
Fuzzy Systems - Fuzzy Clustering - OVGU - Otto-von-Guericke
76
Fuzzy Systems Fuzzy Clustering Rudolf Kruse Christian Moewes {kruse,cmoewes}@iws.cs.uni-magdeburg.de Otto-von-Guericke University of Magdeburg Faculty of Computer Science Department of Knowledge Processing and Language Engineering R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 1 / 76
Transcript of Fuzzy Systems - Fuzzy Clustering - OVGU - Otto-von-Guericke

Fuzzy SystemsFuzzy Clustering
Rudolf Kruse Christian Moewes{kruse,cmoewes}@iws.cs.uni-magdeburg.de
Otto-von-Guericke University of MagdeburgFaculty of Computer Science
Department of Knowledge Processing and Language Engineering
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 1 / 76

Outline
1. Fuzzy Data AnalysisRepresentation of a DatumData Analysis
2. Clustering
3. Basic Clustering Algorithms
4. Distance Function Variants
5. Objective Function Variants
6. Cluster Validity
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 2 / 76

Fuzzy Data Analysis
datum:
• something given
• gets its sense in a certain context
• describes the condition of a certain “thing”
• carries only information if there are at least two differentpossibilities of the condition
• is seen as the realization of a certain variable of a universe
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 3 / 76

Representation of a Datum
• characteristic yes/no: universe consists of two elements
• characteristic gradiations: universe (finite), grade (figures)
• observations/measurements: universe (Euclidean space)
• continuous observations in space or time: universe (Hilbertspace), e.g., spectrogram
• gray-shaded images: universe (depends), e.g., x-ray images
• expert opinion: universe (logic), e.g., statements, facts, rules
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 4 / 76

Data Analysis
1st level
• valuation and examination with regard to simple, essentialcharacteristics
• analysis of frequency, reliability test, runaway, credibility
2nd level
• pattern matching
• grouping observations (according to background knowledge, . . . )
• maybe transformation with the aim of finding structures withingdata
explorative data analysis
• examination of data without previously chosen mathematic model
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 5 / 76

Data Analysis
3rd level
• analysis of data regarding one or more mathematical models
• qualitative• formation relating to additional characteristics expressed by quality• e.g., introduction of the term of similarity for cluster analysis
• quantitative• recognition of functional relations• e.g., approximation of regression analysis
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 6 / 76

Data Analysis
4th level
• conclusion and evaluation of the conclusion
• prediction of future or missing data (e.g., time line analysis)
• data assign to standards (e.g., spectrogram analysis)
• combination of data (e.g., data fusion)
• valuation of conclusions
• possibly learning from data, model revision
problem
• what to do in case of vague, imprecise or inconsistent data
⇒ fuzzy data analysis
• common data is analyzed with fuzzy methods
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 7 / 76

Outline
1. Fuzzy Data Analysis
2. Clustering
3. Basic Clustering Algorithms
4. Distance Function Variants
5. Objective Function Variants
6. Cluster Validity
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 8 / 76

Clustering
• clustering is an unsupervised learning task
• goal: divide dataset s.t. both constraints hold• objects belonging to same cluster are as similar as possible• objects belonging to different clusters are as dissimilar as possible
• similarity is usually measured in terms of distance function
• the smaller the distance, the more similar two data tuples
Definition
d : IRp × IR
p → [0, ∞) is a distance function if ∀x, y , z ∈ IRp :
(i) d(x, y) = 0 ⇔ x = y (identity),(ii) d(x, y) = d(y , x) (symmetry),(iii) d(x, z) ≤ d(x, y) + d(y , z) (triangle inequality).
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 9 / 76

Distance FunctionsIllustration of distance functions
• Minkowski family
dk(x, y) =
( p∑
d=1
(xd − yd)k
) 1k
• well-known special cases from this family are
k = 1 : Manhattan or city block distance,k = 2 : Euclidean distance,k → ∞ : maximum distance, i.e. d∞(x, y) = maxp
d=1 |xd − yd |
k = 1 k = 2 k → ∞R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 10 / 76

Partitioning Algorithms
• here, we only focus on partitioning algorithms• i.e., given c ∈ IN, find best partition of data into c groups
• different from hierarchical techniques, i.e., organize data in nestedsequence of groups
• usually number of (true) clusters is unknown
• using partitioning methods, however, we must specify c
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 11 / 76

Prototype-based Clustering
• we focus on prototype-based clustering algorithms• i.e., clusters are represented by cluster prototypes Ci , i = 1, . . . , c
• prototypes capture structure (distribution) of data in each cluster
• set of prototypes C = {C1, . . . , Cc}
• prototype Ci is n-tuple which consists of• cluster center c i , and
• some additional parameters about size and shape of cluster
• prototypes are constructed by clustering algorithms
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 12 / 76

Outline
1. Fuzzy Data Analysis
2. Clustering
3. Basic Clustering AlgorithmsHard c-meansFuzzy c-meansPossibilistic c-meansComparison of FCM and PCM
4. Distance Function Variants
5. Objective Function Variants
6. Cluster ValidityR. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 13 / 76

Basic Clustering AlgorithmsCenter Vectors and Objective Functions
• consider simplest cluster prototypes, i.e., center vectors Ci = (c i)
• distance measure d based on inner product, e.g., Euclideandistance
• all algorithms are based on objective functions J
• quantify goodness of cluster models
• must be minimized to obtain optimal clusters
• algorithms determine best decomposition by minimizing J
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 14 / 76

Hard c-means
• each data point xj in dataset X = {x1, . . . , xn}, X ⊆ IRp is
assigned to exactly one cluster
⇒ each cluster Γi ⊂ X
• set of clusters Γ = {Γ1, . . . ,Γc} must be exhaustive partition of X
into c non-empty and pairwise disjoint subsets Γi , 1 < c < n
• data partition is optimal when sum of squared distances betweencluster centers and data points assigned to them is minimal
• clusters should be as homogeneous as possible
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 15 / 76

Hard c-means• objective function of the hard c-means:
Jh(X , Uh, C) =c∑
i=1
n∑
j=1
uijd2ij
• U = (uij ∈ {0, 1})c×n is called partition matrix with
uij =
{
1, if x j ∈ Γi
0, otherwise
• each data point is assigned exactly to one clusterc∑
i=1
uij = 1, ∀j ∈ {1, . . . , n}
• every cluster must contain at least one data pointn∑
j=1
uij > 0, ∀i ∈ {1, . . . , c}
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 16 / 76

Alternating Optimization Scheme
• Jh depends on c and assignment U of data points to clusters
• finding parameters that minimize Jh is NP-hard
• hard c-means minimizes Jh by alternating optimization (AO)
1. parameters to optimize are split into two groups
2. one group is optimized holding the other group fixed (and viceversa)
3. iterative update scheme is repeated until convergence
• it cannot be guaranteed that global optimum will be reached
• algorithm may get stuck in local minimum
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 17 / 76

AO Scheme for Hard c-means
1. chose initial c i , e.g., randomly picking c data points ∈ X
2. hold C fixed and determine U that minimize Jh
• each data point is assigned to its closest cluster center
uij =
{
1, if i = arg minck=1 dkj
0, otherwise
• any other assignment would not minimize Jh for fixed clusters
3. hold U fixed, update c i as mean of all xj assigned to them• mean minimizes sum of square distances in Jh, formally
c i =
∑nj=1 uijx j∑n
j=1 uij
4. both steps are repeated until no change in C or U can be observed
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 18 / 76

Example
• symmetric dataset with two clusters
• hard c-means assigns crisp label to data point in middle
• is this very intuitive?
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 19 / 76

Discussion
• hard c-means tends to get stuck in local minimum
• it is necessary to conduct several runs with differentinitializations [Duda and Hart, 1973]
• sophisticated initialization methods can be used as well, e.g.,Latin hypercube sampling [McKay et al., 1979]
• best result of many clusterings can be chosen based on Jh
• crisp memberships {0, 1} prohibit ambiguous assignments
• when clusters are badly delineated or overlapping, relaxingrequirement uij ∈ {0, 1} needed
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 20 / 76

Fuzzy Clustering
• allows gradual memberships of data points to clusters in [0, 1]
• flexibility to express: data point can belong to more than 1 cluster
• membership degrees• offer finer degree of detail of data model
• express how ambiguously/definitely x j should belong to Γi
• solution spaces in form of fuzzy partitions of X = {x1, . . . , xn}
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 21 / 76

Fuzzy Clustering
• clusters Γi have been classical subsets so far
• now, they are represented by fuzzy sets µΓiof X
• cluster assignment uij is now membership degree of x j to Γi
s.t. uij = µΓi(x j) ∈ [0, 1]
• fuzzy label vector u = (u1j , . . . , ucj)T is linked to each x j
• U = (uij) = (u1, . . . , un) is then called fuzzy partition matrix
• two types of fuzzy cluster partitions have evolved• i.e., probabilistic and possibilistic
• differ in constraints they place on membership degrees
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 22 / 76

Probabilistic Cluster Partition
Definition
Let X = {x1, . . . , xn} be the set of given examples and let c be thenumber of clusters (1 < c < n) represented by the fuzzy setsµΓi
, (i = 1, . . . , c). Then we call Uf = (uij) = (µΓi(x j)) a probabilistic
cluster partition of X if
n∑
j=1
uij > 0, ∀i ∈ {1, . . . , c}, and
n∑
i=1
uij = 1, ∀j ∈ {1, . . . , n}
hold. The uij ∈ [0, 1] are interpreted as the membership degree ofdatum x j to cluster Γi relative to all other clusters.
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 23 / 76

Probabilistic Cluster Partition
• first constraint guarantees that no cluster is empty• corresponds to requirement in classical cluster analysis
⇒ no cluster, represented as (classical) subset of X , is empty
• 2nd condition: sum of membership degrees must be 1 for each x j
• each datum receives same weight in comparison to all other data⇒ all data are (equally) included into cluster partition• related to classical clustering: partitions are exhaustive
• consequence of both constraints:• no cluster can contain full membership of all data points• membership degrees for given datum resemble probabilities of
being member of corresponding cluster
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 24 / 76

Example
hard c-means fuzzy c-means
• equidistant data point in middle of figure does not have arbitraryassignment anymore
• in fuzzy partition, it can be associated with membership vector(0.5, 0.5)T to express ambiguity of assignment
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 25 / 76

Objective Function
• minimize objective function
Jf (X , Uh, C) =c∑
i=1
n∑
j=1
umij d2
ij
subject toc∑
i=1
uij = 1, ∀j ∈ {1, . . . , n}
andn∑
j=1
uij > 0, ∀i ∈ {1, . . . , c}
• parameter m ∈ IR with m > 1 is called fuzzifier
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 26 / 76

Fuzzifier
• actual value of m determines “fuzziness” of classification
• for m = 1 (i.e., Jh = Jf ), assignments remain hard
• fuzzifiers m > 1 lead to fuzzy memberships [Bezdek, 1973]
• clusters become softer/harder with higher/lower m
• usually m = 2
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 27 / 76

Reminder: Function Optimization
• task: find x = (x1, . . . , xm) s.t. f (x) = (x1, . . . , xm) is optimal
• often feasible approach:• necessary condition for (local) optimum (max./min.):
partial derivatives w.r.t. parameters vanish⇒ (try to) solve equation system coming from setting all partial
derivatives w.r.t. parameters equal to zero
• example task: minimize f (x , y) = x2 + y2 + xy − 4x − 5y
• solution procedure:
1. take partial derivatives of objective function and set them to zero:
∂f
∂x= 2x + y − 4 = 0,
∂f
∂y= 2y + x − 5 = 0
2. solve resulting (here: linear) equation system: x = 1, y = 2
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 28 / 76

Function Optimization with Constraints
• often function must be optimized subject to certain constraints
• here: restriction to k equality constraints Ci(x) = 0, i = 1, . . . , k
• note: equality constraints describe subspace of domain of f
• problem of optimization with constraints• gradient of f may vanish outside constrained subspace
⇒ unacceptable solution (violated constraints)• derivatives need not vanish at optimum in constrained subspace
• one way to handle this problem are generalized coordinates:• exploit dependence of parameters specified by Ci to express some
parameters by others ⇒ reduce set x to set x′ of independent
parameters (generalized coordinates)• problem: can be clumsy cumbersome (if possible at all) because
Ci ’s may not allow this
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 29 / 76

Function Optimization with Constraints
• much more elegant approach is based on following insights:
• let x∗ be (local) optimum of f (x) in constrained subspace
⇒ gradient ∇x f (x∗) must be perpendicular to constrained subspace
• gradients ∇x Cj(x∗), 1 ≤ j ≤ k, must all be perpendicular ⊥ to
constrained subspace (because they are constant, i.e., 0)
• together they span subspace ⊥ to constrained subspace
⇒ it must be possible to find values λj , 1 ≤ j ≤ k s.t.
∇x f (x∗) +s∑
j=1
λj∇x Cj(x∗) = 0
• if constraints are linearly independent, λj are uniquely determined
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 30 / 76

Function Optimization: Lagrange Theory
⇒ we obtain Method of Lagrange Multipliers:
• given: f (x) to be optimized and k equality constraintsCj(x) = 0, 1 ≤ j ≤ k
• procedure:1. construct so-called Lagrange function by incorporating
Ci , i = 1, . . . , k , with (unknown) Lagrange multipliers λi :
L(x, λ1, . . . , λk) = f (x) +
k∑
i=1
λi Ci(x)
2. set partial derivatives of Lagrange function equal to zero:
∂L
∂x1= 0, . . . ,
∂L
∂xm= 0,
∂L
∂λ1= 0, . . . ,
∂L
∂λk= 0
3. (try to) solve resulting equation system
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 31 / 76

Function Optimization: Lagrange TheoryObservations
• due to representation of gradient of f (x) at local optimum x∗ in
constrained subspace, gradient of L w.r.t. x vanishes at x∗
⇒ standard approach works again
• if constraints are satisfied, then additional terms have no influence
⇒ original task is not modified (same objective function)
• taking partial derivative w.r.t. Lagrange multiplier reproducescorresponding equality constraint:
∀j ; 1 ≤ j ≤ k :∂
∂λjL(x, λ1, . . . , λk) = Cj(x),
⇒ constraints enter equation system to solve in natural way
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 32 / 76

Lagrange Theory: Example 1
• example task: minimize f (x , y) = x2 + y2 subject to x + y = 1
• solution procedure:1. rewrite constraint s.t. one side gets zero x + y − 1 = 0
2. construct Lagrange function by incorporating constraint into f
with Lagrange multiplier λ:
L(x , y , λ) = x2 + y2 + λ(x + y − 1)
3. take partial derivatives of Lagrange function and set them to zero(necessary conditions for minimum):
∂L
∂x= 2x +λ = 0,
∂L
∂y= 2y +λ = 0,
∂L
∂λ= x + y − 1 = 0
4. solve resulting (here: linear) equation system:
λ = −1, x = y = 12 .
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 33 / 76

Lagrange Theory: Example 2
• example task: find side lengths x , y , z of box with maximumvolume for given area S of the surface
• formally: max. f (x , y , z) = xyz s.t. 2xy + 2xz + 2yz = S
• solution procedure:1. constraint is C(x , y , z) = 2xy + 2xz + 2yz − S = 0
2. Lagrange function is
L(x , y , z, λ) = xyz + λ(2xy + 2xz + 2yz − S)
3. taking partial derivatives yields (in addition to constraint):
∂L
∂x= yz + 2λ(y + z) = 0,
∂L
∂y= xz + 2λ(x + z) = 0,
∂L
∂y= xy + 2λ(x + y) = 0
4. solution is: λ = − 14
√S6 , x = y = z =
√S6 (i.e., box is a cube)
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 34 / 76

Optimizing the Membership Degrees
• Jf is alternately optimized, i.e.,
1. optimize U for fixed cluster parameters Uτ = jU(Cτ−1)2. optimize C for fixed membership degrees Cτ = jC (Uτ )
• update formulas: set derivative Jf w.r.t. parameters U, C to zero
• resulting equations form the fuzzy c-means (FCM) algorithm
• membership degrees are chosen according to [Bezdek, 1981]
uij =1
∑ck=1
(d2
ij
d2kj
) 1m−1
=d
− 2m−1
ij
∑ck=1 d
− 2m−1
kj
• independent of the chosen distance measure
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 35 / 76

First Step: Fix the cluster parameters
• introduce Lagrange multipliers λj , 0 ≤ j ≤ n, to incorporateconstraints ∀j ; 1 ≤ j ≤ n :
∑ci=1 uij = 1
• this yields Lagrange function (to be minimized)
L(X , Uf , C ,Λ) =c∑
i=1
n∑
j=1
umij d2
ij
︸ ︷︷ ︸
=J(X ,Uf ,C)
+n∑
j=1
λj
(
1 −c∑
i=1
uij
)
• necessary condition for minimum: partial derivatives of Lagrangefunction w.r.t. membership degrees vanish, i.e.,
∂
∂uklL(X , Uf , C ,Λ) = mum−1
kl d2kl − λl
!= 0
which leads to
∀i ; 1 ≤ i ≤ c : ∀j ; 1 ≤ j ≤ n : uij =
(
λj
md2ij
) 1m−1
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 36 / 76

Optimizing the Membership Degrees
• summing these equations over clusters (in order to be able toexploit corresponding constraints on membership degrees), we get
1 =c∑
i=1
uij =c∑
i=1
(
λj
md2ij
) 1m−1
⇒ λj , 1 ≤ j ≤ n are
λj =
(c∑
i=1
(
md2ij
) 11−m
)1−m
• inserting this into equation for membership degrees yields
∀i ; 1 ≤ i ≤ c : ∀j ; 1 ≤ j ≤ n : uij =d
21−m
ij
∑ck=1 d
21−m
kj
• update formula results regardless of distance measureR. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 37 / 76

Optimizing the Cluster Prototypes
• update formula jC depend on• cluster parameters (location, shape, size) and
• chosen distance measure
⇒ general update formula cannot be given
• for basic fuzzy c-means model• cluster centers serve as prototypes
• distance measure: induced metric by inner product
⇒ second step: derivations of Jf w.r.t. centers yield [Bezdek, 1981]
c i =
∑nj=1 um
ij x j∑n
j=1 umij
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 38 / 76

Discussion
• FCM can be initialized with randomly places cluster centers
• updating in the AO scheme can be stopped if• number of iterations τ exceeds some predefined τmax, or
• changes in prototypes are smaller than some termination accuracy
• fuzzy c-means algorithm is stable and robust
• compared with hard c-means• it is quite insensitive to initialization and
• it is not likely to get stuck in an undesired local minimum
• FCM converges in saddle point or minimum (but not inmaximum) [Bezdek, 1981]
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 39 / 76

Problems with Probabilistic c-means
Γ2bb
bb
bb
bb
bbbb
bb
bb
bb
bbx1
Γ1bb
bb
bb
bb
bb
bb
bbbb
bb
bb x2
• x1 has same distance to Γ1 and Γ2 ⇒ µΓ1(x1) = µΓ2
(x1) = 0.5
• however, same degrees of membership are assigned to x2
• problem is due to normalization
• better reading of memberships “If x j must be assigned to acluster, then with probability uij to Γi ”.
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 40 / 76

Problems with Probabilistic c-means
• normalization of memberships: problem for noise and outliers
• fixed data point weight ⇒ high membership of noisy data,although large distance from the bulk of data
⇒ bad effect on clustering result
• by dropping normalization constraint
c∑
i=1
uij = 1, ∀j ∈ {1, . . . , n}
more intuitive membership assignments
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 41 / 76

Possibilistic Cluster Partition
Definition
Let X = {x1, . . . , xn} be the set of given examples and let c be thenumber of clusters (1 < c < n) represented by the fuzzy setsµΓi
, (i = 1, . . . , c). Then we call Up = (uij) = (µΓi(x j)) a possibilistic
cluster partition of X if
n∑
j=1
uij > 0, ∀i ∈ {1, . . . , c}
holds. The uij ∈ [0, 1] are interpreted as degree of representativity ortypicality of the datum x j to cluster Γi .
• now, uij for x j resemble possibility of being member ofcorresponding cluster
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 42 / 76

Possibilistic Fuzzy Clustering
• Jf would not be appropriate for possibilistic fuzzy clustering
• dropping normalization constraint leads to minimum for all uij = 0
• i.e., data points are not assigned to any Γi and all Γi are empty
⇒ penalty term is introduced which forces all uij away from zero
• objective function Jf is modified to
Jp(X , Up, C) =c∑
i=1
n∑
j=1
umij d2
ij +c∑
i=1
ηi
n∑
j=1
(1 − uij)m
where ηi > 0(1 ≤ i ≤ c)
• ηi balance contrary objectives expressed in the two terms of Jp
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 43 / 76

Optimizing the Membership Degrees
• update formula for membership degrees
uij =1
1 +
(d2
ij
ηi
) 1m−1
• membership of x j to cluster i depends only on dij to this cluster
• small distance corresponds to high degree of membership
• larger distances result in low membership degrees
⇒ uij ’s have typicality interpretation
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 44 / 76

Interpretation of ηi
• update equation helps to explain parameters ηi
• consider m = 2 and substitute ηi for d2ij yields uij = 0.5
⇒ ηi determines distance to Γi at which uij should be 0.5
• ηi can have different geometrical interpretation• hyperspherical clusters (e.g., PCM) ⇒ √
ηi is mean diameter
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 45 / 76

Estimating ηi
• if such properties are known, ηi can be set a priori
• if all clusters have same properties, same value for all clusters
• however, information on actual shape is often unknown a priori• parameters must be estimated, e.g., by FCM
• use fuzzy intra-cluster distance i.e., for all Γi , 1 ≤ i ≤ n
ηi =
∑nj=1 um
ij d2ij
∑nj=1 um
ij
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 46 / 76

Optimizing the Cluster Centers
• update equations jC are derived by setting derivative of Jp
w.r.t. prototype parameters to zero (holding Up fixed)
• update equations for cluster prototypes are identical
⇒ cluster centers in PCM algorithm are re-estimated as
c i =
∑nj=1 uijx j∑n
j=1 uij
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 47 / 76

Comparison of FCM and PCM
• FCM (left) and PCM (right) of Iris dataset into 3 clusters
• FCM divides space, PCM depends on typicality to closest clusters
• FCM and PCM divide dataset into 3 and 2 clusters, resp.• behavior is specific to PCM• FCM drives centers apart due to normalization, PCM does not
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 48 / 76
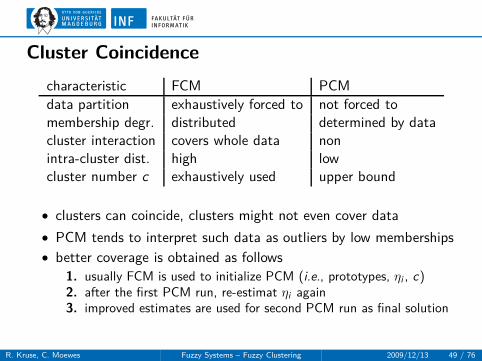
Cluster Coincidence
characteristic FCM PCM
data partition exhaustively forced to not forced tomembership degr. distributed determined by datacluster interaction covers whole data nonintra-cluster dist. high lowcluster number c exhaustively used upper bound
• clusters can coincide, clusters might not even cover data
• PCM tends to interpret such data as outliers by low memberships
• better coverage is obtained as follows
1. usually FCM is used to initialize PCM (i.e., prototypes, ηi , c)2. after the first PCM run, re-estimat ηi again3. improved estimates are used for second PCM run as final solution
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 49 / 76

Cluster Repulsion I
• Jp is truly minimized only if all cluster centers are identical
• other results are achieved when PCM gets stuck in local minimum
• PCM can be improved by modifying Jp
Jrp(X , Up , C) =c∑
i=1
n∑
j=1
umij d2
ij +c∑
i=1
ηi
n∑
j=1
(1 − uij)m
+c∑
i=1
γi
c∑
k=1,k 6=i
1
ηd(c i , ck)2
• γi controls strength of cluster repulsion
• η makes repulsion independent of normalization of data attributes
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 50 / 76

Cluster Repulsion II
• minimization conditions lead to the update equation
c i =
∑nj=1 um
ij x j − γi∑c
k=1,k 6=i1
d(c i ,ck)4 ck∑n
j=1 umij − γi
∑ck=1,k 6=i
1d(c i ,ck)4
• this equation shows effect of repulsion between clusters• cluster is attracted by data assigned to it
• it is simultaneously repelled by other clusters
• update equation of PCM for membership degrees is not modified
• better detection of shape of very close or overlapping clusters
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 51 / 76

Recognition of Positions and Shapes
• possibilistic models do not only carry problematic properties
• cluster prototypes are more intuitive• memberships depend only on distance to one cluster
• shape & size of clusters better fits data clouds than FCM• less sensitive to outliers and noise
⇒ attractive tool in image processing
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 52 / 76

Outline
1. Fuzzy Data Analysis
2. Clustering
3. Basic Clustering Algorithms
4. Distance Function VariantsGustafson-Kessel AlgorithmFuzzy Shell ClusteringKernel-based Fuzzy Clustering
5. Objective Function Variants
6. Cluster ValidityR. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 53 / 76

Distance Function Variants
• so far, only Euclidean distance leading to standard FCM and PCM
• Euclidean distance only allows spherical clusters
• several variants have been proposed to relax this constraint• fuzzy Gustafson-Kessel algorithm
• fuzzy shell clustering algorithms
• kernel-based variants
• they can be applied to both FCM and PCM
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 54 / 76

Gustafson-Kessel Algorithm
• [Gustafson and Kessel, 1979] replaced Euclidean distance bycluster-specific Mahalanobis distance
• for cluster Γi , its associated Mahalanobis distance is defined as
d2(x j , Cj) = (x j − c i)TΣ−1
i (x j − c i)
where Σi is covariance matrix of cluster
• Euclidean distance leads to ∀i : Σi = I, i.e., identity matrix
• Gustafson-Kessel (GK) algorithm leads to prototypes Ci = (c i ,Σi)
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 55 / 76

Gustafson-Kessel Algorithm
• specific constraints can be taken into account, e.g.,• restricting to axis-parallel cluster shapes
• by considering only diagonal matrices
• usually preferred when clustering is applied for fuzzy rule generation
• to be discussed later in the lecture
• cluster sizes can be controlled by %i > 0 demanding det(Σi ) = %i
• usually clusters are equally sized by det(Σi) = 1
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 56 / 76

Objective Function
• J , update equations for ci and U are identical to FCM and PCM,resp.
• update equations for covariance matrices are
Σi =Σ∗
i
p
√
det(Σ∗i )
where
Σ∗i =
∑nj=1 uij(x j − c i)(x j − c i)
T
∑nj=1 uij
• they are defined as covariance of data assigned to cluster i
• Σi are modified to incorporate fuzzy assignment
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 57 / 76

Summary
• GK extracts more information than standard FCM and PCM
• GK is more sensitive to initialization
• initializing GK using few runs of FCM or PCM is recommended
• compared to FCM or PCM, due to matrix inversions GK is• computationally costly
• hard to apply to huge datasets
• restriction to axis-parallel clusters reduces computational costs
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 58 / 76

Fuzzy Shell Clustering
• up to now we searched for convex “cloud-like” clusters
• corresponding algorithms are called solid clustering algorithms
• specially useful in data analysis
• for image recognition and analysis, variants of FCM and PCMhave been proposed to detect lines, circles or ellipses
⇒ shell clustering algorithms
• replace Euclidean by other distances
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 59 / 76

Fuzzy c-varieties Algorithm
• fuzzy c-varieties (FCV) algorithmrecognizes lines, planes, or hyperplanes
• each cluster is affine subspace characterizedby point and set of orthogonal unit vectors,Ci = (c i , e i1, . . . , e iq) where q is dimensionof affine subspace
• distance between data point x j and cluster i
d2(x j , c i) = ‖x j − c i‖2 −q∑
l=1
(x j − c i)T
e il
• also used for locally linear models of datawith underlying functional interrelations
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 60 / 76
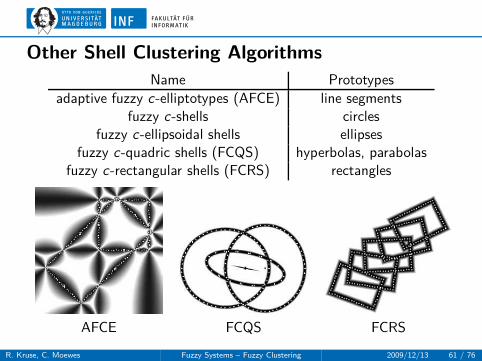
Other Shell Clustering Algorithms
Name Prototypes
adaptive fuzzy c-elliptotypes (AFCE) line segmentsfuzzy c-shells circles
fuzzy c-ellipsoidal shells ellipsesfuzzy c-quadric shells (FCQS) hyperbolas, parabolas
fuzzy c-rectangular shells (FCRS) rectangles
AFCE FCQS FCRS
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 61 / 76

Kernel-based Fuzzy Clustering
• kernel variants modify distance function to handle non-vectorialdata, e.g., sequences, trees, graphs
• kernel methods [Schölkopf and Smola, 2001] extend classic linearalgorithms to non-linear ones without changing algorithms
• data points can be vectorial or not ⇒ xj instead of x j
• kernel methods are based on mapping φ : X → H
• input space X , feature space H (higher or infinite dimensions)
• H must be Hilbert space, i.e., dot product is defined
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 62 / 76

Principle
• data are not handled directly in H, only handled by dot products
• kernel functionk : X × X → IR, ∀x , x ′ ∈ X : 〈φ(x), φ(x ′)〉 = k(x , x ′)
⇒ no need to known φ explicitly
• scalar products in H only depend on k and data ⇒ kernel trick
• kernel methods are algorithms using scalar products between data
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 63 / 76

Kernel Fuzzy Clustering
• kernel framework has been applied to fuzzy clustering
• fuzzy shell clustering extracts prototypes, kernel methods are not
• they compute similarity between x , x ′ ∈ X• cluster representatives have no explicit representation
• kernel variant of FCM [Wu et al., 2003] transposes Jf to H• centers c
φi ∈ H are linear combinations of transformed data
cφi =
n∑
r=1
airφ(xr )
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 64 / 76

Kernel Fuzzy Clustering
• Euclidean distance between points and centers in H is
d2φir
=∥∥∥φ(xr ) − c
φi
∥∥∥
2= krr − 2
n∑
s=1
aiskrs +n∑
s,t=1
aisaitkst
whereas krs ≡ k(xr , xs)
• the objective function becomes
Jφ(X , Uφ, C) =c∑
i=1
n∑
r=1
umir d2
φir
• minimization leads to following update equations
uir =1
∑cl=1
(d2
φir
d2φlr
) 1m−1
, air =um
ir∑n
s=1 umis
, cφi =
∑nr=1 um
ir φ(xr )∑n
s=1 umis
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 65 / 76

Kernel Fuzzy ClusteringSummary
• update equations (and Jφ) are expressed solely by k
• for Euclidean distance, membership degrees are identical to FCM
• cluster centers: weighted mean of data (comparable to FCM)
• disadvantage of kernel methods• choice of proper kernel and its parameters is needed• similar to feature selection and data representation• cluster centers belong to H (no explicit representation)• only weighting coefficients air are known
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 66 / 76

Outline
1. Fuzzy Data Analysis
2. Clustering
3. Basic Clustering Algorithms
4. Distance Function Variants
5. Objective Function VariantsNoise ClusteringFuzzifier Variants
6. Cluster Validity
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 67 / 76

Objective Function Variants
• so far, variants of FCM with different distance functions
• now, other variants based on modifications of J
• aim: improving clustering results, e.g., noisy data
• there are lots of different variants, following categories• explicitly handling noisy data
• modifying fuzzifier m in objective function
• new terms in objective function (e.g., optimize cluster number)
• improving PCM w.r.t. coinciding cluster problem
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 68 / 76

Noise Clustering
• noise clustering (NC) adds to c clusters one noise cluster• shall group noisy data points or outliers
• not explicitly associated to any prototype
• directly associated to distance between implicit prototype and data
• center of noise cluster has constant distance δ to all data points
1. all points have same “probability” of belonging to noise cluster
2. during optimization, “probability” is adapted
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 69 / 76

Noise Clustering
• noise cluster is added to objective function as any other cluster
Jnc(X , U, C) =c∑
i=1
n∑
j=1
umij d2
ij +n∑
k=1
δ2
(
1 −c∑
i=1
uik
)m
• added term is similar to terms in the first sum• distance to cluster prototype is replaced by δ• outliers can have low membership degrees to standard clusters
• Jnc requires setting of parameter δ, e.g.,
δ = λ1
c · n
c∑
i=1
n∑
j=1
d2ij
• λ user-defined parameter: if low λ, then high number of outliers
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 70 / 76

Fuzzifier Variants
• fuzzifier m introduces problem:
uij =
{
{0, 1} if m = 1,
]0, 1[ if m > 1
• disadvantage for noisy datasets (to be discussed in the exercise)
• possible solution: convex combination of hard and fuzzy c-means
Jhf (X , U, C) =c∑
i=1
n∑
j=1
[
αuij + (1 − α)u2ij
]
d2ij
where α ∈ [0, 1] is user-defined threshold
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 71 / 76

Outline
1. Fuzzy Data Analysis
2. Clustering
3. Basic Clustering Algorithms
4. Distance Function Variants
5. Objective Function Variants
6. Cluster Validity
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 72 / 76

Cluster ValidityJudgment of Classification by Validity Measures
• validity measures can be based on several criteria, e.g.,• membership degrees should be ≈ 0/1, e.g., partition coefficient
PC =1
n
c∑
i=1
n∑
j=1
u2ij
• compactness of clusters, e.g., average partition density
APD =1
c
c∑
i=1
∑
j∈Yiuij
√
|Σi |
where Yi = {j ∈ IN, j ≤ n | (x j − µi)>Σ
−1i (x j − µi) < 1}
• especially for FCM: partition entropy
PE = −c∑
i=1
n∑
j=1
uij log uij
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 73 / 76
Software and Literature“Information Miner 2” and “Fuzzy Cluster Analysis”
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 74 / 76

References I
Bezdek, J. (1973).Fuzzy Mathematics in Pattern Classification.PhD thesis, Applied Math. Center, Ithaca, USA.
Bezdek, J. (1981).Pattern Recognition With Fuzzy Objective Function Algorithms.Plenum Press, New York, NY, USA.
Duda, R. and Hart, P. (1973).Pattern Classification and Scene Analysis.John Wiley & Sons, Inc., New York, NY, USA.
Gustafson, E. E. and Kessel, W. C. (1979).Fuzzy clustering with a fuzzy covariance matrix.In Proceedings of the IEEE Conference on Decision and Control, pages 761–766,Piscataway, NJ, USA. IEEE Press.
Höppner, F., Klawonn, F., Kruse, R., and Runkler, T. (1999).Fuzzy Cluster Analysis: Methods for Classification, Data Analysis and ImageRecognition.John Wiley & Sons Ltd, New York, NY, USA.
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 75 / 76

References II
McKay, M. D., Beckman, R. J., and Conover, W. J. (1979).A comparison of three methods for selecting values of input variables in the analysisof output from a computer code.Technometrics, 21(2):239–245.
Schölkopf, B. and Smola, A. J. (2001).Learning With Kernels: Support Vector Machines, Regularization, Optimization andBeyond.MIT Press, Cambridge, MA, USA.
Wu, Z., Xie, W., and Yu, J. (2003).Fuzzy c-means clustering algorithm based on kernel method.In Proceedings of the Fifth International Conference on Computational Intelligenceand Multimedia Applications (ICCIMA), pages 1–6.
R. Kruse, C. Moewes Fuzzy Systems – Fuzzy Clustering 2009/12/13 76 / 76


















