
Fast Algorithms for Association Rule Mining Presented by Muhammad Aurangzeb Ahmad Nupur Bhatnagar R....
30
Fast Algorithms for Association Rule Mining Presented by Muhammad Aurangzeb Ahmad Nupur Bhatnagar R. Agrawal and R. Srikant
-
date post
21-Dec-2015 -
Category
Documents
-
view
223 -
download
1
Transcript of Fast Algorithms for Association Rule Mining Presented by Muhammad Aurangzeb Ahmad Nupur Bhatnagar R....

Fast Algorithms for Association Rule
Mining
Presented by
Muhammad Aurangzeb Ahmad
Nupur Bhatnagar
R. Agrawal and R. Srikant

Outline
Background and Motivation Problem Definition Major Contribution Key Concepts Validation Assumptions Future Revision

Background & Motivation Basket Data:
Collection of records consisting of transaction identifier and the items bought in a transaction.
Mining for associations among items in a large database of sales transaction to predict the occurrence of an item based on the occurrences of other items in the transaction.
For Example:
TID Transactions1 {bread, milk, beer, diapers}2 {beer, apples, diapers} 3 {diapers, milk, beer}
4 {beer, apples, diapers}
5 {milk, bread, chocolate}

Terms and Notations Items : I = {i1,i2,…,im}
Transaction – set of items such as Items are sorted lexicographically
TID – unique identifier for each transaction Association Rule : X->Y where

Terms and Notations
Confidence :
A rule X->Y holds in the transaction set D with confidence c if
c% of transactions in D that contain X also contain Y. Support:
A rule X->Y has support s ifs% of transactions in D contain X and Y.
Large ItemsetItemsets having support greater than minimum support and minimum confidence are called large itemsets other they are called small itemsets.
Candidate ItemsetsA set of itemsets which are generated from a seed of itemsets which were found to be large in the previous pass having
support ≥ minsup threshold confidence ≥ minconf threshold

Problem Definition INPUT A set of transactions
Objective:
Given a set of transactions D, generate all association rules that have support and confidence greater than the user-specified minimum support and minimum confidence.
Minimize computation time by pruning.
Constraints:
Items should be in lexicographical order
Association Rules
{Diaper} {Beer},
{Milk, Bread} {Eggs, Coke},
{Beer, Bread} {Milk},
TID Transactions1 {bread, milk, beer, diapers}2 {beer, apples, diapers} 3 {diapers, milk, beer}
4 {beer, apples, diapers}
5 {milk, bread, chocolate}
Real World ApplicationsNCR (Terradata) does ARM for more than 20 large retail organizations including Walmart.
Used for pattern discovery in biological DBs.

Major Contribution Proposed two new algorithms for fast association rule
mining: Apriori and AprioriTID, along with a hybrid of the two
algorithms .
Empirical evaluations of the performance of the proposed algorithms as compared with the contemporary algorithms.
Completeness: Find all rules.

Related Work -SETM and AIS
Major difference in Candidate Itemset generation In pass k, read a database transaction t Determine which of the large itemsets in Lk-1 are
present in t. Each of these large itemsets l is then extended with
all those large items that are present in t and occur later in the lexicographic ordering than any of the items in l.
Results: A lot of Candidate Itemsets are generated which are later discarded.

Key Concepts: Support and Confidence Why do we need Support and Confidence? Given a rule : X->Y
Support determines how often a rule is applicable to a given data set. Confidence determines how frequently items in Y appear in
transactions that contains X. A rule having low support may occur by chance!! A low support rule tends to be uninteresting from a business
perspective. Confidence measures the reliability of the inference made by a rule.

Key Concepts –Association Rule Mining Problem
Problem:Given a set of transactions T, find all rules having support >= minsupport
and confidence>=minconfidence.
Decomposition of Problem:
1. Frequent Itemset Generation :
Find all itemsets having transaction support above minimum support.
These itemsets are called frequent itemsets.
2. Rule Generation:
Use the large itemsets to generate rules. These rules are high-confidence rules extracted from the frequent itemsets found in the previous step.
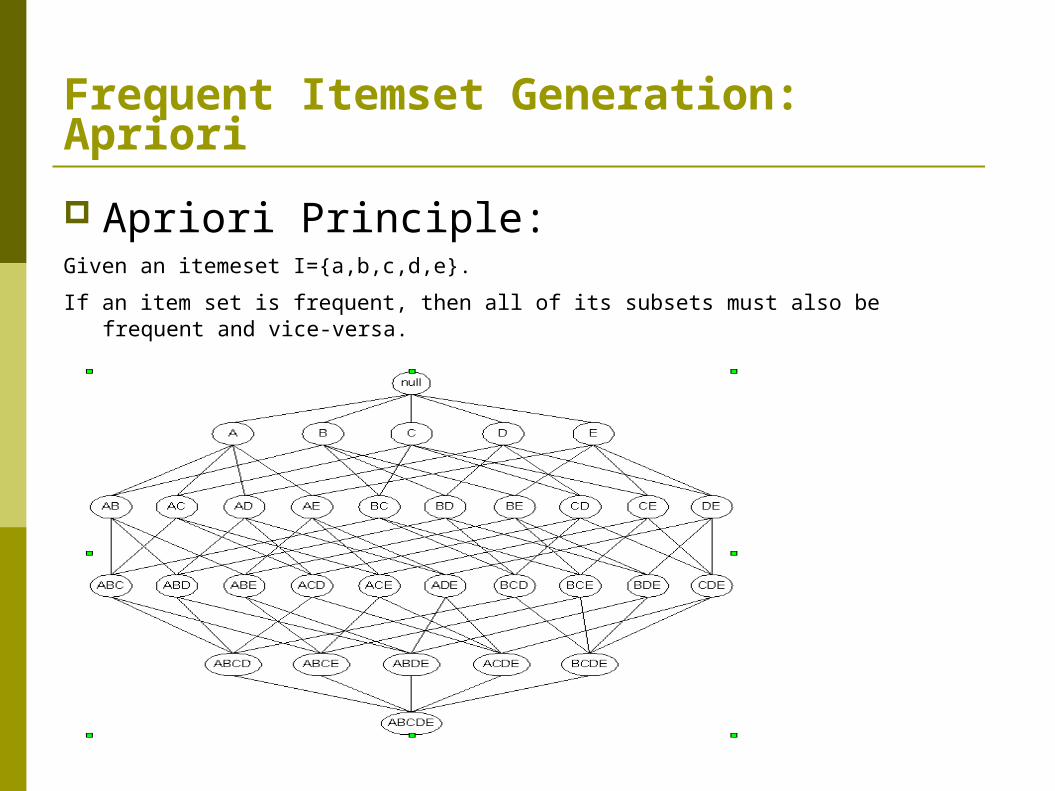
Frequent Itemset Generation: Apriori
Apriori Principle:Given an itemeset I={a,b,c,d,e}.
If an item set is frequent, then all of its subsets must also be frequent and vice-versa.
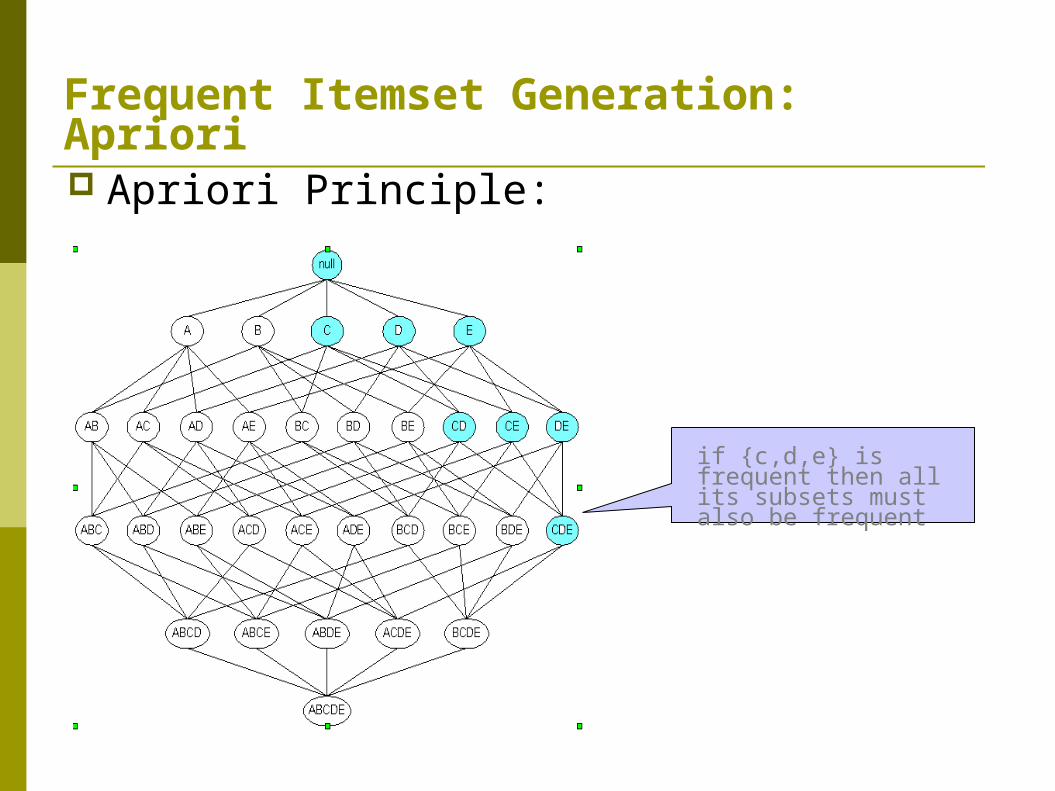
Frequent Itemset Generation: Apriori Apriori Principle:
if {c,d,e} is frequent then all its subsets must also be frequent

Frequent Itemset Generation: Apriori
Apriori Principle: Candidate Pruning
If {a,b} is infrequent, then all it supersets are infrequent

Key Concepts –Frequent Itemset Generation :
Apriori AlgorithmInput
The market base transaction dataset.
Process
Determine large 1-itemsets. Repeat until no new large 1-itemsets are identified. Generate (k+1) length candidate itemsets from length k large itemsets. Prune candidate itemsets that are not large. Count the support of each candidate itemset. Eliminate candidate itemsets that are small.
Output
Itemsets that are “large” and qualify the min support and min confidence thresholds.
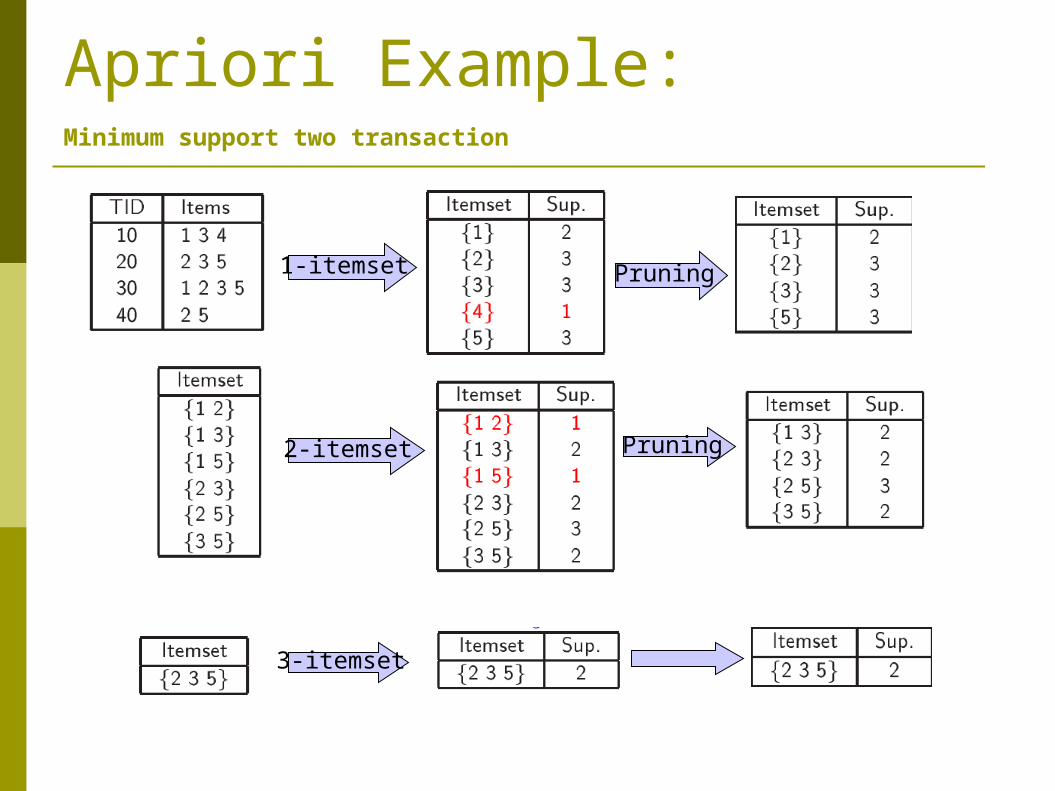
Apriori Example:Minimum support two transaction
3-itemset
1-itemset
2-itemset
Pruning
Pruning

Apriori Candidate GenerationGiven an k-itemset, generate k+1 itemset in two steps:
C(4)={{135},{235}}
C(4) = {{235}}
Join k- itemset with k-itemset, with the join condition that the first k-1 items
should be the same.
JOIN STEPP
RU
NE
Delete all candidates having non-frequentsubset

AprioriTID
AprioriTID
Same candidate generation function as Apriori. Does not use database for counting support after the first
pass. Encoding of the candidate itemsets used in the previous
pass. Saves reading effort.

Apriori Tid Example:Support Count:2
Database
TID Items
100 1 3 4
200 2 3 5
300 1 2 3 5
400 2 5
TID Set-of-itemsets
100 { {1},{3},{4} }
200 { {2},{3},{5} }
300 { {1},{2},{3},{5} }
400 { {2},{5} }
Itemset Support
{1} 2
{2} 3
{3} 3
{5} 3
Item Support
{1 2} 1
{1 3} 2
{1 5} 1
{2 3} 2
{2 5} 3
{3 5} 2
TID Set-of-itemsets
100 { {1 3} }
200 { {2 3},{2 5} {3 5} }
300 { {1 2},{1 3},{1 5},{2 3}, {2 5}, {3 5} }
400 { {2 5} }
Itemset Support
{1 3} 2
{2 3} 3
{2 5} 3
{3 5} 2
itemset
{2 3 5}
TID Set-of-itemsets
200 { {2 3 5} }
300 { {2 3 5} }
Itemset Support
{2 3 5} 2
C^1
L2
C2 C^2
C^3
L1
L3C3

Apriori Tid : Analysis
Advantages :
If a transaction does not contain k-itemset candidates, then Ck will not have an entry for this transaction.
For large k, each entry may be smaller than the transaction because very few candidates may be present in the transaction.
Disadvantages:
For small k, each entry may be larger than the corresponding transaction.
An entry includes all k-itemsets contained in the transaction.

Apriori Hybrid Apriori Hybrid :
It uses Apriori in the initial passes and switches to AprioriTid when it expects that the candidate itemsets at the end of the pass will be in memory.

Validation : Computer Experiments
Parameters for data generation D – Number of transactions T – Average size of the transaction I – Average size of the maximal potentially large itemsets L – Number of maximal potentially large itemsets N – Number of Items.
Parameter Settings : 6 synthetic data sets
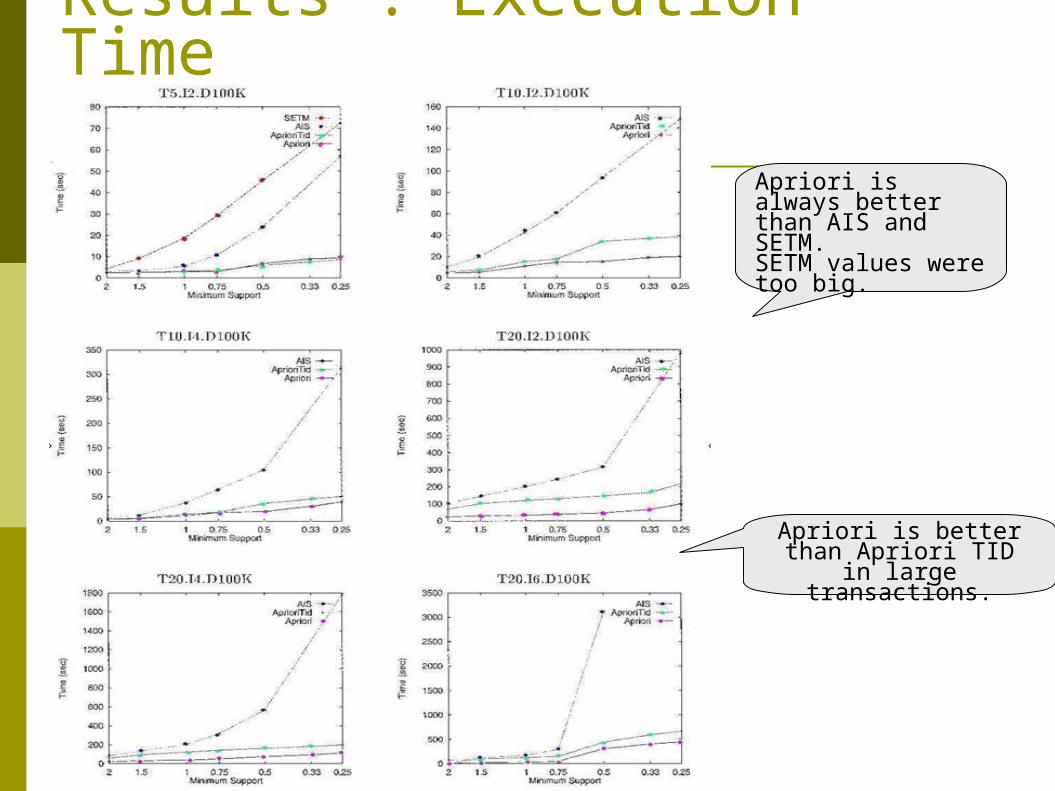
Results : Execution Time
Apriori is better than Apriori TID in large
transactions.
Apriori is always better than AIS and SETM.SETM values were too big.

Results : Analysis AprioriTid uses C^k instead of the database. If C^k fits in
memory AprioriTid is faster than Apriori.
When C^k is too big to fit in memory, the computation time is much longer. Thus Apriori is faster than AprioriTid.
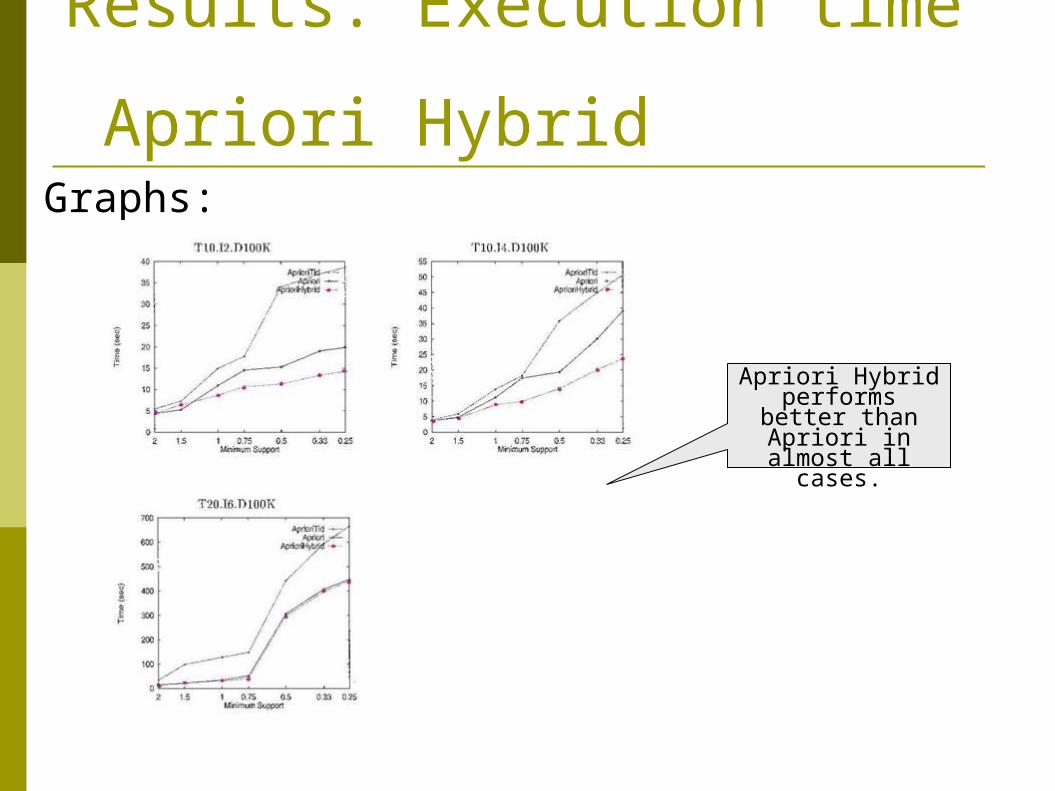
Results: Execution time Apriori Hybrid
Graphs:
Apriori Hybrid performs better than Apriori in
almost all cases.

Scale Up - Experiments
Apriori Hybrid scales up as the number of transactions is increased from 100,000 to 10 million.Minimum support .75%
Apriori Hybrid scales up when average transaction size was increased. Done to see the affect on data structures independent of physical db size and number of large item sets.

Results: The Apriori algorithms are better than the SETM and
AIS. The algorithms performs there best when combined. The algorithm shows good results in scale-up
experiments.

Validation Methodology-Weakness and StrengthStrength:
Author use a substantial basket data for guiding the process of designing fast algorithms for association rule mining.
Weakness:
Synthetic data set is used for validation. The data might be too synthetic as to not give any valuable information about real world datasets.

Assumptions Synthetic dataset is used. It is assumed that performance of the algorithm in
the synthetic dataset is indicative of its performance on a real world dataset.
All the items in the data are in a lexicographical order.
Assume that all data is categorical.
It is assumed that all the data is present in the same site or table and there are no cases which there would be a requirement to make joins.

Possible Revision
Some real world datasets should be used to perform the experiments .
The number of large itemsets could exponentially increase with large databases. Modification in the representation structure is required that captures just a subset of the candidate large itemsets.
Limitations of Support and Confidence Framework Support : Potentially interesting patterns involving low support items might
be eliminated. Confidence: Confidence ignores the support of the itemset in the rule
consequent. Improvement : Interestingness measure : Computes the ratio between the rule’s confidence and the support
of the itemset in the rule consequent. = S(a,b)/s(a) * s(b) Effect of Skewed support Distribution

Questions?









![[A3] SHASTY Srikant and SRIDHAR Sanjay_Transit Oriented Development](https://static.fdocuments.in/doc/165x107/577ce47a1a28abf1038e703b/a3-shasty-srikant-and-sridhar-sanjaytransit-oriented-development.jpg)








