
High dimesional data (FAST clustering ALG) PPT
21
Presented by DEEPAN SHAKARAVARTHY V M.Tech.,
-
Upload
deepan-v -
Category
Engineering
-
view
241 -
download
1
Transcript of High dimesional data (FAST clustering ALG) PPT

Presented by
DEEPAN SHAKARAVARTHY V M.Tech.,

Using FAST Algorithm to identify a subset.
Based on A fast clustering-based feature selection algorithm
(FAST) and experimentally evaluated.
Efficiency and effectiveness it adopt the efficient (MST)
clustering method.

Subset selection is an effective way for reducing
dimensionality.
Removing irrelevant data.
Increasing learning accuracy.
Improving results.

Accuracy of the learning algorithms is not
guaranteed.
Selected features is limited and the computational
complexity is large.
Many irrelevant and redundant features are
possible.

The selected features is limited.
The computational complexity is large.
The accuracy of the learning algorithms is not
guaranteed.

Forming clusters by using graph-theoretic
clustering methods.
Selection algorithms effectively eliminate
irrelevant features.
Achieve significant reduction of dimensionality.

It provide good feature subsets selection.
The efficiently deal with both irrelevant and redundant
features.
Totally find the duplicate data set.
Less time to find results.


Distributed clustering Subset Selection Algorithm Time complexity Microarray data Data source Irrelevant feature

Cluster words into groups.
Cluster evaluation measure based on distance.
Even compared with other feature selection
methods the obtained accuracy is lower.

The Irrelevant features, along with redundant
features.
Identify and remove as much of the irrelevant data.
Good feature subsets contain features highly
correlated.

Calculated in terms of the number of instances in a
given dataset.
Features selection as relevant ones in the first part.
Construct a complete graph from relevant feature.
Partitions the MST and choose the representative
features with the complexity.

Use to identify length of the data.
It manage a searchable index.
Subset selection feature has been improved.
FAST ranks 1 again with the proportion of
selected features.

Purposes of evaluating the performance and
effectiveness of our proposed FAST algorithm.
Data sets have more than 10,000 features.
Hospitality dataset is used.

Right relevance measure is selected
1. Minimum spanning tree
2. The partitioning of cluster
3. Representative features from the clusters

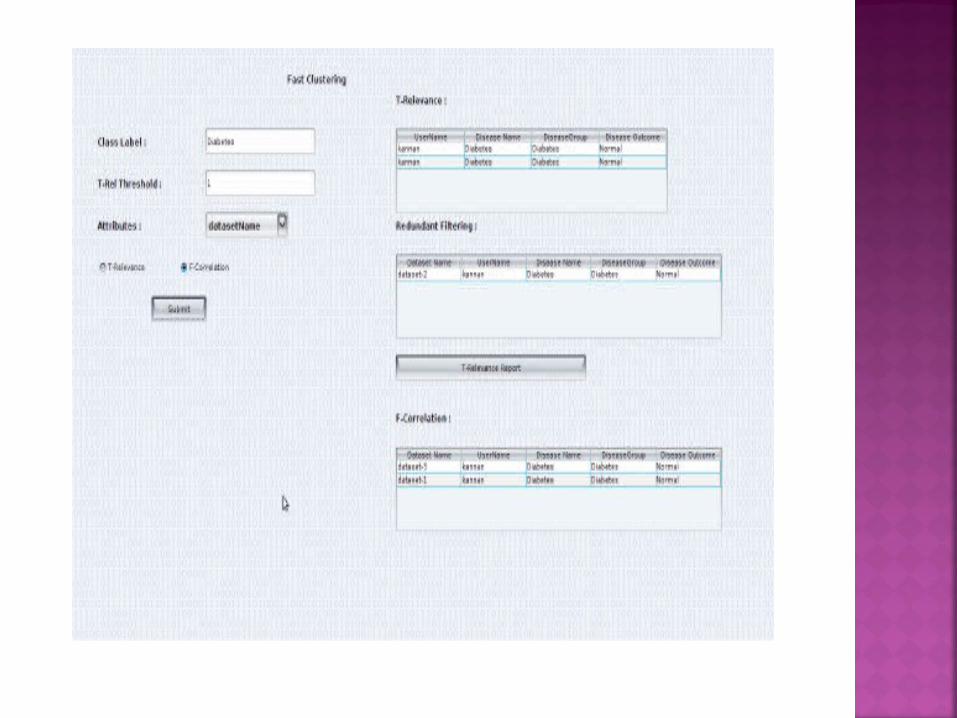


The conclusion of the project is a subset of good
features with respect to the target concepts.
Feature selection is used to cluster the related data
in databases.
Feature subset selection is an effective way for
reducing dimensionality, removing irrelevant data,
increasing learning accuracy.

[1] H. Almuallim and T.G. Dietterich, (1994), ““Algorithms for
Identifying Relevant Features,” Artificial Intelligence, vol. 69,
nos. 1/2, pp. 279-305.
[2] L.D. Baker and A.K. McCallum, (1998), “ Learning boolean
concepts in the presence of many irrelevant features,” Proc. 21st
Ann. Int’l ACM SIGIR Conf. Research and Development in
information Retrieval, pp. 96-103.
[3] Arauzo-Azofra, J.M. Benitez, and J.L. Castro, (2004), “A
Feature Set Measure Based on Relief,” Proc. Fifth Int’l Conf.
Recent Advances in Soft.



















