
From fermi to kepler
20
NVIDIA GPU Architecture: From Fermi to Kepler Ofer Rosenberg Jan 21 st 2013
-
Upload
ofer-rosenberg -
Category
Technology
-
view
2.557 -
download
0
description
The presentation covers NVIDIA GPU architectures: Fermi, Fermi refresh and Kepler
Transcript of From fermi to kepler

NVIDIA GPU Architecture:
From Fermi to Kepler
Ofer Rosenberg
Jan 21st 2013

Scope
This presentation covers the main features of
Fermi, Fermi refresh & Kepler architectures
The overview is done from compute perspective,
and as such Graphics features are not discussed
Polyphase Engine, Raster, ROBs, etc.
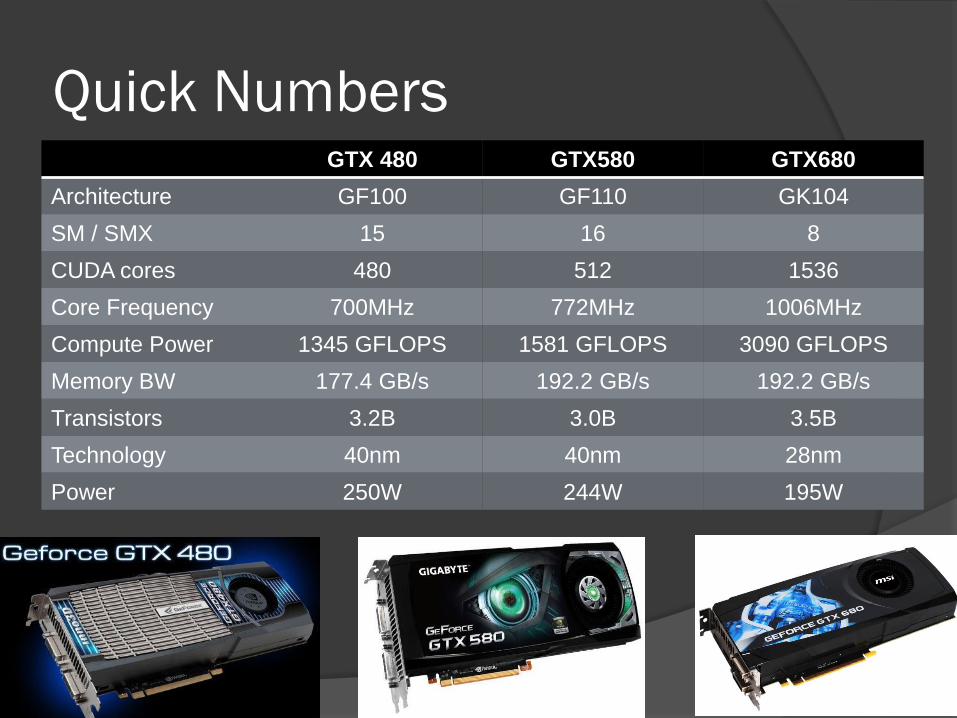
Quick Numbers GTX 480 GTX580 GTX680
Architecture GF100 GF110 GK104
SM / SMX 15 16 8
CUDA cores 480 512 1536
Core Frequency 700MHz 772MHz 1006MHz
Compute Power 1345 GFLOPS 1581 GFLOPS 3090 GFLOPS
Memory BW 177.4 GB/s 192.2 GB/s 192.2 GB/s
Transistors 3.2B 3.0B 3.5B
Technology 40nm 40nm 28nm
Power 250W 244W 195W


GF100 SM SM - Stream Multiprocessor
32 “CUDA cores”, organized into two clusters, 16 cores each
Warp is 32 threads – two cycles to complete a Warp
NVIDIA solution - ALU clock is double the Core clock
4 SFUs (accelerate transcendental functions)
16 Load / Store units
Dual Warp scheduler – execute two warps concurrently
Note bottlenecks on LD/ST & SFU – architecture decision
Each SM can hold up to 48 Warps, divided up to 8 blocks
Hold “in-flight” warps to hide latency
Typically no. of blocks is lower.
For example, 24 warps per block = 2 blocks per SM
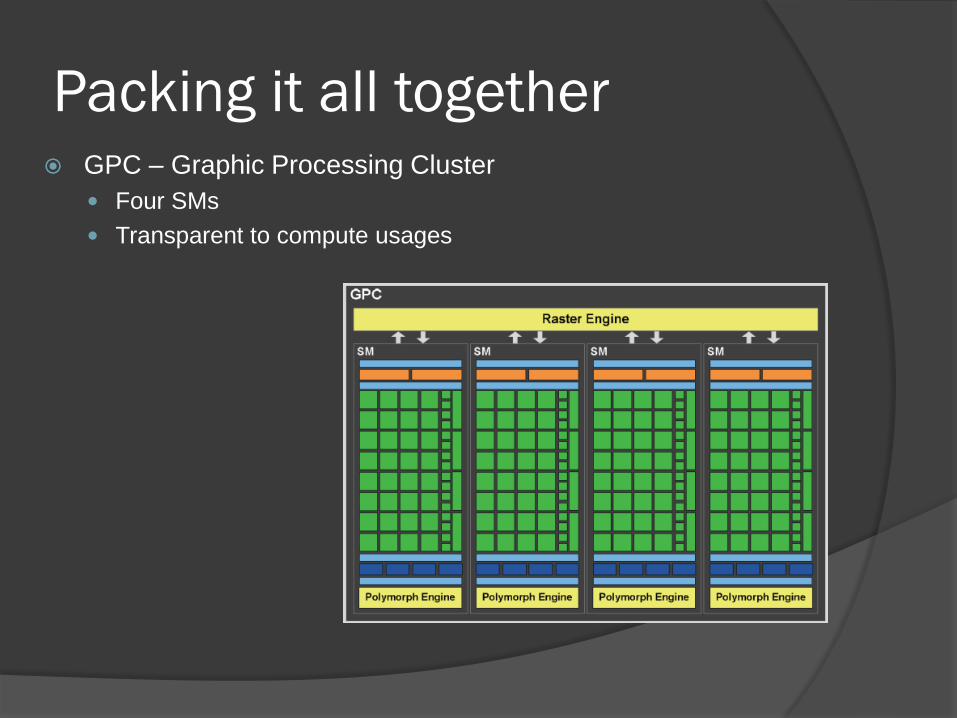
Packing it all together GPC – Graphic Processing Cluster
Four SMs
Transparent to compute usages

Packing it all together
Four GPCs
768K L2 shared between SMs
Support L2 only or L1&L2 caching
384-bit GDDR5
GigaThread Scheduler
Schedule thread blocks to SMs
Concurrent Kernel Execution - separated
kernels per SM.


Fermi GF104 SM Changes from GF100 SM:
48 “CUDA cores”, organized into three clusters of 16 cores
each
8 SFUs instead of 4
Rest remains the same (32K 32-bit registers, 64K L1/Shared,
etc.)
Wait a sec…three clusters, but still schedule two warps ?
Under-utilization study of GF100 led to scheduling redesign –
Next slide…
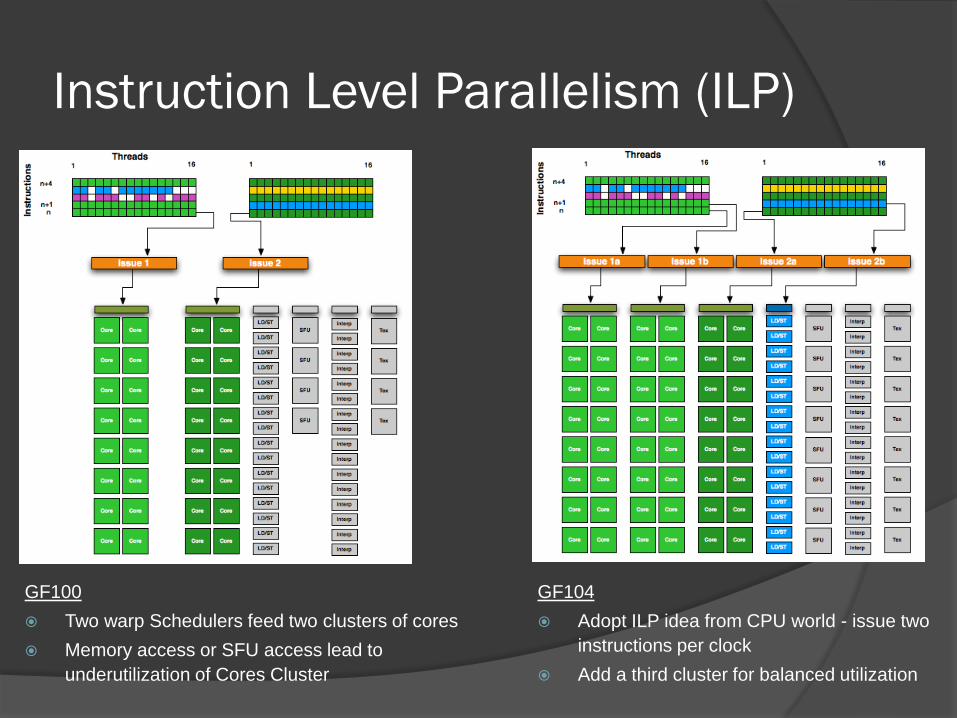
Instruction Level Parallelism (ILP)
GF100
Two warp Schedulers feed two clusters of cores
Memory access or SFU access lead to
underutilization of Cores Cluster
GF104
Adopt ILP idea from CPU world - issue two
instructions per clock
Add a third cluster for balanced utilization


Meet GK104 SMX
192 “CUDA Cores”
Organized into 6 clusters of 32 cores each
No more “dual clocked ALU”
16 Load/Store units
16 SFUs
64K 32-bit registers
Same 64K L1/Shared
Same dual-issued Warp scheduling:
Execute 4 warps concurrently
Issue two instructions per cycle
Each SMX can hold up to 64 warps,
divided up to 16 blocks

From GF104 to GK104 Look at Half of SMX
Same:
Two warp schedulers
Two dispatch units per
scheduler
32K register file
6 rows of cores
1 row of load/store
1 row of SFU
Different:
On SMX, a row of cores
is 16 vs 8 on SM
On SMX a row of SFU is
16 vs 8 on SM
SMX SM

Packing it all together
Four GPCs, each has two SMXs
512K L2 shared between SMs
L1 is no longer used for CUDA
256-bit GDDR5
GigaThread Scheduler
Dynamic Parallelism

GK104 vs. GF104 Kepler has less “multiprocessors”
8 vs. 16
Less flexible on executing different kernels concurrently
Each “multiprocessor” is stronger
Issue twice the warps (6 vs. 3)
Twice the register file
Execute warp in a single cycle
More SFUs
10x Faster atomic operations
But:
SMX Holds 64 warps vs. the 48 for SM – less latency hiding per warp cluster
L1/Shared Memory stayed the same size – and totally bypassed in CUDA/OpenCL
Memory BW did not scale as compute/cores did (192GB/Sec, same as in GF110)

GK110 SMX
Tesla only (no GeForce
version)
Very similar to GK104 SMX
Additional Double-Precision
units, otherwise the same

GK110
Production versions: 14 & 13 SMXs (not 15)
Improved device-level scheduling (next slides):
HyperQ
Dynamic Parallelism
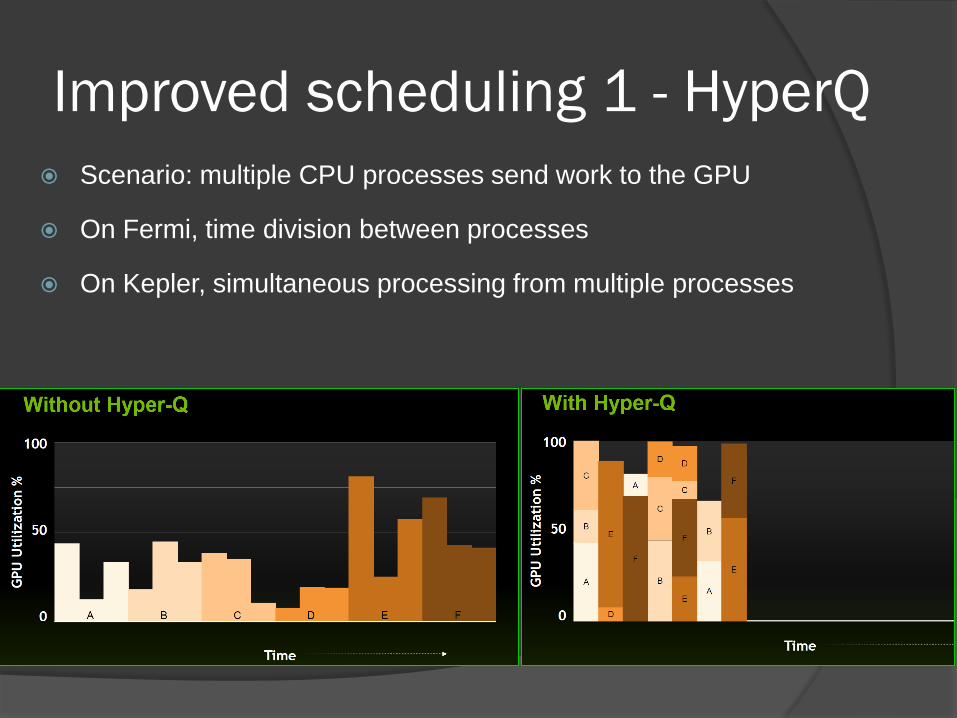
Improved scheduling 1 - HyperQ
Scenario: multiple CPU processes send work to the GPU
On Fermi, time division between processes
On Kepler, simultaneous processing from multiple processes

Improved scheduling 2
A new age in GPU programmability:
moving from Master-Salve pattern to self-feeding

Questions ?


















