
Essential ingredients for real time stream processing @Scale by Kartik pParamasivam at Big Data...
48
-
Upload
big-data-spain -
Category
Technology
-
view
264 -
download
1
Transcript of Essential ingredients for real time stream processing @Scale by Kartik pParamasivam at Big Data...


Essential Ingredients of Stream Processing @
ScaleKartik Paramasivam

About Me
• ‘Streams Infrastructure’ at LinkedIn – Pub-sub messaging : Apache Kafka– Change Capture from various data systems:
Databus– Stream Processing platform : Apache Samza
• Previous– Built Microsoft Cloud Messaging (EventHub)
and Enterprise Messaging(Queues/Topics)– .NET WebServices and Workflow stack – BizTalk Server

Agenda
• What is Stream Processing ?• Scenarios• Canonical Architecture• Essential Ingredients of Stream
Processing• Close

Response latency
Stream processing
Milliseconds to minutes
RPC
Synchronous Later. Possibly much later.
0 ms

Agenda
• Stream processing Intro• Scenarios• Canonical Architecture• Essential Ingredients of Stream
Processing• Close

Newsfeed

Cyber-security

Internet of Things

Agenda
• Stream processing Intro• Scenarios• Canonical Architecture• Essential Ingredients of Stream
Processing• Close

CANONICAL ARCHITECTURE
Data-Bus
Data-Bus
Real Time Processing (Samza)
Real Time Processing (Samza)
Batch Processing
(Hadoop/Spark)
Batch Processing
(Hadoop/Spark)
Voldemort R/O
Voldemort R/O
e.g.Espress
o
e.g.Espress
o
Processing
Bulk upload
EspressoEspresso
Services TierServices Tier
Ingestion Serving
Clients(browser,devices, sensors ….)
KafkaKafka

Agenda
• Stream processing Intro• Scenarios• Canonical Architecture• Essential Ingredients of Stream
Processing• Close

Essential Ingredients to Stream Processing
1.Scale2.Reprocessing3.Accuracy of results4.Easy to program

SCALE.. but not at any cost

Basics : Scaling Ingestion
- Streams are partitioned
- Messages sent to partitions based on PartitionKey
- Time based message retention
Stream A
producersproducers
Pkey=10
consumerA(machine1)consumerA(machine1)
consumerA(machine2)consumerA(machine2)
Pkey=25 Pkey=45
e.g. Kafka, AWS Kinesis, Azure EventHub

Scaling Processing.. E.g. Samza
Stream A
Task 1Task 1 Task 2Task 2 Task 3Task 3
Stream B
Samza Job

Samza – Streaming Dataflow
Stream A
Stream c
Stream D
Job 1
Job 2
Stream B

Horizontal Scaling is great ! But..
• But more machines means more $$
• Need to do more with less.• So what’s the key bottleneck
during Event/Stream Processing ?

Key Bottleneck: “Accessing Data”
• Big impact on CPU, Network, Disk
• Types of Data Access 1. Adjunct data – Read only data2. Scratchpad/derived data - Read-
Write data

Adjunct Data – typical access
KafkaKafka
AdClicks Processing Job
Processing Job
AdQuality update
KafkaKafka
Member
Database
Member
Database
Read Member Info
Concerns1. Latency2. CPU3. Network4. DDOS

Scratch pad/Derived Data – typical access
KafkaKafka
Sensor Data
Processing Job
Processing Job
Alerts
KafkaKafka
DeviceState
Database
DeviceState
Database
Concerns1. Latency2. CPU3. Network4. DDOS
Read + Update per Device Info

Adjunct Data – with Samza
KafkaKafka
AdClicks
Processing Job
outputKafkaKafka
Member Databas
e(espress
o)
Member Databas
e(espress
o)DatabusDatabus
Kafka, Databus, Database, Samza Job are all partitioned by MemberId
Member Updates
Task1Task1
Task2Task2
Task3Task3
Rocks D
bR
ocks D
b

Fault Tolerance in a stateful Samza job
P0
P1
P2
P3
Task-0Task-0 Task-1Task-1 Task-2Task-2 Task-3Task-3
P0P1
P2
P3
Host-A Host-B Host-C
Changelog Stream
Stable State

Fault Tolerance in a stateful Samza job
P0
P1
P2
P3
Task-0Task-0 Task-1Task-1 Task-2Task-2 Task-3Task-3
P0P1
P2
P3
Host-A Host-B Host-C
Changelog Stream
Host A dies/fails
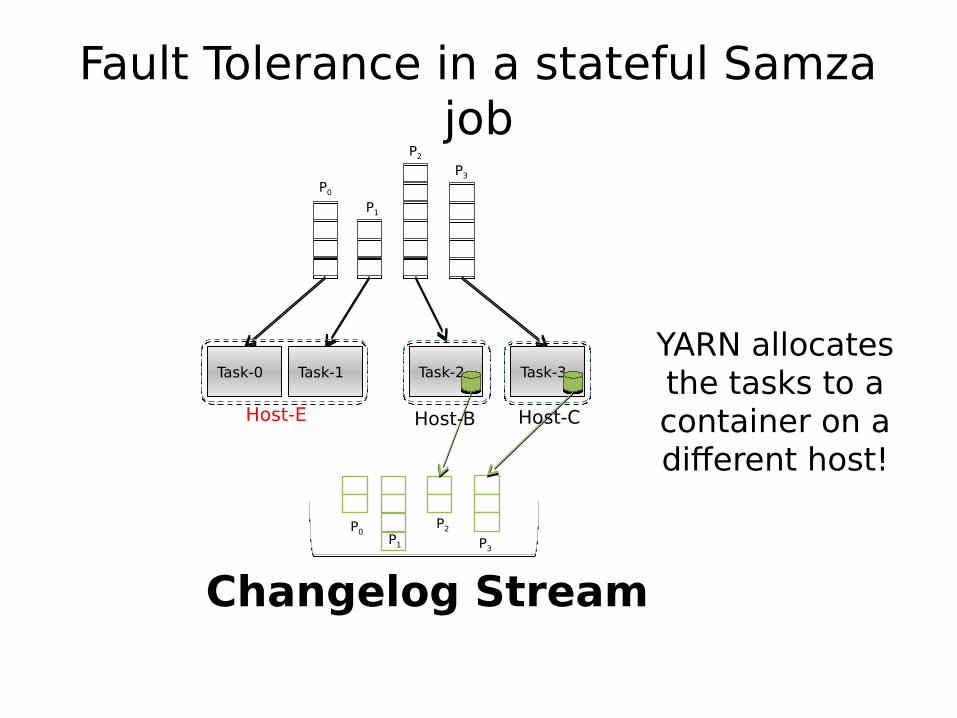
Fault Tolerance in a stateful Samza job
P0
P1
P2
P3
Task-0Task-0 Task-1Task-1 Task-2Task-2 Task-3Task-3
P0P1
P2
P3
Host-E Host-B Host-C
Changelog Stream
YARN allocates the tasks to a container on a different host!
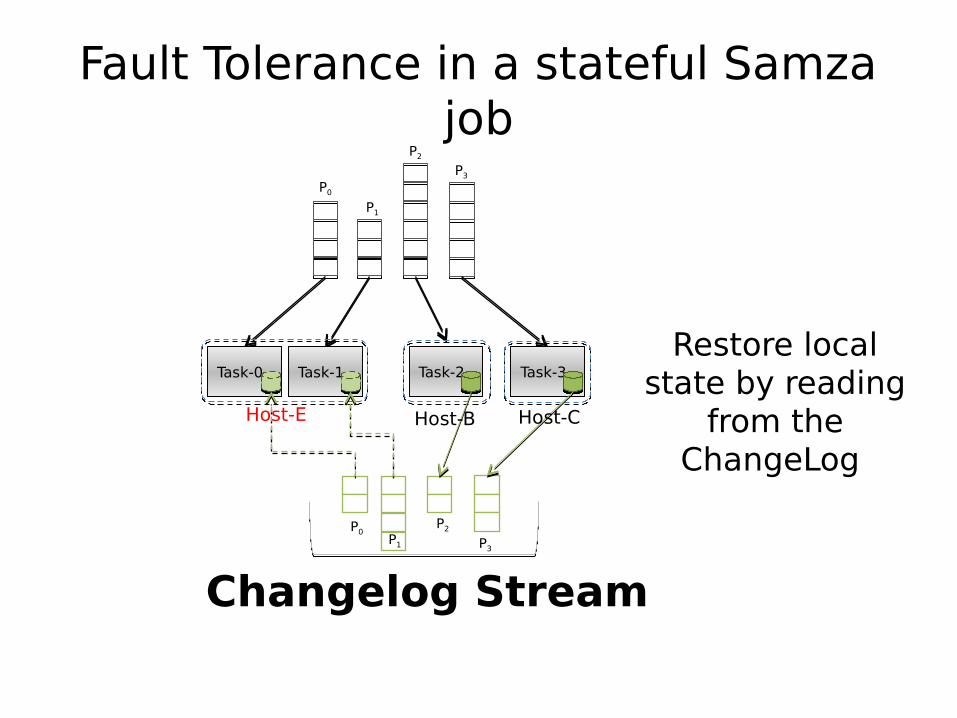
Fault Tolerance in a stateful Samza job
P0
P1
P2
P3
Task-0Task-0 Task-1Task-1 Task-2Task-2 Task-3Task-3
P0P1
P2
P3
Host-E Host-B Host-C
Changelog Stream
Restore local state by reading
from the ChangeLog

Fault Tolerance in a stateful Samza job
P0
P1
P2
P3
Task-0Task-0 Task-1Task-1 Task-2Task-2 Task-3Task-3
P0P1
P2
P3
Host-E Host-B Host-C
Changelog Stream
Back to Stable State

Hardware Spec: 24 cores, 1Gig NIC, SSD
• (Baseline) Simple pass through job with no local state – 1.2 Million msg/sec
• Samza job with local state – 400k msg/sec
• Samza job with local state with Kafka backup– 300k msg/sec
Performance Numbers with Samza

Local State - Summary
• Great for both read-only data and read-write data
• Secret sauce to make local state work 1. Change Capture System:
Databus/DynamoDB streams2. Durable backup with Kafka Log
Compacted topics

Essential Ingredients to Stream Processing
1.Scale2.Reprocessing 3.Accuracy of results4.Easy to program

REPROCESSING

Why do we need it ?
• Software upgrades.. Yes bugs are a reality
• Business logic changes• First time job deployment

Reprocessing Data – with Samza
outputKafkaKafka
Member Databas
e(espress
o)
Member Databas
e(espress
o)
DatabusDatabus
Member Updates
Company/Title/Location
StandardIzation
Job
Company/Title/Location
StandardIzation
Job
Machine
Learning
model
Machine
Learning
model
bootstrap

Reprocessing- Caveats
• Stream processors are fast.. They can DOS the system if you reprocess – Control max-concurrency of your job– Quotas for Kafka, Databases– Async load into databases (Project Venice)
• Capacity– Reprocessing a 100 TB source ?
• Doesn’t reprocessing mean you are no-longer being real-time ?

Essential Ingredients to Stream Processing
1.Scale but at not at any cost
2.Reprocessing 3.Accuracy of results4.Easy to Program

ACCURACY OF RESULTS

Querying over an infinite stream
1.00
pm
Ad View Event
1:01pm
Ad Click Event
AdQuality
Processor
AdQuality
ProcessorUser1
Did user click the Ad within 2 minutes of seeing the Ad

WHY DELAYS HAPPEN ?
Ad Quality Processor(Samza)
Ad Quality Processor(Samza)
Services TierServices Tier
KafkaKafka
Services TierServices Tier
Ad Quality Processor(Samza)
Ad Quality Processor(Samza)
KafkaKafka
Mirrored
kartik
DATACENTER 1
DATACENTER 2
AdViewEvent
LB

WHY DELAYS HAPPEN ?
Real Time Processing (Samza)
Real Time Processing (Samza)
Services TierServices Tier
KafkaKafka
Services TierServices Tier
Real Time Processing (Samza)
Real Time Processing (Samza)
KafkaKafka
Mirrored
kartik
DATACENTER 1
DATACENTER 2
AdClick Event
LB

What do we need to do to get accurate results?
Deal with• Late Arrivals
– E.g. AdClick event showed up 5 minutes late.
• Out of order arrival– E.g. AdClick event showed up before
AdView event
• Influenced by “Google MillWheel”
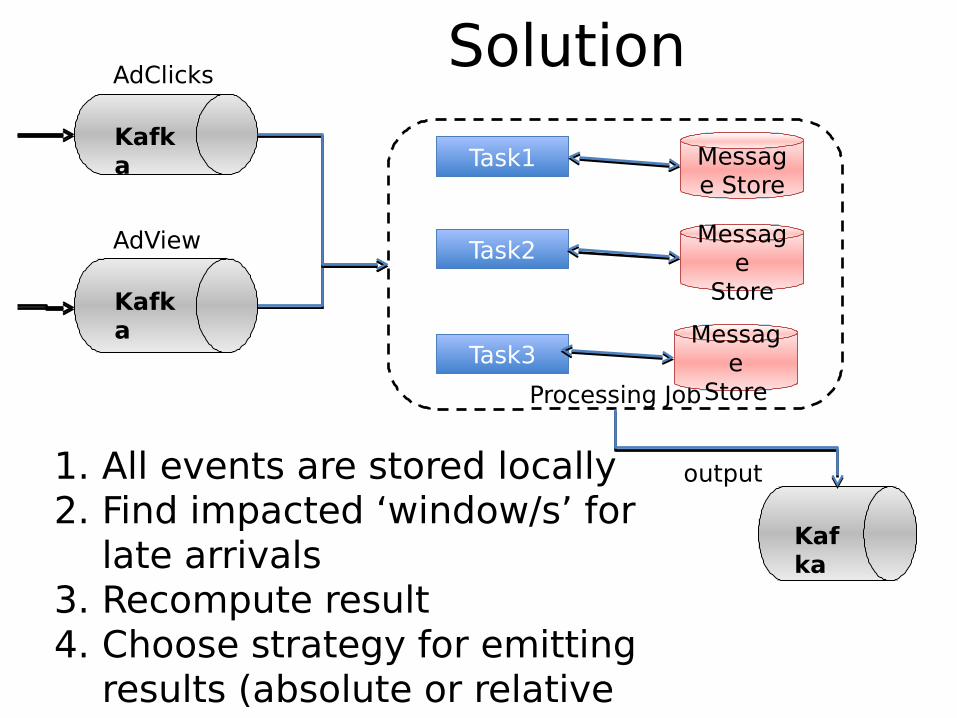
SolutionKafkaKafka
AdClicks
Processing Job
output
KafkaKafka
Task1Task1
Task2Task2
Task3Task3
Message StoreMessage Store
KafkaKafka
AdView Message
Store
Message
Store
Message
Store
Message
Store
1. All events are stored locally2. Find impacted ‘window/s’ for
late arrivals3. Recompute result4. Choose strategy for emitting
results (absolute or relative value)

Myth: This isn’t a problem with Lambda Architecture..
• Theory: Since the processing happens 1 hour or several hours later delays are not a problem.
• Ok.. But what about the “edges”– Some “sessions” start before the cut off
time for processing.. And end after the cut off time.
– Delays and out of order processing make things worse on the edges

Essential Ingredients to Stream Processing
1.Scale but at not at any cost
2.Reprocessing 3.Accuracy of results4.Easy Programmability

Easy Programmability
• Support for “accurate” Windowing/Joins.( Google Cloud Dataflow )
• Ability to express workflows/DAGs in config and DSL (e.g. Storm)
• SQL support for querying over streams– Azure Stream Insight
• Apache Samza – working on the above

Agenda
• Stream processing Intro• Scenarios• Canonical Architecture• Essential Ingredients of Stream
Processing• Close

Some scale numbers at LinkedIn
• 1.3 Trillion Messages get ingested into Kafka per day – Each message gets consumed 4-5 times
• Database change capture :– A few Trillion Messages get consumed
per week
• Samza jobs in production which process more than 1 Million messages/sec

References
• http://samza.apache.org/• http://kafka.apache.org/ • https://github.com/linkedin/databus • http://cs.brown.edu/~ugur/
8rulesSigRec.pdf• http://www.cs.cmu.edu/~pavlo/courses
/fall2013/static/papers/p734-akidau.pdf

Thank You!


















