File systems, processes and system calls, scheduler By Team Sandbox Asaf Cohen, Yaron Rozen.
59
Linux Kernel Internals File systems, processes and system calls, scheduler By Team Sandbox Asaf Cohen, Yaron Rozen
-
Upload
lilian-tucker -
Category
Documents
-
view
215 -
download
0
Transcript of File systems, processes and system calls, scheduler By Team Sandbox Asaf Cohen, Yaron Rozen.
Linux Kernel Internals
File systems, processes and system calls, scheduler
By Team SandboxAsaf Cohen, Yaron Rozen

What is sandboxing?
Sandbox is security mechanism for separating processes from the whole system. It is often used to run untested programs, even with root privileges with no worry.
The sandbox often supply limited and controlled set of resources for guest programs to run in like separate file system, limited system calls and almost always disallow access to the host system or networking devices.

What is sandboxing? (cont)
If these programs can be executed in a restricted environment, even if the programs behave maliciously , their damage is confined within the restricted environment.

Example
Imagine a server that treats requests from its clients.
Malicious client could send a request generating buffer overflow in the server main program.
If the program is not separated from other system components, the client can damage the whole system.
But, if the server main program run in sandbox mode the buffer overflow can’t cause damage out of the sandbox.

File systems
To support sandboxing we need to separate the sandbox file system from the whole file system.
It’s look like that our first task is to understand how The Linux File System works.
Actually, Linux supports almost all types of the file system follows the interface declared by the Virtual File System.
We will speak in this field about the following things: File and File system concepts (shortly) Virtual File System (shortly) Superblocks and inode (shortly) Dentry File object Data Structures Associated with processes Root directory,

File
File is an ordered string of bytes. Each file has name for identification by
both the system and the user. There are some types of files: fifo,
sockets, block devices etc. Files are organized in directories.
Directory is a file also (file containing entries for other files).

File System
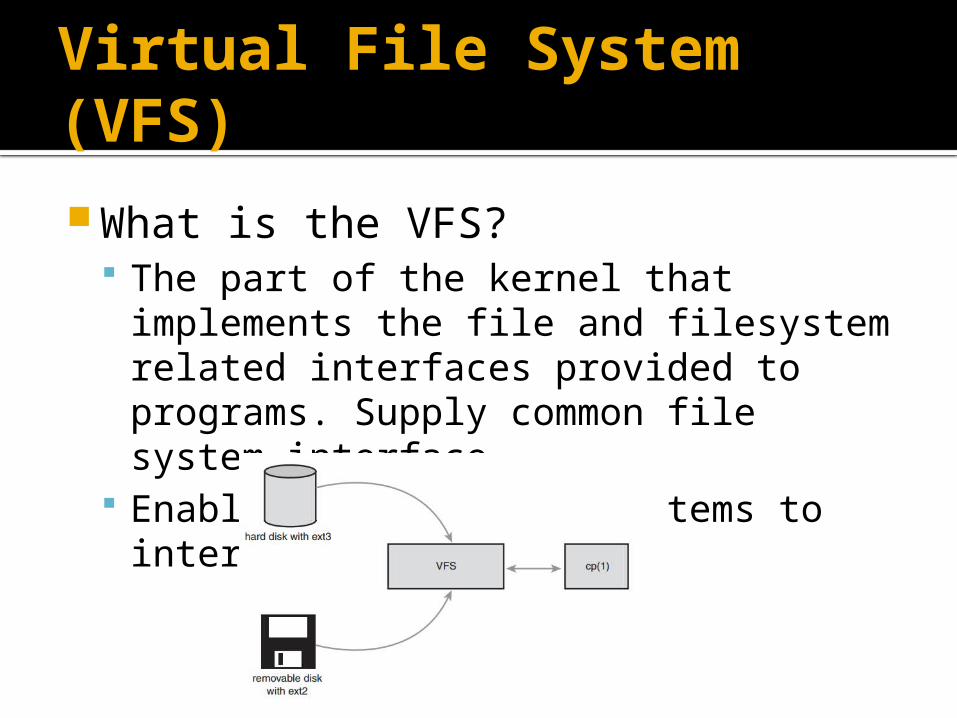
The file system is hierarchy of directories rooted in some location. This location called mount point.
Before we can access the file residing in the file system we need to mount it (sys call mount())
The command tells the kernel that the fs is ready to use and the fs will be associate with a particular point of overall file system hierarchy.
This point called the mount point of the fs.
Virtual File System (VFS)
What is the VFS? The part of the kernel that implements
the file and filesystem related interfaces provided to programs. Supply common file system interface.
Enable distinct file systems to interoperate

Abstraction Layer
The abstraction layer enables Linux to support different filesystems, even if they differ in supported features or behavior.
This is possible because the VFS provides a common file model that can represent any filesystem’s general feature set and behavior.
The abstraction layer define the basic conceptual interfaces and data structures that all filesystems support.
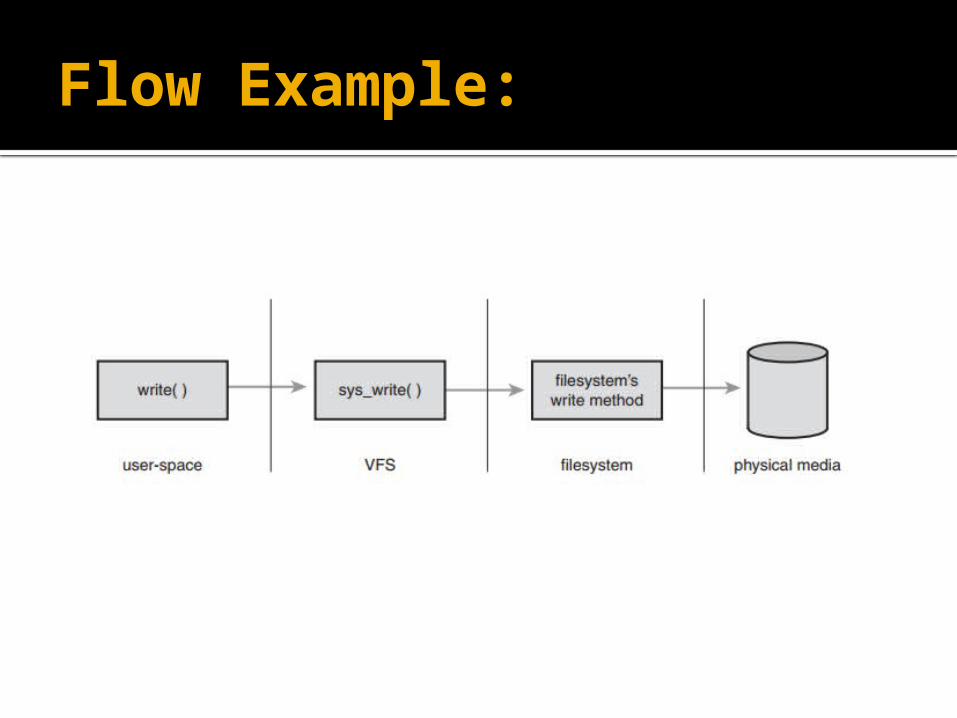
Flow Example:

Superblock Struct
The file system own control information stored in the superblock.
The superblock struct declaration residing in the file fs.h.
The superblock contains also pointer to operation struct contains pointer to functions called by the superblock.
Part of these operations has default implementation by the VFS and the real file system doesn’t need to implement these. In this case the pointer to this function set to NULL.

inode
Linux separate the contents of the file from the data about it. (size, permissions, etc…)
The data about a file (metadata) stored in separate data structure from the file, called inode (index node).
Like in superblock, operations on inode (create, link, mknod) resides in operation object.

Directory Entries
Directories may be nested to form paths. Each component of a path is called a Directory
Entry (dentry). (both files and directories) A dentry is not the same as a directory. For example: in the path
/usr/geva/sandboxProject/grade the root directory “/”, the sub directories usr,geva,sandboxProject and the file grade, all of them are dentries.
In contrast to superblock and inode, dentry doesn’t represent any data structure residing in the disk.

Directory Entries
Used to resolving the path (require heavy string operations), not always trivial.
The dentry makes this process easier.
The VFS constructs dentry objects on the-fly, as needed, when performing directory operations.

Dentry Struct
struct dentry { atomic_t d_count; /* usage count */ unsigned int d_flags; /* dentry flags */ spinlock_t d_lock; /* per-dentry lock */ int d_mounted; /* is this a mount point? */ struct inode *d_inode; /* associated inode */ struct hlist_node d_hash; /* list of hash table entries */ struct dentry *d_parent; /* dentry object of parent */ struct qstr d_name; /* dentry name */ struct list_head d_lru; /* unused list */ union {struct list_head d_child; /* list of dentries within */ struct rcu_head d_rcu; /* RCU locking */} d_u; struct list_head d_subdirs; /* subdirectories */ struct list_head d_alias; /* list of alias inodes */ unsigned long d_time; /* revalidate time */ struct dentry_operations *d_op; /* dentry operations table */ struct super_block *d_sb; /* superblock of file */ void *d_fsdata; /* filesystem-specific data */ unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* short name */};

Dentry State
A valid dentry can be in one of three states: Used – the dentry corresponds to a valid inode e
(d_inode points to an associated inode) and indicates that there are one or more users (when d_count is positive)
Unused - corresponds to a valid inode (d_inode points to an inode), but the VFS is not currently using the dentry object (d_count is zero)..
Negative - dentry is not associated with a valid inode (d_inode is NULL) because either the inode was deleted or the path name was never correct.

Dentry Cache
After the VFS resolves the path it is it would be quite wasteful to throw away all that work.
The VFS caches the dentry objects in dcache. The cache contains three data structures:
Lists of “used” dentries linked off their associated inode via the i_dentry field of the inode object. Because the given inode can have multiple links – multiple dentries, we use linked list.
A doubly linked ” list of unused and negative dentry objects the policy of inserting and removing dentries from the cache is LRU.
A hash table and hashing function used to quickly resolve a given path into the associated dentry object.
The hash table is represented by the dentry_hashtable array. Each element is a pointer to a list of dentries that hash to the same value. The size of this array depends on the amount of physical RAM in the system.The actual hash value is determined by d_hash().This enables filesystems to provide a unique hashing function. Hash table lookup is performed via d_lookup(). If a matching dentry object is found in the dcache, it is returned. On failure, NULL is returned.
The dcache is also icache!

Dentry Operations
int (*d_revalidate) (struct dentry *, struct nameidata *); Determines whether the given dentry object is valid. The VFS calls this function whenever it is preparing to use a dentry from the dcache.
int (*d_hash) (struct dentry *, struct qstr *); Creates a hash value from the given dentry.
int (*d_compare) (struct dentry *, struct qstr *, struct qstr *); Compare two filenames. Most filesystems leave this at the VFS default, which is a simple string compare.
int (*d_delete) (struct dentry *); Called by the VFS when the d_count became zero.
void (*d_release) (struct dentry *); Called by the VFS when the specified dentry is going to be freed.
void (*d_iput) (struct dentry *, struct inode *); Called by the VFS when a dentry object loses its associated inode (say, because the entry was deleted from the disk). By default, the VFS simply calls the iput() function to release the inode.

File object
File object used to represent file opened by a process.
Process sees file as file object, doesn’t need to know about superblocks, inodes and dentries.
The file object is the most familiar object and it’s operations are the familiar sys_calls such read and write.
Similar to dentry objects, file object doesn’t represent any entity residing in the disk.

File Struct
struct file { union {struct list_head fu_list; /* list of file objects */ struct rcu_head fu_rcuhead; /* RCU list after freeing */} f_u; struct path f_path; /* contains the dentry */ struct file_operations *f_op; /* file operations table */ spinlock_t f_lock; /* per-file struct lock */ atomic_t f_count; /* file object’s usage count */ unsigned int f_flags; /* flags specified on open */ mode_t f_mode; /* file access mode */ loff_t f_pos; /* file offset (file pointer) */ struct fown_struct f_owner; /* owner data for signals */ const struct cred *f_cred; /* file credentials */ struct file_ra_state f_ra; /* read-ahead state */ u64 f_version; /* version number */ void *f_security; /* security module */ void *private_data; /* tty driver hook */struct list_head f_ep_links; /* list of epoll links */spinlock_t f_ep_lock; /* epoll lock */ struct address_space *f_mapping; /* page cache mapping */ unsigned long f_mnt_write_state; /* debugging state */};

File Operations
struct file_operations { struct module *owner; loff_t (*llseek) (struct file *, loff_t, int); ssize_t (*read) (struct file *, char __user *, size_t, loff_t *); ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *); ssize_t (*aio_read) (struct kiocb *, const struct iovec *,unsigned long, loff_t); ssize_t (*aio_write) (struct kiocb *, const struct iovec *,unsigned long, loff_t); int (*readdir) (struct file *, void *, filldir_t); unsigned int (*poll) (struct file *, struct poll_table_struct *); int (*ioctl) (struct inode *, struct file *, unsigned int,unsigned long); long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long); long (*compat_ioctl) (struct file *, unsigned int, unsigned long); int (*mmap) (struct file *, struct vm_area_struct *); int (*open) (struct inode *, struct file *); int (*flush) (struct file *, fl_owner_t id); int (*release) (struct inode *, struct file *); int (*fsync) (struct file *, struct dentry *, int datasync); int (*aio_fsync) (struct kiocb *, int datasync); int (*fasync) (int, struct file *, int); int (*lock) (struct file *, int, struct file_lock *); ssize_t (*sendpage) (struct file *, struct page *,int, size_t, loff_t *, int); unsigned long (*get_unmapped_area) (struct file *,unsigned long,unsigned long, unsigned long, unsigned long);int (*check_flags) (int); int (*flock) (struct file *, int, struct file_lock *); ssize_t (*splice_write) (struct pipe_inode_info *,struct file *, loff_t *, size_t, unsigned int);ssize_t (*splice_read) (struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int);int (*setlease) (struct file *, long, struct file_lock **); };

Data Structures Associated with Filesystems
struct file_system_type - special structure for describing the capabilities and behavior of each filesystem.
struct vfsmount - There is only one file_system_type per filesystem, regardless of how many instances of the filesystem are mounted on the system. This structure represents a specific instance of a filesystem in a mount point.
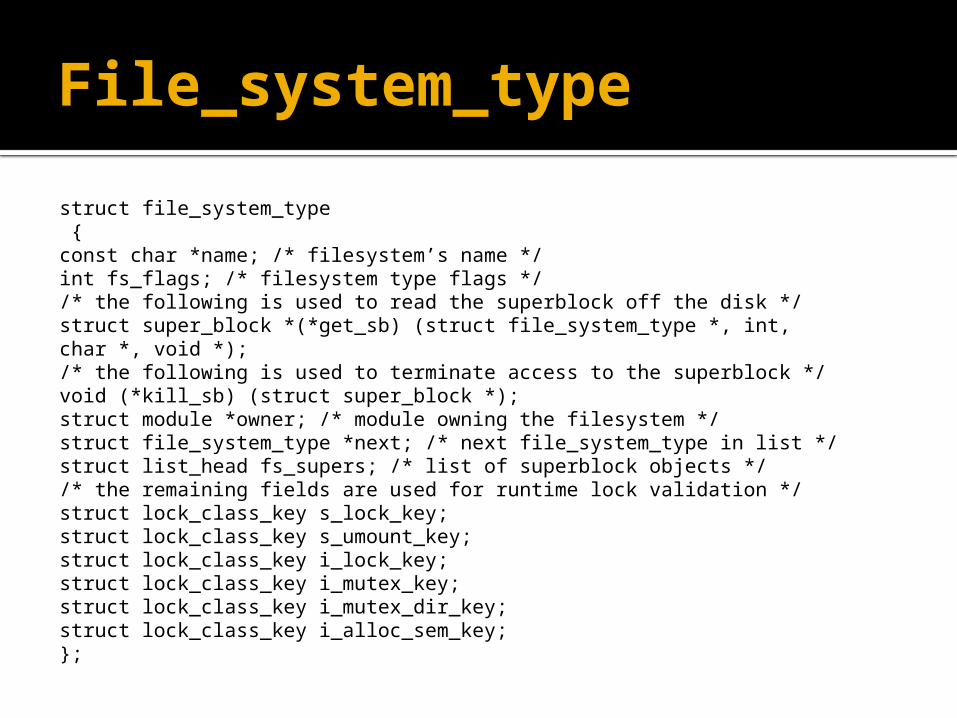
File_system_type
struct file_system_type { const char *name; /* filesystem’s name */ int fs_flags; /* filesystem type flags *//* the following is used to read the superblock off the disk */ struct super_block *(*get_sb) (struct file_system_type *, int,char *, void *);/* the following is used to terminate access to the superblock */ void (*kill_sb) (struct super_block *);struct module *owner; /* module owning the filesystem */ struct file_system_type *next; /* next file_system_type in list */ struct list_head fs_supers; /* list of superblock objects *//* the remaining fields are used for runtime lock validation */ struct lock_class_key s_lock_key; struct lock_class_key s_umount_key; struct lock_class_key i_lock_key; struct lock_class_key i_mutex_key; struct lock_class_key i_mutex_dir_key; struct lock_class_key i_alloc_sem_key;};
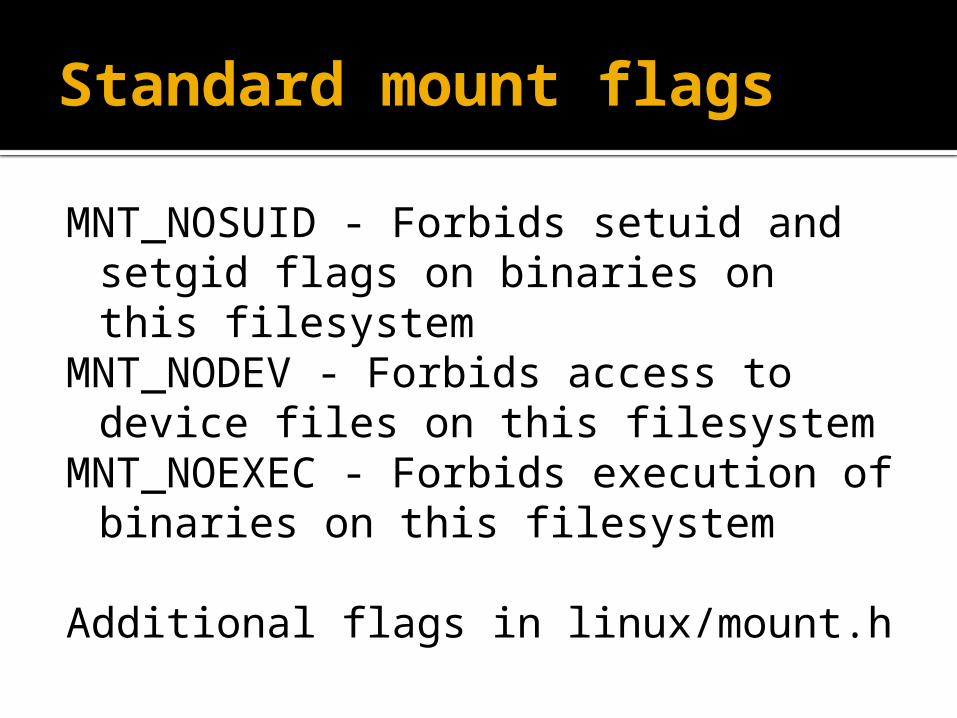
Standard mount flags
MNT_NOSUID - Forbids setuid and setgid flags on binaries on this filesystem
MNT_NODEV - Forbids access to device files on this filesystem
MNT_NOEXEC - Forbids execution of binaries on this filesystem
Additional flags in linux/mount.h

Data structures used by process In our project we interest most what is the
process view of the filesystem. Each process in the system has a list of its
open files, root filesystem, current working directory, current root directory, mount points and so on.
Process has three data structures bind the VFS layer to it: files_struct – contains the file descriptor table. fs_struct namespace

Files_struct and the fdt
struct files_struct {
atomic_t count;struct fdtable __rcu *fdt;struct fdtable fdtab;spinlock_t file_lock ____cacheline_aligned_in_smp;int next_fd;unsigned long close_on_exec_init[1];unsigned long open_fds_init[1];struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};
struct fdtable {
unsigned int max_fds;struct file __rcu **fd; /* current fd array */unsigned long *close_on_exec;unsigned long *open_fds;struct rcu_head rcu;struct fdtable *next;
};

Fs_structure
Pointed by the fs field in the process descriptor This structure contains filesystem information
related to a process and is pointed at by the fs field in the process descriptor.
The structure contains the root directory and the working directory of the process

Fs_structure.h
struct fs_struct {int users;spinlock_t lock;seqcount_t seq;int umask;int in_exec;struct path root, pwd;
};
extern struct kmem_cache *fs_cachep;
extern void exit_fs(struct task_struct *);extern void set_fs_root(struct fs_struct *, const struct path *);extern void set_fs_pwd(struct fs_struct *, const struct path *);extern struct fs_struct *copy_fs_struct(struct fs_struct *);extern void free_fs_struct(struct fs_struct *);extern int unshare_fs_struct(void);
static inline void get_fs_root(struct fs_struct *fs, struct path *root){
spin_lock(&fs->lock);*root = fs->root;path_get(root);spin_unlock(&fs->lock);
}
static inline void get_fs_pwd(struct fs_struct *fs, struct path *pwd){
spin_lock(&fs->lock);*pwd = fs->pwd;path_get(pwd);spin_unlock(&fs->lock);
}
The Root directory
In computer file systems the root directory is the top most directory in hierarchy all file systems entries, including mounted file systems are branches of this root.
In Linux, all processes have own root directory. In the most scenarios is the actual system root directory.

chroot
Change the root directory of process is one step in sandbox implementation
chroot is a system call that change the root directory of the current process to any directory.
The function: int chroot(const char *path); Only a privileged process (Linux: one with
the CAP_SYS_CHROOT capability) may call chroot().
If the process fork a child, the child inherit the parent’s root directory.

Example
if the process redefine its root directory to: /tmp/sandbox. Now it is see /tmp/sandbox as its root directory (“/”).
If the process is trying to access a file named /usr/geva/ignored_mails, it will in fact access the file named /tmp/sandbox/usr/geva/ignored_mails.
Actually, the process can’t name and (in hope) can’t access files out the new root directory.

chroot is insufficient
Chroot changes an ingredient in the pathname resolution process and does nothing else.
Chroot doesn’t change the current working directory of the process and it can to be outside the new root directory.
In addition, it doesn’t close open file descriptors pointing outside the chroot directory.

Ways to break the chroot
With root privileges it is almost trivial. One way is by second chroot (next slide)
With no root privileges it is more difficult but it is not impossible. The system could contains holes allow sandboxed processes to access files outside the sandbox.

Code to break the chroot with root privielges.

Processes, System Calls, and Scheduling
A process in linux The task structure and thread_info process creation
▪ fork() and clone()▪ copy_process() and copy on write
The road of the lonely system call The Entry to the kernel Process context
And we will talk a bit about the scheduler

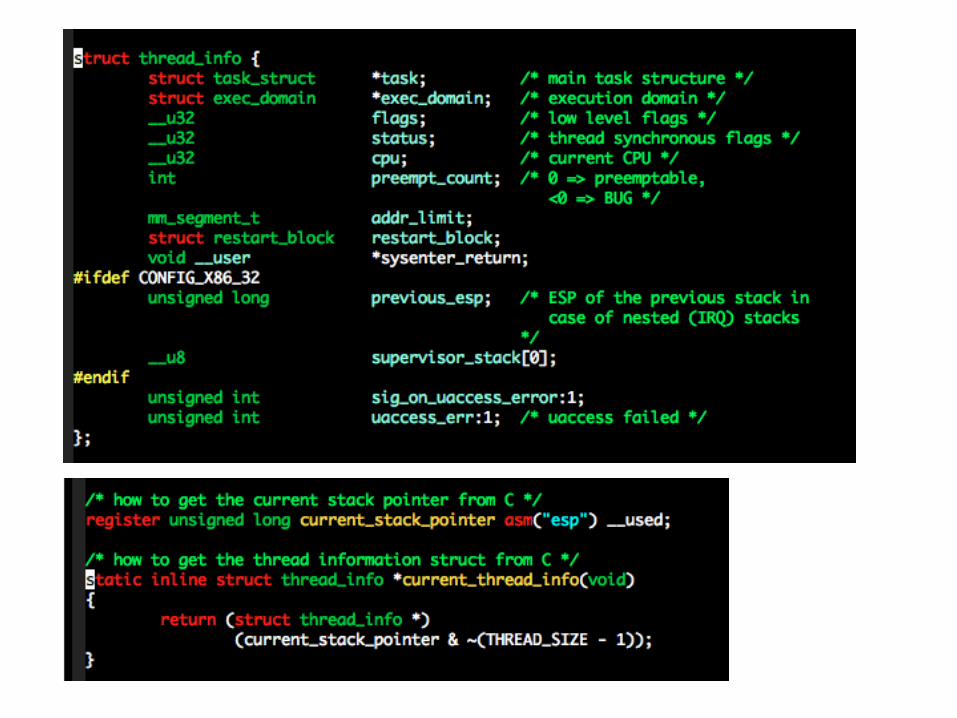
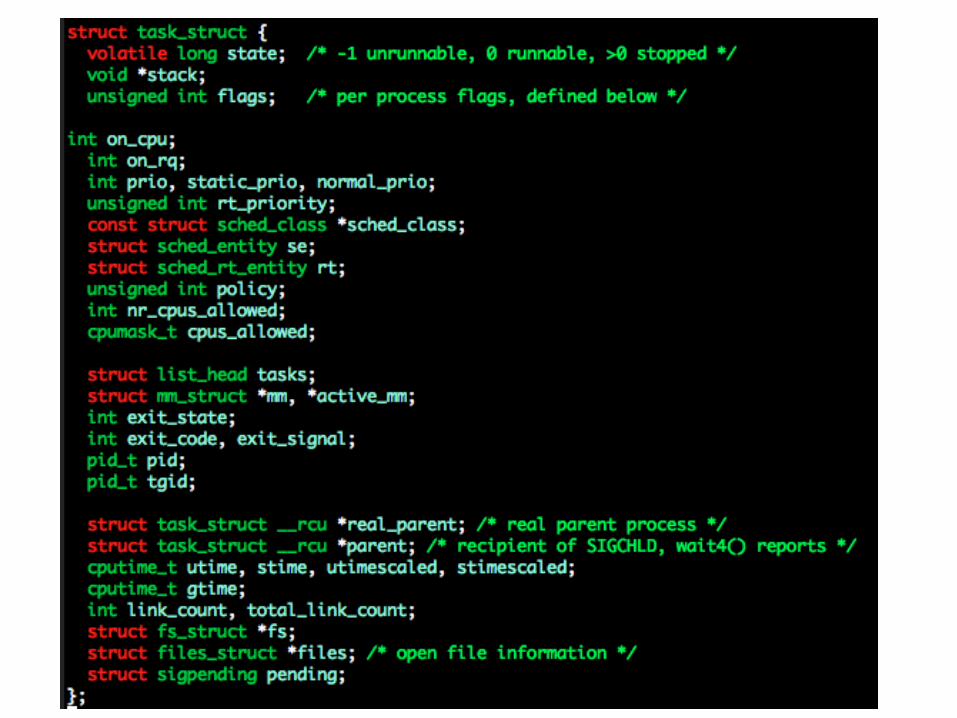
The task struct
Today the task_struct is allocated dynamically.
We want the kernel to be able to find this structure fast, even in architectures with few registers (e.g x86).
Solution: at the bottom of the kernel stack, we have the thread_info struct, and the current() macro.
Available only in process context.
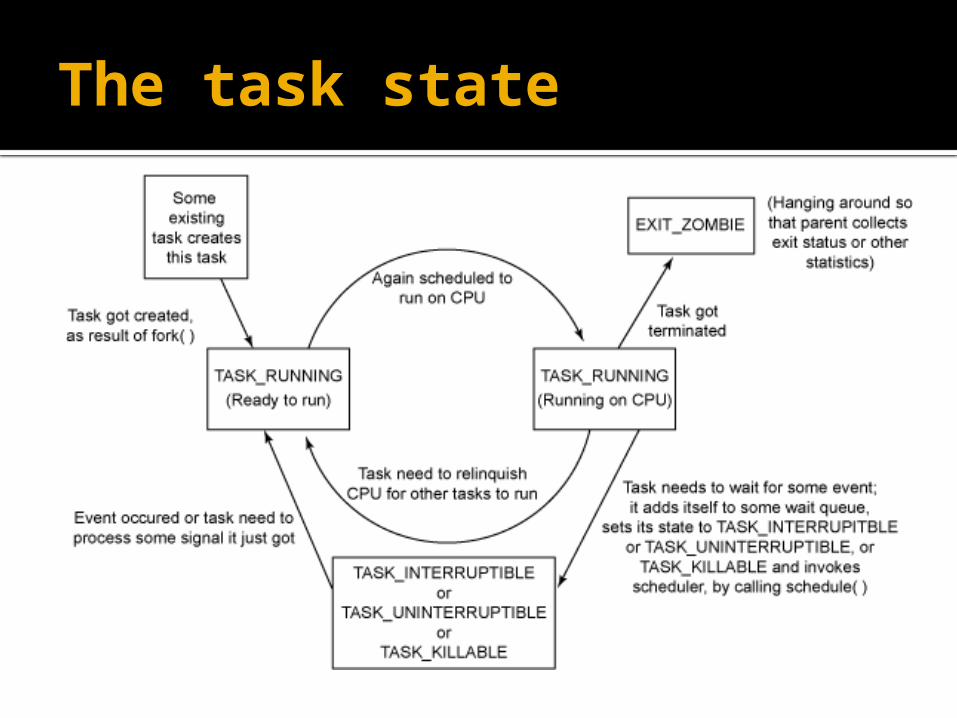
The task state

fork and clone
fork() libcall calls sys_clone() sys_clone calls do_fork() in kernel/fork.c do_fork() actions:
Check for correct CLONE parameters before actually allocating stuff.
Determine which event to report to ptrace()▪ Could be CLONE, FORK or VFORK
Calls copy_process() Wake up the child (because exec() and COW)
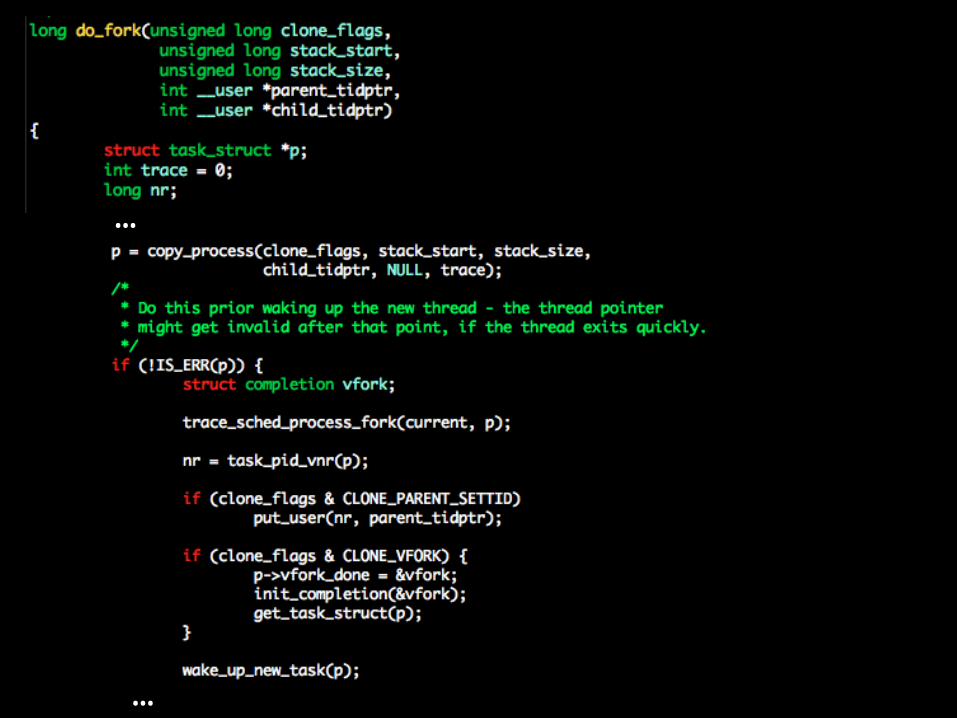
…
…

copy_process()
dup_task_struct() duplicated task_struct, thread_info and kernel stack
Checks that the child will not exceed the resource limit for the current user.
Clear the task_struct for initial values.
Assigns a new pid. Duplicates or shares FS, open files,
VM, etc. Init scheduler data. A gigantic function, read at home!
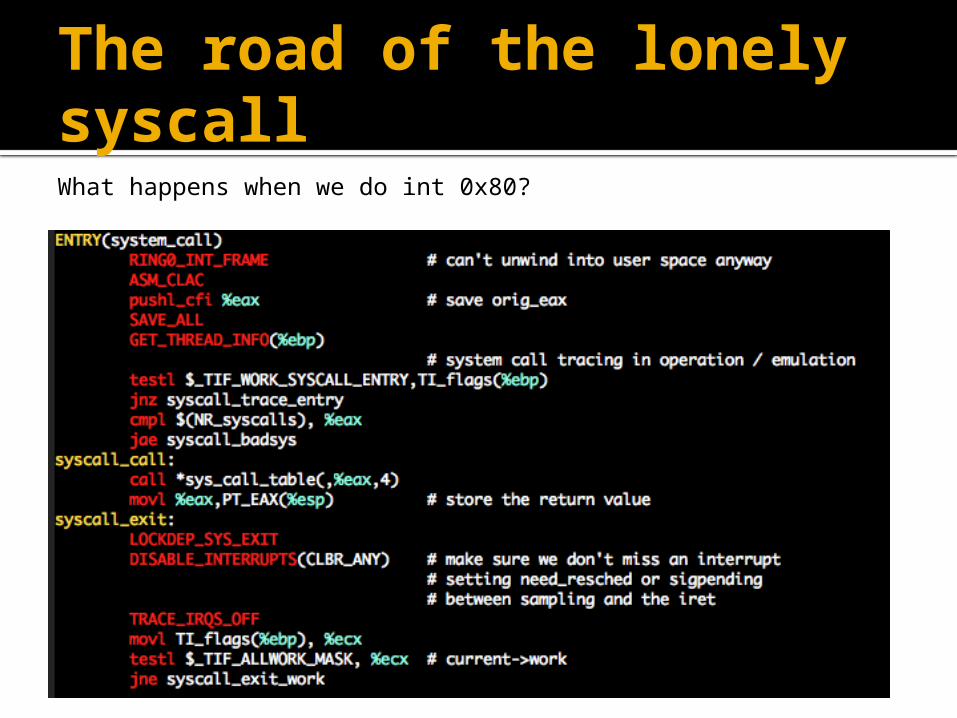
The road of the lonely syscallWhat happens when we do int 0x80?
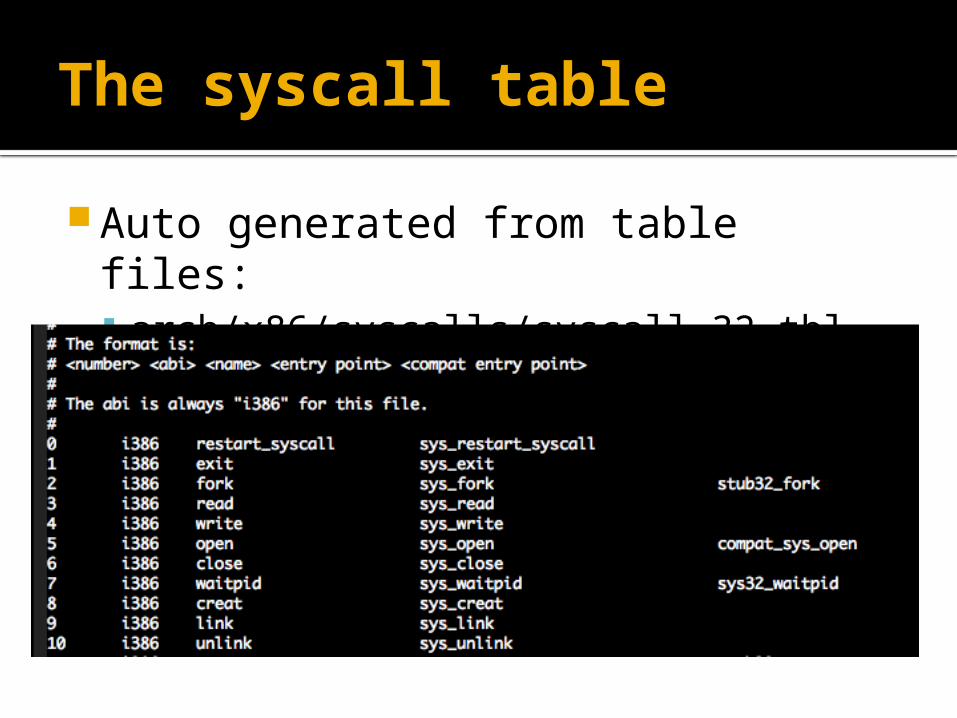
The syscall table
Auto generated from table files: arch/x86/syscalls/syscall_32.tbl

But int 0x80 is slow!
In order to find the address of ENTRY(system_call) two memory addresses must be read from memory.
What happens if they are not in cache? Even if they are in cache, do we really
need to access the memory just to get the address of such an important routine?
The solution: the address should be “hardcoded” into a register.
This mechanism is called sysenter.
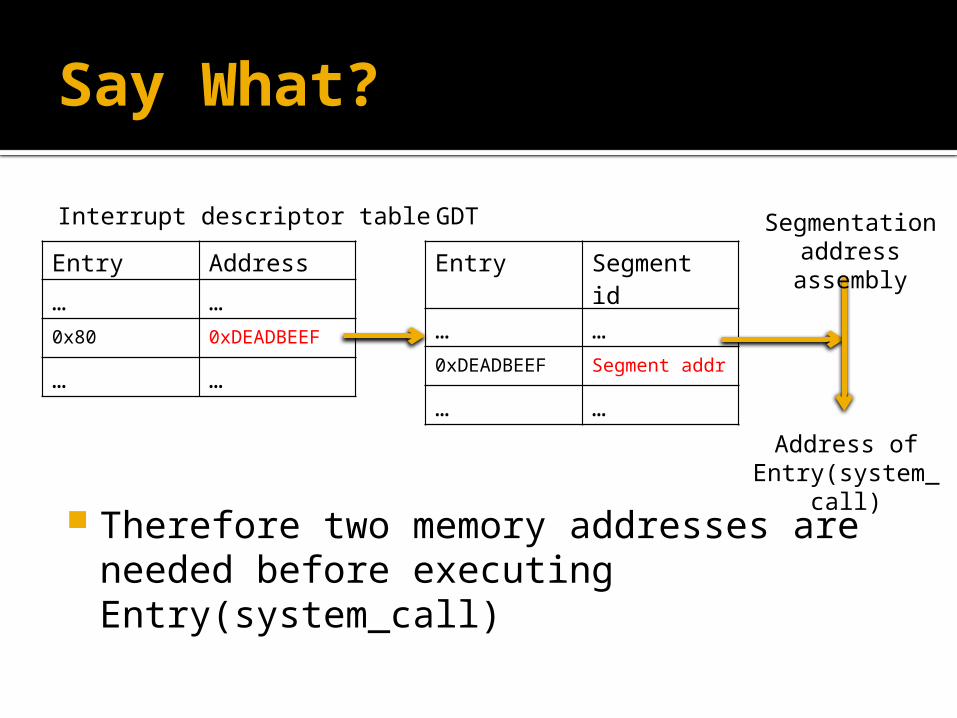
Say What?
Interrupt descriptor table
Entry Address
… …0x80 0xDEADBEEF
… …
Entry Segment id
… …0xDEADBEEF Segment addr
… …
GDT
Address of Entry(system_c
all)
Segmentation address
assembly
Therefore two memory addresses are needed before executing Entry(system_call)

The sysenter way
Sysenter basically allows the OS to load upfront the address of Entry(sysenter) inside a model specific register (MSR).
Fetching the address of the entry point to the system call handler is done by the CPU only.
No access to the memory controller is made. When the process (or the libcall) run the
instruction SYSENTER the cpu immediately jumps to Entry(sysenter) without accessing the memory.

Implementation
The SYSENTER instruction sets the following registers according to values specified by the operating system in certain model-specific registers.
CS register set to the value of (SYSENTER_CS_MSR) EIP register set to the value of (SYSENTER_EIP_MSR) SS register set to the sum of (8 plus the value in
SYSENTER_CS_MSR) ESP register set to the value of (SYSENTER_ESP_MSR)
Linux sets up the registers during init phase:

The Scheduler
Scheduling policy Scheduler internals
Runqueues and Priority Arrays schedule() wait queues
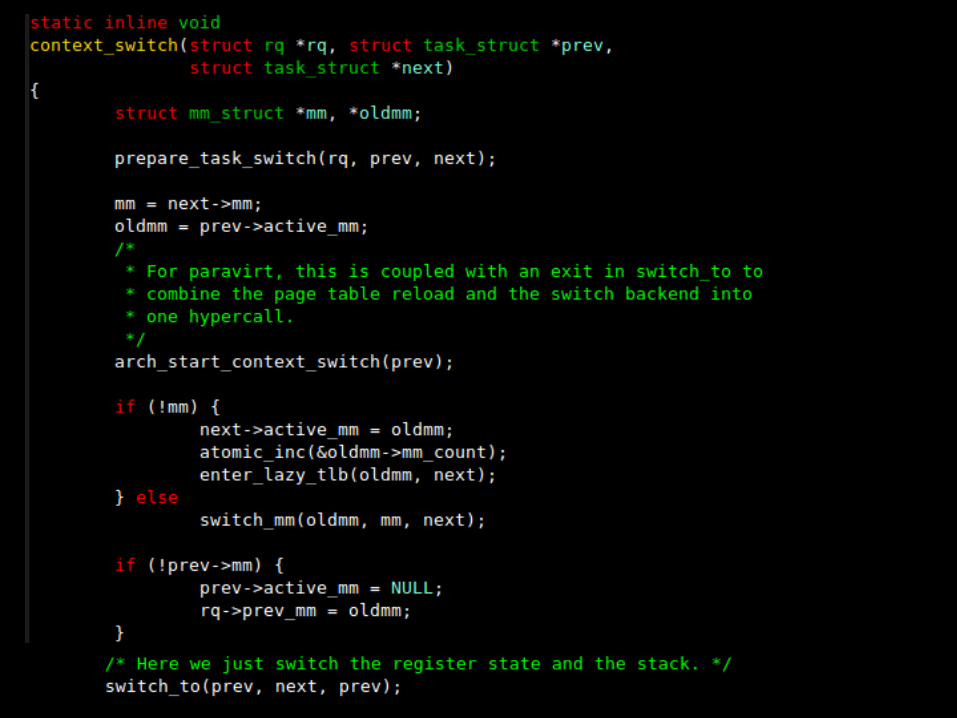
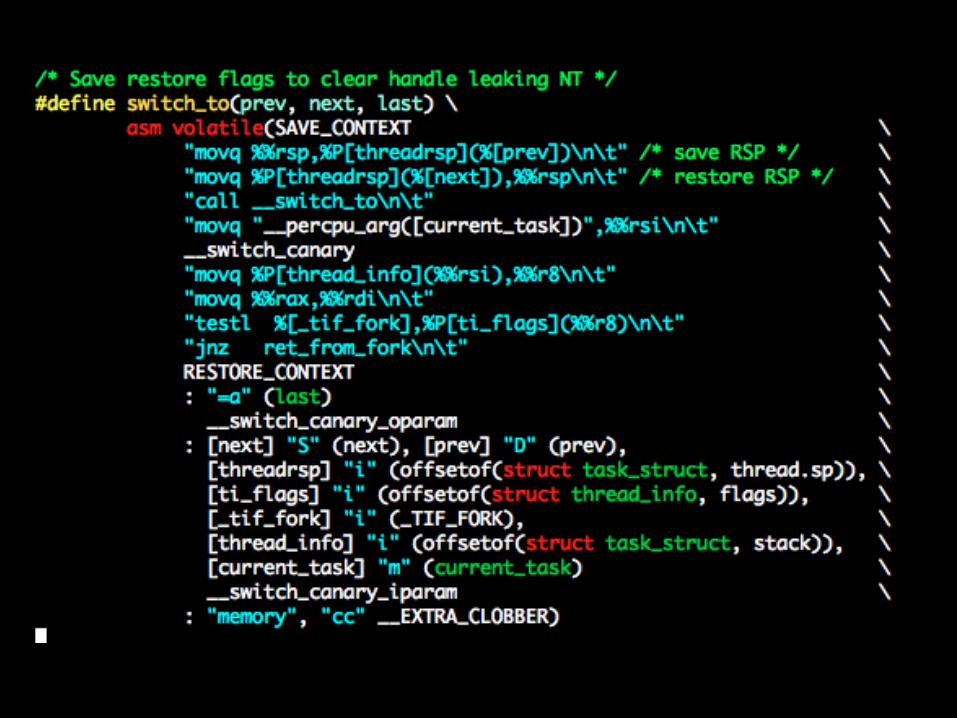
Preemptions and Context Switching

Scheduling policy in Linux Linux provides dynamic priority-based
scheduling. Tasks are prioritized by interactivity:
▪ I/O bound tasks receive elevated priority = more time▪ CPU bound tasks receive lowered priority = less time▪ Priority is recalculated every time a process ends its
current timeslice. Priority has two ranges:
▪ Nice value = +19 to -20▪ Real time priority = 0 to 99
The most sacred rule of the scheduler: The highest priority runnable process always runs!
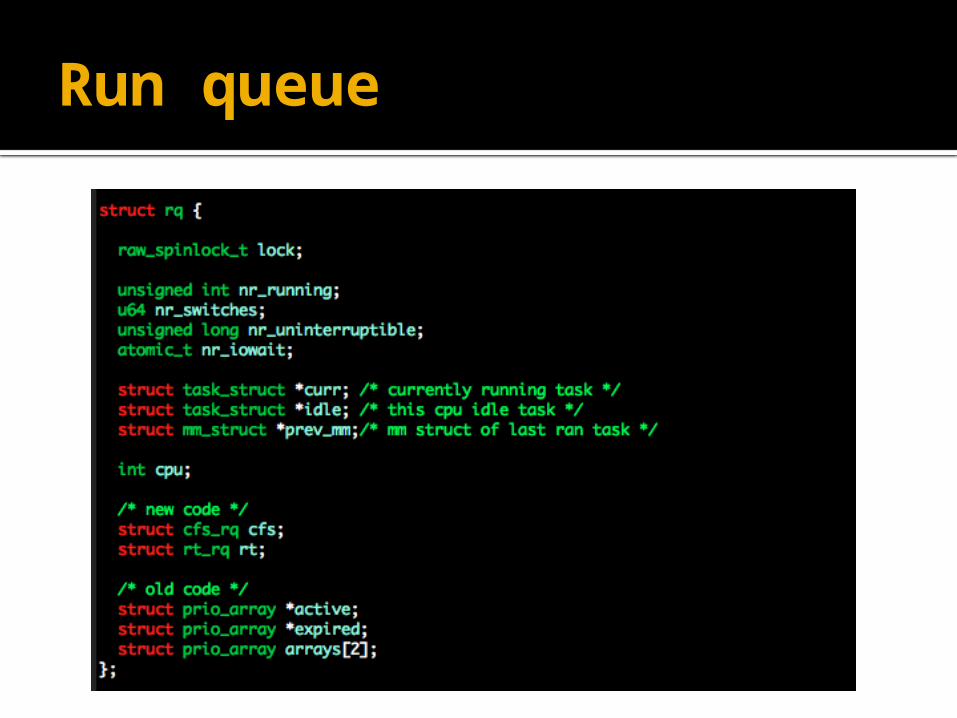
Run queue

Priority array (deprecated?)
Linux now have multiple scheduling classes in each runqueue.
In previous versions, each runqueue contained 2 priority arrays – active and expired.
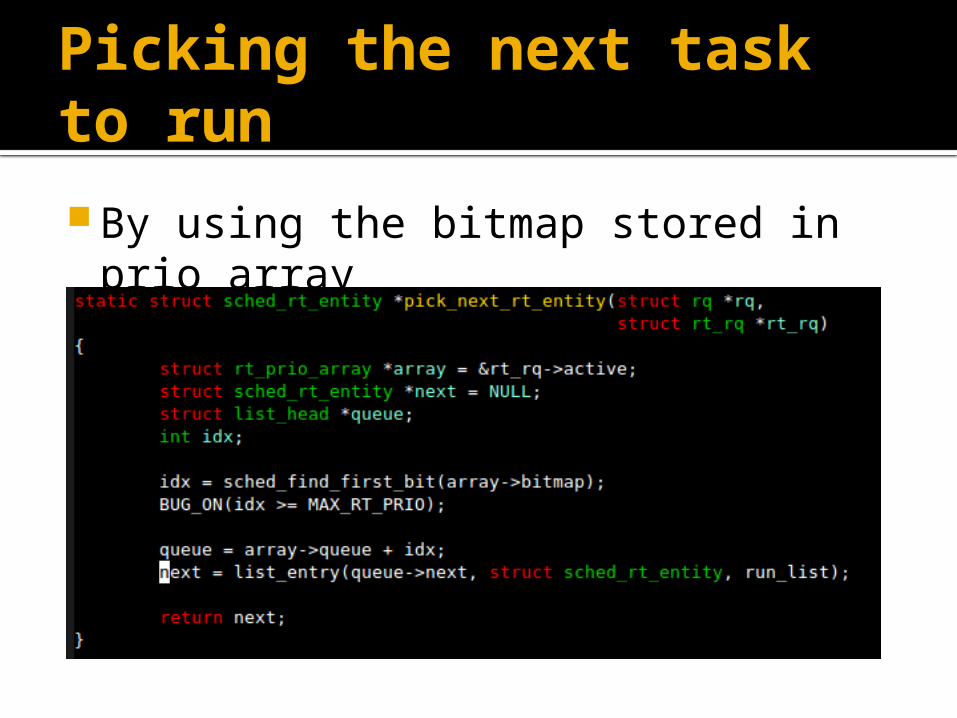
Picking the next task to run
By using the bitmap stored in prio_array

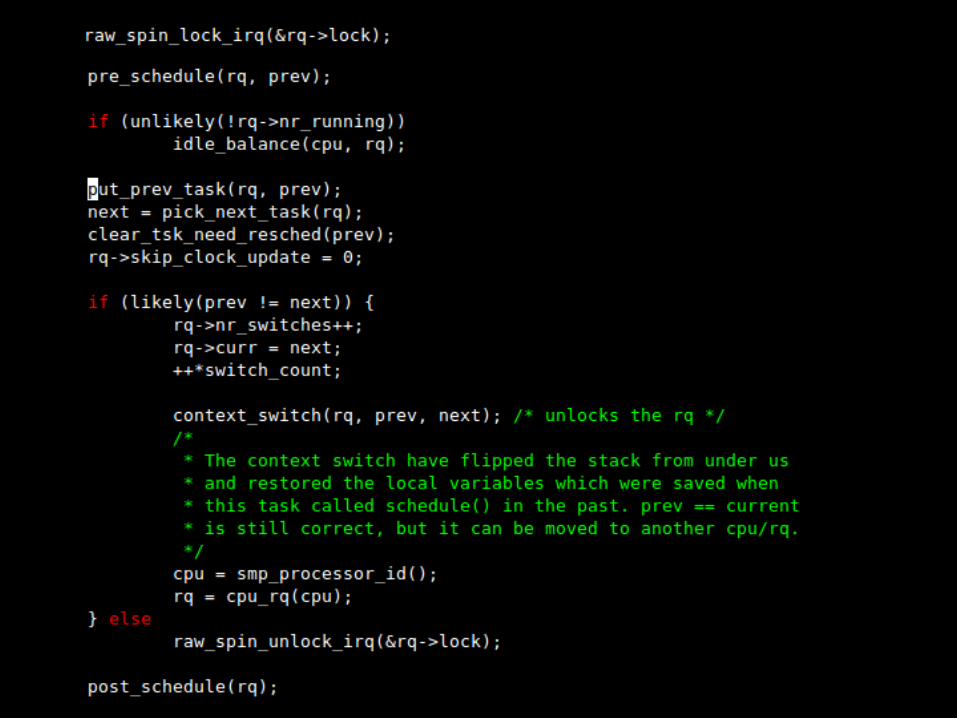
schedule()
The act of picking the next task to run and switching to it is implemented in schedule()
Explicit calls to schedule() happen when: The current task wants to sleep (blocks)
Schedule is also called upon returning to userspace if need_resched is set: scheduler_tick() – when timeslice exceeded try_to_wake_up() – when a task is leaving a wait
queue, or when clone() created a child Upon returning from interrupt handler