
Programming Many-Core Systems with GRAMPS Jeremy Sugerman 14 May 2010.
date post
21-Dec-2015Category
view
223download
1
1
GRAMPS: A Programming Model
For Graphics PipelinesJeremy Sugerman,
Kayvon Fatahalian, Solomon Boulos,Kurt Akeley, Pat Hanrahan

2
“The Graphics Pipeline”
Central to the rise of 3D hardware and software.
A stable and universal abstraction
Shaped the evolution of the field…
… while leaving enormous room for innovation.
InputAssembler
VertexShader
RastOutputMerger
PixelShader
3
RastOutputMerger
PixelShader
Fixed Function
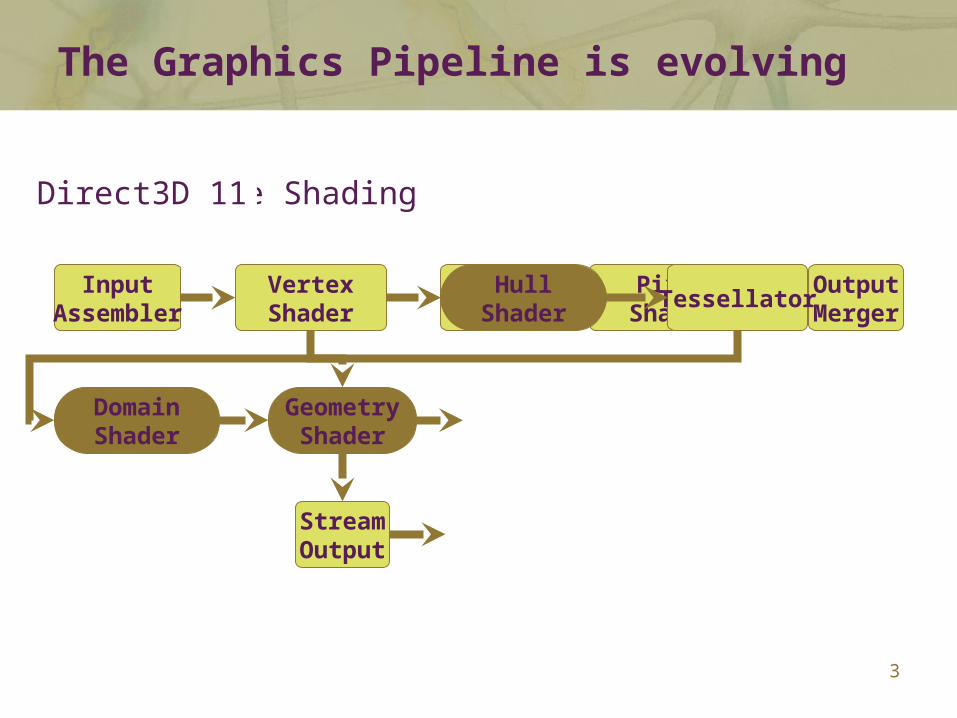
The Graphics Pipeline is evolving
Programmable Shading
InputAssembler
VertexShader
Direct3D 10Direct3D 11
PixelShader
VertexShader
HullShader
DomainShader
Tessellator
GeometryShader
StreamOutput

4
“GPU” is evolving, too
Continued drive for algorithmic innovation and advanced rendering techniques
First class programming models for compute:
– OpenCL, compute shaders, vendor specific, …
New / different hardware implementations:
– E.g., Larrabee, CPU-GPU combinations / hybrids
– Even NVIDIA and AMD GPUs are very different

5
From fixed to programmable (again)
Idea: Evolve the pipeline itself from preset configurations to a programmable entity

6
Programming model and run-time for parallel hardware
Graphs of stages and queues
GRAMPS handles scheduling, parallelism, data-flow
GRAMPS
Example: Simple GRAMPS Graph
ShaderThreadFixed
Function

7
The Graphics Pipeline becomes an app!
Structure/setup is (application) software
– Customized or completely novel renderers
Reuses current hardware: FIFOs, shader cores, rast, …
Analogous to the transition to programmable shading
– Proliferation of new use cases and parameters
– Not (unthinkably) radical
Fra
me
Buf
fer
VertexInput PixelRast Merge
8
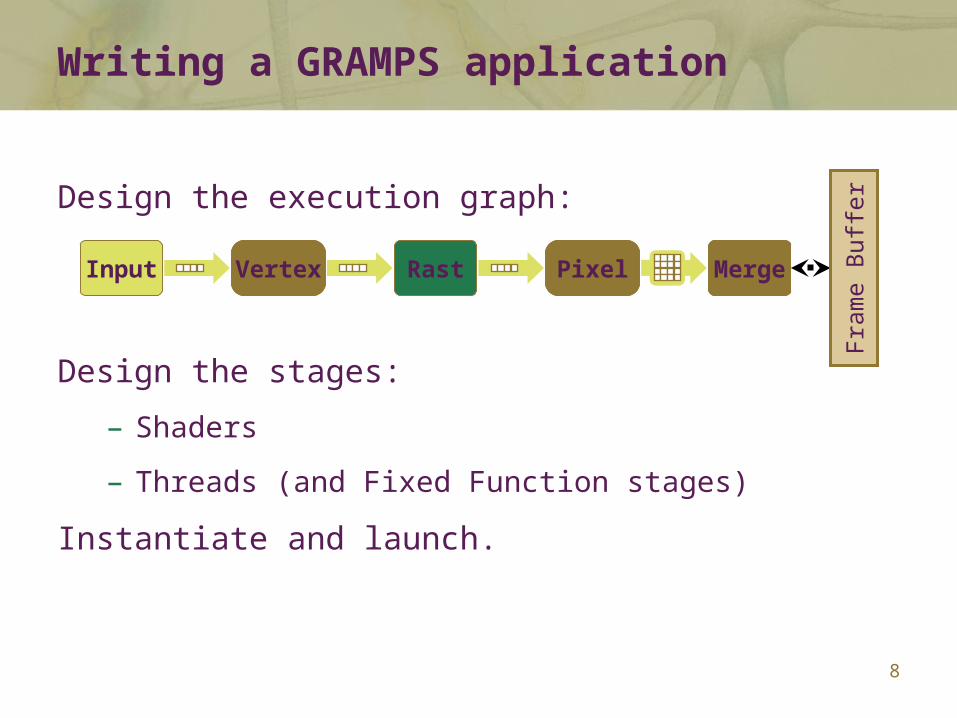
Writing a GRAMPS application
Design the execution graph:
Design the stages:
– Shaders
– Threads (and Fixed Function stages)
Instantiate and launch.
VertexInput Pixel MergeRast
Fra
me
Buf
fer
Merge

9
Fra
me
Buf
fer
VertexInput Pixel MergeRast
More Detail – Queues
Queues operate at a “packet” granularity
– “Large bundles of coherent work”
GRAMPS can optionally enforce ordering
– Required for some workloads, adds overhead

10
Fra
me
Buf
fer
RastVertex PixelInput Merge
More Detail – Shaders
Shaders: Like pixel (or compute) shaders, stateless
– Automatic instancing, pre-reserve/post-commit
“Collection” packets: shared header and N elements
New: “Push” operation to coalesce variable outputs
Vertex

11
Fra
me
Buf
fer
RastVertex PixelInput Merge
More Detail – Thread/Fixed Function
Threads: Like POSIX threads, stateful
– Explicit reserve/commit on queues
Fixed Function: Effectively non-programmable Threads
Rast

12
More Detail – Queue Sets
Queue sets enable binning-style algorithms
One logical queue with multiple lanes (or bins)
– One consumer at a time per lane
– Many lanes with data allows many parallel consumers
VertexInput Rast
Fra
me
Buf
fer
Pixel MergeMerge
Fra
me
Buf
fer
Pixel

13
Quick Comparison to “Streaming”
Streaming: “squeeze out every FLOP”
– Goals: throughput, bulk transfer, arithmetic intensity
– Intensive static analysis, program transformation
– Bound space, data access, execution time
GRAMPS: “interesting applications are irregular”
– Goals: throughput, dynamic, data-dependent code
– Aggregate work at run-time, heterogeneous hardware
– Streaming apps are GRAMPS apps

14
Evaluation: Design Goals
Broad application scope: preferable to roll-your-own
Multi-platform: suits many hardware configurations
High performance: competitive with roll-your-own
Tunable: expert users can optimize their apps
Optimized Implementations: inform, and are informed by, hardware

15
Broad Application Scope
Ray Tracing Graph
= Thread = Queue
= Shader = Stage Output
= Fixed-Func = Push Output
Rasterization Pipeline (with ray tracing extension)
Ray Tracing Extension
Fra
me
Buf
fer
PSRastRO
Ver
tex
Buf
fers
VSNIAN
VS1IA1 OM
Trace PS2
Tiler Sampler Camera Intersect
ShadeShadowIntersect
Blend
Fra
me
Buf
fer

16
Multi-Platform: Two (Simulated) Machines
CPU-Like: 8 Fat Cores, Rast
GPU-Like: 1 Fat Core, 4 Micro Cores, Rast, Sched

17
High Performance – Metrics
Priority #1: Show scale out parallelism
– Can GRAMPS exploit the application parallelism and fill the machine?
Priority #2: Show ‘reasonable’ bandwidth / storage requirements for queueing
– What is the worst case total footprint of all queues?
– A scheduling problem: trade-off with possible parallelism

18
High Performance – Scheduling
Very simple static prototype scheduler (both platforms):
Static stage priorities:
Limited pre-emption points
No dynamic weighting of current queue depths
(Lowest)
(Highest)
1 2 3 4
5 6 7
Fra
me
Buf
fer

19
High Performance – Results
Three scenes x { Rasterization, Ray Tracer, Hybrid }
Parallelism is 95+% for all but rasterized fairy (~80%).
Queues are small: < 600KB CPU-like, < 1.5MB GPU-like
Order costs footprint

20
Also: raw counters, statistics, text log of run-time activity
Tunability – Understanding Performance
GRAMPSviz:

21
Tiler Sampler Camera Intersect
ShadeShadowIntersect
Blend
Fra
me
Buf
fer
Execution Graph topology / design:
Sizing critical queues:
Tunability – Lessons Learned
PSRast
Fra
me
Buf
fer
PS + OMRast
Fra
me
Buf
fer
Sort-Middle Sort-Last
OM

22
Summary
After a long era of stability, the Graphics Pipeline is undergoing rapid change.
GRAMPS enables software-defined custom pipelines.
– The Graphics Pipeline becomes an app
– Prototypes show plausible performance, resource needs
– Handles heterogeneous parallelism well
– Applicable beyond rendering and beyond GPUs

23
Thank You
Our funding agencies:
Stanford Pervasive Parallelism Lab
Department of the Army Research
Intel Corporation
Rambus Stanford Graduate Fellowship
Intel PhD Fellowship
NSF Graduate Research Fellowship
http://graphics.stanford.edu/papers/gramps-tog/


















