
HKG15-300: Art's Quick Compiler: An unofficial overview
59
ART’s Quick Compiler: an unofficial overview Matteo Franchin <[email protected]> LCA15, February 2015 1
Transcript of HKG15-300: Art's Quick Compiler: An unofficial overview

ART’s Quick Compiler:an unofficial overview
Matteo Franchin <[email protected]>LCA15, February 2015
1

PrefaceWho am I?
Worked on 64-bit port of Android™ for ARM® (ARMv8, AArch64).Focus on 64-bit port of ART’s Quick Compiler for the A64 instruction set.
Why am I talking about ART and its Quick Compiler?Where we are with ARMv8 support in Android.Generate useful documentation for Open Source Community.
Interaction between runtime and compiler.
Disclaimer: This presentation does solely represent its author’s opinion. It doesnot represent in any ways the opinions of other parties (e.g. Google).
2

OutlinePART I: ART: a developer’s approach
HelloWorld.java: from source, to compilation, and executionART’s output: oat files and compiled codeStructure of output code (Quick Compiler)Suspend points and deoptimization
PART II: How the ART Quick Compiler worksIntermediate Representations (IR) in Quick CompilerIRs translation phasesThe good and the bad
PART III: Generated codeExample of generated code and discussion
3

PART IART: A developer’s approach
HelloWorld.java: from source, to compilation, and executionART’s output: oat files and compiled codeStructure of output code (Quick Compiler)Suspend points and deoptimization
4

What is ART?
Compatible with Dalvik: uses same APKs.Added 64-bit VM: dalvikvm64.Ahead Of Time (AOT) compilation, rather than Just In Time (JIT).Input compiled to oat files, special ELF files.
5

HelloWorld.java: from source, to compilation, and executionGiven a Java source file:
HelloWorld.javapublic class HelloWorld {
static public void main(String[] args) {System.out.println("Hello world!");
}}
This is compiled on a desktop machine and transferred to the device.$ javac HelloWorld.java ## ->HelloWorld.class (generic compilation)$ dx --dex --output=HelloWorld.jar HelloWorld.class ## ->HelloWorld.jar (Android specific)$ adb connect IP.ADD.RE.SS ## Connect to Android device$ adb push HelloWorld.jar /data/user/ ## Move jar file to device
It can then be executed on the device:$ adb shell ## Connect to device# cd /data/user# dalvikvm64 -cp HelloWorld.jar HelloWorld ## Run JAR fileHello world!# ls -l /data/dalvik-cache/arm64/*HelloWorld* ## Show the output oat file.-rw-rw-rw- root root 12720 1970-01-01 00:22 data@[email protected]@classes.dex
6

ART’s output: *.oat files and compiled codeLet’s inspect the oat file for HelloWorld.oat on the host:$ adb pull /data/dalvik-cache/arm64/data@[email protected]@classes.dex ## Get the oat file.$ oatdump --oat-file=data@[email protected]@classes.dex ## Dump content.[...]0: LHelloWorld; (offset=0x00000500) (type_idx=0) (StatusInitialized) (OatClassAllCompiled)[...]
1: void HelloWorld.main(java.lang.String[]) (dex_method_idx=1)DEX CODE:
0x0000: sget-object v0, Ljava/io/PrintStream; java.lang.System.out // field@00x0002: const-string v1, "Hello world!" // string@10x0004: invoke-virtual {v0, v1}, void java.io.[...].println(java.lang.String) // method@20x0007: return-void
[...]vmap_table: (offset=0x00000548)v3/r20, v0/r21, v1/r22, v65535/r30
QuickMethodFrameInfoframe_size_in_bytes: 64core_spill_mask: 0x40700000 (r20, r21, r22, r30)fp_spill_mask: 0x00000000vr_stack_locations:
locals: v0[sp + #20] v1[sp + #24]ins: v2[sp + #68]method*: v3[sp + #0]outs: v0[sp + #4] v1[sp + #8]
CODE: (code_offset=0x00001098 size_offset=0x00001094 size=184)...0x00001098: d1400be8 sub x8, sp, #0x2000 (8192)
[...]
7

Quick Compiler ABI for A64: RegistersBefore showing the assembly code generated for the function HelloWorld.main() inthe HelloWorld.oat file, let’s have a look at the ABI for the A64 instruction set:
Roughly in line with AAPCS64:r0-r7 used for arguments (w0 current method)
r8-r17 for tempsr18 platform register (thread object)w19 used in suspend checks
r20-r29 callee-saved registersr30 link-register
Compressed references: pointers stored as 32-bit.ldr w0, [x20, #20] // Load compressed reference (32-bit) into w0ldr w0, [x0, #48] // x0 is decompressed and used as regular pointer....str w0, [x20, #20] // Reference compressed again (truncated to 32-bit and stored).
8
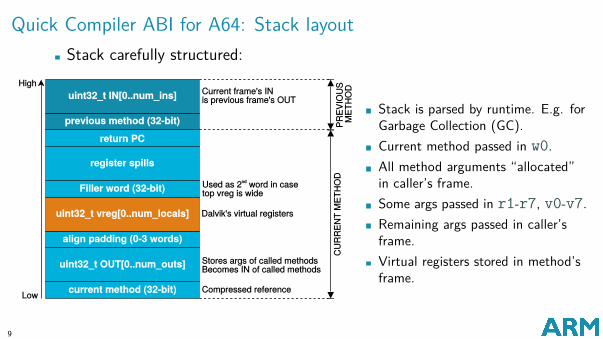
Quick Compiler ABI for A64: Stack layoutStack carefully structured:
Stack is parsed by runtime. E.g. forGarbage Collection (GC).Current method passed in w0.All method arguments “allocated”in caller’s frame.Some args passed in r1-r7, v0-v7.Remaining args passed in caller’sframe.Virtual registers stored in method’sframe.
9

Structure of output code (Quick Compiler)
10

Structure of output code (Quick Compiler)
11

Structure of output code (Quick Compiler)
12

Structure of output code (Quick Compiler)
13
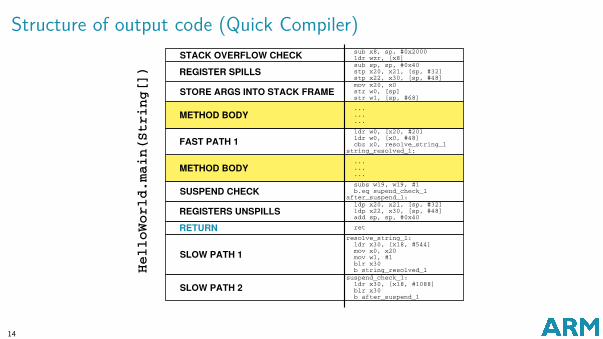
Structure of output code (Quick Compiler)
14
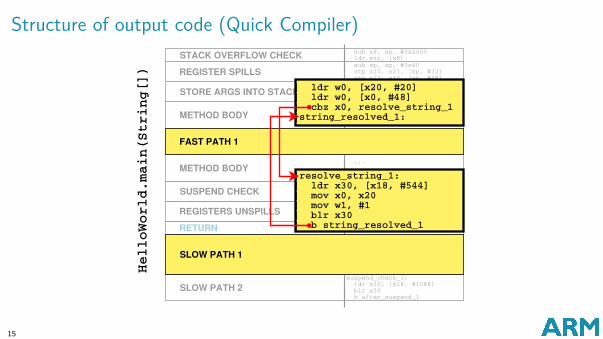
Structure of output code (Quick Compiler)
15

Structure of output code (Quick Compiler)
16

Structure of output code (Quick Compiler)
17

Design decisions and constraintsBefore looking more closely at how suspend-points work, let’s discuss some ofthe motivations behind their use. It will then be easier to see howsuspend-points allow achieving some of the goals of ART.
Requirements:Java ⇒ automatic memory management (Garbage Collection).
Elimination of “Jank” (good GUI responsiveness).Aid development, Dalvik compatibility ⇒ Full-speed debugging andprofiling.
Constraints:Consistency between: compiled code, interpreter, runtime.
Low-latency Garbage Collection.Optimisations must not affect profiling.Transition compiled-code to interpreter: deoptimization.
18

Design decisions and constraintsBefore looking more closely at how suspend-points work, let’s discuss some ofthe motivations behind their use. It will then be easier to see howsuspend-points allow achieving some of the goals of ART.
Requirements:Java ⇒ automatic memory management (Garbage Collection).Elimination of “Jank” (good GUI responsiveness).
Aid development, Dalvik compatibility ⇒ Full-speed debugging andprofiling.
Constraints:Consistency between: compiled code, interpreter, runtime.Low-latency Garbage Collection.
Optimisations must not affect profiling.Transition compiled-code to interpreter: deoptimization.
19

Design decisions and constraintsBefore looking more closely at how suspend-points work, let’s discuss some ofthe motivations behind their use. It will then be easier to see howsuspend-points allow achieving some of the goals of ART.
Requirements:Java ⇒ automatic memory management (Garbage Collection).Elimination of “Jank” (good GUI responsiveness).Aid development, Dalvik compatibility ⇒ Full-speed debugging andprofiling.
Constraints:Consistency between: compiled code, interpreter, runtime.Low-latency Garbage Collection.Optimisations must not affect profiling.Transition compiled-code to interpreter: deoptimization.
20

ImplementationAll these constraints are fulfilled using:
Suspend-points (also known as safe-points or interrupt-points).Deoptimization.
This methodology is well known in the literature:U. Hölzle, C. Chambers, and D. Ungar, “Debugging Optimized Code withDynamic Deoptimization,” pp. 32-43, ACM SIGPLAN Notices 27(7),1992.T. Rodriguez, K. Russell, and D. Cox, “Design of the Java HotSpot™Client Compiler for Java 6,” ACM Transactions on Architecture and CodeOptimization 5(1), Article 7, 2008.
21
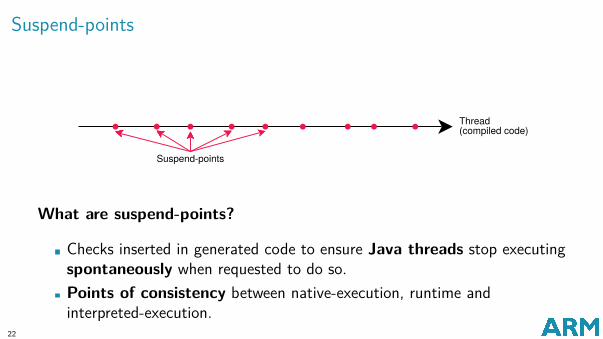
Suspend-points
What are suspend-points?
Checks inserted in generated code to ensure Java threads stop executingspontaneously when requested to do so.Points of consistency between native-execution, runtime andinterpreted-execution.
22

Suspend-points
In the figure above:Compiled code subdivided in intervals, separated by suspend-points.
Can optimise between suspend points.At suspend points stack and memory need to be in consistent state:“ready” for GC and for deoptimization.
23

Suspend-points
In the figure above:Compiled code subdivided in intervals, separated by suspend-points.Can optimise between suspend points.At suspend points stack and memory need to be in consistent state:“ready” for GC and for deoptimization.
24
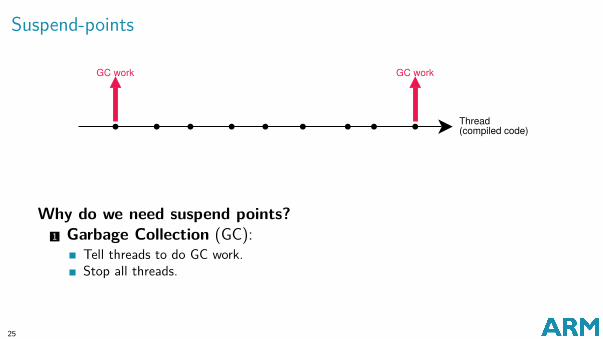
Suspend-points
Why do we need suspend points?1 Garbage Collection (GC):
Tell threads to do GC work.Stop all threads.
25

Suspend-points
Why do we need suspend points?2 Profiling:
profiling data collected at suspend points. The suspend-point is used as acheck-point (task executed without suspending the thread).
26

Suspend-points
Why do we need suspend points?3 Debugging:
Full speed debugging: debug compiled code!Debugger may switch to interpreter to handle breakpoints, etc. →deoptimization.
27
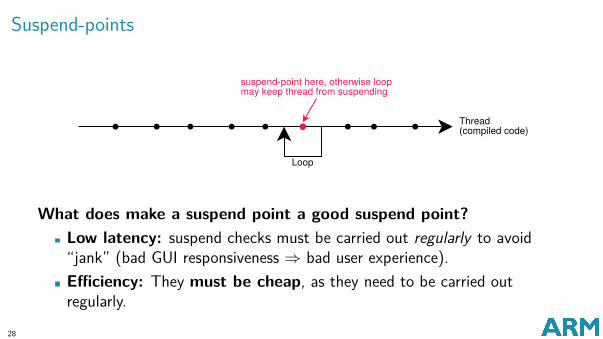
Suspend-points
What does make a suspend point a good suspend point?Low latency: suspend checks must be carried out regularly to avoid“jank” (bad GUI responsiveness ⇒ bad user experience).Efficiency: They must be cheap, as they need to be carried outregularly.
28

How is suspension done?There are different implementations of suspend-points in ART.For A64, we reserve register w19. This is initially set toSUSPEND_CHECK_INTERVAL (= 1000). Then at suspend points,
all registers are flushed to stack.w19 decremented. If w19 == 0, suspend handler is called.handler suspends thread if needed and resets w19.method_entry:
... / Safe point: all registerssubs w19, w19, #1 <---|_ flushed to stack here.b.eq suspend_check_1
after_suspend_1:...ret
suspend_check_1:ldr x30, [x18, #1088]blr x30b after_suspend_1
29

Summary of first part
ART introduces AOT compilation.Consistency between compiled execution, interpreted execution, runtime.
Stack is carefully structured: it is parsed by runtime for GC, deoptimization, etc.Methodology based on suspend-points and deoptimization.
30

PART IIQuick Compiler: internal organisation
Intermediate Representations (IR) in Quick CompilerIRs translation phasesThe good and the bad
31

ART Quick Compiler: introduction
ART written to support multiple compilers.Quick Compiler is only option in Android Lollipop.Simple, fast, derived from Dalvik JIT.May be replaced/complemented by “optimizing compiler” in futureAndroid releases.
32

Intermediate Representations (IR) in Quick Compiler
Java method is the compilation unit for the Quick Compiler.dalvikvm64 calls the compiler, dex2oat, to generate OAT file in/data/dalvik-cache/arm64.dex2oat uses several threads to compile all the methods.
33
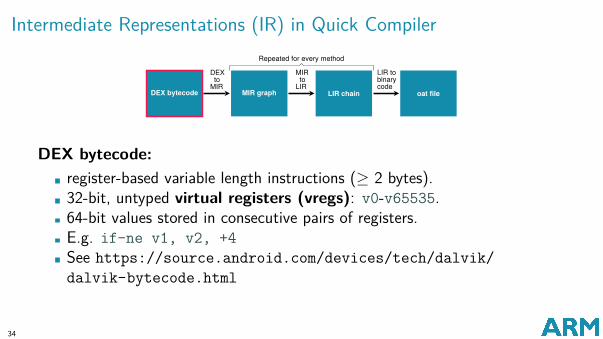
Intermediate Representations (IR) in Quick Compiler
DEX bytecode:register-based variable length instructions (≥ 2 bytes).32-bit, untyped virtual registers (vregs): v0-v65535.64-bit values stored in consecutive pairs of registers.E.g. if-ne v1, v2, +4See https://source.android.com/devices/tech/dalvik/dalvik-bytecode.html
34

Intermediate Representations (IR) in Quick Compiler
MIR: Mid-level Intermediate Representation:Methods as control-flow graphs made by sequences of MIR nodes(organised in basic blocks).Faithful to DEX bytecode: 1 DEX op → 1 MIR node.+ pseudo MIR nodes for annotation purposes.+ extended MIR nodes for optimisation purposes.
35
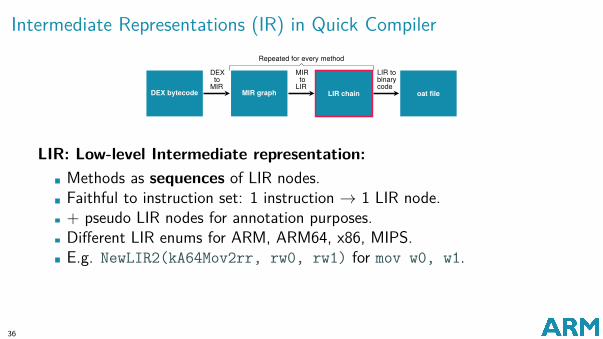
Intermediate Representations (IR) in Quick Compiler
LIR: Low-level Intermediate representation:Methods as sequences of LIR nodes.Faithful to instruction set: 1 instruction → 1 LIR node.+ pseudo LIR nodes for annotation purposes.Different LIR enums for ARM, ARM64, x86, MIPS.E.g. NewLIR2(kA64Mov2rr, rw0, rw1) for mov w0, w1.
36

Intermediate Representations (IR) in Quick Compiler
OAT file:Cached in /data/dalvik-cache/arm64.Contain binary executable code.Contain source DEX bytecode.Contain metadata for runtime (GC, deoptimization).
37
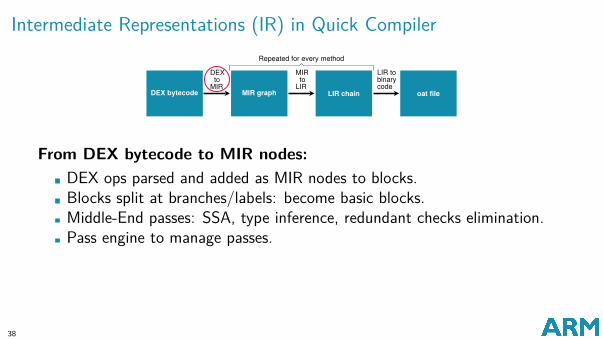
Intermediate Representations (IR) in Quick Compiler
From DEX bytecode to MIR nodes:DEX ops parsed and added as MIR nodes to blocks.Blocks split at branches/labels: become basic blocks.Middle-End passes: SSA, type inference, redundant checks elimination.Pass engine to manage passes.
38
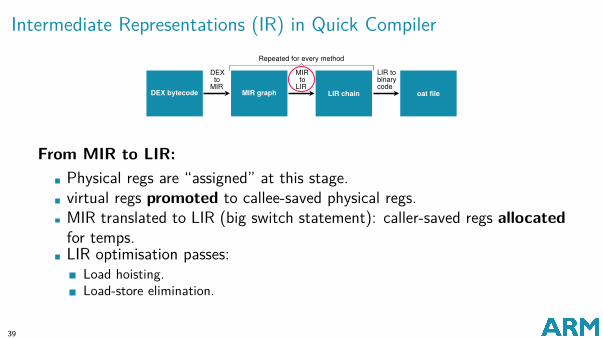
Intermediate Representations (IR) in Quick Compiler
From MIR to LIR:Physical regs are “assigned” at this stage.virtual regs promoted to callee-saved physical regs.MIR translated to LIR (big switch statement): caller-saved regs allocatedfor temps.LIR optimisation passes:
Load hoisting.Load-store elimination.
39

Intermediate Representations (IR) in Quick Compiler
From LIR to native:Fixups (branches resolved, instructions replaced if args out-of-range).LIR translated to binary code.Global (inter-method) fixups.
40

The good and the badThe good:
ART is typically 80% faster than Dalvik (Google I/O 2014 - The ARTRuntime).Quick compiler is quick indeed (on target device must be able to producehundreds of MBs in minutes).
The bad:LIR, MIR are sequences of nodes, rather than graphs:
Difficult to detect dead code and perform code motion.Difficult to detect instructions sequences (and replace them with better ones).
MIR and LIR are quite different representations: difficult to shareoptimisation passes among the two.
41

PART IIIExample of generated code and discussion
42

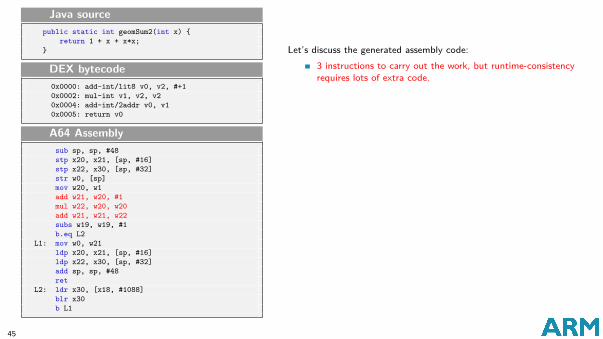
Simple example: Java source and DEX bytecodeConsider a very simple Java method:
Java sourcepublic static int geomSum2(int x) {
return 1 + x + x*x;}
Its DEX bytecode is shown below:
DEX bytecode0x0000: add-int/lit8 v0, v2, #+10x0002: mul-int v1, v2, v20x0004: add-int/2addr v0, v10x0005: return v0
This is an extreme case (very short leaf method), but is still useful tounderstand the overheads.
43

Java sourcepublic static int geomSum2(int x) {
return 1 + x + x*x;}
DEX bytecode0x0000: add-int/lit8 v0, v2, #+10x0002: mul-int v1, v2, v20x0004: add-int/2addr v0, v10x0005: return v0
A64 Assemblysub sp, sp, #48stp x20, x21, [sp, #16]stp x22, x30, [sp, #32]str w0, [sp]mov w20, w1add w21, w20, #1mul w22, w20, w20add w21, w21, w22subs w19, w19, #1b.eq L2
L1: mov w0, w21ldp x20, x21, [sp, #16]ldp x22, x30, [sp, #32]add sp, sp, #48ret
L2: ldr x30, [x18, #1088]blr x30b L1
Let’s discuss the generated assembly code:
3 instructions to carry out the work, but runtime-consistencyrequires lots of extra code.Stack frame created in case transition to runtime happens.Arguments always flushed into stack or promoted registers(callee-saved registers).Need suspend point: for profiler, for GC.
Problems:Excessive spilling due to register promotion.Cost of stack frame maintainance paid even when nottransitioning to runtime.
Possible improvements:Method inlining.Two versions of same function: one for suspension, the otheroptimised.
44
Java sourcepublic static int geomSum2(int x) {
return 1 + x + x*x;}
DEX bytecode0x0000: add-int/lit8 v0, v2, #+10x0002: mul-int v1, v2, v20x0004: add-int/2addr v0, v10x0005: return v0
A64 Assemblysub sp, sp, #48stp x20, x21, [sp, #16]stp x22, x30, [sp, #32]str w0, [sp]mov w20, w1add w21, w20, #1mul w22, w20, w20add w21, w21, w22subs w19, w19, #1b.eq L2
L1: mov w0, w21ldp x20, x21, [sp, #16]ldp x22, x30, [sp, #32]add sp, sp, #48ret
L2: ldr x30, [x18, #1088]blr x30b L1
Let’s discuss the generated assembly code:3 instructions to carry out the work, but runtime-consistencyrequires lots of extra code.
Stack frame created in case transition to runtime happens.Arguments always flushed into stack or promoted registers(callee-saved registers).Need suspend point: for profiler, for GC.
Problems:Excessive spilling due to register promotion.Cost of stack frame maintainance paid even when nottransitioning to runtime.
Possible improvements:Method inlining.Two versions of same function: one for suspension, the otheroptimised.
45

Java sourcepublic static int geomSum2(int x) {
return 1 + x + x*x;}
DEX bytecode0x0000: add-int/lit8 v0, v2, #+10x0002: mul-int v1, v2, v20x0004: add-int/2addr v0, v10x0005: return v0
A64 Assemblysub sp, sp, #48stp x20, x21, [sp, #16]stp x22, x30, [sp, #32]str w0, [sp]mov w20, w1add w21, w20, #1mul w22, w20, w20add w21, w21, w22subs w19, w19, #1b.eq L2
L1: mov w0, w21ldp x20, x21, [sp, #16]ldp x22, x30, [sp, #32]add sp, sp, #48ret
L2: ldr x30, [x18, #1088]blr x30b L1
Let’s discuss the generated assembly code:3 instructions to carry out the work, but runtime-consistencyrequires lots of extra code.Stack frame created in case transition to runtime happens.
Arguments always flushed into stack or promoted registers(callee-saved registers).Need suspend point: for profiler, for GC.
Problems:Excessive spilling due to register promotion.Cost of stack frame maintainance paid even when nottransitioning to runtime.
Possible improvements:Method inlining.Two versions of same function: one for suspension, the otheroptimised.
46

Java sourcepublic static int geomSum2(int x) {
return 1 + x + x*x;}
DEX bytecode0x0000: add-int/lit8 v0, v2, #+10x0002: mul-int v1, v2, v20x0004: add-int/2addr v0, v10x0005: return v0
A64 Assemblysub sp, sp, #48stp x20, x21, [sp, #16]stp x22, x30, [sp, #32]str w0, [sp]mov w20, w1add w21, w20, #1mul w22, w20, w20add w21, w21, w22subs w19, w19, #1b.eq L2
L1: mov w0, w21ldp x20, x21, [sp, #16]ldp x22, x30, [sp, #32]add sp, sp, #48ret
L2: ldr x30, [x18, #1088]blr x30b L1
Let’s discuss the generated assembly code:3 instructions to carry out the work, but runtime-consistencyrequires lots of extra code.Stack frame created in case transition to runtime happens.Arguments always flushed into stack or promoted registers(callee-saved registers).
Need suspend point: for profiler, for GC.
Problems:Excessive spilling due to register promotion.Cost of stack frame maintainance paid even when nottransitioning to runtime.
Possible improvements:Method inlining.Two versions of same function: one for suspension, the otheroptimised.
47

Java sourcepublic static int geomSum2(int x) {
return 1 + x + x*x;}
DEX bytecode0x0000: add-int/lit8 v0, v2, #+10x0002: mul-int v1, v2, v20x0004: add-int/2addr v0, v10x0005: return v0
A64 Assemblysub sp, sp, #48stp x20, x21, [sp, #16]stp x22, x30, [sp, #32]str w0, [sp]mov w20, w1add w21, w20, #1mul w22, w20, w20add w21, w21, w22subs w19, w19, #1b.eq L2
L1: mov w0, w21ldp x20, x21, [sp, #16]ldp x22, x30, [sp, #32]add sp, sp, #48ret
L2: ldr x30, [x18, #1088]blr x30b L1
Let’s discuss the generated assembly code:3 instructions to carry out the work, but runtime-consistencyrequires lots of extra code.Stack frame created in case transition to runtime happens.Arguments always flushed into stack or promoted registers(callee-saved registers).Need suspend point: for profiler, for GC.
Problems:Excessive spilling due to register promotion.Cost of stack frame maintainance paid even when nottransitioning to runtime.
Possible improvements:Method inlining.Two versions of same function: one for suspension, the otheroptimised.
48

Java sourcepublic static int geomSum2(int x) {
return 1 + x + x*x;}
DEX bytecode0x0000: add-int/lit8 v0, v2, #+10x0002: mul-int v1, v2, v20x0004: add-int/2addr v0, v10x0005: return v0
A64 Assemblysub sp, sp, #48stp x20, x21, [sp, #16]stp x22, x30, [sp, #32]str w0, [sp]mov w20, w1add w21, w20, #1mul w22, w20, w20add w21, w21, w22subs w19, w19, #1b.eq L2
L1: mov w0, w21ldp x20, x21, [sp, #16]ldp x22, x30, [sp, #32]add sp, sp, #48ret
L2: ldr x30, [x18, #1088]blr x30b L1
Let’s discuss the generated assembly code:3 instructions to carry out the work, but runtime-consistencyrequires lots of extra code.Stack frame created in case transition to runtime happens.Arguments always flushed into stack or promoted registers(callee-saved registers).Need suspend point: for profiler, for GC.
Problems:Excessive spilling due to register promotion.Cost of stack frame maintainance paid even when nottransitioning to runtime.
Possible improvements:Method inlining.Two versions of same function: one for suspension, the otheroptimised.
49

Java sourcepublic static int geomSum2(int x) {
return 1 + x + x*x;}
DEX bytecode0x0000: add-int/lit8 v0, v2, #+10x0002: mul-int v1, v2, v20x0004: add-int/2addr v0, v10x0005: return v0
A64 Assemblysub sp, sp, #48stp x20, x21, [sp, #16]stp x22, x30, [sp, #32]str w0, [sp]mov w20, w1add w21, w20, #1mul w22, w20, w20add w21, w21, w22subs w19, w19, #1b.eq L2
L1: mov w0, w21ldp x20, x21, [sp, #16]ldp x22, x30, [sp, #32]add sp, sp, #48ret
L2: ldr x30, [x18, #1088]blr x30b L1
Let’s discuss the generated assembly code:3 instructions to carry out the work, but runtime-consistencyrequires lots of extra code.Stack frame created in case transition to runtime happens.Arguments always flushed into stack or promoted registers(callee-saved registers).Need suspend point: for profiler, for GC.
Problems:Excessive spilling due to register promotion.Cost of stack frame maintainance paid even when nottransitioning to runtime.
Possible improvements:Method inlining.Two versions of same function: one for suspension, the otheroptimised.
50

SummaryART introduces Ahead-Of-Time (AOT) compilation.Compatible with Dalvik, adds 64-bit support.Significant performance improvements w.r.t. Dalvik.Framework easier to extend. E.g. supports multiple compilers, GCs.Consistency between compiler, interpreter, runtime requires extra carefrom ART developers/contributors.
Further reading:A64 instruction set: http://community.arm.com/docs/DOC-7263.AAPCS64: http://infocenter.arm.com/help/topic/com.arm.doc.ihi0055b/IHI0055B_aapcs64.pdf:64-bit port of Android: http://community.arm.com/groups/android-community/blog/2014/12/03/more-presentations-on-porting-to-64-bit
51

Thank You
The trademarks featured in this presentation are registered and/or unregistered trademarks of ARMLimited (or its subsidiaries) in the EU and/or elsewhere. All rights reserved. All other marks featuredmay be trademarks of their respective owners.
52

Extra slides
53

A64 and ART
A64 AdvantagesLess code for 64-bit doubles & longMore registersCleaner instruction set
Assembler encodingUniform instruction selection
Ldm/stm vs stp/ldpOptimisations for exploiting stp/ldp
Compressed references
54

Deoptimization (transition compiled-code to interpreter)Transitions compiled-code to interpreter requires the so-calleddeoptimization. This is quite involved, and is simplified below:
Debug thread is told to initiate deoptimization, e.g. after Java DebugWire Protocol (JDWP) command.All threads are suspended.Their stack is altered installing interceptors (stubs).Threads are restarted.
Thread wakes up and enters deoptimization interceptor (stub).DeoptimizationException raised to go back to interpreter.Stack parsed: quick frames translated to interpreter frames.Interpreter resumes execution using translated frames.
55

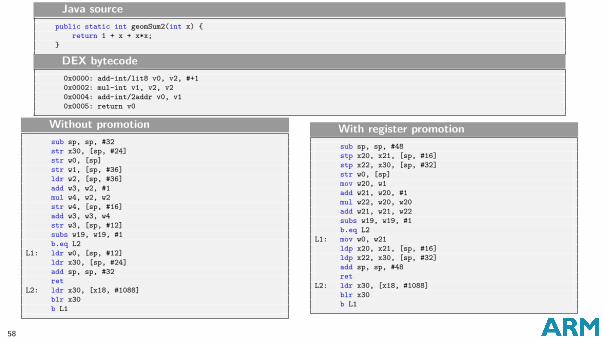
MIR to LIR: Register allocation
One virtual register can be associated to two kinds of “home locations”:A slot in the method’s stack frame.A callee-saved register (r20-r29). We then say it has been “promoted”.
Register promotion performed before MIR to LIR translation:MIR graph scanned. References to vregs are counted.vregs promoted: frequently used vregs are promoted first until all callee-saved registershave been used.Mapping done globally over method.One vreg can be promoted multiple times (e.g. v1 → w25, s10).
56

Register locations and register promotion
After register promotion, MIR to LIR starts.During LIR code generation:
Caller-saved registers (r0-r17) used as temps.Non-promoted vregs loaded from stack to temp reg.If temp (containing vreg) changes, it becomes dirty.At safe points everything back to home location: all dirty temporary registers arehence flushed back to the stack.
57
Java sourcepublic static int geomSum2(int x) {
return 1 + x + x*x;}
DEX bytecode0x0000: add-int/lit8 v0, v2, #+10x0002: mul-int v1, v2, v20x0004: add-int/2addr v0, v10x0005: return v0
Without promotionsub sp, sp, #32str x30, [sp, #24]str w0, [sp]str w1, [sp, #36]ldr w2, [sp, #36]add w3, w2, #1mul w4, w2, w2str w4, [sp, #16]add w3, w3, w4str w3, [sp, #12]subs w19, w19, #1b.eq L2
L1: ldr w0, [sp, #12]ldr x30, [sp, #24]add sp, sp, #32ret
L2: ldr x30, [x18, #1088]blr x30b L1
With register promotionsub sp, sp, #48stp x20, x21, [sp, #16]stp x22, x30, [sp, #32]str w0, [sp]mov w20, w1add w21, w20, #1mul w22, w20, w20add w21, w21, w22subs w19, w19, #1b.eq L2
L1: mov w0, w21ldp x20, x21, [sp, #16]ldp x22, x30, [sp, #32]add sp, sp, #48ret
L2: ldr x30, [x18, #1088]blr x30b L1
58

Short call tree for the Quick Compiler
Approximate call tree in the Quick Compiler:quick_compiler.cc: QuickCompiler::Compile()--> frontend.cc: CompileOneMethod()
--> frontend.cc: CompileMethod()--> mir_graph.cc: mir_graph->InlineMethod() // Generate MIR graph--> pass_driver.h: pass_driver->Launch() // Optimise MIR graph--> codegen_util.cc: mir2lir->Materialize() // Compile MIR graph
--> ralloc_util.cc: mir2lir->SimpleRegAlloc() // Register promotion--> mir_to_lir.cc: mir2lir->MethodMIR2LIR() // MIR to LIR: iter over basic blocks--> mir2lir->MethodBlockCodeGen() // MIR to LIR for one basic block
--> GenEntrySequence(), GenExitSequence(),HandleExtendedMethodMIR()
--> CompileDalvikInstruction() // Big switch over MIR node type--> call lots of methods,
many are in gen_common.cc--> assemble_$ARCH.cc: mir2lir->AssembleLIR() // Map LIR to binary
59


















