
Enterprise information extraction: recent developments and open challenges
122
© 2009 IBM Corporation Enterprise Information Extraction SIGMOD 2010 Tutorial Frederick Reiss, Yunyao Li, Laura Chiticariu, and Sriram Raghavan IBM Almaden Research Center
-
Upload
yunyao-li -
Category
Technology
-
view
791 -
download
0
Transcript of Enterprise information extraction: recent developments and open challenges

© 2009 IBM Corporation
Enterprise Information Extraction
SIGMOD 2010 Tutorial
Frederick Reiss, Yunyao Li, Laura Chiticariu, and Sriram Raghavan
IBM Almaden Research Center

© 2009 IBM Corporation2
Who we are
Researchers from the Search and Analytics group at IBM Almaden Research Center
– Frederick Reiss
– Yunyao Li
– Laura Chiticariu
– Sriram Raghavan (virtual)
Working on information extraction since 2006-08
– SystemT project
– Code shipping with 8 IBM products

© 2009 IBM Corporation3
Road Map
What is Information Extraction? (Fred Reiss)
Declarative Information Extraction (Fred Reiss)
What the Declarative Approach Enables
– Scalable Infrastructure (Yunyao Li)
– Development Support (Laura Chiticariu)
Conclusion / Q&A (Fred Reiss)
You are here

© 2009 IBM Corporation4
Obligatory “What is Information Extraction?” Slide Distill structured data from unstructured and semi-structured text
Exploit the extracted data in your applications
For years, Microsoft Corporation CEO Bill Gates was against open source. But today he appears to have changed his mind. "We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“
Richard Stallman, founder of the Free Software Foundation, countered saying…
Name Title OrganizationBill Gates CEO MicrosoftBill Veghte VP MicrosoftRichard Stallman Founder Free Soft..
(from Cohen’s IE tutorial, 2003)
AnnotationsAnnotations

© 2009 IBM Corporation5
SIGMOD 2006 Tutorial [Doan06] in One Slide
Information extraction has been an area of study in Natural Language Processing and AI for years
Core ideas from database research not a part of existing work in this area
– Declarative languages– Well-defined semantics– Cost-based optimization
The challenge: Can we build a “System R” for information extraction?
Survey of early-stage projects attacking this problem
Bibliography at the end of the slide deck.

© 2009 IBM Corporation6
What’s new?
New enterprise-focused applications…
…driving new requirements…
…leading to declarative approaches

© 2009 IBM Corporation7
Enterprise Applications of Information Extraction
Previous tutorial showed research prototypes– Avatar: Semantic search on personal emails– DBLife: Use IE to build a knowledge base about
database researchers– AliBaba: IE over medical research papers
Since then, IE has gone mainstream– Enterprise Semantic Search– Enterprise Data as a Service– Business Intelligence– Data-driven Enterprise Mashups

© 2009 IBM Corporation8
Enterprise Semantic Search
Use information extraction to improve accuracy and presentation of search results
Gumshoe (IBM)[Zhu07,Li06]
Extract acronyms and their meanings
Extract geographical information
Identify pages in different parts of the intranet that are about the same topic

© 2009 IBM Corporation9
Enterprise Data as a Service
Extract and clean useful information hidden in publicly available documents
Rent the extracted informationover the Internet
DBLife [1]
Midas (IBM)
(Demo today!)
...<issuer> <issuerCik>0000070858</issuerCik> <issuerName>BANK OF AMERICA CORP /DE/</issuerName> <issuerTradingSymbol>BAC</issuerTradingSymbol> </issuer> <reportingOwner> <reportingOwnerId> <rptOwnerCik>0001090355</rptOwnerCik> <rptOwnerName>THAIN JOHN A</rptOwnerName> </reportingOwnerId> <reportingOwnerAddress> <rptOwnerStreet1>C/O GOLDMAN SACHS GROUP</rptOwnerStreet1> <rptOwnerStreet2>85 BROAD STREET</rptOwnerStreet2> <rptOwnerCity>NEW YORK</rptOwnerCity> ... </reportingOwnerAddress> <reportingOwnerRelationship> <isOfficer>1</isOfficer> <officerTitle>Pres Glbl Bkg Sec & Wlth Mgmt</officerTitle> </reportingOwnerRelationship> </reportingOwner> ...
...<issuer> <issuerCik>0000070858</issuerCik> <issuerName>BANK OF AMERICA CORP /DE/</issuerName> <issuerTradingSymbol>BAC</issuerTradingSymbol> </issuer> <reportingOwner> <reportingOwnerId> <rptOwnerCik>0001090355</rptOwnerCik> <rptOwnerName>THAIN JOHN A</rptOwnerName> </reportingOwnerId> <reportingOwnerAddress> <rptOwnerStreet1>C/O GOLDMAN SACHS GROUP</rptOwnerStreet1> <rptOwnerStreet2>85 BROAD STREET</rptOwnerStreet2> <rptOwnerCity>NEW YORK</rptOwnerCity> ... </reportingOwnerAddress> <reportingOwnerRelationship> <isOfficer>1</isOfficer> <officerTitle>Pres Glbl Bkg Sec & Wlth Mgmt</officerTitle> </reportingOwnerRelationship> </reportingOwner> ...
© 2009 IBM Corporation10
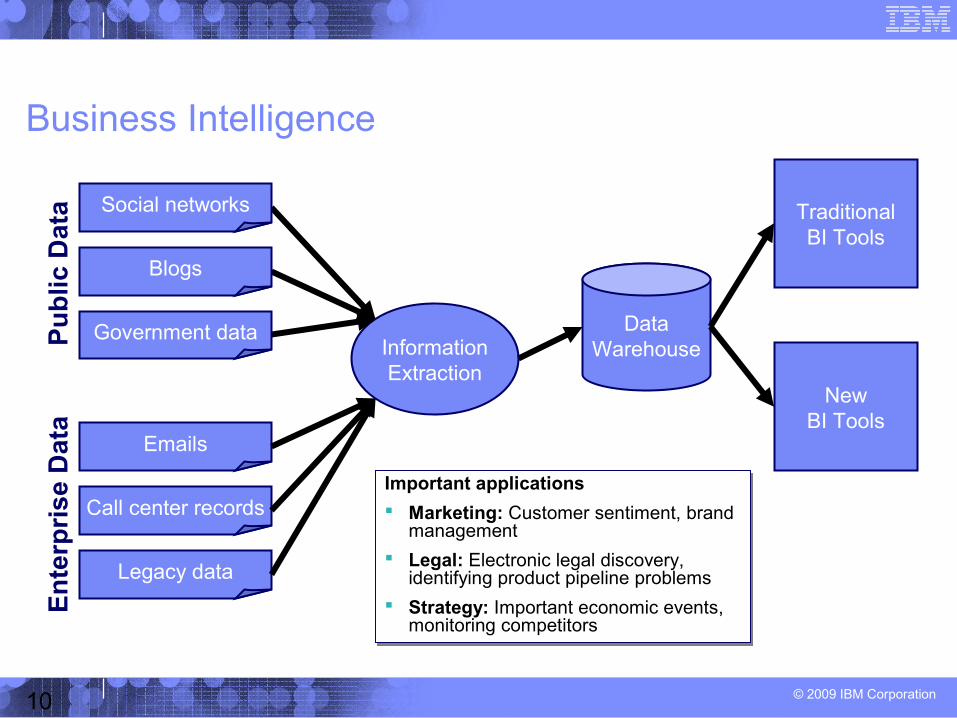
Business Intelligence
InformationExtraction
DataWarehouse
TraditionalBI Tools
NewBI Tools
Pu
blic
Dat
aE
nte
rpri
se
Dat
a
Social networks
Blogs
Government data
Emails
Call center records
Legacy data
Important applications
Marketing: Customer sentiment, brand management
Legal: Electronic legal discovery, identifying product pipeline problems
Strategy: Important economic events, monitoring competitors
Important applications
Marketing: Customer sentiment, brand management
Legal: Electronic legal discovery, identifying product pipeline problems
Strategy: Important economic events, monitoring competitors
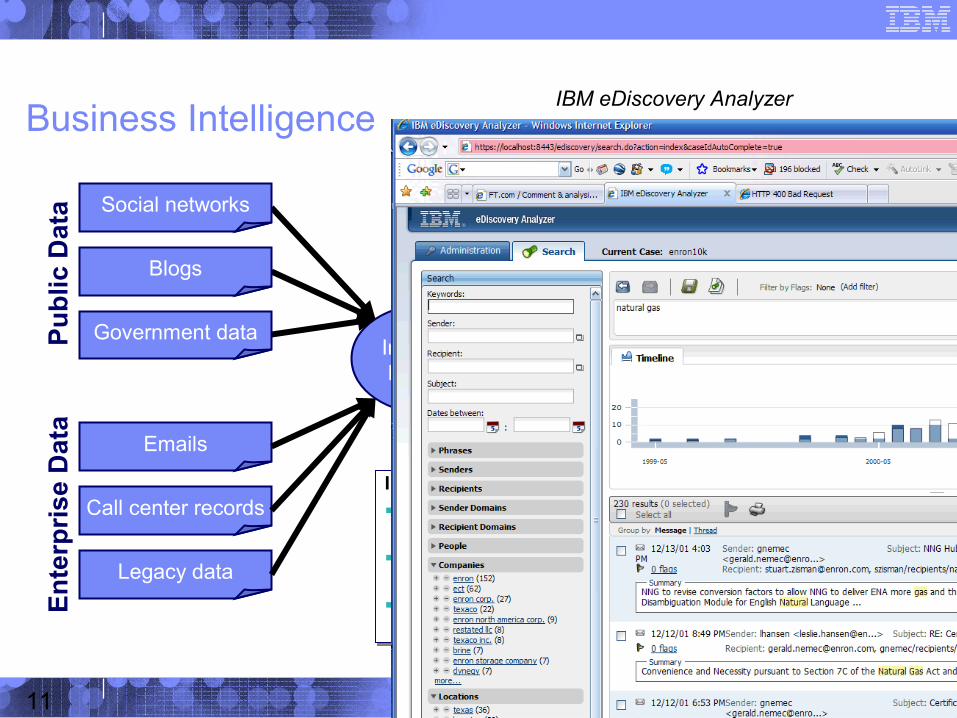
© 2009 IBM Corporation11
Business Intelligence
InformationExtraction
DataWarehouse
TraditionalBI Tools
NewBI Tools
Pu
blic
Dat
aE
nte
rpri
se
Dat
a
Social networks
Blogs
Government data
Emails
Call center records
Legacy data
Important applications
Marketing: Customer sentiment, brand management
Legal: Electronic legal discovery, identifying product pipeline problems
Strategy: Important economic events, monitoring competitors
Important applications
Marketing: Customer sentiment, brand management
Legal: Electronic legal discovery, identifying product pipeline problems
Strategy: Important economic events, monitoring competitors
IBM eDiscovery Analyzer
© 2009 IBM Corporation12
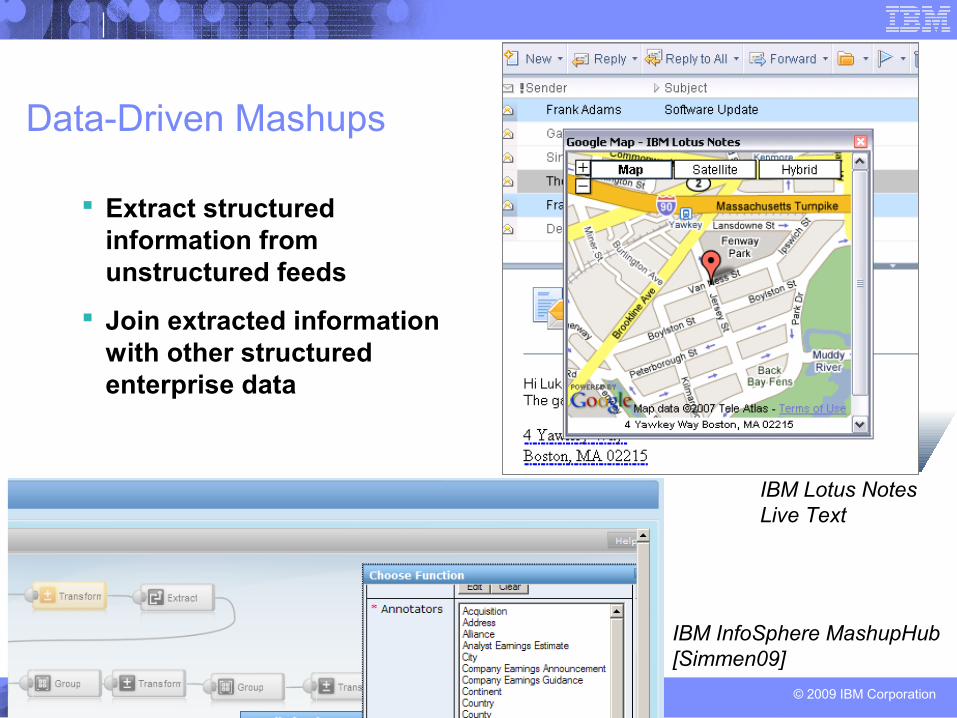
Data-Driven Mashups
Extract structured information from unstructured feeds
Join extracted information with other structured enterprise data
IBM Lotus NotesLive Text
IBM InfoSphere MashupHub[Simmen09]

© 2009 IBM Corporation13
Enterprise Information Extraction
IE has become increasingly important to emerging enterprise applications
Set of requirements driven by enterprise apps that use information extraction
– Scalability• Large data volumes, often orders of magnitude larger than classical NLP
corpora
– Accuracy• Garbage-in garbage-out: Usefulness of application is often tied to quality
of extraction
– Usability• Building an accurate IE system is labor-intensive• Professional programmers are much more expensive than grad students!

© 2009 IBM Corporation14
A Canonical IE System
FeatureSelection
EntityIdentification
EntityResolution
Text FeaturesEntities and
RelationshipsStructured
Information

© 2009 IBM Corporation15
A Canonical IE System
Boundaries between these stages are not clear-cut
This diagram shows a simplified logical data flow
– Traditionally, physical data flow the same as logical– But the systems we’ll talk about take a very different
approach to the actual order of execution
FeatureSelection
EntityIdentification
EntityResolution
Text FeaturesEntities and
RelationshipsStructured
Information

© 2009 IBM Corporation16
Feature Selection
Identify features– Very simple, “atomic” entities– Inputs for other stages
Examples of features– Dictionary match– Regular expression match– Part of speech
Typical components used– Off-the-shelf morphology package– Many simple rules
Very time-consuming and underappreciated

© 2009 IBM Corporation17
Entity Identification
Use basic features to build more complex features
– Example:
Use other features to determine which of the complex features are instances of entities and relationships
Most information extraction research focuses on this stage
– Variety of different techniques
…was done by Mr. Jack Gurbingal at the…
Dictionary match: Common first name
Regular expr match: Capitalized word
Complex feature: Potential person name+ =

© 2009 IBM Corporation18
Entity Resolution
Perform complex analyses over entities and relationships
Examples
– Identify entities that refer to the same person or thing
– Join extracted information with external structured data
Not the main focus of this tutorial
– But interacts with other parts of information extraction

© 2009 IBM Corporation19
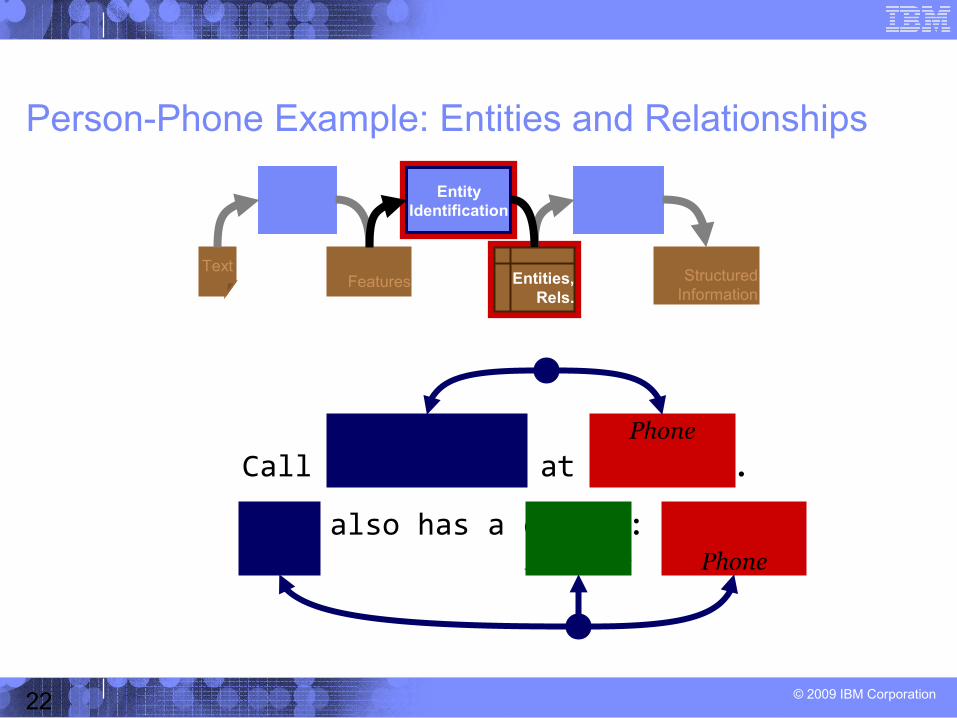
Obligatory Person-Phone Example
Call John Merker at 555-1212.
John also has a cell #: 555-1234

© 2009 IBM Corporation20
Person-Phone Example: Input
Call John Merker at 555-1212.
John also has a cell #: 555-1234
FeatureSelection
EntityIdentification
EntityResolution
TextFeatures Entities,
Rels.Structured
Information

© 2009 IBM Corporation21
Person-Phone Example: Features
Call John Merker at 555-1212.
John also has a cell #: 555-1234
FeatureSelection
EntityIdentification
EntityResolution
TextFeatures Entities,
Rels.Structured
Information
© 2009 IBM Corporation22
.
EntityIdentification
Person-Phone Example: Entities and Relationships
Call John Merker at 555-1212.
John also has a cell #: 555-1234
Person
FeatureSelection
EntityIdentification
EntityResolution
TextFeatures Entities,
Rels.Structured
Information
Phone
PhonePerson NumType

© 2009 IBM Corporation23
Person-Phone Example: Entities and Relationships
Call John Merker at 555-1212.
John also has a cell #: 555-1234
Person
FeatureSelection
EntityIdentification
EntityResolution
TextFeatures Entities,
Rels.Structured
Information
Phone
PhonePerson NumType
SamePerson
SamePerson
Join withoffice phone
directory
Join withoffice phone
directory

© 2009 IBM Corporation24
Road Map
What is Information Extraction?
Declarative Information Extraction
What the Declarative Approach Enables
– Scalable Infrastructure (Yunyao Li)
– Development Support (Laura Chiticariu)
Conclusion / Q&A (Fred Reiss)
You are here

© 2009 IBM Corporation25
Declarative Information Extraction
Overview of traditional approaches to information extraction
Practical issues with applying traditional approaches
How recent work has used declarative approaches to address these issues
Different types of declarative approaches

© 2009 IBM Corporation26
Traditional Approaches to Information Extraction
Two dominant types:
– Rule-Based
– Machine Learning-Based
Distinction is based on how Entity Identification is performed
FeatureSelection
EntityIdentification
EntityResolution
Text FeaturesEntities and
RelationshipsStructured
Information
© 2009 IBM Corporation27
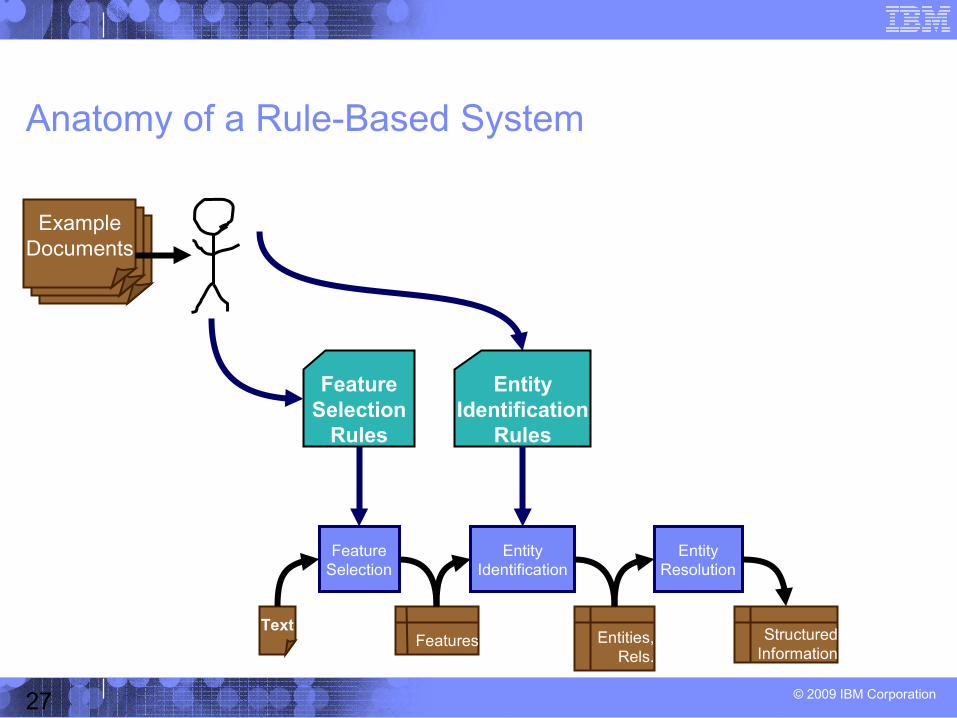
Anatomy of a Rule-Based System
FeatureSelection
EntityIdentification
EntityResolution
TextFeatures Entities,
Rels.Structured
Information
ExampleDocuments
FeatureSelection
Rules
EntityIdentification
Rules

© 2009 IBM Corporation28
Anatomy of a Machine Learning-Based System
ExampleDocuments
FeatureSelection
Rules
FeatureSelection
LabeledDocuments
Featuresand
Labels
Training
Model
FeatureSelection
EntityIdentification
EntityResolution
TextFeatures Entities,
Rels.Structured
Information

© 2009 IBM Corporation29
A Brief History of IE in the NLP Community
1978-1997: MUC (Message Understanding Conference) – DARPA competition 1987 to 1997
– FRUMP [DeJong82]– FASTUS [Appelt93],– TextPro, PROTEUS
1998: Common Pattern Specification Language (CPSL) standard [Appelt98]
– Standard for subsequent rule-based systems
1999-2010: Commercial products, GATE
At first: Simple techniques like Naive Bayes
1990’s: Learning Rules
– AUTOSLOG [Riloff93]– CRYSTAL [Soderland98]– SRV [Freitag98]
2000’s: More specialized models
– Hidden Markov Models [Leek97]– Maximum Entropy Markov
Models [McCallum00]– Conditional Random Fields
[Lafferty01]– Automatic feature expansion
Rule-Based Machine Learning
For further reading:Sunita Sarawagi’s Survey [Sarawagi08], Claire Cardie’s Survey [Cardie97]

© 2009 IBM Corporation30
Tying the System Together: Traditional IE Frameworks
Traditional approach: Workflow system
– Sequence of discrete steps
– Data only flows forward
GATE1 and UIMA2 are the most popular frameworks
– Type systems and standard data formats
Web services and Hadoop also in common use
– No standard data format
1. GATE (General Architecture for Text Engineering) official web site: http://gate.ac.uk/
2. Apache UIMA (Unstructured Information Management Architecture) official web site: http://uima.apache.org/
Workflow for the ANNIE system [Cunningham09]

© 2009 IBM Corporation31
Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Proin l enina i facilisis, <Person> at <Digits>-<Digits> arcu tincidunt orci. Pellentesque justo tellus , scelerisque quis, facilisis nunc volutpat enim, quis viverra lacus nulla sit amet lectus. Nulla
Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Proin elementum neque at justo. Aliquam erat volutpat. Curabitur a massa. Vivamus
luctus, risus in sagittis facilisis arcu augue velit, <FirstName> <CapsWord> at <Digits>-<Digits>. hendrerit faucibus pede mi ipsum. Curabitur cursus tincidunt orci. Pellentesque justo tellus , scelerisque quis, facilisis quis, interdum non, ante. Suspendisse feugiat, erat in feugiat tincidunt, est nunc volutpat enim, quis viverra lacus nulla sit amet lectus. Nulla odio lorem, feugiat et, volutpat dapibus, ultrices sit amet, sem. Vestibulum quis dui vitae massa euismod faucibus. Pellentesque id neque id tellus hendrerit tincidunt. Etiam augue. Class aptent taciti sociosqu ad litora
Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Proin elementum neque at justo. Aliquam erat volutpat. Curabitur a massa. Vivamus luctus, risus in e sagittis facilisis, arcu augue rutrum velit, sed <PersonPhone>, hendrerit faucibus pede mi sed ipsum. Curabitur cursus tincidunt orci. Pellentesque justo tellus , scelerisque quis, facilisis quis, interdum non, ante. Suspendisse feugiat, erat in feugiat tincidunt, est nunc volutpat enim, quis viverra lacus nulla sit amet lectus. Nulla odio lorem, feugiat et, volutpat dapibus, ultrices sit amet, sem. Vestibulum quis dui vitae massa euismod faucibus. Pellentesque id neque id tellus hendrerit tincidunt. Etiam augue. Class aptent taciti
Sequential Execution in CPSL Rules
⟨Person⟩ ⟨Token⟩[~ “at”] ⟨Phone⟩ ⟨PersonPhone⟩⟨Person⟩ ⟨Token⟩[~ “at”] ⟨Phone⟩ ⟨PersonPhone⟩
⟨FirstName⟩ ⟨CapsWord⟩ ⟨Person⟩⟨FirstName⟩ ⟨CapsWord⟩ ⟨Person⟩
Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Proin elementum neque at justo. Aliquam erat volutpat. Curabitur a massa. Vivamus luctus, risus in sagittis facilisis arcu auguet rum velit, sed <Person> at <Phone> hendrerit faucibus pede mi ipsum. Curabitur cursus tincidunt orci. Pellentesque justo tellus , scelerisque quis, facilisis quis, interdum non, ante. Suspendisse feugiat, erat in feugiat tincidunt, est
Level 0 (Feature Selection)
Level 2
Lorem ipsum dolor sit amet, consectetuer adipiscing elit.
Proin, in <FirstName> <CapsWord> at <Phone> amet lt arcu tincidunt orci. Pellentesque justo tellus , scelerisque quis,
facilisis nunc volutpat enim, quis viverra lacus nulla sit lectus.
⟨Digits⟩ ⟨Token⟩[~ “-”] ⟨Digits⟩ ⟨Phone⟩⟨Digits⟩ ⟨Token⟩[~ “-”] ⟨Digits⟩ ⟨Phone⟩
Level 1

© 2009 IBM Corporation32
Problems with Traditional IE Approaches
Complex, fixed pipelines and rule sets
Semantics tied to order of execution
Scalability
Accuracy
Usability
Data only flows forward, leading towasted work in early stages.
Lots of custom procedural code.
Hard to understand why the systemproduces a particular result.

© 2009 IBM Corporation33
Declarative to the Rescue!
Define the logical constraints between rules/components
System determines order of execution
Optimizer avoids wasted work
More expressive rule languages;Combine different tools easily
Describe what to extract, instead of how to extract it
Scalability
Accuracy
Usability

© 2009 IBM Corporation34
What do we mean by “declarative”?
Common vision:
– Separate semantics from order of execution – Build the system around a language like SQL or Datalog
Different systems have different interpretations
Three main categories
– High-Level Declarative• Most common approach
– Completely Declarative– Mixed Declarative

© 2009 IBM Corporation35
High-Level Declarative
Replace the overall IE framework with a declarative language
Each individual extraction component is still a “black box”
Example 1: SQoUT[Jain08]
Catalog ofExtractionModules
SQL query
Optimizer
Query plan combines extraction modules with scan and index access to data.
Query plan combines extraction modules with scan and index access to data.

© 2009 IBM Corporation36
High-Level Declarative
Replace the overall IE framework with a declarative language
Each individual extraction component is still a “black box”
Example 1: SQoUT[Jain08]
Example 2: PSOX[Bohannon08]

© 2009 IBM Corporation37
High-Level Declarative
Replace the overall IE framework with a declarative language
Each individual extraction component is still a “black box”
Example 1: SQoUT[Jain08]
Example 2: PSOX[Bohannon08]
Advantages:– Allows use of many existing “black box” packages– High-level performance optimizations possible– Clear semantics for using different packages for the same task
Drawbacks:– Doesn’t address issues that occur within a given “black box”– Limited opportunities for optimization, unless “black boxes” can
provide hints
© 2009 IBM Corporation38
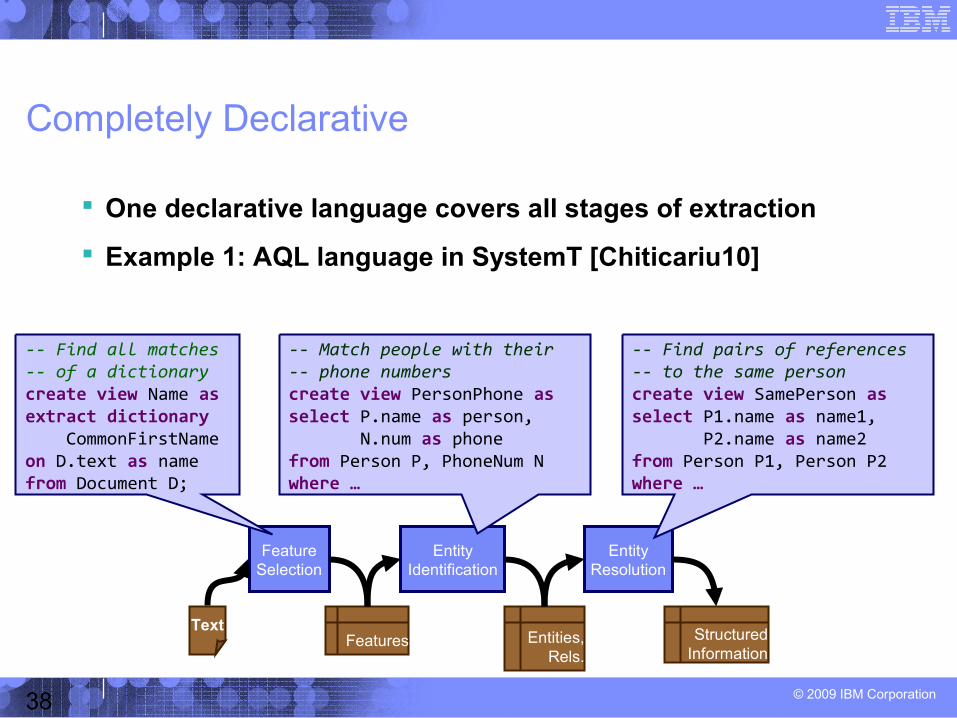
Completely Declarative
One declarative language covers all stages of extraction
Example 1: AQL language in SystemT [Chiticariu10]
FeatureSelection
EntityIdentification
EntityResolution
TextFeatures Entities,
Rels.Structured
Information
-- Find all matches-- of a dictionarycreate view Name asextract dictionary CommonFirstNameon D.text as namefrom Document D;
-- Match people with their-- phone numbers create view PersonPhone asselect P.name as person, N.num as phonefrom Person P, PhoneNum Nwhere …
-- Find pairs of references-- to the same person create view SamePerson asselect P1.name as name1, P2.name as name2from Person P1, Person P2where …

© 2009 IBM Corporation39
Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Proin l enina i facilisis, <Person> at <Digits>-<Digits> arcu tincidunt orci. Pellentesque justo tellus , scelerisque quis, facilisis nunc volutpat enim, quis viverra lacus nulla sit amet lectus. Nulla
Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Proin elementum neque at justo. Aliquam erat volutpat. Curabitur a massa. Vivamus
luctus, risus in sagittis facilisis arcu augue velit, <FirstName> <CapsWord> at <Digits>-<Digits>. hendrerit faucibus pede mi ipsum. Curabitur cursus tincidunt orci. Pellentesque justo tellus , scelerisque quis, facilisis quis, interdum non, ante. Suspendisse feugiat, erat in feugiat tincidunt, est nunc volutpat enim, quis viverra lacus nulla sit amet lectus. Nulla odio lorem, feugiat et, volutpat dapibus, ultrices sit amet, sem. Vestibulum quis dui vitae massa euismod faucibus. Pellentesque id neque id tellus hendrerit tincidunt. Etiam augue. Class aptent taciti sociosqu ad litora
Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Proin elementum neque at justo. Aliquam erat volutpat. Curabitur a massa. Vivamus luctus, risus in e sagittis facilisis, arcu augue rutrum velit, sed <PersonPhone>, hendrerit faucibus pede mi sed ipsum. Curabitur cursus tincidunt orci. Pellentesque justo tellus , scelerisque quis, facilisis quis, interdum non, ante. Suspendisse feugiat, erat in feugiat tincidunt, est nunc volutpat enim, quis viverra lacus nulla sit amet lectus. Nulla odio lorem, feugiat et, volutpat dapibus, ultrices sit amet, sem. Vestibulum quis dui vitae massa euismod faucibus. Pellentesque id neque id tellus hendrerit tincidunt. Etiam augue. Class aptent taciti
Sequential Execution in CPSL Rules
⟨Person⟩ ⟨Token⟩[~ “at”] ⟨Phone⟩ ⟨PersonPhone⟩⟨Person⟩ ⟨Token⟩[~ “at”] ⟨Phone⟩ ⟨PersonPhone⟩
⟨FirstName⟩ ⟨CapsWord⟩ ⟨Person⟩⟨FirstName⟩ ⟨CapsWord⟩ ⟨Person⟩
Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Proin elementum neque at justo. Aliquam erat volutpat. Curabitur a massa. Vivamus luctus, risus in sagittis facilisis arcu auguet rum velit, sed <Person> at <Phone> hendrerit faucibus pede mi ipsum. Curabitur cursus tincidunt orci. Pellentesque justo tellus , scelerisque quis, facilisis quis, interdum non, ante. Suspendisse feugiat, erat in feugiat tincidunt, est
Level 0 (Feature Selection)
Level 2
Lorem ipsum dolor sit amet, consectetuer adipiscing elit.
Proin, in <FirstName> <CapsWord> at <Phone> amet lt arcu tincidunt orci. Pellentesque justo tellus , scelerisque quis,
facilisis nunc volutpat enim, quis viverra lacus nulla sit lectus.
⟨Digits⟩ ⟨Token⟩[~ “-”] ⟨Digits⟩ ⟨Phone⟩⟨Digits⟩ ⟨Token⟩[~ “-”] ⟨Digits⟩ ⟨Phone⟩
Level 1

© 2009 IBM Corporation40
Declarative Semantics Example:Identifying Musician-Instrument Relationships
(pipe | guitar | hammond organ |…) Instrument(Person Annotator) Person
⟨Person⟩ ⟨0-5 tokens⟩ ⟨Instrument⟩ PersonPlaysInstrument
John⟨Person⟩
plays⟨Token⟩
the⟨Token⟩
Pipe⟨Person⟩
guitar⟨Instrument⟩
John Pipe⟨Person⟩
plays⟨Token⟩
the⟨Token⟩
guitar⟨Instrument⟩
John⟨Person⟩
plays⟨Token⟩
the⟨Token⟩
Pipe⟨Instrument⟩
guitar⟨Instrument⟩
Person
Person
Instrument
Person Instrument
John Pipe plays the guitar

© 2009 IBM Corporation41
Completely Declarative
One declarative language covers all stages of extraction
Example 1: AQL language in SystemT [Chiticariu10]
Example 2: Conditional Random Fields in SQL [Wang10]

© 2009 IBM Corporation42
Completely Declarative
One declarative language covers all stages of extraction
Example 1: AQL language in SystemT [Chiticariu10]
Example 2: Conditional Random Fields in SQL [Wang10]
Advantages:
– Unified language clear semantics from top to bottom– Optimizer has full control over low-level operations– Can incorporate existing packages using user-defined
functions
Drawbacks:
– Code inside UDFs doesn’t benefit from declarativeness

© 2009 IBM Corporation43
Mixed Declarative
Language provides declarativeness at the level of some, but not all, of the extraction operations, both at the individual and pipeline level
Example: Xlog (CIMPLE) [Shen07]
This Datalog predicate represents a large, opaque
block of extraction code.
This predicate is defined in Datalog, using low-level
operations.
Extraction program for talk extracts, from [1]

© 2009 IBM Corporation44
Mixed Declarative
Language provides declarativeness at the level of some, but not all, of the extraction operations, both at the individual and pipeline level
Example: Xlog (CIMPLE) [Shen08]
Advantages:
– Ability to reuse existing “black box” packages– Optimizer gets some flexibility to reorder low-level operations
Drawbacks:
– Challenging to build an optimizer that does both “high-level” and “low-level” optimizations

© 2009 IBM Corporation45
Declarative to the Rescue!
Different notions of declarativeness in different systems
All kinds address the major issues in enterprise IE, but in different ways
Optimizer avoids wasted work
More expressive rule languages;Combine different tools easily
Describe what to extract, instead of how to extract it
Scalability
Accuracy
Usability

© 2009 IBM Corporation46
Road Map
What is Information Extraction? (Fred Reiss)
Declarative Information Extraction (Fred Reiss)
What the Declarative Approach Enables
– Scalable Infrastructure (Yunyao Li)
– Development Support (Laura Chiticariu)
Conclusion/QuestionsYou are here

© 2009 IBM Corporation
Scalable Infrastructure
Yunyao Li
IBM Almaden Research Center

© 2009 IBM Corporation48
Declarative to the Rescue!
Define the logical constraints between rules/components
System determines order of execution
Optimizer avoids wasted work
More expressive rule languages;Combine different tools easily
Describe what to extract, instead of how to extract it
Scalability
Accuracy
Usability

© 2009 IBM Corporation49
Conventional vs. Declarative IE Infrastructure
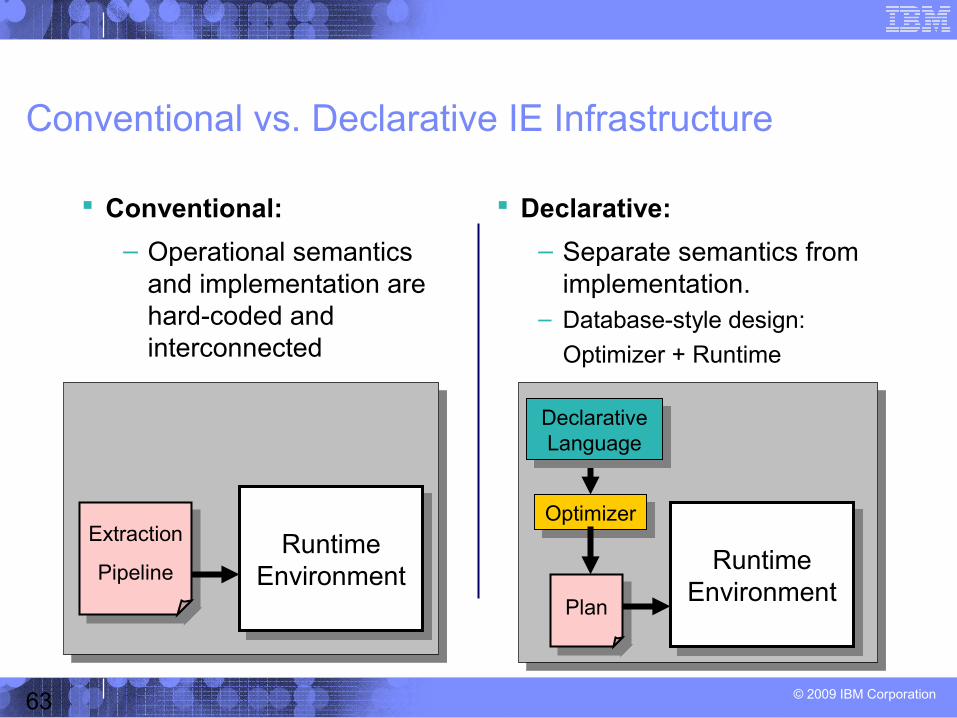
Conventional:
– Operational semantics and implementation are hard-coded and interconnected
Declarative:
– Separate semantics from implementation.
– Database-style design:
Optimizer + Runtime
OptimizerOptimizer
PlanPlan
RuntimeEnvironment
RuntimeEnvironment
Declarative Language
Declarative Language
Extraction
Pipeline
Extraction
PipelineRuntime
Environment
RuntimeEnvironment
© 2009 IBM Corporation50
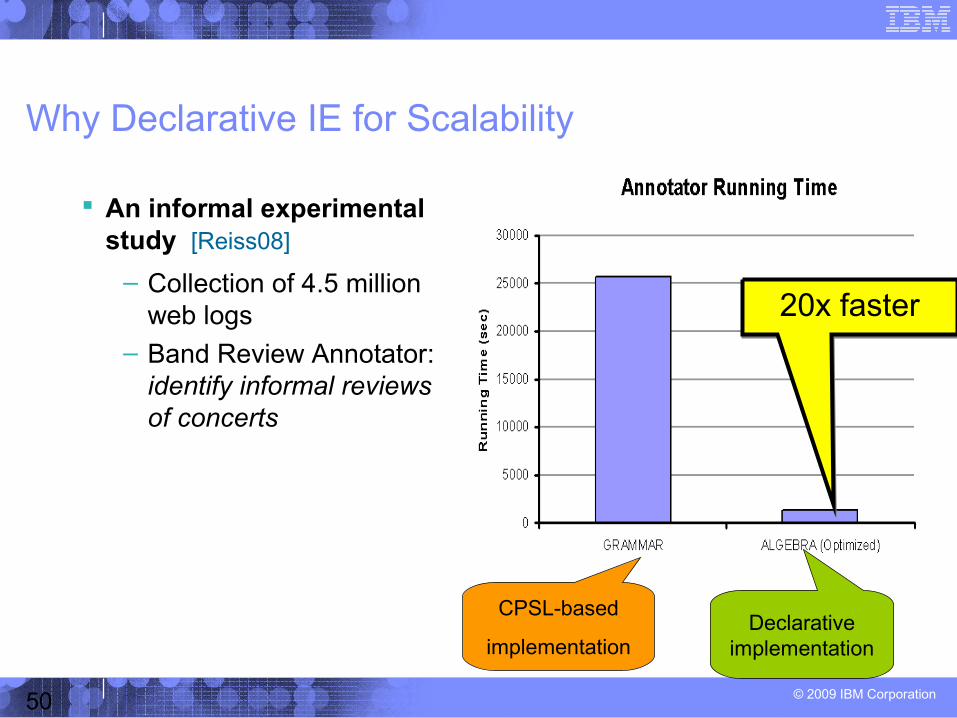
Why Declarative IE for Scalability
An informal experimental study [Reiss08]
– Collection of 4.5 million web logs
– Band Review Annotator: identify informal reviews of concerts
20x faster20x faster
CPSL-based
implementationDeclarative
implementation

© 2009 IBM Corporation51
Different Aspects of Design for Scalability
Optimization
– Granularity• High-level: annotator composition• Low-level: basic extraction operators
– Strategy: • Rewrite-based• Cost-based
Runtime Model
– Document-Centric vs. Collection-Centric

© 2009 IBM Corporation52
Optimization Granularity for Declarative IE
Basic Extraction Operator
– Each operator represents an atomic extraction operation• E.g. dictionary matching,
regular expression, join,…– System is fully aware of
how each extraction operator works
– Optimizing each basic extraction operator
Annotator Composition
– Each annotator extracts one or more entities or relationships • E.g. Person annotator
– Black box assumption on how an annotator works
– Optimizing composition of extraction pipeline
High-level declarative Mixed declarative Completely declarative

© 2009 IBM Corporation53
Optimization Strategies for Declarative IE
Rewrite-based
– Applying rewrite rules to transform the declarative form of the annotators to a equivalent form that is more efficient
Cost-Based
– Enumerating all possible physical execution plans, estimate their cost, and choose the one with the minimum expected cost
Systems may mix these two approaches

© 2009 IBM Corporation54
Document-Centric
Runtime Model for Declarative IE
InputDocument
Stream
AnnotatedDocument
Stream
Collection-Centric
RuntimeEnvironment
RuntimeEnvironment
Document
Collection
Document
Collection
RuntimeEnvironment
RuntimeEnvironment
Annotations
AnnotationsAnnotations Auxiliary
index
Auxiliary
index

© 2009 IBM Corporation55
Systems
CIMPLE
RAD
SQout
SystemT
BayesStore

© 2009 IBM Corporation56
Cimple
Rewrite-based optimization – Inverted-index based simple pattern matching
• Shared document scan
Simple patterns
Parse trees
P1= “(Jeff|Jeffery)\s\s*Ullman”
P2=“(Jeff|Jeffery)\s\s*Naughton”
P3=“Laura\s\s*Haas”
P4=“Peter\s\s*Haas”
AND
ANDOR
Jeff\s Jeffery\s \s*
*Ullman
AND
AND
OR
Jeff\s Jeffery\s \s*
*Naughton
(p1) (p2)
AND
AND
\s*
*
(p3)
Laura\s
AND
AND
\s*
*
(p4)
Peter\s
Ullman
Naughton
Laura\s
Peter\s
Haas
P2
P1
P3
P4
P3, P4
Inverted IndexHaas Haas
[Shen07]

© 2009 IBM Corporation57
Cimple
Pushing down text properties – Eg: To find an all-capitalized line
Scoping
– Imposing location conditions on where to extract spans• Eg: Check for names only within two lines of the occurrence of titles
Incorporating cost-model to decide how to apply the rewrite.
[Shen07]
[Shen07]
lines(d,x,n)
σallcaps(x)
Plan a
lines(d,x,n)
σallcaps(x)
σcontainCaps(d)
Plan b

© 2009 IBM Corporation58
Cimple
Collection-centric runtime model
– Document collection (or snapshots of document collection)– Previous extraction results
Reusing previous extraction results• Similar to maintaining materialized views
[Chen08][Chen09]
• Cyclex: IE program viewed as one big blackbox
• Delex: IE program viewed as a workflow of blackboxes
[Chen08]
[Chen09]
© 2009 IBM Corporation59
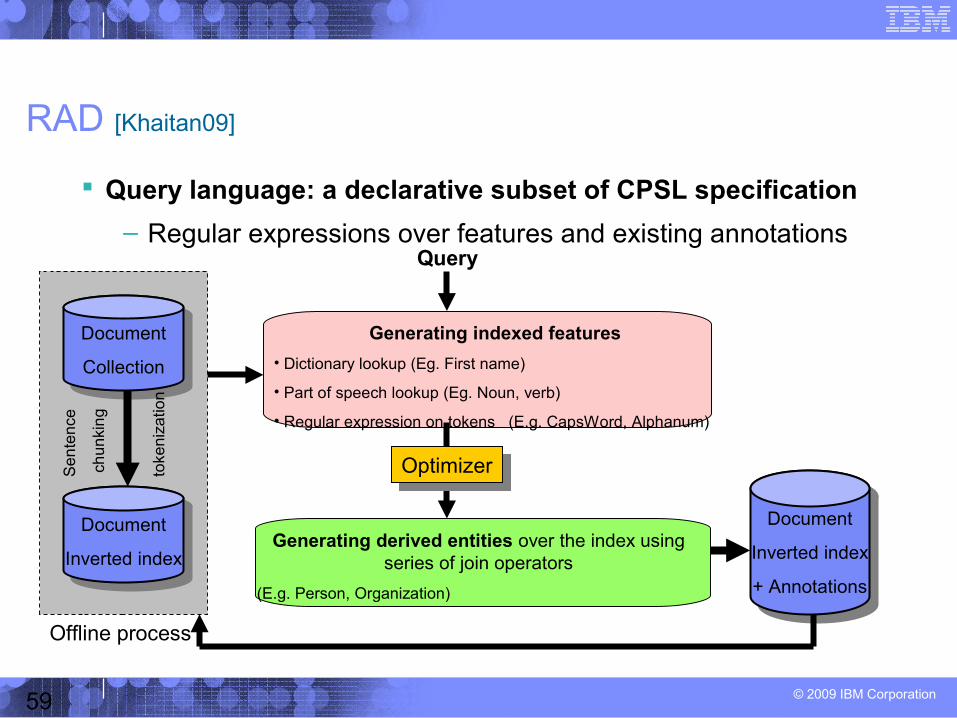
RAD [Khaitan09]
Query language: a declarative subset of CPSL specification
– Regular expressions over features and existing annotations
Generating derived entities over the index using series of join operators
(E.g. Person, Organization)
Document
Inverted index
+ Annotations
Document
Inverted index
+ Annotations
Document
Collection
Document
Collection
Document
Inverted index
Document
Inverted index
Se
nte
nce
ch
un
kin
g
toke
niz
atio
n
Offline process
Generating indexed features
• Dictionary lookup (Eg. First name)
• Part of speech lookup (Eg. Noun, verb)
• Regular expression on tokens (E.g. CapsWord, Alphanum)
Query
OptimizerOptimizer
© 2009 IBM Corporation60
RAD
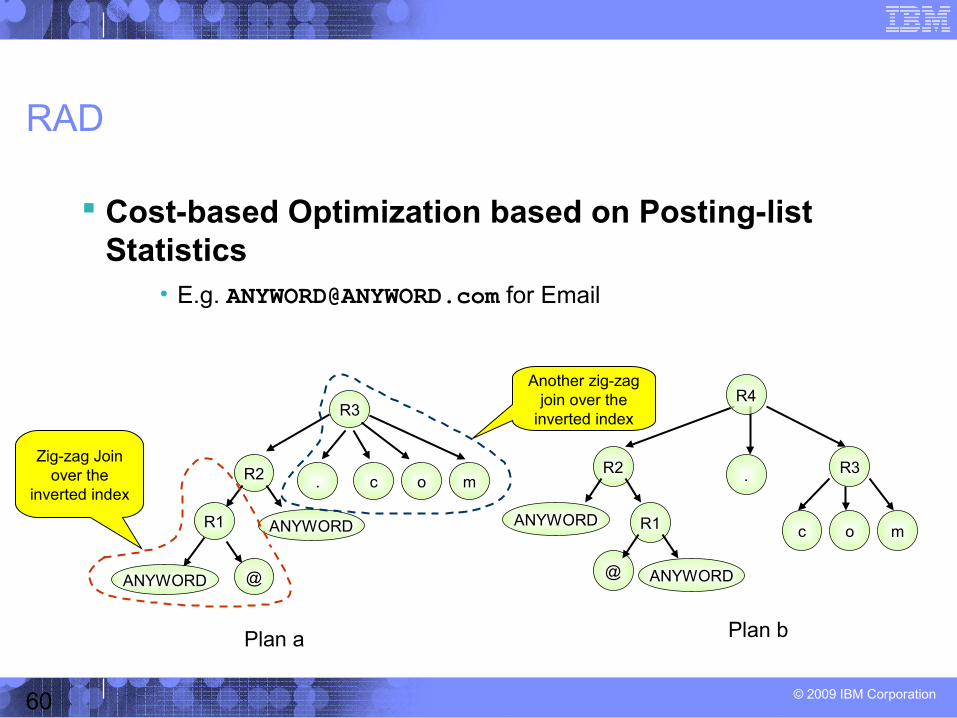
Cost-based Optimization based on Posting-list Statistics
• E.g. [email protected] for Email
@ANYWORD
ANYWORDR1
R2
R3
. c o m
Plan a
@
ANYWORD
ANYWORD
R1
R2 R3.
c o m
R4
Plan b
Zig-zag Join over the
inverted index
Another zig-zag join over the
inverted index

© 2009 IBM Corporation61
RAD
Rewrite-based Optimization
– Share sub-expression evaluation• Evaluate the same sub-expression only once

© 2009 IBM Corporation62
Declarative to the Rescue!
Define the logical constraints between rules/components
System determines order of execution
Optimizer avoids wasted work
More expressive rule languages;Combine different tools easily
Describe what to extract, instead of how to extract it
Scalability
Accuracy
Usability
© 2009 IBM Corporation63
Conventional vs. Declarative IE Infrastructure
Conventional:
– Operational semantics and implementation are hard-coded and interconnected
Declarative:
– Separate semantics from implementation.
– Database-style design:
Optimizer + Runtime
OptimizerOptimizer
PlanPlan
RuntimeEnvironment
RuntimeEnvironment
Declarative Language
Declarative Language
Extraction
Pipeline
Extraction
PipelineRuntime
Environment
RuntimeEnvironment

© 2009 IBM Corporation64
Different Aspects of Design for Scalability
Optimization
– Granularity• High-level: annotator composition• Low-level: basic extraction operators
– Strategy: • Rewrite-based• Cost-based
Runtime Model
– Document-Centric vs. Collection-Centric
© 2009 IBM Corporation65
Systems
CIMPLE
RAD
SQout
SystemT
BayesStore

© 2009 IBM Corporation66
SQoUT [Ipeirotis07][Jain07,08,09]
Focus on composition of extraction systemsSQL Query
Retrieval
Strategy
Retrieval
Strategy
Retrieval
Strategy
Retrieval
Strategy
……
Extraction
System Em
Extraction
System Em
Extraction
System E0
Extraction
System E0…… Document
Collection
Document
Collection
Extraction results
Query
resultsData
Cleaning
Data
Cleaning
Extracted View
Entities/relations
to extract
Extraction
System Repository
Extraction
System Repository

© 2009 IBM Corporation67
SQoUT
Cost-based Query Optimization
New Plan Enumeration Strategies
– Document retrieval strategies• Eg: filtered scan
– Running the annotator only over potentially relevant docs
– Join execution• Independent join, outer/inner join, zig-zag join:
– Extraction results of one relation can determine the docs retrieved for another relation.
Efficiency vs. Quality Cost Model
Goodness Quality EfficiencyWeight

© 2009 IBM Corporation68
SystemT [Reiss08] [Krishnamurthy08] [Chiticariu10]
Pre-processor
Pre-processor
Blocks
Rules
• Divide rules into compilation blocks.
• Rewrite-based optimization within each block
PlannerPlanner
PlanEnumerator
Cost Model
BlockPlans
• System R Style Cost-based optimization within each block.
Post-processor
Post-processor
FinalPlan
• Merge block plans into a single operator graph.
• Rewrite-based optimization across blocks.

© 2009 IBM Corporation69
Example: Restricted Span Evaluation (RSE)
Leverage the sequential nature of text
– Join predicates on character or token distance
Only evaluate the inner on the relevant portions of the document
Limited applicability
– Need to guarantee exact same results
…John Smith at 555-1212…
John Smith555-1212
John Smith at 555-1212
DictionaryRegex
RSEJoin
Only look for dictionary matches in the vicinity of a
phone number.

© 2009 IBM Corporation70
Example: Shared Dictionary Matching (SDM)
Rewrite-based optimization
– Applied to the algebraic plan during postprocessing
Evaluate multiple dictionaries in a single pass
DictD1 D2
subplan
D1
D2
subplan
Dict SDMDict
SDM Dictionary Operator
© 2009 IBM Corporation71
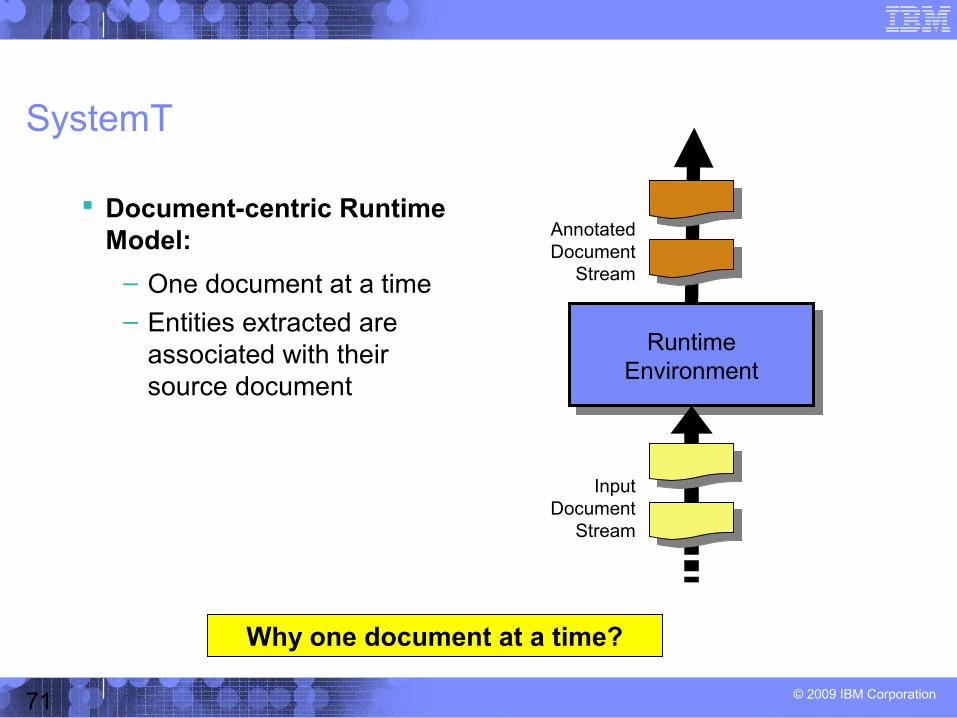
SystemT
Document-centric Runtime Model:
– One document at a time– Entities extracted are
associated with their source document
RuntimeEnvironment
RuntimeEnvironment
InputDocument
Stream
AnnotatedDocument
Stream
Why one document at a time?

© 2009 IBM Corporation72
Hadoop Cluster
Jaql Function WrapperJaql Function Wrapper
SystemTRuntime
InputAdapter
OutputAdapter
Jaql Function WrapperJaql Function Wrapper
SystemTRuntime
InputAdapter
OutputAdapter
Jaql Function WrapperJaql Function Wrapper
SystemTRuntime
InputAdapter
OutputAdapter
Jaql Function WrapperJaql Function Wrapper
SystemTRuntime
InputAdapter
OutputAdapter
Jaql Function WrapperJaql Function Wrapper
SystemTRuntime
InputAdapter
OutputAdapter
Jaql Function WrapperJaql Function Wrapper
SystemTRuntime
InputAdapter
OutputAdapter
Lotus NotesClient
Lotus NotesClient
Scaling SystemT: From Laptop to Cluster
Cognos Toro AnalyticsIn Lotus Notes Live Text In Cognos Toro Text Analytics
SystemTRuntime
EmailMessage Display
Annotated Email
Documents
Jaql Runtime
Hadoop Map-Reduce
Jaql Function WrapperJaql Function Wrapper
SystemTRuntime
InputAdapter
OutputAdapter
Jaql Function WrapperJaql Function Wrapper
SystemTRuntime
InputAdapter
OutputAdapter
Jaql Function WrapperJaql Function Wrapper
SystemTRuntime
InputAdapter
OutputAdapter

© 2009 IBM Corporation73
BayesStore [Wang10]
Probabilistic declarative IE
– In-database machine learning for efficiency and scalability
Text Data and Conditional Random Fields (CRF) Model
document
Token table
CRF model
Factor table

© 2009 IBM Corporation74
BayesStore
Viterbi Inference SQL Implementation
– Implementing dynamic programming algorithm using recursive queries
Rewrite-based optimization.

© 2009 IBM Corporation75
Summary
[A table here shows design choices of the systems]
Systems
Optimization Granularity
Optimization Strategy Runtime Model
Basic operator
Annotator composition
Rewrite-based Cost-based Document level Collection Level
Cimple RAD
SQoUT
SystemT
BayesStore

© 2009 IBM Corporation76
Road Map
What is Information Extraction? (Fred Reiss)
Declarative Information Extraction (Fred Reiss)
What the Declarative Approach Enables
– Scalable Infrastructure (Yunyao Li)
– Development Support (Laura Chiticariu)You are here

© 2009 IBM Corporation
Development Support (Tooling)
Laura Chiticariu
IBM Almaden Research Center

© 2009 IBM Corporation78
Declarative to the Rescue!
Define the logical constraints between rules/components
System determines order of execution
Optimizer avoids wasted work
More expressive rule languages;Combine different tools easily
Describe what to extract, instead of how to extract it
Scalability
Accuracy
Usability
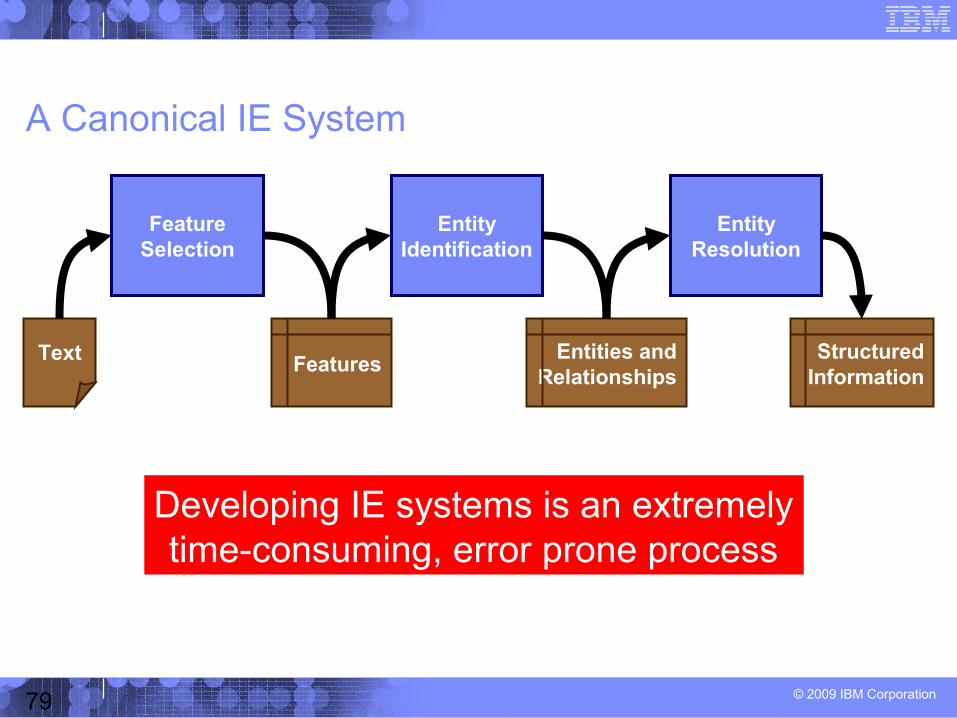
© 2009 IBM Corporation79
A Canonical IE System
FeatureSelection
EntityIdentification
EntityResolution
Text FeaturesEntities and
RelationshipsStructured
Information
Developing IE systems is an extremelytime-consuming, error prone process

© 2009 IBM Corporation80
Development
The Life Cycle of an IE System
Analyze
Develop1. Features
2. Rules / labeled data
Test
Developer
Usage / Maintenance
UseUser
TestRefine

© 2009 IBM Corporation81
---------------------------------------create view ValidLastNameAll asselect N.lastname as lastnamefrom LastNameAll N-- do not allow partially all capitalized wordswhere Not(MatchesRegex(/(\p{Lu}\p{M}*)+-.*([\p{Ll}\p{Lo}]\p{M}*).*/, N.lastname)) and Not(MatchesRegex(/.*([\p{Ll}\p{Lo}]\p{M}*).*-(\p{Lu}\p{M}*)+/, N.lastname)); create view LastName asselect C.lastname as lastname--from Consolidate(ValidLastNameAll.lastname) C;from ValidLastNameAll Cconsolidate on C.lastname;
-- Find dictionary matches for all first names-- Mostly US first namescreate view StrictFirstName1 asselect D.match as firstnamefrom Dictionary('strictFirst.dict', Doc.text) D--where MatchesRegex(/\p{Upper}\p{Lower}[\p{Alpha}]{0,20}/, D.match); -- changed to enable unicode matchwhere MatchesRegex(/\p{Lu}\p{M}*.{1,20}/, D.match);
-- German first namescreate view StrictFirstName2 asselect D.match as firstnamefrom Dictionary('strictFirst_german.dict', Doc.text) D--where MatchesRegex(/\p{Upper}\p{Lower}[\p{Alpha}]{0,20}/, D.match); --where MatchesRegex(/\p{Upper}.{1,20}/, D.match);-- changed to enable unicode matchwhere MatchesRegex(/\p{Lu}\p{M}*.{1,20}/, D.match);
-- nick names for US first namescreate view StrictFirstName3 asselect D.match as firstnamefrom Dictionary('strictNickName.dict', Doc.text) D--where MatchesRegex(/\p{Upper}\p{Lower}[\p{Alpha}]{0,20}/, D.match); --where MatchesRegex(/\p{Upper}.{1,20}/, D.match);-- changed to enable unicode matchwhere MatchesRegex(/\p{Lu}\p{M}*.{1,20}/, D.match);
-- german first name from blue pagecreate view StrictFirstName4 asselect D.match as firstnamefrom Dictionary('strictFirst_german_bluePages.dict', Doc.text) D--where MatchesRegex(/\p{Upper}\p{Lower}[\p{Alpha}]{0,20}/, D.match); --where MatchesRegex(/\p{Upper}.{1,20}/, D.match);-- changed to enable unicode matchwhere MatchesRegex(/\p{Lu}\p{M}*.{1,20}/, D.match);
-- Italy first name from blue pagescreate view StrictFirstName5 asselect D.match as firstnamefrom Dictionary('names/strictFirst_italy.dict', Doc.text) Dwhere MatchesRegex(/\p{Lu}\p{M}*.{1,20}/, D.match);
-- France first name from blue pagescreate view StrictFirstName6 asselect D.match as firstnamefrom Dictionary('names/strictFirst_france.dict', Doc.text) Dwhere MatchesRegex(/\p{Lu}\p{M}*.{1,20}/, D.match);
-- Spain first name from blue pagescreate view StrictFirstName7 asselect D.match as firstnamefrom Dictionary('names/strictFirst_spain.dict', Doc.text) Dwhere MatchesRegex(/\p{Lu}\p{M}*.{1,20}/, D.match);
-- Indian first name from blue pages-- TODO: still need to clean up the remaining entriescreate view StrictFirstName8 asselect D.match as firstnamefrom Dictionary('names/strictFirst_india.partial.dict', Doc.text) Dwhere MatchesRegex(/\p{Lu}\p{M}*.{1,20}/, D.match);
-- Israel first name from blue pagescreate view StrictFirstName9 asselect D.match as firstnamefrom Dictionary('names/strictFirst_israel.dict', Doc.text) Dwhere MatchesRegex(/\p{Lu}\p{M}*.{1,20}/, D.match);
-- union all the dictionary matches for first namescreate view StrictFirstName as (select S.firstname as firstname from StrictFirstName1 S) union all (select S.firstname as firstname from StrictFirstName2 S) union all (select S.firstname as firstname from StrictFirstName3 S) union all (select S.firstname as firstname from StrictFirstName4 S) union all (select S.firstname as firstname from StrictFirstName5 S) union all (select S.firstname as firstname from StrictFirstName6 S) union all (select S.firstname as firstname from StrictFirstName7 S) union all (select S.firstname as firstname from StrictFirstName8 S) union all (select S.firstname as firstname from StrictFirstName9 S);
-- Relaxed versions of first namecreate view RelaxedFirstName1 asselect CombineSpans(S.firstname, CP.name) as firstnamefrom StrictFirstName S, StrictCapsPerson CPwhere FollowsTok(S.firstname, CP.name, 1, 1) and MatchesRegex(/\-/, SpanBetween(S.firstname, CP.name));
create view RelaxedFirstName2 asselect CombineSpans(CP.name, S.firstname) as firstnamefrom StrictFirstName S, StrictCapsPerson CPwhere FollowsTok(CP.name, S.firstname, 1, 1) and MatchesRegex(/\-/, SpanBetween(CP.name, S.firstname)); -- all the first namescreate view FirstNameAll as (select N.firstname as firstname from StrictFirstName N) union all (select N.firstname as firstname from RelaxedFirstName1 N) union all (select N.firstname as firstname from RelaxedFirstName2 N);
create view ValidFirstNameAll asselect N.firstname as firstnamefrom FirstNameAll Nwhere Not(MatchesRegex(/(\p{Lu}\p{M}*)+-.*([\p{Ll}\p{Lo}]\p{M}*).*/, N.firstname)) and Not(MatchesRegex(/.*([\p{Ll}\p{Lo}]\p{M}*).*-(\p{Lu}\p{M}*)+/, N.firstname)); create view FirstName asselect C.firstname as firstname--from Consolidate(ValidFirstNameAll.firstname) C;from ValidFirstNameAll Cconsolidate on C.firstname;
-- Combine all dictionary matches for both last names and first namescreate view NameDict asselect D.match as namefrom Dictionary('name.dict', Doc.text) D--where MatchesRegex(/\p{Upper}\p{Lower}[\p{Alpha}]{0,20}/, D.match); --where MatchesRegex(/\p{Upper}.{1,20}/, D.match); -- changed to enable unicode matchwhere MatchesRegex(/\p{Lu}\p{M}*.{1,20}/, D.match);
create view NameDict1 asselect D.match as namefrom Dictionary('names/name_italy.dict', Doc.text) Dwhere MatchesRegex(/\p{Lu}\p{M}*.{1,20}/, D.match);
create view NameDict2 asselect D.match as namefrom Dictionary('names/name_france.dict', Doc.text) Dwhere MatchesRegex(/\p{Lu}\p{M}*.{1,20}/, D.match);
create view NameDict3 asselect D.match as namefrom Dictionary('names/name_spain.dict', Doc.text) Dwhere MatchesRegex(/\p{Lu}\p{M}*.{1,20}/, D.match);
create view NameDict4 asselect D.match as name
from FirstName FN, InitialWord IW, CapsPerson CP where FollowsTok(FN.firstname, IW.word, 0, 0) and FollowsTok(IW.word, CP.name, 0, 0);
/** * Translation for Rule 3r2 * * This relaxed version of rule '3' will find person names like Thomas B.M. David * But it only insists that the second word is in the person dictionary *//*<rule annotation=Person id=3r2><internal><token attribute={etc}>CAPSPERSON</token><token attribute={etc}>INITIALWORD</token><token attribute={etc}PERSON:ST:LNAME{etc}>CAPSPERSON</token></internal></rule>*/
create view Person3r2 asselect CombineSpans(CP.name, LN.lastname) as personfrom LastName LN, InitialWord IW, CapsPerson CPwhere FollowsTok(CP.name, IW.word, 0, 0) and FollowsTok(IW.word, LN.lastname, 0, 0);
/** * Translation for Rule 4 * * This rule will find person names like David Thomas */ /* <rule annotation=Person id=4><internal><token attribute={etc}PERSON:ST:FNAME{etc}>CAPSPERSON</token><token attribute={etc}PERSON:ST:LNAME{etc}>CAPSPERSON</token></internal></rule>*/create view Person4WithNewLine asselect CombineSpans(FN.firstname, LN.lastname) as personfrom FirstName FN, LastName LNwhere FollowsTok(FN.firstname, LN.lastname, 0, 0);
-- Yunyao: 05/20/2008 revised to Person4WrongCandidates due to performance reason-- NOTE: current optimizer execute Equals first thus make Person4Wrong very expensive--create view Person4Wrong as--select CombineSpans(FN.firstname, LN.lastname) as person--from FirstName FN,-- LastName LN--where FollowsTok(FN.firstname, LN.lastname, 0, 0)-- and ContainsRegex(/[\n\r]/, SpanBetween(FN.firstname, LN.lastname))-- and Equals(GetText(FN.firstname), GetText(LN.lastname));
create view Person4WrongCandidates asselect FN.firstname as firstname, LN.lastname as lastnamefrom FirstName FN, LastName LNwhere FollowsTok(FN.firstname, LN.lastname, 0, 0) and ContainsRegex(/[\n\r]/, SpanBetween(FN.firstname, LN.lastname));
create view Person4 as (select P.person as person from Person4WithNewLine P) minus (select CombineSpans(P.firstname, P.lastname) as person from Person4WrongCandidates P where Equals(GetText(P.firstname), GetText(P.lastname))); /** * Translation for Rule4a * This rule will find person names like Thomas, David */ /*<rule annotation=Person id=4a><internal><token attribute={etc}PERSON:ST:LNAME{etc}>CAPSPERSON</token><token attribute={etc}>\,</token><token attribute={etc}PERSON:ST:FNAME{etc}>CAPSPERSON</token></internal></rule> */create view Person4a asselect CombineSpans(LN.lastname, FN.firstname) as personfrom FirstName FN, LastName LNwhere FollowsTok(LN.lastname, FN.firstname, 1, 1)and ContainsRegex(/,/,SpanBetween(LN.lastname, FN.firstname)); -- relaxed version of Rule4a-- Yunyao: split the following rules into two to improve performance-- TODO: Test case for optimizer -- create view Person4ar1 as-- select CombineSpans(CP.name, FN.firstname) as person--from FirstName FN,-- CapsPerson CP--where FollowsTok(CP.name, FN.firstname, 1, 1)--and ContainsRegex(/,/,SpanBetween(CP.name, FN.firstname))--and Not(MatchesRegex(/(.|\n|\r)*(\.|\?|!|'|\sat|\sin)( )*/, LeftContext(CP.name, 10)))--and Not(MatchesRegex(/(?i)(.+fully)/, CP.name))--and GreaterThan(GetBegin(CP.name), 10);
create view Person4ar1temp asselect FN.firstname as firstname, CP.name as namefrom FirstName FN, CapsPerson CPwhere FollowsTok(CP.name, FN.firstname, 1, 1) and ContainsRegex(/,/,SpanBetween(CP.name, FN.firstname));
create view Person4ar1 asselect CombineSpans(P.name, P.firstname) as person from Person4ar1temp Pwhere Not(MatchesRegex(/(.|\n|\r)*(\.|\?|!|'|\sat|\sin)( )*/, LeftContext(P.name, 10))) --' and Not(MatchesRegex(/(?i)(.+fully)/, P.name)) and GreaterThan(GetBegin(P.name), 10);
create view Person4ar2 asselect CombineSpans(LN.lastname, CP.name) as personfrom CapsPerson CP, LastName LNwhere FollowsTok(LN.lastname, CP.name, 0, 1)and ContainsRegex(/,/,SpanBetween(LN.lastname, CP.name));
/** * Translation for Rule2 * * This rule will handles names of persons like B.M. Thomas David, where Thomas occurs in some person dictionary */ /*<rule annotation=Person id=2><internal><token attribute={etc}>INITIALWORD</token><token attribute={etc}PERSON{etc}>CAPSPERSON</token><token attribute={etc}>CAPSPERSON</token></internal></rule>*/
create view Person2 asselect CombineSpans(IW.word, CP.name) as personfrom InitialWord IW, PersonDict P, CapsPerson CPwhere FollowsTok(IW.word, P.name, 0, 0) and FollowsTok(P.name, CP.name, 0, 0);
/** * Translation for Rule 2a * * The rule handles names of persons like B.M. Thomas David, where David occurs in some person dictionary *//*<rule annotation=Person id=2a><internal><token attribute={etc}>INITIALWORD</token><token attribute={etc}>CAPSPERSON</token><token attribute={etc}>NEWLINE</token>?<token attribute={etc}PERSON{etc}>CAPSPERSON</token></internal></rule>*/
create view Person2a asselect CombineSpans(IW.word, P.name) as personfrom InitialWord IW, CapsPerson CP, PersonDict Pwhere FollowsTok(IW.word, CP.name, 0, 0) and FollowsTok(CP.name, P.name, 0, 0);
/*<rule annotation=Person id=4r1><internal><token attribute={etc}PERSON:ST:FNAME{etc}>CAPSPERSON</token><token attribute={etc}>NEWLINE</token>?<token attribute={etc}>CAPSPERSON</token></internal></rule>*/create view Person4r1 asselect CombineSpans(FN.firstname, CP.name) as personfrom FirstName FN, CapsPerson CPwhere FollowsTok(FN.firstname, CP.name, 0, 0);
/** * Translation for Rule 4r2 * * This relaxed version of rule '4' will find person names Thomas, David * But it only insists that the SECOND word is in some person dictionary */ /*<rule annotation=Person id=4r2><token attribute={etc}>ANYWORD</token><internal><token attribute={etc}>CAPSPERSON</token><token attribute={etc}>NEWLINE</token>?<token attribute={etc}PERSON:ST:LNAME{etc}>CAPSPERSON</token></internal></rule>*/create view Person4r2 asselect CombineSpans(CP.name, LN.lastname) as personfrom CapsPerson CP, LastName LNwhere FollowsTok(CP.name, LN.lastname, 0, 0);
/** * Translation for Rule 5 * * This rule will find other single token person first names */ /* <rule annotation=Person id=5><internal><token attribute={etc}>INITIALWORD</token>?<token attribute={etc}PERSON:ST:FNAME{etc}>CAPSPERSON</token></internal></rule>*/create view Person5 asselect CombineSpans(IW.word, FN.firstname) as personfrom InitialWord IW, FirstName FNwhere FollowsTok(IW.word, FN.firstname, 0, 0);
/** * Translation for Rule 6 * * This rule will find other single token person last names */ /* <rule annotation=Person id=6><internal><token attribute={etc}>INITIALWORD</token>?<token attribute={etc}PERSON:ST:LNAME{etc}>CAPSPERSON</token></internal></rule>*/
create view Person6 asselect CombineSpans(IW.word, LN.lastname) as personfrom InitialWord IW, LastName LNwhere FollowsTok(IW.word, LN.lastname, 0, 0);
--==========================================================-- End of rules---- Create final list of names based on all the matches extracted----==========================================================
/** * Union all matches found by strong rules, except the ones directly come * from dictionary matches */create view PersonStrongWithNewLine as (select P.person as person from Person1 P)--union all -- (select P.person as person from Person1a_more P)union all (select P.person as person from Person3 P)union all (select P.person as person from Person4 P)union all (select P.person as person from Person3P1 P);
create view PersonStrongSingleTokenOnly as (select P.person as person from Person5 P)union all (select P.person as person from Person6 P)union all (select P.firstname as person from FirstName P)union all (select P.lastname as person from LastName P)union all (select P.person as person from Person1a P);
-- Yunyao: added 05/09/2008 to expand person names with suffixcreate view PersonStrongSingleTokenOnlyExpanded1 asselect CombineSpans(P.person,S.suffix) as personfrom PersonStrongSingleTokenOnly P, PersonSuffix Swhere FollowsTok(P.person, S.suffix, 0, 0);
-- Yunyao: added 04/14/2009 to expand single token person name with a single initial -- extend single token person with a single initialcreate view PersonStrongSingleTokenOnlyExpanded2 as select CombineSpans(R.person, RightContext(R.person,2)) as personfrom PersonStrongSingleTokenOnly Rwhere MatchesRegex(/ +[\p{Upper}]\b\s*/, RightContext(R.person,3)); create view PersonStrongSingleToken as (select P.person as person from PersonStrongSingleTokenOnly P) union all (select P.person as person from PersonStrongSingleTokenOnlyExpanded1 P) union all (select P.person as person from PersonStrongSingleTokenOnlyExpanded2 P); /** * Union all matches found by weak rules */create view PersonWeak1WithNewLine as (select P.person as person from Person3r1 P)union all (select P.person as person from Person3r2 P)union all (select P.person as person from Person4r1 P)union all (select P.person as person from Person4r2 P)union all (select P.person as person from Person2 P)union all (select P.person as person from Person2a P)union all (select P.person as person from Person3P2 P)union all (select P.person as person from Person3P3 P); -- weak rules that identify (LastName, FirstName)create view PersonWeak2WithNewLine as (select P.person as person from Person4a P)union all (select P.person as person from Person4ar1 P)union all (select P.person as person from Person4ar2 P);
--include 'core/GenericNE/Person-FilterNewLineSingle.aql';--include 'core/GenericNE/Person-Filter.aql';
create view PersonBase as (select P.person as person from PersonStrongWithNewLine P)union all (select P.person as person from PersonWeak1WithNewLine P)union all (select P.person as person from PersonWeak2WithNewLine P);
output view PersonBase;
from Dictionary('names/name_israel.dict', Doc.text) Dwhere MatchesRegex(/\p{Lu}\p{M}*.{1,20}/, D.match);
create view NamesAll as (select P.name as name from NameDict P) union all (select P.name as name from NameDict1 P) union all (select P.name as name from NameDict2 P) union all (select P.name as name from NameDict3 P) union all (select P.name as name from NameDict4 P) union all (select P.firstname as name from FirstName P) union all
create view PersonDict asselect C.name as name--from Consolidate(NamesAll.name) C;from NamesAll Cconsolidate on C.name;
--==========================================================-- Actual Rules--==========================================================
-- For 3-part Person namescreate view Person3P1 as select CombineSpans(F.firstname, L.lastname) as personfrom StrictFirstName F, StrictCapsPersonR S, StrictLastName Lwhere FollowsTok(F.firstname, S.name, 0, 0) --and FollowsTok(S.name, L.lastname, 0, 0) and FollowsTok(F.firstname, L.lastname, 1, 1) and Not(Equals(GetText(F.firstname), GetText(L.lastname))) and Not(Equals(GetText(F.firstname), GetText(S.name))) and Not(Equals(GetText(S.name), GetText(L.lastname))) and Not(ContainsRegex(/[\n\r\t]/, SpanBetween(F.firstname, L.lastname))); create view Person3P2 as select CombineSpans(P.name, L.lastname) as personfrom PersonDict P, StrictCapsPersonR S, StrictLastName Lwhere FollowsTok(P.name, S.name, 0, 0) --and FollowsTok(S.name, L.lastname, 0, 0) and FollowsTok(P.name, L.lastname, 1, 1) and Not(Equals(GetText(P.name), GetText(L.lastname))) and Not(Equals(GetText(P.name), GetText(S.name))) and Not(Equals(GetText(S.name), GetText(L.lastname))) and Not(ContainsRegex(/[\n\r\t]/, SpanBetween(P.name, L.lastname)));
create view Person3P3 as select CombineSpans(F.firstname, P.name) as personfrom PersonDict P, StrictCapsPersonR S, StrictFirstName Fwhere FollowsTok(F.firstname, S.name, 0, 0) --and FollowsTok(S.name, P.name, 0, 0) and FollowsTok(F.firstname, P.name, 1, 1) and Not(Equals(GetText(P.name), GetText(F.firstname))) and Not(Equals(GetText(P.name), GetText(S.name))) and Not(Equals(GetText(S.name), GetText(F.firstname))) and Not(ContainsRegex(/[\n\r\t]/, SpanBetween(F.firstname, P.name)));
/** * Translation for Rule 1 * Handles names of persons like Mr. Vladimir E. Putin *//*<rule annotation=Person id=1><token attribute={etc}INITIAL{etc}>CANYWORD</token><internal><token attribute={etc}>CAPSPERSON</token><token attribute={etc}>INITIALWORD</token><token attribute={etc}>CAPSPERSON</token></internal></rule>*/ create view Person1 as select CombineSpans(CP1.name, CP2.name) as person from Initial I, CapsPerson CP1, InitialWord IW, CapsPerson CP2 where FollowsTok(I.initial, CP1.name, 0, 0) and FollowsTok(CP1.name, IW.word, 0, 0) and FollowsTok(IW.word, CP2.name, 0, 0); --and Not(ContainsRegex(/[\n\r]/, SpanBetween(I.initial, CP2.name))); /** * Translation for Rule 1a * Handles names of persons like Mr. Vladimir Putin *//* <rule annotation=Person id=1a><token attribute={etc}INITIAL{etc}>CANYWORD</token><internal><token attribute={etc}>CAPSPERSON</token>{1,3}</internal></rule>*/
-- Split into two rules so that single token annotations are serperated from others -- Single token annotations create view Person1a1 as select CP1.name as person from Initial I, CapsPerson CP1 where FollowsTok(I.initial, CP1.name, 0, 0) --- start changing this block--- disallow allow newline and Not(ContainsRegex(/[\n\t]/,SpanBetween(I.initial,CP1.name)))--- end changing this block;
-- Yunyao: added 05/09/2008 to match patterns such as "Mr. B. B. Buy"/* create view Person1a2 as select CombineSpans(name.block, CP1.name) as person from Initial I, BlockTok(0, 1, 2, InitialWord.word) name, CapsPerson CP1 where FollowsTok(I.initial, name.block, 0, 0) and FollowsTok(name.block, CP1.name, 0, 0) and Not(ContainsRegex(/[\n\t]/,CombineSpans(I.initial, CP1.name)));*/
create view Person1a as-- ( select P.person as person from Person1a1 P-- )-- union all-- (select P.person as person from Person1a2 P);
/* create view Person1a_more as select name.block as person from Initial I, BlockTok(0, 2, 3, CapsPerson.name) name where FollowsTok(I.initial, name.block, 0, 0) and Not(ContainsRegex(/[\n\t]/,name.block))--- start changing this block-- disallow newline and Not(ContainsRegex(/[\n\t]/,SpanBetween(I.initial,name.block)))
--- end changing this block ; */
/** * Translation for Rule 3 * Find person names like Thomas B.M. David */ /*<rule annotation=Person id=3><internal><token attribute={etc}PERSON{etc}>CAPSPERSON</token><token attribute={etc}>INITIALWORD</token><token attribute={etc}PERSON{etc}>CAPSPERSON</token></internal></rule>*/
create view Person3 as select CombineSpans(P1.name, P2.name) as person from PersonDict P1, --InitialWord IW, WeakInitialWord IW, PersonDict P2 where FollowsTok(P1.name, IW.word, 0, 0) and FollowsTok(IW.word, P2.name, 0, 0) and Not(Equals(GetText(P1.name), GetText(P2.name))); /** * Translation for Rule 3r1 * * This relaxed version of rule '3' will find person names like Thomas B.M. David * But it only insists that the first word is in the person dictionary */ /*<rule annotation=Person id=3r1><internal><token attribute={etc}PERSON:ST:FNAME{etc}>CAPSPERSON</token><token attribute={etc}>INITIALWORD</token><token attribute={etc}>CAPSPERSON</token></internal></rule>*/
create view Person3r1 as
create view Initial as
--'Junior' (Yunyao: comments out to avoid mismatches such as Junior National [team player], -- If we can have large negative dictionary to eliminate such mismatches, -- then this may be recovered --'Name:' ((Yunyao: comments out to avoid mismatches such as 'Name: Last Name') -- for German names -- TODO: need further test ,'herr', 'Fraeulein', 'Doktor', 'Herr Doktor', 'Frau Doktor', 'Herr Professor', 'Frau professor', 'Baron', 'graf');
-- Find dictionary matches for all title initials
select D.match as initial --'Name:' ((Yunyao: comments out to avoid mismatches such as 'Name: Last Name') -- for German names -- TODO: need further test ,'herr', 'Fraeulein', 'Doktor', 'Herr Doktor', 'Frau Doktor', 'Herr Professor', 'Frau professor', 'Baron', 'graf');
-- Find dictionary matches for all title initials
from Dictionary('InitialDict', Doc.text) D;
-- Yunyao: added 05/09/2008 to capture person name suffixcreate dictionary PersonSuffixDict as( ',jr.', ',jr', 'III', 'IV', 'V', 'VI');
create view PersonSuffix asselect D.match as suffixfrom Dictionary('PersonSuffixDict', Doc.text) D;
-- Find capitalized words that look like person names and not in the non-name dictionarycreate view CapsPersonCandidate asselect R.match as name--from Regex(/\b\p{Upper}\p{Lower}[\p{Alpha}]{1,20}\b/, Doc.text) R--from Regex(/\b\p{Upper}\p{Lower}[\p{Alpha}]{0,10}(['-][\p{Upper}])?[\p{Alpha}]{1,10}\b/, Doc.text) R -- change to enable unicode match--from Regex(/\b\p{Lu}\p{M}*[\p{Ll}\p{Lo}]\p{M}*[\p{L}\p{M}*]{0,10}(['-][\p{Lu}\p{M}*])?[\p{L}\p{M}*]{1,10}\b/, Doc.text) R --from Regex(/\b\p{Lu}\p{M}*[\p{Ll}\p{Lo}]\p{M}*[\p{L}\p{M}*]{0,10}(['-][\p{Lu}\p{M}*])?(\p{L}\p{M}*){1,10}\b/, Doc.text) R -- Allow fully capitalized words--from Regex(/\b\p{Lu}\p{M}*(\p{L}\p{M}*){0,10}(['-][\p{Lu}\p{M}*])?(\p{L}\p{M}*){1,10}\b/, Doc.text) R from RegexTok(/\p{Lu}\p{M}*(\p{L}\p{M}*){0,10}(['-][\p{Lu}\p{M}*])?(\p{L}\p{M}*){1,10}/, 4, Doc.text) R --'where Not(ContainsDicts( 'FilterPersonDict', 'filterPerson_position.dict', 'filterPerson_german.dict', 'InitialDict', 'StrongPhoneVariantDictionary', 'stateList.dict', 'organization_suffix.dict', 'industryType_suffix.dict', 'streetSuffix_forPerson.dict', 'wkday.dict', 'nationality.dict', 'stateListAbbrev.dict', 'stateAbbrv.ChicagoAPStyle.dict', R.match)); create view CapsPerson asselect C.name as namefrom CapsPersonCandidate Cwhere Not(MatchesRegex(/(\p{Lu}\p{M}*)+-.*([\p{Ll}\p{Lo}]\p{M}*).*/, C.name)) and Not(MatchesRegex(/.*([\p{Ll}\p{Lo}]\p{M}*).*-(\p{Lu}\p{M}*)+/, C.name));
-- Find strict capitalized words with two letter or more (relaxed version of StrictCapsPerson)
--============================================================--TODO: need to think through how to deal with hypened name -- one way to do so is to run Regex(pattern, CP.name) and enforce CP.name does not contain '-- need more testing before confirming the change
create view CapsPersonNoP asselect CP.name as namefrom CapsPerson CPwhere Not(ContainsRegex(/'/, CP.name)); --'
create view StrictCapsPersonR asselect R.match as name--from Regex(/\b\p{Lu}\p{M}*(\p{L}\p{M}*){1,20}\b/, CapsPersonNoP.name) R;from RegexTok(/\p{Lu}\p{M}*(\p{L}\p{M}*){1,20}/, 1, CapsPersonNoP.name) R;
--============================================================ -- Find strict capitalized words--create view StrictCapsPerson ascreate view StrictCapsPerson asselect R.name as namefrom StrictCapsPersonR Rwhere MatchesRegex(/\b\p{Lu}\p{M}*[\p{Ll}\p{Lo}]\p{M}*(\p{L}\p{M}*){1,20}\b/, R.name);
-- Find dictionary matches for all last namescreate view StrictLastName1 asselect D.match as lastnamefrom Dictionary('strictLast.dict', Doc.text) D--where MatchesRegex(/\p{Upper}\p{Lower}[\p{Alpha}]{0,20}/, D.match); -- changed to enable unicode matchwhere MatchesRegex(/((\p{L}\p{M}*)+\s+)?\p{Lu}\p{M}*.{1,20}/, D.match);
create view StrictLastName2 asselect D.match as lastnamefrom Dictionary('strictLast_german.dict', Doc.text) D--where MatchesRegex(/\p{Upper}\p{Lower}[\p{Alpha}]{0,20}/, D.match); --where MatchesRegex(/\p{Upper}.{1,20}/, D.match);-- changed to enable unicode matchwhere MatchesRegex(/((\p{L}\p{M}*)+\s+)?\p{Lu}\p{M}*.{1,20}/, D.match);
create view StrictLastName3 asselect D.match as lastnamefrom Dictionary('strictLast_german_bluePages.dict', Doc.text) D--where MatchesRegex(/\p{Upper}\p{Lower}[\p{Alpha}]{0,20}/, D.match); --where MatchesRegex(/\p{Upper}.{1,20}/, D.match);-- changed to enable unicode matchwhere MatchesRegex(/((\p{L}\p{M}*)+\s+)?\p{Lu}\p{M}*.{1,20}/, D.match);
create view StrictLastName4 asselect D.match as lastnamefrom Dictionary('uniqMostCommonSurname.dict', Doc.text) D--where MatchesRegex(/\p{Upper}\p{Lower}[\p{Alpha}]{0,20}/, D.match); --where MatchesRegex(/\p{Upper}.{1,20}/, D.match);-- changed to enable unicode matchwhere MatchesRegex(/((\p{L}\p{M}*)+\s+)?\p{Lu}\p{M}*.{1,20}/, D.match);
create view StrictLastName5 asselect D.match as lastnamefrom Dictionary('names/strictLast_italy.dict', Doc.text) Dwhere MatchesRegex(/((\p{L}\p{M}*)+\s+)?\p{Lu}\p{M}*.{1,20}/, D.match);
create view StrictLastName6 asselect D.match as lastnamefrom Dictionary('names/strictLast_france.dict', Doc.text) Dwhere MatchesRegex(/((\p{L}\p{M}*)+\s+)?\p{Lu}\p{M}*.{1,20}/, D.match);
create view StrictLastName7 asselect D.match as lastnamefrom Dictionary('names/strictLast_spain.dict', Doc.text) Dwhere MatchesRegex(/((\p{L}\p{M}*)+\s+)?\p{Lu}\p{M}*.{1,20}/, D.match);
create view StrictLastName8 asselect D.match as lastnamefrom Dictionary('names/strictLast_india.partial.dict', Doc.text) Dwhere MatchesRegex(/((\p{L}\p{M}*)+\s+)?\p{Lu}\p{M}*.{1,20}/, D.match);
create view StrictLastName9 asselect D.match as lastnamefrom Dictionary('names/strictLast_israel.dict', Doc.text) Dwhere MatchesRegex(/((\p{L}\p{M}*)+\s+)?\p{Lu}\p{M}*.{1,20}/, D.match);
create view StrictLastName as (select S.lastname as lastname from StrictLastName1 S) union all (select S.lastname as lastname from StrictLastName2 S) union all (select S.lastname as lastname from StrictLastName3 S) union all (select S.lastname as lastname from StrictLastName4 S) union all (select S.lastname as lastname from StrictLastName5 S) union all (select S.lastname as lastname from StrictLastName6 S) union all (select S.lastname as lastname from StrictLastName7 S) union all (select S.lastname as lastname from StrictLastName8 S) union all (select S.lastname as lastname from StrictLastName9 S);
-- Relaxed version of last namecreate view RelaxedLastName1 asselect CombineSpans(SL.lastname, CP.name) as lastnamefrom StrictLastName SL, StrictCapsPerson CPwhere FollowsTok(SL.lastname, CP.name, 1, 1) and MatchesRegex(/\-/, SpanBetween(SL.lastname, CP.name));
create view RelaxedLastName2 asselect CombineSpans(CP.name, SL.lastname) as lastnamefrom StrictLastName SL, StrictCapsPerson CPwhere FollowsTok(CP.name, SL.lastname, 1, 1) and MatchesRegex(/\-/, SpanBetween(CP.name, SL.lastname));
-- all the last namescreate view LastNameAll as (select N.lastname as lastname from StrictLastName N) union all (select N.lastname as lastname from RelaxedLastName1 N) union all (select N.lastname as lastname from RelaxedLastName2 N);
create view ValidLastNameAll asselect N.lastname as lastname
----------------------------------------- Document Preprocessing---------------------------------------create view Doc asselect D.text as textfrom DocScan D;
------------------------------------------ Basic Named Entity Annotators----------------------------------------
-- Find initial words create view InitialWord1 as select R.match as word --from Regex(/\b([\p{Upper}]\.\s*){1,5}\b/, Doc.text) R from RegexTok(/([\p{Upper}]\.\s*){1,5}/, 10, Doc.text) R -- added on 04/18/2008 where Not(MatchesRegex(/M\.D\./, R.match)); -- Yunyao: added on 11/21/2008 to capture names with prefix (we use it as initial -- to avoid adding too many commplex rules) create view InitialWord2 as select D.match as word from Dictionary('specialNamePrefix.dict', Doc.text) D; create view InitialWord as (select I.word as word from InitialWord1 I) union all (select I.word as word from InitialWord2 I); -- Find weak initial words create view WeakInitialWord as select R.match as word --from Regex(/\b([\p{Upper}]\.?\s*){1,5}\b/, Doc.text) R; from RegexTok(/([\p{Upper}]\.?\s*){1,5}/, 10, Doc.text) R -- added on 05/12/2008 -- Do not allow weak initial word to be a word longer than three characters where Not(ContainsRegex(/[\p{Upper}]{3}/, R.match)) -- added on 04/14/2009 -- Do not allow weak initial words to match the timezon and Not(ContainsDict('timeZone.dict', R.match)); ------------------------------------------------- Strong Phone Numbers-----------------------------------------------create dictionary StrongPhoneVariantDictionary as ( 'phone', 'cell', 'contact', 'direct', 'office', -- Yunyao: Added new strong clues for phone numbers 'tel', 'dial', 'Telefon', 'mobile', 'Ph', 'Phone Number', 'Direct Line', 'Telephone No', 'TTY', 'Toll Free', 'Toll-free', -- German 'Fon', 'Telefon Geschaeftsstelle', 'Telefon Geschäftsstelle', 'Telefon Zweigstelle', 'Telefon Hauptsitz', 'Telefon (Geschaeftsstelle)', 'Telefon (Geschäftsstelle)', 'Telefon (Zweigstelle)', 'Telefon (Hauptsitz)', 'Telefonnummer', 'Telefon Geschaeftssitz', 'Telefon Geschäftssitz', 'Telefon (Geschaeftssitz)', 'Telefon (Geschäftssitz)', 'Telefon Persönlich', 'Telefon persoenlich', 'Telefon (Persönlich)', 'Telefon (persoenlich)', 'Handy', 'Handy-Nummer', 'Telefon arbeit', 'Telefon (arbeit)');
--include 'core/GenericNE/Person.aql';
create dictionary FilterPersonDict as( 'Travel', 'Fellow', 'Sir', 'IBMer', 'Researcher', 'All','Tell', 'Friends', 'Friend', 'Colleague', 'Colleagues', 'Managers','If', 'Customer', 'Users', 'User', 'Valued', 'Executive', 'Chairs', 'New', 'Owner', 'Conference', 'Please', 'Outlook', 'Lotus', 'Notes', 'This', 'That', 'There', 'Here', 'Subscribers', 'What', 'When', 'Where', 'Which', 'With', 'While', 'Thanks', 'Thanksgiving','Senator', 'Platinum', 'Perspective', 'Manager', 'Ambassador', 'Professor', 'Dear', 'Contact', 'Cheers', 'Athelet', 'And', 'Act', 'But', 'Hello', 'Call', 'From', 'Center', 'The', 'Take', 'Junior', 'Both', 'Communities', 'Greetings', 'Hope', 'Restaurants', 'Properties', 'Let', 'Corp', 'Memorial', 'You', 'Your', 'Our', 'My', 'His','Her', 'Their','Popcorn', 'Name', 'July', 'June','Join', 'Business', 'Administrative', 'South', 'Members', 'Address', 'Please', 'List', 'Public', 'Inc', 'Parkway', 'Brother', 'Buy', 'Then', 'Services', 'Statements', 'President', 'Governor', 'Commissioner', 'Commitment', 'Commits', 'Hey', 'Director', 'End', 'Exit', 'Experiences', 'Finance', 'Elementary', 'Wednesday', 'Nov', 'Infrastructure', 'Inside', 'Convention', 'Judge', 'Lady', 'Friday', 'Project', 'Projected', 'Recalls', 'Regards', 'Recently', 'Administration', 'Independence', 'Denied', 'Unfortunately', 'Under', 'Uncle', 'Utility', 'Unlike', 'Was', 'Were', 'Secretary', 'Speaker', 'Chairman', 'Consider', 'Consultant', 'County', 'Court', 'Defensive', 'Northwestern', 'Place', 'Hi', 'Futures', 'Athlete', 'Invitational', 'System', 'International', 'Main', 'Online', 'Ideally' -- more entries ,'If','Our', 'About', 'Analyst', 'On', 'Of', 'By', 'HR', 'Mkt', 'Pre', 'Post', 'Condominium', 'Ice', 'Surname', 'Lastname', 'firstname', 'Name', 'familyname', -- Italian greeting 'Ciao', -- Spanish greeting 'Hola', -- French greeting 'Bonjour', -- new entries 'Pro','Bono','Enterprises','Group','Said','Says','Assistant','Vice','Warden','Contribution', 'Research', 'Development', 'Product', 'Sales', 'Support', 'Manager', 'Telephone', 'Phone', 'Contact', 'Information', 'Electronics','Managed','West','East','North','South', 'Teaches','Ministry', 'Church', 'Association', 'Laboratories', 'Living', 'Community', 'Visiting', 'Officer', 'After', 'Pls', 'FYI', 'Only', 'Additionally', 'Adding', 'Acquire', 'Addition', 'America', -- short phrases that are likely to be at the start of a sentence 'Yes', 'No', 'Ja', 'Nein','Kein', 'Keine', 'Gegenstimme', -- TODO: to be double checked 'Another', 'Anyway','Associate', 'At', 'Athletes', 'It', 'Enron', 'EnronXGate', 'Have', 'However', 'Company', 'Companies', 'IBM','Annual', -- common verbs appear with person names in financial reports -- ideally we want to have a general comprehensive verb list to use as a filter dictionary 'Joins', 'Downgrades', 'Upgrades', 'Reports', 'Sees', 'Warns', 'Announces', 'Reviews' -- Laura 06/02/2009: new filter dict for title for SEC domain in filterPerson_title.dict);
create dictionary GreetingsDict as( 'Hey', 'Hi', 'Hello', 'Dear', -- German greetings 'Liebe', 'Lieber', 'Herr', 'Frau', 'Hallo', -- Italian 'Ciao', -- Spanish 'Hola', -- French 'Bonjour');
create dictionary InitialDict as( 'rev.', 'col.', 'reverend', 'prof.', 'professor.', 'lady', 'miss.', 'mrs.', 'mrs', 'mr.', 'pt.', 'ms.', 'messrs.', 'dr.', 'master.', 'marquis', 'monsieur', 'ds', 'di' --'Dear' (Yunyao: comments out to avoid mismatches such as Dear Member), --'Junior' (Yunyao: comments out to avoid mismatches such as Junior National [team player], -- If we can have large negative dictionary to eliminate such mismatches, -- then this may be recovered
Example 1: Explaining Extraction Results---------------------------------------
-- Document Preprocessing---------------------------------------create view Doc asselect D.text as textfrom DocScan D;
------------------------------------------ Basic Named Entity Annotators----------------------------------------
-- Find initial words create view InitialWord1 as select R.match as word --from Regex(/\b([\p{Upper}]\.\s*){1,5}\b/, Doc.text) R from RegexTok(/([\p{Upper}]\.\s*){1,5}/, 10, Doc.text) R -- added on 04/18/2008 where Not(MatchesRegex(/M\.D\./, R.match)); -- Yunyao: added on 11/21/2008 to capture names with prefix (we use it as initial -- to avoid adding too many commplex rules) create view InitialWord2 as select D.match as word from Dictionary('specialNamePrefix.dict', Doc.text) D; create view InitialWord as (select I.word as word from InitialWord1 I) union all (select I.word as word from InitialWord2 I); -- Find weak initial words create view WeakInitialWord as select R.match as word --from Regex(/\b([\p{Upper}]\.?\s*){1,5}\b/, Doc.text) R; from RegexTok(/([\p{Upper}]\.?\s*){1,5}/, 10, Doc.text) R -- added on 05/12/2008 -- Do not allow weak initial word to be a word longer than three characters where Not(ContainsRegex(/[\p{Upper}]{3}/, R.match)) -- added on 04/14/2009 -- Do not allow weak initial words to match the timezon and Not(ContainsDict('timeZone.dict', R.match)); ------------------------------------------------- Strong Phone Numbers-----------------------------------------------create dictionary StrongPhoneVariantDictionary as ( 'phone', 'cell', 'contact', 'direct', 'office', -- Yunyao: Added new strong clues for phone numbers 'tel', 'dial', 'Telefon', 'mobile', 'Ph', 'Phone Number', 'Direct Line', 'Telephone No', 'TTY', 'Toll Free', 'Toll-free', -- German 'Fon', 'Telefon Geschaeftsstelle', 'Telefon Geschäftsstelle', 'Telefon Zweigstelle', 'Telefon Hauptsitz', 'Telefon (Geschaeftsstelle)', 'Telefon (Geschäftsstelle)', 'Telefon (Zweigstelle)', 'Telefon (Hauptsitz)', 'Telefonnummer', 'Telefon Geschaeftssitz', 'Telefon Geschäftssitz', 'Telefon (Geschaeftssitz)', 'Telefon (Geschäftssitz)', 'Telefon Persönlich', 'Telefon persoenlich', 'Telefon (Persönlich)', 'Telefon (persoenlich)', 'Handy', 'Handy-Nummer', 'Telefon arbeit', 'Telefon (arbeit)');
--include 'core/GenericNE/Person.aql';
create dictionary FilterPersonDict as( 'Travel', 'Fellow', 'Sir', 'IBMer', 'Researcher', 'All','Tell', 'Friends', 'Friend', 'Colleague', 'Colleagues', 'Managers','If', 'Customer', 'Users', 'User', 'Valued', 'Executive', 'Chairs', 'New', 'Owner', 'Conference', 'Please', 'Outlook', 'Lotus', 'Notes', 'This', 'That', 'There', 'Here', 'Subscribers', 'What', 'When', 'Where', 'Which', 'With', 'While', 'Thanks', 'Thanksgiving','Senator', 'Platinum', 'Perspective', 'Manager', 'Ambassador', 'Professor', 'Dear', 'Contact', 'Cheers', 'Athelet', 'And', 'Act', 'But', 'Hello', 'Call', 'From', 'Center', 'The', 'Take', 'Junior', 'Both', 'Communities', 'Greetings', 'Hope', 'Restaurants', 'Properties', 'Let', 'Corp', 'Memorial', 'You', 'Your', 'Our', 'My', 'His','Her', 'Their','Popcorn', 'Name', 'July', 'June','Join', 'Business', 'Administrative', 'South', 'Members', 'Address', 'Please', 'List', 'Public', 'Inc', 'Parkway', 'Brother', 'Buy', 'Then', 'Services', 'Statements', 'President', 'Governor', 'Commissioner', 'Commitment', 'Commits', 'Hey', 'Director', 'End', 'Exit', 'Experiences', 'Finance', 'Elementary', 'Wednesday', 'Nov', 'Infrastructure', 'Inside', 'Convention', 'Judge', 'Lady', 'Friday', 'Project', 'Projected', 'Recalls', 'Regards', 'Recently', 'Administration', 'Independence', 'Denied', 'Unfortunately', 'Under', 'Uncle', 'Utility', 'Unlike', 'Was', 'Were', 'Secretary', 'Speaker', 'Chairman', 'Consider', 'Consultant', 'County', 'Court', 'Defensive', 'Northwestern', 'Place', 'Hi', 'Futures', 'Athlete', 'Invitational', 'System', 'International', 'Main', 'Online', 'Ideally' -- more entries ,'If','Our', 'About', 'Analyst', 'On', 'Of', 'By', 'HR', 'Mkt', 'Pre', 'Post', 'Condominium', 'Ice', 'Surname', 'Lastname', 'firstname', 'Name', 'familyname', -- Italian greeting 'Ciao', -- Spanish greeting 'Hola', -- French greeting 'Bonjour', -- new entries 'Pro','Bono','Enterprises','Group','Said','Says','Assistant','Vice','Warden','Contribution', 'Research', 'Development', 'Product', 'Sales', 'Support', 'Manager', 'Telephone', 'Phone', 'Contact', 'Information', 'Electronics','Managed','West','East','North','South', 'Teaches','Ministry', 'Church', 'Association', 'Laboratories', 'Living', 'Community', 'Visiting', 'Officer', 'After', 'Pls', 'FYI', 'Only', 'Additionally', 'Adding', 'Acquire', 'Addition', 'America', -- short phrases that are likely to be at the start of a sentence 'Yes', 'No', 'Ja', 'Nein','Kein', 'Keine', 'Gegenstimme', -- TODO: to be double checked 'Another', 'Anyway','Associate', 'At', 'Athletes', 'It', 'Enron', 'EnronXGate', 'Have', 'However', 'Company', 'Companies', 'IBM','Annual', -- common verbs appear with person names in financial reports -- ideally we want to have a general comprehensive verb list to use as a filter dictionary 'Joins', 'Downgrades', 'Upgrades', 'Reports', 'Sees', 'Warns', 'Announces', 'Reviews' -- Laura 06/02/2009: new filter dict for title for SEC domain in filterPerson_title.dict);
create dictionary GreetingsDict as( 'Hey', 'Hi', 'Hello', 'Dear', -- German greetings 'Liebe', 'Lieber', 'Herr', 'Frau', 'Hallo', -- Italian 'Ciao', -- Spanish 'Hola', -- French 'Bonjour');
create dictionary InitialDict as( 'rev.', 'col.', 'reverend', 'prof.', 'professor.', 'lady', 'miss.', 'mrs.', 'mrs', 'mr.', 'pt.', 'ms.', 'messrs.', 'dr.', 'master.', 'marquis', 'monsieur', 'ds', 'di' --'Dear' (Yunyao: comments out to avoid mismatches such as Dear Member),
SystemT’s Person extractor
~250 AQL rules
SystemT’s Person extractor
~250 AQL rules
“Global financial services firm Morgan Stanley announced … ““Global financial services firm Morgan Stanley announced … “
Person

© 2009 IBM Corporation82
<annotations>
<text>
<Person>
<start>52</start>
<end>68</end>
<annotation>Peter Blackburn
</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>351</start>
<end>367</end>
<annotation>Werner Zwingmann</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>617</start>
<end>637</end>
<annotation>Nikolaus van der Pas</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>849</start>
<end>863</end>
<annotation>Franz Fischler</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>1021</start>
<end>1029</end>
<annotation>Fischler</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>1215</start>
<end>1223</end>
<annotation>Fischler</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>1450</start>
<end>1467</end>
<annotation>Loyola de Palacio</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>1488</start>
<end>1496</end>
<annotation>Fischler</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>1634</start>
<end>1642</end>
<annotation>Fischler</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>2388</start>
<end>2404</end>
<annotation>John Lloyd Jones</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Organization>
<start>2</start>
<end>4</end>
<annotation>EU</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Organization>
<start>94</start>
<end>113</end>
<annotation>European Commission</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Organization>
<start>312</start>
<end>326</end>
<annotation>European Union</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Organization>
<start>587</start>
<end>597</end>
<annotation>Commission</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Organization>
<start>777</start>
<end>791</end>
<annotation>European Union</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Organization>
<start>828</start>
<end>830</end>
<annotation>EU</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Organization>
<start>1264</start>
<end>1266</end>
<annotation>EU</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Organization>
<start>1503</start>
<end>1505</end>
<annotation>EU</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Organization>
<start>1662</start>
<end>1664</end>
<annotation>EU</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Organization>
<start>2340</start>
<end>2370</end>
<annotation>Welsh National Farmers ' Union</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Organization>
<start>2373</start>
<end>2376</end>
<annotation>NFU</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Organization>
<start>2413</start>
<end>2422</end>
<annotation>BBC radio</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Location>
<start>69</start>
<end>77</end>
<annotation>BRUSSELS</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>279</start>
<end>286</end>
<annotation>Germany</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>443</start>
<end>450</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1075</start>
<end>1082</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1087</start>
<end>1093</end>
<annotation>France</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1608</start>
<end>1614</end>
<annotation>France</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1619</start>
<end>1626</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>2227</start>
<end>2233</end>
<annotation>Europe</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>2320</start>
<end>2327</end>
<annotation>Germany</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>2426</start>
<end>2430</end>
<annotation>Bonn</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>2641</start>
<end>2648</end>
<annotation>Germany</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>2676</start>
<end>2683</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
</Location>
</text>
</annotations>
<annotations>
<text>
<Person>
<start>7</start>
<end>14</end>
<annotation>Hendrix</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>137</start>
<end>149</end>
<annotation>Jimi Hendrix</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>362</start>
<end>369</end>
<annotation>Hendrix</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>655</start>
<end>662</end>
<annotation>Hendrix</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>684</start>
<end>700</end>
<annotation>Kathy Etchingham</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>812</start>
<end>819</end>
<annotation>Hendrix</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Location>
<start>55</start>
<end>61</end>
<annotation>LONDON</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>118</start>
<end>122</end>
<annotation>U.S.</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>264</start>
<end>271</end>
<annotation>Florida</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>391</start>
<end>397</end>
<annotation>London</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>491</start>
<end>501</end>
<annotation>Nottingham</annotation>
<typeinfo>LOC</typeinfo>
</Location>
</text>
</annotations>
<annotations>
<text>
<Person>
<start>7</start>
<end>14</end>
<annotation>Hendrix</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>137</start>
<end>149</end>
<annotation>Jimi Hendrix</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>362</start>
<end>369</end>
<annotation>Hendrix</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>655</start>
<end>662</end>
<annotation>Hendrix</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>684</start>
<end>700</end>
<annotation>Kathy Etchingham</annotation>
<typeinfo>PER</typeinfo>
</Person>
<annotations>
<text>
<Person>
<start>477</start>
<end>497</end>
<annotation>Tadeusz Awdankiewicz</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>621</start>
<end>633</end>
<annotation>Awdankiewicz</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Organization>
<start>505</start>
<end>512</end>
<annotation>Reuters</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Location>
<start>44</start>
<end>49</end>
<annotation>Libya</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>53</start>
<end>58</end>
<annotation>TUNIS</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>147</start>
<end>152</end>
<annotation>Libya</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>356</start>
<end>361</end>
<annotation>Libya</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>467</start>
<end>474</end>
<annotation>Tripoli</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>529</start>
<end>535</end>
<annotation>Poland</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>594</start>
<end>599</end>
<annotation>Libya</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>823</start>
<end>828</end>
<annotation>Libya</annotation>
<typeinfo>LOC</typeinfo>
</Location>
</text>
</annotations>
typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>279</start>
<end>286</end>
<annotation>Germany</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>443</start>
<end>450</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1075</start>
<end>1082</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1087</start>
<end>1093</end>
<annotation>France</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1608</start>
<end>1614</end>
<annotation>France</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1619</start>
<end>1626</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
<typeinfo>ORG</typeinfo>
</Organization>
<Location>
<start>44</start>
<end>49</end>
<annotation>Libya</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>53</start>
<end>58</end>
<annotation>TUNIS</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>147</start>
<end>152</end>
<annotation>Libya</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>356</start>
<end>361</end>
<annotation>Libya</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>467</start>
<end>474</end>
<annotation>Tripoli</annotation>
<typeinfo>LOC</typeinfo>
</Location>
Organization>
<start>2340</start>
<end>2370</end>
<annotation>Welsh National Farmers ' Union</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Organization>
<start>2373</start>
<end>2376</end>
<annotation>NFU</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Organization>
<start>2413</start>
<end>2422</end>
<annotation>BBC radio</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Location>
<start>69</start>
<end>77</end>
<annotation>BRUSSELS</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>279</start>
<end>286</end>
<annotation>Germany</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>443</start>
<end>450</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1075</start>
<end>1082</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1087</start>
<end>1093</end>
<annotation>France</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1608</start>
<end>1614</end>
<annotation>France</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1619</start>
<end>1626</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>2227</start>
<end>2233</end>
<annotation>Europe</annotation>
<typeinfo>LOC</typeinfo><end>1626</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
<Person>
<start>621</start>
<end>633</end>
<annotation>Awdankiewicz</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Organization>
<start>505</start>
<end>512</end>
<annotation>Reuters</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Location>
<start>44</start>
<end>49</end>
<annotation>Libya</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>53</start>
<end>58</end>
<annotation>TUNIS</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>147</start>
<end>152</end>
<annotation>Libya</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>356</start>
<end>361</end>
<annotation>Libya</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>467</start>
<end>474</end>
<annotation>Tripoli</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>529</start>
<end>535</end>
<annotation>Poland</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>594</start>
<end>599</end>
<annotation>Libya</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>823</start>
<end>828</end>
<annotation>Libya</annotation>
<typeinfo>LOC</typeinfo>
</Location>
</text>
</annotations>
typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>279</start>
<end>286</end>
<annotation>Germany</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>443</start>
<end>450</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1075</start>
<end>1082</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1087</start>
<end>1093</end>
<annotation>France</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1608</start>
<end>1614</end>
<annotation>France</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1619</start>
<end>1626</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
</Person>
<Person>
<start>1021</start>
<end>1029</end>
<annotation>Fischler</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>1215</start>
<end>1223</end>
<annotation>Fischler</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>1450</start>
<end>1467</end>
<annotation>Loyola de Palacio</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>1488</start>
<end>1496</end>
<annotation>Fischler</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>1634</start>
<end>1642</end>
<annotation>Fischler</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Person>
<start>2388</start>
<end>2404</end>
<annotation>John Lloyd Jones</annotation>
<typeinfo>PER</typeinfo>
</Person>
<Organization>
<start>2</start>
<end>4</end>
<annotation>EU</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Organization>
<start>94</start>
<end>113</end>
<annotation>European Commission</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Organization>
<start>312</start>
<end>326</end>
<annotation>European Union</annotation>
<typeinfo>ORG</typeinfo></Location>
<Location>
<start>279</start>
<end>286</end>
<annotation>Germany</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>443</start>
<end>450</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1075</start>
<end>1082</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1087</start>
<end>1093</end>
<annotation>France</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1608</start>
<end>1614</end>
<annotation>France</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1619</start>
<end>1626</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>2227</start>
<end>2233</end>
<annotation>Europe</annotation>
<typeinfo>LOC</typeinfo><end>1626</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
<typeinfo>ORG</typeinfo>
</Organization>
<Location>
<start>44</start>
<end>49</end>
<annotation>Libya</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>53</start>
<end>58</end>
<annotation>TUNIS</annotation>
<typeinfo>LOC</typeinfo>
</Location>
Organization>
<start>2340</start>
<end>2370</end>
<annotation>Welsh National Farmers ' Union</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Organization>
<start>2373</start>
<end>2376</end>
<annotation>NFU</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Organization>
<start>2413</start>
<end>2422</end>
<annotation>BBC radio</annotation>
<typeinfo>ORG</typeinfo>
</Organization>
<Location>
<start>69</start>
<end>77</end>
<annotation>BRUSSELS</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>279</start>
<end>286</end>
<annotation>Germany</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>443</start>
<end>450</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1075</start>
<end>1082</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1087</start>
<end>1093</end>
<annotation>France</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1608</start>
<end>1614</end>
<annotation>France</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1619</start>
<end>1626</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>2227</start>
<end>2233</end>
<annotation>Europe</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>2320</start>
<end>2327</end>
<annotation>Germany</annotation>
<typeinfo>LOC</typeinfo>
</Location>
</Location>
<Location>
<start>1608</start>
<end>1614</end>
<annotation>France</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>1619</start>
<end>1626</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
</Location>
<Location>
<start>2227</start>
<end>2233</end>
<annotation>Europe</annotation>
<typeinfo>LOC</typeinfo><end>1626</end>
<annotation>Britain</annotation>
<typeinfo>LOC</typeinfo>
Example 2: Correcting Extraction Results
CoNLL 2003 Named Entity Recognition Competition
Training Data ~ 150 of 20,000 labels
CoNLL 2003 Named Entity Recognition Competition
Training Data ~ 150 of 20,000 labels

© 2009 IBM Corporation83
Development Support in Conventional IE Systems
Grammar-based Systems
– GATE’s CPSL debugger, AnnotationDiff/Benchmark Tools [Cunningham02]
Machine Learning Systems
– Active learning of training examples [Thompson99]– Interfaces to verify/correct extraction results [Kristjansson04]
Lack of transparency makes it difficultfor humans to understand/debug/refine the system
[Das Sarma et al. SIGMOD 2010. I4E: Interactive Investigation of Iterative IE]

© 2009 IBM Corporation84
Different Aspects of Tooling for Declarative IE
1. Explaining Trace Provenance
– Type: Answers vs. Non-answers– Granularity: Coarse-grained vs. Fine-grained
2. Refining Leverage Provenance + User Feedback
– Scope: • Feedback on input forward propagation• Feedback on output backward propagation
3. Using Novel User Interfaces
– Enable building/maintaining– Enable collaboration

© 2009 IBM Corporation85
Provenance in DB and Scientific Communities
Explains output data in terms of the input data, the intermediate data, and the transformation
– Transformation = query, ETL, workflow– Recent surveys: [Davidson08] [Cheney09]
Approaches for computing provenance:
Eager
Transformation is changed to carry over additional information
Provenance readily available in output
Lazy
No changes to the transformation Requires knowledge of Q’s semantics,
or re-executing Q
Q
Q’
Q

© 2009 IBM Corporation86
Types of Provenance for Declarative IE
Provenance of answers
– Why is this in the result?– Useful to explain wrong
results– Helps in removing false
positives– Benefits from previous work
on provenance
Provenance of non-answers
– Why is this not in the result?– Useful to explain missing
results– Helps in removing false
negatives

© 2009 IBM Corporation87
Granularity of Provenance for Declarative IE
Fine grained
– Enables understanding the entire IE system down to basic operator level
– Can use both eager or lazy computation
Coarse grained
– Enables understanding of the IE system at a higher level
– Individual components remain “black boxes”
– More amenable to lazy computation
High-level declarative Mixed declarative Completely declarative

© 2009 IBM Corporation88
Scope of User Feedback for Declarative IE
Feedback on intermediate results of IE program propagates forward
– Goal is to repair specific problems with the intermediate data
Feedback on the output of IE program propagates backwards
– Goal is to refine the program
IP
O
P’O’
IP
O
P’O’I’
Feedback Feedback

© 2009 IBM Corporation89
Goals of User Interfaces for Declarative IE
Build & Maintain IE Systems
– GUI builders
– Wiki interfaces
How to do it collaboratively ?
– Share & Reuse
– Reconcile feedback

© 2009 IBM Corporation90
Tooling in Various Declarative IE Systems
SystemT
CIMPLE
PSOX

© 2009 IBM Corporation91
SystemT: Provenance of Answers
create view Person as…
Call John now (555-1212). He’s busy after 11:30 AM.
create view Phone asextract regex /(\d+\W)+\d+/…
Simple PersonPhone extractor
Person
Fine-grained provenance
Example:
create view PersonPhone asselect P.name, Ph.numberfrom Person P, Phone Phwhere Follows(P.name, Ph.number, 0, 40);
name number
John 555-1212
John 11:30
PersonPhone
Phone Phone

© 2009 IBM Corporation92
4
Eager approach: Rewrite AQL to maintain one-step derivation of each tuple– Extends work on how-provenance for relational queries [Green07] [Glavic09]– Core subset of AQL: SPJUD, Regex, Dictionary, Consolidate
SystemT: Provenance of Answers
create view PersonPhone asselect GenerateID() as ID, P.name, P.number, P.id as nameProv, Ph.id as numberProv ‘AND’ as howfrom Person P, Phone Phwhere Follows(P.name, Ph.number, 0, 40);
Call John now (555-1212). He’s busy after 11:30 AM.Person
name number
John 555-1212
John 11:30
PersonPhone
ID: 1 ID: 2 ID: 3
Rewritten PersonPhone How-Provenance
1 2∧1 3∧
Phone Phone

© 2009 IBM Corporation93
SystemT: Provenance of Answers
PersonDictionary
FirstNames.dict
PhoneRegex
(\d+\W)+\d+
Doc
PersonPhoneJoin
Follows(name,phone,0,40)
John 11:30
Can we automate this ?
Provenance of wrong result John11:30
John11:30
TestRefine

© 2009 IBM Corporation94
SystemT: Automatic Rule Refinement using Provenance [Liu10]
Input: User feedback = labels on the output of AQL program P
Goal: Automatically refine P to remove false positives
Idea: cut any provenance link wrong tuple disappears
PersonDictionary
FirstNames.dict
Doc
PersonPhoneJoin
Follows(name,phone,0,40)
John
John11:30
Provenance of wrong result John11:30
PhoneRegex
(\d+\W)+\d+
11:30
© 2009 IBM Corporation95
SystemT: Automatic Rule Refinement using Provenance [Liu10]
Input: User feedback = labels on the output of AQL program P
Goal: Automatically refine P to remove false positives
1. High-level changes (HLC)
What operator to modify? Leverages provenance
HLC 3 Remove 11:30 from
output of Phone
HLC 2 Remove John from output of Person
PersonDictionary
FirstNames.dict
Doc
PersonPhoneJoin
Follows(name,phone,0,40)
John
John11:30HLC 1: Remove
John11:30 from output of PersonPhone
Provenance of wrong result John11:30
PhoneRegex
(\d+\W)+\d+
11:30

© 2009 IBM Corporation96
SystemT: Automatic Rule Refinement using Provenance [Liu10]
PersonDictionary
FirstNames.dict
Doc
PersonPhoneJoin
Follows(name,phone,0,40)
John
LLC 2 Remove ‘John’ from
FirstNames.dict
LLC 3 Change regex to
(\d{3}\W)+\d+
Input: User feedback = labels on the output of AQL program P
Goal: Automatically refine P to remove false positives
1. High-level changes (HLC)
What operator to modify?
2. Low-level changes (LLC)
– How to modify it?
3. Evaluate and rank LLCs
Leverage provenance
LLC 1 Change join predicate to
Follows(name,phone,0,30)
Provenance of wrong result John11:30
John11:30
PhoneRegex
(\d+\W)+\d+
11:30

© 2009 IBM Corporation97
A Simple Phone Pattern
Blocks of digits separated by non-word character:
R0 = (\d+\W)+\d+
Identifies valid phone numbers (e.g. 555-1212, 800-865-1125)
Produces invalid matches (e.g. 11:30, 10/19/2002, 1.25 …)
Misses valid phone numbers (e.g. (800) 865-CARE)
© 2009 IBM Corporation98
Conventional Regex Writing Process for IE
Regex0
SampleDocuments
Match 1Match 2
…
Good Enough?
No
YesRegexfinal
(\d+\W)+\d+(\d{3}\W)+\d+
800-865-1125555-1212…11:3010/19/20021.25…
Regex1
800-865-1125555-1212…11:3010/19/20021.25…
© 2009 IBM Corporation99
Learning Regexfinal automatically [Li08]
Regex0
SampleDocuments
Match 1Match 2
…
NegMatch 1…
NegMatch m0
PosMatch 1…
PosMatch n0
Labeled matches for R0
Regex LLCModule
Regexfinal
HLCEnumerator
AQL rulesw/ R0
800-865-1125555-1212…11:3010/19/20021.25…
John555-1212…John11:30
…

© 2009 IBM Corporation100
Intuition [Li08]
R0 ([A-Z][a-zA-Z]{1,10}\s){1,5}\s*(\w{0,2}\d[\.]?){1,4}
([A-Z][a-zA-Z]{1,10}\s){1,5}\s*(\ [a-zA-Z] {0,2}\d[\.]?){1,4}
([A-Z][a-zA-Z]{1,10}\s){1,2}\s*(\w{0,2}\d[\.]?){1,4}
([A-Z][a-zA-Z]{1,10}\s){1,5}\s* (?!(201|…|330))(\w{0,2}\d[\.]?){1,4}
([A-Z] [a-z] {1,10}\s){1,5}\s*(\\w{0,2}\d[\.]?){1,4}
…
([A-Z][a-zA-Z]{1,10}\s){2,4}\s*(\w{0,2}\d[\.]?){1,4}
…
“Goodness” measure
F1
F7
F8
F34
F48
…
((?!(Copyright|Page|Physics|Question| · · · |Article|Issue)
[A-Z][a-zA-Z]{1,10}\s){1,5}\s*(\w{0,2}\d[\.]?){1,4} F35
R’
([A-Z] [a-z] {1,10}\s){1,5}\s*( [a-zA-z] {0,2}\d[\.]?){1,4}
([A-Z] [a-z] {1,10}\s) {1,2} \s*(\\w{0,2}\d[\.]?){1,4}
(((?!(Copyright|Page|Physics|Question| · · · |Article|Issue)
[A-Z] [a-z] {1,10}\s){1,5}\s*(\\w{0,2}\d[\.]?){1,4}
……
([A-Z] [a-z] {1,10}\s){1,5} \s*( \d {0,2}\d[\.]?){1,4}
([A-Z] [a-z] {1,10}\s){1,5} \s*(\\w{0,2}\d[\.]?){1,3}
……
([A-Z] [a-z] {1,10}\s){1,5}\s* (?!(201|…|330))(\w{0,2}\d[\.]?){1,4}
…………..
……
…
……
…
• Generate candidate regular expressions by modifying current regular expression• Select the “best candidate” R’
• If R’ is better than current regular expression, repeat the process

© 2009 IBM Corporation101
SystemT: Named-Entity Recognition (NER) Interface
Interface for exposing complex NER annotators
– Common NER operations exposed in a compact language
– Simplifies maintenance
Enabled by declarativity
– Seamless translation to AQL, since semantics are separate from implementation

© 2009 IBM Corporation102
SystemT: Tagger UI [Kandogan06] [Kandogan07]
Simple language for combining existing complex annotators
– Dictionary, regex, sequence, union– Similar in spirit to SQL Query Builders
Focus on collaboration within a community of users

© 2009 IBM Corporation103
Tooling in Various Declarative IE Systems
SystemT
CIMPLE
PSOX

© 2009 IBM Corporation104
Cimple: Provenance for Non-answers [Huang08]
To explain missing answers
– Updates to extracted relations that would cause the missing answer to appear in the result
Focus on SPJ queries
School State Opening
Stanford CA yes
MIT MA no
CMU PA yes
School Rank
Stanford 1
MIT 2
Berkeley 3
CMU 4
Example from [Huang08]
TopJobs (s,r):- Openings(s,’CA’,’yes’), Rankings(s,r), r<4
Openings Rankings
School Rank
Stanford 1
TopJobs
Why is ‘Berkeley’ *not* in the result ?

© 2009 IBM Corporation105
Cimple: Provenance for Non-answers [Huang08]
To explain missing answers
– Updates to extracted relations that would cause the missing answer to appear in the result
Focus on SPJ queries
Lazy approach
School State Opening
Stanford CA yes
MIT MA no
CMU PA yes
Berkeley CA yes
School Rank
Stanford 1
MIT 2
Berkeley 3
CMU 4
TopJobs (s,r):- Openings(s,’CA’,’yes’), Rankings(s,r), r<4
Openings Rankings
School Rank
Stanford 1
Berkeley 3
TopJobs
‘Berkley is a potential answer
Example from [Huang08]

© 2009 IBM Corporation106
Example from [Shen08]
Cimple: Best-Effort IE [Shen08]
Scope: feedback on output data refine IE program
Based on Alog = “skeletal” xlog + predicate description rules
Example:
R1: houses(x,price,area,hs) :− housePages(x), extractHouses(x,price,area,hs)
R3: Q(x,p,a,h) :− houses(x,price,area,hs), schools(school), p>500000, a>4500, approxMatch(hs,school)
R2: schools(school):− schoolPages(y), extractSchools(y,school)
Extraction predicates partially specified
approximate program
Next effort assistant:
Is price Bold? Is-bold(price)
Is area numerical? Is-numeric(area)
What is the maximum value of price? Max-val(price, 750000)
Ordering strategy:
Sequential or simulation

© 2009 IBM Corporation107
Cimple: Incorporate User-Feedback in IE Programs [Chai09]
Scope: feedback on intermediate data refine IE results
– Feedback = data corrections
Based on hlog = xlog + declarative user feedback rules
Example:
R1: webPages(p) :− dataSources(url, date), crawl(url, page)
R3: abstracts(abstract, p) :− webPages(p), extractAbstract(p, abstract)
R2: titles(title, p):− webPages(p), extractTitle(p, title)
R4: talks(title, abstract) :− titles(title, p), abstracts(abstract, p), immBefore(title,abstract)
R5: dataSourcesForUserFeedback(url) #spreadsheet-UI :− dataSources(url, date), date >= “01/01/2009”
xlog
feedbackrules
dataSource tuples with date after 1/1/09 can be
edited through a spreadsheet interface
Example from [Chai09]

© 2009 IBM Corporation108
Cimple: Incorporate User-Feedback in IE Programs [Chai09]
Scope: feedback on intermediate data refine IE results
– Feedback = data corrections
Based on hlog = xlog + declarative user feedback rules
Challenges:
– How to incorporate user feedback?• Leverage provenance to resolve conflicting updates• Provenance is eagerly computed
– How to efficiently execute an hlog program?• Leverage provenance to incrementally propagate user edits upward in
the pipeline
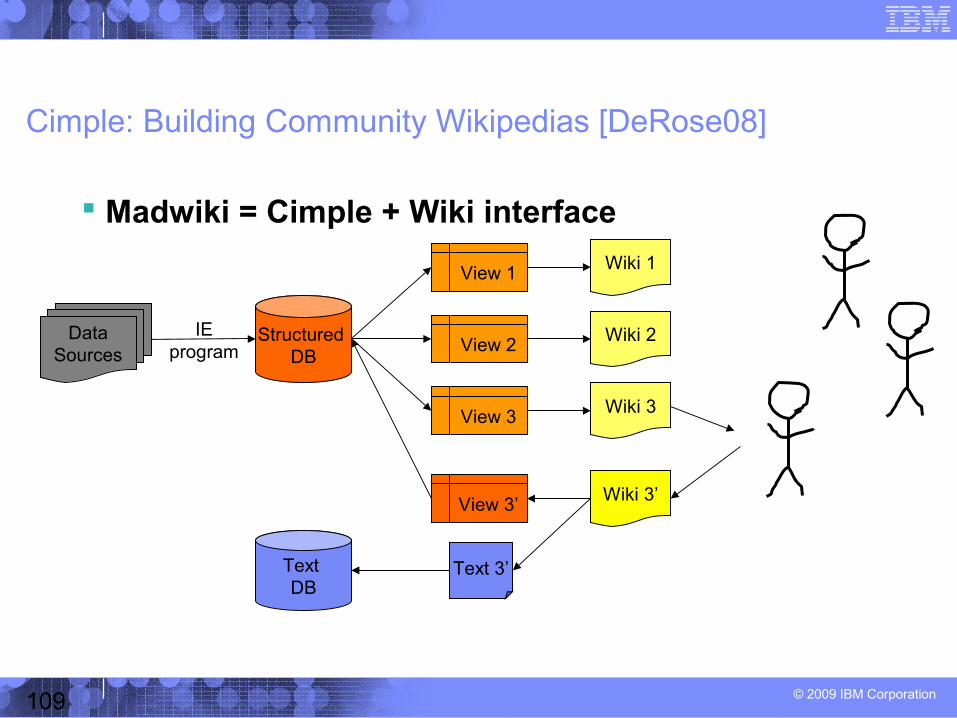
© 2009 IBM Corporation109
Cimple: Building Community Wikipedias [DeRose08]
Madwiki = Cimple + Wiki interface
Structured DB
Text DB
DataSources
View 1
View 2
View 3 Wiki 3
Wiki 2
Wiki 1
View 3’ Wiki 3’
IEprogram
Text 3’

© 2009 IBM Corporation110
Tooling in Various Declarative IE Systems
SystemT
CIMPLE
PSOX
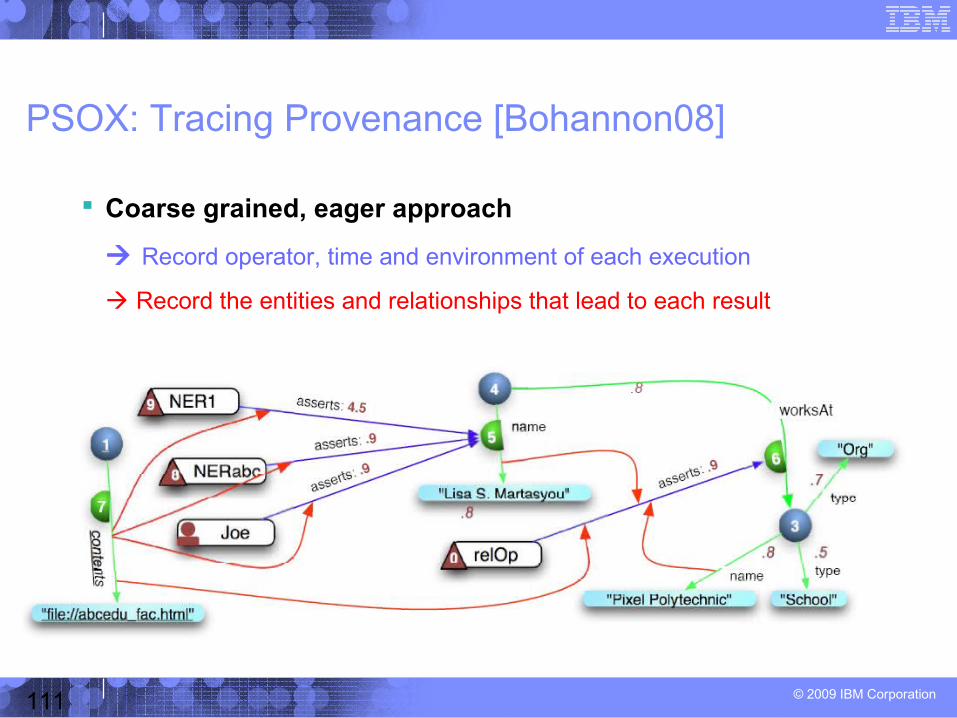
© 2009 IBM Corporation111
PSOX: Tracing Provenance [Bohannon08]
Coarse grained, eager approach
Record operator, time and environment of each execution
Record the entities and relationships that lead to each result

© 2009 IBM Corporation112
PSOX: Incorporating Social Feedback [Bohannon08]
User modeled as operator
– Feedback = confidence for relationships inferred by the system– Flexible scoring model for combining confidence scores
Score changes propagate forward (leveraging provenance)

© 2009 IBM Corporation113
Provenance-Based Debugger (PROBER) [Das Sarma10]
Focus on IE pipelines with monotonic “black box” operators– 1-1, 1-m, m-1, arbitrary
Coarse grained provenance (operator level)– MISet: Minimum set of input records sufficient for deriving an output record
Lazy approach: repeatedly re-execute the operator
Trade-offs between provenance completeness and efficiency– Any MISet (P-any): efficient for arbitrary operators– All MiSets (P-all): efficient for 1-1, 1-m operators
Composition of operators:
– P-*(Op1 ° Op2) can be always computed from P-all(Op1) and P-all(Op2)– Can be done efficiently for certain combinations of operators

© 2009 IBM Corporation114
Summary
Systems
Provenance
Granularity
Provenance Type
Automatic refinement User Interfaces
Fine Coarse Answers Non-answers
Type of Feedback
Forward propagation
Backward propagation Maintain Collaborate
SystemT Output labels
Cimple Q&A
Data edits PSOX Confidence
scores PROBER

© 2009 IBM Corporation115
Road Map
What is Information Extraction? (Fred Reiss)
Declarative Information Extraction (Fred Reiss)
What the Declarative Approach Enables
– Scalable Infrastructure (Yunyao Li)
– Development Support (Laura Chiticariu)
Conclusion/Questions
You are here

© 2009 IBM Corporation116
Open Challenges
Scalability
Accuracy
Usability
Better cost and selectivity modelsfor IE
Using provenance of non-answersfor automatic extractor refinement
More declarative approaches to machine learning

© 2009 IBM Corporation117
Thank you!
Our web page:
– http://www.almaden.ibm.com/cs/projects/systemt/
Our software:
– http://www.alphaworks.ibm.com/tech/systemt
– Updated release coming soon!

© 2009 IBM Corporation118
References
[Appelt93] D. Appelt, J. Hobbs, J. Bear, D. Israel, M. Tyson. “FASTUS: A Finite-State Processor for Information Extraction.” IJCAI 1993, VOL 13; NUMBER 2, pages 1172.
[Appelt98] D. Appelt and B. Onyshkevych, “The Common Pattern Specification Language.” ACL 1998, pages 23-30.
[Bohannon08] P. Bohannon, S. Merugu, C. Yu, V. Agarwal, P. DeRose, A. Iyer, A. Jain, V. K. M. Muralidharan, R. Ramakrishnan, W. Shen. 2008. Purple SOX Extraction Management System, SIGMOD Record. 37(4): 21-27
[Cardie97] C. Cardie, “Empirical Methods in Information Extraction.” AI Magazine 18:4, 1997. http://www.cs.cornell.edu/home/cardie/
[Chai09] X. Chai, B. Vuong, A. Doan, J. Naughton. Efficiently Incorporating User Feedback into Information Extraction and Integration Programs. SIGMOD 2009, pages 87-100.
[Chen08] F. Chen, A. Doan, J. Yang, R. Ramakrishnan. Efficient Information Extraction over Evolving Text Data. ICDE 2008, pages 943-952.
[Chen09] F. Chen, B. J. Gao, A. Doan, J. Yang, R. Ramakrishnan. “Optimizing Complex Extraction Programs Over Evolving Text Data”. SIGMOD 2009, 321-334.
[Cheney 09] J. Cheney, L. Chiticariu, W. Tan. Provenance in Databases: Why, How, and Where. Foundations and Trends in Databases 1(4): 379-474 (2009)
[Chiticariu10] L. Chiticariu, R. Krishnamurthy, Y. Li, S. Raghavan, F. Reiss, S. Vaithyanathan . "SystemT: An Algebraic Approach to Declarative Information Extraction”. To appear, ACL 2010.

© 2009 IBM Corporation119
References (continued)
[Cohen03] W. Cohen, “Information Extraction and Integration: an Overview.” KDD (Tutorial) 2003
[Cunningham02] H. Cunningham, D. Maynard, K. Bontcheva, V. Tablan. GATE: A Framework and Graphical Development Environment for Robust NLP Tools and Applications. ACL 2002, pages 168-175.
[Cunningham09] H. Cunningham et. Al. “ANNIE: A Nearly-New Information Extraction System”. In Developing Language Processing Components with GATE Version 5 (a User Guide); September 4, 2009. http://gate.ac.uk/sale/tao/split.html
[DasSarma10] A. Das Sarma, A. Jain, P. Bohannon. Sarma et al. PROBER: Ad-Hoc Debugging of Extraction and Integration Pipelines. CoRR abs 1004.1614, 2010.
[Davidson08] S. Davidson, J. Freire. Provenance and Scientific Workflows: Challenges and Opportunities (Tutorial). SIGMOD 2008, pages 1345-1350.
[DeJong82] G. DeJong, “An overview of the FRUMP system” in Lehnert, W.G. and Ringle, M.H. (eds.) Strategies for natural language processing (Hillsdale: Erlbaum, 1982), pages149-176.
[DeRose08] P. DeRose, X. Chai, B. J. Gao, W. Shen, A. Doan, P. Bohannon, X. Zhu: Building Community Wikipedias: A Machine-Human Partnership Approach. ICDE 2008, pages 646-655.
[Doan06] A. Doan, R. Ramakrishnan, S. Vaithyanathan, “Managing Information Extraction” (Tutorial), SIGMOD 2006, pages 799-800.
[Freitag98] D. Freitag. “Toward General-Purpose Learning for Information Extraction.” COLING-ACL 1998, pages 404 - 408.
[Green07] T. J. Green, G. Karvounarakis, V. Tannen. Provenance Semirings. PODS 2007, pages 31-40.
[Glavic09] B. Glavic, G. Alonso, Perm: Processing provenance and data on the same data model through query rewriting, ICDE 2009, pages 174-185.

© 2009 IBM Corporation120
References (continued)
[Huang08] J. Huang, T. Chen, A. Doan, J. Naughton. On the Provenance of Non-answers to Queries over Extracted Data. PVLDB 1(1) 2008, pages 736-747.
[Ipeirotis07] P. G. Ipeiros, E. Agichtein, P. Jain, L. Gravano. Towards a Query Optimizer for Text-Centric Tasks. ACM Transactions on Database Systems (TODS), 32 (4), article 21, November 2007
[Jain08] A. Jain, AnHai Doan, and Luis Gravano, “Optimizing SQL Queries over Text Databases”. ICDE 2008, pages 636-645.
[Jain09] A. Jain, P. Ipeirotis, L. Gravano. Building Query Optimizers for Information Extraction: The SQoUT Project. SIGMOD Record. 37(4): 28-34
[Jain09b] A. Jain, P. Ipeirotis, A. Doan, L. Gravano: Join Optimization of Information Extraction Output: Quality Matters! ICDE 2009, pages 186-197.
[Khaitan09] S. Khaitan, G. Ramakrishnan, S. Joshi, A. Chalamalla. RAD: A Scalable Framework for Annotator Development. ICDE 2008, pages 1624-1627.
[Kandogan06] E. Kandogan, R. Krishnamurthy, S. Raghavan, S. Vaithyanathan, H. Zhu: Avatar semantic search: a database approach to information retrieval. SIGMOD 2006 (Demo), pages 790-792.
[Kandogan07] E. Kandogan et al. Avatar: Beyond Keywords – Collaborative Information Extraction and Search. ACM CHI Workshop on Exploratory Search and HCI 2007 (Poster).
[Krishnamurthy07] R. Krishnamurthy, S. Raghavan, S. Vaithyanathan, H. Zhu. Using Structured Queries for Keyword Information Retrieval. IBM Research Report RJ 10413. 2007
[Krishnamurthy08] R. Krishnamurthy, Y. Li, S. Raghavan, F. Reiss, S. Vaithyanathan, H. Zhu. SystemT: a system for declarative information extraction. SIGMOD Record 37(4): 7-13

© 2009 IBM Corporation121
References (continued)
[Kristjansson04] T. Kristjansson, A. Culotta, P. Viola, A. McCallum. Interactive Information Extraction with Constrained Conditional Random Fields. AAAI 2004, pages 412-418.
[Lafferty01] J. Lafferty, A. McCallum, and F. Pereira, “Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data.” ICML 2001, pages 282 – 289.
[Leek97] T. Leek, Information extraction using hidden Markov models. Master’s thesis. UC San Diego.
[Li06] Y. Li, R. Krishnamurthy, S. Vaithyanathan, H.V. Jagadish. Getting Work Done on the Web: Supporting Transactional Queries. SIGIR, 2006, pages 557 - 564.
[Li08] Y. Li, R. Krishnamurthy, S. Raghavan, S. Vaithyanathan, H.V. Jagadish. Regular Expression Learning for Information Extraction. EMNLP 2008, pages 21-30.
[Liu10] B. Liu, L. Chiticariu, V. Chu, H.V. Jagadish, F. Reiss. “Automatic Rule Refinement for Information Extraction.” to appear, VLDB 2010.
[McCallum00] A. McCallum, D. Freitag, and F. Pereira, “Maximum Entropy Markov Models for Information Extraction and Segmentation.” ICML 2000, pages 591 – 598.
[Reiss08] F. Reiss, S. Raghavan, R. Krishnamurthy, H. Zhu, S. Vaithyanathan. An Algebraic Approach to Rule-Based Information Extraction. ICDE 2008, pages 933-942.
[Riloff93] E. Riloff, “Automatically Constructing a Dictionary for Information Extraction Tasks.” AAAI 1993, pages 811-816.
[Sang03] E. Sang, F. De Meulder. Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition, HLT-NAACL 2003 - Volume 4, pages 142 - 147.

© 2009 IBM Corporation122
References (continued)
[Sarawagi08] S. Sarawagi, “Information Extraction.” Foundations and Trends in Databases 1(3): 261-377, 2008.
[Shen07] W. Shen, A.Doan, J. F. Naughton, R. Ramakrishnan. Declarative Information Extraction Using Datalog with Embedded Extraction Predicates. VLDB 2007, pages 1033-1044.
[Shen08] W. Shen, P. DeRose, R. McCann, A. Doan, R. Ramakrishnan. Toward Best-effort Information Extraction. SIGMOD 2008, pages 1031-1042.
[Simmen09] D. E. Simmen, F. Reiss, Y. Li, S. Thalamati. Enabling Enterprise Mashups over Unstructured Text Feeds with InfoSphere MashupHub and SystemT”. SIGMOD 2008 (Demo), pages 1123-1126.
[Soderland98] S. Soderland, D. Fisher, J. Aseltine, W. Lehnert. “CRYSTAL: Inducing a Conceptual Dictionary.” IJCAI 1995 , pages 1314-1319.
[Thompson99] C. A. Thompson, M. E. Califf, R. J. Mooney. Active Learning for Natural Language Parsing and Information Extraction. ICML 1999, pages 406 – 414.
[Wang10] D. Z. Wang, E. Michelakis, M.J. Franklin, M. Garofalakis, J. M. Hellerstein. Probabilistic Declarative Information Extraction. ICDE 2010, pages 173-176.
[Zhu07] H. Zhu, A. Loeser, S. Raghavan, S. Vaithyanathan. Navigating the Intranet with High Precision. WWW 2007, 491 – 500.


















