

HPC in linguistic research
25
-
Upload
benjamin-morton -
Category
Documents
-
view
34 -
download
0
description
HPC in linguistic research. Andrew Meade University Of Reading [email protected]. HPC use in linguistic research. Linguistic and biological models Phylogenies Linguistic data Models of evolution Parallelism Scaling Results On going work Key challenges. - PowerPoint PPT Presentation
Transcript of HPC in linguistic research

HPC use in linguistic research• Linguistic and biological models• Phylogenies • Linguistic data• Models of evolution• Parallelism• Scaling• Results• On going work• Key challenges

Linguistic and biological systems
Attribute Genetics Linguistics
Discrete units nucleotides, codons, genes, individuals
words, grammar, syntax
Replication transcription teaching, learning,imitation
Dominant mode(s) of inheritance parent-offspring, clonal parent-offspring, peer
groups, teaching
Horizontal transmission many mechanisms borrowing
Mutation many mechanisms SNP’s, mobile DNA,
mistakes, vowel shifts, innovation
Selection fitness differences among alleles ?

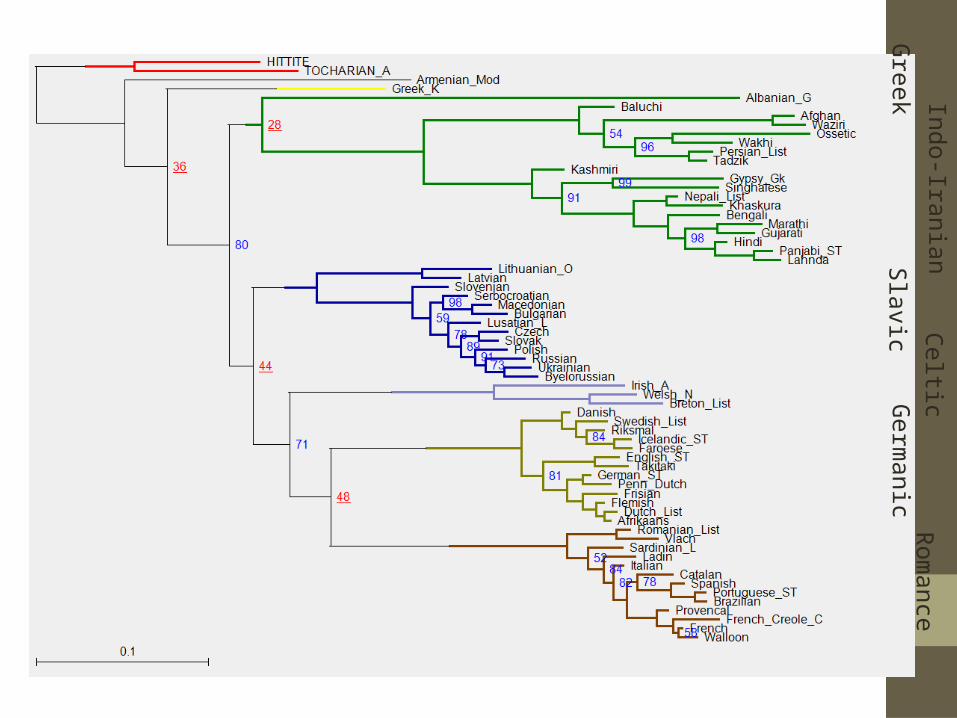
Inferring evolutionary histories form linguistic data• Evolutionary histories, phylogenies• Tools for understand evolution• Depicts relationships between languages• Identify groups which share a common ancestor• Calculate timing events • Account for lack of independence in the data
• Inferred from data, taken from different languages • Using an explicate statistical model of evolution • Problem is NP-hard, growth is a double factorial. • Markov chain Monte Carlo search methods, heuristic search,
hill climber • Product of Data + Model
Gre
ek
Ind
o-Ira
nia
n
Sla
vic
Germ
anic
Celtic
Rom
ance

The Data• Swadesh list, Morris Swadesh 1940, onwards
• 200 meaning, present in all languages (all most)
• Chosen to be stable, slowly evolving and resistant to borrowing
• Some what of a language “gene”


Cognate classes• Word with a common evolutionary ancestry and meaning
EnglishFish
DanishFisk
DutchVisch
Fish Ryba
CzechRyba
Russian Ryba
BulgarianRiba
23 other languages34other languages

Data coding, Cognates • Cognates, words and meaning what are derived from a
common ancestor• Languages evolve by a processes of descent with modification
English when water German wann wasser French quand eau Italian quando acqua Greek qote nero Hittite kuwapi watar
English 1 1 0 0
German 1 1 0 0
French 1 0 1 0
Italian 1 0 1 0
Greek 1 0 0 1
Hittite 1 1 0 0
“Water”3 cognates
“When” 1 cognate

Continuous-time Markov Model
Q01
0Non cognate
1Cognate
Q10
Q01 Rate at which cognates are gainedQ10 Rate at which cognates are lost
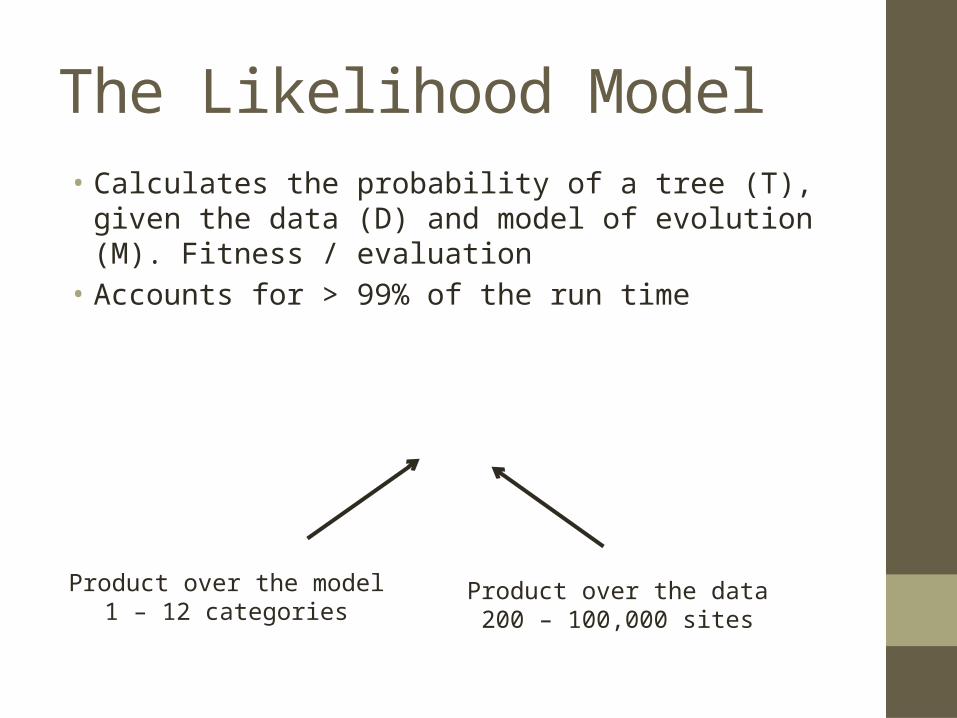
The Likelihood Model• Calculates the probability of a tree (T), given the data (D) and
model of evolution (M). Fitness / evaluation • Accounts for > 99% of the run time
Product over the model1 – 12 categories
Product over the data200 – 100,000 sites

Level of parallelism
Data – Analysis of multiple datasets (3-5)
Model – Test a range of models (10-20)
Run – Stochastic process multiple runs (5-10)
Code – individual run can still take years
Triv
ially
par
alle
l

The problem• 2003 – 16 taxa, 125 sites, 1 x model
• 2005 – 87 taxa, 2450 sites, 4 x model
• 2007 – 400 taxa, 34,440 sites, 100 x model
• Complexity 700,000x, 5-6 order of magnitude
• 4.8 years per run, typically 5 publication quality runs + 10 model tests
• 4.8 years < attention span of academics• results are required in days

Parallel method 1Distribute the data (MPI)
Cognates
Lang
uage
s
Data
Core 1 Core 2 Core 3
0 1 1
0 1 1
0 1 0
1 1 0
1 1 1
1 0 1
0 0 1
0 0 1
1 0 1
1 0 1
0 0 0
1 0 1
1 0 1
1 0 1
0 0 1
0 0 1
1 1 1
1 0 0
1 0 0
1 0 0
……………………..……………..
……………………..……………..
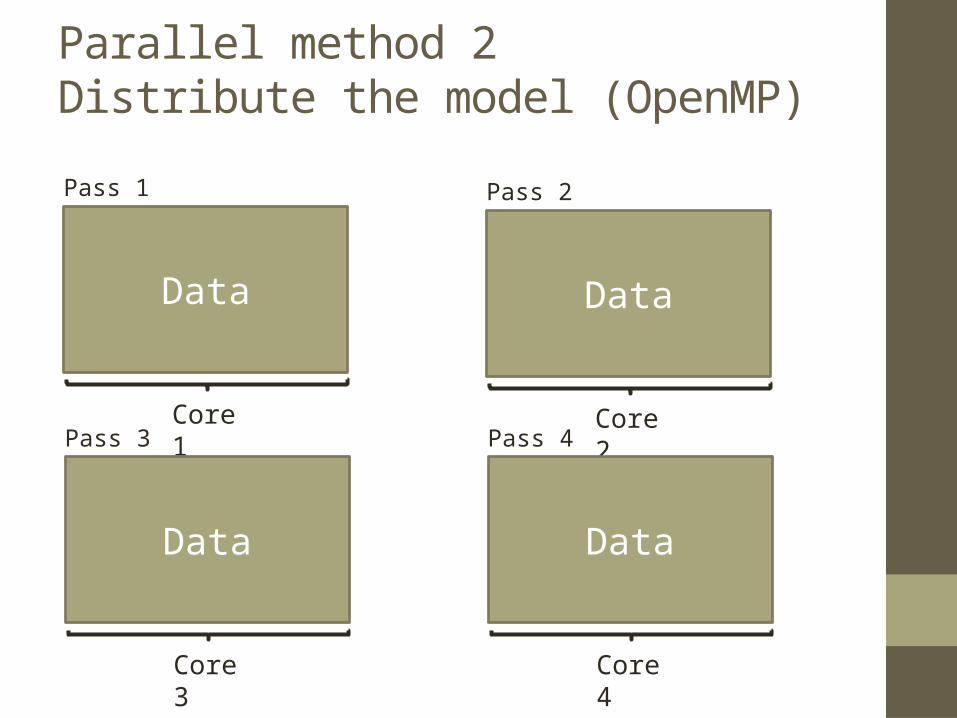
Parallel method 2 Distribute the model (OpenMP)
Data
Core 1
Pass 1
Data
Core 2
Pass 2
Data
Core 3
Pass 3
Data
Core 4
Pass 4

Distribute the data and the model (MPI + OpenMP)
Data
Core 1
Pass 1
Core 2
Data
Core 3
Pass 2
Core 4
Data
Core 5
Pass 3
Core 6
Data
Core 7
Pass 4
Core 8

Cores
Seco
nds
- log
10
Cores
Effici
ency
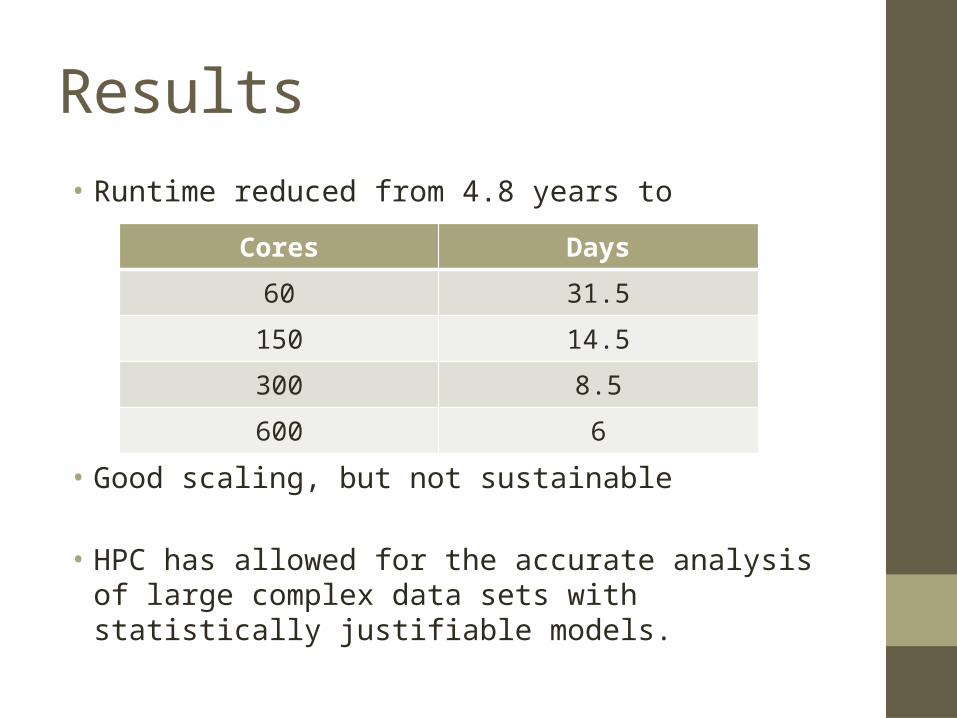
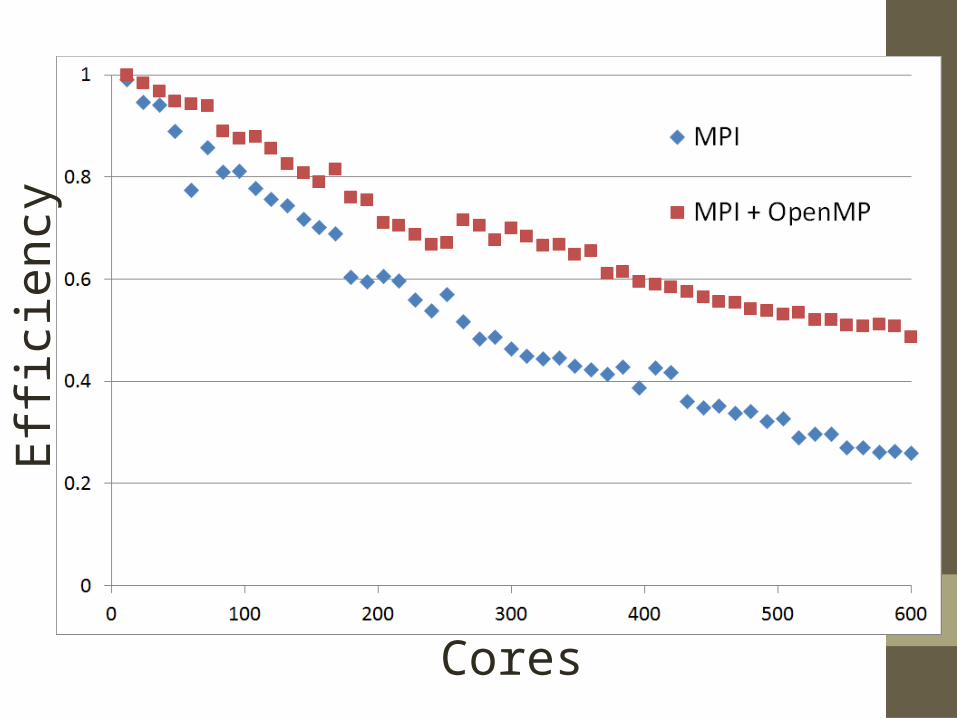
Results• Runtime reduced from 4.8 years to
• Good scaling, but not sustainable
• HPC has allowed for the accurate analysis of large complex data sets with statistically justifiable models.
Cores Days60 31.5
150 14.5300 8.5600 6

Current work• Phoneme data• Modelling sound utterances
• Better resolution than cogency data• Relevant linguistics patterns are emerging• 120 phonemes, 2 cogency judgments • Another 3 order of magnitude complexity
• Accelerator implementation CUDA / OpenCL
Language Word Cogency PhonemeEnglish Fish 1 FishDanish Fisk 1 Fisk

Scalable computing• Last 10 years, 5-6 order of magnate increase in complexity
• Reasonably scalable code redesign needed.
• Need to change the how not the what• What – statistical framework, realistic models• How – algorithm, language, parallelisation method, hardware
• Scalable algorithms
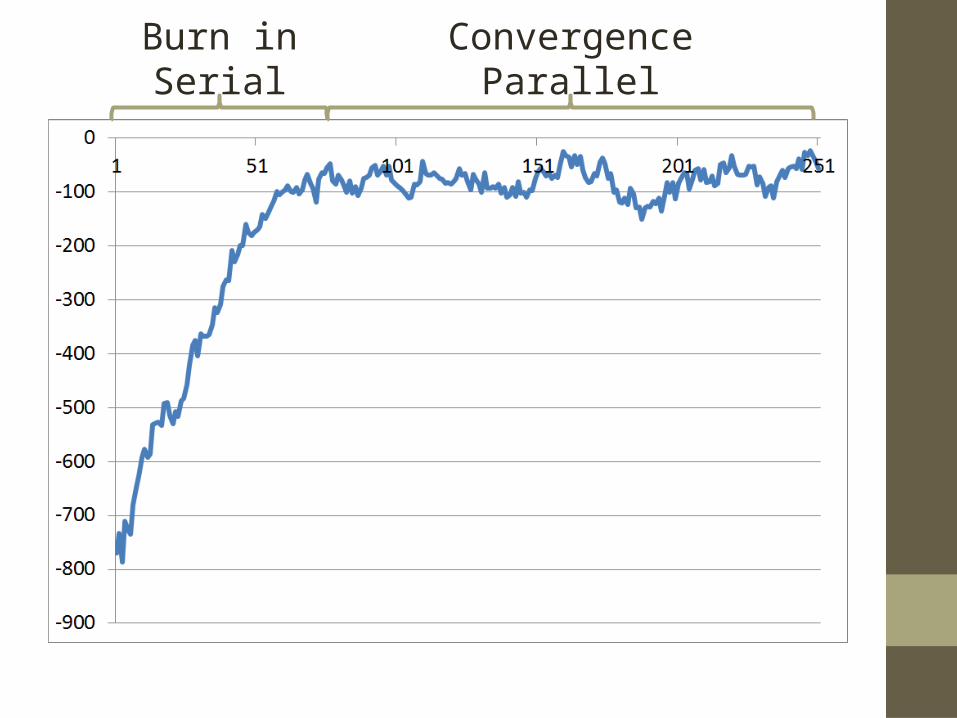
Burn inSerial
ConvergenceParallel
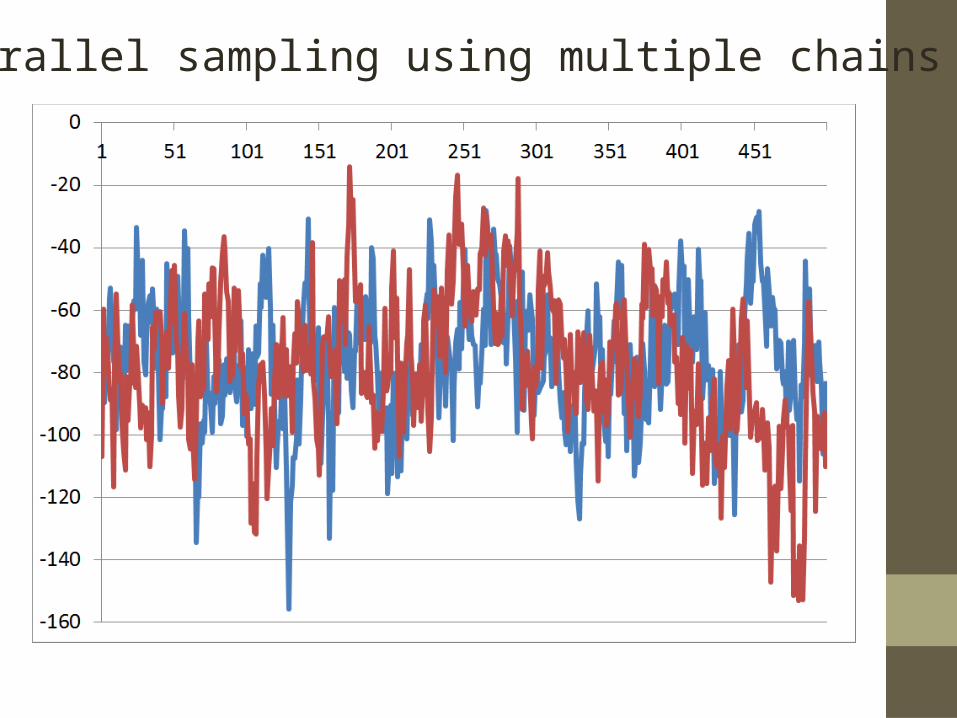
Parallel sampling using multiple chains

Key challenges• Computing is a rate limiting step• Trending water / drowning• Widening gap between computing power and data models complexity• Data set size and model complexity restricted• 20-30 year old methods, which are less accurate and non statistical are
returning
• Connecting researchers with results not HPC
• HPC is a nuisance in science• Steep learning curve• High cost. Hardware, running costs and personnel• Access and flexibility• Not one off activity, thousands of data sets are produced each year, 3000+
published in 2011

AcknowledgmentsMark Pagel


















