
Expected tensor decomposition with stochastic gradient descent
19
Expected Tensor Decomposition with Stochastic Gradient Descent Takanori Maehara (Shizuoka Univ) Kohei Hayashi (NII -> AIST) Ken-ichi Kawarabayashi (NII)
-
Upload
kohei-hayashi -
Category
Data & Analytics
-
view
528 -
download
4
Transcript of Expected tensor decomposition with stochastic gradient descent

Expected Tensor Decomposition with Stochastic Gradient Descent
Takanori Maehara (Shizuoka Univ) Kohei Hayashi (NII -> AIST) Ken-ichi Kawarabayashi (NII)

Text Overflow
• Too many information to catch up
• How can we know what’s going on? --- Machine learning!
http://blogs.transparent.com/
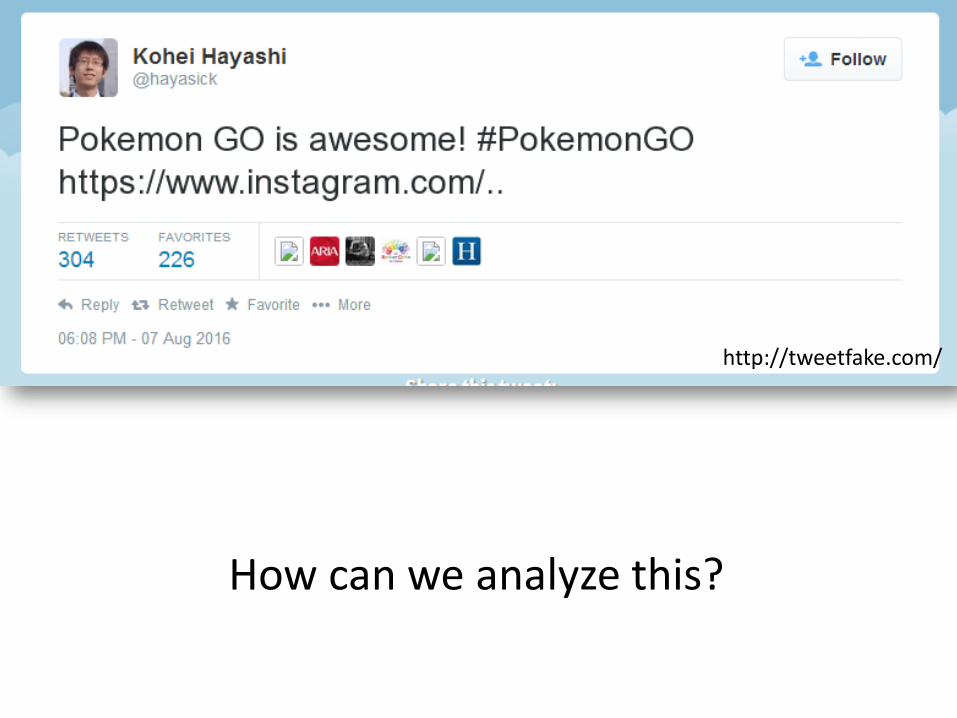
How can we analyze this?
http://tweetfake.com/

Word Co-occurance w
ord
word matrix decomposition
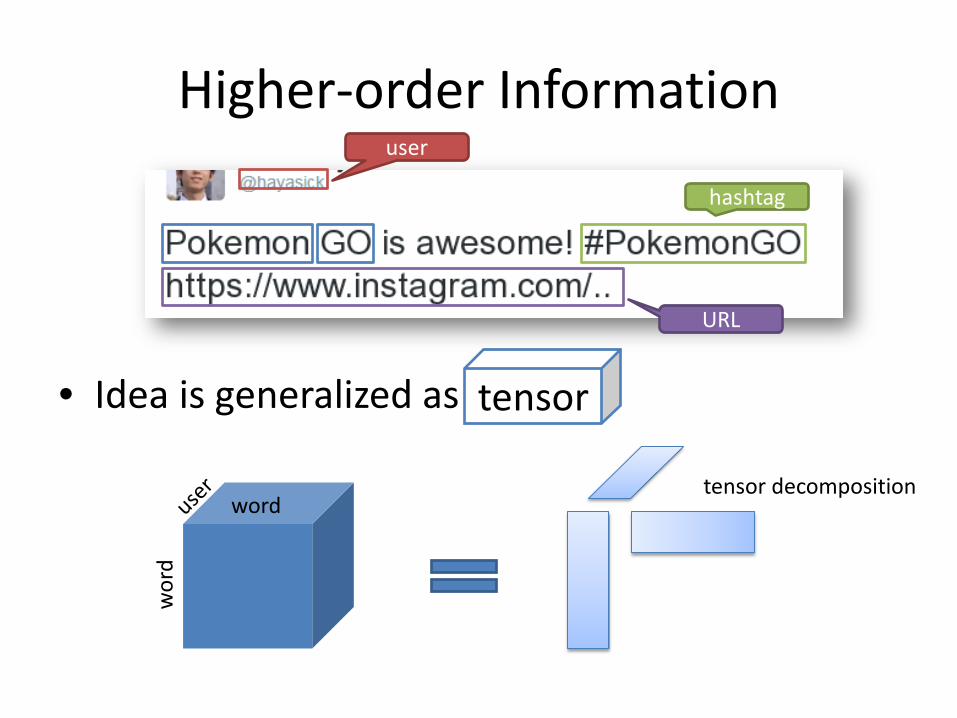
Higher-order Information
• Idea is generalized as tensor
wor
d
word
tensor
hashtag
URL
user
tensor decomposition

Scalability Issue
1. To compute decomposition, we need beforehand.
2. Sometimes is too huge to put on memory.
tensor
tensor

Questions
• Can we get decomposition without ?
• If possible, when and how?
YES
• When: is given by sum • How: stochastic optimization
tensor
tensor

Revisit: Word Co-occurance
• : “Heavy” tensor (e.g. dense) • : “Light” tensor (e.g. sparse)
tweet 1 tweet 2 tweet T
𝑋
𝑋𝑡
we want to decompose
this
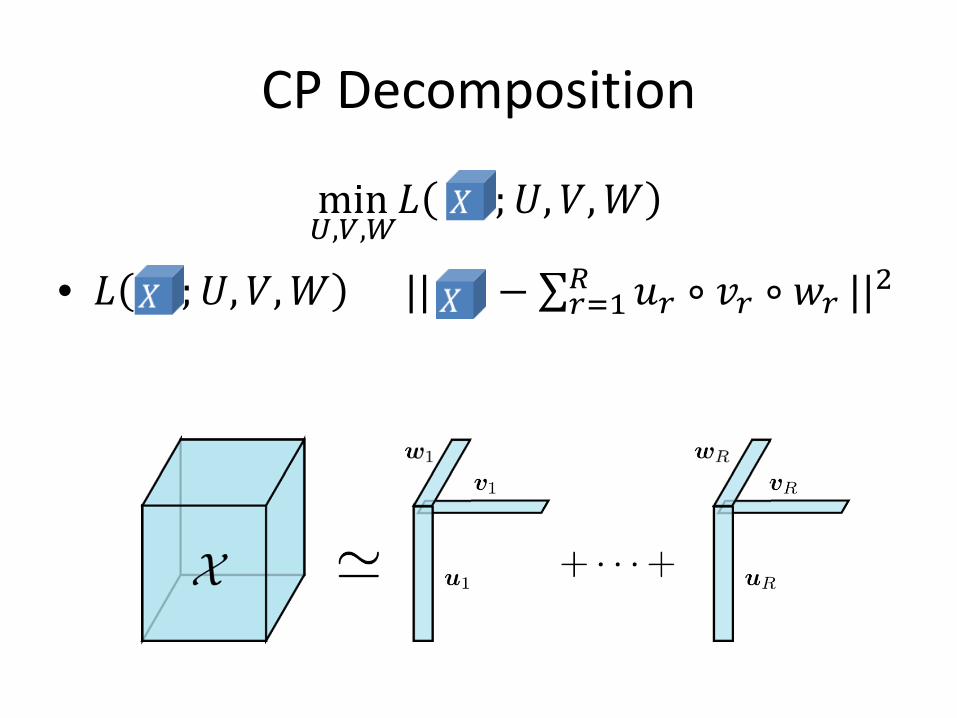
CP Decomposition
min𝑈,𝑉,𝑊
𝐿 ;𝑈,𝑉,𝑊
• 𝐿 ;𝑈,𝑉,𝑊 = || − ∑ 𝑢𝑟 ∘ 𝑣𝑟 ∘ 𝑤𝑟𝑅𝑟=1 ||2

Batch Optimization
• CP decomposition is non-convex • Use alternating least squares
Repeat until convergence: • 𝑈 ← 𝑈 − 𝜂𝛻𝑈𝐿 • 𝑉 ← 𝑉 − 𝜂𝛻𝑉𝐿 • 𝑊 ← 𝑊 − 𝜂𝛻𝑊𝐿
ALS
𝑋
𝑋
𝑋
step size

Key Fact: Loss is Decomposable
L( ) =L( + + …. + ) =L( ) + L( ) + … + L( ) + const
𝑋
𝑋1 𝑋2 𝑋𝑇
𝑋1 𝑋2 𝑋𝑇
𝐿 𝑋 = ||𝑋 −�𝑢𝑟 ∘ 𝑣𝑟 ∘ 𝑤𝑟
𝑅
𝑟=1
||2
E𝑥 − 𝑎 2 = E𝑥 2 − 2𝑎E𝑥 + 𝑎2 = E 𝑥2 − 2𝑎E𝑥 + 𝑎2 + E𝑥 2 − E 𝑥2 = E[𝑥 − 𝑎]2+Var[𝑥]
Intuition: for stochastic variable 𝑥 and constant 𝑎,

Stochastic Optimization
• If 𝐿 = 𝐿1 + 𝐿2 + ⋯+ 𝐿𝑇, we can use 𝛻𝐿𝑡 instead of 𝛻𝐿
• Stochastic ALS
for 𝑡 = 1, … ,𝑇: • 𝑈 ← 𝑈 − 𝜂𝑡𝛻𝑈𝐿 • 𝑉 ← 𝑉 − 𝜂𝑡𝛻𝑉𝐿 • 𝑊 ← 𝑊 − 𝜂𝑡𝛻𝑊𝐿
SALS
Repeat until convergence: • 𝑈 ← 𝑈 − 𝜂𝛻𝑈𝐿 • 𝑉 ← 𝑉 − 𝜂𝛻𝑉𝐿 • 𝑊 ← 𝑊 − 𝜂𝛻𝑊𝐿
ALS
𝑋
𝑋
𝑋 𝑋𝑡
𝑋𝑡
𝑋𝑡

Observations
• ALS and SALS have the same solution set – (𝐿ALS−𝐿SALS) = const
• SALS does not require to precompute – Batch gradient: ∇L( ) – Stochastic gradient: ∇L( )
• One step of SALS is lighter – is sparse, whereas is not – ∇L( ) is also sparse
𝑋
𝑋
𝑋𝑡
𝑋 𝑋𝑡
𝑋𝑡

Related Work
• Element-wise SGD A special case of SALS
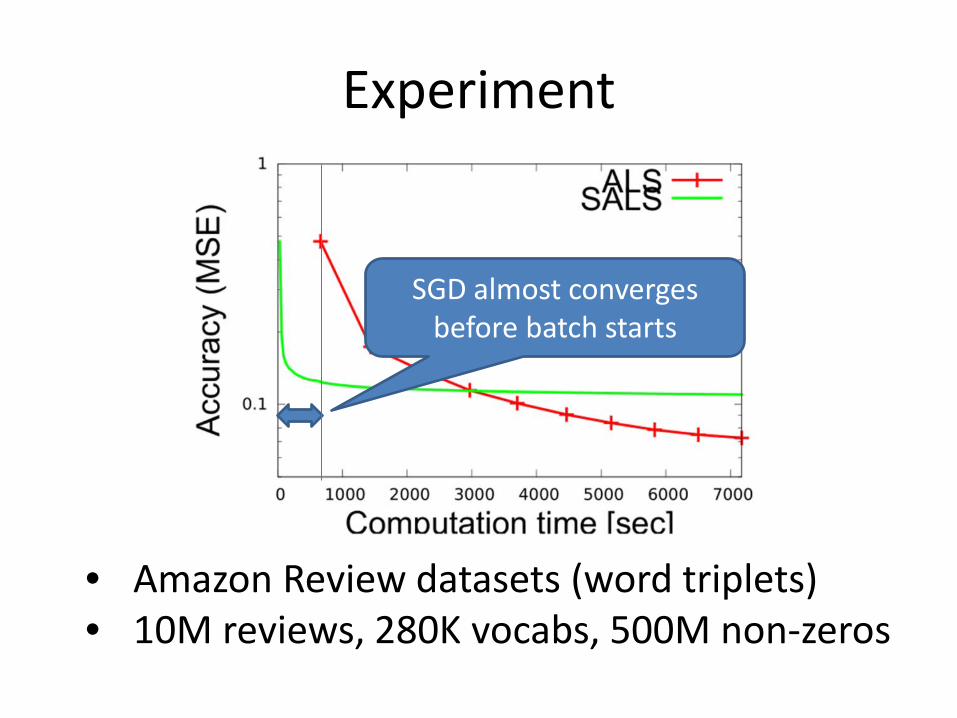
Experiment
• Amazon Review datasets (word triplets) • 10M reviews, 280K vocabs, 500M non-zeros
SGD almost converges before batch starts
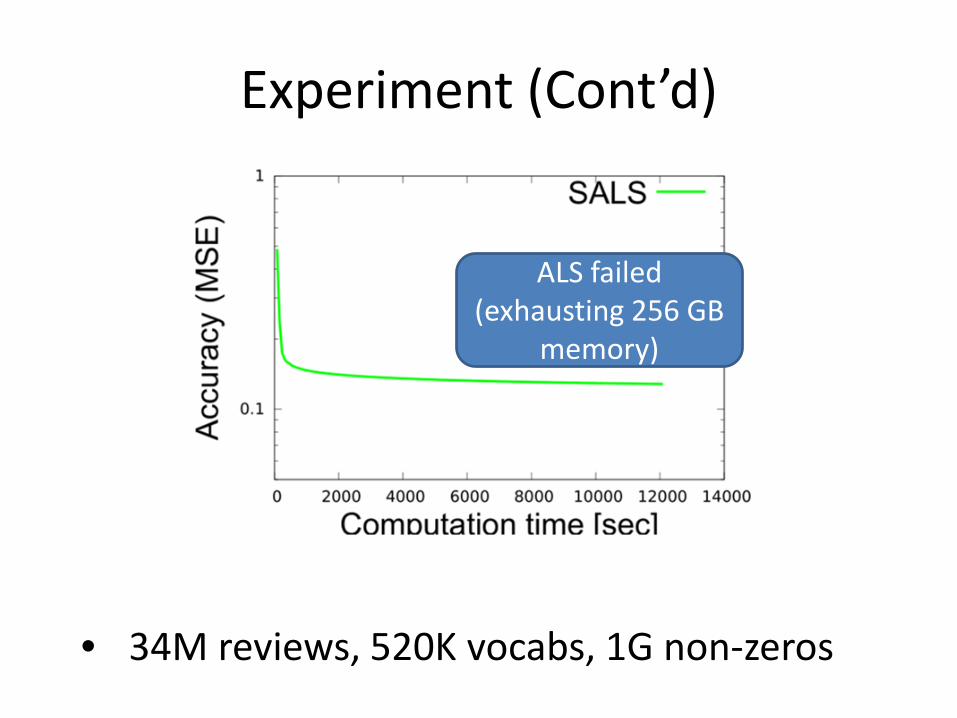
Experiment (Cont’d)
• 34M reviews, 520K vocabs, 1G non-zeros
ALS failed (exhausting 256 GB
memory)

More on Paper
• 2nd-order SALS – Using block diagonal of Hessian – Faster convergence, low sensitivity of 𝜂
• With l2 norm regularizer:
– min L(X; U, V, W) + R(U, V, W), 𝑅 𝑈,𝑉,𝑊 = 𝜆(||𝑈||2 + ||𝑉||2 + ||𝑊||2)
• Theoretical analysis of convergence
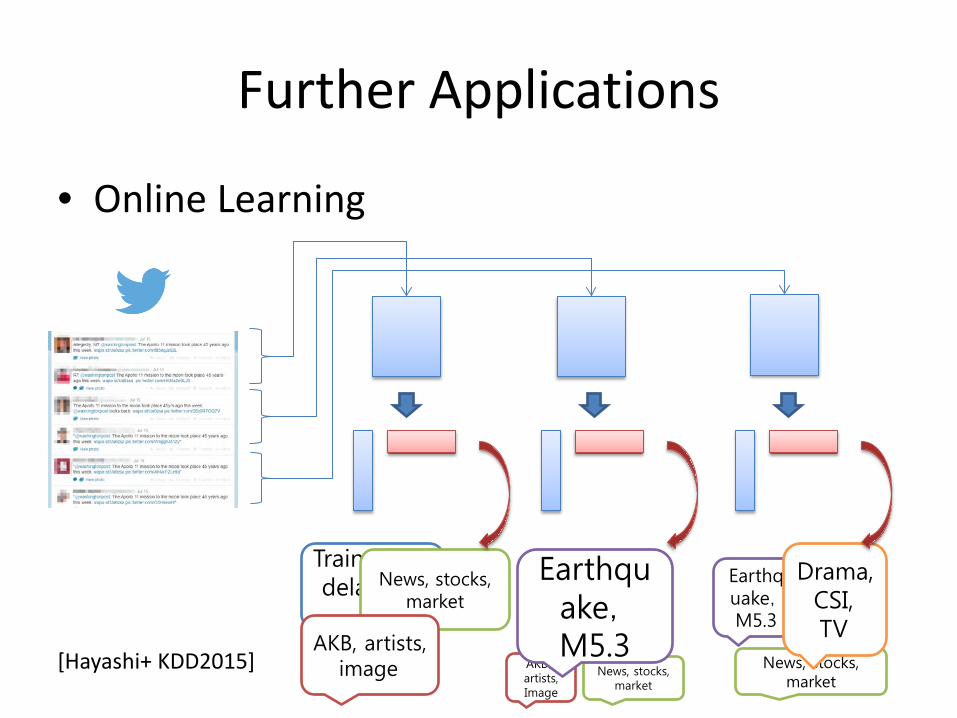
Further Applications
• Online Learning
News, stocks, market
Train ,line, delay,遅
れ
News, stocks, market
AKB, artists, image AKB,
artists, Image
News, stocks, market
Earthquake,M5.3
Earthquake,M5.3
Drama, CSI, TV
[Hayashi+ KDD2015]
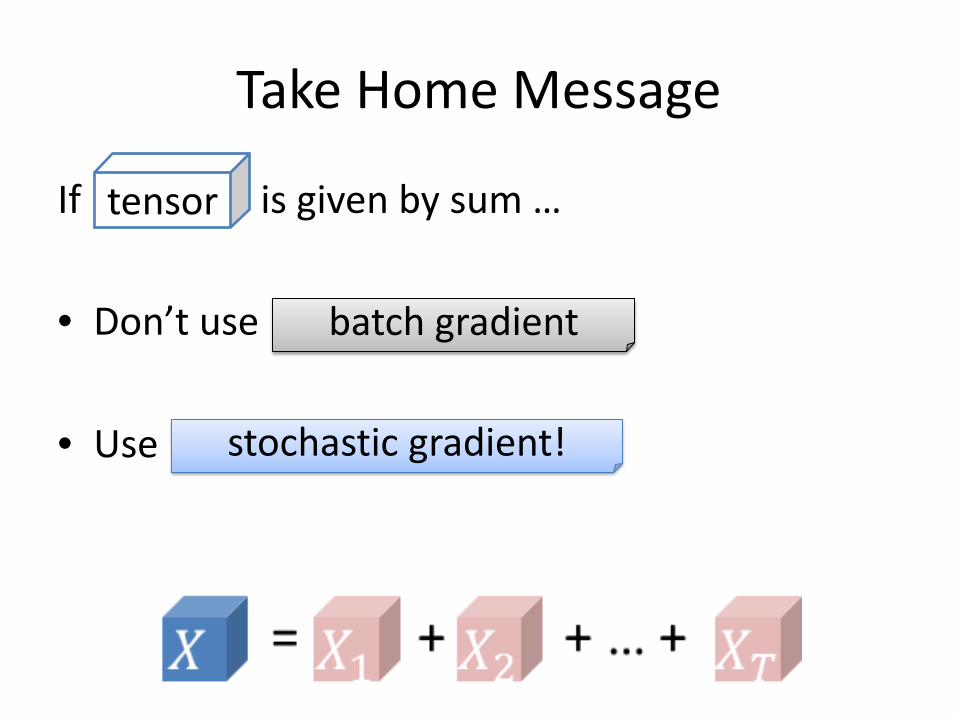
Take Home Message
If is given by sum …
• Don’t use
• Use
tensor
batch gradient
stochastic gradient!





![Ranking Methods for Tensor Components Analysis and their ...cet/TieneFilisbino_sibgrapi13.pdf · [6], tensor discriminant analysis (TDA) [7], [8] and tensor rank-one decomposition](https://static.fdocuments.in/doc/165x107/5f78fbe48023322255060d71/ranking-methods-for-tensor-components-analysis-and-their-cettienefilisbino.jpg)





![Probabilistic Streaming Tensor Decompositionzhe/pdf/POST.pdf · Probabilistic Streaming Tensor Decomposition Yishuai Du y, Yimin Zheng , Kuang-chih Lee], Shandian Zhey University](https://static.fdocuments.in/doc/165x107/5eb6be1e3d209031916fd245/probabilistic-streaming-tensor-decomposition-zhepdfpostpdf-probabilistic-streaming.jpg)






