Extracting and analysing information from electronic...
94
Extracting And Analysing Information From Patient Records In Order To Track Disease Progression Over Time A Dissertation Submitted To The University Of Manchester For The Degree Of Master Of Science In The Faculty Of Engineering And Physical Sciences 2015 By Aleksandra Ivaylova Nacheva School of Computer Science
-
Upload
trinhquynh -
Category
Documents
-
view
213 -
download
0
Transcript of Extracting and analysing information from electronic...

Extracting And Analysing Information From Patient Records In Order To Track Disease Progression Over
Time
A Dissertation Submitted To The University Of Manchester For The Degree Of Master Of Science In The Faculty Of Engineering And Physical Sciences
2015
By Aleksandra Ivaylova Nacheva School of Computer Science

0. Contents
Contents 1
List of Figures 3
List of Tables 4
1 Introduction 9
1.1 Aim . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.2 Objectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.2.1 Learning objectives . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.2.2 Deliverable objectives . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.3 Report outline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2 Background 13
2.1 Text Mining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.1.1 General architecture of Text Mining systems . . . . . . . . . . . . 14
2.1.2 Text Mining stages . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.1.2.1 Pre-processing stage . . . . . . . . . . . . . . . . . . . . . 15
2.1.2.2 Information Extraction stage . . . . . . . . . . . . . . . . 16
2.1.3 Named Entity Recognition Approaches . . . . . . . . . . . . . . . . 18
2.1.3.1 Dictionary–based approaches . . . . . . . . . . . . . . . . 18
2.1.3.2 Rule–based approaches . . . . . . . . . . . . . . . . . . . 19
2.1.3.3 Machine Learning–based approach . . . . . . . . . . . . . 19
2.1.3.4 Hybrid approaches . . . . . . . . . . . . . . . . . . . . . . 20
2.2 Clinical Text Mining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.2.1 Evaluation methods . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.2.2 Related work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.3 Sentiment analysis of clinical data . . . . . . . . . . . . . . . . . . . . . . 29
2.4 Classification approaches . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.5 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3 Specification and Design 33
3.1 Project scope . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.2 Challenges for developing the project . . . . . . . . . . . . . . . . . . . . . 33
3.3 Data Description . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.4 System requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.5 Initial analysis of data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.5.1 Identification of disease factors that need to be extracted . . . . . 38
3.5.2 Lexical profiling . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
1

2
3.6 Method overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.7 System Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.7.1 Modeling the system boundaries . . . . . . . . . . . . . . . . . . . 44
3.7.2 Modeling the system components . . . . . . . . . . . . . . . . . . . 46
3.7.3 Modeling the system interactions . . . . . . . . . . . . . . . . . . . 51
3.7.4 Modeling the system workflows . . . . . . . . . . . . . . . . . . . . 53
3.7.5 Classification rules design . . . . . . . . . . . . . . . . . . . . . . . 58
3.7.6 Quality attributes . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
3.8 Database Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
3.8.1 Types of information that needs to be stored . . . . . . . . . . . . 62
3.8.2 Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4 Implementation 68
4.1 Development environment preparation . . . . . . . . . . . . . . . . . . . . 68
4.1.1 Ethical approvals . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
4.1.2 Hospital environment preparation . . . . . . . . . . . . . . . . . . 68
4.1.3 Development Language Choice . . . . . . . . . . . . . . . . . . . . 69
4.1.4 Database Platform and Type Choice . . . . . . . . . . . . . . . . . 70
4.1.5 Preparation of Feature Extraction tools . . . . . . . . . . . . . . . 70
4.2 Classifier creation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.3 Software Testing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
4.3.1 Regression Testing . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
4.3.2 Integration Testing . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
4.3.3 Tests Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
5 Evaluation 77
5.1 Evaluation methodology . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
5.2 Description of Data set . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
5.3 SentiStrength Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
5.4 Classification approaches evaluation . . . . . . . . . . . . . . . . . . . . . 80
5.4.1 Rule-based approach evaluation . . . . . . . . . . . . . . . . . . . . 80
5.4.2 Machine learning approach evaluation . . . . . . . . . . . . . . . . 81
5.4.3 Comparison between approaches . . . . . . . . . . . . . . . . . . . 83
6 Conclusion and Future work 84
6.1 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
6.1.1 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
6.1.2 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
6.2 Future work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
6.2.1 Integrate application within hospital environment . . . . . . . . . . 87
6.2.2 Expand Information Extraction functionality . . . . . . . . . . . . 87
6.2.3 Improve run time . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
6.2.4 Extending the system functionality . . . . . . . . . . . . . . . . . . 88
thomasedwards
Typewritten Text
thomasedwards
Typewritten Text
thomasedwards
Typewritten Text
Word Count 17556
thomasedwards
Typewritten Text
thomasedwards
Typewritten Text
thomasedwards
Typewritten Text
thomasedwards
Typewritten Text
thomasedwards
Typewritten Text

0. List of Figures
2.1 General Architecture of TM systems . . . . . . . . . . . . . . . . . . . . . 14
2.2 IE task example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.3 Confusion matrix . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.4 Example of system architecture (Spasic et al, 2010) . . . . . . . . . . . . . 25
2.5 DNorm architecture (Leaman et al, 2013) . . . . . . . . . . . . . . . . . . 27
2.6 MedEx architecture (Xu et al, 2010) . . . . . . . . . . . . . . . . . . . . . 28
2.7 CliNER architecture (Kovacevic et al, 2013) . . . . . . . . . . . . . . . . . 29
2.8 Weka . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.9 Orange . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.1 Explicit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.2 Implicit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.3 2-grams . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.4 3-grams . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.5 4-grams . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.6 Negative sentiment note example . . . . . . . . . . . . . . . . . . . . . . . 42
3.7 Positive sentiment note example . . . . . . . . . . . . . . . . . . . . . . . 42
3.8 System workflow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.9 Context Diagram . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
3.10 Context diagram for Classifier . . . . . . . . . . . . . . . . . . . . . . . . . 46
3.11 Component Diagram . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
3.12 Sequence Diagram . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
3.13 System Workflow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.14 Metastatic Rules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
3.15 Non-metastatic Rules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
3.16 Quality Factors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
3.17 Database Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
3.18 Classifier Table . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
3

0. List of Tables
2.1 Pre-processing tasks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.2 Comparison between NER approaches . . . . . . . . . . . . . . . . . . . . 20
2.3 Comparison between clinical Text Mining systems . . . . . . . . . . . . . 24
3.1 Table columns description . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.2 Disease factor identified . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.1 Work environment set up . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
4.2 Functionality Tests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
5.1 Notes statistics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
5.2 SentiStrength accuracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
5.3 Confusion Matrix for Rules . . . . . . . . . . . . . . . . . . . . . . . . . . 81
5.4 Results for Rules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
5.5 Confusion Matrix for ML . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
5.6 Results for ML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
4

5
Abstract
Cancer is a disease that has caused the death of many people around the world which
makes it a threat that needs to be coped with.
Even though the Electronic Health Records (EHRs) are a rich source of information
regarding cancer, the data stored in them is mainly in free text form, which make them
di�cult to analyse. Thus, there is a lot of research going into the clinical domain in
order to create methods for analysing the data available in the EHRs in order to improve
the services provided in hospitals.
In collaboration with The Christie hospital in Manchester this project aims to provide
an automatic method for identifying the metastatic breast cancer patients that need to
be contacted for immediate support. For this purposes a clinical text mining system for
extracting and analysing information from patient records (free text) has been created.
The project consists of two main parts. The first part focuses on analysing, extracting
and structuring the relevant features to metastasis patient by using text mining tech-
niques.The second part uses a classification method in order to identify the metastatic
patients.
Sentiment analysis has also been performed on the data since clinical narratives are
written by clinicians who very often express emotions in the notes. The sentiments
associated with the notes can help identifying metastasis easier.
For the classification two approaches are used: rule - based approach and machine learn-
ing approach. The results from rule-based approach are 83% recall and 89% precision.
The machine learning approach has been evaluated with and without sentiment rankings
and it has produced its better result with included sentiments, which is 76% recall and

6
85% precision. The rule-based approach has been considered the more suitable method
for the purposes of the project. Further to that, it has been found that sentiments in
clinical notes help to find hidden valuable information.

7
Declaration
No portion of the work referred to in this dissertation has been submitted in support of
an application for another degree or qualification of this or any other university or other
institute of learning.
Copyright
1. The author of this thesis (including any appendices and/or schedules to this the-
sis) owns certain copyright or related rights in it (the “Copyright”) and s/he has
given The University of Manchester certain rights to use such Copyright, including
for administrative purposes.
2. Copies of this thesis ,either in full or in extracts and whether in hard or electronic
copy, may be made only in accordance with the Copyright, Designs and Patents
Act 1988 (as amended) and regulations issued under it or, where appropriate, in
accordance with licensing agreements which the University has from time to time.
This page must form part of any such copies made.
3. The ownership of certain Copyright, patents, designs, trade marks and other intel-
lectual property (the “Intellectual Property”) and any reproductions of copy- right
works in the thesis, for example graphs and tables (“Reproductions”), which may
be described in this thesis, may not be owned by the author and may be owned by
third parties. Such Intellectual Property and Reproductions cannot and must not
be made available for use without the prior written permission of the owner(s) of
the relevant Intellectual Property and/or Reproductions.

8
4. Further information on the conditions under which disclosure, publication and
commercialisation of this thesis, the Copyright and any Intellectual Property
and/or Reproductions described in it may take place is available in the Uni-
versity IP Policy (see http://documents.manchester.ac.uk/DocuInfo.aspx? Do-
cID=487), in any relevant Thesis restriction declarations deposited in the Univer-
sity Library, The University Library’s regulations (see http://www.manchester.
ac.uk/library/aboutus/regulations) and in The University’s policy on presentation
of Theses
Acknowledgments
This section acknowledges and thanks all those who helped make this project possible.
I would like to give special thanks to the following people:
Dr Goran Nenadic For academic and moral support
Mr Tom Liptrot For academic support
Mrs Claire Gaskell For academic support
Christie Hospital For use of their facilities and academic support
Mr Thomas Edwards For moral support
Mrs Jeni Nacheva For moral support

1. Introduction
Cancer is a disease that has caused the death of many people around the world. The
recent statistics released for cancer research for the UK show that more than 331,000
people were diagnosed with cancer in 2011 (All Cancers Combined, 2015). As a result
of this there has been a lot of research into understanding this disease, its causes, and
its cures.
Electronic Health Records (EHRs) are a rich source of valuable cancer related data,
which could be used for the creation of automated applications for improving the health
care services and clinical research. However, the creation of such applications is chal-
lenging since most of the clinical information is available in clinical narratives (notes,
letters and reports) that are in free text form (Friedman et al, 2004). Further to that,
there are two other problems associated with the creation of clinical automated systems
related to cancer data (Spasic et al., 2014):
First, there are many types of cancer, each with di↵erent causes, symptoms and treat-
ments. Thus, existing systems and approaches for one type of cancer might not be
applicable to another type of cancer.
Another problem concerns the ethical and legal issues associated with patient’s data.
Therefore, most systems are developed on local data and their testing on a larger sample
or comparison to other methods is di�cult.
9

10
There is an ongoing collaboration between the School of Computer Science at Manch-
ester University and the Christie hospital to extract important information from clinical
records. The hospital has been collecting cancer patient data over 30 years and includes
free text in the form of notes and letters that have been sent to GPs. Previous infor-
mation extraction tasks performed on the hospital’s clinical data include extraction of
cancer outcomes from clinical notes (Litrot et al., 2015) and identifying heart disease
factors in clinical notes (Karystianis et al, 2015).
One of the tasks the hospital is currently pursuing is tracking disease progression (cancer
in the patient becoming more advanced due to growth and/or spread of a tumour) over
time. However, this is not a straightforward task since the data is mainly in free text
and very often the disease is not mentioned explicitly but needs to be deducted from the
context. Therefore, it is di�cult to identify the patients whose condition has deteriorated
and need to be contacted for additional support. Currently a nurse goes through the
records manually in order to identify those patients, which is a time consuming and
subjective process.
1.1 Aim
The aim of the project is to create a system (software suite) that takes raw medical
notes of breast cancer as input and generates an output of the patients diagnosed with
metastasis at the last date of their visit. The project will be of help in two main
ways: One by supporting the work of the nurses and the hospital in providing better
treatments and support, and secondly by helping to provide a faster identification of
metastatic patients. Further to this, the system will ease the workload of the nurses since
they would not need to go through the notes manually. The project needs to address the

11
following problems: terminological variability and ambiguity, negation, highly condensed
text, and abbreviations with multiple meanings.The system will need to be evaluated in
order to know whether it is able to identify the metastatic patients. For this purposes,
we will compare the output of the system to a Gold standard (manually annotated notes)
provided by a nurse from the hospital.
1.2 Objectives
1.2.1 Learning objectives
• Investigate and understand text mining approaches and techniques
• Investigate and understand how similar clinical text mining systems work and how
they can be used in the project
• Identify tools that can be re-used for the implementation of the di↵erent stages
• Investigate di↵erent algorithms and software that can be used for the classification
stage of the project
1.2.2 Deliverable objectives
• Investigate and discuss with the nurse the type of information that needs to be
extracted
• Develop an application that performs an initial analysis of the data in order to
understand the type of data that is stored in the notes
• Discuss and outline the main requirements of the system with the nurse

12
• Develop an application that pre-process the notes and extracts the information
needed
• Design and implement a classifier to be included into the application
• Develop a database that stores the extracted information and the output from the
classifier
• Evaluate the performance of the classifier against a given Gold standard from the
nurse
1.3 Report outline
This report is structured as follows: Chapter 2 exposes the background related to Text
mining approaches and techniques as well as classification and evaluation methods. Fur-
ther to this, this chapter presents an overview of existing clinical text mining systems
that can be of help for the completion of the project. Chapter 3 explains the methodol-
ogy used for the system creation as well as the system design and provides justification
of choices made. Chapter 4 presents the main points of the implementation process and
tests performed in order to measure system quality. The evaluation of the classification
method used is explained in chapter 5 while in chapter 6 conclusions and future work
plans are presented.

2. Background
2.1 Text Mining
Text mining (TM) is used for processing large amounts of unstructured text in free
form in order to find useful information. Its goal is to identify implicit knowledge that
hides in unstructured text and present it in an explicit form. It is an interdisciplinary
field, which employs many computational technologies, such as Machine Learning (ML),
Natural language Processing (NLP), statistics, information technologies and pattern
recognition (Zhu et al, 2007).
The most natural and common way for storing data is text, thus text mining finds
applications in many fields. For instance, in marketing it is used in survey research
for analysing open-ended surveys (DELL, 2015). Another application of text mining
technique is the automatic classification of text. For example, emails, in order to filter
out junk messages (DELL, 2015). Other examples of its usage includes the mining of
patents and research articles by the pharmacological industry in order to improve drug
discovery and academic research for finding new knowledge and trends (McDonald and
Kelly, 2015).
13

14
2.1.1 General architecture of Text Mining systems
At an abstract level, a text mining system takes in input (raw documents) and generates
various types of output (patterns, trends maps of connections) (Feldman and Sanger,
2007).
The general architecture of TM system is given in Figure 2.1.
Figure 2.1: General Architecture of TM systems
As it can be seen from Figure 2.1 a TM system usually consists of four main stages:
1. Information Retrieval (IR): This is the first task to be performed. It is concerned
with extracting relevant documents that answer a query. The IR systems can
also be called search engines (Ananiadou and McNaught, 2006). It is usually
domain–independent and returns a number of documents that satisfy a given query
(Spasic et al, 2014).
2. Pre-processing of data: It involves methods that prepare data for the information
extraction tasks.
3. Information Extraction (IE): IE task is usually applied after IR and its goal is to
extract specific information from text documents (Hotho et al, 2005). It converts
free text into structured information (Spasic et al, 2014).
4. Data Mining: This stage involves operations that help finding patterns of interest,
trend analysis, etc. Examples of data mining techniques that are usually per-
formed are classification and association rules. For instance, a classification can

15
be performed after all relevant data is extracted from the text in order to classify
patients as metastatic or non-metastatic.
2.1.2 Text Mining stages
In this section we will revisit the above mentioned text mining stages and outline the
main tasks they include in the order in which they are usually performed. However, we
will exclude the Information Retrieval stage because it is irrelevant to the project. We
do not need to extract text documents related to breast cancer since we will be provided
with the specific data that we need to analyse from the hospital. Instead, we need to
extract specific terms of interest from the given medical records.
2.1.2.1 Pre-processing stage
The pre-processing stage usually includes tasks that are not problem-specific and are
more generic operations (Nadkarni et al, 2011). The main pre-processing tasks are:
sentence boundary detection, tokenization, part-of-speech tagging (POS tagging), mor-
phological analysis, and syntax analysis.
The main pre-processing tasks usually performed are explained in Table 2.1. We are not
focusing on the problems associated with each of them since they can be implemented
using existing tools and frameworks.

16
Table 2.1: Pre-processing tasks
2.1.2.2 Information Extraction stage
The IE stage includes tasks that are problem–specific and are built on the top of the pre-
processing tasks (Nadkarni et al, 2011) and (Ben-Dov and Feldman, 2010), they mainly
include Named Entity Recognition (NER), Relations extraction, Temporal IE and Term
Classification. These techniques enable us to obtain formal, structured representations
of documents.
The IE tasks are key for the project since they will help to structure the patient notes
and extract the useful information based on which the classification model will be built.

17
An example of how IE tasks would work for the purposes of the project (identifying
metastatic patients) is given in Figure 2.2.
Figure 2.2: IE task example
In figure 2.2 it can be seen that the input to the IE task is an anonymised patient
note. The IE task extracts terms that prove whether a patient is metastatic or not and
normalise and structure them in a format that allows further analysis. In this specific
case, the term ”stable disease” is proof that the patient’s condition is improving and
thus the disease is not progressing.
The main IE tasks are:
• NER: NER task (Nadkarni et al, 2011) identifies specific terms and relations be-
tween them that could be of interest such as treatments, drugs, and diagnoses.
Problems (Nadkarni et al, 2011) related to medical data that need to be solved dur-
ing this stage include: ambiguity of abbreviations and terms, grammar and spelling
mistakes, term variability and synonyms, heavy use of domain specific terminology
(only internally known terminology), typographical variants, word/phrase order
variation, and negation and uncertainty identification. This task will be re-visited
in the next section as it is considered important for the project.

18
• Relations extraction: Relationships(Nadkarni et al, 2011) between entities also
need to be extracted. Entities that show relevance and connection between terms
should also be extracted since they can reveal more hidden information in the text.
• Temporal IE: Temporal data (Kovacevic et al, 2013) such as dates, time, frequency,
etc have di↵erent characteristics and are associated with problems di↵erent from
those typical for named entities. Therefore, temporal data might need to be ex-
tracted separately.
• Term Classification (Term Categorization): The recognized named entities can
be further classified in a number of pre-defined classes (Spasic et al, 2014). For
instance, if a named entity denotes a medication, then it would be classified into
the class of medication names. This will provide more structure and metadata
and thus help for the creation of a classification method which takes into account
the presence of a specific combination of terms from di↵erent classes and based on
that, build a classifier.
2.1.3 Named Entity Recognition Approaches
The four approaches that can be used for performing NER are:
2.1.3.1 Dictionary–based approaches
Dictionary–based approach (Spasic et al., 2014) involves the creation of dictionaries that
include all synonyms and variations of the terms that need to be extracted and thus help
locate term occurrences in text. The explicit use of already created dictionaries or the
use of specialised well–known biomedical databases is not feasible as very often the
clinical notes consist of terms that are not available in the more general dictionaries.

19
Therefore, there is need to tune existing dictionaries to the particular case or to create
a new one manually with the help of o�cial sources.
A drawback of this approach is that this approach can only recognize entities if the
names by which they are denoted in text are part of the dictionaries. Further to that,
the biomedical domain is changing constantly and consequently the terms used within
a text can change often. Thus, the dictionaries created for the specific text must be
updated constantly.
2.1.3.2 Rule–based approaches
Rule–base approach (Appelt and Israel, 1999) is also called Knowledge engineering ap-
proach. In this approach careful analysis of the text needs to be performed in order
to find common patterns. Then, sets of rules are written manually in order to capture
these patterns and are used to extract useful information from the text. This approach
is a time–consuming iterative process because it requires rules to be tested and changed
many times until they give the desired results. Another drawback of this approach is
that it cannot be generalized and applied to other cases. However, the creation of a
system that can be applied to di↵erent clinical cases is out of the scope of this project
and thus we are not concerned with this problem.
2.1.3.3 Machine Learning–based approach
ML approach (Appelt and Israel, 1999) is also called Automatic approach. In this
approach a machine learning algorithm creates the rules for extracting information au-
tomatically. This method requires a large number of training sets related to the specific
domain, which can be di�cult to obtain. An advantage of this approach is that it

20
is domain–independent and can be applied to di↵erent cases as long as a corpus of
domain–dependent texts is available. Possible ML algorithms that can be used for the
implementation of this approach are: Decision trees, hidden Markov models (hMM), con-
ditional random fields (CRFs) and maximum entropy models(Appelt and Israel, 1999).
2.1.3.4 Hybrid approaches
This approach (Appelt and Israel, 1999) combines rules and machine learning algorithms
for extraction of relevant information. Also, combination of the three approaches or a
mixture of rule–based and dictionary–based is also possible. The main advantage of this
approach is that it can combine the advantages of the main three approaches and give
more flexibility in the implementation of the NER.
A comparison between the first three approaches is given in Table 2.2.
Table 2.2: Comparison between NER approaches
From Table 2.2 can be concluded that the main advantage of dictionary and rule - based
approaches over the ML approach is that they do not require training data. Further to
that, the main advantage of ML approach over the other two is that it can be applied

21
to di↵erent hospital cases with minimum changes and can cope with term changes over
time more easily.
2.2 Clinical Text Mining
One of the areas in which the importance of text mining techniques constantly grows
is clinical research. The reason for this is that medical records are valuable sources of
information but are di�cult to perform analysis on due to the fact that most of the
information is available in clinical narratives in free–text form and have rich contextual
meaning. Further to that, the amount of data available in the narratives is growing and
therefore becoming more di�cult for manual processing (Zhu et al, 2007).
Due to the ability of text mining techniques to process large amounts of unstructured text
automatically, text mining is believed to bridge the gap between unstructured clinical
notes and structured data representation (Kovacevic, 2013).
2.2.1 Evaluation methods
Evaluation will be performed on two of the stages of the system development – the Text
mining stage for evaluating the performance of the Information Extraction systems and
the classification stage. We can use the same evaluation approach for both of them.
The evaluation method should be able to test how good your classifier is in predicting
the class label of a tuple and also how good is the Information Extraction system is in
extracting the correct terms from the text.
We can use measures based on a confusion matrix (example given in Figure 2.3) where
each column of the matrix represents the instances in the predicted class and each row

22
represents the instances of the actual class. For a binary classification problem there are
four possible outcomes of a single prediction:
• true positives (TP): These refer to the positive tuples correctly labeled by the
classifier
• true negatives (TN): These are negative tuples that were correctly labeled by the
classifier
• false positives (FP): These are the negative tuples that were incorrectly labeled as
positive
• false negatives (FN): These are the positive tuples that were incorrectly labeled as
negative
Figure 2.3: Confusion matrix
Based on the features summerised in the confusion matrix, there are three main measures
used to evaluate the performance of a classifier:
• Accuracy: The accuracy of a classifier on a given test set is the percentage of test
set tuples that are correctly classified by the classifier. In other words, it reflects
how well the classifier recognises tuples of various classes. That is,
accuracy = (TP + TN)/(P+N)
• Precision: The precision metric represents the percentage of positive instances that
were presented as positive. It is used to measure the exactness of the classifier

23
(what percentage of tuples labeled as positive are actually such). That is,
TP/(TP + FP)
• Recall: Recall is a measure of completeness (what percentage of positive tuples
are labeled as such). That is,
recall = TP/(TP + FN)
• F-measure: Precision and recall are naturally opposed in sense that if the precision
measure is increased, the recall measure is typically degreased and vice versa.
Thus, the two measures need to be balanced. This is done using F-measure, which
is the harmonic mean of precision and recall and it is calculated with the formula:
(P + R)/2PR (Spasic et al, 2014).
2.2.2 Related work
Many projects focus on extracting useful patient information from medical records au-
tomatically using a variety of TM approaches and methods. For example, Goryachev et
al (2008) extracted family history information from clinical reports using a rule–based
approach while Patrick et al (2010) extracted medication information using hybrid ap-
proach (machine learning and rule–based algorithms).
In Table 2.3 explains four di↵erent systems which extract di↵erent types of information
from clinical notes. Their approaches and design choices will be used as examples for
the creation of our system.
The first two papers use mainly rule–based approaches and the other two use hybrid
approaches. The similarities between the systems are the following:

24
Table 2.3: Comparison between clinical Text Mining systems
• All of them use 3–stage implementation process always starting with a pre-processing
stage. For the pre-processing stage they use mainly general frameworks.
• Both of the rule–based systems use the same software for rule – creation – Mixup
and also both use dictionaries. They also use Unified Medical Language System
–UMLS, a generic knowledge representation system that brings together many
health and biomedical vocabularies to support the dictionary creation.
• Both of the hybrid systems use NegEx in the pre-processing stage in order to
detect negation. NegEx uses regular expressions and a list of terms to determine
whether clinical conditions are negated in a sentence (Negex, 2009). Further to
that, both of them create di↵erent modules, which process data depending on
their characteristics. The first one creates a module for processing notes where a
disease status is mentioned explicitly and a module for processing notes where a
25
disease status needs to be derived by the context. The second system performs
the temporal extraction and the entity extraction separately. Further to that, the
second system uses JAPE for creating rules for the TE module.
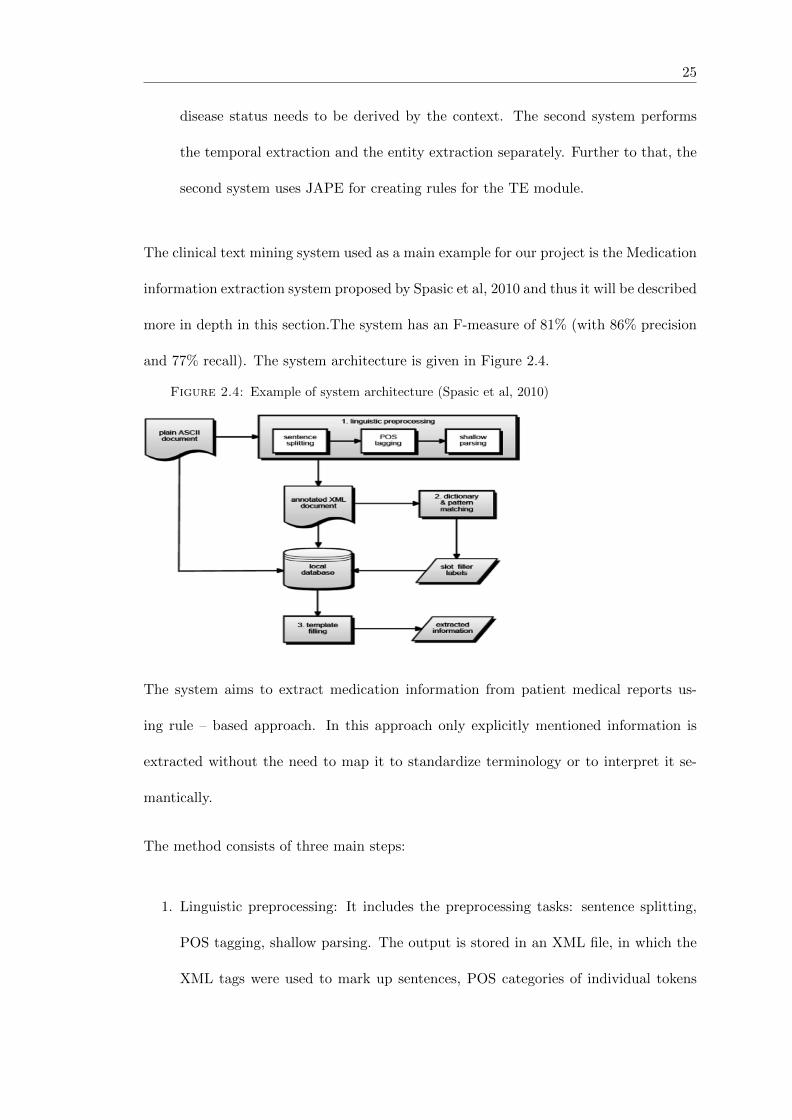
The clinical text mining system used as a main example for our project is the Medication
information extraction system proposed by Spasic et al, 2010 and thus it will be described
more in depth in this section.The system has an F-measure of 81% (with 86% precision
and 77% recall). The system architecture is given in Figure 2.4.
Figure 2.4: Example of system architecture (Spasic et al, 2010)
The system aims to extract medication information from patient medical reports us-
ing rule – based approach. In this approach only explicitly mentioned information is
extracted without the need to map it to standardize terminology or to interpret it se-
mantically.
The method consists of three main steps:
1. Linguistic preprocessing: It includes the preprocessing tasks: sentence splitting,
POS tagging, shallow parsing. The output is stored in an XML file, in which the
XML tags were used to mark up sentences, POS categories of individual tokens

26
and syntactic categories of word chunks. The XML document is stored in the
database where the original notes reside.
2. Dictionary and pattern matching: The annotated XML document from the first
step is used as an input for this step. Rules were used to exploit morphologic,
lexical, and syntactic properties that will help for the dictionary creation, and also
for acquiring slot filler labels. Rules were implemented using Mixup. The approach
for medication name recognition is mainly dictionary – based. Three types of
dictionaries were created: dictionaries for medication recognition, dictionaries to
help recognition of generic medication types, and dictionaries to store reason –
related terms in order to support the recognition of the reason for medication.
The obtained slot filler labels are stored in the database.
3. Template filling: The slot filler labels extracted in the second step are combined to
fill the information extraction template with the slots: medication, dosage, mode,
frequency, duration and reason. XML tags are marking the slot fillers.
The Information Extraction stage is the most time-consuming part of the project need-
ing to be implemented. Thus, in this section we will investigate existing Information
Extraction systems that can be used for extracting metastasis - related data in order to
ease the workload for the implementation of this stage.
DNorm
DNorm (Disease name Normalisation Information Extraction system) is a information
extraction system (Leaman et al, 2013), which automatically determines diseases men-
tioned in text. It uses machine learning methods to normalize disease names in biomed-
ical text and relies on on dictionary lookup techniques and various string matching
algorithms to account for term variation(Leaman et al,2013). The algorithm achieves

27
an 80.9% F-measure with precision 82.8% and 80.9% recall. An example of the basic
architecture of DNorm is given in Figure 2.5
Figure 2.5: DNorm architecture (Leaman et al, 2013)
From Figure 2.5 it can be seen that DNorm works on a sentence level and the main steps
it performs are to locate disease names, abbreviation resolution and normalisation. The
output is a set of concepts found within each sentence of the input text, and ID of the
term and a position of the term within the sentence.
MedEx
Medication Extraction system (MedEx) (Xu et al, 2010) was developed to extract medi-
cation information from clinical notes and represent it in a structured way. An evaluation
using a data set of 50 discharge summaries showed it performed well on identifying not
only drug names (F-measure 93.2%), but also signature information, such as strength,

28
route, and frequency, with F-measures of 94.5%, 93.9%, and 96.0% respectively(Xu et
al, 2010). It uses a rule-based approach. An overview of the architecture of MedEx is
given in Figure 2.6.
Figure 2.6: MedEx architecture (Xu et al, 2010)
Similar to DNorm, MedEx works on a sentence-level and outputs the found medication
information to a text file including an ID for each concept and the position of the term
in the sentence.
CliNER
CliNER (Kovacevic et al, 2013) is a command line tool for identification of mentions of
four categories of clinically relevant events: Problems, Tests, Treatments, and Clinical
Departments.It also recognises and normalises clinical temporal expressions. The system
combines rules and machine learning approaches for extracting events for clinical nar-
ratives. The system achieves F scores of 90% for the extraction of temporal expressions
and 87% for clinical event extraction. The system architecture is given in Figure 2.7.

29
Figure 2.7: CliNER architecture (Kovacevic et al, 2013)
2.3 Sentiment analysis of clinical data
Clinical narratives are usually written in natural language by clinicians who express emo-
tions in the notes. Thus, the patients notes contain sentiments that can reveal whether
a patient’s condition is worsening or improving and thus can help to gain more infor-
mation about the patient. Currently, there are not many cases of performing sentiment
analysis on clinical data and thus existing sentiment analysis systems specifically for the
clinical domain do not exist.
SentiStrength (SentiStrength website, no date) is a system that performs automatic
sentiment analysis of mainly unstructured informal text. It perofrms sentiment strength
analysis which means that it predicts the strength of positive or negative sentiment
within a text. It has been mainly used for analysing twitter data. However, it can be used
in the clinical sphere as well. SentiStrength estimates the positive and negative sentiment
in text. It can work on sentence-level or note-level and reports two sentiment strengths:
-1(not negative) to -5(extremely negative) AND 1(not positive) to 5(extremely positive)
The reason for producing two scores for a given text input is because a psychology study
has revealed that we process positive and negative sentiment in parallel - hence mixed
emotions. SentiStrength is using a lexicon of 2310 sentiment words and word stems

30
that have been assigned weights and it is based on a dictionary lookup approach. The
performance of SentiStrength for Twitter data is 70% for positive ranking and 75.4%
for negative ranking. Its performance for MySpace data is 63% for positive ranking and
77.3% for negative ranking (Mike Thelwall,no date).
2.4 Classification approaches
The classification method that will be used for classification of patient data will depend
on the output of the text mining stage. However, in this section we will present the two
main classification methods that might be used - Decision tree algorithm or Rule-based
approach. The first one is a machine learning, data-driven approach, like Decision tree.
The other approach is a knowledge-based approach Rule – based classification.
Decision tree induction (Han et al, 2012) is a top-down recursive tree induction algo-
rithm, which uses an attribute selection measure to select the attribute tested for each
non-leaf node in the tree. Decision tree approach can also be called Data-driven ap-
proach and is based on machine-learning principles. For this particular case, the main
class labels can be – metastatic and non-metastatic and each branch will present a
specific combination of attribute values of the disease factors, identified from the text
classification stage. The decision tree creation process consists of two steps: a learning
step during which the classifier is built using previously annotated data and a testing
step in which the classifier performance is measured by applying it on unseen cases. An
advantage of the decision tree is that they do not require any domain specific knowledge
or parameter settings, and therefore are appropriate for exploratory knowledge discov-
ery. The learning and classification steps of decision tree induction are simple and fast.
In general, decision tree classifiers have good accuracy.

31
Rules (Han et al, 2012) are another good way of representing information. The manually
created rules are not created using machine learning methods, but are created by a
human as they will require more knowledge of the data. A rule-based classifier uses
a set of IF-THEN rules for classification. The IF part of a rule is known as the rule
antecedent or precondition, and the THEN part is the rule consequent (it contains the
class prediction). For the specific case, an example of if – then rule will be:
if disease factor1 = value1 and disease factor2=value2, then class = metastatic — non-
metastatic
In comparison with a decision tree, the IF-THEN rules may be easier for humans to
understand, particularly if the decision tree is very large. Problems (Han et al, 2012) that
can be encountered during the classification stage are: data overfitting (the classification
model fit the training data too well and it is unable to make predictions for unseen cases)
and class imbalance (the main class of interest, e.g., metastatic patients, is represented
by only few tuples).
Two of the frameworks that can be used for implementing the classification stage are:
Weka (Hall et al, 2009) and Orange. Both are software that represent a collection of
machine learning algorithms for data mining tasks. Further to that, they can be can
be applied directly to a dataset from their visual panels (given in Figure 2.8 and Figure
2.9) or can be called from a development environment. However, Weka is Java- based
and can be called from Java code while Orange can be called from Python code or visual
scripting.

32
Figure 2.8: Weka Figure 2.9: Orange
2.5 Summary
in summary this chapter has provided an overview of the literature research done so
far. It first identified what Text Mining is and how Text Mining approaches can help
in clinical research. It also explained some of the main features of existing clinical text
mining systems and the main steps they implement. These are:
• Pre-processing stage
• Information Extraction stage
• Post-processing
• Data mining
Further to this a couple of Information Extraction systems suitable for use in clinical
domain have been identified: DNorm for disease mentions, MedEx for medication names,
CliNER for treatments, and SentiStrength for sentiment analysis. At the end various
classification methods and frameworks have been reviewed that can be used for the
implementation of the classifier of the system as well as an evaluation method, based on
Confusion matrix that can be used for evaluating the performance of the classifier.

3. Specification and Design
3.1 Project scope
This project is concerned with the creation of a software that extracts relevant data
from clinical notes, structures the extracted data and classifies it in order to find the
metastatic and non-metastatic patients that have been diagnosed at the last date of
their visit.
The project will be limited to the mining of EHRs that include data exclusively on
breast cancer and no other types of cancer. The project is not concerned with the
creation of a user interface or the integration of the software into the hospital system.
The implementation stage will not be concerned with the development of any security
mechanisms since the data and respectively the system (when it is using the data) must
not be exported and used outside the hospital boundaries. Therefore, it is the hospital
concern to protect the security of the system and the results.
3.2 Challenges for developing the project
Firstly challenges of building a clinical text mining system need to be taken into account,
as there are some factors to it that do not exist for standalone software.Some of the
most important factors is the data protection and data sensitivity. Due to the fact
33

34
that the project is dealing with patients data the Data Protection Act and the hospital
restrictions need to be taken into account. The system needs to be implemented mainly
in the hospital since patient’s data cannot be taken outside. Security measures and
policies should also be taken into account and discussed with people from the hospital.
Another challenge is that the project requires medical knowledge in order to know what
type of data indicates whether a patient is metastatic or not. Therefore, a collaboration
with the nurse from the hospital needs to be established in order to discuss with her the
medical aspects of the project.
The third challenge for building a clinical text mining system is that it needs to be
created in the hospital environment in the presence of a person working in the hospital.
Therefore, it is important to carry out initial research on limitations of the environment
and take them into account when creating the system. Further to this, the fact that the
project needs to be supervised by a person in the hospital who is not always available
can cause problems regarding the time frame provided for the project. In order to solve
this problem careful planing is needed and also a higher priority should be given to the
most important requirements.
3.3 Data Description
Before outlining the system requirements it is important to look at the patient data that
will need to be classified. In this way we will understand the needs of the project better.
The data is available in an SQL database. The records of interest are presented in a
table that has the following structure:

35
A description of the type of information that is included in each column is given in Table
3.1.
Table 3.1: Table columns description
The main sources of information are the patient notes, stored in the ‘Note’ column and
the date on which the event described in the note has happened (available in Date-
OfEvent column). The patient notes can be split in two types: doctors annotations
and letters. The doctors annotations are only free text and do not have any metadata
such as: History, Diagnosis, Treatments sections. The letters (send to other specialists)
include specified sections for diagnosis, treatments performed etc which makes them
easier to analyse. Also, notes include HTML tags that might need to be removed when
performing initial analysis of the data.
The column ‘DateOfEvent’ is also important since it provides structured representation
of the date on which the examination has happened.
It also can be observed that the condition of a patient (metastatic or non-metastatic) is
given in two ways:
• Explicitly – it is clearly mentioned in the notes that a patient is metastatic or the
disease has progressed
• Implicitly - The condition of the patient’s progression needs to be deducted by the
context

36
Examples of two notes, one explicitly mentioning a patient is metastatic and one implic-
itly showing progression are given in Figure 3.1 and Figure 3.2. Both are presented in
their original form as they appear in the hospital database (i.e without removing HTML
tags or structuring them).
Figure 3.1: Explicit
Figure 3.2: Implicit
3.4 System requirements
The system requirements have been discussed with the nurse currently involved in the
manual identification of the metastatic patients. The functional requirements can be
split into two groups: essential and desirable.
Essential Functional requirements
1. The system must be able to extract the relevant information based on whether a
patient is metastatic or not
2. The system must be able to identify the patients with metastasis (both curable
and incurable)
3. The system must return only patients diagnosed as metastatic at the last date of
their visit to the hospital
4. The system must return the patient id and whether they have been diagnosed as
metastatic or not.

37
5. The system must store the results in a structured format
Desirable Functional requirements
1. The system may return additional information regarding the patients condition
such as: a justification of classifying the patient as metastatic, date of diagnoses,
and whether the metastatic condition is curable or incurable
2. The system may return patients that are likely to be metastatic but have not been
diagnosed as such yet
3. The system may store the results in the hospital database
4. The system may display the results on the online system of the hospital
Non-functional requirements
1. Portability: The system must be able to work on the machines in the hospital.
2. Reliability: The system must return almost all metastatic patients with high cov-
erage (recall)
3. Performance: The system must return the results within a timely manner
3.5 Initial analysis of data
This section will be split into two parts. In the first one, we will identify the main types
of disease factors that show a patient is metastatic and thus need to be extracted. In
the second part we will perform lexical analysis, which will give us more understanding
of the type of data stored in the notes.

38
3.5.1 Identification of disease factors that need to be extracted
In order to identify the type of information which proof a patient is metastatic and thus
needs to be extracted another meeting with the nurse who is currently identifying the
metastatic patients has to be organised. During the second meeting the main disease
factor classes which indicate that a person is metastatic were identified. Six main classes
are identified. These are given in Table 3.2.
Table 3.2: Disease factor identified
The identification of the disease factors will assist in the implementation of the entity
extraction module of the system. The main types of information considered to identify
whether a patient is metastatic or not are the disease names, drug names, and symptoms.
Thus, these factors will be the first priority in the creation of the information extraction
module.
3.5.2 Lexical profiling
In order to understand what terms/phrases need to be extracted from the notes, we not
only need to know the disease factors proving metastasis but we also need to know the

39
key information residing in them. For this purposes we need to perform lexical profiling.
This process will be split into two steps: data preparation and lexical profiling. The
analyses is performed on a sample of 200 patients (104 029 notes).
The Data preparation step converts the data into a suitable format. For this purpose a
Java program has been created that takes a csv file with the patient notes as an input,
removes the HTML tags and punctuation. Then, the output is used for performing
lexical profiling.
Lexical profiling is performed using an N-gram model. This model allows performing
feature extraction of an object by describing it in terms of its subsequences. An n-gram
is a subsequence of length n (Tauriz, no date). For a given sequence of tokens, an n-gram
of the sequence is n-long subsequence of consecutive tokens (Tauriz, no date).
The produced n-grams will help us to identify the type of information more frequently
residing in the notes and whether this information could be useful in identifying the
disease progression and thus needed to be considered for extraction. For the creation
of n-grams we use a corpus analysis toolkit, called AntCon (Anthony, 2015). We have
generated 2-grams, 3-grams, 4-grams, presented in Figure 3.3, Figure 3.4, and Figure
3.5. For anonymity purposes some of the results are hidden.
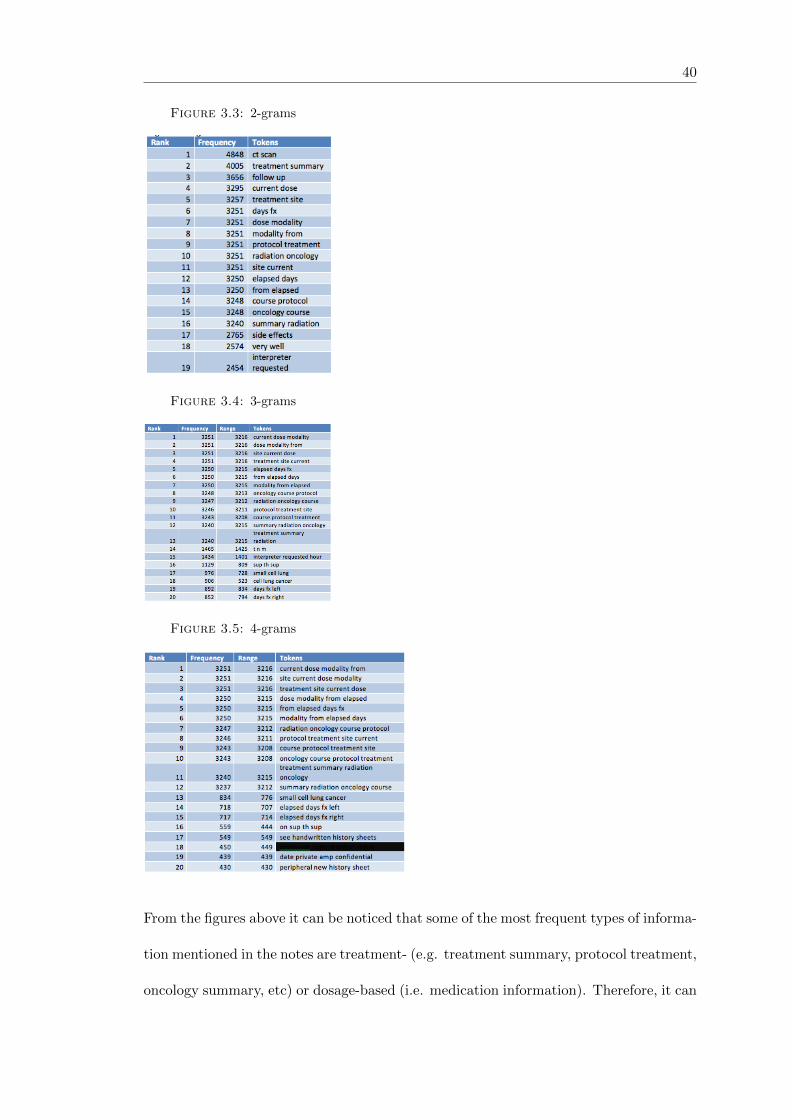
40
Figure 3.3: 2-grams
Figure 3.4: 3-grams
Figure 3.5: 4-grams
From the figures above it can be noticed that some of the most frequent types of informa-
tion mentioned in the notes are treatment- (e.g. treatment summary, protocol treatment,
oncology summary, etc) or dosage-based (i.e. medication information). Therefore, it can

41
be judged that we need to focus on extracting treatment information as well, not only
disease names, drugs, and symptoms). Further to that, it can be noticed that the notes
include sentiment terms such as ’very well’ which means that performing sentiment anal-
ysis on the notes can also help to extract hidden information that will help in identifying
metastasis.
3.6 Method overview
The general idea underlying our approach is to identify the text snippets in the separate
notes that contain evidence to support a judgment for a metastatic disease, and then to
integrate evidence gathered at the notes level to make a prediction at document (patient)
level as to whether a patient is metastatic or not. Temporal extraction for dates on which
patients have been diagnosed as metastatic is not needed since the dates are given in
the Date Of Event column in a structured format.Therefore, Entity extraction will be
the main focus for the project. For the implementation of the NER stage we will use
existing IE systems since the time frame for the project will not allow for the creation
of an entirely new IE system. The benefits of this approach are:
• It does not force us to ”re-invent the wheel” as the main types of data we are
interested in can be extracted with existing tools
• It will save time
• The finished application can be applied to various hospital cases since the IE tools
that it uses are applicable to di↵erent types of data
From the term lists provided by the nurse and the initial analysis conducted on the
data it can be concluded that the main types of information needing to be extracted

42
are: Disease names, Treatments, Medications, and Symptoms and thus the Information
Extraction tools that will be used to extract this types of entities are DNorm, CliNER
and MedEx.
An important feature of the approach chosen is that we will also perform sentiment anal-
ysis of the data. This can be beneficial for identifying metastatic patients more easily
since very often nurses and doctors express their judgments and observations towards a
patient’s health status via sentiment phrases (Deng et al, 2014). The identification of
whether there are positive or negative sentiments used within a note can show whether
a patient is metastatic or not. In Figure 3.6, it can be seen that the negative sentiment
phrase ”Unfortunately” is used in a note where it is mentioned that the patient’s condi-
tion is progresing while in Figure 3.7 the positive sentiment phrase ”remains well” shows
that a patient remaining stable.
Figure 3.6: Negative sentiment note example
Figure 3.7: Positive sentiment note example
The classification is also considered an important aspect of the project since the project
requires almost all metastatic patients to be identified (i.e. the system must has high
coverage). Therefore, two approaches will be used separately for the creation of the
classifier. The first approach is knowledge-based, i.e. based on manually-created rules
and the second approach is data-based, i.e. based on the creation of a machine learning
algorithm that derive rules automatically from the data.
The rule-based approach requires a good understanding of the data and partial medi-
cal knowledge but does not require training data while the machine learning approach

43
requires a training set but does not require understanding of the data or medical back-
ground. Since, the two methods have di↵erent characteristics and advantages it will be
useful to use both and then based on the results judge which approach is more suitable
for the project.

44
The system workflow, given in Figure 3.8, will consist of four main stages:
1. Pre-processing of notes: Includes the performance of low–level pre-processing tasks
that will prepare the data for performing IE tasks
2. Information Extraction: Includes the extraction of relevant features, including
NER sentiments from the notes
3. Post-processing: Includes the performance of post-processing steps that will pre-
pare the extracted data for classification
4. Classification: As the good performance of the classifier stage is important, two
classification approaches will be used for identifying the metastatic patients. The
first approach will consist of manually-created rules while the second approach
will consist of a machine learning algorithm. The implementation of two di↵erent
classification methods will help us to make a comparison and choose the one that
suits the project purposes the best.
Figure 3.8: System workflow
3.7 System Design
This section shows explicit details of the process of design of the software based on the
methodology and the requirements outlined earlier.
3.7.1 Modeling the system boundaries
The first step in the design process consists of modeling the context diagram (or level
0 diagram) with final goal being to identify the boundaries of the system, and the way

45
it interacts with external components. Figure 3.9 shows that the system will consist of
four main modules each accomplishing a step described in the ’Method overview section’.
The system will interact with two external entities.
First, the system will take as an input a CSV file with a set of the patient notes. The
reason for not creating a direct connection to the hospital database is the fact that there
is a possibility for the connection to the hospital server to get lost and thus the access
to the database denied. By using CSV instead, we speed up the implementation process
and eliminate the possibility of unexpected crashes due to connection loss to the server.
Secondly, the system will store the results, produced by the first two modules in a
database, di↵erent from the hospital database. These results will be used for further
processing and classification by the ”Post-processing” module and the ”Classifier”. The
results from the classifier will be stored in the same database. The reason for not using
the hospital database is the fact that no write permissions to this database are provided
for the project.
Figure 3.9: Context Diagram
Figure 3.10 extends the case of Figure 3.9 by showing how the machine learning classifier
will interact with the local database. In order to build the classifier we need to have

46
a learning set of data that will be used for building the classifier and a testing set
of data, which will help to evaluate the classifier. Both, the learning and testing set
will be saved in the local database. As the classifier needs to be able to identify both
the metastatic and non-metastatic patients, the learning set of data needs to include
notes of metastatic and non-metastatic patients. In comparison to the machine learning
approach, the rule-based will not need to go through a learning stage.
Figure 3.10: Context diagram for Classifier
3.7.2 Modeling the system components
The figure 3.11 shows a level 1 diagram having more details about the components that
interact in the software. The system consists of four main components: Pre-processing
component, Information Extraction component, Post-processing component, and Clas-
sification component. Each of them consists of sub-components, described below:
1. Pre-processing module: This component will perform tasks that prepare the notes
for extraction
• HTML Tags stripper: It removes the HTML tags from the notes.
• Sentence splitter: It splits the notes into sentences since some of the sub-
modules of the Information Extraction component will be implemented on
sentence-level.

47
2. Information Extraction module: This component consists mainly of sub-modules
that extract the main types of information outlined earlier as important for find-
ing the metastatic patients (i.e. Treatments and Symptoms information, Disease
names information, Medication names information, and Sentiments). For each
type of data a di↵erent Information Extraction system will be integrated into the
component.
• CliNER sub-module: It is responsible for the Treatment and Symptoms in-
formation extraction. This module will extract information on note-level.
The reason for working on note-level is because very often treatments and
symptoms information can be spread over a couple of sentences and thus if
this kind of information is extracted on sentence-level, the meaning of the
extracted features might be lost.
• XML parser: The CliNER output is in XML format and thus an XML parse
need to be created in order to strip the XML tags and structure the output
in a format that matches the database structure.
• DNorm sub-module: It is responsible for Disease names extraction. Since
we only need to extract disease names that cannot be spread over a multiple
sentences this module will work on sentence-level.
• MedEx sub-module: It is responsible for Medication names extraction. It
works on sentence-level because of the same reasons as the previous module.
• NegEx: It is used to identify whether the extracted features are negated.
This is important feature since if the Disease name extraction module output
disease progression but the term is negated, it will change the meaning from
identifying metastasis to identifying non-metastasis. Only the results pro-
duced from DNorm and MedEx are checked for negation by NegEx. CliNER

48
results are not checked for negation as CliNER has integrated function to
check for negation.
• SentiStrength sub-module: This module will perform sentiment analysis to
the data on sentence-level by giving to each sentence a positive sentiment rank
and negative sentiment rank. The reason to perform sentiment analysis on
sentence-level is because it will give us the opportunity on a later stage to see
how the sentiment in a note changes over time and thus get more information
about the note and the feelings expressed in it. If sentiment analysis were
performed only on note-level this will give us only a single average rank for the
entire note. SentiStrength will give to each sentence a positive rank between
1 and 5 where 1 denotes neutral and 5 denotes very positive and a negative
rank between -1 and -5 denotes where -1 denotes neutral and -5 denotes very
negative.
3. Post-processing module: This module will clear the inappropriate results and com-
bine them on note-level where necessary.More about this module will be said in
another section.
• Combination of results on note-level: The results produced from some of
the Information Extraction sub-modules are on sentence-level. However, the
classifier works on notes-level and thus the results produced on sentence -
level need to be combined on notes-level.
• Post-processing rules: It includes rules that clear the results produced from
the Information Extraction module and prepare them for classification.
4. Classification module: This module will consist of the two classification approaches
that will be created.

49
• Classification rules: It will include a set of manually created rules that can
classify the notes to metastatic and non-metastatic.
• ML algorithm: This component integrates ML algorithm for classifying the
notes as metastatic or non-metastatic.

50
Figure 3.11: Component Diagram

51
The components presented in Figure 3.11 will be the classes implemented for the pro-
gram.
3.7.3 Modeling the system interactions
One of the last steps of the design process is the sequence diagram which presents the
order of interactions between the main components of the system. Figure 3.12 focuses
mainly on the order in which the Information Extraction components (DNorm, CliNER,
SentiStrength, MedEx, and NegEx) are interacting with the other modules of the system
(Pre-processing, Post-processing, Classification, and Database).
The Information Extraction components are executing and writing to the database in a
sequential way. Once all the results from the Information Extraction module are stored
in the database, they are passed to the Post-processing module where the results are
prepared for classification and then stored back in the database. The Classifier module is
using the results from the Post-processing module that are already cleaned and combined
on note-level in order to apply the classification approaches to them. The output of the
Classifier module is stored back to the database.

52
Figure3.12:Sequence
Diagram

53
3.7.4 Modeling the system workflows
The system workflow will be presented using an Activity diagram, given in Figure 3.13.
As in the previous section we focused mainly on the Information Extraction module,
in this section we will focus on two other main aspects of the system. The first one is
the Post-processing module and the second one is the combination of the results from
sentence-level to note-level and from note-level to patient-level.
The Post-processing module consists of two sub-modules (Combination of results on
note-level and Post-processing rules). The first sub-module role is to combine the results
produced on sentence-level to note-level. The role of the Post-processing rules is to clear
the inappropriate results that should not be passed to the Classification module. This
will be done by using lists that contain terms given by the nurse and some other terms
that have been found from observing the results from the Information Extraction sub-
modules and are considered important.The rules created will be mainly term-matching
based where for each term produced by one of the Information Extraction sub-modules it
will be checked as to whether this term is in the list and if it is not, it will be deleted from
the database. The reasons why we have decided to use Information Extraction systems
for extracting the important features instead of creating a dictionary-based approach in
first place are as follows:
• The Information Extraction systems perform normalisation of the terms so the
results produced are in a basic form, which makes the matching to the list of terms
easier. In a dictionary-based approach we would need to do the normalisation or
extend the dictionaries used in order to include all variations of terms, which is a
time-consuming process.

54
• The lists of terms given by the nurse are not exhaustive and thus the dictionaries
created based on them would not be su�cient for extracting all features that could
be helpful in identifying metastasis. The Information Extraction systems used can
extract important information that we could not know about and thus help in
extracting more features that can participate in the classification.
In the Post-processing module the types of rules needing to be created are split into two
groups:’Combination of results on note level’ and ’Post-processing rules’. The first set
of rules take as an input the results produced by SentiStrength, DNorm, and MedEx on
sentence-level in order to combine results on a note-level and clear inappropriate results.
The steps involved in this part of the module are as follows:
1. First, the sub-module takes the SentiStrength results on sentence-level and per-
forms the following steps:
• It calculates statistic information about each note that can help in the clas-
sification stage later on, including the following:
– Average rank for the note: This will give us knowledge about the overall
sentiments in the note (i.e. whether the note is with positive, negative
or neutral feelings)
– Maximum negative and positive result for the note: This is the highest
positive or negative score for a note. This can give us information about
whether there are very negative or positive sentiments in a note in which
case it can be prove that the note definitely mentions that a patient has
disease progression or a stable disease.
– Keeping the results for the first sentence and the last sentence in a
note: This can give us information about the how the sentiment changes

55
throughout the note. For instance, it is highly likely that a sentence that
starts with a very negative score but changes in a positive direction at the
end of the note to show an improvement in the patients condition and the
opposite if a note starts with positive sentiment but finishes with negative
sentiment, it can indicate that the patient’s condition is improving.
• The calculated statistics from the SentiStrength results are saved on note-
level.
2. Secondly, the sub-module takes the terms produced by DNorm and MedEx on
sentence-level and performs the following steps:
• It checks whether the term is the only one found for the note. If yes, it prints
the term on note-level.
• If the term is not the only one found for the note, it checks whether the found
terms are in the list given by the nurse and prints on note-level only the terms
that are relevant.
The second sub-module ”Post-processing rules” of the Post-processing component con-
sists of two steps as follows:
1. First, it takes as input the DNorm, MedEx, and CliNER results on note-level and
applies post-processing rules in order to clear the results from inappropriate terms.
The results that do not appear in the lists of terms are deleted.
2. The second step involves the preparation of the post-processed data for classifica-
tion. This includes the mapping of the extracted data on note-level as a format
that is suitable for classification. More information about that will be given in the
Database design section.

56
As it can be seen from Figure 4.1, another important aspect of the system is the com-
bination of results from sentence-level to note-level and from note-level to patient-level.
The reason for the need to do this aggregation is that some of the Information Ex-
traction sub-modules need to work on sentence-level, the Classifier module will need to
make judgments on note-level and the requirement for the system is to show results for
a specific patient instead of showing results on note-level.
This is done in the following way:
First, the Information Extraction sub-modules DNorm, MedEx, and SentiStrength pro-
duce results on sentence-level, which are combined on note-level by the Post-processing
sub-module and saved to the database.
Then, the classifier takes the results aggregated on note-level and assigns a class (metastatic
or non-metastatic) to each note. In order to combine the results on patient-level, we will
search for the latest note for each patient (i.e. the note that was generated on the last
date of visit for the patient) and print it on a patient-level. The reason for choosing the
note at the last date of visit is because one of the requirements is to find the condition
of the patient at her last visit to the hospital.
In case, the outcome of the last note is that the patient is non-metastatic we will search
for the latest note which says a patient is metastatic and print the date of it. As in the
cases when a patient has been identified as non-metastatic incorrectly it can be danger-
ous we need a system that helps the nurse judge these false cases.This is why in cases in
which the outcome of the last note is that the patient is non-metastatic we will search
for the latest note which says a patient is metastatic and print the date of it.In this way
we ensure that the nurse can track the patients condition over time.
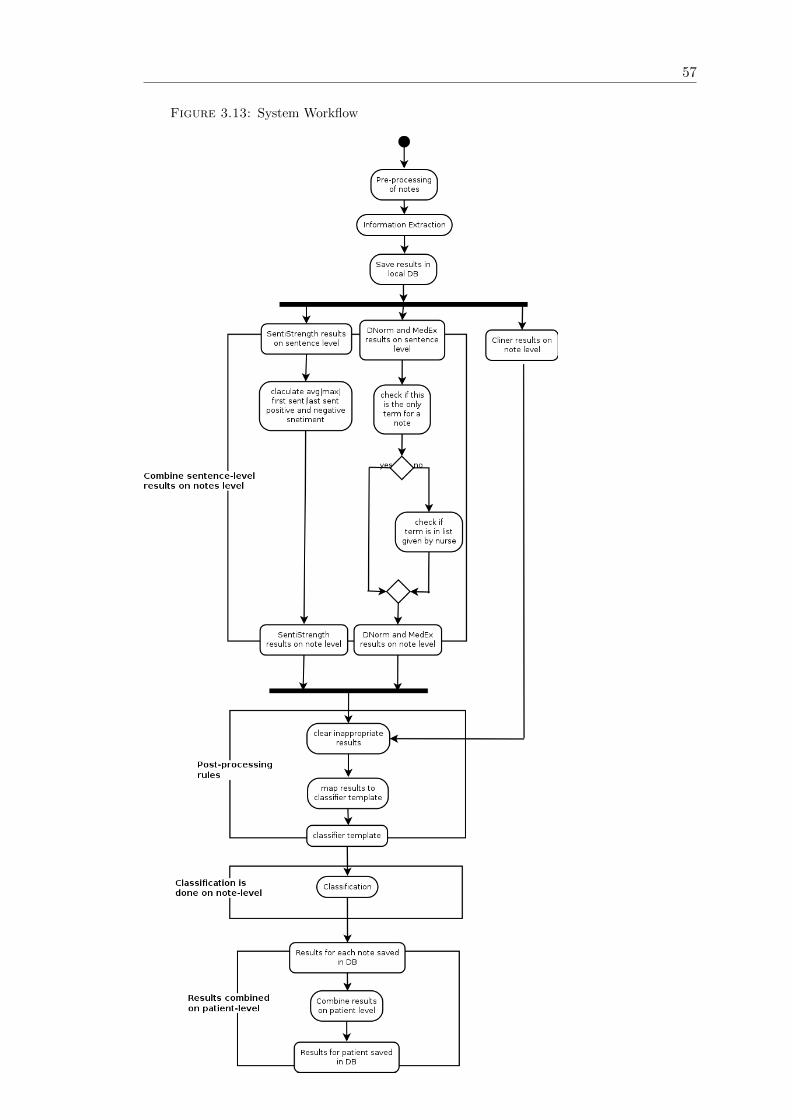
57
Figure 3.13: System Workflow

58
3.7.5 Classification rules design
As mentioned before for the classification of the notes we will use two approaches: rule-
based approach and machine learning approach. The main advantage of using both is
that we will be able to compare their outcome and decide which one is more suitable
for the given data. In the rest of the section we will present the design of the rule-based
approach.
The rules can be split into two groups. The first group of rules are those used to find
indications of metastasis in the notes while the second group of rules are used to find
non-metastasis in the notes.
Metastatic Rules
The rules used to identify the metastatic notes are given in Figure 3.14.
The rules are 6 and they are explained below:
• The first rule uses only SentiStrength results and its goal is to catch the cases of
incurable metastasis.
From observations it can be seen that the notes that show incurable metastasis
are with very negative sentiment ranks. Thus, it would be enough to classify those
cases with a rule where the threshold for the sentiment ranking is -4.
• The second rule uses DNorm and SentiStrength results and its main goal is to
catch cases of curable and incurable metastasis where sentiments are not strongly
presented in the note
As the sentiment ranking of some notes that show curable metastasis are not very
negative but at the same time the diagnoses is mentioned, we use both DNorm
and SentiStrength to catch both of these cases. !DNorm cannot be used by itself

59
as in some cases diagnoses are mentioned but they are part of a patient history
and thus using only these terms by themselves can lead to incorrect classification.
• The third rule uses DNorm and MedEx results trying the catch the cases of curable
metastasis in which sentiment ranking is neutral.
In some cases (from what has been told by the nurse)the combination of some
diagnosis and medications mean that a patient is metastatic.
• The lists (diagnose list,medication list,treatment list, symptoms list,and scans list),
used in the creation of the rules are created regarding the main groups of terms
the nurse has provided and have been found important (diagnoses, treatments,
symptoms, and medications). Depending on the type of terms extracted by each
of the tools, they are associated with a di↵erent list type. For instance, Dnorm
extract diagnosis and thus the rules including DNorm check whether the terms
extracted are in the diagnosis list. For the CliNER results which are from type
treatment, the rules check whether the terms are in the treatment list.
• The last three rules use results from CliNER and SentiStrength in order to try to
catch curable and incurable metastasis for the cases where diagnosis and medica-
tions have not been mentioned and the sentiment rankings are mainly negative.
• For each of the rules where DNorm, MedEx and CliNER results have been used
we also have checked that the terms are not negated.
• The options for first and last sentence rankings have not been used in the rules
since it is di�cult to judge only by observations how those rankings a↵ect the
classification. They will be used in the ML approach.

60
Figure 3.14: Metastatic rules
Non-metastatic Rules
The rules used to identify the non-metastatic notes are given in Figure 3.15.
There are only two non-metastatic rules and they focus on finding notes that are either
very positive or include diagnosis such as stable disease and response to treatment and
have positive ranking higher than the negative. Thus, these rules combine results from
DNorm and SentiStrength.
Figure 3.15: Non-metastatic rules
3.7.6 Quality attributes
The quality attributes (given in Figure 3.16) taken into account in the design of the
system are as follows:

61
• Portability – The system needs to work on the main computer platforms and
mainly on Windows and Linux as these are the main platforms used within the
hospital
• Reliability – The system needs to be able to identify almost all metastatic patients.
This is one of the most important quality attributes the system needs to have.
• Performance (Response Time) – Even though it is not a first priority for the system
to return results very quickly, the response time of the system should be still fast
enough not to a↵ect the work of the nurses in a negative aspect
• Interoperability – The system must be easy to integrate within the hospital database
• Reusability – The system components must be easily replaced or extended in order
to support improvements and changes in future
Figure 3.16: Quality Factors
3.8 Database Design
A well structured database is a key component of the project as it will store the extracted
data during the IE stage, provide structure to the extracted data and thus help the
classification of it. This section is split into two parts. In the first part, we will identify

62
the types of information that need to be stored and then based on that in the second
part the actual design of the database will be presented.
3.8.1 Types of information that needs to be stored
The database needs to store each type of information extracted by the di↵erent compo-
nents of the program, the information prepared to be passed to the classifier as well as
the results from the classifier. The main groups of data that the database needs to store
are explained below:
1. Pre-processed Notes: These are the notes that have been cleaned from HTML
tags by the HTML Stripper sub-module as well as the sentences returned by the
Sentence Splitter module.
2. DNorm results on sentence level: These are the results returned from DNorm
on sentence-level including information on whether they are negated or not
3. MedEx results on sentence level: These are the results returned from MedEx
including whether they are negated or not
4. SentiStrength results: These are the results returned from SentiStrength on
sentence-level
5. CliNER results: These are the results returned from CliNER on note-level
6. Results from Post-processing module: These are the results returned by
DNorm, MedEx, and SentiStrength aggregated on notes – level as well as CliNER
results cleaned and prepared for classification
7. Classifier data: This is the data produced by the Post-Processing module struc-
tured in a way so that it is appropriate to be passed to the machine learning

63
classification approach. The rule-based approach is using the results produced by
the Post-processing module without additional re-structuring
8. Classifier results: These are the results returned from both of the classification
approaches.
3.8.2 Design
Figure 3.17 illustrates the database design taking into account the types of information
needing to be stored. Following the information presented in the section above, we can
derive 8 tables as follows:
• Data Source: It includes the notes with unique IDs, cleaned from HTML tags.
It also stores the results from the classifier on note-level.
• Data Sentence: It includes the sentences with unique IDs for each note. This
table also includes the position of the sentence in the note (start and end character).
• CliNER Event results: It includes the results produced from CliNER regarding
the events extracted from the notes.
• CliNER Timex results: It includes the results produced from CliNER regard-
ing temporal data extracted from the notes.
• DNorm SentLevel: It includes the results from DNorm and on sentence-level.
Further to that, it includes information whether the results produced from DNorm
are negated or not and stores the position of the term in the sentence.
• MedEx SentLevel: It includes the results from MedEx on sentence-level. Fur-
ther to that, it includes information whether the results are negated or not and
stores the position of the term in the sentence.

64
• SentiStrength SentLevel: It includes the SentiStrength positive and negative
ranking for each sentence.
• DNorm NoteLevel: It includes the DNorm results aggregated on note-level.
These results have also been cleaned form inappropriate terms.
• MedEx NotesLevel: It includes the MedEx results aggregated on notes-level.
These results have also been cleaned form inappropriate terms.
• SentiStrength NoteLevel: It includes statistics information about the positive
and negative ranking within the note based on the performed aggregation of the
SentiStrength results on sentence-level.
• Classifier Rules: It includes the results produced by the rule-based classification
approach.
• Classifier ML: It includes all the data from SentiStrength, DNorm, MedEx, and
CliNER, combined and structured in a way so that it is suitable for the machine
learning-based classification approach. I also inlcudes the results,produced by the
classifier.More about the creation of the classification template that will be passed
to the ML algorithm will be given below.
• Patient Diagnose: This table stores the final results for a patient (i.e. whether
she is metastatic or not).

65
Figure 3.17: Database Design
Assumptions and Justifications for design
• Generation of the IDs for notes and sentences: These are generated in a way in
which it will be easier to derive the patient associated with the note, the date on
which the note has been created and the position of the sentence in the note
– The IDs for the notes are formed using the patient id and a number generated
depending on the date on which the note has been written.
– The sentence IDs are formed with the note id and the index of the sentence
in the note.
• The results produced by DNorm, MedEx, and CliNER are also held the positions
of the extracted terms in case they need to be backtracked to the original notes.

66
• SentiStrength information on note-level: The sentiment information saved on note-
level is the following: Average (combined positive and negative) score for the note,
Max positive/negative score in a note,The score of the first and the last sentence
• Classifier ML table information: This table serves as a classifier template that
helps to structure the results in the most suitable format for performing ML-based
classification.It is given in Figure 3.12
– The columns of the template will be presented by the features that indicate
whether a note shows metastasis or non-metastasis. The features can be split
into 4 groups: DrugName List, DiseaseName List,and TreatmentsName List,
and SentiStr Values. Each group of features represents a type of information
that has been extracted from the notes and thus each column will represent
a term for which, if it is present or not present in a note it will mean that the
note is more likely to show either metastasis or non-metastasis.
– The columns representing terms from the groups DrugName List, Disease-
Name List, and TreatmentsName List will be of binary type and will be able
to take only values 1 or 0 where 1 indicates that the term is present in the
note and 0 indicates that the term is not present. The columns represent-
ing the SentiStrength results will hold for each note the average ranking, the
maximum positive and negative ranking, the ranking for the first and last
sentence for a note.
– An example for a note represented in the template is: A note can have a
value for column ’stable disease’ 1, value for column ’adjuvant metastasis’ 0
and value for column ’SentiStr avg’ 3.This could mean that the note indicates
that the patient is non-metastatic.

67
– The reason for creating a classification template instead of using the post-
processed data for the creation of the algorithm is that it provides a unified
way for representing the data in each note and thus will ensure that the
classifier is passed the same type of data with the same structure. Further to
that, the values of the classifier template are numerical values, most of which
binary and the classifier is more easily built on binary numeric values than
on other types of data.
– This table will also include the columns Class Actual, which will store the
actual class for a note and Class Predicted, which will store the class given
by the classifier.
Figure 3.18: Classifier Table

4. Implementation
4.1 Development environment preparation
4.1.1 Ethical approvals
Due to the fact that the project is concerned with processing and analysing patient data
there are some data security and ethical aspects that needed to be considered.
First, an ethical approval from the hospital has been obtained. In order to accomplish
this online application has been submitted and approval has been received. Secondly,
two Information Governance (IG) and Data protection Act declarations needed to be
filled within the hospital and training needed to be completed. All this has been done
and access to the data and the hospital has been permitted.
4.1.2 Hospital environment preparation
Due to the sensitivity of the EHRs, the hospital has a set of restrictions, which have
been taken into account and appropriate actions have been performed. In Table 4.1 the
restrictions and the associate actions performed are presented.
68

69
Table 4.1: Work environment set up
4.1.3 Development Language Choice
Based on the quality attributes described in the previous chapter, the programming
language selected to build the software is Java. Due to the fact that Java runs on top of
the JVM, it employs a build once run everywhere style of application and thus satisfies
the portability quality attribute. Due to its Oriented Object Programming paradigm,
many architectural patterns, design patterns and best practices rules can be applied to
reach the performance, itneroperability and reusability attributes. Other advantages of
using Java as the language for developing the system are:
• Compatibility with SQLite:
As the project uses a database, the chosen language would need to be able to
communicate with SQL. Java is able to give us this ability through the use of
well-established projects
• Timeliness:
The code needs to be fast and responsive. Java performs at speeds comparable to
native code such as C and C++, but it is much more flexible and easier to use
• Security and Reliability:
Java is an Open-Source project that is constantly being updated and should not

70
cause security issues. As JVM runs the code natively in protected memory other
languages would not o↵er any significant reliability benefits over Java
• Maintainability:
A Java is widely used language. Therefore, it is feasible that other developers
could continue the project in future
4.1.4 Database Platform and Type Choice
The Relational Database Management System (RDBMS) is the most suitable option for
the purposes of the project since this is the database type used in the hospital. Further
to that, it is vendor- and community- supported and it has capabilities to deal with
data semantics, consistency and redundancy problems. It also provides simple logical
structure for storing data. The database platform that will be used is SQLite. Even
though, the platform used in the hospital is SQL we do not have write permissions to it
and thus it cannot be used for storing data. However, the SQLite operations that will be
used have equivalent in SQL and thus the integration of the system within the hospital
will not be a problem. Advantages of SQlite over SQL is that it requires no server and
needs little or no configuration.
4.1.5 Preparation of Feature Extraction tools
In this section we will present the systems/tools that will be used for the implementation
of the Feature Extraction module of the system in more depth. These are: DNorm,
MedEx, CliNER, NegEx, and SentiStrength. Even though, they have been presented in
the previous sections of the report, we will re-visit them again in order to describe their
specific requirements and how they have been prepared in order to be able to integrate

71
them in the application. In the rest of this section we will present each tool with its
requirements and the preparation actions taken in order to be integrated later on:
1. DNorm
• It requires 10GB of RAM: In order to reduce the memory required for this
tool, we will remove some of the dictionaries that it uses and are irrelevant
to cancer disease.
• It is initially suited to run on Linux: Since it is preferable for the system to
work on Windows, we will include the necessary packages that are needed in
order for DNorm to work on Windows.
• It takes as input and produces as output text file: The program is changed
in order to take variables as input and store the results in variables
2. MedEx
• It is initially suited to run on Linux: Since it is preferable for the system to
work on Windows, we will include the necessary packages that are needed in
order for MedEx to work on Windows.
• It prints out not only medication names but also other information concerned
with medication intake:Since the only information we are interested in are the
medication names, the rest of the data produced by MedEx is ignored
• It takes as input and produces as output text file:The program is changed in
order to take variables as input and store the results in variables
3. NegEx
• It is working on all platforms: No actions needed

72
• It is associated with GUI: The tool’s GUI has been removed and suited to be
included in the application.
4. CliNER
• It is initially suited to run on Linux: Since it is preferable for the system to
work on Windows, we will include the necessary packages that are needed in
order for CliNER to work on Windows.
• It provides the output as an XML file: In order to transform the output to a
format suitable to be saved in the database, we need to create an XML parser
• It takes text files as an input: The program will be suited to take variables
as input instead
5. SentiStrength
• It is working on all platforms: No actions are needed.
• It provides the output on the command line: The tool has been transformed
to store the output in variables.
• It uses modules specific for social media (emoticons, dictionaries with words
that cannot be seen in clinical text): These modules are removed
4.2 Classifier creation
To create the classifier module of the system, the following steps have been performed:
1. Step 1: Installation of classification platform
The platform chosen for implementing the classifier is Weka. The reasons for
choosing it is the wide use and maturity of the software as well as the large amounts
of help information available.

73
2. Transfer of classifier data to suitable format
The most suitable is the default format for Weka - ar↵. Even though Weka can
read csv files, the advantages of using ar↵ format are the following:
• CSV files cannot be read incrementally (Weka, 2015): In order to determine
whether a column is numeric or nominal, all the rows need to be inspected
first. ARFF files contain a header defining the attributes, i.e. the internal
data structures can be set up correctly before reading the actual data.
• Train and test set may not be compatible with csv files (Weka, 2015): Since
CSV files do not contain any information about the attributes, WEKA needs
to determine the labels for nominal attributes itself. Not only does the order
of the appearance of these labels create di↵erent nominal attributes (”1,2,3”
vs ”1,3,2”), it is also does not guarantee that all the labels that appeared in
the train set also appear in the test set (”1,2,3,4” vs ”1,3,4”) and vice versa.
3. Using decision tree method(i.e.J48 for classification)
The reason for choosing decision tree method is because it is an easy to understand
method, there are no prior assumptions about the nature data, and can classify
both categorical and numerical data.
4. Evaluate by calculating confusion matrix
The classifier will be evaluated by calculating precision and recall. Recall is con-
sidered the more important measure since it is important that the most of the
metastatic patients are found.

74
4.3 Software Testing
Software testing is one of the core practices of software engineering. In order to prove
that the system will have a positive impact on the intended users and will support
the successful identification of metastatic patients we must test the system. Testing
needs to be done on an ongoing basis and not just at the end when the software has
been finalised. In this way, we can find bugs and issues more easily and on an earlier
basis which also makes the debugging much easier. Therefore, the system has been
tested during development and its finalisation. Two main types of testing have been
performed: Regression Testing and Integration Testing.
The main goals of software testing will be to determine the system and information
quality. The system quality will be determined on whether the system provides all
necessary functions in order to extract information that proves a patient is metastatic
and then classifying the patients correctly. In this instance information quality will be
judged on whether or not the data extracted is accurate and discrepancy free.
For accomplishing the stated goals two main types of testing have been performed:
Regression Testing and Integration Testing.
4.3.1 Regression Testing
The objective of regression testing is to check that old functionality has not been broken
by new functionality or changes made in application (Narayan Singh,2013).This type of
testing has been done throughout the implementation of the system. It has been done
in the form of test cases every time when a new functionality is added in order to check

75
that the old modules still work. This has been particularly useful during the integration
of the Information Extraction tools (DNorm, MedEx, and CliNER).
4.3.2 Integration Testing
The objective of Integration testing is to ensure that aggregates of units perform ac-
curately together(Narayan Singh,2013). Integration testing is useful since it helps to
identify problems that occur when units are combined. In order for the testing to be
successful a test plan needs to be created that requires the use of a bottom-up approach
in which we first test individual units and then when units are combined. In this way
we will know that any errors discovered when combining units are likely related to the
interface between units. This method reduces the number of possibilities to a far simpler
level of analysis. For instance, we first need to test whether CliNER work well individ-
ually and extracts data and then tests it together with XML Parser. For this stage of
testing we also have created test cases before the implementation.
4.3.3 Tests Summary
In this section the Regression and Integration tests are summerised . They have been
performed on Mint 12 (Linux) with Java version 1.6.0. The tests as well as description
of them is given in Table 4.1.

76
Table 4.2: Functionality Tests

5. Evaluation
In this chapter we will describe the data set used to train and evaluate the classifier.
Further to that we will perform evaluation of SnetiStrength performance. Both classi-
fication approaches (rule-based and ML-based) will be evaluated and compared and we
will also conduct error analysis.
5.1 Evaluation methodology
The evaluation method (Spasic et al, 2014) should be able to test whether the system
is able to correctly identify the metastatic patients and most importantly whether the
system is able to find all metastatic patients (i.e. it has good coverage,recall). The
methodology we will use for evaluating the two classification approaches will be based
on a confusion matrix as explained in the Background section. In this particular case,
the positives will be the metastatic patients and the negatives the patients without
metastasis. The precision is the fraction of the patients that have been identified as
metastatic and are truly metastatic and recall is the percentage of the correctly identified
metastatic patients overall. We are mainly interested in the coverage of the system (all
patients with metastasis are found) and thus we want the recall of the system to give
good results. Due to this fact, in the calculation of the F-measure the recall will be given
a higher importance by including a non-negative real number (i.e.b) in the calculation
77

78
of F-measure, which will give a preference to the recall. This version of F-measure is
called F2 measure with as it weights recall twice as much as precision.
5.2 Description of Data set
We will use 50 notes for both testing and training the classifier. From these notes
around 20 notes are annotated by the nurse while the rest are annotated specifically
for the project by non-medical person. Statistic information about the notes is given in
Table 5.1.
Table 5.1: Notes statistics
The notes have been chosen in this way so that they are representative of the main
types of data that need to be classified: curable and non-curable metastasis and non-
metastatic patients. Each of the groups have almost the same number of representative
notes. In this way we are trying to avoid cases in which the classes representatives
are unbalanced and there are no examples of a particular group of notes and thus the
classifier cannot be trained to recognize those cases and fail to classify the unseen ones.
5.3 SentiStrength Evaluation
SentiStrength is the only tool integrated into the Information Extraction module that
is not specifically created for clinical data. Thus, its performance needs to be evaluated

79
before including its results as attributes for classification. The data set used for its
evaluation is the same as the data set that will be used for the evaluation of the classifier.
For this purpose we will manually assign positive and negative sentiment ranks to each
sentence, stored in the SQLite database for which SentiStrength has performed sentiment
analysis. This will be done without looking at the output from SentiStrength in order to
avoid bias. Then, we will compare the manually given rankings with the SentiStrength
rankings. In Table 5.2 presents the overall number of incorrectly ranked sentences,
the number of sentences given incorrect positive and negative ranks separately and
the overall accuracy, the accuracy of the correctly identified positive rankings and the
correctly identified negative rankings.
Table 5.2: SentiStrength accuracy
From the results shown in the table above it can be concluded that SentiStrength has
high enough accuracy in order to be included as a factor in the classification. It can
also be seen that the positive rankings give a little bit higher results then the negative
rankings. Further to that, after observation of the ranked sentences, we have found the
following information which can be useful during the evaluation of the classifier:
1. SentiStrength could be used by itself to find the cases of non-curable cancer
The sentences that show a patient’s condition is non-curable produce very strong
negative sentiment (ex. unfortunately, very unlikely) which is included in the
SentiStrength dictionaries and is easy to identify. From observations, the accuracy
of SentiStrength for given only cases of non-curable cancer will be higher.

80
However, cases with curable cancer are more di�cult to notice by SentiStrenth
since they usually lack sentiments. For example, the sentence:”She had mammo-
gram and ultrasound and was found to have a tumour in the left breast” shows that
a patient has metastasis but does not include sentiments and thus the sentiment
rankings are neutral.
2. In some cases SentiStrength produces rankings that can a↵ect the classification
negatively
In some cases SentiStrength gives ranking that do not respond to the real senti-
ments of the sentence. Examples include: ”No ovarian cancer” with ranking +1
and -4 and ” On Examination: Height 169.6cm, weight 62.65kg, no red flag
symptoms including paraesthesia or weakness in the spine” with ranking +1 and
-2. Both of the cases show positive information but are classified as negative.
However, there are no cases in which a sentence will be with negative sentiment
but ranked as positive. This means that, SentiStrength might a↵ect the precision
of the classifier but not the recall, which is the more important metric of the two.
5.4 Classification approaches evaluation
In this section we will evaluate the two approaches, make error analysis on the results
and compare their performance.
5.4.1 Rule-based approach evaluation
In Table 5.3 identifies the confusion matrix produced for evaluating the rule-based ap-
proach in which the positives are the metastatic patients and the negatives the non-
metastatic patients.

81
Table 5.3: Confusion Matrix for Rules
Recall, precision, accuracy and f-measure are calculated based on the values given in the
confusion matrix. When calculating F-Measure preference will be given to recall over
precision, as in this scenario, recall is a value of a higher importance. The results are
given in Table 5.4.
Table 5.4: Results for Rules
From Table 5.4 above it can be seen that the approach is working better than the
threshold given in order to be considered successful with recall 83%. The problems that
might have caused the wrong classification of some of the metastatic and non-metastatic
patients are as follows:
1. A reason for non-metastatic patients being classified as metastatic is that Sen-
tiStrength has given negative ranking to sentences that are with positive senti-
ments and thus some of the rules where SentiStrength is used gave wrong results
2. A reason for cases of metastasis not being found CliNER results are not su�cient
in isolation for metastasis to be correctly identified
5.4.2 Machine learning approach evaluation
The machine learning approach will be evaluated by using all features that have been
extracted or by removing some of them in order to judge which version gives better

82
results. The versions that will be tested are:
1. First we evaluated the original version in which all features are kept (the confusion
matrix for it is given in Table 5.5)
2. Secondly, a version without sentiment analysis is evaluated in order to see whether
sentiments actually help in the classification
3. Finally, we evaluated a version without CliNER results: The reason for choosing to
remove CliNER is because it is observed that in the rule-based approach the rules
with CliNER do not work correctly and thus it is likely that a classifier without
considering these results will give higher performance
The measures produced for each version is given in Table 5.6. It can be seen that the
best performance of the algorithm is produced when CliNER results do not participate
in the classification process. The version with excluded sentiment analysis gives slightly
higher precision, however it’s recall is much lower. This result might be due to the fact
that SentiStrength is good in capturing incurable metastasis but produces mistakes for
cases of non-metastasis.
Due to the fact that recall is the most important measure as it shows whether the
classifier is able to find the metastatic patients, the best version is the one with a 76%
recall without taking into account CliNER.
Table 5.5: Confusion Matrix for ML

83
Table 5.6: Results for ML
5.4.3 Comparison between approaches
The rule-based approach gives much higher recall (83%) while the machine learning
approach gives a highest result of 76% recall. From this it can be concluded that the
rule-based approach works better for the given case. However, a problem that can be
associated with the rule-based approach is overfitting and a problem with the machine
learning approach is that the data set used is very small.

6. Conclusion and Future work
6.1 Conclusion
6.1.1 Summary
The project’s aim was to develop a software that takes as an input, patient notes and
output whether a patient is with metastatic breast cancer or not. In order to accomplish
this aim, four main components were implemented: Pre-processing component, which
prepares the notes for performing Information Extraction approaches on them; Infor-
mation Extraction component which integrates various existing Information Extraction
tools for extracting relevant data from the notes; Post-processing component which pre-
pares the results produced from the previous module for classification and Classification
component which implements two classification approaches (rule-based and machine
learning-based). After evaluation has been performed the rule-based approach has been
considered better as it has a recall of 83%.
Learning and deliverable objectives were established, and they were used as a trace route
for developing the project. The learning objectives were reached because we completed
the following activities:
84

85
• The background process was carried out in order to understand previous studies
in this subject and to know the actual state of this topic. General research on
Text Mining concepts and techniques have been done.
• Relevant to the project, clinical text mining systems and techniques have been
reviewed and studied. Further to that, existing Information Extraction tools have
been investigated that can be integrated within the system
• Existing classifying algorithms and evaluation methods have been reviewed and
understood
The deliverable objectives were reached because with this project we are delivering the
following artefacts:
• An application that performs initial analysis of the data and establishes the main
types of data that need to be extracted have been performed
• The requirements of the system have been identified and discussed with people
from the hospital
• A system that meets the requirements have been developed and performs the
following actions: pre-process the patient notes, extract the important types of
information, classify the patients as metastatic or non-metastatic
• The system also satisfies the quality attributes stated in the following way:
– Portability:The system has been tested on Linux. However, as it is a Java
application portability is inherited with the JVM being able to run across
most platforms. Additionally, the tools used for the creation of the system are
able to work on Windows and Mac OS thus the system should be executable
on all main platforms.

86
– Reliability: The system recall is above the threshold given in the beginning
– Performance: The response time for the system for 50 notes is 3 hours which
is less than the given threshold
– Interoperability: Due to the fact that the SQLite operations used are available
for SQL database, the system can be easily adapted to work with the hospital
database
– Reusability: The system modules can be easily expanded or replaced
6.1.2 Limitations
The main limitations of the system and the project conduction as a whole that need to
be taken into account in future plans are:
• Lack of evaluation of Information Extraction systems
The only Information Extraction system that was evaluated is SentiStrength. The
main reason for that is the lack of time. The way in which we have tried to ensure
correctness of the results produced by the other systems is to create post-processing
rules that clear the irrelevant results and also during Software testing when we have
manually looked at the produced results and whether they are relevant to the data
given. However, more clear overview of the performance and suitability of the
systems will be given by evaluating them.
• Lack of annotated data
Another drawback is the inability to collect more annotated notes from the nurse
in order to test the system on a larger sample. This would give us a better overview
of the performance of the system and the quality of the results produced. However,
the samples used are chosen to be the best representative of the data.

87
• Lack of testing on all computer platforms
Due to limited time, the software testing has been performed only on Linux. How-
ever, the tools integrated in the system work on Windows and the implementation
language is Java and thus the system should work on Windows.
6.2 Future work
Next stages of the research could deal with some of the limitations that were found
during the execution of the project. The main areas in which the project could be
continued are as follows:
6.2.1 Integrate application within hospital environment
Currently the system uses SQLite database for storing the results. In future, the system
needs to be integrated to work with the hospital database and system. The integration
of the software to work with the hospital database would not be a challenge since the
SQlite operations used within the software is the same as the operations available in
SQL.
6.2.2 Expand Information Extraction functionality
The Information Extraction module is extracting only some types of information that
were discussed as important with the nurse due to time restrictions. Even though the
features extracted are enough at this stage for identifying the metastatic patients, it will
be better in future to expand the Information Extraction functionality of the software
in order to extract more types of information that can help in the identification of the

88
metastatic patients such as relations between terms and notes, more disease symptoms
and scan information. This can also improve the accuracy of the software.
6.2.3 Improve run time
Due to the use of existing IE systems for the implementation of the Feature extraction
component of the system, the run time of the system is quite slow. This problem can be
solved in future by replacing the more time-consuming tools with a rule-based approach
for extracting information from the notes.
6.2.4 Extending the system functionality
Currently, the system accomplishes only the essential requirements. However, in future
the system can be extended to satisfy the desirable requirements such as displaying the
reason for identifying the patient as metastatic and whether the patient condition is
curable or not.

6. References
[1] Ananiadou, and McNaught, 2006. Text Mining for Biology and Biomedicine. United
States of America: Artech House.
[2] Anthony, 2015. AntConc software.
Available from: http://www.laurenceanthony.net/software.html.
[3] Appelt and Israel, 1999. Introduction to Information Extraction
Technology Available from:
http://www.dfki.de/ neumann/esslli04/reader/overview/IJCAI99.pdf.
[4] Ben-Dov and Feldman, 2010. Text Mining and Information Extraction.
In Data Mining and Knowledge Discovery Handbook. 2nd ed. Springer Science.
pp.809-835.
[5] Cancer Research UK, 2015. All cancers combined Key Stats.
[6] Cancer Research UK, Stages of cancer.
[7] Cunningham, et al, 2013. Getting More Out of Biomedical Documents with GATE’s
Full Lifecycle Open Source Text Analytics, PLOS Computational Biology.
[8] Dehghan, TERN: TEmporal expressions Recognizer and Normalizer.
Available from: http://gnode1.mib.man.ac.uk/hecta.html#tools
89

90
[9] Dehghan, TEid: TEmporal expressions IDentifier.
Available from: http://gnode1.mib.man.ac.uk/hecta.html#tools
[10] DeLone and McLean, 2003. The DeLone and McLean Model of Information Systems
Success: a Ten-Year Update
The DeLone and McLean Model of Information Systems. Journal of Management
Information Systems, 19 (4), p. 9–30.
[11] Deng et al, 2014. Retrieving Attitudes: Sentiment Analysis from Clinical Narratives.
MedIR, p. 12-15.
[12] DELL, 2015. Text Mining. Available from:
http://documents.software.dell.com/Statistics/Textbook/Text-
Mining#applications
[13] Feldman and Sanger, 2007. The Text Mining Handbook: Advanced Approaches in
Analysing Unstructured Data. 1st ed. United States of America: Cambridge Univer-
sity Press.
[14] Filannino, Clinical NorMA: temporal expression normaliser.
Available from: http://gnode1.mib.man.ac.uk/hecta.html#tools
[15] Friedman et al, 2004. Automated Encoding of Clinical Documents Based on Natural
Language Processing. Journal of the American Medical Informatics Association, pp.
392-402.
[16] Goryachev et al, 2008. Identification and Extraction of Family History Information
from Clinical Reports. Journal of the American Medical Informatics Associatation,
p. pp. 247-251.

91
[17] Han et al, 2012. Classification: Basic Concepts. In Data Mining: Concepts and
Techniques. 3rd ed. United States of America: Morgan Kaufmann. p. pp. 327-389.
[18] Hotho et al, 2005. A Brief Survey of Text Mining. 13 May.
[19] Impact of Information Systems. Cardi↵ School of Computer Science and Informat-
ics.
[20] Ipalakova, M., 2010. Information Extraction. MSc Manchester.
[21] Jakob Nielsen, 2000. Why You Only Need to Test with 5 Users. Nielsen Norman
Group, 19 March.
[22] Karystianis et al, 2014. Using Local Lexicalized Rules to Identify Heart Disease
Factors in Clinical Notes.
[23] Kovacevic, A., et. al, 2013. Combining rules and machine learning for extraction of
temporal expressions and events from clinical narratives. Journal of the American
Medical Informatics Association, 20 (5), pp. 859–866.
[24] Kovacevic A, 2012. HECTA - Healthcare Text Analytics @ gnTEAM.
[25] Leaman et al, 2013. DNorm: disease name normalization with pairwise learning to
rank. Bioinformatics, 29 (22).
[26] Litrot, T. et al, 2015. Using natural language processing to automatically extract
cancer outcomes data from clinical notes.
[27] Mansouri et al, 2008. Named Entity Recognition Approaches. International Journal
of Computer Science and Network Security, 8 (2). Nadkarni et al, 2011. Natural
language processing: an introduction. Journal of the American Medical Informatics
Association, 18 (5), pp.544–551.

92
[28] Marafino, B., et. al, 2015. E�cient and sparse feature selection for biomedical text
classification via the elastic net: Application to ICU risk stratification from nursing
notes. Biomedical informatics.
[29] Mark Hall, Eibe Frank, Geo↵rey Holmes, Bernhard Pfahringer, Peter Reutemann,
Ian H. Witten (2009); The WEKA Data Mining Software: An Update; SIGKDD
Explorations, Volume 11, Issue 1.
[30] McDonald and Kelly, 2015. Value and benefits of text mining. Jisc.
[31] Microsoft,2015.Chapter 16:Quality Attributes.
Available from: https://msdn.microsoft.com/en-gb/library/ee658094.aspx
[32] Narayan Singh, 2013. Test Plan for Mobile Application Testing. [Software Testing
Concepts]
[33] Savova, G., et. al, 2010. Mayo clinical Text Analysis and Knowledge Extraction
System (cTAKES): architecture, component evaluation and applications. Journal of
the American Medical Informatics Association, 17 (5), pp. 507–513.
[34] SentiStrength. Available from: http://sentistrength.wlv.ac.uk
[35] Spasic et al, 2014. Text mining of cancer-related information: Review of current
status and future directions. ISMI, 83 (9), pp. 605-23.
[36] Spasic et al, 2010. Medication information extraction with linguistic pattern match-
ing and semantic rules. Journal of teh American Medical Informatics Association, 17
(5), pp. 532-535.
[37] Thelwall, M. (in press). Heart and soul: Sentiment strength detection in the social
web with SentiStrength (summary book chapter)

93
[38] University of Ljubljana, Data Mining - Fruitful and Fun. Available from:
http://orange.biolab.si
[39] Witte, R, 2006. Introduction to Text Mining. Universitat Karlsruhe, Germany.
[40] Xu et al, 2010. MedEx: a medication information extraction system for clinical
narratives. Journal of the American Medical Informatics Association, 17 (1).
[41] Yang et al, 2009. A Text Mining Approach to the Prediction of Disease Status
from Clinical Discharge Summaries. Journal of the American Medical Informatics
Association, 16 (4), 7 April, pp.596 - 600.
[42] Zhou, X. and Han, H., 2006. Approaches to Text Mining for Clinical Medical
Records. CiteSeer, April.
[43] Zhu, F., et al, 2013. Biomedical text mining and its applications in cancer research.
Biomedical Informatics, 46 (2), pp. 200–211.