
Final Report for WP4 - CommRob · • RFID Radio-Frequency Identification ... ends the report. 2...
30
Basic Functions for Detection/Recognition of People CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots page 1/30 Final Report for WP4 Workpackage WP4 Task All Document type Deliverable 4.6 Title Synthetic report Subtitle COMMROB Project Authors T.Germa, F.Lerasle, P. Danès (LAAS) M.Goeller, T.Kerscher (FZI) Internal Reviewers V.Cadenat, J. Manhès, A.Mekonnen, N.Ouadah, A.Petiteville (LAAS) Version V0 Status Final Distribution Public
Transcript of Final Report for WP4 - CommRob · • RFID Radio-Frequency Identification ... ends the report. 2...

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 1/30
Final Report for WP4
Workpackage WP4 Task All Document type Deliverable 4.6 Title Synthetic report Subtitle COMMROB Project Authors T.Germa, F.Lerasle, P. Danès (LAAS)
M.Goeller, T.Kerscher (FZI) Internal Reviewers V.Cadenat, J. Manhès, A.Mekonnen, N.Ouadah, A.Petiteville (LAAS)Version V0 Status Final Distribution Public

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 2/30
History of changes
Date Ver.
Author(s) Change description
2010/05/21 0.x V.Cadenat, P. Danès, T. Germa, F. Lerasle, N.Ouadah (LAAS) M.Goeller, T.Kerscher (FZI)
Initial iterations between the authors
2010/05/27 1.0 P. Danès, T. Germa, F. Lerasle (LAAS)
Integration of internal reviews

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 3/30
Summary This deliverable lists one after another the functionalities that have been developed in this WP and which have already been enumerated in the deliverable D4.1@m8 titled “report on Human-Robot interaction specification”. The required hardware and software were presented while details concerning the input, description, output of components and their importance in the overall layered architecture were given. This deliverable gives an overview of these functionalities, together with their current status and associated results. The entire details regarding theory, evaluations, and comments can be found in the associated papers which can be sent to the reviewers on request.

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 4/30
Table of contents
1 Introduction ............................................................................................................................. 5
1.1. Purpose of the Document .......................................................................................................... 5
1.2. Definitions, Acronyms, Abbreviations, and Notation Conventions............................................ 5
1.3. Organization of the Document................................................................................................... 6
2 Trolley locomotion ................................................................................................................... 6
2.1 Haptic command interpretation................................................................................................. 7
2.2 Person detection ........................................................................................................................ 8
2.2.1 Framework.................................................................................................................................. 8
2.2.2 Recent developments and evaluations ...................................................................................... 9
2.2.3 Framework................................................................................................................................ 12
2.2.4 Recent developments and evaluations .................................................................................... 12
2.3 Person tracking: framework ..................................................................................................... 15
3 User‐Trolley communication ................................................................................................. 17
3.1 Localization and voice extraction ............................................................................................. 17
3.1.1 Framework................................................................................................................................ 17
3.1.2 Recent developments and evaluations .................................................................................... 19
3.2 Focus of attention detection .................................................................................................... 22
3.3 Upper body parts detection an tracking: framework............................................................... 23
3.4 Gesture interpretation ............................................................................................................. 24
3.4.1 Framework................................................................................................................................ 24
3.4.2 Recent developments and evaluations .................................................................................... 25
4 Conclusion.............................................................................................................................. 25
5 Publications related to WP4 .................................................................................................. 26
References............................................................................................................................................. 28

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 5/30
1 Introduction
1.1. Purpose of the Document This document reports the final investigations carried out within the tasks of the workpackage WP4. Recall that the aims of COMMROB’s WP4 is the development and implementation of functionalities enabling two main tasks: (1) coordinated User/Trolley motions thanks to physical (haptic) or non-physical (vision, audio, laser) contact, and (2) human friendly User/Trolley multimodal communication through speech and/or gesture.
Evaluations of the LAAS functionalities are twofold. Off-line evaluations rely on sensor stream collected by the LAAS platform Rackham during several runs under a wide variety of H/R situations and environmental conditions. Online evaluations for coordinated U/T motions (resp. U/T communication) characterize the whole on-board functionalities on Rackham (resp. Jido) before further transfer on the trolley InBot. Recall that Rackham is an iRobot B21r mobile platform (Figure 1). Its standard equipment has been extended with one pan-tilt Sony camera EVI-D70, one digital camera mounted on a Directed Perception pan-tilt unit, a SICK laser range finder, 8 RF antennas and a reader. Jido is equipped with a 6-DOF arm, a pan-tilt stereo head system at the top of a mast and two laser scanners.
Figure 1: Rackham and Jido and their sensor equipments.
The entire details, theory, evaluations, and comments regarding these functionalities have been published in international conferences or journals that can be sent to the reviewers on request.
1.2. Definitions, Acronyms, Abbreviations, and Notation Conventions The basic terminology introduced in the previous deliverables is hereafter reminded, together with the associated acronyms.
• Trolley (T) • User (U)
Other Acronyms, Abbreviations and Notation are as follows: • RFID Radio-Frequency Identification

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 6/30
• LRF Laser Range Finder • HRI Human-Robot Interaction • FR Face Recognition • IAV Inscribed Angle Variance • ROI Region Of Interest • PCA Principal Component Analysis • LDA Linear Discriminant Analysis • GA Genetic Algorithm • SVM Support Vector Machine • ROC Receiver Operator Characteristics • PF Particle Filtering • HOG Histogram Oriented of Gradients • TPR True Positive Rate • FPR False Positive Rate • SURF Speeded Up Robust Features • HMM Hidden Markov Models • DBN Dynamic Bayesian Network • EAR “Embedded Audition for Robotics” project, developed by LAAS-CNRS • MUSIC MUltiple SIgnal Classification method to sound source localization • AIC / MAICE Akaike Information Criterion / Minimum Akaike Information Criterion
Estimate of the number of sources, for source detection • MDL Minimum Description Length criterion for source detection • SMF Stochastic Matched Filter for acoustic pattern detection
1.3. Organization of the Document Recall that the prototypical robot in the COMMROB project will support different functionalities for interaction with the human user. In the following, those relevant to trolley locomotion and U/T communication based human perception are summarized. They are outlined together with their actual state-of-affairs in terms of implementation and evaluations. It complements the previous deliverables D4.X@mY with recent theoretical and experimental considerations investigated. Section 2 deals with perceptual functionalities devoted to trolley locomotion while functionalities for U/T communication are presented in section 3. Section 4 lists the WP4 publications achieved during the project. Section 5, together with some references, ends the report.
2 Trolley locomotion Recall that these functionalities dedicated to locomotion are categorized in two classes: (1) locomotion through physical contact namely haptic handle, and (2) locomotion through non-physical contact which requires person detection, identification, tracking based on a robust and probabilistically motivated integration of multiple heterogeneous cues (vision, laser, possibly laser). The diversity of the developed functionalities reminds us that vision systems deliver plethora of information about the scene and consequently they constitute the central sensors. The framework, recent developments and evaluations associated to all these functionalities are briefly detailed herebelow.

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 7/30
2.1 Haptic command interpretation FZI had the responsibility of developing a touch sensitive device for controlling the shopping robot just as steering an ordinary shopping cart (including assistive functionalities which are part of WP3) as part of the WP4 human perception concept. This haptic command interpretation functionality (annotated HaCI in D4.1@m12) has been provided in D4.2.2@m18 therefore the reader is kindly referred to this deliverable. Especially the data acquisition and processing from this device is still the same. Only the hardware itself has undergone significant changes which will be described here: Early in the project a first early prototype of the Haptic Handle (Figure 2 –left-) was designed and constructed to prevent loosing time on the development of the corresponding control and behaviours. Then we first concentrated on the software part of the haptic-based control. This was the state of the measurement hardware at D4.2.2@m18. Later on a first experimental version has been constructed (Figure 2 –middle-). It was outfitted with two H-shaped force sensors instead of the single beams of the first version. But this version tends towards having internal stress on temperature changes and lost the calibration too frequently. On the gathered experiences the last and final version has been constructed (Figure 2 –right- and Figure 3 –left-). This time a single circular force receptor was used to prevent inner stress. Several Finite element Simulations have been run to get the best shape for the sensor and the best position for mounting the strain gauges (Figure 3 –right-). Intending to name the third version the final version robustness was put into focus. The number of strain gauges was doubled as well as the number of measurement boards. Additionally shielded cables and electronic boxes have been used to ensure a good quality of the very sensitive measurements. For more details, the reader can refer to [Goeller et al. 2009], [Goeller et al. 2010], and [Kerscher et al. 2009].

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 8/30
Figure 2: Early prototype to be able to start with the development of behaviours and commands ‐left, first experimental version of handle ‐middle‐, final improved version of
the handle ‐right‐.
Figure 3: Construction of the third version of the Haptic Handle ‐left‐, finite element simulation with various forces, torques and temperatures –right‐.
2.2 Person detection
2.2.1 Framework Person detection functionalities (annotated PD in D4.1@m8) are crucial in crowded scenes such as supermarkets because any trolley user mis-detection (and also mis-identification, see section 2.3) can ruin any HRI session. Moreover they constitute the basis for automatic (re)-initialization of the human user tracker during trolley locomotion. These detector outputs are typically involved in the saliency maps devoted to the user tracker in order to select, in a computationally efficient manner, conspicuous state space to be explored by the associated particle filter. Another issue for PD is to detect all passers-by in the trolley vicinity to avoid them during trolley locomotion. Section 2.3.1 recalls some preliminary developments about either vision or RF detection while section 2.3.2 presents some ongoing investigations on a multimodal person detector based on laser scan and vision.
Face detection based on Adaboost – Human face, due to its characteristics shape, is a strong aid to track human motion if the visual attributes of face are captured and discriminated against non-face appearance. The well-known face detector based on Adaboost, pioneered in [Viola et al. 2003], has been considered in this project and embedded on our mobile robots.

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 9/30
The main limitation remains its non-detection during out-of-plane rotation of the head e.g. more than ± 45°.
2.2.2 Recent developments and evaluations Leg detection based on Laser Range Finder (LRF) – A SICK-based feature detection has been developed for real-time identification of lines, circles (corresponding to walls and pillars in indoor scenes), and people legs. The LRF swipes an arc of 180° measuring the radial distance of an obstacle in steps of 0.5° (Figure 4). First, the SICK impacts are grouped into blobs based on the distance between consecutive points. Then the blobs are checked to see if the number of points in them correspond to a scan of a leg with a radius between minimum and maximum radius of a leg. All the blobs which do not fulfil this requirement are filtered out. The blobs having a line structure, determined by checking the distance of a midpoint to the line determined by the end points of the blobs, are filtered out. Then the arcs/circles corresponding to legs are segmented based on the Inscribed Angle Variance (IAV) [Xavier et al. 2005]. The IAV technique makes use of trigonometric arc properties: every point in an arc has congruent angles in respect to the extremes. The mean and variance of these internal angles characterize the shape of an arc. By allowing a range of these values, mean 90° to 135° and variance 15° as determined empirically in [Xavier et al. 2005], blobs having different shapes than a leg arc are again filtered out. At this stage blobs that are close to each other are paired to make a leg pair. In case no nearby pair can be found to a blob, it is assumed that one leg was occluding the other one during scanning and a virtual leg is placed in the radial direction away from the scanner in the detected blob direction. Each blob pair now makes a person, positioned at the center of the blobs. This detection system has a strong disadvantage because of its false-positive detection of table legs, chair legs, and other narrow objects with circular pattern. Nevertheless, compared to other techniques like the Hough transform for circle detection that have parameters to tune, ours is simpler to implement, with lower computational cost, providing to be an excellent method for real time applications. This functionality has been very recently integrated Rackham robot and preliminary qualitative evaluations are relevant. Figure 4 shows an example of leg detection from the on-board laser scan.
Figure 4: A human/robot situation and saliency map from the leg detection based on SICK.
Upper human body detection based on vision – Recent developments concern the evaluations of state-of-the-art upper human body visual detectors in the literature. Three detectors have been evaluated on sequences acquired from our Rackham robot:
1. Histogram Oriented of Gradients (HOG) + Adaboost [Laptev 2006]. 2. HOG + a single Support Vector Machine (SVM) using training set of upper human body images [Dalal et al. 2005].

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 10/30
3. HOG + multiple SVMs devoted to body parts with associated deformations in terms of image scale and relative positions [Felzenszwalb et al. 2009]. This classifier has achieved state-of-the-art results in the PASCAL Visual Object Classes (VOC) competition1 and the INRIA person dataset2. The latter outperforms logically the other detectors in overcrowded scenes (inducing occlusions) as illustrated in Figure 5. These snapshots are extracted from a key sequence of 400 images for which quantitative evaluations in terms of true positives (TP), false positives (FP), and false negatives (FN) are counted in each frame. Two criteria are used to quantify the performances for each detector (see Table 1):
FPTPTPecision
FNTPTPcall
+=
+= Pr,Re
Two lines of investigations aim to speed-up the system #3 and so to limit drastically the number of image window candidates as this system outperforms the other detectors. Recall that the principle is to apply sliding window candidates at all positions and scales of an image. First, the flat world assumption is used to avoid the so-called exhaustive search. Second, the filtering of the candidate windows that do not correspond to circle-based laser features should provide a significant performance improvement in terms of computational cost.
Figure 5: From left to right, examples of detections in crowded scenes by detectors n° 1, 2,
and 3.
Recall Precision
1: [Laptev 2006] 32% 82%
2: [Dalal et al. 2005] 28% 72%
3: [Felzenszwalb et al. 2009]. 68% 97%
Table 1: Performances of visual person detectors.
Multimodal person detection - People detection using LRFs suffers from false positives due to structures resembling that of a person leg. The principle is then to fuse data with the aforementioned visual detector to reduce the high False Positives Rate (FPR) if considered independently. A good way to fuse the laser and vision detection possibly would be to perform the detection independently and then to cross validate the occurring detection in a
1 See the URL http://www.pascal-network.org/challenges/VOC/voc2008/workshop/index.html. 2 See the URL http://pascal.inrialpes.fr/data/human/.

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 11/30
way to maximize true positives while minimizing false-positives. But unfortunately this is not possible as the visual detector takes roughly 5s to detect people in a 320x240 image on the Rackham robot. Hence the adopted approach is to define Regions of Interest (ROIs) using the detections from the laser scanner and then validate this by running the visual detector on these regions. So, first peoples are detected from the above laser detector. Assuming a flat world, i.e. all people around would be standing on a leveled ground plane, and an average height of 1.8 m, a rectangle is projected on the image plane of the calibrated camera with an aspect ratio of 4:11 (width:height). The projected rectangular regions now represent possible hypothesis for persons and would contain false positives. The visual person detector is run on these rectangular regions and it is a detection if it is confirmed by the visual detector. Currently the speed of the overall system depends on how many ROI are generated from the laser scanner. But thus far during tests it has varied from 2 fps minimum to 4.5 fps at a maximum.
In order to evaluate the multimodal detector, a dataset of 992 frames containing a total of 1257 persons, who are walking/static while the Rackham robot is moving or not, is acquired. To evaluate the person detection performance, True Positives (TP), False Positives (FP), and False Negatives (FN) were counted in each frame. The total number of persons in each frame is determined by counting the number of people that were captured by either the SICK laser sensor, as determined by visually looking at leg signatures in the scan data, or the vision system, determined by the visibility of a person in the acquired image. To be able to compare the performance of both systems, only the region in the camera field of view is considered. As a rule, all persons outside the field of view of the camera or lying on the border of the field of view are not considered. By considering laser only person detection, the criteria Recall (resp. Precision) leads to 89% (resp. 60%). When considering the multimodal detector, the criteria Recall remains the same while the criteria Precision increases significantly (96%) as expected. Figure 6 shows a sample image showing a U/T situation and the corresponding person detections based on Laser and Vision. The green boxes on the video image in the right sub-figure show the hypothesis generated from the laser scans, and the detections with the corresponding laser detection are shown in various colors. On the laser scan map, small white circle denotes detected leg and a green circle, detected person. The actual scan data is shown in red while blobs are shown as thin blue circle. The gray shaded region corresponds to the camera field of view.
Figure 6: Sample image showing U/T situation and associated multimodal person detections.

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 12/30
2.2.3 Framework The person learning ( annotated PL in D4.1@m8) functionality is launched each time a given person checks in as an assigned user of the trolley by collecting the trolley in the trolley queue while interacting with the touch screen and taking the RFID tag from Trolley. The principle is then to learn his/her face, then to recognize it during trolley locomotion thanks to a holistic appearance-based strategy launched by the person identification (annotated PI in D4.1@m8) functionality. The RF tag worn by the trolley user is also considered for the human user re-identification.
User’s face learning and recognition based on vision - The deliverable D4.3.2@m18 detailed some preliminary results about face recognition (FR) systems which differ by the representations (PCA and LDA basis) characterized by the PL functionality, and the decision rules (error norm [Turk et al. 1991], Mahanalobis distance, and SVM) implemented in the PI functionality. Recall that the objective is to classify facial regions, segmented from the input image, into either one class out of the set of M subjects faces using a priori face images learnt during the trolley assignment. For detecting faces, we apply the well-known window scanning technique proposed in [Viola et al. 2003]. The bounding boxes of faces segmented by the detector are then fed into the FR systems, namely:
Syst. #1: face specific subspace i.e. Eigenface per class and error norm [Turk et al. 1991]. Syst. #2: global PCA i.e. global Eigenface and Mahanalobis distance. Syst. #3: LDA i.e. Fisherface [Belhumeur et al. 1996] and Mahanalobis distance. Syst. #4. global PCA and SVM.
A preliminary comparative study have been presented in D4.3.2@m18 based on a face database composed of 6600 examples including 11 individuals.
User’s recognition based on RFID – We have customized an off-the-shelf RFID system to make it able to detect tags in 360° view field, by multiplexing eight antennas. The goal is to detect passive RFID-tagged individuals in the range [0.5m; 4.5m] all around the robot. Given the placement of the antennas and their own field-of-view, the robot surrounding is divided into 24 areas, depending on the number of antennas detecting (by the on-board reader) simultaneously the RF tag. By this way, the RF sensor can estimate the coarse tag/reader distance and the azimuthal angle which can be represented by Gaussian measure models. The principal limitations remain (i) the sensibility to occlusion due to the passive nature of the system, and (ii) the antenna compactness which should be improved. Yet, the RF system has been mounted on Rackham and evaluated successfully in a crowded context. It has been more recently integrated on InBot but solely with four antennas due to embeddability limitations.
2.2.4 Recent developments and evaluations Tuning of the FR systems based on vision - A major concern for the aforementioned visual FR systems is the free-parameters subject to optimization and which mainly influence classification performances e.g. the threshold value for distance-based decision rule (all systems), the ratio of the total class variance in PC basis (systems #1, #2, and #4) or LD basis (system #3), the width of the Gaussian kernel or the upper bound of Lagrangian multipliers (system #4). The performances of the above classifiers are analyzed by means of ROCs when
Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 13/30
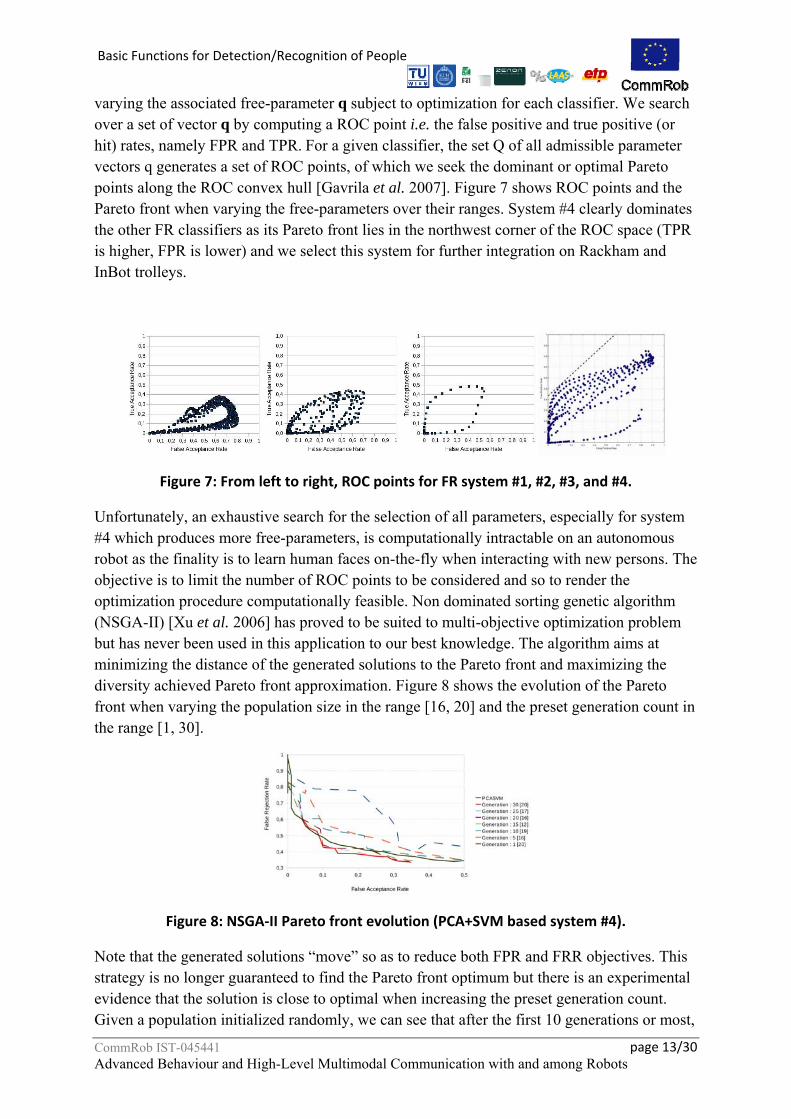
varying the associated free-parameter q subject to optimization for each classifier. We search over a set of vector q by computing a ROC point i.e. the false positive and true positive (or hit) rates, namely FPR and TPR. For a given classifier, the set Q of all admissible parameter vectors q generates a set of ROC points, of which we seek the dominant or optimal Pareto points along the ROC convex hull [Gavrila et al. 2007]. Figure 7 shows ROC points and the Pareto front when varying the free-parameters over their ranges. System #4 clearly dominates the other FR classifiers as its Pareto front lies in the northwest corner of the ROC space (TPR is higher, FPR is lower) and we select this system for further integration on Rackham and InBot trolleys.
Figure 7: From left to right, ROC points for FR system #1, #2, #3, and #4.
Unfortunately, an exhaustive search for the selection of all parameters, especially for system #4 which produces more free-parameters, is computationally intractable on an autonomous robot as the finality is to learn human faces on-the-fly when interacting with new persons. The objective is to limit the number of ROC points to be considered and so to render the optimization procedure computationally feasible. Non dominated sorting genetic algorithm (NSGA-II) [Xu et al. 2006] has proved to be suited to multi-objective optimization problem but has never been used in this application to our best knowledge. The algorithm aims at minimizing the distance of the generated solutions to the Pareto front and maximizing the diversity achieved Pareto front approximation. Figure 8 shows the evolution of the Pareto front when varying the population size in the range [16, 20] and the preset generation count in the range [1, 30].
Figure 8: NSGA‐II Pareto front evolution (PCA+SVM based system #4).
Note that the generated solutions “move” so as to reduce both FPR and FRR objectives. This strategy is no longer guaranteed to find the Pareto front optimum but there is an experimental evidence that the solution is close to optimal when increasing the preset generation count. Given a population initialized randomly, we can see that after the first 10 generations or most,

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 14/30
there is already one solution that outperforms the one without optimization while 30 generations increase the performance compared to ROC means slightly. Our approach, based on PCA and SVM improved by GA optimization of the free-parameters, is found to outperform conventional appearance-based holistic classifiers (eigenface and fisherface) which are used as benchmarks. The entire details regarding theory, evaluations, and comments can be found in our papers [Germa et al. 2009b] and [Germa et al. 2009c]. System #4, without the GA implementation, has been integrated and demonstrated on the robots Rackham and InBot.
Improvement of the RFID hardware system – Recall that the device consists of: (i) an off-the-shelf RFID reader, (ii) eight directive antennas to detect passive tags, (iii) a prototype circuit in order to sequentially initialize each antenna. A new version of this multiplexing circuit has been designed by the computing and instrumentation service at LAAS. Figure 9 shows the new RF multiplexing prototype to address the antennas set. Two prototypes have been developed and integrated on the Rackham and InBot robots.
Figure 9: The new RF multiplexing prototype to address eight antennas.
New and compact antennas are actually prototyping as embeddability is essential for autonomous robots. The work is underway in collaboration with the MINC group (“Micro and Nanosystems for Wireless Communications” group) within the LAAS-CNRS. It deals with the design of compact circularly polarized RFID reader antennas which are compatible with the unusual embeddability imposed by the autonomous robotics context. These antennas should be adapted to an existing RFID tags operating between 860-960MHz. An original set of 8 antennas is under development to provide an optimum RFID coverage of the robot’s surroundings. To fulfil such requirements, a compact antenna composed of 4 inverted L radiating elements arranged as a cross is proposed (Figure 10). The circular polarization of this antenna is obtained by the means of a feeding circuit providing a quadrature phase excitation. This feeding circuit consists of three miniaturized power dividers. The antenna is printed on a flexible substrate of 635 µm thick that will be mounted on Rackham body. The designed antenna radiates quasi- omnidirectional radiation patterns with a gain of 4dBi and a bandwidth of 13% (centred at 900 MHz). It occupies an area of 20 cm x 20 cm with a height

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 15/30
of 4 cm. Further details about this antenna structure and its performance can be found in [Bouaziz et al. 2010] which can be sent on request.
Figure 10: Prototype of the new antenna.
2.3 Person tracking: framework One of the most successful paradigms for person tracking, focused here, concerns sequential Monte Carlo simulation methods, also known as Particle Filters (PF) [Arulampalam et al. 2002]. Within the generic PF algorithm or "Sampling Importance Resampling" (SIR), the key idea is to represent the posterior distribution at each time by a set of samples, or particles, with associated importance weights. This weighted particles set is (i) first sampled/drawn from the state vector initial probability distribution and an importance function, and (ii) then suitably updated over time by their likelihoods w.r.t. the measurements. Our 2D tracker goal is to fit the template relative to the RFID-tagged person all along the video stream through the estimation of his/her image coordinates and its scale factor of his/her head in order to characterize the coarse H/R distance. All these parameters are accounted for in the state vector to be estimated by the PF related to each frame. With regard to the filter dynamics, the image motions of the human user is difficult to characterize over time. This weak knowledge is formalized by assuming the state vector entries evolve according to mutually independent Gaussian random walk models. The underlying unified likelihood in the weighting stage is more or less conventional. It is computed by means of several measurement functions, according to persistent visual cues, namely: (1) multiple color distributions to represent the person's appearance (both head and torso) [Pérez et al. 2004], (2) edges to model the head silhouette [Isard et al. 1998a]. Given such measurement sources and assuming they are mutually independent conditioned on the state, the unified measurement function in step (ii) can be categorized as their product. With respect to the sampling step (i), we opt for using ICONDENSATION [Isard et al. 1998b], that consists in sampling some particles from the current observation, some from the dynamics. Regarding the data driven sampling, we propose a genuine importance function based on probabilistic saliency maps issued from skin probability image, RF person identification, and face recognition as well as a rejection sampling mechanism to (re)-position samples on the desired person during tracking. This particle sampling strategy, which is unique in the literature, improves our tracker so that it becomes much more resilient to occlusions, data association (to distinguish the user from the others), and target losses than vision-based only systems. Figure 11 illustrates the principle on a key sequence where the RF tagged person wears a white tee-shirt and a Bermuda short. The Rackham robot is assumed to be static but the targeted person is frequently occluded by the other people while one of them has a similar clothes appearance. For each row, the images (annotated (a)) correspond to some sequence snapshots, the images annotated (b) represent the associated saliency maps (based on RFID, face recognition) for particle sampling where the vertical stripes correspond to the RF identification. The images annotated (c) show the sampled particles cloud and their associated

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 16/30
weights (red color highlights likely particles). Finally, the images (d) show the resampled particles cloud and the MMSE3 estimate with corresponds to the superimposed template. We can notice that the particle filter tracks successfully the targeted person despite the strong occlusions induced by the other people and this is possible thanks to our advanced importance sampling mechanism based on saliency maps and rejection sampling.
(a) (b) (c) (d)
Figure 11: Snapshots of a typical sequence. For each row: input image (a), saliency map (b), particles after the weighting stage (c), particles after resampling and MMSE estimate (d).
In brief, our multimodal person tracker combines the accuracy and information richness advantages of vision with the identification certainty of RFID. Furthermore, the ID-sensor can act as reliable stimuli that trigger the vision system. The tracker has been integrated on Rackham (tracking thanks to the digital camera) and InBot. This information is then used to enable the robot’s social behaviours to control the distance between user and robot as described in the last WP3 deliverable D3.3@m24. First experiments are conducted in the LAAS crowded robotic hall. The goal is to control Rackham to follow a tagged person while respecting his/her personal space. The task requirements are: (1) the U must be always centered in the image and (2) a distance md follow 2= must be maintained between the tagged person and the Rackham robot. Up to now, the robot habilities of obstacle avoidance are rather coarse. These Robotic experiments demonstrate that the person following task inherits the advantage of both sensor types, thereby being able to robustly track people and identify them.
3 For « Minimum Mean Squared Error ».

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 17/30
For more details, the reader can refer to D4.3.2@m18, the associated publications [Germa et al. 2010a], [Germa et al. 2010b], [Ouadah et al. 2010], and [Germa et al. 2009a] while illustrative videos are available at the URL www.laas.fr/homepages/tgerma.
3 UserTrolley communication The primary motivation is here to show that our communication interface can interpret multimodal commands like “come to me”, “go there”, etc. and responds to them through corresponding local motions of the trolley. Some of these functionalities related to speech i.e. “speech interpretation” (GI) and “multimodal communication understanding” (MuCU) are out of the scope as they are outlined in WP5 deliverables.
3.1 Localization and voice extraction
3.1.1 Framework Localization and Voice Extraction (annotated LVE in D4.1@m8) can constitute a valuable complement to vision for User-Trolley communication. Indeed, the auditory modality is omnidirectional and insensitive to changes in lighting conditions, which are common in COMMROB environments and may hinder visual-based human-robot interaction. In addition, extracting the User utterance out of the ambient noise and other valueless sources is a mandatory requirement to enable voice control of the robot without headset. Importantly, the distortion induced by this extraction process must be minimum in order not to degrade the performances of the downstream speech recognition process.
The last achievements, to be presented hereafter, extend or solve issues developed in the previous deliverables. To improve the readability of the document, these issues are first briefly summarized.
The EAR prototypes – The auditory functions are built on the basis of the “EAR” (Embedded Audition for Robotics) integrated auditory sensor developed by LAAS-CNRS. It includes a 40cm-long linear array of 8 microphones, a microphone polarization and signal conditioning unit (which can be connected to a 24V DC battery for embedded use), a fully parameterizable 8-channel acquisition stage (with tunable sampling frequency, anti-aliasing filters cut-off frequency, and channels gains), a FPGA processing unit, and USB communication (entailing a dedicated protocol for control and data retrieval from a UNIX host). From the acquisition of data @15kHz, the initial main objectives were to compute acoustic localization cues @15Hz and to perform spatial filtering (extraction) of sound sources in real time @15kHz. Importantly, in §4.2 of D4.3.1@m12, speaker/voice detection was identified as a necessary “add-on” in order to enable a robot to tell its User from valueless sounds such as fans noise, heaters, etc.
D4.5.2@m30 introduced the new-generation EAR sensor under development. This second prototype will be much more powerful than the first one, as it hosts a Xilinx Virtex-5sx50 FPGA instead of the older Virtex-4sx35, includes flash memory and RAM, and will be endowed with a high-speed USB2.0 connection instead of USB1.1. However, both releases share the following properties:

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 18/30
• a modular architecture is hardcoded on the FPGA, in which modules communicate with each other through dedicated buses; the arbiter module is in charge of the management of the bus sharing and of the control of all the other modules; these are dedicated to signals acquisition, signal processing, computation of acoustic cues, data time stamping, generation of external triggering signals (e.g. for cameras synchronization), and frames construction/transmission and reception/deconstruction; the aim of this modular design is to ease the insertion of new modules and to ensure that no transmission error nor information loss occurs;
• on the UNIX host, a C libfpga library enables the dialog (dynamic configuration and data exchange) with the sensor via USB communication; on the top of this, a multithreaded C++ software implements an operator interface for sensor fine tuning, online computation of acoustic localization cues, online array focusing (spatial filtering), and visualization/storage of raw or filtered data; the development of “low-level” localization and extraction functions has followed three steps: MATLAB prototyping and offline assessment on real data acquired by the sensor, C++ implementation and testing, then VHDL hardcoding.
Sound source extraction – D4.3.1@m12 introduced the cornerstone of source extraction, namely an original frequency-invariant broadband beamforming method based on modal analysis and convex optimization [Argentieri et al. 2006], which leads to a set of FIR filters to be used downwards the transducers, and whose outputs sum performs the array focusing on a selected direction of arrival. This method enables a much better spatial filtering of low-frequency sources than the conventional (Bartlett) beamformer. It leads to an invariant pattern over the bandwidth [400Hz-3kHz] (which captures most of the power of the human voice while ensuring the intelligibility of the message for further post-processing) and handles the tradeoff between the array selectivity and white noise gain. In order to lower the computational cost when the array must simultaneously extract several sources (e.g. prior to discriminating meaningful from valueless ones), a new C/C++ implementation was done, based on the “overlap-and-save” fast convolution algorithm.
The exploitation of beamforming for the computation of acoustic energy maps through the electronic polarization of the array towards successive azimuths was tested on experimental data, first in D4.5.1@m24 then (after a hardware problem was solved) in D4.5.2@m30. As a conclusion, no dominant mode could be extracted from these maps for source localization, unless when considering nearfield sources with unrealistically low SNRs in comparison with the COMMROB context.
Sound source detection and localization – The original broadband beamspace MUSIC method introduced in D4.3.1@m12 for the determination of the azimuths and ranges of up to 3 sources was assessed on real data (after the solution of an hardware problem) in D4.5.2@m30. Faithful azimuths estimates were obtained except for farfield sources (range ≥ 1.2m) with SNR greater than 10-20dB, but the estimated ranges were subject to caution. More importantly, the attempts to its coupling with a detector of the number of sources often led to meaningless conclusions, especially in the farfield or at low RSBs. A preliminary study was conducted concerning the hardcoding of MUSIC on FPGA (D4.5.2@m30). As the related

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 19/30
VHDL development is extremely heavy and cannot fit on a single FPGA in conjunction with all the other functions, it has been postponed and only the C/C++ existing implementation is used.
3.1.2 Recent developments and evaluations The EAR prototypes – All the ingredients necessary to the new-generation EAR sensor have been manufactured. These consist of two DAQ mezzanine boards similar to these of the first prototype, and of the new homemade FPGA-based processing board. This board, which layout was presented in D4.5.2@m30, is shown on Figure 12.
As elaborated acoustic cues were being hardcoded on the FPGA, it appeared necessary to revisit the VHDL modular architecture. Indeed, in the first version of this architecture, the frames sent to the UNIX host and corresponding to raw data acquisition were labeled by a time index. This way, loss of raw data or failure in their transmission could be checked for. However, such a time stamping did not apply to other variables or events inside the FPGA, such as beamformers outputs, generated triggers, etc. So, a second major release of the architecture has been implemented, which enables a better handling of some resources as well as the time stamping of any data inside the FPGA. Thanks to this development (which has represented a significant involvement of ~3 persons*months) failures can be checked whatever the handled acoustic data. This new architecture has been successfully simulated and validated. Remaining work consists in its upload on the EEPROM of the FPGA board and in extensive tests.
Sound source extraction – Another important work on the EAR sensor has concerned the VHDL hardcoding of source extraction. The overlap-and-save version of beamforming for one direction of polarization was designed using the Synplify® DSP software in conjunction with MATLAB/SIMULINK. The current work concerns the integration the simultaneous electronic polarization of the EAR sensor towards a set of azimuths selectable online. The approach consists in hardcoding separately the critical parts (e.g. finite state automata), and in using Intellectual Properties cores generated by Synplify® DSP for higher-level functions (e.g. FFTs). Notice that a specific module in charge of the communication with the flash memory (which hosts the beamformers coefficients relative to all possible polarization azimuths) needs to be developed as well.
Figure 12: The homemade FPGA board of the new‐generation EAR sensor

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 20/30
Sound source detection and localization – The conclusions obtained in terms of source detection and localization, together with the result of some literature on theoretical analysis of MUSIC [Paulraj et al.] [Swindlehurst et al.1992], led us to investigate two problems. On the one hand, we revisited in depth the way how a detector of the number of sources can be integrated within our broadband beamspace MUSIC localization. On the other hand, we implemented a simple online estimator of the noise statistics, and inserted it into our detection & localization schemes. These points are detailed herebelow.
Information-theoretic detection of broadband sources within the broadband beamspace MUSIC algorithm. As already mentioned in previous deliverables, in our broadband beamspace MUSIC localization strategy [Argentieri et al. 2007] the sources azimuths and ranges are determined by looking for the maximum values of the pseudo-spectrum. In fact, the pseudo-spectrum modes express the orthogonality between the array vectors (i.e. the vectors of transfer functions from the midpoint of the array to the transducers) at the true source locations and a so-called “coherent noise space”. The starting point of the approach is the set of covariance matrices of the components onto frequency “bins” of the sensed signals and noises at the transducers. On each frequency bin, the signal and noise covariance matrices are pre- and post- multiplied by matrices of Q=4 dedicated narrowband beamformers coefficients so as to turn the problem into an orthogonal processing structure. Summing the results over the whole frequency range leads to the so-called “focalized array covariance” and “focalized noise covariance” matrices. The generalized eigendecomposition of this Q*Q complex matrix pencil is then performed. The coherent noise space comes as the span of the generalized eigenvectors associated to the Q-D smallest generalized eigenvalues, where D<Q is the number of sources.
In theory, the unknown number of sources D can be deduced from the fact that the smallest Q-D generalized eigenvalues of the above matrix pencil are minimum and equal to each other. However, this property does not hold in practice, because the genuine (focalized) covariance matrices are not available in closed-form and can just be estimated. Some approaches to the detection of D can be easily ruled out, e.g. introducing a threshold on the sorted eigenvalues, or selecting D which leads to the maximum peak within the family of pseudo-spectra computed for each D∈{0,1,...,Q-1} (see [Danès et al. 2010] for more details). A mathematically sound viewpoint to solve the problem is to model the focalized array covariance matrix as the sum of a (unknown) Hermitian symmetric positive definite matrix whose rank is the (unknown) number of sources plus a (unknown) scalar constant times the focalized noise covariance matrix [Wax et al. 1985]. Yet, the statistical identification of all the parameters which best explain a sample estimate of the focalized array covariance matrix cannot rely on maximum likelihood estimation (MLE), because the number of free parameters of the competing models varies with the hypothesized number of sources [Akaike 74]. In such a situation, looking for the minimum of an estimate of the Kullback-Leibler divergence (which underlies the MLE in the single-model case) leads to the Minimum Akaike Information Criterion Estimate (MAICE), and selecting the way to encode the observed data with the minimum code length leads to the Minimum Description Length (MDL) estimate [Wax et al. 1985]. Quite surprisingly, this sound mathematical approach, which can be extended to coherent MUSIC schemes [Argentieri et al. 2007][Wang et al. 1985] leads to

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 21/30
very simple calculations in practice. Indeed, whatever the selected strategy (MAICE or MDL) to source number detection, a criterion AIC(d) or MDL(d) is defined for each hypothesized number of sources d which just involves the ratio of the geometrical and arithmetic means of the (Q-d) smallest generalized eigenvalues of the aforementioned focalized matrix pencil. The detected number of sources then just comes as the argmin of AIC(.) or MDL(.).
Insertion of the estimation of the noise statistics into the detection-localization scheme. Theoretical analyses of MUSIC [Swindlehurst et al.1992] show that a mismatch between the assumed and real noise statistics strongly affect the quality of the localization. So, we introduced a simple estimator of these statistics into our online algorithm. The practical impact of this add-on is illustrated on Figure 13.
Figure 13: MAICE‐based source detection within a broadband beamspace MUSIC scheme. Left: despite no informatory source is active, assuming that the background noise is temporally and spatially white, the robotics hall humming system is detected and
localized, which may prevent detection and localization of additional sources. – Right: no source is detected after introducing an estimator of the background noise statistics.
Acoustic pattern (e.g. Voice Activity) detection – Once the sources are detected and localized, the EAR sensor can simultaneously focus on all of them. In order to tell meaningful sources from valueless ones, a detector of stationary acoustic patterns within a noisy audio sequence has been prototyped. One particular goal is to detect voiced signals through a theoretically sound algorithm able to function in real time.
The theoretical roots of the proposed approach are formalized into the stochastic matched filtering (SMF), first proposed in [Cavassilas 1991] for oceanography applications. The pattern to be detected and the corrupting noise are assumed stationary zero-mean, mutually independent, with known autocorrelation matrices. Their sum constitutes the raw noisy audio sequence. From the generalized eigenvectors of the pattern and noise autocorrelation matrices, the Karhunen-Loève expansion of the raw signal can be computed. A truncation of this expansion can be defined, corresponding to a projection of the raw signal in such a way that the consequent average SNR is improved, thus enabling to focus on the pattern while lowering the effect of noise. This projection, takes the form of a simple filtering by a FIR filter defined offline.
Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 22/30
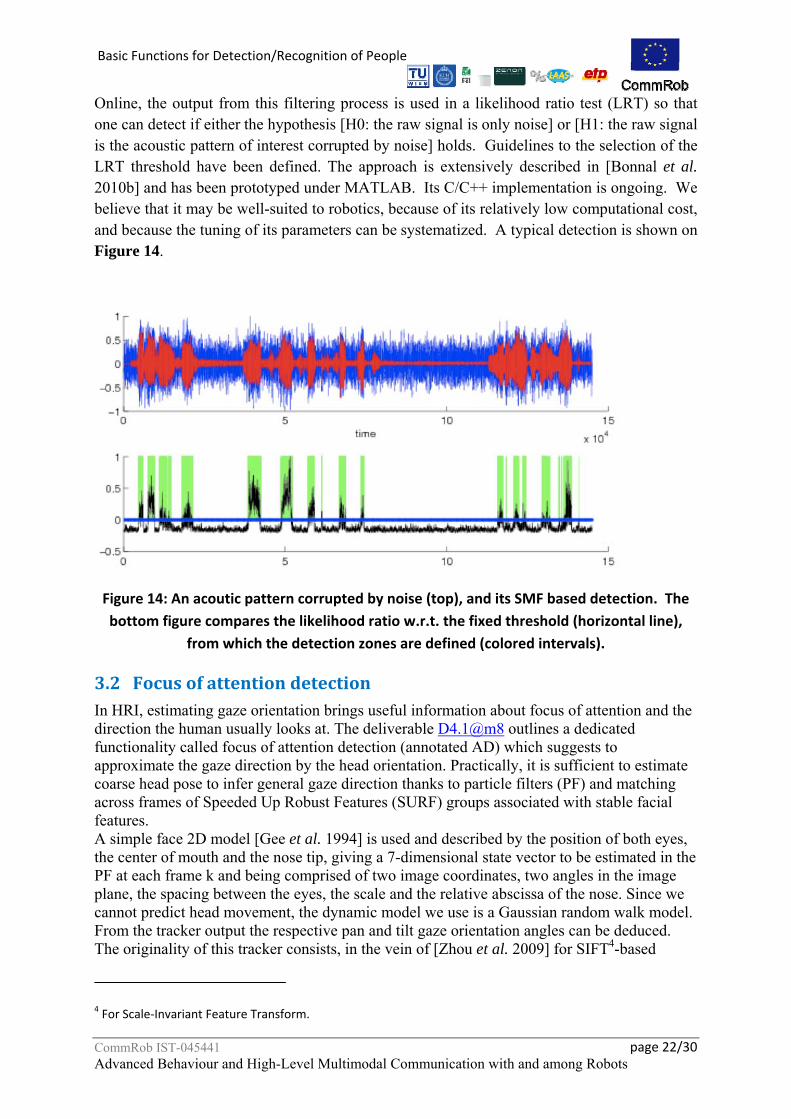
Online, the output from this filtering process is used in a likelihood ratio test (LRT) so that one can detect if either the hypothesis [H0: the raw signal is only noise] or [H1: the raw signal is the acoustic pattern of interest corrupted by noise] holds. Guidelines to the selection of the LRT threshold have been defined. The approach is extensively described in [Bonnal et al. 2010b] and has been prototyped under MATLAB. Its C/C++ implementation is ongoing. We believe that it may be well-suited to robotics, because of its relatively low computational cost, and because the tuning of its parameters can be systematized. A typical detection is shown on Figure 14.
Figure 14: An acoutic pattern corrupted by noise (top), and its SMF based detection. The bottom figure compares the likelihood ratio w.r.t. the fixed threshold (horizontal line),
from which the detection zones are defined (colored intervals).
3.2 Focus of attention detection In HRI, estimating gaze orientation brings useful information about focus of attention and the direction the human usually looks at. The deliverable D4.1@m8 outlines a dedicated functionality called focus of attention detection (annotated AD) which suggests to approximate the gaze direction by the head orientation. Practically, it is sufficient to estimate coarse head pose to infer general gaze direction thanks to particle filters (PF) and matching across frames of Speeded Up Robust Features (SURF) groups associated with stable facial features. A simple face 2D model [Gee et al. 1994] is used and described by the position of both eyes, the center of mouth and the nose tip, giving a 7-dimensional state vector to be estimated in the PF at each frame k and being comprised of two image coordinates, two angles in the image plane, the spacing between the eyes, the scale and the relative abscissa of the nose. Since we cannot predict head movement, the dynamic model we use is a Gaussian random walk model. From the tracker output the respective pan and tilt gaze orientation angles can be deduced. The originality of this tracker consists, in the vein of [Zhou et al. 2009] for SIFT4-based
4 For Scale‐Invariant Feature Transform.

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 23/30
object tracking, in taking into account both the SURF spatial distributions as well as their visual descriptors for real-time tracking of eyes, mouth, and nose. For each facial feature, this measure, considered in the particle weighting stage, is estimated based on the learnt SURF set (modelling eye, mouth, and nose) and the SURF set extracted at the predicted location. Figure 15 illustrates SURF extracted from an eye. We have about 100 SURF stored for mouth, 20 for eyes, it is varying a lot for nose (from 0 to 40) depending on the visibility of nostrils and light saturation. The initial SURF is learned and updated from frontal images where face and associated features are detected thanks to face detector (Viola’s face detector which covers a range of ±45° out-of-plane rotations). This online learning allows fitting with the current view conditions (illumination, observed subject) while the tracker determines a wider range of gaze pose i.e. beyond such limited range of motion. For more details, the interest reader is encouraged to read [Burger et al. 2009c] while videos are available at the URL www.laas.fr/homepages/bburger.
Figure 15: SURF extracted from an eye ‐left‐ and example of gaze tracking –right‐.
Even the preliminary results are promising, this functionality needs further development, especially to speed up the process and to extend the SURF representation to other facial features e.g. the ears. Consequently, this functionality is not yet mature to be integrated into the InBot robot.
3.3 Upper body parts detection an tracking: framework The upper body parts detection functionality (annotated BPD in D4.1@m8) involves visual features to detect the upper extremities of the user’s human body at medium H/R distance (1m to 4m) in order to track gestures. The upper body parts tracking functionality (annotated BPT in D4.1@m8) involves the 3D tracking of the user’s head and of his/her hands based on probabilistic fusion of vision cues. Active vision is also considered to control the pan unit depending on the current tracker status and so keep the tracked parts in the field-of-view. Regarding the BPD functionality, human skin colors have a specific distribution in color space. Training images from the database [Jones et al. 2000] are used to construct a reference (L*, a*, b*) color histogram model. Blob detection devoted to the upper human body extremities is performed by subsampling the input image prior to grouping the classified skin-like pixels. Regarding the BPT functionality, the full tracking of all the human body kinematics is not essential for further gesture recognition. We model solely the upper human body extremities thanks to deformable and coarse ellipsoids for computational tractability and person-independency. The upper extremities of the human body are tracked in 3D in stereoscopic video stream thanks to interactively distributed particle filters devoted to the user’s hands and head (inspired from [Qu et al. 2007] for video surveillance application). The bank of PF aims to fit the projections of a sphere and two ellipsoids (resp. for the head and the two hands) to the segmented blobs or face (see section 2.2.1) all along the binocular stream. In our framework, when two particles for two different extremities do not interact with the other i.e. their relative Euclidian distance exceed a predefined threshold, the approach performs like

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 24/30
multiple independent filters. When they are in close proximity in space, magnetic repulsion and inertia likelihoods are added in each filter. By this way, the human multi-part tracker solves data association and labelling problems (between detected skin blobs for instance), as well as automatic filter (re)-initialization, when the targeted limbs are in close proximity, present occlusions. These situations usually occur when performing natural gestures in front of a mobile robot. Finally, our data fusion principle in the likelihood functions (based on both appearance and 3D cues) is shown to improve the tracker versatility and robustness to clutter. Moreover, our strategy is shown to outperform conventional multiple independent particle filter at an appropriate speed (10Hz). For more details, the reader can refer to D4.5.1@m24 or the following publications: [Burger et al. 2010], [Burger et al. 2008a], and [Burger et al. 2008b]. Videos concerning BPT functionality are available at the URL www.laas.fr/homepages/bburger. Such advanced tracker has immediate impact on gesture interpretation in a bottom-up strategy.
3.4 Gesture interpretation
3.4.1 Framework Dynamic gesture recognition is carried out in a bottom-up strategy. First, the BPT functionality is launched. Second, the gesture interpretation functionality (annotated GI in D4.1@m8) takes as inputs the 3D localization of head and both hands in order to classify legitimate gestures. These gestures are assumed to start and end in the same natural/rest position (the hands lying along the thighs). The origin of the hand location system in spherical coordinate (ρ, θ, ϕ) is set up to the centre of the head to achieve invariance with respect to the person location. The y and z axis of this coordination represent the “human plane” i.e. the plane formed by the head and both hands at their rest position. We can then write the feature vector corresponding to the frame at time t as:
),,,,,,,(LR HHLLLRRRt Do −= ϕθρϕθρ
where the feature ρ(.),θ(.),ϕ(.) are the spherical coordinates for the right R and left L tracked hand and
LR HHD − is the distance between two hands. Given an isolated gesture segment,
classification outputs the class of the gesture depending on its motion template. Recall that the one or two-handed gesture vocabulary is composed of symbolic gestures (“hello”, “stop”, “go away”, etc.) and deictic gestures depending on the coarse pointed direction relatively to the user who performs the gesture e.g. “in front of”, “bottom up”, etc. The pointing direction is calculated by the connecting line between the centre of the head and the hand in 3D.
Each gesture is here straightforward modelled by a dedicated Hidden Markov Model (HMM). The features used as model’s inputs are derived from tracking the 3D positions of both hands relatively to the head to achieve invariance with respect to the person location. We are interested in characterizing the relative performance of HMMs [Rabiner 1989] and Dynamic Bayesian networks (DBN) [Infantes 2006]. Evaluations consisting of videos shots of gestures (7 symbolic gestures and 5 deictic ones) carried out by 11 different people in front the Jido platform. From these experiments, about 76% of the examples are correctly classified. 79% of the whole database sequences are classified correctly using a single DBN while the HMM bank leads to a score of 76%. Another observation is that bi-manual gestures are better

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 25/30
classified their mono-manual counterparts as their motion templates are more discriminating. The most prominent error was a failure to recognize “stop” and “hello” gestures which we can attribute to a poor set of motion template for this gesture. Most importantly, DBN imposes less computational burden (factor 3) than HMM i.e. only 25ms per gesture. The HMM-based system has been integrated on the LAAS platform Jido as well as InBot.
For more details, the reader can refer to D4.5.2@m30, the associated publications [Burger et al. 2010], and [Burger et al. 2009b].
3.4.2 Recent developments and evaluations User studies reported strong evidence that people naturally look at the objects or areas involved in interaction, the AD functionality has been added in the current state of our framework. Thus, we are interested in recognizing gesture using the data of the AD functionality in addition of the BPT one. The goal is here to prove that fusing these two visual data sources can improve the gesture recognition rate, in particular for deictic gestures. The DBN-based full model in Figure 16 is then considered with the “pan” gaze (in red color) performed by the AD module.
Figure 16: DBN model used for gesture recognition based on data from functionalities AD and BPT.
Preliminary off-line experiments were carried out aiming to quantify the improvement brought by gaze information during deictic gesture interpretation. We built a specific corpus composed of 5 deictic gestures repeated 15 times. This corpus was acquired on the LAAS platform through the modules AD and BPT. The recognition rate obtained by the module GI is 84% when fusing these two visual data sources and 9% higher than the rate obtained without any gaze information. This significant improvement is logical considering that humans usually look in the direction they are pointing to during such a gesture.
4 Conclusion This document constitutes the final WP4 deliverable which outlines the development and implementation about human perception. Recall that these functionalities have been categorized as: (1) coordinated U/T motions, and (2) U/T multimodal communication through speech and/or gestures. Those that exhibit the more relevant contributions are probably:
- The prototyping of a new haptic handle and the classification of the U intention based on physical contact. The haptic device consists of 3D force torque sensor and strain gauges for the detection of contact to the U. It has

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 26/30
been fully integrated in the overall InBot trolley especially in its behaviour based control.
- The EAR sensor for sound sources detection, real-time generation of acoustic maps, and spatial filtering of broadband signals. This work was published in a special issue of a peer-reviewed Japanese journal, upon invitation of the world’s leading team in robot audition. Our broadband beamspace MUSIC strategy to source detection and localization may be one of the most versatile, computationally cheap and mathematically sound existing approaches. A journal paper is in preparation. As for the acoustic pattern detection, the promising SMF approach will be extensively tested and improved.
- The person tracking functionality and especially the underlying importance function, based on RF and face recognition cues, which is innovative in the Robotics and Computer Vision literature. We demonstrated the tracker robustness to occlusions, camera out FOV during robotics experiments. This work has been published in a major journal [Germa et al. 2010a] (impact factor: 2.938) and numerous international or national conferences in Vision or Robotics.
Those that exhibit secondary contributions are probably:
- The upper body parts tracking with this bank of interactive and distributed particle filters for the simultaneous tracking of two-handed gestures and head in 3D. This principle initiated for multi-person tracking has not been applied to gesture tracking.
- The person identification functionality based on face recognition, especially the fine tuning of the free-parameters underlying in the classifiers. This work has been published in a journal [Germa et al. 2009b] and international conferences.
- The gesture interpretation functionality which endows several human perception capabilities i.e. upper human body extremities tracking as well as gaze tracking (here head orientation). Fusing these two visual sources within the Dynamic Bayesian Network is particularly suited for deictic gesture interpretation as preliminary evaluations on the LAAS platforms are very promising. To our best knowledge, this framework is relatively original in the literature.
5 Publications related to WP4 [Bonnal et al. 2010a] The EAR project. J. Bonnal, S. Argentieri, P. Danès, J. Manhès, P. Souères, M. Renaud. Journal of the Robotics Society of Japan. January 2010. [Bonnal et al. 2010b] Detection of acoustic patterns by stochastic matched filtering. J. Bonnal and P. Danès. IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS’10), Taipei, Taiwan, submitted.

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 27/30
[Bouaziz et al. 2010] Antennes lecteur RFID pour application robotique. S.Bouaziz, S.Hebib, T.Germa, H.Aubert, and F.Lerasle. Internal LAAS report n° 10236, 14 pages, 2010. [Burger et al. 2010] Two-handed gesture recognition and fusion with speech to command a robot. B.Burger, I.Ferrané, F.Lerasle, and G.Infantes. Autonomous Robots, 2010. Submission. [Brèthes et al. 2010] Particle filtering strategies for data fusion dedicated to visual tracking from a mobile robot. L.Brèthes, F.Lerasle, P.Danès, and M.Fontmarty. Journal Machine Vision and Applications (MVA’10), Vol. 21, Issue 4, pp 427—448, June 2010. [Burger et al. 2009a] Towards multimodal interface for interactive robots: challenges and robotic systems description. B.Burger, I.Ferrané, and F.Lerasle. Book chapter entitled Cutting Edge Robotics. Edited by Int. Journal of Advanced Robotic Systems, 2009. ISBN 978-3-902613-46-2. [Burger et al. 2009b] Evaluations of embedded modules dedicated to multimodal human-robot interaction. B.Burger, F.Lerasle, and I.Ferrané. IEEE Symp. On Robot and Human Interactive Communication (RO-MAN’09), Toyama (Japan), October 2009. [Burger et al. 2009c] Measuring gaze orientation for human-robot interaction. R.Brochard, B.Burger, A.Herbulot, and F.Lerasle. Workshop during IEEE Symp. On Robot and Human Interactive Communication (RO-MAN’09), Toyama (Japan), October 2009. [Burger et al. 2009d] DBN versus HMM for gesture recognition in human-robot interaction. B.Burger, G.Infantes, I.Ferrané, F.Lerasle. Int. Workshop on Electronics, Control Modelling, Measurement and Signals (ECMS’09), Mondragon (Spain), July 2009. [Burger et al. 2008a] Mutual assistance between speech and vision for human-robot interaction. B.Burger, F.Lerasle, and I.Ferrané. IEEE/RSJ Int. Conf. On Intelligent Robots and Systems (IROS’08), Nice (France), October 2008. [Burger et al. 2008b] Multimodal interaction abilities for a robot companion. B.Burger, I.Ferrané, and F.Lerasle. Int. Conf. On Vision Systems (ICVS’08), Santorini (Greece), May 2008. [Danès et al. 2010] Information-Theoretic detection of broadband sources in a coherent beamspace MUSIC scheme. P. Danès and J. Bonnal. IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS’10), Taipei, Taiwan, submitted. [Germa et al. 2010a] Vision and RFID data fusion for tracking people in crowds by a mobile robot. T.Germa, F.Lerasle, N.Ouadah, and V.Cadenat. Int. Journal of Computer Vision and Image Understanding (CVIU’10). To appear. See the URL http://dx.doi.org/10.1016/j.cviu.2010.01.008 [Germa et al. 2010b] Fusion de données visuelles et RFID pour le suivi de personnes en environnement encombré depuis un robot mobile. T.Germa, F.Lerasle, N.Ouadah, V.Cadenat, and C.Lemaire. National Conf. Reconnaissance des Formes et Intelligence Artificielle (RFIA’10), Caen (France), January 2010. [Germa et al. 2009a] Vision and RFID-based person tracking in crowds from a mobile robot. T.Germa, F.Lerasle, N.Ouadah, V.Cadenat, and M.Devy. IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS’09), St Louis (USA), October 2009. [Germa et al. 2009b] Video-based Face Recognition and Tracking from a Robot Companion. T. Germa, F.Lerasle, and T.Simon. Int. Journal of Pattern Recognition and Artificial Intelligence (IJPRAI’09), Vol. 23, Issue 3, pp 591—616.

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 28/30
[Germa et al. 2009c] A tuning strategy for face recognition in Robotic application. T.Germa, M.Devy, R.Rioux, F.Lerasle. Int. Conf. On Computer Vision Theory and Applications (VISAPP’09), Lisboa (Portugal), February 2009. [Goeller et al. 2009] Control for the Interactive Behavior Operated Shopping Trolley InBOT. M.Goeller, T.Kerscher, M.Ziegenmeyer, A.Roennau, J.M.Zoellner, R.Dillmann, Haptic New Frontiers in Human-Robot Interaction Workshop of the 2009 Convention Artificial Intelligence and Simulation of Behaviour (AISB’09), Edinburgh (Scotland), April 2009. [Goeller et al. 2010] Control-sharing and trading of a service robot acting as intelligent shopping cart. M.Goeller, F.Steinhardt, T.Germa, T.Kerscher, R.Dillmann, M.Devy, and Frederic Lerasle. Int. Symp. in Robot and Human Interactive Communication (Ro-Man), Viareggio, Italy, Sept 2010, Submission. [Kerscher et al. 2009] Intuitive Control for the Mobile Service Robot InBOT using Haptic Interaction. T.Kerscher, M.Goeller, M.Ziegenmeyer, A.Roennau, J. M.Zoellner, and R.Dillmann, Int. Conf. on Advanced Robotics (ICAR’09), Munich (Germany), June 2009. [Ouadah et al. 2010] A multi-sensor based contrzol strategy for initiating and maintaining interaction between a robot and a human. N.Ouadah, V.Cadenat, F.Lerasle, M.Hamerlain, T.Germa, F.Boudjema. Int. Journal of Advanced Robotics, 2010. Submission. [Vallée et al. 2009] Improving user interfaces of interactive robots with multimodality. M.Vallée, B.Burger, D.Ertl, F.Lerasle, and J.Falb. Int. Conf. On Advanced Robotics (ICAR’09), Munich (Germany), June 2009.
References [Akaike 1974] A new look at the statistical model identification. H. Akaike. IEEE Trans. on Automatic Control, 19(6), pp. 716-723, 1974. [Argentieri et al. 2006] Modal analysis based beamforming for nearfield or farfield speaker localization in robotics. S. Argentieri, P. Danès and P. Souères. IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS’06), Beijing, China, pp. 866-871. [Argentieri et al. 2007] Broadband variations of the MUSIC high-resolution method for sound source localization in robotics. S. Argentieri and P. Danès. IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS’07), San Diego, CA, oct. 2007, pp. 2009-2014. [Arulampalam et al. 2002] A tutorial on particle filters for on-line non linear/non gaussian Bayesian tracking. S.Arulampalam, S.Maskell, N.Gordon, and T.Clapp. IEEE Trans. On Signal Processing, Vol. 50, Issue 2, pp 174—188, 2002. [Belhumeur et al. 1996] Eigenfaces vs. Fisherfaces. P.Belhumeur, J.Hespanha, and D.Kriegman. European Conf. on Computer Vision (ECCV’96), pp 45—48, Cambridge (UK), April 1996. [Cavassilas 1991] Stochastic matched filter. Int. Conf. on Sonar Signal Processing, 1991, pp. 194-199. [Dalal et al. 2005] Histograms of oriented gradients for human detection. N. Dalal, B. Triggs. IEEE Int. Conf. On Computer Vision and Pattern Recognition (CVPR’05), San Diego (USA), June 2005. [Felzenswalb et al. 2009] Object detection with discriminatively trained part based models. P.F.Felzenswalb, R.Girshick, D.McAllester, and D.Ramanan. IEEE Pattern Analysis and Machine Intelligence (PAMI’09), Vol. 99, Issue 1, 2009.

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 29/30
[Gavrila et al. 2007] Multi-cue pedestrian detection and tracking from a moving vehicle. D.M.Gavrila and S.Munder. Int. Journal of Computer Vision (IJCV’07), Vol. 72, Issue 1, pp 41—59, 2007. [Gee et al. 1994] Determining the gaze of faces in images. A.H.Gee, and R.Cipolla. Image and Vision Computing (IVC’94), Vol. 12, pp 639—647, 1994. [Infantes 2006] Apprentissage de modèles de comportements pour le contrôle d’exécution et la planification robotique. PhD thesis, Paul Sabatier University, Toulouse (France). [Isard et al. 1998a] CONDENSATION – conditional density propagation for visual tracking. M.Isard, and A.Blake. Int. Journal of Computer Vision (IJCV’98), 29(1), 5—28, 1998. [Isard et al. 1998b] I-CONDENSATION : Unifying low-level and high-level tracking in a stochastic framework. M.Isard, and A.Blake. European Conf. on Computer Vision (ECCV’98), 893—908, Freibourg (Germany), June 1998. [Jones et al. 2000] Statistical color models with application to skin detection. Int. Conf. On Computer Vision and Pattern recognition (CVPR’00), pp274—280, 2000. [Laptev et al. 2006] Improvements of object detection using boosted histograms. I.Laptev. British Machine Vision Conf. (BMVC’06), Edinburgh (UK), 2006 [Paulraj et al. 1986] A. Pauraj and T. Kailath. Eigenstructure Methods for Direction of Arrival Estimation in the Presence of Unknown Noise Fields. IEEE Transactions on Acoustics, Speech, and Signal Processing 34(1), pp. 13-20, 1986. [Pérez et al. 2004] Data fusion for visual tracking with particles. P. Pérez, J. Vermaak, and A. Blake. IEEE, 92(3), 495—513, 2004. [Qu et al. 2007] Distributed Bayesian multiple-target tracking in crowded environments using collaborative cameras. EURASIP journal on Advances in Signal Processing, 2007. [Rabiner 1989] A tutorial on Hidden Markov Models and selected applications in speech recognition. L.Rabiner, IEEE, 77(2):257—286, 1989. [Smith et al. 2005] Using particles to track varying numbers of interacting people. K.Smith, D.Gatica-Perez, and J.Odobez. IEEE Int. Conf. On Computer Vision and Pattern recognition (CVPR’05), San Diego (USA), June 2005. [Swindlehurst et al.1992] A. L. Swindlehurst and T. Kailath. A Performance Analysis of Subspace-Based Methods in the Presence of Model Errors, Part I: The MUSIC Algorithm. IEEE Transactions on Signal Processing 40(7), pp.1758-1774, 1993. [Turk et al. 1991] Face recognition using eigenfaces. M.Turk, and A.Pentland. IEEE Int. Conf. On Computer Vision and Pattern Recognition (CVPR’91), pp 586—591, Hawaii, June 1991. [Viola et al. 2003] Fast multi-view face detection. P.Viola and M.Jones. IEEE Int. Conf. On Computer Vision and Pattern Recognition (CVPR’03), 2003. [Wang et al. 1985] H. Wang and M. Kaveh. Coherent signal-subspace processing for the detection and estimation of angles of arrival of multiple wide-band sources. IEEE Transactions on Acoustics, Speech, and Signal Processing 33, pp. 823-831, 1985. [Wax et al. 1985] M. Wax and T. Kailath. Detection of signals by information theoretic criteria. IEEE Transactions on Acoustics, Speech, and Signal Processing 33(2), pp. 387-392, 1985. [Xavier et al. 2005] Fast line, arc/circle and leg detection from laser scan data in a player driver. J.Xavier, M.Pacheco, D.Castro, A.Ruano, and U.Nunes. IEEE Int. Conf. On Robotics and Automation (ICRA’05), Barcelona (Spain), pp 3930—3935, April 2005.

Basic Functions for Detection/Recognition of People
CommRob IST-045441 Advanced Behaviour and High-Level Multimodal Communication with and among Robots
page 30/30
[Xu et al. 2006] Multi-objective parameters selection for SVM classification using NSGA-II. L.Xu and C.Li. In Industrial Conf. On Data Mining (ICDM’06), Hong-Kong, pp 365—376, December 2006. [Zhou et al. 2009] Object tracking using SIFT features and mean shift. H.Zhou, Y. Yuan, and C.Shi. Computer Vision and Image Understanding (CVIU’09), 113(3):345—352, 2009.







![Locomotion [2015]](https://static.fdocuments.in/doc/165x107/55d39c9ebb61ebfd268b46a2/locomotion-2015.jpg)






![Locomotion [2014]](https://static.fdocuments.in/doc/165x107/5564e3eed8b42ad3488b4e94/locomotion-2014.jpg)



