
Grid Datafarm Architecture for Petascale Data Intensive Computing Osamu Tatebe Grid Technology...
28
Grid Datafarm Architecture for Petascale Data Intensiv e Computing Osamu Tatebe Grid Technology Research Center, AIST On behalf of the Gfarm project On behalf of the Gfarm project http:// http:// datafarm.apgrid.org datafarm.apgrid.org / / ACAT 2002 June 28, 2002 Moscow, Russia
-
date post
18-Dec-2015 -
Category
Documents
-
view
217 -
download
0
Transcript of Grid Datafarm Architecture for Petascale Data Intensive Computing Osamu Tatebe Grid Technology...

Grid Datafarm Architecture for Petascale Data Intensive Computing
Grid Datafarm Architecture for Petascale Data Intensive Computing
Osamu TatebeGrid Technology Research Center, AIST
On behalf of the Gfarm projectOn behalf of the Gfarm projecthttp://http://datafarm.apgrid.orgdatafarm.apgrid.org//
ACAT 2002June 28, 2002Moscow, Russia

Petascale Data Intensive Computing /Large-scale Data Analysis
Petascale Data Intensive Computing /Large-scale Data Analysis
Data intensive computing, large-scale data Data intensive computing, large-scale data analysis, data mininganalysis, data mining High Energy PhysicsHigh Energy Physics Astronomical Observation, Earth ScienceAstronomical Observation, Earth Science Bioinformatics…Bioinformatics… Good support still neededGood support still needed
Large-scale database search, data miningLarge-scale database search, data mining E-Government, E-Commerce, Data warehouseE-Government, E-Commerce, Data warehouse Search EnginesSearch Engines Other Commercial StuffOther Commercial Stuff
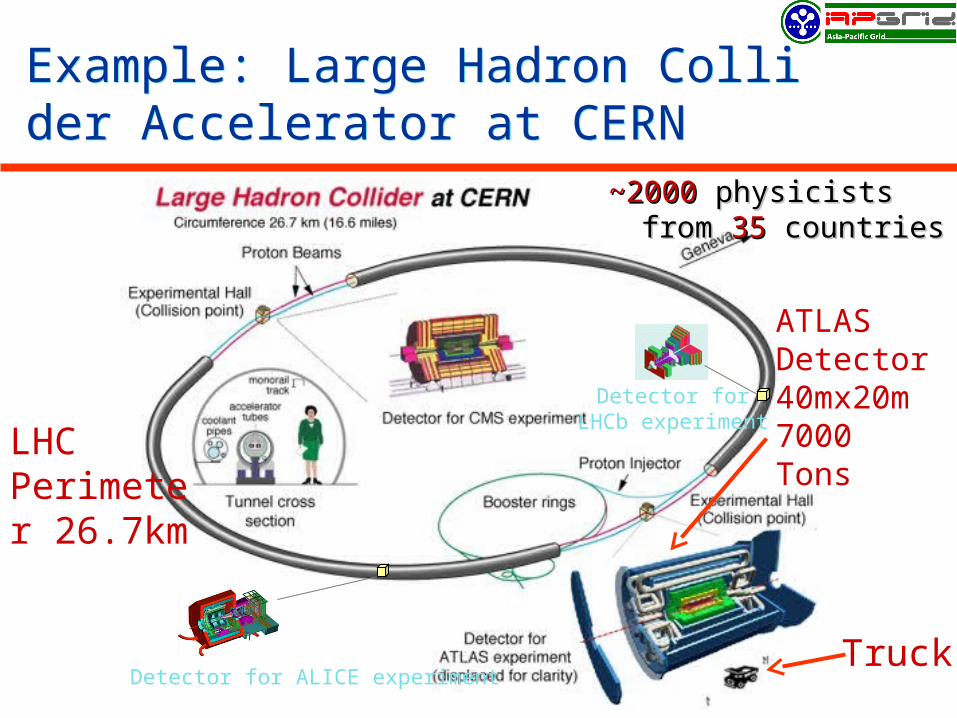
Example: Large Hadron Collider Accelerator at CERNExample: Large Hadron Collider Accelerator at CERN
Detector for ALICE experiment
Detector forLHCb experiment
Truck
ATLAS Detector40mx20m7000 Tons
LHCPerimeter 26.7km
~2000~2000 physicists physicists from from 35 35 countriescountries

Peta/Exascale Data Intensive Computing RequirementsPeta/Exascale Data Intensive Computing Requirements
Peta/Exabyte scale filesPeta/Exabyte scale files Scalable parallel I/O throughputScalable parallel I/O throughput
> 100GB/s> 100GB/s, hopefully > 1TB/s , hopefully > 1TB/s withinwithin a system and a system and betweenbetween systems systems
Scalable computational powerScalable computational power > 1TFLOPS> 1TFLOPS, hopefully > 10TFLOPS, hopefully > 10TFLOPS
Efficiently global sharingEfficiently global sharing with group-oriented with group-oriented authentication and access controlauthentication and access control
Resource Management and SchedulingResource Management and Scheduling System monitoring and administrationSystem monitoring and administration Fault ToleranceFault Tolerance / Dynamic re-configuration / Dynamic re-configuration Global Computing EnvironmentGlobal Computing Environment

Current storage approach 1:HPSS/DFS, . . .Current storage approach 1:HPSS/DFS, . . .
Mover Mover Mover MoverMetadataManager
IP Network (-10Gbps)
PetascaleTape
ArchiveSingle system image & Parallel I/OI/O bandwidth limited by IP network
Disk cache
Super-computer Disk
Meta DB

Current storage approach 2: Striping cluster filesystem, ex. PVFS, GPFSCurrent storage approach 2: Striping cluster filesystem, ex. PVFS, GPFS
ComputeNode
ComputeNode
I/ONode
I/ONode
MetadataManager
IP Network (-10Gbps)
Meta DB
Single system image & Parallel I/OI/O bandwidth limited by IP network
File stripe

For Petabyte-scale ComputingFor Petabyte-scale Computing
Wide-area efficient sharingWide-area efficient sharing Wide-area fast file transferWide-area fast file transfer Wide-area file replica managementWide-area file replica management
Scalable I/O bandwidth, >TB/sScalable I/O bandwidth, >TB/s I/O bandwidth limited by network bandwidthI/O bandwidth limited by network bandwidth Utilize local disk I/O as much as possibleUtilize local disk I/O as much as possible Avoid data movement through network as much as Avoid data movement through network as much as
possiblepossible Fault toleranceFault tolerance
Temporal failure of wide-area network is commonTemporal failure of wide-area network is common Node and disk failures not exceptional cases but commonNode and disk failures not exceptional cases but common
Fundamentally Fundamentally New ParadigmNew Paradigm is necessary is necessary
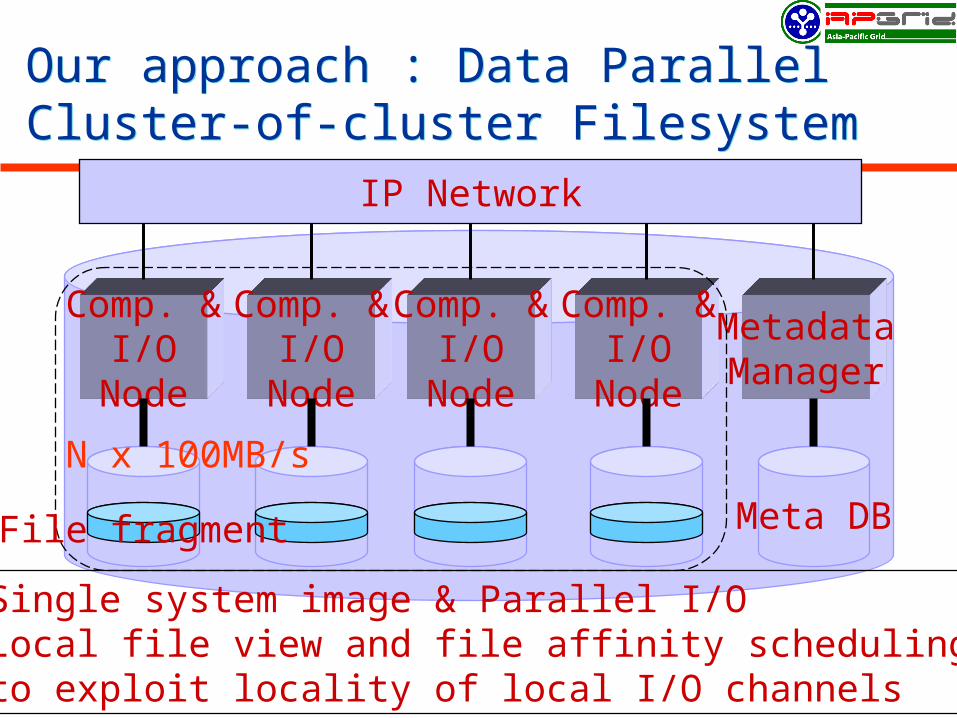
Our approach : Data Parallel Cluster-of-cluster FilesystemOur approach : Data Parallel Cluster-of-cluster Filesystem
Comp. &I/O
Node
Comp. &I/O
Node
Comp. &I/O
Node
Comp. &I/O
Node
MetadataManager
IP Network
Meta DB
Single system image & Parallel I/OLocal file view and file affinity schedulingto exploit locality of local I/O channels
N x 100MB/s
File fragment

Our approach (2) : Parallel Filesystem for Grid of ClustersOur approach (2) : Parallel Filesystem for Grid of Clusters
Cluster-of-cluster filesystem on the GridCluster-of-cluster filesystem on the Grid File replicas among clustersFile replicas among clusters for for fault tolerancefault tolerance and and loaloa
d balancingd balancing Extension of striping cluster filesystemExtension of striping cluster filesystem
Arbitrary file block lengthArbitrary file block lengthUnified I/O and compute nodeUnified I/O and compute nodeParallel I/O, parallel file transfer, and moreParallel I/O, parallel file transfer, and more
Extreme I/O bandwidth, >TB/sExtreme I/O bandwidth, >TB/s Exploit data access localityExploit data access locality File affinity scheduling and local file viewFile affinity scheduling and local file view
Fault tolerance – file recoveryFault tolerance – file recovery Write-once files can be re-generated using a command Write-once files can be re-generated using a command
history and re-computationhistory and re-computation

Inter-cluster~10Gbps
MS
Meta-server
MS
Gfarm cluster-of-cluster filesystem (1)Gfarm cluster-of-cluster filesystem (1)
Extension of cluster filesyExtension of cluster filesystemstem File is divided into file fragmFile is divided into file fragm
entsents Arbitrary length for each file Arbitrary length for each file
fragmentfragment Arbitrary number of I/O nodArbitrary number of I/O nod
es for each filees for each file Filesystem metadata is manFilesystem metadata is man
aged by metaserveraged by metaserver Parallel I/O and parallel file Parallel I/O and parallel file
transfertransfer
Cluster-of-cluster filesystemCluster-of-cluster filesystem File replicas among (or within) File replicas among (or within)
clustersclustersfault tolerancefault tolerance and and load balaload bala
ncingncing Filesystem metaserver managFilesystem metaserver manag
es metadata at each sitees metadata at each site

Gfarm cluster-of-cluster filesystem (2)Gfarm cluster-of-cluster filesystem (2)
Gfsd – I/O daemon runninGfsd – I/O daemon running on each filesystem nodeg on each filesystem node Remote file operationsRemote file operations Authentication / access conAuthentication / access con
trol (via GSI, . . .)trol (via GSI, . . .) Fast executable invocationFast executable invocation Heartbeat / load monitorHeartbeat / load monitor
Process / resource monitorProcess / resource monitoring, managementing, management
Gfmd – metaserver and prGfmd – metaserver and process manager running at ocess manager running at each siteeach site Filesystem metadata managFilesystem metadata manag
ementement Metadata consists ofMetadata consists of
MappingMapping from logical filena from logical filename to physical distributed fme to physical distributed fragment filenamesragment filenames
Replica catalogReplica catalogCommand history Command history for regenfor regen
eration of lost fileseration of lost filesPlatform informationPlatform informationFile status informationFile status information
Size, protection, . . .Size, protection, . . .

Extreme I/O bandwidth (1)Extreme I/O bandwidth (1)
Petascale file tends to be accessed with access localityPetascale file tends to be accessed with access locality Local I/O aggressively utilized for scalable I/O throughputLocal I/O aggressively utilized for scalable I/O throughput Target architecture – cluster of clusters, each node facilitating larTarget architecture – cluster of clusters, each node facilitating lar
ge-scale fast local disksge-scale fast local disks File affinity process schedulingFile affinity process scheduling
Almost Disk-owner computationAlmost Disk-owner computation Gfarm parallel I/O extension - Gfarm parallel I/O extension - Local file viewLocal file view
MPI-IO insufficient especially for irregular and dynamically distributMPI-IO insufficient especially for irregular and dynamically distributed dataed data
Each parallel process accesses only its own file fragmentEach parallel process accesses only its own file fragment Flexible and portable management in single system imageFlexible and portable management in single system image Grid-aware parallel I/O libraryGrid-aware parallel I/O library

Extreme I/O bandwidth (2)Process manager - schedulingExtreme I/O bandwidth (2)Process manager - scheduling
File affinity schedulingFile affinity scheduling
PC PC PC PCProcess.0 Process.1 Process.2 Process.3
File.0 File.2 File.3File.1
Process scheduling based on file distributionEx. % gfrun –H gfarm:File Process
gfarm:FileHost0.ch Host1.ch Host2.jpHost3.jp
gfmd
Host0.ch Host1.ch Host2.jp Host3.jp
gfsdgfsdgfsdgfsd

Extreme I/O bandwidth (3)Gfarm I/O API – File View (1)Extreme I/O bandwidth (3)Gfarm I/O API – File View (1)
Global file viewGlobal file view
PC PC PC PCProcess.0 Process.1 Process.2 Process.3
gfarm:FileHost0.ch Host1.ch Host2.jpHost3.jp
gfmd
Host0.ch Host1.ch Host2.jp Host3.jp
gfsdgfsdgfsdgfsd
File.0 File.2 File.3File.1
(I/O bandwidth limited by bisection bandwidth,~GB/s, as an ordinal parallel filesystem)
File

Extreme I/O bandwidth (4)Gfarm I/O API - File View (2)Extreme I/O bandwidth (4)Gfarm I/O API - File View (2)
Local file viewLocal file view
File.0 File.2 File.3File.1
Process.0 Process.1 Process.2 Process.3
gfarm:FileHost0.ch Host1.ch Host2.jpHost3.jp
gfmd
Host0.ch Host1.ch Host2.jp Host3.jp
gfsdgfsdgfsdgfsd
Accessible data set is restricted to a local file fragmentScalable disk I/O bandwidth (>TB/s)(Local file fragment may be stored in remote node)
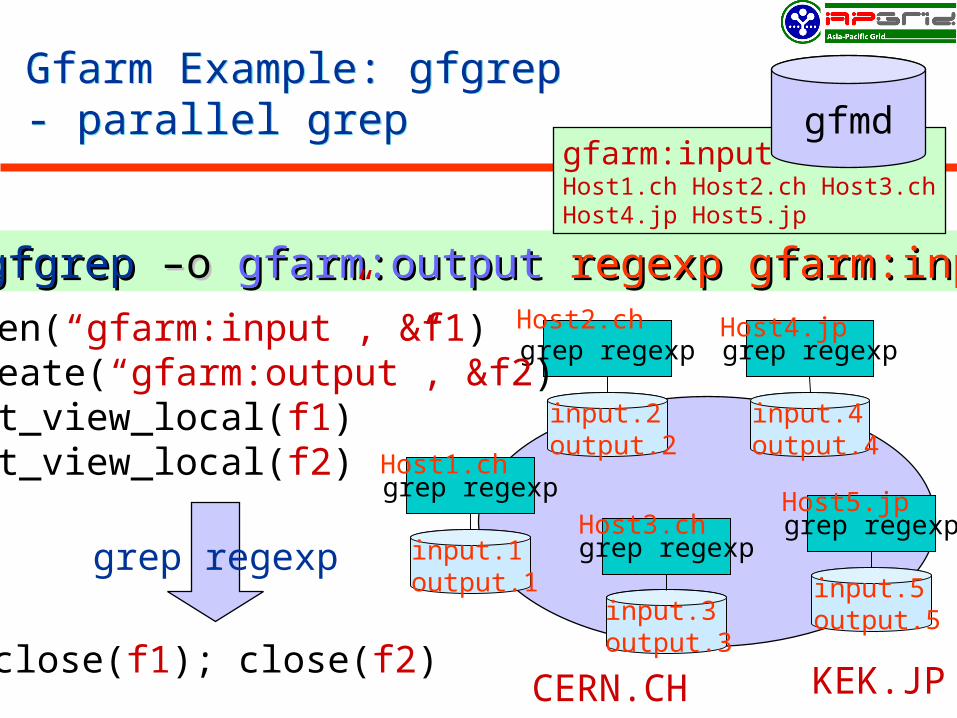
Gfarm Example: gfgrep- parallel grepGfarm Example: gfgrep- parallel grep
%% gfgrepgfgrep –o –o gfarm:outputgfarm:output regexpregexp gfarm:inputgfarm:input
grep regexp
grep regexp
grep regexp
grep regexp
CERN.CH KEK.JP
input.1output.1
input.2output.2
input.3output.3
input.4output.4
open(“gfarm:input”, &f1)create(“gfarm:output”, &f2)set_view_local(f1)set_view_local(f2)
close(f1); close(f2)
grep regexp
Host2.ch
Host1.ch
Host3.ch
Host4.jp
gfarm:inputHost1.ch Host2.ch Host3.chHost4.jp Host5.jp
gfmd
grep regexp
input.5output.5
Host5.jp

Fault-tolerance supportFault-tolerance support
File replicas on an individual fragment basiFile replicas on an individual fragment basiss
Re-generation of lost or needed write-once Re-generation of lost or needed write-once files using a command historyfiles using a command historyProgram and input files stored in fault-tolerant Program and input files stored in fault-tolerant
Gfarm filesystemGfarm filesystemProgram should be deterministicProgram should be deterministicRe-generation also supports GriPhyN virtual datRe-generation also supports GriPhyN virtual dat
a concept a concept

Specifics of Gfarm APIs and commandsSpecifics of Gfarm APIs and commands
(For Details, Please See Paper (For Details, Please See Paper at at http://datafarm.apgrid.org/http://datafarm.apgrid.org/))

Gfarm Parallel I/O APIsGfarm Parallel I/O APIs
gfs_pio_create / open / closegfs_pio_create / open / close gfs_pio_set_view_local / indexgfs_pio_set_view_local / index / global / global gfs_pio_read / write / seek / flushgfs_pio_read / write / seek / flush gfs_pio_getc / ungetc / putcgfs_pio_getc / ungetc / putc gfs_mkdir / rmdir / unlinkgfs_mkdir / rmdir / unlink gfs_chdir / chown / chgrp / chmodgfs_chdir / chown / chgrp / chmod gfs_statgfs_stat gfs_opendir / readdir / closedirgfs_opendir / readdir / closedir

Major Gfarm CommandsMajor Gfarm Commands
gfrepgfrep Replicate a Gfarm file using Replicate a Gfarm file using
parallel streamsparallel streams gfsched / gfwheregfsched / gfwhere
List hostnames where each List hostnames where each Gfarm fragment and replica Gfarm fragment and replica is stored is stored
gflsgfls Lists contents of directoryLists contents of directory
gfcpgfcp Copy files using Copy files using parallel strparallel str
eamseams
gfrm, gfrmdirgfrm, gfrmdir Remove directory entriesRemove directory entries
gfmkdirgfmkdir Make directoriesMake directories
gfdfgfdf Displays number of free disDisplays number of free dis
k blocks and filesk blocks and files gfsckgfsck
Check and repair file systeCheck and repair file systemsms

Porting Legacy or Commercial ApplicationsPorting Legacy or Commercial Applications
Hook syscalls open(), close(), write(), . . . to utilizHook syscalls open(), close(), write(), . . . to utilize Gfarm filesysteme Gfarm filesystem Intercepted syscalls executed in local file viewIntercepted syscalls executed in local file view This allows thousands of files to be This allows thousands of files to be groupedgrouped automaticautomatic
allyally and processed in parallel. and processed in parallel. Quick upstart for legacy apps (but some portability proQuick upstart for legacy apps (but some portability pro
blems have to be coped with)blems have to be coped with) gfreg commandgfreg command
After creation of thousands of files, gfreg explicitly grouAfter creation of thousands of files, gfreg explicitly groups files into a single Gfarm file.ps files into a single Gfarm file.

Initial Performance Evaluation– Presto III Gfarm Development Cluster (Prototype)
Initial Performance Evaluation– Presto III Gfarm Development Cluster (Prototype)
Dual Athlon MP 1.2GHz Nodes x128
768 MB, 200GB HDD each Total 98GB Mem, 25TB Stora
ge Myrinet 2K Full Bandwidth, 6
4bit PCI 614 GFLOPS (Peak) 331.7 GFLOPS Linpack for To
p500
Operation from Oct 2001

0
5
10
15
20
25
30
35
40
Gfarm parallelwrite
Unixindependent
write
Gfarm parallelread
Unixindependent
read
Initial Performance Evaluation (2)- parallel I/O (file affinity scheduling and local file view)
Initial Performance Evaluation (2)- parallel I/O (file affinity scheduling and local file view)
1742 MB/s on writes1974 MB/s on reads
Presto III 64 nodes for comp. & IO nodes640 GB of data
[MB/s] open(“gfarm:f”, &f);set_view_local(f);write(f, buf, len);close(f);

Initial Performance Evaluation (3)- File replication (gfrep)Initial Performance Evaluation (3)- File replication (gfrep)
Gfarm parallel copy bandwidth [MB/sec]
0
100
200
300
400
0 5 10 15 20
The number of nodes (fragments)
Seagate ST380021A
Maxtor 33073H3
Presto III, Myrinet 2000, 10 GB each fregment
443 MB/s23 parallel streams
180 MB/s7 parallel streams
[1] O.tatebe, et al, Grid Datafarm Architecture for Petascale Data IntensiveComputing, Proc. of CCGrid 2002, Berlin, May 2002

Design of AIST Gfarm cluster Iand Gfarm testbedDesign of AIST Gfarm cluster Iand Gfarm testbed
Cluster nodeCluster node 1U, Dual 2.4GHz Xeon, GbE1U, Dual 2.4GHz Xeon, GbE 480GB RAID480GB RAID with 8 2.5” 60GB with 8 2.5” 60GB
HDDsHDDs 105MB/s105MB/s on writes, on writes, 85MB/s85MB/s
on readson reads 10-node experimental cluster 10-node experimental cluster
(will be installed by July 2002)(will be installed by July 2002) 10U + GbE switch10U + GbE switch Totally Totally 5TB5TB RAID with 80 disks RAID with 80 disks
1050MB/s1050MB/s on writes, on writes, 850MB/850MB/ss on reads on reads
Gfarm testbedGfarm testbed AIST 10 + 10 nodesAIST 10 + 10 nodes Titech 256 nodesTitech 256 nodes KEK, ICEPPKEK, ICEPP Osaka Univ. 108 nodesOsaka Univ. 108 nodes
ApGrid/PRAGMA testbedApGrid/PRAGMA testbed AIST, Titech, KEK, . . .AIST, Titech, KEK, . . . Indiana Univ., SDSC, . . .Indiana Univ., SDSC, . . . ANU, APAC, Monash, . . .ANU, APAC, Monash, . . . KISTI (Korea)KISTI (Korea) NCHC (Taiwan)NCHC (Taiwan) Kasetsart U., NECTEC (Thai)Kasetsart U., NECTEC (Thai) NTU, BII (Singapore)NTU, BII (Singapore) USM (Malaysia), . . .USM (Malaysia), . . .
480GB 100MB/s
10GFlops
Gb
E sw
itch

Related WorkRelated Work
MPI-IOMPI-IO No local file view that is a key issuNo local file view that is a key issu
e to maximize local I/O scalabilitye to maximize local I/O scalability PVFS – striping cluster filesystemPVFS – striping cluster filesystem
UNIX I/O API, MPI-IOUNIX I/O API, MPI-IO I/O bandwidth limited by network bI/O bandwidth limited by network b
andwidthandwidth Fault-tolerance??? Wide-area??? SFault-tolerance??? Wide-area??? S
calability??calability?? IBM PIOFS, GPFSIBM PIOFS, GPFS HPSS – hierarchical mass storage HPSS – hierarchical mass storage
systemsystem Also limited by network bandwidthAlso limited by network bandwidth
Distributed filesystemsDistributed filesystems NFS, AFS, Coda, xFS, GFS, . . .NFS, AFS, Coda, xFS, GFS, . . . Poor bandwidth for parallel writPoor bandwidth for parallel writ
ee Globus – Grid ToolkitGlobus – Grid Toolkit
GridFTP – Grid security and parallel GridFTP – Grid security and parallel streamsstreams
Replica ManagementReplica Management Replica catalog and GridFTPReplica catalog and GridFTP
Kangaroo – Condor approachKangaroo – Condor approach Latency hiding to utilize local disks Latency hiding to utilize local disks
as a cacheas a cache No solution for bandwidthNo solution for bandwidth
Gfarm is the first attempt of cluster-of-Gfarm is the first attempt of cluster-of-cluster filesystem on the Gridcluster filesystem on the Grid File replicaFile replica File affinity scheduling, . . .File affinity scheduling, . . .

Grid Datafarm Development ScheduleGrid Datafarm Development Schedule
Initial Prototype 2000-2001Initial Prototype 2000-2001 Gfarm filesystem, Gfarm API, file affinity scheduling, and Gfarm filesystem, Gfarm API, file affinity scheduling, and
data streamingdata streaming Deploy on Development Gfarm ClusterDeploy on Development Gfarm Cluster
Second Prototype 2002(-2003)Second Prototype 2002(-2003) Grid security infrastructure Grid security infrastructure Load balance, Fault Tolerance, ScalabilityLoad balance, Fault Tolerance, Scalability Multiple metaservers with coherent cacheMultiple metaservers with coherent cache Evaluation in cluster-of-cluster environmentEvaluation in cluster-of-cluster environment Study of replication and scheduling policiesStudy of replication and scheduling policies ATLAS full-geometry Geant4 simulation (1M events) ATLAS full-geometry Geant4 simulation (1M events) Accelerate by National “Advanced Network Computing initiAccelerate by National “Advanced Network Computing initi
ative” (US$10M/5y)ative” (US$10M/5y) Full Production Development (2004-2005 and beyond)Full Production Development (2004-2005 and beyond)
Deploy on Production GFarm clusterDeploy on Production GFarm cluster Petascale online storagePetascale online storage
Synchronize with ATLAS scheduleSynchronize with ATLAS schedule ATLAS-Japan Tier-1 RC “prime customer”ATLAS-Japan Tier-1 RC “prime customer”
5km
KEK
AIST/TACC
10xN Gbps
U-Tokyo (60km)TITECH (80km)
SuperSINET
TsukubaWAN
10 Gbps

SummarySummary
Petascale Data Intensive Computing WavePetascale Data Intensive Computing Wave Key technology: Grid and clusterKey technology: Grid and cluster Grid datafarm is an architecture forGrid datafarm is an architecture for
Online >10PB storage, >TB/s I/O bandwidthOnline >10PB storage, >TB/s I/O bandwidth Efficient sharing on the GridEfficient sharing on the Grid Fault toleranceFault tolerance
Initial performance evaluation shows scalable performancInitial performance evaluation shows scalable performancee 1742 MB/s on writes on 64 cluster nodes1742 MB/s on writes on 64 cluster nodes 1974 MB/s on reads on 64 cluster nodes1974 MB/s on reads on 64 cluster nodes 443 MB/s using 23 parallel streams443 MB/s using 23 parallel streams
Metaserver overhead is negligibleMetaserver overhead is negligible I/O bandwidth limited by not network but disk I/O (good!)I/O bandwidth limited by not network but disk I/O (good!)
[email protected]://datafarm.apgrid.org/


















