
How are these?
62
How similar are these? 1
Transcript of How are these?

How similar are these?
1

What’s the Problem?
• Finding similar items with respect to some distance metric
• Two variants of the problem:– Offline: extract all similar pairs of objects from a large collection
– Online: is this object similar to something I’ve seen before?
2

Application: Plagiarism Detection
3

Application: Content‐based Search
4

Other Applications
• Near‐duplicate detection of webpages– Mirror pages– Similar news articles
• Recommender systems– Find users with similar tastes in movies, etc– Find products with similar customer sets
• Sequence/tree alignment– Find similar DNA or protein sequences
• …
5

Finding similar items ‐ Three Components
• How to quantify similarity?– Distance measures
• Euclidean distance – based on locations of points in space, e.g., Lr‐norm
• Non‐Euclidean distance, ‐ based on properties of points, e.g., Jaccard, cosine, edit
• Compute representation– Shingling, tf.idf, etc.
• Space and Time Efficient algorithms– Transformation: Minhash– All‐pair comparison: Locality sensitive hashing
6

(Axioms of) Distance Metrics
d is a distance measure between points x and y
1. Non‐negativity:
2. Identity:
3. Symmetry:
4. Triangle Inequality
7

Problem: Finding Similar Documents
• Given N text documents, find pairs that are “near duplicates”– Find similarity between a pair– For large N, it can be very compute intensive
• Can we avoid all‐pair comparisons?
8
degree of similaritybetween doc i and j
Doc 1 to N

Comparing two documents …
• Naïve methods– Feature: Treat each document as a set/bag of words
– Distance: Jaccard distance (or cosine distance or hamming distance)
9

Distance: Jaccard
• Given two sets A, B• Jaccard similarity:
• Jaccard distance:
• E.g., A = {I, like, CS5344}; B = {CS5344, is, not, for, me}, d(A, B) = 6/7
10

Comparing two documents …
• Naïve methods– Feature: Treat each document as a set/bag of words
– Distance: Jaccard distance or cosine distance or hamming distance
– Textual rather than semantics • Documents with many common words are more similar, even if the text appears in different order
– What good is this?• Fast filtering before the slower refinement
11

The BIG Picture (All‐pair comparison)
12
Minhashing
Signature forthe set of strings
(can capture similarity)
Locality SensitiveHashing Signatures falling
into the same bucket are “similar”
Set of strings of length k
Shingling
is about big
This course iscourse is about
about big databig data analytics
Shingling
Another document

Shingling: Account for ordering of words …
• Instead of treating each word independently, we can consider a sequence of k words– More effective in terms of accuracy
• A k‐shingle (or k‐gram) for a document D is a sequence of k tokens that appear in D– Tokens can be characters or words or some feature/object depending on the application
• E.g., k = 3 characters; D = {This is a test} will give rise to the following set of 3‐shingles: S(D) = {Thi, his, is_, s_i, _is, is_, s_a, _a_, a_t, _te, tes, est}
• E.g., k = 3 words; we have S(D) = {{This is a}, {is a test}}
13NOTE: Assume “characters” in our discussion

Shingles and Similarity
• Documents that are similar should have many shingles in common
• What if two documents differ by a word?– Affects only k‐shingles within distance k from the word
• What if we reorder paragraphs?– Affects only the 2k shingles that cross paragraph boundaries
• Example: k=3 – The dog which chased the cat vs The dog that chased the dog
– Only 3‐shingles replaced are g_w, _wh, whi, hic, ich, ch_, and h_c

Shingles • We can represent D as a set of its k‐shingles
– Distance metrics: Jaccard distance
• What’s the effect of the value of k (in terms of characters)?– Recommended values of k
• 5 for small documents• 10 for large documents
15

Shingles
• How about space overhead?– Each character can be represented as a byte– k‐shingle requires k bytes
• Can compress by hashing a k‐shingle to say 4 bytes– D is now a set of 4‐byte hash values of its k‐shingles– False positive may occur in matching
• What’s the advantage?– Tradeoffs between ability to differentiate vs space
• It is better to hash 10‐shingles to say 4 bytes than to use 4‐shingles!
16

So far …• Represent a document as a set of k‐shingles or its hash values
• Use Jaccard distance to compare two documents• How to parallelize this phase?• This scheme works but …
– What if the set of hash values (or k‐shingles) is too large to fit in the memory?
– Or the number of documents are too large?
17
Idea: Find a way to hash a document to a single (small size) value!and similar documents to the same value!

Minhash
• Seminal algorithm for near‐duplicate detection of webpages– Used by AltaVista– Documents (HTML pages) represented by shingles (n‐grams)
– Jaccard similarity: dups are pairs with high similarity
18

MinHash – Key Idea• Hash the set of document shingles (big in terms of space requirement) into a signature (relatively small size)
• Instead of comparing shingles, we compare signatures– ESSENTIAL: Similarities of signatures and similarities of shingles MUST BE related!!
– Not every hashing function is applicable!– Need one that satisfies the following:
• if Sim(D1,D2) is high, then with high prob. h(D1) = h(D2)• if Sim(D1,D2) is low, then with high prob. h(D1) ≠ h(D2)
– It is possible to have false positives, and false negatives!• minhashing turns out to be one such function for Jaccard similarity
19

Preliminaries: Representation & JacaadMeasure
• Sets:– A = {e1, e3, e7}– B = {e3, e5, e7}
• Can be equivalently expressed as matrices:
20
M00 = # rows where both elements are 0Let:
M11 = # rows where both elements are 1M01 = # rows where A=0, B=1M10 = # rows where A=1, B=0

Computing Minhash• Start with the matrix representation of the set• Randomly permute the rows of the matrix• minhash (which is the signature) is the first row with a “1”• Example:
21
h(A) = e3
h(B) = e5
Input matrix Permuted matrix

Minhash and Jaccard
M00
M00
M01
M11
M11
M00
M10
22

MinHash – False positive/negative
• Instead of comparing sets, we now compare only 1 bit!
• False positive?– False positive can be easily dealt with by doing an additional layer of checking (treat minhash as a filtering mechanism)
• False negative? • High error rate! Can we do better?
23

Using multiple minhash signatures
24
Comparison between two sets (original matrix) becomes comparison between two columns of minhash values (signature matrix)
Input Permutations Minhash signatures
Similarities
The similarity between signatures of two columns is given by the fraction of hash functions in which they agree

Implementation of MinHashComputation
• Permutations are expensive– Incur space and random access (if data cannot fit into memory)
• Interpret the hash value as the permutation• Only need to keep track of the minimum hash values
25

Implementation of minhash (By example)
26
Initialization: set signatures to Apply all hash functions on each row• If column value is 1, keep the minimum value• Otherwise, do nothing

So far …
• Represent a document as a set of hash values (of its k‐shingles)
• Transform set of k‐shingles to a set of minhashsignatures
• Use Jaccard to compare two documents by comparing their signatures
• Is this method (i.e., transforming sets to signature) necessarily “better”??
27

Find all near‐duplicates among N documents
• Naïve solution– For each document, compare with the other N‐1 documents
• Takes N‐1 comparisons• Can optimize using filter‐and‐refine mechanisms
– Requires N*(N‐1)/2 comparisons– For large N, still takes ages …
• E.g., N = 107, we have ~1014 comparisons; if each comparison takes 1 μs, we need 108 sec ( ~ 3 years!)
28

Locality Sensitive Hashing (LSH)
• Suppose we have N documents• For each document, we can derive say k minhash signatures
29
minhash D1 D2 D3 D4 …. DN
1 3 3 2 2 3
2 7 7 5 5 7
k‐1 2 2 2 2 2
k 1 1 1 1 2

LSH – Idea of hashing
30
minhash D1 D2 D3 D4 …. DN
1 3 3 2 2 3
2 7 7 5 5 7
k‐1 2 2 2 2 2
k 1 1 1 1 1
Hash functionF(column)
Buckets

LSH• Documents that fall into the same buckets are likely to be similar – More false positive (as a result of LSH) possible
• Why? Because of collision (subject to hash function and number of buckets)
• How to deal with this? Refinement step– More false negative? Of course!
• Finding all pairs within a bucket is computationally cheaper– Declare all pairs within a bucket to be “matching” OR– Perform pair‐wise comparisons for those
documents that fall into the same bucket • Much smaller than pair‐wise over all documents
31

LSH
• With only 1 hash function on one entire column of signature, likely to have many false negatives
• Key idea: Apply the hash function on the column multiple times, each on a partition of the column– Similar columns will be hashed to the same bucket (with high probability)
– Candidate pairs are those that hash at least once to the same bucket
32

n different kMinhash Signatures• For each document,
compute n sets of kminhash values
• For each set, concatenate kminhash values together
33
• Within each set:– Hash on the concatenated values (this has the “same” effect as ensuring
all columns have the same values)– All documents with the same hash value will be bucketed together– Output all pairs within each bucket
• Candidate pairs are those that have the same bucket for ≥ 1 set • De‐dup pairs

n sets of k minhash signatures
34
Documents 1 and 3potentially similar Documents 6 and 7
potentially dis‐similar
Documents 1 and 3potentially similar
1. Duplicates2. D1 and D3are similar overat least 2k signatures
Number of buckets is set to be as largeas possible to minimizecollision
Candidate column pairs arethose that hash to the samebucket for more than 1 set

Example
• Given 100,000 columns (documents)• Let there be 100 signatures• Let n = 20 and k = 5• Goal: Find pairs that are at least 80% similar
NOTE: If each signature is represented as a 4 byte integer value, we need only 100*4*100,000 = 40 MB of memory!
35

Example
• Suppose C1 and C2 are 80% similar• Probability that C1 and C2 are identical in one set = (0.8)5 = 0.328
• Probability that C1 and C2 are not similar in any of the 20 sets = (1‐0.328)20= 0.00035– About 0.00035 of the 80%‐similar column pairs are false negatives
– We would find 99.965% pairs of truly similar documents
36

Example
• Suppose C1 and C2 are 30% similar• Probability that C1 and C2 are identical in one set = (0.3)5 = 0.00243
• Probability that C1 and C2 are identical in at least 1 of the 20 sets ≤ 20*0.00243= 0.0486– About 4.86% pairs with similarity 30% end up becoming candidate pairs – false positives
37

Need to tune LSH
• Choose n and k to balance between false positives and false negatives
• What if we use only 15 sets instead of 20?– Lower number of false positives – Higher number of false negatives
38

Ideally, ….
39
Probability of hashing to the same
bucket
Similarity s of two sets
When n = 1, k = 1
Similarity s of two sets
False negatives
False positives

n sets, k signatures/set
• C1 and C2 have similarity s• For any set (k rows)
– Prob that all rows are equal = sk– Prof that some rows are not the same = 1 ‐ sk
• Prob that all sets are not identical = (1 – sk)n
• Prob that at least 1 set is identical = 1 ‐ (1 – sk)n
• Tune n and k to minimize false negatives and false positives
40

The S‐curve for arbitrary n and k (> 1)
41
Probability of hashing to the same
bucket
Similarity s of two sets
t ~ (1/n)1/k t= 1/2We haven = 16, k = 4

Example: n = 20, k = 5
42
s 1 ‐ (1 – sk)n
0.2 0.006
0.3 0.047
0.4 0.186
0.5 0.470
0.6 0.802
0.7 0.975
0.8 0.9996

MapReduce Implementation
• Map over objects:– Generate Mminhash values, randomly select k of them n times
– Each draw yields a signature: emit as intermediate key, value is object id
• Shuffle/sort:• Reduce:
– Receive all object ids with same signature, generate candidate pairs
– Okay to buffer in memory?• Second pass to de‐dup
43

So far, …
• Tune to minimize false positives and false negatives
• Need to check that candidate pairs have similar signatures
• Need further refinement to find really similar documents
• Jaccaad distance is useful also for other applications, e.g., customer/item purchase histories
44

Generalizing LSH: Multiple Hash Functions
• So far, we have assumed only one hash function – h(x) = h(y) implies “h says x and y are equal”
• We could have used a family of hash functions and use any of them
45

Locality‐Sensitive (LS) Families• Consider a space S of points with a distance measure d
46
• A family H of hash functions is said to be (d1, d2, p1, p2)‐sensitive if for any x and y in S:– If d(x, y) ≤ d1, then prob over all h in H that h(x) = h(y) is at least p1– If d(x, y) ≥ d2, then prob over all h in H that h(x) = h(y) is at most p2

Example
• Let S = sets, d = Jaccard distance• Minhashing gives a (d1, d2, p1, p2)‐sensitive family for any d1 < d2– E.g., H is a (1/3, 2/3, 2/3, 1/3)‐sensitive family for S and d
– If distance ≤ 1/3 (i.e., similarity ≥ 2/3), then prob that minhash values agree is ≥ 2/3
– This is because Pr(h(x)=h(y)) = 1‐d(x,y)• No guarantees about fraction of false positives
– the theory leaves unknown what happens to pairs that are at distance between d1 and d2
47

Amplifying a LS‐family: AND Construction of Hash Functions
48
• Given family H, construct family H’consisting of r functions from H
• For h= [h1,…,hr] in H’, h(x)=h(y) if and only if hi(x)=hi(y) for all i
• This has the same effect as “n sets of k signatures”– x and y are considered a candidate pair if every one of the r rows say that x and y are equal
• Theorem: If H is (d1, d2, p1, p2)‐sensitive, then H’ is (d1, d2, p1r, p2r)‐sensitive.– That is, for any p, if p is the probability that a member of F will declare (x, y) to be a candidate pair, then the probability that a member of F′ will so declare is pr

Amplifying a LS‐family: OR Construction of Hash Functions
49
• Given family H, construct family H’consisting of b functions from H• For h= [h1,…,hb] in H’, h(x)=h(y) if and only if hi(x)=hi(y) for at least
one i• Mirrors the effect of combining several sets: x and y become a
candidate pair if any set makes them a candidate pair• Theorem: If H is (d1, d2, p1, p2)‐sensitive, then H’ is (d1, d2, 1‐(1‐p1)b,
1‐(1‐p2)b)‐sensitive.– That is, for any p, if p is the probability that a member of F will declare
(x, y) to be a candidate pair, then (1‐p) is the probablity that it will not declare so.
– (1‐p)b is the probability that the probability that none of the family h1, hb will declare x and y a candidate pair
– 1 − (1 − p)b is the probability that at least one hi will declare (x, y) a candidate pair, and therefore that f will declare (x, y) to be a candidate pair.

Effect of AND and OR Constructions• AND makes all probs. shrink, but by choosing r correctly, we
can make the lower prob. approach 0 while the higher does not
• OR makes all probs. grow, but by choosing b correctly, we can make the upper prob. approach 1 while the lower does not
50

Composing Constructions: AND‐OR Composition
• r‐way AND construction followed by b‐way OR construction– Exactly what we did with minhashing
• Take points x and y s.t. Pr[h(x) = h(y)] = p• H will make (x,y) a candidate pair with prob. P• Construction makes (x,y) a candidate pair with probability 1‐(1‐pr)b
– The S‐Curve!
51
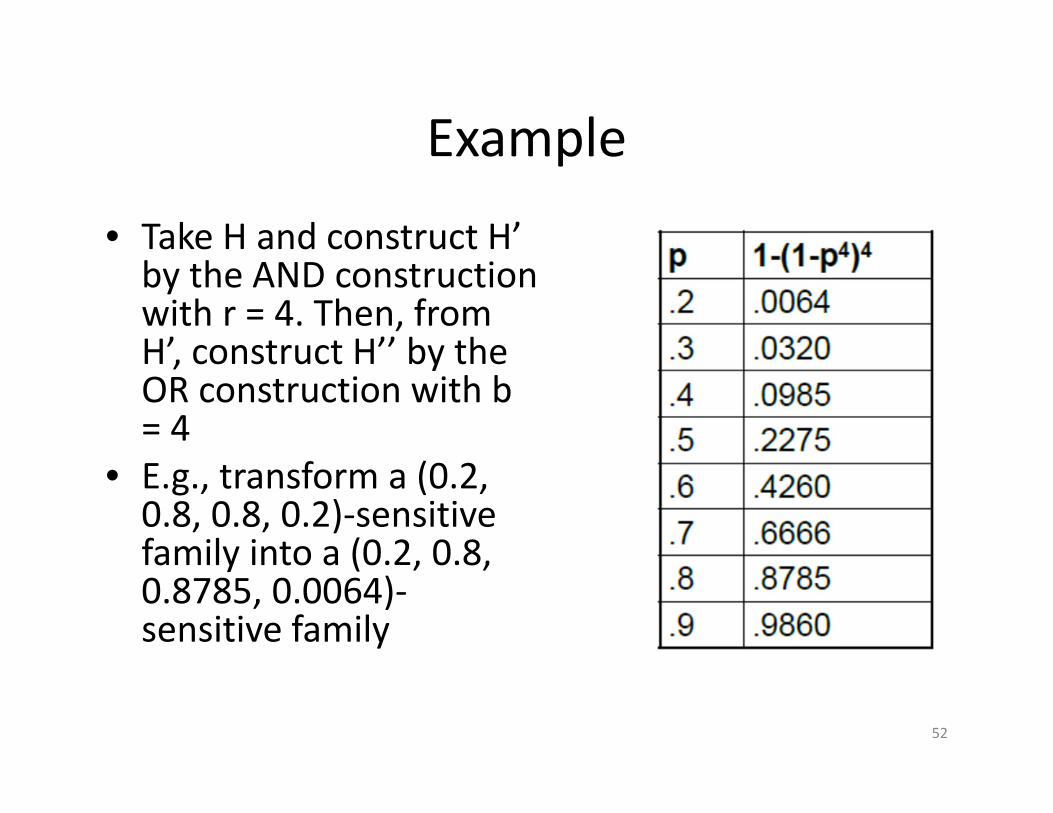
Example
• Take H and construct H’ by the AND construction with r = 4. Then, from H’, construct H’’ by the OR construction with b = 4
• E.g., transform a (0.2, 0.8, 0.8, 0.2)‐sensitive family into a (0.2, 0.8, 0.8785, 0.0064)‐sensitive family
52

Composing Constructions: OR‐AND Composition
• b‐way OR construction followed by r‐way AND construction
• Transforms probability p into (1‐(1‐p)b)r
53

Example
• Take H and construct H’ by the OR construction with b = 4. Then, from H’, construct H’’ by the AND construction with r = 4
• E.g., transform a (0.2, 0.8, 0.8, 0.2)‐sensitive family into a (0.2, 0.8, 0.9936, 0.1215)‐sensitive family
54

Cascading Constructions
• Apply the (4,4) OR‐AND construction followed by the (4,4) AND‐OR construction.
• Transforms a (.2,.8,.8,.2)‐sensitive family into a (.2,.8,.9999996,.0008715)‐sensitive family.
• Note this family uses 256 (= 4*4*4*4) of the original hash functions.
55

So far …
• Pick any two distances x< y• Start with a (x, y, (1‐x), (1‐y))‐sensitive family• Apply constructions to produce (x, y, p, q)‐sensitive family, where p is almost 1 and q is almost 0.
• The closer to 0 and 1 we get, the more hash functions must be used.
• What about other distances? Euclidean distance? Cosine distance?
56

Limitations of Minhash
• Minhash is great for near‐duplicate detection– Set high threshold for Jaccard similarity
• Limitations:– Jaccard similarity only– Set‐based representation, no way to assign weights to features
• Random projections:– Works with arbitrary vectors using cosine similarity– Same basic idea, but details differ– Slower but more accurate: no free lunch!
57

Example: A LHS Family for Fingerprint
Matching
58
• Fingerprint can be uniquely defined by its minutiae
• By overlaying a grid on the fingerprint image, we can extract the grid squares where the minutiae are located
• Two fingerprints are similar if the set of grid squares significantly overlap – Jaccard distance and minhash can be used, but … benefit is unclear (as the set of grid squares is relatively small already)

LSH for Fingerprint Matching
• Let F be a family of functions• f F is defined by, say 3, grid squares such that f returns the same bucket whenever the fingerprint has minutiae in all three grid squares– f sends all fingerprints that have minutiae in all three of f’s grid points to the same bucket
– Two fingerprints match if they are in the same bucket
59

LSH for Fingerprint Matching
• Suppose prob of finding a minutiae in a random grid square of a random finger is 0.2
• And prob of finding one in the same grid square of the same finger (different finerprint) is 0.8
• Prob two fingerprints from different fingers match = (0.2)3 x (0.2)3 = 0.000064
• Prob two fingerprints from the same finger match = (0.2)3 x (0.8)3 = 0.004096– 1 in 200 – Is this good enough???
60

LSH for Fingerprint Matching
• Use more functions from F!• Take 1024 functions and do a OR construction
– Prob putting the fingerprints from the same finger in at least one bucket is 1 – (1‐0.004096)1024 = 0.985
– Prob two fingerprints from different fingers falling into the same bucket is 1 – (1‐0.000064)1024 = 0.063
– We have 1.5% false negatives and 6.3% false positives
• Using AND construction will – Greatly reduce the prob of a false positive– Small increase in false‐negative rate
61

Conclusion
• Many applications require finding similar items• 3 key components
– Feature representation, distance measure, efficient algorithms
• Focus on finding similar documents at various levels– Shingles, minhashing and LSH
• LSH for other distance measures (cosine and euclidean distance)
62


















