
GPU$accelerated$signal$processing$in$the$$...
39
GPU accelerated signal processing in the Ion Proton TM whole genome sequencer Mohit Gupta and Jakob Siegel
Transcript of GPU$accelerated$signal$processing$in$the$$...

GPU accelerated signal processing in the Ion ProtonTM whole genome sequencer
Mohit Gupta and Jakob Siegel

Why sequence DNA ?
5/22/13 2

What is DNA • Hereditary material in
humans and almost all other living organisms
• Comprises of four chemical base pairs: (A,T), (C,G) in double helix structure
• Sequence of these base pairs determines how an organism develops, survives and reproduce
5/22/13 3
Guanine
Thymine
Cytosine
Adenine

Next GeneraMon DNA Sequencing
• High throughput sequencing – Enable rapid advances in genome level research
• Massively parallel – Requires advanced compute technologies – Big data problem in some sense
• Rapid turnaround Mme – Human Genome Project: 1990-‐2003 ( $3 billion)
• Need to be affordable
– DemocraMze DNA sequencing – $1000 genome
• Form factor
5/22/13 4

Ion ProtonTM sequencer in 2012
5/22/13 5

Scalable Sequencing Machine on a Chip
Leverages $3 Trillion Investment
5/22/13 6

200M
400M
600M
Num
ber o
f wel
ls p
er c
hip
800M
0
Unprecedented Scaling
Ion 316™ Ion 314 Ion 318™
Ion PI™
Chips
1.0 G
Ion PII™
1.2 G
1.2M 6.1M 11M
165M
660M
Try to imagine: a 165 Megapixel camera recording RAW images at 30 FPS for 5 seconds for each of 400 nucleotide flows à 3.7 TB compressed data in less than 4 hours.
Ion PIII™
1.2G
5/22/13 7 The content provided herein may relate to products that have not been officially released and is subject to change without notice.

Sensor Plate
Silicon Substrate Drain Source Bulk
dNTP
To column receiver
∆ pH
∆ Q
∆ V
Sensing Layer
H+
Rothberg J.M. et al Nature doi:10.1038/nature10242
Transistor as a pH meter
5/22/13 8
Compute Intensive signal processing

Data Processing Pipeline
9
Data acquisiMon and compression
in FPGA
Signal Processing BaseCalling and
Alignment to reference genome
3.7 TB 260 GB
19 TB
5/22/13

How to process data at the source ?
§ Big data on ProtonTM Sequencer
§ Cloud/Cluster not an option § Dual 8-core Intel® Xeon® Sandy
Bridge
§ Dual Altera® Stratix® V
§ NVIDIA® Tesla® C2075 (soon K20)
§ 11 TB (SSD and HDD)
5/22/13 10

GPU to the rescue
• Removed main hotspot in signal processing pipeline • Speedups of more than 200x over a CPU core!
0 20 40 60 80 100 120 140 160
CPU
GPU
9me in s
bead find
first 20 flows
block of 20 flows ader flow 20 fieng
…
…
5/22/13 11

Signal Processing

Signal Processing Flow Reading flow data
WriMng signal values
Image Processing
Post Fit Processing
Parameter EsMmaMon unique to each well (LM
fieng)
Regional Parameter EsMmaMon
(Common to all wells)
5/22/13 13
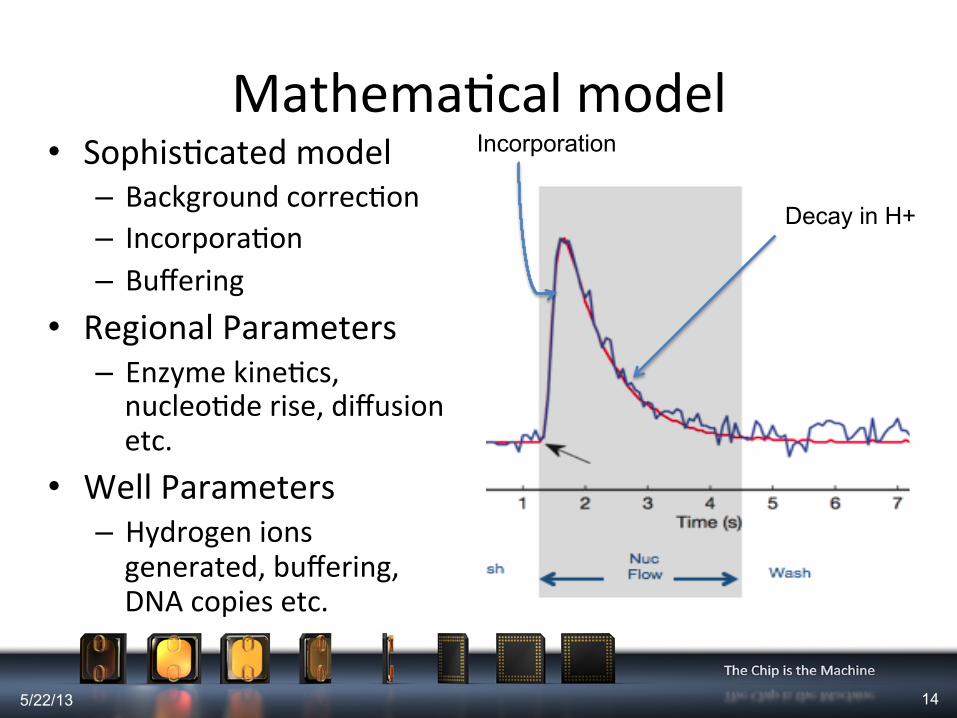
MathemaMcal model • SophisMcated model
– Background correcMon – IncorporaMon – Buffering
• Regional Parameters – Enzyme kineMcs, nucleoMde rise, diffusion etc.
• Well Parameters – Hydrogen ions generated, buffering, DNA copies etc.
Decay in H+
Incorporation
5/22/13 14

• Rich data fieng on first 20 flows – Custom Levenberg-‐Marquardt algorithm is used for fieng – MulMple parameters are esMmated – Requires a full matrix solve like Cholesky decomposiMon – Required for each well
• A two parameter fit is required in rest of the flows
• Generates signal value corresponding to hydrogen ions generated in each flow
Parameter EsMmaMon
5/22/13 15

Levenberg Marquardt (LM) Algorithm • Least squares curve fieng where sum of squared residuals
between observed and predicted data is minimized where S: sum of squared residuals between observed and predicted data β: set of model parameters y, x: observed data • EssenMally Gauss Newton (GM) algorithm with a damping
factor λ tuned in every solve iteraMon to progress in the direcMon of gradient descent
S(β ) = 2[yi− f (xi,β )]i=1m∑
5/22/13 16

LM algorithm cont’d
• For our applicaMon – Minimize the residual between raw data and signal value obtained from the mathemaMcal model for each well
– Provides numerical soluMon for the parameters governing the model
– IteraMve algorithm executed repeatedly Mll there is no appreciable change in parameters
– Convergence in reasonable Mme and iteraMons depends on the iniMal guess for parameters
5/22/13 17

GPU AcceleraMon

Challenges with the CPU codebase • Original code based on many small funcMons that limit the efficient use of the GPU resources
• Large input buffers need to be transferred to the GPU for every job – PCIe bandwidth becomes bokleneck for small jobs – MiMgated by end to end implementaMon on GPU to remove PCIe transfers for intermediate steps
• Data layout not opMmal to perform coalesced reads and writes for GPU threading model
5/22/13 19

ExecuMon Model • Stream based execuMon allows for overlap of – Kernel execuMon – PCIe transfers – host side data reorganizaMon – CPU pre and post processing
• Queue system for heterogeneous execuMon – Balances execuMon of different tasks between CPU and GPU
5/22/13 20

ExecuMon Model cont’d • ImplementaMon Concept
– Resources needed for stream execuMon are pre-‐allocated and obtained from a resource pool.
– If resources to create a Stream ExecuMon Unit (SEU) are available the Stream Manager will try to poll a new job from a job queue.
– The Stream Manager can drive mulMple SEUs which can be of different types.
– TheoreMcally up to 16 SEUs can be spawned in one Stream Manager if enough resources are available
5/22/13 21

GPU Code OpMmizaMons
• Merging smaller kernels into one fat kernel – No kernel launch overheads – Removes lot of redundant global memory reads and writes
• Invariant code moMon • InstrucMon reordering to allow for beker caching • Loop unrolling • ReducMon in integer operaMon for address calculaMons • ReducMon in register pressure
– Occupancy was register limited – Did a sweep over ‘maxrregcount’ to arrive at opMmal value
5/22/13 22

GPU Memory OpMmizaMons for C2075
• Global memory access opMmizaMon
– Data transform from AoS to SoA. – Data reorganizaMon to allow for vec4 reads – Use of shared memory to store some heavily accessed elements
– Padded buffers to allow for more efficient 128byte segment reads
– “Excessive” use of constant memory – OpMmizaMon for L1 cache
5/22/13 23

LM implementaMon on GPU • LM for each well is done by one thread on GPU
• Millions of wells – Embarrassingly parallel problem – High on compute – Several iteraMons required to obtain a soluMon with a reasonable tolerance
• Thread exits once numerical soluMon is obtained for the parameters
5/22/13 24

Out
er lo
op it
erat
ion
…
0
1
2
39
t0 t1 t2 t3
λ-iteration outer loop iteration
idle time return
threads within same warp Boklenecks of GPU implementaMon of LM
Divergence among GPU threads in a warp • Each well is sequencing different DNA
fragment • Need different number of iteraMons
– Different number of iteraMons of increasing or decreasing λ for each iteraMon
• Towards the end of the algorithm execuMon, only few threads are acMve in a warp
• Scarce resources on GPU doesn’t allow LM kernels from two different jobs to overlap
5/22/13 25

0
t0 t1 t2 t3
Gauss Newton iteration
idle time return
Threads within same warp
1 2 3 4 5 6 7
itera
tion
Switch to Gauss Newton Algorithm
• Same as LM algorithm without damping parameter λ to be tuned in every iteraMon
• Converges faster if iniMal guess is in the vicinity of the soluMon
• MiMgated the divergence problem caused by LM to a great extent – No λ tuning iteraMons are involved
• Reduced code and complexity • Limit maximum iteraMons to be
performed in worst case scenario
5/22/13 26
0
100
200
300
400
500
600
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39
Fi<ed
Wells in Tho
usan
ds
Itera9ons un9l finished

TransiMon from C2075 to K20 • As expected the codebase worked without changes out of
the box.
• IniMally the heavily C2075 opMmized code and kernel seengs did not show a speedup. (?!) – Kernel seengs fine tuned for occupancy, shared memory and cache usage.
• K20: same shared/L1 size for more threads in acMve state
– Heavy use of L1 for global memory read and write access • K20: no more L1 caching for global writes and reads
– MulMple processes using the GPU occupying all it’s memory • K20: only ~5GB instead of the ~6GB available on C2075
5/22/13 27

K20 tweaks • No more L1 caching for global write and reads
– Use __ldg() to cache global reads in texture cache – Intermediate results moved from global to local memory to benefit from write and read caching in L1
• ReducMon in available global memory size (no effect on GPU performance but on our CPU side execuMon model)
– Dynamic memory management – Variable number of streams per GPU context
5/22/13 28

K20 tweaks • Same shared/L1 size for more threads in acMve state
Correct L1 seeng to K20 opMmal seeng
50
70
90
110
130
150
170
190
64 96 128 160 192 224 256
time
in m
s
block size
Performance C2075 vs K20 for different L1 settings
K20 L1>
C2075 L1> 1.65x
5/22/13 29

Results

Performance Results • Speedup of a GPU over
a single CPU core
– more than 200x • Speedup achieved over
a 12 core Intel Xeon X5650 @ 2.67GHz and a K20 GPU
– 17x for algorithm – 4.1x whole pipeline
5/22/13 31
0 5 10 15 20 25 30 35 40
CPU
GPU
9me in minutes
non-‐GPU code
CPU Fieng
GPU Fieng
17x

Conclusion and Future Work • If divergence is the performance limiter
– Look for alternate algorithm which suits the GPU • Profiling alone doesn’t help
– Need to search for opMmum over the space (cache size, reg count, block size etc.)
• Timing bokleneck shided to other parts of the pipeline – Alignment
• Well known algorithm Smith waterman for detailed alignments • Some good GPU implementaMons already out there
• Prepare for PII and PIII chips – Exploit Keplar architecture to its maximum potenMal – Take some parts of signal processing pipeline to GPU
• Crucial with high density of wells on these chips
5/22/13 32

Shid focus to secondary Analysis Current Template PreparaMon, Sequencing, and Analysis Mmes for PI Chip
(customer configuraMon: Dual 8-‐core Intel® Xeon® Sandy Bridge, NVIDIA® Tesla® C2075)
5/22/13 33
7 4
7
0 2 4 6 8 10 12 14 16 18 20 Template Prep Sequencing Run On Instrument Analysis secondary Analysis
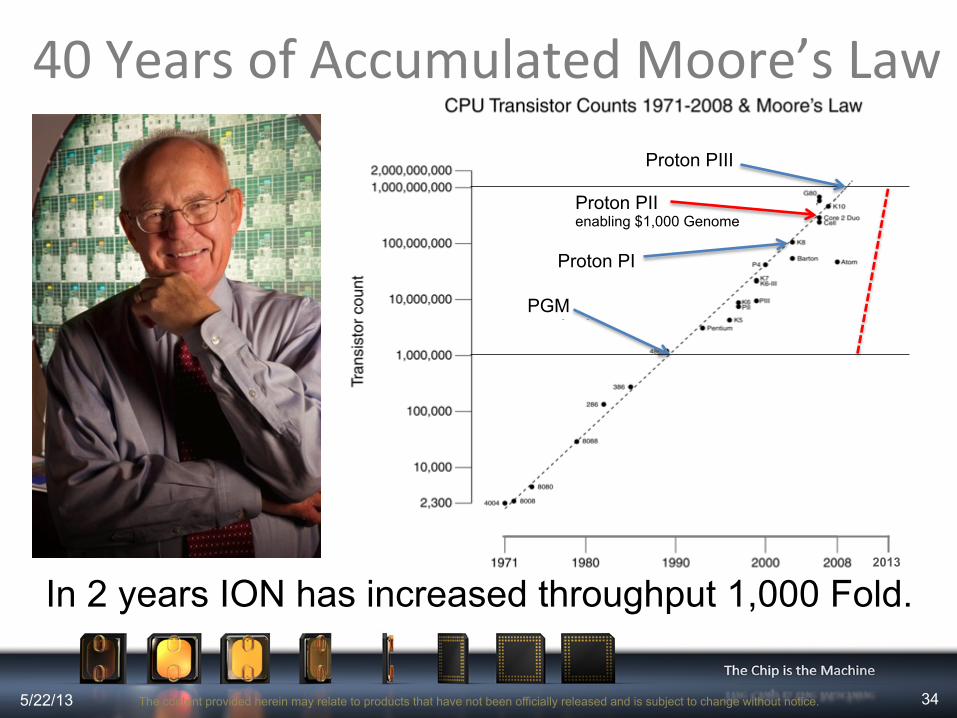
PGM
Proton PI
40 Years of Accumulated Moore’s Law
In 2 years ION has increased throughput 1,000 Fold.
5/22/13 34 The content provided herein may relate to products that have not been officially released and is subject to change without notice.
2013
Proton PIII
Proton PII enabling $1,000 Genome

Thank You
NVIDIA specifically the DevTech Team
Sarah Tariq Jonathan Bentz Mark Berger
Kimberley Powell
The enMre Ion Torrent R&D team
5/22/13 35

For Research Use Only; Not for use in diagnostic procedures.
All data shown in this presentation was generated by Life Technologies, except where indicated
© 2013 Life Technologies Corporation. All rights reserved.
The trademarks mentioned herein are the property of Life Technologies Corporation and/or its affiliate(s) or their respective owners.
5/22/13 36

LM algorithm • Need to solve the following equaMon for δ
where
J: Jacobian matrix δ: Increment vector to be added to parameter vector β y: vector of observed values at (x0 , . . . , xn) f: vector of funcMon values calculated from the model for given vector of x and parameter vector β λ: damping parameter to steer the movement in the direcMon of decreasing gradient
JT J +λdiag(JT J )( )δ = JT y− f (β )( )
5/22/13 37

LM algorithm cont’d
• Run an outer loop on some maximum number of iteraMons – Exit if no appreciable change in parameter value from previous to current iteraMon
• Run an inner loop – Worse case loop count depends on max or min value of λ – Increase λ if residuals increase compared to previous outer iteraMon
– Decrease λ if residual decrease compared to previous outer iteraMon
5/22/13 38

Effect of cache seengs on performance
50
70
90
110
130
150
170
190
64 96 128 160 192 224 256
time
in m
s
block size
Performance C2075 vs K20 for different L1 settings
K20 SM=L1
K20 SM>
K20 L1>
C2075 SM>
C2075 L1>
5/22/13 39


















