
Generation of CDFGs from Scheduled and Pipelined Assembly Code
18
Generation of CDFGs from Scheduled and Pipelined Assembly Code The 18th International Workshop on Languages and Compilers for Parallel Computing October 20, 2005 David Zaretsky, Gaurav Mittal, Robert Dick, and Prith Banerjee Department of Electrical Engineering and Computer Science, Northwestern University College of Engineering, University of Illinois at Chicago
-
Upload
courtney-mclean -
Category
Documents
-
view
28 -
download
1
description
Generation of CDFGs from Scheduled and Pipelined Assembly Code. The 18th International Workshop on Languages and Compilers for Parallel Computing October 20, 2005 David Zaretsky, Gaurav Mittal, Robert Dick, and Prith Banerjee - PowerPoint PPT Presentation
Transcript of Generation of CDFGs from Scheduled and Pipelined Assembly Code

Generation of CDFGs from Scheduled and Pipelined Assembly Code
The 18th International Workshop on Languages and Compilers for Parallel Computing
October 20, 2005
David Zaretsky, Gaurav Mittal, Robert Dick, and Prith Banerjee
Department of Electrical Engineering and Computer Science, Northwestern University
College of Engineering, University of Illinois at Chicago

The Future of DSP Applications Recent advances in embedded communications and control
systems are pushing the computational limits of DSP applications, driving the need for hardware/software co-design system.
DSP performance requirements
for new communication
technologies
Standard DSP Performance
Roadmap
DS
P O
per
atio
ns
per
sec
on
d(B
illi
on
MA
C/s
)
500
1000
1500
2000
2500
2000 2001 2002 2003 2004
Voiceover IP
HDTV,MPEG4
Videoover IP
3G Wireless /WCDMA
4GWireless
FutureBroadband

Binary Translation Problems with high-level synthesis
High-level application unavailable Hardware compiler unavailable
Binary Translation Grammar Operation Latencies Software Pipelining
Processor Architecture Limitations Functional Units Data Paths Physical Registers Memory Spilling
Control and Data Flow Graphs Optimizations Scheduling Design decisions
Original Binary Software Program
Software Partitioned on new Processor
Hardware Implementation on FPGA/ASIC
Software Partitioned on new Processor
SW/HW Interface
HW/SW Interface
Compile portion
to Hardware
Compile portionto Software
Compile portionto Software
Original Binary Software Program
Software Partitioned on new Processor
Hardware Implementation on FPGA/ASIC
Software Partitioned on new Processor
SW/HW Interface
HW/SW Interface
Compile portion
to Hardware
Compile portionto Software
Compile portionto Software

FREEDOM: Bridging the Gap
FREEDOM compiler automates the task of hw/sw partitioning for software binaries.
FREEDOM is an acronym for: Fabrication of Reconfigurable Hardware Environments from DSP Optimized Machine Code
FPGA designers unfamiliar with DSP concepts
DSP designers not versed in FPGA design
AssemblyAssembly
BinaryBinary
DSP Design Environment
VHDLVerilog
VHDLVerilog
RTL SimulationRTL Simulation
Logic SynthesisLogic Synthesis
Place & RoutePlace & Route
Manually created RTL
Models
Verified RTL Models
Netlist of Primitives
ASIC / FPGA Design Environment

Related Work Binary Decompilation & Translation
Cifuentes93/96/98 Kruegel04 Dehnert03 Stitt02/03
Dynamic Binary Optimizations Bala00 Gschwind00 Ye00 Levine03
Control and Data Flow Analysis Kastner02 Decker03 Amme00 Cooper02

Presentation Overview FREEDOM Compiler Infrastructure Data Dependency Analysis CDFG Generation from Scheduled Assembly
Code Experimental Results Summary & Conclusions

The FREEDOM Compiler
DSP Assembly Language Semantics
DSP Assembly Code
DSP Binary Code
Parser
MST
CDFG
HDL
ArchitectureDescriptionLanguage
RTL VHDL RTL Verilog Testbench
Optimizations, Linearization, and Procedure Extraction
Optimizations, Loop Unrolling, Scheduling,
and Resource Binding
Optimizations,Customizations
DSP Assembly Language Semantics
DSP Assembly Code
DSP Binary Code
Parser
MST
CDFG
HDL
ArchitectureDescriptionLanguage
RTL VHDL RTL Verilog Testbench
Optimizations, Linearization, and Procedure Extraction
Optimizations, Loop Unrolling, Scheduling,
and Resource Binding
Optimizations,Customizations
Common entry point for multiple assembly languages.
Intermediate levels: Machine Language Syntax
Tree
Control & Data Flow Graph
Hardware Description Language
Architecture Description Language provides resource information for target FPGA architecture.
Output: RTL VHDL/Verilog and testbench.

Machine Language Abstract Syntax Tree (MST) Generic language encapsulates most ISAs, including
predicated and parallel instruction sets. All MST instructions are three-operand, predicated
instructions: [pred] op src1 src2 dst
Operand Types: Memory Address, Label, Register, Immediate.
Operator types: Logical: AND, NAND, NEG, NOR, NOT, OR, XOR, SLL, SRL, etc. Arithmetic: ADD, DIV, MULT, SUB Branch: BEQ, BGEQ, BGT, BLEQ, BLT, BNEQ, GOTO, CALL Comparison: CMPEQ, CMPNE, CMPLT, CMPLE, CMPGT, CMPGE Assignment: LD, ST, MOVE, UNION General: NOP

Data Dependency Analysis MST instructions are assigned
A timestep T An operation delay
Each instruction in a parallel set is incremented by:Tn = T + 0.01 * n
Each instructions in an expanded set is incremented by: Tm = Tn + 0.0001 * m
The write-back stage of an instruction is defined as: wb = timestep + delay
TIMESTEP PC OP DELAY SRC1 SRC2 DST 1.0000 0X0020 MULT (2) $A4, 2, $A4 2.0000 0X0024 LD (5) *($A4), $A2 2.0100 0X0028 ADD (1) $A4, 4, $A2 3.0000 0X002c ADD (1) $A4, $A2, $A3
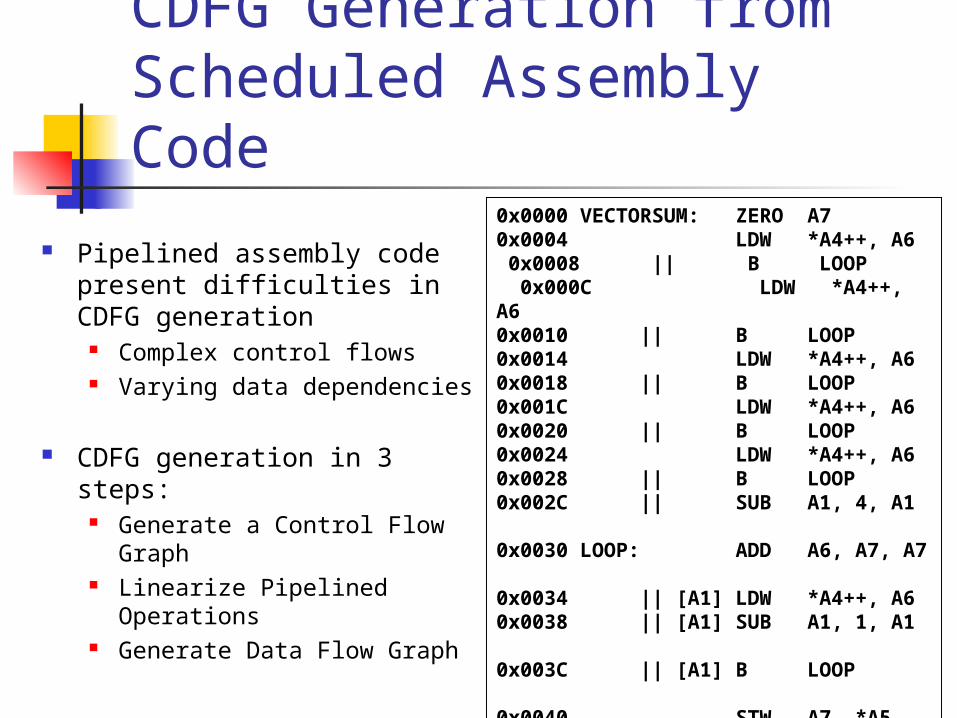
CDFG Generation from Scheduled Assembly Code
Pipelined assembly code present difficulties in CDFG generation
Complex control flows Varying data dependencies
CDFG generation in 3 steps: Generate a Control Flow
Graph Linearize Pipelined
Operations Generate Data Flow Graph
0x0000 VECTORSUM: ZERO A70x0004 LDW *A4++, A6 0x0008 || B LOOP 0x000C LDW *A4++, A6 0x0010 || B LOOP 0x0014 LDW *A4++, A6 0x0018 || B LOOP 0x001C LDW *A4++, A6 0x0020 || B LOOP 0x0024 LDW *A4++, A6 0x0028 || B LOOP 0x002C || SUB A1, 4, A1
0x0030 LOOP: ADD A6, A7, A7 0x0034 || [A1] LDW *A4++, A6 0x0038 || [A1] SUB A1, 1, A1 0x003C || [A1] B LOOP
0x0040 STW A7, *A50x0044 NOP 4

Building a Control Flow Graph
Based on work by K. Cooper et al, “Building a Control-Flow Graph from Scheduled Assembly Code,” Dept. of Computer Science, Rice University.
Generates a CFG in O(n) time. Requires 3 Stages:
Partition the code at labels into a set of basic blocks.
Add edges between CFG blocks to represent normal flow of control.
Iteratively propagate pipelined branch and counter information in a simulated control flow.
0x0000 VECTORSUM: ZERO A70x0004 LDW *A4++, A6 0x0008 || B LOOP 0x000C LDW *A4++, A6 0x0010 || B LOOP 0x0014 LDW *A4++, A6 0x0018 || B LOOP 0x001C LDW *A4++, A6 0x0020 || B LOOP 0x0024 LDW *A4++, A6 0x0028 || B LOOP 0x002C || SUB A1, 4, A10x0030 LOOP: ADD A6, A7, A7 0x0034 || [A1] LDW *A4++, A6 0x0038 || [A1] SUB A1, 1, A1 0x003C || [A1] B LOOP 0x0040 STW A7, *A50x0044 NOP 4
0x0000 VECTORSUM: ZERO A70x0004 LDW *A4++, A6 0x0008 || B LOOP 0x000C LDW *A4++, A6 0x0010 || B LOOP 0x0014 LDW *A4++, A6 0x0018 || B LOOP 0x001C LDW *A4++, A6 0x0020 || B LOOP 0x0024 LDW *A4++, A6 0x0028 || B LOOP 0x002C || SUB A1, 4, A1
0x0030 LOOP: ADD A6, A7, A7 0x0034 || [A1] LDW *A4++, A6 0x0038 || [A1] SUB A1, 1, A1 0x003C || [A1] B LOOP 0x0040 STW A7, *A50x0044 NOP 4
0x0000 VECTORSUM: ZERO A70x0004 LDW *A4++, A6 0x0008 || B LOOP 0x000C LDW *A4++, A6 0x0010 || B LOOP 0x0014 LDW *A4++, A6 0x0018 || B LOOP 0x001C LDW *A4++, A6 0x0020 || B LOOP 0x0024 LDW *A4++, A6 0x0028 || B LOOP 0x002C || SUB A1, 4, A1
0x0030 LOOP: ADD A6, A7, A7 0x0034 || [A1] LDW *A4++, A6 0x0038 || [A1] SUB A1, 1, A1 0x003C || [A1] B LOOP 0x0040 STW A7, *A50x0044 NOP 4
0x0000 VECTORSUM: ZERO A70x0004 LDW *A4++, A6 0x0008 || B LOOP 0x000C LDW *A4++, A6 0x0010 || B LOOP 0x0014 LDW *A4++, A6 0x0018 || B LOOP 0x001C LDW *A4++, A6 0x0020 || B LOOP 0x0024 LDW *A4++, A6 0x0028 || B LOOP 0x002C || SUB A1, 4, A1
0x0030 LOOP: ADD A6, A7, A7 0x0034 || [A1] LDW *A4++, A6 0x0038 || [A1] SUB A1, 1, A1 0x003C || [A1] B LOOP
0x0040 STW A7, *A5
0x0044 NOP 1
0x0044 NOP 1
0x0044 NOP 1
0x0044 NOP 1
0x0000 VECTORSUM: ZERO A70x0004 LDW *A4++, A6 0x0008 || B LOOP 0x000C LDW *A4++, A6 0x0010 || B LOOP 0x0014 LDW *A4++, A6 0x0018 || B LOOP 0x001C LDW *A4++, A6 0x0020 || B LOOP 0x0024 LDW *A4++, A6 0x0028 || B LOOP 0x002C || SUB A1, 4, A1
0x0030 LOOP: ADD A6, A7, A7 0x0034 || [A1] LDW *A4++, A6 0x0038 || [A1] SUB A1, 1, A1 0x003C || [A1] B LOOP
0x0040 STW A7, *A5
0x0044 NOP 1
0x0044 NOP 1
0x0044 NOP 1
0x0044 NOP 1
0x0000 VECTORSUM: ZERO A70x0004 LDW *A4++, A6 0x0008 || B LOOP 0x000C LDW *A4++, A6 0x0010 || B LOOP 0x0014 LDW *A4++, A6 0x0018 || B LOOP 0x001C LDW *A4++, A6 0x0020 || B LOOP 0x0024 LDW *A4++, A6 0x0028 || B LOOP 0x002C || SUB A1, 4, A1
0x0030 LOOP: ADD A6, A7, A7 0x0034 || [A1] LDW *A4++, A6 0x0038 || [A1] SUB A1, 1, A1 0x003C || [A1] B LOOP 0x0040 STW A7, *A50x0044 NOP 4
0x0000 VECTORSUM: ZERO A70x0004 LDW *A4++, A6 0x0008 || B LOOP 0x000C LDW *A4++, A6 0x0010 || B LOOP 0x0014 LDW *A4++, A6 0x0018 || B LOOP 0x001C LDW *A4++, A6 0x0020 || B LOOP 0x0024 LDW *A4++, A6 0x0028 || B LOOP 0x002C || SUB A1, 4, A1
0x0030 LOOP: ADD A6, A7, A7 0x0034 || [A1] LDW *A4++, A6 0x0038 || [A1] SUB A1, 1, A1 0x003C || [A1] B LOOP 0x0040 STW A7, *A50x0044 NOP 4
0x0000 VECTORSUM: ZERO A70x0004 LDW *A4++, A6 0x0008 || B LOOP 0x000C LDW *A4++, A6 0x0010 || B LOOP 0x0014 LDW *A4++, A6 0x0018 || B LOOP 0x001C LDW *A4++, A6 0x0020 || B LOOP 0x0024 LDW *A4++, A6 0x0028 || B LOOP 0x002C || SUB A1, 4, A1
0x0030 LOOP: ADD A6, A7, A7 0x0034 || [A1] LDW *A4++, A6 0x0038 || [A1] SUB A1, 1, A1 0x003C || [A1] B LOOP 0x0040 STW A7, *A50x0044 NOP 4

Event-Triggered Operations Analogous to a read/write
pipeline architecture. Event trigger and execution
stages are offset by operation delay (d).
Implemented using a virtual shift register of size d.
Event is triggered by assigning a ‘1’ to the highest bit (d-1).
SRL operation is performed on the register in successive cycles.
Event is executed after d cycles, when a ‘1’ appears in the zero bit.
1 1 0 0 0 0
1 1 1 0 0 0
1 1 1 1 0 0
1 1 1 1 1 0
0 1 1 1 1 1
0 0 1 1 1 1
Event 1 Triggered
Event 2 Triggered
Event 3 Triggered
Event 4 Triggered
Event 5 Triggered
Event 1 Executed
Event 2 Executed
Iteration 1
Iteration 2
Iteration 3
Iteration 4
Iteration 5
Iteration 6
Iteration 7
0 0 0 0 0 1 Event 5 ExecutedIteration 10
Bit 5 Bit 0SRL
1 0 0 0 0 0
1 1 0 0 0 01 1 0 0 0 01 1 0 0 0 0
1 1 1 0 0 01 1 1 0 0 01 1 1 0 0 0
1 1 1 1 0 01 1 1 1 0 01 1 1 1 0 0
1 1 1 1 1 01 1 1 1 1 01 1 1 1 1 0
0 1 1 1 1 10 1 1 1 1 10 1 1 1 1 1
0 0 1 1 1 10 0 1 1 1 10 0 1 1 1 1
Event 1 Triggered
Event 2 Triggered
Event 3 Triggered
Event 4 Triggered
Event 5 Triggered
Event 1 Executed
Event 2 Executed
Iteration 1
Iteration 2
Iteration 3
Iteration 4
Iteration 5
Iteration 6
Iteration 7
0 0 0 0 0 10 0 0 0 0 10 0 0 0 0 1 Event 5 ExecutedIteration 10
Bit 5 Bit 0SRL
1 0 0 0 0 01 0 0 0 0 01 0 0 0 0 0

Linearizing Pipelined Branch Operations
Iteratively propagate pipelined branch and counter information in a simulated control flow.
Trigger a change in control flow after a number of delay cycles.
Only the event is propagated using the SRL operation.
Copy of branch instruction inserted at each execution point.
The branch is predicated on the event shift-register.
Intersecting branch paths are merged by OR-ing predicates.
The original branch instructions are replaced with NOPs.
: :11.000 0x0008 MOVE(0) 1, $P1[5] 11.001 0x0008 SRL(1) $P1, 1, $P111.002 0x0008 NOP(1) 1
: :12.000 0x0008 SRL(1) $P1, 1, $P1
: :13.000 0x0008 SRL(1) $P1, 1, $P1
: :14.000 0x0008 SRL(1) $P1, 1, $P1
: :15.000 0x0008 SRL(1) $P1, 1, $P1
: :
16.000 0x0008 LOOP: SRL(1) $P1, 1, $P1 16.008 0x0008 OR(0) $P1[0], $P2[0], $MP016.009 0x0010 OR(0) $MP0, $P3[0], $MP116.010 0x0018 OR(0) $MP1, $P4[0], $MP216.011 0x0020 OR(0) $MP2, $P5[0], $MP316.012 0x0028 OR(0) $MP3, $P6[0], $MP416.013 0x003C [$MP4] GOTO(0) LOOP
: :
: :11.000 0x0008 MOVE(0) 1, $P1[5] 11.001 0x0008 SRL(1) $P1, 1, $P111.002 0x0008 NOP(1) 1
: :12.000 0x0008 SRL(1) $P1, 1, $P1
: :13.000 0x0008 SRL(1) $P1, 1, $P1
: :14.000 0x0008 SRL(1) $P1, 1, $P1
: :15.000 0x0008 SRL(1) $P1, 1, $P1
: :
16.000 0x0008 LOOP: SRL(1) $P1, 1, $P1 16.008 0x0008 OR(0) $P1[0], $P2[0], $MP016.009 0x0010 OR(0) $MP0, $P3[0], $MP116.010 0x0018 OR(0) $MP1, $P4[0], $MP216.011 0x0020 OR(0) $MP2, $P5[0], $MP316.012 0x0028 OR(0) $MP3, $P6[0], $MP416.013 0x003C [$MP4] GOTO(0) LOOP
: :

Linearizing Pipelined Computational Operations
Multi-cycle instructions are serialized into well-defined data flow paths along the pipeline.
For an instruction with n delay slots, the value is propagated through virtual registers Rn-1Rn, Rn-2Rn-1, … R0R1, where R0 is the original register name.
Each instruction in the sequence is guarded by a predicate on an event-triggering register bit.
Intersecting data paths are merged by OR-ing predicates.
: :12.000 0x000C MOVE(0) 1, $P1[4]12.001 0x000C SRL(1) $P1, 1, $P112.002 0x000C [$P1[4]] LD(1) *mem($A4), $A6_4
: :13.000 0x000C SRL(1) $P1, 1, $P1 13.001 0x000C [$P1[3]] MOVE(1) $A6_4, $A6_3
: :14.000 0x000C SRL(1) $P1, 1, $P1 14.001 0x000C [$P1[2]] MOVE(1) $A6_3, $A6_2
: :15.000 0x000C SRL(1) $P1, 1, $P1 15.001 0x000C [$P1[1]] MOVE(1) $A6_2, $A6_1
: :
16.000 0x000C LOOP: SRL(1) $P1, 1, $P116.001 0x0014 OR(0) $P1[0], $P2[0], $MP016.002 0x001C OR(0) $MP0, $P3[0], $MP116.003 0x0024 OR(0) $MP1, $P4[0], $MP216.004 0x0034 OR(0) $MP2, $P5[0], $MP316.005 0x000C [$MP3] MOVE(1) $A6_1, $A6
: :
: :12.000 0x000C MOVE(0) 1, $P1[4]12.001 0x000C SRL(1) $P1, 1, $P112.002 0x000C [$P1[4]] LD(1) *mem($A4), $A6_4
: :13.000 0x000C SRL(1) $P1, 1, $P1 13.001 0x000C [$P1[3]] MOVE(1) $A6_4, $A6_3
: :14.000 0x000C SRL(1) $P1, 1, $P1 14.001 0x000C [$P1[2]] MOVE(1) $A6_3, $A6_2
: :15.000 0x000C SRL(1) $P1, 1, $P1 15.001 0x000C [$P1[1]] MOVE(1) $A6_2, $A6_1
: :
16.000 0x000C LOOP: SRL(1) $P1, 1, $P116.001 0x0014 OR(0) $P1[0], $P2[0], $MP016.002 0x001C OR(0) $MP0, $P3[0], $MP116.003 0x0024 OR(0) $MP1, $P4[0], $MP216.004 0x0034 OR(0) $MP2, $P5[0], $MP316.005 0x000C [$MP3] MOVE(1) $A6_1, $A6
: :

Building the Data Flow Graph
DFG represents data dependencies in each MST procedure. DFG is generated using write-back times of MST instructions.
DOTPROD: MVK .S1 500,A1 ZERO .L1 A7 MVK .S1 2000,A3
LOOP: LDW .D1 *A4++,A2 LDW .D1 *A3++,A5 NOP 4 MPY .M1 A2,A5,A6 SUB .S1 A1,1,A1 ADD .L1 A6,A7,A7 [A1] B .S2 LOOP NOP 5
STW .D1 A7,*A3
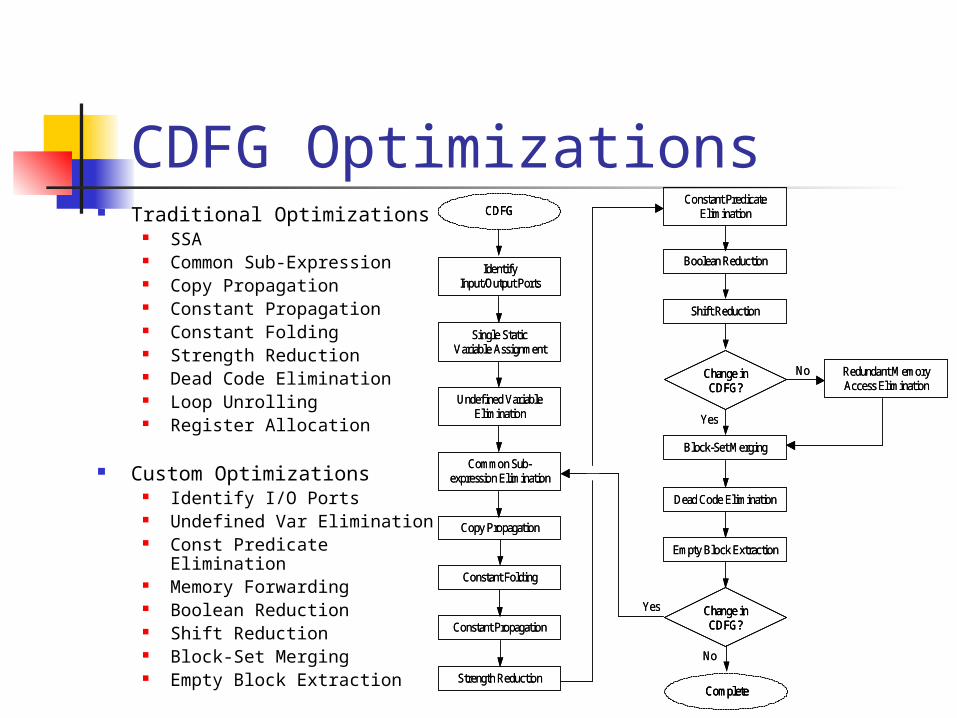
CDFG Optimizations Traditional Optimizations
SSA Common Sub-Expression Copy Propagation Constant Propagation Constant Folding Strength Reduction Dead Code Elimination Loop Unrolling Register Allocation
Custom Optimizations Identify I/O Ports Undefined Var Elimination Const Predicate Elimination Memory Forwarding Boolean Reduction Shift Reduction Block-Set Merging Empty Block Extraction
Identify Input/Output Ports
Single Static Variable Assignment
Constant Folding
Constant Propagation
Strength Reduction
Block-Set Merging
Undefined Variable Elimination
Common Sub-expression Elimination
Constant Predicate Elimination
Dead Code Elimination
Change in CDFG?
Copy Propagation
CDFG
Yes
No
Redundant Memory Access Elimination
Boolean Reduction
Shift Reduction
Change in CDFG?
Yes
No
Complete
Empty Block Extraction
Identify Input/Output Ports
Single Static Variable Assignment
Constant Folding
Constant Propagation
Strength Reduction
Block-Set Merging
Undefined Variable Elimination
Common Sub-expression Elimination
Constant Predicate Elimination
Dead Code Elimination
Change in CDFG?
Change in CDFG?
Copy Propagation
CDFGCDFG
Yes
No
Redundant Memory Access Elimination
Boolean Reduction
Shift Reduction
Change in CDFG?
Change in CDFG?
Yes
No
CompleteComplete
Empty Block Extraction

Experimental Results
Benchmark
DSP Cycles
FPGA Cycles
# Pipelined Instructions
# Added Instructions
memmove 125747 2516 33 352 (24.7%) memcpy 69615 2004 14 136 (52.3%) divi 282301 16127 17 141 (27.3%) mpyd 1329176 39669 26 269 (14.0%) remi 260148 16888 13 130 (34.6%) dsp_fir_gen 30851 685 49 683 (43.1%) lms_filter 33537580 773288 147 967 (13.7%) noise_canceller_fir 8239397 163778 21 105 ( 5.3%)
Each benchmark verified bit-true accurate using Modelsim. ~9 instructions were added for each pipelined operation. ~27% increase in code size during the linearization process. Values reflect the size of the design before CDFG optimizations.

Summary & Conclusions HLS compilers generally convert designs into CDFGs.
Optimizations Scheduling Design decisions
Generating CDFGs from pipelined and scheduled assembly code is complex.
FREEDOM compiler generates CDFGs in three stages: Generate the control flow graph Linearize the assembly code Generate the data flow graph
Verification on highly pipelined benchmarks show improved performance.


















