Cray X2
Cray XT line did not include Cray BLAS
Cray’s expertise was in vector processors
GotoBLAS was the best performing x86 BLAS
LibGoto is now discontinued
In Q3 2011 LibSci will be released with Cray BLAS
77June 20, 20112011 HPCMP User Group © Cray Inc.

1. Customers require more OpenMP features unobtainable with current library
2. Customers require more adaptive performance for unusual problems .e.g. DCA++
3. Interlagos / Bulldozer is a dramatic shift in ISA/architecture/performance
4. Our auto-tuning framework has advanced to the point that we can tackle this problem (good BLAS is easy, excellent BLAS is very hard)
5. Need for Bit-reproducable BLAS at high-performance
78June 20, 20112011 HPCMP User Group © Cray Inc.

"anything that can be represented in C, Fortran or ASM code can be generated automatically by one instance of an abstract operator in high-level code“
In other words, if we can create a purely general model of matrix-multiplication, and create every instance of it, then at least one of the generated schemes will perform well
79June 20, 20112011 HPCMP User Group © Cray Inc.

Start with a completely general formulation of the BLAS
Use a DSL that expresses every important optimization
Auto-generate every combination of orderings, buffering, and optimization
For every combination of the above, sweep all possible sizes
For a given input set ( M, N, K, datatype, alpha, beta ) map the best dgemm routine to the input
The current library should be a specific instance of the above
Worst-case performance can be no worse than current library
The lowest level of blocking is a hand-written assembly kernel
80June 20, 20112011 HPCMP User Group © Cray Inc.

81
7.05
7.1
7.15
7.2
7.25
7.3
7.35
7.4
7.45
7.52 7 12 17 22 27 32 37 42
47 52 57 62
67 72 95
100
105
128
133
138
143
bframe GFLOPS
libsci
June 20, 20112011 HPCMP User Group © Cray Inc.

New optimizations for Gemini network in the ScaLAPACK LU and Choleskyroutines
1. Change the default broadcast topology to match the Gemini network
2. Give tools to allow the topology to be changed by the user
3. Give guidance on how grid-shape can affect the performance
82June 20, 20112011 HPCMP User Group © Cray Inc.

Parallel Version of LAPACK GETRF
Panel Factorization
Only single column block is involved
The rest of PEs are waiting
Trailing matrix update
Major part of the computation
Column-wise broadcast (Blocking)
Row-wise broadcast (Asynchronous)
Data is packed before sending using PBLAS
Broadcast uses BLACS library
These broadcasts are the major communication patterns
June 20, 2011 832011 HPCMP User Group © Cray Inc.

MPI default
Binomial Tree + node-aware broadcast
All PEs makes implicit barrier to make sure the completion
Not suitable for rank-k update
Bidirectional-Ring broadcast
Root PE makes 2 MPI Send calls to both of the directions
The immediate neighbor finishes first
ScaLAPACK’s default
Better than MPI
June 20, 2011 842011 HPCMP User Group © Cray Inc.

Increasing Ring Broadcast (our new default)
Root makes a single MPI call to the immediate neighbor
Pipelining
Better than bidirectional ring
The immediate neighbor finishes first
Multi-Ring Broadcast (2, 4, 8 etc)
The immediate neighbor finishes first
The root PE sends to multiple sub-rings Can be done with tree algorithm
2 rings seems the best for row-wise broadcast of LU
June 20, 2011 852011 HPCMP User Group © Cray Inc.

Hypercube
Behaves like MPI default
Too many collisions in the message traffic
Decreasing Ring
The immediate neighbor finishes last
No benefit in LU
Modified Increasing Ring
Best performance in HPL
As good as increasing ring
June 20, 2011 862011 HPCMP User Group © Cray Inc.

87
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
32 64 32 64 32 64 32 64 32 64
48 48 24 24 12 12 32 32 16 16
64 64 128 128 256 256 96 96 192 192
Gfl
op
s
NB / P / Q
XDLU performance: 3072 cores, size=65536
SRING
IRING
June 20, 20112011 HPCMP User Group © Cray Inc.

88
0
2000
4000
6000
8000
10000
12000
14000
32 64 32 64 32 64 32 64 32 64
48 48 24 24 12 12 64 64 32 32
128 128 256 256 512 512 96 96 192 192
Gfl
op
s
NB / P / Q
XDLU performance: 6144 cores, size=65536
SRING
IRING
June 20, 20112011 HPCMP User Group © Cray Inc.

Row Major Process Grid puts adjacent PEs in the same row
Adjacent PEs are most probably located in the same node
In flat MPI, 16 or 24 PEs are in the same node
In hybrid mode, several are in the same node
Most MPI sends in I-ring happen in the same node
MPI has good shared-memory device
Good pipelining
89
Node 0 Node 1 Node 2
June 20, 20112011 HPCMP User Group © Cray Inc.

For PxGETRF:
SCALAPACK_LU_CBCAST
SCALAPACK_LU_RBCAST
For PxPOTRF:
SCALAPACK_LLT_CBCAST
SCALAPCK_LLT_RBCAST
SCALAPACK_UTU_CBCAST SCALAPACK_UTU_RBCAST
There is also a set function, allowing the user to change these on the fly
The variables let users to choose broadcast algorithm :
IRING increasing ring (default value)
DRING decreasing ring
SRING split ring (old default value)
MRING multi-ring
HYPR hypercube
MPI mpi_bcast
TREE tree
FULL full connected
91June 20, 20112011 HPCMP User Group © Cray Inc.

Grid shape / size
Square grid is most common
Try to use Q = x * P grids, where x = 2, 4, 6, 8
Square grids not often the best
Blocksize
Unlike HPL, fine-tuning not important.
64 usually the best
Ordering
Try using column-major ordering, it can be better
BCAST
The new default will be a huge improvement if you can make your grid the right way. If you cannot, play with the environment variables.
92June 20, 20112011 HPCMP User Group © Cray Inc.

June 20, 2011 932011 HPCMP User Group © Cray Inc.

Full MPI2 support (except process spawning) based on ANL MPICH2
Cray used the MPICH2 Nemesis layer for Gemini
Cray-tuned collectives
Cray-tuned ROMIO for MPI-IO
Current Release: 5.3.0 (MPICH 1.3.1)
Improved MPI_Allreduce and MPI_alltoallv
Initial support for checkpoint/restart for MPI or Cray SHMEM on XE systems
Improved support for MPI thread safety.
module load xt-mpich2
Tuned SHMEM library
module load xt-shmem
June 20, 20112011 HPCMP User Group © Cray Inc. 94

June 20, 20112011 HPCMP User Group © Cray Inc. 95
0
5000000
10000000
15000000
20000000
25000000
256 512 1024 2048 4096 8192 16384 32768
Mic
rose
con
ds
Message Size (in bytes)
MPI_Alltoall with 10,000 ProcessesComparing Original vs Optimized Algorithms
on Cray XE6 Systems
Original Algorithm
Optimized Algorithm

June 20, 20112011 HPCMP User Group © Cray Inc. 96
0
5000
10000
15000
20000
25000
30000
35000
40000
45000
1024p 2048p 4096p 8192p 16384p 32768p
Mic
rose
con
ds
Number of Processes
8-Byte MPI_Allgather and MPI_Allgatherv ScalingComparing Original vs Optimized Algorithms
on Cray XE6 Systems
Original Allgather
Optimized Allgather
Original Allgatherv
Optimized Allgatherv
MPI_Allgather and
MPI_Allgatherv algorithms
optimized for Cray XE6.

Default is 8192 bytes
Maximum size message that can go through the eager protocol.
May help for apps that are sending medium size messages, and do better when loosely coupled. Does application have a large amount of time in MPI_Waitall? Setting this environment variable higher may help.
Max value is 131072 bytes.
Remember for this path it helps to pre-post receives if possible.
Note that a 40-byte CH3 header is included when accounting for the message size.
97June 20, 20112011 HPCMP User Group © Cray Inc.

Default is 64 32K buffers ( 2M total )
Controls number of 32K DMA buffers available for each rank to use in the Eager protocol described earlier
May help to modestly increase. But other resources constrain the usability of a large number of buffers.
98June 20, 20112011 HPCMP User Group © Cray Inc.

June 20, 2011 992011 HPCMP User Group © Cray Inc.

What do I mean by PGAS?
Partitioned Global Address Space
UPC
CoArray Fortran ( Fortran 2008 )
SHMEM (I will count as PGAS for convenience)
SHMEM: Library based
Not part of any language standard
Compiler independent
Compiler has no knowledge that it is compiling a PGAS code and does nothing different. I.E. no transformations or optimizations
2011 HPCMP User Group © Cray Inc. 100June 20, 2011

UPC
Specification that extends the ISO/IEC 9899 standard for C
Integrated into the language
Heavily compiler dependent
Compiler intimately involved in detecting and executing remote references
Flexible, but filled with challenges like pointers, a lack of true multidimensional arrays, and many options for distributing data
Fortran 2008
Now incorporates coarrays
Compiler dependent
Philosophically different from UPC
Replication of arrays on every image with “easy and obvious” ways to access those remote locations.
2011 HPCMP User Group © Cray Inc. 101June 20, 2011

102June 20, 20112011 HPCMP User Group © Cray Inc.

Translate the UPC source code into hardware executable operations that produce the proper behavior, as defined by the specification
Storing to a remote location?
Loading from a remote location?
When does the transfer need to be complete?
Are there any dependencies between this transfer and anything else?
No ordering guarantees provided by the network, compiler is responsible for making sure everything gets to its destination in the correct order.
2011 HPCMP User Group © Cray Inc. 103June 20, 2011

2011 HPCMP User Group © Cray Inc. 104
for ( i = 0; i < ELEMS_PER_THREAD; i+=1 ) {
local_data[i] += global_2d[i][target];
}
The compiler must
Recognize you are referencing a shared location
Initiate the load of the remote data
Make sure the transfer has completed
Proceed with the calculation
Repeat for all iterations of the loop
for ( i = 0; i < ELEMS_PER_THREAD; i+=1 ) {
temp = pgas_get(&global_2d[i]); // Initiate the get
pgas_fence(); // makes sure the get is complete
local_data[i] += temp; // Use the local location to complete the operation
}
June 20, 2011

Simple translation results in
Single word references
Lots of fences
Little to no latency hiding
No use of special hardware
Nothing here says “fast”
for ( i = 0; i < ELEMS_PER_THREAD; i+=1 ) {
temp = pgas_get(&global_2d[i]); // Initiate the get
pgas_fence(); // makes sure the get is complete
local_data[i] += temp; // Use the local location to complete the operation
}
1052011 HPCMP User
Group © Cray Inc.June 20, 2011

Want the compiler to generate code that will run as fast as possible given what the user has written, or allow the user to get fast performance with
simple modifications.
Increase message size
Do multi / many word transfers whenever possible, not single word.
Minimize fences
Delay fence “as much as possible”
Eliminate the fence in some circumstances
Use the appropriate hardware
Use on-node hardware for on-node transfers
Use transfer mechanism appropriate for this message size
Overlap communication and computation
Use hardware atomic functions where appropriate
2011 HPCMP User Group © Cray Inc. 106June 20, 2011

Primary Loop Type Modifiers
A - Pattern matched a - atomic memory operation
b - blocked
C - Collapsed c - conditional and/or computed
D - Deleted
E - Cloned f - fused
G - Accelerated g - partitioned
I - Inlined i - interchanged
M - Multithreaded m - partitioned
n - non-blocking remote transfer
p - partial
r - unrolled
s - shortloop
V - Vectorized w - unwound
2011 HPCMP User Group © Cray Inc. 107June 20, 2011

108June 20, 20112011 HPCMP User Group © Cray Inc.

15. shared long global_1d[MAX_ELEMS_PER_THREAD * THREADS];
…
83. 1 before = upc_ticks_now();
84. 1 r8------< for ( i = 0, j = target; i < ELEMS_PER_THREAD ;
85. 1 r8 i += 1, j += THREADS ) {
86. 1 r8 n local_data[i]= global_1d[j];
87. 1 r8------> }
88. 1 after = upc_ticks_now();
1D get BW= 0.027598 Gbytes/s
1092011 HPCMP User
Group © Cray Inc.June 20, 2011

15. shared long global_1d[MAX_ELEMS_PER_THREAD * THREADS];
…
101. 1 before = upc_ticks_now();
102. 1 upc_memget(&local_data[0],&global_1d[target],8*ELEMS_PER_THREAD);
103. 1
104. 1 after = upc_ticks_now();
1D get BW= 0.027598 Gbytes/s
1D upc_memget BW= 4.972960 Gbytes/s
upc_memget is 184 times faster!!
1102011 HPCMP User
Group © Cray Inc.June 20, 2011

16. shared long global_2d[MAX_ELEMS_PER_THREAD][THREADS];
…
121. 1 A-------< for ( i = 0; i < ELEMS_PER_THREAD; i+=1) {
122. 1 A local_data[i] = global_2d[i][target];
123. 1 A-------> }
1D get BW= 0.027598 Gbytes/s
1D upc_memget BW= 4.972960 Gbytes/s
2D get time BW= 4.905653 Gbytes/s
Pattern matching can give you the same performance as if using upc_memget
1112011 HPCMP User
Group © Cray Inc.June 20, 2011

112June 20, 20112011 HPCMP User Group © Cray Inc.

PGAS data references made by the single statement immediately following the pgasdefer_sync directive will not be synchronized until the next fence instruction.
Only applies to next UPC/CAF statement
Does not apply to upc “routines”
Does not apply to shmem routines
Normally the compiler synchronizes the references in a statement as late as possible without violating program semantics. The purpose of the defer_syncdirective is to synchronize the references even later, beyond where the compiler can determine it is safe.
Extremely powerful!
Can easily overlap communication and computation with this statement
Can apply to both “gets” and “puts”
Can be used to implement a variety of “tricks”. Use your imagination!
2011 HPCMP User Group © Cray Inc. 113June 20, 2011

CrayPAT
June 20, 2011 1142011 HPCMP User Group © Cray Inc.

Future system basic characteristics:
Many-core, hybrid multi-core computing
Increase in on-node concurrency
10s-100s of cores sharing memory
With or without a companion accelerator
Vector hardware at the low level
Impact on applications:
Restructure / evolve applications while using existing programming models to take advantage of increased concurrency
Expand on use of mixed-mode programming models (MPI + OpenMP + accelerated kernels, etc.)
June 20, 20112011 HPCMP User Group © Cray Inc. 115

Focus on automation (simplify tool usage, provide feedback based on analysis)
Enhance support for multiple programming models within a program (MPI, PGAS, OpenMP, SHMEM)
Scaling (larger jobs, more data, better tool response)
New processors and interconnects
Extend performance tools to include pre-runtime optimization information from the Cray compiler
June 20, 20112011 HPCMP User Group © Cray Inc. 116

New predefined wrappers (ADIOS, ARMCI, PetSc, PGAS libraries)
More UPC and Co-array Fortran support
Support for non-record locking file systems
Support for applications built with shared libraries
Support for Chapel programs
pat_report tables available in Cray Apprentice2
June 20, 20112011 HPCMP User Group © Cray Inc. 117

Enhanced PGAS support is available in perftools 5.1.3 and later
Profiles of a PGAS program can be created to show:
Top time consuming functions/line numbers in the code
Load imbalance information
Performance statistics attributed to user source by default
Can expose statistics by library as well
To see underlying operations, such as wait time on barriers
Data collection is based on methods used for MPI library
PGAS data is collected by default when using Automatic Profiling Analysis (pat_build –O apa)
Predefined wrappers for runtime libraries (caf, upc, pgas) enable attribution of samples or time to user source
UPC and SHMEM heap tracking coming in subsequent release
-g heap will track shared heap in addition to local heap
June 20, 2011 2011 HPCMP User Group © Cray Inc. 118

Table 1: Profile by Function
Samp % | Samp | Imb. | Imb. |Group
| | Samp | Samp % | Function
| | | | PE='HIDE'
100.0% | 48 | -- | -- |Total
|------------------------------------------
| 95.8% | 46 | -- | -- |USER
||-----------------------------------------
|| 83.3% | 40 | 1.00 | 3.3% |all2all
|| 6.2% | 3 | 0.50 | 22.2% |do_cksum
|| 2.1% | 1 | 1.00 | 66.7% |do_all2all
|| 2.1% | 1 | 0.50 | 66.7% |mpp_accum_long
|| 2.1% | 1 | 0.50 | 66.7% |mpp_alloc
||=========================================
| 4.2% | 2 | -- | -- |ETC
||-----------------------------------------
|| 4.2% | 2 | 0.50 | 33.3% |bzero
|==========================================
June 20, 2011 2011 HPCMP User Group © Cray Inc. 119

Table 2: Profile by Group, Function, and Line
Samp % | Samp | Imb. | Imb. |Group
| | Samp | Samp % | Function
| | | | Source
| | | | Line
| | | | PE='HIDE'
100.0% | 48 | -- | -- |Total
|--------------------------------------------
| 95.8% | 46 | -- | -- |USER
||-------------------------------------------
|| 83.3% | 40 | -- | -- |all2all
3| | | | | mpp_bench.c
4| | | | | line.298
|| 6.2% | 3 | -- | -- |do_cksum
3| | | | | mpp_bench.c
||||-----------------------------------------
4||| 2.1% | 1 | 0.25 | 33.3% |line.315
4||| 4.2% | 2 | 0.25 | 16.7% |line.316
||||=========================================
June 20, 2011 2011 HPCMP User Group © Cray Inc. 120

Table 1: Profile by Function and Callers, with Line Numbers
Samp % | Samp |Group
| | Function
| | Caller
| | PE='HIDE’
100.0% | 47 |Total
|---------------------------
| 93.6% | 44 |ETC
||--------------------------
|| 85.1% | 40 |upc_memput
3| | | all2all:mpp_bench.c:line.298
4| | | do_all2all:mpp_bench.c:line.348
5| | | main:test_all2all.c:line.70
|| 4.3% | 2 |bzero
3| | | (N/A):(N/A):line.0
|| 2.1% | 1 |upc_all_alloc
3| | | mpp_alloc:mpp_bench.c:line.143
4| | | main:test_all2all.c:line.25
|| 2.1% | 1 |upc_all_reduceUL
3| | | mpp_accum_long:mpp_bench.c:line.185
4| | | do_cksum:mpp_bench.c:line.317
5| | | do_all2all:mpp_bench.c:line.341
6| | | main:test_all2all.c:line.70
||==========================
June 20, 2011 2011 HPCMP User Group © Cray Inc. 121

Table 1: Profile by Function and Callers, with Line Numbers
Time % | Time | Calls |Group
| | | Function
| | | Caller
| | | PE='HIDE'
100.0% | 0.795844 | 73904.0 |Total
|-----------------------------------------
| 78.9% | 0.628058 | 41121.8 |PGAS
||----------------------------------------
|| 76.1% | 0.605945 | 32768.0 |__pgas_put
3| | | | all2all:mpp_bench.c:line.298
4| | | | do_all2all:mpp_bench.c:line.348
5| | | | main:test_all2all.c:line.70
|| 1.5% | 0.012113 | 10.0 |__pgas_barrier
3| | | | (N/A):(N/A):line.0
…
June 20, 2011 2011 HPCMP User Group © Cray Inc. 122

…
||========================================
| 15.7% | 0.125006 | 3.0 |USER
||----------------------------------------
|| 12.2% | 0.097125 | 1.0 |do_all2all
3| | | | main:test_all2all.c:line.70
|| 3.5% | 0.027668 | 1.0 |main
3| | | | (N/A):(N/A):line.0
||========================================
| 5.4% | 0.042777 | 32777.2 |UPC
||----------------------------------------
|| 5.3% | 0.042321 | 32768.0 |upc_memput
3| | | | all2all:mpp_bench.c:line.298
4| | | | do_all2all:mpp_bench.c:line.348
5| | | | main:test_all2all.c:line.70
|=========================================
June 20, 2011 2011 HPCMP User Group © Cray Inc. 123

June 20, 20112011 HPCMP User Group © Cray Inc. 124
New text table icon
Right click for table
generation options
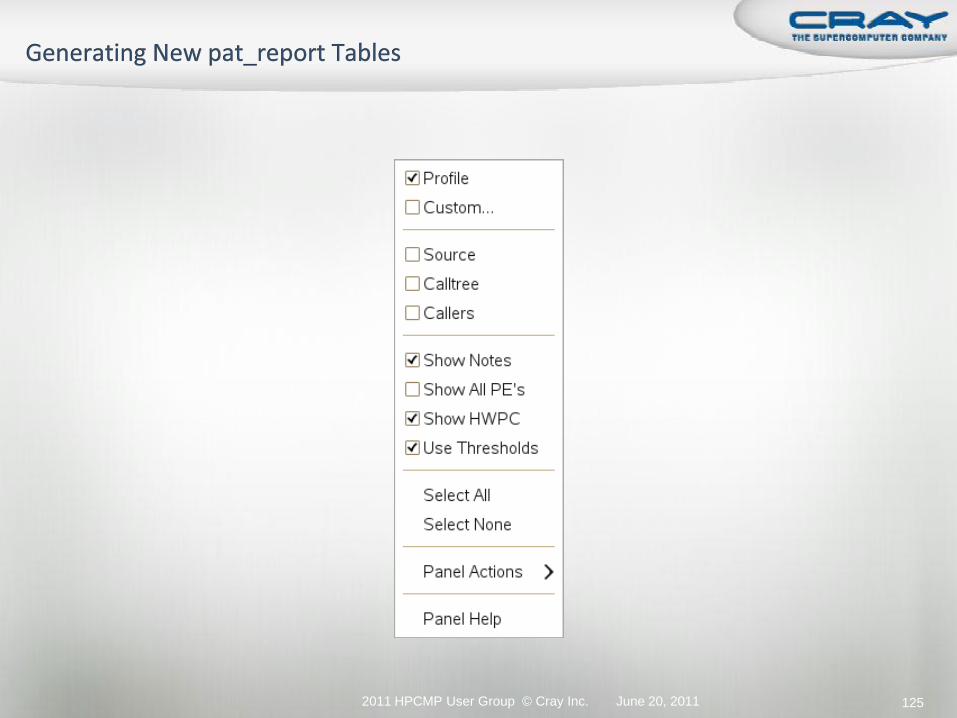
June 20, 20112011 HPCMP User Group © Cray Inc. 125

Scalability
New .ap2 data format and client / server model
Reduced pat_report processing and report generation times
Reduced app2 data load times
Graphical presentation handled locally (not passed through sshconnection)
Better tool responsiveness
Minimizes data loaded into memory at any given time
Reduced server footprint on Cray XT/XE service node
Larger jobs supported
Distributed Cray Apprentice2 (app2) client for Linux
app2 client for Mac and Windows laptops coming later this year
June 20, 20112011 HPCMP User Group © Cray Inc. 126

CPMD
MPI, instrumented with pat_build –u, HWPC=1
960 cores
VASP
MPI, instrumented with pat_build –gmpi –u, HWPC=3
768 cores
June 20, 20112011 HPCMP User Group © Cray Inc. 127
Perftools 5.1.3 Perftools 5.2.0
.xf -> .ap2 88.5 seconds 22.9 seconds
ap2 -> report 1512.27 seconds 49.6 seconds
Perftools 5.1.3 Perftools 5.2.0
.xf -> .ap2 45.2 seconds 15.9 seconds
ap2 -> report 796.9 seconds 28.0 seconds

From Linux desktop –
% module load perftools
% app2
% app2 kaibab:
% app2 kaibab:/lus/scratch/heidi/swim+pat+10302-0t.ap2
File->Open Remote…
June 20, 20112011 HPCMP User Group © Cray Inc. 128
‘:’ signifies a remote
host instead of
ap2 file

Optional app2 client for Linux desktop available as of 5.2.0
Can still run app2 from Cray service node
Improves response times as X11 traffic is no longer passed through the ssh connection
Replaces 32-bit Linux desktop version of Cray Apprentice2
Uses libssh to establish connection
app2 clients for Windows and Mac coming in subsequent release
June 20, 20112011 HPCMP User Group © Cray Inc. 129

Log into Cray XT/XE login node
% ssh –Y seal
Launch Cray Apprentice2 on Cray XT/XE login node
% app2 /lus/scratch/mydir/my_program.ap2
User Interface displayed on desktop via ssh trusted X11 forwarding
Entire my_program.ap2 file loaded into memory on XT login node (can be Gbytes of data)
June 20, 20112011 HPCMP User Group © Cray Inc. 130
Linux desktop Cray XT login Compute nodesAll data from
my_program.ap2 +
X11 protocolapp2
my_program.ap2
X Window
System
applicationmy_program+apa
Collected
performance
data

Launch Cray Apprentice2 on desktop, point to data
% app2 seal:/lus/scratch/mydir/my_program.ap2
User Interface displayed on desktop via X Windows-based software
Minimal subset of data from my_program.ap2 loaded into memory on Cray XT/XE service node at any given time
Only data requested sent from server to client
June 20, 20112011 HPCMP User Group © Cray Inc. 131
Linux desktop Cray XT login Compute nodesUser requested data
from
my_program.ap2 app2 server
my_program.ap2
X Window
System
application
app2 clientmy_program+apa
Collected
performance
data

June 20, 20112011 HPCMP User Group © Cray Inc. 132

Major change to the way HW counters are collected starting with CPMAT 5.2.1 and CLE 4.0 (In conjunction with Interlagos support)
Linux has officially incorporated support for accessing counters through a perf_events subsystem. Until this, Linux kernels have had to be patched to add support for perfmon2 which provided access to the counters for PAPI and for CrayPat.
Seamless to users except –
Overhead incurred when accessing counters has increased
Creates additional application perturbation
Working to bring this back in line with perfmon2 overhead
June 20, 20112011 HPCMP User Group © Cray Inc. 133

When possible, CrayPat will identify dominant communication grids (communication patterns) in a program
Example: nearest neighbor exchange in 2 or 3 dimensions
Sweep3d uses a 2-D grid for communication
Determine whether or not a custom MPI rank order will produce a significant performance benefit
Custom rank orders are helpful for programs with significant point-to-point communication
Doesn’t interfere with MPI collective communication optimizations
June 20, 20112011 HPCMP User Group © Cray Inc. 134

Focuses on intra-node communication (place ranks that communication frequently on the same node, or close by)
Option to focus on other metrics such as memory bandwidth
Determine rank order used during run that produced data
Determine grid that defines the communication
Produce a custom rank order if it’s beneficial based on grid size, grid order and cost metric
Summarize findings in report
Describe how to re-run with custom rank order
June 20, 20112011 HPCMP User Group © Cray Inc. 135

For Sweep3d with 768 MPI ranks:
This application uses point-to-point MPI communication between nearest neighbors in a 32 X 24 grid pattern. Time spent in this communication accounted for over 50% of the execution time. A significant fraction (but not more than 60%) of this time could potentially be saved by using the rank order in the file MPICH_RANK_ORDER.g which was generated along with this report.
To re-run with a custom rank order …
June 20, 20112011 HPCMP User Group © Cray Inc. 136

Assist the user with application performance analysis and optimization
Help user identify important and meaningful information from potentially massive data sets
Help user identify problem areas instead of just reporting data
Bring optimization knowledge to a wider set of users
Focus on ease of use and intuitive user interfaces Automatic program instrumentation Automatic analysis
Target scalability issues in all areas of tool development Data management
Storage, movement, presentation
June 20, 2011 1372011 HPCMP User Group © Cray Inc.

Supports traditional post-mortem performance analysis
Automatic identification of performance problems
Indication of causes of problems
Suggestions of modifications for performance improvement
CrayPat
pat_build: automatic instrumentation (no source code changes needed)
run-time library for measurements (transparent to the user)
pat_report for performance analysis reports
pat_help: online help utility
Cray Apprentice2
Graphical performance analysis and visualization tool
June 20, 2011 1382011 HPCMP User Group © Cray Inc.

CrayPat
Instrumentation of optimized code
No source code modification required
Data collection transparent to the user
Text-based performance reports
Derived metrics
Performance analysis
Cray Apprentice2
Performance data visualization tool
Call tree view
Source code mappings
June 20, 2011 1392011 HPCMP User Group © Cray Inc.

When performance measurement is triggered
External agent (asynchronous)
Sampling
Timer interrupt
Hardware counters overflow
Internal agent (synchronous)
Code instrumentation
Event based
Automatic or manual instrumentation
How performance data is recorded
Profile ::= Summation of events over time
run time summarization (functions, call sites, loops, …)
Trace file ::= Sequence of events over time
June 20, 2011 1402011 HPCMP User Group © Cray Inc.

Millions of lines of code
Automatic profiling analysis
Identifies top time consuming routines
Automatically creates instrumentation template customized to your application
Lots of processes/threads
Load imbalance analysis
Identifies computational code regions and synchronization calls that could benefit most from load balance optimization
Estimates savings if corresponding section of code were balanced
Long running applications
Detection of outliers
June 20, 2011 1412011 HPCMP User Group © Cray Inc.

Important performance statistics:
Top time consuming routines
Load balance across computing resources
Communication overhead
Cache utilization
FLOPS
Vectorization (SSE instructions)
Ratio of computation versus communication
June 20, 2011 1422011 HPCMP User Group © Cray Inc.

No source code or makefile modification required
Automatic instrumentation at group (function) level
Groups: mpi, io, heap, math SW, …
Performs link-time instrumentation
Requires object files
Instruments optimized code
Generates stand-alone instrumented program
Preserves original binary
Supports sample-based and event-based instrumentation
June 20, 2011 1432011 HPCMP User Group © Cray Inc.

Analyze the performance data and direct the user to meaningful information
Simplifies the procedure to instrument and collect performance data for novice users
Based on a two phase mechanism
1. Automatically detects the most time consuming functions in the application and feeds this information back to the tool for further (and focused) data collection
2. Provides performance information on the most significant parts of the application
June 20, 2011 1442011 HPCMP User Group © Cray Inc.

Performs data conversion
Combines information from binary with raw performance data
Performs analysis on data
Generates text report of performance results
Formats data for input into Cray Apprentice2
June 20, 2011 1452011 HPCMP User Group © Cray Inc.

Craypat / Cray Apprentice2 5.0 released September 10, 2009
New internal data format
FAQ
Grid placement support
Better caller information (ETC group in pat_report)
Support larger numbers of processors
Client/server version of Cray Apprentice2
Panel help in Cray Apprentice2
June 20, 2011 2011 HPCMP User Group © Cray Inc. 146
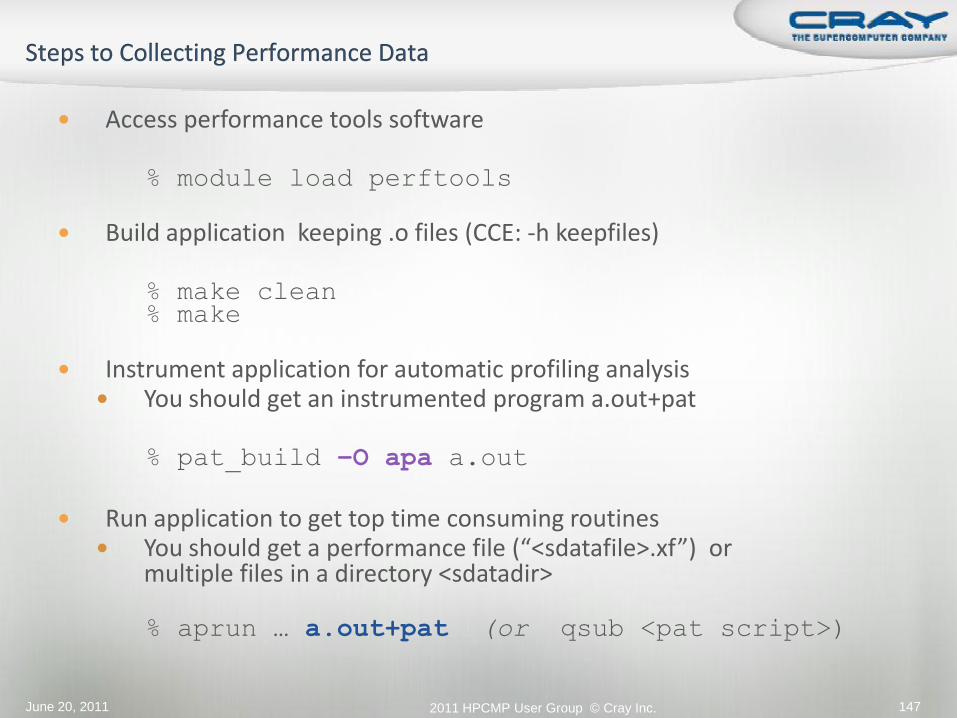
Access performance tools software
% module load perftools
Build application keeping .o files (CCE: -h keepfiles)
% make clean% make
Instrument application for automatic profiling analysis You should get an instrumented program a.out+pat
% pat_build –O apa a.out
Run application to get top time consuming routines You should get a performance file (“<sdatafile>.xf”) or
multiple files in a directory <sdatadir>
% aprun … a.out+pat (or qsub <pat script>)
June 20, 2011 2011 HPCMP User Group © Cray Inc. 147

June 20, 2011 2011 HPCMP User Group © Cray Inc. Slide 148
Generate report and .apa instrumentation file
% pat_report –o my_sampling_report [<sdatafile>.xf | <sdatadir>]
Inspect .apa file and sampling report
Verify if additional instrumentation is needed

# You can edit this file, if desired, and use it
# to reinstrument the program for tracing like this:
#
# pat_build -O mhd3d.Oapa.x+4125-401sdt.apa
#
# These suggested trace options are based on data from:
#
# /home/crayadm/ldr/mhd3d/run/mhd3d.Oapa.x+4125-401sdt.ap2, /home/crayadm/ldr/mhd3d/run/mhd3d.Oapa.x+4125-401sdt.xf
# ----------------------------------------------------------------------
# HWPC group to collect by default.
-Drtenv=PAT_RT_HWPC=1 # Summary with instructions metrics.
# ----------------------------------------------------------------------
# Libraries to trace.
-g mpi
# ----------------------------------------------------------------------
# User-defined functions to trace, sorted by % of samples.
# Limited to top 200. A function is commented out if it has < 1%
# of samples, or if a cumulative threshold of 90% has been reached,
# or if it has size < 200 bytes.
# Note: -u should NOT be specified as an additional option.
# 43.37% 99659 bytes
-T mlwxyz_
# 16.09% 17615 bytes
-T half_
# 6.82% 6846 bytes
-T artv_
# 1.29% 5352 bytes
-T currenh_
# 1.03% 25294 bytes
-T bndbo_
# Functions below this point account for less than 10% of samples.
# 1.03% 31240 bytes
# -T bndto_
. . .
# ----------------------------------------------------------------------
-o mhd3d.x+apa # New instrumented program.
/work/crayadm/ldr/mhd3d/mhd3d.x # Original program.
June 20, 2011 1492011 HPCMP User Group © Cray Inc.

biolib Cray Bioinformatics library routines
blacs Basic Linear Algebra communication subprograms
blas Basic Linear Algebra subprograms
caf Co-Array Fortran (Cray X2 systems only)
fftw Fast Fourier Transform library (64-bit only)
hdf5 manages extremely large and complex data collections
heap dynamic heap
io includes stdio and sysio groups
lapack Linear Algebra Package
lustre Lustre File System
math ANSI math
mpi MPI
netcdf network common data form (manages array-oriented scientific data)
omp OpenMP API (not supported on Catamount)
omp-rtl OpenMP runtime library (not supported on Catamount)
portals Lightweight message passing API
pthreads POSIX threads (not supported on Catamount)
scalapack Scalable LAPACK
shmem SHMEM
stdio all library functions that accept or return the FILE* construct
sysio I/O system calls
system system calls
upc Unified Parallel C (Cray X2 systems only)
June 20, 2011 1502011 HPCMP User Group © Cray Inc.

0 Summary with instruction
metrics
1 Summary with TLB metrics
2 L1 and L2 metrics
3 Bandwidth information
4 Hypertransport information
5 Floating point mix
6 Cycles stalled, resources
idle
7 Cycles stalled, resources
full
8 Instructions and branches
9 Instruction cache
10 Cache hierarchy
11 Floating point operations
mix (2)
12 Floating point operations
mix (vectorization)
13 Floating point operations
mix (SP)
14 Floating point operations
mix (DP)
15 L3 (socket-level)
16 L3 (core-level reads)
17 L3 (core-level misses)
18 L3 (core-level fills caused
by L2 evictions)
19 Prefetches
June 20, 2011 Slide 1512011 HPCMP User Group © Cray Inc.

Regions, useful to break up long routines
int PAT_region_begin (int id, const char *label)
int PAT_region_end (int id)
Disable/Enable Profiling, useful for excluding initialization
int PAT_record (int state)
Flush buffer, useful when program isn’t exiting cleanly
int PAT_flush_buffer (void)
June 20, 2011 1532011 HPCMP User Group © Cray Inc.

June 20, 2011 2011 HPCMP User Group © Cray Inc. Slide 154
Instrument application for further analysis (a.out+apa)
% pat_build –O <apafile>.apa
Run application
% aprun … a.out+apa (or qsub <apa script>)
Generate text report and visualization file (.ap2)
% pat_report –o my_text_report.txt [<datafile>.xf | <datadir>]
View report in text and/or with Cray Apprentice2
% app2 <datafile>.ap2

MUST run on Lustre ( /work/… , /lus/…, /scratch/…, etc.)
Number of files used to store raw data
1 file created for program with 1 – 256 processes
√n files created for program with 257 – n processes
Ability to customize with PAT_RT_EXPFILE_MAX
June 20, 2011 1552011 HPCMP User Group © Cray Inc.

June 20, 2011 Slide 156
Full trace files show transient events but are too large
Current run-time summarization misses transient events
Plan to add ability to record:
Top N peak values (N small)
Approximate std dev over time
For time, memory traffic, etc.
During tracing and sampling
2011 HPCMP User Group © Cray Inc.

Call graph profile
Communication statistics
Time-line view
Communication
I/O
Activity view
Pair-wise communication statistics
Text reports
Source code mapping
Cray Apprentice2
is target to help identify and correct:
Load imbalance
Excessive communication
Network contention
Excessive serialization
I/O Problems
June 20, 2011 1572011 HPCMP User Group © Cray Inc.

Switch Overview display
June 20, 2011 1582011 HPCMP User Group © Cray Inc.

June 20, 2011 Slide 1592011 HPCMP User Group © Cray Inc.

June 20, 2011 1602011 HPCMP User Group © Cray Inc.

June 20, 2011 1612011 HPCMP User Group © Cray Inc.

Min, Avg, and Max
Values
-1, +1
Std Dev
marks
June 20, 2011 1622011 HPCMP User Group © Cray Inc.

Function
List
Load balance overview:
Height Max time
Middle bar Average time
Lower bar Min time
Yellow represents
imbalance time
Zoom
Height exclusive time
Width inclusive time
DUH Button:
Provides hints
for performance
tuning
Filtered
nodes or
sub tree
June 20, 2011 1632011 HPCMP User Group © Cray Inc.

Function
List off
Right mouse click:
Node menu
e.g., hide/unhide
children
Sort options
% Time,
Time,
Imbalance %
Imbalance time
Right mouse click:
View menu:
e.g., Filter
June 20, 2011 1642011 HPCMP User Group © Cray Inc.

June 20, 2011 1652011 HPCMP User Group © Cray Inc.

June 20, 2011 Slide 1662011 HPCMP User Group © Cray Inc.

June 20, 2011 Slide 1672011 HPCMP User Group © Cray Inc.

June 20, 2011 Slide 1682011 HPCMP User Group © Cray Inc.

-1, +1
Std Dev
marks
Min, Avg, and Max
Values
June 20, 2011 1692011 HPCMP User Group © Cray Inc.

June 20, 2011 1702011 HPCMP User Group © Cray Inc.

Cray Apprentice2 panel help
pat_help – interactive help on the Cray Performance toolset
FAQ available through pat_help
June 20, 2011 2011 HPCMP User Group © Cray Inc. 171

intro_craypat(1)
Introduces the craypat performance tool
pat_build
Instrument a program for performance analysis
pat_help
Interactive online help utility
pat_report
Generate performance report in both text and for use with GUI
hwpc(3)
describes predefined hardware performance counter groups
papi_counters(5)
Lists PAPI event counters
Use papi_avail or papi_native_avail utilities to get list of events when running on a specific architecture
June 20, 2011 2011 HPCMP User Group © Cray Inc. 172
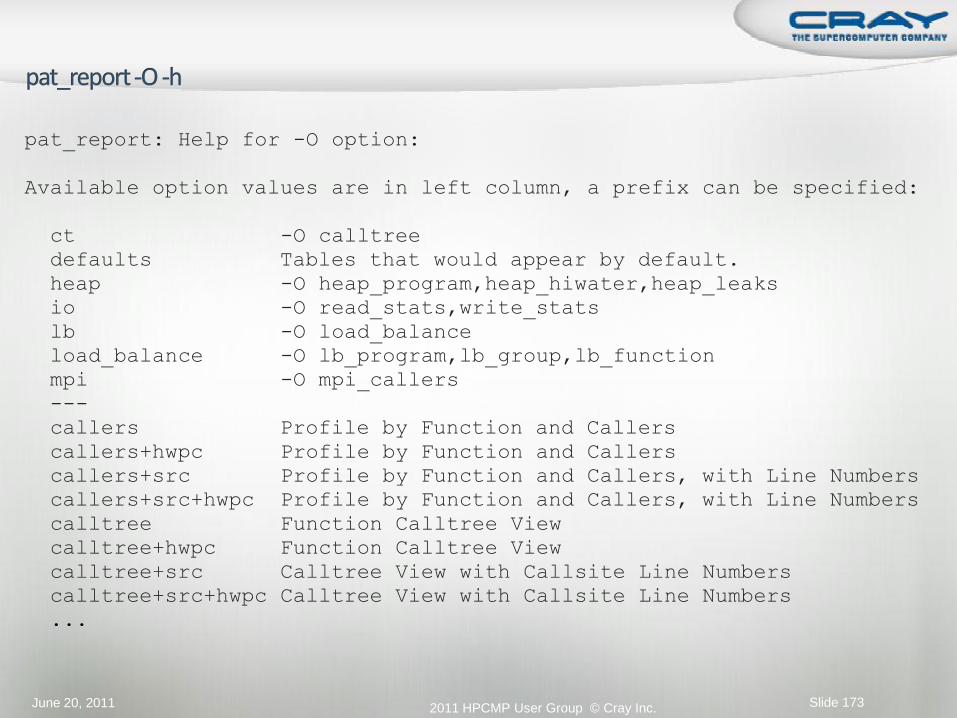
June 20, 2011 Slide 173
pat_report: Help for -O option:
Available option values are in left column, a prefix can be specified:
ct -O calltree
defaults Tables that would appear by default.
heap -O heap_program,heap_hiwater,heap_leaks
io -O read_stats,write_stats
lb -O load_balance
load_balance -O lb_program,lb_group,lb_function
mpi -O mpi_callers
---
callers Profile by Function and Callers
callers+hwpc Profile by Function and Callers
callers+src Profile by Function and Callers, with Line Numbers
callers+src+hwpc Profile by Function and Callers, with Line Numbers
calltree Function Calltree View
calltree+hwpc Function Calltree View
calltree+src Calltree View with Callsite Line Numbers
calltree+src+hwpc Calltree View with Callsite Line Numbers
...
2011 HPCMP User Group © Cray Inc.

Interactive by default, or use trailing '.' to just print a topic:
New FAQ craypat 5.0.0.
Has counter and counter group information
% pat_help counters amd_fam10h groups .
June 20, 2011 2011 HPCMP User Group © Cray Inc. 174

June 20, 2011 2011 HPCMP User Group © Cray Inc. Slide 175
The top level CrayPat/X help topics are listed below.A good place to start is:
overview
If a topic has subtopics, they are displayed under the heading"Additional topics", as below. To view a subtopic, you needonly enter as many initial letters as required to distinguishit from other items in the list. To see a table of contentsincluding subtopics of those subtopics, etc., enter:
toc
To produce the full text corresponding to the table of contents,specify "all", but preferably in a non-interactive invocation:
pat_help all . > all_pat_helppat_help report all . > all_report_help
Additional topics:
API executebalance experimentbuild first_examplecounters overviewdemos reportenvironment run
pat_help (.=quit ,=back ^=up /=top ~=search)=>

June 20, 2011 1762011 HPCMP User Group © Cray Inc.

ATP (Abnormal Termination Processing) or What do you do when task a causes b to crash
Load the ATP Module before compiling
Set ATP_ENABLED before running
Limitations
ATP disables core dumping. When ATP is running, an applications crash does not produce a core dump.
When ATP is running, the application cannot be checkpointed.
ATP does not support threaded application processes.
ATP has been tested at 10,000 cores. Behavior at core counts greater than 10,000 is still being researched.
April 19, 2011Cray Proprietary 177

April 19, 2011Cray Proprietary 178
Application 926912 is crashing. ATP analysis proceeding...
Stack walkback for Rank 3 starting:
Stack walkback for Rank 3 done
Process died with signal 4: 'Illegal instruction'
View application merged backtrace tree file
'atpMergedBT.dot' with 'statview'
You may need to 'module load stat'.

April 19, 2011Cray Proprietary 179

June 20, 2011 1802011 HPCMP User Group © Cray Inc.

What CCM is NOT
It is Not a virtual machine or any os within an os
It is NOT an emulator
April 19, 2011Cray Proprietary 181

What is CCM Then?
Provides the runtime environment on compute nodes expected by ISV applications
Dynamically allocates and configures compute nodes at job start Nodes are not permanently dedicated to CCM
Any compute node can be used
Allocated like any other batch job (on demand)
MPI and third-party MPI runs over TCP/IP using high-speed network
Supports standard services: ssh, rsh, nscd, ldap
Complete root file system on the compute nodes Built on top of the Dynamic Shared Libraries (DSL) environment
Apps run under CCM: Abaqus, Matlab, Castep, Discoverer, Dmo13, Mesodyn, Ensight and more
Under CCM, everything the application can “see” is like a standard Linux cluster: Linux OS, x86 processor, and MPI

• Many applications running in Extreme Scalability Mode (ESM)
• Submit CCM application through batch scheduler, nodes reserved
qsub –l ccm=1 Qname AppScript
• Previous jobs finish, nodes configured for CCM
• Executes the batch script and application
• Other nodes scheduled for ESM or CCM applications as available
• After CCM job completes, CCM nodes cleared
• CCM nodes available for ESM or CCM applications
Cray XT6/XE6 System
Service Nodes
Compute NodesCCM Mode Running
ESM Mode Running
ESM Mode Idle
11/03/2010Cray Product Roadmap - Presented Under NDA

Support MPIs that are configured to work with the OFED stack
CCM1 supports ISV Applications over TCP/IP only
CCM2 supports ISV Applications over TCP/IP and Gemini on XE6
ISV Application Acceleration (IAA) directly utilizes HSN through the Gemini user-space APIs.
Goal of IAA/CCM2 is to deliver latency and bandwidth improvement over CCM1 over TCP/IP.
CCM2 infrastructure is currently in system test.
IAA design and implementation phase is complete
CCM2 with IAA is currently in integration test phase

A code binary compiled for SLES and an Opteron
DSO’s are OK
A third party MPI library that can use TCP/IP
We have tried OpenMPI, HP-MPI, LAM-MPI.
Most of the bigger apps are packaged with their own library (usually HP-MPI)
Add CCMRUN to the run script.
The IP address of the License server for the Applications
Note that right now CCM cannot do an NSLOOKUP
LMHOSTS must be specified by IP address
With CLE 4.0: An MPI Library that IBVERBS
April 19, 2011Cray Proprietary 185

CCMRUN: Analogous to aprun runs a third party batch job
In Most cases if you already have a runscript for your third party app adding ccmrun prior to the application command will set it up.
CCMLOGIN: Allows interactive access to the head node of a allocated compute pool. Takes Optional ssh options
CCM uses the ssh known_hosts to set up a an paswordless ssh between a set of compute nodes. You can go to allocated nodes but no further.
April 19, 2011Cray Proprietary 186

April 19, 2011Cray Proprietary 187
Boot RAID
XE6
System
ExternalLogin Server
10 GbE
IB QDR
External Login Servers
Internal Login Nodes (PBS Nodes)
Compute Nodes

April 19, 2011Cray Proprietary 188
External Login Nodes: Dell 4 socket servers that the user enters the System Over
PBS Nodes: Internal single socket 6 core nodes that run the PBS MOM’s
Aprun must be issued from a node on the System Database
Compute Nodes: 2 Socket 8 Core Opteron nodes that run trimmed down OS (still Linux)

April 19, 2011Cray Proprietary 189
news: diskuse_work diskuse_home system_info.txt
aminga@garnet01:~> uname -a
Linux garnet01 2.6.27.48-0.12-default #1 SMP 2010-09-20 11:03:26 -0400
x86_64 x86_64 x86_64 GNU/Linux
aminga@garnet01:~> qsub -I -lccm=1 -q debug -l walltime=01:00:00 -l
ncpus=32 -A ERDCS97290STA
qsub: waiting for job 104868.sdb to start
qsub: job 104868.sdb ready
In CCM JOB: 104868.sdb JID sdb USER aminga GROUP erdcssta
Initializing CCM environment, Please Wait
CCM Start success, 2 of 2 responses
aminga@garnet13:~> uname -a
Linux garnet13 2.6.27.48-0.12.1_1.0301.5737-cray_gem_s #1 SMP Mon Mar 28
22:20:59 UTC 2011 x86_64 x86_64 x86_64 GNU/Linux

April 19, 2011Cray Proprietary 190
aminga@garnet13:~> cat
$PBS_NODEFILE
nid00972
nid00972
nid00972
nid00972
nid00972
nid00972
nid00972
nid00972
<snip>
nid01309
nid01309
nid01309
nid01309
nid01309
nid01309
nid01309
nid01309
aminga@garnet13:~> ccmlogin
Last login: Mon Jun 13 13:03:26 2011 from nid01028
-------------------------------------------------------------------------------
aminga@nid00972:~> uname -a
Linux nid00972 2.6.27.48-0.12.1_1.0301.5737-cray_gem_c #1
SMP Mon Mar 28 22:26:26 UTC 2011 x86_64 x86_64 x86_64
GNU/Linux
aminga@nid00972:~> ssh nid01309
Try `uname --help' for more information.
aminga@nid01309:~> uname -a
Linux nid01309 2.6.27.48-0.12.1_1.0301.5737-cray_gem_c #1
SMP Mon Mar 28 22:26:26 UTC 2011 x86_64 x86_64 x86_64
GNU/Linux
aminga@nid01309:~>
aminga@nid00972:~> ssh nid01310
Redirecting to /etc/ssh/ssh_config
ssh: connect to host nid01310 port 203: Connection refused

April 19, 2011Cray Proprietary 191
#!/bin/csh
#PBS -l mppwidth=2
#PBS -l mppnppn=1
#PBS -q ccm_queue
#PBS -j oe
cd $PBS_O_WORKDIR
perl ConstructMachines.LINUX.pl
setenv DSD_MachineLIST $PBS_O_WORKDIR/machines.LINUX
setenv MPI_COMMAND "
/usr/local/applic/accelrys/MSModeling5.5/hpmpi/opt/hpmpi/bin/mpi
run -np "
ccmrun ./RunDiscover.sh -np 2 nvt_m

April 19, 2011Cray Proprietary 192
#PBS -l mppwidth=2
#PBS -l mppnppn=1
#PBS -j oe
#PBS -N gauss-test-ccm
#PBS -q ccm_queue
cd $PBS_O_WORKDIR
cp $PBS_NODEFILE node_file
./CreatDefaultRoute.pl
mkdir -p scratch
setenv DVS_CACHE off
setenv g09root /usr/local/applic/gaussian/
setenv GAUSS_EXEDIR ${g09root}/g09
setenv GAUSS_EXEDIR ${g09root}/g09/linda-exe:$GAUSS_EXEDIR
setenv GAUSS_SCRDIR `pwd`
setenv TMPDIR `pwd`
source ${g09root}/g09/bsd/g09.login
setenv GAUSS_LFLAGS "-vv -nodefile node_file -opt Tsnet.Node.lindarsharg:ssh"
setenv LINDA_PATH ${g09root}/g09/linda8.2/opteron-linux
set LINDA_LAUNCHVERBOSE=1
ccmrun ${g09root}/g09/g09 < gauss-test-ccm.com
setenv TEND `echo "print time();" | perl`
echo "Gaussian CCM walltime: `expr $TEND - $TBEGIN` seconds"
April 19, 2011Cray Proprietary 193
cd $PBS_O_WORKDIR
/bin/rm -rf bhost.def
cat $PBS_NODEFILE > bhost.def
/bin/rm -rf job.script
cat > job.script << EOD
#!/bin/csh
set echo
cd $PWD
setenv AEROSOFT_HOME /work/aminga/captest/isvdata/GASP/GASPSTD/aerosoft
setenv LAMHOME /work/aminga/captest/isvdata/GASP/GASPSTD/aerosoft
setenv PATH /work/aminga/captest/isvdata/GASP/GASPSTD/aerosoft/bin:\$PATH
setenv TMPDIR /work/aminga
ln -s /usr/lib64/libpng.so libpng.so.3
setenv LD_LIBRARY_PATH \`pwd\`:\$LD_LIBRARY_PATH
setenv LAMRSH "ssh -x"
lamboot bhost.def
time mpirun -np 2 -x LD_LIBRARY_PATH gasp --mpi -i duct.xml --run 2 --elmhost 140.31.
9.44
EOD
chmod +x job.script
ccmrun job.script

April 19, 2011Cray Proprietary 194
#!/bin/sh
#PBS -q ccm_queue
#PBS -lmppwidth=48
#PBS -j oe
#PBS -N CFX
cd $PBS_O_WORKDIR
TOP_DIR=/usr/local/applic/ansys
export ANSYSLIC_DIR=$TOP_DIR/shared_files/licensing
export LD_LIBRARY_PATH=$TOP_DIR/v121/CFX/tools/hpmpi-2.3/Linux-amd64/lib/linux_amd64:
$LD_LIBRARY_PATH
export PATH=$TOP_DIR/v121/CFX/bin:$PATH
export CFX5RSH=ssh
export MPIRUN_OPTIONS="-TCP -prot -cpu_bind=MAP_CPU:0,1,2,3,4,5,6,7,8,9,10,11,12,13,1
4,15,16,17,18,19,20,21,22,23"
/bin/rm -rf host.list
cat $PBS_NODEFILE > host.list
export proc_list=`sort host.list | uniq -c | awk '{ printf("%s*%s ", $2, $1) ; }'`
echo $proc_list
which cfx5solve
ccmrun cfx5solve \
-def S*400k.def -par-dist "$proc_list" -start-method "HP MPI Distributed Para
llel"
rm -f host.list

April 19, 2011Cray Proprietary 195
#!/bin/bash
#PBS -lmppwidth=16
#PBS -q ccm_queue
#PBS -j oe
#PBS -N abaqus_e1
cd $PBS_O_WORKDIR
TMPDIR=.
ABAQUS=/usr/local/applic/abaqus
#cp ${ABAQUS}/input/e1.inp e1.inp
cat $PBS_NODEFILE
echo "Run Abaqus"
ccmrun ${ABAQUS}/6.10-1/exec/abq6101.exe input=e1.inp job=e1 cpus=16
interactive
April 19, 2011Cray Proprietary 196
#!/bin/csh
#PBS -q ccm_queue
#PBS -l mppwidth=32
#PBS -j oe
#PBS -N AFRL_Fluent
cd $PBS_O_WORKDIR
setenv FLUENT_HOME /usr/local/applic/fluent/12.1/fluent
setenv FLUENT_ARCH lnamd64
setenv PATH /usr/local/applic/fluent/12.1/v121/fluent/bin:$PATH
setenv FLUENT_INC /usr/local/applic/fluent/12.1/v121/fluent
###setenv LM_LICENSE_FILE [email protected]
setenv LM_LICENSE_FILE [email protected]
setenv ANSYSLMD_LICENSE_FILE /home/applic/ansys/shared_files/licensing/license.dat
echo ${LM_LICENSE_FILE}
setenv FLUENT_VERSION -r12.1.1
cd $PBS_O_WORKDIR
rm -rf host.list
cat $PBS_NODEFILE > host.list
module load ccm dot
setenv MALLOC_MMAP_MAX_ 0
setenv MALLOC_TRIM_THRESHOLD_ 536870912
setenv MPIRUN_OPTIONS " -TCP -cpu_bind=MAP_CPU:0,1,2,3,4,5,6,7"
setenv MPIRUN_OPTIONS "${MPIRUN_OPTIONS},8,9,10,11,12,13,14,15 "
setenv MPI_SOCKBUFSIZE 524288
setenv MPI_WORKDIR $PWD
setenv MPI_COMMD 1024,1024
ccmrun /usr/local/applic/fluent/v121/fluent/bin/fluent -r12.1.2 2ddp -mpi=hp -gu -dri
ver null -t4 -i blast.inp > tstfluent-blast.jobout

ALPS allows you to run aprun instance per node. Using CCM you can get around that.
So suppose you want to run 16 single core jobs and only use one node
qsub -lccm=1 -q debug -l walltime=01:00:00 -l ncpus=16 -A ERDCS97290STA
#PBS –J oe
cd $PBS_O_WORKDIR
./myapp&
./myapp&
./myapp&
./myapp&
./myapp&
./myapp&
April 19, 2011Cray Proprietary 197

Engineering for Multi-level Parallelism
June 20, 2011 1982011 HPCMP User Group © Cray Inc.

Flat, all-MPI parallelism is beginning to be too limited as the number of compute cores rapidly increase
It is becoming necessary to design applications with multiple levels of parallelism:
High-level MPI parallelism between nodes
You’re probably already doing this
Loose, on-node parallelism via threads at a high level
Most codes today are using MPI, but threading is becoming more important
Tight, on-node, vector parallelism at a low level
SSE/AVX on CPUs
GPU threaded parallelism
Programmers need to expose the same parallelism for all future architectures
June 20, 20112011 HPCMP User Group © Cray Inc. 199

A benchmark problem was defined to closely resemble the target simulation
52 species n-heptane chemistry and 483 grid points per node
– 483 * 18,500 nodes = 2 billion grid points
– Target problem would take two months on today’s Jaguar
• Code was benchmarked and profiled on dual-hexcore XT5
• Several kernels identified and extracted into stand-alone driver programs
Mini-Apps!
Chemistry
Core S3D
June 20, 2011 2002011 HPCMP User Group © Cray Inc.

Goals:
Convert S3D to a hybrid multi-core application suited for a multi-core node with or without an accelerator.
Hoisted several loops up the call tree
Introduced high-level OpenMP
Be able to perform the computation entirely on the accelerator if available.
- Arrays and data able to reside entirely on the accelerator.
- Data sent from accelerator to host CPU for halo communication, I/O and monitoring only.
Strategy:
To program using both hand-written and generated code.
- Hand-written and tuned CUDA*.
- Automated Fortran and CUDA generation for chemistry kernels
- Automated code generation through compiler directives
S3D kernels are now a part of Cray’s compiler development test cases* Note: CUDA refers to CUDA-Fortran, unless mentioned otherwise
June 20, 2011 2012011 HPCMP User Group © Cray Inc.

June 20, 20112011 HPCMP User Group © Cray Inc. 202
RHS – Called 6 times for each time step –
Runge Kutta iterations
Calculate Primary Variable – point wiseMesh loops within 5 different routines
Perform Derivative computation – High order differencing
Calculate Diffusion – 3 different routines with some derivative computation
Perform Derivative computation for forming rhs – lots of communication
Perform point-wise chemistry computation
All major loops are at low level of theCall treeGreen – major computation –point-wiseYellow – major computation –Halos 5 zones thick

June 20, 20112011 HPCMP User Group © Cray Inc.
RHS – Called 6 times for each time step –
Runge Kutta iterations
Calculate Primary Variable – point wiseMesh loops within 3 different routines
Perform Derivative computation – High order differencing
Perform derivative computation
Perform Derivative computation for forming rhs – lots of communication
Perform point-wise chemistry computation (1)
OMP loop over grid
Calculate Primary Variable – point wiseMesh loops within 2 different routines
Overlapped
Perform point-wise chemistry computation (2)
Calculate Diffusion – 3 different routines with some derivative computation
Overlapped
Overlapped
OMP loop over grid
OMP loop over grid
OMP loop over grid

June 20, 2011 2042011 HPCMP User Group © Cray Inc.

Create good granularity OpenMP Loop
Improves cache re-use
Reduces Memory usage significantly
Creates a good potential kernel for an accelerator
June 20, 2011
2052011 HPCMP User Group © Cray Inc.

CPU Optimizations
Optimizing Communication
I/O Best Practices
June 20, 2011 2062011 HPCMP User Group © Cray Inc.

June 20, 2011 2072011 HPCMP User Group © Cray Inc.

55. 1 ii = 0
56. 1 2-----------< do b = abmin, abmax
57. 1 2 3---------< do j=ijmin, ijmax
58. 1 2 3 ii = ii+1
59. 1 2 3 jj = 0
60. 1 2 3 4-------< do a = abmin, abmax
61. 1 2 3 4 r8----< do i = ijmin, ijmax
62. 1 2 3 4 r8 jj = jj+1
63. 1 2 3 4 r8 f5d(a,b,i,j) = f5d(a,b,i,j)
+ tmat7(ii,jj)
64. 1 2 3 4 r8 f5d(b,a,i,j) = f5d(b,a,i,j)
- tmat7(ii,jj)
65. 1 2 3 4 r8 f5d(a,b,j,i) = f5d(a,b,j,i)
- tmat7(ii,jj)
66. 1 2 3 4 r8 f5d(b,a,j,i) = f5d(b,a,j,i)
+ tmat7(ii,jj)
67. 1 2 3 4 r8----> end do
68. 1 2 3 4-------> end do
69. 1 2 3---------> end do
70. 1 2-----------> end do
The inner-most loop
strides on a slow
dimension of each
array.
The best the compiler
can do is unroll.
Little to no cache
reuse.
Poor loop order results in poor
striding
June 20, 2011 2082011 HPCMP User Group © Cray Inc.

USER / #1.Original Loops
-----------------------------------------------------------------
Time% 55.0%
Time 13.938244 secs
Imb.Time 0.075369 secs
Imb.Time% 0.6%
Calls 0.1 /sec 1.0 calls
DATA_CACHE_REFILLS:
L2_MODIFIED:L2_OWNED:
L2_EXCLUSIVE:L2_SHARED 11.858M/sec 165279602 fills
DATA_CACHE_REFILLS_FROM_SYSTEM:
ALL 11.931M/sec 166291054 fills
PAPI_L1_DCM 23.499M/sec 327533338 misses
PAPI_L1_DCA 34.635M/sec 482751044 refs
User time (approx) 13.938 secs 36239439807 cycles
100.0%Time
Average Time per Call 13.938244 sec
CrayPat Overhead : Time 0.0%
D1 cache hit,miss ratios 32.2% hits 67.8% misses
D2 cache hit,miss ratio 49.8% hits 50.2% misses
D1+D2 cache hit,miss ratio 66.0% hits 34.0% misses
For every L1 cache
hit, there’s 2 misses
Overall, only 2/3 of
all references were in
level 1 or 2 cache.
Poor loop order results in poor
cache reuse
June 20, 2011 2092011 HPCMP User Group © Cray Inc.

June 20, 2011 2102011 HPCMP User Group © Cray Inc.

June 20, 2011 2112011 HPCMP User Group © Cray Inc.

75. 1 2-----------< do i = ijmin, ijmax
76. 1 2 jj = 0
77. 1 2 3---------< do a = abmin, abmax
78. 1 2 3 4-------< do j=ijmin, ijmax
79. 1 2 3 4 jj = jj+1
80. 1 2 3 4 ii = 0
81. 1 2 3 4 Vcr2--< do b = abmin, abmax
82. 1 2 3 4 Vcr2 ii = ii+1
83. 1 2 3 4 Vcr2 f5d(a,b,i,j) = f5d(a,b,i,j)
+ tmat7(ii,jj)
84. 1 2 3 4 Vcr2 f5d(b,a,i,j) = f5d(b,a,i,j)
- tmat7(ii,jj)
85. 1 2 3 4 Vcr2 f5d(a,b,j,i) = f5d(a,b,j,i)
- tmat7(ii,jj)
86. 1 2 3 4 Vcr2 f5d(b,a,j,i) = f5d(b,a,j,i)
+ tmat7(ii,jj)
87. 1 2 3 4 Vcr2--> end do
88. 1 2 3 4-------> end do
89. 1 2 3---------> end do
90. 1 2-----------> end do
Now, the inner-most
loop is stride-1 on
both arrays.
Now memory
accesses happen
along the cache line,
allowing reuse.
Compiler is able to
vectorize and better-
use SSE instructions.
Reordered loop nest
June 20, 2011 2122011 HPCMP User Group © Cray Inc.

USER / #2.Reordered Loops
-----------------------------------------------------------------
Time% 31.4%
Time 7.955379 secs
Imb.Time 0.260492 secs
Imb.Time% 3.8%
Calls 0.1 /sec 1.0 calls
DATA_CACHE_REFILLS:
L2_MODIFIED:L2_OWNED:
L2_EXCLUSIVE:L2_SHARED 0.419M/sec 3331289 fills
DATA_CACHE_REFILLS_FROM_SYSTEM:
ALL 15.285M/sec 121598284 fills
PAPI_L1_DCM 13.330M/sec 106046801 misses
PAPI_L1_DCA 66.226M/sec 526855581 refs
User time (approx) 7.955 secs 20684020425 cycles
100.0%Time
Average Time per Call 7.955379 sec
CrayPat Overhead : Time 0.0%
D1 cache hit,miss ratios 79.9% hits 20.1% misses
D2 cache hit,miss ratio 2.7% hits 97.3% misses
D1+D2 cache hit,miss ratio 80.4% hits 19.6% misses
Runtine was cut
nearly in half.
Still, some 20% of all
references are cache
misses
Improved striding greatly improved
cache reuse
June 20, 2011 2132011 HPCMP User Group © Cray Inc.

First loop, partially vectorized and unrolled by 495. 1 ii = 0
96. 1 2-----------< do j = ijmin, ijmax
97. 1 2 i---------< do b = abmin, abmax
98. 1 2 i ii = ii+1
99. 1 2 i jj = 0
100. 1 2 i i-------< do i = ijmin, ijmax
101. 1 2 i i Vpr4--< do a = abmin, abmax
102. 1 2 i i Vpr4 jj = jj+1
103. 1 2 i i Vpr4 f5d(a,b,i,j) =
f5d(a,b,i,j) + tmat7(ii,jj)
104. 1 2 i i Vpr4 f5d(a,b,j,i) =
f5d(a,b,j,i) - tmat7(ii,jj)
105. 1 2 i i Vpr4--> end do
106. 1 2 i i-------> end do
107. 1 2 i---------> end do
108. 1 2-----------> end do
109. 1 jj = 0
110. 1 2-----------< do i = ijmin, ijmax
111. 1 2 3---------< do a = abmin, abmax
112. 1 2 3 jj = jj+1
113. 1 2 3 ii = 0
114. 1 2 3 4-------< do j = ijmin, ijmax
115. 1 2 3 4 Vr4---< do b = abmin, abmax
116. 1 2 3 4 Vr4 ii = ii+1
117. 1 2 3 4 Vr4 f5d(b,a,i,j) =
f5d(b,a,i,j) - tmat7(ii,jj)
118. 1 2 3 4 Vr4 f5d(b,a,j,i) =
f5d(b,a,i,j) + tmat7(ii,jj)
119. 1 2 3 4 Vr4---> end do
120. 1 2 3 4-------> end do
121. 1 2 3---------> end do
122. 1 2-----------> end do
Second loop, vectorized and unrolled by 4
June 20, 2011 2142011 HPCMP User Group © Cray Inc.

USER / #3.Fissioned Loops
-----------------------------------------------------------------
Time% 9.8%
Time 2.481636 secs
Imb.Time 0.045475 secs
Imb.Time% 2.1%
Calls 0.4 /sec 1.0 calls
DATA_CACHE_REFILLS:
L2_MODIFIED:L2_OWNED:
L2_EXCLUSIVE:L2_SHARED 1.175M/sec 2916610 fills
DATA_CACHE_REFILLS_FROM_SYSTEM:
ALL 34.109M/sec 84646518 fills
PAPI_L1_DCM 26.424M/sec 65575972 misses
PAPI_L1_DCA 156.705M/sec 388885686 refs
User time (approx) 2.482 secs 6452279320 cycles
100.0%Time
Average Time per Call 2.481636 sec
CrayPat Overhead : Time 0.0%
D1 cache hit,miss ratios 83.1% hits 16.9% misses
D2 cache hit,miss ratio 3.3% hits 96.7% misses
D1+D2 cache hit,miss ratio 83.7% hits 16.3% misses
Runtime further
reduced.
Cache hit/miss ratio
improved slightly
Loopmark file points
to better
vectorization from
the fissioned loops
Fissioning further improved cache reuse and resulted in better
vectorization
June 20, 2011 2152011 HPCMP User Group © Cray Inc.

June 20, 2011 2162011 HPCMP User Group © Cray Inc.

June 20, 2011 217
( 52) C THE ORIGINAL( 53)
( 54) DO 47020 J = 1, JMAX
( 55) DO 47020 K = 1, KMAX
( 56) DO 47020 I = 1, IMAX( 57) JP = J + 1
( 58) JR = J - 1
( 59) KP = K + 1
( 60) KR = K - 1
( 61) IP = I + 1
( 62) IR = I - 1
( 63) IF (J .EQ. 1) GO TO 50
( 64) IF( J .EQ. JMAX) GO TO 51( 65) XJ = ( A(I,JP,K) - A(I,JR,K) ) * DA2
( 66) YJ = ( B(I,JP,K) - B(I,JR,K) ) * DA2
( 67) ZJ = ( C(I,JP,K) - C(I,JR,K) ) * DA2
( 68) GO TO 70
( 69) 50 J1 = J + 1
( 70) J2 = J + 2
( 71) XJ = (-3. * A(I,J,K) + 4. * A(I,J1,K) - A(I,J2,K) ) * DA2
( 72) YJ = (-3. * B(I,J,K) + 4. * B(I,J1,K) - B(I,J2,K) ) * DA2
( 73) ZJ = (-3. * C(I,J,K) + 4. * C(I,J1,K) - C(I,J2,K) ) * DA2
( 74) GO TO 70
( 75) 51 J1 = J - 1
( 76) J2 = J - 2
( 77) XJ = ( 3. * A(I,J,K) - 4. * A(I,J1,K) + A(I,J2,K) ) * DA2
( 78) YJ = ( 3. * B(I,J,K) - 4. * B(I,J1,K) + B(I,J2,K) ) * DA2
( 79) ZJ = ( 3. * C(I,J,K) - 4. * C(I,J1,K) + C(I,J2,K) ) * DA2
( 80) 70 CONTINUE
( 81) IF (K .EQ. 1) GO TO 52
( 82) IF (K .EQ. KMAX) GO TO 53( 83) XK = ( A(I,J,KP) - A(I,J,KR) ) * DB2
( 84) YK = ( B(I,J,KP) - B(I,J,KR) ) * DB2
( 85) ZK = ( C(I,J,KP) - C(I,J,KR) ) * DB2
( 86) GO TO 71
continues…
Triple nested loop at a high level
Ifs inside the inner loop can signifantly reduce the chancesof vectorization
2011 HPCMP User Group © Cray Inc.

June 20, 2011 218
PGI
55, Invariant if transformation
Loop not vectorized: loop count too small
56, Invariant if transformation
2011 HPCMP User Group © Cray Inc.

June 20, 2011 219
( 141) C THE RESTRUCTURED
( 142)
( 143) DO 47029 J = 1, JMAX
( 144) DO 47029 K = 1, KMAX( 145)
( 146) IF(J.EQ.1)THEN( 147)
( 148) J1 = 2
( 149) J2 = 3
( 150) DO 47021 I = 1, IMAX( 151) VAJ(I) = (-3. * A(I,J,K) + 4. * A(I,J1,K) - A(I,J2,K) ) * DA2
( 152) VBJ(I) = (-3. * B(I,J,K) + 4. * B(I,J1,K) - B(I,J2,K) ) * DA2
( 153) VCJ(I) = (-3. * C(I,J,K) + 4. * C(I,J1,K) - C(I,J2,K) ) * DA2
( 154) 47021 CONTINUE
( 155)
( 156) ELSE IF(J.NE.JMAX) THEN( 157)
( 158) JP = J+1
( 159) JR = J-1
( 160) DO 47022 I = 1, IMAX( 161) VAJ(I) = ( A(I,JP,K) - A(I,JR,K) ) * DA2
( 162) VBJ(I) = ( B(I,JP,K) - B(I,JR,K) ) * DA2
( 163) VCJ(I) = ( C(I,JP,K) - C(I,JR,K) ) * DA2
( 164) 47022 CONTINUE
( 165)
( 166) ELSE
( 167)
( 168) J1 = JMAX-1
( 169) J2 = JMAX-2
( 170) DO 47023 I = 1, IMAX
( 171) VAJ(I) = ( 3. * A(I,J,K) - 4. * A(I,J1,K) + A(I,J2,K) ) * DA2
( 172) VBJ(I) = ( 3. * B(I,J,K) - 4. * B(I,J1,K) + B(I,J2,K) ) * DA2
( 173) VCJ(I) = ( 3. * C(I,J,K) - 4. * C(I,J1,K) + C(I,J2,K) ) * DA2
( 174) 47023 CONTINUE
( 175)
( 176) ENDIF
Continues…
Stride-1 loop brought insideif statements
2011 HPCMP User Group © Cray Inc.

June 20, 2011 220
PGI
144, Invariant if transformation
Loop not vectorized: loop count too small
150, Generated 3 alternate loops for the inner loop
Generated vector sse code for inner loop
Generated 8 prefetch instructions for this loop
Generated vector sse code for inner loop
Generated 8 prefetch instructions for this loop
Generated vector sse code for inner loop
Generated 8 prefetch instructions for this loop
Generated vector sse code for inner loop
Generated 8 prefetch instructions for this loop
160, Generated 4 alternate loops for the inner loop
Generated vector sse code for inner loop
Generated 6 prefetch instructions for this loop
Generated vector sse code for inner loop
o o o
2011 HPCMP User Group © Cray Inc.

June 20, 2011 221
0
500
1000
1500
2000
2500
0 50 100 150 200 250 300 350 400 450 500
M
F
L
O
P
S
Vector Length
CCE-Original - Fortran CCE-Restructured- Fortran
PGI-Original - Fortran PGI-Restructured - Fortran
2011 HPCMP User Group © Cray Inc.

Max Vector length doubled to 256 bit
Much cleaner instruction set
Result register is unique from the source registers
Old SSE instruction set always destroyed a source register
Floating point multiple-accumulate
A(1:4) = B(1:4)*C(1:4) + D(1:4) ! Now one instruction
Next gen of both AMD and Intel will have AVX
Vectors are becoming more important, not less
June 20, 2011 2222011 HPCMP User Group © Cray Inc.

June 20, 2011 2232011 HPCMP User Group © Cray Inc.

Cache blocking is a combination of strip mining and loop interchange, designed to increase data reuse.
Takes advantage of temporal reuse: re-reference array elements already referenced
Good blocking will take advantage of spatial reuse: work with the cache lines!
Many ways to block any given loop nest
Which loops get blocked?
What block size(s) to use?
Analysis can reveal which ways are beneficial
But trial-and-error is probably faster
June 20, 2011 2242011 HPCMP User Group © Cray Inc.

2D Laplacian
do j = 1, 8
do i = 1, 16
a = u(i-1,j) + u(i+1,j) &
- 4*u(i,j) &
+ u(i,j-1) + u(i,j+1)
end do
end do
Cache structure for this example:
Each line holds 4 array elements
Cache can hold 12 lines of u data
No cache reuse between outer loop iterations34679101213151830120
i=1
i=16
j=1
j=8
June 20, 2011 2252011 HPCMP User Group © Cray Inc.

Unblocked loop: 120 cache misses
Block the inner loop
do IBLOCK = 1, 16, 4
do j = 1, 8
do i = IBLOCK, IBLOCK + 3
a(i,j) = u(i-1,j) + u(i+1,j) &
- 2*u(i,j) &
+ u(i,j-1) + u(i,j+1)
end do
end do
end do
Now we have reuse of the “j+1” data
3467891011122080
i=1
i=13
j=1
j=8
i=5
i=9
June 20, 2011 2262011 HPCMP User Group © Cray Inc.

One-dimensional blocking reduced misses from 120 to 80
Iterate over 4×4 blocks
do JBLOCK = 1, 8, 4
do IBLOCK = 1, 16, 4
do j = JBLOCK, JBLOCK + 3
do i = IBLOCK, IBLOCK + 3
a(i,j) = u(i-1,j) + u(i+1,j) &
- 2*u(i,j) &
+ u(i,j-1) + u(i,j+1)
end do
end do
end do
end do
Better use of spatial locality (cache lines)34678910111213151617183060
i=1
i=13
j=1
j=5
i=5
i=9
June 20, 2011 2272011 HPCMP User Group © Cray Inc.

Matrix-matrix multiply (GEMM) is the canonical cache-blocking example
Operations can be arranged to create multiple levels of blocking
Block for register
Block for cache (L1, L2, L3)
Block for TLB
No further discussion here. Interested readers can see
Any book on code optimization Sun’s Techniques for Optimizing Applications: High Performance Computing contains a decent introductory discussion in
Chapter 8
Insert your favorite book here
Gunnels, Henry, and van de Geijn. June 2001. High-performance matrix multiplication algorithms for architectures with hierarchical memories. FLAME Working Note #4 TR-2001-22, The University of Texas at Austin, Department of Computer Sciences Develops algorithms and cost models for GEMM in hierarchical memories
Goto and van de Geijn. 2008. Anatomy of high-performance matrix multiplication. ACM Transactions on Mathematical Software 34, 3 (May), 1-25 Description of GotoBLAS DGEMM
June 20, 2011 2282011 HPCMP User Group © Cray Inc.

You’re doing it wrong.
Your block size is too small (too much loop overhead).
Your block size is too big (data is falling out of cache).
You’re targeting the wrong cache level (?)
You haven’t selected the correct subset of loops to block.
The compiler is already blocking that loop.
Prefetching is acting to minimize cache misses.
Computational intensity within the loop nest is very large, making blocking less important.
“I tried cache-blocking my code, but it didn’t help”
June 20, 2011 2292011 HPCMP User Group © Cray Inc.

Multigrid PDE solver
Class D, 64 MPI ranks
Global grid is 1024 × 1024 × 1024
Local grid is 258 × 258 × 258
Two similar loop nests account for >50% of run time
27-point 3D stencil
There is good data reuse along leading dimension, even without blocking
do i3 = 2, 257
do i2 = 2, 257
do i1 = 2, 257
! update u(i1,i2,i3)
! using 27-point stencil
end do
end do
end do
i1 i1+1i1-1
i2-1
i2
i2+1
i3-1
i3
i3+1
cache lines
June 20, 2011 2302011 HPCMP User Group © Cray Inc.

Block the inner two loops
Creates blocks extending along i3 direction
do I2BLOCK = 2, 257, BS2
do I1BLOCK = 2, 257, BS1
do i3 = 2, 257
do i2 = I2BLOCK, &
min(I2BLOCK+BS2-1, 257)
do i1 = I1BLOCK, &
min(I1BLOCK+BS1-1, 257)
! update u(i1,i2,i3)
! using 27-point stencil
end do
end do
end do
end do
end do
Block sizeMop/s/proces
s
unblocked 531.50
16 × 16 279.89
22 × 22 321.26
28 × 28 358.96
34 × 34 385.33
40 × 40 408.53
46 × 46 443.94
52 × 52 468.58
58 × 58 470.32
64 × 64 512.03
70 × 70 506.92June 20, 2011 Slide 2312011 HPCMP User Group © Cray Inc.

Block the outer two loops
Preserves spatial locality along i1 direction
do I3BLOCK = 2, 257, BS3
do I2BLOCK = 2, 257, BS2
do i3 = I3BLOCK, &
min(I3BLOCK+BS3-1, 257)
do i2 = I2BLOCK, &
min(I2BLOCK+BS2-1, 257)
do i1 = 2, 257
! update u(i1,i2,i3)
! using 27-point stencil
end do
end do
end do
end do
end do
Block sizeMop/s/proces
s
unblocked 531.50
16 × 16 674.76
22 × 22 680.16
28 × 28 688.64
34 × 34 683.84
40 × 40 698.47
46 × 46 689.14
52 × 52 706.62
58 × 58 692.57
64 × 64 703.40
70 × 70 693.87June 20, 2011 Slide 2322011 HPCMP User Group © Cray Inc.

June 20, 2011 2332011 HPCMP User Group © Cray Inc.

( 53) void mat_mul_daxpy(double *a, double *b, double *c, int rowa,
int cola, int colb)
( 54) {
( 55) int i, j, k; /* loop counters */
( 56) int rowc, colc, rowb; /* sizes not passed as arguments */
( 57) double con; /* constant value */
( 58)
( 59) rowb = cola;
( 60) rowc = rowa;
( 61) colc = colb;
( 62)
( 63) for(i=0;i<rowc;i++) {
( 64) for(k=0;k<cola;k++) {
( 65) con = *(a + i*cola +k);
( 66) for(j=0;j<colc;j++) {
( 67) *(c + i*colc + j) += con * *(b + k*colb + j);
( 68) }
( 69) }
( 70) }
( 71) }
mat_mul_daxpy:
66, Loop not vectorized: data dependency
Loop not vectorized: data dependency
Loop unrolled 4 times
C pointers don’t carry
the same rules as
Fortran Arrays.
The compiler has no
way to know whether
*a, *b, and *c
overlap or are
referenced differently
elsewhere.
The compiler must
assume the worst,
thus a false data
dependency.
C pointers
June 20, 2011 Slide 2342011 HPCMP User Group © Cray Inc.

( 53) void mat_mul_daxpy(double* restrict a, double* restrict b,
double* restrict c, int rowa, int cola, int colb)
( 54) {
( 55) int i, j, k; /* loop counters */
( 56) int rowc, colc, rowb; /* sizes not passed as arguments */
( 57) double con; /* constant value */
( 58)
( 59) rowb = cola;
( 60) rowc = rowa;
( 61) colc = colb;
( 62)
( 63) for(i=0;i<rowc;i++) {
( 64) for(k=0;k<cola;k++) {
( 65) con = *(a + i*cola +k);
( 66) for(j=0;j<colc;j++) {
( 67) *(c + i*colc + j) += con * *(b + k*colb + j);
( 68) }
( 69) }
( 70) }
( 71) }
C99 introduces the
restrict keyword,
which allows the
programmer to
promise not to
reference the
memory via another
pointer.
If you declare a
restricted pointer and
break the rules,
behavior is undefined
by the standard.
C pointers, restricted
June 20, 2011 Slide 2352011 HPCMP User Group © Cray Inc.

66, Generated alternate loop with no peeling - executed if loop count <= 24
Generated vector sse code for inner loop
Generated 2 prefetch instructions for this loop
Generated vector sse code for inner loop
Generated 2 prefetch instructions for this loop
Generated alternate loop with no peeling and more aligned moves -
executed if loop count <= 24 and alignment test is passed
Generated vector sse code for inner loop
Generated 2 prefetch instructions for this loop
Generated alternate loop with more aligned moves - executed if loop
count >= 25 and alignment test is passed
Generated vector sse code for inner loop
Generated 2 prefetch instructions for this loop
• This can also be achieved with the PGI safe pragma or –Msafeptrcompiler option or Pathscale –OPT:alias option
June 20, 20112011 HPCMP User Group © Cray Inc. Slide 236

June 20, 2011 Slide 2372011 HPCMP User Group © Cray Inc.

GNU malloc library malloc, calloc, realloc, free calls
Fortran dynamic variables
Malloc library system calls Mmap, munmap =>for larger allocations Brk, sbrk => increase/decrease heap
Malloc library optimized for low system memory use Can result in system calls/minor page faults
2011 HPCMP User Group © Cray Inc. 238June 20, 2011

Detecting “bad” malloc behavior Profile data => “excessive system time”
Correcting “bad” malloc behavior Eliminate mmap use by malloc Increase threshold to release heap memory
Use environment variables to alter malloc MALLOC_MMAP_MAX_ = 0 MALLOC_TRIM_THRESHOLD_ = 536870912
Possible downsides Heap fragmentation User process may call mmap directly User process may launch other processes
PGI’s –Msmartalloc does something similar for you at compile time
2011 HPCMP User Group © Cray Inc. 239June 20, 2011

Google created a replacement “malloc” library
“Minimal” TCMalloc replaces GNU malloc
Limited testing indicates TCMalloc as good or better than GNU malloc
Environment variables not required
TCMalloc almost certainly better for allocations in OpenMP parallel regions
There’s currently no pre-built tcmalloc for Cray XT/XE, but some users have successfully built it.
2011 HPCMP User Group © Cray Inc. 240June 20, 2011

Linux has a “first touch policy” for memory allocation
*alloc functions don’t actually allocate your memory
Memory gets allocated when “touched”
Problem: A code can allocate more memory than available
Linux assumed “swap space,” we don’t have any
Applications won’t fail from over-allocation until the memory is finally touched
Problem: Memory will be put on the core of the “touching” thread
Only a problem if thread 0 allocates all memory for a node
Solution: Always initialize your memory immediately after allocating it
If you over-allocate, it will fail immediately, rather than a strange place in your code
If every thread touches its own memory, it will be allocated on the proper socket
Slide 241June 20, 20112011 HPCMP User Group © Cray Inc.

This may help both compute and communication.
2011 HPCMP User Group © Cray Inc. 242June 20, 2011

Opterons support 4K, 2M, and 1G pages We don’t support 1G pages
4K pages are used by default
2M pages are more difficult to use, but…
Your code may run with fewer TLB misses (hence faster). The TLB can address more physical memory with 2M pages than
with 4K pages
The Gemini perform better with 2M pages than with 4K pages.
2M pages use less GEMINI resources than 4k pages (fewer bytes).
2432011 HPCMP User Group © Cray Inc. June 20, 2011

Link in the hugetlbfs library into your code ‘-lhugetlbfs’
Set the HUGETLB_MORECORE env in your run script.
Example : export HUGETLB_MORECORE=yes
Use the aprun option –m###h to ask for ### Meg of HUGE pages.
Example : aprun –m500h (Request 500 Megs of HUGE pages as available, use 4K pages thereafter)
Example : aprun –m500hs (Request 500 Megs of HUGE pages, if not available terminate launch)
Note: If not enough HUGE pages are available, the cost of filling the remaining with 4K pages may degrade performance.
2442011 HPCMP User Group © Cray Inc. June 20, 2011

June 20, 2011 2452011 HPCMP User Group © Cray Inc.

Short Message Eager Protocol
The sending rank “pushes” the message to the receiving rank Used for messages MPICH_MAX_SHORT_MSG_SIZE bytes or less Sender assumes that receiver can handle the message
Matching receive is posted - or - Has available event queue entries (MPICH_PTL_UNEX_EVENTS) and
buffer space (MPICH_UNEX_BUFFER_SIZE) to store the message
Long Message Rendezvous Protocol
Messages are “pulled” by the receiving rank Used for messages greater than MPICH_MAX_SHORT_MSG_SIZE bytes Sender sends small header packet with information for the receiver to pull
over the data Data is sent only after matching receive is posted by receiving rank
June 20, 2011 2462011 HPCMP User Group © Cray Inc.

MPI_RECV is posted prior to MPI_SEND call
MPI
Unexpected
Buffers
Unexpected
Msg Queue
Sender
RANK 0
Receiver
RANK 1
Eager
Short Msg ME
Incoming Msg
Rendezvous
Long Msg MEApp ME
Unexpected
Event Queue
Match Entries Posted by MPI
to handle Unexpected Msgs
STEP 3
Portals DMA PUT
STEP 2
MPI_SEND call
STEP 1
MPI_RECV call
Post ME to Portals
(MPICH_PTL_UNEX_EVENTS)
Other Event Queue
(MPICH_PTL_OTHER_EVENTS)
(MPICH_UNEX_BUFFER_SIZE)
SEASTAR
June 20, 2011 2472011 HPCMP User Group © Cray Inc.
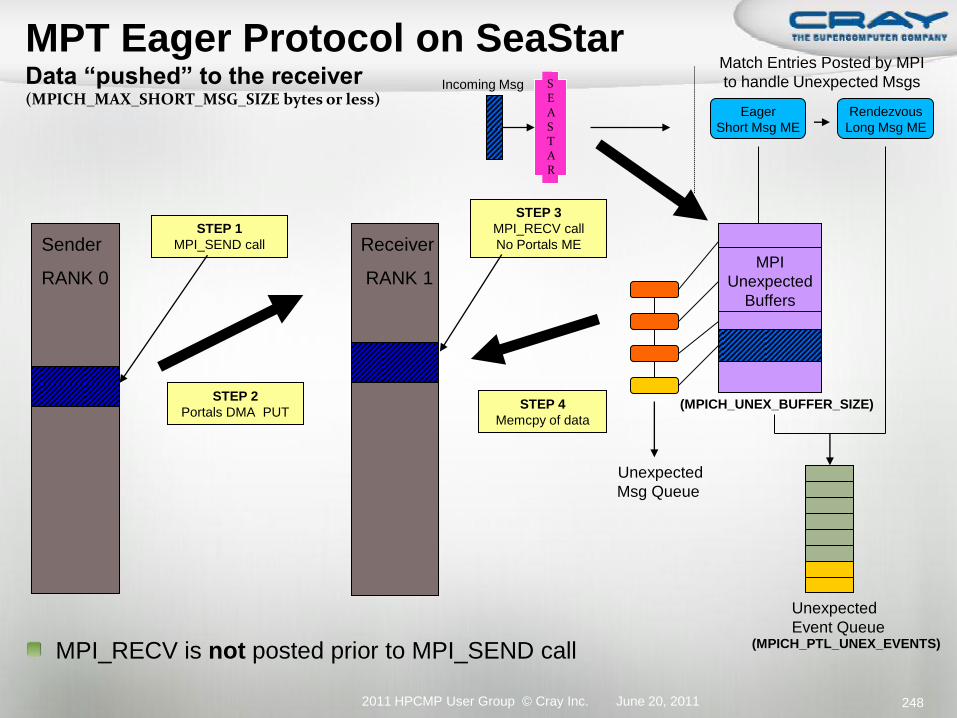
MPT Eager Protocol on SeaStarData “pushed” to the receiver(MPICH_MAX_SHORT_MSG_SIZE bytes or less)
MPI_RECV is not posted prior to MPI_SEND call
MPI
Unexpected
Buffers
Unexpected
Msg Queue
Sender
RANK 0
Receiver
RANK 1
Eager
Short Msg ME
Incoming Msg
Rendezvous
Long Msg ME
Unexpected
Event Queue
Match Entries Posted by MPI
to handle Unexpected Msgs
STEP 2
Portals DMA PUTSTEP 4
Memcpy of data
STEP 1
MPI_SEND call
STEP 3
MPI_RECV call
No Portals ME
SEASTAR
(MPICH_UNEX_BUFFER_SIZE)
(MPICH_PTL_UNEX_EVENTS)
June 20, 2011 2482011 HPCMP User Group © Cray Inc.

Data is not sent until MPI_RECV is issued
MPI
Unexpected
Buffers
Unexpected
Msg Queue
Sender
RANK 0
Receiver
RANK 1
Eager
Short Msg ME
Incoming Msg
Rendezvous
Long Msg ME
Unexpected
Event Queue
App ME
STEP 2
Portals DMA PUT
of Header
STEP 4
Receiver issues
GET request to
match Sender ME
STEP 5
Portals DMA of Data
Match Entries Posted by MPI
to handle Unexpected Msgs
STEP 1
MPI_SEND call
Portals ME created
STEP 3
MPI_RECV call
Triggers GET request
SEASTAR
June 20, 2011 2492011 HPCMP User Group © Cray Inc.

June 20, 2011 2502011 HPCMP User Group © Cray Inc.

The default ordering can be changed using the following environment variable:
MPICH_RANK_REORDER_METHOD
These are the different values that you can set it to:0: Round-robin placement – Sequential ranks are placed on the next node in the
list. Placement starts over with the first node upon reaching the end of the list.
1: SMP-style placement – Sequential ranks fill up each node before moving to the next.
2: Folded rank placement – Similar to round-robin placement except that each pass over the node list is in the opposite direction of the previous pass.
3: Custom ordering. The ordering is specified in a file named MPICH_RANK_ORDER.
When is this useful? Point-to-point communication consumes a significant fraction of program time and a
load imbalance detected
Also shown to help for collectives (alltoall) on subcommunicators (GYRO)
Spread out IO across nodes (POP)
June 20, 2011 2512011 HPCMP User Group © Cray Inc.

One can also use the CrayPat performance measurement tools to generate a suggested custom ordering.
Available if MPI functions traced (-g mpi or –O apa)
pat_build –O apa my_program
see Examples section of pat_build man page
pat_report options:
mpi_sm_rank_order
Uses message data from tracing MPI to generate suggested MPI rank order. Requires the program to be instrumented using the pat_build -gmpi option.
mpi_rank_order
Uses time in user functions, or alternatively, any other metric specified by using the -s mro_metric options, to generate suggested MPI rank order.
June 20, 2011 2522011 HPCMP User Group © Cray Inc.

module load xt-craypat
Rebuild your code
pat_build –O apa a.out
Run a.out+pat
pat_report –Ompi_sm_rank_order a.out+pat+…sdt/ > pat.report
Creates MPICH_RANK_REORDER_METHOD.x file
Then set env var MPICH_RANK_REORDER_METHOD=3 AND
Link the file MPICH_RANK_ORDER.x to MPICH_RANK_ORDER
Rerun code
June 20, 2011 2532011 HPCMP User Group © Cray Inc.

Table 1: Suggested MPI Rank Order
Eight cores per node: USER Samp per node
Rank Max Max/ Avg Avg/ Max Node
Order USER Samp SMP USER Samp SMP Ranks
d 17062 97.6% 16907 100.0% 832,328,820,797,113,478,898,600
2 17213 98.4% 16907 100.0% 53,202,309,458,565,714,821,970
0 17282 98.8% 16907 100.0% 53,181,309,437,565,693,821,949
1 17489 100.0% 16907 100.0% 0,1,2,3,4,5,6,7
•This suggests that
1. the custom ordering “d” might be the best
2. Folded-rank next best
3. Round-robin 3rd best
4. Default ordering last
June 20, 2011 2542011 HPCMP User Group © Cray Inc.

GYRO 8.0 B3-GTC problem with 1024 processes
Run with alternate MPI orderings Custom: profiled with with –O apa and used reordering file
MPICH_RANK_REORDER.d
Reorder method Comm. time
Default 11.26s
0 – round-robin 6.94s
2 – folded-rank 6.68s
d-custom from apa 8.03s
CrayPAT
suggestion
almost right!
June 20, 2011 2552011 HPCMP User Group © Cray Inc.

TGYRO 1.0
Steady state turbulent transport code using GYRO, NEO, TGLF components
ASTRA test case
Tested MPI orderings at large scale
Originally testing weak-scaling, but found reordering very useful
Reorder method
TGYRO wall time (min)
20480 40960 81920
Default 99m 104m 105m
Round-robin 66m 63m 72m
Huge win!
June 20, 2011 2562011 HPCMP User Group © Cray Inc.

June 20, 2011 2572011 HPCMP User Group © Cray Inc.

Time % | Time | Imb. Time | Imb. | Calls |Experiment=1
| | | Time % | |Group
| | | | | Function
| | | | | PE='HIDE'
100.0% | 1530.892958 | -- | -- | 27414118.0 |Total
|---------------------------------------------------------------------
| 52.0% | 796.046937 | -- | -- | 22403802.0 |USER
||--------------------------------------------------------------------
|| 22.3% | 341.176468 | 3.482338 | 1.0% | 19200000.0 |getrates_
|| 17.4% | 266.542501 | 35.451437 | 11.7% | 1200.0 |rhsf_
|| 5.1% | 78.772615 | 0.532703 | 0.7% | 3200000.0 |mcavis_new_looptool_
|| 2.6% | 40.477488 | 2.889609 | 6.7% | 1200.0 |diffflux_proc_looptool_
|| 2.1% | 31.666938 | 6.785575 | 17.6% | 200.0 |integrate_erk_jstage_lt_
|| 1.4% | 21.318895 | 5.042270 | 19.1% | 1200.0 |computeheatflux_looptool_
|| 1.1% | 16.091956 | 6.863891 | 29.9% | 1.0 |main
||====================================================================
| 47.4% | 725.049709 | -- | -- | 5006632.0 |MPI
||--------------------------------------------------------------------
|| 43.8% | 670.742304 | 83.143600 | 11.0% | 2389440.0 |mpi_wait_
|| 1.9% | 28.821882 | 281.694997 | 90.7% | 1284320.0 |mpi_isend_
|=====================================================================
June 20, 2011 2582011 HPCMP User Group © Cray Inc.

Time % | Time | Imb. Time | Imb. | Calls |Experiment=1
| | | Time % | |Group
| | | | | Function
| | | | | PE='HIDE'
100.0% | 1730.555208 | -- | -- | 16090113.8 |Total
|---------------------------------------------------------------------
| 76.9% | 1330.111350 | -- | -- | 4882627.8 |MPI
||--------------------------------------------------------------------
|| 72.1% | 1247.436960 | 54.277263 | 4.2% | 2389440.0 |mpi_wait_
|| 1.3% | 22.712017 | 101.212360 | 81.7% | 1234718.3 |mpi_isend_
|| 1.0% | 17.623757 | 4.642004 | 20.9% | 1.0 |mpi_comm_dup_
|| 1.0% | 16.849281 | 71.805979 | 81.0% | 1234718.3 |mpi_irecv_
|| 1.0% | 16.835691 | 192.820387 | 92.0% | 19999.2 |mpi_waitall_
||====================================================================
| 22.2% | 384.978417 | -- | -- | 11203802.0 |USER
||--------------------------------------------------------------------
|| 9.9% | 171.440025 | 1.929439 | 1.1% | 9600000.0 |getrates_
|| 7.7% | 133.599580 | 19.572807 | 12.8% | 1200.0 |rhsf_
|| 2.3% | 39.465572 | 0.600168 | 1.5% | 1600000.0 |mcavis_new_looptool_
|=====================================================================
|=====================================================================
June 20, 2011 2592011 HPCMP User Group © Cray Inc.

Differencing in the X direction
Differencing in the Y directionDifferencing in the Z direction
MPI Task K +1200
MPI Task K
MPI Task K-1200
MPI Task K +30
MPI Task K
MPI Task K-30
MPI Task K +1
MPI Task K
MPI Task K - 1
June 20, 2011 2602011 HPCMP User Group © Cray Inc.

Optimized mapping of the MPI tasks on the node
Still performs 72 communications, but now only 32 are off node
June 20, 2011 261
Code must perform one communication across each surface of a cube
12 cubes perform 72 communications, 63 of which go “off node”
2011 HPCMP User Group © Cray Inc.

Application data is in
a 3D space, X x Y x Z.
Communication is
nearest-neighbor.
Default ordering
results in 12x1x1
block on each node.
A custom reordering
is now generated:
3x2x2 blocks per
node, resulting in
more on-node
communication
Rank Reordering Case Study
June 20, 2011 2622011 HPCMP User Group © Cray Inc.

June 20, 2011 Slide 263
% pat_report -O mpi_sm_rank_order -s rank_grid_dim=8,6 ...
Notes for table 1:
To maximize the locality of point to point communication,
specify a Rank Order with small Max and Avg Sent Msg Total Bytes
per node for the target number of cores per node.
To specify a Rank Order with a numerical value, set the environment
variable MPICH_RANK_REORDER_METHOD to the given value.
To specify a Rank Order with a letter value 'x', set the environment
variable MPICH_RANK_REORDER_METHOD to 3, and copy or link the file
MPICH_RANK_ORDER.x to MPICH_RANK_ORDER.
Table 1: Sent Message Stats and Suggested MPI Rank Order
Communication Partner Counts
Number Rank
Partners Count Ranks
2 4 0 5 42 47
3 20 1 2 3 4 ...
4 24 7 8 9 10 ...
2011 HPCMP User Group © Cray Inc.

June 20, 2011 Slide 264
Four cores per node: Sent Msg Total Bytes per node
Rank Max Max/ Avg Avg/ Max Node
Order Total Bytes SMP Total Bytes SMP Ranks
g 121651200 73.9% 86400000 62.5% 14,20,15,21
h 121651200 73.9% 86400000 62.5% 14,20,21,15
u 152064000 92.4% 146534400 106.0% 13,12,10,4
1 164505600 100.0% 138240000 100.0% 16,17,18,19
d 164505600 100.0% 142387200 103.0% 16,17,19,18
0 224640000 136.6% 207360000 150.0% 1,13,25,37
2 241920000 147.1% 207360000 150.0% 7,16,31,40
2011 HPCMP User Group © Cray Inc.

June 20, 2011 Slide 265
% $CRAYPAT_ROOT/sbin/grid_order -c 2,2 -g 8,6
# grid_order -c 2,2 -g 8,6
# Region 0: 0,0 (0..47)
0,1,6,7
2,3,8,9
4,5,10,11
12,13,18,19
14,15,20,21
16,17,22,23
24,25,30,31
26,27,32,33
28,29,34,35
36,37,42,43
38,39,44,45
40,41,46,47
This script will also handle the case that cells do not
evenly partition the grid.
2011 HPCMP User Group © Cray Inc.

June 20, 2011 Slide 267
X X o o
X X o o
o o o o
o o o o
Nodes marked X heavily use a shared resource
If memory bandwidth, scatter the X's
If network bandwidth to others, again scatter
If network bandwidth among themselves, concentrate
2011 HPCMP User Group © Cray Inc.

June 20, 20112011 HPCMP User Group © Cray Inc. 268

Call mpi_send(a, 10, …)Call mpi_send(b, 10, …)Call mpi_send(c, 10, …)Call mpi_send(d, 10, …)
Copy messages into a contiguous buffer and send once
Sendbuf(1:10) = a(1:10)Sendbuf(11:20) = b(1:10)Sendbuf(21:30) = c(1:10)Sendbuf(31:40) = d(1:10)
Call mpi_send(sendbuf, 40, …)
Effectiveness of this optimization is machine dependent
June 20, 2011 269
Each message incurs latency and library overhead
Latency and library overhead incurred only once
2011 HPCMP User Group © Cray Inc.

Most collectives have been tuned to take advantage of algorithms and hardware to maximize performance
MPI_ALLTOALL Reorder communications to spread traffic around the network efficiently
MPI_BCAST/_REDUCE/_ALLREDUCE Use tree based algorithms to reduce the number of messages.
Needs to strike a balance between width and depth of tree.
MPI_GATHER Use tree algorithm to reduce resource contention aggregate messages.
You don’t want to have to reinvent the wheel
June 20, 2011 2702011 HPCMP User Group © Cray Inc.

MPI_ALLTOALL
Message size decreases as number of ranks grows
Number of messages is O(num_ranks2)
Very difficult to scale to very high core counts
MPI_BCAST/_REDUCE/_ALLREDUCE/_BARRIER
All are O(log (num_ranks))
All represent global sync points
Expose ANY load imbalance in the code
Expose ANY “jitter” induced by the OS or other services
MPI_GATHER
Many-to-one
The greater the frequency of collectives, the harder it will be to scale
June 20, 2011 2712011 HPCMP User Group © Cray Inc.

June 20, 2011 2722011 HPCMP User Group © Cray Inc.

Filesystem
Lustre, GPFS, and Panasas are “parallel filesystems”
I/O operations are broken down to basic units and distributed to multiple endpoints
Spreading out operations in this way can greatly improve performance at large processor counts
Just as a problem gets partitioned to multiple processors, I/O operations can be done in parallel
MPI-IO is a standard API for doing parallel I/O operations
By performing I/O operations in parallel, an application can reduce I/O bottlenecks and take advantage of parallel filesystems
HDF5, NetCDF, and ADIOS all provide parallel I/O in a portable file format
Program
June 20, 2011 2732011 HPCMP User Group © Cray Inc.

To maximize I/O performance, parallel filesystems Break I/O operations into chunks, much like inodes on standard filesystems,
which get distributed among I/O servers
Provide a means of controlling how much concurrency to use for a given file
Make the distributed nature of the data invisible to the program/programmer
File metadata may be distributed (GPFS) or centralized (Lustre)
In order to take advantage of a parallel filesystem, a user must Ensure that multiple processes are sharing I/O duties, one process is incapable
of saturating the filesystem
Prevent multiple processes from using the same “chunk” simultaneously (more important with writes)
Choose a concurrency that is “distributed enough” without spreading data too thin to be effective (ideally, 1 process shouldn’t need to access several I/O servers)
June 20, 2011 2742011 HPCMP User Group © Cray Inc.

I/O is simply data migration.
Memory Disk
I/O is a very expensive operation.
Interactions with data in memory and on disk.
Must get the kernel involved
How is I/O performed?
I/O Pattern
Number of processes and files.
File access characteristics.
Where is I/O performed?
Characteristics of the computational system.
Characteristics of the file system.
275 2011 HPCMP User Group © Cray Inc.June 20, 2011

There is no “One Size Fits All” solution to the I/O problem.
Many I/O patterns work well for some range of parameters.
Bottlenecks in performance can occur in many locations. (Application and/or File system)
Going to extremes with an I/O pattern will typically lead to problems.
276 2011 HPCMP User Group © Cray Inc.June 20, 2011

277 2011 HPCMP User Group © Cray Inc.
The best performance comes from situations when the data is accessed contiguously in memory and on disk.
Facilitates large operations and minimizes latency.
Commonly, data access is contiguous in memory but noncontiguous on disk or vice versa. Usually to reconstruct a global data structure via parallel I/O.
Memory Disk
Memory Disk
June 20, 2011

Spokesperson
One process performs I/O.
Data Aggregation or Duplication
Limited by single I/O process.
Pattern does not scale.
Time increases linearly with amount of data.
Time increases with number of processes.
278 2011 HPCMP User Group © Cray Inc.
Disk
June 20, 2011

File per process
All processes perform I/O to individual files.
Limited by file system.
Pattern does not scale at large process counts.
Number of files creates bottleneck with metadata operations.
Number of simultaneous disk accesses creates contention for file system resources.
279 2011 HPCMP User Group © Cray Inc.
Disk
June 20, 2011

Shared File
Each process performs I/O to a single file which is shared.
Performance
Data layout within the shared file is very important.
At large process counts contention can build for file system resources.
280 2011 HPCMP User Group © Cray Inc.
Disk
June 20, 2011

Subset of processes which perform I/O.
Aggregation of a group of processes data.
Serializes I/O in group.
I/O process may access independent files.
Limits the number of files accessed.
Group of processes perform parallel I/O to a shared file.
Increases the number of shared files to increase file system usage.
Decreases number of processes which access a shared file to decrease file system contention.
281 2011 HPCMP User Group © Cray Inc.June 20, 2011

128 MB per file and a 32 MB Transfer size
0
2000
4000
6000
8000
10000
12000
0 1000 2000 3000 4000 5000 6000 7000 8000 9000
Wri
te (
MB
/s)
Processes or Files
File Per ProcessWrite Performance
1 MB Stripe
32 MB Stripe
282 2011 HPCMP User Group © Cray Inc.June 20, 2011

32 MB per process, 32 MB Transfer size and Stripe size
0
1000
2000
3000
4000
5000
6000
7000
8000
0 1000 2000 3000 4000 5000 6000 7000 8000 9000
Wri
te (
MB
/s)
Processes
Single Shared FileWrite Performance
POSIX
MPIIO
HDF5
283 2011 HPCMP User Group © Cray Inc.June 20, 2011

Lustre
Minimize contention for file system resources.
A process should not access more than one or two OSTs.
Performance
Performance is limited for single process I/O.
Parallel I/O utilizing a file-per-process or a single shared file is limited at large scales.
Potential solution is to utilize multiple shared file or a subset of processes which perform I/O.
284 2011 HPCMP User Group © Cray Inc.June 20, 2011
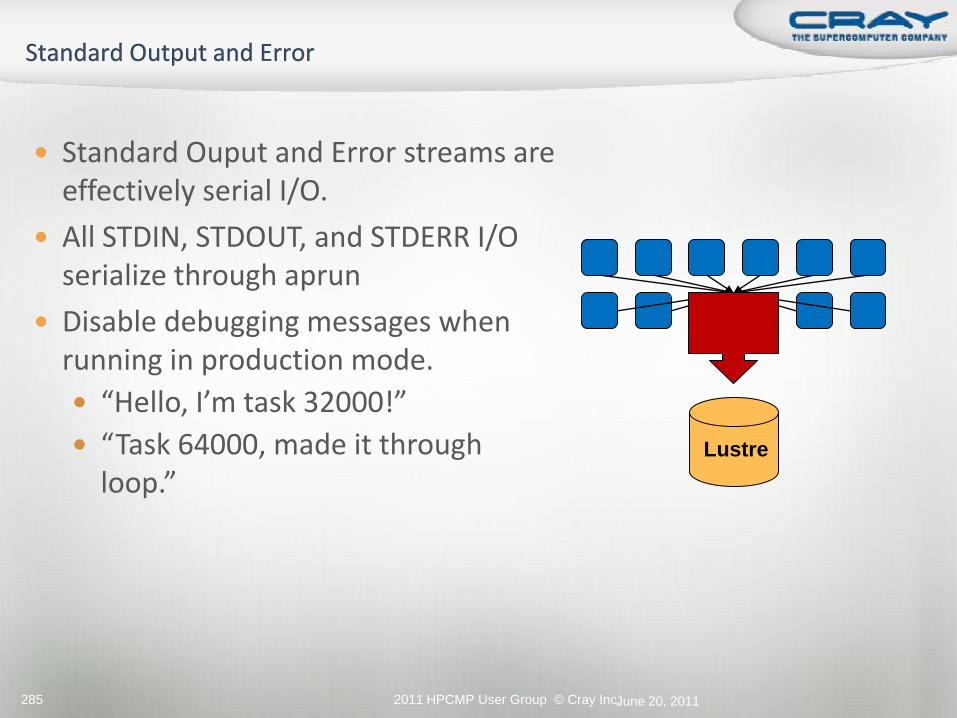
Standard Ouput and Error streams are effectively serial I/O.
All STDIN, STDOUT, and STDERR I/O serialize through aprun
Disable debugging messages when running in production mode.
“Hello, I’m task 32000!”
“Task 64000, made it through loop.”
285 2011 HPCMP User Group © Cray Inc.
Lustre
June 20, 2011
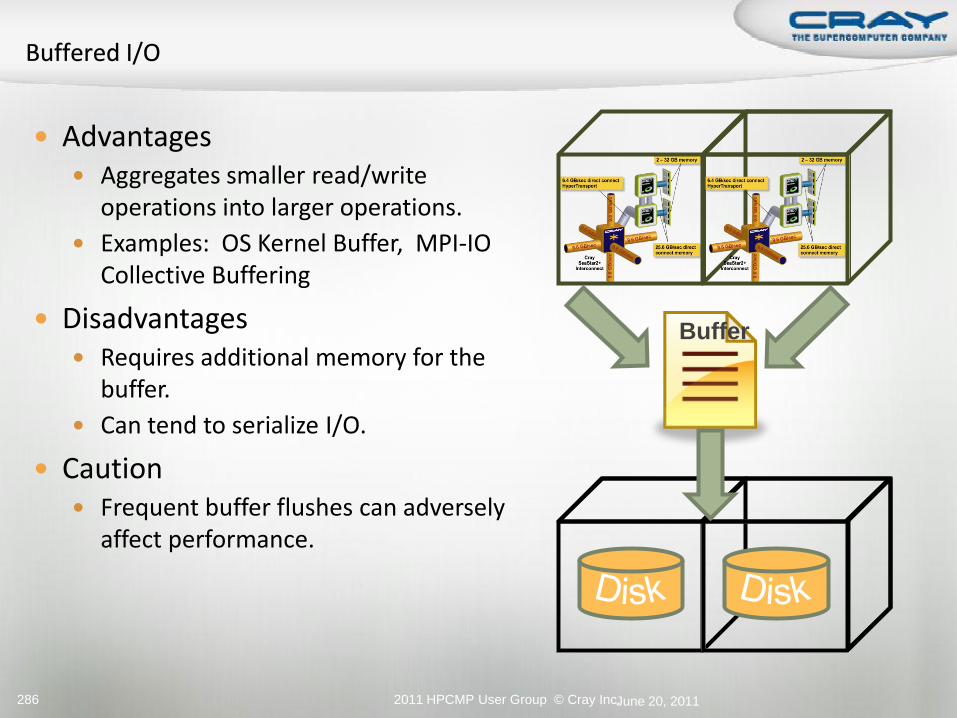
Advantages Aggregates smaller read/write
operations into larger operations.
Examples: OS Kernel Buffer, MPI-IO Collective Buffering
Disadvantages Requires additional memory for the
buffer.
Can tend to serialize I/O.
Caution Frequent buffer flushes can adversely
affect performance.
286 2011 HPCMP User Group © Cray Inc.
Buffer
June 20, 2011

If an application does extremely small, irregular I/O, explicitly buffering may improve performance.
A post processing application writes a 1GB file.
This case study is an extreme example.
This occurs from one writer, but occurs in many small write operations.
Takes 1080 s (~ 18 minutes) to complete.
IOBUF was utilized to intercept these writes with 64 MB buffers.
Takes 4.5 s to complete. A 99.6% reduction in time.
File "ssef_cn_2008052600f000"
Calls Seconds Megabytes Megabytes/sec Avg Size
Open 1 0.001119
Read 217 0.247026 0.105957 0.428931 512
Write 2083634 1.453222 1017.398927 700.098632 512
Close 1 0.220755
Total 2083853 1.922122 1017.504884 529.365466 512
Sys Read 6 0.655251 384.000000 586.035160 67108864
Sys Write 17 3.848807 1081.145508 280.904052 66686072
Buffers used 4 (256 MB)
Prefetches 6
Preflushes 15
287 2011 HPCMP User Group © Cray Inc.
Lustre
June 20, 2011

Writing a big-endian binary file with compiler flag byteswapio
File “XXXXXX"
Calls Megabytes Avg Size
Open 1
Write 5918150 23071.28062 4088
Close 1
Total 5918152 23071.28062 4088
Writing a little-endian binaryFile “XXXXXX"
Calls Megabytes Avg Size
Open 1
Write 350 23071.28062 69120000
Close 1
Total 352 23071.28062 69120000
288 2011 HPCMP User Group © Cray Inc.June 20, 2011

MPI-IO allows multiple MPI processes to access the same file in a distributed manner
Like other MPI operations, it’s necessary to provide a data type for items being written to the file (may be a derived type)
There are 3 ways to declare the “file position”
Explicit offset: each operation explicitly declares the necessary file offset
Individual File Pointers: Each process has its own unique handle to the file
Shared File Pointers: The MPI library maintains 1 file pointer and determines how to handle parallel access (often via serialization)
For each file position type, there are 2 “coordination” patterns
Non-collective: Each process acts on its own behalf
Collective: The processes coordinate, possibly allowing the library to make smart decisions on how to access the filesystem
MPI-IO allows the user to provide “hints” to improve I/O performance. Often I/O performance can be improved via hints about the filesystem or problem-specific details
June 20, 2011 2892011 HPCMP User Group © Cray Inc.

int mode, ierr;
char tmps[24];
MPI_File fh;
MPI_Info info;
MPI_Status status;
mode = MPI_MODE_CREATE|MPI_MODE_RDWR;
MPI_Info_create(&info);
MPI_File_open(comm, "output/test.dat", mode, info, &fh);
MPI_File_set_view(fh, commrank*iosize, MPI_DOUBLE, MPI_DOUBLE, "native",
info);
MPI_File_write_all(fh, dbuf, iosize/sizeof(double), MPI_DOUBLE, &status);
MPI_File_close(&fh);
Open a file across all ranks as read/write. Hints can be set between
MPI_Info_create and MPI_File_open.
Set the “view” (offset) for each rank.
Collectively write from all ranks.
Close the file from all ranks.
June 20, 2011 2902011 HPCMP User Group © Cray Inc.

Several parallel libraries are available to provide a portable, metadata-rich file format
On Cray machines, it’s possible to set MPI-IO hints in your environment to improve out-of-the-box performance
HDF5 (http://www.hdfgroup.org/HDF5/)
Has long supported parallel file access
Currently in version 1.8
NetCDF (http://www.unidata.ucar.edu/software/netcdf/)
Multiple parallel implementations of NetCDF exist
Beginning with version 4.0, HDF5 is used under the hood to provide native support for parallel file access.
Currently inversion 4.0.
ADIOS ( http://adiosapi.org)
Fairly young library in development by ORNL, GA Tech, and others
Has a native file format, but also supports POSIX, NetCDF, HDF5, and other file formats
Version 1.0 was released at SC09.
June 20, 2011 2912011 HPCMP User Group © Cray Inc.

Parallel Filesystems Minimize contention for file system resources.
A process should not access more than one or two OSTs.
Ideally I/O Buffers and Filesystem “Chunk” sizes should match evenly to avoid locking
Performance Performance is limited for single process I/O.
Parallel I/O utilizing a file-per-process or a single shared file is limited at large scales.
Potential solution is to utilize multiple shared file or a subset of processes which perform I/O.
Large buffer will generally perform best
292 2011 HPCMP User Group © Cray Inc.June 20, 2011

Load the IOBUF module:
% module load iobuf
Relink the program. Set the IOBUF_PARAMS environment variable as needed.
% setenv IOBUF_PARAMS='*:verbose‘
Execute the program.
IOBUF has a large number of options for tuning behavior from file to file. See man iobuf for details.
May significantly help codes that write a lot to stdout or stderr.
June 20, 20112011 HPCMP User Group © Cray Inc. 293

A particular code both reads and writes a 377 GB file. Runs on 6000 cores.
Total I/O volume (reads and writes) is 850 GB.
Utilizes parallel HDF5
Default Stripe settings: count 4, size 1M, index -1.
1800 s run time (~ 30 minutes)
Stripe settings: count -1, size 1M, index -1.
625 s run time (~ 10 minutes)
Results
66% decrease in run time.
294 2011 HPCMP User Group © Cray Inc.
Lustre
June 20, 2011

Included in the Cray MPT library.
Environmental variable used to help MPI-IO optimize I/O performance.
MPICH_MPIIO_CB_ALIGN Environmental Variable. (Default 2)
MPICH_MPIIO_HINTS Environmental Variable
Can set striping_factor and striping_unit for files created with MPI-IO.
If writes and/or reads utilize collective calls, collective buffering can be utilized (romio_cb_read/write) to approximately stripe align I/O within Lustre.
295 2011 HPCMP User Group © Cray Inc.June 20, 2011

MPI-IO API , non-power-of-2 blocks and transfers, in this case blocks and
transfers both of 1M bytes and a strided access pattern. Tested on an
XT5 with 32 PEs, 8 cores/node, 16 stripes, 16 aggregators, 3220
segments, 96 GB file
0
200
400
600
800
1000
1200
1400
1600
1800
MB
/Sec
June 20, 2011 2962011 HPCMP User Group © Cray Inc.

MPI-IO API , non-power-of-2 blocks and transfers, in this case blocks and
transfers both of 10K bytes and a strided access pattern. Tested on an
XT5 with 32 PEs, 8 cores/node, 16 stripes, 16 aggregators, 3220
segments, 96 GB file
MB
/Sec
0
20
40
60
80
100
120
140
160
June 20, 2011 2972011 HPCMP User Group © Cray Inc.

On 5107 PEs, and by application design, a subset of the Pes(88), do the
writes. With collective buffering, this is further reduced to 22 aggregators
(cb_nodes) writing to 22 stripes. Tested on an XT5 with 5107 Pes, 8
cores/node
MB
/Sec
0
500
1000
1500
2000
2500
3000
3500
4000
June 20, 2011 2982011 HPCMP User Group © Cray Inc.
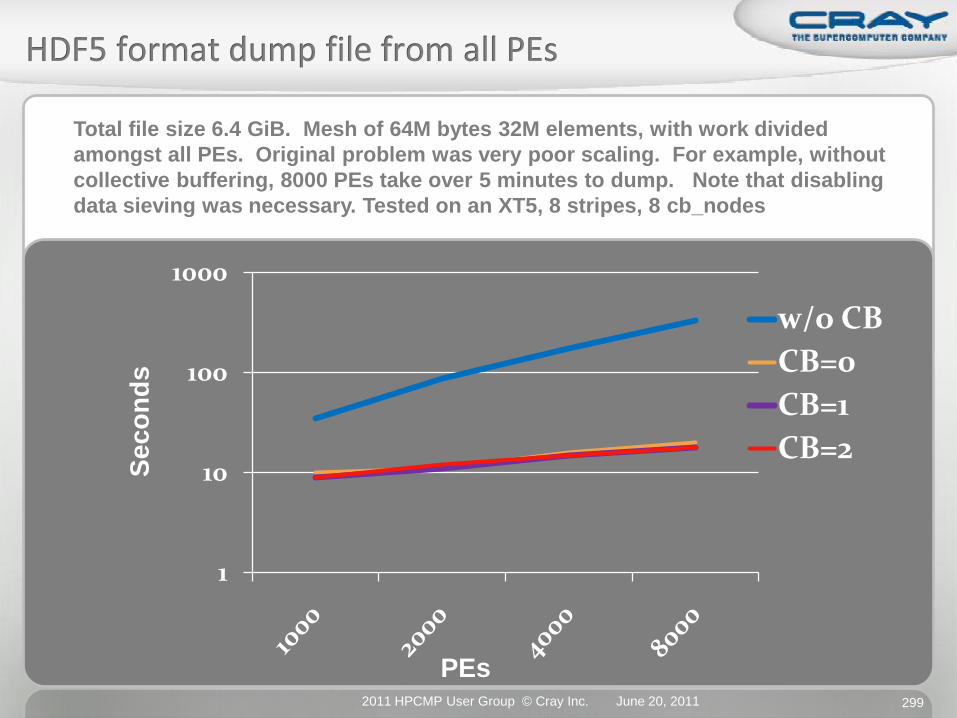
Total file size 6.4 GiB. Mesh of 64M bytes 32M elements, with work divided
amongst all PEs. Original problem was very poor scaling. For example, without
collective buffering, 8000 PEs take over 5 minutes to dump. Note that disabling
data sieving was necessary. Tested on an XT5, 8 stripes, 8 cb_nodes
Se
co
nd
s
PEs
1
10
100
1000
w/o CB
CB=0
CB=1
CB=2
June 20, 2011 2992011 HPCMP User Group © Cray Inc.

Do not open a lot of files all at once (Metadata Bottleneck)
Use a simple ls (without color) instead of ls -l (OST Bottleneck)
Remember to stripe files
Small, individual files => Small stripe counts
Large, shared files => Large stripe counts
Never set an explicit starting OST for your files (Filesystem Balance)
Open Files as Read-Only when possible
Limit the number of files per directory
Stat files from just one processes
Stripe-align your I/O (Reduces Locks)
Read small, shared files once and broadcast the data (OST Contention)
June 20, 2011 3002011 HPCMP User Group © Cray Inc.

Adaptable IO System (ADIOS)
http://www.olcf.ornl.gov/center-projects/adios/
“Optimizing MPI-IO for Applications on Cray XT System” (CrayDoc S-0013-10)
“A Pragmatic Approach to Improving the Large-scale Parallel I/O Performance of Scientic Applications.” Crosby, et al. (CUG 2011)
June 20, 20112011 HPCMP User Group © Cray Inc. 301

June 20, 2011 3022011 HPCMP User Group © Cray Inc.

June 20, 2011 3032011 HPCMP User Group © Cray Inc.


















