
T-76.4115 Iteration demo T-76.4115 Iteration Demo Neula PP Iteration 21.10.2008.

Fitted Q Iteration
Firas Safadi
University of Liège
June 2011

Theory
Part I

State described by 𝒔 = 𝒙𝟏, 𝒙𝟐, … , 𝒙𝒏 ∈ ℝ𝒏
Action defined by 𝒂 = 𝒖𝟏, 𝒖𝟐, … , 𝒖𝒎 ∈ ℝ𝒎
Environment responds with reward and new state
𝒓 ∈ ℝ
𝒔′ ∈ ℝ𝒏
Environment

Maps state-action pairs to rewards 𝑹 𝒔, 𝒂 → 𝒓
We need 𝑹 to take good actions!
Reward function

Assume a horizon 𝑻 ∈ ℕ
Maximum cumulated reward 𝑽𝑻 𝒔 = max
𝒂,𝒂′,… 𝑹 𝒔, 𝒂 + 𝑹 𝒔′, 𝒂′ + ⋯
𝑻
Maximum cumulated reward for state-action pairs 𝑸𝑻+𝟏 𝒔, 𝒂 = 𝒓 + 𝑽𝑻 𝒔′
Maximizing reward over a horizon

Fitted Q idea
Start with a set of samples 𝒔, 𝒂, 𝒓, 𝒔′
𝒋𝒋
Incrementally build 𝑸𝑻 using supervised learning
Use 𝑸𝒊 to compute 𝑽𝒊
Use 𝑽𝒊 to compute 𝑸𝒊+𝟏
Learn 𝑸𝒊+𝟏
Increase 𝒊

Fitted Q algorithm
Input 𝒔 set of states
𝒂 set of actions
𝒓 set of rewards
𝒔′ set of next states
𝑲 number of samples
𝑻 horizon
Output 𝑸𝑻
𝑸 𝒔, 𝒂 ← 𝒓 𝑓𝑜𝑟 𝒊 = 𝟏 𝑡𝑜 𝑻 − 𝟏
𝑓𝑜𝑟 𝒋 = 𝟎 𝑡𝑜 𝑲 − 𝟏 𝑹𝒋 = 𝒓𝒋 + max
𝒂′𝑸 𝒔𝒋
′ , 𝒂′
𝑒𝑛𝑑 𝑸 𝒔, 𝒂 ← 𝑹
𝑒𝑛𝑑

Experiment
Part II

Problem
World: 10 × 10 surface
State: 𝑥, 𝑦, 𝑎, 𝑏 in 0,10 4
Action: 𝑢, 𝑣 in −1,1 2
Goal: reach target (dist. ≤ 1)
Reward: 1 if dist. ≤ 1, else 0
Random initial position
Random initial target position
Only 10 moves available

Feed-forward backpropagation neural network
Approx. 16,000 samples
Simulate 100 random actions to estimate optimum
Learning

Learn for horizon = 1, 2, …, 10 and play 1,000 games
Repeat 10 times
Total of 10,000 games per horizon
Assessing the impact of the learning horizon on performance
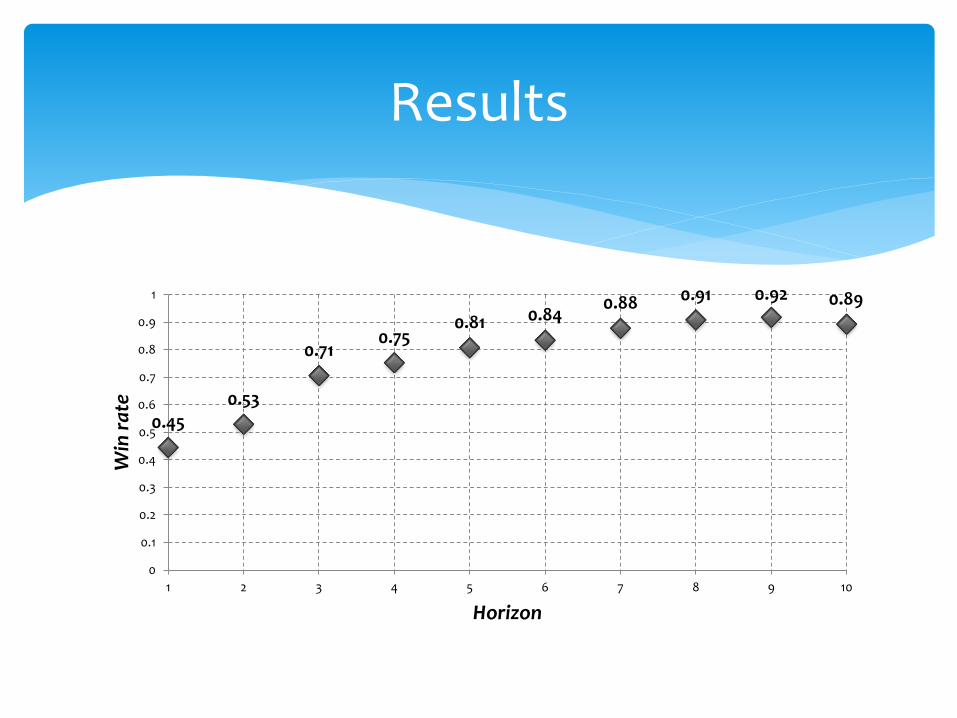
Results
0.45 0.53
0.71 0.75
0.81 0.84 0.88 0.91 0.92 0.89
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1 2 3 4 5 6 7 8 9 10
Win
ra
te
Horizon

Wrap-up
Part III

Offline
Model-free
Works with random trajectories
Advantages of fitted Q iteration

Try random forests and compare with neural networks performance
Try different sampling methods Generate samples around edges
Generate complete trajectories
Resampling
Try on bigger problems with larger state space (i.e., MASH)
Future work

Acknowledgments
Part IV

Charles Desjardins Neural Fitted Q-Iteration (Martin Riedmiller, ECML 2005),
2007
Damien Ernst Computing near-optimal policies from trajectories by solving a
sequence of standard supervised learning problems, 2006
Yin Shih Neuralyst User Guide, 2001
References

Jean-Baptiste Hoock
Implementation (MASH)
Nataliya Sokolovska
Testing
Olivier Teytaud
Concepts (fitted Q iteration, benchmark)
Thanks

The End Thanks for listening!

![T-76.4115 Iteration Demo BaseByters [I1] Iteration 04.12.2005.](https://static.fdocuments.in/doc/165x107/56649cff5503460f949d053f/t-764115-iteration-demo-basebyters-i1-iteration-04122005.jpg)


![T-76.4115 Iteration Demo Tikkaajat [PP] Iteration 18.10.2007.](https://static.fdocuments.in/doc/165x107/5a4d1b607f8b9ab0599ace21/t-764115-iteration-demo-tikkaajat-pp-iteration-18102007.jpg)













