Hadoop Tutorial with @techmilind
91
Hadoop Overview & Architecture Milind Bhandarkar Chief Scientist, Machine Learning Platforms, Greenplum, A Division of EMC (Twitter: @techmilind)
-
Upload
emc-academic-alliance -
Category
Technology
-
view
106 -
download
1
description
Apache Hadoop has emerged as the storage and processing platform of choice for Big Data. In this tutorial, I will give an overview of Apache Hadoop and its ecosystem, with specific use cases. I will explain the MapReduce programming framework in detail, and outline how it interacts with Hadoop Distributed File System (HDFS). While Hadoop is written in Java, MapReduce applications can be written using a variety of languages using a framework called Hadoop Streaming. I will give several examples of MapReduce applications using Hadoop Streaming.
Transcript of Hadoop Tutorial with @techmilind

Hadoop Overview & Architecture
Milind Bhandarkar Chief Scientist, Machine Learning Platforms,
Greenplum, A Division of EMC (Twitter: @techmilind)

About Me • http://www.linkedin.com/in/milindb
• Founding member of Hadoop team at Yahoo! [2005-2010]
• Contributor to Apache Hadoop since v0.1
• Built and led Grid Solutions Team at Yahoo! [2007-2010]
• Parallel Programming Paradigms [1989-today] (PhD cs.illinois.edu)
• Center for Development of Advanced Computing (C-DAC), National Center for Supercomputing Applications (NCSA), Center for Simulation of Advanced Rockets, Siebel Systems, Pathscale Inc. (acquired by QLogic), Yahoo!, LinkedIn, and EMC-Greenplum

2
Agenda • Motivation
• Hadoop
• Map-Reduce
• Distributed File System
• Hadoop Architecture
• Next Generation MapReduce
• Q & A

3
Hadoop At Scale���(Some Statistics)
• 40,000 + machines in 20+ clusters
• Largest cluster is 4,000 machines
• 170 Petabytes of storage
• 1000+ users
• 1,000,000+ jobs/month

EVERY CLICK BEHIND

Hadoop Workflow

Who Uses Hadoop ?

7
Why Hadoop ?

Big Datasets���(Data-Rich Computing theme proposal. J. Campbell, et al, 2007)

Cost Per Gigabyte���(http://www.mkomo.com/cost-per-gigabyte)

Storage Trends ���(Graph by Adam Leventhal, ACM Queue, Dec 2009)

11
Motivating Examples

Yahoo! Search Assist

13
Search Assist • Insight: Related concepts appear close
together in text corpus
• Input: Web pages
• 1 Billion Pages, 10K bytes each
• 10 TB of input data
• Output: List(word, List(related words))

// Code Samples
14
// Input: List(URL, Text)foreach URL in Input : Words = Tokenize(Text(URL)); foreach word in Tokens : Insert (word, Next(word, Tokens)) in Pairs; Insert (word, Previous(word, Tokens)) in Pairs;// Result: Pairs = List (word, RelatedWord)Group Pairs by word;// Result: List (word, List(RelatedWords)foreach word in Pairs : Count RelatedWords in GroupedPairs;// Result: List (word, List(RelatedWords, count))foreach word in CountedPairs : Sort Pairs(word, *) descending by count; choose Top 5 Pairs;// Result: List (word, Top5(RelatedWords))
Search Assist

People You May Know

16
People You May Know • Insight: You might also know Joe Smith if a
lot of folks you know, know Joe Smith
• if you don’t know Joe Smith already
• Numbers:
• 100 MM users
• Average connections per user is 100

// Code Samples
17
// Input: List(UserName, List(Connections)) foreach u in UserList : // 100 MM foreach x in Connections(u) : // 100 foreach y in Connections(x) : // 100 if (y not in Connections(u)) : Count(u, y)++; // 1 Trillion Iterations Sort (u,y) in descending order of Count(u,y); Choose Top 3 y; Store (u, {y0, y1, y2}) for serving;
People You May Know

18
Performance
• 101 Random accesses for each user
• Assume 1 ms per random access
• 100 ms per user
• 100 MM users
• 100 days on a single machine

19
MapReduce Paradigm

20
Map & Reduce
• Primitives in Lisp (& Other functional languages) 1970s
• Google Paper 2004
• http://labs.google.com/papers/mapreduce.html

21
Output_List = Map (Input_List)
Square (1, 2, 3, 4, 5, 6, 7, 8, 9, 10) =(1, 4, 9, 16, 25, 36,49, 64, 81, 100)
Map

22
Output_Element = Reduce (Input_List)
Sum (1, 4, 9, 16, 25, 36,49, 64, 81, 100) = 385
Reduce

23
Parallelism
• Map is inherently parallel
• Each list element processed independently
• Reduce is inherently sequential
• Unless processing multiple lists
• Grouping to produce multiple lists

// Example
24
// Input: http://hadoop.apache.org Pairs = Tokenize_And_Pair ( Text ( Input ) )
Search Assist Map

25
// Input: GroupedList (word, GroupedList(words))CountedPairs = CountOccurrences (word, RelatedWords)
Output = {(hadoop, apache, 7) (hadoop, DFS, 3) (hadoop, streaming, 4) (hadoop, mapreduce, 9) ...}
Search Assist Reduce

26
Issues with Large Data
• Map Parallelism: Chunking input data
• Reduce Parallelism: Grouping related data
• Dealing with failures & load imbalance


28
Apache Hadoop
• January 2006: Subproject of Lucene
• January 2008: Top-level Apache project
• Stable Version: 1.0.3
• Latest Version: 2.0.0 (Alpha)

29
Apache Hadoop
• Reliable, Performant Distributed file system
• MapReduce Programming framework
• Ecosystem: HBase, Hive, Pig, Howl, Oozie, Zookeeper, Chukwa, Mahout, Cascading, Scribe, Cassandra, Hypertable, Voldemort, Azkaban, Sqoop, Flume, Avro ...

30
Problem: Bandwidth to Data
• Scan 100TB Datasets on 1000 node cluster
• Remote storage @ 10MB/s = 165 mins
• Local storage @ 50-200MB/s = 33-8 mins
• Moving computation is more efficient than moving data
• Need visibility into data placement

31
Problem: Scaling Reliably • Failure is not an option, it’s a rule !
• 1000 nodes, MTBF < 1 day
• 4000 disks, 8000 cores, 25 switches, 1000 NICs, 2000 DIMMS (16TB RAM)
• Need fault tolerant store with reasonable availability guarantees
• Handle hardware faults transparently

32
Hadoop Goals
• Scalable: Petabytes (1015 Bytes) of data on thousands on nodes
• Economical: Commodity components only
• Reliable
• Engineering reliability into every application is expensive

33
Hadoop MapReduce

34
Think MapReduce
• Record = (Key, Value)
• Key : Comparable, Serializable
• Value: Serializable
• Input, Map, Shuffle, Reduce, Output

// Code Samples
35
cat /var/log/auth.log* | \ grep “session opened” | cut -d’ ‘ -f10 | \sort | \uniq -c > \~/userlist
Seems Familiar ?

36
Map
• Input: (Key1, Value1)
• Output: List(Key2, Value2)
• Projections, Filtering, Transformation

37
Shuffle
• Input: List(Key2, Value2)
• Output
• Sort(Partition(List(Key2, List(Value2))))
• Provided by Hadoop

38
Reduce
• Input: List(Key2, List(Value2))
• Output: List(Key3, Value3)
• Aggregation

39
Hadoop Streaming • Hadoop is written in Java
• Java MapReduce code is “native” • What about Non-Java Programmers ?
• Perl, Python, Shell, R
• grep, sed, awk, uniq as Mappers/Reducers
• Text Input and Output

40
Hadoop Streaming • Thin Java wrapper for Map & Reduce Tasks
• Forks actual Mapper & Reducer
• IPC via stdin, stdout, stderr
• Key.toString() \t Value.toString() \n
• Slower than Java programs
• Allows for quick prototyping / debugging

// Code Samples
41
$ bin/hadoop jar hadoop-streaming.jar \ -input in-files -output out-dir \ -mapper mapper.sh -reducer reducer.sh# mapper.shsed -e 's/ /\n/g' | grep .# reducer.shuniq -c | awk '{print $2 "\t" $1}'
Hadoop Streaming

42
Hadoop Distributed File System (HDFS)

43
HDFS
• Data is organized into files and directories
• Files are divided into uniform sized blocks (default 128MB) and distributed across cluster nodes
• HDFS exposes block placement so that computation can be migrated to data

44
HDFS
• Blocks are replicated (default 3) to handle hardware failure
• Replication for performance and fault tolerance (Rack-Aware placement)
• HDFS keeps checksums of data for corruption detection and recovery

45
HDFS
• Master-Worker Architecture
• Single NameNode
• Many (Thousands) DataNodes

46
HDFS Master���(NameNode)
• Manages filesystem namespace
• File metadata (i.e. “inode”) • Mapping inode to list of blocks + locations
• Authorization & Authentication
• Checkpoint & journal namespace changes

47
Namenode
• Mapping of datanode to list of blocks
• Monitor datanode health
• Replicate missing blocks
• Keeps ALL namespace in memory
• 60M objects (File/Block) in 16GB

48
Datanodes • Handle block storage on multiple volumes &
block integrity
• Clients access the blocks directly from data nodes
• Periodically send heartbeats and block reports to Namenode
• Blocks are stored as underlying OS’s files

HDFS Architecture

Example: Unigrams
• Input: Huge text corpus
• Wikipedia Articles (40GB uncompressed)
• Output: List of words sorted in descending order of frequency

$ cat ~/wikipedia.txt | \sed -e 's/ /\n/g' | grep . | \sort | \uniq -c > \~/frequencies.txt$ cat ~/frequencies.txt | \# cat | \sort -n -k1,1 -r |# cat > \~/unigrams.txt
Unigrams

mapper (filename, file-contents):for each word in file-contents: emit (word, 1)
reducer (word, values):
sum = 0for each value in values: sum = sum + valueemit (word, sum)
MR for Unigrams

mapper (word, frequency):emit (frequency, word)
reducer (frequency, words):
for each word in words: emit (word, frequency)
MR for Unigrams

public static class MapClass extends MapReduceBaseimplements Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString(); StringTokenizer itr = new StringTokenizer(line); while (itr.hasMoreTokens()) { Text word = new Text(itr.nextToken()); output.collect(word, new IntWritable(1)); }}
}
Unigrams: Java Mapper

public static class Reduce extends MapReduceBaseimplements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key,Iterator<IntWritable> values,
OutputCollector<Text,IntWritable> output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum));}
}
Unigrams: Java Reducer

public void run(String inputPath, String outputPath) throws Exception{
JobConf conf = new JobConf(WordCount.class);conf.setJobName("wordcount");conf.setMapperClass(MapClass.class);
conf.setReducerClass(Reduce.class); FileInputFormat.addInputPath(conf, new Path(inputPath));
FileOutputFormat.setOutputPath(conf, new Path(outputPath));JobClient.runJob(conf);
}
Unigrams: Driver

Configuration • Unified Mechanism for
• Configuring Daemons
• Runtime environment for Jobs/Tasks
• Defaults: *-default.xml
• Site-Specific: *-site.xml
• final parameters

<configuration><property> <name>mapred.job.tracker</name> <value>head.server.node.com:9001</value></property><property> <name>fs.default.name</name> <value>hdfs://head.server.node.com:9000</value></property><property><name>mapred.child.java.opts</name><value>-Xmx512m</value><final>true</final></property>
....</configuration>
Example

Running Hadoop Jobs

[milindb@gateway ~]$ hadoop jar \$HADOOP_HOME/hadoop-examples.jar wordcount \/data/newsarchive/20080923 /tmp/newsoutinput.FileInputFormat: Total input paths to process : 4mapred.JobClient: Running job: job_200904270516_5709mapred.JobClient: map 0% reduce 0%mapred.JobClient: map 3% reduce 0%mapred.JobClient: map 7% reduce 0%....mapred.JobClient: map 100% reduce 21%mapred.JobClient: map 100% reduce 31%mapred.JobClient: map 100% reduce 33%mapred.JobClient: map 100% reduce 66%mapred.JobClient: map 100% reduce 100%mapred.JobClient: Job complete: job_200904270516_5709
Running a Job

mapred.JobClient: Counters: 18mapred.JobClient: Job Countersmapred.JobClient: Launched reduce tasks=1mapred.JobClient: Rack-local map tasks=10mapred.JobClient: Launched map tasks=25mapred.JobClient: Data-local map tasks=1mapred.JobClient: FileSystemCountersmapred.JobClient: FILE_BYTES_READ=491145085mapred.JobClient: HDFS_BYTES_READ=3068106537mapred.JobClient: FILE_BYTES_WRITTEN=724733409mapred.JobClient: HDFS_BYTES_WRITTEN=377464307
Running a Job

mapred.JobClient: Map-Reduce Frameworkmapred.JobClient: Combine output records=73828180mapred.JobClient: Map input records=36079096mapred.JobClient: Reduce shuffle bytes=233587524mapred.JobClient: Spilled Records=78177976mapred.JobClient: Map output bytes=4278663275mapred.JobClient: Combine input records=371084796mapred.JobClient: Map output records=313041519mapred.JobClient: Reduce input records=15784903
Running a Job

// Code Samples
JobTracker WebUI

JobTracker Status

Jobs Status

Job Details

Job Counters

Job Progress

All Tasks

Task Details

Task Counters

Task Logs

MapReduce Dataflow

MapReduce

Job Submission

Initialization

Scheduling

Execution

Map Task

Sort Buffer

Reduce Task

82
Next Generation MapReduce

MapReduce Today (Courtesy: Arun Murthy, Hortonworks)

84
Why ? • Scalability Limitations today
• Maximum cluster size: 4000 nodes
• Maximum Concurrent tasks: 40,000
• Job Tracker SPOF
• Fixed map and reduce containers (slots)
• Punishes pleasantly parallel apps

85
Why ? (contd) • MapReduce is not suitable for every
application
• Fine-Grained Iterative applications
• HaLoop: Hadoop in a Loop
• Message passing applications
• Graph Processing

86
Requirements
• Need scalable cluster resources manager
• Separate scheduling from resource management
• Multi-Lingual Communication Protocols

87
Bottom Line
• @techmilind #mrng (MapReduce, Next Gen) is in reality, #rmng (Resource Manager, Next Gen)
• Expect different programming paradigms to be implemented
• Including MPI (soon)

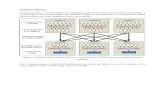
Architecture (Courtesy: Arun Murthy, Hortonworks)

89
The New World • Resource Manager
• Allocates resources (containers) to applications
• Node Manager
• Manages containers on nodes
• Application Master
• Specific to paradigm e.g. MapReduce application master, MPI application master etc

90
Container
• In current terminology: A Task Slot
• Slice of the node’s hardware resources
• #of cores, virtual memory, disk size, disk and network bandwidth etc
• Currently, only memory usage is sliced