
Hadoop tutorials. Todays agenda Hadoop Introduction and Architecture Hadoop Distributed File System...
15
Hadoop tutorials
-
Upload
lilian-gibbs -
Category
Documents
-
view
243 -
download
2
Transcript of Hadoop tutorials. Todays agenda Hadoop Introduction and Architecture Hadoop Distributed File System...

Hadoop tutorials

2
Todays agenda
• Hadoop Introduction and Architecture• Hadoop Distributed File System• MapReduce• Spark

3
Cloudera Image for hands-on• Installation instruction• https://cern.ch/test-zbaranow/CVM.txt

Hadoop Introduction

5
What is Hadoop? (1)
• A framework for large scale data processing
• Volume
• Variety
• Velocity

6
What Hadoop is? (2)
• Solution for big data processing• Sequential data access – a brute force approach• Simplified data structures (no relational model)• Ideal for ad-hoc data analytics
• Instead of some clever data lookups with indexing etc.• Data analytic cases has to be known before hand• Complex data design
7
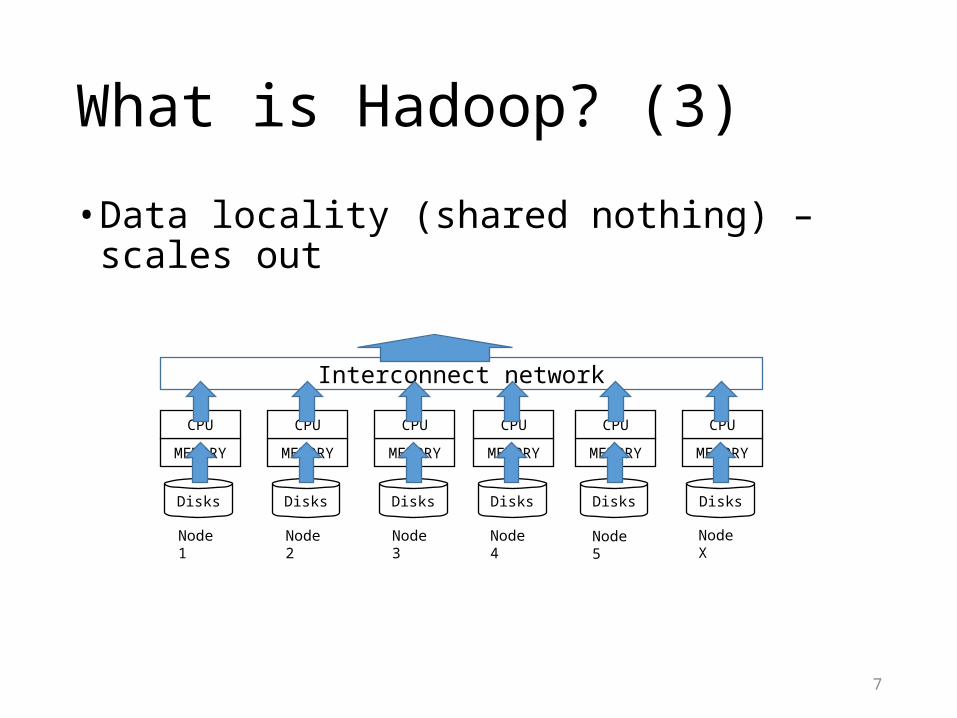
What is Hadoop? (3)
• Data locality (shared nothing) – scales out
Interconnect network
MEMORY
CPU
Disks
MEMORY
CPU
Disks
MEMORY
CPU
Disks
MEMORY
CPU
Disks
MEMORY
CPU
Disks
MEMORY
CPU
Disks
Node 1 Node 2 Node 3 Node 4 Node 5 Node X

8
What is Hadoop? (4)
• Optimized storage access (for HDD)• Big data blocks >=128MB• Seqential IO instead of Random IO
HDD drive 7200rpm speed:- Sequential IO: ~120MB/s- Random IO: 0.5 - 50MB/s

9
Hadoop eco system
HDFSHadoop Distributed File System
Hba
seN
oSql
col
umna
r sto
re
YARNCluster resource manager
MapReduce
Hiv
eSQ
L
Pig
Scrip
ting
Flum
eLo
g da
ta c
olle
ctor Sq
oop
Dat
a ex
chan
ge w
ith R
DBM
S
Ooz
ieW
orkfl
ow m
anag
er
Mah
out
Mac
hine
lear
ning
Zook
eepe
rCo
ordi
natio
n Impa
laSQ
L
Spar
kLa
rge
scal
e da
ta p
roce
esin
g

10
Hadoop cluster architecture• Master and slaves approach
Interconnect network
Node 1 Node 2 Node 3 Node 4 Node 5 Node X
HDFS DataNode
Various component agents and
masters
YARN Node Manager
HDFS NameNode
HDFS DataNode
Various component agents and
masters
YARN Node Manager
YARN ResourceManager
HDFS DataNode
Various component agents and
demons
YARN Node Manager
Hive metastore
HDFS DataNode
Various component agents and
demons
YARN Node Manager
HDFS DataNode
Various component agents and
demons
YARN Node Manager
HDFS DataNode
Various component agents and
demons
YARN Node Manager

11
What to not use the Hadoop for?• Online Transaction Processing system• No transactions• No locks• No data updates (only appends and overwrites)• Response time in seconds rather milliseconds
• Not good for systems with relational data• Interactive applications• Accounting systems• Etc.

12
What to use the Hadoop for?• For Big Data!
• Storing• Analysis
• Write once – read many• Scalable out system (CPU, IO, RAM)
• transparent to the users (data placement, data analysis)
• Good for data exploration:• in a batch fashion• statistics, aggregations, correlation
• Data warehouses• Logs
13
Hadoop @CERN
• 4 main clusters (provided by IT)• 16-20 machines each• 24GB – 256GB of RAM
• Main users• ATLAS (EventIndex, PandaMon, Rucio)• CASTOR logs• WLCG Dasboards• IT Monitoring• Computer Security• …
• Available services• HDFS, YARN (MR), Hbase, Hive, Pig, Spark, Impala (upcoming)
• Contact• SNOW: https://cern.service-now.com/service-portal/report-ticket.do?
name=request&se=Hadoop-Service

14
Summary
• Hadoop is a solution for massive data processing• Designed to scale out• On a commodity hardware• Optimized for sequential reads
• Hadoop architecture• HDFS is a core• Many components with multiple functionalities
distributed across cluster nodes

15
Questions?


















