
2013-01-18 C31=SG (DBS Vickers) (SG) Population White Paper_ Potential beneficiaries
Upload
ryan-ellingsonCategory
view
99download
0
Ryan Ellingson Herzing University 4/26/2016
Network Infrastructure for Big Data
Using Hadoop and Cloudera

1
Table of Contents I. Executive Summary ............................................................................................... 2
II. Project Introduction .............................................................................................. 3
III. Business Case ........................................................................................................ 4
IV. Project Planning .................................................................................................... 5
V. Project Timeline .................................................................................................... 6
VI. Network Diagram .................................................................................................. 7
VII. Technical Planning ............................................................................................... 8
Hadoop Cluster Node 1 Specifications
Hadoop Cluster Node 2 Specifications
Hadoop Cluster Node 3 Specifications
Windows Client Specifications
VIII. Implementation ..................................................................................................... 9
Install Centos
Set Networking Configuration
Generate SSH Key
Clone Virtual Machines
Edit Clones
Cloudera Manager Installer
Installing Cloudera Services
Further secure Hadoop/Cloudera
IX. Running Jobs in Hadoop ..................................................................................... 15
Using Hue
Using Pig
X. Difficulties ............................................................................................................ 17
XI. Conclusion ............................................................................................................ 18
XII. References............................................................................................................. 19
XIII. Appendix .............................................................................................................. 20
Progress Report 01
Progress Report 02
Progress Report 03
Progress Report 04
Progress Report 05
Progress Report 06
Progress Report 07
Course Objectives
Images

2
Executive Summary
‘Big data’ is becoming an increasingly important skillset and
knowledgeable subject for IT professionals. Having a sound
understanding of how processing ‘big data’ works, how to set up the
infrastructure needed to process big data, and knowledge of what
‘big data’ means for a company is highly beneficial. ‘Big data’ is used
in many industries including marketing and healthcare. For example,
in marketing, processing ‘big data’ is necessary to obtain many
demographic statistics of a company’s consumer.
My solution to this is to use three Centos Linux machines that can be
clustered together to run Hadoop. To manage the software and jobs,
I will use Cloudera. With this solution, upgrading the server is as simple
as adding another node to the cluster, which is more cost effective
than outright buying an upgraded application server to process 'big
data'.

NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
3
Project Introduction
Big Data is a term that has been thrown around very often in the
technology industry. Big data is a large volume of data that can be both
structured and unstructured. Entire industries have been built on the very
existence of the ability of processing large amounts of data. A very good
example of this is healthcare. In healthcare, using large amounts of patient
statistics to figure out if patients are taking medicine when they are
supposed to, how likely it will be that conditions show up in certain
patients, and much more can be determined by processing these large
amounts of data.
The proposed method to process big data is to use Hadoop running on
Centos Linux. Cloudera will manage the services. With this solution,
upgrading the server is as simple as adding in another node to the cluster,
which is more cost effective than outright buying an upgraded application
server to process big data.
Hadoop is a free, java-based programming framework. It is used to process
large datasets. It can run apps with thousands of nodes and is able to run
through thousands of terabytes. Hadoop uses DFS (Distributed File System)
for rapid data transfers between nodes and is able to run uninterrupted in
the event of a node failure.
Cloudera is a “one stop shop” for Hadoop processing. It is a single place to
store, process, and analyze data. It uses a web based apache server to
maintain a web interface, making the product easier to use for new IT users
setting the clusters up and programmers looking to run jobs efficiently. It
also offers a secure way to work on large datasets.

4
Business Case
As a marketing firm, harnessing the ability to process big data efficiently is
utterly important. If approached by a school to help market to the right
people, processed big data can be used to determine where to focus
marketing efforts (i.e. high school age students, military, etc.).
Using these products in unison effectively gives any company a larger
bottom line over many other competitors. For example, using an
application server for processing big data is a great choice until the
company gets more data than the server can process. If the company
wants to process that big data, they will either need to upgrade the
internals (which can only be upgraded to a certain point before the
motherboard does not support any further expansions) or purchase a
newer and more capable application server. With a Hadoop cluster, once
the processing power has reached its limit in processing big data, adding
more capability is as simple as adding a new node to the cluster. This node
does not have to be a powerhouse server, but can be a lower powered
standardized server. This will effectively save the company exponentially
more money as years go on.
Another benefit to using Hadoop along with Cloudera is the user interface.
The setup is very simple and quick compared to competitors such as
Condor, which only offer a command line interface. Training new
programmers on something like Condor will be more difficult and time
consuming than teaching a user how to use a GUI based management
system like Hadoop and Cloudera.
This project is a solid capstone project since it utilizes everything learned in
the Herzing curriculum. On top of culminating Herzing’s curriculum, this
project makes use of new technologies and requires troubleshooting skills
and the ability to learn as you go. Furthermore, this project follows all the
course objectives.

5
Project Planning
To complete this project, I will use VMWare Workstation to run the
Centos Linux Machines needed to create the cluster. I will also use a
Windows 7 Machine to view the Cloudera Management window
through a browser. A network diagram will also be shown, along with
detailed IP scheming.
Cloudera offers software, services and support in three different
bundles:
Cloudera Enterprise includes CDH and an annual subscription
license (per node) to Cloudera Manager and technical
support. It comes in three editions: Basic, Flex, and Data Hub.
Cloudera Express includes CDH and a version of Cloudera
Manager lacking enterprise features such as rolling upgrades
and backup/disaster recovery.
CDH may be downloaded from Cloudera's website at no
charge, but with no technical support nor Cloudera Manager.
Online sources suggest the typical cost is $2,600 per server annually.
Having three nodes would be a minimum of $7,800 for licensing
Cloudera. On top of that purchasing the server heavily depends on
what the business needs. Application servers to run Hadoop can cost
anywhere from $1,000-100,000 depending on the need of the
company.
The Methodology used for completing this project will be NDLC for the
following reasons:
Analysis of Hadoop/Cloudera
Designing Network infrastructure
Simulate cluster processing big data
Implementation of complete infrastructure
Monitor data processing
Manage services
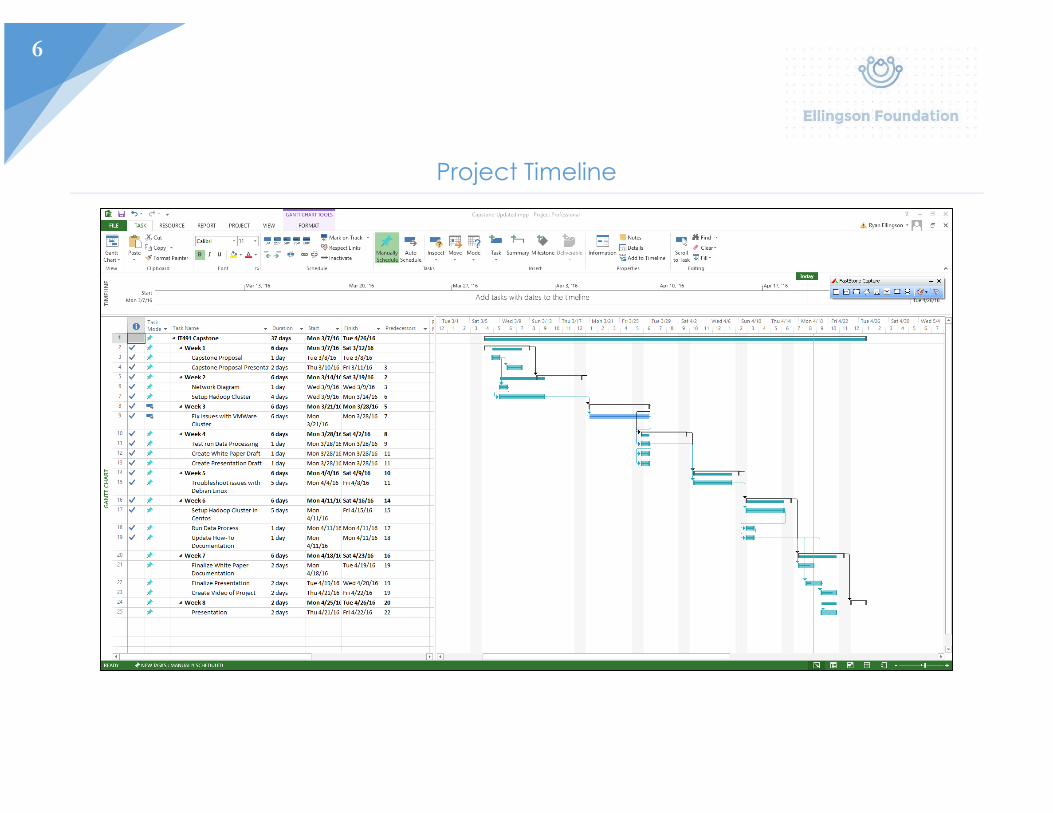
6
Project Timeline
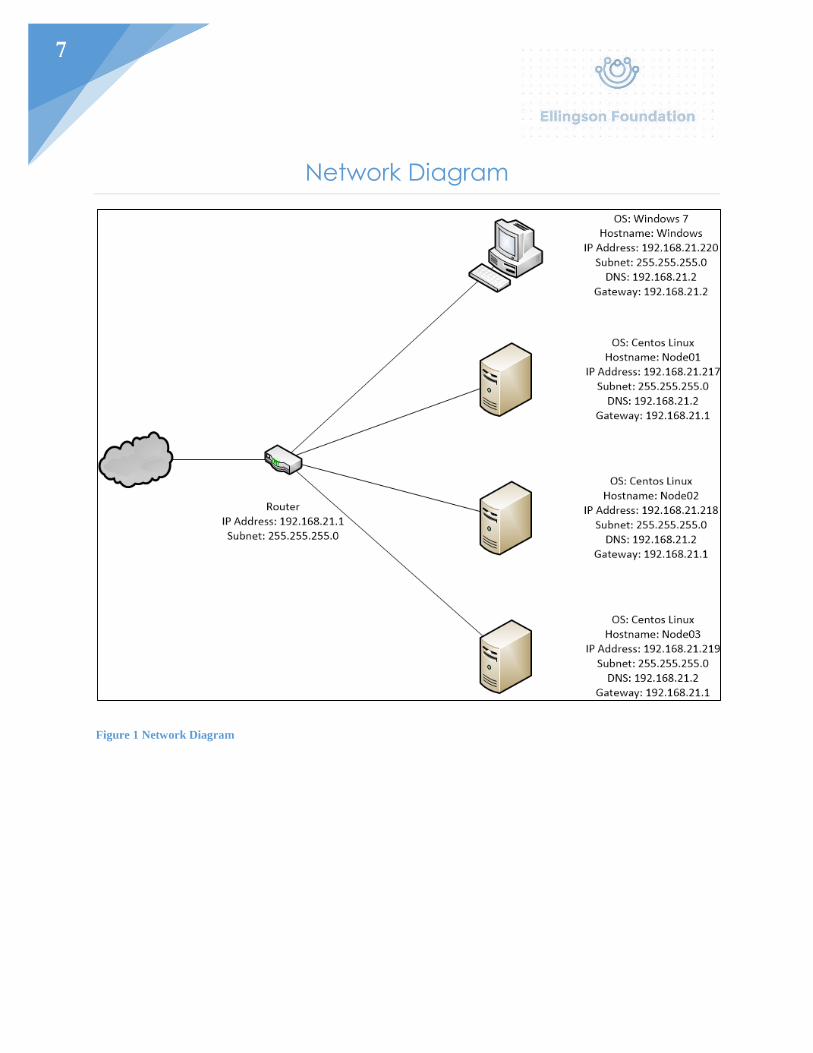
7
Network Diagram
Figure 1 Network Diagram

NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
8
Technical Planning
The following specifications were used as part of the technical planning of the project entities. For this project, a Centos Linux node was used as the first node on the Hadoop cluster. Once the accounts and base services were setup to properly use the first node, the other two were cloned (in VMware Workstation 11). These other two cloned nodes are then given unique IP Addresses. Cloudera is then installed on the first node, allowing Hadoop to properly download, define all nodes, and start any services. Cloudera is accessed through the web on any other client. In this case, the client accessing Cloudera is a Windows 7 client.
Hadoop Cluster Node 1 Specifications
Operating System Centos 6.2
Memory 4GB
Hard Disk 80 GB
Network Cards 1 NIC
Hadoop Cluster Node 2 Specifications
Operating System Centos 6.2
Memory 2GB
Hard Disk 80 GB
Network Cards 1 NIC
Hadoop Cluster Node 3 Specifications
Operating System Centos 6.2
Memory 2GB
Hard Disk 80 GB
Network Cards 1 NIC
Windows Client Specifications
Operating System Windows 7
Memory 2 GB
Hard Disk 20 GB
Network Cards 1 NIC

NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
9
Implementation
Implementation (for the purpose of this project) was completed in VMware Workstation 11. Depending on the network, the time that implementation will take may vary.
Install Centos
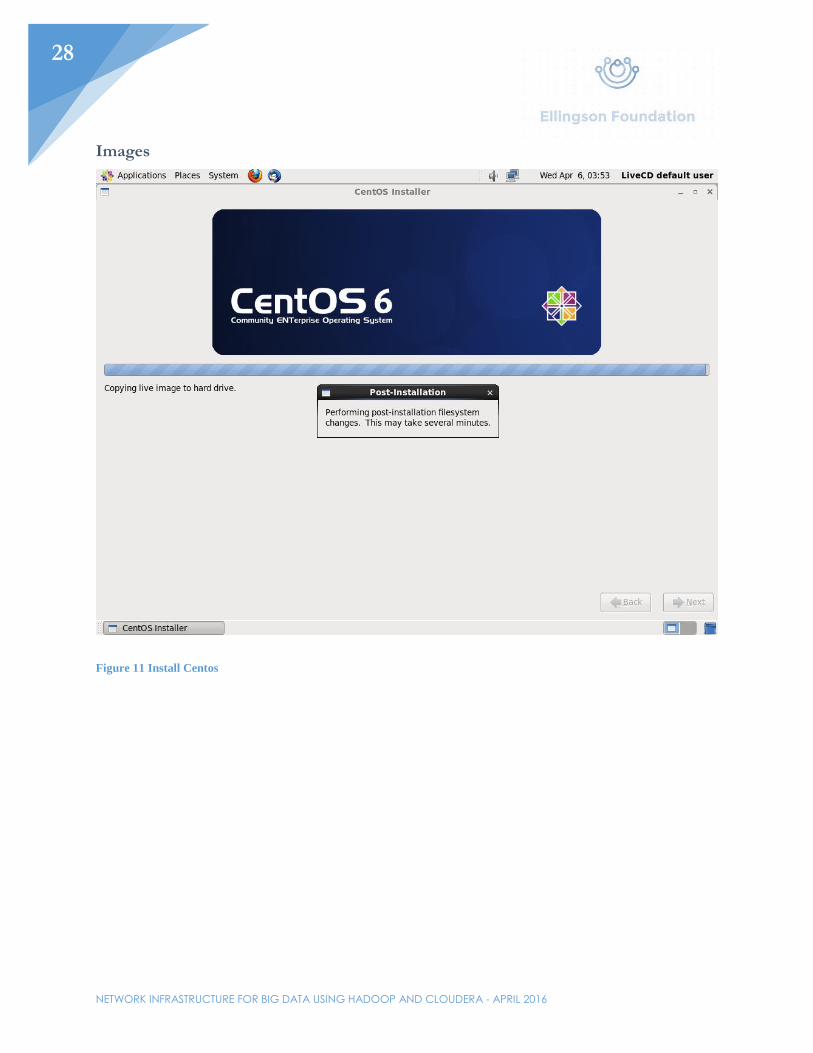
First, Centos 6.2 should be installed on a single Virtual Machine. The specifications should follow at minimum Node 1’s specification shown above. The hard drive is going to be 80GB. This will be used to install the operating system. Give the machine a minimum of 2 cores for a single processor. Make sure to make two accounts. One of these two accounts will be the standard root account –
Username: Root | Password: Password123.
The other account will be a personal user account – Username: Ryan | Password: Password123.
Set Networking Configuration
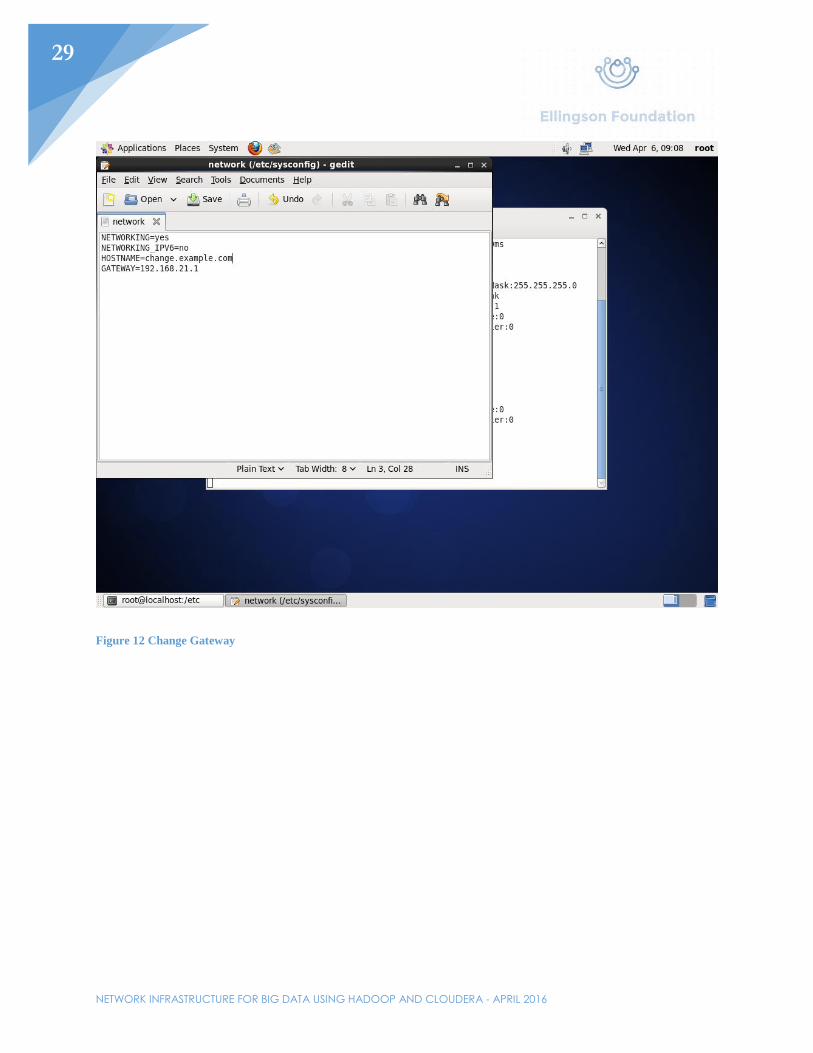
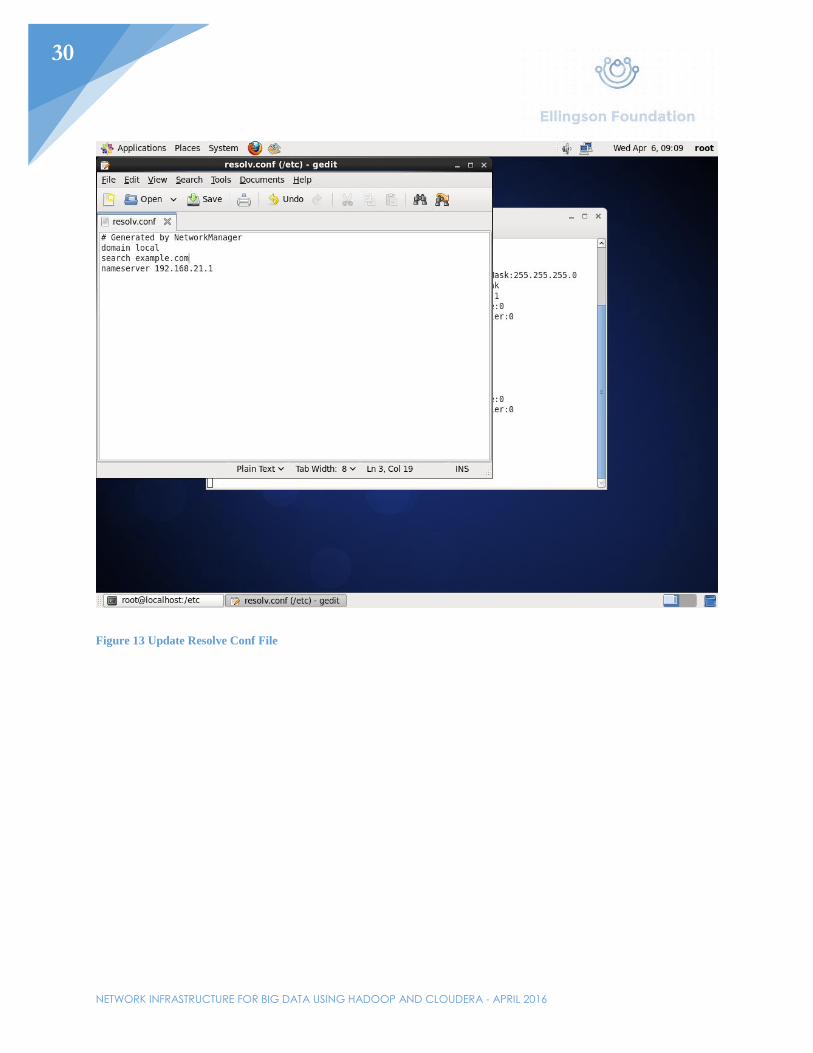
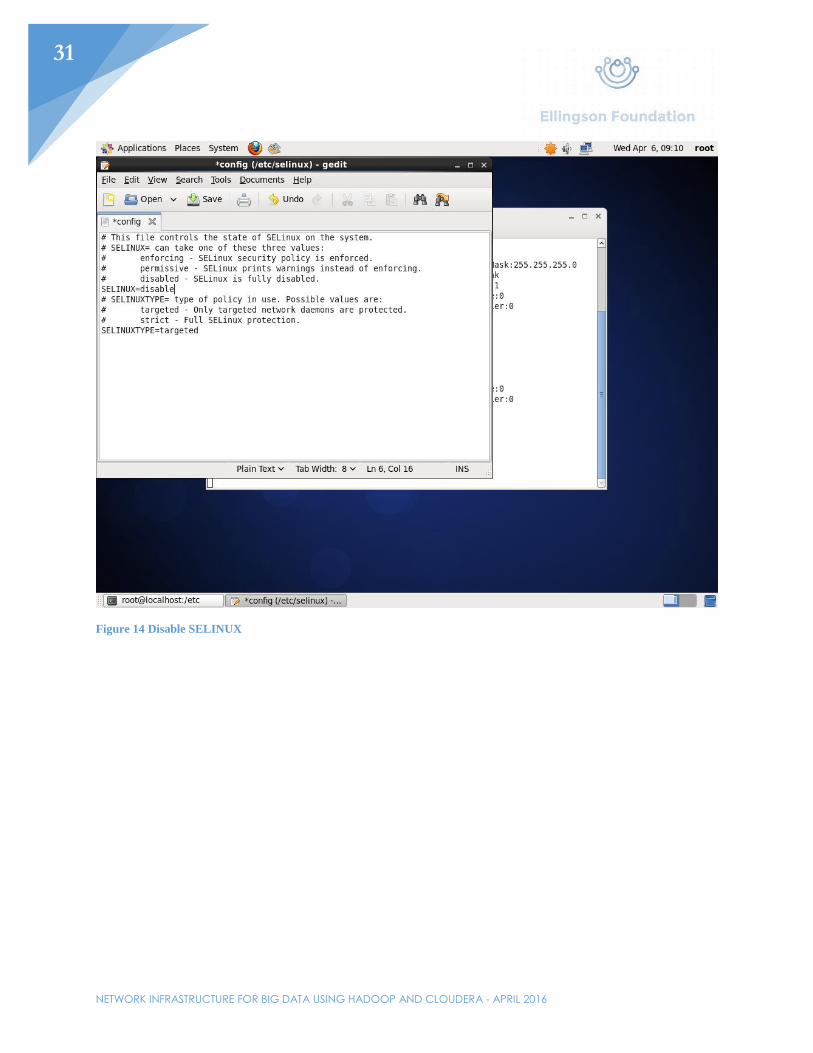
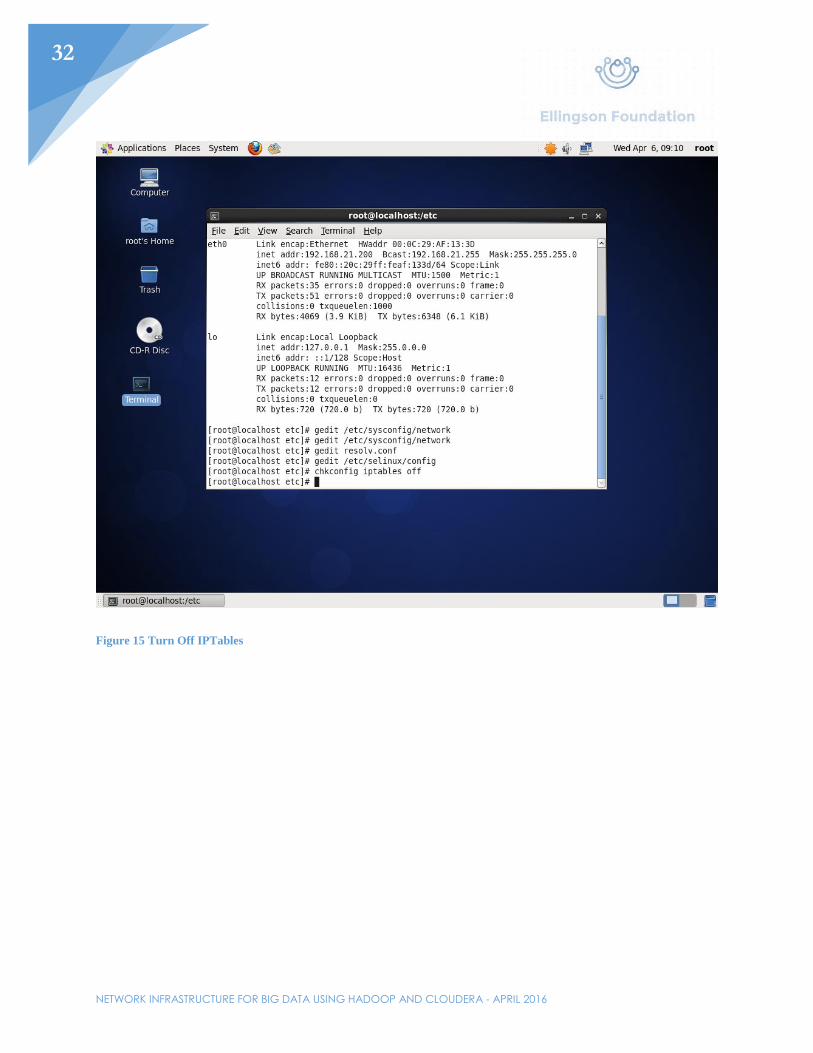
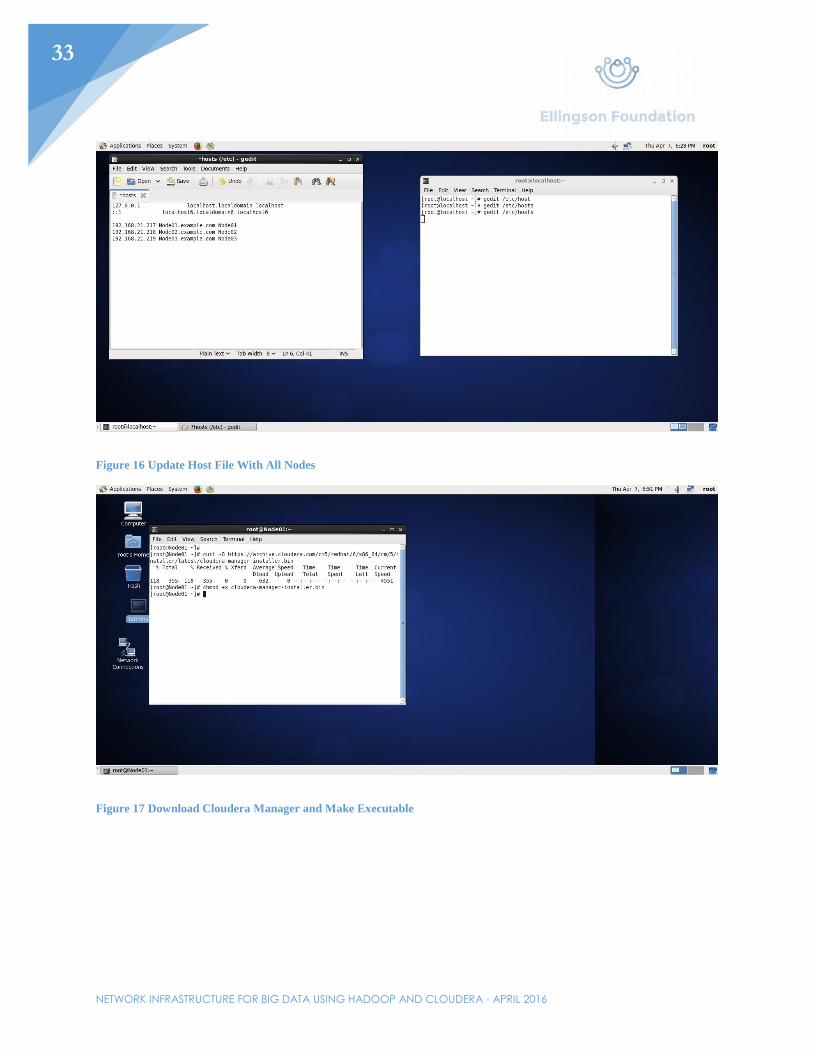
Before installing any of the Cloudera/Hadoop services, networking will have to be setup first. Set the IP address of the first node. In this example, the first node will be given the IP address 192.168.21.217/24 with the gateway being the router. The gateway can also be set by editing /etc/sysconfig/network. Edit the /etc/resolv.conf file to include the domain and the DNS server. In this example, the router will be used as the nameserver. Perhaps one of the most important files needed to be edited would be the /etc/selinux/config file. Here, SELINUX needs to be switched from “enabled” to “disabled”. Afterwards, turn of all firewalls with the chkconfig iptables off command. Lastly, in the /etc/hosts file, add all the hosts that will be used in said cluster. For this example, Node01-Node03 will be added and the IP addresses will range from 192.168.21.217-192.168.21.219.
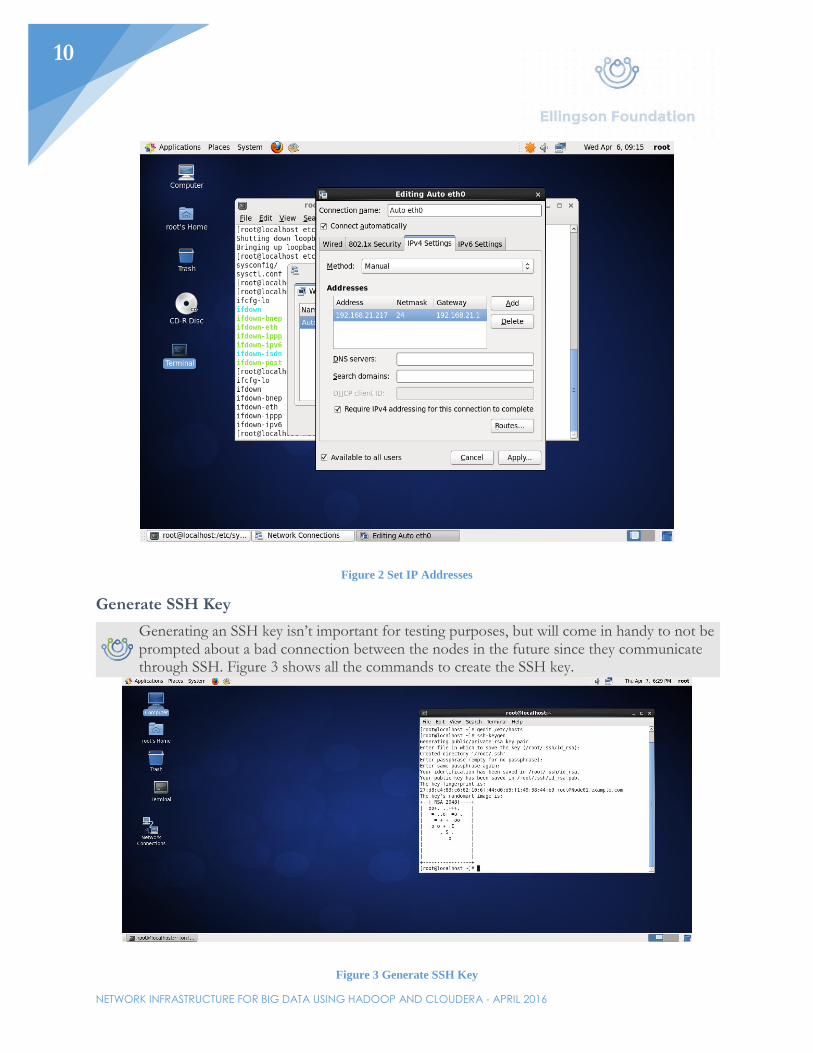
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
10
Figure 2 Set IP Addresses
Generate SSH Key
Generating an SSH key isn’t important for testing purposes, but will come in handy to not be prompted about a bad connection between the nodes in the future since they communicate through SSH. Figure 3 shows all the commands to create the SSH key.
Figure 3 Generate SSH Key
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
11
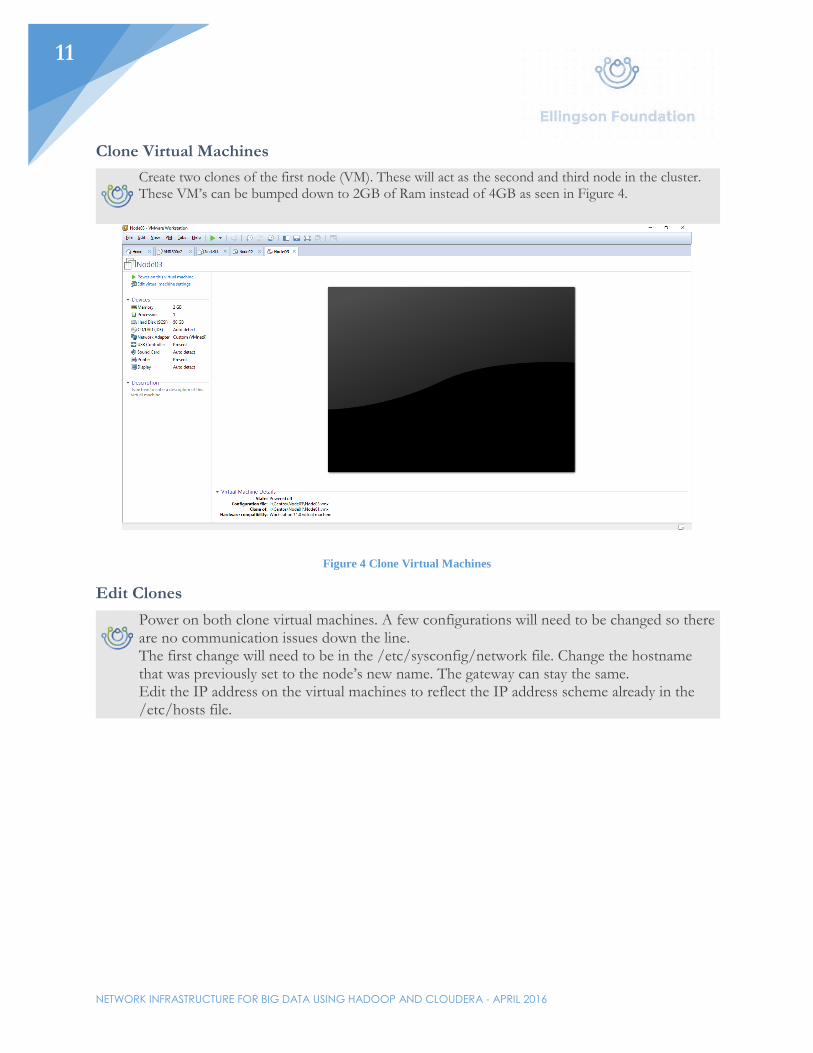
Clone Virtual Machines
Create two clones of the first node (VM). These will act as the second and third node in the cluster. These VM’s can be bumped down to 2GB of Ram instead of 4GB as seen in Figure 4.
Figure 4 Clone Virtual Machines
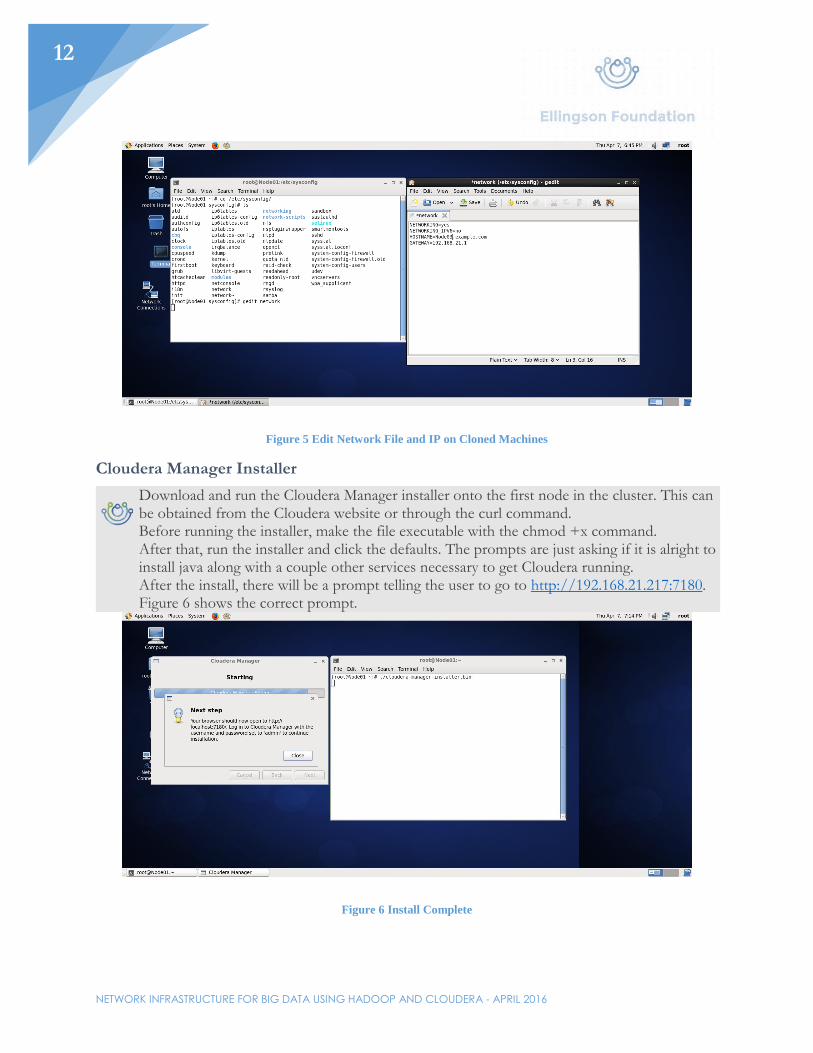
Edit Clones
Power on both clone virtual machines. A few configurations will need to be changed so there are no communication issues down the line. The first change will need to be in the /etc/sysconfig/network file. Change the hostname that was previously set to the node’s new name. The gateway can stay the same. Edit the IP address on the virtual machines to reflect the IP address scheme already in the /etc/hosts file.
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
12
Figure 5 Edit Network File and IP on Cloned Machines
Cloudera Manager Installer
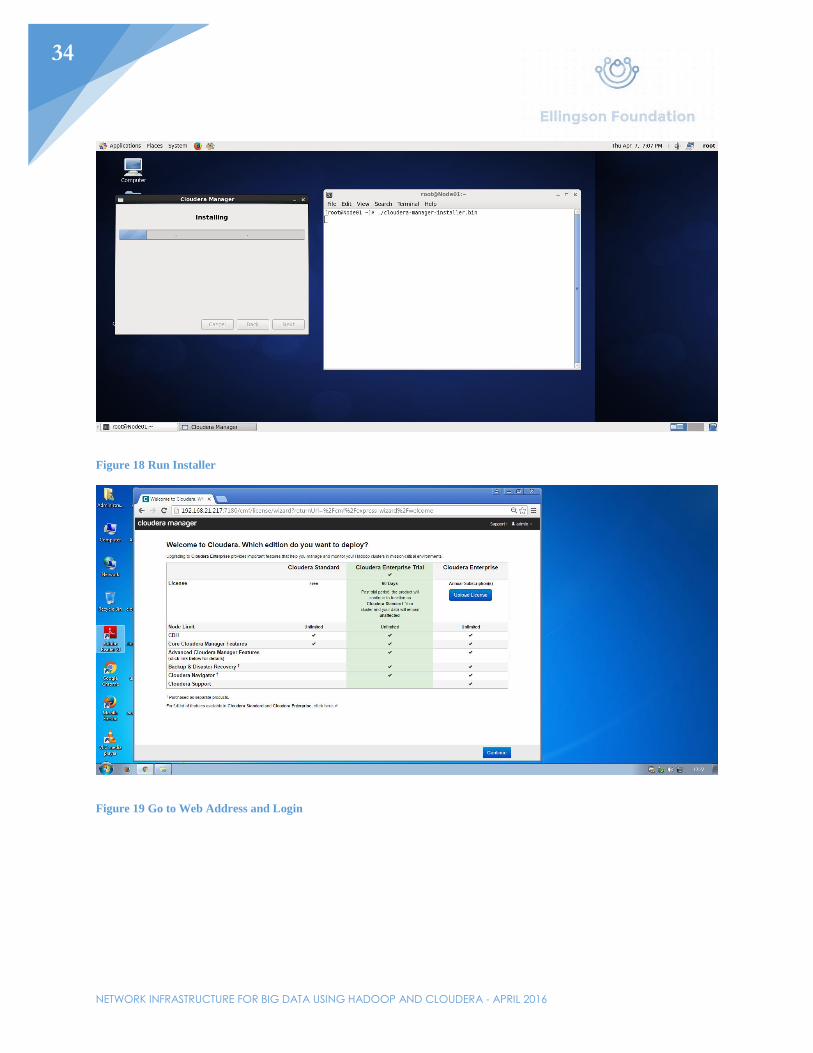
Download and run the Cloudera Manager installer onto the first node in the cluster. This can be obtained from the Cloudera website or through the curl command. Before running the installer, make the file executable with the chmod +x command. After that, run the installer and click the defaults. The prompts are just asking if it is alright to install java along with a couple other services necessary to get Cloudera running. After the install, there will be a prompt telling the user to go to http://192.168.21.217:7180. Figure 6 shows the correct prompt.
Figure 6 Install Complete

NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
13
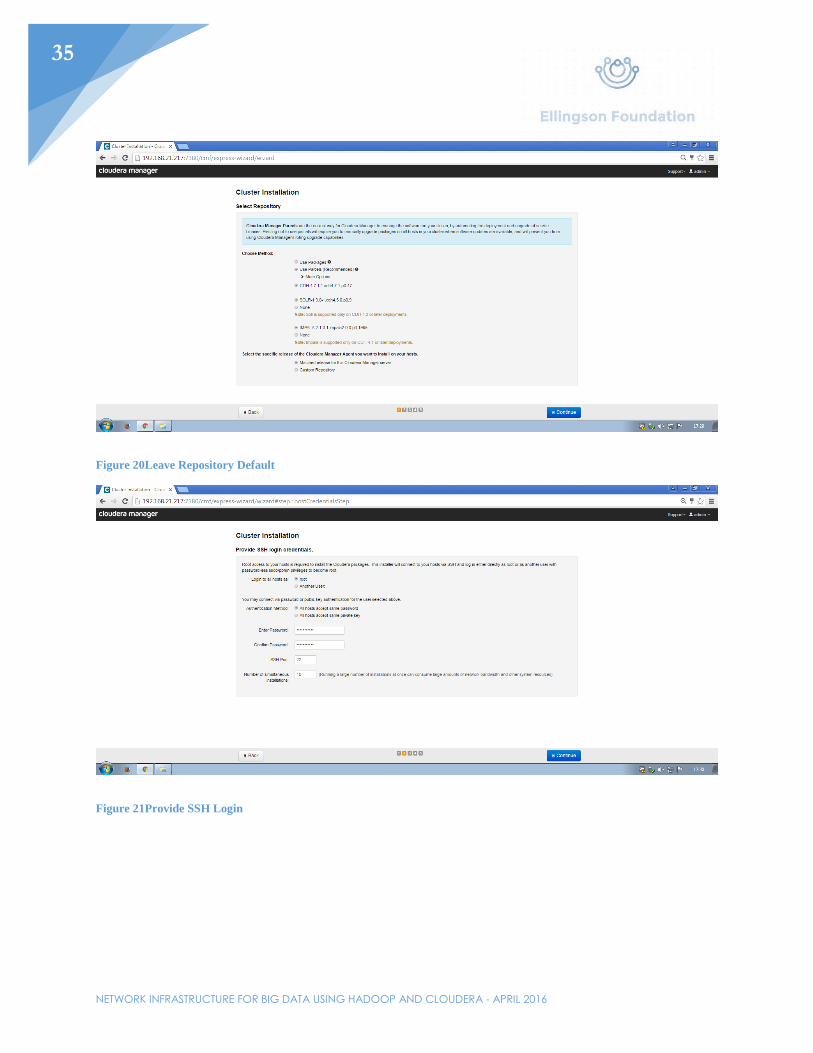
Installing Cloudera Services
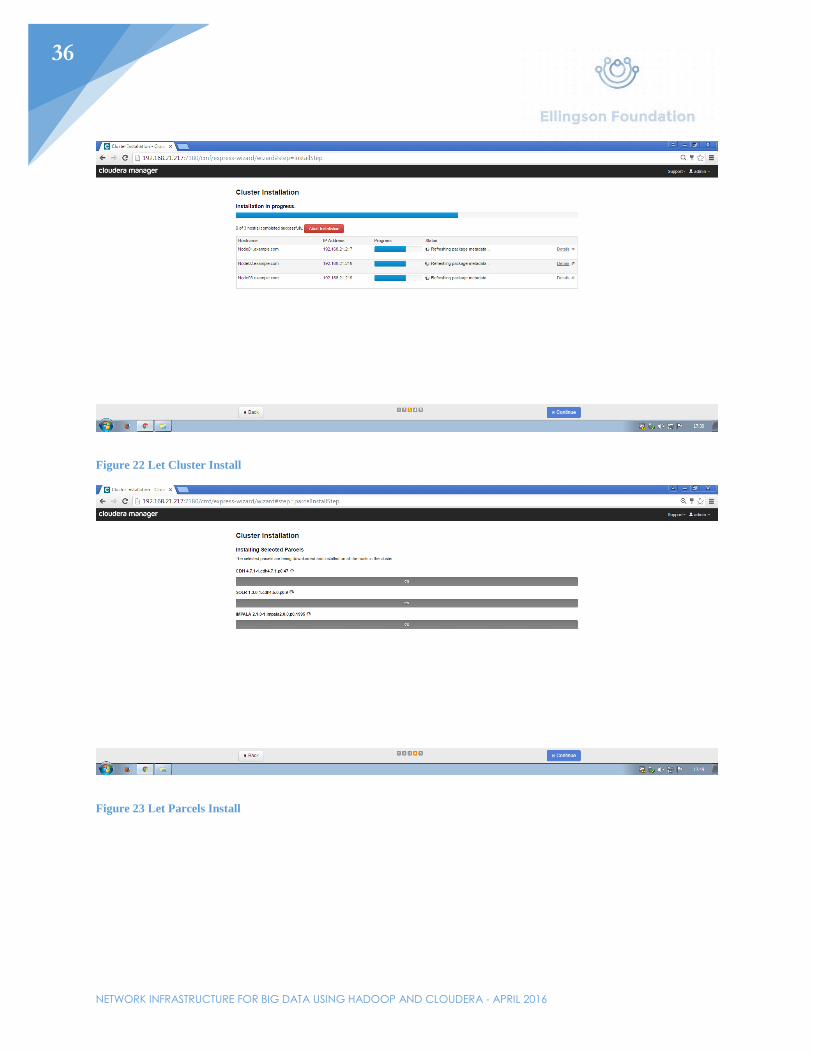
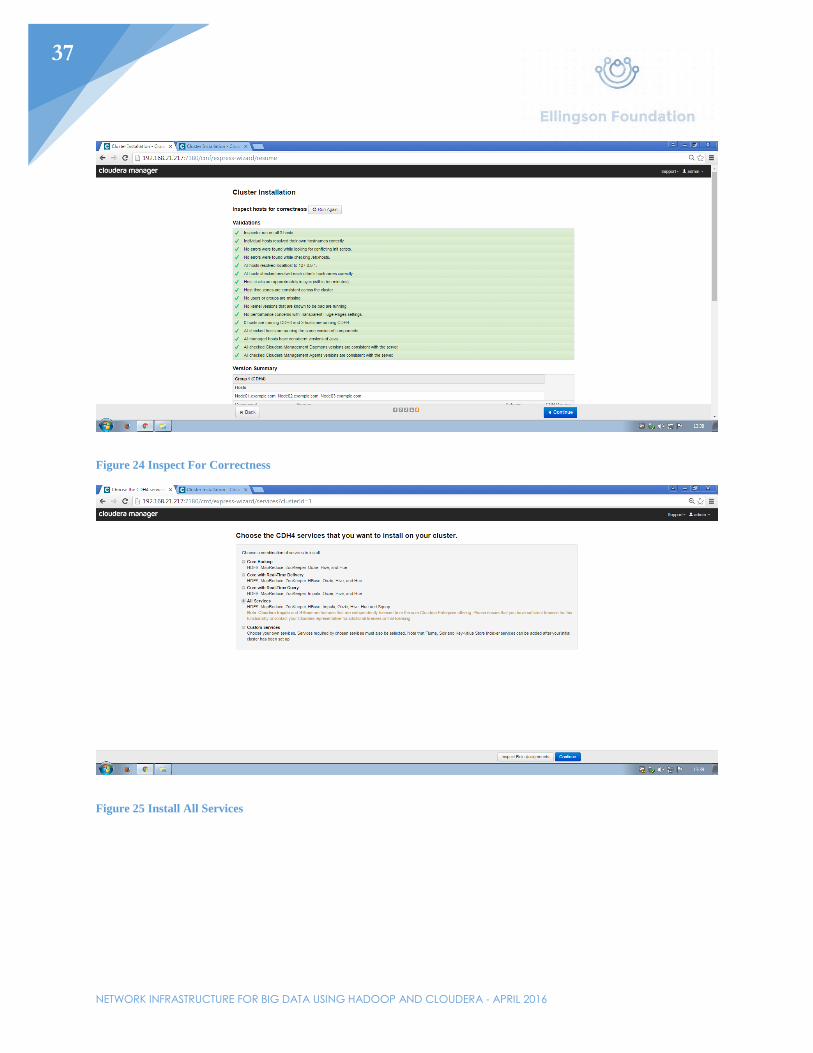
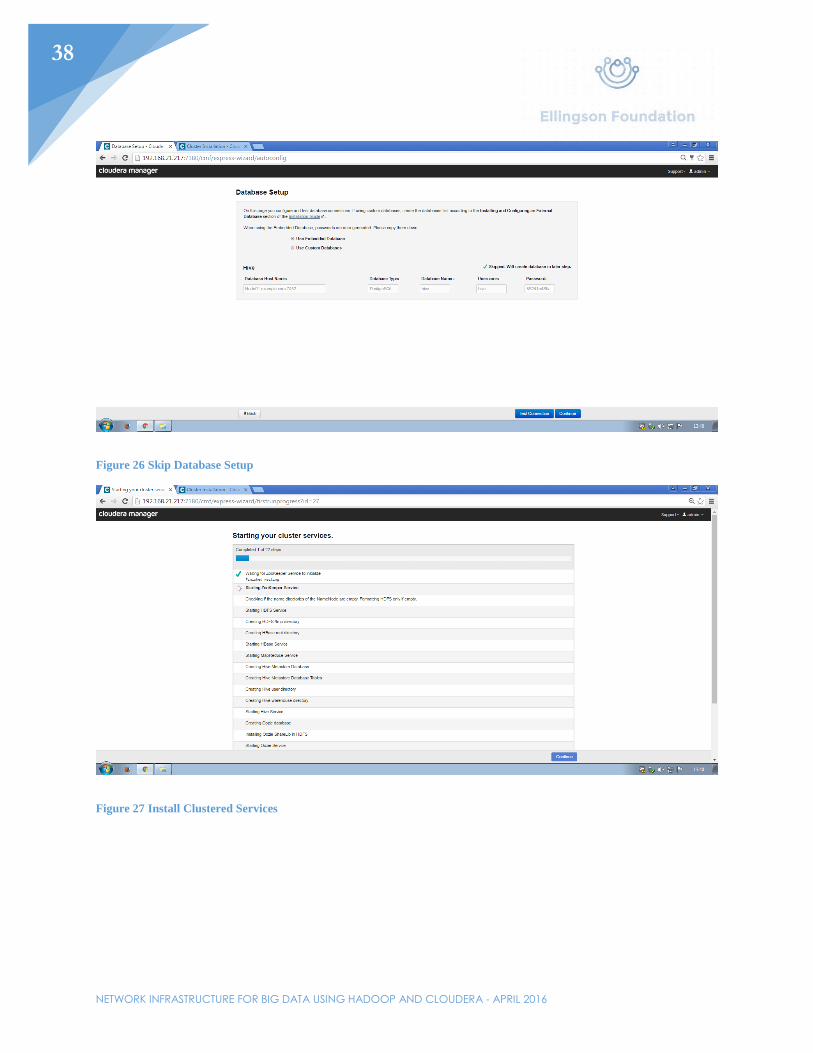
Once at http://192.168.21.217, click through the prompts for installing Cloudera manager’s services. The first prompt will ask which version of Cloudera should be installed. The standard will be used for this example. The second prompt will ask for each host in the cluster. Specify each node by IP address or hostname (shown in Figure 7). Third, select the default repository for installation. The fourth prompt will be creating an SSH login credential. Normally, another user would be selected, but for the purpose of this example, root was selected. Enter the password. As stated before, SSH is what the nodes will use to communicate with each other through secure means. This will secure the data in motion later while processing between all three nodes. After selecting “Continue”, cluster installation will begin. Let that finish and continue to the next page. Next, parcels will be installed. Let that finish and continue. On the next page, the installer will check for correctness. If there were any issues with the installation, they would show up here. Lastly, select the services that will be needed on this cluster. Select “All Services” and continue. All the services should install and a prompt for a database setup will pop up. Continue past this prompt since a database will be unnecessary for the demonstration purposes of this cluster. All services should then start.
Figure 7 Select Nodes to Install On
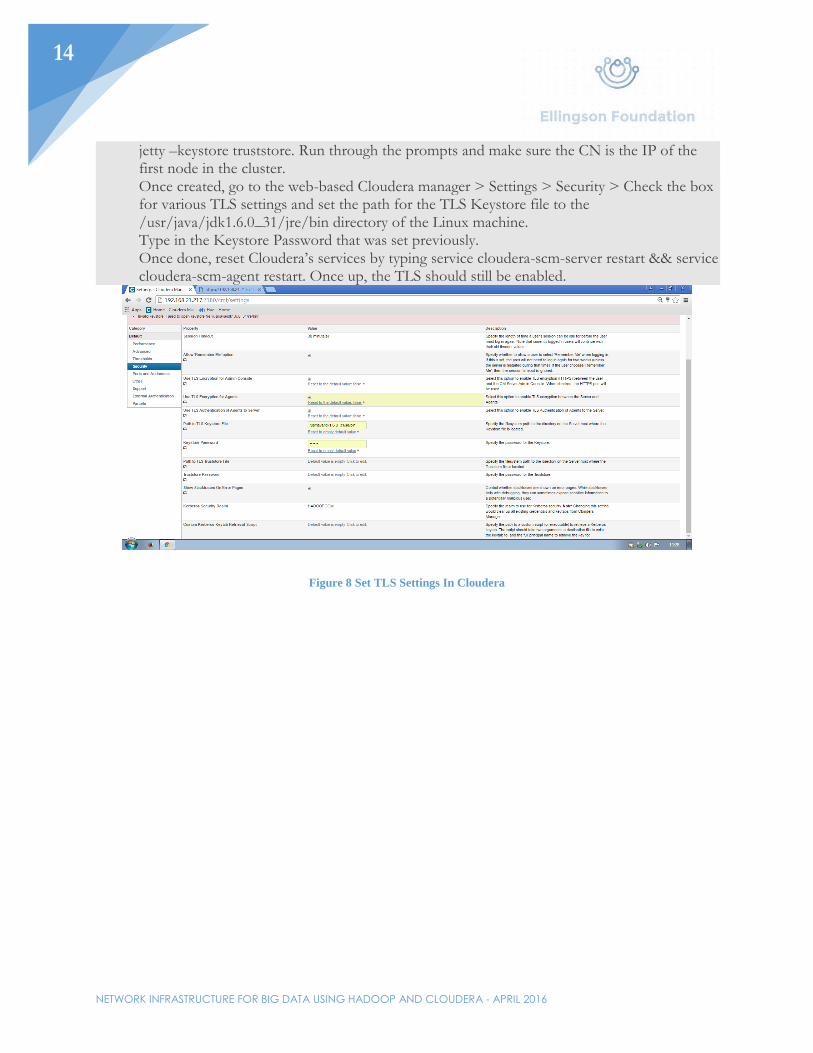
Further secure Hadoop/Cloudera
All nodes in the Hadoop cluster already communicate through SSH, which is inherently secure. This means data in motion is secured between the nodes. HDFS, when installed on the Linux system by Cloudera is secured by a basic level of encryption, which keeps the data at rest secured. More security settings for HDFS are put behind a paywall. There are settings for TLS on the agent, however. To set this up, go to Node01 and change directories to /usr/java/jdk1.6.0_31/jre/bin. Run the command, ./keytool –genkey –alias
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
14
jetty –keystore truststore. Run through the prompts and make sure the CN is the IP of the first node in the cluster. Once created, go to the web-based Cloudera manager > Settings > Security > Check the box for various TLS settings and set the path for the TLS Keystore file to the /usr/java/jdk1.6.0_31/jre/bin directory of the Linux machine. Type in the Keystore Password that was set previously. Once done, reset Cloudera’s services by typing service cloudera-scm-server restart && service cloudera-scm-agent restart. Once up, the TLS should still be enabled.
Figure 8 Set TLS Settings In Cloudera

NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
15
Running Jobs in Hadoop
The services have been installed, so the next thing to do would be to run a job. The job that was ran in this example consists of processing through 61,393 lines of code. Hadoop is able to tell which node of the cluster will take over which portion of the processing job. In turn, this creates a system where data is processed more efficiently. There is a constant heartbeat between the nodes, so if one goes down while in the middle of a job, that node’s processing will be handed off to another node without disturbing operations. This portion of the paper will focus on using the available services in an effort to kick off a simple project. This will be a small scale focus of something that will work almost exactly the same on a larger scale with more capable hardware. Just to keep the scope of this project in mind, think of Cloudera as the management platform in which Hadoop runs to cluster Nodes together. Hue is a service that Hadoop is able to run and manage. Pig is a process editor that runs MapReduce programs in a language called “Pig Latin” which is based off of Java and SQL. Users can also write programs for Pig in Java, Python, Javascript, Ruby, or Groovy.
Using Hue
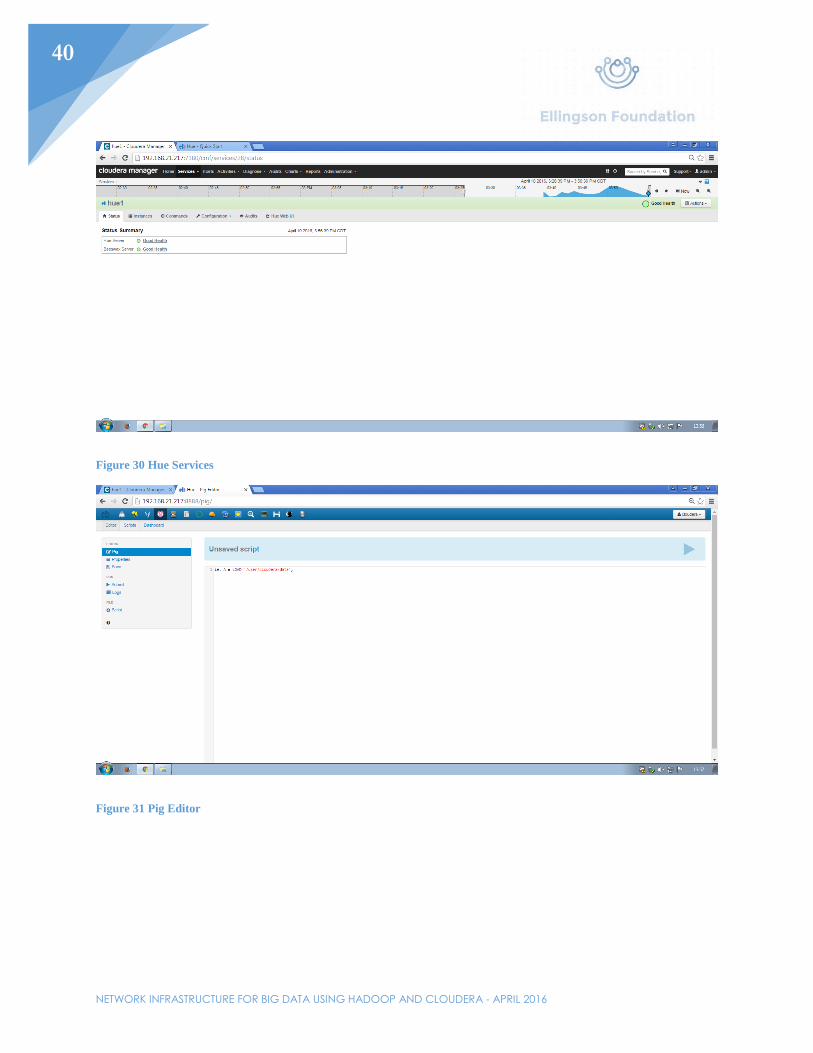
First, check to make sure Hue1 services installed correctly and are in good health. The web manager UI can be opened by going to Services > Hue1 > Hue Web UI. The IP address for this service is http://192.168.21.217:8888. The first time using this service, the user will need to create a login account. Once logged in, there are many different interfaces for running processes. Pig is the service that is going to be used in this example.
Figure 9 Hue Web Interface
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
16
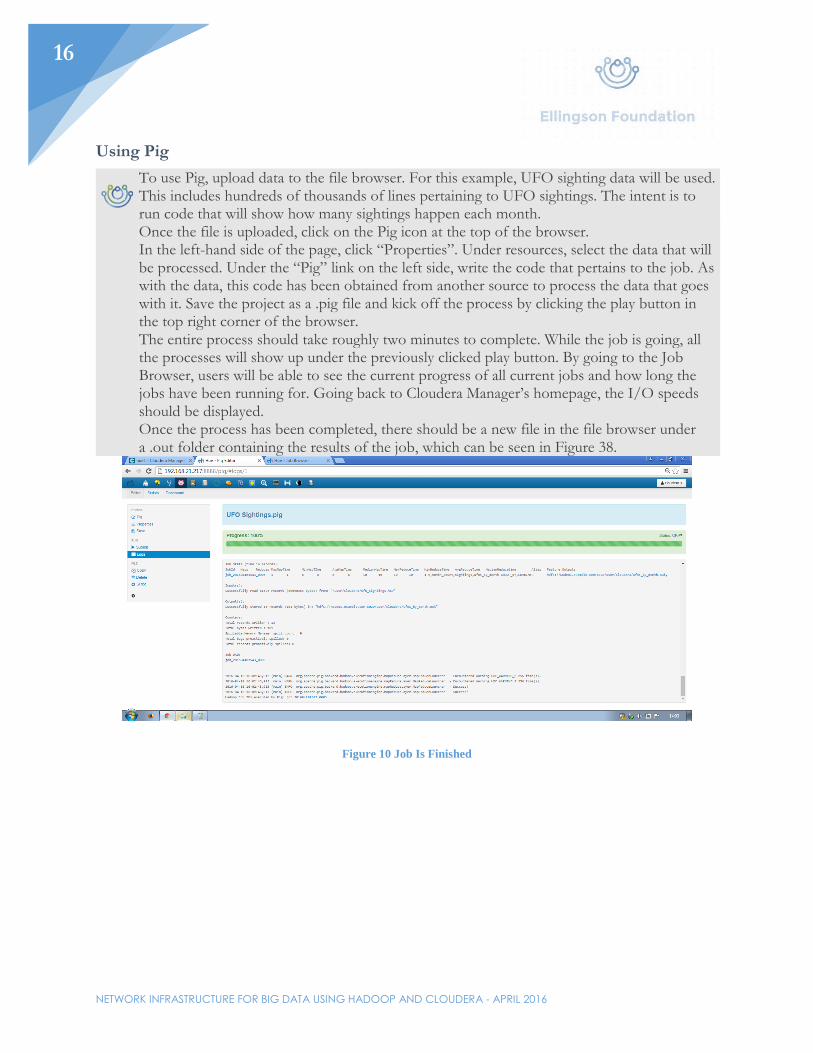
Using Pig
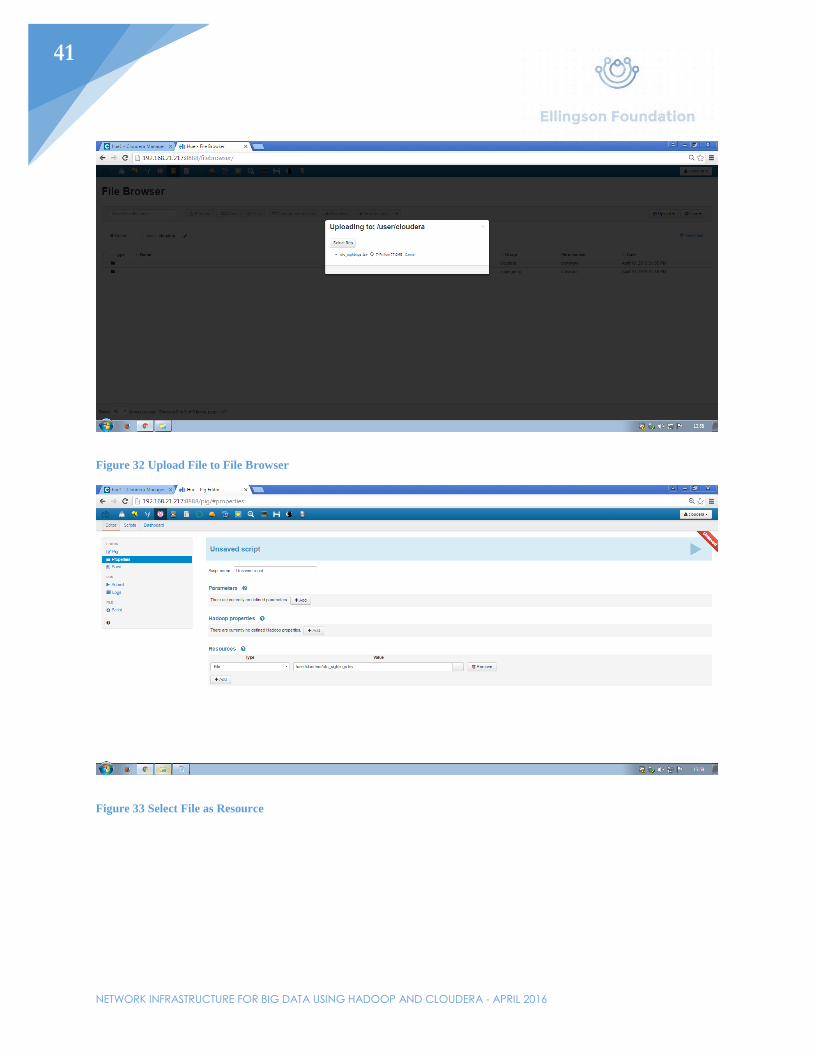
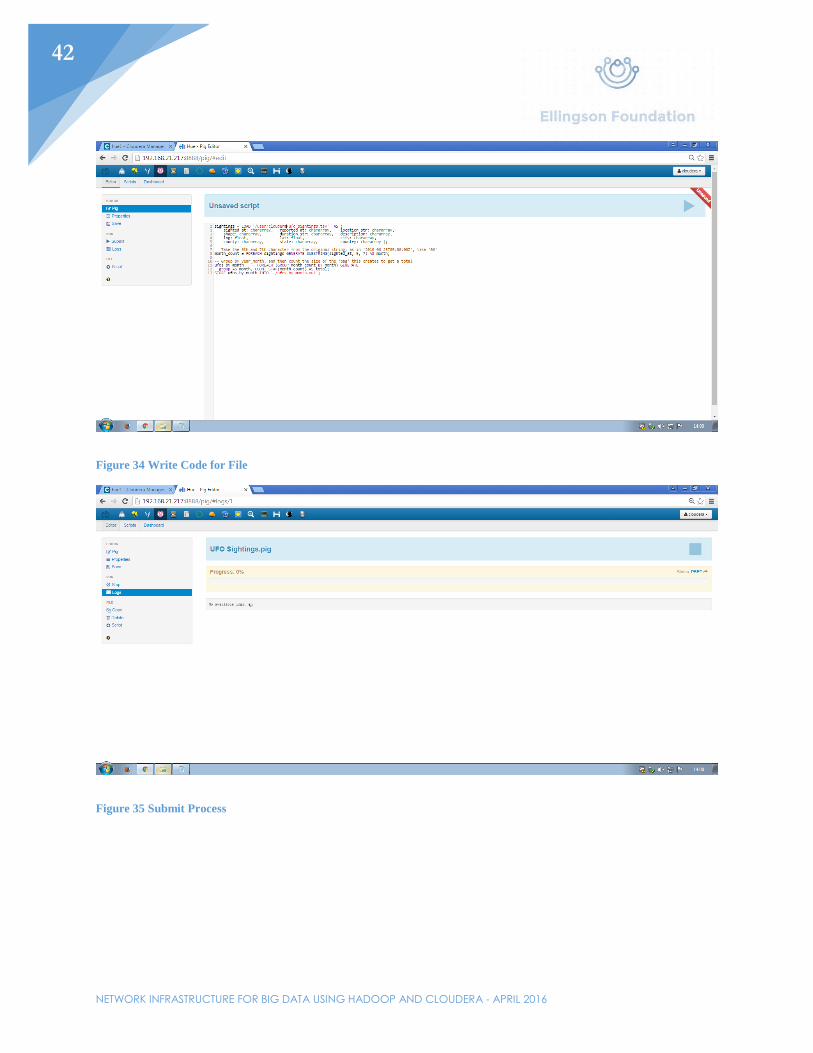
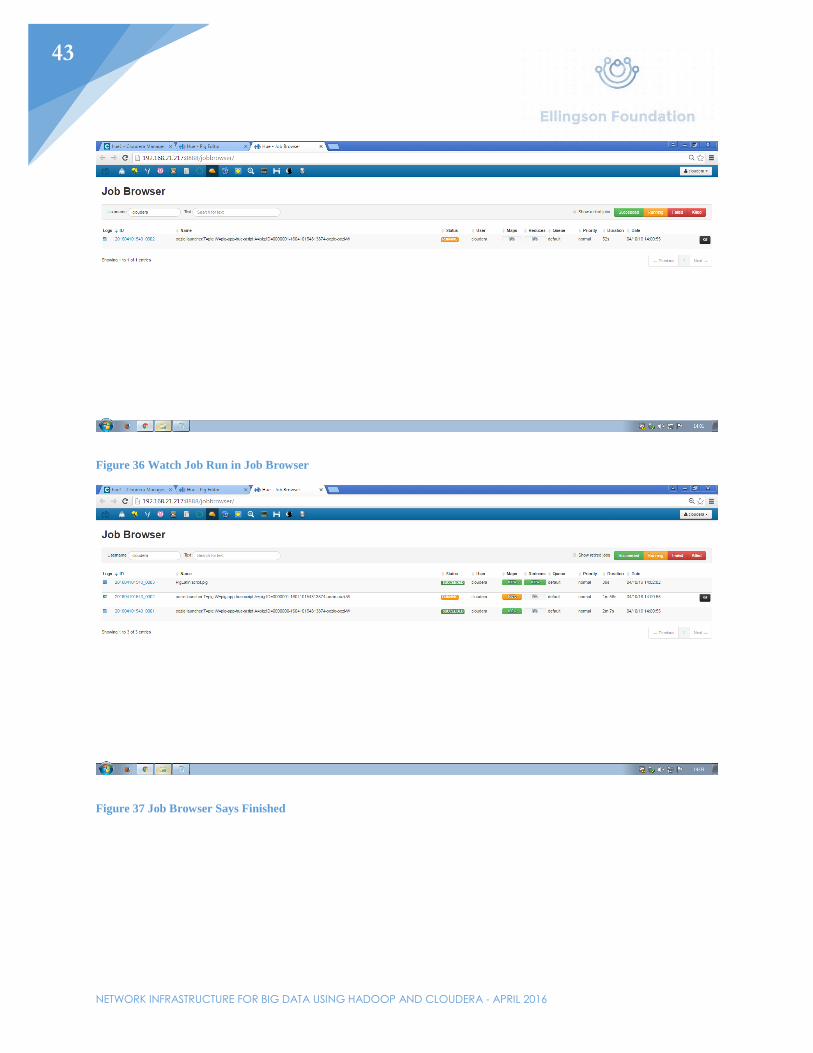
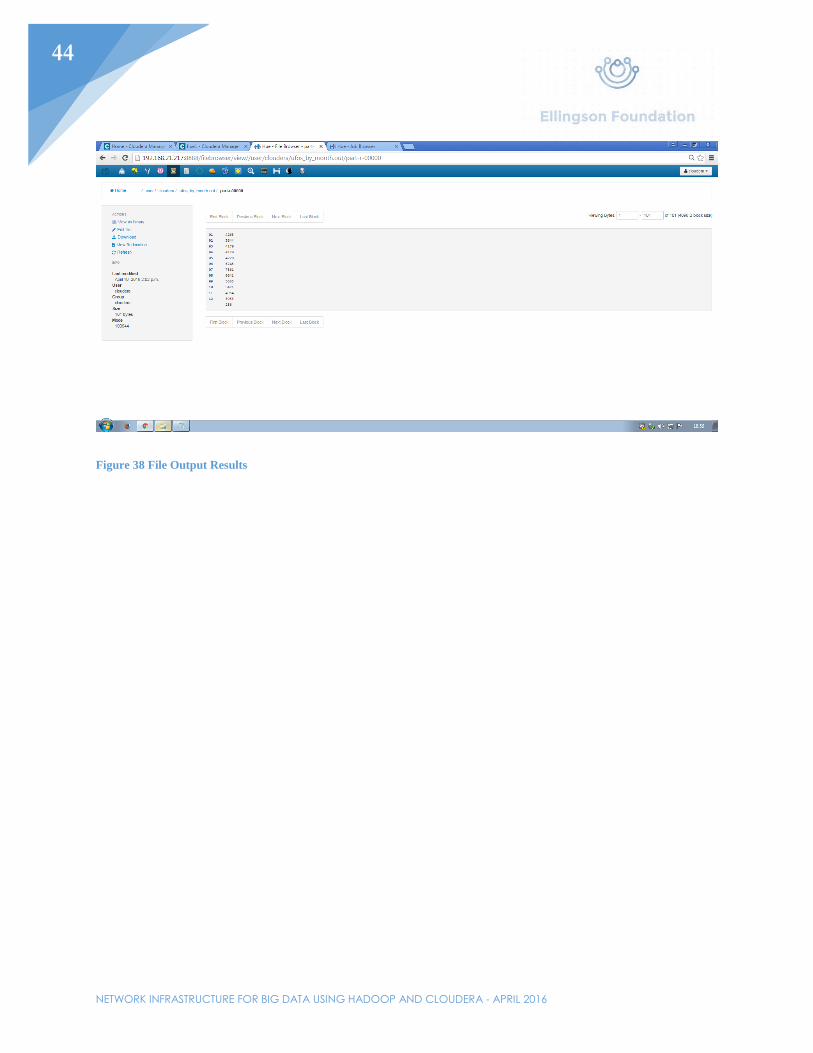
To use Pig, upload data to the file browser. For this example, UFO sighting data will be used. This includes hundreds of thousands of lines pertaining to UFO sightings. The intent is to run code that will show how many sightings happen each month. Once the file is uploaded, click on the Pig icon at the top of the browser. In the left-hand side of the page, click “Properties”. Under resources, select the data that will be processed. Under the “Pig” link on the left side, write the code that pertains to the job. As with the data, this code has been obtained from another source to process the data that goes with it. Save the project as a .pig file and kick off the process by clicking the play button in the top right corner of the browser. The entire process should take roughly two minutes to complete. While the job is going, all the processes will show up under the previously clicked play button. By going to the Job Browser, users will be able to see the current progress of all current jobs and how long the jobs have been running for. Going back to Cloudera Manager’s homepage, the I/O speeds should be displayed. Once the process has been completed, there should be a new file in the file browser under a .out folder containing the results of the job, which can be seen in Figure 38.
Figure 10 Job Is Finished

17
Difficulties
This project is full of major glaring issues. One of the first issues that could have been
easily avoided was to add more space in the hard drive from the beginning. Originally,
the hard drive that was used for the OS and log files was recommended to be 8GB.
This ended up being too small, and it was too late to extend the hard drive because of
snapshots and clones that needed the snapshots.
Next, since the hard drive in the original cluster was too small, a new cluster was built.
The original operating system that was used was Debian 6. The original cluster was
built in January of 2016 and support for the operating system was discontinued in
February of 2016. Since this was discovered half-way through the term, a quick decision
needed to be made. The project was quickly shifted to Centos after testing the
capabilities of Hadoop on a quick start virtual machine provided by Cloudera. After this
change, the rest of the project was fairly straightforward.

NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
18
Conclusion
To conclude, big data is becoming a crucial part in many markets. The ability to process
large amounts of data is necessary to properly understand a market. Using Hadoop
alongside with Cloudera provides a cost-effective solution for processing big data, while
also holding up to industry standards. Hadoop allows for thousands of terabytes to be
processed by many nodes. Each node can take over for another node in the event of
failure, making Hadoop very robust and dependable. Cloudera allows for IT and
processing teams to navigate a well-made user interface, allowing training time to lower
significantly compared to competitors. Having these services in a cluster allows the
platform to be modular and grow, while still keeping costs lower than dedicated
application servers.

NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
19
References
Cloudera. (2015). HDFS Data At Rest Encryption. Retrieved from Cloudera: http://www.cloudera.com/documentation/enterprise/5-4-x/topics/cdh_sg_hdfs_encryption.html Grubbs, G. (2012). First job in Hadoop using Syncsort DMExpress. Retrieved from Youtube: https://www.youtube.com/watch?v=1ArXR5cl9fk Hadoop. (2015). What Is Apache Hadoop? Retrieved from Hadoop: http://hadoop.apache.org/ Hansen, C. A. (2012). Optimizing Hadoop for the cluster. Institue for Computer Science, University of Troms0, Norway, http://oss. csie. fju. edu. tw/~ tzu98/Optimizing% 20Hadoop% 20for% 20the% 20cluster. pdf, Retrieved online October. Islam, M., Huang, A. K., Battisha, M., Chiang, M., Srinivasan, S., Peters, C., ... & Abdelnur, A. (2012, May). Oozie: towards a scalable workflow management system for hadoop. In Proceedings of the 1st ACM SIGMOD Workshop on Scalable Workflow Execution Engines and Technologies (p. 4). ACM. Rohloff, K., & Schantz, R. E. (2010, October). High-performance, massively scalable distributed systems using the MapReduce software framework: the SHARD triple-store. In Programming Support Innovations for Emerging Distributed Applications (p. 4). ACM. Shvachko, K., Kuang, H., Radia, S., & Chansler, R. (2010, May). The hadoop distributed file system. In Mass Storage Systems and Technologies (MSST), 2010 IEEE 26th Symposium on (pp. 1-10). IEEE. Taylor, R. C. (2010). An overview of the Hadoop/MapReduce/HBase framework and its current applications in bioinformatics. BMC bioinformatics,11(Suppl 12), S1. Vavilapalli, V. K., Murthy, A. C., Douglas, C., Agarwal, S., Konar, M., Evans, R., ... & Saha, B. (2013, October). Apache hadoop yarn: Yet another resource negotiator. In Proceedings of the 4th annual Symposium on Cloud Computing (p. 5). ACM. White, T. (2012). Hadoop: The definitive guide. " O'Reilly Media, Inc.". Wilson, C. (2015, 7 15). (R. Ellingson, Interviewer)
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
20
Appendix
Progress Report 01
Project Name Network Infrastructure For Big Data Using Hadoop And Cloudera
Report by Ryan Ellingson
Reporting Date 3-11-15
Section One: Summary
This projects is to use three Debian Linux (virtual) machines that will be clustered together to run Hadoop. To manage the software and the jobs, I will use Cloudera. With this solution, upgrading the server is as simple as adding in another node to the cluster, which is more cost effective than outright buying an upgraded application server to process ‘big data’.
In this week, I have filled out my Capstone Proposal Template and the PowerPoint that goes along with it.
Section Two: Activities and Progress
Challenges this week included filling out everything in the template to convey the exact message I needed to get through to the audience.
Section Three: Issues and Challenges
No real issues yet other than potentially not understanding exactly what the template is asking.
Section Four: Outputs and Deliverables
My presentation and template have been uploaded (pending updates after in class discussion).
Section Five: Outcomes and Lessons Learned
Going off of the course objectives presents a challenge when conveying my project to an audience. While not impossible, further clarification might be needed.
Section Six: Next Steps
I need to diagram my network, create a comprehensive project file of my weekly accomplishments, and further research Hadoop/Cloudera.
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
21
Progress Report 02
Project Name Network Infrastructure For Big Data Using Hadoop And Cloudera
Report by Ryan Ellingson
Reporting Date 3-15-16
Section One: Summary
In this week, I have created the project file, basic network diagram (will add more detail later), and have researched more about Hadoop/Cloudera.
Section Two: Activities and Progress
The project file created will outline my weekly work (will be uploading with this document). It details how complete my project is and which dependencies each task will need. The visio diagram I created is very simplistic and will probably have more added to it later. Information I have researched includes encryption and other Hadoop securities.
Section Three: Issues and Challenges
The issue this week was figuring out how to get some sort of security features integrated with Hadoop. Although I knew I would need security, the different avenues that can be taken are going to require more thought. Otherwise, after presentations, I realized my proposal should be a little more descriptive, and as such will need to be updated.
Section Four: Outputs and Deliverables
I will be uploaded my (work in progress) Network Diagram and Microsoft Project files.
Section Five: Outcomes and Lessons Learned
Right now the biggest things I am learning relate to the scope of the project and how long it will take to complete. The security measures needed for Hadoop are also a learning point, but I will invest more time and research into that at a later date.
Section Six: Next Steps
The next big steps will be larger research and setting up my implementation of the capstone project.
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
22
Progress Report 03
Project Name Network Infrastructure For Big Data Using Hadoop And Cloudera
Report by Ryan Ellingson
Reporting Date 3-25-2016
Section One: Summary
Please provide a short overview (1-2 paragraphs) of project progress during this reporting period, which could be disseminated to stakeholders.
Section Two: Activities and Progress
This week I had to fix virtual machines, which wasn’t necessarily in my paperwork. I had set up my virtual machines, and the cloned second and third node wouldn’t boot up. No processes have been done, but the correct services have been installed.
Section Three: Issues and Challenges
My progress was halted for a couple of days because of a strange error with the .vmx file. In this file, the path showing where the VMDK files were located did not change once copied to a new location. As a result, my two cloned nodes would not boot.
Section Four: Outputs and Deliverables
I have a few screenshots I can zip together with this progress report. These screenshots will show the progress of the project.
Section Five: Outcomes and Lessons Learned
The next step would be more research on how HDFS works exactly and potentially setting up a working process. I’d also like to eventually see what more can be done about security through Cloudera. It might take more research before being implemented though.
Section Six: Next Steps
In this section you should very briefly list the activities planned and/ other information of relevance for
the next stage of the project.
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
23
Progress Report 04
Project Name Network Infrastructure For Big Data Using Hadoop And Cloudera
Report by Ryan Ellingson
Reporting Date 4/1/2016
Section One: Summary
During this week, I worked out all the kinks with starting up my Virtual Machines. I also worked on getting a .jar file ready to be ran. I want to use this as a word count process for some documents that I have.
Section Two: Activities and Progress
I was able to research the needed HDFS security settings, but still have yet to implement them. I will implement them once I get a process kicked off.
Section Three: Issues and Challenges
I was getting an error with the .jar file that was included in the cloudera demos. After some research, I was able to write my own .jar file for wordcount, but will need more time to test it properly.
Section Four: Outputs and Deliverables
I don’t have anymore screenshots from this week. Instead, I have the .jar file that I am going to use.
Section Five: Outcomes and Lessons Learned
I was able to streamline a method for getting my vmx files to setup properly, something that’s been an issue for a couple weeks now. I was also able to research how to secure cloudera and Hadoop properly. Another thing that I was able to learn was how to make a (hopefully) proper .jar file that can run on the cluster.
Section Six: Next Steps
I want to run the .jar wordcount file this next week and hopefully be able to get some sort of documentation wrapped up for the process of it. I’d also like to potentially have a video of something working. If not, I’m going to look back at some of the basics on Cloudera to see if it could be setup a little more efficiently.
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
24
Progress Report 05
Project Name Network Infrastructure for Big Data Using Hadoop and Cloudera
Report by Ryan Ellingson
Reporting Date 4/7/2016
Section One: Summary
I was able to get to the processing of data on my cluster. There were a few issues that will be covered in section three that I will be able to overcome. As for right now, I’m setting my project up again in an effort to maximize service efficiency.
Section Two: Activities and Progress
I will be changing the back end infrastructure of my project from Debian Linux to CentOS. The version of Debian Linux that was being used has gone out of service and is no longer being supported (very recently). As such, I have done research on the issue and have found CentOS will better fit the needs of the outlined project.
Section Three: Issues and Challenges
As stated above, CentOS will be the new back end of the Hadoop cluster. The problem with Debian is that some of the services won’t start properly on any of the current systems since Cloudera doesn’t support it fully. When I use the OS that I had been using up to this point, some of the services wouldn’t start at all, meaning I could not run any program to test the cluster out. After doing research, I have found that CentOS 6.2 fully supports all the necessary services to run a program on the cluster.
Section Four: Outputs and Deliverables
Currently, since I will have to redo some of my documentation and start new virtual machines (even though it shouldn’t take too long to setup now that I have more information on how the setup should work) I don’t have any new documentation to share.
Section Five: Outcomes and Lessons Learned
This week, I was able to learn more about security for the cluster (how exactly to secure the data in both transit and at rest), I learned a lot about log files that Cloudera outputs and the important to the infrastructure they hold, various services, and compatibility with different Linux distributions.
Section Six: Next Steps
By next week, I want to have processed something on the new CentOS infrastructure and begin the editing/updating of my documentation (PowerPoint, screenshots, project file, and white paper).
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
25
Progress Report 06
Project Name Network Infrastructure for Big Data Using Hadoop and Cloudera
Report by Ryan Ellingson
Reporting Date 4/14/2016
Section One: Summary
During this week, I have setup the new Centos Hadoop Cluster that I mentioned in my previous progress report. As of today, some documentation has been created, but I still will need the next week to finalize and prepare everything.
Section Two: Activities and Progress
This week, I used all the previous knowledge from setting Hadoop up on Debian Linux to set everything up on Centos Linux. This process took significantly less time since I already have an understanding of what needed to be done. I was able to secure the system and run data processing that produced a result file.
Section Three: Issues and Challenges
The main issue is security at this point. Though it was setup, there is still some security measures behind a paywall, which I will address in my final presentation and white paper. Other than that, I have to get all my documentation done. This should take me the next week to finalize.
Section Four: Outputs and Deliverables
I have finished part of my white paper (which will be uploaded separately to another upload link in blackboard). I am also working to update my project file. I will upload the project file with this sheet.
Section Five: Outcomes and Lessons Learned
I finally learned how to streamline the process of setting up the Hadoop/Cloudera cluster and which supported operating systems work better than the others. Security availability was also a lesson learned this week. Some forms of security are locked behind a paywall, while others can be accessed with other means.
Section Six: Next Steps
As stated above, the next and final step will be to finalize my documentation this next week. I have most of the how-to documentation completed, but I still need to correct everything else in my white paper. I will also need to make a lot of changes to my presentation this next week.
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
26
Progress Report 07
Project Name Network Infrastructure For Big Data Using Hadoop And Cloudera
Report by Ryan Ellingson
Reporting Date 4/20/2016
Section One: Summary
In this week, I have created finalized all of my documentation, finalized the demonstration for class, and prepped for the upcoming presentation.
Section Two: Activities and Progress
Nothing has really changed besides everything. Overall, I have kept on track for creating all the documentation that I needed last week. I have met with Joe and found out exactly everything that needs to be updated and changed.
Section Three: Issues and Challenges
The only issue that I am having right now is formatting, which will be simple enough to sort out. There is nothing technical that is causing issues for me right now.
Section Four: Outputs and Deliverables
I will have finalized versions of my documentation ready to upload next week.
Section Five: Outcomes and Lessons Learned
This week, I learned how to better create a white paper. My template was somewhat wrong.
Section Six: Next Steps
The next big step is presenting my project, graduating it, and making it in the real world like the 300 Spartan that I trained for three years to be.

NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
27
Course Objectives
1. Demonstrate proficiency in networking, standards, and security issues necessary
to design, implement, and evaluate information technology solutions. This project is based around setting up a secure network infrastructure. This project utilizes
specific network and security standards such as account creation for specific user management, and logging of said user's actions.
2. Design, develop, and evaluate systems based on end-user profiles and interactions.
This project is being made with users’ ease of use in mind. Implementing
Cloudera will not only make setup easier for IT professionals, but also be
easier for the end-users that will be interacting with the Hadoop cluster. Users
will be given a comprehensive UI with Cloudera to navigate the cluster.
3. Reconcile conflicting project objectives in the design of networking and security
systems, finding acceptable compromises within limitations of cost, time,
knowledge, existing systems, design choices, and organizational requirements.
Instead of utilizing one application server to “rule them all”, I will be creating
a cluster that can easily and quickly be expanded upon. Adding more
nodes to the cluster will increase processing, while still being cheaper that
buying a new application server. Cloudera will also allow users to securely
log into the cluster to process their jobs.
4. Articulate organizational, operational, ethical, social, legal, and economic issues
impacting the design of information technology systems.
This project shows improved processing efficiency in a company with
industry leading cluster technology that is both faster than competitors and
efficient in the event of node failure.
5. Apply current theories, models, and techniques in the analysis, design,
implementation, and testing of secure network infrastructures across LANs and
WANs.
This project is the culmination of research on technology dealing with ‘big
data’ and what the best way to process it would be. Data will have to be
secured in an effort to secure personal data. Connection to Cloudera will be
secured to Cloudera.
6. Think critically at a conceptual level and by using mathematical analysis as well
as the scientific method; write and speak effectively; use basic computer
applications; and understand human behavior in the context of the greater
society in a culturally diverse world.
This project is being designed as a means to implement 'big data'. As such,
conceptualizing network diagrams, use cases, and proper procedures is
necessary to comprehensively detail the project. For example, using
Hadoop could be cumbersome by itself, but getting a management solution
like Cloudera to allow easier management is an effective choice to allow
easy human interaction with Hadoop.
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
28
Images
Figure 11 Install Centos
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
29
Figure 12 Change Gateway
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
30
Figure 13 Update Resolve Conf File
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
31
Figure 14 Disable SELINUX
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
32
Figure 15 Turn Off IPTables
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
33
Figure 16 Update Host File With All Nodes
Figure 17 Download Cloudera Manager and Make Executable
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
34
Figure 18 Run Installer
Figure 19 Go to Web Address and Login
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
35
Figure 20Leave Repository Default
Figure 21Provide SSH Login
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
36
Figure 22 Let Cluster Install
Figure 23 Let Parcels Install
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
37
Figure 24 Inspect For Correctness
Figure 25 Install All Services
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
38
Figure 26 Skip Database Setup
Figure 27 Install Clustered Services
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
39
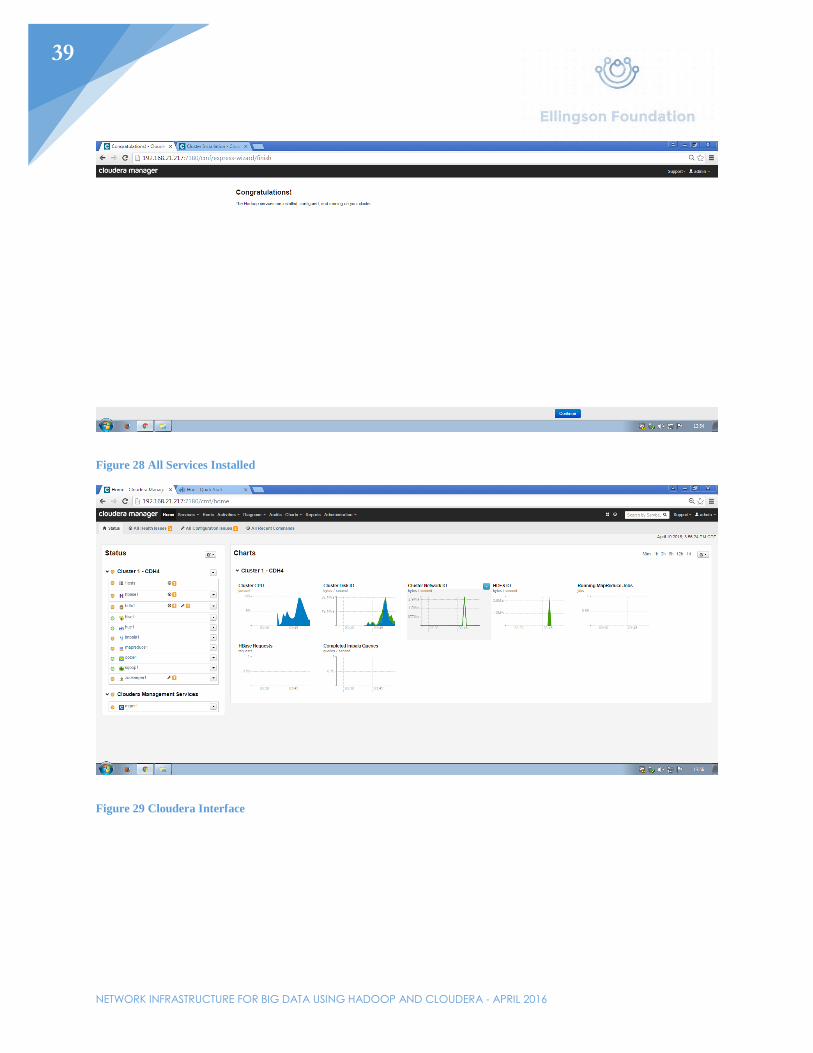
Figure 28 All Services Installed
Figure 29 Cloudera Interface
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
40
Figure 30 Hue Services
Figure 31 Pig Editor
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
41
Figure 32 Upload File to File Browser
Figure 33 Select File as Resource
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
42
Figure 34 Write Code for File
Figure 35 Submit Process
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
43
Figure 36 Watch Job Run in Job Browser
Figure 37 Job Browser Says Finished
NETWORK INFRASTRUCTURE FOR BIG DATA USING HADOOP AND CLOUDERA - APRIL 2016
44
Figure 38 File Output Results


















