
Ghislain Fourny Big Data for Engineers Spring 2020 · Ghislain Fourny Big Data for Engineers Spring...
144
Ghislain Fourny Big Data for Engineers Spring 2020 10. Distributed Computations II: Spark 1
Transcript of Ghislain Fourny Big Data for Engineers Spring 2020 · Ghislain Fourny Big Data for Engineers Spring...

Ghislain Fourny
Big Data for Engineers Spring 202010. Distributed Computations II: Spark
1

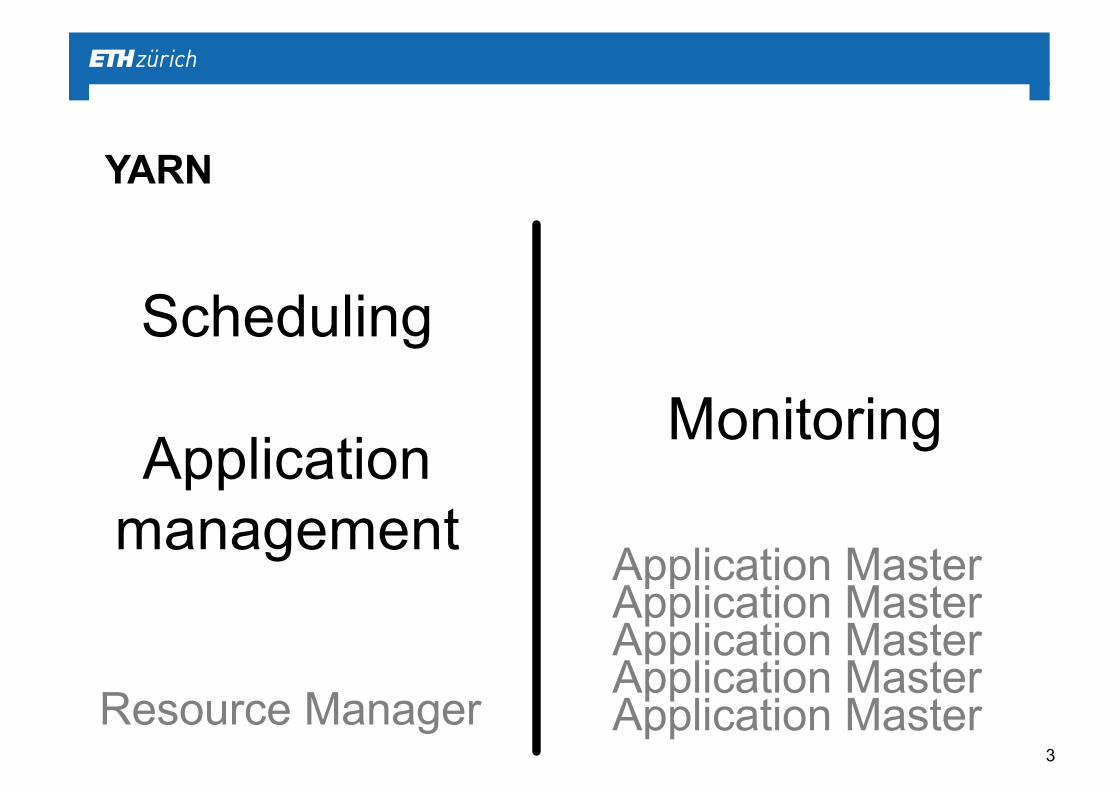
YARN
kirtchanut / 123RF Stock Photo
2
YARN
Scheduling
Applicationmanagement
Monitoring
3
Resource Manager Application MasterApplication MasterApplication MasterApplication MasterApplication Master

YARN
ResourceManager
NodeManager NodeManager NodeManager NodeManager NodeManager
Container
ContainerContainer
4

Forward compatibility with DAGs of transformations
5

Introduction to Spark
Nikki Zalewski / 123RF Stock Photo
6

MapReduce high-level data
MapShuffleMap
7

MapReduce high-level data
This is a very
specific topology!
8

... and it's under-using YARN
9

... because YARN supports any DAG
10

YARN
we can build somethingmoregeneral
11

MapReduce (even more) high-level: two-step...
Map
Reduce
12

... to any DAGs
13

Full-DAG query processing
entersSpark
14

ResilientDistributedDataset
Spark's first-class citizen
RDD
15

it's just a
Bigcollection
Spark's first-class citizen
RDD
16

Spark's first-class citizen
RDD
... and it is par ti tion ed17
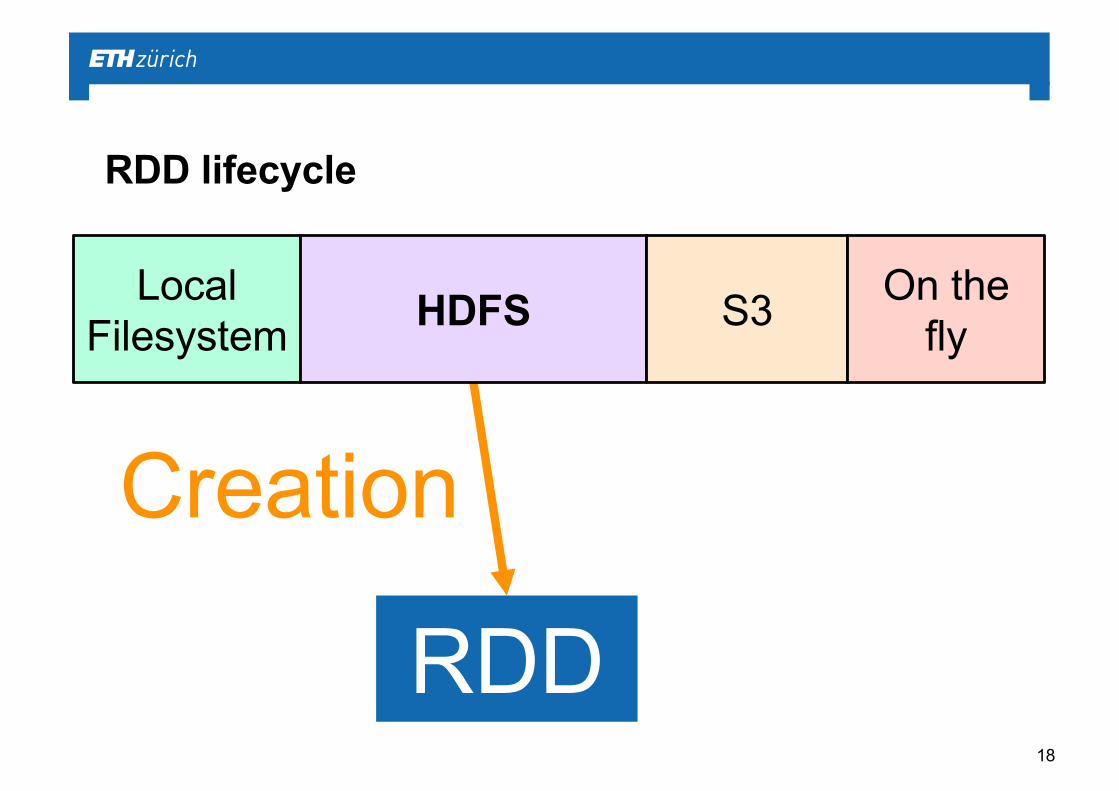
Creation
RDD lifecycle
RDD
LocalFilesystem HDFS S3 On the
fly
18

Transformation
RDD lifecycle RDD
RDD19

ActionRDD lifecycle RDD
LocalFilesystem HDFS S3 On
screen
20

Lineage graphRDD
RDD
RDD
RDDRDD
RDD
RDD
RDD
21

Lazy EvaluationRDD
RDD
RDD
RDDRDD
RDD
RDD
RDD
Each actiontriggers anevaluation
22

Lazy EvaluationRDD
RDD
RDD
RDDRDD
RDD
RDD
RDD
23

Spark: Execution
Applicationor
Shell
24

Spark: Hello, World!
val rdd1 = sc.parallelize(List("Hello, World!", "Hello, there!")
)
25

Spark: Hello, World!
val rdd1 = sc.parallelize(List("Hello, World!", "Hello, there!")
)
ValueHello, World!Hello, there!
26

Spark: Hello, World!
val rdd1 = sc.parallelize(List("Hello, World!", "Hello, there!")
)
val rdd2 = rdd1.flatMap(value => value.split(" ")
)
27
ValueHello, World!Hello, there!

Spark: Hello, World!
val rdd1 = sc.parallelize(List("Hello, World!", "Hello, there!")
)
val rdd2 = rdd1.flatMap(value => value.split(" ")
)ValueHello,World!Hello,there!
28

Spark: Hello, World!
val rdd1 = sc.parallelize(List("Hello, World!", "Hello, there!")
)
val rdd2 = rdd1.flatMap(value => value.split(" ")
)
rdd2.countByValue()
29
ValueHello,World!Hello,there!

Spark: Hello, World!
val rdd1 = sc.parallelize(List("Hello, World!", "Hello, there!")
)
val rdd2 = rdd1.flatMap(value => value.split(" ")
)
rdd2.countByValue() Key ValueHello, 2there! 1World! 1
30

Overview of transformations
31

Transformations
32
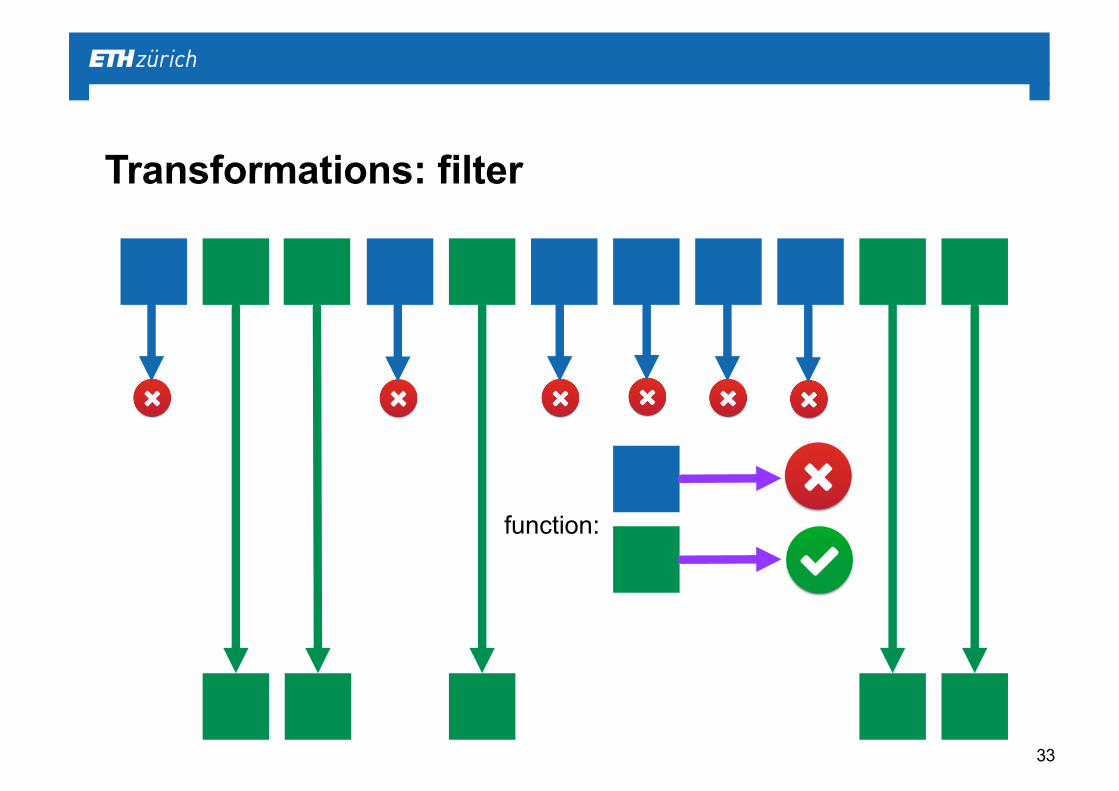
Transformations: filter
function:
33

Transformations: map
function:
34

Transformations: flatMap
function:
35

Transformations: distinct
36

Transformations: sample
fraction+ seed
37

Transformations on two RDDs
38

Transformations: union
39

Transformations: intersection
40

Transformations: subtract
41

Transformations: cartesian product
42

Overview of actions
43
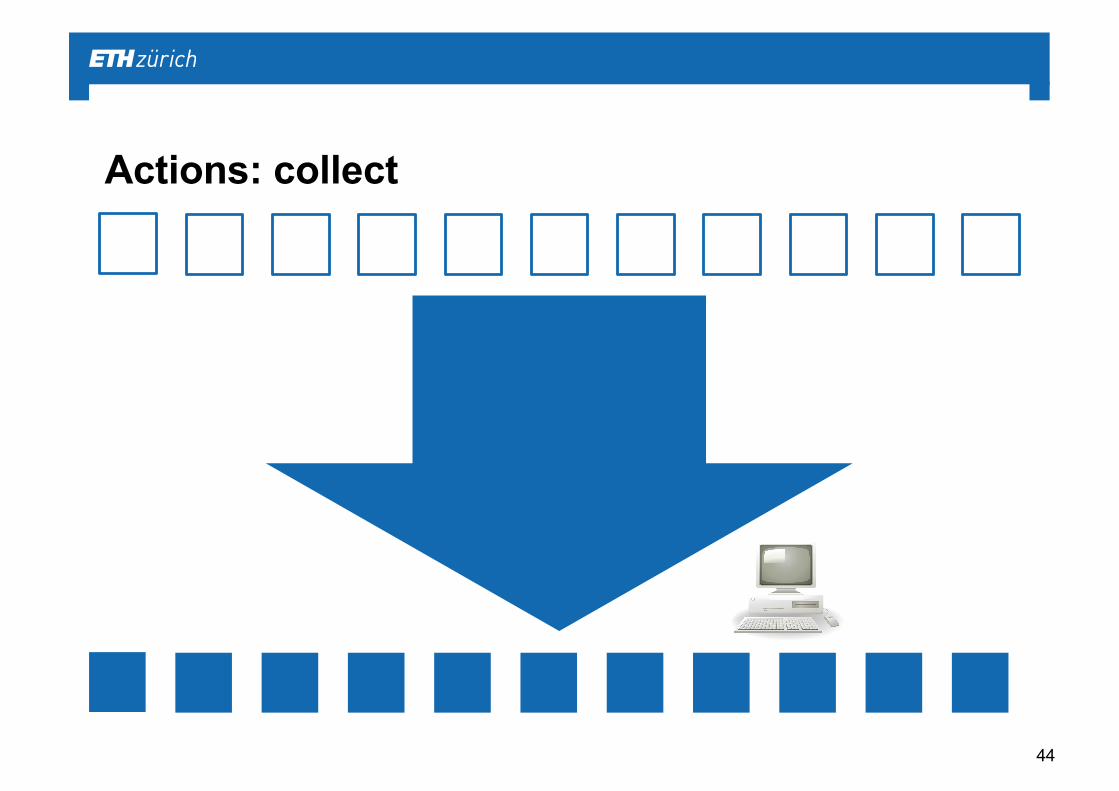
Actions: collect
44

Actions: count
22 45

Actions: count by value
12 4 646

Actions: take
4
47

Actions: top
4
48

Actions: takeSample
4
49

Actions: reduce
+
50

Pair RDDs
51

Transformations: keys
52

Transformations: values
53

Transformations: reduce by key
+
54

Transformations: group by key
55

Transformations: sort by key
<=
56

Transformations: map values
function:
57

Transformations: join
58

Transformations: subtract by key
59

Actions: count by key
6 1 460

Actions: lookup
61

Physical layer
62

Parallel execution
63

Parallel execution
Task 1 Task 2 Task 3 Task 464

Parallel execution
Task 1 Task 2 Task 3 Task 465
Default: one task per HDFS block

Transformation
Parallel executionLogicallayer
Physicallayer
RDD 1
RDD 2
66Task 1 Task 2 Task 3 Task 4

Spreading tasks over executors
67
Executor 1
Executor 2
Executor 3
Executor 4
Task 1
Task 2
Task 3
Task 4
Task 5
Task 6
Task 7
Task 8
Task 9
Task 10 Task 11

Spreading tasks over cores
68
Executor 1
Executor 2
Task 1
Task 2
Task 3
Task 4
Task 5
Task 6
Task 7
Task 8
Task 9
Task 10 Task 11
Core 1
Core 2
Core 1
Core 2
Memory
Memory
Transformation
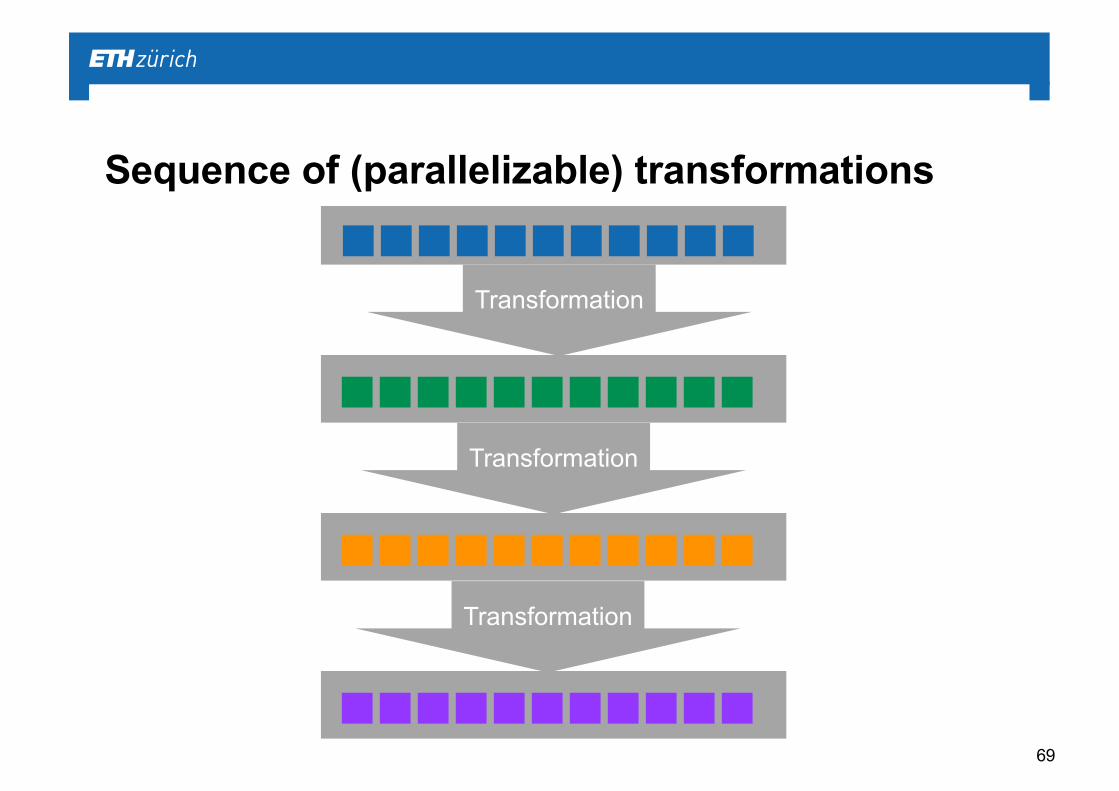
Sequence of (parallelizable) transformations
69
Transformation
Transformation

Physical layer (3 transformations)
70

Optimization
71

Stage
Optimization
72

Sequence of (parallelizable) transformationsLogicallayer
Stage
73
Transformation
Transformation
Transformation

Narrow Dependency
74

Narrow Dependency
75
Stays on same machine Same stage

Spreading a stage over cores
76
Executor 1
Executor 2
Task 1
Task 2
Task 3
Task 4
Task 5
Task 6
Task 7
Task 8
Task 9
Task 10 Task 11
Core 1
Core 2
Core 1
Core 2
Memory
Memory

Setting up executors
spark-submit --num-executors 42my-application.jar

Setting up cores
spark-submit --executor-cores 2my-application.jar

Setting up memory
spark-submit --executor-memory 5Gmy-application.jar

Most important parameters
spark-submit –-num-executors 42--executor-cores 2--executor-memory 3Gmy-application.jar

Wide Dependency
81

Wide Dependency
82
Needs to be sent overthe network
New stage

Job as sequence of stages
83
Stage 1
Stage 2
Stage 3
wait for completion
wait for completion
Shuffle
Shuffle

General DAG with stages
Join
Simple shuffle
84
Stage 1 Stage 2
Stage 3
Stage 4

Terminology
85
Stage
Transformation
Task
Verticalgrouping
Horizontal splitting
Job
Sequence

Performance tuning
86

Inefficiency
87

Inefficiency
88

Inefficiency
89

Inefficiency
90

Inefficiency
91

Inefficiency
92

Inefficiency
93

Persisting RDDs
94

Persisting RDDs
95

Persisting RDDs
96
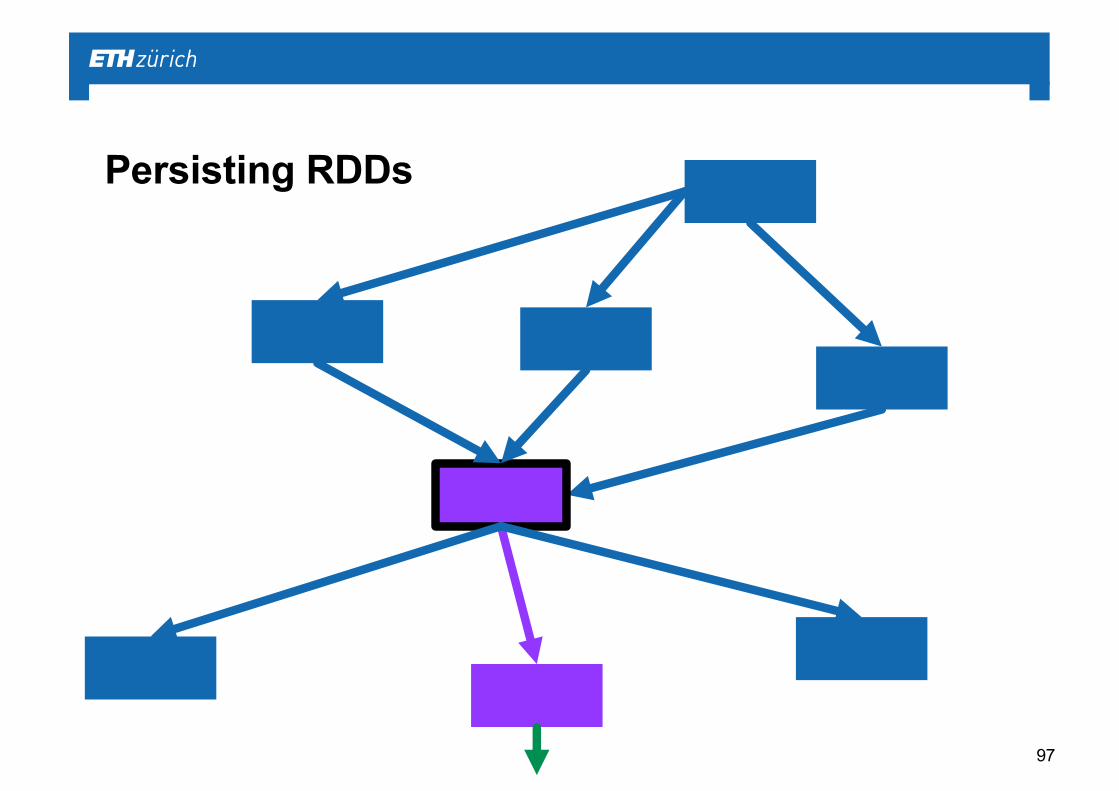
Persisting RDDs
97

Persisting RDDs
98

General DAG with stages
Join
Simple shuffle
99

Avoiding a wide dependency
100

Avoiding a wide dependency
101
Pre-partitioning

Avoiding a wide dependency
102
Key-values with samekey already on same machine

Avoiding a wide dependency
103
No need to leave the machine(No shuffling needed!)

General DAG with stages
Join
Simple shuffle
104

Pre-partitioning
Pre-partitioned
Optimized Join
Simple shuffle
105

Data Frames
106

RDDs...
function:
107

Spark and Python (PySpark)
108
rdd = spark.sparkContext.textFile('hdfs:///dataset.txt')
rdd2 = rdd.filter(lambda l: "Spark" in l)
rdd3 = rdd2.map(lambda l: (count(l), l))
rdd4 = rdd3.reduceByKey(lambda l1, l2: l1+l2)
result = rdd4.take(10)

Spark and Python (PySpark): with JSON
109
rdd = spark.sparkContext.textFile('hdfs:///dataset.json')
rdd2 = rdd.filter(lambda l: parseJSON(l))
rdd3 = rdd2.filter(lambda l: l['key'] = 0)
rdd4 = rdd3.map(lambda l: (l['key'], l['otherfield']))
result = rdd4.countByKey()

DataFrames
110
DataSet<Row>

DataFrames
111

Columnar storage
112

Memory footprint
113
"Raw" Spark DataFrames

DataFrames
114
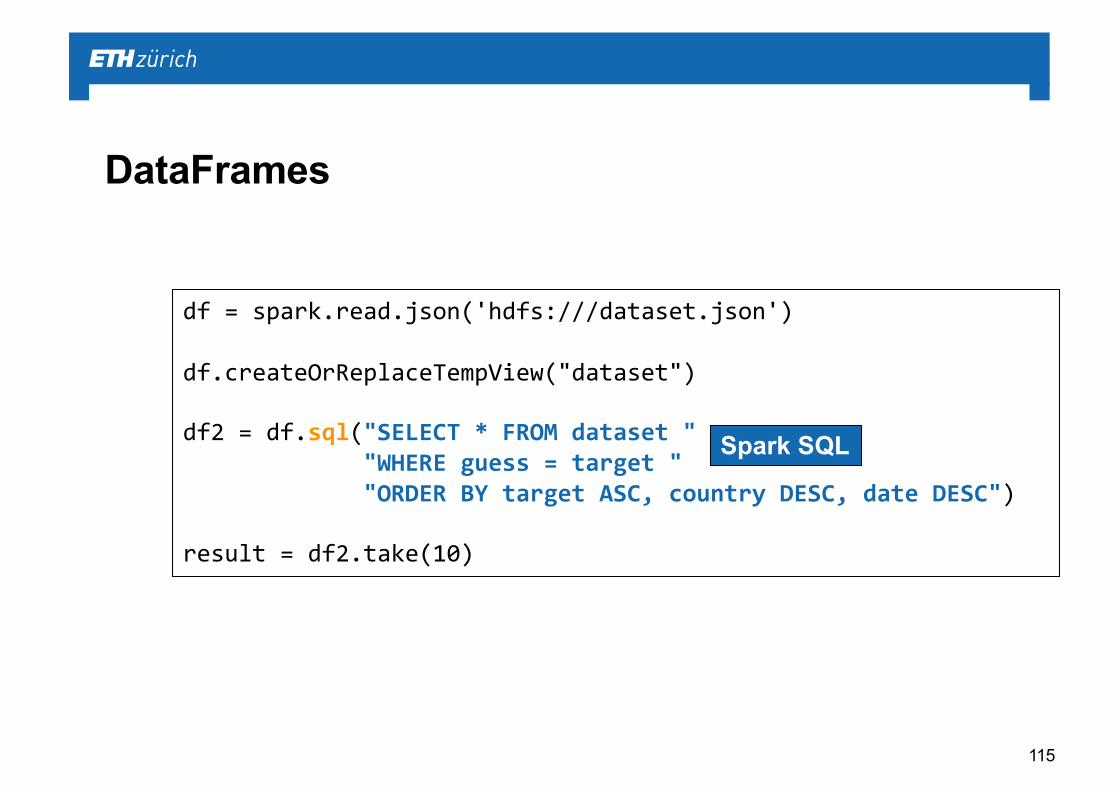
df = spark.read.json('hdfs:///dataset.json')
df.createOrReplaceTempView("dataset")
df2 = df.sql("SELECT * FROM dataset ""WHERE guess = target ""ORDER BY target ASC, country DESC, date DESC")
result = df2.take(10)
DataFrames
115
df = spark.read.json('hdfs:///dataset.json')
df.createOrReplaceTempView("dataset")
df2 = df.sql("SELECT * FROM dataset ""WHERE guess = target ""ORDER BY target ASC, country DESC, date DESC")
result = df2.take(10)
Spark SQL

Schema inference
116
foo,bar1,true2,true3,false4,true5,true6,false7,true
dataset.csv

Schema inference
117
foo,bar1,true2,true3,false4,true5,true6,false7,true
foointeger1234567
barbooleantruetruefalsetruetruefalsetrue
dataset.csv DataFrame

Schema inference
118
{ "foo" : 1, "bar" : true}{ "foo" : 2, "bar" : true}{ "foo" : 3, "bar" : false}{ "foo" : 4, "bar" : true}{ "foo" : 5, "bar" : true}{ "foo" : 6, "bar" : false}{ "foo" : 7, "bar" : true}
dataset.json

Schema inference
119
{ "foo" : 1, "bar" : true}{ "foo" : 2, "bar" : true}{ "foo" : 3, "bar" : false}{ "foo" : 4, "bar" : true}{ "foo" : 5, "bar" : true}{ "foo" : 6, "bar" : false}{ "foo" : 7, "bar" : true}
foointeger1234567
barbooleantruetruefalsetruetruefalsetrue
dataset.json DataFrame

DataFrames (with logical transformations)
120
df = spark.read.json('hdfs:///dataset.json')
df2 = df.filter(df['name'] = 'Einstein')
df3 = df.sortBy(asc("theory"), desc("date"))
df4 = df.select('year')
result = df4.take(10)

Available types
121
Byte ShortIntegerLong
FloatDouble
Decimal
String
Boolean
Binary
Timestamp
Date
Array
Struct
Map
Numbers Other atomics Structured

Type mapping
122
DataFrame JavaByteType byteShortType shortIntegerType intLongType longFloatType floatDoubleType doubleBooleanType booleanStringType StringDecimalType java.math.BigDecimalTimestampType java.sql.TimestampDateType java.sql.DateBinaryType byte[]
DataFrame JavaArrayType java.util.ListMapType java.util.MapStructType Row

Other data formats
123
df = spark.read.json("hdfs:///dataset.json")
df = spark.read.parquet("hdfs:///dataset.parquet")
df = spark.read.csv("hdfs:///dir/*.csv")
df = spark.read.text("hdfs:///dataset[0-7].txt")
df = spark.read.jdbc("jdbc:postgresql://localhost/test?user=fred&password=secret",
...)
df = spark.read.format("avro").load("hdfs:///dataset.avro")
...

Your own schema
124124
First Last Picture Birthday FlagString String byte[] Date boolean
DataSet<Person>
Statically known

DataFrames
125
df = spark.read.json('hdfs:///dataset.json')
df.createOrReplaceTempView("dataset")
df2 = df.sql("SELECT * FROM dataset ""WHERE guess = target ""ORDER BY target ASC, country DESC, date DESC")
result = df2.take(10)

DataFrames
126
df = spark.read.json('hdfs:///dataset.json')
df.createOrReplaceTempView("dataset")
df2 = df.sql("SELECT * FROM dataset ""WHERE guess = target ""ORDER BY target ASC, country DESC, date DESC")
result = df2.take(10)
Spark SQL
SQL Brush-Up!

DataFrames (with logical transformations)
127
df = spark.read.json('hdfs:///dataset.json')
df2 = df.filter(df['name'] = 'Einstein')
df3 = df.sortBy(asc("theory"), desc("date"))
df4 = df.select('year')
result = df4.take(10)

DataFrames
128
Query (DataFrames/SparkSQL)
Physical query (RDDs)
Logical plan
Physical plan

Optimizations with Catalyst
129
Source: DataBricks blog entry on Catalyst

Dealing with nestedness: arrays
SELECT Last, EXPLODE(Countries)FROM input
First (String) Last (String) Countries (Array of Strings)
Albert Einstein [ "D", "I", "CH", "A", "BE", "US" ]
Srinivasa Ramanujan [ "IN", "UK" ]
Kurt Gödel [ "CZ", "A", "US" ]
Leonhard Euler [ "CH", "RU" ] Last (String) Countries (String)
Einstein D
Einstein I
Einstein CH
Einstein A
Einstein BE
Einstein US
Ramanujan IN
Ramanujan UK
Gödel CZ
Gödel A
Gödel US
Euler CH
Euler RU

Dealing with nestedness: objects
SELECT Name.First, Name.LastFROM input
Name (Object) Countries (Int)
{ "First" : "Albert", "Last" : "Einstein" } 6
{ "First" : "Srinivasa", "Last" : "Ramanujan" } 2
{ "First" : "Kurt", "Last" : "Gödel" } 3
{ "First" : "John", "Last" : "Nash" } 1
{ "First" : "Alan", "Last" : "Turing" }, 1
{ "First" : "Leonhard", "Last" : "Euler" } 2
First (String) Last (String)Albert Einstein
Srinivasa Ramanujan
Kurt Gödel
John Nash
Alan Turing
Leonhard Euler

Limits of DataFrames: Heterogeneity
{ "foo" : 1, "bar" : true}{ "foo" : 2, "bar" : true}{ "foo" : [3, 4], "bar" : false}{ "foo" : 4, "bar" : true}{ "foo" : 5, "bar" : true}{ "foo" : 6, "bar" : false}{ "foo" : 7, "bar" : true}
foostring"1""2""[3, 4]""4""5""6""7"
barbooleantruetruefalsetruetruefalsetrue
dataset.json DataFrame

DataFrames and RDDs
133
rdd = df.rdddf = sc.createDataFrame(rdd, schema)
df = rdd.toDF()or

10 Design Principles of Big Data

1. Learn from the past

2. Keep the design simple

3. Modularize the architecture

4. Homogeneity in the large
5. Heterogeneity in the small

6. Separate metadata from data

7. Abstract logical model from its physical implementation

8. Shard the data

9. Replicate the data

10. Buy lots of cheap hardware


















