
GeForce 8800 & NVIDIA CUDA
29
GeForce 8800 & NVIDIA CUDA A New Architecture for Computing on the GPU
Transcript of GeForce 8800 & NVIDIA CUDA

GeForce 8800 & NVIDIA CUDAA New Architecture for Computing on the GPU

© NVIDIA Corporation 2006
Lush, Rich WorldsStunning Graphics Realism
Core of the Definitive Gaming PlatformIncredible Physics Effects
Hellgate: London © 2005-2006 Flagship Studios, Inc. Licensed by NAMCO BANDAI Games America, Inc.
Crysis © 2006 Crytek / Electronic Arts
Full Spectrum Warrior: Ten Hammers © 2006 Pandemic Studios, LLC. All rights reserved. © 2006 THQ Inc. All rights reserved.
© NVIDIA Corporation 2006
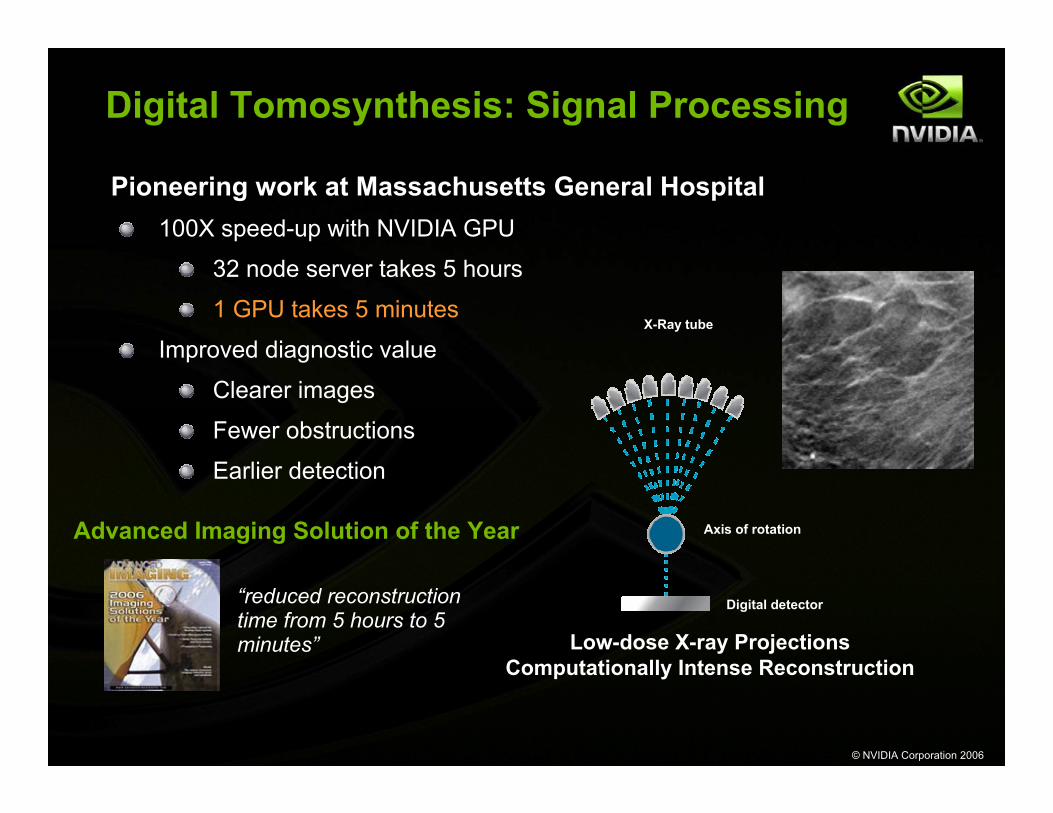
Digital Tomosynthesis: Signal Processing
Pioneering work at Massachusetts General Hospital100X speed-up with NVIDIA GPU
32 node server takes 5 hours
1 GPU takes 5 minutes
Improved diagnostic value
Clearer images
Fewer obstructions
Earlier detection
Axis of rotation
Digital detector
X-Ray tube
Low-dose X-ray ProjectionsComputationally Intense Reconstruction
Advanced Imaging Solution of the Year
“reduced reconstruction time from 5 hours to 5 minutes”
© NVIDIA Corporation 2006
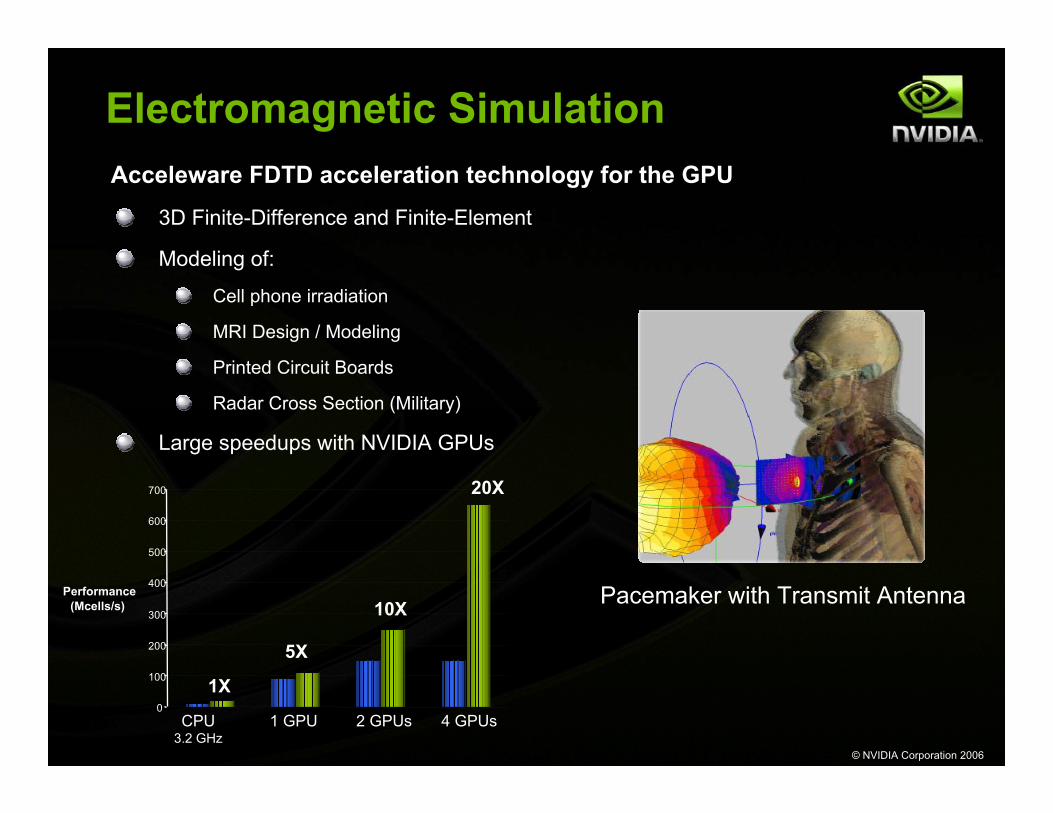
Electromagnetic SimulationAcceleware FDTD acceleration technology for the GPU
3D Finite-Difference and Finite-Element
Modeling of:
Cell phone irradiation
MRI Design / Modeling
Printed Circuit Boards
Radar Cross Section (Military)
Large speedups with NVIDIA GPUs
Pacemaker with Transmit Antenna10X
1X
4 GPUs2 GPUs1 GPUCPU3.2 GHz
0
100
200
300
400
500
600
700
Performance (Mcells/s)
20X
5X

© NVIDIA Corporation 2006
CUDA & GPU Computing
dim3 DimGrid(100, 50); // 5000 thread blocksdim3 DimBlock(4, 8, 8); // 256 threads per blocksize_t SharedMemBytes = 64; // 64 bytes of shared memoryKernelFunc<<< DimGrid, DimBlock, SharedMemBytes >>>(...);
Standard C Programming
New ApplicationsUnprecedented Performance
New Architecturefor Computing
Parallel
Data Cache
P’ = P + V * t
P’ = P + V * t
P’ = P + V * t
ThreadExecutionManager
ALU
Control
ALU
Control
ALU
Control
ALU
DRAMP1, V1P2, V2P3, V3P4, V4P5, V5
SharedData
Parallel
Data Cache
P’ = P + V * t
P’ = P + V * t
P’ = P + V * t
ThreadExecutionManager
ALU
Control
ALU
Control
ALU
Control
ALU
DRAMP1, V1P2, V2P3, V3P4, V4P5, V5
SharedData

GPU Computing Model
© NVIDIA Corporation 2006
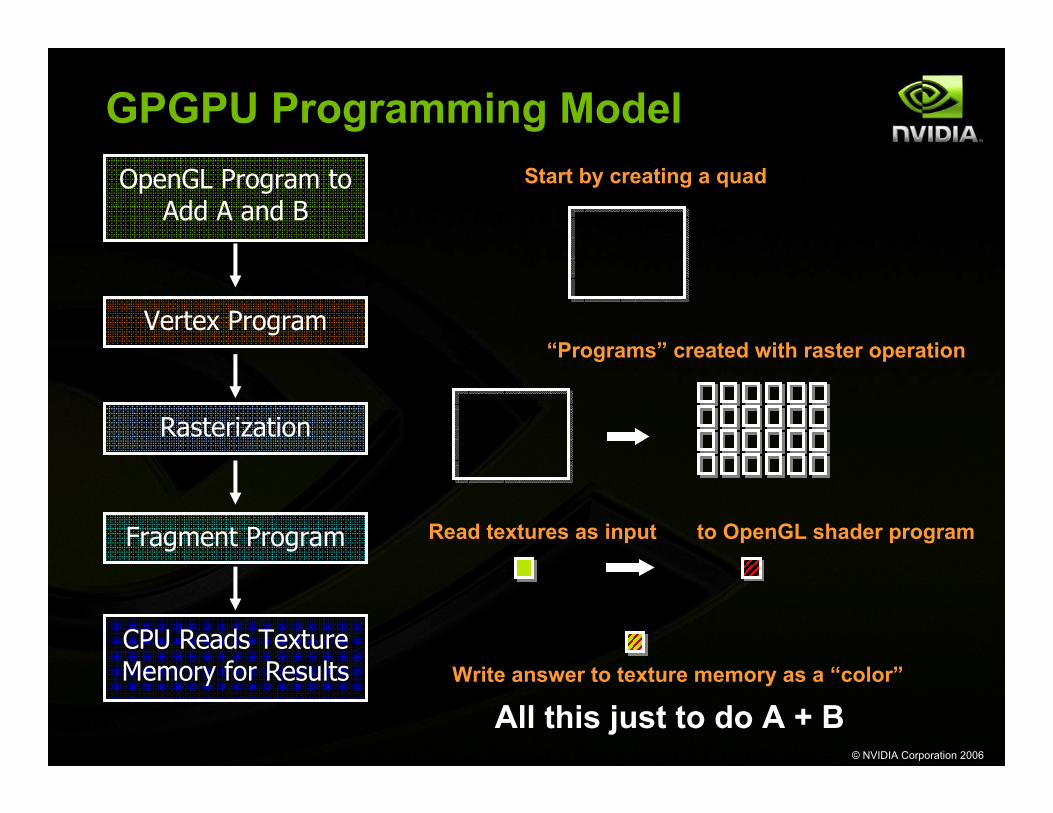
GPGPU Programming Model OpenGL Program to
Add A and B
Vertex Program
Rasterization
Fragment Program
CPU Reads Texture Memory for Results
Start by creating a quad
“Programs” created with raster operation
Write answer to texture memory as a “color”
Read textures as input to OpenGL shader program
All this just to do A + B

© NVIDIA Corporation 2006
Current Constraints
Graphics APIAddressing modes
Limited texture size/dimensionShader capabilities
Limited outputsInstruction sets
Integer & bit opsCommunication limited
Between pixelsScatter a[i] = p
Input Registers
Fragment Program
Output Registers
Constants
Texture
Registers
© NVIDIA Corporation 2006
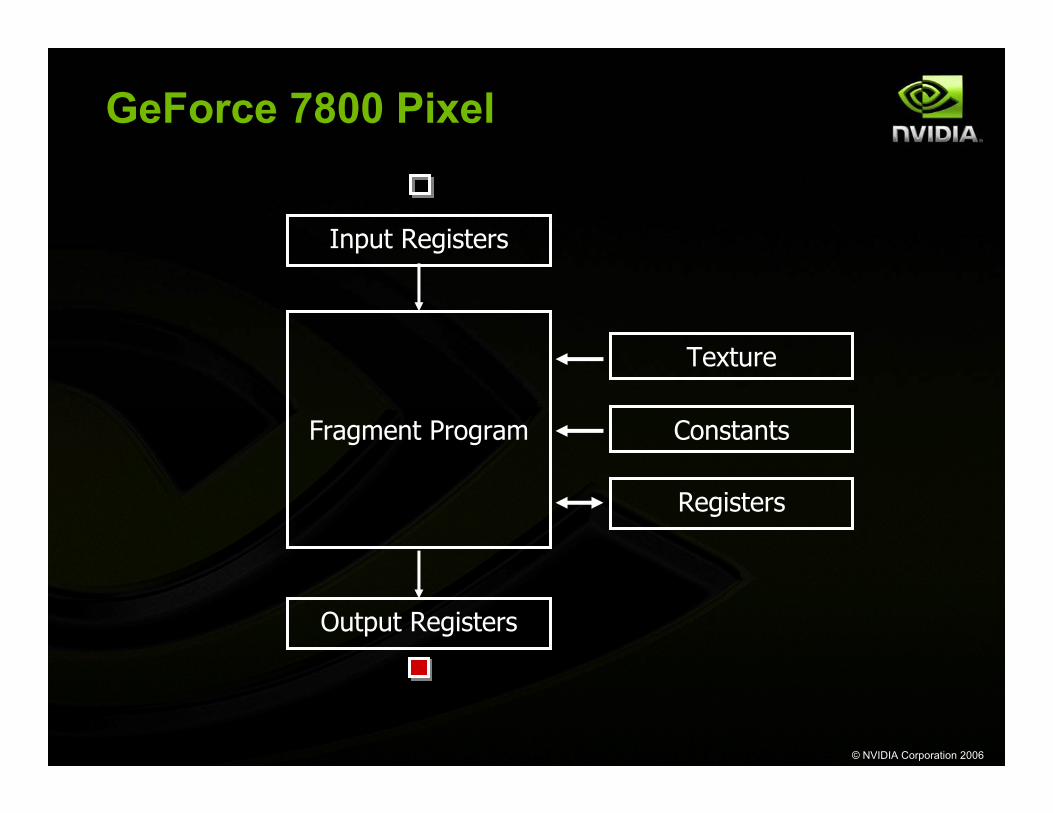
GeForce 7800 Pixel
Input Registers
Fragment Program
Output Registers
Constants
Texture
Registers
© NVIDIA Corporation 2006
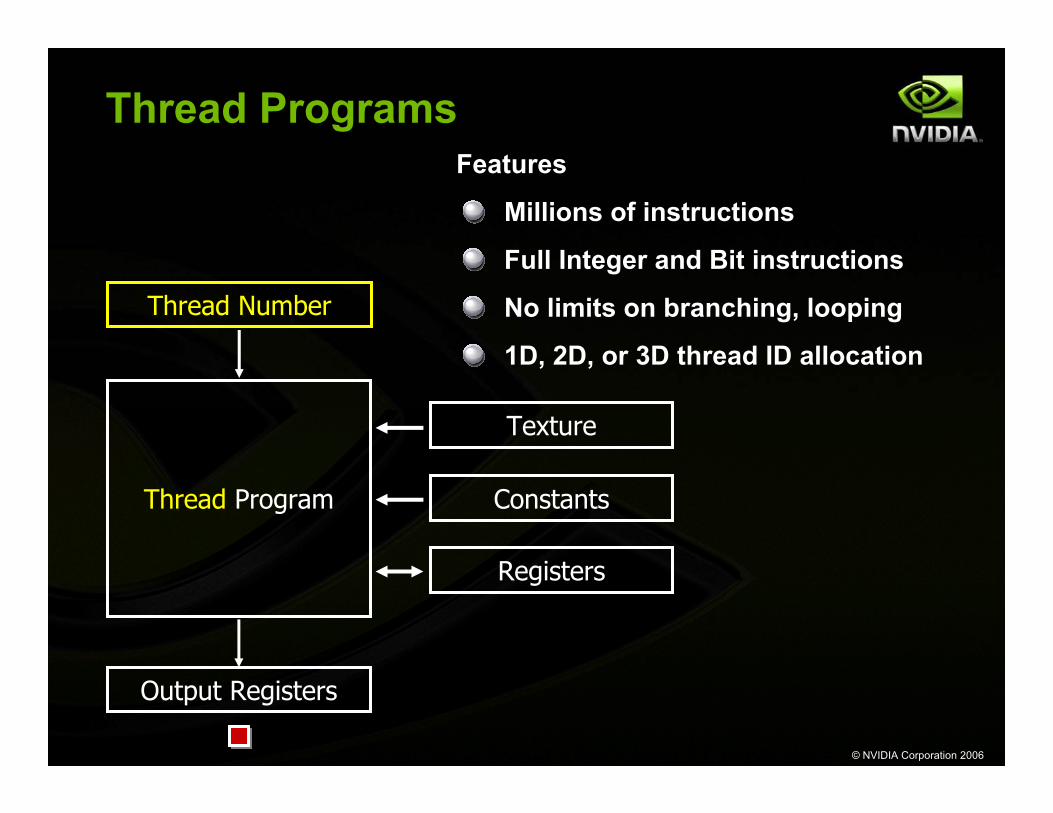
Thread Programs
Thread Program
Output Registers
Constants
Texture
Registers
Thread Number
Features
Millions of instructions
Full Integer and Bit instructions
No limits on branching, looping
1D, 2D, or 3D thread ID allocation
© NVIDIA Corporation 2006
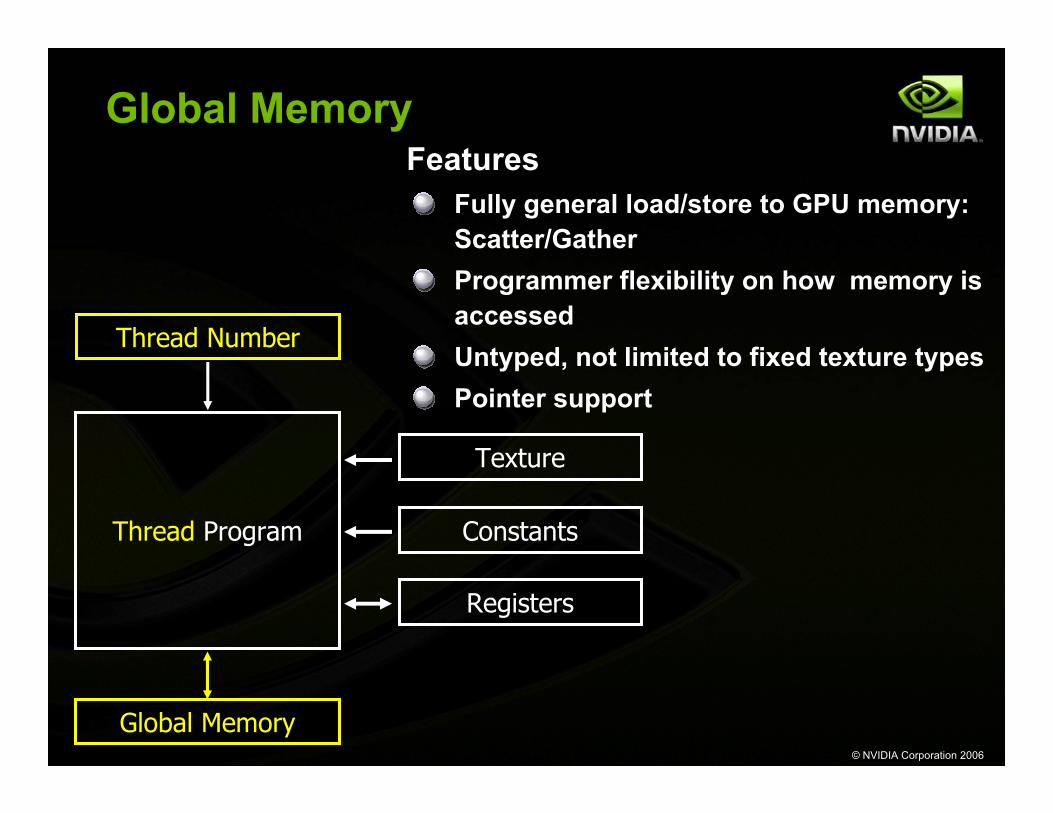
Global Memory
Thread Program
Global Memory
Thread Number
Constants
Texture
Registers
FeaturesFully general load/store to GPU memory: Scatter/GatherProgrammer flexibility on how memory is accessedUntyped, not limited to fixed texture typesPointer support
© NVIDIA Corporation 2006
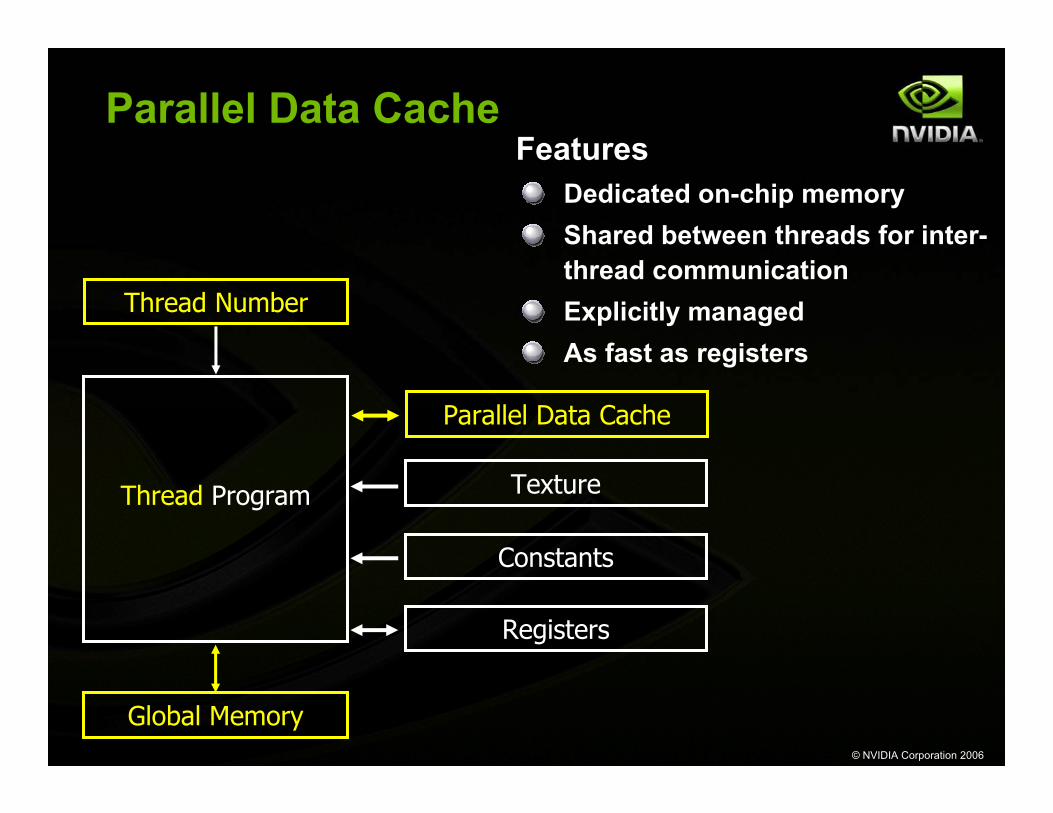
Parallel Data Cache
Thread Program
Global Memory
Constants
Texture
Registers
Parallel Data Cache
Thread Number
FeaturesDedicated on-chip memoryShared between threads for inter-thread communicationExplicitly managedAs fast as registers

© NVIDIA Corporation 2006
Example Algorithm - Fluids
So the pressure for each particle is…
Pressure1 = P1 + P2 + P3 + P4
Pressure2 = P3 + P4 + P5 + P6
Pressure3 = P5 + P6 + P7 + P8
Pressure4 = P7 + P8 + P9 + P10
Pressure depends on neighbors
Goal: Calculate PRESSURE in a fluid
Pressure = Sum of neighboring pressuresPn’ = P1 + P2 + P3 + P4
© NVIDIA Corporation 2006
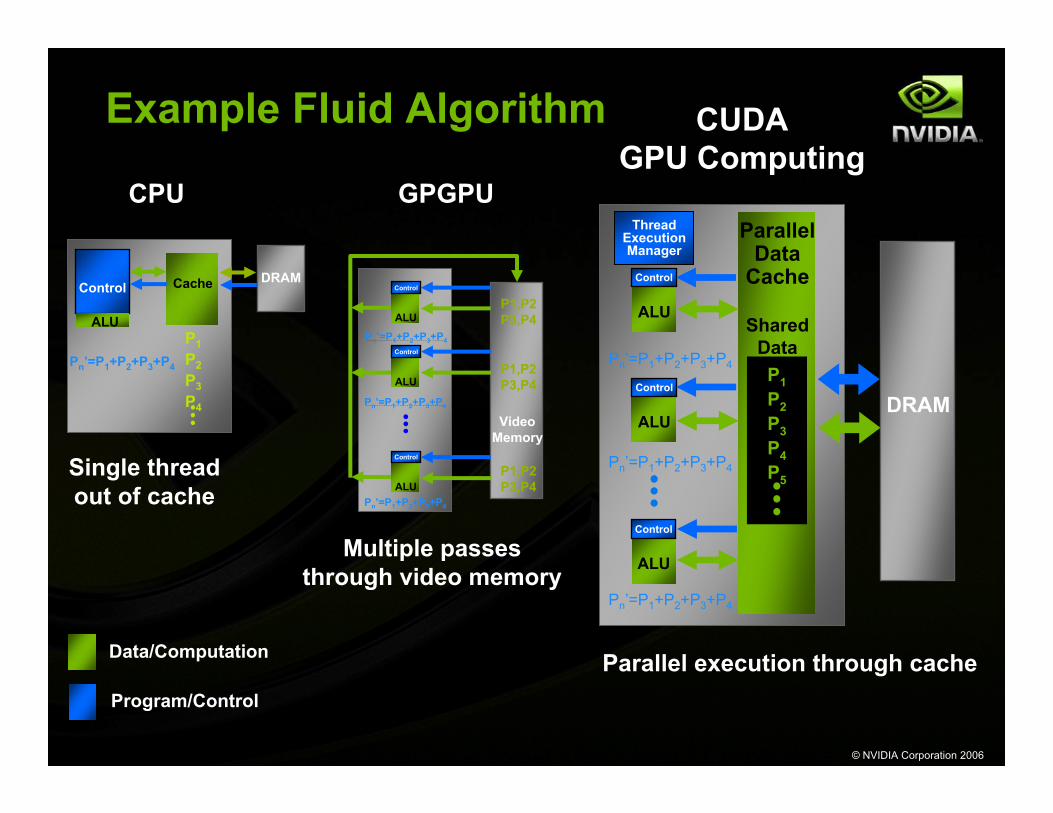
Example Fluid Algorithm
CPU GPGPU
CUDAGPU Computing
Multiple passes through video memory
Parallel execution through cache
Single thread out of cache
Program/Control
Data/Computation
Control
ALU
Cache DRAM
P1P2P3P4
Pn’=P1+P2+P3+P4
ALU
VideoMemory
Control
ALU
Control
ALU
Control
ALUP1,P2P3,P4
P1,P2P3,P4
P1,P2P3,P4
Pn’=P1+P2+P3+P4
Pn’=P1+P2+P3+P4
Pn’=P1+P2+P3+P4
ParallelData
Cache
ThreadExecutionManager
ALU
Control
ALU
Control
ALU
Control
ALU
DRAMP1P2P3P4P5
SharedDataPn’=P1+P2+P3+P4
Pn’=P1+P2+P3+P4
Pn’=P1+P2+P3+P4
© NVIDIA Corporation 2006
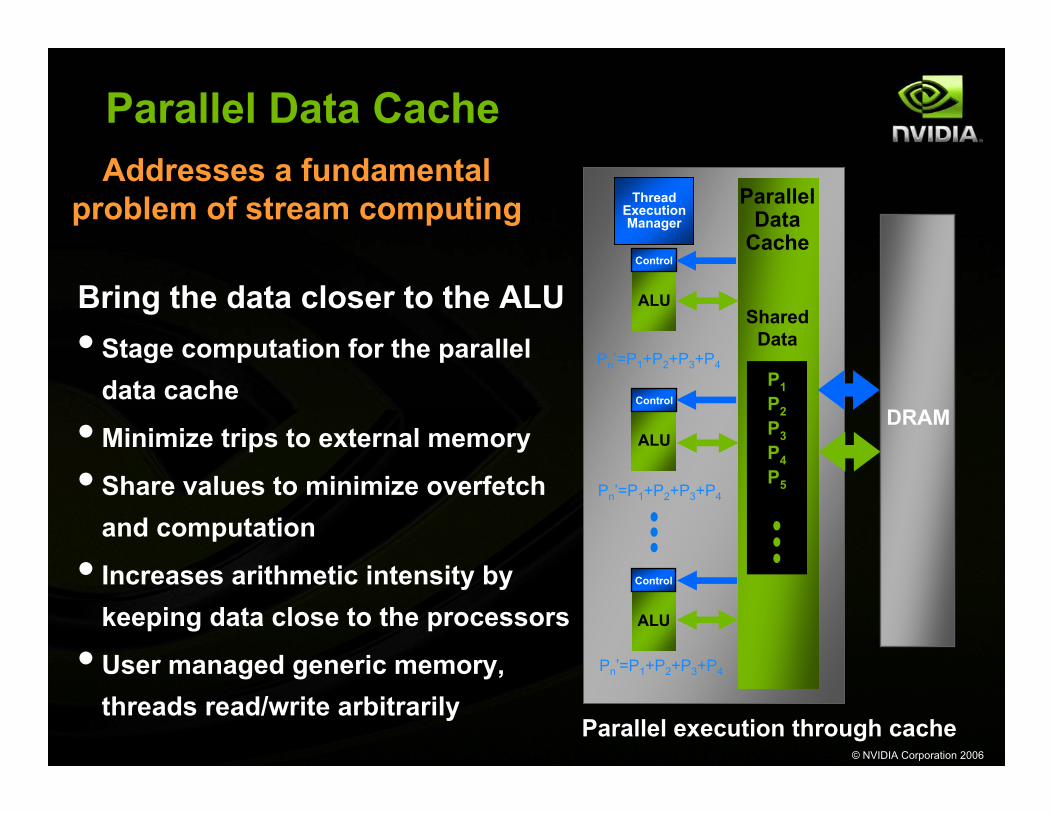
Parallel Data Cache
Parallel execution through cache
ParallelData
Cache
ThreadExecutionManager
ALU
Control
ALU
Control
ALU
Control
ALU
DRAM
P1P2P3P4P5
SharedData
Pn’=P1+P2+P3+P4
Pn’=P1+P2+P3+P4
Pn’=P1+P2+P3+P4
Bring the data closer to the ALU• Stage computation for the parallel
data cache
• Minimize trips to external memory
• Share values to minimize overfetch and computation
• Increases arithmetic intensity by keeping data close to the processors
• User managed generic memory, threads read/write arbitrarily
Addresses a fundamental problem of stream computing

© NVIDIA Corporation 2006
Streaming vs. GPU Computing
GPGPUCUDA
ALU
ALU
StreamingGather in, Restricted writeMemory is far from ALUNo inter-element communication
CUDAMore general data parallel modelFull Scatter / GatherPDC brings the data closer to the ALUApp decides how to decompose the problem across threadsShare and communicate between threads to solve problems efficiently

© NVIDIA Corporation 2006
GeForce 8800 GTX Graphics Board
128Multi-Processors
575MHzCore
1350MHzShader
900MHzMemory
768MB GDDR3Memory
$599 e$599 e--tailtail

© NVIDIA Corporation 2006
Processors execute computing threads
GeForce 8800 GPU Computing
Global Memory
Thread Execution Manager
Input Assembler
Host
Parallel DataCache
Parallel DataCache
Parallel DataCache
Parallel DataCache
Parallel DataCache
Parallel DataCache
Parallel DataCache
Parallel DataCache
Load/store
Thread Processors Thread ProcessorsThread ProcessorsThread ProcessorsThread ProcessorsThread ProcessorsThread ProcessorsThread Processors
© NVIDIA Corporation 2006
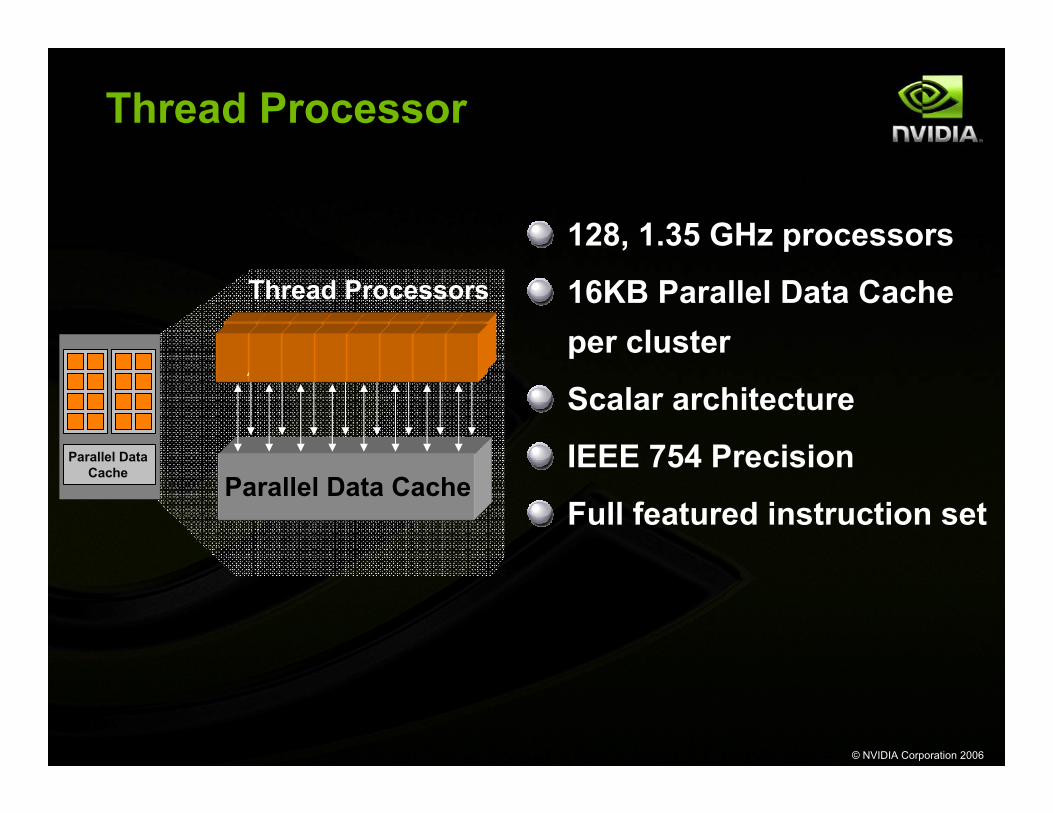
Thread Processor
128, 1.35 GHz processors
16KB Parallel Data Cache per cluster
Scalar architecture
IEEE 754 Precision
Full featured instruction setParallel Data Cache
Thread Processors
Parallel DataCache

CUDA Programming Model

© NVIDIA Corporation 2006
Programming Model:A Highly Multi-threaded Coprocessor
The GPU is viewed as a compute device that:Is a coprocessor to the CPU or hostHas its own DRAM (device memory)Runs many threads in parallel
Data-parallel portions of an application execute on the device as kernels which run many cooperative threads in parallel
Differences between GPU and CPU threads GPU threads are extremely lightweight
Very little creation overheadGPU needs 1000s of threads for full efficiency
Multi-core CPU needs only a few

© NVIDIA Corporation 2006
C on the GPU
A simple, explicit programming language solutionExtend only where necessary
__global__ void KernelFunc(...);
__device__ int GlobalVar;
__shared__ int SharedVar;
KernelFunc<<< 500, 128 >>>(...);

© NVIDIA Corporation 2006
Runtime Component:Memory Management
Explicit GPU memory allocationReturns pointers to GPU memoryDevice memory allocation
cudaMalloc(), cudaFree()
Memory copy from host to device, device to host, device to device
cudaMemcpy(), cudaMemcpy2D(), ...cudaGetSymbolAddress()
OpenGL & DirectX interoperabilitycudaGLMapBufferObject()

© NVIDIA Corporation 2006
CUDA SDK
NVIDIA C Compiler
CUDA Runtime & Driver
NVIDIA Assemblyfor Computing CPU Host Code
Integrated CPUand GPU C Source Code
Standard Libraries:FFT, BLAS,…
Profiler

© NVIDIA Corporation 2006
CUDA Stable Fluids Demo
CUDA port of:Jos Stam, "Stable Fluids", In SIGGRAPH 99
Conference Proceedings, Annual Conference Series, August 1999, 121-128.
© NVIDIA Corporation 2006
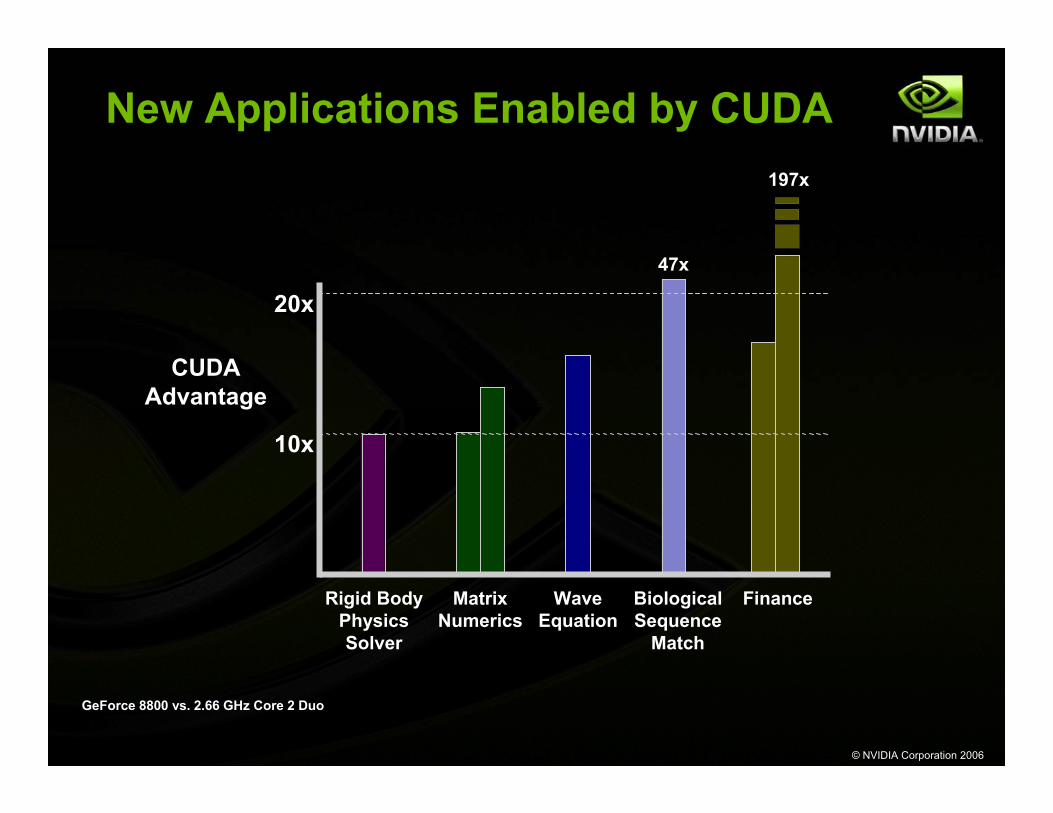
New Applications Enabled by CUDA
GeForce 8800 vs. 2.66 GHz Core 2 Duo
CUDAAdvantage
Rigid BodyPhysicsSolver
10x
20x47x
197x
MatrixNumerics
WaveEquation
BiologicalSequence
Match
Finance

© NVIDIA Corporation 2006
CUDA Performance Advantages
Performance:
BLAS1: 60+ GB/sec
BLAS3: 100+ GFLOPS
FFT: 52 benchFFT* GFLOPS
FDTD: 1.2 Gcells/sec
SSEARCH: 5.2 Gcells/sec
Black Scholes: 4.7 GOptions/sec
Benefits:
Leveraging the parallel data cache
GPU memory bandwidth
GPU GFLOPS performance
Custom hardware intrinsics__sinf, __cosf, __expf, __logf, ...
*GFLOPS as defined by http://www.fftw.org/benchfft
All benchmarks are compiled code!

© NVIDIA Corporation 2006
Conclusions
GPU Computing on GeForce 8800Simple threading modelParallel data cacheGeneral global memory access
CUDA Programming modelC on GPUsTool chain and driver designed for computation
Libraries optimized for GPU ComputingCUFFT, CUBLAS
AvailabilityLinux and WindowsRegister for the Beta online
http://developer.nvidia.com/CUDA

Questions?
http://developer.nvidia.com/CUDA


















