
Flexible tools for integrating observations and models Johan De Keyser Emmanuel Gamby Belgian...
23
Flexible tools for integrating observations and models Johan De Keyser Emmanuel Gamby Belgian Institute for Space Aeronomy
-
Upload
joy-mcdonald -
Category
Documents
-
view
212 -
download
0
Transcript of Flexible tools for integrating observations and models Johan De Keyser Emmanuel Gamby Belgian...

Flexible tools for integrating
observations and modelsJohan De Keyser
Emmanuel Gamby
Belgian Institute for Space Aeronomy

November 2007 ESWW 2007 2
Objective
• There exist several packages for processing and visualizing space-related data. Some are meant to be general (e.g. QSAS, MIM, NSSDC), and some are specific (e.g. Cluster Science Data System, Cluster Active Archive, Themis Data Analysis System).
• The goal is to infer some general conclusions about the needs of such software infrastructure, and to offer useful recommendations for data and modeling services in the space science and space weather arena.

November 2007 ESWW 2007 3
Space weather clients and servers
• The commercial model:
• The scientist’s model:– user, service provider, and data provider coincide
user user
data provider
service provider
data provider
service provider
user
November 2007 ESWW 2007 4
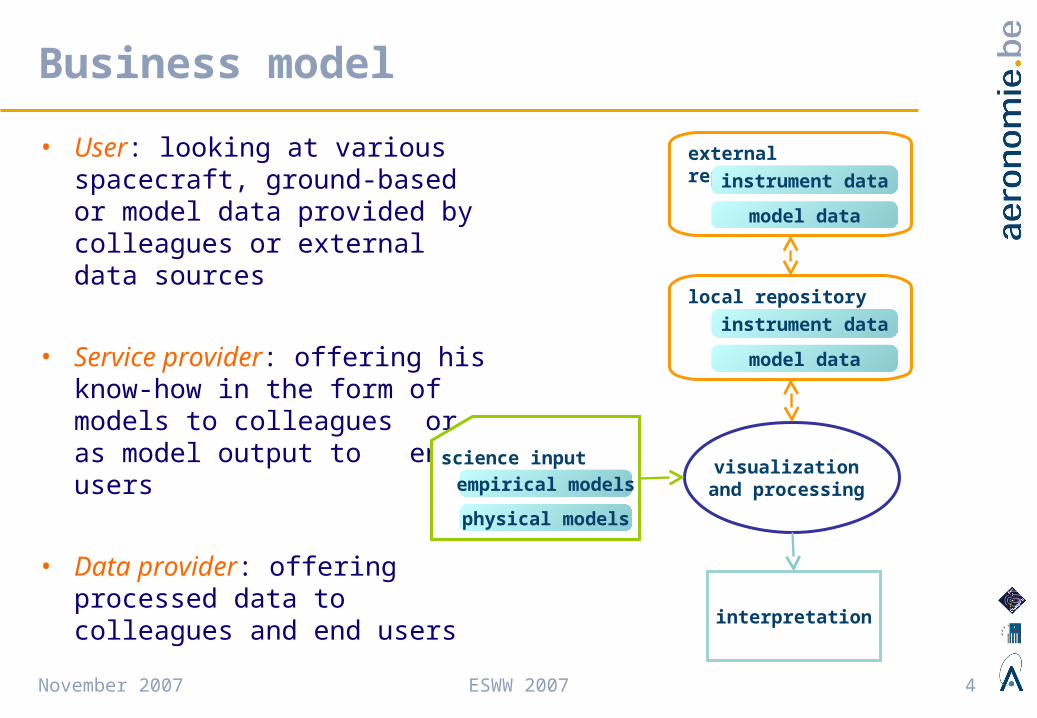
Business model
• User: looking at various spacecraft, ground-based or model data provided by colleagues or external data sources
• Service provider: offering his know-how in the form of models to colleagues or as model output to end users
• Data provider: offering processed data to colleagues and end users
visualization and processing
external repositoryinstrument data
model data
local repository
instrument data
model data
science input
empirical models
physical models
interpretation

November 2007 ESWW 2007 5
Sharing scientific know-how
• Scientists are end users as they derive knowledge, by bringing together different kinds of information.– What are the observations?
• Observational data– What is the interpretation?
• Model data– How do you bring it together?
• Algorithms• This is all brought together by the data processing and
visualization tool.
• Scientists turn into service providers– by making observational data available,– by offering their model data, or– by publishing their algorithms.

November 2007 ESWW 2007 6
Examples
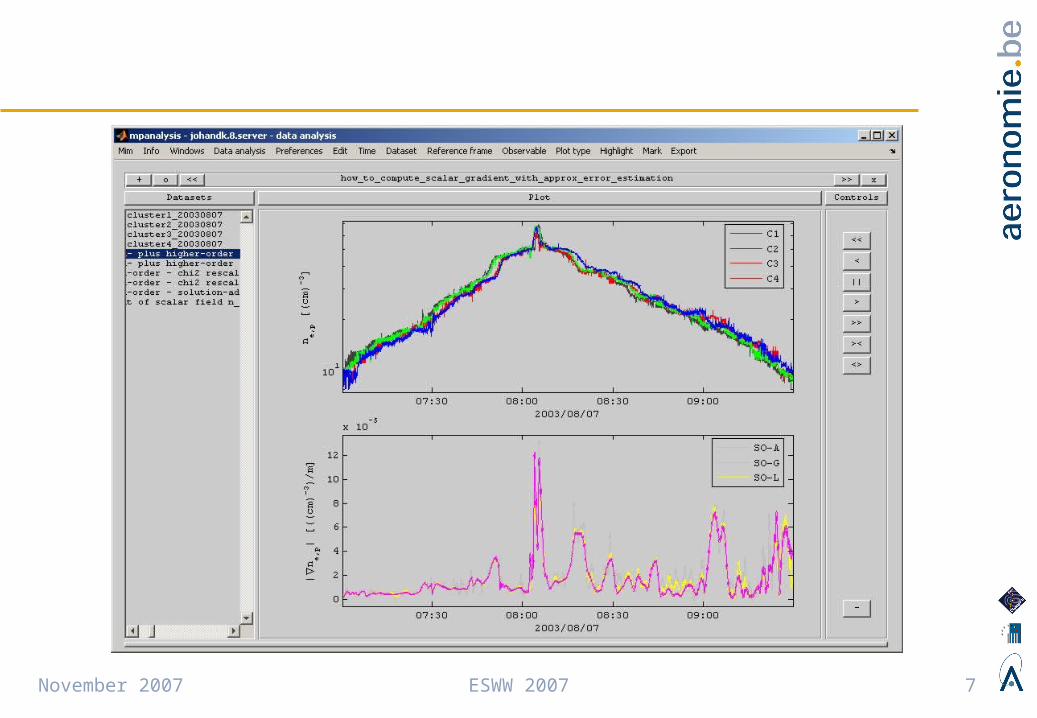
• Scientists develop algorithms to bring together data from different sources. The algorithm proposes a model, possibly parameterized, to compute model output.
• Example 1 : Gradients– Gradients are computed from measurements on the 4 Cluster spacecraft.
– The model assumes locally constant gradients.– Model input parameters: e.g. estimate of the distance over which the gradients can safely be considered constant
– Model output: the computed gradient vector with its error margins.
November 2007 ESWW 2007 7

November 2007 ESWW 2007 8
• Example 2 : Modeling of cometary comae– Computing chemical composition in a cometary coma.– The model assumes thermodynamic equilibrium and computes how the composition evolves due to chemistry.
– Model input: chemical reaction constants, neutral gas production rates, numerical parameters.
– Model output: particle abundances throughout the coma

November 2007 ESWW 2007 9

November 2007 ESWW 2007 10
Sharing data
• Access type– Manual:
• Interactively look up and download data through a human-oriented graphic interface (e.g. web browser to CSDS, CAA, NSSDC)
– Automatic: • Automated machine-based data access procedure. • Definition of “channels”: generic specification of where and how to find spacecraft data for a given time (TDAS, MIM)
• Physical access is always based on some protocol– NFS access: for a local repository– FTP access: NSSDC, Themis repository– Web access: Cluster Active Archive– Access restrictions require the use of login/password

November 2007 ESWW 2007 11
• Automated access downloads data to a local repository or cache.– Cache management based on reserved cache size and minimum guaranteed lifetime of files. File removal exploits the time of last usage.
• Automated access can lead to significant wait times– E.g. access to a 20 Mb data set over a 0.1 Mb/s connection takes several minutes; cache hits are therefore important.
– A high cache hit rate can be achieved as scientists often work for a prolonged time with a limited set of events (if the cache is big enough to hold that set).
– Caching is of not much help when scanning the whole archive, e.g. for statistical studies.
– Access may be done as a background activity.

November 2007 ESWW 2007 12
• There is a plethora of available data formats– Archived data may be structured in ways that reflect their origin: • time series of scalar or vector values, of particle distribution functions, or of wave spectra; multi-dimensional spatial fields; images …
• data might be grouped in a particular way, e.g. particle distribution moments are usually provided together on a common timescale
– Archived data may be stored in a common file exchange format, such as ASCII, CDF, or HDF files.• NSSDC offers data in these formats; ASCII only for low time resolution data.
– Archived data might be compressed.• NSSDC compresses ASCII data files.

November 2007 ESWW 2007 13
• Data fed into a visualization/processing tool need a specific format to load quickly.– MIM expresses time in Julian Days, enforces SI units.
• Therefore there is a need to convert various archive formats into the desired input format.– MIM uses a generic data format description to steer a data translator. This process maintains/provides metadata.
– QSAS uses the QTRAN data format translator
• The formatted data volume is usually bigger than that of the archived data. It is the formatted data that are stored in the local cache, while the archive data from which they are derived have transient downloaded copies.

November 2007 ESWW 2007 14
Recommendations
• Even if you offer a sophisticated web protocol with graphic data selection and preview possibilities, make the data accessible via FTP-server: is the easiest solution for automated access.
• Make data available in ASCII table form, or a compressed version of it, or in CDF or HDF.– Do not invent a new ad hoc format, such as CEF (Cluster Exchange Format)
• Data should always be accompanied with error estimates, both in terms of systematic and random errors.
• Offer adequate metadata.
• Provide documentation.

November 2007 ESWW 2007 15
Sharing model data
• Sharing model output is similar to sharing observations (calibrated observations are the output from an instrument model anyway). It is essential to specify the systematic and random errors on the model output.
– Example: Gradient computation from 4 non-coplanar data points, as often done with Cluster, cannot provide an estimate of the total error on the gradient: Specified error margins usually refer only to the effect of measurement errors – such limitations should be clearly stated when publishing model output.

November 2007 ESWW 2007 16
• Sharing model parameters may warrant even more attention since the meaning of the parameters might be less obvious.
– Example: Modeling the chemistry in cometary comae is a complicated thing. Among the input parameters is a database containing a compilation of relevant reactions and temperature-dependent reaction rates, including uncertainty.
• Sharing model parameters is essential for comparing
– model output obtained with different sets of model parameters;
– model output obtained from different models, in order to be sure that the same input is used.

November 2007 ESWW 2007 17
Recommendations
• Try to parameterize your models as much as possible. Do not hardcode model parameters.
• Offer the model parameter sets and the model results in a readable form; ASCII will often be preferred for the model parameters.
• Provide clear documentation about the model input parameters.
• Model output should be treated in the same way as observational data.

November 2007 ESWW 2007 18
Sharing algorithms
• Sharing algorithms is still in its infancy.– There is no standard interface, depends on the software environment you want to incorporate it into;
– issue of programming language and portability;– provide documentation.
• Preference for high-level languages– Matlab, IDL routines: offer features to assist defining and documenting the interface, automatically ensuring portability over a range of platforms
– C++ library: also a portable format

November 2007 ESWW 2007 19
• Sharing algorithms can be avoided if the algorithm is run on demand as a web service.
• Advantages– No portability issues– Version control is easy– Secrecy to safeguard commercial interests
• Disadvantages– The data have to be imported and the results have to be exported over the web: slow
– The server must be powerful enough to run the service for all clients
– The algorithm is not open for critical review; no improvements/extensions from other parties.

November 2007 ESWW 2007 20
• Provide interactive on-line documentation for your algorithms, e.g. through a hypertext-based documentation system.

November 2007 ESWW 2007 21
Recommendations: Algorithms
• Publish your algorithms, have them reviewed by as many people as possible.
• Describe algorithms in a high-level language, in terms of a number of simpler primitive operations, to enhance implementation on different platforms.
• Carefully compare different algorithms to establish correctness, efficiency, and error propagation properties.
• Provide detailed documentation as well as test examples.

November 2007 ESWW 2007 22
Conclusions
• There is a need for general-purpose packages for processing and visualizing space-related data since data interpretation is a multi-instrument and multi-spacecraft activity, so mission-specific packages are too limited (though they can be useful for mission-specific archiving).
• Portability across a variety of platforms is desirable.
• Such packages should be well-documented, easily installed, and have an intuitive graphical user interface.
• Computational efficiency is a must since data volumes become increasingly larger.

November 2007 ESWW 2007 23
• Such a package should support – manual and automated data access; – conversion of various formats;– simultaneous processing of data from various sources, always including error estimates;
– commanding from an interactive graphical user interface as well as running batch jobs, i.e. it must implement some scripting language;
– documentation of observational data and model output data sets, including access to meta-data;
– interactive definition, manipulation, and documentation of model input parameter sets;
– implementation and documentation of new algorithms.



![Networking Basics - [email protected] | Aeronomy and RadioPropagation](https://static.fdocuments.in/doc/165x107/613cffa00c37c14a830ceb5b/networking-basics-emailprotected-aeronomy-and-radiopropagation.jpg)














