
Graph Algorithms in Bioinformatics - UCSD CSE - Bioinformatics

How Bioinformatics HelpedReveal the Human Metabolome
David WishartUniversity of Alberta, Edmonton, Canada
InCoB 2007, Hong Kong Aug. 28, 2007

Inspiration for the Title

Outline
• Metabolomics - Backgrounder
• The Human Metabolome Project (HMP)
• Bioinformatics Challenges & the HMP
• HMP Resources
• Applications
• Conclusion & the Future

The Pyramid Of Life
35,000 Genes35,000 Genes
3500 Enzymes3500 Enzymes
3000 Chemicals
Metabolomics
Proteomics
Genomics
(the human metabolome project)
(the human proteome project)
(the human genome project)

Small Molecules Count…
• >95% of all diagnostic clinical assays test forsmall molecules
• 89% of all known drugs are small molecules
• 50% of all drugs are derived from pre-existing metabolites
• 30% of identified genetic disorders involvediseases of small molecule metabolism
• Metabolites serve as cofactors and signalingmolecules to 1000’s of proteins

Metabonomics & Metabolomics
• Metabonomics:The quantitative measurement
of the time-related “total” metabolic response
of vertebrates to pathophysiological
(nutritional, xenobiotic or toxic) stimuli
• Metabolomics:The quantitative measurement
of the metabolic profiles of model organisms
to characterize their phenotype or phenotypic
response to genetic or nutritional
perturbations
MetaboXomics

What is a Metabolite?
• Any organic molecule detectable in thebody with a MW < 1500 Da
• Includes peptides, oligonucleotides,sugars, nucelosides, organic acids,ketones, aldehydes, amines, aminoacids, lipids, steroids, alkaloids, foods,food additives and drugs (xenobiotics)
• Includes human & microbial products
• Concentration > detectable (1μM)

Defining Metabolites
M mM μM nM pM fM
Endogenous metabolites
Drugs
Food additives
Drug metabolites
Toxins/Env. Chemicals

The Metabolome is “Fuzzy”

What Can You Do WithMetabolomics?
• Generate metabolic “signatures”
• Monitor/measure metabolite flux
• Monitor enzyme/pathway kinetics
• Assess/identify phenotypes
• Monitor gene/environment interactions
• Track effects from toxins/perturbants
• Monitor consequences from gene KOs
• Identify functions of unknown genes

Other MetabolomicApplications
• Genetic Disease Tests
• Nutritional Analysis
• Clinical Blood Analysis
• Clinical Urinalysis
• Cholesterol Testing
• Drug Compliance
• Transplant Monitoring
• MRS and fMRI
• Toxicology Testing
• Clinical Trial Testing
• Fermentation Monitoring
• Food & Beverage Tests
• Nutraceutical Analysis
• Drug Phenotyping
• Water Quality Testing
• Petrochemical Analysis

What Are The Technologies?
• UPLC, HPLC
• CE/microfluidics
• LC-MS
• FT-MS
• QqQ-MS
• NMR spectroscopy
• X-ray crystallography
• GC-MS
• LIF detection

What Does the Data Look Like?
-25
-20
-15
-10
-5
0
5
10
15
20
25
-30 -20 -10 0 10
PC1
PC2
PAP
ANIT
Control

2 Routes to Metabolomics
1234567ppm
hippurate urea
allantoin creatininehippurate
2-oxoglutarate
citrate
TMAO
succinatefumarate
water
creatinine
taurine
1234567ppm
-25
-20
-15
-10
-5
0
5
10
15
20
25
-30 -20 -10 0 10
PC1
PC2
PAP
ANIT
Control
QuantitativeMethods
Chemometric (Pattern)Methods

Quantitative vs. Chemometric
• Identifies compounds
• Quantifies compds
• Concentration rangeof 1 μM to 1 M
• Handles wide range ofsamples/conditions
• Allows identification ofdiagnostic patterns
• Limited by DB size
• No compound ID
• No compound conc.
• No compoundconcentration range
• Requires strict sampleuniformity
• Allows identificationof diagnostic patterns
• Limited by training set
Both Methods Need A Metabolite “Parts List” to be Effective

The Human Metabolome Project
• $7.5 million Genome Canada Projectlaunched in Jan. 2005
• Mandate to quantify (normal andabnormal ranges) and identify allmetabolites in biofluids (urine, CSF,plasma) and tissues
• Make all data freely and electronicallyaccessible (HMDB, DrugBank, FooDB)
• Make all cmpds publicly available (HML)

HGP vs. HMP
• Focus on genome
• Alphabet’s known,need the sequence
• 3,000,000,000 bases
• Public Repository(GenBank)
• Lots of pre-existingelectronic data
• $1 billion
• Start 1990, end2003
• Focus on metabolome
• Alphabet’s not known,need concentrations
• 8000 compounds
• Public Repository(HMDB + others)
• Almost no pre-existing electronicrecords
• $7.5 million
• Start 2005, end 2008

Project Investigators

Project Resources
• 400 MHz NMR, 2x500MHz NMR, 2x600 MHzNMR, 700 MHz NMR,800 MHz NMR
• 9.4 Tesla FT-MS, 4 iontrap LC-MS, 2 QStar-TOFs, 1 triple quad MS
• 2 prep HPLC systems, 3nano-HPLC systems, 1UPLC system
• 30 staff and students

The Bionformatics Challenge
?
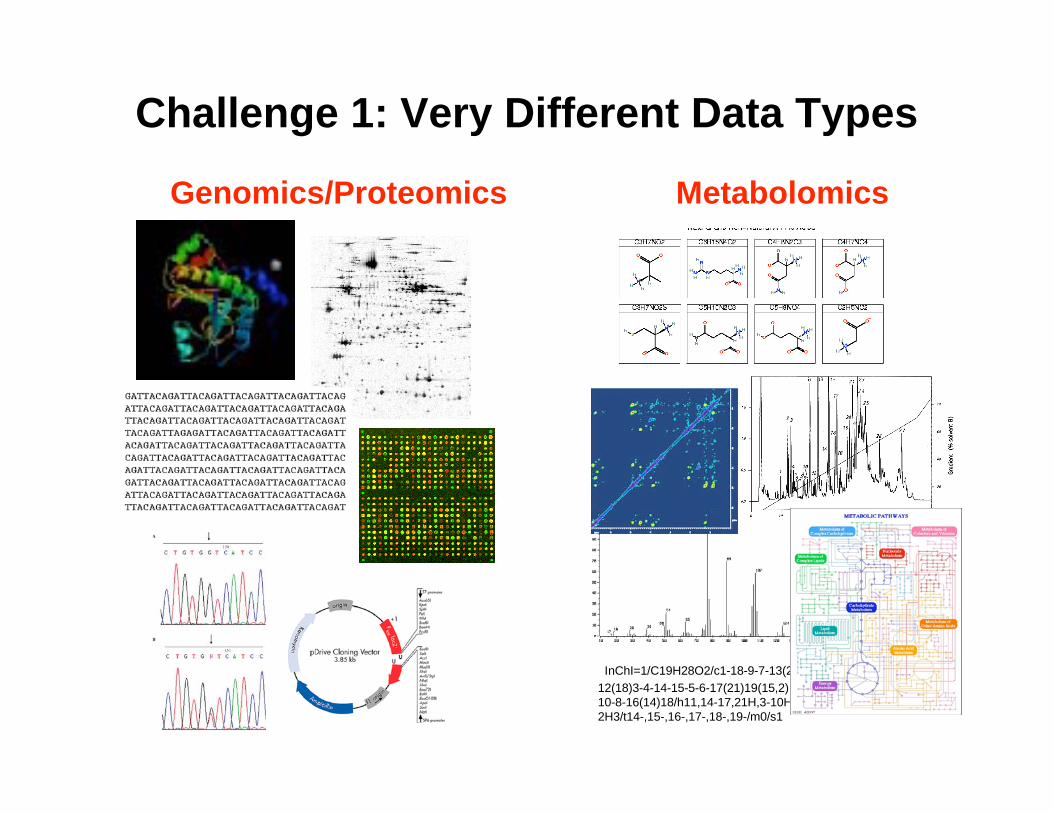
Challenge 1: Very Different Data Types
Genomics/Proteomics Metabolomics
InChI=1/C19H28O2/c1-18-9-7-13(20)11-
12(18)3-4-14-15-5-6-17(21)19(15,2)
10-8-16(14)18/h11,14-17,21H,3-10H2,1-
2H3/t14-,15-,16-,17-,18-,19-/m0/s1

Challenge 2: Very Little MetabolomicData is Electronically Accessible
• Sequence Databases
– GenBank, UniProt
• Expression Databases
– GEO, SMDB
• Structure Databases
– PDB, MSD, SCOP
• Pathway Databases
– KEGG, BioCarta
• Electronic Deposition
– GenBank, PDB, GEO
• Metabolite DBs
– ????
• Concentration DBs
– ????
• Spectral DBs
– ????
• Pathway DBs
– KEGG, BioCyc
• Electronic Deposition
– ????
Genomics/Proteomics Metabolomics

The Bioinformatics Challenge
• What’s already known?
• How to assemble, elaborate and linkchemical data with biological data?
• How to manage data flow in a multi-centred project?
• How to make this data public (anduseful)?

What’s Already Known?
• Databases (KEGG,HumanCyc) suggested ~800cmpds
• Comparative metabolomicsstudies with mouse, yeast &E. coli suggested ~1000cmpds
• #Peaks seen in NMR and FT-MS spectra suggested ~1000cmpds
• What about drugs?
• What about foods and foodadditives?
• What about environmentalchemicals?

Sherlock ChemLoc
• Build chemical name, drug name andmetabolite name recognition tools using“training sets” from existing databasesand concepts borrowed from proteinname recognition systems
• Scour Pubmed, Google, SProt, OMMBID
• Track all synonyms (>50,000 so far)
• Supplement with old-fashionedsleuthing

What We (and others) HaveFound…
M mM μM nM pM fM
Endogenous metabolites
Drugs
Food additives
Drug metabolites
Toxins/Env. Chemicals
2800 cmpds
1400 cmpds
2100 cmpds
900 cmpds
800 cmpds

The Bioinformatics Challenge
• What’s already known?
• How to assemble, elaborate and linkchemical data with biological data?
• How to manage data flow in a multi-centred project?
• How to make this data public (anduseful)?

Assembling & LinkingBiochemical Data - BioSpider
• Searches web databasesto extract and compilelarge volumes of dataabout metabolites, drugsand associated proteins
• Scans about 20 webdatabases
• Uses chemical propertypredictors & sketch tools
• Also assemblesprotein/gene/SNP data iftarget is ID’d
PubChem
KEGGSwissProt
Wikipedia
NIST-library PharmGKB
Prediction/Processing Engine

The BioSpider Server
www.biospider.ca

Assembling & Linking BiologicalData - PolySearch
• Searches PubMedabstracts to extract andcompile data aboutassociations betweendrugs, metabolites,genes, diseases,tissues, fluids andmutations
• Also searchesSwissProt, OMIM, ,DrugBank, GAD, HPRD,HMBD, HGMD, CGAP
http://wishart.biology.ualberta.ca/polysearch

The Bioinformatics Challenge
• What’s already known?
• How to assemble, elaborate and linkchemical data with biological data?
• How to manage data flow in a multi-centred project?
• How to make this data public (anduseful)?

Data Sources & Data Flow
• Backfilling (Phase I)
• Text mining (Phase II)
• Experiment (Phase III)
2 Sites, 18 months
3 Sites, 12 months
5 Sites, 36 months

A Common Problem
Collaborator
In Timbuktu
Sample
Collection
Sample
Analysis
Data Analysis
& Informatics
Solution? LIMS

What’s A LIMS?

MetaboLIMS
• Web-based, portable, robust, andscalable laboratory informationmanagement system designed to meetthe high throughput processing and/orclinical needs of laboratories involvedin metabolomics research
• Designed to be “generic” with somecustomizable features
• Very simple, intuitive interface

MetaboLIMS
• Compound and SampleTracking
• Electronic Notebook Entry
• GANTT Charting
• Audit Trail Tracking
• Text Data Entry
• Spectral Trace or ImageEntry
• Automated CompoundAnnotation
• Relational Query Searches

The Bioinformatics Challenge
• What’s already known?
• How to assemble, elaborate and linkchemical data with biological data?
• How to manage data flow in a multi-centred project?
• How to make this data public (anduseful)?

Making Data Accessible
• Need to create web-based databases
• Need to anticipate all possiblebrowsing and query options
• Need to make data views user friendlyand data content as appealing aspossible for a very broad audience
• Need to make data current and easilyupdatable (link to LIMS)
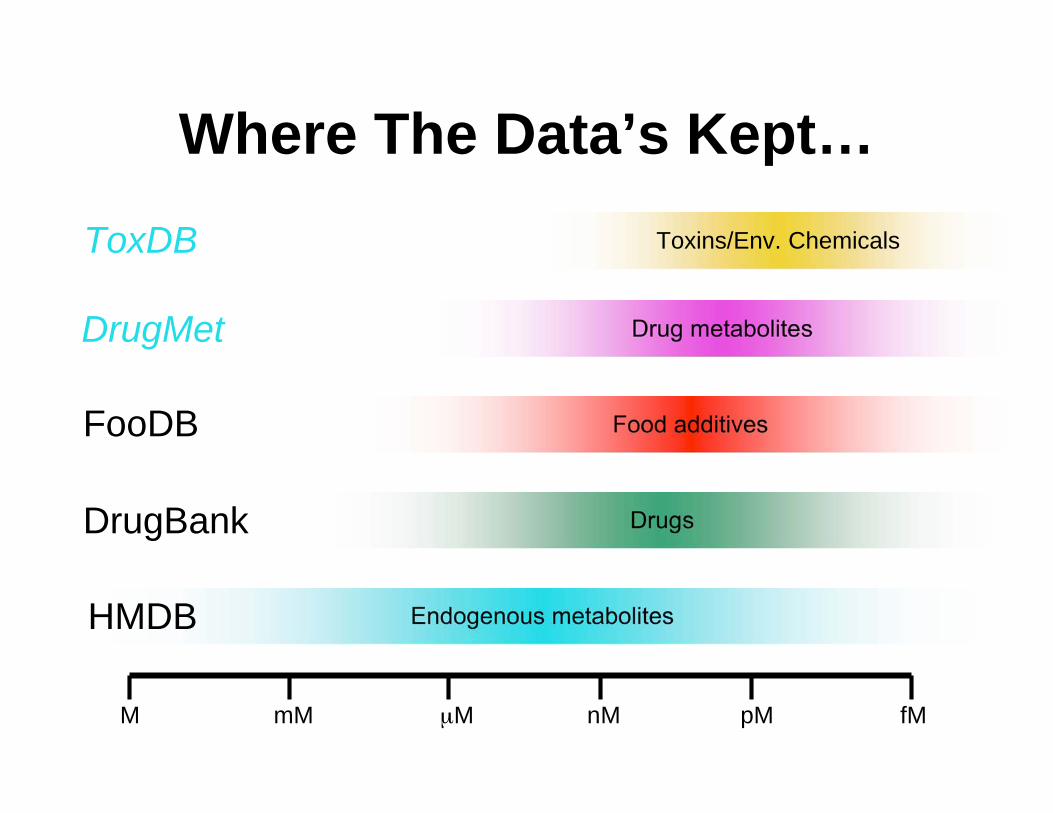
Where The Data’s Kept…
M mM μM nM pM fM
Endogenous metabolites
Drugs
Food additives
Drug metabolites
Toxins/Env. Chemicals
HMDB
DrugBank
FooDB
DrugMet
ToxDB

Human Metabolome Database
www.hmdb.ca


HMDB
• ~95 data fields for each metaboliteentry
• 30+ fields pertaining to chemical orphysico-chemical data
• 50+ fields pertaining to biological,biomedical or clinical data
• >550 reference and assigned NMRspectra, 1600+ MS spectra
• Extensive search and query tools

DrugBank
http://redpoll.pharmacy.ualberta.ca/drugbank/

FooDB (Beta)
http://hmdb.med.ualberta.ca/foodb

Human Metabolite Library
http://www.metabolibrary.com/
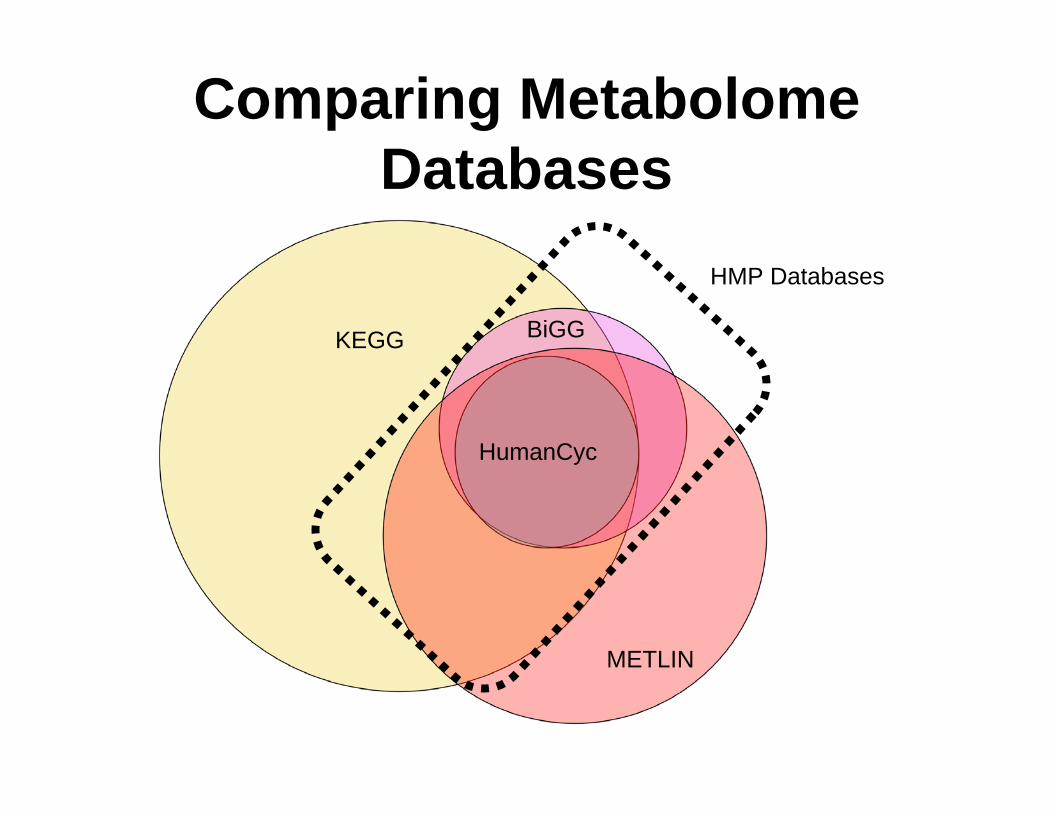
Comparing MetabolomeDatabases
METLIN
KEGG
HumanCyc
BiGG
HMP Databases

Applications

Improving Data Linkage
• HMDB, DrugBank, FooDB, etc. are NOT justlists of compounds, they are encyclopedias
• Extensive clinical and physiological data isprovided on many metabolites, foods anddrugs
• Extensive disease data (normal vs. abnormalcompound concentrations)
• Extensive protein, pathway, gene and SNPdata for metabolizing enzymes andmacromolecular interacting partners
Systems Biology Databases

Improving Data Linkage

Improving Targeted Profiling - TheHMDB Spectral Library

Characterizing Clinically ImportantBiofluids: The CSF Metabolome
NMR
(56 cmpds
16 unique)
GC-MS
(48 cmpds
12 unique)
LC-MS
(19 cmpds
6 unique)
NMR+GC
(18 cmpds)
LC+GC
(1 cmpd)
LC+NMR
(3 cmpds)
LC+NMR+GC
(9 cmpds)
274
cmpds
76 cmpds
from 3 methods

Providing Quantitative Datafor Metabolic Simulation
• Petri Nets
• Flux Balance Analysis
• ODE’s and PDE’s
• Pi Calculus
• S-equations
• Agent-based Methods
• Cellular Automata
• Boolean Networks

Facilitating Drug Discovery
PharmaBrowse ChemQuery
SeqSearch Data Extractor

Facilitating Drug Discovery
• Matching drugs/chemicals to protein targets
• BLAST new sequences (viral, bacterial) tofind similarities to known drug targets
• Query newly isolated/synthesizedcompounds to check for similarities toexisting drugs
• Generating novel drug “ideas” fromstructure/function comparisons to knownmetabolites and drugs

Finding Novel Drug ToxicityBiomarkers
Trimethylamine-N-oxide
Glucose
Creatine
Creatinine

Applications in Drug (Dosage)Monitoring
Drug Signature
Missed a dose

Conclusions• Bioinformatics proved integral (once
again) to nearly all aspects ofdevelopment and implementation of alarge scale “omics” project
• The tools and resources developed bythe HMP are mandated by GC to bemade freely available to all
• The lessons learned (and tools made)for the HMP may be useful for otherlarge scale metabolomics projects

Conclusions• Many of the bioinformatics needs in
metabolomics are only beginning to beaddressed -- lots of opportunity for
innovation and new ideas
• Technology changes in metabolomicsare quite rapid, requiring changes tothe computational/analytical tools
• Metabolomics is like proteomics ~1995or transcriptomics in ~1998

The Future of Metabolomics
1990 1995 2000 2005 2010 2015 2020
Genomics
Proteomics
Metabolomics???

Acknowledgements
• Craig Knox
• Roman Eisner
• Dean Cheng
• Russ Greiner
• An Chi Guo
• Savita Shrivastava
• Nelson Young
• Dan Tzur
• Leslie Jia
• David Arndt
• Ian Forsythe


















