
geni-act - ubwp.buffalo.eduubwp.buffalo.edu/wnygirahcp/wp-content/uploads/sites/25/2017/11/... ·...
39
Stephen Koury ([email protected]) | profile | logout [ ] geni-act geni-act :: genomes :: Kytococcus sedentarius DSM 20547 CP001686 :: Ksed_00010 :: Lab Notebook 8ed2a45227a744df Lab Notebook Organism: Kytococcus sedentarius DSM 20547 CP001686 Locus: Ksed_00010 [-] Basic Information Module Instructions DNA Coordinates go to the Gene Page DNA coordinates 209..1729 DNA Sequence go to the Gene Page Nucleotide sequence (FASTA format; see module Quick Links for instructions) >Ksed_00010 nucleotide sequnce GTGAGCCAGACCCCCGACGACCACGCCACCGCCATCTGGCAGGAGGCC ATGGTCCACCTCCAGGGAGCAGGCCTGGCCCCGCGCGACATCGGGGTGCTCCGGCTGGCCACGC TCGTGGGTCTGCTGGAGGGCACTGCCCTGCTCGCGGTGAAGTACGACCACGTCAAGGACGCCGT CGAGGGGCACCTGCGCGAGGACGTGTCCACCGCCCTGGCGGAGGTCCTGGACCGTGACATCCGG CTGGCCGTCTCGGTGGACCCCGATGCGGTGAGCGCCGCCCAGGAGGAGGCCGCACCCCCGGCCC CGTCCCCGGCCGATGAGGACGACCCGGCCACAGGTGAGGGACCGTTGTCCACAGCTGTGGACGG AGCCGTGGAAAAGCACGAGGGAAGCAGTCCGGCACGTGCCGGGGAATCGGTGGCGCCGGCCACG ACGGCCAGCCTGACGGCGACAAACTCCTCACCCGGTGTGGAGCGCGATTACTCCGCGCTGAACC ACAAGTACACTTTCGACACCTTCGTGCTGGGGTCGTCGAACCGTTTCGCCCACGCCGCAGCGAC CGCCGTGGCCGAAGCCCCCGCCCGCGCCTACAACCCGCTGTTCATCTACGGCGGATCAGGTCTG GGCAAGACCCACCTGTTGCACGCCATCGGCCACTACGCCCGCACCCTGGATTCCTCGGTGCGCG TGAAGTACGTGAACTCGGAGGAGTTCACCAACCAGTTCATCAACGCGGTCTCGGCCGGCCAGGC GAATGCCTTCCAGCGCCAGTACCGCGATGTGGACGTCCTGCTCATCGACGACATCCAGTTCCTG CAGGGCAAGGAGCAGACGATGGAGGAGTTCTTCCACACCTTCAACACCCTGCACAACAGCGAGA AGCAGATCGTCATCACCTCCGACCAGCCCCCGAAGAAGCTCAGTGGCTTCGCCGAGCGCATGCG CTCGCGTTTCGAGTGGGGTCTGCTCACCGACGTGCAGCCGCCGGACCTGGAGACCCGCATCGCG ATCCTCCGGCGCAAGGCAGCGGCCGACAAGCTGGACATCCCCGATGACGTGCTCCACCTCATCG CGTCGAAGATCTCCTCGAACATCCGCGAGCTCGAGGGGGCCCTGACCCGGGTGACGGCCTTCGC GAGCCTGTCCGGGTCGCCCCTGGACGAGTACCTGGCCCGCACGGTGCTCAAGGACGTGATGCCC GGCGGTGACAGCGGCCAGATCACGCCCACGATGATCCTGGAGGAGACCGCGGGGTACTTCGTCA TCTCCGTCGAGGAGATCCAGGGCGCCTCCCGCTCGCGCAACCTGACCCGGGCCCGGCAGATCGC CATGTACCTGTGCCGCGAGCTCACGGACCTCTCGCTGCCGAAGATCGGCAAGGAGTTCGGCGGC http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PM Page 1 of 39
Transcript of geni-act - ubwp.buffalo.eduubwp.buffalo.edu/wnygirahcp/wp-content/uploads/sites/25/2017/11/... ·...

Stephen Koury ([email protected]) | profile | logout
[ ] geni-act
geni-act :: genomes :: Kytococcus sedentarius DSM 20547 CP001686 :: Ksed_00010 :: Lab Notebook 8ed2a45227a744df
Lab NotebookOrganism: Kytococcus sedentarius DSM 20547 CP001686Locus: Ksed_00010
[-] Basic Information
Module Instructions
DNA Coordinates
go to the Gene Page
DNA coordinates209..1729
DNA Sequence
go to the Gene Page
Nucleotide sequence (FASTA format; see module Quick Links for instructions)>Ksed_00010 nucleotide sequnce GTGAGCCAGACCCCCGACGACCACGCCACCGCCATCTGGCAGGAGGCCATGGTCCACCTCCAGGGAGCAGGCCTGGCCCCGCGCGACATCGGGGTGCTCCGGCTGGCCACGCTCGTGGGTCTGCTGGAGGGCACTGCCCTGCTCGCGGTGAAGTACGACCACGTCAAGGACGCCGTCGAGGGGCACCTGCGCGAGGACGTGTCCACCGCCCTGGCGGAGGTCCTGGACCGTGACATCCGGCTGGCCGTCTCGGTGGACCCCGATGCGGTGAGCGCCGCCCAGGAGGAGGCCGCACCCCCGGCCCCGTCCCCGGCCGATGAGGACGACCCGGCCACAGGTGAGGGACCGTTGTCCACAGCTGTGGACGGAGCCGTGGAAAAGCACGAGGGAAGCAGTCCGGCACGTGCCGGGGAATCGGTGGCGCCGGCCACGACGGCCAGCCTGACGGCGACAAACTCCTCACCCGGTGTGGAGCGCGATTACTCCGCGCTGAACCACAAGTACACTTTCGACACCTTCGTGCTGGGGTCGTCGAACCGTTTCGCCCACGCCGCAGCGACCGCCGTGGCCGAAGCCCCCGCCCGCGCCTACAACCCGCTGTTCATCTACGGCGGATCAGGTCTGGGCAAGACCCACCTGTTGCACGCCATCGGCCACTACGCCCGCACCCTGGATTCCTCGGTGCGCGTGAAGTACGTGAACTCGGAGGAGTTCACCAACCAGTTCATCAACGCGGTCTCGGCCGGCCAGGCGAATGCCTTCCAGCGCCAGTACCGCGATGTGGACGTCCTGCTCATCGACGACATCCAGTTCCTGCAGGGCAAGGAGCAGACGATGGAGGAGTTCTTCCACACCTTCAACACCCTGCACAACAGCGAGAAGCAGATCGTCATCACCTCCGACCAGCCCCCGAAGAAGCTCAGTGGCTTCGCCGAGCGCATGCGCTCGCGTTTCGAGTGGGGTCTGCTCACCGACGTGCAGCCGCCGGACCTGGAGACCCGCATCGCGATCCTCCGGCGCAAGGCAGCGGCCGACAAGCTGGACATCCCCGATGACGTGCTCCACCTCATCGCGTCGAAGATCTCCTCGAACATCCGCGAGCTCGAGGGGGCCCTGACCCGGGTGACGGCCTTCGCGAGCCTGTCCGGGTCGCCCCTGGACGAGTACCTGGCCCGCACGGTGCTCAAGGACGTGATGCCCGGCGGTGACAGCGGCCAGATCACGCCCACGATGATCCTGGAGGAGACCGCGGGGTACTTCGTCATCTCCGTCGAGGAGATCCAGGGCGCCTCCCGCTCGCGCAACCTGACCCGGGCCCGGCAGATCGCCATGTACCTGTGCCGCGAGCTCACGGACCTCTCGCTGCCGAAGATCGGCAAGGAGTTCGGCGGC
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 1 of 39

CGCGACCACACGACCGTCATGCACGCCGAGCGCAAGATCAAGCAGCTGCTCGGGGAGGACCGCCGGGTCTACGACGAGGTGAGCGAGCTCACCAGCATCATCCGCAAGAAGGCGGCGCGCGGCCGCTG A
Sequence Length1521 nucleotides
Protein Sequence
go to the Gene Page
Amino acid sequence
>Ksed_00010_amino acid seqMSQTPDDHATAIWQEAMVHLQGAGLAPRDIGVLRLATLVGLLEGTALLAVKYDHVKDAVEGHLREDVSTALAEVLDRDIRLAVSVDPDAVSAAQEEAAPPAPSPADEDDPATGEGPLSTAVDGAVEKHEGSSPARAGESVAPATTASLTATNSSPGVERDYSALNHKYTFDTFVLGSSNRFAHAAATAVAEAPARAYNPLFIYGGSGLGKTHLLHAIGHYARTLDSSVRVKYVNSEEFTNQFINAVSAGQANAFQRQYRDVDVLLIDDIQFLQGKEQTMEEFFHTFNTLHNSEKQIVITSDQPPKKLSGFAERMRSRFEWGLLTDVQPPDLETRIAILRRKAAADKLDIPDDVLHLIASKISSNIRELEGALTRVTAFASLSGSPLDEYLARTVLKDVMPGGDSGQITPTMILEETAGYFVISVEEIQGASRSRNLTRARQIAMYLCRELTDLSLPKIGKEFGGRDHTTVMHAERKIKQLLGEDRRVYDEVSELTSIIRKKAARGR
Sequence Length506 aa
[-] Sequence-based Similarity Data
Module Instructions
BLAST
go to BLAST at http://www.ncbi.nlm.nih.gov/blast
Gene product name (top hit)
Note that results from both the Swiss-Prot and nr databases have been recorded. The Swiss-Prot data for both tophits are shown in the "BLAST first hit" section of the notebook and the nr data are shown in the second hit section ofthe notebook.
Hit #1 Swis Prot Database - chromosomal replication initiator protein DnaA
Hit #2 Swis Prot Database - chromosomal replication initiator protein DnaA
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 2 of 39

Organism
Hit #1 Swis Prot Database - Kineococcus radiotolerans SRS30216
Hit #2 Swis Prot Database - Mycobacterium vanbaalenii PYR-1
Alignment Length
Hit #1 Swis Prot Database - 493
Hit #2 Swis Prot Database - 504
Score
See image files below for both SwissProt hits
E-value
See image files below for both SwissProt hits
Alignment of the top hit and the query sequence
SwissProt Database 2 top hits:
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 3 of 39

http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 4 of 39

Gene product name (second hit)
Hit #1 nr Database - chromosomal replication initiator protein DnaA
Hit #2 nr Database - chromosomal replication initiator protein DnaA
Organism
Hit #1 nr Database - Ornithinimicrobium pekingense
Hit #2 nr Database- Serinicoccus profundi
Alignment Length
Hit #1 nr Database - 503
Hit #2 nr Database - 503
Score
See image files below for both nr hits
E-value
See image files below for both nr hits
Alignment of the second hit and the query sequence
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 5 of 39

http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 6 of 39

CDD
click on the CDD search results at the top of the BLAST results page
COG number (top hit)COG0593
COG nameDnaA: Chromosomal replication initiation ATPase DnaA [Replication, recombination and repair]
E-value1.03e-153
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 7 of 39

COG number (second hit)No second found
COG name
E-value
T-Coffee
go to T-Coffee at http://www.ebi.ac.uk/Tools/msa/tcoffee
Sequences used for alignmentNote that the nr database BLAST results were used to select sequences for alginment since there were a much larger number of good hitsin those results.
>Kytococcus sedentarius DSM 20547]
MSQTPDDHATAIWQEAMVHLQGAGLAPRDIGVLRLATLVGLLEGTALLAVKYDHVKDAVEGHLREDVSTALAEVLDRDIR
LAVSVDPDAVSAAQEEAAPPAPSPADEDDPATGEGPLSTAVDGAVEKHEGSSPARAGESVAPATTASLTATNSSPGVERD
YSALNHKYTFDTFVLGSSNRFAHAAATAVAEAPARAYNPLFIYGGSGLGKTHLLHAIGHYARTLDSSVRVKYVNSEEFTN
QFINAVSAGQANAFQRQYRDVDVLLIDDIQFLQGKEQTMEEFFHTFNTLHNSEKQIVITSDQPPKKLSGFAERMRSRFEW
GLLTDVQPPDLETRIAILRRKAAADKLDIPDDVLHLIASKISSNIRELEGALTRVTAFASLSGSPLDEYLARTVLKDVMP
GGDSGQITPTMILEETAGYFVISVEEIQGASRSRNLTRARQIAMYLCRELTDLSLPKIGKEFGGRDHTTVMHAERKIKQL
LGEDRRVYDEVSELTSIIRKKAARGR
>gi|551300082|ref|WP_022920049.1| chromosomal replication initiator protein DnaA [Ornithinimicrobium pekingense]
MTSQSPAESAEVWQRVVSQLESQGVTARDRAFLRLTQLVGLLDTTALLAVPYQHTKETLETTLRQPIVDALAGELGHDVR
LAITVDEDLRRQVEDEGDPAPGPAVTEQVPSDPDRTPYRSNGAGPGEPRSDGHRTPSGAVQTASAEDARLNPKYTFDTFV
SGSSNRFAHAASLAVAESPARAYNPLFIYGESGLGKTHLLHAIGHYARSLYPGVRVRYVNSEEFTNDFINSIRDDKAGAF
QRRYRNVDFLLVDDIQFLQGKEQTVEEFFHTFNTLHNSEKQVVITSDQPPKRLSGFAERMRSRFEWGLLTDVQPPDLETR
IAILKKKAAQEGMQLPDEVLELIGSKISTNIRELEGALIRVTAFASLSSTPPDAALASHVLKDIIPNSESAAITVPTIMA
EVADYFQISNDDLCGTSRSRTLVNARQIAMYLCRELTDLSLPKIGQEFGGRDHTTVMHAERKIRQLIGERRALYDQITEL
TGIIRKASAR
>gi|497833122|ref|WP_010147278.1| chromosomal replication initiator protein DnaA [Serinicoccus profundi]
MSQPSTDSGDTWRRVVSELEDKGLGAREKAFLRLTTMVGVLDSTVLLAVPYPHTKEMLETTLRQPIVDLLSRELDREVRL
AITVDDDVRQRVEDEADDEADEDAQTRESLTRPASQPSSSAGAGVPGPSGNGIPRPATPAGPAVTGAADEARLNPKYSFD
TFVSGPSNRFAHAASLAVAESPARAYNPLFIYGESGLGKTHLLHAIGHYARKLYPGVRVRYVNSEEFTNDFINSIRDDKA
GAFQRRYRNVDFLLVDDIQFLQGKEQTVEEFFHTFNTLHNSEKQVVITSDQPPKRLSGFAERMRSRFEWGLLTDVQPPDL
ETRIAILRKKAAQEGMQLPDEVLEHIASRITTNIRELEGALIRVTAFASLSSQPADADLAAHVLKDIVPGSDTAQITVST
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 8 of 39

IIREVSEYFQISIDELCGTSRSRTLVNARQIAMYLCRELTDLSLPKIGQEFGGRDHTTVMHAERKIRAQIGERRALYDQI
AELTGTIRRASQR
>gi|737975618|ref|WP_035938084.1| chromosomal replication initiator protein DnaA [Knoellia aerolata] >gi|700180054|gb|KGN40755.1|chromosomal replication initiation protein [Knoellia aerolata DSM 18566]
MDQIWRTTLDALDSDGIPVQQRAFLSLARLVGLLDETALIAVPNDFTKDIVETRLRDRVTETLSSQLGHTVRLAVTVDSS
LGDVPVLDPPADAPSGSTTTEPRPAAGTEGDGRHAERRAELDGIALVEDDDDGDSSRTGRSVAHTRSPGALRPRPGVTVP
EQVELTRLNPKYTFDTFVIGASNRFANAAALAVAETPAKAYNPLFIYGESGLGKTHLLHAIGHYARNLFPHVKVRYVNSE
EFTNDFINSIRDDKAANFQRRYRDVDVLLIDDIQFLQGKVQTQEEFFHTFNTLHNANKQVVITSDLPPKLLSGFEERMRS
RFEWGLMTDVQPPDLETRIAILRKKAAQEKLSVPDDVLEFIASRISTNIRELEGALIRVTAFASLNRQPVDISLAEIVLK
DLIPHDSSSQITSATIMAQTAAYFGLTLEDLQGQSRSRVLVTARQIAMYLCRELTDLSLPKIGQQFGGRDHTTVMHADKK
IRQLMAERRAIYNQVTELTNRIKQQSR
>gi|914680953|ref|WP_050671265.1| chromosomal replication initiation protein [Luteipulveratus sp. C296001] >gi|912506872|gb|KNX38763.1|chromosomal replication initiation protein [Luteipulveratus sp. C296001]
MSEDKPDLAHVWHSTVMALEETGIAARDRAFLRLTRLVGLVDQTALLAVPFDHTKDILETSLREPVSSALSRLLDRDVRL
AVTVDPQLQQTVSASAEAKDAGIGEDEVAETDAEEAGTPAPALIRPVRASNRPPVEPVTDARLNPKYTFDTFVIGASNRF
AHAAAFAVAEAPAKSYNPLFVYGDSGLGKTHLLHAIGHYVRNLYPSMRVRYVNSEEFTNDFINSIRDDKASSFQKRYRDD
VDVLLIDDVQFLQGKDGTQEEFFHTFNALHDSEKQIVLTSDQPPKKLSGFADRMRSRFEWGLQTDVTPPDLETRIAILRK
KAIAERMNVPDDVLELIASKFSTNIRELEGALIRVMAFASLSQQPVDQQVAGYVLKDLVPSAGSSQITATLIMTKTAEYF
HVSVEELCGSSRSRTLVTARQIAMYLCRELTELSLPKIGQQFGGRDHTTVMHADRKIRQLIGERRPIYDQITELTGQITR
AAAG
>gi|497462772|ref|WP_009776970.1| chromosomal replication initiator protein DnaA [Janibacter sp. HTCC2649] >gi|84382082|gb|EAP97964.1|chromosomal replication initiator protein [Janibacter sp. HTCC2649]
MDQIWRTTLDALDSDGIPVQQRAFLSLAKLVGLLDETALIAVPNDFTKDIVETRLRDRVTETLSSQLGHDVRLAVTVDHS
LADVPVTIPADTTTVDGAGADQVPRTATTIGLEPGPADADGRRAKRRAELDGIALVEDDEGEDDSRNNGAIGRTRSPGAL
RPRPGATVPEQVELTRLNPKYTFDTFVIGASNRFANAAALAVAETPAKAYNPLFIYGESGLGKTHLLHAIGHYARNLYPH
VKVRYVNSEEFTNDFINSIRDDKAANFQRRYRDVDVLLIDDIQFLQGKVQTQEEFFHTFNTLHNANKQVVITSDLPPKLL
SGFEERMRSRFEWGLMTDVQPPDLETRIAILRKKAAQEKLSVPDDVLEFIASRISTNIRELEGALIRVTAFASLNRQPVD
ISLAEIVLKDLIPHDSANQITSATIMAQTAAYFGLTLEDLQGQSRSRVLVTARQIAMYLCRELTDLSLPKIGQQFGGRDH
TTVMHADKKIRQLMAERRAIYNQVTELTNRIKQQSR
>gi|872700517|ref|WP_048552171.1| chromosomal replication initiation protein [Tetrasphaera japonica] >gi|665501165|emb|CCH80159.1|chromosomal replication initiator protein DnaA [Tetrasphaera japonica T1-X7]
MDYSRVWRTALDELDADGLPIQQRAFLSLARFVGLLDDTALIAVPNDYTKEFVETRVRQQLTQTLSNHAGRELRLAVTVD
PGLKAADEAEPTLGAPAEAWGPRPRAGIGPVDDEEDHEAQDVIDARGVDTFHIQRPTPGQRPVPELIENTRLNPKYTFDT
FVIGASNRFAHAAAVAVAEAPAKAYNPLFVYGDSGLGKTHLLHAIGHYARNLYPTVRVRYVNSEEFTNDFINSIRDDKAA
NFQSRYRDVDVLLIDDIQFLQGKVQTQEEFFHTFNTLHNANKQVVITSDVPPKLLSGFEERMRSRFEWGLLTDVQPPDLE
TRIAILRKKAIQERLSVPDDVLEFIASRISTNIRELEGALIRVTAFASLNRQPVDMSLAEIVLKDLIPSDGANQITSATI
MAQTATYFGLTVEDLQGASRSRVLVTARQIAMYLCRELTDLSLPKIGQQFGGRDHTTVMHADKKIRQLMAERRAIYNQVT
ELTNRIKQQSR
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 9 of 39

>gi|656266264|ref|WP_029212190.1| chromosomal replication initiator protein DnaA [Arsenicicoccus bolidensis]
MTDAQVDVPRVWRDTLRALESGGISAQHRGFLRLSRLVGLLEGTALIAVPNDYTRDIVEKRIRTELVAALQEQLGRDVRL
AVTVDSSLELSEAEDRDDSTQRPGSPGEVPHVVTSSDPVRHDGERGGSDPRSTYGPRLVRDERVPRPVSTDASFGGERPY
ADPARHDGGPGHAPGIRPAQDDDADDDRELLAEGDGIREMFRKPFVPEDGRDAKLNPKYTFDTFVIGSSNRFAHAAAIAV
AEAPAKAYNPLFIYGGSGLGKTHLLHAIGHYAQQIYPNVRVKYVNSEEFTNDFINSIGANKASDFQRRYRDIDFLLIDDI
QFLQGKVQTQEEFFHTFNTLHNANKQVVITSDVAPKLLSGFEERMRSRFEWGLLTDVQPPDLETRIAILRKKAVQERMTA
PDDVLEFIASKISTNIRELEGALIRVTAFASLNHQGVDMTLAEVVLKDLIPADQTNQITPATIMAQTASYFGLTVDDLCG
TSRSRVLVTARQIAMYLCRELTDLSLPKIGQQFGGRDHTTVMHADRKIRELMSERRAIYNQVTELTNRIKSNPS
>gi|918414635|ref|WP_052465811.1| chromosomal replication initiation protein [Mobilicoccus sp. SIT2]
MSGSGEPPTTPAVDDPARIWGATLRALDQAGIPAPQRAFLRQAMLVGVLDTTALIAVPDDFTKEIVESRARDYLVKALTE
QVGREVRLAVTVDASLREQIAAAEQPVLEGYADPDSDVAAAEPPAASPTAAAPASPPVEDSPAPVGERRPRPAPTGRREE
SSQLNPKYTFDTFVIGASNRFAHAAAVAVAEAPAKAYNPLFVYGDSGLGKTHLLHAIGHYARNLYPHVKVKYVNSEEFTN
DFINSIRDDKAAGFQRRYRDMDVLLIDDIQFLQGKMQTQEEFFHTFNTLHNSNKQVVITSDVPPKQLSGFEERMRSRFEW
GLLTDVQPPDLETRIAILRKKAVQEHLALPDEVMEFIASRISTNIRELEGALIRVTAFANLNRQPVEMSLAEIVLKDLIP
DKESSQITASMIMGQTAAYFGLSIDDLCGSSRSRGLVTARQIAMYLCRELTELSLPKIGQQFGGRDHTTVMHADRKIRQL
MAERRSVYNQVTELTTRIRSQAS
>gi|503647989|ref|WP_013882065.1| chromosomal replication initiator protein DnaA [[Cellvibrio] gilvus] >gi|336102716|gb|AEI10535.1| chromosomalreplication initiator protein DnaA [[Cellvibrio] gilvus ATCC 13127]
MAQDEELSRVWGHVVTTLEESPDITQRQLAFVRLAQPLGLLDGTIILAVGNEYTKEYLETKVRAEVTSALGSALGRDGRF
AITVDPSLVDDAPPAVRAMTSAPELGVVTDGTDERGAPNRTVPTDADTGRHERSPMLSESAEPTRPVRETASSRRPAAEP
ARLNPHYLFETFVIGSSNRFAHAAAVAVAEAPAKAYNPLFIYGDSGLGKTHLLHAIGHYAQNLYPSVRVRYVNSEEFTND
FINSISEGKAGAFQRRYREVDVLLIDDIQFLQGKEQTMEEFFHTFNTLHNANKQVVITSDLPPKQLNGFEDRMRSRFEWG
LITDVQPPDLETRIAILRKKAGGDNMQAPPDVLEYIASKISTNIRELEGALIRVTAFASLNRQQVDLSLAEIVLKDLITD
DQTTEITATQVIGQTAAYFGLSIEDLCGSSRSRVLVTARQIAMYLCRELTDLSLPKIGQAFGGRDHTTVMHANRKIRELM
AERRSIYNQVTELTNRIKQQSRG
>gi|739084600|ref|WP_036955733.1| chromosomal replication initiator protein DnaA [Promicromonosporaceae bacterium W15]
MAEVWSAARIQLENDPDVTPRQRGYVRLVAPLAHIDDTVFLKVSDEPIRSFIETNLRADLVGALAGVLGYEPKLAISVDP
DLQIADDDTDPAAPVYARPAPTTATSPAAQRMPTDEPDHGLSNPVGFGATVGLPEAMPAAPGSARAAQHAPRHAEPTAPL
GENSRLNPKYLFETFVIGASNRFAHAAAVAVAEAPAKAYNPLFIYGDSGLGKTHLLHAIGHYAQSLYPNVRVRYVNSEEF
TNDFINSIGEGKAGAFQRRYRDVDVLLIDDIQFLQGKEQTMEEFFHTFNALHNANKQVVITSDLPPKQLNGFEDRLRSRF
EWGLITDVQPPDLETRIAILRKKALQERLDAPDDVLEYIASRISTNIRELEGALIRVTAFANLNRQPVDQSLAEIVLKDL
ITDDDAGEITAASVIAQTAAYFGLTIDDLCGSSRSRVLVTARQIAMYLCRELTDLSLPKIGQQFGGRDHTTVMHANRKIS
EQMAERRSIYNQVTELTSRIKQQHRG
Multiple sequence alignment
[Kytococcus MSQTPDDHATAIWQEAMVHLQ-GAGLAPRDIGVLRLATLVGLLEGTALLAgi|478759289|emb|CCH68940.1| MADA---SMTSVWVRILRALD-REGVSHQERAFLSITRLAGVLDETALIA
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 10 of 39

gi|497462772|ref|WP_009776970.1| M--------DQIWRTTLDALD-SDGIPVQQRAFLSLAKLVGLLDETALIAgi|497833122|ref|WP_010147278.1| MSQ-PSTDSGDTWRRVVSELE-DKGLGAREKAFLRLTTMVGVLDSTVLLAgi|503647989|ref|WP_013882065.1| MAQD--EELSRVWGHVVTTLEESPDITQRQLAFVRLAQPLGLLDGTIILAgi|551300082|ref|WP_022920049.1| MTSQSPAESAEVWQRVVSQLE-SQGVTARDRAFLRLTQLVGLLDTTALLAgi|656266264|ref|WP_029212190.1| MTDA-QVDVPRVWRDTLRALE-SGGISAQHRGFLRLSRLVGLLEGTALIAgi|665501165|emb|CCH80159.1| MD------YSRVWRTALDELD-ADGLPIQQRAFLSLARFVGLLDDTALIAgi|737975618|ref|WP_035938084.1| M--------DQIWRTTLDALD-SDGIPVQQRAFLSLARLVGLLDETALIAgi|750471801|ref|WP_040753674.1| M--------TSVWVRILRALD-REGVSHQERAFLSITRLAGVLDETALIA * * : *: .: :. ..: :: *:*: * ::*
[Kytococcus VKYDHVKDAVEGHLREDVSTALAEVLDRDIRLAVSVDPDAVSAAQEEAAPgi|478759289|emb|CCH68940.1| VPNDFSKDIVETRLRGRISGHLTAELDRPLRLAVTVDPSLAEAEPLDLDAgi|497462772|ref|WP_009776970.1| VPNDFTKDIVETRLRDRVTETLSSQLGHDVRLAVTVDHSLADVPVTIPADgi|497833122|ref|WP_010147278.1| VPYPHTKEMLETTLRQPIVDLLSRELDREVRLAITVDDDVRQRVEDEADDgi|503647989|ref|WP_013882065.1| VGNEYTKEYLETKVRAEVTSALGSALGRDGRFAITVDPSLVDDAPPAVRAgi|551300082|ref|WP_022920049.1| VPYQHTKETLETTLRQPIVDALAGELGHDVRLAITVDEDLRRQVEDEGD-gi|656266264|ref|WP_029212190.1| VPNDYTRDIVEKRIRTELVAALQEQLGRDVRLAVTVDSSLELSEAEDRDDgi|665501165|emb|CCH80159.1| VPNDYTKEFVETRVRQQLTQTLSNHAGRELRLAVTVDPGLKAADEAEPTLgi|737975618|ref|WP_035938084.1| VPNDFTKDIVETRLRDRVTETLSSQLGHTVRLAVTVDSSLGDVPVLDPPAgi|750471801|ref|WP_040753674.1| VPNDFSKDIVETRLRGRISGHLTAELDRPLRLAVTVDPSLAEAEPLDLDA * . :: :* :* : * .: *:*::** .
[Kytococcus -PAP----------SPADEDDPATGEGPLS--------------------gi|478759289|emb|CCH68940.1| HDSQDHSLATD--PQRATQDDPALVNGVADL----AVVD-----------gi|497462772|ref|WP_009776970.1| -TTTVDGAGADQVPRTATTI--GLEPGP----------------------gi|497833122|ref|WP_010147278.1| -EAD----------EDAQTRESL---------------------------gi|503647989|ref|WP_013882065.1| M-------TSA--PELGVVTDGTDERGAPNR----TV-P-----------gi|551300082|ref|WP_022920049.1| -PAP----------GPAVTEQVP---------------------------gi|656266264|ref|WP_029212190.1| STQRPGSPGEV--PHVVTSSDPVRHDGERGGSDPRSTYGPRLVRDERVPRgi|665501165|emb|CCH80159.1| -GAPAEA--WG--PRPRA--------------------------------gi|737975618|ref|WP_035938084.1| -DAPSGSTTTE--PRPAA----G---------------------------gi|750471801|ref|WP_040753674.1| HDSQDHSLATD--PQRATQDDPALVNGVADL----AVVD-----------
[Kytococcus -------------------------TAVDG--AVEKHEGSSPARA-GESVgi|478759289|emb|CCH68940.1| ---L----------DDPEVRRAQRRLELDGL-------DADETPM-PRAAgi|497462772|ref|WP_009776970.1| --------------ADADGRRAKRRAELDGIALVEDDEGEDDSRN-NGAIgi|497833122|ref|WP_010147278.1| -----------------------------------TRPASQPSSSAGAGVgi|503647989|ref|WP_013882065.1| --------------TDADTGR------------------HERSPMLSESAgi|551300082|ref|WP_022920049.1| -----------------------------------SDPDRTPYRSNGAGPgi|656266264|ref|WP_029212190.1| PVSTDASFGGERPYADP-ARHDGGPGHAPGIRPAQDDD-ADDDRE-LL-Agi|665501165|emb|CCH80159.1| -----------------------------GIGPVDDEEDHEAQDV-IDA-gi|737975618|ref|WP_035938084.1| --------------TEGDGRHAERRAELDGIALVEDDDDGDSSRT-GRSVgi|750471801|ref|WP_040753674.1| ---L----------DDPEVRRAQRRLELDGL-------DADETPM-PRAA
[Kytococcus A-PATTASL---TATNSSPGVERDYSALNHKYTFDTFVLGSSNRFAHAAAgi|478759289|emb|CCH68940.1| EPTGIPANLR-----RGSNPENVELTRLNPKYTFETFVIGASNRFAHAAAgi|497462772|ref|WP_009776970.1| GRTRSPGALRP-RPG-ATVPEQVELTRLNPKYTFDTFVIGASNRFANAAAgi|497833122|ref|WP_010147278.1| PGPSGNGIPRPATPAGPAVTGAADEARLNPKYSFDTFVSGPSNRFAHAASgi|503647989|ref|WP_013882065.1| EPTR-PVRE----T-ASSRRPAAEPARLNPHYLFETFVIGSSNRFAHAAAgi|551300082|ref|WP_022920049.1| GEPRSDGHR---TPSGAVQTASAEDARLNPKYTFDTFVSGSSNRFAHAASgi|656266264|ref|WP_029212190.1| EGDGIREMFR-----KPFVPEDGRDAKLNPKYTFDTFVIGSSNRFAHAAAgi|665501165|emb|CCH80159.1| RGVDTFHIQRP-TPGQRPVPELIENTRLNPKYTFDTFVIGASNRFAHAAAgi|737975618|ref|WP_035938084.1| AHTRSPGALRP-RPG-VTVPEQVELTRLNPKYTFDTFVIGASNRFANAAAgi|750471801|ref|WP_040753674.1| EPTGIPANLR-----RGSNPENVELTRLNPKYTFETFVIGASNRFAHAAA : ** :* *:*** *.*****:**:
[Kytococcus TAVAEAPARAYNPLFIYGGSGLGKTHLLHAIGHYARTLDSSVRVKYVNSEgi|478759289|emb|CCH68940.1| TAVGETPAKAYNPLFIYGGSGLGKTHLLHAIGHYARSLYPNVKVRYVNSEgi|497462772|ref|WP_009776970.1| LAVAETPAKAYNPLFIYGESGLGKTHLLHAIGHYARNLYPHVKVRYVNSEgi|497833122|ref|WP_010147278.1| LAVAESPARAYNPLFIYGESGLGKTHLLHAIGHYARKLYPGVRVRYVNSEgi|503647989|ref|WP_013882065.1| VAVAEAPAKAYNPLFIYGDSGLGKTHLLHAIGHYAQNLYPSVRVRYVNSEgi|551300082|ref|WP_022920049.1| LAVAESPARAYNPLFIYGESGLGKTHLLHAIGHYARSLYPGVRVRYVNSEgi|656266264|ref|WP_029212190.1| IAVAEAPAKAYNPLFIYGGSGLGKTHLLHAIGHYAQQIYPNVRVKYVNSEgi|665501165|emb|CCH80159.1| VAVAEAPAKAYNPLFVYGDSGLGKTHLLHAIGHYARNLYPTVRVRYVNSEgi|737975618|ref|WP_035938084.1| LAVAETPAKAYNPLFIYGESGLGKTHLLHAIGHYARNLFPHVKVRYVNSEgi|750471801|ref|WP_040753674.1| TAVGETPAKAYNPLFIYGGSGLGKTHLLHAIGHYARSLYPNVKVRYVNSE **.*:**:******:** ****************: : . *:*:*****
[Kytococcus EFTNQFINAVSAGQANAFQRQYRDVDVLLIDDIQFLQGKEQTMEEFFHTFgi|478759289|emb|CCH68940.1| EFTNDFINSVRDGKAAEFQRRYRYVDVLLIDDIQFLQGKEQTQEEFFHTFgi|497462772|ref|WP_009776970.1| EFTNDFINSIRDDKAANFQRRYRDVDVLLIDDIQFLQGKVQTQEEFFHTFgi|497833122|ref|WP_010147278.1| EFTNDFINSIRDDKAGAFQRRYRNVDFLLVDDIQFLQGKEQTVEEFFHTFgi|503647989|ref|WP_013882065.1| EFTNDFINSISEGKAGAFQRRYREVDVLLIDDIQFLQGKEQTMEEFFHTFgi|551300082|ref|WP_022920049.1| EFTNDFINSIRDDKAGAFQRRYRNVDFLLVDDIQFLQGKEQTVEEFFHTFgi|656266264|ref|WP_029212190.1| EFTNDFINSIGANKASDFQRRYRDIDFLLIDDIQFLQGKVQTQEEFFHTFgi|665501165|emb|CCH80159.1| EFTNDFINSIRDDKAANFQSRYRDVDVLLIDDIQFLQGKVQTQEEFFHTFgi|737975618|ref|WP_035938084.1| EFTNDFINSIRDDKAANFQRRYRDVDVLLIDDIQFLQGKVQTQEEFFHTFgi|750471801|ref|WP_040753674.1| EFTNDFINSVRDGKAAEFQRRYRYVDVLLIDDIQFLQGKEQTQEEFFHTF ****:***:: .:* ** :** :*.**:********* ** *******
[Kytococcus NTLHNSEKQIVITSDQPPKKLSGFAERMRSRFEWGLLTDVQPPDLETRIAgi|478759289|emb|CCH68940.1| NALHNANKQVVVTSDVAPKQLAGMEERLRSRLEWGLLTDVQPPDLETRIAgi|497462772|ref|WP_009776970.1| NTLHNANKQVVITSDLPPKLLSGFEERMRSRFEWGLMTDVQPPDLETRIAgi|497833122|ref|WP_010147278.1| NTLHNSEKQVVITSDQPPKRLSGFAERMRSRFEWGLLTDVQPPDLETRIAgi|503647989|ref|WP_013882065.1| NTLHNANKQVVITSDLPPKQLNGFEDRMRSRFEWGLITDVQPPDLETRIAgi|551300082|ref|WP_022920049.1| NTLHNSEKQVVITSDQPPKRLSGFAERMRSRFEWGLLTDVQPPDLETRIAgi|656266264|ref|WP_029212190.1| NTLHNANKQVVITSDVAPKLLSGFEERMRSRFEWGLLTDVQPPDLETRIAgi|665501165|emb|CCH80159.1| NTLHNANKQVVITSDVPPKLLSGFEERMRSRFEWGLLTDVQPPDLETRIAgi|737975618|ref|WP_035938084.1| NTLHNANKQVVITSDLPPKLLSGFEERMRSRFEWGLMTDVQPPDLETRIAgi|750471801|ref|WP_040753674.1| NALHNANKQVVVTSDVAPKQLAGMEERLRSRLEWGLLTDVQPPDLETRIA *:***::**:*:*** .** * *: :*:***:****:*************
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 11 of 39

[Kytococcus ILRRKAAADKLDIPDDVLHLIASKISSNIRELEGALTRVTAFASLSGSPLgi|478759289|emb|CCH68940.1| ILRKKAIHERLSVPDDVMEFIASRISTNIRELEGALIRVTAFANLNRQPVgi|497462772|ref|WP_009776970.1| ILRKKAAQEKLSVPDDVLEFIASRISTNIRELEGALIRVTAFASLNRQPVgi|497833122|ref|WP_010147278.1| ILRKKAAQEGMQLPDEVLEHIASRITTNIRELEGALIRVTAFASLSSQPAgi|503647989|ref|WP_013882065.1| ILRKKAGGDNMQAPPDVLEYIASKISTNIRELEGALIRVTAFASLNRQQVgi|551300082|ref|WP_022920049.1| ILKKKAAQEGMQLPDEVLELIGSKISTNIRELEGALIRVTAFASLSSTPPgi|656266264|ref|WP_029212190.1| ILRKKAVQERMTAPDDVLEFIASKISTNIRELEGALIRVTAFASLNHQGVgi|665501165|emb|CCH80159.1| ILRKKAIQERLSVPDDVLEFIASRISTNIRELEGALIRVTAFASLNRQPVgi|737975618|ref|WP_035938084.1| ILRKKAAQEKLSVPDDVLEFIASRISTNIRELEGALIRVTAFASLNRQPVgi|750471801|ref|WP_040753674.1| ILRKKAIHERLSVPDDVMEFIASRISTNIRELEGALIRVTAFANLNRQPV **::** : : * :*:. *.*:*::********* ******.*.
[Kytococcus DEYLARTVLKDVMPGGDSGQITPTMILEETAGYFVISVEEIQGASRSRNLgi|478759289|emb|CCH68940.1| DLALAEIVLRDLIPTE-GGEITSATIMAQTAAYFGLTLEDLRGSSRSRVLgi|497462772|ref|WP_009776970.1| DISLAEIVLKDLIPHDSANQITSATIMAQTAAYFGLTLEDLQGQSRSRVLgi|497833122|ref|WP_010147278.1| DADLAAHVLKDIVPGSDTAQITVSTIIREVSEYFQISIDELCGTSRSRTLgi|503647989|ref|WP_013882065.1| DLSLAEIVLKDLITDDQTTEITATQVIGQTAAYFGLSIEDLCGSSRSRVLgi|551300082|ref|WP_022920049.1| DAALASHVLKDIIPNSESAAITVPTIMAEVADYFQISNDDLCGTSRSRTLgi|656266264|ref|WP_029212190.1| DMTLAEVVLKDLIPADQTNQITPATIMAQTASYFGLTVDDLCGTSRSRVLgi|665501165|emb|CCH80159.1| DMSLAEIVLKDLIPSDGANQITSATIMAQTATYFGLTVEDLQGASRSRVLgi|737975618|ref|WP_035938084.1| DISLAEIVLKDLIPHDSSSQITSATIMAQTAAYFGLTLEDLQGQSRSRVLgi|750471801|ref|WP_040753674.1| DLALAEIVLRDLIPTE-GGEITSATIMAQTAAYFGLTLEDLRGSSRSRVL * ** **:*::. ** . :: :.: ** :: ::: * **** *
[Kytococcus TRARQIAMYLCRELTDLSLPKIGKEFGGRDHTTVMHAERKIKQLLGEDRRgi|478759289|emb|CCH68940.1| VNARQIAMYLCRELTSMSLPEIGKEFN-KDHTTVMHANKKIGQLMAERRAgi|497462772|ref|WP_009776970.1| VTARQIAMYLCRELTDLSLPKIGQQFGGRDHTTVMHADKKIRQLMAERRAgi|497833122|ref|WP_010147278.1| VNARQIAMYLCRELTDLSLPKIGQEFGGRDHTTVMHAERKIRAQIGERRAgi|503647989|ref|WP_013882065.1| VTARQIAMYLCRELTDLSLPKIGQAFGGRDHTTVMHANRKIRELMAERRSgi|551300082|ref|WP_022920049.1| VNARQIAMYLCRELTDLSLPKIGQEFGGRDHTTVMHAERKIRQLIGERRAgi|656266264|ref|WP_029212190.1| VTARQIAMYLCRELTDLSLPKIGQQFGGRDHTTVMHADRKIRELMSERRAgi|665501165|emb|CCH80159.1| VTARQIAMYLCRELTDLSLPKIGQQFGGRDHTTVMHADKKIRQLMAERRAgi|737975618|ref|WP_035938084.1| VTARQIAMYLCRELTDLSLPKIGQQFGGRDHTTVMHADKKIRQLMAERRAgi|750471801|ref|WP_040753674.1| VNARQIAMYLCRELTSMSLPEIGKEFN-KDHTTVMHANKKIGQLMAERRA . *************.:***:**: *. :********::** :.* *
[Kytococcus VYDEVSELTSIIRKKAARGRgi|478759289|emb|CCH68940.1| IYNNVTELTGRIKQQS---Rgi|497462772|ref|WP_009776970.1| IYNQVTELTNRIKQQS---Rgi|497833122|ref|WP_010147278.1| LYDQIAELTGTIRRAS--QRgi|503647989|ref|WP_013882065.1| IYNQVTELTNRIKQQS--RGgi|551300082|ref|WP_022920049.1| LYDQITELTGIIRKAS--ARgi|656266264|ref|WP_029212190.1| IYNQVTELTNRIKSNP---Sgi|665501165|emb|CCH80159.1| IYNQVTELTNRIKQQS---Rgi|737975618|ref|WP_035938084.1| IYNQVTELTNRIKQQS---Rgi|750471801|ref|WP_040753674.1| IYNNVTELTGRIKQQS---R :*::::***. *: .
WebLogo
go to WebLogo at http://weblogo.berkeley.edu
Sequence Logo
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 12 of 39

http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 13 of 39

http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 14 of 39

Comments/observationsThe N-terminal end of this protein is indicated to be reasonably well conserved. There is a gap from positions 128 to 164 in the alignment showingthat gaps were added in this region of the alignment. The C-terminal end of the protein is highly conserved showing several regions with hydrophobicamino acids.
[-] Cellular Localization Data
Module Instructions
Gram Stain
go to NCBI Pubmed at http://www.ncbi.nlm.nih.gov/pubmed
Gram stain of the microbeGram Positive
TMHMM
go to TMHMM at http://www.cbs.dtu.dk/services/TMHMM
Number of predicted transmembrane helices0
Transmembrane topology graph
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 15 of 39

Comments/observationsNo transmembrane helicies were predicted by TMHMM, suggesting that Ksed_00010 does not reside within the cell membrane.
SignalP
go to SignalP at http://www.cbs.dtu.dk/services/SignalP
Signal peptide probabilityNo
0.131
Most likely cleavage site (between position # and #)N/A - no signal peptide is predicted, thus there is no predicted cleavage site.
Signal peptide graph
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 16 of 39

LipoP
Go to LipoP at http://www.cbs.dtu.dk/services/LipoP/
Best Prediction (options = cytoplasm, signal peptidase I, signal peptidases II)This was not done for Kytococcus since it only applies to Gram negative bacteria and Kytococcus is Gram positive.
Cleavage site, if predicted, after AA #
PSORT-B
go to PSORT-B at http://www.psort.org/psortb
Cytoplasmic score9.97
CytoplasmicMembrane score
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 17 of 39

0.00
Cellwall score
0.01
Periplasmic scoreN/A
OuterMembrane scoreN/A
Extracellular score0.02
PSORT-B final prediction
Phobius
go to Phobius at http://phobius.sbc.su.se
Phobius probability graph
The Phobius tool predicts that there is neither a signal peptide nor transmembrane helicies found in the amino acid sequence of Ksed_00010. Thestatement that amino acids 1-506 are "non cytoplasmic" in the Phobius probablilty graph is meaningless in predicting location.
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 18 of 39

Hypothesis
Based on the results of these tools, where do you expect to find this protein?TMHMM indicates that there are no transmembrane helices, Signal IP revelas low probability for signal peptide, pSORTB predicts Ksed_00010 to bea cytoplasmic protein . Phobius coroborates negative results for TMHs and Signal peptide. Taking all of these results into account, the final predictionfor localization is that Ksed_00010 is a cytoplasmic protein.
[-] Alternative Open Reading Frame
Module Instructions
DNA Coordinates
login to IMG/EDU and find the gene page for this gene
Proposed DNA coordinates (if different from those predicted by IMG)..
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 19 of 39

Explanation of choice
There is no shine dalgarno sequence upstream of the predicted start codon for Ksed_00010. No alternative start codons with a better start codonwere seen when 99 bases of upstream sequence was added, but a start codon with a shine-dalgarno sequence was found downstream of the startcodon called by the computer. This was tested as a potential alternative start codon (see image below).
The sequence tested was as follows:
>Ksed_00010_amino acid seq - downstream start codonMSQTPDDHATAIWQEAMVHLQGAGLAPRDIGVLRLATLVGLLEGTALLAVKYDHVKDAVEGHLREDVSTALAEVLDRDIRLAVSVDPDAVSAAQEEAAPPAPSPADEDDPATGEGPLSTAVDGAVEKHEGSSPARAGESVAPATTASLTATNSSPGVERDYSALNHKYTFDTFVLGSSNRFAHAAATAVAEAPARAYNPLFIYGGSGLGKTHLLHAIGHYARTLDSSVRVKYVNSEEFTNQFINAVSAGQANAFQRQYRDVDVLLIDDIQFLQGKEQTMEEFFHTFNTLHNSEKQIVITSDQPPKKLSGFAERMRSRFEWGLLTDVQPPDLETRIAILRRKAAADKLDIPDDVLHLIASKISSNIRELEGALTRVTAFASLSGSPLDEYLARTVLKDVMPGGDSGQITPTMILEETAGYFVISVEEIQGASRSRNLTRARQIAMYLCRELTDLSLPKIGKEFGGRDHTTVMHAERKIKQLLGEDRRVYDEVSELTSIIRKKAARGR
The BLAST scores for the sequence starting with the downstream start codon was less than that observed when the sequence beginning with the computer called start codon was used in either Swiss-Prot or nr databases. Therefore is no evidence to suggest the computer called start codon is incorrect.
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 20 of 39

[-] Structure-based Evidence
Module Instructions
TIGRFAM
go to TIGRFAM at http://tigrblast.tigr.org/web-hmm
TIGRFAM numberFirst Hit: TIGR00362
Second Hit: TIGR03420
TIGRFAM name
First Hit: DnaA: chromosomal replication initiator protein DnaA
DnaA is involved in DNA biosynthesis; initiation of chromosome replication and can also be transcription regulator. The C-terminal of the family hits the pfam bacterial DnaA (bac_dnaA) domain family. For a review, see Kaguni (2006).
Second Hit: DnaA_homol_Hda: DnaA regulatory inactivator Hda
Members of this protein family are Hda (Homologous to DnaA). These proteins are about half the length of DnaA and homologous over length of Hda. In the model species Escherichia coli, the initiation of DNA replication requires DnaA bound to ATP rather than ADP; Hda helps facilitate the conversion of DnaA-ATP to DnaA-ADP.
Score
First Hit: 740.9 Second Hit: 13.9
E-value
First Hit: 3.8e-220
Second Hit: 1.2e-13
Pfam
go to Pfam at http://pfam.sanger.ac.uk/search
Pfam number (PF#####) for top hit
PF00308
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 21 of 39

Pfam name
Bac_DnaA
The following was copied from the wiki link for PF00308. "DnaA is a protein that activates initiation of DNA replication in bacteria.[1] It is areplication initiation factor which promotes the unwinding of DNA at oriC.[1] The onset of the initiation phase of DNA replication is determined by theconcentration of DnaA.[1] DnaA accumulates during growth and then triggers the initiation of replication.[1]Replication begins with active DnaA bindingto 9-mer (9-bp) repeats upstream of oriC.[1] Binding of DnaA leads to strand separation at the 13-mer repeats.[1] This binding causes the DNA to loopin preparation for melting open by the helicase DnaB.[1]"
Clan name
P-loop_NTPase
P-loop containing nucleoside triphosphate hydrolase superfamilyAAA family proteins often perform chaperone-like functions that assist in the assembly, operation, or disassembly of protein complexes [2].
This clan contains 198 families and the total number of domains in the clan is 5072865. The clan was built by DJ Studholme.
Clan number (CL####)
CL0023
Score329.1
E-value1.3e-98
Pairwise alignment
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 22 of 39
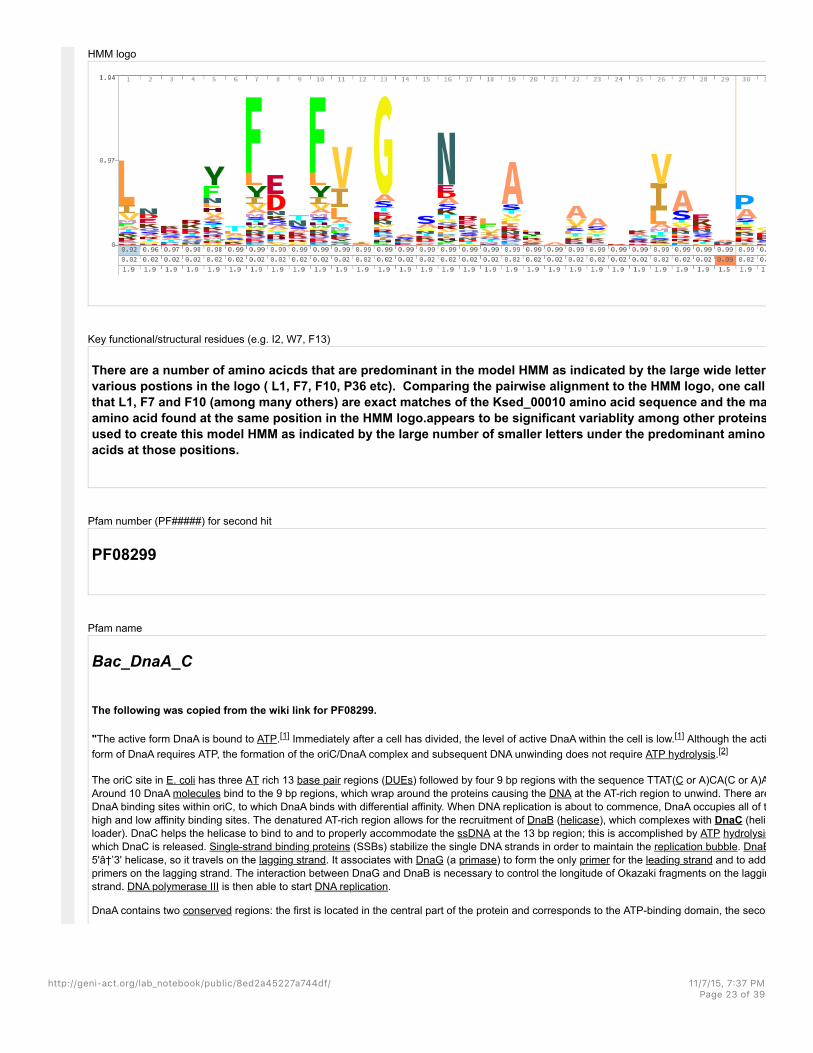
HMM logo
Key functional/structural residues (e.g. I2, W7, F13)
There are a number of amino acicds that are predominant in the model HMM as indicated by the large wide letters atvarious postions in the logo ( L1, F7, F10, P36 etc). Comparing the pairwise alignment to the HMM logo, one call seethat L1, F7 and F10 (among many others) are exact matches of the Ksed_00010 amino acid sequence and the majoramino acid found at the same position in the HMM logo.appears to be significant variablity among other proteinsused to create this model HMM as indicated by the large number of smaller letters under the predominant aminoacids at those positions.
Pfam number (PF#####) for second hit
PF08299
Pfam name
Bac_DnaA_C
The following was copied from the wiki link for PF08299.
"The active form DnaA is bound to ATP.[1] Immediately after a cell has divided, the level of active DnaA within the cell is low.[1] Although the activeform of DnaA requires ATP, the formation of the oriC/DnaA complex and subsequent DNA unwinding does not require ATP hydrolysis.[2]
The oriC site in E. coli has three AT rich 13 base pair regions (DUEs) followed by four 9 bp regions with the sequence TTAT(C or A)CA(C or A)A.Around 10 DnaA molecules bind to the 9 bp regions, which wrap around the proteins causing the DNA at the AT-rich region to unwind. There are 8DnaA binding sites within oriC, to which DnaA binds with differential affinity. When DNA replication is about to commence, DnaA occupies all of thehigh and low affinity binding sites. The denatured AT-rich region allows for the recruitment of DnaB (helicase), which complexes with DnaC (helicaseloader). DnaC helps the helicase to bind to and to properly accommodate the ssDNA at the 13 bp region; this is accomplished by ATP hydrolysiswhich DnaC is released. Single-strand binding proteins (SSBs) stabilize the single DNA strands in order to maintain the replication bubble. DnaB5'→3' helicase, so it travels on the lagging strand. It associates with DnaG (a primase) to form the only primer for the leading strand and to add primers on the lagging strand. The interaction between DnaG and DnaB is necessary to control the longitude of Okazaki fragments on the laggingstrand. DNA polymerase III is then able to start DNA replication.
DnaA contains two conserved regions: the first is located in the central part of the protein and corresponds to the ATP-binding domain, the second is
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 23 of 39

located in the C-terminal half and is involved in DNA-binding.[4]"
Clan name
HTH
Helix-turn-helix clan This family contains a diverse range of mostly DNA-binding domains that contain a helix-turn-helix motif.
This clan contains 217 families and the total number of domains in the clan is 4270183. The clan was built by A Bateman.
Clan number (CL####)
CL0123
Score
101.8
E-value
1.4e-29
Pairwise alignment
HMM logo
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 24 of 39

Key functional/structural residues (e.g. I2, W7, F13)I4, V8, R24, R32, I50, G51, T61 and V62 are all exact matches for the HTH domain in Ksed_00010 and the model HMM
PDB
go to PDB at http://www.rcsb.org/pdb/home/home.do
PDB code2Z4R
PDB nameCrystal structure of domain III from the Thermotoga maritima replication initiation protein DnaA
Alignment length346
E-value9.20639E-59
Pairwise alignment
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 25 of 39

[-] Enzymatic Function
Module Instructions
KEGG
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 26 of 39

go to KEGG at http://www.genome.jp/kegg/pathway.html
KEGG pathway ID
ko02020 Two-component system
The following was obtained from a PubMedSearch:
Annu Rev Biochem. 2000;69:183-215.
Two-component signaltransduction.Stock AM 1, Robinson VL, Goudreau PN.
Author information
Abstract
Most prokaryotic signal-transduction systems and a few eukaryoticpathways use phosphotransfer schemes involving two conservedcomponents, a histidine protein kinase and a response regulatorprotein. The histidine protein kinase, which is regulated byenvironmental stimuli, autophosphorylates at a histidine residue,creating a high-energy phosphoryl group that is subsequentlytransferred to an aspartate residue in the response regulator protein.Phosphorylation induces a conformational change in the regulatorydomain that results in activation of an associated domain that effectsthe response. The basic scheme is highly adaptable, and numerousvariations have provided optimization within specific signaling systems.The domains of two-component proteins are modular and can beintegrated into proteins and pathways in a variety of ways, but the corestructures and activities are maintained. Thus detailed analyses of arelatively small number of representative proteins provide a foundationfor understanding this large family of signaling proteins.
Pathway map
Below is a portion of the general two component map that shows the location of DnaA
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 27 of 39

Below is the same section of the two component system, but with the genes called in Kytococcus highlighted in green. DnaA has been called by thecomputer. Clicking on the DnaA hyperlink confirmst that DnaA in Kytococcus is, in fact, Ksed_00010
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 28 of 39

MetaCyc
go to MetaCyc at http://metacyc.org
Pathway mapNot applicable: Ksed-00010 is not an enzyme and therefore not found in Metacyc
E.C. Number
go to ExPASy ENZYME at http://www.expasy.ch/enzyme/enzyme-search-ec.html
EC NumberNot applicable: Ksed-00010 is not an enzyme and therefore does not have an E.C. number or name
EC NameN/A
[-] Duplication and Degradation
Module Instructions
DNA Coordinates
Paralog gene product nameNo significant paralog hits were found.
Percent identity
Alignment length
E-value
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 29 of 39

Pairwise alignment
Pseudogene
Use the instructions provided by your professor
Is this a pseudogene?By the three criteria used in the project manual there no evidence that the Ksed_00010 is a pseudogene.
[-] Horizontal Gene Transfer
Module Instructions
Phylogenetic Tree
go to Phylogeny.fr at http://www.phylogeny.fr
Phylogenetic tree
Sequences used to contruct the tree:
>Kytococcus sedentarius DSM 20547] MSQTPDDHATAIWQEAMVHLQGAGLAPRDIGVLRLATLVGLLEGTALLAVKYDHVKDAVEGHLREDVSTALAEVLDRDIR LAVSVDPDAVSAAQEEAAPPAPSPADEDDPATGEGPLSTAVDGAVEKHEGSSPARAGESVAPATTASLTATNSSPGVERD YSALNHKYTFDTFVLGSSNRFAHAAATAVAEAPARAYNPLFIYGGSGLGKTHLLHAIGHYARTLDSSVRVKYVNSEEFTN QFINAVSAGQANAFQRQYRDVDVLLIDDIQFLQGKEQTMEEFFHTFNTLHNSEKQIVITSDQPPKKLSGFAERMRSRFEW GLLTDVQPPDLETRIAILRRKAAADKLDIPDDVLHLIASKISSNIRELEGALTRVTAFASLSGSPLDEYLARTVLKDVMP GGDSGQITPTMILEETAGYFVISVEEIQGASRSRNLTRARQIAMYLCRELTDLSLPKIGKEFGGRDHTTVMHAERKIKQL LGEDRRVYDEVSELTSIIRKKAARGR >Ornithinimicrobium pekingense] MTSQSPAESAEVWQRVVSQLESQGVTARDRAFLRLTQLVGLLDTTALLAVPYQHTKETLETTLRQPIVDALAGELGHDVR LAITVDEDLRRQVEDEGDPAPGPAVTEQVPSDPDRTPYRSNGAGPGEPRSDGHRTPSGAVQTASAEDARLNPKYTFDTFV SGSSNRFAHAASLAVAESPARAYNPLFIYGESGLGKTHLLHAIGHYARSLYPGVRVRYVNSEEFTNDFINSIRDDKAGAF QRRYRNVDFLLVDDIQFLQGKEQTVEEFFHTFNTLHNSEKQVVITSDQPPKRLSGFAERMRSRFEWGLLTDVQPPDLETR IAILKKKAAQEGMQLPDEVLELIGSKISTNIRELEGALIRVTAFASLSSTPPDAALASHVLKDIIPNSESAAITVPTIMA EVADYFQISNDDLCGTSRSRTLVNARQIAMYLCRELTDLSLPKIGQEFGGRDHTTVMHAERKIRQLIGERRALYDQITEL TGIIRKASAR >Serinicoccus profundi] MSQPSTDSGDTWRRVVSELEDKGLGAREKAFLRLTTMVGVLDSTVLLAVPYPHTKEMLETTLRQPIVDLLSRELDREVRL AITVDDDVRQRVEDEADDEADEDAQTRESLTRPASQPSSSAGAGVPGPSGNGIPRPATPAGPAVTGAADEARLNPKYSFD TFVSGPSNRFAHAASLAVAESPARAYNPLFIYGESGLGKTHLLHAIGHYARKLYPGVRVRYVNSEEFTNDFINSIRDDKA GAFQRRYRNVDFLLVDDIQFLQGKEQTVEEFFHTFNTLHNSEKQVVITSDQPPKRLSGFAERMRSRFEWGLLTDVQPPDL ETRIAILRKKAAQEGMQLPDEVLEHIASRITTNIRELEGALIRVTAFASLSSQPADADLAAHVLKDIVPGSDTAQITVST IIREVSEYFQISIDELCGTSRSRTLVNARQIAMYLCRELTDLSLPKIGQEFGGRDHTTVMHAERKIRAQIGERRALYDQI AELTGTIRRASQR >Knoellia aerolata] >gi|700180054|gb|KGN40755.1| chromosomal replication initiation protein [Knoellia aerolata DSM 18566] MDQIWRTTLDALDSDGIPVQQRAFLSLARLVGLLDETALIAVPNDFTKDIVETRLRDRVTETLSSQLGHTVRLAVTVDSS LGDVPVLDPPADAPSGSTTTEPRPAAGTEGDGRHAERRAELDGIALVEDDDDGDSSRTGRSVAHTRSPGALRPRPGVTVP EQVELTRLNPKYTFDTFVIGASNRFANAAALAVAETPAKAYNPLFIYGESGLGKTHLLHAIGHYARNLFPHVKVRYVNSE EFTNDFINSIRDDKAANFQRRYRDVDVLLIDDIQFLQGKVQTQEEFFHTFNTLHNANKQVVITSDLPPKLLSGFEERMRS
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 30 of 39

RFEWGLMTDVQPPDLETRIAILRKKAAQEKLSVPDDVLEFIASRISTNIRELEGALIRVTAFASLNRQPVDISLAEIVLK DLIPHDSSSQITSATIMAQTAAYFGLTLEDLQGQSRSRVLVTARQIAMYLCRELTDLSLPKIGQQFGGRDHTTVMHADKK IRQLMAERRAIYNQVTELTNRIKQQSR >Luteipulveratus sp. C296001] MSEDKPDLAHVWHSTVMALEETGIAARDRAFLRLTRLVGLVDQTALLAVPFDHTKDILETSLREPVSSALSRLLDRDVRL AVTVDPQLQQTVSASAEAKDAGIGEDEVAETDAEEAGTPAPALIRPVRASNRPPVEPVTDARLNPKYTFDTFVIGASNRF AHAAAFAVAEAPAKSYNPLFVYGDSGLGKTHLLHAIGHYVRNLYPSMRVRYVNSEEFTNDFINSIRDDKASSFQKRYRDD VDVLLIDDVQFLQGKDGTQEEFFHTFNALHDSEKQIVLTSDQPPKKLSGFADRMRSRFEWGLQTDVTPPDLETRIAILRK KAIAERMNVPDDVLELIASKFSTNIRELEGALIRVMAFASLSQQPVDQQVAGYVLKDLVPSAGSSQITATLIMTKTAEYF HVSVEELCGSSRSRTLVTARQIAMYLCRELTELSLPKIGQQFGGRDHTTVMHADRKIRQLIGERRPIYDQITELTGQITR AAAG >Janibacter sp. HTCC2649] MDQIWRTTLDALDSDGIPVQQRAFLSLAKLVGLLDETALIAVPNDFTKDIVETRLRDRVTETLSSQLGHDVRLAVTVDHS LADVPVTIPADTTTVDGAGADQVPRTATTIGLEPGPADADGRRAKRRAELDGIALVEDDEGEDDSRNNGAIGRTRSPGAL RPRPGATVPEQVELTRLNPKYTFDTFVIGASNRFANAAALAVAETPAKAYNPLFIYGESGLGKTHLLHAIGHYARNLYPH VKVRYVNSEEFTNDFINSIRDDKAANFQRRYRDVDVLLIDDIQFLQGKVQTQEEFFHTFNTLHNANKQVVITSDLPPKLL SGFEERMRSRFEWGLMTDVQPPDLETRIAILRKKAAQEKLSVPDDVLEFIASRISTNIRELEGALIRVTAFASLNRQPVD ISLAEIVLKDLIPHDSANQITSATIMAQTAAYFGLTLEDLQGQSRSRVLVTARQIAMYLCRELTDLSLPKIGQQFGGRDH TTVMHADKKIRQLMAERRAIYNQVTELTNRIKQQSR >Tetrasphaera japonica T1-X7] MDYSRVWRTALDELDADGLPIQQRAFLSLARFVGLLDDTALIAVPNDYTKEFVETRVRQQLTQTLSNHAGRELRLAVTVD PGLKAADEAEPTLGAPAEAWGPRPRAGIGPVDDEEDHEAQDVIDARGVDTFHIQRPTPGQRPVPELIENTRLNPKYTFDT FVIGASNRFAHAAAVAVAEAPAKAYNPLFVYGDSGLGKTHLLHAIGHYARNLYPTVRVRYVNSEEFTNDFINSIRDDKAA NFQSRYRDVDVLLIDDIQFLQGKVQTQEEFFHTFNTLHNANKQVVITSDVPPKLLSGFEERMRSRFEWGLLTDVQPPDLE TRIAILRKKAIQERLSVPDDVLEFIASRISTNIRELEGALIRVTAFASLNRQPVDMSLAEIVLKDLIPSDGANQITSATI MAQTATYFGLTVEDLQGASRSRVLVTARQIAMYLCRELTDLSLPKIGQQFGGRDHTTVMHADKKIRQLMAERRAIYNQVT ELTNRIKQQSR >Arsenicicoccus bolidensis] MTDAQVDVPRVWRDTLRALESGGISAQHRGFLRLSRLVGLLEGTALIAVPNDYTRDIVEKRIRTELVAALQEQLGRDVRL AVTVDSSLELSEAEDRDDSTQRPGSPGEVPHVVTSSDPVRHDGERGGSDPRSTYGPRLVRDERVPRPVSTDASFGGERPY ADPARHDGGPGHAPGIRPAQDDDADDDRELLAEGDGIREMFRKPFVPEDGRDAKLNPKYTFDTFVIGSSNRFAHAAAIAV AEAPAKAYNPLFIYGGSGLGKTHLLHAIGHYAQQIYPNVRVKYVNSEEFTNDFINSIGANKASDFQRRYRDIDFLLIDDI QFLQGKVQTQEEFFHTFNTLHNANKQVVITSDVAPKLLSGFEERMRSRFEWGLLTDVQPPDLETRIAILRKKAVQERMTA PDDVLEFIASKISTNIRELEGALIRVTAFASLNHQGVDMTLAEVVLKDLIPADQTNQITPATIMAQTASYFGLTVDDLCG TSRSRVLVTARQIAMYLCRELTDLSLPKIGQQFGGRDHTTVMHADRKIRELMSERRAIYNQVTELTNRIKSNPS >Mobilicoccus sp. SIT2] MSGSGEPPTTPAVDDPARIWGATLRALDQAGIPAPQRAFLRQAMLVGVLDTTALIAVPDDFTKEIVESRARDYLVKALTE QVGREVRLAVTVDASLREQIAAAEQPVLEGYADPDSDVAAAEPPAASPTAAAPASPPVEDSPAPVGERRPRPAPTGRREE SSQLNPKYTFDTFVIGASNRFAHAAAVAVAEAPAKAYNPLFVYGDSGLGKTHLLHAIGHYARNLYPHVKVKYVNSEEFTN DFINSIRDDKAAGFQRRYRDMDVLLIDDIQFLQGKMQTQEEFFHTFNTLHNSNKQVVITSDVPPKQLSGFEERMRSRFEW GLLTDVQPPDLETRIAILRKKAVQEHLALPDEVMEFIASRISTNIRELEGALIRVTAFANLNRQPVEMSLAEIVLKDLIP DKESSQITASMIMGQTAAYFGLSIDDLCGSSRSRGLVTARQIAMYLCRELTELSLPKIGQQFGGRDHTTVMHADRKIRQL MAERRSVYNQVTELTTRIRSQAS >Cellvibrio] gilvus ATCC 13127] MAQDEELSRVWGHVVTTLEESPDITQRQLAFVRLAQPLGLLDGTIILAVGNEYTKEYLETKVRAEVTSALGSALGRDGRF AITVDPSLVDDAPPAVRAMTSAPELGVVTDGTDERGAPNRTVPTDADTGRHERSPMLSESAEPTRPVRETASSRRPAAEP ARLNPHYLFETFVIGSSNRFAHAAAVAVAEAPAKAYNPLFIYGDSGLGKTHLLHAIGHYAQNLYPSVRVRYVNSEEFTND FINSISEGKAGAFQRRYREVDVLLIDDIQFLQGKEQTMEEFFHTFNTLHNANKQVVITSDLPPKQLNGFEDRMRSRFEWG LITDVQPPDLETRIAILRKKAGGDNMQAPPDVLEYIASKISTNIRELEGALIRVTAFASLNRQQVDLSLAEIVLKDLITD DQTTEITATQVIGQTAAYFGLSIEDLCGSSRSRVLVTARQIAMYLCRELTDLSLPKIGQAFGGRDHTTVMHANRKIRELM AERRSIYNQVTELTNRIKQQSRG >Promicromonosporaceae bacterium W15] MAEVWSAARIQLENDPDVTPRQRGYVRLVAPLAHIDDTVFLKVSDEPIRSFIETNLRADLVGALAGVLGYEPKLAISVDP DLQIADDDTDPAAPVYARPAPTTATSPAAQRMPTDEPDHGLSNPVGFGATVGLPEAMPAAPGSARAAQHAPRHAEPTAPL GENSRLNPKYLFETFVIGASNRFAHAAAVAVAEAPAKAYNPLFIYGDSGLGKTHLLHAIGHYAQSLYPNVRVRYVNSEEF TNDFINSIGEGKAGAFQRRYRDVDVLLIDDIQFLQGKEQTMEEFFHTFNALHNANKQVVITSDLPPKQLNGFEDRLRSRF EWGLITDVQPPDLETRIAILRKKALQERLDAPDDVLEYIASRISTNIRELEGALIRVTAFANLNRQPVDQSLAEIVLKDL ITDDDAGEITAASVIAQTAAYFGLTIDDLCGSSRSRVLVTARQIAMYLCRELTDLSLPKIGQQFGGRDHTTVMHANRKIS EQMAERRSIYNQVTELTSRIKQQHRG >Nocardioides sp. Iso805N] METPPDNGQHDELGQAWQSVVAELQPHQRAWLTACQPEALHGTTVLVGVPNDFTRNQLEGRLRAELEDALSTRFGQEMRI AAIVKPELEDRPLEATTPAPAISDAPVAPIKPHIDLSTNRFGGSSHNDTPDSGGAAPNFQLPPLRHEAPETERTTSESRL NPKYTFETFVIGSSNRFPHAAAVAVAEAPGRAYNPLLVYGESGLGKTHLLHAIGHYVRSLYNGAKVRYVSSEEFTNEFIN AIRDDRQDRFKRKYRDIDVLLIDDIQFLEGKTQTQEEFFHTFNTLHNANKQIVLTSDRAPKRLEALEDRLRNRFEWGLIT DVQPPDVETRIAILRKKAAMERLKAPADVLEFIATKIQTNIRELEGALIRVTAFANLNRQEVDMTLAEIVLKDLIPEGGE
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 31 of 39

PEITAGLIIAQTAAYFGLSIDELTGPSRGRHLVMARQIAMYLCRELTDLSLPKIGQQFGGRDHTTVMYAERKINQLLAER RSVFNQVSELTNRVKMQARQA >Arthrobacter globiformis NBRC 12137] MTVDEANHANTVGSSWRRVVTLLEQDDRVSPRQRGFVILAQAQGLIGSTLLVAVPNELTREVLQTQVKDALDDALRNVFS DDIRCAIDVDTDLVPIHEEPEPAVELSLANDPSIEQKPQPMLPSTSHEFGRLNPKYVFDTFVIGSSNRFAHAAAVAVAEA PAKAYNPLFIYGDSGLGKTHLLHAIGHYARRLYSGIRVRYVNSEEFTNDFINSIRDDEGASFKTTYRNVDVLLIDDIQFL AGKDRTLEEFFHTFNSLHNNNKQVVITSDQPPKLLAGFEDRMKSRFEWGLLTDIQPPELETRIAILRKKALSEGLSAPDD ALEYIASKIASNIRELEGALIRVTAFASLNRQPVDVALAEMVLKDLITDDGAQEITSGQILQQTADYFKLSMEELCSKSR TRTLVTARQIAMYLCRELTDMSLPKIGQELGGRDHTTVIHADRKIRELMAERRVIYNQVTELTNRIKQQQRDS
The T-Coffee Alignment:
CLUSTAL W (1.83) multiple sequence alignment
Arsenicicoccus MTDA--------QVDVPRVWRDTLRALES-GGISAQHRGFLRLSRLVGLLArthrobacter MTVDE---AN-HANTVGSSWRRVVTLLEQDDRVSPRQRGFVILAQAQGLICellvibrio] MAQD---------EELSRVWGHVVTTLEESPDITQRQLAFVRLAQPLGLLJanibacter M---------------DQIWRTTLDALDS-DGIPVQQRAFLSLAKLVGLLKnoellia M---------------DQIWRTTLDALDS-DGIPVQQRAFLSLARLVGLLKytococcus MSQTP-------DDHATAIWQEAMVHLQG-AGLAPRDIGVLRLATLVGLLLuteipulveratus MSED--------KPDLAHVWHSTVMALEE-TGIAARDRAFLRLTRLVGLVMobilicoccus MSGSGEPPTTPAVDDPARIWGATLRALDQ-AGIPAPQRAFLRQAMLVGVLNocardioides METPP---DNGQHDELGQAWQSVVAELQ------PHQRAWLTACQPEALHOrnithinimicrobium MTSQS-------PAESAEVWQRVVSQLES-QGVTARDRAFLRLTQLVGLLPromicromonosporaceae M---------------AEVWSAARIQLENDPDVTPRQRGYVRLVAPLAHISerinicoccus MSQP--------STDSGDTWRRVVSELED-KGLGAREKAFLRLTTMVGVLTetrasphaera M-------------DYSRVWRTALDELDA-DGLPIQQRAFLSLARFVGLL * * . *: . . : .
Arsenicicoccus EGTALIAVPNDYTRDIVEKRIRTELVAALQEQLGRDVRLAVTVDSSLELSArthrobacter GSTLLVAVPNELTREVLQTQVKDALDDALRNVFSDDIRCAIDVDTDLVPICellvibrio] DGTIILAVGNEYTKEYLETKVRAEVTSALGSALGRDGRFAITVDPSLVDDJanibacter DETALIAVPNDFTKDIVETRLRDRVTETLSSQLGHDVRLAVTVDHSLADVKnoellia DETALIAVPNDFTKDIVETRLRDRVTETLSSQLGHTVRLAVTVDSSLGDVKytococcus EGTALLAVKYDHVKDAVEGHLREDVSTALAEVLDRDIRLAVSVDPDAVSALuteipulveratus DQTALLAVPFDHTKDILETSLREPVSSALSRLLDRDVRLAVTVDPQLQQTMobilicoccus DTTALIAVPDDFTKEIVESRARDYLVKALTEQVGREVRLAVTVDASLREQNocardioides GTTVLVGVPNDFTRNQLEGRLRAELEDALSTRFGQEMRIAAIVKPELEDROrnithinimicrobium DTTALLAVPYQHTKETLETTLRQPIVDALAGELGHDVRLAITVDEDLRRQPromicromonosporaceae DDTVFLKVSDEPIRSFIETNLRADLVGALAGVLGYEPKLAISVDPDLQIASerinicoccus DSTVLLAVPYPHTKEMLETTLRQPIVDLLSRELDREVRLAITVDDDVRQRTetrasphaera DDTALIAVPNDYTKEFVETRVRQQLTQTLSNHAGRELRLAVTVDPGLKAA * :: * :. :: : : * . : * *.
Arsenicicoccus EAEDR-DDSTQRPG-SPGEVPHVVT--SSDPVRHDGERGGSDPRSTYGPRArthrobacter HEE-P-EPAVE-----------LSL--ANDPS------------------Cellvibrio] ---APPA-VRAM---TS--APELGV--VTDGTDERG--------------Janibacter PVTI-PADTTTVDGAGADQVPRTATTIGLEPGPADA--------------Knoellia PVLDPPADAPS-----------GST--TTEPRPAAG----TE--------Kytococcus AQEEAAPPAPS-----------PAD--EDDPAT--G----E---------Luteipulveratus VSASAE--AKD-----------AGI--GEDEVA-----------------Mobilicoccus IAAAE-QPVL--EG-YADPDSDVAA--AEPPAASP---------------Nocardioides PLEAT-TPAPA-----------IS----DAPV------------------Ornithinimicrobium VEDEGDP-APG-----------PAV--TEQVPS-----------------Promicromonosporaceae DDDTDPA-APV----YA--RPAPTT--ATSPAA-----------------Serinicoccus VEDEADDEADE-----------DAQ--TRESLT-----------------Tetrasphaera DEAEPTLGAPA-----------EA----WGPRPRAG----I---------
Arsenicicoccus LVRDERVPRPVSTDASFGGERPYADPARHDGGPGHAPGIRPAQDDDADDDArthrobacter --------------------------------------------------Cellvibrio] --------------AP-NRTVP-------------------T-DA-DT--Janibacter -------------DGRRAKRRA------------ELDGIALVEDDEGEDDKnoellia ------------GDGRHAERRA------------ELDGIALVEDDDDGDSKytococcus -----------------GPLST---A---------VDG--AVEKHEGSSPLuteipulveratus -----------------ET-------------------------------Mobilicoccus --------------TAAAPASP---P---------------VED------Nocardioides -----------------APIKP---H---------IDL-S-TNRFGGSSHOrnithinimicrobium -----------------DPD---------------------------RTPPromicromonosporaceae ------------------QRMP-------------------T-DEPDHGLSerinicoccus -----------------RPA---------------------------SQPTetrasphaera ---------------------------------------GPVDDEEDHEA
Arsenicicoccus RE-----LLA-------------EGDGIR-EM-FRKPFVPEDGRDAKLNPArthrobacter --------------------------IEQKPQ-P--MLPSTSHEFGRLNPCellvibrio] -----------GRHERSPMLSESAEPTRPVR-ETA-SSRRPAAEPARLNPJanibacter SR---N-NGA---------IGRTRSPGALRPR-PG-ATVPEQVELTRLNPKnoellia SR---T-GRS---------VAHTRSPGALRPR-PG-VTVPEQVELTRLNPKytococcus AR---AGES-----------VAPATT---ASLTATNSSPGVERDYSALNHLuteipulveratus -D---AEEAG---------TPAP---ALIRPVRASNRPPVEPVTDARLNPMobilicoccus ---------------------SPAPVGERRPR-P--APTGRREESSQLNPNocardioides ND-----TPD---------SGGAAPNFQLPPLRHEAPETERTTSESRLNPOrnithinimicrobium YR---SNGAG---------PGEPRSDGHR---TPSGAVQTASAEDARLNPPromicromonosporaceae SNPVGF-GATVGLPEAMPAAPGSARAAQHAP-RHA-EPTAPLGENSRLNPSerinicoccus SS---SAGAG---------VPGPSGNGIPRPATPAGPAVTGAADEARLNP
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 32 of 39

Tetrasphaera QD-----VID---------ARGVDTFHIQRPT-PGQRPVPELIENTRLNP **
Arsenicicoccus KYTFDTFVIGSSNRFAHAAAIAVAEAPAKAYNPLFIYGGSGLGKTHLLHAArthrobacter KYVFDTFVIGSSNRFAHAAAVAVAEAPAKAYNPLFIYGDSGLGKTHLLHACellvibrio] HYLFETFVIGSSNRFAHAAAVAVAEAPAKAYNPLFIYGDSGLGKTHLLHAJanibacter KYTFDTFVIGASNRFANAAALAVAETPAKAYNPLFIYGESGLGKTHLLHAKnoellia KYTFDTFVIGASNRFANAAALAVAETPAKAYNPLFIYGESGLGKTHLLHAKytococcus KYTFDTFVLGSSNRFAHAAATAVAEAPARAYNPLFIYGGSGLGKTHLLHALuteipulveratus KYTFDTFVIGASNRFAHAAAFAVAEAPAKSYNPLFVYGDSGLGKTHLLHAMobilicoccus KYTFDTFVIGASNRFAHAAAVAVAEAPAKAYNPLFVYGDSGLGKTHLLHANocardioides KYTFETFVIGSSNRFPHAAAVAVAEAPGRAYNPLLVYGESGLGKTHLLHAOrnithinimicrobium KYTFDTFVSGSSNRFAHAASLAVAESPARAYNPLFIYGESGLGKTHLLHAPromicromonosporaceae KYLFETFVIGASNRFAHAAAVAVAEAPAKAYNPLFIYGDSGLGKTHLLHASerinicoccus KYSFDTFVSGPSNRFAHAASLAVAESPARAYNPLFIYGESGLGKTHLLHATetrasphaera KYTFDTFVIGASNRFAHAAAVAVAEAPAKAYNPLFVYGDSGLGKTHLLHA :* *:*** *.****.:**: ****:*.::****::** ***********
Arsenicicoccus IGHYAQQIYPNVRVKYVNSEEFTNDFINSIGANKASDFQRRYRD-IDFLLArthrobacter IGHYARRLYSGIRVRYVNSEEFTNDFINSIRDDEGASFKTTYRN-VDVLLCellvibrio] IGHYAQNLYPSVRVRYVNSEEFTNDFINSISEGKAGAFQRRYRE-VDVLLJanibacter IGHYARNLYPHVKVRYVNSEEFTNDFINSIRDDKAANFQRRYRD-VDVLLKnoellia IGHYARNLFPHVKVRYVNSEEFTNDFINSIRDDKAANFQRRYRD-VDVLLKytococcus IGHYARTLDSSVRVKYVNSEEFTNQFINAVSAGQANAFQRQYRD-VDVLLLuteipulveratus IGHYVRNLYPSMRVRYVNSEEFTNDFINSIRDDKASSFQKRYRDDVDVLLMobilicoccus IGHYARNLYPHVKVKYVNSEEFTNDFINSIRDDKAAGFQRRYRD-MDVLLNocardioides IGHYVRSLYNGAKVRYVSSEEFTNEFINAIRDDRQDRFKRKYRD-IDVLLOrnithinimicrobium IGHYARSLYPGVRVRYVNSEEFTNDFINSIRDDKAGAFQRRYRN-VDFLLPromicromonosporaceae IGHYAQSLYPNVRVRYVNSEEFTNDFINSIGEGKAGAFQRRYRD-VDVLLSerinicoccus IGHYARKLYPGVRVRYVNSEEFTNDFINSIRDDKAGAFQRRYRN-VDFLLTetrasphaera IGHYARNLYPTVRVRYVNSEEFTNDFINSIRDDKAANFQSRYRD-VDVLL ****.: : :*:**.******:***:: .. *: **: :*.**
Arsenicicoccus IDDIQFLQGKVQTQEEFFHTFNTLHNANKQVVITSDVAPKLLSGFEERMRArthrobacter IDDIQFLAGKDRTLEEFFHTFNSLHNNNKQVVITSDQPPKLLAGFEDRMKCellvibrio] IDDIQFLQGKEQTMEEFFHTFNTLHNANKQVVITSDLPPKQLNGFEDRMRJanibacter IDDIQFLQGKVQTQEEFFHTFNTLHNANKQVVITSDLPPKLLSGFEERMRKnoellia IDDIQFLQGKVQTQEEFFHTFNTLHNANKQVVITSDLPPKLLSGFEERMRKytococcus IDDIQFLQGKEQTMEEFFHTFNTLHNSEKQIVITSDQPPKKLSGFAERMRLuteipulveratus IDDVQFLQGKDGTQEEFFHTFNALHDSEKQIVLTSDQPPKKLSGFADRMRMobilicoccus IDDIQFLQGKMQTQEEFFHTFNTLHNSNKQVVITSDVPPKQLSGFEERMRNocardioides IDDIQFLEGKTQTQEEFFHTFNTLHNANKQIVLTSDRAPKRLEALEDRLROrnithinimicrobium VDDIQFLQGKEQTVEEFFHTFNTLHNSEKQVVITSDQPPKRLSGFAERMRPromicromonosporaceae IDDIQFLQGKEQTMEEFFHTFNALHNANKQVVITSDLPPKQLNGFEDRLRSerinicoccus VDDIQFLQGKEQTVEEFFHTFNTLHNSEKQVVITSDQPPKRLSGFAERMRTetrasphaera IDDIQFLQGKVQTQEEFFHTFNTLHNANKQVVITSDVPPKLLSGFEERMR :**:*** ** * ********:**: :**:*:*** .** * .: :*::
Arsenicicoccus SRFEWGLLTDVQPPDLETRIAILRKKAVQERMTAPDDVLEFIASKISTNIArthrobacter SRFEWGLLTDIQPPELETRIAILRKKALSEGLSAPDDALEYIASKIASNICellvibrio] SRFEWGLITDVQPPDLETRIAILRKKAGGDNMQAPPDVLEYIASKISTNIJanibacter SRFEWGLMTDVQPPDLETRIAILRKKAAQEKLSVPDDVLEFIASRISTNIKnoellia SRFEWGLMTDVQPPDLETRIAILRKKAAQEKLSVPDDVLEFIASRISTNIKytococcus SRFEWGLLTDVQPPDLETRIAILRRKAAADKLDIPDDVLHLIASKISSNILuteipulveratus SRFEWGLQTDVTPPDLETRIAILRKKAIAERMNVPDDVLELIASKFSTNIMobilicoccus SRFEWGLLTDVQPPDLETRIAILRKKAVQEHLALPDEVMEFIASRISTNINocardioides NRFEWGLITDVQPPDVETRIAILRKKAAMERLKAPADVLEFIATKIQTNIOrnithinimicrobium SRFEWGLLTDVQPPDLETRIAILKKKAAQEGMQLPDEVLELIGSKISTNIPromicromonosporaceae SRFEWGLITDVQPPDLETRIAILRKKALQERLDAPDDVLEYIASRISTNISerinicoccus SRFEWGLLTDVQPPDLETRIAILRKKAAQEGMQLPDEVLEHIASRITTNITetrasphaera SRFEWGLLTDVQPPDLETRIAILRKKAIQERLSVPDDVLEFIASRISTNI .****** **: **::*******::** : : * :.:. *.::: :**
Arsenicicoccus RELEGALIRVTAFASLNHQGVDMTLAEVVLKDLIPADQTNQITPATIMAQArthrobacter RELEGALIRVTAFASLNRQPVDVALAEMVLKDLITDDGAQEITSGQILQQCellvibrio] RELEGALIRVTAFASLNRQQVDLSLAEIVLKDLITDDQTTEITATQVIGQJanibacter RELEGALIRVTAFASLNRQPVDISLAEIVLKDLIPHDSANQITSATIMAQKnoellia RELEGALIRVTAFASLNRQPVDISLAEIVLKDLIPHDSSSQITSATIMAQKytococcus RELEGALTRVTAFASLSGSPLDEYLARTVLKDVMPGGDSGQITPTMILEELuteipulveratus RELEGALIRVMAFASLSQQPVDQQVAGYVLKDLVPSAGSSQITATLIMTKMobilicoccus RELEGALIRVTAFANLNRQPVEMSLAEIVLKDLIPDKESSQITASMIMGQNocardioides RELEGALIRVTAFANLNRQEVDMTLAEIVLKDLIPEGGEPEITAGLIIAQOrnithinimicrobium RELEGALIRVTAFASLSSTPPDAALASHVLKDIIPNSESAAITVPTIMAEPromicromonosporaceae RELEGALIRVTAFANLNRQPVDQSLAEIVLKDLITDDDAGEITAASVIAQSerinicoccus RELEGALIRVTAFASLSSQPADADLAAHVLKDIVPGSDTAQITVSTIIRETetrasphaera RELEGALIRVTAFASLNRQPVDMSLAEIVLKDLIPSDGANQITSATIMAQ ******* ** ***.*. : :* ****::. ** :: :
Arsenicicoccus TASYFGLTVDDLCGTSRSRVLVTARQIAMYLCRELTDLSLPKIGQQFGGRArthrobacter TADYFKLSMEELCSKSRTRTLVTARQIAMYLCRELTDMSLPKIGQELGGRCellvibrio] TAAYFGLSIEDLCGSSRSRVLVTARQIAMYLCRELTDLSLPKIGQAFGGRJanibacter TAAYFGLTLEDLQGQSRSRVLVTARQIAMYLCRELTDLSLPKIGQQFGGRKnoellia TAAYFGLTLEDLQGQSRSRVLVTARQIAMYLCRELTDLSLPKIGQQFGGRKytococcus TAGYFVISVEEIQGASRSRNLTRARQIAMYLCRELTDLSLPKIGKEFGGRLuteipulveratus TAEYFHVSVEELCGSSRSRTLVTARQIAMYLCRELTELSLPKIGQQFGGRMobilicoccus TAAYFGLSIDDLCGSSRSRGLVTARQIAMYLCRELTELSLPKIGQQFGGRNocardioides TAAYFGLSIDELTGPSRGRHLVMARQIAMYLCRELTDLSLPKIGQQFGGROrnithinimicrobium VADYFQISNDDLCGTSRSRTLVNARQIAMYLCRELTDLSLPKIGQEFGGRPromicromonosporaceae TAAYFGLTIDDLCGSSRSRVLVTARQIAMYLCRELTDLSLPKIGQQFGGRSerinicoccus VSEYFQISIDELCGTSRSRTLVNARQIAMYLCRELTDLSLPKIGQEFGGRTetrasphaera TATYFGLTVEDLQGASRSRVLVTARQIAMYLCRELTDLSLPKIGQQFGGR .: ** :: ::: . ** * *. *************::******: :***
Arsenicicoccus DHTTVMHADRKIRELMSERRAIYNQVTELTNRIKSNP---S
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 33 of 39

Arthrobacter DHTTVIHADRKIRELMAERRVIYNQVTELTNRIKQQQ-RDSCellvibrio] DHTTVMHANRKIRELMAERRSIYNQVTELTNRIKQQS--RGJanibacter DHTTVMHADKKIRQLMAERRAIYNQVTELTNRIKQQS---RKnoellia DHTTVMHADKKIRQLMAERRAIYNQVTELTNRIKQQS---RKytococcus DHTTVMHAERKIKQLLGEDRRVYDEVSELTSIIRKKAARGRLuteipulveratus DHTTVMHADRKIRQLIGERRPIYDQITELTGQITRAA--AGMobilicoccus DHTTVMHADRKIRQLMAERRSVYNQVTELTTRIRSQA---SNocardioides DHTTVMYAERKINQLLAERRSVFNQVSELTNRVKMQA-RQAOrnithinimicrobium DHTTVMHAERKIRQLIGERRALYDQITELTGIIRKAS--ARPromicromonosporaceae DHTTVMHANRKISEQMAERRSIYNQVTELTSRIKQQH--RGSerinicoccus DHTTVMHAERKIRAQIGERRALYDQIAELTGTIRRAS--QRTetrasphaera DHTTVMHADKKIRQLMAERRAIYNQVTELTNRIKQQS---R *****::*::** :.* * ::::::*** :
The Cladogram from T-COFFEE:
The Tree File in Newick Format from PhyML at Phylogeny.fr:
((((((Arsenicicoccus:0.363182,(Tetrasphaera:0.164269,(Knoellia:0.031567,Janibacter:0.053012)1.000000:0.157616)0.944000:0.077073)0.903000:0.074505,Mobilicoccus:0.285031)0.880000:0.062980,(Nocardioides:0.686282,((Promicromonosporaceae:0.278553,Cellvibrio:0.267551)0.969000:0.118671,Arthrobacter:0.550811)0.522000:0.056440)0.926000:0.080531)0.998000:0.210238,Luteipulveratus:0.307826)0.864000:0.084907,Kytococcus:0.618026)0.995000:0.205025,Serinicoccus:0.196835,Ornithinimicrobium:0.129401);
The phylogram from TreeDyn:
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 34 of 39

The radial version of the phlogenetic tree from TreeDyn:
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 35 of 39

Interpretation of phylogenetic treeLooking at the names of the different genera on the phylogenetic trees, it is clear that the three that are in a clade with Kytococcus are related torelated down to the same order or family. Since few closer relatives of Kytococcus have had their genomes sequenced, there is no evidencesuggesting that horizontal gene transfer of Ksed_00010 has occured. In fact, just about all of the genera in the tree have a realtionship to the sameorder, with the notable exception of Cellvibrio. Given that Ksed_00010 is an enzyme of DNA metabolism and the ecvalues and scores of all 100 hitsin the nr database are highly signficant, DnaA is likely very highly coserved across microbial species, and it would be hard to find evidence ofhorizontal transfer as a result.
Ornithinimicrobium - same order Serinicoccus - same order Luteipulveratus - same family
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 36 of 39

Cellvibrio - different phylum Promicromonosporaceae - same order Arsenicicoccus - same order Mobilicoccus - same order
Gene Context
login to IMG/ER and find the gene page for this gene
Ortholog Neighborhood Region of organism and examples of similarities or differences
Comment on the ortholog neighborhood regionsThe neighborhoods in the image above have similarity in the region immediately downstream of and including Ksed_00010 and are all as closelyrelated to Kytococcus sedentarius as we can expect to find. Therefore there is no evidence of horizontal gene transfer from th ortholog neighborhoodregions approach.
Chromosome Viewer GC Heat Map
go to the IMG Gene Detail page
Characteristic GC% of the genome72%
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 37 of 39

Average GC% of the geneKsed_00010 has a GC content of 68%. The average GC content of the genome of Kytococcus sedentarius is 72%. Therefore the GC content ofKsed_00010 is similar to that of the genome as a whole, and there is no evidence of horizontal gene transfer using the %GC approach.
[-] RNA
Module Instructions
Rfam
go to Rfam at http://rfam.sanger.ac.uk
Rfam number (RF#####)Not applicable. Ksed_00010 is not an RNA gene
Rfam name
Score
E-value
Pairwise Alignment
[-] Proposed Annotation
Proposed Annotation
Enter the proposed annotation for the gene
chromosomal replication initiator protein DnaA
The top two BLAST hits in both the nr and Swiss-prot databases have name of chromosomal replication initiatorprotein DnaA, the top COG hit is DnaA: Chromosomal replication initiation ATPase DnaA [Replication,recombination and repair]; the top TIGRFAM hit is DnaA: chromosomal replication initiator protein DnaA and the topPfam hit is Bac_DnaA. All of these findings support the annotation of Ksed_00010 as chromosomal replicationinitiator protein DnaA as indicated by the computer annotation.
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 38 of 39

Return to Gene Page
http://geni-act.org/lab_notebook/public/8ed2a45227a744df/ 11/7/15, 7:37 PMPage 39 of 39


















