
Finite-state automata and Morphology. Outline Morphology What is it? Why do we need it? How do we...
24
Finite-state automata and Morphology
-
Upload
louis-tibbett -
Category
Documents
-
view
239 -
download
2
Transcript of Finite-state automata and Morphology. Outline Morphology What is it? Why do we need it? How do we...

Finite-state automata and Morphology

Outline
Morphology
• What is it?
• Why do we need it?
• How do we model it?
Computational Model: Finite-state transducer

Structure of Words
What are words?
• Orthographic tokens separated by white space.
In some languages the distinction between words and sentences is less clear.
• Chinese, Japanese: no white space between words– nowhitespace no white space/no whites pace/now hit esp ace
• Turkish: words could represent a complete “sentence”– Eg: uygarlastiramadiklarimizdanmissinizcasina
• “(behaving) as if you are among those whom we could not civilize”
Morphology: the structure of words
• Basic elements: morphemes
• Morphological Rules: how to combine morphemes.
Syntax: the structure of sentences
• Rules for ordering words in a sentence

Morphology and Syntax
Interplay between syntax and morphology
• How much information does a language allow to be packed in a word, and how easy is it to unpack.
• More information less rigid syntax more free word order
• Eg: Hindi: John likes Mary – all six orders are possible, due to rich morphological information.

Why Study Morphology?
Morphology provides • systematic rules for forming new words in a language.
• can be used to verify if a word is legitimate in a language.
• efficient storage methods.
• improving lexical coverage of a system.
• group words into classes.
Applications• Improving recall in search applications
– Try “fish” as a query in a search engine
• Text-to-speech synthesis – category of a word determines its pronunciation
• Parsing– Morphological information eliminates spurious parses for a sentence

Structure of Words
Morphology: The study of how words are composed from smaller, meaning-bearing units (morphemes)• Stems: children, undoubtedly, • Affixes (prefixes, suffixes, circumfixes, infixes)
– Immaterial, Trying, Gesagt, Absobl**dylutely
Different ways of creating words• Concatenative
– Adding strings to the stems (examples above)• Non-concatenative
– Infixation (e.g. Tagalog: hingi (order) humingi)– Templatic (e.g. Arabic root-and-pattern) morphological systems
• Triconsonant CCC expands into words using templates that represent more semantic information.
• Hebrew: lmd (study) lamad (he studied), limed (he taught), lumad (he was taught)
Stacking of affixes in English is limited (three or four); but in Turkish nine or ten affixes can be stacked.• Agglutinative languages

Different Classifications
Sets of words display (almost) regular patterns.Open class words: Noun, Verb, Adverb, Adjectives
Closed class words: Pronoun, Preposition, Conjunction, Determiners.
Kinds of morphologyInflectional
Word stem + grammatical morpheme results in a word of the same class. Morpheme serves a syntactic function: grammatical agreement, case marker
-s for plural on nouns, -ed for past tense on verbsOnly Nouns and Verbs inflect in English for grammatical reasonsIn French, adjectives agree (match on gender and number) with nouns they modify.
DerivationalWord stem + grammatical morpheme results in a different class of word.Nominalization: -ation suffix makes verbs into nouns (e.g. Computerize computerization-ly suffix makes adjectives into adverbs (e.g. beautiful beautifully)

Inflectional Morphology
Word stem + grammatical morpheme
Morpheme serves a syntactic function: grammatical agreement, case marker• -s for plural on nouns, -ed for past tense on verbs
Results in word of the same class as the stem• (bat bats; man man’s; jump jumps, jumped, jumping)
Noun morphology:• Regular nouns: bat bats, fish fishes• Irregular nouns: spelling changes (mouse mice; ox oxen)
Verb morphology:• Regular verbs: jump jumps (-s form), jumped (past/ -ed participle), jumping (-ing
participle)• Irregular verbs: eat eats (-s form), ate (past), eaten (-ed participle), eating (-ing
participle)
Irregular forms have to be stored. • Language learners typically make errors on irregular forms. • hit hitted

Inflectional Morphology
Nominal morphology• Plural forms
– s or es– Irregular forms (goose/geese)– Mass vs. count nouns (fish/fish,email or emails?)
• Possessives (cat’s, cats’)
Verbal inflection• Main verbs (sleep, like, fear) verbs relatively regular
– -s, ing, ed – And productive: Emailed, instant-messaged, faxed, homered– But some are not regular: eat/ate/eaten, catch/caught/caught
• Primary (be, have, do) and modal verbs (can, will, must) often irregular and not productive– Be: am/is/are/were/was/been/being
• Irregular verbs few (~250) but frequently occurring– Irregularity a consequence of frequency?
• So….English inflectional morphology is fairly easy to model….with some special cases...

(English) Derivational Morphology
Word stem + grammatical morpheme
• Usually produces word of different class
• More complicated than inflectional
E.g. verbs --> nouns
• -ize verbs -ation nouns
• generalize, realize generalization, realization
E.g.: verbs, nouns adjectives
• embrace, pity embraceable, pitiable
• care, wit careless, witless
E.g.: adjective adverb
• happy happily
• But “rules” have many exceptions
• Less productive: *evidence-less, *concern-less, *go-able, *sleep-able
• Meanings of derived terms harder to predict by rule– clueless, careless, nerveless

How do humans represent words?
Hypotheses:• Full listing hypothesis: words listed • Minimum redundancy hypothesis: morphemes listed
– Words are formed using rules.
Experimental evidence:• Priming experiments (Does seeing/hearing one word facilitate
recognition of another?) suggest neither• Regularly inflected forms prime stem but not derived forms • But spoken derived words can prime stems if they are semantically
close (e.g. government/govern but not department/depart)
Speech errors suggest affixes must be represented separately in the mental lexicon• easy enoughly

Finite-State Morphological Parsing
Morphological Parsing:• takes : root=take, category=V, person=3, number=sg
• cities : root=city, category=N, number=plural
• ships: a. root=ship, category=N, number=plural
b. root=ship, category=V, person=3, number=sg
What does a parser need?• Lexicon: root forms of the words in a language
• Morphological Rules: morpheme ordering rules
• Orthographic Rules: spelling change rules
We will represent each of these components as finite-state automata.
Parsing versus Recognition• Recognition: yes/no
• Parsing: derivation structure– indecipherable [in [[de [cipher]] able]]

Lexicon as an FSA
Words can be represented as paths in a FSA with characters as transition symbols.
• Also called a “trie” structure
List of words: bat, cat, mat, sat
c a t
b
m
s

Morphological Recognition
Check if a word is a valid word in the language.
For nouns: cats, geese, goose
For adjectives: Derivational morphology
• Adj-root1: clear, happy, real (clearly)
• Adj-root2: big, red (~bigly)
q0 q2q1
reg-n
irreg-sg-n
irreg-pl-n
plural (-s)
q3
q5
q4
q0
q1 q2
un- adj-root1 -er, -ly, -est
adj-root1
adj-root2
-er, -est

Morphotactic Rules
An automaton that encodes valid English word forming rules.
Koskenniemi’s two-level morphology
• Lexical string: stem and morphemes
• Surface string: spelling of the derived word
• Pair up lexical string with the surface string.
• (N,bat,pl; bats)
• (V,bat,3sg; bats)
• Align the strings at the character level– N: b:b a:a t:t pl:s– V:b:b a:a t:t 3sg:s
Relation that maps characters to other characters.

Finite-State Transducers
Finite State Acceptors represent regular sets.
Finite State Transducers represent regular relations.
Relation
• If A and B are two regular sets; relation R ⊆ A x B
• Example: {(x,y) | x ∊ a*, y ∊ b*}
FSTs can be considered as
• Translators (Hello:Ciao)
• Parser/generators (Hello:How may I help you?)
• As well as Kimmo-style morphological parsing

Finite State Transducers – formally speaking
FST is a 5-tuple consisting of
• Q: set of states {q0,q1,q2,q3,q4}
• : an alphabet of complex symbols, each an i:o pair s.t. i I (an input alphabet) and o O (an output alphabet) and ⊆ I x O
• q0: a start state
• F: a set of final states in Q {q4}
• (q,i:o): a transition function mapping Q x to Q
q0 q4q1 q2 q3
b:m a:o
a:o
a:o !:?

More FST examplesFSTs are functions, • Compose (L1,L2) = {(x,y) | (x,z) ∊ L1 and (z,y) ∊ L2}
– 3((q1,q2),(x,y)) = (q3,q4) if ∃z 1(q1,(x,z)) = q3 and 2(q2,(z,y)) = q4
• Inverse(L) = {(x,y) | (y,x) ∊ L}
• FirstProjection(L) = {x | (x,y) ∊ L}
• SecondProjection(L) = {y | (x,y) ∊ L}
Speech Recognition as FST composition• A: Acoustic phones
• Lex: phones Words
• Gram: Words Words
• Speech Recognition: A ● Lex ● Gram
Machine Translation as FST composition• LexTrans: SourceWords TargetWords
• LexReorder: UnOrderedTargetWords OrderedTargetWords
Weighted FSTs allow for ranking of the generated outputs.
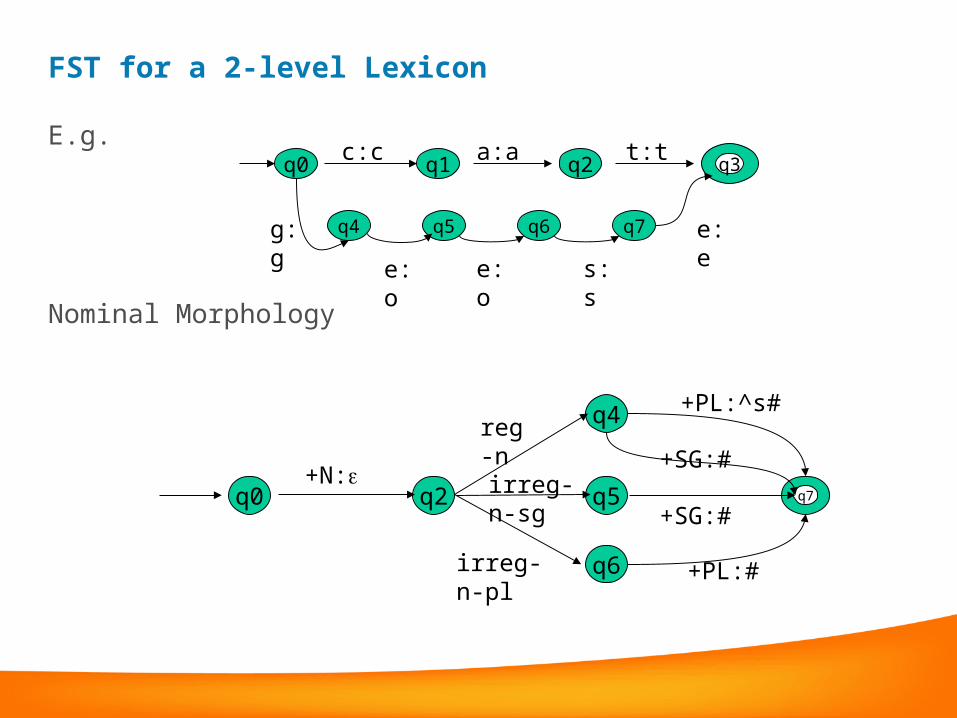
FST for a 2-level Lexicon
E.g.
Nominal Morphology
q0 q1 q2 q3c:c a:a t:t
q4 q6 q7q5
s:se:o e:o
e:eg:g
q0 q7
+PL:^s#q4
q2 q5
q6
reg-n
irreg-n-sg
irreg-n-pl
+N:
+PL:#
+SG:#
+SG:#

Orthographic Rules
Define additional FSTs to implement spelling rules• Gemination: consonant doubling (beg begging),
• Elision: ‘e’ deletion (make making),
• Epenthesis: ‘e’ insertion (fox foxes), etc.
• Y replacement: ‘y’ changes to ‘ie’ before ‘ed’ (trytries)
• I spelling: ‘I’ changes to ‘y’ before a vowel (lielying)
Rewrite rule notation: / _
Examples: Rule: a b/a _ b• aaabaab aabbabb (Sequential; there are other control strategies:
parallel, feedback).
Spelling rules: e / x ^ _ s (eg. fox^s foxes)
Multiple spelling rules might apply for a given word.• Eg: spy^s spies (yi, e)
All spelling rules execute in parallel.
Rewrite rules can be compiled into FSTs.

FST-based Morphological Parsing
Remember FSTs can be composed.
Lexicon : List of stems
Morphotactics: Rules for adding morphemes
Orthographic Rules: Spelling Rules
Morphology =
Lexicon ● Morphotactics ● Orhtographics
All morphological analyses generated for a given word,
…but in a context a preference ordering on the analysis is needed.
• Weighted FSTs to the rescue.

Porter Stemmer
Lexicon free stemmer; heuristic rules for deriving the stem.
Rules to rewrite the suffix of a word.
• “ational” “ate” (eg. relational relate)
• “-ing” (eg. motoring motor)
Details of the rules in Appendix B in the book.
Purported to improve recall in IR engines.

Role of Morphology in Machine TranslationEvery MT system contains a bilingual lexicon
Bilingual lexicon: a table mapping the source language token to target language token(s).
Two options:
1. Full-form lexicon– every word form of the source token is paired with the target token– large table if the vocabulary is large for morphologically rich languages
2. Root-form lexicon– pairing of stems from the two languages– Reduces the size of the lexicon– requires morphological analysis for source language – bats (bat, V, 3sg) (bat, N, pl)– morphological generation for target language– (bat, V, 3sg) bats
Unknown words: words not covered in the bilingual lexicon
- with morphology, one can guess the syntactic function
Compounding of words:
English: simple juxtaposition (“car seat”), some times (“seaweed”)
German: fusion is more common
(“Dampfschiffahrtsgesellschaft” steamship company

Readings
For this class
HS: pages 15-16, 81-85
JM: chapter on Morphology
For next class
Machine Translation divergences (Dorr 94)
Example based Machine Translation (Somers 99)


















