
A Scheduling Service Oriented Approach for Workflow Scheduling
description

Cluster Comput (2010) 13: 421–434DOI 10.1007/s10586-010-0126-7
Failure-aware workflow scheduling in cluster environments
Zhifeng Yu · Chenjia Wang · Weisong Shi
Received: 25 June 2008 / Accepted: 24 February 2010 / Published online: 13 March 2010© Springer Science+Business Media, LLC 2010
Abstract The goal of workflow application scheduling isto achieve minimal makespan for each workflow. Schedul-ing workflow applications in high performance cluster en-vironments is an NP-Complete problem, and becomes morecomplicated when potential resource failures are considered.While more research on failure prediction has been wit-nessed in recent years to improve system availability and re-liability, very few of them attack the problem in the contextof workflow application scheduling. In this paper, we studyhow a workflow scheduler benefits from failure predictionand propose FLAW, a failure-aware workflow schedulingalgorithm. We propose two important definitions on accu-racy, Application Oblivious Accuracy (AOA) and Applica-tion Aware Accuracy (AAA), from the perspectives of systemand scheduling respectively, as we observe that the predic-tion accuracy defined conventionally imposes different per-formance implications on different applications and fails tomeasure how that improves scheduling effectiveness. Thecomprehensive evaluation results using real failure tracesshow that FLAW performs well with practically achievableprediction accuracy by reducing the average makespan, theloss time and the number of job rescheduling.
Keywords Failure-aware · Workflow scheduling · Clustercomputing
This work is in part supported by National Science FoundationCAREER grant CCF-0643521.
Z. Yu · C. Wang · W. Shi (�)Wayne State University, Detroit, USAe-mail: [email protected]
Z. Yue-mail: [email protected]
C. Wange-mail: [email protected]
1 Introduction
Workflow applications become to prevail in recent years,resulting from stronger demands from scientific computa-tion and more provision of high performance cluster sys-tems. Typically, a workflow application is represented as aDirected Acyclic Graph (DAG), where nodes represent indi-vidual jobs and edges represent the inter-job dependence. Ina DAG, nodes and edges are weighed for computation costand communication cost respectively. Makespan, the timedifference between the start and completion of a workflowapplication, is used to measure the application performanceand scheduler efficiency. In the rest of the paper, we useDAG and workflow application interchangeably in this pa-per.
The goal of scheduling a workflow application is toachieve minimal makespan. The scheduling problem, of-ten referred to as DAG scheduling in research literature,was recognized as an NP-Complete problem even in a lim-ited scale environment of a few processors [1]. A sub-optimal schedule often results in unnecessarily excessivedata movement and/or long waiting time thanks to inter-job dependence. With the resource failure considered, DAGscheduling is significantly more difficult and unfortunatelyfew existing algorithms tackle this. Furthermore, the actualfailure rate in production environment is extremely high.Both OSG [2] and TaraGrid [3] report over 30% failuresat times [4]. On the other side, the failure tolerance poli-cies applicable to ordinary job scheduling is a reactive ap-proach and deserves another look as job inter-dependenciesin workflows and usually longer computation complicate thefailure handling.
Recent years have seen many analysis on published fail-ure traces of large scale cluster systems [5–9]. These re-search efforts contribute to better understanding of the fail-

422 Cluster Comput (2010) 13: 421–434
ure characteristics and result in more advanced failure pre-diction models, and help improve the system reliability andavailability. However, not sufficient attention has been paidto how workflow scheduling can benefit from these accom-plishments to reduce the impact of failures on applicationperformance. In particular, we want to answer the followingtwo related questions: One is what is the right and practi-cal objective of failure prediction in the context of workflowscheduling? The other is how does the failure predicationaccuracy affect workflow scheduling? Note that we defer thedesign of a good failure protection algorithm as our futurework.
Failures can have a significant impact on job executionunder existing scheduling policies that ignore failures [8].In an error prone computing environment, failure predic-tion will improve the scheduling efficiency if it can answerqueries with a great success rate such as: “Will a node failduring data staging and job execution if the job is goingto execute on this node?” The job will be assigned to thisnode only when the answer is “NO” with high confidence.Like any other non-workflow application, the unexpectedfailure causes rescheduling of the failed job and resourcewaste on the uncompleted job execution. But more impor-tantly, job rescheduling will affect the subsequent schedul-ing decisions for not-scheduled-yet child or peer jobs in theworkflow, and potentially further imposes negative impacton overall performance which is determined by the job-resource mapping as a whole. We propose a FaiLure AwareWorkflow scheduling algorithm (FLAW) in this paper toschedule workflow applications with resource failure pres-ence.
On the other side, we argue that the conventional defini-tion of failure prediction accuracy does not well reflect howaccuracy affects scheduling effectiveness. The conventionaldefinition borrows “precision” and “recall” metrics from in-formational retrieval theory, which measure prediction ef-fectiveness statistically. Driven by these definitions, mostexisting failure prediction techniques attempt to forecastfailures regardless of which jobs are running. Intuitively, alonger running job may require failure prediction to be moreaccurate than a shorter one. But what about scheduling aworkflow application which is not just lengthy but also hasjob dependence involved? We argue that the conventionalprediction approach and accuracy requirement are not in-tended for failure aware scheduling and two new definitionsof failure prediction accuracy are proposed as a result: Appli-cation Oblivious Accuracy (AOA) from a system’s perspec-tive and Application Aware Accuracy (AAA) from a sched-uler’s perspective, which we believe better reflect how fail-ure prediction accuracy impacts scheduling effectiveness.
The contributions of this paper are three-fold: (1) de-sign FLAW that takes potential resource failures into con-sideration when scheduling workflow applications and de-fines the failure prediction requirement in a practical way;
(2) propose two new definitions of failure prediction ac-curacy, which reflects its effect on workflow applicationscheduling more precisely, in the context of job schedulingin high performance computing environments; and (3) per-form comprehensive simulations using real failure tracesand find that our proposed FLAW algorithm performs welleven with moderate prediction accuracy, which is much eas-ier to achieve using existing algorithms. The number ofjob resubmission (rescheduling) due to resource failure de-creased significantly with trivial AOA level with presence ofintensive workload.
The rest of the paper is organized as follows. A brief re-view of related work which motivates our work is given inSect. 2. The new definitions of failure prediction accuracyare proposed in Sect. 3. Then we describe the FLAW algo-rithm design in Sect. 4. Section 5 elaborates the simulationdesign and analyzes simulation results. Finally, we summa-rize and lay out our future work in Sect. 6.
2 Related work
Noticeable progress has been made on failure prediction re-search and practice, following that more failure traces aremade public available since 2006 and the failure analysis [5–10] reveals more failure characteristics in high performancecomputing systems. Zhang et al. evaluate the performanceimplications of failures in large scale cluster [8]. Fu et al.propose both online and offline failure prediction modelsin coalitions of clusters. Another failure prediction modelis proposed by Liang et al. [5] based on failure analysis ofBlueGene/L system. Recently, Ren et al. [11] develop a re-source failure prediction model for fine-grained cycle shar-ing systems. However, most of them focus on improving thepredication accuracy, and few of them address how to lever-age their predication results in practice.
Salfner et al. [12] suggest that proactive failure han-dling provides the potential to improve system availabilityup to an order of magnitude, and the FT-Pro project [13]and the FARS project [14] demonstrate a significant perfor-mance improvement for long-running applications providedby proactive fault tolerance policies. [15] demonstrated afault aware job scheduling algorithms for BlueGene/L sys-tem and simulation studies show that it can significantly im-prove the system performance with even trivial fault pre-diction confidence or accuracy levels (as low as 10%). It isworth noting that though, as a specially designed toroidalsystem, BlueGene/L requires job partitions must be bothrectangular (in a multidimensional sense) and contiguous.So the goal of job scheduling [15] is to reduce the frag-mentation with failure awareness and eventually improve thesystem utilization. The jobs in the system are independent ofeach other and the failure prediction employs conventional

Cluster Comput (2010) 13: 421–434 423
accuracy concept, which is quite different than our study onscheduling workflow applications in a cluster or grid of acommon form without job partition constraint.
Failure handling is considered in some workflow man-agement systems but only limited to reactive failure re-covery policy. Grid Workflow [16] presents a failure toler-ance framework to address the Grid-unique failure recov-ery, which allows users to specify the failure recovery pol-icy in the workflow structure definition. Abawajy [17] pro-poses a fault-tolerant scheduling policy that loosely couplesjob scheduling with job replication scheme such that appli-cations are reliably executed but with cost of resource effi-ciency. Other systems such as DAGMan [18] simply ignorethe failed jobs and the job will be rescheduled later whenit is required for dependant jobs. Dogan et al. [19] developReliable Dynamic Level Scheduling (RDLS) algorithm tofactor resource availability into conventional static schedul-ing algorithms.
In practice, the workflow scheduling algorithms go totwo extremes: static approach, which makes scheduling de-cisions before execution dependent on knowledge of inter-job dependence and estimation of computation and commu-nication time, or dynamic one, which makes decisions onlywhen the individual job is ready to execute [20]. Static ap-proaches arguably outperform dynamic ones even with in-accurate estimation.
We argue that, however, proactive failure handling cannot be easily integrated into existing static schedulingschemes as it is not possible to predict all failures accu-rately in advance for a long running workflow application.Even for other non-workflow applications, the analysis [7]finds that node placement decision can become ill-suited af-ter about 30 minutes in a shared federated environment suchas PlanetLab [21]. Furthermore, another analysis [10] con-cludes that Time-To-Fail (TTF) and Time-To-Repair (TTR)can not be predicted with reasonable accuracy based oncurrent uptime, downtime, Mean-Time-To-Fail (MMTF) orMean-Time-To-Repair (MMTR) and a system should notrely on such predictions. Despite these mentioned difficul-ties, our previous work [22], a hybrid of static and dynamicscheduling strategies, opens a possibility which allows inte-gration of failure prediction into the planner while looseningprediction accuracy requirement.
Inspired by these observations, we design the FLAW al-gorithm to augment the hybrid scheduling scheme proposedin our previous work [22], redefine the failure prediction re-quirement and accuracy definition in the context of work-flow scheduling. The new failure prediction requirementsare better measurable and achievable practically. The exten-sive simulations using real failure trace from Los AlamosNational Laboratory [23] demonstrate that FLAW reducesthe failure impact on performance significantly with moder-ate prediction accuracy.
3 Failure prediction accuracy
Reliability based failure prediction techniques use variousmetrics to measure prediction quality, where precision andrecall are two popular ones adopted in the literature [12–14, 24]. The precision is the ratio of the number of correctlyidentified failures (true positive) to the number of all positivepredictions and the recall is the ratio of the number of cor-rectly predicted failures to the total number of failures thatactually occurred [12]. In other research efforts the accuracyis defined in a statistics context, by measuring how the pre-dicted time between failures is close to actual one [6].
The precision and recall are calculated by comparing theactual failure occurrences (time points when actual failuresoccur) with failure predictions (time points when failuresare predicted to occur). With a given fixed prediction period�tp , a failure prediction is a true positive if a true failureoccurs within �tp of the predicted failure time point [12].One may quickly notice that, firstly, the definition only caresabout when the failure occurs instead of the failure duration,i.e., down time. Secondly, whether a failure prediction is truepositive depends on the size of �tp . Even with the same fail-ure prediction results, a larger �tp will help to classify morepredictions as true positive and “statistically” improve pre-diction quality measured by precision.
As illustrated in Fig. 1, the failure prediction is rated100% for both precision and recall given the prediction pe-riod �tp . But with a smaller predication period �t ′p , bothprecision and recall change to 50% for the identical predic-tion.
Obviously, the above accuracy metrics do not fit wellwith the workflow scheduling context. In an error pronesystem, the job scheduler requires failure prediction to an-swer the query before a job is scheduled to the chosen node:Will this node fail during the data staging and job execu-tion? Intuitively, the quality of failure prediction should bemeasured by how well those queries can be answered. Thescheduler’s effectiveness will be adversely impacted if eithera failure is not predicted, i.e., the job has to be resubmittedlater, or the predicted failure does not actually happen, i.e.,the job is not assigned to the best suitable resource.
Fig. 1 An example of actual failure trace and associated failure pre-diction

424 Cluster Comput (2010) 13: 421–434
We want to know if such definition can be used to mea-sure how much failure prediction impact job schedulingeffectiveness and justify what level of accuracy is goodenough. With this in mind, we introduce failure predictionrequirements in the context of job scheduling. A failure pre-dictor should be able to predict if a node will fail in the nextgiven time window. The prediction is correct if the node ac-tually goes down in that time window. Before introducingthe prediction accuracy, we define three prediction cases asfollowing:
• True Positive (Hit): A failure is predicted to occur withinthe down time of a true failure.
• False Negative (Fn): An actual failure event is not pre-dicted at all.
• False Positive (Fp): A predicted failure does not matchany true failure event.
Each failure prediction includes both time and location ofpredicted failure. By using the same example in Fig. 1, pre-diction P1 is a false positive as node is actually not down atthe time P1 predicts. P2 is a hit as it predicts the down time.Failure 1 counts as a false negative as it is not predicted.
AccuracyAOA = Hit
Hit + Fn + Fp. (1)
Finally, we define a so called Application Oblivious Ac-curacy (AOA) by (1). The failure prediction accuracy inabove example is rated as 33.3% accordingly (in this casethere is one Hit, one Fn and one Fp). The definition con-siders failure downtime, penalizes both false negatives andfalse positives. It does not use any predefined �tp and hencemore objective. Furthermore, we observe that the failure pre-diction with same level of AOA has different impact on jobscheduling and the prediction efficiency is application spe-cific, which leads us to define an Application Aware Accu-racy (AAA) in Sect. 4.3 later.
4 FaiLure Aware Workflow scheduling
Inspired by the recent progresses in failure prediction re-search and increasing popularity of workflow applications,we explore the practical solutions for scheduling a workflowapplication in an error prone high performance computingenvironment. In this section, we first discuss the motivationof our research, then describe the solution design and finallyillustrate the design by examples.
4.1 Motivation
There have been extensive research efforts on workflowscheduling and numerous heuristics are proposed as a result.
However, they are yet to address the challenges of schedul-ing workflow applications in a cluster environment: dynamicwork load and dynamic resource availability.
Our previous work [22, 25] proposed an Heterogeneous-Earliest-Finish-Time (HEFT) [26] based hybrid schedulingalgorithm which not only inherits the performance advan-tages of static scheduling but also helps handling dynam-ics of workload and resource in a proactive way. Given es-timation of job execution time, data transfer size and net-work bandwidth, the algorithm ranks each individual job ofa DAG in the order of length of the critical path from it tothe exit task, including the computation time. The rankingreflects the significance of respective impact level of eachjob on overall makespan, and also guarantees that the rankvalue of predecessor job is always higher than any succes-sor and the entry job(s) have the highest values in a DAG.Intuitively, scheduling the job with higher rank earlier natu-rally observes the inter-job dependency and helps minimiz-ing the overall makespan. After all jobs are ranked, only thejobs ready to execute will be scheduled and the job withhighest rank will be dispatched to the best resource whichensures the earliest finish time of this job. Without con-sidering the potential resource failures, RANK_HYBD out-performs the widely used (FIFO) algorithm significantly inthe case of dynamic work load [22]. It outperforms betterwhen there are more concurrent DAGs running in the sys-tem.
Furthermore, the design rationale of RANK_HYBD pro-vides itself an intrinsic capability to handle resource fail-ures in a proactive way by seamlessly integrating with anonline failure predictor. In RANK_HYBD, scheduling deci-sion is made only when a job is ready to execute and re-source is predicted available during data staging and job ex-ecution. Therefore, failures can be probatively handled dur-ing job scheduling. A workflow typically takes long timeto finish, it is very difficult, if not impossible, for a purelystatic scheduling approach to plan for all potential fail-ures in advance. However, resource failures can be muchbetter predicted and handled at individual job level as thejob execution time is significantly shorter compared withentire workflow. Moreover, it is practically easier to pre-dict a failure in shorter period. This assumption is wellsupported by recent research results [13–15] which pro-pose failure tolerant scheduling schemes for non-workflowjobs.
On the other hand, the advancement in failure predictiontechniques based on analysis of real traces of large scaleclusters, is not yet to be leveraged by workflow applicationschedulers. The profound comprehension of failure patternsand characteristics makes a reasonable accurate failure pre-dictor a practically achievable goal, so for the failure awareworkflow scheduler.

Cluster Comput (2010) 13: 421–434 425
Fig. 2 An overview of FLAWdesign
4.2 Design
FLAW factors in failure handling by adding an online failurepredictor component into the original RANK_HYBD design,as Fig. 2 shows. The proposed system consists of four corecomponents: DAG Planners, a Job Pool, an Executor andan online failure predictor. The DAG Planner assigns eachindividual job a local priority as defined in [22], managesthe job interdependence and job submission to the Job Pool,which is an unsorted collection containing all ready to exe-cute jobs from different users. The Executor re-prioritizesthe jobs in the Job Pool and schedules jobs to the avail-able resources in the order of job priority. When making ascheduling decision, the Executor will consult the FailurePredictor about whether a resource will keep alive for theentire job execution period if the job is assigned to this re-source. If a job is terminated due to unpredicted resourcefailure, the Executor will place the job back into Job Pooland the job will be rescheduled. When a job finishes suc-cessfully, the Executor notifies the DAG Planner which thejob belongs to of the completion status.
The above collaboration among these core componentsis achieved by the dynamic event driven design illustrated inFig. 2 and explained as follows:
(1) Job submission. When a new DAG arrives, it is asso-ciated with an instance of DAG Planner by the system.After ranking all individual jobs within the DAG locally,the Planner submits whichever job is ready to the JobPool. At the beginning, only entry job(s) will be sub-mitted. Afterwards, upon notification by the Executorof the completion of a job, the Planner will determineif any dependant job(s) become ready and submit them.During the course of workflow execution, the job termi-nated due to resource failure is put back to the Job Poolby the Executor to be rescheduled later.
(2) Job scheduling. Whenever there are resources availableand a job is waiting in the Job Pool, the Executor willrepeatedly do:
(a) Re-prioritize all jobs residing in the Job Pool basedon individual job ranks in a real time fashion. Thejobs in the pool are ready to execute and they maycome from different users. The local priority as-sociated with each job will be used to computeglobal priority. Finally, the jobs in the pool are re-prioritized according to their corresponding globalpriorities, as defined in [22].
(b) Remove the job with the highest global priorityfrom Job Pool to schedule.
(c) Schedule the job to the resource which allows theearliest finish time and will not fail during job exe-cution. For the chosen job, the available resourcesare ordered by the estimated finish time startingfrom the earliest one. If the resource with higherpreference, in terms of estimated finish time, is pre-dicted to fail during the job execution, the next re-source will be attempted. One may notice that thejob execution time varies with resource and so doesthe failure prediction time window. If none of the re-sources can keep alive during the period of the cho-sen job execution, this job will remain in the JobPool and next job will be picked out for scheduling.Otherwise, the job is scheduled and will run on theassigned resource. Figure 3 describes this schedul-ing algorithm in more details.
(3) Job completion notification. When a job finishes suc-cessfully, the Executor will notify the correspondingDAG Planner of job completion status.
(4) Failure Prediction. The Failure Predictor will answerqueries coming from the Executor: Will the resource Xfail in next Y time units? Y is the estimated job exe-cution time if the job is scheduled on resource X. Theanswer “YES” or “NO” drives the Executor make com-pletely different scheduling decisions and therefore im-pose potentially great impact on the effectiveness ofscheduler and overall application performance as well.

426 Cluster Comput (2010) 13: 421–434
Fig. 3 The scheduling algorithm in FLAW
As each design comes with predefined objectives, the de-sign of FLAW is to:
• Reduce the loss time. Accurate failure prediction will helpthe scheduler avoid placing jobs on a resource to fail inthe middle of job execution. The abnormally terminatedexecution contributes to system resource waste, i.e., losstime caused by failures, including time spending on bothunfinished data transmission and computation.
• Reduce the number of job rescheduling. Checkpoint-ing/restarting is a simple and popular fault tolerance tech-nique, but it incurs considerable overhead of lower systemutilization and work loss. Indeed, the checkpointing canbe more detrimental than the failures themselves and itshould be more intelligent [27]. As the number of nodesgrows, failure rate will increase and the current check-pointing techniques has to cope with speedup and datacompression issues otherwise total system cost will in-crease significantly in the future [28]. Therefore check-pointing is not utilized in our system design. Instead, afailed job will be rescheduled later and start over. Thenumber of job rescheduling can measure how a schedulerbenefit from failure prediction from another angle. We en-vision that this metric will be of great interest to domainexperts who are using cluster environments.
• Reduce the makespan. The makespan is the overall per-formance indicator for workflow applications and the ef-fectiveness measure of a workflow scheduler.
4.3 Application Aware Accuracy (AAA)
The key success factor to the FLAW design is the accuracy offailure prediction, which is measured by how effectively the
Failure Predictor can answer the query: “Will the resourceX fail in next Y time units?” The effectiveness of failure pre-diction can be quantified by the ratio of correct answers tototal queries in context of job scheduling. It is worth notingthat how to predict failures accurately and effectively is notthe goal of this paper. Instead, we intend to find out whatis the practical requirement for failure prediction from theprospective of scheduling and how a scheduler can leveragefailure prediction in an error prone environment.
Different than the AOA defined earlier, the above ratio isapplication and prediction timing specific. For example, as-suming that the present time is at time unit 0, a node will godown between 100 and 120 time units and a job can be com-pleted on this node by 140 time units if starting from now. Itis further assumed that the Failure Predictor forecasts a fail-ure will occur at time unit of 130, which is actually a falsepositive. In this case, the Failure Predictor can still give acorrect answer to the query “if the node will be down innext 140 time units?” by telling “Yes”.
We referred to this ratio as Application Aware Accu-racy (AAA) and use it to measure the failure predictioneffectiveness. Given a schedule S for a set of workflowapplications and failure predictions P = {P1(T1,N1, δ1),P2(T2,N2, δ2), . . . ,Pn(Tn,Nn, δn)} specifically inquired forschedule S, Pi(Ti,Ni, δi) denotes a prediction or answer ofwhether node Ni will fail from time point Ti to Ti + δi . Pi isa correct prediction if the answer is actually right. The AAAis defined as:
AccuracyAAA(S,P ) = Total number of correct predictions
Size of P.
(2)
Even though a higher AOA helps improve AAA, however,the AAA highly depends on the application behaviors andhow and when the query is made. In an extreme example, ifa resource is highly error prone and none of the failures onthis resource is predicted, the AAA can still be very high ifthis resource is never a preferred one and no query is madeabout it. This sounds strange but can be very true in work-flow scheduling. For instance, in a resource rich environ-ment a node with very low capability can not produce com-pletive earliest finish time for any job and is hardly consid-ered in scheduling. And for a data intensive workflow appli-cation, in order to reduce cost on data movement the sched-uler may narrow the resource choices to certain nodes whichhave executed many jobs and retain the data for next depen-dant jobs.
4.4 An example
In this section, we illustrate the FLAW design by using ex-amples of a workflow application and a failure trace, asshown in Fig. 4. It is assumed that the sample DAG will

Cluster Comput (2010) 13: 421–434 427
Fig. 4 Example of a DAG andfailure trace
Fig. 5 Failure prediction with50% of AOA
run in a environment consisted of three nodes. The nodesencounter some failures as defined in the box of the figure.
We further assume that a Failure Predictor makes the fol-lowing failure prediction: node P0 fails at 18, node P2 failsat 8 and 90 respectively, as shown by Fig. 5. This predic-tion achieves AOA accuracy of 50%, which includes 2 hits,1 false positive and 1 false negative.
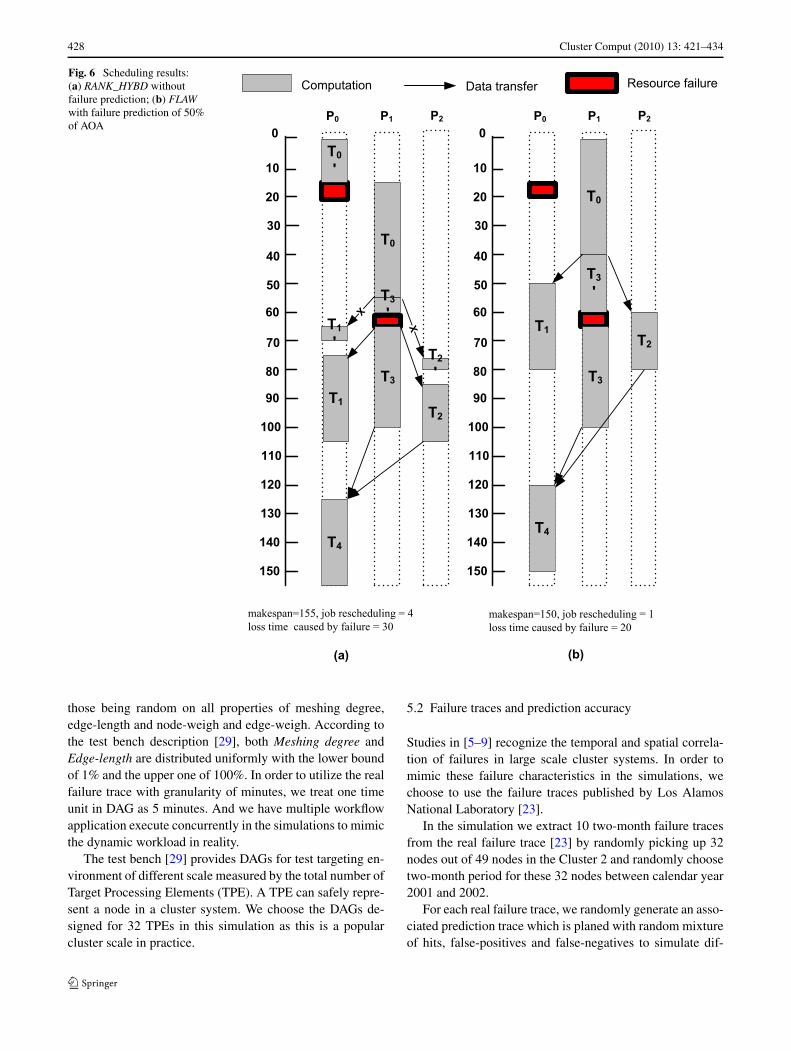
Figure 6 gives the scheduling result by the RANK_HYBDalgorithm without failure prediction and the FLAW algo-rithm with presence of failures defined. It shows that theFLAW finishes the sample application with 150 time unitmakespan, 20 time unit loss time and 1 job rescheduling.FLAW outperforms RANK_HYBD in all areas which com-pletes with makespan of 155, loss time of 30 and 4 jobrescheduling.
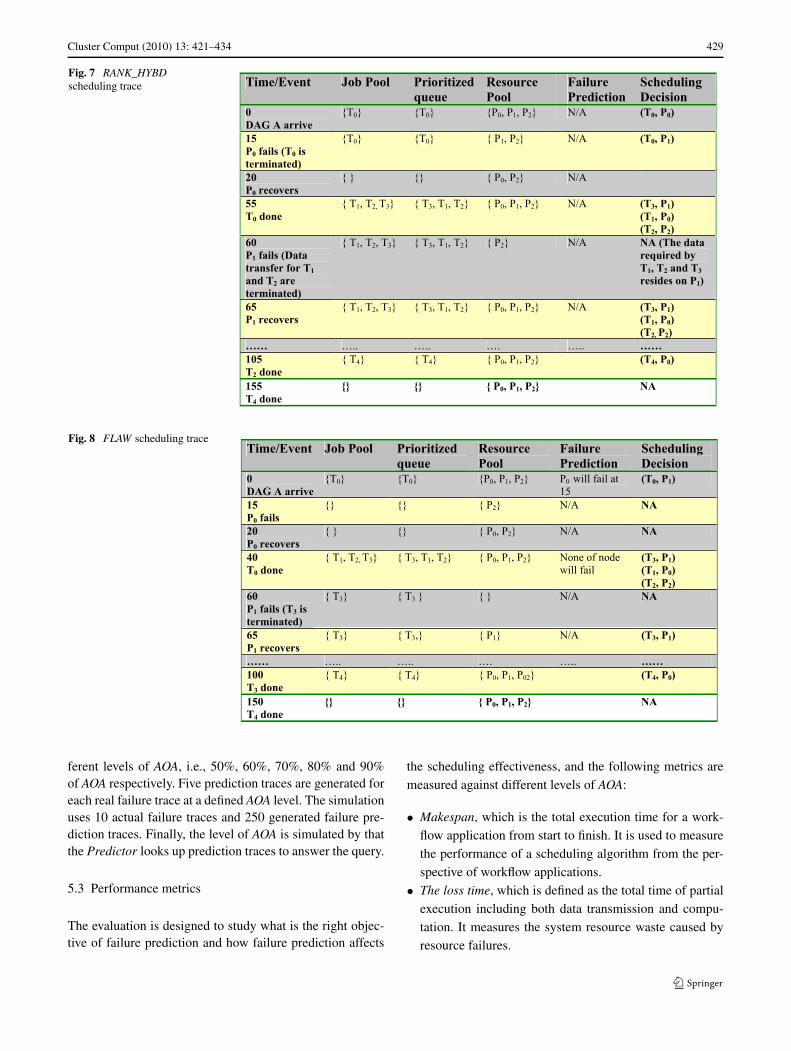
A detailed trace which records how each schedulingdecision is made is illustrated in Fig. 7 and Fig. 8 forRANK_HYBD and FLAW respectively. FLAW finishes with90% of AAA accuracy, as there are totally 10 queries andonly one false negative prediction is made.
5 Performance evaluation and analysis
To verify the design of FLAW and study how failure pre-diction accuracy affects the scheduling effectiveness, wepresent the simulation design and result analysis in this sec-tion. As Garey and Johnson pointed out that developingan optimal schedule is computational intractable even with
a limited number of processors [1], and the experimentsin [29] further prove the practical hardness, we choose atypical evaluation approach by comparing the proposed al-gorithm with “HEFT” based ones which are observed instudy [30] as the best heuristics for randomly generatedDAGs in terms of average makespan and robustness.
5.1 Workload simulation
The published test bench [29] for workflow applications isused in the simulation. The test bench consists of randomlygenerated DAGs and is structured according to the followingDAG graph properties:
• DAG Size: the total number of jobs in a DAG. As our goalis to evaluate the algorithm performance with intensiveworkloads, we only use the DAG group with the mostjobs, i.e. the DAG consists of 175 to 249 jobs.
• Meshing degree: the extent to which the nodes are con-nected with each other.
• Edge-length: the distance between the connected nodes,i.e., the average number of nodes located between thesender and receiver.
• Node- and Edge-weight. These two parameters describethe time required for a job’s computation and communi-cation cost and are related to CCR, the communication tocomputation ratio.
As our simulation focuses on how to handle failures inscheduling, the DAGs we choose for this simulation are
428 Cluster Comput (2010) 13: 421–434
Fig. 6 Scheduling results:(a) RANK_HYBD withoutfailure prediction; (b) FLAWwith failure prediction of 50%of AOA
those being random on all properties of meshing degree,edge-length and node-weigh and edge-weigh. According tothe test bench description [29], both Meshing degree andEdge-length are distributed uniformly with the lower boundof 1% and the upper one of 100%. In order to utilize the realfailure trace with granularity of minutes, we treat one timeunit in DAG as 5 minutes. And we have multiple workflowapplication execute concurrently in the simulations to mimicthe dynamic workload in reality.
The test bench [29] provides DAGs for test targeting en-vironment of different scale measured by the total number ofTarget Processing Elements (TPE). A TPE can safely repre-sent a node in a cluster system. We choose the DAGs de-signed for 32 TPEs in this simulation as this is a popularcluster scale in practice.
5.2 Failure traces and prediction accuracy
Studies in [5–9] recognize the temporal and spatial correla-tion of failures in large scale cluster systems. In order tomimic these failure characteristics in the simulations, wechoose to use the failure traces published by Los AlamosNational Laboratory [23].
In the simulation we extract 10 two-month failure tracesfrom the real failure trace [23] by randomly picking up 32nodes out of 49 nodes in the Cluster 2 and randomly choosetwo-month period for these 32 nodes between calendar year2001 and 2002.
For each real failure trace, we randomly generate an asso-ciated prediction trace which is planed with random mixtureof hits, false-positives and false-negatives to simulate dif-
Cluster Comput (2010) 13: 421–434 429
Fig. 7 RANK_HYBDscheduling trace
Fig. 8 FLAW scheduling trace
ferent levels of AOA, i.e., 50%, 60%, 70%, 80% and 90%of AOA respectively. Five prediction traces are generated foreach real failure trace at a defined AOA level. The simulationuses 10 actual failure traces and 250 generated failure pre-diction traces. Finally, the level of AOA is simulated by thatthe Predictor looks up prediction traces to answer the query.
5.3 Performance metrics
The evaluation is designed to study what is the right objec-tive of failure prediction and how failure prediction affects
the scheduling effectiveness, and the following metrics aremeasured against different levels of AOA:
• Makespan, which is the total execution time for a work-flow application from start to finish. It is used to measurethe performance of a scheduling algorithm from the per-spective of workflow applications.
• The loss time, which is defined as the total time of partialexecution including both data transmission and compu-tation. It measures the system resource waste caused byresource failures.
430 Cluster Comput (2010) 13: 421–434
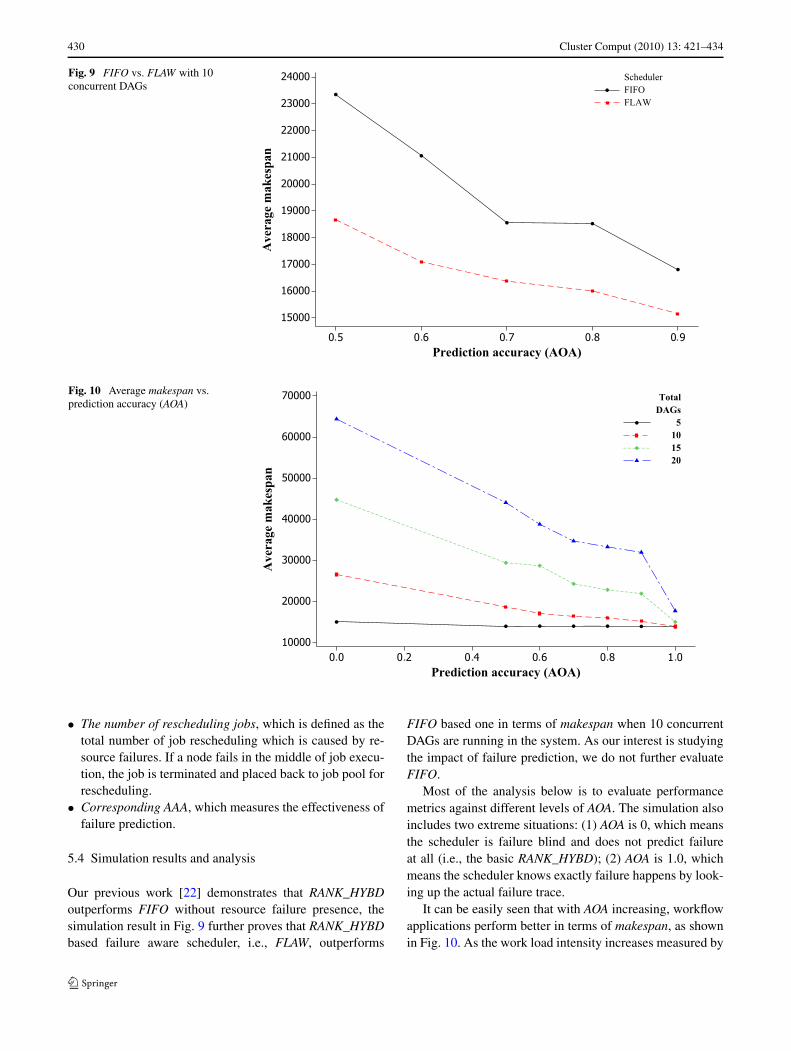
Fig. 9 FIFO vs. FLAW with 10concurrent DAGs
Fig. 10 Average makespan vs.prediction accuracy (AOA)
• The number of rescheduling jobs, which is defined as thetotal number of job rescheduling which is caused by re-source failures. If a node fails in the middle of job execu-tion, the job is terminated and placed back to job pool forrescheduling.
• Corresponding AAA, which measures the effectiveness offailure prediction.
5.4 Simulation results and analysis
Our previous work [22] demonstrates that RANK_HYBDoutperforms FIFO without resource failure presence, thesimulation result in Fig. 9 further proves that RANK_HYBDbased failure aware scheduler, i.e., FLAW, outperforms
FIFO based one in terms of makespan when 10 concurrentDAGs are running in the system. As our interest is studyingthe impact of failure prediction, we do not further evaluateFIFO.
Most of the analysis below is to evaluate performancemetrics against different levels of AOA. The simulation alsoincludes two extreme situations: (1) AOA is 0, which meansthe scheduler is failure blind and does not predict failureat all (i.e., the basic RANK_HYBD); (2) AOA is 1.0, whichmeans the scheduler knows exactly failure happens by look-ing up the actual failure trace.
It can be easily seen that with AOA increasing, workflowapplications perform better in terms of makespan, as shownin Fig. 10. As the work load intensity increases measured by
Cluster Comput (2010) 13: 421–434 431
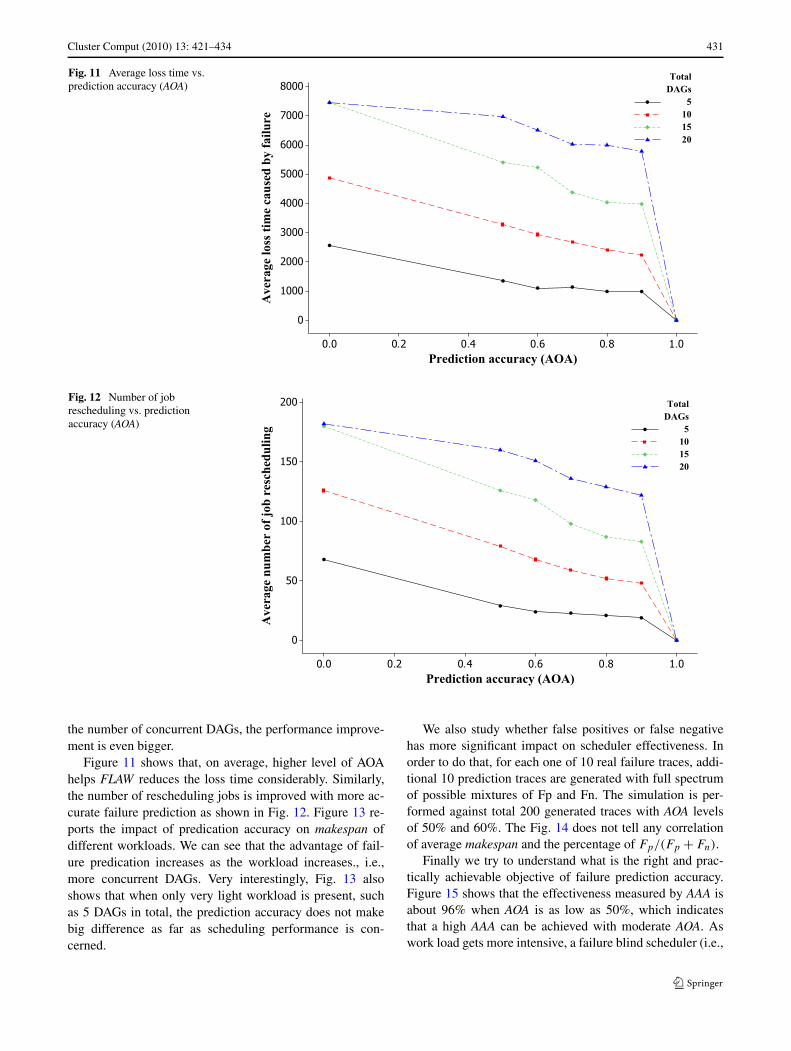
Fig. 11 Average loss time vs.prediction accuracy (AOA)
Fig. 12 Number of jobrescheduling vs. predictionaccuracy (AOA)
the number of concurrent DAGs, the performance improve-ment is even bigger.
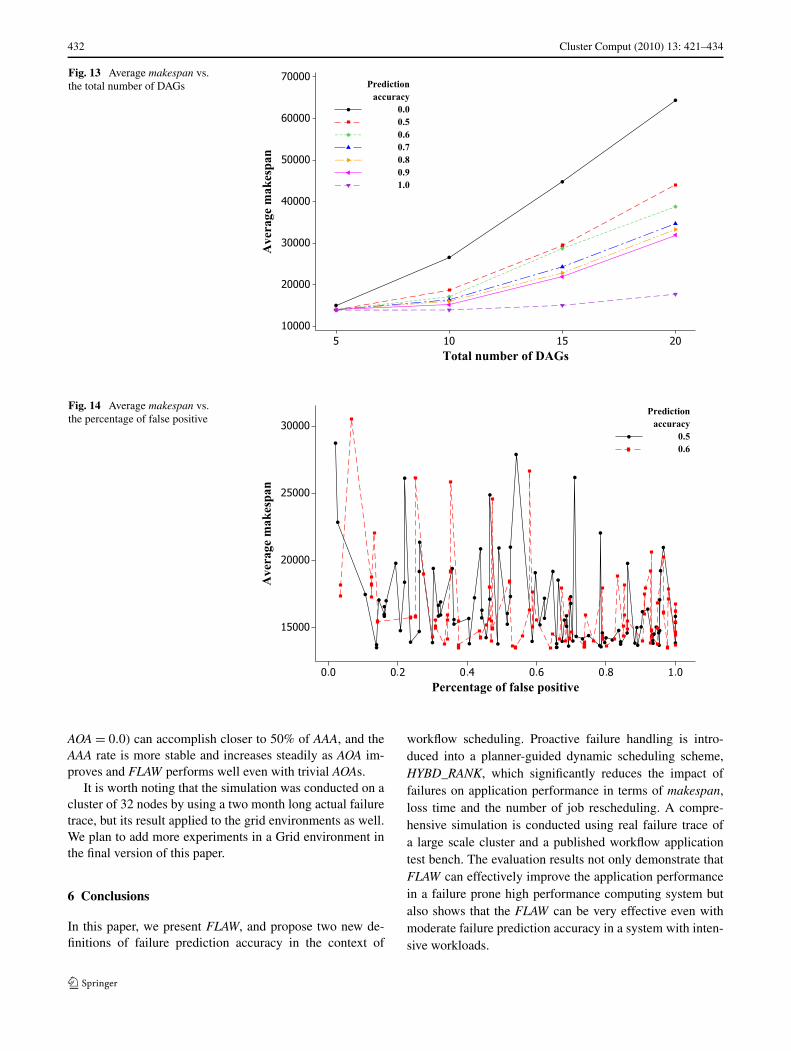
Figure 11 shows that, on average, higher level of AOAhelps FLAW reduces the loss time considerably. Similarly,the number of rescheduling jobs is improved with more ac-curate failure prediction as shown in Fig. 12. Figure 13 re-ports the impact of predication accuracy on makespan ofdifferent workloads. We can see that the advantage of fail-ure predication increases as the workload increases., i.e.,more concurrent DAGs. Very interestingly, Fig. 13 alsoshows that when only very light workload is present, suchas 5 DAGs in total, the prediction accuracy does not makebig difference as far as scheduling performance is con-cerned.
We also study whether false positives or false negativehas more significant impact on scheduler effectiveness. Inorder to do that, for each one of 10 real failure traces, addi-tional 10 prediction traces are generated with full spectrumof possible mixtures of Fp and Fn. The simulation is per-formed against total 200 generated traces with AOA levelsof 50% and 60%. The Fig. 14 does not tell any correlationof average makespan and the percentage of Fp/(Fp + Fn).
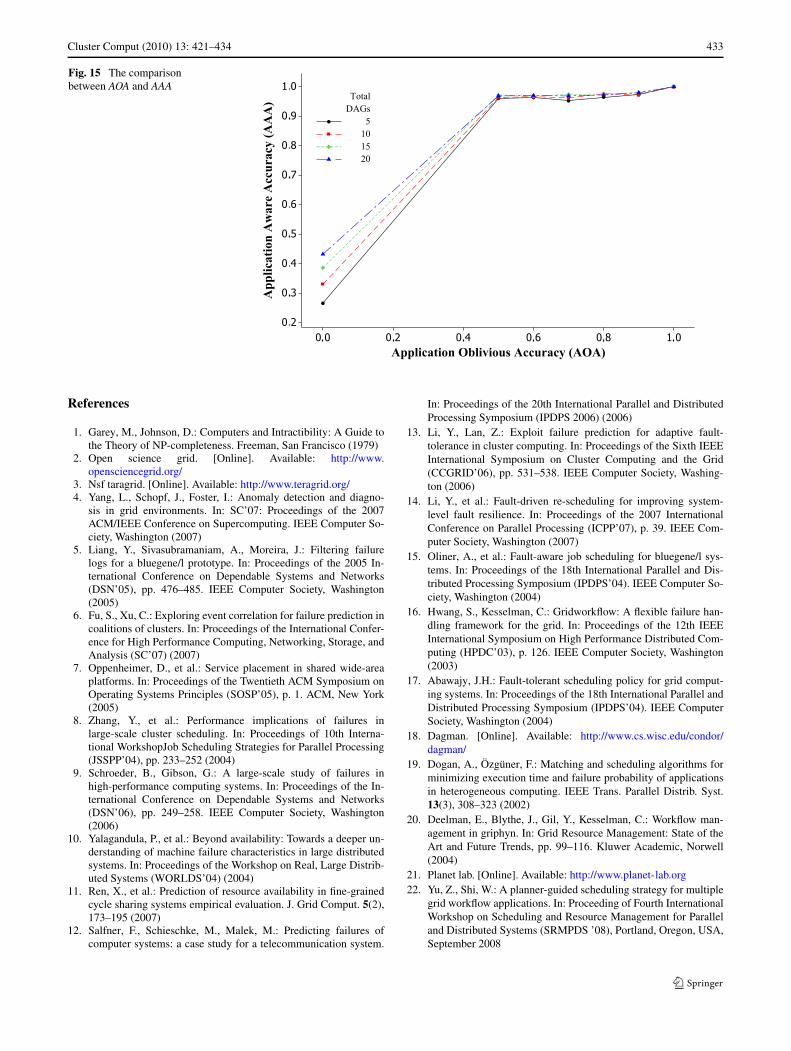
Finally we try to understand what is the right and prac-tically achievable objective of failure prediction accuracy.Figure 15 shows that the effectiveness measured by AAA isabout 96% when AOA is as low as 50%, which indicatesthat a high AAA can be achieved with moderate AOA. Aswork load gets more intensive, a failure blind scheduler (i.e.,
432 Cluster Comput (2010) 13: 421–434
Fig. 13 Average makespan vs.the total number of DAGs
Fig. 14 Average makespan vs.the percentage of false positive
AOA = 0.0) can accomplish closer to 50% of AAA, and theAAA rate is more stable and increases steadily as AOA im-proves and FLAW performs well even with trivial AOAs.
It is worth noting that the simulation was conducted on acluster of 32 nodes by using a two month long actual failuretrace, but its result applied to the grid environments as well.We plan to add more experiments in a Grid environment inthe final version of this paper.
6 Conclusions
In this paper, we present FLAW, and propose two new de-finitions of failure prediction accuracy in the context of
workflow scheduling. Proactive failure handling is intro-duced into a planner-guided dynamic scheduling scheme,HYBD_RANK, which significantly reduces the impact offailures on application performance in terms of makespan,loss time and the number of job rescheduling. A compre-hensive simulation is conducted using real failure trace ofa large scale cluster and a published workflow applicationtest bench. The evaluation results not only demonstrate thatFLAW can effectively improve the application performancein a failure prone high performance computing system butalso shows that the FLAW can be very effective even withmoderate failure prediction accuracy in a system with inten-sive workloads.
Cluster Comput (2010) 13: 421–434 433
Fig. 15 The comparisonbetween AOA and AAA
References
1. Garey, M., Johnson, D.: Computers and Intractibility: A Guide tothe Theory of NP-completeness. Freeman, San Francisco (1979)
2. Open science grid. [Online]. Available: http://www.opensciencegrid.org/
3. Nsf taragrid. [Online]. Available: http://www.teragrid.org/4. Yang, L., Schopf, J., Foster, I.: Anomaly detection and diagno-
sis in grid environments. In: SC’07: Proceedings of the 2007ACM/IEEE Conference on Supercomputing. IEEE Computer So-ciety, Washington (2007)
5. Liang, Y., Sivasubramaniam, A., Moreira, J.: Filtering failurelogs for a bluegene/l prototype. In: Proceedings of the 2005 In-ternational Conference on Dependable Systems and Networks(DSN’05), pp. 476–485. IEEE Computer Society, Washington(2005)
6. Fu, S., Xu, C.: Exploring event correlation for failure prediction incoalitions of clusters. In: Proceedings of the International Confer-ence for High Performance Computing, Networking, Storage, andAnalysis (SC’07) (2007)
7. Oppenheimer, D., et al.: Service placement in shared wide-areaplatforms. In: Proceedings of the Twentieth ACM Symposium onOperating Systems Principles (SOSP’05), p. 1. ACM, New York(2005)
8. Zhang, Y., et al.: Performance implications of failures inlarge-scale cluster scheduling. In: Proceedings of 10th Interna-tional WorkshopJob Scheduling Strategies for Parallel Processing(JSSPP’04), pp. 233–252 (2004)
9. Schroeder, B., Gibson, G.: A large-scale study of failures inhigh-performance computing systems. In: Proceedings of the In-ternational Conference on Dependable Systems and Networks(DSN’06), pp. 249–258. IEEE Computer Society, Washington(2006)
10. Yalagandula, P., et al.: Beyond availability: Towards a deeper un-derstanding of machine failure characteristics in large distributedsystems. In: Proceedings of the Workshop on Real, Large Distrib-uted Systems (WORLDS’04) (2004)
11. Ren, X., et al.: Prediction of resource availability in fine-grainedcycle sharing systems empirical evaluation. J. Grid Comput. 5(2),173–195 (2007)
12. Salfner, F., Schieschke, M., Malek, M.: Predicting failures ofcomputer systems: a case study for a telecommunication system.
In: Proceedings of the 20th International Parallel and DistributedProcessing Symposium (IPDPS 2006) (2006)
13. Li, Y., Lan, Z.: Exploit failure prediction for adaptive fault-tolerance in cluster computing. In: Proceedings of the Sixth IEEEInternational Symposium on Cluster Computing and the Grid(CCGRID’06), pp. 531–538. IEEE Computer Society, Washing-ton (2006)
14. Li, Y., et al.: Fault-driven re-scheduling for improving system-level fault resilience. In: Proceedings of the 2007 InternationalConference on Parallel Processing (ICPP’07), p. 39. IEEE Com-puter Society, Washington (2007)
15. Oliner, A., et al.: Fault-aware job scheduling for bluegene/l sys-tems. In: Proceedings of the 18th International Parallel and Dis-tributed Processing Symposium (IPDPS’04). IEEE Computer So-ciety, Washington (2004)
16. Hwang, S., Kesselman, C.: Gridworkflow: A flexible failure han-dling framework for the grid. In: Proceedings of the 12th IEEEInternational Symposium on High Performance Distributed Com-puting (HPDC’03), p. 126. IEEE Computer Society, Washington(2003)
17. Abawajy, J.H.: Fault-tolerant scheduling policy for grid comput-ing systems. In: Proceedings of the 18th International Parallel andDistributed Processing Symposium (IPDPS’04). IEEE ComputerSociety, Washington (2004)
18. Dagman. [Online]. Available: http://www.cs.wisc.edu/condor/dagman/
19. Dogan, A., Özgüner, F.: Matching and scheduling algorithms forminimizing execution time and failure probability of applicationsin heterogeneous computing. IEEE Trans. Parallel Distrib. Syst.13(3), 308–323 (2002)
20. Deelman, E., Blythe, J., Gil, Y., Kesselman, C.: Workflow man-agement in griphyn. In: Grid Resource Management: State of theArt and Future Trends, pp. 99–116. Kluwer Academic, Norwell(2004)
21. Planet lab. [Online]. Available: http://www.planet-lab.org22. Yu, Z., Shi, W.: A planner-guided scheduling strategy for multiple
grid workflow applications. In: Proceeding of Fourth InternationalWorkshop on Scheduling and Resource Management for Paralleland Distributed Systems (SRMPDS ’08), Portland, Oregon, USA,September 2008

434 Cluster Comput (2010) 13: 421–434
23. Los Alamos National Laboratory. Operational data to supportand enable computer science research (2006). [Online]. Available:http://institutes.lanl.gov/data/fdata/
24. Salfner, F., Malek, M.: Proactive fault handling for systemavailability enhancement. In: Proceedings of the 19th IEEEInternational Parallel and Distributed Processing Symposium(IPDPS’05)—Workshop 16, p. 281.1. IEEE Computer Society,Washington (2005)
25. Yu, Z., Shi, W.: An adaptive rescheduling strategy for grid work-flow applications. In: Proceeding of 21st International Paralleland Distributed Processing Symposium (IPDPS’07), Long Beach,Florida, USA, March 2007
26. Topcuouglu, H., Hariri, S., Wu, M.: Performance-effective andlow-complexity task scheduling for heterogeneous computing.IEEE Trans. Parallel Distrib. Syst. 13(3), 260–274 (2002)
27. Oliner, A., Sahoo, R., Moreira, J., Gupta, M.: Performance impli-cations of periodic checkpointing on large-scale cluster systems.In: Proceedings of the 19th IEEE International Parallel and Dis-tributed Processing Symposium (IPDPS’05), p. 299.2. IEEE Com-puter Society, Washington (2005)
28. Schroeder, B., Gibson, G.: Understanding failures in petascalecomputers. J. Phys., Condens. Matter 19(45) (2007)
29. Hönig, U., Schiffmann, W.: A comprehensive test bench for theevaluation of scheduling heuristics. In: Proceedings of the 16thInternational Conference on Parallel and Distributed Computingand Systems (PDCS’04). IEEE, New York (2004)
30. Canon, L.-C., Jeannot, E., Sakellariou, R., Zheng, W.: Compara-tive evaluation of the robustness of dag scheduling heuristics. In:Integration Research in Grid Computing, CoreGRID IntegrationWorkshop, pp. 63–74. Crete University Press, Heraklion (2008)
Zhifeng Yu received the B.S. de-gree in applied mathematics andM.S. degree in economics and man-agement from Tongji University,Shanghai, China, in 1990 and 1993respectively and the Ph.D. degree incomputer science from Wayne StateUniversity, Detroit, USA in 2009.He is currently Manager of Appli-cation Development and Integra-tion of T-Systems North America,Rochester Hills, MI. His researchinterests include computer systemsand enterprise computing.
Chenjia Wang received his Bache-lor’s degree of Engineering in Elec-tronic Information Engineering fromShanghai University, Shanghai, Chinain 2007 and his Master Sciencedegree in Computer Science fromWayne State University, Detroit,U.S. in 2009. His interests includemobile computing and enterprisecomputing. Currently, he is an ITanalyst in the IT division under Rev-stone Industries LLC.
Weisong Shi is an Associate Pro-fessor of Computer Science at WayneState University. He received hisB. S. from Xidian University in1995, and Ph.D. degree from theChinese Academy of Sciences in2000, both in Computer Engineer-ing. His current research focuses onmobile computing, distributed sys-tems and high performance com-puting. Dr. Shi has published morethan 80 peer-reviewed journal andconference papers in these areas.He is the author of the book “Per-formance Optimization of Software
Distributed Shared Memory Systems” (High Education Press, 2004).He has also served on technical program committees of several inter-national conferences, including WWW, ICPP, MASS. He is a recipi-ent of Microsoft Fellowship in 1999, the President outstanding awardof the Chinese Academy of Sciences in 2000, one of 100 outstand-ing Ph.D. dissertations (China) in 2002, “Faculty Research Award” ofWayne State University in 2004 and 2005, the “Best Paper Award” ofICWE’04 and IPDPS’05. He is a recipient of the NSF CAREER awardand Wayne State University Career Development Chair award.


















