
GUPT:&Privacy&Preserving&Data Analysis&Made&Easy&
44
GUPT: Privacy Preserving Data Analysis Made Easy Prashanth Mohan, Abhradeep Thakurta, Elaine Shi, Dawn Song and David Culler 1
Transcript of GUPT:&Privacy&Preserving&Data Analysis&Made&Easy&

GUPT: Privacy Preserving Data Analysis Made Easy
Prashanth Mohan, Abhradeep Thakurta, Elaine Shi, Dawn Song and David Culler
1

Mean Clustering ClassificaDon
Data mining/ Machine learning
….
David
Charlie
Bob
Alice
2
What is the privacy risk?
Salary Database
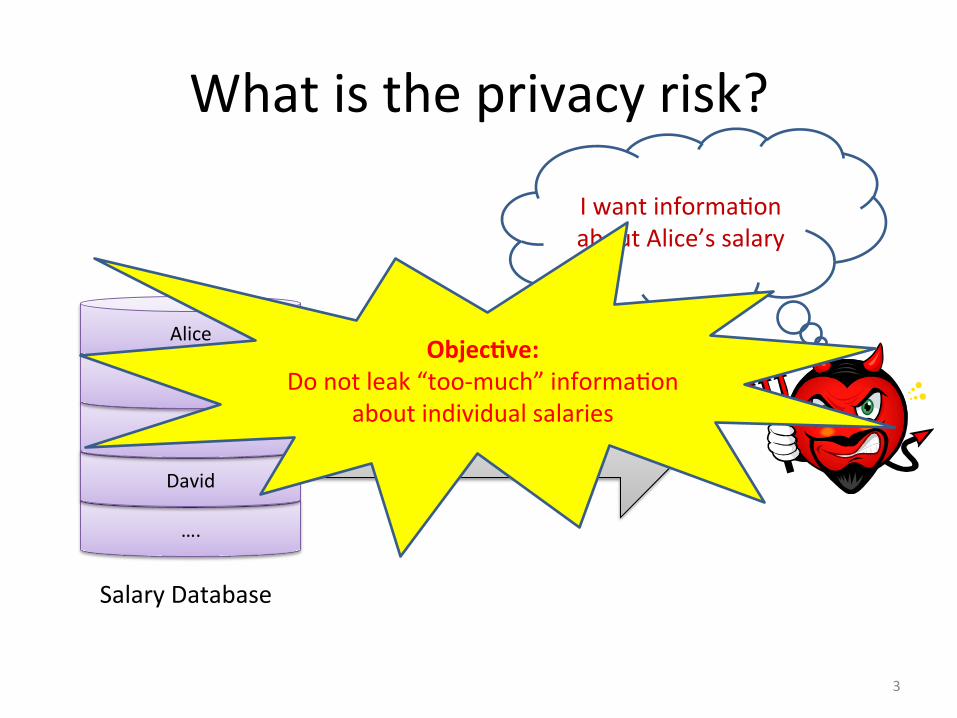
Salary Database
I want informaDon about Alice’s salary
….
David
Charlie
Bob
Alice
Output of mining algorithm
What is the privacy risk?
3
Objec4ve: Do not leak “too-‐much” informaDon
about individual salaries

Privacy Mechanism
(A)
How can we define privacy?
Alice
Charlie Bob
DB1
Record T
Alice
Charlie Bob
DB2
Record T’
From the output, any “neighboring pair” DB1 and DB2 should be indisDnguishable
4

DifferenDal privacy [DMNS06]
[ ] [ ]SDASDA ∈ʹ′×≤∈ )(Pr)exp()(Pr ε
Privacy budget
Randomized algorithm
5
Any measurable set Neighbors: two datasets
differing in exactly one entry
Δf =D, "Dmax f (D)− f ( "D )
1
Func4on Sensi4vity
dfLapDfDA ⎟⎠
⎞⎜⎝
⎛ Δ+=ε
)()( ex
Lap λ
λλ
||
21~)(
−

Current approaches [McSherry09, RSKSW10, HPN11]
Restricted Query Interface
Data Query App
Data mining
App developer or Analyst
….
David
Charlie
Bob
Alice
Noisy Answer
6

Restricted Query Interface
Convex opDmizaDon package
App developer or Analyst
….
David
Charlie
Bob
Alice
Compliant version
Rewrite
7
Current approaches [McSherry09, RSKSW10, HPN11]

Challenge: Making DP usable
• ExecuDng unmodified code/ binaries
• Privacy budget allocaDon
– The privacy parameter 𝜖 (also called privacy budget) is a limited quanDty
– 𝜖 needs to be allocated effecDvely for a given task
• Improve accuracy of results
• Handle side channel ahacks
8

9
ContribuDons GUPT: plajorm for differenDally private execuDon of unmodified user code
1. Improve output accuracy: resampling, opDmal block size esDmaDon
2. Usability: describing privacy budget in terms of accuracy, privacy budget allocaDon
3. ProtecDon against side-‐channel ahacks: state ahack, privacy-‐budget ahack, Dming ahack

10
Talk outline • System design
• Improving result accuracy
• Privacy budget maintenance
• EvaluaDon

DifferenDally private answer
GUPT
11
GUPT Data Analyst
1. Dataset 2. Overall privacy ↵Budget (εTotal) Data Owner
1. User defined funcDon (UDF) be executed (f) 2. Accuracy (𝜌)/privacy budget (ε)
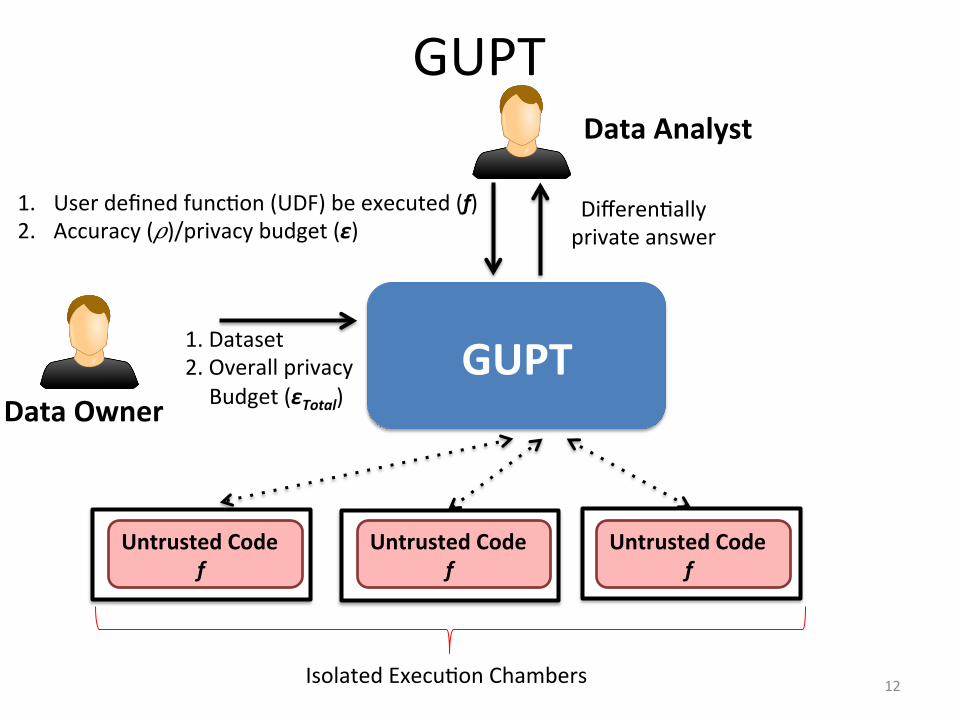
DifferenDally private answer
Data Analyst
1. Dataset 2. Overall privacy ↵Budget (εTotal) Data Owner
GUPT
12
GUPT
Untrusted Code f
Isolated ExecuDon Chambers
Untrusted Code f
Untrusted Code f
1. User defined funcDon (UDF) be executed (f) 2. Accuracy (𝜌)/privacy budget (ε)

Main idea: Sample and Aggregate [NRS07, Smith11]
Data Set
D1 D2 D3 D4 Dk
f f f f f
13
Isolated ExecuDon Chambers

Data Set
D1 D2 D3 D4 Dk
f f f f f
Average
DifferenDally Private Output 14
Main idea: Sample and Aggregate [NRS07, Smith11]
Implica4on for GUPT: No need to compute the sensiDvity ∆𝑓 for the user code 𝑓 for the user code 𝑓

Sample and Aggregate: Algorithm 1. ParDDon the dataset in to blocks 𝐷1,…, 𝐷𝑘 of equal size 2. Clamp the output on each block 𝑓(𝐷↓𝑖 ) between predefined
bounds 𝑚𝑖𝑛 and 𝑚𝑎𝑥 3. Output 1/𝑘 ∑𝑓(𝐷↓𝑖 )+ 𝐿𝑎𝑝(𝑑|𝑚𝑎𝑥−𝑚𝑖𝑛|/𝑘𝜖 )↑𝑑
Privacy:
– Algorithm saDsfies 𝜖-‐differenDal privacy Accuracy:
– In this talk we show experimental results
– For theoreDcal bounds see either our paper or [Smith11] 15
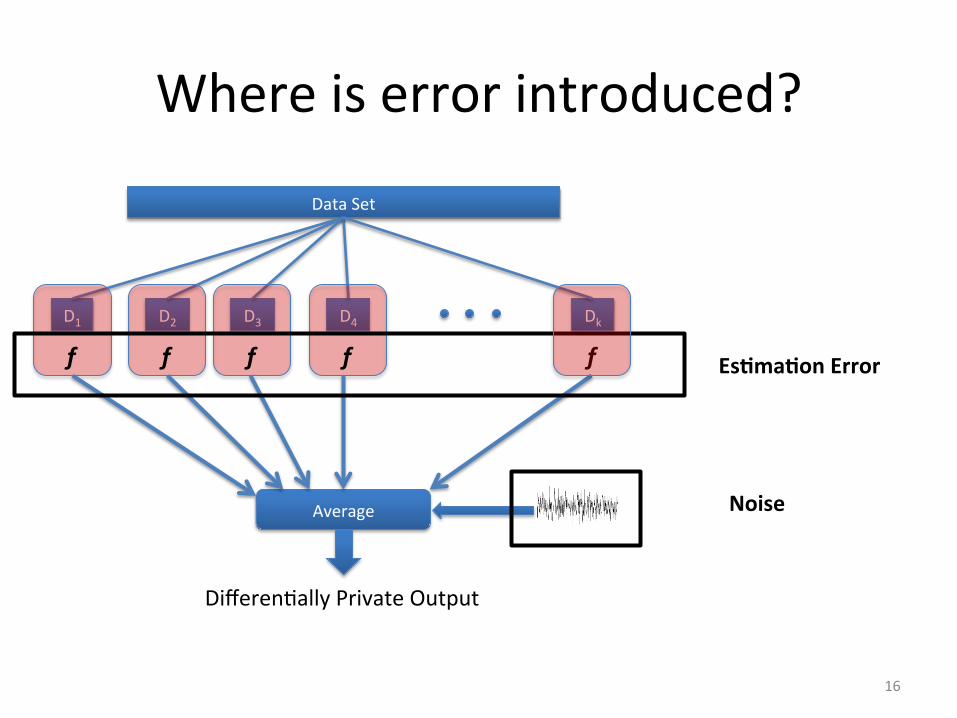
Where is error introduced?
DifferenDally Private Output
16
Data Set
D1 D2 D3 D4 Dk
f f f f
Average
Es4ma4on Error
Noise
f

Noise in Sample and Aggregate
Data Set
D1 D2 D3 D4 Dk
n
𝛃
βnk =Number of blocks
d
i kdLapDf
kDA ⎟
⎠
⎞⎜⎝
⎛ −+= ∑ ε
|minmax|)(1)(
17

Reduce variance by resampling
Data Set
D1 D2 D3 D4 Dk’
18
• Each entry in 𝐷 appear in exactly ℓ𝓁 blocks • Consider 𝑘↑′ = ℓ𝓁𝑛/𝛽 number of blocks • Each block contains exactly one copy of each data entry
𝛃

Data Set
D1 D2 D3 D4 Dk’
19
Reduce variance by resampling
𝛃
• Each entry in 𝐷 appear in exactly ℓ𝓁 blocks • Consider 𝑘↑′ = ℓ𝓁𝑛/𝛽 number of blocks • Each block contains exactly one copy of each data entry

Data Set
D1 D2 D3 D4 Dk’
20
• Changing one data entry affects only ℓ𝓁 blocks
Reduce variance by resampling

Data Set
D1 D2 D3 D4 Dk’
n
𝛃
βlnk ='Number of blocks
21
d
i kdlLapDf
kDA ⎟
⎠
⎞⎜⎝
⎛ −+= ∑ ε'
|minmax|)('1)(
Reduce variance by resampling

Data Set
D1 D2 D3 D4 Dk’
n
𝛃
22
Reduce variance by resampling
Advantage: • Reduce variance in the output without increasing the noise

Recap
• Introduced GUPT with its essenDal building blocks
• Discussed the main algorithmic idea (Sample and Aggregate [NRS07, Smith11])
• Proposed an idea to reduce the variance in the output via resampling
23

• A new model where the privacy concern of data degrades over Dme
• ImplicaDons for GUPT: – EsDmaDng opDmal block size
– Relate privacy budget to accuracy requirement
24
New model: Aging of sensiDvity

New model: Aging of sensiDvity
Dataset: 𝐷↓𝑇𝑂𝑇𝐴𝐿
Dataset: 𝐷↓𝑂𝐿𝐷 Dataset: 𝐷
• 𝐷↓𝑂𝐿𝐷 has lihle or no privacy concern as compared to 𝐷
• 𝐷↓𝑂𝐿𝐷 is used for selng opDmal parameters for GUPT 25
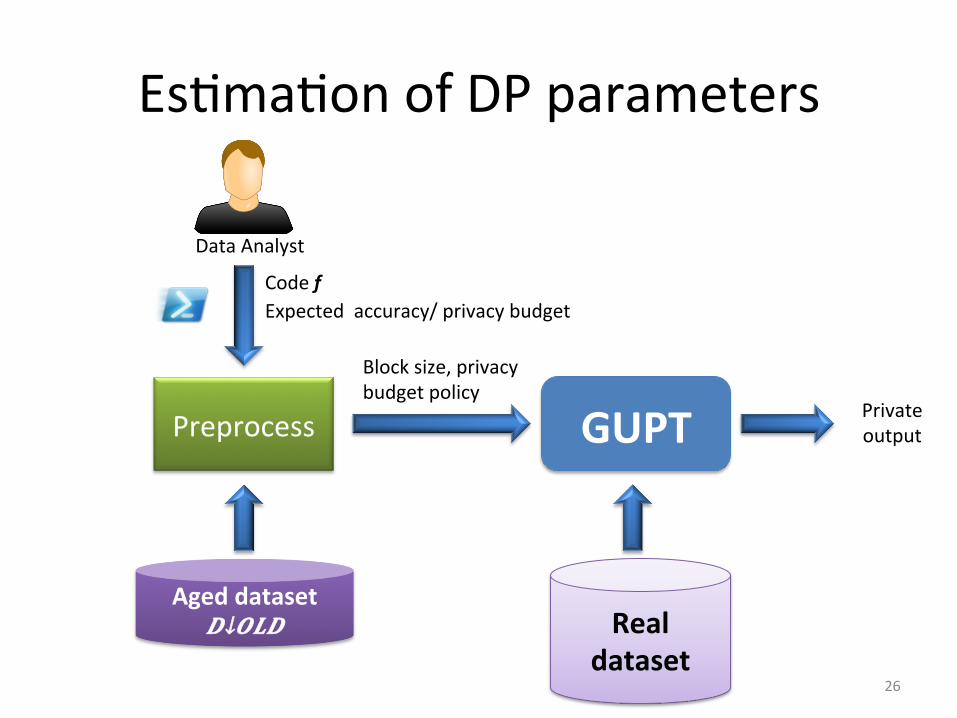
EsDmaDon of DP parameters
Aged dataset 𝑫↓𝑶𝑳𝑫
Preprocess
Real dataset
Block size, privacy budget policy
Expected accuracy/ privacy budget
GUPT Private output
Data Analyst
26
Code f

What is the right block size?
|𝛽/| 𝐷↓𝑂𝐿𝐷 | ∑𝑓(𝐷↓𝑖 )−𝑓( 𝐷↓𝑂𝐿𝐷 )|+ Noise(𝑚𝑖𝑛,𝑚𝑎𝑥,𝜖,𝛽)
Es4ma4on Error Noise
Total Error:
27
• There is a trade-‐off between esDmaDon error and noise • Select a block size 𝛽 that minimizes the total error

IdenDfying opDmal block size
28

Privacy budget management
Database
Computa4on Manager
Provide (approx.) 90% accurate answer for 90% of
my queries
Query
𝜖-‐differenDally private output
Privacy budget 𝜖 selected automa4cally based selected automa4cally based
on accuracy requirement
End-‐Users understand accuracy goal beher than privacy budget ε
29
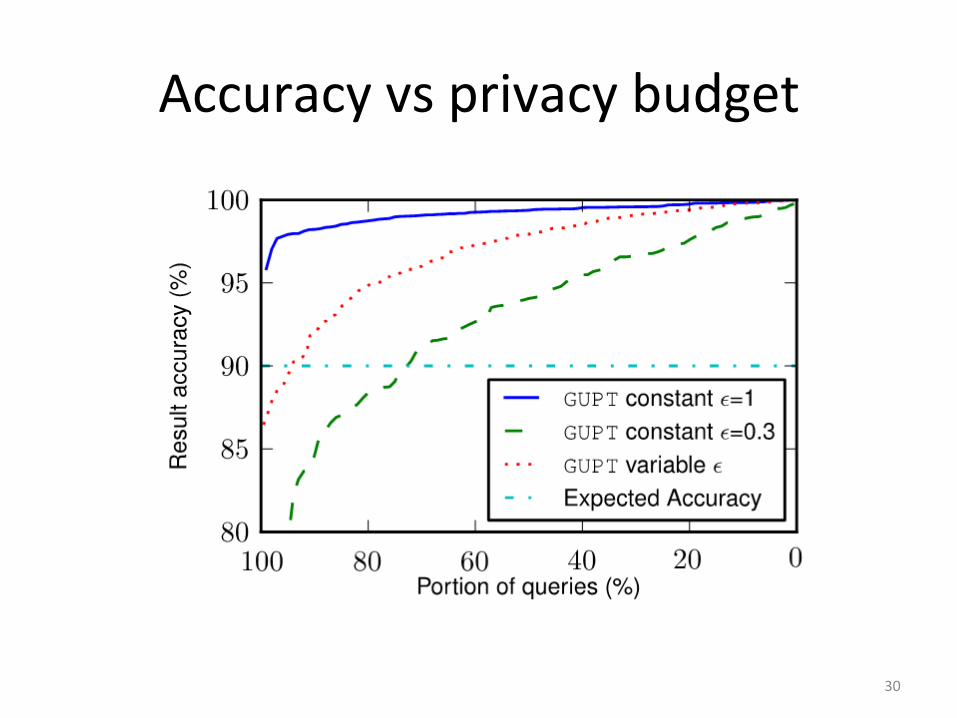
Accuracy vs privacy budget
30

Experimental result: Output accuracy
31

LimitaDons
• Works only for outputs with fixed dimensions – Average – Median, percenDle – K-‐means clustering – LogisDc regression – MLE
• Expects an implicit ordering of outputs • Needs reasonably large datasets • Works well for applicaDons which esDmates property of the data generaDng distribuDon
32

Future work
• Most exciDng: Explore the use of GUPT for Dme series data
• Reduce error dependence on the dimensionality of the output
• EsDmate the opDmal block size and privacy budget privately (instead of using Aging of sensiDvity model)
33

Public release of GUPT available at hhps://github.com/prashmohan/GUPT
34

…. David Charlie Bob Alice
RecommendaDons Traffic advice
Data mining
35
Type 1: Silo-‐based services
Bob’s financial documents
Tax applicaDon Bob
Two kind of data services

Bob’s financial documents
…. David Charlie Bob Alice
RecommendaDons Traffic advice
Data mining
Tax applicaDon
Type 2: Data intelligence
Bob
Two kind of data services
This talk 36

Related Work: PINQ [McSherry09]
Dataset PINQ
• Flexible programming layer abstracDon
• Privacy operaDons mostly transparent to programmers
37

Related Work: Airavat [RSKSW10]
Dataset
Data Data Data Data Data
Trusted Reducer
Untrusted Mapper
38

Increased lifeDme of privacy budget
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0N
orm
aliz
edpr
ivac
ybu
dget
lifet
ime
GUPT constant ✏=1GUPT variable ✏
GUPT constant ✏=0.3
39

Side-‐channel ahacks [HPN11]
• Timing Ahack: Use computaDon Dme as a side-‐channel informaDon to idenDfy a data record
• State Ahack: Use global state variable for microqueries to idenDfy a data record
• Privacy Budget Ahack: Use the privacy budget 𝜖 to leak informaDon
40

Side-‐channel ahacks
ProtecDon against
GUPT PINQ [McSherry09]
Airavat [RSKSW10]
Fuzz [HPN11]
Timing ahack YES NO NO YES
State ahack YES NO NO YES
Privacy Budget ahack
YES NO YES YES
Note: Fuzz has 2.5-‐6x computaDon overhead due to protecDon against side-‐channel ahacks
41

ProtecDon against Dming ahack Data Set
D1 D2 D3 D4 Dk
f f f f f
Average
DifferenDally Private Output
• Make each block take exactly the same computaDon Dme 𝑇
• If any block takes more than 𝑇, then output a default value
42

// runs one step of the iterative k-‐means algorithm. public static void kMeansStep(PINQueryable<double[]> input, double[][] centers, double epsilon) { // partition data set by the supplied centers; somewhat icky in pure LINQ... (( and it assumes centers[0] exists )) var parts = input.Partition(centers, x => NearestCenter(x, centers)); // update each of the centers foreach (var center in centers) { var part = parts[center];
foreach (var index in Enumerable.Range(0, center.Length)) center[index] = part.NoisyAverage(epsilon, x => x[index]); } }
Budget management across iteraDons is hard
43
Private k -‐Means clustering code in PINQ [McSherry09]
𝜖↓𝑖
• Total privacy budget 𝜖= ∑↓𝑖=1,⋯,𝑚 𝜖↓𝑖 • m is the number of iteraDons

k-‐means clustering: Comparison between PINQ and GUPT
20 80 200k-means iteration count
0
20
40
60
80
100
120In
traC
lust
erVa
rianc
ePINQ ✏=2PINQ ✏=4GUPT ✏=1GUPT ✏=2
44
Take away: The system should internally manage the privacy budget


















