
Exploiting Relationships for Domain-Independent Data Cleaning Dmitri V. Kalashnikov Sharad Mehrotra...
31
Exploiting Relationships for Domain-Independent Data Cleaning Dmitri V. Kalashnikov Sharad Mehrotra Stella Chen Computer Science Department University of California, Irvine http://www.ics.uci.edu/~dvk/RelDC http://www.itr-rescue.org (RESCUE) Copyright(c) by Dmitri V. Kalashnikov, 2005 SIAM Data Mining Conference, 2005
-
date post
19-Dec-2015 -
Category
Documents
-
view
221 -
download
0
Transcript of Exploiting Relationships for Domain-Independent Data Cleaning Dmitri V. Kalashnikov Sharad Mehrotra...

Exploiting Relationships for Domain-Independent
Data Cleaning
Dmitri V. Kalashnikov Sharad Mehrotra Stella Chen
Computer Science DepartmentUniversity of California, Irvine
http://www.ics.uci.edu/~dvk/RelDChttp://www.itr-rescue.org (RESCUE)
Copyright(c) by Dmitri V. Kalashnikov, 2005
SIAM Data Mining Conference, 2005

2
Talk Overview
• Examples – motivating data cleaning (DC)– motivating analysis of relationships for DC
• Reference disambiguation – one of the DC problems– this work addresses
• Proposed approach – RelDC (Relationship-based Data Cleaning)– employs analysis of relationships for DC
– the main contribution
• Experiments

3
Why do we need “Data Cleaning”?
An actual excerpt from a person’s CV– sanitized for privacy – quite common in CVs, etc– this particular person
– argues he is good
– because his work is well-cited
– but, there is a problem with using CiteSeer ranking– in general, it is not valid (in CVs)
– let’s see why...
“... In June 2004, I was listed as the 1000th most cited author in computer science (of 100,000 authors) by CiteSeer, available at
http://citeseer.nj.nec.com/allcited.html. ...”
4
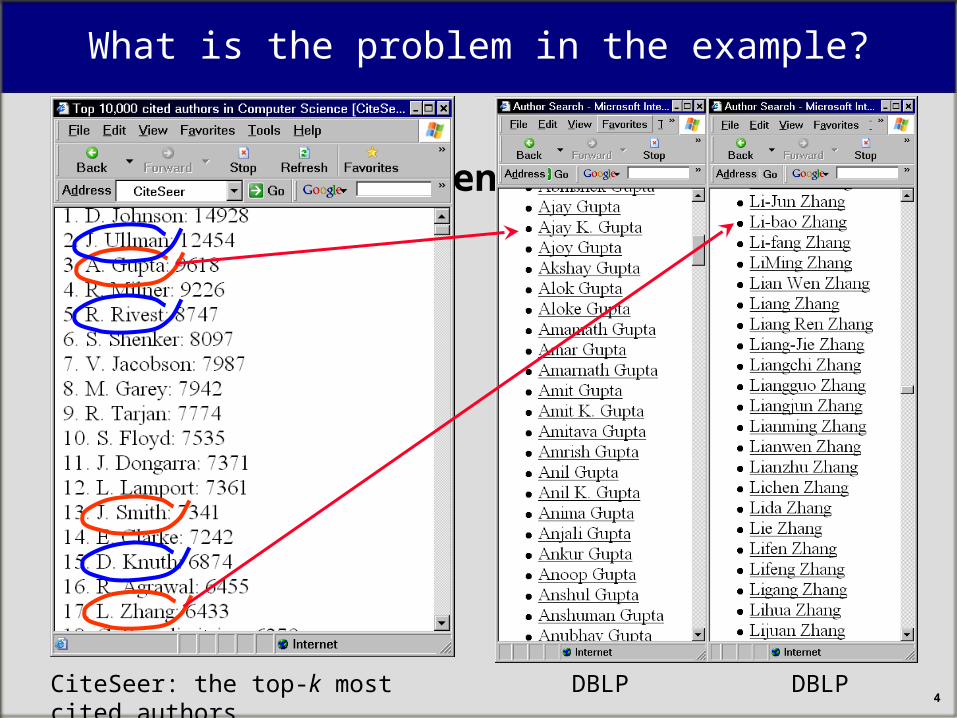
Suspicious entries– Let us go to the DBLP website
– which stores bibliographic entries of many CS authors
– Let us check who are– “A. Gupta”
– “L. Zhang”
What is the problem in the example?
CiteSeer: the top-k most cited authors DBLP DBLP

5
Comparing raw and cleaned CiteSeer
Rank Author Location # citations
1 (100.00%) douglas schmidt cs@wustl 5608
2 (100.00%) rakesh agrawal almaden@ibm 4209
3 (100.00%) hector garciamolina @ 4167
4 (100.00%) sally floyd @aciri 3902
5 (100.00%) jennifer widom @stanford 3835
6 (100.00%) david culler cs@berkeley 3619
6 (100.00%) thomas henzinger eecs@berkeley 3752
7 (100.00%) rajeev motwani @stanford 3570
8 (100.00%) willy zwaenepoel cs@rice 3624
9 (100.00%) van jacobson lbl@gov 3468
10 (100.00%) rajeev alur cis@upenn 3577
11 (100.00%) john ousterhout @pacbell 3290
12 (100.00%) joseph halpern cs@cornell 3364
13 (100.00%) andrew kahng @ucsd 3288
14 (100.00%) peter stadler tbi@univie 3187
15 (100.00%) serge abiteboul @inria 3060
CiteSeer top-k
Cleaned CiteSeer top-k

6
What is the lesson?
– data should be cleaned first– e.g., determine the (unique) real authors of publications– solving such challenges is not always “easy”– that explains a large body of work on data cleaning– note
– CiteSeer is aware of the problem with its ranking– there are more issues with CiteSeer – many not related to data cleaning
“Garbage in, garbage out” principle: Making decisions based on bad data, can lead to wrong results.

7
High-level view of the problem
...??
"J. Smith"
Raw Dataset
...J. Smith ...
.. John Smith ...
.. Jane Smith ...
MIT
Intel Inc.
?
Normalized Dataset(now can apply data analysis techniques)
Extraction(uncertainty,
duplicates, ...)
John Smith Intel
Jane Smith MIT
... ...
John SmithJane Smith
Intel
MIT
=
Attributed Relational Graph (ARG)
??
The problem:
...
(nodes, edges can have labels)(for any objects, not only people)
8
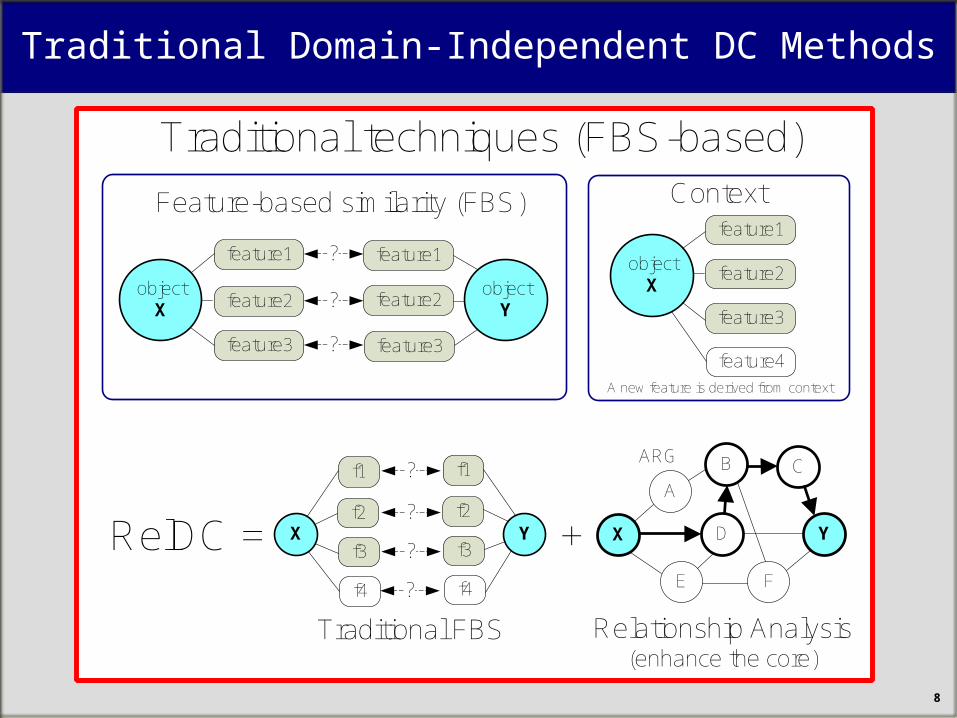
Traditional Domain-Independent DC Methods
objectX
feature1
feature2
feature3
objectY
feature1
feature2
feature3
?
?
?
Feature-based similarity (FBS)
objectX
feature1
feature2
feature3
Context
feature4A new feature is derived from context
f1
f2
f3
?
?
?
f4
Y
f1
f2
f3
f4?
XRelDC =
Traditional FBS
+ X Y
A
B C
D
E F
Relationship Analysis(enhance the core)
ARG
Traditional techniques (FBS-based)

9
What is “Reference Disambiguation”?
A1, ‘Dave White’, ‘Intel’A2, ‘Don White’, ‘CMU’A3, ‘Susan Grey’, ‘MIT’A4, ‘John Black’, ‘MIT’A5, ‘Joe Brown’, unknownA6, ‘Liz Pink’, unknown
P1, ‘Databases . . . ’, ‘John Black’, ‘Don White’P2, ‘Multimedia . . . ’, ‘Sue Grey’, ‘D. White’P3, ‘Title3 . . .’, ‘Dave White’P4, ‘Title5 . . .’, ‘Don White’, ‘Joe Brown’P5, ‘Title6 . . .’, ‘Joe Brown’, ‘Liz Pink’P6, ‘Title7 . . . ’, ‘Liz Pink’, ‘D. White’
Author table (clean) Publication table (to be cleaned)?
Analysis (‘D. White’ in P2, our approach):
1. ‘Don White’has a paper with ‘John Black’@MIT
2. ‘Dave White’is not connected to MIT in any way
3. ‘Sue Grey’
is coauthor of P2 too, and @ MIT
Thus: ‘D. White’ in P2 is probably Don
(since we know he collaborates with MIT ppl.)
Analysis (‘D. White’ in P6, our approach):
1. ‘Don White’has a paper (P4) with Joe Brown;Joe has a paper (P5) with Liz Pink;Liz Pink is a coauthor of P6.
2. ‘Dave White’
does not have papers with Joe or Liz
Thus: ‘D. White’ in P6 is probably Don
(since co-author networks often form clusters)

10
Attributed Relational Graph (ARG)
• View dataset as a graph– nodes for entities
– papers, authors, organizations– e.g., P2, Susan, MIT
– edges for relationships– “writes”, “affiliated with”– e.g. Susan → P2 (“writes”)
• “Choice” nodes – for uncertain relationships– mutual exclusion– “1” and “2” in the figure
• Analysis can be viewed as– application of the “Context AP”– to this graph– defined next...
w1 = ?
P1
P2
P3
Dave White
Don White
Susan Grey
John Black
Intel
CMU
MIT
1
Joe BrownP4
Liz Pink
P5
P62
w3 = ?
Q: How come domain-independent?

11
In designing the RelDC approach- our goal was to use CAP as an axiom - then solve problem formally, without heuristics
if– reference r, made in the context of entity x,
refers to an entity yj – but, the description, provided by r, matches
multiple entities: y1,…,yj,…,yN,
then
–x and yj are likely to be more strongly connected to each other via chains of relationships
– than x and yk (k = 1, 2, … , N; k j).
Context Attraction Principle (CAP)
“J. Smith” publication P1
John E. SmithSSN = 123
Joe A. SmithP1 John E. Smith Jane Smith

12
Analyzing paths: linking entities and contexts
D. White is a reference– in the context of P2, P6
– can link P2, P6 to Don
– cannot link P2, P6 to Dave
– more complex paths in general
w1 = ?
P1
P2
P3
Dave White
Don White
Susan Grey
John Black
Intel
CMU
MIT
1
Joe BrownP4
Liz Pink
P5
P62
w3 = ?
Analysis (‘D. White’ in P2): path P2→Don
1. ‘Don White’has a paper with ‘John Black’@MIT
2. ‘Dave White’is not connected to MIT in any way
3. ‘Sue Grey’
is coauthor of P1 too, and @ MIT
Thus: ‘D. White’ is probably Don White
Analysis (‘D. White’ in P6): path P6→Don
1. ‘Don White’has a paper (P4) with Joe Brown;Joe has a paper (P5) with Liz Pink;Liz Pink is a coauthor of P6.
2. ‘Dave White’
does not have papers with Joe or Liz
Thus: ‘D. White’ is probably Don White

13
Questions to answer
1. Does the CAP principle hold over real datasets? That is, if we disambiguate references based on it,
will the references be correctly disambiguated?
2. Can we design a generic solution to exploiting relationships for disambiguation?

14
Problem formalization
Notation Meaning
X={x1, x2, ... , xN}
the set of all entities in in the database
xi .rk the k-th reference of entity xi
a reference a description of an object, multiple attributes
d[xi .rk] the “answer” for xi .rk -- the real entity xi .rk refers to (unknown, the goal is to find it)
CS[xi .rk] the “choice set” for xi .rk -- the set of all entities matching the description provided by xi .rk
y1, y2, ... , yN the “options” for xi .rk -- elements in CS[xi .rk]
v[xi] the node in the graph for entity xi
the name of k-th author of paper xi, e.g. ‘J. Smith’
the true k-th author of paper xi
‘John A. Smith’, ‘Jane B. Smith’, ...

15
Handling References: Linking(references correspond to relationships)
if |CS[xi .rk]| = 1 then
– we know the answer d[xi .rk]– link xi and d[xi .rk] directly, w = 1
else – the answer is uncertain for xi .rk
– create a “choice” node, link it– “option-weights”, w1 + ... + wN = 1– option-weights are variables
Entity-Relationship Graph
RelDC views dataset as a graph– undirected– nodes for entities
– don’t have weights
– edges for relationships– have weights– real number in [0,1]– the confidence the relationship exists
w1 = ?
P1
P2
P3
Dave White
Don White
Susan Grey
John Black
Intel
CMU
MIT
1
Joe BrownP4
Liz Pink
P5
P62
w3 = ?
v[xi]
v[yN]
cho[xi.rk]
v[y1]
v[y2]w0=1
...
N nodesfor entities in CS[xi.rk]
e0
“J. Smith”
P1
“Jane Smith”
“John Smith”

16
Definition:
To resolve a reference xi .rk means – to pick one yj from CS[xi .rk] as d[xi .rk].
Graph interpretation – among w1, w2, ... , wN, assign wj = 1 to one wj
– means yj is chosen as the answer d[xi .rk]
Definition: Reference xi .rk is resolved correctly, if the chosen yj = d[xi .rk].
Definition:
Reference xi .rk is unresolved or uncertain, if not yet resolved...
Goal: Resolve all uncertain references as correctly as possible.
Objective of Reference Disambiguation
v[xi]
v[yN]
cho[xi.rk]
v[y1]
v[y2]
...

17
Alterative goal– for each reference xi .rk
– assign option-weights w1, ... ,wN
– but it [0,1], not binary as before
– wj reflects the degree of
confidence that yj=d[xi .rk]
– w1 + w2 + ... + wN = 1
Mapping the alternative goal to the original– use an interpretation procedure
– pick yi with the max wi as the answer for xi .rk
– a final step
RelDC deals with the alternative goal!– the bulk of the discussion on computing those option-weights
Alternative Goal
v[xi]
v[yN]
cho[xi.rk]
v[y1]
v[y2]
...

18
Formalizing the CAP
CAP– is based on “connection strength”– c(u,v) for entities u and v
– measures how strongly u and v are connected to each other via relationships
– e.g. c(u,v) > c(u,z) in the figure– will formalize c(u,v) later
if c(xi, yj) ≥ c(xi, yk)
then wj ≥ wk (most of the time)
Context Attraction Principle (CAP)
u v
A
B C
D
E F
G H z
v[xi]
v[yN]
cho[xi.rk]
v[y1]
v[y2]
...
w 1=?
wN=?
w2=?e 1
eN
e2
We use proportionality:
c(xi, yj) ∙ wk = c(xi, yk) ∙ wj

19
RelDC approach
Input: the ARG for the dataset
1. Computing connection strengths− for each unresolved reference xi .rk
− determine equations for all (i.e., N) c(xi , yj)’s
− c(xi , yj) = gij(w) − a function of other option-weights
2. Determining equations for option-weights− use CAP to relate all wj’s and connection strengths− since c(xi , yj) = gij(w), hence wij = fij(w)
3. Computing option-weights− solve the system of equations from Step 2.
4. Resolving references− use the interpretation procedure to resolve weights
v[xi]
v[yN]
cho[xi.rk]
v[y1]
v[y2]
...
2
2

20
Computing connection strength (Step 1)
Computation of c(u,v) consists of two phases– Phase 1: Discover connections
– all L-short simple paths between u and v– bottleneck– optimizations, not in SDM05
– Phase 2: Measure the strength– in the discovered connections– many c(u,v) models exist – we use random walks in graphs model
cho[xi.rk]
?
?Graph
?
v[xi]
v[y1]
v[y2]
v[yN]u va
N-2... ... ... ... ...
b

21
Measuring connection strength
wk,
i
w1,
i
w2,
i
v1 vkw1,0
w1,n
1 w 1,1
n1
... ...
Sou
rce wk-1,0
...
wk,n
k w k,1
nk
... ...
Des
tina
tion
edge E1,0
v2w2,0
w2,n
2 w 2,1
n2
... ...
u v
A
B C
D
E F
G H z
Note:
– c(u,v) returns an equations
– because paths can go via various option-edges
– cuv = c(u,v) = guv(w)

22
Equations for option-weights (Step 2)
CAP (proportionality):
System (over-constrained):
Add slack:

23
Solving the system (Steps 3 and 4)
Step 3: Solve the system of equations1. use a math solver, or
2. iterative method (approx. solution ), or
3. bounding-interval-based method (tech. report).
Step 4: Interpret option-weights– to determine the answer for each reference
– pick yj with the largest weight as the answer

24
Experimental Setup
Parameters– When looking for L-short simple paths, L = 7– L is the path-length limit
RealPub dataset:
– CiteSeer + HPSearch– publications (255K) – authors (176K) – organizations (13K)– departments (25K)
– ground truth is not known– accuracy...
SynPub datasets:
– many ds of two types– emulation of RealPub
– publications (5K) – authors (1K) – organizations (25K)– departments (125K)
– ground truth is known
RealMov:– movies (12K) – people (22K)
– actors– directors– producers
– studious (1K) – producing – distributing

25
Sample Publication Data
CiteSeer: publication records
HPSearch: author records
26
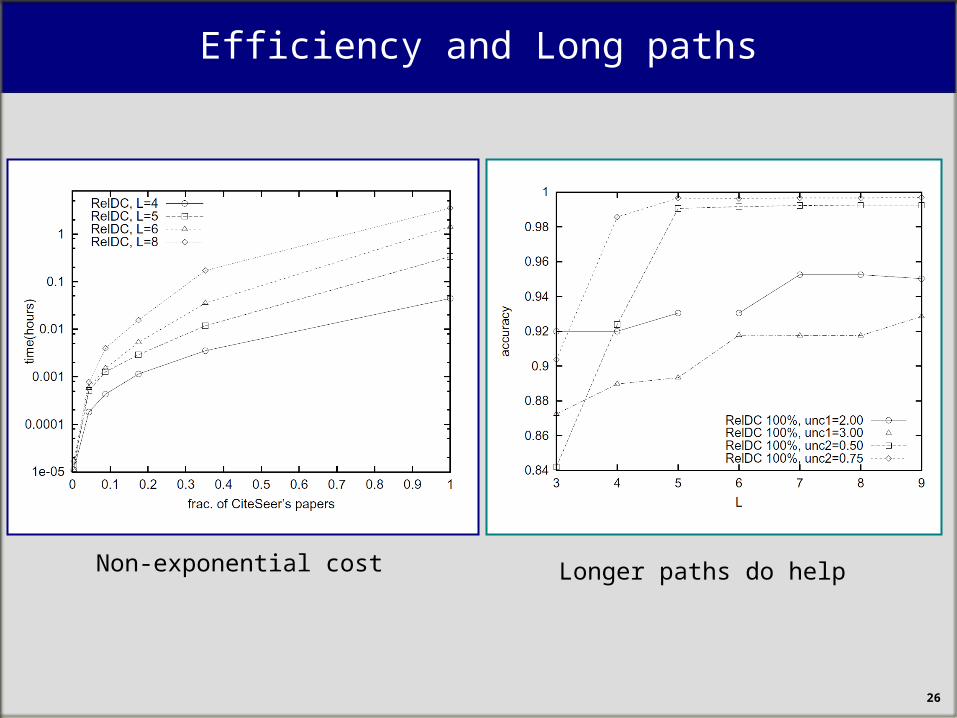
Efficiency and Long paths
Non-exponential cost Longer paths do help

27
Accuracy on SynPub

28
Sample Movies Data

29
Accuracy on RealMov
References to Directors References to Studios

30
Summary
• DC and “Garbage in, Garbage out” principle
• Our main contributions– showing that analyzing relationship can help DC– an approach, that achieves that
• RelDC– developed in Aug 2003– domain-independent data cleaning framework
– not about cleaning CiteSeer
– uses relationships for data cleaning
• Ongoing work– “learning” the importance of relationships from data

31
Contact Information
RelDC projectwww.ics.uci.edu/~dvk/RelDC
www.itr-rescue.org (RESCUE)
Dmitri V. Kalashnikov (contact author)
www.ics.uci.edu/~dvk
Sharad Mehrotrawww.ics.uci.edu/~sharad
Zhaoqi Chenwww.ics.uci.edu/~chenz


















