
High-Performance Computing for Stencil Computations Using...
42
. . High-Performance Computing for Stencil Computations Using a High-Level Domain-Specific Language Justin Holewinski Tom Henretty Kevin Stock Louis-No¨ el Pouchet Atanas Rountev P. Sadayappan Department of Computer Science and Engineering The Ohio State University Presented at WOLFHPC 2011 May 31, 2011 Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 1
Transcript of High-Performance Computing for Stencil Computations Using...

.
......
High-Performance Computing forStencil Computations Using a
High-Level Domain-Specific Language
Justin Holewinski Tom Henretty Kevin StockLouis-Noel Pouchet Atanas Rountev P. Sadayappan
Department of Computer Science and EngineeringThe Ohio State University
Presented at WOLFHPC 2011
May 31, 2011
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 1

Stencil Computations
5-pt 2D Stencil 9-pt 2D Stencil
1 for(i = 1; i < N-1; ++i) {2 for(j = 1; j < N-1; ++j) {3 A[i][j] = CNST * (B[i ][j ] +4 B[i ][j-1] +5 B[i ][j+1] +6 B[i-1][j ] +7 B[i+1][j ]);8 }9 }
▶ Operate on each point in a discrete n-dimensional space▶ Use neighboring points in computation▶ Often surrounded by time loop▶ Have diverse boundary conditions
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 2

Domain-Specific Language for Stencils
Why do we need a domain-specific language?
▶ Easier for application developers and scientists▶ Write stencil as point-function and grid instead of loop nest
▶ More opportunity for compiler optimization▶ Restricted to a simple expression language▶ Not restricted by C/C++/Fortran specification
e.g. aliasing, memory life-cycle▶ Control-flow is implicit instead of discovered at compile-time▶ Iteration domain is easily obtained, enabling polyhedral
transformations for tiling, parallelism, memory optimizations▶ Computations on grids ease dependency analysis
.Goal..
......Use high-level abstractions to achieve write-once performanceportability for stencil computations.
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 3

Domain-Specific Language for Stencils
Why do we need a domain-specific language?▶ Easier for application developers and scientists
▶ Write stencil as point-function and grid instead of loop nest
▶ More opportunity for compiler optimization▶ Restricted to a simple expression language▶ Not restricted by C/C++/Fortran specification
e.g. aliasing, memory life-cycle▶ Control-flow is implicit instead of discovered at compile-time▶ Iteration domain is easily obtained, enabling polyhedral
transformations for tiling, parallelism, memory optimizations▶ Computations on grids ease dependency analysis
.Goal..
......Use high-level abstractions to achieve write-once performanceportability for stencil computations.
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 4

Domain-Specific Language for Stencils
Why do we need a domain-specific language?▶ Easier for application developers and scientists
▶ Write stencil as point-function and grid instead of loop nest▶ More opportunity for compiler optimization
▶ Restricted to a simple expression language▶ Not restricted by C/C++/Fortran specification
e.g. aliasing, memory life-cycle▶ Control-flow is implicit instead of discovered at compile-time▶ Iteration domain is easily obtained, enabling polyhedral
transformations for tiling, parallelism, memory optimizations▶ Computations on grids ease dependency analysis
.Goal..
......Use high-level abstractions to achieve write-once performanceportability for stencil computations.
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 5

Domain-Specific Language for Stencils
Why do we need a domain-specific language?▶ Easier for application developers and scientists
▶ Write stencil as point-function and grid instead of loop nest▶ More opportunity for compiler optimization
▶ Restricted to a simple expression language▶ Not restricted by C/C++/Fortran specification
e.g. aliasing, memory life-cycle▶ Control-flow is implicit instead of discovered at compile-time▶ Iteration domain is easily obtained, enabling polyhedral
transformations for tiling, parallelism, memory optimizations▶ Computations on grids ease dependency analysis
.Goal..
......Use high-level abstractions to achieve write-once performanceportability for stencil computations.
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 6
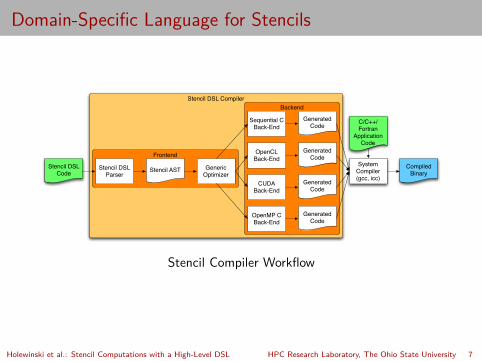
Domain-Specific Language for Stencils
C/C++/Fortran
Application Code
Stencil DSL Code
SystemCompiler(gcc, icc)
CompiledBinary
Stencil DSL CompilerBackend
Generated Code
OpenMP CBack-End
CUDABack-End
OpenCLBack-End
Sequential CBack-End
Generated Code
Generated Code
Generated CodeFrontend
Stencil DSLParser
Stencil AST GenericOptimizer
Stencil Compiler Workflow
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 7

Domain-Specific Language for Stencils
Define stencil operation as a point-function over a grid using[time]grid[i-offset][j-offset] notation:
1 pointfunction five_point_avg(p) {2 float ONE_FIFTH;3 ONE_FIFTH = 0.2;4 [1]p[0][0] = ONE_FIFTH*([0]p[-1][0] + [0]p[0][-1] + [0]p[0][0]5 + [0]p[0][1] + [0]p[1][0]);6 }
Define stencil range, functions, and convergence:1 iterate 1000 {2 stencil jacobi_2d {3 [0][0:Nx-1] : [1]a[0][0] = [0]a[0][0];4 [Ny-1][0:Nx-1] : [1]a[0][0] = [0]a[0][0];5 [0:Ny-1][0] : [1]a[0][0] = [0]a[0][0];6 [0:Ny-1][Nx-1] : [1]a[0][0] = [0]a[0][0];78 [1:Ny-2][1:Nx-2] : five_point_avg(a);9 }
1011 reduction max_diff max {12 [0:Ny-1][0:Nx-1] : [1]a[0][0] - [0]a[0][0];13 }14 } check (max_diff < .00001) every 4 iterations
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 8

Domain-Specific Language for Stencils
Define stencil operation as a point-function over a grid using[time]grid[i-offset][j-offset] notation:
1 pointfunction five_point_avg(p) {2 float ONE_FIFTH;3 ONE_FIFTH = 0.2;4 [1]p[0][0] = ONE_FIFTH*([0]p[-1][0] + [0]p[0][-1] + [0]p[0][0]5 + [0]p[0][1] + [0]p[1][0]);6 }
Define stencil range, functions, and convergence:1 iterate 1000 {2 stencil jacobi_2d {3 [0][0:Nx-1] : [1]a[0][0] = [0]a[0][0];4 [Ny-1][0:Nx-1] : [1]a[0][0] = [0]a[0][0];5 [0:Ny-1][0] : [1]a[0][0] = [0]a[0][0];6 [0:Ny-1][Nx-1] : [1]a[0][0] = [0]a[0][0];78 [1:Ny-2][1:Nx-2] : five_point_avg(a);9 }
1011 reduction max_diff max {12 [0:Ny-1][0:Nx-1] : [1]a[0][0] - [0]a[0][0];13 }14 } check (max_diff < .00001) every 4 iterations
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 9

Domain-Specific Language for Stencils
1 int Nx;2 int Ny;3 grid g [Ny][Nx];45 float griddata a on g at 0,1;67 pointfunction five_point_avg(p) {8 float ONE_FIFTH;9 ONE_FIFTH = 0.2;
10 [1]p[0][0] = ONE_FIFTH*([0]p[-1][0] + [0]p[0][-1] + [0]p[0][0]11 + [0]p[0][1] + [0]p[1][0]);12 }1314 iterate 1000 {15 stencil jacobi_2d {16 [0][0:Nx-1] : [1]a[0][0] = [0]a[0][0];17 [Ny-1][0:Nx-1] : [1]a[0][0] = [0]a[0][0];18 [0:Ny-1][0] : [1]a[0][0] = [0]a[0][0];19 [0:Ny-1][Nx-1] : [1]a[0][0] = [0]a[0][0];2021 [1:Ny-2][1:Nx-2] : five_point_avg(a);22 }2324 reduction max_diff max {25 [0:Ny-1][0:Nx-1] : [1]a[0][0] - [0]a[0][0];26 }27 } check (max_diff < .00001) every 4 iterations
Complete stencil programHolewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 10

Optimizing CPU vs. GPU PerformanceFloating-Point Throughput
▶ Need fine-grain and coarse-grain parallelism
▶ On a CPU▶ Use vector processing units (SIMD)▶ Use threads to exploit multi-/many-cores
▶ On a GPU▶ Exploit SIMT parallelism across hundreds of cores▶ Multiprocessors operate in lock-step ⇒ divergence = BAD
But this is not the whole story...
10x41 1202x58520
2
4
6
8
10
12
14
16
18
GFl
op/s
Bandwidth Starved
Jacobi 5-pt on Core i7 2600K (single-threaded, no time tiling)
base
AVX intrinsics
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 11

Optimizing CPU vs. GPU PerformanceFloating-Point Throughput
▶ Need fine-grain and coarse-grain parallelism▶ On a CPU
▶ Use vector processing units (SIMD)▶ Use threads to exploit multi-/many-cores
▶ On a GPU▶ Exploit SIMT parallelism across hundreds of cores▶ Multiprocessors operate in lock-step ⇒ divergence = BAD
But this is not the whole story...
10x41 1202x58520
2
4
6
8
10
12
14
16
18
GFl
op/s
Bandwidth Starved
Jacobi 5-pt on Core i7 2600K (single-threaded, no time tiling)
base
AVX intrinsics
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 12

Optimizing CPU vs. GPU PerformanceFloating-Point Throughput
▶ Need fine-grain and coarse-grain parallelism▶ On a CPU
▶ Use vector processing units (SIMD)▶ Use threads to exploit multi-/many-cores
▶ On a GPU▶ Exploit SIMT parallelism across hundreds of cores▶ Multiprocessors operate in lock-step ⇒ divergence = BAD
But this is not the whole story...
10x41 1202x58520
2
4
6
8
10
12
14
16
18
GFl
op/s
Bandwidth Starved
Jacobi 5-pt on Core i7 2600K (single-threaded, no time tiling)
base
AVX intrinsics
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 13
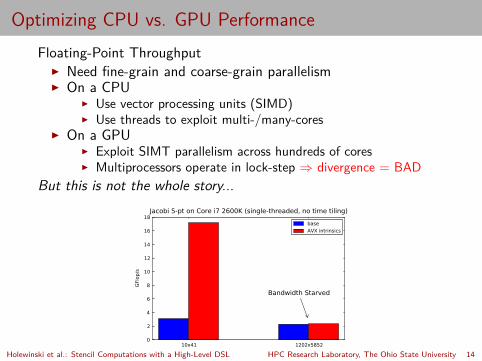
Optimizing CPU vs. GPU PerformanceFloating-Point Throughput
▶ Need fine-grain and coarse-grain parallelism▶ On a CPU
▶ Use vector processing units (SIMD)▶ Use threads to exploit multi-/many-cores
▶ On a GPU▶ Exploit SIMT parallelism across hundreds of cores▶ Multiprocessors operate in lock-step ⇒ divergence = BAD
But this is not the whole story...
10x41 1202x58520
2
4
6
8
10
12
14
16
18
GFl
op/s
Bandwidth Starved
Jacobi 5-pt on Core i7 2600K (single-threaded, no time tiling)
base
AVX intrinsics
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 14

Optimizing CPU vs. GPU Performance
Memory Hierarchy▶ Increasingly complex (multiple levels)▶ Fast but small on-chip memory▶ Slow but abundant off-chip memory
▶ On a CPU▶ Exploit hardware caches through data re-use
▶ On a GPU▶ Exploit per-multiprocessor shared/local memory▶ Maximize work per read/write operation
▶ Need time tiling to efficiently utilize available main memorybandwidth
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 15

Optimizing CPU vs. GPU Performance
Memory Hierarchy▶ Increasingly complex (multiple levels)▶ Fast but small on-chip memory▶ Slow but abundant off-chip memory▶ On a CPU
▶ Exploit hardware caches through data re-use
▶ On a GPU▶ Exploit per-multiprocessor shared/local memory▶ Maximize work per read/write operation
▶ Need time tiling to efficiently utilize available main memorybandwidth
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 16

Optimizing CPU vs. GPU Performance
Memory Hierarchy▶ Increasingly complex (multiple levels)▶ Fast but small on-chip memory▶ Slow but abundant off-chip memory▶ On a CPU
▶ Exploit hardware caches through data re-use▶ On a GPU
▶ Exploit per-multiprocessor shared/local memory▶ Maximize work per read/write operation
▶ Need time tiling to efficiently utilize available main memorybandwidth
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 17

Optimizing Stencils on GPUsTypical Approach
▶ Use spatial tiling to distribute work among thread blocks▶ Use shared/local memory as program-controlled cache
Problems▶ Global (off-chip) memory latency is high▶ Limited data re-use within a thread block▶ Cannot schedule enough threads to hide memory latency▶ Traditional time tiling is not efficient due to branch divergence
and a lack of memory access coalescingResult
▶ Compute units are mostly idle waiting for memory operationsto complete
A possible solution?▶ Overlapped tiling
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 18

Optimizing Stencils on GPUsTypical Approach
▶ Use spatial tiling to distribute work among thread blocks▶ Use shared/local memory as program-controlled cache
Problems▶ Global (off-chip) memory latency is high▶ Limited data re-use within a thread block▶ Cannot schedule enough threads to hide memory latency▶ Traditional time tiling is not efficient due to branch divergence
and a lack of memory access coalescing
Result▶ Compute units are mostly idle waiting for memory operations
to completeA possible solution?
▶ Overlapped tiling
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 19

Optimizing Stencils on GPUsTypical Approach
▶ Use spatial tiling to distribute work among thread blocks▶ Use shared/local memory as program-controlled cache
Problems▶ Global (off-chip) memory latency is high▶ Limited data re-use within a thread block▶ Cannot schedule enough threads to hide memory latency▶ Traditional time tiling is not efficient due to branch divergence
and a lack of memory access coalescingResult
▶ Compute units are mostly idle waiting for memory operationsto complete
A possible solution?▶ Overlapped tiling
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 20

Optimizing Stencils on GPUsTypical Approach
▶ Use spatial tiling to distribute work among thread blocks▶ Use shared/local memory as program-controlled cache
Problems▶ Global (off-chip) memory latency is high▶ Limited data re-use within a thread block▶ Cannot schedule enough threads to hide memory latency▶ Traditional time tiling is not efficient due to branch divergence
and a lack of memory access coalescingResult
▶ Compute units are mostly idle waiting for memory operationsto complete
A possible solution?▶ Overlapped tiling
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 21

Overlapped Tiling
Replace inter-tile communication with redundant computation▶ Tile borders are redundantly computed by all neighboring tiles▶ Trades extra FLOPs for a decrease in needed synchronization▶ Enables time tiling without skewing (introduces divergence,
load imbalance, and bank conflicts)
Originally proposed by Krishnamoorthy et al. for parallelization▶ We want fully-automatic code generation for arbitrary stencils▶ Use OpenCL for performance-portable code generation, but
tune parameters for different GPU architectures
Let us look at an example for a 2× 2 tile with a time tile size of 2...
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 22

Overlapped Tiling
Replace inter-tile communication with redundant computation▶ Tile borders are redundantly computed by all neighboring tiles▶ Trades extra FLOPs for a decrease in needed synchronization▶ Enables time tiling without skewing (introduces divergence,
load imbalance, and bank conflicts)Originally proposed by Krishnamoorthy et al. for parallelization
▶ We want fully-automatic code generation for arbitrary stencils▶ Use OpenCL for performance-portable code generation, but
tune parameters for different GPU architectures
Let us look at an example for a 2× 2 tile with a time tile size of 2...
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 23

Overlapped Tiling
Replace inter-tile communication with redundant computation▶ Tile borders are redundantly computed by all neighboring tiles▶ Trades extra FLOPs for a decrease in needed synchronization▶ Enables time tiling without skewing (introduces divergence,
load imbalance, and bank conflicts)Originally proposed by Krishnamoorthy et al. for parallelization
▶ We want fully-automatic code generation for arbitrary stencils▶ Use OpenCL for performance-portable code generation, but
tune parameters for different GPU architectures
Let us look at an example for a 2× 2 tile with a time tile size of 2...
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 24

Overlapped Tiling
Tile at time t +1
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 25

Overlapped Tiling
Data needed at time t +1
Computed in time step t
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 26

Overlapped Tiling
Computation at time t
Also computed by neighboring tiles
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 27

Overlapped Tiling
Data needed at time t
Halo/Shadow data
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 28

Overlapped TilingGPU Implementation
▶ Schedule extra threads for redundant border cell computations▶ In general, need (n + 2 ∗ r ∗ (t − 1))× (m + 2 ∗ r ∗ (t − 1))
threads
▶ Use shared memory to store results across time▶ Only need to access global memory in first and last time step
of tile▶ Synchronize threads, not blocks, after each time step
▶ Thread synchronization efficiently supported in hardware;block synchronization is not
▶ Use host to synchronize across time tiles1 for(t = 0; t < TIME_STEPS; t += TIME_TILE_SIZE) {2 invoke_kernel(input, output);3 swap(input, output);4 // Implicit barrier5 }
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 29

Overlapped TilingGPU Implementation
▶ Schedule extra threads for redundant border cell computations▶ In general, need (n + 2 ∗ r ∗ (t − 1))× (m + 2 ∗ r ∗ (t − 1))
threads
▶ Use shared memory to store results across time▶ Only need to access global memory in first and last time step
of tile
▶ Synchronize threads, not blocks, after each time step▶ Thread synchronization efficiently supported in hardware;
block synchronization is not▶ Use host to synchronize across time tiles
1 for(t = 0; t < TIME_STEPS; t += TIME_TILE_SIZE) {2 invoke_kernel(input, output);3 swap(input, output);4 // Implicit barrier5 }
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 30

Overlapped TilingGPU Implementation
▶ Schedule extra threads for redundant border cell computations▶ In general, need (n + 2 ∗ r ∗ (t − 1))× (m + 2 ∗ r ∗ (t − 1))
threads
▶ Use shared memory to store results across time▶ Only need to access global memory in first and last time step
of tile▶ Synchronize threads, not blocks, after each time step
▶ Thread synchronization efficiently supported in hardware;block synchronization is not
▶ Use host to synchronize across time tiles1 for(t = 0; t < TIME_STEPS; t += TIME_TILE_SIZE) {2 invoke_kernel(input, output);3 swap(input, output);4 // Implicit barrier5 }
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 31

Overlapped TilingGPU Implementation
▶ Schedule extra threads for redundant border cell computations▶ In general, need (n + 2 ∗ r ∗ (t − 1))× (m + 2 ∗ r ∗ (t − 1))
threads
▶ Use shared memory to store results across time▶ Only need to access global memory in first and last time step
of tile▶ Synchronize threads, not blocks, after each time step
▶ Thread synchronization efficiently supported in hardware;block synchronization is not
▶ Use host to synchronize across time tiles1 for(t = 0; t < TIME_STEPS; t += TIME_TILE_SIZE) {2 invoke_kernel(input, output);3 swap(input, output);4 // Implicit barrier5 }
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 32

What about block size?Block size considerations
▶ Block size has large impact on performance▶ Need enough threads to keep compute units busy...
▶ ... but it is also beneficial to use smaller blocks to increase thenumber of available registers per block
▶ Problem size: 4096× 4096× 256
10 20 30 40 50 60
Block Size (X)
10
20
30
40
50
60
Blo
ck S
ize (
Y)
NVidia Tesla C2050 (GFlop/s)
0
15
30
45
60
75
90
105
120
135
10 15 20 25 30
Block Size (X)
10
15
20
25
30
Blo
ck S
ize (
Y)
AMD Radeon HD 6970 (GFlop/s)
0
15
30
45
60
75
90
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 33

What about block size?Block size considerations
▶ Block size has large impact on performance▶ Need enough threads to keep compute units busy...▶ ... but it is also beneficial to use smaller blocks to increase the
number of available registers per block
▶ Problem size: 4096× 4096× 256
10 20 30 40 50 60
Block Size (X)
10
20
30
40
50
60
Blo
ck S
ize (
Y)
NVidia Tesla C2050 (GFlop/s)
0
15
30
45
60
75
90
105
120
135
10 15 20 25 30
Block Size (X)
10
15
20
25
30
Blo
ck S
ize (
Y)
AMD Radeon HD 6970 (GFlop/s)
0
15
30
45
60
75
90
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 34

What about block size?Block size considerations
▶ Block size has large impact on performance▶ Need enough threads to keep compute units busy...▶ ... but it is also beneficial to use smaller blocks to increase the
number of available registers per block▶ Problem size: 4096× 4096× 256
10 20 30 40 50 60
Block Size (X)
10
20
30
40
50
60
Blo
ck S
ize (
Y)
NVidia Tesla C2050 (GFlop/s)
0
15
30
45
60
75
90
105
120
135
10 15 20 25 30
Block Size (X)
10
15
20
25
30
Blo
ck S
ize (
Y)
AMD Radeon HD 6970 (GFlop/s)
0
15
30
45
60
75
90
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 35
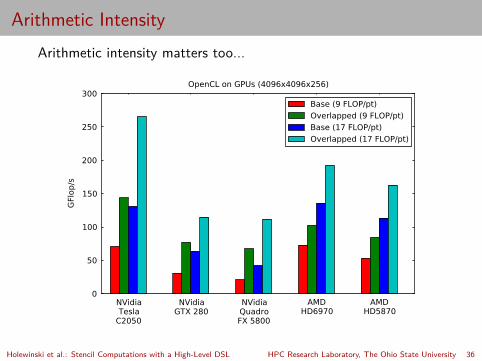
Arithmetic IntensityArithmetic intensity matters too...
NVidiaTesla
C2050
NVidiaGTX 280
NVidiaQuadroFX 5800
AMDHD6970
AMDHD5870
0
50
100
150
200
250
300
GFl
op/s
OpenCL on GPUs (4096x4096x256)
Base (9 FLOP/pt)
Overlapped (9 FLOP/pt)
Base (17 FLOP/pt)
Overlapped (17 FLOP/pt)
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 36

Performance
512 1024 2048 4096 8192
Problem Size (N x N)
0
2
4
6
8
10
12
14
16
GFl
op/s
Jacobi 5-pt on Multi-Core with OpenMP
Intel Xeon E5640
Intel Core i7 2600K
Intel Core 2 Quad Q6600
AMD Phenom 9850
512 1024 2048 4096 8192
Problem Size (N x N)
0
20
40
60
80
100
GFl
op/s
Jacobi 5-pt on GPU with OpenCL
NVidia GTX 280
NVidia Tesla C2050
AMD Radeon HD6970
AMD Radeon HD5870
▶ Fixed CPU tile sizes▶ Fixed GPU block/tile sizes
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 37

Conclusion
▶ A DSL for stencils enables high productivity and performance▶ Higher-level for application developers▶ More information for compilers▶ Increased performance-portability
▶ Overlapped tiling enables high-performance stencils on GPUs▶ Trade redundant computation for less communication▶ Exploit high compute-per-memory-op ratio on GPUs
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 38

Questions?
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 39

Performance Evaluation
IntelXeon E56404 Threads
NVidiaTesla C2050
Base
NVidiaTesla C2050Overlapped
0
500
1000
1500
2000
2500
3000
3500
4000Ela
pse
d T
ime (
ms)
Jacobi 5-pt on CPU and GPU (4096x4096x256)
GPU Block Size: 64× 8 (512 of 1024 max)
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 40
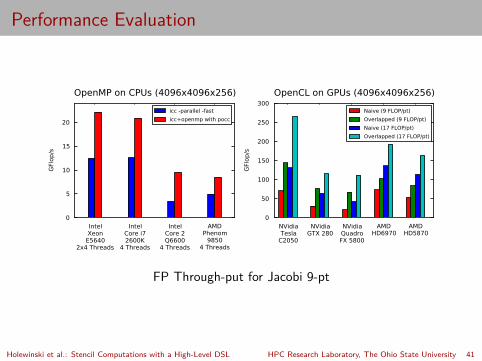
Performance Evaluation
IntelXeonE5640
2x4 Threads
IntelCore i72600K
4 Threads
IntelCore 2Q6600
4 Threads
AMDPhenom
98504 Threads
0
5
10
15
20
GFl
op/s
OpenMP on CPUs (4096x4096x256)
icc -parallel -fast
icc+openmp with pocc
NVidiaTesla
C2050
NVidiaGTX 280
NVidiaQuadroFX 5800
AMDHD6970
AMDHD5870
0
50
100
150
200
250
300
GFl
op/s
OpenCL on GPUs (4096x4096x256)
Naive (9 FLOP/pt)
Overlapped (9 FLOP/pt)
Naive (17 FLOP/pt)
Overlapped (17 FLOP/pt)
FP Through-put for Jacobi 9-pt
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 41
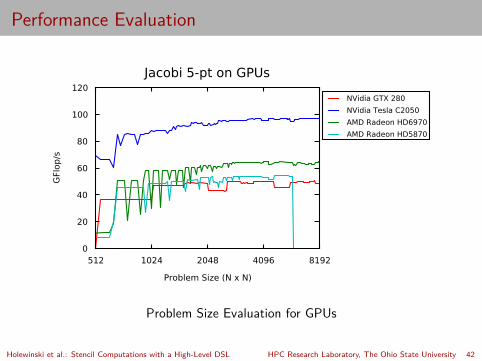
Performance Evaluation
512 1024 2048 4096 8192
Problem Size (N x N)
0
20
40
60
80
100
120
GFl
op/s
Jacobi 5-pt on GPUs
NVidia GTX 280
NVidia Tesla C2050
AMD Radeon HD6970
AMD Radeon HD5870
Problem Size Evaluation for GPUs
Holewinski et al.: Stencil Computations with a High-Level DSL HPC Research Laboratory, The Ohio State University 42


















