
ETRACES at GESIS Brigitte Mathiak, Farag Ahmed and Andreas Oscar Kempf [email protected]...
32
eTRACES at GESIS Brigitte Mathiak, Farag Ahmed and Andreas Oscar Kempf [email protected] Leipzig, 07-05-2012
-
Upload
lynne-price -
Category
Documents
-
view
217 -
download
1
Transcript of ETRACES at GESIS Brigitte Mathiak, Farag Ahmed and Andreas Oscar Kempf [email protected]...

eTRACES at GESIS
Brigitte Mathiak, Farag Ahmed and Andreas Oscar Kempf
Leipzig, 07-05-2012
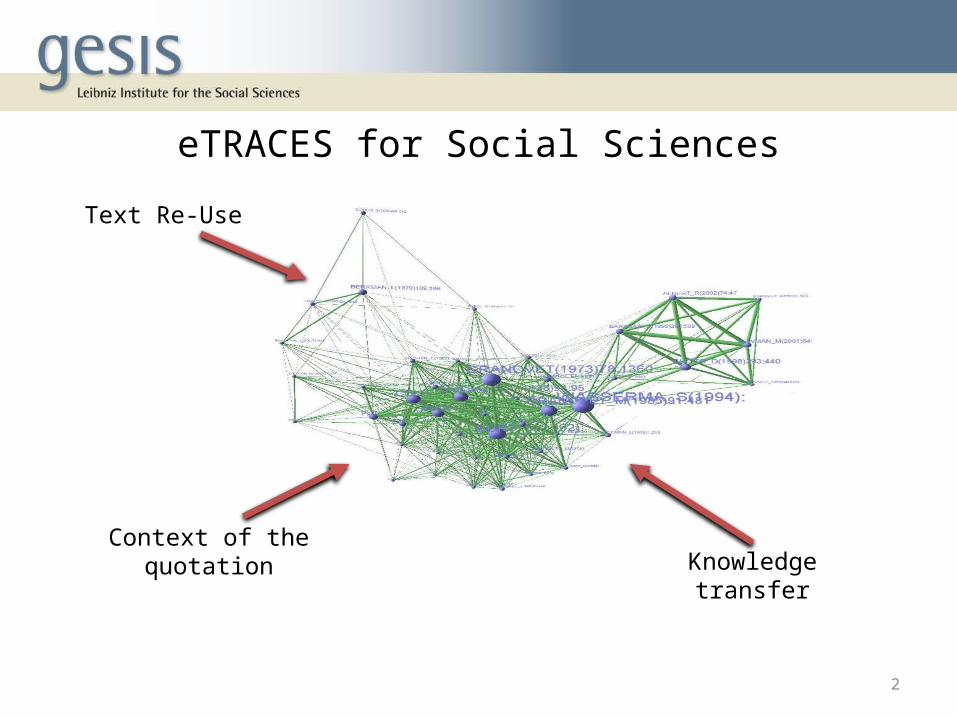
Text Re-Use
Context of the quotationKnowledge transfer
eTRACES for Social Sciences
2
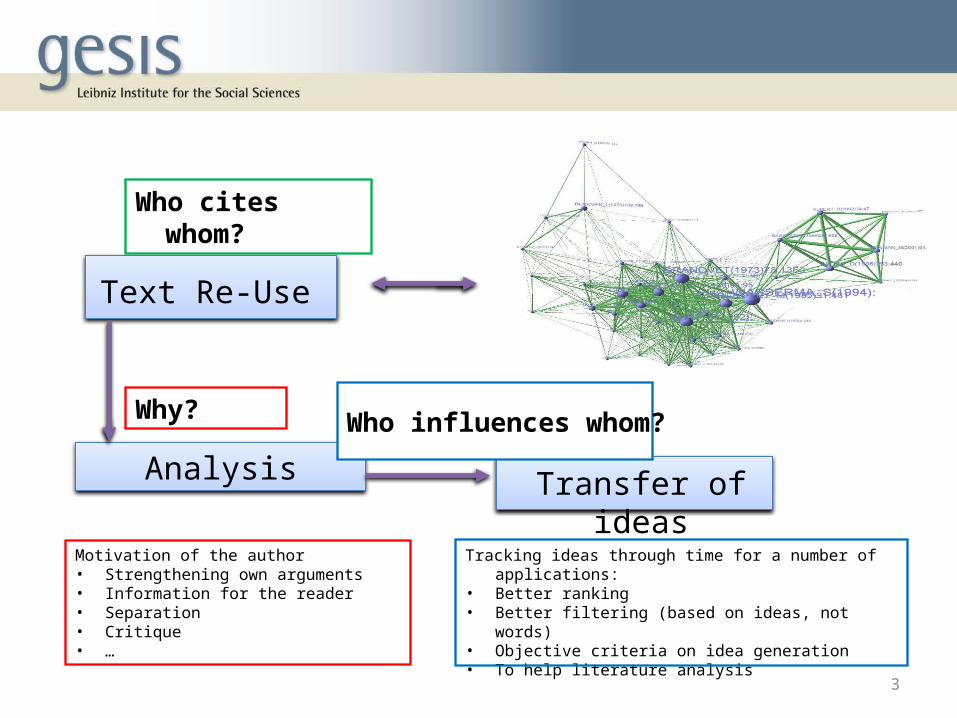
Text Re-Use
Analysis Transfer of ideas
Who cites whom?
Why?
Motivation of the author• Strengthening own arguments• Information for the reader• Separation• Critique• …
Tracking ideas through time for a number of applications: • Better ranking• Better filtering (based on ideas, not words)• Objective criteria on idea generation• To help literature analysis
Who influences whom?
3

Why eTRACES* is interesting
• Text re-use instead of bibliometrics to find inter-document relationships
• We are the first to use this on Social Sciences texts
• Analysis of citation intention• Results become immediately available to
the end user
4
*from GESIS point of view

AP 5.1 Social Scientific Annotation
5
• The Habermas-Luhmann-Debate– Habermas, Jürgen/Luhmann, Niklas (1971) Theorie der
Gesellschaft oder Sozialtechnologie. Was leistet die Systemforschung? Frankfurt/Main: Suhrkamp.
• We chose about 30 Documents in that context• The texts are annotated with CiTO (Citation Typing
Ontology)• Two dimensions: intention and type• The Method is based on qualitative social science
research– Especially reconstructive and sequential
analysis

Theoretical background for the Methodology
„Erzähltheorie“ by Fritz Schütze (1976, 1977)
Development of central categories for the formal analysis of stories („Erzählungen“)
Distinction between three different modes:story, description, argumentation/evaluation
Expansion for this project: Distinction between direct and indirect
citation and paraphrasing/summarizing of authors in scientific texts
6

Methodology
• We start with reconstructive and sequential text analysis
• When looking at citations, the functional reason for the citation is most important, which can be deduced from the overall context
• Texts are segmented within the text and differentiated according to mode
• That way describing, argumentative and evaluating passages can be identified and differentiated from the summarizing passages
7
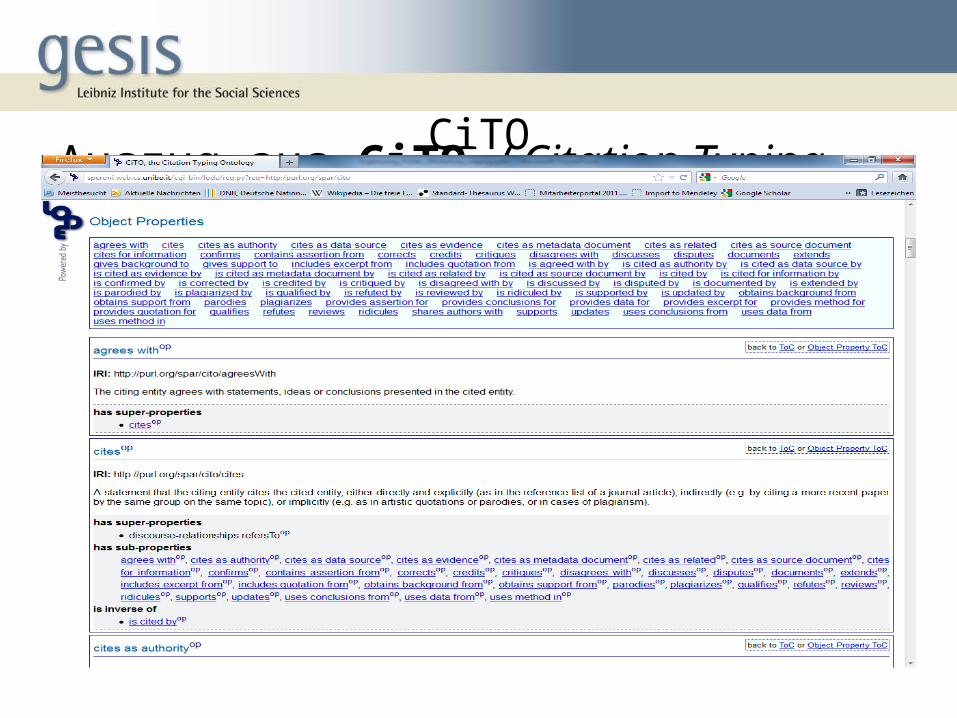
Auszug aus CiTO (Citation Typing Ontology)
CiTO

9
Direct Citation with Text-Reuse
Paraphrase with source
Text-Reuse w/o source Friedrich Schiller, Wilhelm Tell I,3 / Tell

10
Cites as authority
Refutes
Includes quotation from

Annotation
11

Goals of the annotation
• The annotation will be (is already) used to
– Train algorithms to find similar pattern automatically
– Make original social scientific research– Support bibliometrical research at our institute
• We plan to annotate a second distinctly different data set before the end of the project for comparison
12

AP 2 Data Cleansing
• The DGS corpus has 5,594 documents with 523,834 unique terms
• It includes the proceedings of the German Society for the Social Sciences spanning 100 years
• There are mostly German texts as PDF • Some are derived from OCR, newer ones have
been converted directly
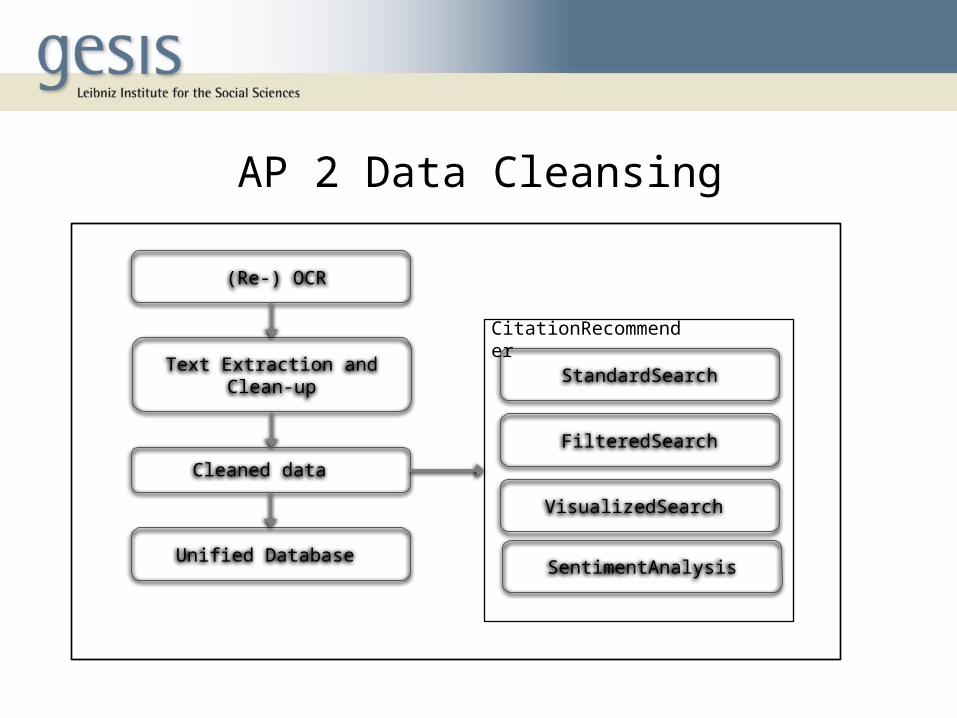
AP 2 Data Cleansing
(Re-) OCR
Text Extraction and Clean-up
FilteredSearch
Cleaned data
Unified Database
VisualizedSearch
StandardSearch
SentimentAnalysis
CitationRecommender
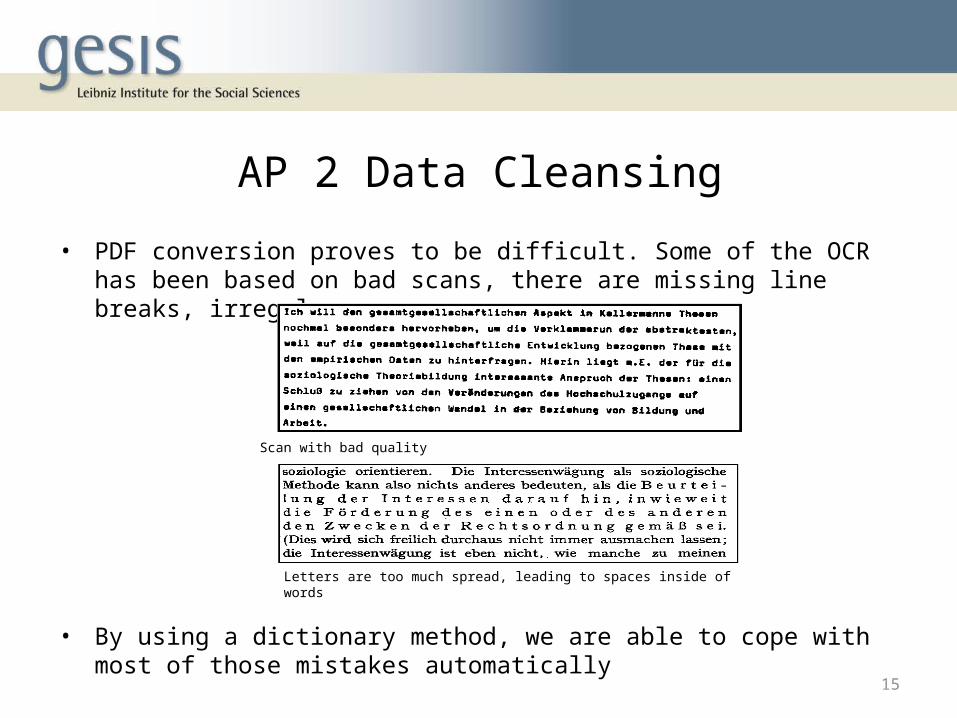
• PDF conversion proves to be difficult. Some of the OCR has been based on bad scans, there are missing line breaks, irregular spaces
• By using a dictionary method, we are able to cope with most of those mistakes automatically
15
Scan with bad quality
Letters are too much spread, leading to spaces inside of words
AP 2 Data Cleansing
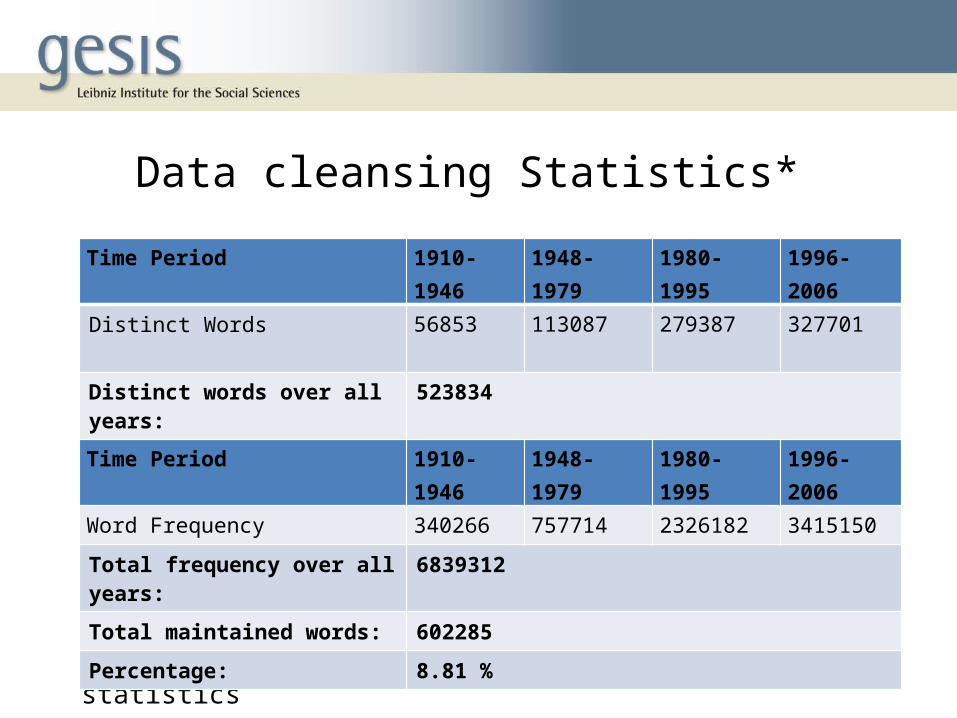
Data cleansing Statistics*
• 155 untreated OCR documents were automatically identified and Re-OCRed
* Function words were excluded from the corpus statistics16
Time Period 1910-1946 1948-1979 1980-1995 1996-2006
Distinct Words 56853 113087 279387 327701
Distinct words over all years: 523834
Time Period 1910-1946 1948-1979 1980-1995 1996-2006
Word Frequency 340266 757714 2326182 3415150
Total frequency over all years: 6839312
Total maintained words: 602285
Percentage: 8.81 %
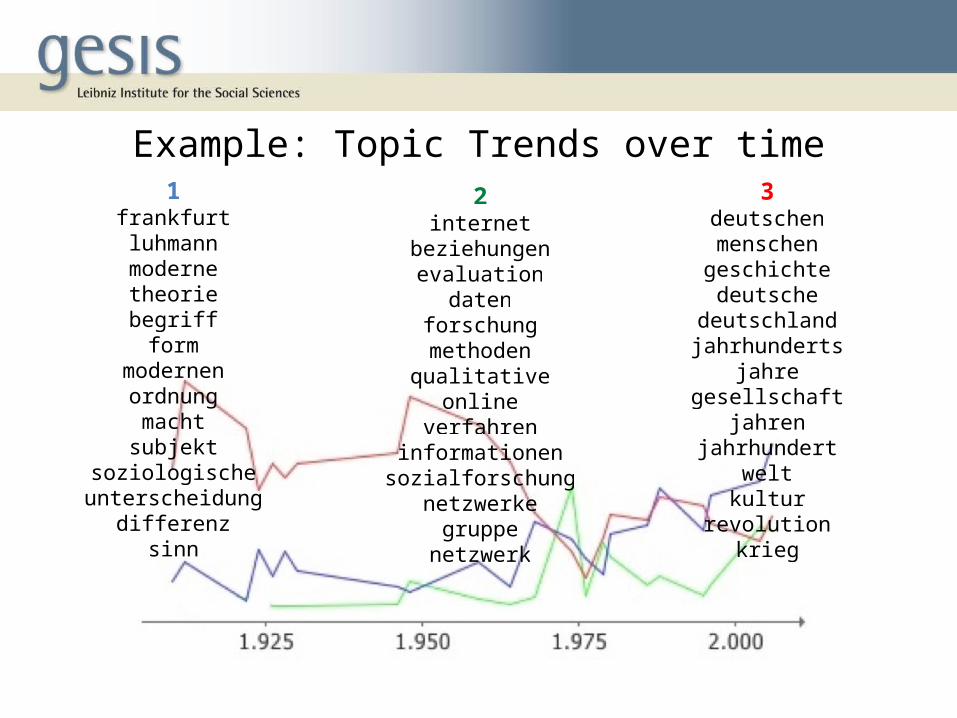
Example: Topic Trends over time1
frankfurtluhmannmodernetheoriebegriffform
modernenordnungmachtsubjekt
soziologischeunterscheidung
differenzsinn
2internet
beziehungenevaluation
datenforschungmethodenqualitative
onlineverfahren
informationensozialforschung
netzwerkegruppe
netzwerk
3deutschenmenschengeschichtedeutsche
deutschlandjahrhunderts
jahregesellschaft
jahrenjahrhundert
weltkultur
revolutionkrieg

First results with text re-use• At first we found mainly references and duplicate documents• The algorithm is very robust versus wrong space recognition• Example:
– In fact, Weber’s sociology of reli gion turned into an ambivalent intellectualist and moralistic affirmation of asceti cism, individualism, professionalism, and institutional rationalization.
– The affirmative project of modernity is largely engaged in a reversion of Nietzsche’s critique, turning it into an ambivalent intellectualist and moralistic affirmation of asceticism, individualism, professionalism, and institutional rationalization.
• We can see here that the context and intention is important
18

Components – Current Status
• StandardSeach is implemented ([Histo] Suche).• FilteredSearch: near duplicate can be filtered,
based on “Tracer” tool, ASV-Leipzig more filters are to come
• VisualisedSearch: supports users in exploring and navigating through the displayed result is still in the concept phase
• SentimentSearch: improve the retrieved results, by recommending specific articles to the user, also still in the concept phase
19

• Integrates all tools, available as mock-up
CitationRecommender
20
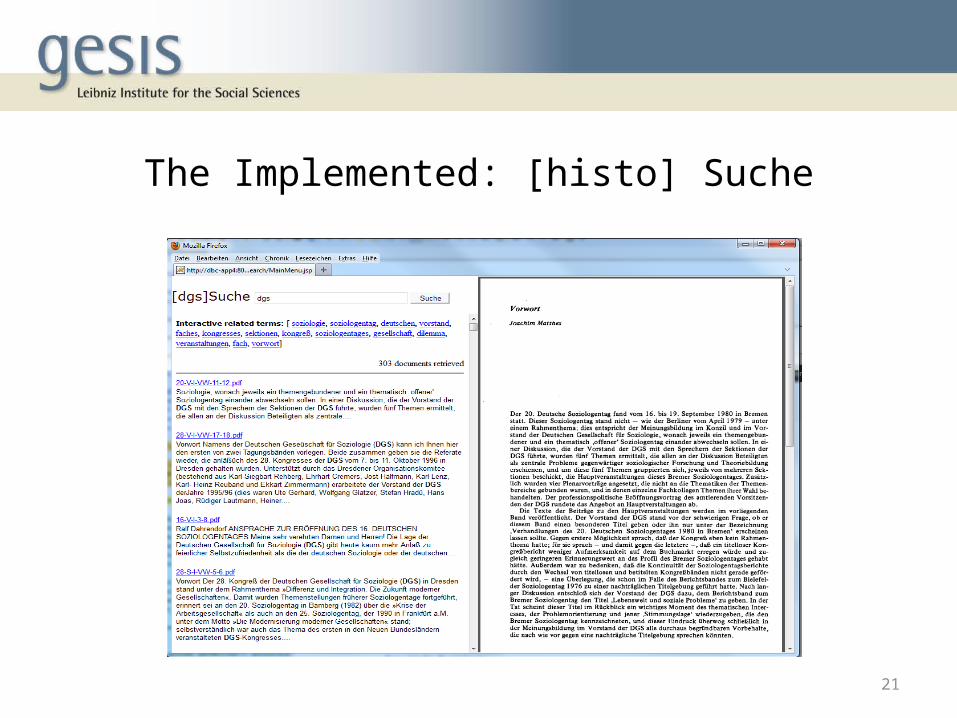
The Implemented: [histo] Suche
21

Sentiment Analysis
• The task of studying whether the expressed opinion in a piece of text is positive, negative, or neutral
• Why sentiment analysis is important :• Support a decision making (hearing others
opinion about a certain thing)• For our goal, to support citation search
e.g., ranking based on the work quality rather than citations frequency
22

Sentiment Analysis of Citation Challenges
• Citation context extraction:– Citation context boundaries can vary greatly.
Therefore a fixed window size might not effectively include all citation terms
– Citations that are in close proximity can interact with each other which leads to ownership ambiguity for the surrounding words
• Citing author motivation is not an easy to identify automatically e.g., is it persuasiveness or to notify the reader about something or positive, negative or neutral mining
23

Sentiment Analysis of Citation Challenges
• Not much work has been done in this regard, but esp. for Humanities it is very relevant
• It is a very tough problem, therefore even small advances are valuable, e.g. semi-automatic or partial processes
24

Sentiment Analysis of CitationMain Components
• In order to perform a sentiment analysis of citation, we need:
• Citing author information (name, address, organization etc.)
• Citing article information (paper id, title, place of publication etc.)
• Citation context (which words the citing author used to describe the cited article)
• Cited article information – Author information– Paper information
25

Author Information Structure
26

Paper Information Structure
27

Citation Information Structure
28
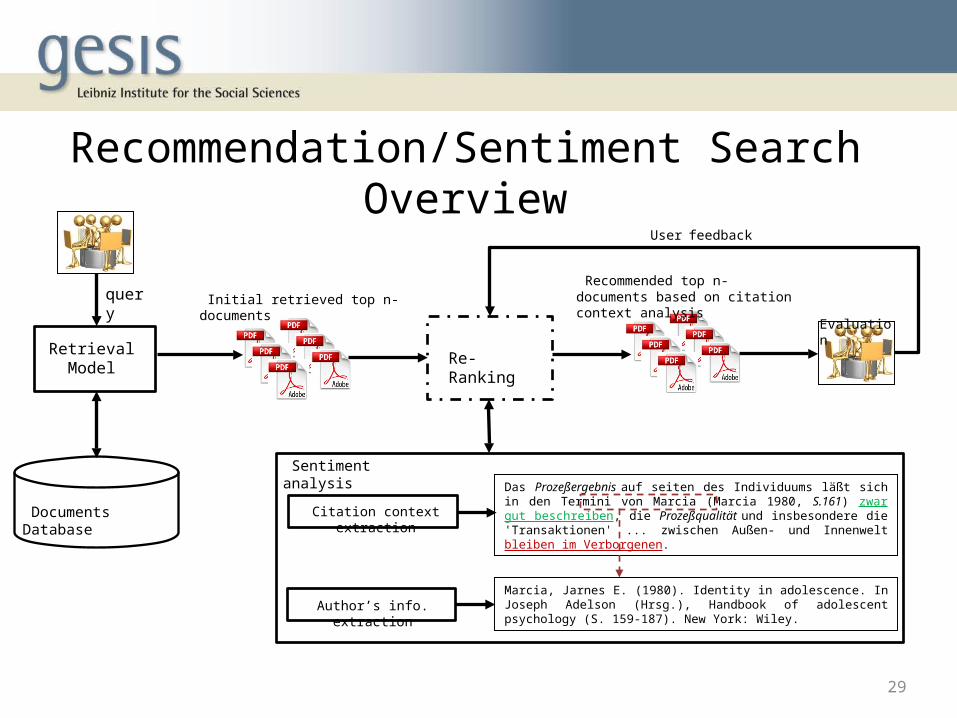
Recommendation/Sentiment Search Overview
29
Retrieval Model
query
Documents Database
Re-Ranking
Initial retrieved top n-documents
Sentiment analysis
Recommended top n-documents based on citation context analysis
Citation context extraction
Author’s info. extraction
Das Prozeßergebnis auf seiten des Individuums läßt sich in den Termini von Marcia (Marcia 1980, S.161) zwar gut beschreiben, die Prozeßqualität und insbesondere die 'Transaktionen' ... zwischen Außen- und Innenwelt bleiben im Verborgenen.
Marcia, Jarnes E. (1980). Identity in adolescence. In Joseph Adelson (Hrsg.), Handbook of adolescent psychology (S. 159-187). New York: Wiley.
Evaluation
User feedback
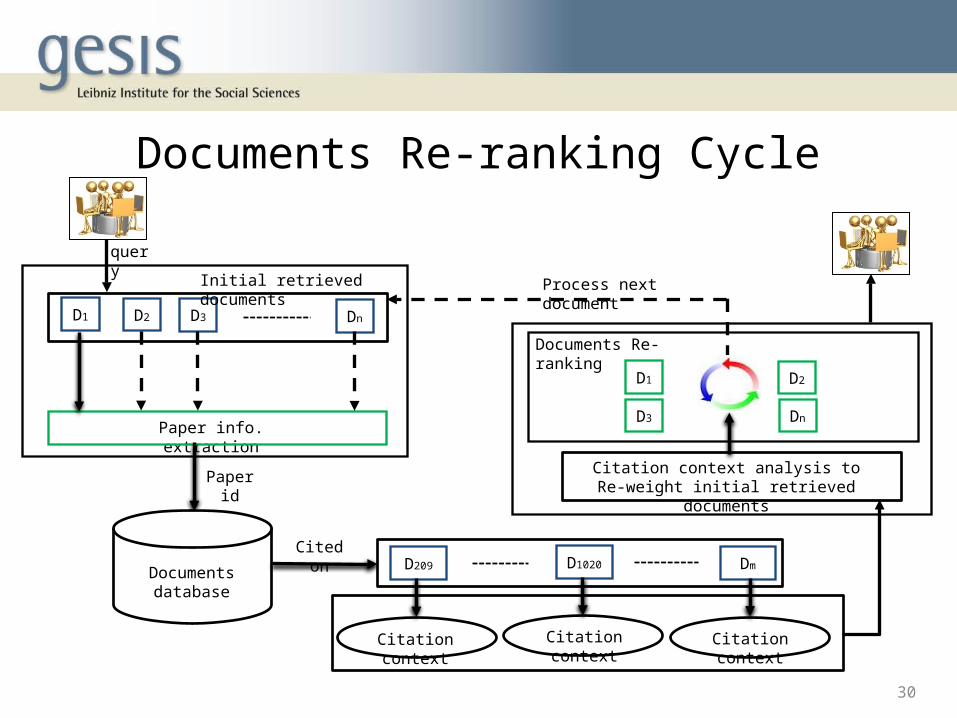
Documents Re-ranking Cycle
30
query
D1 D2 D3 Dn
Paper info. extraction
Paper id
Documents database
Citation context analysis to Re-weight initial retrieved documents
D1 D2
D209 D1020
Initial retrieved documents
Cited on
Citation context Citation context Citation context
Dn
Documents Re-ranking
D3
Process next document
Dm
More Future Work
31
• Based on the citation temperature used in eAqua
• We will color often cited works (e.g. Luhmann, Marx, Weber) based on the citation context
• Agreeable sections will be distinguishable from controversial and from negatively judged sections

Conclusion
• Text re-use instead of bibliometrics to find inter-document relationships
• Build interactive tool to support effectively citation context extraction
• In eTRACES citation ranking will be done based on the work quality rather than citations frequency
• CitationRecommender supports social scientists to perform their information search tasks in an effective way
32





![QDDS [ Questionnaire Developmen Documentation System ] State and strategy for DDI 3 oliver.hopt@gesis.org andias.wira-alam@gesis.org 1.](https://static.fdocuments.in/doc/165x107/56649d425503460f94a1d1bb/qdds-questionnaire-developmen-documentation-system-state-and-strategy-for.jpg)
![MISSY 2 [ Microdata Information System – part 2] andias.wira-alam@gesis.org oliver.hopt@gesis.org 1 Implementing DDI 3: The German Microcensus Case Study.](https://static.fdocuments.in/doc/165x107/56649d255503460f949fb60a/missy-2-microdata-information-system-part-2-andiaswira-alamgesisorg.jpg)











