
Game Theory and Security Human Behavior Modeling & Learning · Game Theory and Security Human...
74
Game Theory and Security Human Behavior Modeling & Learning Fei Fang Harvard University Carnegie Mellon University [email protected]
-
Upload
hoangduong -
Category
Documents
-
view
224 -
download
1
Transcript of Game Theory and Security Human Behavior Modeling & Learning · Game Theory and Security Human...

Game Theory and Security
Human Behavior Modeling & Learning
Fei Fang
Harvard UniversityCarnegie Mellon University

Wildlife Population Threatened by Poaching
6/26/20172/67
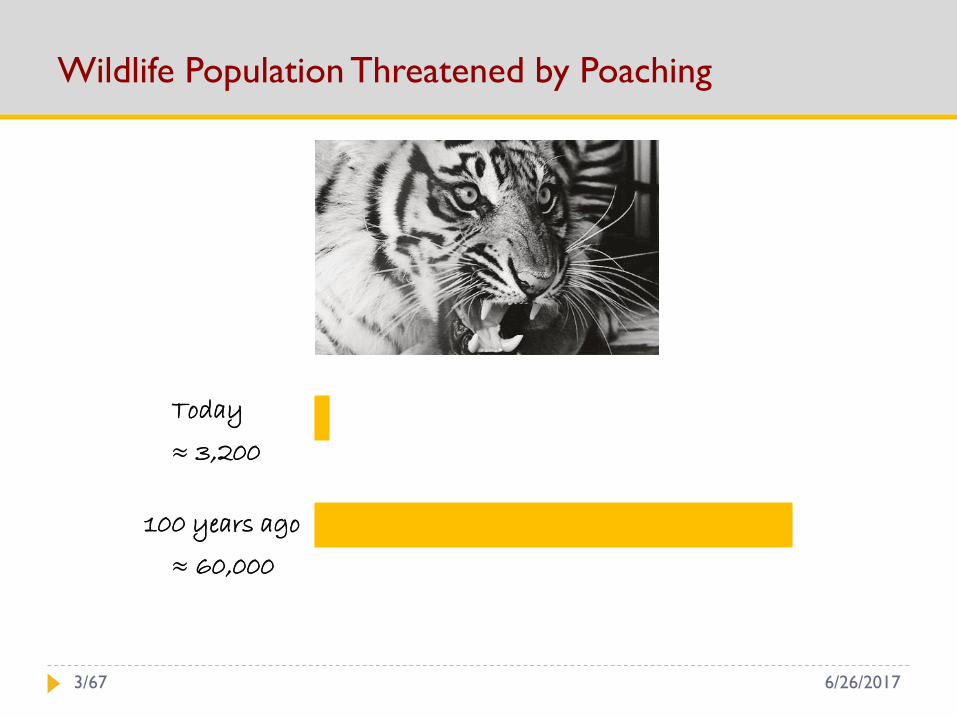
Wildlife Population Threatened by Poaching
Today
≈ 3,200
100 years ago
≈ 60,000
6/26/20173/67

Wildlife Population Threatened by Poaching
Get the most out of the patrols
Game theory + machine learning
6/26/20174/67

Challenges in Wildlife Conservation
Frequent and repeated attacks Not one-shot
Attacker decision making Limited surveillance / Less effort / Boundedly rational
Real-world data Sparse / Incomplete / Uncertainty / Noise
Real-world deployment Practical constraints
Field test
6/26/20175/67

Challenges in Wildlife Conservation
Perfectly rational (Maximize expected utility)? No!
6/26/20176/67

Challenges in Wildlife Conservation
Real-world data
?
??
? ? ?
6/26/20177/67

Human Behavior Modeling & Learning
Uncertainty and Bias Based Models Prospect Theory [Kahneman and Tvesky, 1979]
Anchoring bias and epsilon-bounded rationality [Pita et al, 2010]
Attacker aims to reduce the defender’s utility [Pita et al, 2012]
Quantal Response Based Models Quantal Response [McKelvey and Palfrey, 1995]
Subjective Utility Quantal Response [Nguyen et al, 2013]
Latest Models Incorporating delayed observation [Fang et al, 2015]
Bounded rationality in repeated games [Kar et al, 2015]
Two-layered model [Nguyen et al, 2016]
Decision tree-based model [Kar & Ford et al, 2017]
PAWS
6/26/20178/67

Human Behavior Modeling & Learning
Uncertainty and Bias Based Models Prospect Theory [Kahneman and Tvesky, 1979]
Anchoring bias and epsilon-bounded rationality [Pita et al, 2010]
Attacker aims to reduce the defender’s utility [Pita et al, 2012]
Quantal Response Based Models Quantal Response [McKelvey and Palfrey, 1995]
Subjective Utility Quantal Response [Nguyen et al, 2013]
Latest Models Incorporating delayed observation [Fang et al, 2015]
Bounded rationality in repeated games [Kar et al, 2015]
Two-layered model [Nguyen et al, 2016]
Decision tree-based model [Kar & Ford et al, 2017]
PAWS
6/26/20179/67

PT: Prospect Theory
Model human decision making under uncertainty
Maximize the ‘prospect’ [Kahneman and Tvesky, 1979]
π(·): weighting function
V(·): value function
Defender: choose a strategy that maximizes DefEU when
attacker best responds to the expected prospect (instead of
AttEU)
sAllOutcomei
ii CVx )()( prospect
6/26/201710/67 Kahneman, D., & Tversky, A. (1979). Prospect theory: An analysis of decision
under risk. Econometrica: Journal of the econometric society, 263-291.
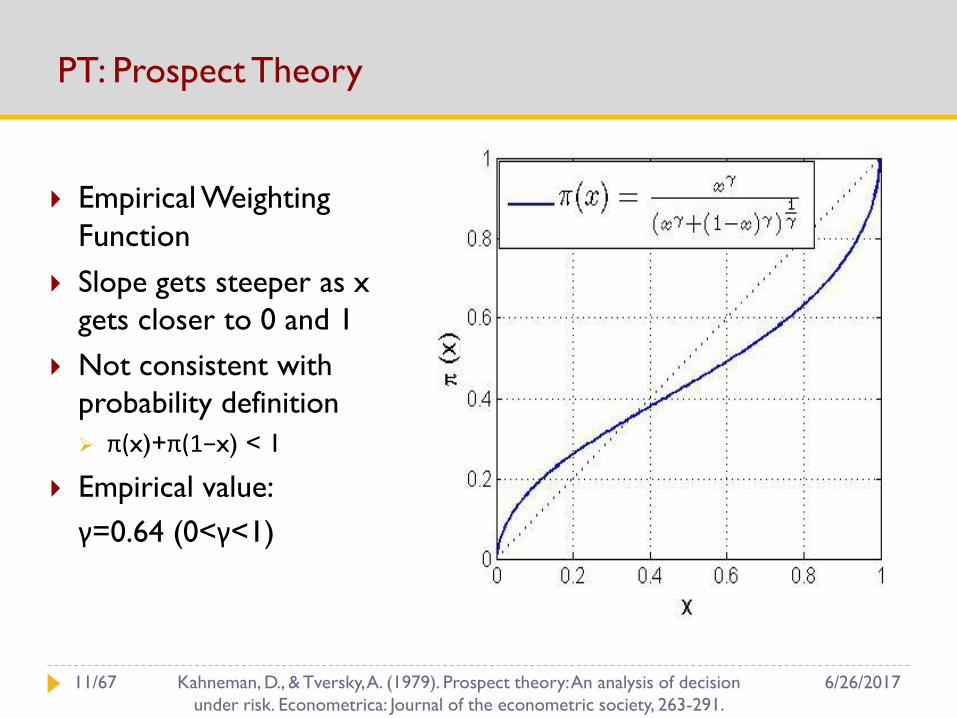
PT: Prospect Theory
Empirical Weighting
Function
Slope gets steeper as x
gets closer to 0 and 1
Not consistent with
probability definition
π(x)+π(1−x) < 1
Empirical value:
γ=0.64 (0<γ<1)
6/26/201711/67 Kahneman, D., & Tversky, A. (1979). Prospect theory: An analysis of decision
under risk. Econometrica: Journal of the econometric society, 263-291.
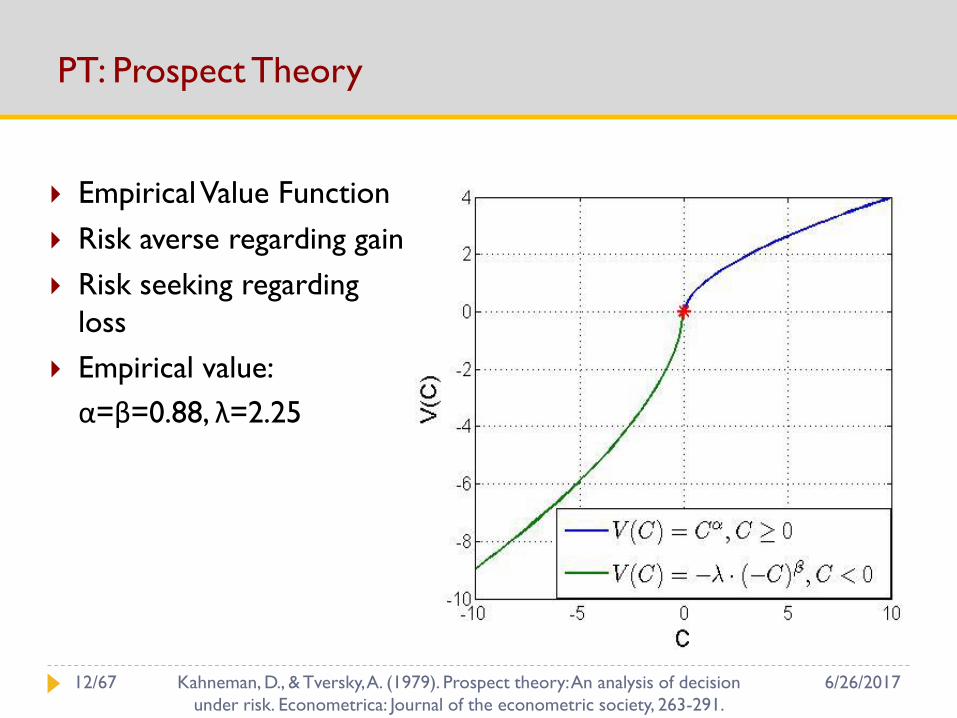
PT: Prospect Theory
Empirical Value Function
Risk averse regarding gain
Risk seeking regarding
loss
Empirical value:
α=β=0.88, λ=2.25
6/26/201712/67 Kahneman, D., & Tversky, A. (1979). Prospect theory: An analysis of decision
under risk. Econometrica: Journal of the econometric society, 263-291.

COBRA: Anchoring Bias and Epsilon-Bounded Rationality
“epsilon optimality”
Anchoring bias: Full observation (𝛼 = 0) vs no
observation (𝛼 = 1)
Experiments: 𝛼 = 0.37 works best
max𝑥,𝑞,𝛾,𝑎
𝛾
𝑠. 𝑡. 𝑥′ = 1 − 𝛼 𝑥 +𝛼
𝑁𝑎 is attacker’s highest expected utility given 𝑥′
𝑞𝑗 = 1 if AttEU𝑗(𝑥′) ≥ 𝑎 − 𝜖
𝛾 ≤ DefEU𝑗(x) if 𝑞𝑗 = 1
6/26/201713/67 Pita et al. Effective solutions for real-world stackelberg games: When agents
must deal with human uncertainties. In AAMAS, 2009.

MATCH: Attacker aims to reduce the defender’s utility
Attacker may deviate from the best response to
reduce the defender’s expected utility
Choose a target to maximizeDefender’s utility loss due to deviation
Adversary’s utility loss due to deviation
Defender: choose a strategy that maximize DefEUwhile bound the above value by 𝛽
Experiments: 𝛽 = 1
6/26/201714/67 Pita et al. A robust approach to addressing human adversaries in security games.
In ECAI, 2012

Human Behavior Modeling & Learning
Uncertainty and Bias Based Models Prospect Theory [Kahneman and Tvesky, 1979]
Anchoring bias and epsilon-bounded rationality [Pita et al, 2010]
Attacker aims to reduce the defender’s utility [Pita et al, 2012]
Quantal Response Based Models Quantal Response [McKelvey and Palfrey, 1995]
Subjective Utility Quantal Response [Nguyen et al, 2013]
Latest Models Incorporating delayed observation [Fang et al, 2015]
Bounded rationality in repeated games [Kar et al, 2015]
Two-layered model [Nguyen et al, 2016]
Decision tree-based model [Kar & Ford et al, 2017]
PAWS
6/26/201715/67

QR: Quantal Response Model
Error in individual’s response
Still: more likely to select better choices than worse choices
Probability distribution of different responses
Quantal best response:
λ: represents error level (=0 means uniform random)
Maximal likelihood estimation (λ=0.76)
𝑞𝑗 =𝑒𝜆∗AttEU𝑗(𝑥)
𝑖 𝑒𝜆∗AttEU𝑖(𝑥)
6/26/201716/67 McKelvey, R. D., & Palfrey, T. R. (1995). Quantal response equilibria for normal
form games. Games and economic behavior, 10(1), 6-38.
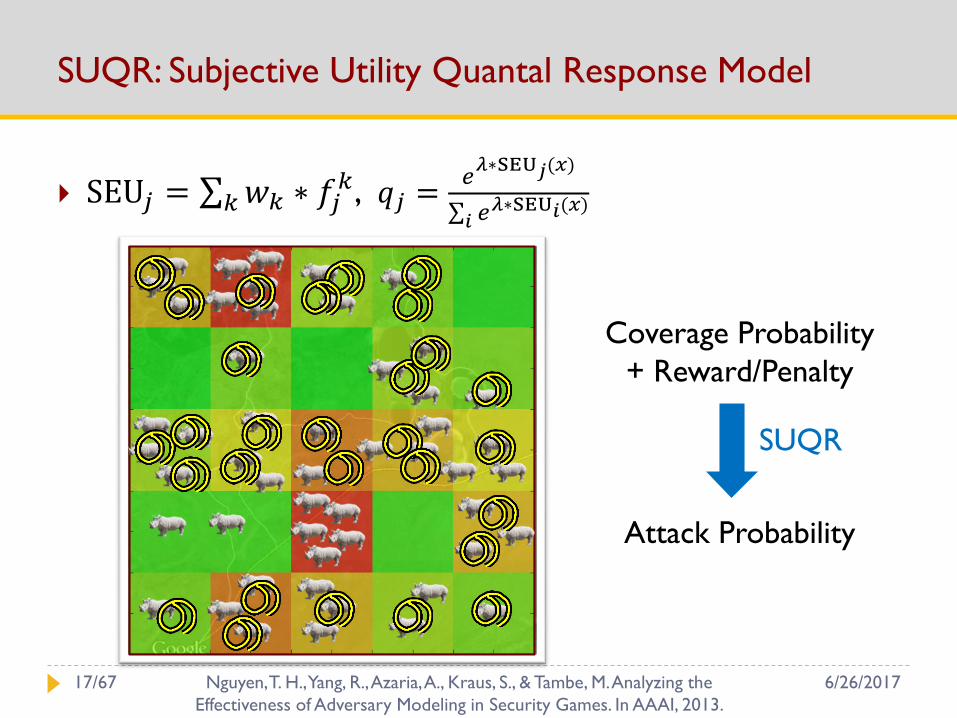
SUQR: Subjective Utility Quantal Response Model
SEU𝑗 = 𝑘𝑤𝑘 ∗ 𝑓𝑗𝑘, 𝑞𝑗 =
𝑒𝜆∗SEU𝑗(𝑥)
𝑖 𝑒𝜆∗SEU𝑖(𝑥)
Coverage Probability
+ Reward/Penalty
Attack Probability
SUQR
6/26/201717/67 Nguyen, T. H., Yang, R., Azaria, A., Kraus, S., & Tambe, M. Analyzing the
Effectiveness of Adversary Modeling in Security Games. In AAAI, 2013.
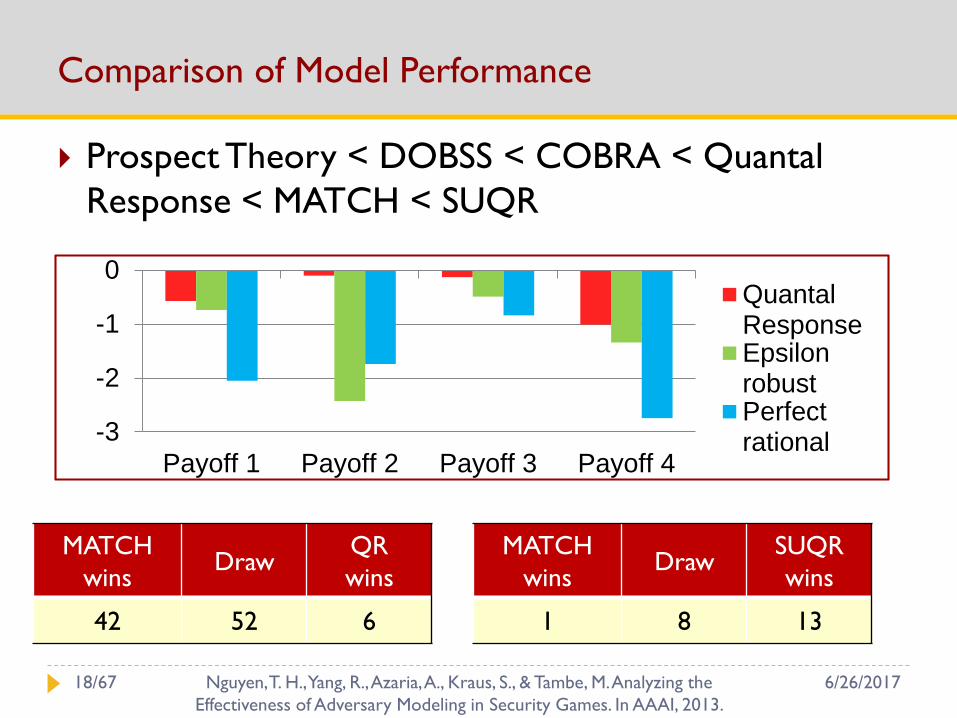
Comparison of Model Performance
Prospect Theory < DOBSS < COBRA < Quantal
Response < MATCH < SUQR
-3
-2
-1
0
Payoff 1 Payoff 2 Payoff 3 Payoff 4
QuantalResponseEpsilonrobustPerfectrational
MATCH
winsDraw
QR
wins
42 52 6
MATCH
winsDraw
SUQR
wins
1 8 13
6/26/201718/67 Nguyen, T. H., Yang, R., Azaria, A., Kraus, S., & Tambe, M. Analyzing the
Effectiveness of Adversary Modeling in Security Games. In AAAI, 2013.

Human Behavior Modeling & Learning
Uncertainty and Bias Based Models Prospect Theory [Kahneman and Tvesky, 1979]
Anchoring bias and epsilon-bounded rationality [Pita et al, 2010]
Attacker aims to reduce the defender’s utility [Pita et al, 2012]
Quantal Response Based Models Quantal Response [McKelvey and Palfrey, 1995]
Subjective Utility Quantal Response [Nguyen et al, 2013]
Latest Models Incorporating delayed observation [Fang et al, 2015]
Bounded rationality in repeated games [Kar et al, 2015]
Two-layered model [Nguyen et al, 2016]
Decision tree-based model [Kar & Ford et al, 2017]
PAWS Application
6/26/201719/67

GSG: Incorporating Delayed Observation
Frequent and repeated attacks
Not one-shot / More data
Attacker decision making
Limited surveillance / Less effort / Boundedly rational
New model: Green Security Games
Wildlife Forest Fishery
6/26/201720/67 Fang, F., Stone, P., & Tambe, M. When Security Games Go Green: Designing
Defender Strategies to Prevent Poaching and Illegal Fishing. In IJCAI, 2015.
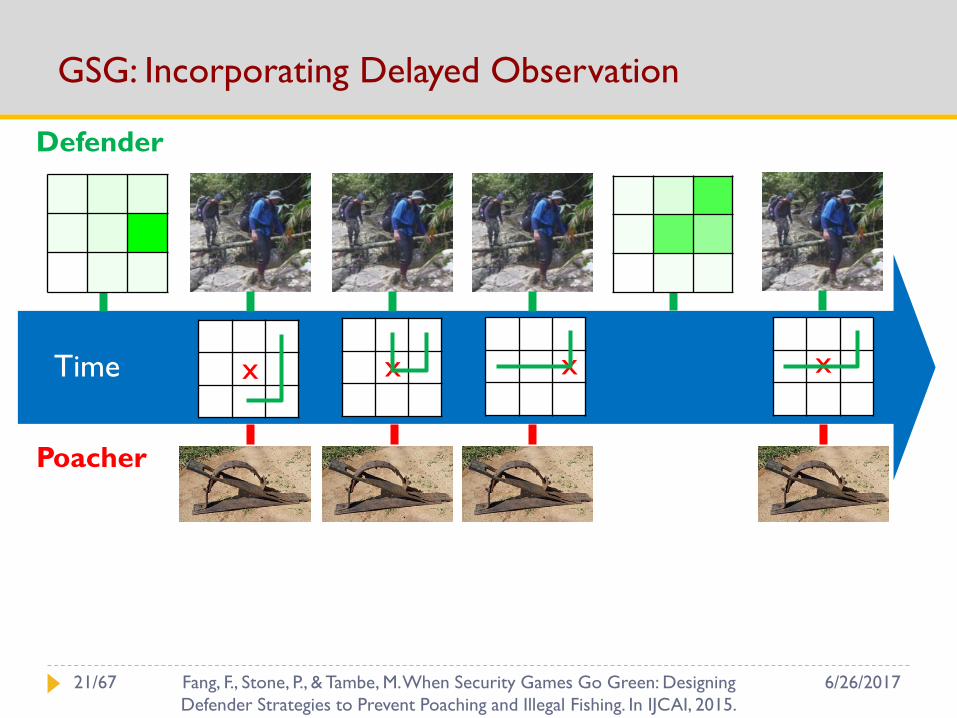
GSG: Incorporating Delayed Observation
Defender
Poacher
x x x xTime
6/26/201721/67 Fang, F., Stone, P., & Tambe, M. When Security Games Go Green: Designing
Defender Strategies to Prevent Poaching and Illegal Fishing. In IJCAI, 2015.
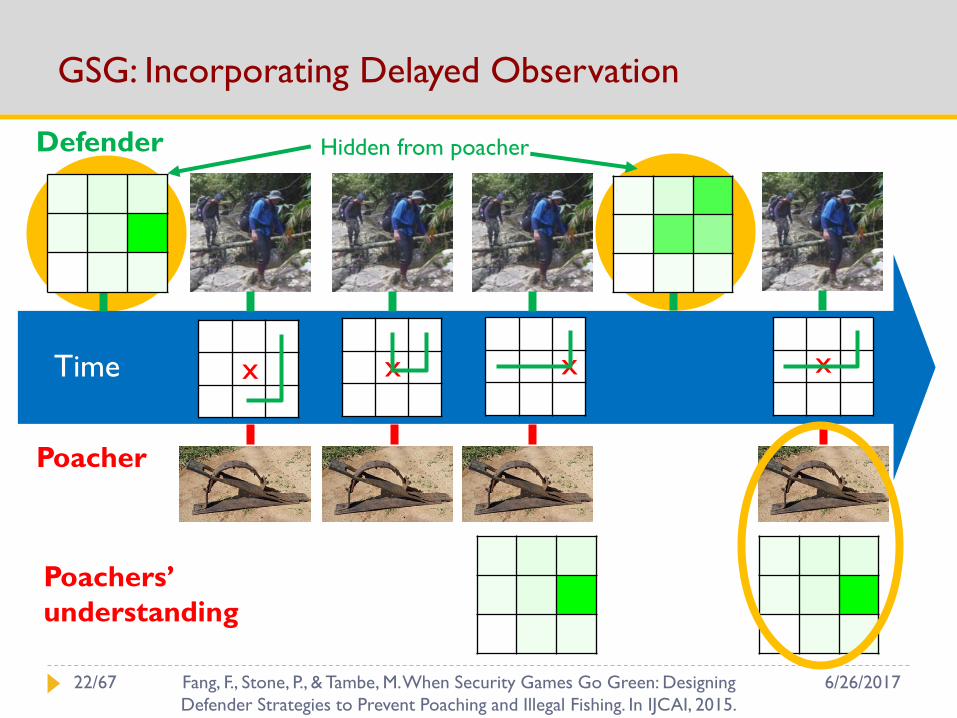
GSG: Incorporating Delayed Observation
Poacher
Defender Hidden from poacher
x x x x
Poachers’
understanding
Time
6/26/201722/67 Fang, F., Stone, P., & Tambe, M. When Security Games Go Green: Designing
Defender Strategies to Prevent Poaching and Illegal Fishing. In IJCAI, 2015.
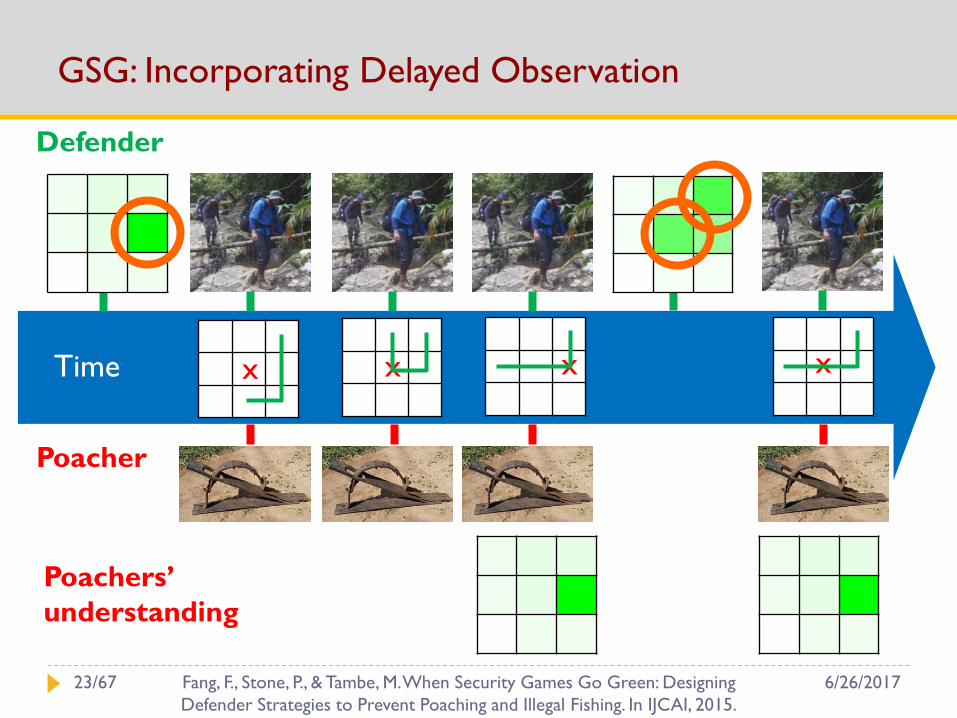
GSG: Incorporating Delayed Observation
Poacher
Defender
x x x x
Poachers’
understanding
Time
6/26/201723/67 Fang, F., Stone, P., & Tambe, M. When Security Games Go Green: Designing
Defender Strategies to Prevent Poaching and Illegal Fishing. In IJCAI, 2015.

GSG: Incorporating Delayed Observation
A Green Security Game (GSG) is a 𝑇 stage game
where the defender protects 𝑁 targets against 𝐿attackers. Defender chooses a mixed strategy 𝑐𝑡 in
stage 𝑡.
A GSG attacker is characterized by his memory
length Γ, coefficients 𝛼0, … , 𝛼Γ and SUQR model
parameter 𝜔. In stage 𝑡, he responds to a convex
combination of defender strategy in recent Γ + 1
rounds: 𝜂𝑡 = 𝜏=0Γ 𝛼𝜏𝑐
𝑡−𝜏
6/26/201724/67 Fang, F., Stone, P., & Tambe, M. When Security Games Go Green: Designing
Defender Strategies to Prevent Poaching and Illegal Fishing. In IJCAI, 2015.
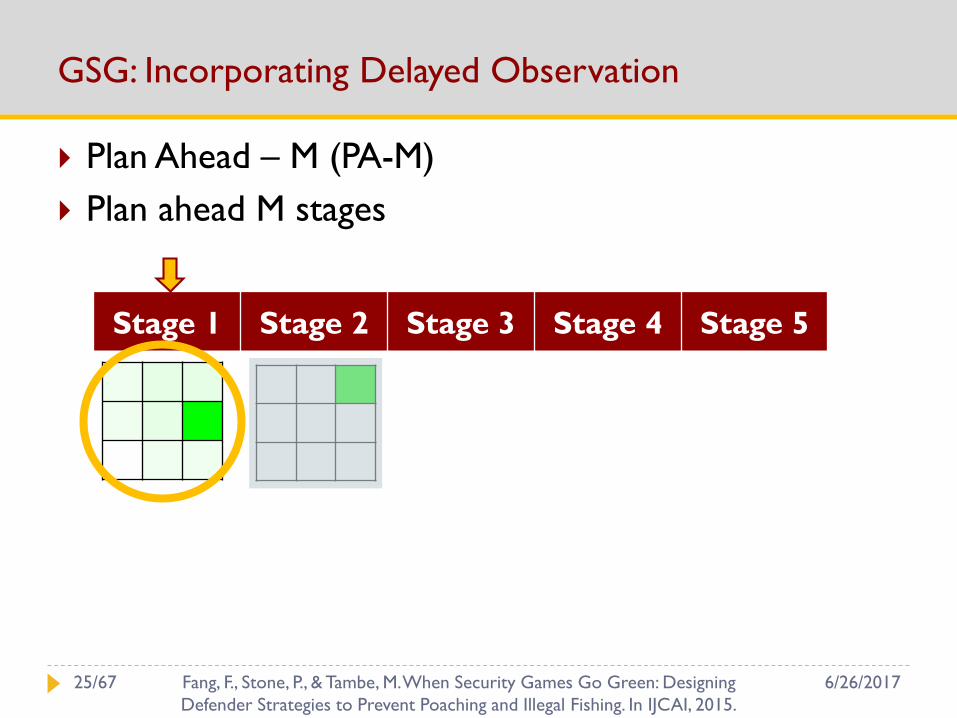
GSG: Incorporating Delayed Observation
Plan Ahead – M (PA-M)
Plan ahead M stages
Stage 1 Stage 2 Stage 3 Stage 4 Stage 5
6/26/201725/67 Fang, F., Stone, P., & Tambe, M. When Security Games Go Green: Designing
Defender Strategies to Prevent Poaching and Illegal Fishing. In IJCAI, 2015.
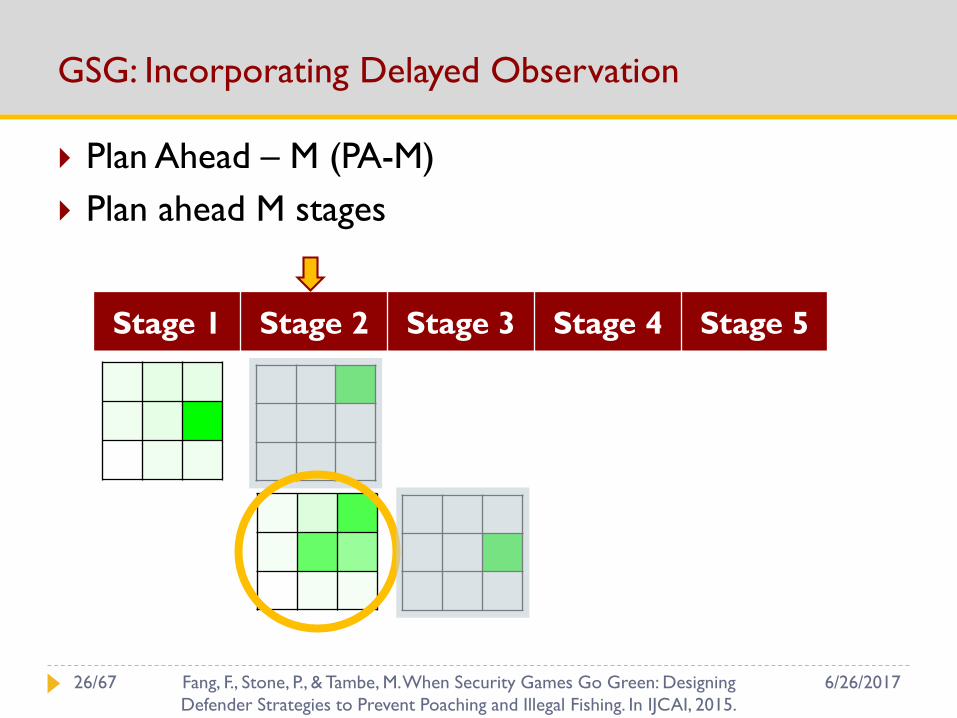
GSG: Incorporating Delayed Observation
Plan Ahead – M (PA-M)
Plan ahead M stages
Stage 1 Stage 2 Stage 3 Stage 4 Stage 5
6/26/201726/67 Fang, F., Stone, P., & Tambe, M. When Security Games Go Green: Designing
Defender Strategies to Prevent Poaching and Illegal Fishing. In IJCAI, 2015.
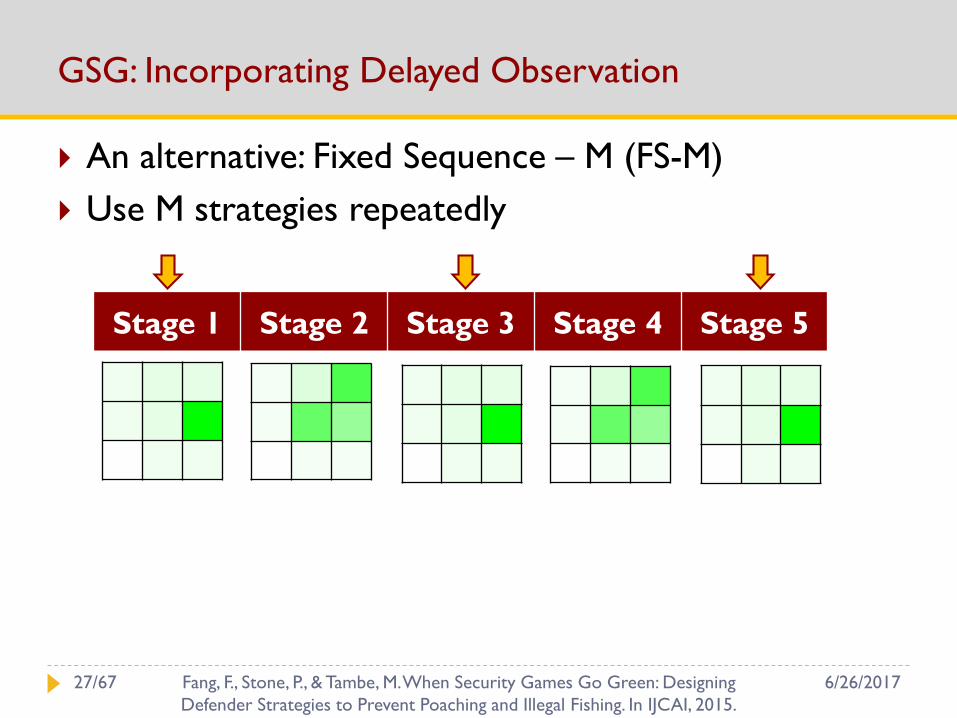
GSG: Incorporating Delayed Observation
An alternative: Fixed Sequence – M (FS-M)
Use M strategies repeatedly
Stage 1 Stage 2 Stage 3 Stage 4 Stage 5
6/26/201727/67 Fang, F., Stone, P., & Tambe, M. When Security Games Go Green: Designing
Defender Strategies to Prevent Poaching and Illegal Fishing. In IJCAI, 2015.
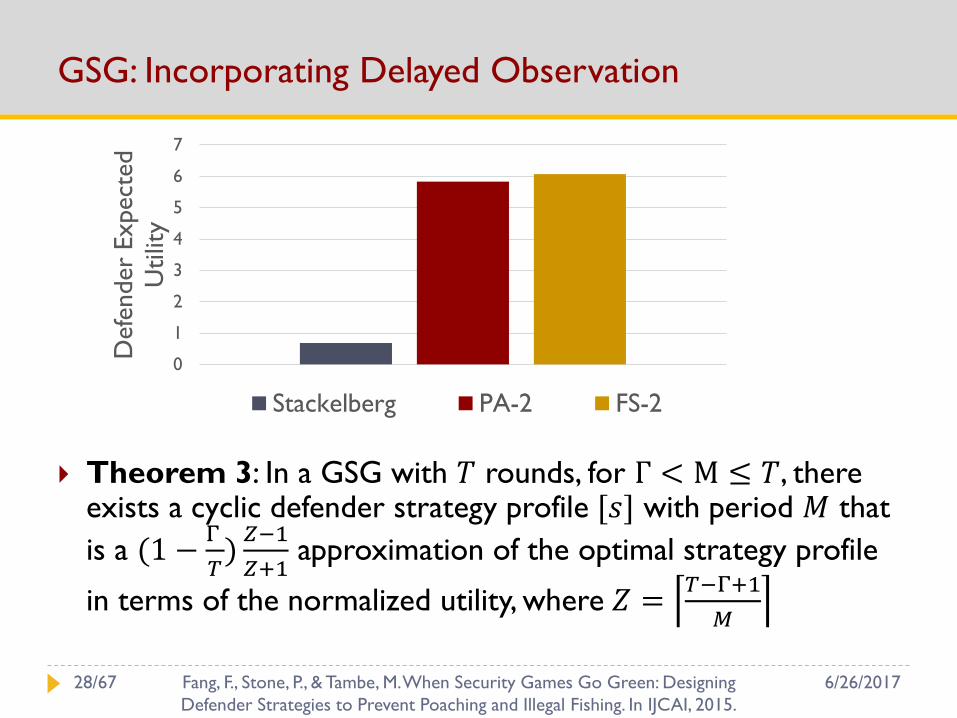
GSG: Incorporating Delayed Observation
Theorem 3: In a GSG with 𝑇 rounds, for Γ < M ≤ 𝑇, there exists a cyclic defender strategy profile [𝑠] with period 𝑀 that
is a (1 −Γ
𝑇)𝑍−1
𝑍+1approximation of the optimal strategy profile
in terms of the normalized utility, where 𝑍 =𝑇−Γ+1
𝑀
0
1
2
3
4
5
6
7D
efe
nder
Expect
ed
Uti
lity
Stackelberg PA-2 FS-2
6/26/201728/67 Fang, F., Stone, P., & Tambe, M. When Security Games Go Green: Designing
Defender Strategies to Prevent Poaching and Illegal Fishing. In IJCAI, 2015.

Human Behavior Modeling & Learning
Uncertainty and Bias Based Models Prospect Theory [Kahneman and Tvesky, 1979]
Anchoring bias and epsilon-bounded rationality [Pita et al, 2010]
Attacker aims to reduce the defender’s utility [Pita et al, 2012]
Quantal Response Based Models Quantal Response [McKelvey and Palfrey, 1995]
Subjective Utility Quantal Response [Nguyen et al, 2013]
Latest Models Incorporating delayed observation [Fang et al, 2015]
Bounded rationality in repeated games [Kar et al, 2015]
Two-layered model [Nguyen et al, 2016]
Decision tree-based model [Kar & Ford et al, 2017]
PAWS Application
6/26/201729/67

SHARP: Bounded Rationality in Repeated Games
6/26/201730/67 Kar, D., Fang, F., Delle Fave, F., Sintov, N., & Tambe, M. A game of thrones: when human
behavior models compete in repeated Stackelberg security games. In AAMAS, 2015
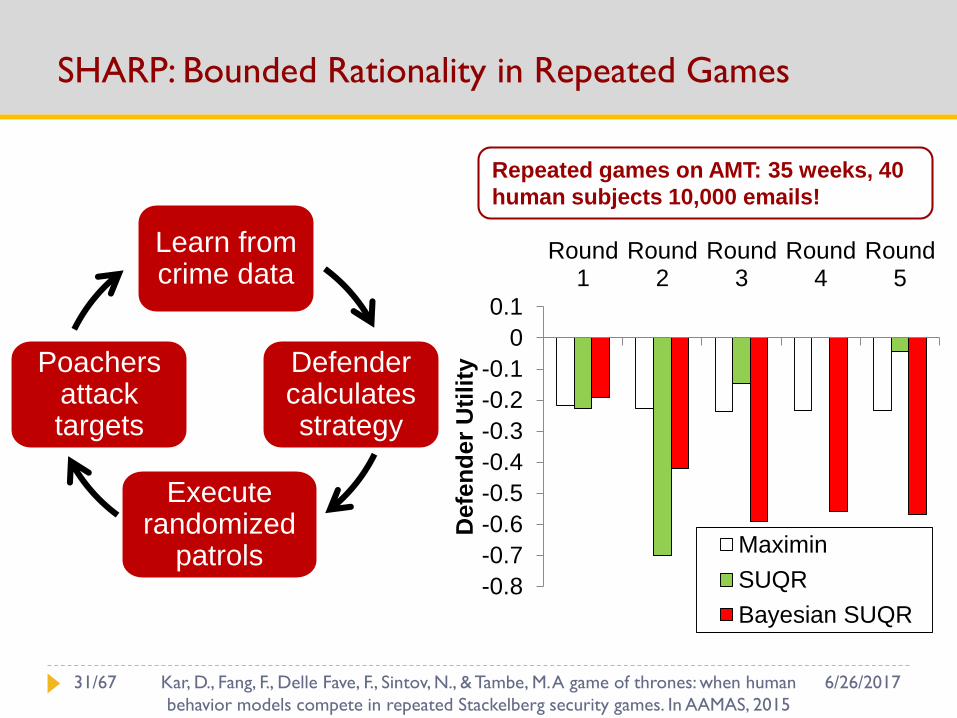
SHARP: Bounded Rationality in Repeated Games
-0.8
-0.7
-0.6
-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
Round1
Round2
Round3
Round4
Round5
Defe
nd
er
Uti
lity
Maximin
SUQR
Bayesian SUQR
Repeated games on AMT: 35 weeks, 40
human subjects 10,000 emails!
Learn from crime data
Defender calculates strategy
Execute randomized
patrols
Poachers attack targets
6/26/201731/67 Kar, D., Fang, F., Delle Fave, F., Sintov, N., & Tambe, M. A game of thrones: when human
behavior models compete in repeated Stackelberg security games. In AAMAS, 2015
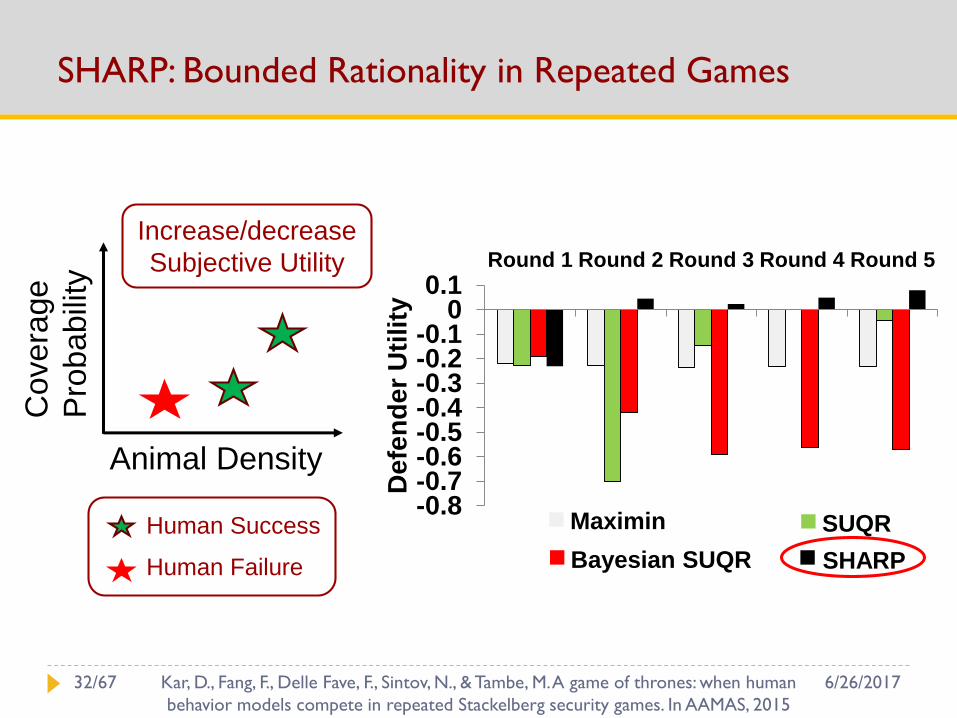
SHARP: Bounded Rationality in Repeated Games
-0.8-0.7-0.6-0.5-0.4-0.3-0.2-0.1
00.1
Round 1 Round 2 Round 3 Round 4 Round 5
De
fen
de
r U
tility
Maximin SUQR
Bayesian SUQR SHARP
Animal Density
Cove
rage
Pro
babili
ty
Human Success
Human Failure
Increase/decrease
Subjective Utility
6/26/201732/67 Kar, D., Fang, F., Delle Fave, F., Sintov, N., & Tambe, M. A game of thrones: when human
behavior models compete in repeated Stackelberg security games. In AAMAS, 2015
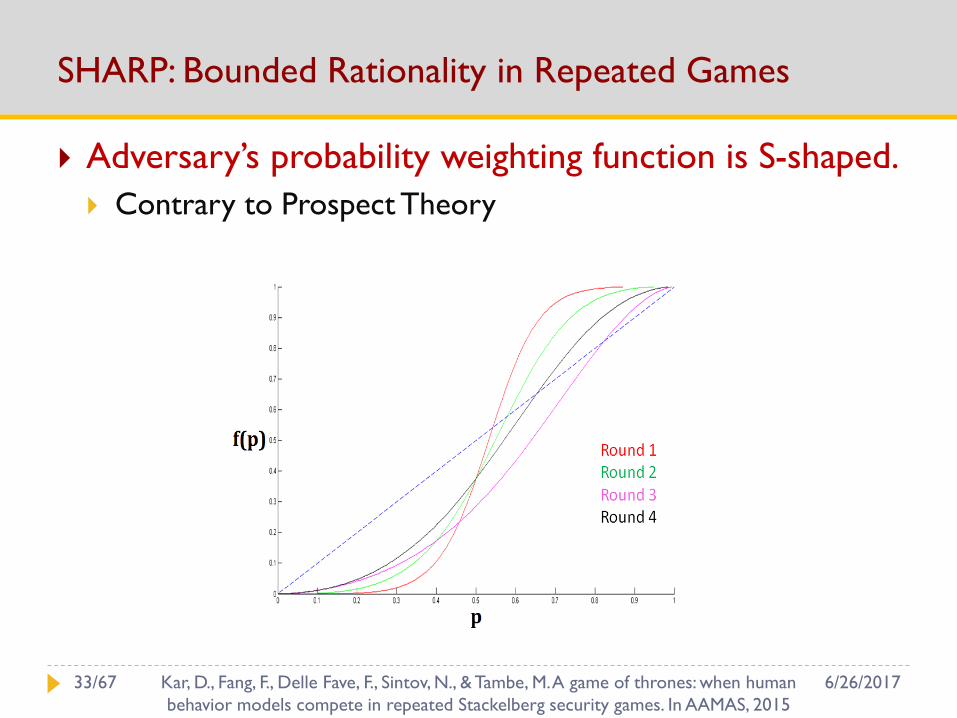
SHARP: Bounded Rationality in Repeated Games
Adversary’s probability weighting function is S-shaped.
Contrary to Prospect Theory
6/26/201733/67 Kar, D., Fang, F., Delle Fave, F., Sintov, N., & Tambe, M. A game of thrones: when human
behavior models compete in repeated Stackelberg security games. In AAMAS, 2015
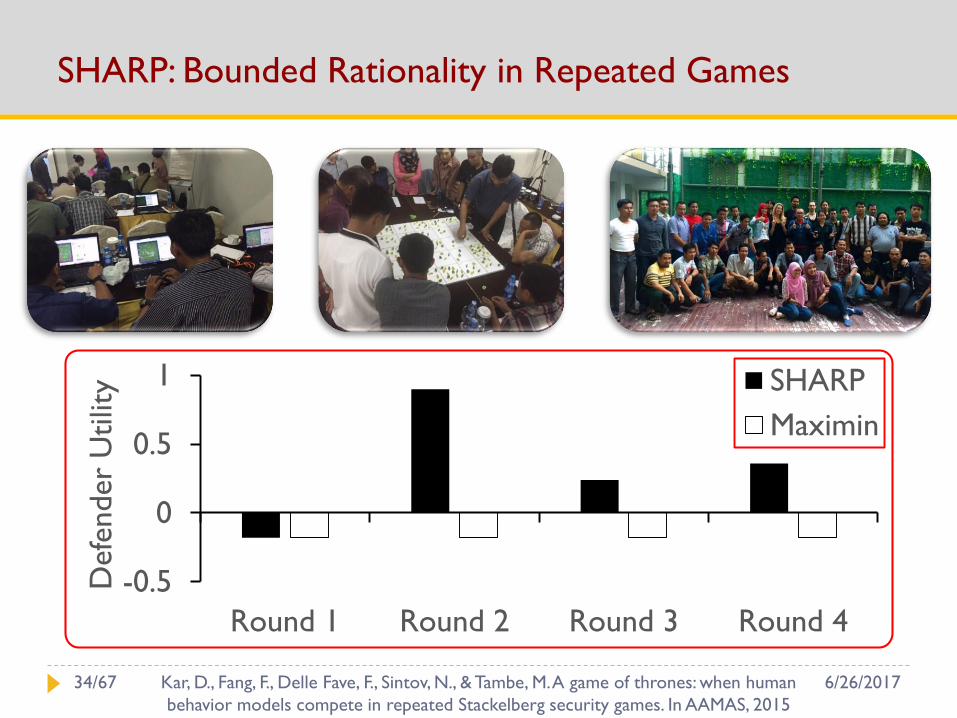
SHARP: Bounded Rationality in Repeated Games
-0.5
0
0.5
1
Round 1 Round 2 Round 3 Round 4
Defe
nder
Utilit
y SHARP
Maximin
6/26/201734/67 Kar, D., Fang, F., Delle Fave, F., Sintov, N., & Tambe, M. A game of thrones: when human
behavior models compete in repeated Stackelberg security games. In AAMAS, 2015

Human Behavior Modeling & Learning
Uncertainty and Bias Based Models Prospect Theory [Kahneman and Tvesky, 1979]
Anchoring bias and epsilon-bounded rationality [Pita et al, 2010]
Attacker aims to reduce the defender’s utility [Pita et al, 2012]
Quantal Response Based Models Quantal Response [McKelvey and Palfrey, 1995]
Subjective Utility Quantal Response [Nguyen et al, 2013]
Latest Models Incorporating delayed observation [Fang et al, 2015]
Bounded rationality in repeated games [Kar et al, 2015]
Two-layered model [Nguyen et al, 2016]
Decision tree-based model [Kar & Ford et al, 2017]
PAWS Application
6/26/201735/67

Real-World Data
Queen Elizabeth National Park 1,978 sq. km
2003-2015
Geospatial Features Terrain (e.g., forest, slope)
Distance to {Town, Water, Outpost}
Ranger Coverage
Crime Observations
6/26/201736/67 Nguyen et al. Capture: A new predictive anti-poaching tool for wildlife
protection. In AAMAS, 2016

Real-World Data: Challenges
“Missing” poaching data
Limited patrol resources
(silent victims)
Imperfect observations
(e.g., hidden snares)
Consequences
Uncertainty in negative labels
Class imbalance
??
?
?
?
?
?
6/26/201737/67 Nguyen et al. Capture: A new predictive anti-poaching tool for wildlife
protection. In AAMAS, 2016
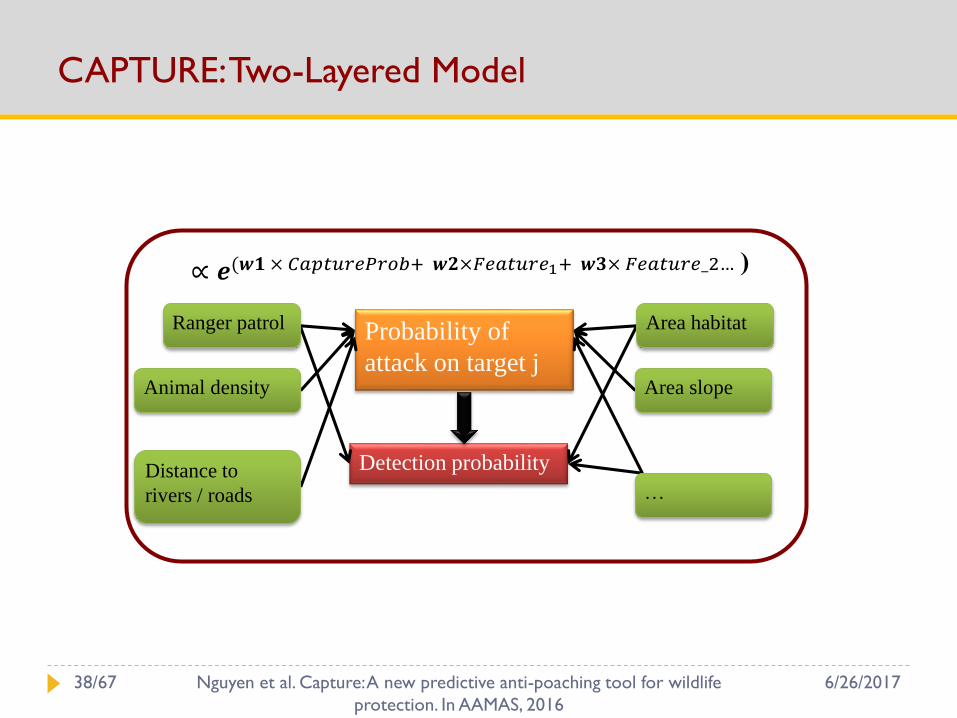
CAPTURE: Two-Layered Model
Probability of
attack on target j
Detection probability
Ranger patrol
Animal density
Distance to
rivers / roads
Area habitat
Area slope
…
∝ 𝒆(𝒘𝟏 × 𝐶𝑎𝑝𝑡𝑢𝑟𝑒𝑃𝑟𝑜𝑏+ 𝒘𝟐×𝐹𝑒𝑎𝑡𝑢𝑟𝑒1+ 𝒘𝟑× 𝐹𝑒𝑎𝑡𝑢𝑟𝑒_2… )
6/26/201738/67 Nguyen et al. Capture: A new predictive anti-poaching tool for wildlife
protection. In AAMAS, 2016
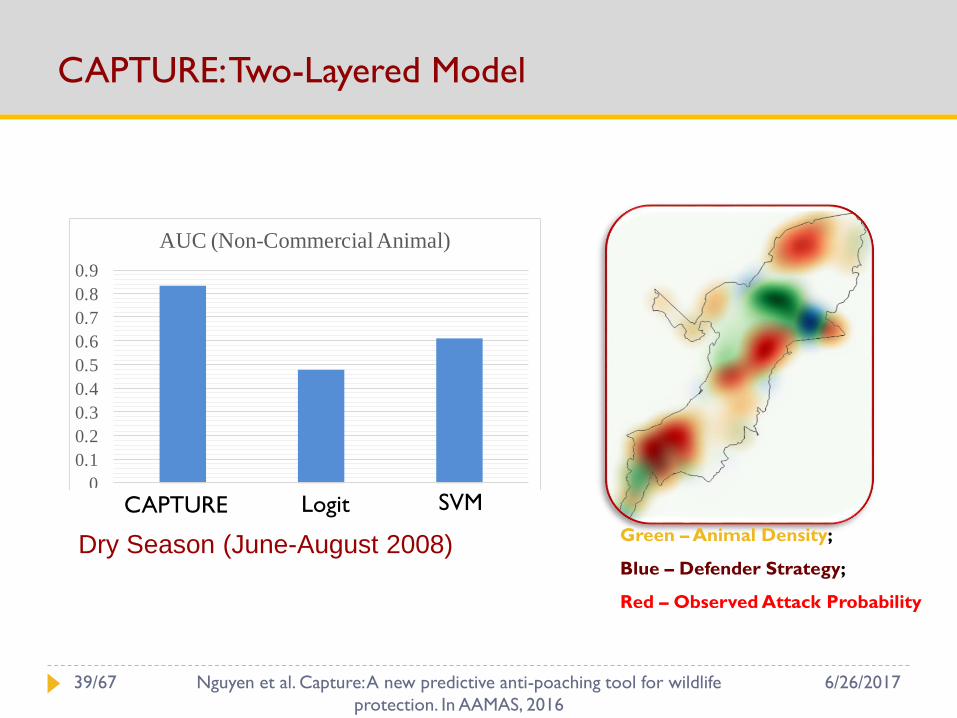
CAPTURE: Two-Layered Model
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
PAWS Logit SVM
AUC (Non-Commercial Animal)
Dry Season (June-August 2008) Green – Animal Density;
Blue – Defender Strategy;
Red – Observed Attack Probability
6/26/201739/67 Nguyen et al. Capture: A new predictive anti-poaching tool for wildlife
protection. In AAMAS, 2016
CAPTURE Logit SVM

CAPTURE: Two-Layered Model
Limitations
Limited Data
Predicting Everywhere
Slow Learning
Variations
Simpler observation layer
Use previous coverage instead of current coverage
Exponentially penalize the attractiveness of inaccessible
areas
No improvement
6/26/201740/67 Kar & Ford et al. Cloudy with a Chance of Poaching: Adversary Behavior
Modeling and Forecasting with Real-World Poaching Data. In AAMAS , 2017
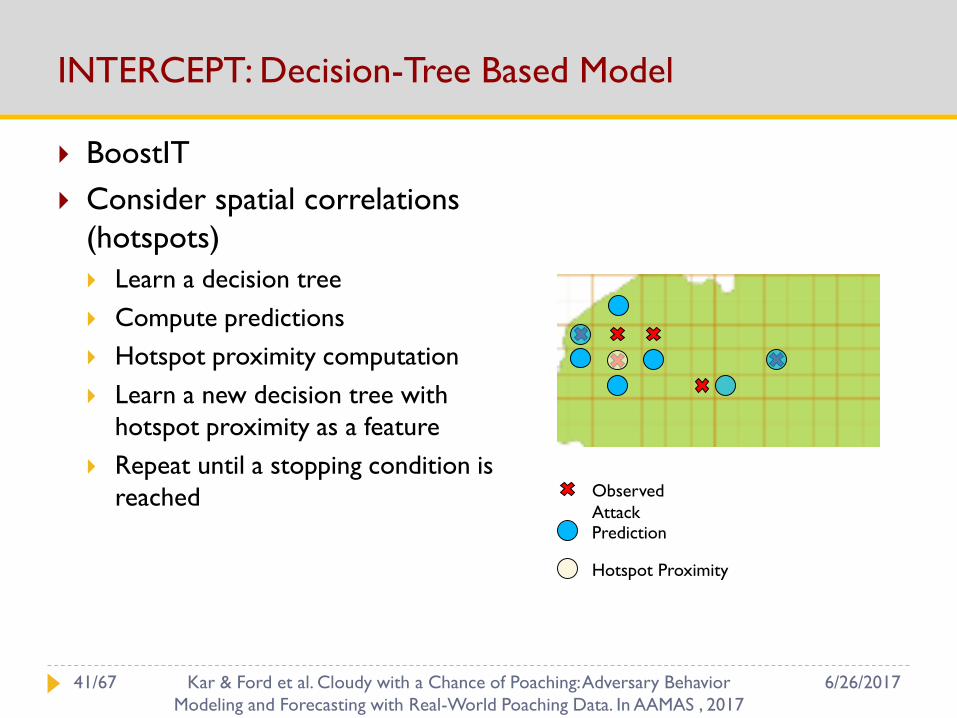
INTERCEPT: Decision-Tree Based Model
BoostIT
Consider spatial correlations
(hotspots)
Learn a decision tree
Compute predictions
Hotspot proximity computation
Learn a new decision tree with
hotspot proximity as a feature
Repeat until a stopping condition is
reached Observed
AttackPrediction
Hotspot Proximity
6/26/201741/67 Kar & Ford et al. Cloudy with a Chance of Poaching: Adversary Behavior
Modeling and Forecasting with Real-World Poaching Data. In AAMAS , 2017

INTERCEPT: Decision-Tree Based Model
Extensive Empirical Evaluation 40 models w/ total of 192 model variations
Decision tree ensemble outperforms all other (complex) models including CAPTURE Standard decision tree, 2 BoostITs (α =2, 3), 2 Decision Trees (FP cost
= 0.6, 0.9)
Fast runtime and interpretability led to its deployment (obstacles for CAPTURE)
Datasets Trained: 2003-2014, Tested: 2015
Trained: 2003-2013, Tested: 2014
6/26/201742/67 Kar & Ford et al. Cloudy with a Chance of Poaching: Adversary Behavior
Modeling and Forecasting with Real-World Poaching Data. In AAMAS , 2017
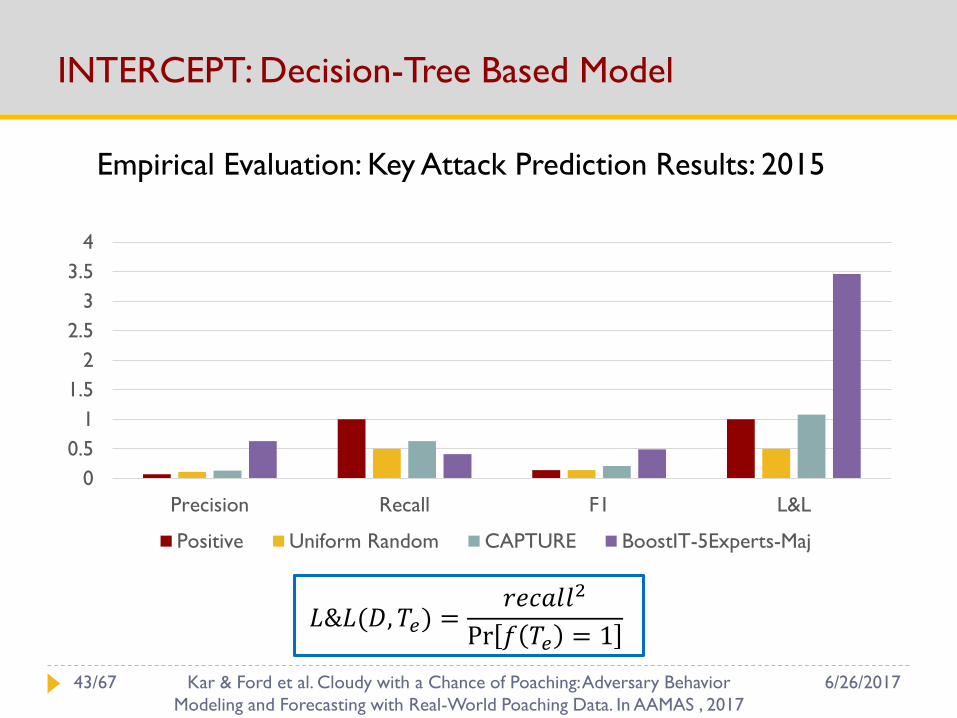
INTERCEPT: Decision-Tree Based Model
0
0.5
1
1.5
2
2.5
3
3.5
4
Precision Recall F1 L&L
Positive Uniform Random CAPTURE BoostIT-5Experts-Maj
𝐿&𝐿(𝐷, 𝑇𝑒) =𝑟𝑒𝑐𝑎𝑙𝑙2
Pr 𝑓 𝑇𝑒 = 1
Empirical Evaluation: Key Attack Prediction Results: 2015
6/26/201743/67 Kar & Ford et al. Cloudy with a Chance of Poaching: Adversary Behavior
Modeling and Forecasting with Real-World Poaching Data. In AAMAS , 2017

Real-world Deployment: Field Test 1 (1 month)
Trespassing 19 signs of litter, ashes,
etc.
Poached animals 1 poached elephant
Snaring 1 active snare
1 cache of 10 antelope snares
1 roll of elephant snares
Snaring hit rates Outperform 91% of
months
Historical
Base
Hit Rate
Our Hit
Rate
Average: 0.73 3
6/26/201744/67 Kar & Ford et al. Cloudy with a Chance of Poaching: Adversary Behavior
Modeling and Forecasting with Real-World Poaching Data. In AAMAS , 2017

Real-world Deployment: Field Test 2 (5 months)
27 areas (9-sq km each)
454 km patrolled in total
2 experiment groups 1: >= 50% attack prediction
rate 5 areas
2: < 50% attack prediction rate 22 areas
Catch Per Unit Effort (CPUE) Unit Effort = km walked
0
0.02
0.04
0.06
0.08
0.1
0.12
High (1) Low (2)C
atc
h p
er
Un
it E
ffo
rt
Experiment Group
0
2
4
6
8
10
12
14
High (1) Low (2)Nu
m S
nare
Ob
servati
on
s
Experiment Group
6/26/201745/67 Gholami & Ford et al. Taking it for a Test Drive: A Hybrid Spatio-temporal Model forWildlife
Poaching Prediction Evaluated through a Controlled Field Test. In ECML, 2017

Deployment Results Summary
First Field Test: Demonstrated potential for predictive
analytics in the field
Second Field Test: Demonstrated the selectiveness of
our model in the field
We saved animals!
6/26/201746/67

Human Behavior Modeling & Learning
Uncertainty and Bias Based Models Prospect Theory [Kahneman and Tvesky, 1979]
Anchoring bias and epsilon-bounded rationality [Pita et al, 2010]
Attacker aims to reduce the defender’s utility [Pita et al, 2012]
Quantal Response Based Models Quantal Response [McKelvey and Palfrey, 1995]
Subjective Utility Quantal Response [Nguyen et al, 2013]
Latest Models Incorporating delayed observation [Fang et al, 2015]
Bounded rationality in repeated games [Kar et al, 2015]
Two-layered model [Nguyen et al, 2016]
Decision tree-based model [Kar & Ford et al, 2017]
PAWS
6/26/201747/67
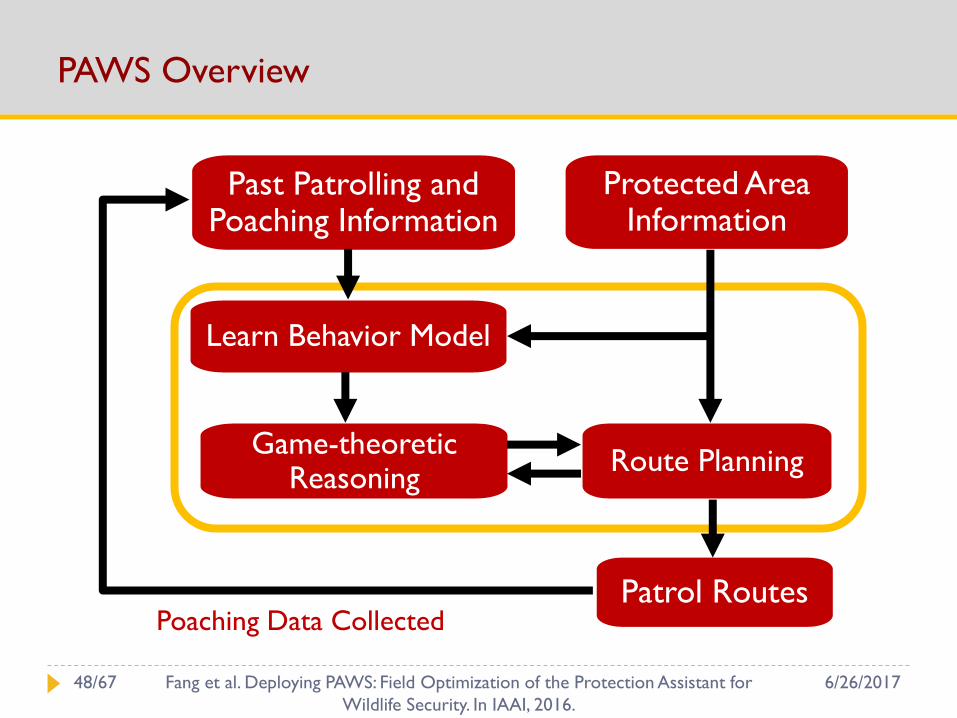
PAWS Overview
Protected Area Information
Past Patrolling and Poaching Information
Patrol RoutesPoaching Data Collected
Learn Behavior Model
Game-theoretic Reasoning
Route Planning
6/26/201748/67 Fang et al. Deploying PAWS: Field Optimization of the Protection Assistant for
Wildlife Security. In IAAI, 2016.
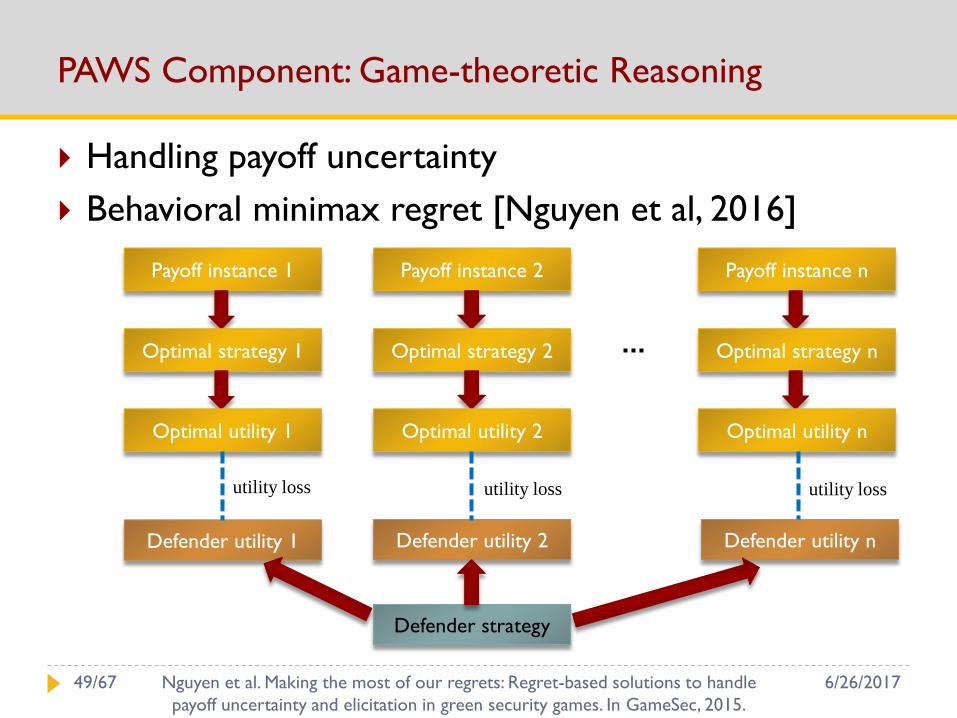
PAWS Component: Game-theoretic Reasoning
Handling payoff uncertainty
Behavioral minimax regret [Nguyen et al, 2016]
Payoff instance 1
Defender strategy
Optimal strategy 1
Optimal utility 1
Payoff instance 2
Optimal strategy 2
Optimal utility 2
Payoff instance n
Optimal strategy n
Optimal utility n
Defender utility 1 Defender utility 2 Defender utility n
utility loss utility loss utility loss
6/26/201749/67 Nguyen et al. Making the most of our regrets: Regret-based solutions to handle
payoff uncertainty and elicitation in green security games. In GameSec, 2015.

PAWS Component: Game-theoretic Reasoning
Uncertainty interval
Target 1 Target 2
Target 1 4, [-4, -2] -1, [0, 2]
Target 2 -5, [4, 6] 2, [-2, 0]Def
en
de
rAdversary
6/26/201750/67 Nguyen et al. Making the most of our regrets: Regret-based solutions to handle
payoff uncertainty and elicitation in green security games. In GameSec, 2015.

PAWS Component: Game-theoretic Reasoning
Defender’s utility of playing “x” given payoff instance
Sampled one payoff instance from interval
Adversary
Def
en
de
r defUtility(x) = -0.5 Target 1 Target 2 x
Target 1 4, -4 -1, 1 0.3
Target 2 -5, 5 2, -2 0.7
q 0.6 0.4
6/26/201751/67 Nguyen et al. Making the most of our regrets: Regret-based solutions to handle
payoff uncertainty and elicitation in green security games. In GameSec, 2015.

PAWS Component: Game-theoretic Reasoning
Defender’s regret for playing “x” given payoff instance
Utility loss of defender to play x compared to optimal.
Adversary
Def
en
de
r defUtility(x) = -0.5
defUtility(x*) = 0.2
regret(x) = 0.7
Target 1 Target 2 x x*,1
Target 1 4, -4 -1, 1 0.3 0.7
Target 2 -5, 5 2, -2 0.7 0.3
q 0.6 0.4
q1 0.4 0.6
6/26/201752/67 Nguyen et al. Making the most of our regrets: Regret-based solutions to handle
payoff uncertainty and elicitation in green security games. In GameSec, 2015.

PAWS Component: Game-theoretic Reasoning
Defender regret of “x” higher for another payoff instance
Max regret: Max over all payoff instances under uncertainty
Adversary
Def
en
de
r
max_regret(x) = 1.2
Target 1 Target 2 x x*,2
Target 1 6, -6 -1, 1 0.3 0.8
Target 2 -4, 4 0, 0 0.7 0.2
q 0.8 0.2
q2 0.2 0.8
defUtility(x) = -0.9
defUtility(x*) = 0.3
regret(x) = 1.2
6/26/201753/67 Nguyen et al. Making the most of our regrets: Regret-based solutions to handle
payoff uncertainty and elicitation in green security games. In GameSec, 2015.

PAWS Component: Game-theoretic Reasoning
Objective
Compute optimal defender strategy that minimizes max regret.
Optimization
minxÎX, rÎR
r
s.t. r ≥ regret x, payoff( ), "payoff Î I
Infinite #regret constraints
Utility loss of playing x
given attacker follows SUQR
6/26/201754/67 Nguyen et al. Making the most of our regrets: Regret-based solutions to handle
payoff uncertainty and elicitation in green security games. In GameSec, 2015.

PAWS Component: Game-theoretic Reasoning
ARROW: Incremental Payoff Generation
minxÎX, rÎR
r
s.t. r ≥ regret x, payoff( ), "payoff Î I
Master: Idea: solve relaxed MMR with small sample
set S of attacker payoffs, obtain LB
Slave: Idea: find new attacker payoff to add to the
sample set, obtain UB
6/26/201755/67 Nguyen et al. Making the most of our regrets: Regret-based solutions to handle
payoff uncertainty and elicitation in green security games. In GameSec, 2015.

PAWS Component: Game-theoretic Reasoning
Payoff 1
Target 1 Target 2
Target 1 4, -4 -1, 1
Target 2 -5, 5 2, -2x1
Target 1 0.3
Target 2 0.7
6/26/201756/67 Nguyen et al. Making the most of our regrets: Regret-based solutions to handle
payoff uncertainty and elicitation in green security games. In GameSec, 2015.
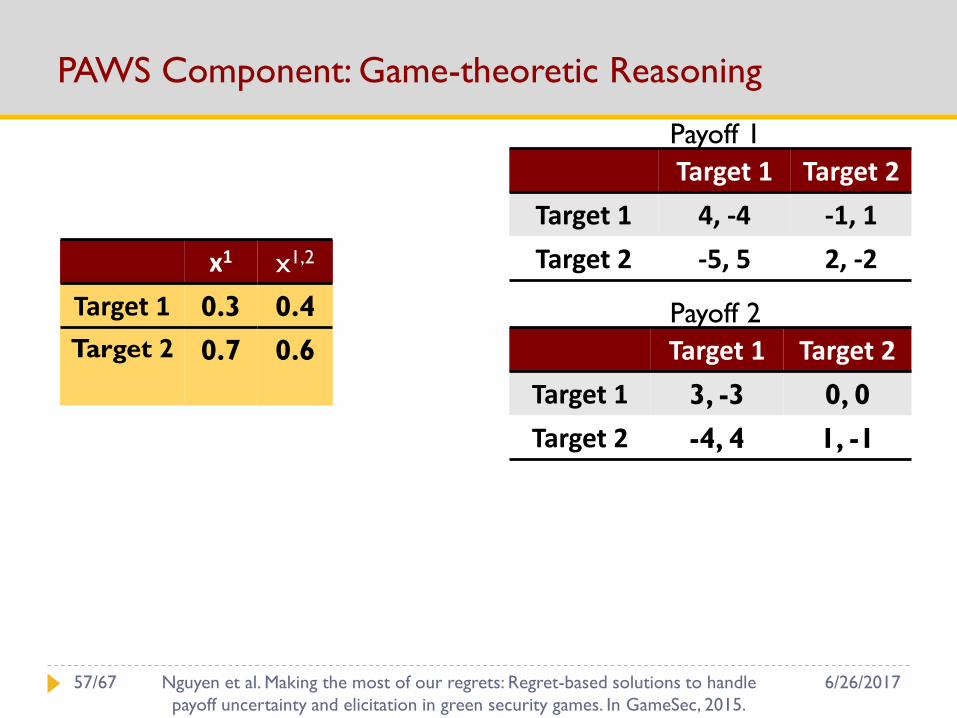
PAWS Component: Game-theoretic Reasoning
Payoff 1
Target 1 Target 2
Target 1 4, -4 -1, 1
Target 2 -5, 5 2, -2
Payoff 2
Target 1 Target 2
Target 1 3, -3 0, 0
Target 2 -4, 4 1, -1
x1 x1,2
Target 1 0.3 0.4
Target 2 0.7 0.6
6/26/201757/67 Nguyen et al. Making the most of our regrets: Regret-based solutions to handle
payoff uncertainty and elicitation in green security games. In GameSec, 2015.
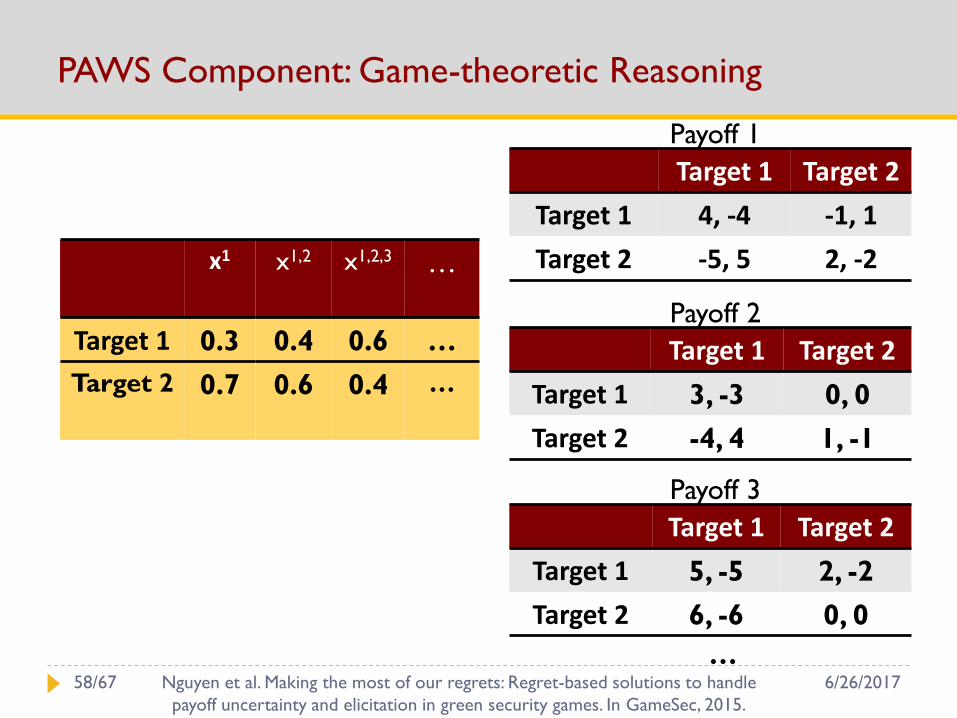
PAWS Component: Game-theoretic Reasoning
Payoff 1
Target 1 Target 2
Target 1 4, -4 -1, 1
Target 2 -5, 5 2, -2
Payoff 2
Target 1 Target 2
Target 1 3, -3 0, 0
Target 2 -4, 4 1, -1
Payoff 3
Target 1 Target 2
Target 1 5, -5 2, -2
Target 2 6, -6 0, 0
…
x1 x1,2 x1,2,3 …
Target 1 0.3 0.4 0.6 …
Target 2 0.7 0.6 0.4 …
6/26/201758/67 Nguyen et al. Making the most of our regrets: Regret-based solutions to handle
payoff uncertainty and elicitation in green security games. In GameSec, 2015.

PAWS Component: Route Planning
6/26/201759/67 Fang et al. Deploying PAWS: Field Optimization of the Protection Assistant for
Wildlife Security. In IAAI, 2016.
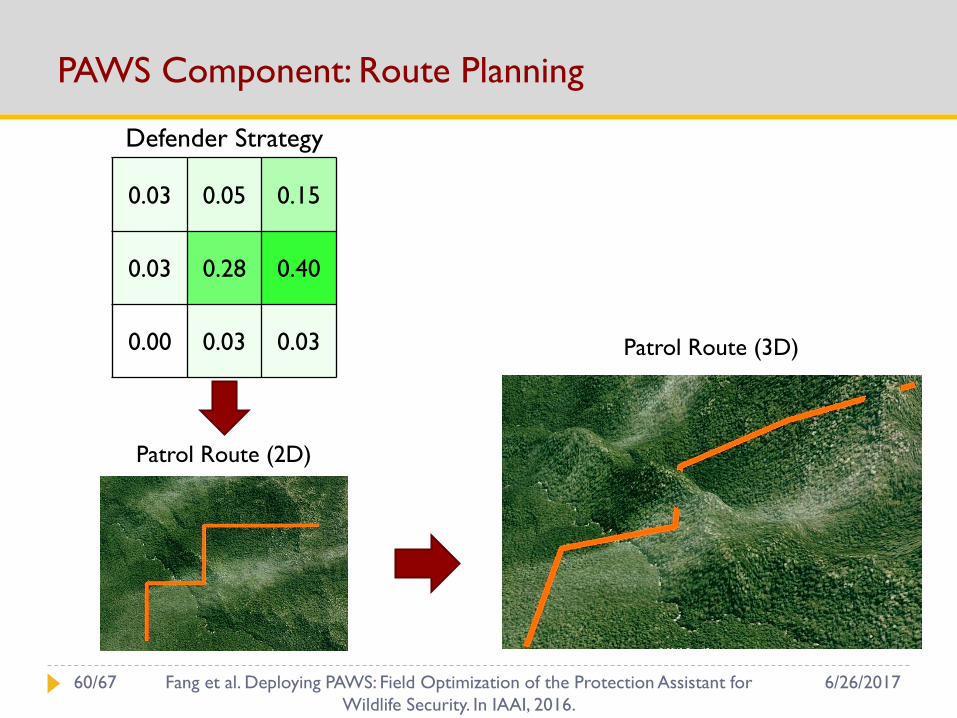
PAWS Component: Route Planning
0.03 0.05 0.15
0.03 0.28 0.40
0.00 0.03 0.03
Defender Strategy
Patrol Route (2D)
Patrol Route (3D)
6/26/201760/67 Fang et al. Deploying PAWS: Field Optimization of the Protection Assistant for
Wildlife Security. In IAAI, 2016.

PAWS Component: Route Planning
8-hour patrol in April 2015: patrolling is not easy!
6/26/201761/67 Fang et al. Deploying PAWS: Field Optimization of the Protection Assistant for
Wildlife Security. In IAAI, 2016.

PAWS Component: Route Planning
6/26/201762/67 Fang et al. Deploying PAWS: Field Optimization of the Protection Assistant for
Wildlife Security. In IAAI, 2016.
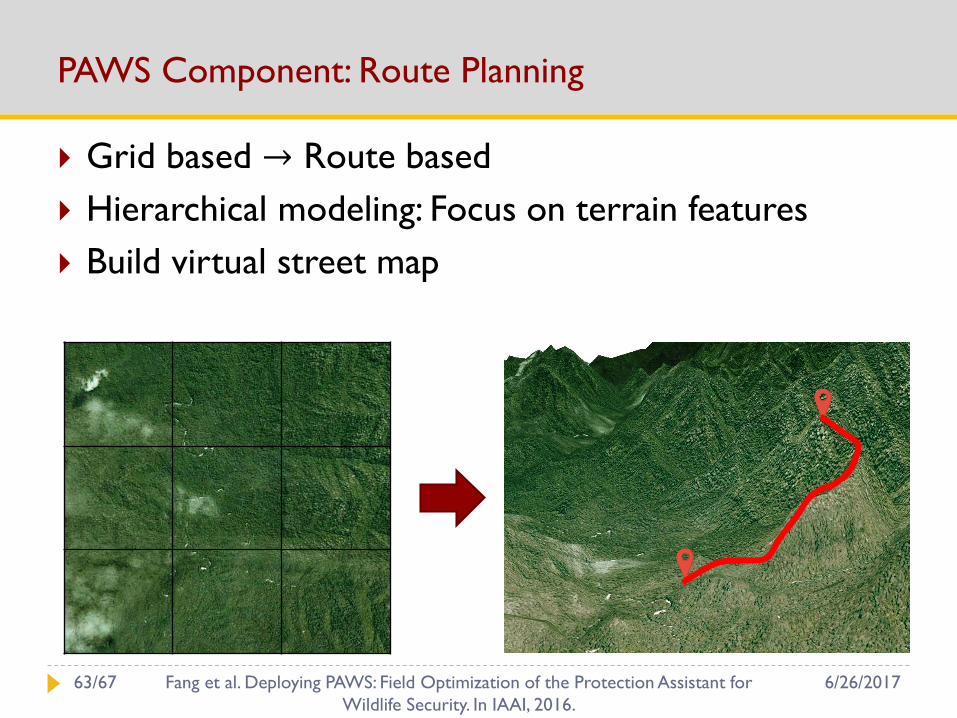
PAWS Component: Route Planning
Grid based → Route based
Hierarchical modeling: Focus on terrain features
Build virtual street map
6/26/201763/67 Fang et al. Deploying PAWS: Field Optimization of the Protection Assistant for
Wildlife Security. In IAAI, 2016.
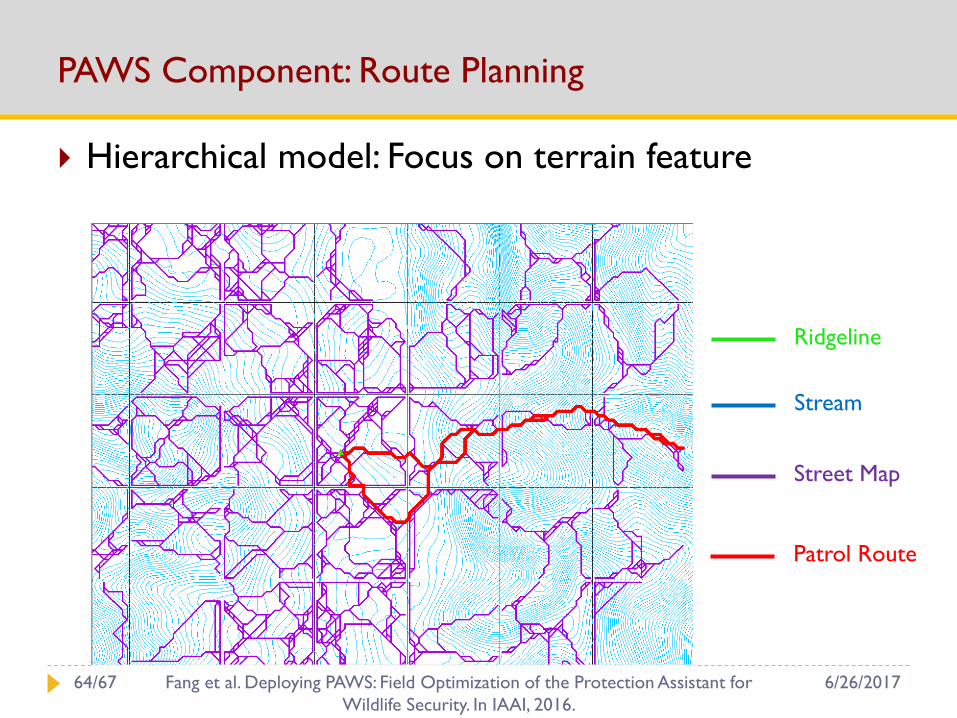
PAWS Component: Route Planning
Hierarchical model: Focus on terrain feature
Ridgeline
Stream
Street Map
Patrol Route
6/26/201764/67 Fang et al. Deploying PAWS: Field Optimization of the Protection Assistant for
Wildlife Security. In IAAI, 2016.
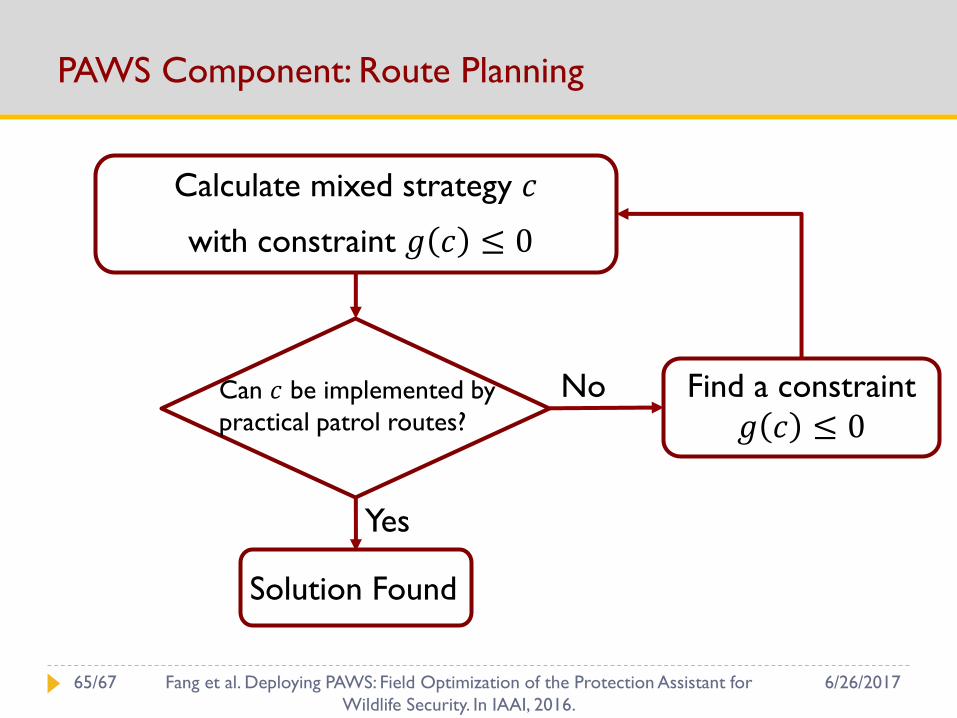
PAWS Component: Route Planning
Calculate mixed strategy 𝑐
Can 𝑐 be implemented by
practical patrol routes?
Yes
Solution Found
No Find a constraint
𝑔 𝑐 ≤ 0
with constraint 𝑔 𝑐 ≤ 0
6/26/201765/67 Fang et al. Deploying PAWS: Field Optimization of the Protection Assistant for
Wildlife Security. In IAAI, 2016.

PAWS Component: Route Planning
6/26/201766/67 Fang et al. Deploying PAWS: Field Optimization of the Protection Assistant for
Wildlife Security. In IAAI, 2016.

PAWS Deployment
In collaboration with Panthera, Rimba
Regular deployment since July 2015 (Malaysia)
6/26/201767/67 Fang et al. Deploying PAWS: Field Optimization of the Protection Assistant for
Wildlife Security. In IAAI, 2016.
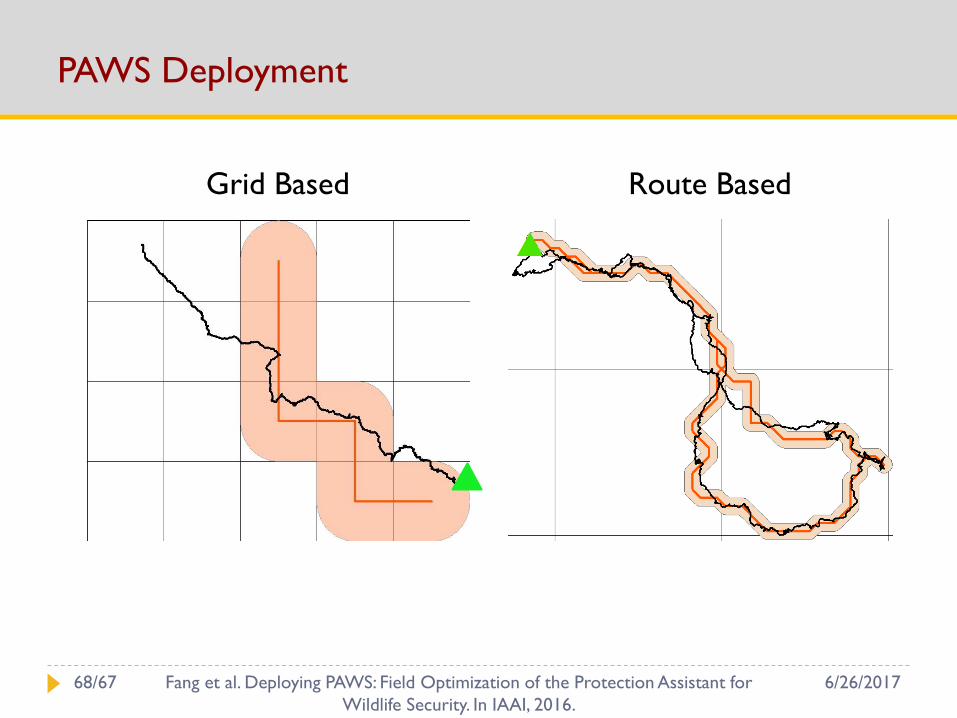
PAWS Deployment
Grid Based Route Based
6/26/201768/67 Fang et al. Deploying PAWS: Field Optimization of the Protection Assistant for
Wildlife Security. In IAAI, 2016.

PAWS Deployment
Animal Footprint
Tiger Sign
Tree Mark
Lighter
Camping Sign
6/26/201769/67 Fang et al. Deploying PAWS: Field Optimization of the Protection Assistant for
Wildlife Security. In IAAI, 2016.
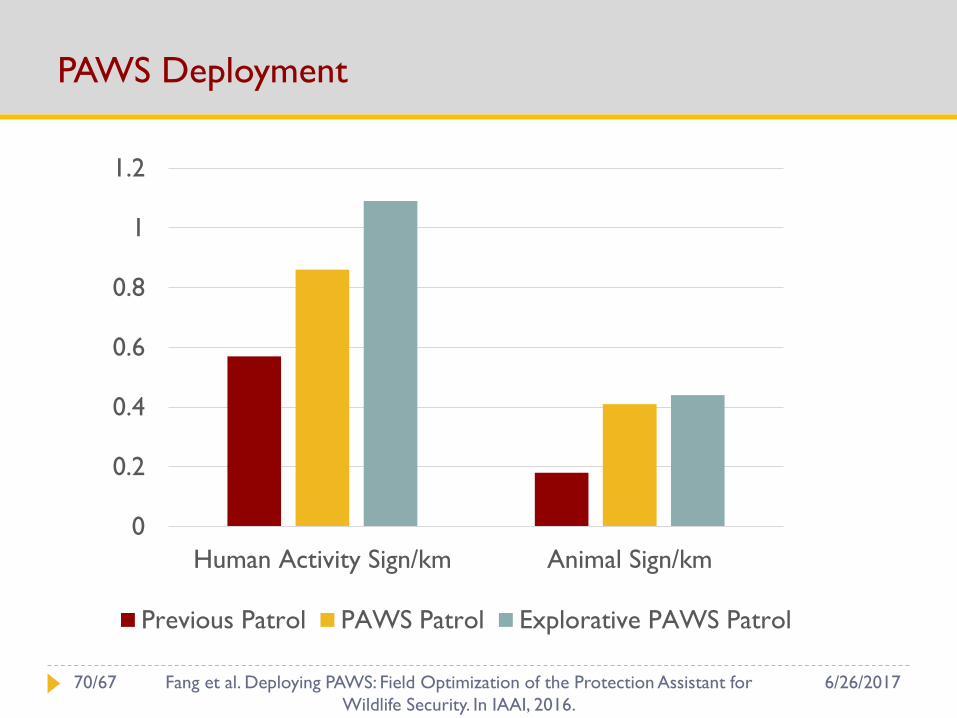
PAWS Deployment
0
0.2
0.4
0.6
0.8
1
1.2
Human Activity Sign/km Animal Sign/km
Previous Patrol PAWS Patrol Explorative PAWS Patrol
6/26/201770/67 Fang et al. Deploying PAWS: Field Optimization of the Protection Assistant for
Wildlife Security. In IAAI, 2016.

PAWS Deployment
PAWS is deployed in the field
Saved animals!
6/26/201771/67 Fang et al. Deploying PAWS: Field Optimization of the Protection Assistant for
Wildlife Security. In IAAI, 2016.

AI and Social Good
AI research that can deliver societal benefits now and
in the near future
http://mashable.com/2015/02/06/hiv-homeless-teens-algorithm/#..k9dRKhxaqm https://www.pastemagazine.com/articles/2017/04/a-new-smart-technology-will-
help-cities-drasticall.html
6/26/2017Fei Fang72/67

THANK YOU!
Fei Fang
Harvard University
Carnegie Mellon University


















