
Fundamentals of Statistical Signal Processing: Estimation ...
Upload
mercy-hancockCategory
view
215download
1
Estimation of authenticity of results of statistical
research

The necessity estimation of authenticity of results is determined by volume of research.
In full research (general aggregate), when all units of supervision are explored it is possible to get only one value of certain index.
The general aggregate is always reliable because in it included her all units of supervision are included. General aggregate official statistics can exemplify.

The distribution of birthwt is shown.


ObjectiveTo describe the distribution and frequency
of a disease in population.

Four primary types of epidemiology studies

How to describe ?
What is the problem of the disease?
How frequent ?
Who are affected?----person
Where and when does it occur?----place and time

Three distributions
Place Person
Time

Population
Age Behavior
SexRace

1 Age Frequency of disease
Severity of disease
Young people : infectious disease
Old people: noninfectious disease accumulation of environmental factors


Examples Children are more susceptible to some
infectious diseases, measles Prevalence of hypertension increase
with age



Mortality rate ---Age
Figure 6-1

incidence rate---Age
Figure 6-2

Serum HDL-cholesterol in Tromsø 1994/95
1
1,5
2 Men
Women
25-29 35-39 45-49 55-59 65-69 75-79 85-89 30-34 40-44 50-54 60-64 70-74 80-84
ISM, UiT
HDL-cholesterol mmol/L
The Tromsø Study
age

Sex
Frequencies and severity of disease differ between male and female population.
It is helpful to identify the risk factor of disease
e.g. endemic struma female > male

Prevalence of obesity in Han students aged 8-18 years in Urumqi , 2003
0. 0
2. 0
4. 0
6. 0
Age, y
Prev
alen
ce,%
Mal e
Femal e

Race (ethnic) Obesity, hypertension are more
prevalent in blacks than in whites T2D is very prevalent in Pima indians Prevalence of hypertension is quite
different among ethnicities.
Why? Genetic
Environment

Prevalence of obesity among ethnicities (adjusted by age)
4
4, 2
4, 4
4, 6
4, 8
5
5, 2
5, 4
5, 6
Han Hui Uygur KazakEthnicities
Pre
vale
nce o
f ob
esity
%

Prevalence of EH among ethnic adults (1991)

Death rate in the U.S.
Blacks: cause of deaths: hypertensive heart disease, stroke, tuberculosis, syphilis, and accidental death.
Whites: cardio artery disease, suicide, and leukemia.

Behaviors Cigarette smoking, alcohol consumption,
abuse of drugs; high salt intake, fat food, and so on.
Determined by biological and social factors.

Place
Countries
Urban and ruralPlacesin different altitude

Estimated number of people at over 35% risk of a major cardiovascular event in the next decade, by WHO sub-region

CHD mortality. Women and men, age adjusted rates per 100.000.
34
59
75
85
118
156
169
170
173
224
233
241
296
383
432
0 50 100 150 200 250 300 350 400 450 500
Japan
France
Spain
Portugal
Netherlands
Germany
Norway
USA
Sweden
Finland
Denmark
England Wales
Scotland
Russia
Estonia
Source: WHO Health statistics annual 1993/94 ISM, UiT

Time
When does the disease occur and transmit in the population?

Mean Plasma Cholesterol Values in China
0
50
100
150
200
250
mg/
dl
1958 1981 1997 2003

Some terms to describe the “time” of diseases
Long-term or secular trends Periodic fluctuations (cyclical changes)
seasonal trends
cyclical trends Short term fluctuations

Secular trends
Changes in the incidence of disease over a long period of time (several years of decades)
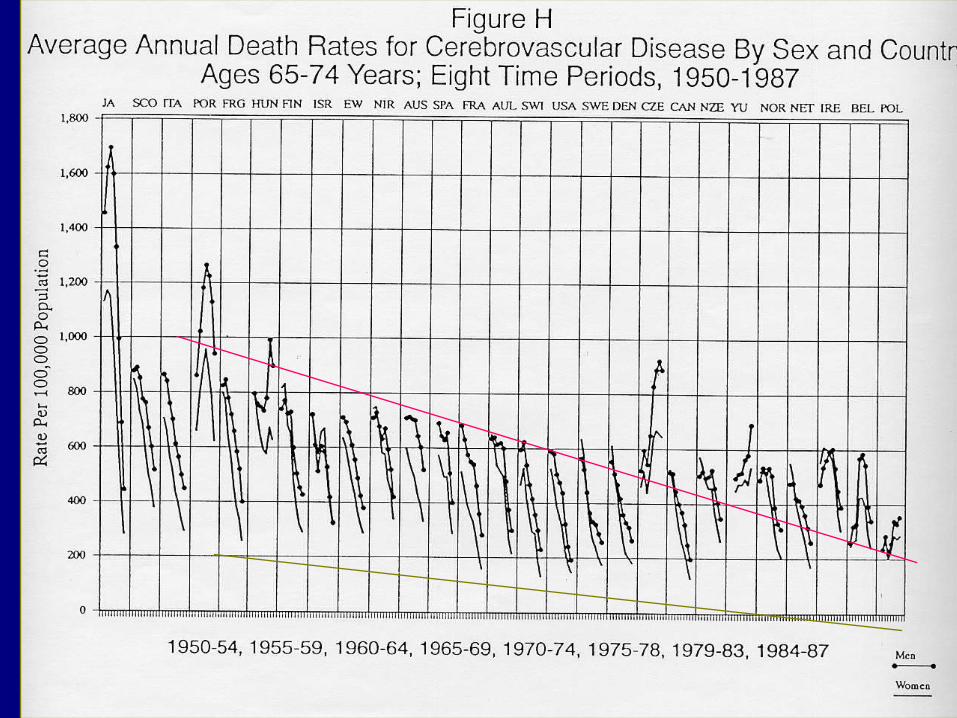
CHD have shown an upward trend in developed countries over decades.

Periodic fluctuations
1. Seasonal trends Diarrhea---summer Respiratory diseases---winter2. Cyclical trends disease occur in cycles spread over
short periods of time (day, weeks, months or years) e.g. influenza 7-10 yrs)

The general aggregate is rarely used in medical-biologic research, mainly part of researches is selective. The law of large numbers is basis for forming of reliable selective aggregate. It sounds so: it is possible to assert with large authenticity, that at achievement of large number of supervisions average of sign, which is studied in a selective aggregate will be a little to differ from an average which is studied at all general aggregate.

The selective aggregate always has errors, because not all units of supervision are included in research. Authenticity of selective research depends from the size of this error. That is why greater number of supervisions, teed to less error, the less sizes of casual vibrations of index. That, to decrease an error it is needed to multiply the number of supervisions.

Basic criteria of authenticity (representation):
Error of representation (w) Confiding scopes The coefficient of authenticity (the student
criterion) is authenticity of difference of middle or relative sizes (t)


Basic criteria of authenticity (representation):
The errors of representation of /m/ are the degree of authenticity of average or relative value shows how much the results of selective research differ from results which it is possible to get from continuous study of general aggregate.

Basic criteria of authenticity (representation):
Confiding scopes – properties of selective aggregate are carried on general one, probability oscillation of index is shown in the general aggregate, its extreme values of minimum and maximal possibility, which the size of general aggregate can be within the limits of.

Basic criteria of authenticity (representation):
The coefficient of authenticity (the Student’s criterion) is authenticity of difference of middle or relative sizes (t). The student’s Criterion shows the difference of the proper indexes in two separate selective aggregates.

Measuring the Occurrence of Disease
Counting
Comparisons
Inference
Action
Cases and populations
Measurement
Risk
Methods - descriptive
- analytic
Association and causality
Generalisability
Clinical/health policy
Further research

Epidemiological Measurements
Rates,Ratios,and Proportions Incidence Rates Prevalence Rates Mortality Rates Fatality Rates Infection Rates

RatiosA ratio expresses the relationship
between two numbers in the form x:y or x/y.

Ratios
1. The ratio of male to female births in the United States in 1979 was 1,791,000 : 1,703,000 or 1.052:1.
2. Sex ratio=
number of live born males
number of live born females

Proportions
A proportion is a specific type of ratio in which the numerator is included in the denominator, and the result value is expressed as a percentage.
For example,the proportion of all births that were male is :
Male births 179×104
= Male+female births (179+170)×104
=51.3%

The proportion of male students of the current class is %.


51. 41 51. 33 51. 07 48. 70
48. 39 48. 67 48. 93 51. 30
0
20
40
60
80
100
120
Han Hui Uygur Kazak
Mal e Femal e
n=41640 n=4736 n=6362 n=2770

Proportion of Overweight in children from 7-18 year old, Urumqi, 2003
Gi r l
0. 0
2. 0
4. 0
6. 0
8. 0
Obesi ty Overwei ght
Prev
alen
ce,%
Han Hui Uygur Kazak

A rate measures the occurrence of some particular events in a
population during a given time period.
Particular event: development of disease or the occurrence of death
Rates

Rates are defined as follows:
Number of events in a specified period
×K
Population at risk of these events in a specified period
K=100%, 1000‰ …

Five components of rateDenominator
is the population at risk of
total events
Place specification
at a given time
Time specification
Constant
multiplier K
Numerator is the number of
People,Episodes

Rate is
The rate is the measure that most clearly expresses probability or risk of disease in a defined population over a specified period of time.
In a rate numerator is part of denominator.

What does Rate tell us
Rates tell us how fast the disease is occurring in a population.
Proportion tell us what fraction of the population is affected.

For example, the death rate from cancer in the United States in 1980 was 186.3 per 100,000 population, the formula:
Deaths from cancer among U.S residents in 1980 100,000
×
U.S. population in 1980 100,000

Incidence Rates
Incidence is defined as the number of new cases of a disease that occur during a specified period of time in a population at risk for developing the disease.

1. Time of onset and the numerator

Denominator is population at risk.
Average Population
We can get this number in two ways. (population in 12.31 of last year+this year)/2
midyear population: 7.31 24:00
3.Specification of Denominator

Prevalence Rates
Prevalence measures the number of people in a population who have disease at a given time.
Point prevalence Period prevalence


Formula:
number of existing cases of a disease
at a point in time ×K
total population

5 points
1.NumeratorIt refers to existing cases, currently
affected, including new and old cases.No matter when did he get the disease, if
only he has disease at the study time,he is one of numerator.

2.Denominator
Total population.
Not population at risk.

3.A point in time
In survey of prevalence rate, time should be very short.
Generally, time should be no more than 1 month, such as 1 week or 2 weeks. (point prevalence)

Coefficient of variation is the relative measure of variety; it is a percent correlation of standard deviation and arithmetic average.

Terms Used To Describe The Quality Of Measurements
Reliability is variability between subjects divided by inter-subject variability plus measurement error.
Validity refers to the extent to which a test or surrogate is measuring what we think it is measuring.

Measures Of Diagnostic Test Accuracy
Sensitivity is defined as the ability of the test to identify correctly those who have the disease.
Specificity is defined as the ability of the test to identify correctly those who do not have the disease.
Predictive values are important for assessing how useful a test will be in the clinical setting at the individual patient level. The positive predictive value is the probability of disease in a patient with a positive test. Conversely, the negative predictive value is the probability that the patient does not have disease if he has a negative test result.
Likelihood ratio indicates how much a given diagnostic test result will raise or lower the odds of having a disease relative to the prior probability of disease.

Measures Of Diagnostic Test Accuracy

Expressions Used When Making Inferences About Data
Confidence Intervals- The results of any study sample are an estimate of the true value
in the entire population. The true value may actually be greater or less than what is observed.
Type I error (alpha) is the probability of incorrectly concluding there is a statistically significant difference in the population when none exists.
Type II error (beta) is the probability of incorrectly concluding that there is no statistically significant difference in a population when one exists.
Power is a measure of the ability of a study to detect a true difference.

Multivariable Regression Methods
Multiple linear regression is used when the outcome data is a continuous variable such as weight. For example, one could estimate the effect of a diet on weight after adjusting for the effect of confounders such as smoking status.
Logistic regression is used when the outcome data is binary such as cure or no cure. Logistic regression can be used to estimate the effect of an exposure on a binary outcome after adjusting for confounders.

Survival Analysis
Kaplan-Meier analysis measures the ratio of surviving subjects (or those without an event) divided by the total number of subjects at risk for the event. Every time a subject has an event, the ratio is recalculated. These ratios are then used to generate a curve to graphically depict the probability of survival.
Cox proportional hazards analysis is similar to the logistic regression method described above with the added advantage that it accounts for time to a binary event in the outcome variable. Thus, one can account for variation in follow-up time among subjects.

Kaplan-Meier Survival Curves

Why Use Statistics?
Cardiovascular Mortality in Males
0
0.2
0.4
0.6
0.8
1
1.2
'35-'44 '45-'54 '55-'64 '65-'74 '75-'84
SMR Bangor
Roseto

Descriptive Statistics
Identifies patterns in the data Identifies outliers Guides choice of statistical test

Percentage of Specimens Testing Positive for RSV (respiratory syncytial virus)
Jul Aug Sep Oct Nov Dec Jan Feb Mar Apr May Jun
South 2 2 5 7 20 30 15 20 15 8 4 3
North-east
2 3 5 3 12 28 22 28 22 20 10 9
West 2 2 3 3 5 8 25 27 25 22 15 12
Mid-west
2 2 3 2 4 12 12 12 10 19 15 8

Descriptive Statistics
Percentage of Specimens Testing Postive for RSV 1998-99
0
5
10
15
20
25
30
35
Jul Sep Nov Jan Mar May Jul
SouthNortheastWestMidwest

Distribution of Course Grades
0
2
4
6
8
10
12
14
Number of Students
A A- B+ B B- C+ C C- D+ D D- F
Grade

Describing the Data with Numbers
Measures of Dispersion• RANGE • STANDARD DEVIATION• SKEWNESS

Measures of Dispersion
• RANGE • highest to lowest values
• STANDARD DEVIATION• how closely do values cluster around the
mean value• SKEWNESS
• refers to symmetry of curve

The Normal Distribution
Mean = median = mode
Skew is zero 68% of values fall
between 1 SD 95% of values fall
between 2 SDs
.
Me
an
, Med
ian
, Mo
de
1
2



















