
Evaluating Multilingual Question Answering Systems at CLEF Pamela Forner 1, Danilo Giampiccolo 1,...
22
Evaluating Multilingual Question Answering Systems at CLEF Pamela Forner 1 , Danilo Giampiccolo 1 , Bernardo Magnini 2 , Anselmo Peñas 3 , Álvaro Rodrigo 3 , Richard Sutcliffe 4 1 - CELCT, Trento, Italy, 2 - FBK, Trento, Italy 3 - UNED, Madrid, Spain 4- University of Limerick, Ireland
-
Upload
audra-anne-joseph -
Category
Documents
-
view
221 -
download
2
Transcript of Evaluating Multilingual Question Answering Systems at CLEF Pamela Forner 1, Danilo Giampiccolo 1,...

Evaluating Multilingual Question Answering Systems at CLEF
Pamela Forner1, Danilo Giampiccolo1, Bernardo Magnini2, Anselmo Peñas3, Álvaro Rodrigo3, Richard Sutcliffe4
1 - CELCT, Trento, Italy, 2 - FBK, Trento, Italy
3 - UNED, Madrid, Spain
4- University of Limerick, Ireland

Outline
• Background
• QA at CLEF
• Resources
• Participation
• Evaluation
• Discussion
• Conclusions

Background – QA
• A Question Answering (QA) system takes as input a short natural language question and a document collection and produces an exact answer to the question, taken from the collection
• In Monolingual QA – Q and A in same language
• In Cross-Lingual QA – Q and A in different languages

Background – Monolingual Example
Question: How many gold medals did Brian Goodel win in the 1979 Pan American Games?
Answer: three gold medals
Docid: LA112994-0248
Context: When comparing Michele Granger and Brian Goodell, Brian has to be the clear winner. In 1976, while still a student at Mission Viejo High, Brian won two Olympic gold medals at Montreal, breaking his own world records in both the 400- and 1,500-meter freestyle events. He went on to win three gold medals in the 1979 Pan American Games.

Background – Cross-Lingual Example
Question: How high is the Eiffel Tower?
Answer: 300 Meter
Docid: SDA.950120.0207
Context: Der Eiffelturm wird jaehrlich von 4,5 bis 5 Millionen Menschen besucht. Das 300 Meter hohe Wahrzeichnen von Paris hatte im vergangenen Jahr vier neue Aufzuege von der zweiten bis zur vierten Etage erhalten.

Background – Grouped Questions
• With grouped questions there are several on the same topic which may be linked even indirectly by co-reference:
Question: Who wrote the song "Dancing Queen"?
Question: When did it come out?
Question: How many people were in the group?

QA at CLEF - Eras
• Origin was QA at Text REtrieval Conference, in 1999 onwards; term factoid coined there
• At CLEF, there have been three Eras
• Era 1 (2003-6): Ungrouped; mainly factoid; monolingual newspapers; exact answers
• Era 2: (2007-8): Grouped; mainly factoid; monolingual newspapers and Wikipedias; exact answers
• Era 3: (2009-10): Ungrouped; factoid + others; multilingual aligned EU documents; passages and exact answers
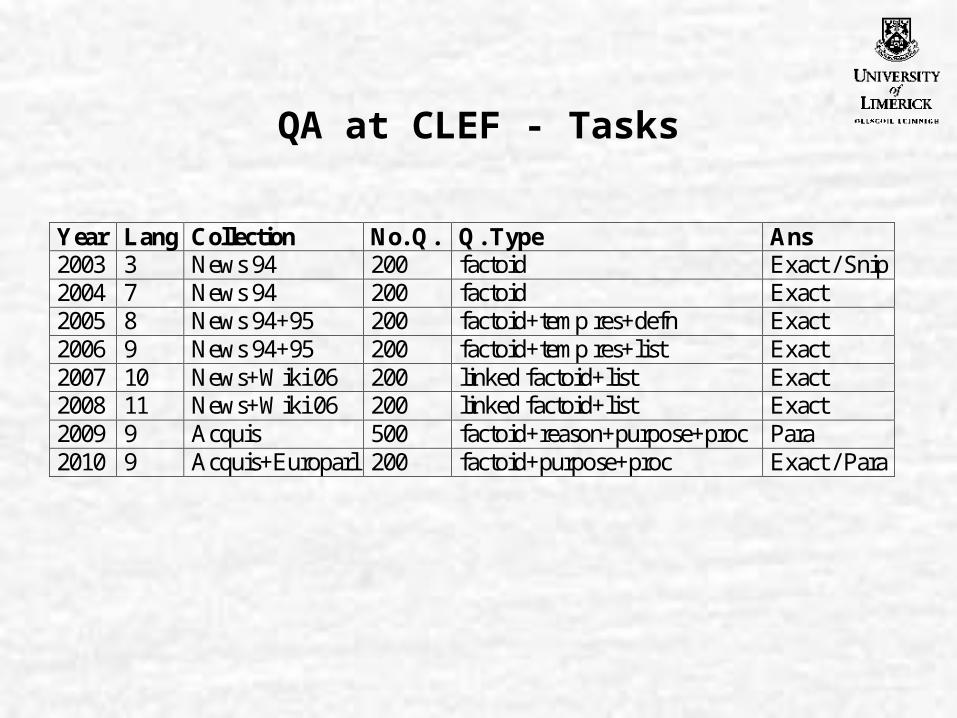
QA at CLEF - Tasks
Year Lang Collection No. Q. Q. Type Ans 2003 3 News 94 200 factoid Exact / Snip 2004 7 News 94 200 factoid Exact 2005 8 News 94+95 200 factoid+temp res+defn Exact 2006 9 News 94+95 200 factoid+temp res+list Exact 2007 10 News+Wiki 06 200 linked factoid+list Exact 2008 11 News+Wiki 06 200 linked factoid+list Exact 2009 9 Acquis 500 factoid+reason+purpose+proc Para 2010 9 Acquis+Europarl 200 factoid+purpose+proc Exact / Para

Resources - Documents
• Originally various newspapers (different in each target language, but same years 94/95)
• For Era-2 (linked questions) Wikipedia 2006 was added
• With Era-3 changed to JRC-Acquis Corpus – European Agreements and Laws
• In 2010 Europarl was added (partly transcribed debates from the European Parliament)
• Acquis and Europarl are Parallel Aligned (Ha Ha)

Resources - Questions
• In all years, questions are back-composed from target language corpus
• They are carefully grouped into various categories (person, place etc etc)
• However, they are not naturally occurring or real

Resources – Back Translation of Questions
• Each group composes questions in their own language, with answers in their target document collection
• They translate these into English (pivot language)
• All resulting English translations are pooled
• Each group translates English questions into their language
• Eras 1 & 2: Questions in a given target language can be asked in any source language
• Era 3: Questions in any target language can be asked in any source language (Ho Ho)

Resources – Back Trans Cont.
• Eras 1 & 2: Each participating group is answering different questions, depending on the target language
• Era 3: Each group is answering same questions
• The Gold Standard comprising questions, answers and contexts in target language is probably the most interesting thing to come out of the QA at CLEF activity
• The back translation paradigm was worked out for the first campaign
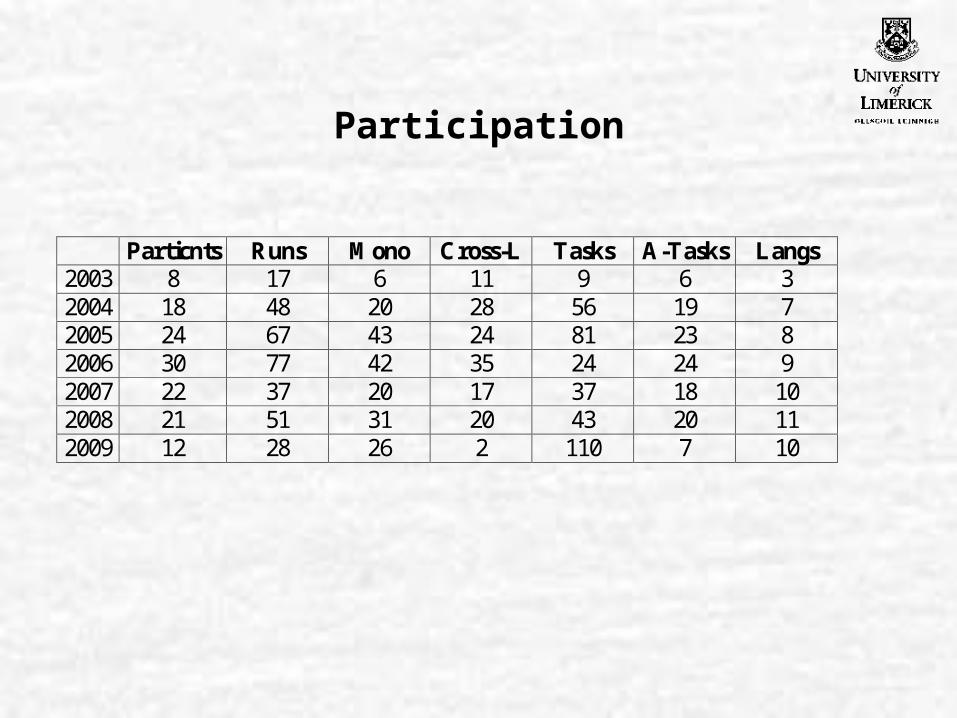
Participation
Particnts Runs Mono Cross-L Tasks A-Tasks Langs 2003 8 17 6 11 9 6 3 2004 18 48 20 28 56 19 7 2005 24 67 43 24 81 23 8 2006 30 77 42 35 24 24 9 2007 22 37 20 17 37 18 10 2008 21 51 31 20 43 20 11 2009 12 28 26 2 110 7 10

Evaluation - Measures
• Right / Wrong / Unsupported / ineXact
• These standard TREC measures have been used all along
• Accuracy: Proportion of answers Right
• MRR: Reciprocal of rank of first correct answer. Thus each answer contributes 1, 0.5, 0.33, or 0
• C@1: Rewards system for not answering wrongly
• CWS: Rewards system for being confident of correct ans
• K1: Also links correctness and confidence

Evaluation - Method
• Originally, runs inspected individually by hand
• LIM used Perl TREC tools incorporating double judging
• WiQA group produced excellent web-based system allowing double judging
• CELCT produced web-based system
• Evaluation is very interesting work!
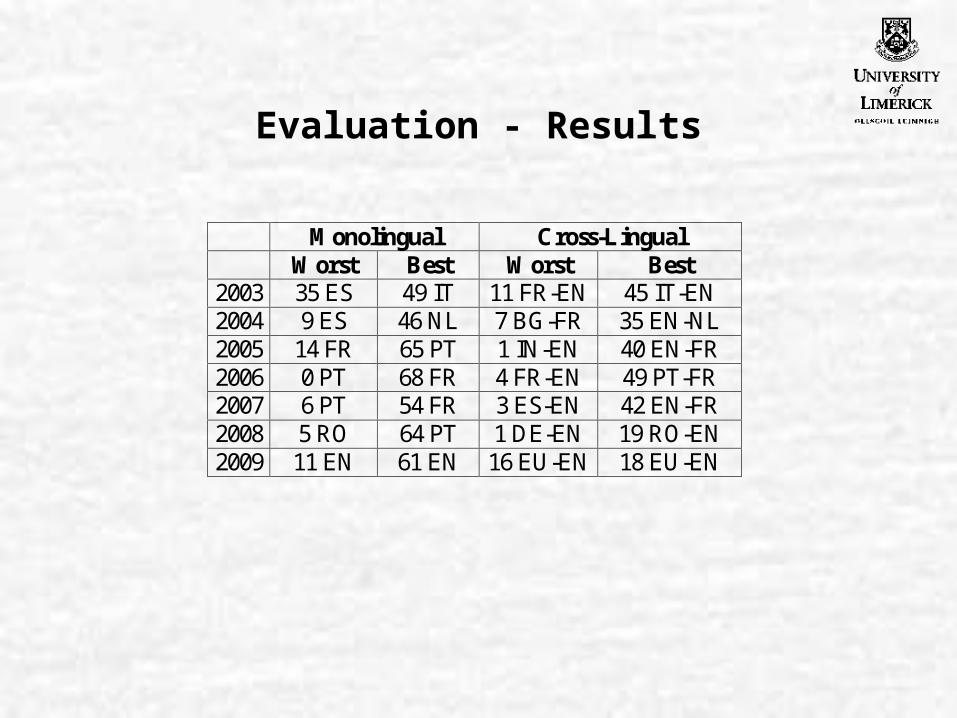
Evaluation - Results
Monolingual Cross-Lingual Worst Best Worst Best 2003 35 ES 49 IT 11 FR-EN 45 IT-EN 2004 9 ES 46 NL 7 BG-FR 35 EN-NL 2005 14 FR 65 PT 1 IN-EN 40 EN-FR 2006 0 PT 68 FR 4 FR-EN 49 PT-FR 2007 6 PT 54 FR 3 ES-EN 42 EN-FR 2008 5 RO 64 PT 1 DE-EN 19 RO-EN 2009 11 EN 61 EN 16 EU-EN 18 EU-EN

Discussion – Era 1 (03-06)
• Monolingual QA improved 49%->68%
• The best system was for a different language each year!
• Reason: Increasingly sophisticated techniques used, mostly learned from TREC, plus CLEF and NTCIR
• Cross-Lingual QA remained 35-45% throughout
• Reason: Required improvement in Machine Translation has not been realised by participants

Discussion – Era 2 (07-08)
• Monolingual QA improved 54%->64%
• However, range of results was greater, as only a few groups were capable of the more difficult task
• Cross-Lingual QA deteriorated 42%->19%!
• Reason: 42% was an isolated result and the general field was much worse

Discussion – Era 3 (09-10)
• In 2009, task was only passage retrieval (easier)
• However, documents are much more difficult than newspapers and questions reflect this
• Monolingual Passage Retrieval was 61%
• Cross-Lingual Passage Retrieval was 18%

Conclusions - General
• A lot of groups around Europe and beyond have been able to participate in their own languages
• Hence, the general capability in European languages has improved considerably – both systems and research groups
• However, people are often interested in their own language only – i.e. Monolingual systems
• Cross-lingual systems mostly X->EN or EN->X, i.e. to or from English
• Many language directions are supported by us but not taken up

Conclusions – Resources & Tools
• During the campaigns, very useful resources have been developed – Gold Standards for each year
• These are readily available and can be used by groups to develop systems even if they did not participate in CLEF
• Interesting tools for devising questions and evaluating results have also been produced

Conclusions - Results
• Monolingual results have improved to the level of TREC English results
• Thus new, more dynamic and more realistic QA challenges must be found for future campaigns
• Cross-Lingual results have not improved to the same degree. High quality MT (on Named Entities especially) is not a solved problem and requires further attention


















