
FEDERAL DATA IN ACTION SUMMIT DATA TALENT - … TALENT-Federal Data in Action...FEDERAL DATA IN...
49
FEDERAL DATA IN ACTION SUMMIT: DATA TALENT DATA SCIENCE EDUCATION AND TRAINING Event Summary Report March 2017
-
Upload
nguyendiep -
Category
Documents
-
view
218 -
download
2
Transcript of FEDERAL DATA IN ACTION SUMMIT DATA TALENT - … TALENT-Federal Data in Action...FEDERAL DATA IN...

FEDERAL DATA IN ACTION SUMMIT: DATA TALENT
DATA SCIENCE EDUCATION AND TRAINING Event Summary Report
March 2017

DATA TALENT: Data in Action Summit | Page 2 of 49
Table of Contents Event Background: ........................................................................................................................................... 3
Agenda: ........................................................................................................................................................... 3
Presentations: .................................................................................................................................................. 4
National Academies of Sciences, Engineering and Medicine: .................................................................................. 4
Office of Personnel Management- Hiring: ................................................................................................................ 4
Panel: Past and Present of Data Science Education and Recruiting: .................................................................... 4
What kind of projects do you work on? ................................................................................................................... 5
Core Qualifications for Data Science: What should the core qualifications be for a Data Scientist? ...................... 5
What is a Data Scientist ............................................................................................................................................ 5
How do you keep a Data Scientist motivated? ......................................................................................................... 6
Panel: Future of Data Science Education and Recruiting .................................................................................... 6
What are the challenges Data Scientists face, both now and in the future? ........................................................... 7
What is the future of delivering data science education? ........................................................................................ 7
What is keeping us from having a PhD in Data Science or “Information Studies” at major universities/colleges .. 8
What are core elements for data science training and recruiting ............................................................................ 9
What takes people to the next level? ....................................................................................................................... 9
What’s the fastest, most efficient way to jump in? .................................................................................................. 9
Appendix A: Bios of Event Participants............................................................................................................ 10
Emcee: .................................................................................................................................................................... 10
Moderator: ............................................................................................................................................................. 10
Presenters: .............................................................................................................................................................. 10
Panel: Past and Present of Data Science Education and Recruiting: ...................................................................... 11
Panel: Future of Data Science Education and Recruiting ....................................................................................... 13
Appendix B: Slide Presentations ..................................................................................................................... 15
Appendix B.1 – Data Science Education ................................................................................................................. 15
Appendix B.2 – Hiring Excellence Campaign Overview .......................................................................................... 24
Appendix B.3 – Hiring Authorities and Flexibilities ................................................................................................. 26
Appendix B.4 – USAJOBS ........................................................................................................................................ 45
Acknowledgements: ....................................................................................................................................... 49

DATA TALENT: Data in Action Summit | Page 3 of 49
Event Background: Description: This event consisted of a series of presentations and two panel discussions on the state of data science vetting, recruiting and training among data science educators and hiring managers – and what that means for government and business leaders today. .
Data Talent Workgroup Lead: Natassja Linzau
Lead, Data Education Initiatives / Front End Engineer
U.S. Department of Commerce / Commerce Data Service
Hosted by Merav Yuravlivker and Dmitri Adler, Data Society (http://datasociety.com ), with additional assistance from Sean Gonzalez, Data Community DC (http://www.datacommunitydc.org/)
Where: WeWork – Metropolitan Square, 655 15th Street NW, Washington, DC 20005 When: Thursday, December 15, 2016, 1:00pm—4:30 p.m.
Agenda:

DATA TALENT: Data in Action Summit | Page 4 of 49
Presentations:
National Academies of Sciences, Engineering and Medicine: Michelle K. Schwalbe, Ph.D., Director of the Committee on Applied and Theoretical Statistics (CATS) provided details on two brand new research efforts underway at the National Academies:
The National Research Council established the Committee on Applied and Theoretical Statistics (CATS) in 1978.
Trains students to extract value from Big Data Discussed the roundtable discussions past and future on how to strengthen data science programs in
undergrad and post-secondary education.
Office of Personnel Management- Hiring : April Davis and Katika Floyd, OPM Hiring Excellence Team—Talk about OPM’s Hiring Excellence initiative and how it could be leveraged for Data Science hiring within the federal government: https://www.opm.gov/policy-data-oversight/hiring-information/hiring-excellence-campaign/
Hiring Excellence Campaign Build competent models Work with HR to source Types of hiring: Veterans, non-competitive appointment, excepted service employment, other (direct
hire, experts & consultants) During a hiring freeze you can still recruit Make sure PD’s are up to date Hiring non-citizens could be an issue Recruiting – network Contact professional organizations Building micro-site by April 2017 HR specialists can tag job announcements as Data Scientists API: https://developer.usajobs.gov/
(Note: See appendix B for presentation slides)
Panel: Past and Present of Data Science Education and Recruiting: Panelist:
Merav Yuravlivker, Data Society Michelle Earley, U.S. Office of Personnel Management Peter Bruce, Statistics.com Ramon Perez, Elder Research Richard Heimann, Cybraics Roger Peng, Johns Hopkins Bloomberg School of Public Health Shay Strong, Omni Earth, Inc.
Moderator: Drew Zachary, U.S. Department of Health and Human Services
Panel Structure: Each Panelist provided a brief introduction that included information about their organization and their specific role. Following theses opening remarks the moderator asked the panelists a series of questions including “What is a data scientist?” The panel, including Q&A and open discussion, was approximately 50 minutes.

DATA TALENT: Data in Action Summit | Page 5 of 49
What kind of projects do you work on? One of the panelists runs a Massively Open Online Course (MOOC) for Data Science, which has recently been picked up by Coursera. He uses data scientists to do research in his organization. Another panelist provides data scientists to other companies for analytics, text mining, and other advanced types of work. Other panelists do data science training and/or connect data science instructors with students. Preparing client data: 80% of data science deals
with cleaning and wrangling the data, but the rest of the expertise data scientists possess is only used 20% of the time. This is somewhat of a problem since new data scientists do not expect the amount of data cleaning they have to do. It’s easy to teach the 20% expertise, but harder to teach the 80% cleaning.
Data preparation is an enormous amount of the effort. People are not thrilled about doing it, plus they don’t often allocate enough time for it.
Figuring out what kind of data it is, and where do you want to go with the data; this determines how you clean it.
Data preprocessing to perform cluster analysis. At statistics.com, they see a whole range of
students, all who are employed, but it’s very difficult to cluster them because the diversity is so great.
There are a lot of companies based on data, such as Google. They need a huge amount of data to make it good (until the data has been collected, the algorithm doesn’t get trained as well).
The biggest challenge was to educate the recruiters on what to look for in a data scientist.
Data Science has become more of an MBA--there is such a range of expertise, you could call it the “Swiss army knife of data” or “grad school on speed”.
Core Qualifications for Data Science: What should the core qualifications be for a Data Scientist?
Mathematics—they should have graduate-level exposure to graduate math; they have to understand the foundations. 20% is what’s making the money (i.e., math and stats pay the bills). More specifically, you have to have the right foundations to be able to ask the right questions; machine learning, algorithms, etc., are all based on math and statistics.
Qualitative Analysis—you have to understand what assumptions you’re making.
Hard Sciences—it’s important to have a background in one or more of the hard sciences, because these disciplines value certain characteristics. For example, astronomy has a lot of computer science. Plus the principle of “analysis that’s reproducible” is an element of both data science and the hard sciences.
Intuitive Knowledge—understanding of probability and uncertainty.
Product Manager—Know how to actually apply machine learning and artificial intelligence techniques, and be capable of developing and managing data products, which can include models, algorithms, visualizations, analyses, etc.
What is a Data Scientist? Someone with math, stats, physics, hard sciences background who can actually apply machine learning (ML), and artificial intelligence (AI) techniques and
many times serve as a product manager.

DATA TALENT: Data in Action Summit | Page 6 of 49
There are a couple of different groups of data science specialties. One example is big data, which requires someone with core computer science training (massive queries, retrieval of data).
There was an interesting article in Harvard Business Review about the different silos of data science: https://hbr.org/2016/12/breaking-down-data-silos. Some of the silos include big data, statistical analysis, machine learning, sampling error.
At the End of the Day, Data Scientists Are Composed of Different Groups but Should…
Data Scientists should be able to both do the work and communicate the results of their work.
Data Scientists should understand what’s possible with data science and be able to find the problems that aren’t being solved in the work you doing.
Predictive modeling (i.e., making predictions) is the majority of how data science is used in business. Buy-in from leadership is very important.
Clients coming to data science firms are looking for strategy—building out teams, cobbling a data strategy together, starting with the basis of a business problem and how to solve the problem, but then also how to grow the business.
How do you keep a Data Scientist motivated? A Few Suggestions Are…
Hire people who are intellectually curious and then give them interesting problems to solve.
Encourage the bigger purpose other than themselves—retain employees based on their commitment to serve the citizens in the federal government, over higher salaries in the private sector.
Give them challenging problems to solve; find problems that aren’t being solved in the work you’re doing.
Design new products and tools to interface. Have the right mission.
Panel: Future of Data Science Education and Recruiting Panelist:
Jason Moss, Metis Jen Golbeck, University of Maryland, College Park Ken Shaw, Georgetown University Michelle Earley, U.S. Office of Personnel Management Robin Thottungal, U.S. Environmental Protection Agency Thomas Jones, Impact Research, LLC Valerie Coffman, Xometry
Moderator: Drew Zachary, U.S. Department of Health and Human Services
Panel Structure: Each Panelist provided a brief introduction that included information about their organization and their specific role. Following these opening remarks the moderator asked the panelist a series of questions including “What is the future of delivering data science education? and What is keeping us from having a Ph.D. degree program in Data Science?” The panel, including Q&A and open discussion, was approximately 50 minutes.

DATA TALENT: Data in Action Summit | Page 7 of 49
What are the challenges Data Scientists face, both now and in the future?
Government has challenges especially around the technologies used in data science. We are trying to figure out how to change the organization so Data Scientists can come in and have/use the tools they need. Another challenge is getting the funding to run a data science program. Also, in order for Data Scientists to solve real-world problems, you need Subject Matter Experts (SMEs) who have expertise in the kind(s) of data for a particular field, but they also have to know what methods to use to work with and analyze that data. Funding: having the technology to change an
organization so a data scientist can come in and have/use the tools they need.
Failure: Data science projects fail not because of technical reasons, but because of business issues. Many data science projects fail because of the human side (human error, decisions made when analyzing the data, etc.).
Subject Matter Experts: Real world problems need SMEs who know what methods to use.
Data-driven: Balancing the conclusions drawn from data science, but also the business needs of the organization. Not every problem is really complex. Reality is there are lots of problems and low-hanging fruit that can be tackled.
Visioning: Seeing data as an asset. Developing Talent: It takes 7-8 years to
develop a data scientist. Computer skills can be acquired in four years, but more time is needed to develop other skills (content + communication).
Ecosystem: No more unicorns; new concept of data science teams is if the team works together they can learn other aspects, not just one perfect data scientist doing everything.
Instructors: In the education/academic field, it’s a supply challenge to find senior Data Scientists who can teach.
What is the future of delivering data science education? The challenge is the speed of change in the field
One of the challenges is new developments, like Deep Learning, which is up-and-coming. Need to get new data scientists with different skill sets—high rate of change in the field.
Management: Data science is largely a management role
and data scientists should learn how to be able to take a managerial role
Communication:
Critical thinking is not just technical In some respects, it is more critical for the
Data Scientist to be a good communicator and then you can get good domain expertise from talking to others.
Team leader who communicates with customers.
Time:
In the academic arena, it takes 7 or 8 years to develop all of those skills. Individuals can get the computer science skills they need in 4 years but they need more time to develop other skills such as content/subject matter expertise and communication.
Problem in the field of data science is that very few people have 7-8 years of training.
People can get technology/technical skills as an undergraduate, but how do we tack on the rest of the skills that data scientists need? They need programming, statistics, and math, but that’s what takes the time.
Question: What do they really have to go through in an academic program that you can’t get from going to evening classes or a MOOC or other online method of delivery?
Diversity:
There is such a surge of interest in the field; it’s hard to get people with such diverse educational backgrounds all moving in the same direction along a data science education track.

DATA TALENT: Data in Action Summit | Page 8 of 49
Purple Unicorn
You can find a decent programmer or communications person or statistics or math expert but not someone who is equally gifted in all these areas at once.
Instead of thinking of Data Scientists as having all these skills in one person, it may make more sense for it to be a team, with each individual on the team having her/his own strengths and then if the team works together they can learn the other aspects they are lacking. This could change the ecosystem and we wouldn’t spend so much time looking for a “unicorn” who has all the qualities we seek.
The evolution of data science is that there is becoming increased specialization and more and more frequently, people are choosing to bring together a team with a suite of skills distributed among them.
Cross-disciplinary teams are becoming popular, where different people specialize in different aspects of the data science pipeline
This could be an “X-Men-like” team of data experts
Team issue: when you’re a very small organization you may start with one data scientist. This varies by the type of organization depending if it’s small or large.
What is keeping us from having a PhD in Data Science or “Information Studies” at major universities/colleges?
We also should not rule out the 7-8 years it would take to grow a new crop of PhD Data Scientists There must be a big demand to create a
data science degree. It takes 3 years to get an education program approved.
Data science as a term is so overloaded and overused because the siloed academic disciplines are crashing into each other.
The following disciplines lend themselves very well to training in data science: physics, engineering, computer science.
You need to understand that the different aspects or circles of expertise are not equal.
Maybe people can get a degree in one of those three fields (hard sciences, engineering, computer science) and then we could offer training certificates to bring them up to speed.
Sometimes in production they are not thinking about the computational structure and the infrastructure.
People could design new products and tools to interface with data science and help people who are training to become data scientists.
Critical thinking is essential, it’s not just technical knowledge or expertise.
Regardless of the specific skillsets needed in certain domains, there are many areas of commonality, namely: programming, statistics, database usage, and human relations.
When we are forming a talent pipeline, we should think creatively but people should also have good social skills.
You can build those skills in and teach people the way to be engaging, more of listening and understanding and then communicating.
Several of the panelists agreed that the team approach is optimal. The people
they hire are “quants” with quantitative analytical skills, but they don’t have
domain expertise.
Domain expertise is the smallest competence (they are not as good at
that aspect) but good management can bring people together and leverage
SMEs on an as-needed basis.

DATA TALENT: Data in Action Summit | Page 9 of 49
What are core elements for data science training and recruiting?
There’s a need to educate recruiters as to what they are looking for. The biggest challenge is that there is so much to data science. Predictive modeling/making predictions are
predominantly how data science is used in business.
Math and statistics are critical to data science recruitment; a candidate should be at a graduate level in math and understanding the fundamentals.
Data science has become more of an MBA field: “Swiss army knife of data” or “Grad school on speed.”
Candidates need to have the right foundations and algorithms in order to ask the right questions, all based on math and statistics.
Need data wrangling skills. Quality Assurance: predicting the future of
the data Must be able to provide a usable product and
have good communication skills Be intuitive, knowledgeable, and understand
probability and uncertainty. Understand what assumptions you’re making
and why. Make analyses that are reproducible. Need someone who understands data types
and measurement scales. Need to possess a deep understanding of
probability, no matter what the mathematics skillset is.
Do analysis that reproduces conclusions. It’s important to balance conclusions drawn
from data science with business needs. Data scientists should have different
backgrounds. Hard sciences value certain characteristics that
are essential in data science; for example, astronomy has a lot of data science.
Companies based on data like Google need a huge amount of data. Until data has been collected, the algorithm doesn’t get trained as well.
At many academic institutions, there is a range of students who are difficult to cluster because of their diversity.
What takes people to the next level? Start with the basis of a business problem,
then move onto how to solve the problem, but then determine how to grow the business.
Understand what’s possible with data science.
Buy-in from leadership is very important. Find senior data scientists who are willing
to learn new things. Deep programming skills and post-degree
investment are critical to continued professional development.
Bring people in and expose them to various government programs.
Engage in participatory research, as well as critical and creative thinking.
What’s the fastest, most efficient way to jump in?
What’s the fastest, most efficient way for people to jump in? What drives the decision making? We have to put effort into helping prospective
data scientists understand statistics, math, computing, programming, the particular mission of the organization, the product(s) they are developing, communication and the whole lifecycle of a data product (think of Data Scientists partially as product managers)
Understanding computation, programming, math/statistics, mission, product, and communication. You need to have all of these tools to be an effective data scientist.
Think creatively and develop social skills. To solve real-world problems, you need
Subject Matter Experts (SMEs) but also expertise to know what methods to use to work with and analyze the data.
Remember: The benefit of working for the public sector is the impact you can make—it’s the mission and the money, but we have to make sure we have the right mission.

DATA TALENT: Data in Action Summit | Page 10 of 49
Appendix A: Bios of Event Participants
Emcee:
Kimya Lee serves as the U.S. Office of Personnel Management’s (OPM) technical advisor on research and evaluation to support data-driven human resource management and policy decision making. One of her chief responsibilities is establishing the strategic direction for the Department’s research and evaluation initiatives, as informed by the analytic needs of the program offices.
Kimya also served as the manager of OPM’s Survey Analysis group were she was responsible for leading the development, administration, data analysis, and reporting of Government-wide Federal employee surveys; in particular the Federal Employee Viewpoint Survey.
Moderator: Drew Zachary is a social scientist currently at the U.S. Department of Health and Human Services where she
works on bringing the tools of data and technology to human services policy. Drew was previously a Policy Advisor at the White House Domestic Policy Council with the team focused on housing, poverty, and economic mobility policy. At HUD, she developed a framework for evaluation of the Promise Zones initiative and created a team of data scientists dedicated to helping high-poverty communities visualize and use local data. Drew has also worked in the private sector on developing health technologies including simulation-based training and VR tools to improve physicians’ cultural competence and
patient outcomes, and digital information-sharing tools to support low-income patients with chronic disease. Drew holds an MPP from Johns Hopkins University and is currently completing a PhD in health policy at Brandeis University.
Presenters:
April Davis is the Director of Classification and Assessment Policy in Recruitment and Hiring/Employee Services at the U.S. Office of Personnel Management. She manages government-wide policy in the areas of position classification, competency modeling, qualifications, personnel assessment, non-pay FLSA policy, and is responsible for leading projects in areas related to multiple OPM and White House high level initiatives – Cybersecurity, Hiring Excellence Campaign, and Closing Critical Skills Gaps for Mission Critical Occupations government-wide. Education has played a pivotal role in enhancing her professional competencies. She received a BA in Human Relations with a Minor in Business Administration and an MSA in Human Resources Management from Trinity University in Washington, DC. Recruitment and Hiring provides Federal-wide policy to almost 2 million Federal employees and over 11 million Americans seeking employment opportunities with the Federal government.

DATA TALENT: Data in Action Summit | Page 11 of 49
Michelle Earley has served as the USAJOBS Program Manager within the U.S. Office of Personnel Management since 2012 where she oversees the product vision and leadership to transform the applicant experience, along with delivering data tools to improve the ability for the agencies to attract and recruit talent. Prior to USAJOBS, Ms. Earley served as Director for Program Management with the Office of Financial Stability and Deputy Program Manager for a major investment within the Department of Homeland Security. She has over 15 years of experience in investment management, program management and software implementation.
Katika Floyd is a Senior Human Resources Specialist within the Hiring Policy Section of OPM’s Employee Services Division. Since joining OPM in 2012, Katika has prepared regulations and provided advice and guidance to agencies on a wide variety of staffing issues including excepted service employment, phased retirement, USERRA, and the Pathways Program for students and recent graduates. She has over 12 years of Federal human resources experience. Ms. Floyd holds a master’s degree in Human Resources Management from Marymount University and a bachelor’s degree in Business Administration from Bowling Green State University.
Michelle Schwalbe is the Director of the Committee on Applied and Theoretical Statistics (CATS) of the National Academies of Sciences, Engineering, and Medicine. She has been involved in various aspects of data science education at the National Academies, including a workshop on Training to Extract Value from Big Data, a Roundtable on Data Science Education, and a study on Envisioning the Data Science Discipline: The Undergraduate Perspective. Michelle received a Ph.D. in Mechanical Engineering and M.S. in Applied Mathematics from Northwestern University, and a B.S. in Applied Mathematics specializing in Computing from University of California, Los Angeles.
Panel: Past and Present of Data Science Education and Recruiting: Peter Bruce is Founder and President of The Institute for Statistics Education at Statistics.com. He is the co-
author of DATA MINING FOR BUSINESS ANALYTICS, (Wiley, 2006, 3rd ed. 2010), and STATISTICS FOR DATA SCIENTISTS (O'Reilly, 2016), and the author of INTRODUCTORY STATISTICS AND ANALYTICS (Wiley, 2015). He serves on the American Statistical Association's Advisory Committee on Professional Development.
Michelle Earley Bio previously provided.
Rich Heimann is the Chief Data Scientist at Cybraics, Inc. He is part of the adjunct Faculty at University of Maryland, Baltimore County and an Instructor of Human Terrain Analysis at George Mason University. Rich serves on the Selection Committee for the AAAS Big Data & Analytics Fellowships Program. He has deep expertise running data science teams and is the co-author of “Social Media Mining with R.”.

DATA TALENT: Data in Action Summit | Page 12 of 49
Roger D. Peng is a Professor of Biostatistics at the Johns Hopkins Bloomberg School of Public Health.
He is also a co-founder of the Johns Hopkins Data Science Specialization, the Simply Statistics blog where he writes about statistics for the general public, the Not So Standard Deviations podcast with Hilary Parker, and The Effort Report podcast with Elizabeth Matsui. He is the recipient of the 2016 Mortimer Spiegelman Award from the American Public Health Association, which honors a statistician who has made outstanding contributions to health statistics.
Ramon Perez focuses on financial modeling and market risk detection. A decorated war veteran, Major Perez served as an Air Force Intelligence Officer specializing in Signals Intelligence. As a mission director at the National Security Agency, Ramon led teams analyzing enormous data sets to produce actionable information in support of worldwide contingency operations--including deployments to Iraq, Afghanistan, and South America in support of Special Operations. Upon leaving the military, Ramon returned to graduate school with an interest in understanding economic models. Prior to joining Elder Research, he analyzed long-term defense budget projections for the Congressional Budget Office. Ramon holds a Bachelor’s degree in Systems Engineering from Georgia Tech as well as Master’s degrees from Harvard and Georgetown in Finance and Economics, respectively. He and his wife
are avid travelers, having lived in Asia and South America, and having visited over 30 countries.
Dr. Shay Strong is the chief data scientist at OmniEarth and heads their analytics team where she applies her background in computational astrophysics to evaluate remotely-sensed imagery through deep-learning and machine-learning techniques – transforming bits and pixels into actionable intelligence that helps customers assess, manage and predict the world around them. Her focus is on automating imagery land-classification and statistical prediction, at scale in the cloud, to support a number of OmniEarth’s analytics products. Her methods have achieved 95% accuracy in distinguishing parcel features such as trees, turf, pools,
solar panels and man-made structures. Shay is also an adjunct physics lecturer at UMBC and, prior to OmniEarth, she held positions at the Johns Hopkins Applied Physics Laboratory and NASA’s Jet Propulsion Laboratory. She holds a PhD in Astronomy from the University of Texas at Austin and a BS in Physics from the College of Charleston.
Merav Yuravlivker is the Co-founder and Chief Executive Officer of Data Society, and has over 10 years of experience in instructional design, training, and teaching. She has helped bring new insights to businesses and move their organizations forward through implementing data analytics strategies and training. Merav manages all product development and instructional design for Data Society and heads all consulting projects related to the education sector. She is passionate about increasing data science knowledge from the executive level to the analyst level.

DATA TALENT: Data in Action Summit | Page 13 of 49
Panel: Future of Data Science Education and Recruiting
Valerie Coffman is a graduate of Johns Hopkins and received a PhD in Physics from Cornell where she wrote software for studying the fracture properties of materials. After graduation, she spent 5 years at the National Institute of Standards and Technology writing open source software for materials science research. Valerie joined Xometry as Chief Technology Officer in 2014.
Michelle Earley Bio previously provided.
Jennifer Golbeck is Director of the Social Intelligence Lab and an Associate Professor in the College of Information Studies at the University of Maryland, College Park. Her research focuses on analyzing and computing with social media focused on predicting user behavior, and improving human experiences with privacy and security systems.
Tommy Jones is the director of data science at Impact Research, LLC. He holds an MS in mathematics and statistics from Georgetown University and a BA in economics from the College of William and Mary. He is a PhD student in the George Mason University Department of Computational and Data Sciences. He specializes in statistical models of language and time series modeling.
Jason Moss is the President and Co-Founder of Metis, a data science training business that operates in New York, San Francisco, Chicago, and Seattle. For almost 20 years, Jason has worked in education. From founding a nonprofit organization in New Orleans to working at companies such as McKinsey & Company, Scholastic, Kaplan, and now Metis (a part of Kaplan), he has sought opportunities to build businesses and work with exceptional teams on creating transformative learning experiences and products. He spends most his time at Metis (1) ensuring the quality of the student experience and outcome, (2) developing the roadmap and building the team to grow the business, and (3) engaging with data scientists and companies around the country with whom Metis can collaborate. He has been married
for 13 years and has two kids. In his spare time, he enjoys kickboxing, participating in muddy obstacle courses, and blogging about billiards movies.
Ken Shaw is director of graduate studies in mathematics and statistics at Georgetown University. He is responsible for curriculum development, student career preparation, employment advising
and all administrative aspects of the graduate program. He connects Georgetown Math/Stat graduate students with the mathematical and data sciences workforce through student career roundtables, numerous contacts in and around the DC area, and through resume and interview preparation. Dr Shaw teaches courses in applied mathematical modeling and computation at Georgetown. His research background includes applied mathematical analysis, optical communications and financial modeling.

DATA TALENT: Data in Action Summit | Page 14 of 49
Robin Thottungal is the EPA's first chief data scientist focused on creating and implementing an agency-wide vision on analytics for effective decision making. Prior to joining the EPA, Robin was at Deloitte Consulting, where he focused on selling and delivering large-scale analytics projects for public-sector and commercial clients. He also led the global big data community of practice for Deloitte, developing analytical frameworks and go-to-market strategy for big data and analytics solutions.
Robin is the vice chair for the Institute of Electrical and Electronics Engineers (IEEE), Washington, DC, section as well as the chapter chair for the IEEE Computational & Intelligence society. He is also a selection panel member for the American Academy of Sciences Hellman Fellowship in Science and Technology Policy. Prior to joining Deloitte, Robin was at Johns Hopkins University, where he lead the development of a computational bioscience software product used for drug discovery by the pharmaceutical industry.
Robin holds a graduate degree in computational sciences from Johns Hopkins University and was the recipient of a National Institute of Health (NIH) pre-doctoral fellowship. He also received the prestigious NIH post-bac research fellowship to do advanced computational medicine research after obtaining his undergraduate degree in computer engineering from the State University of New York. Robin has authored more than 5 scientific publications and presented at 20+ conferences on various aspects of data analytics.

DATA TALENT: Data in Action Summit | Page 15 of 49
Appendix B: Slide Presentations
Appendix B.1 – Data Science Education

DATA TALENT: Data in Action Summit | Page 16 of 49

DATA TALENT: Data in Action Summit | Page 17 of 49

DATA TALENT: Data in Action Summit | Page 18 of 49

DATA TALENT: Data in Action Summit | Page 19 of 49

DATA TALENT: Data in Action Summit | Page 20 of 49

DATA TALENT: Data in Action Summit | Page 21 of 49

DATA TALENT: Data in Action Summit | Page 22 of 49

DATA TALENT: Data in Action Summit | Page 23 of 49

DATA TALENT: Data in Action Summit | Page 24 of 49
Appendix B.2 – Hiring Excellence Campaign Overview

DATA TALENT: Data in Action Summit | Page 25 of 49

DATA TALENT: Data in Action Summit | Page 26 of 49
Appendix B.3 – Hiring Authorities and Flexibilities

DATA TALENT: Data in Action Summit | Page 27 of 49

DATA TALENT: Data in Action Summit | Page 28 of 49

DATA TALENT: Data in Action Summit | Page 29 of 49

DATA TALENT: Data in Action Summit | Page 30 of 49

DATA TALENT: Data in Action Summit | Page 31 of 49

DATA TALENT: Data in Action Summit | Page 32 of 49

DATA TALENT: Data in Action Summit | Page 33 of 49

DATA TALENT: Data in Action Summit | Page 34 of 49

DATA TALENT: Data in Action Summit | Page 35 of 49

DATA TALENT: Data in Action Summit | Page 36 of 49

DATA TALENT: Data in Action Summit | Page 37 of 49

DATA TALENT: Data in Action Summit | Page 38 of 49

DATA TALENT: Data in Action Summit | Page 39 of 49

DATA TALENT: Data in Action Summit | Page 40 of 49

DATA TALENT: Data in Action Summit | Page 41 of 49
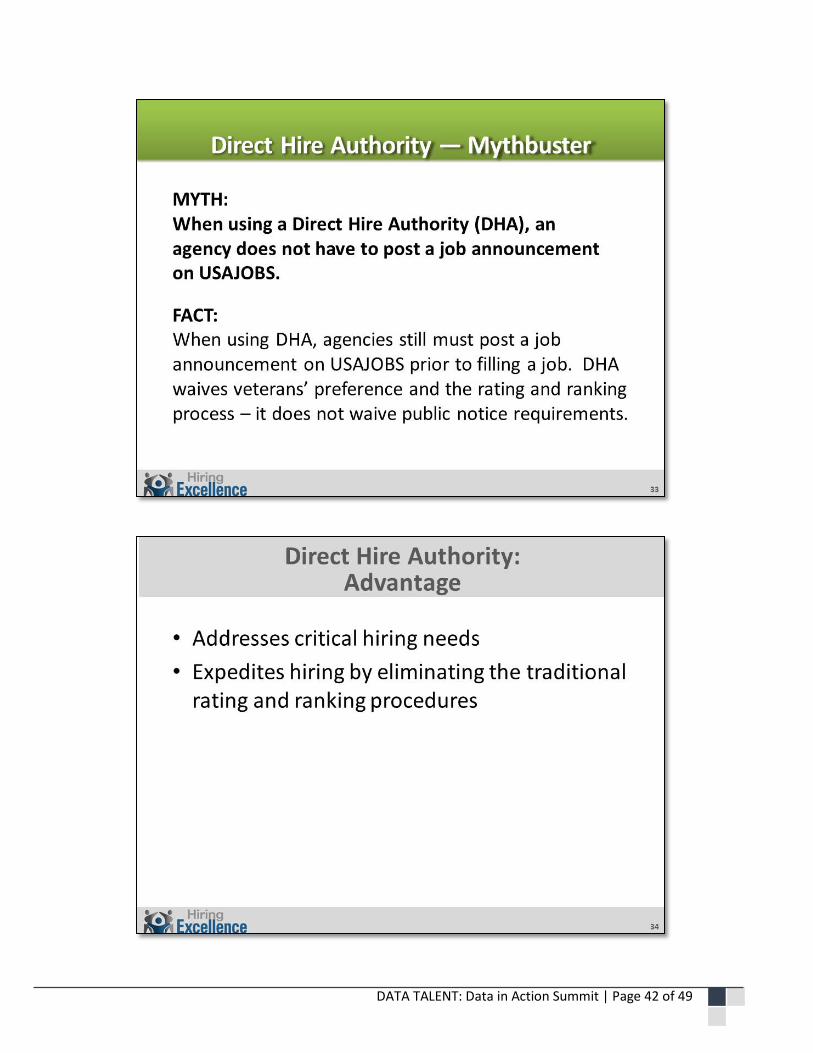
DATA TALENT: Data in Action Summit | Page 42 of 49

DATA TALENT: Data in Action Summit | Page 43 of 49

DATA TALENT: Data in Action Summit | Page 44 of 49

DATA TALENT: Data in Action Summit | Page 45 of 49
Appendix B.4 – USAJOBS

DATA TALENT: Data in Action Summit | Page 46 of 49

DATA TALENT: Data in Action Summit | Page 47 of 49

DATA TALENT: Data in Action Summit | Page 48 of 49

DATA TALENT: Data in Action Summit | Page 49 of 49
Acknowledgements:
A Special Thanks to the U.S. Data Cabinet Steering Committee:
Executive Director: Mimi Reilly (GSA),
Natalie Evans-Harris (Former Director)
Members: Colonel Nevin Taylor (DoD)
Kris Rowley (GSA)
Trey Bradley (GSA)
Stephen Brockelman (GSA)
Working Group Leads: Natassja Linzau (DOC) – Data Talent
Lin Zhang (DOI) - Data Governance
Ryan Swann (GSA) – Data Policy


















