
ENGS 116 Lecture 101 Tomasulo’s Approach and Hardware Based Speculation Vincent H. Berk October...
31
ENGS 116 Lecture 10 1 Tomasulo’s Approach and Hardware Based Speculation Vincent H. Berk October 22nd Reading for Today: 3.1 – 3.7
-
date post
21-Dec-2015 -
Category
Documents
-
view
245 -
download
0
Transcript of ENGS 116 Lecture 101 Tomasulo’s Approach and Hardware Based Speculation Vincent H. Berk October...

ENGS 116 Lecture 10 1
Tomasulo’s Approach andHardware Based Speculation
Vincent H. BerkOctober 22nd
Reading for Today: 3.1 – 3.7

ENGS 116 Lecture 8 2
Hardware Schemes for ILP
• Why in hardware at run time?
– Works when dependence is not known at run time
– Simplifies compiler
– Allows code for one machine to run well on another
• Key idea: Allow instructions behind stall to proceed
DIVD F0, F2, F4ADDD F10, F0, F8SUBD F12, F8, F14
– Enables out-of-order execution out-of-order completion
– ID stage checks for both structural hazards and data dependences

ENGS 116 Lecture 8 3
Hardware Schemes for ILP
Out-of-order execution divides ID stage:
1. Issue — decode instructions, check for structural hazards
2. Read operands — wait until no data hazards, then read operands

ENGS 116 Lecture 8 4
Tomasulo’s Algorithm
For IBM 360/91 about 3 years after CDC 6600
Goal: High performance without special compilers
Differences between IBM 360 & CDC 6600 ISA– IBM has only 2 register specifiers/instruction vs. 3 in CDC 6600
– IBM has 4 FP registers vs. 8 in CDC 6600
Differences between Tomasulo’s Algorithm & Scoreboard– Control & buffers (called “reservation stations”) distributed with
functional units vs. centralized in scoreboard
– Registers in instructions replaced by pointers to reservation station buffer
– HW renaming of registers to avoid WAR, WAW hazards
– Common data bus (CDB) broadcasts results to functional units
– Load and stores treated as functional units as well
Alpha 21264, HP 8000, MIPS 10000, Pentium III, PowerPC 604, ...

ENGS 116 Lecture 8 5
Three Stages of Tomasulo Algorithm
1. Issue: Get instruction from FP operation queue
If reservation station free, issues instruction & sends operands (renames registers).
2. Execution: Operate on operands (EX)
When operands ready then execute; if not ready, watch common data bus for result.
3. Write result: Finish execution (WB)
Write on common data bus to all awaiting units; mark reservation station available.
Common data bus: data + source (“come from” bus)
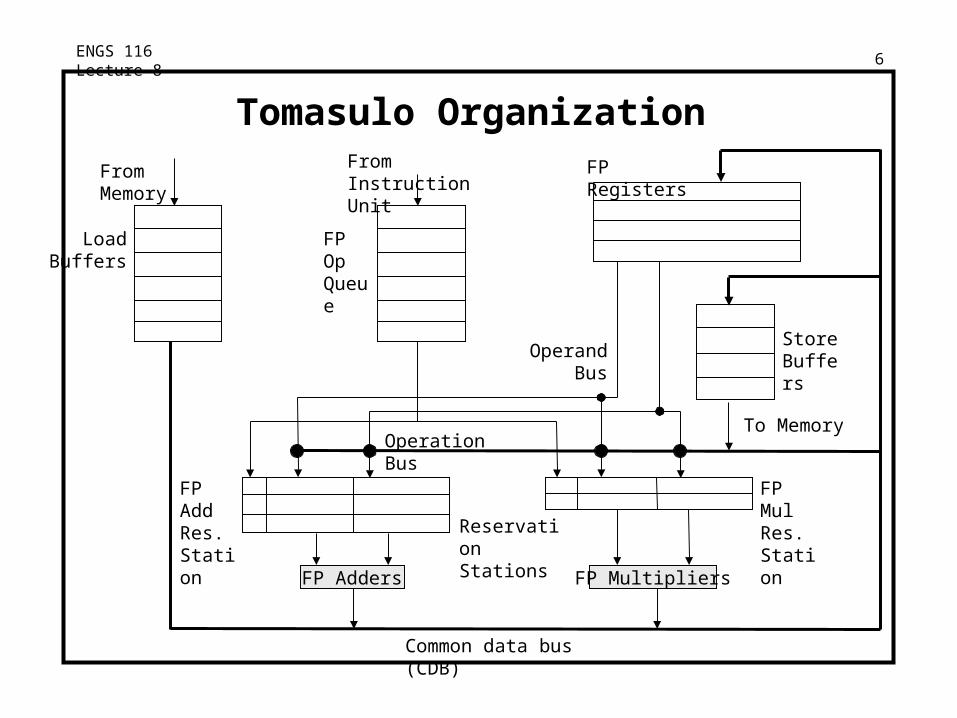
ENGS 116 Lecture 8 6
Tomasulo Organization
FP Adders
Common data bus (CDB)
From Memory
FP Registers
Load Buffers
From Instruction Unit
Operand Bus
Store Buffers
To Memory
FP Multipliers
FP Op Queue
Operation Bus
Reservation Stations
FP Mul Res. Station
FP Add Res. Station

ENGS 116 Lecture 8 7
Reservation Station Components
Op – Operation to perform in the unit (e.g., + or – )
Qj, Qk – Reservation stations producing source registers
Vj, Vk – Value of source operands
Rj, Rk – Flags indicating when Vj, Vk are ready
Busy – Indicates reservation station and FU is busy
Register result status – Indicates which functional unit will write each register, if one exists. Blank when no pending instructions will write that register.
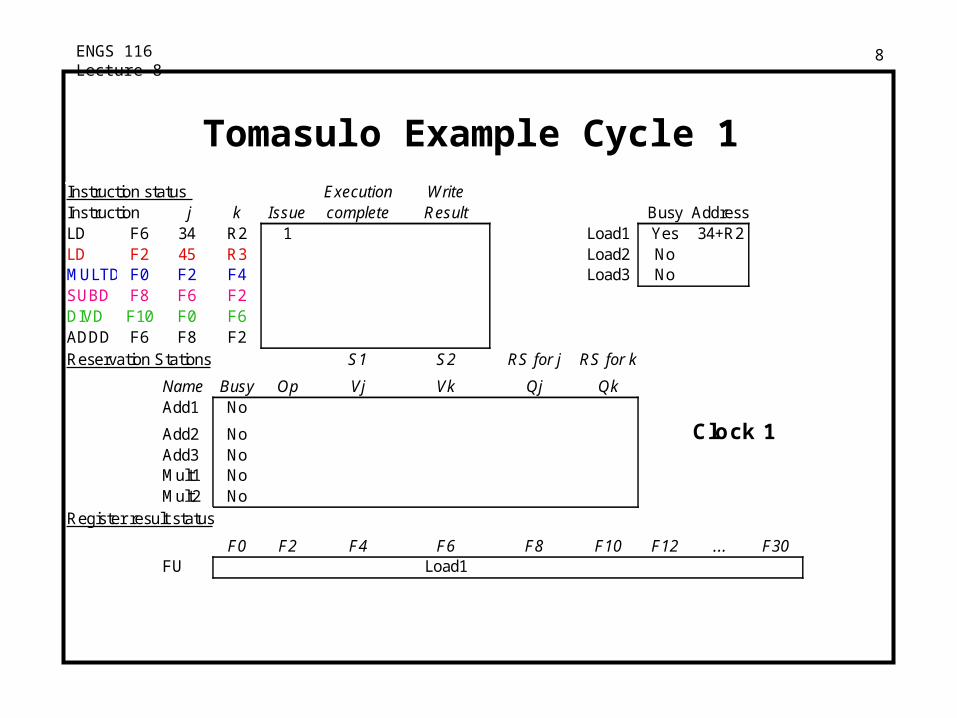
ENGS 116 Lecture 8 8
Tomasulo Example Cycle 1Instruction status Execution WriteInstruction j k Issue complete Result Busy AddressLD F6 34 R2 1 Load1 Yes 34+R2LD F2 45 R3 Load2 NoMULTD F0 F2 F4 Load3 NoSUBD F8 F6 F2DIVD F10 F0 F6ADDD F6 F8 F2Reservation Stations S1 S2 RS for j RS for k
Name Busy OpAdd1 No
Add2 No Clock 1Add3 NoMult1 NoMult2 No
Register result status
F0 F2 F4 F6 F8 F10 F12 ... F30FU Load1
Vj Vk Qj Qk
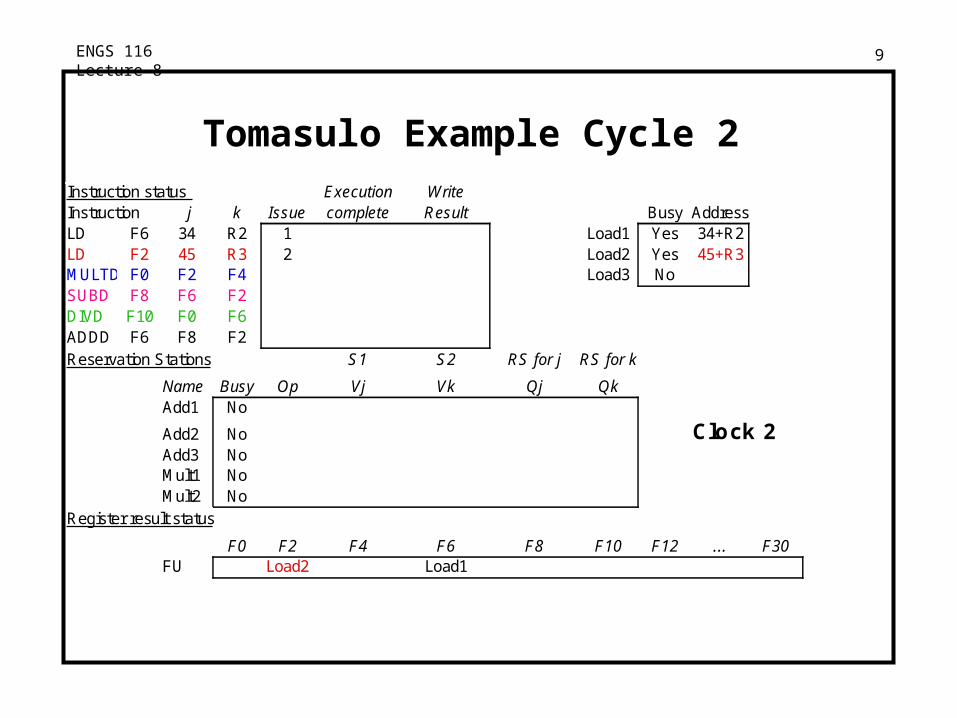
ENGS 116 Lecture 8 9
Tomasulo Example Cycle 2Instruction status Execution WriteInstruction j k Issue complete Result Busy AddressLD F6 34 R2 1 Load1 Yes 34+R2LD F2 45 R3 2 Load2 Yes 45+R3MULTD F0 F2 F4 Load3 NoSUBD F8 F6 F2DIVD F10 F0 F6ADDD F6 F8 F2Reservation Stations S1 S2 RS for j RS for k
Name Busy OpAdd1 No
Add2 No Clock 2Add3 NoMult1 NoMult2 No
Register result status
F0 F2 F4 F6 F8 F10 F12 ... F30FU Load2 Load1
Vj Vk Qj Qk
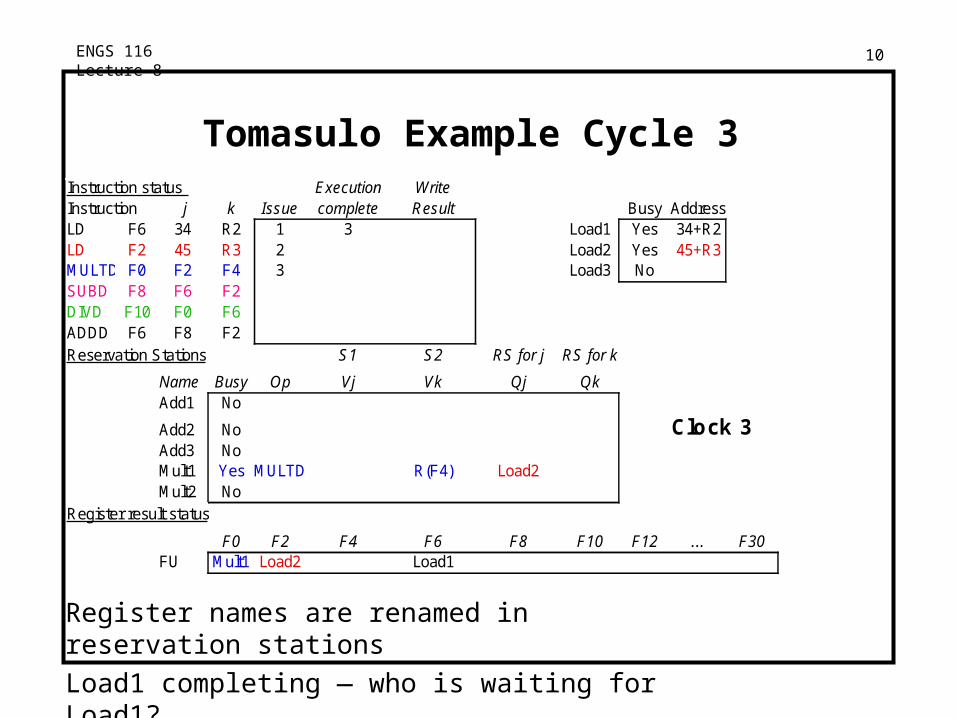
ENGS 116 Lecture 8 10
Tomasulo Example Cycle 3Instruction status Execution WriteInstruction j k Issue complete Result Busy AddressLD F6 34 R2 1 3 Load1 Yes 34+R2LD F2 45 R3 2 Load2 Yes 45+R3MULTD F0 F2 F4 3 Load3 NoSUBD F8 F6 F2DIVD F10 F0 F6ADDD F6 F8 F2Reservation Stations S1 S2 RS for j RS for k
Name Busy OpAdd1 No
Add2 No Clock 3Add3 NoMult1 Yes MULTD R(F4) Load2Mult2 No
Register result status
F0 F2 F4 F6 F8 F10 F12 ... F30FU Mult1 Load2 Load1
Vj Vk Qj Qk
Register names are renamed in reservation stations
Load1 completing — who is waiting for Load1?
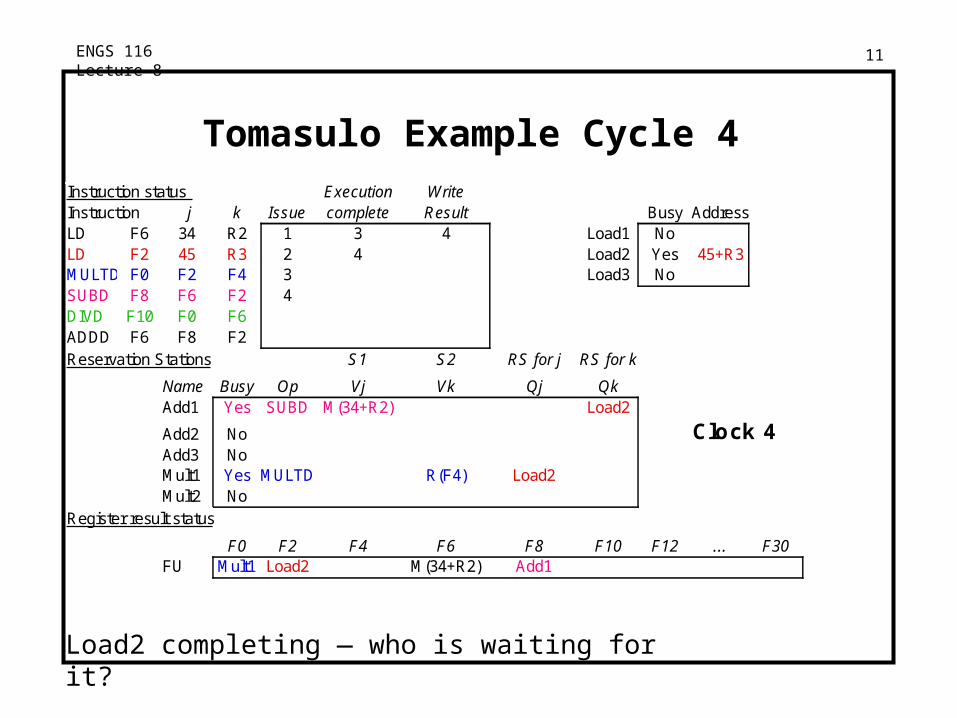
ENGS 116 Lecture 8 11
Tomasulo Example Cycle 4Instruction status Execution WriteInstruction j k Issue complete Result Busy AddressLD F6 34 R2 1 3 4 Load1 NoLD F2 45 R3 2 4 Load2 Yes 45+R3MULTD F0 F2 F4 3 Load3 NoSUBD F8 F6 F2 4DIVD F10 F0 F6ADDD F6 F8 F2Reservation Stations S1 S2 RS for j RS for k
Name Busy OpAdd1 Yes SUBD M(34+R2) Load2
Add2 No Clock 4Add3 NoMult1 Yes MULTD R(F4) Load2Mult2 No
Register result status
F0 F2 F4 F6 F8 F10 F12 ... F30FU Mult1 Load2 M(34+R2) Add1
Vj Vk Qj Qk
Load2 completing — who is waiting for it?
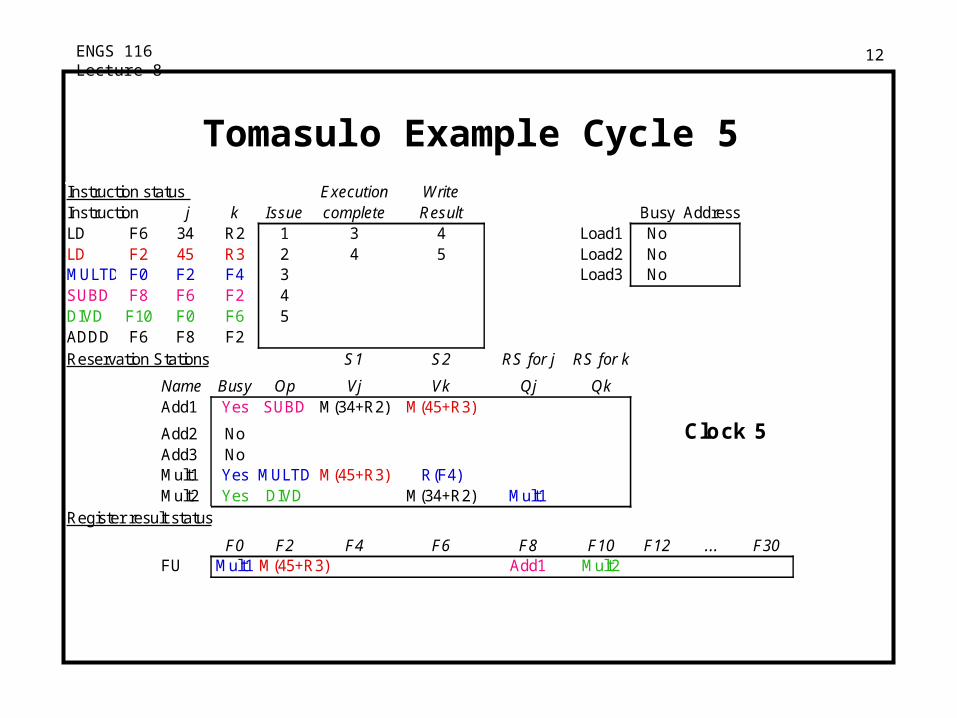
ENGS 116 Lecture 8 12
Tomasulo Example Cycle 5Instruction status Execution WriteInstruction j k Issue complete Result Busy AddressLD F6 34 R2 1 3 4 Load1 NoLD F2 45 R3 2 4 5 Load2 NoMULTD F0 F2 F4 3 Load3 NoSUBD F8 F6 F2 4DIVD F10 F0 F6 5ADDD F6 F8 F2Reservation Stations S1 S2 RS for j RS for k
Name Busy OpAdd1 Yes SUBD M(34+R2) M(45+R3)
Add2 No Clock 5Add3 NoMult1 Yes MULTD M(45+R3) R(F4)Mult2 Yes DIVD M(34+R2) Mult1
Register result status
F0 F2 F4 F6 F8 F10 F12 ... F30FU Mult1 M(45+R3) Add1 Mult2
Vj Vk Qj Qk
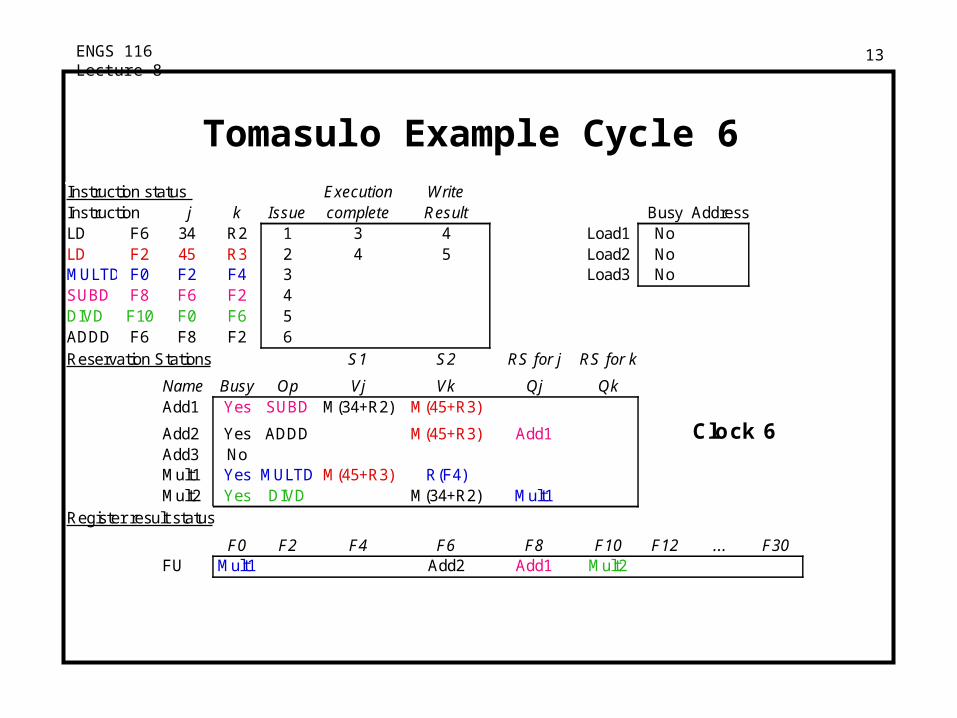
ENGS 116 Lecture 8 13
Tomasulo Example Cycle 6Instruction status Execution WriteInstruction j k Issue complete Result Busy AddressLD F6 34 R2 1 3 4 Load1 NoLD F2 45 R3 2 4 5 Load2 NoMULTD F0 F2 F4 3 Load3 NoSUBD F8 F6 F2 4DIVD F10 F0 F6 5ADDD F6 F8 F2 6Reservation Stations S1 S2 RS for j RS for k
Name Busy OpAdd1 Yes SUBD M(34+R2) M(45+R3)
Add2 Yes ADDD M(45+R3) Add1 Clock 6Add3 NoMult1 Yes MULTD M(45+R3) R(F4)Mult2 Yes DIVD M(34+R2) Mult1
Register result status
F0 F2 F4 F6 F8 F10 F12 ... F30FU Mult1 Add2 Add1 Mult2
Vj Vk Qj Qk

ENGS 116 Lecture 8 14
Tomasulo Summary
Reservation stations: renaming to larger set of registers + buffering source operands
– Prevents registers as bottleneck
– Avoids WAR, WAW hazards of scoreboard
– Allows loop unrolling in HW
Not limited to basic blocks
(integer units get ahead, beyond branches)
Lasting Contributions
– Dynamic scheduling
– Register renaming
– Load/store disambiguation
360/91 descendants are Pentium III; PowerPC 604; MIPS R10000; HP-PA 8000; Alpha 21264

15
Hardware-Based Speculation
Instead of just instruction fetch and decode, also execute instructions based on prediction of branch.
Execute instructions out of order as soon as their operands are available.
Wait with instruction commit until branch is decided.
Re-order instructions after execution and commit them in order
– reorder buffer or ROB
– register file not updated until commit
Do not raise exceptions until instruction is committed
ROB holds and provides operands until commit.

16
Tomasulo with Speculation
1. Issue – Empty reservation station and an empty ROB slot. Send operands to reservation station from register file or from ROB. This stage is often referred to as: dispatch
2. Execute – Monitor CDB for operands, check RAW hazards. When both operands are available, then execute.
3. Write Result – When available, write result to CDB through to ROB and any waiting reservation stations. Stores write to value field in ROB.
4. Commit – Three cases:
• Normal Commit: write registers, in order commit
• Store: update memory
• Incorrect branch: flush ROB, reservation stations and restart execution at correct PC
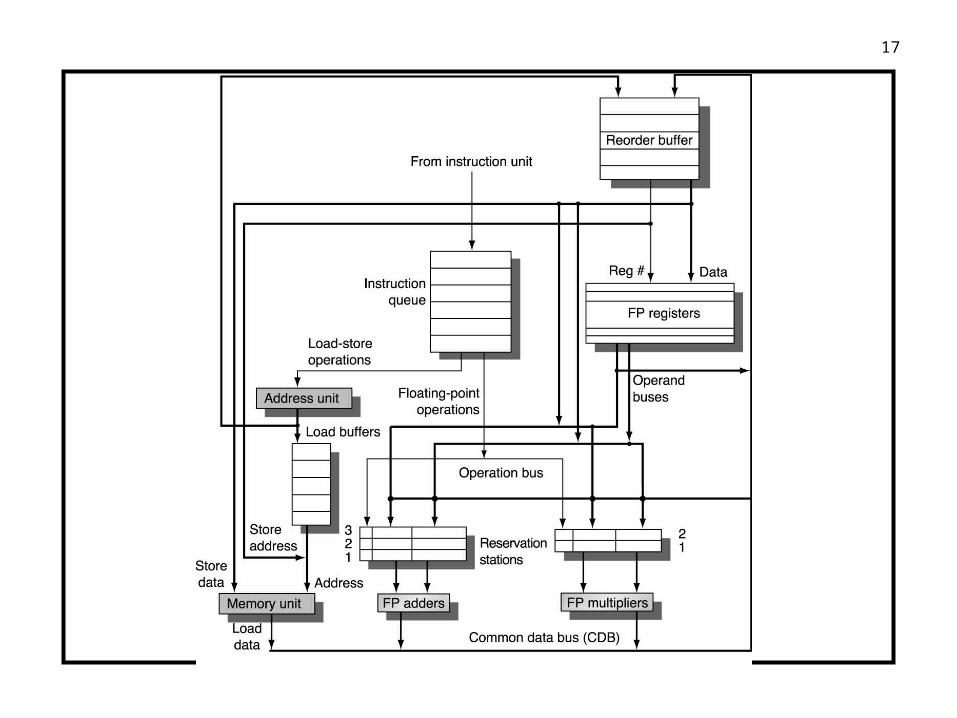
17

18
Problems with speculation
Multi Issue Machines:
– Must be able to commit multiple instructions from ROB
– More registers, more renaming
How much speculation:
– How many branches deep?
– What to do on a cache miss?
– TLB miss?
– Cache interference due to incorrect branch prediction
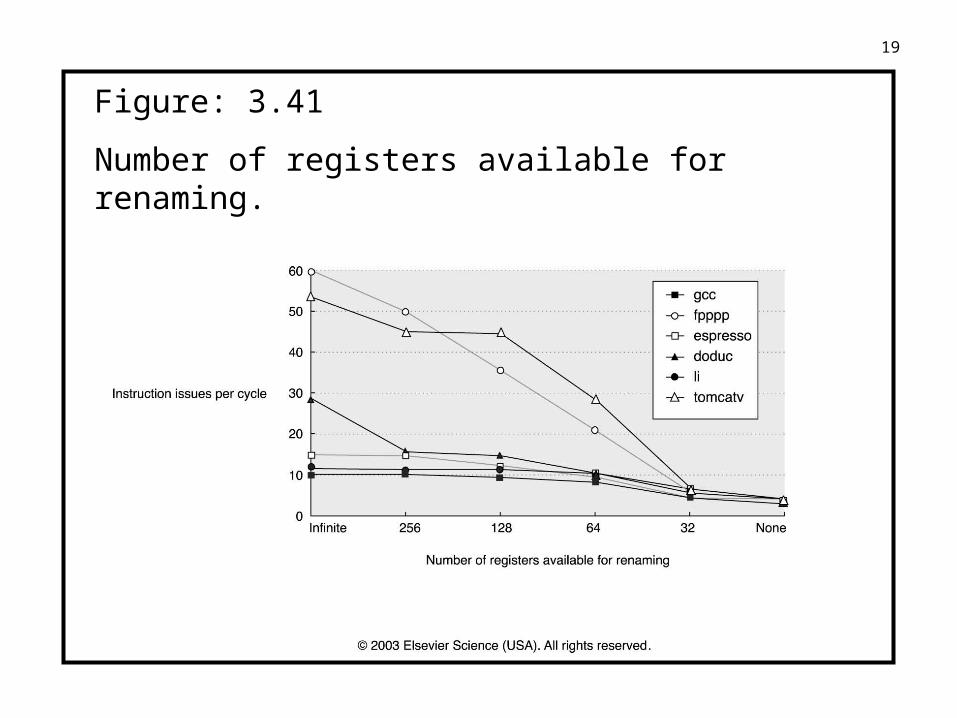
19
Figure: 3.41
Number of registers available for renaming.
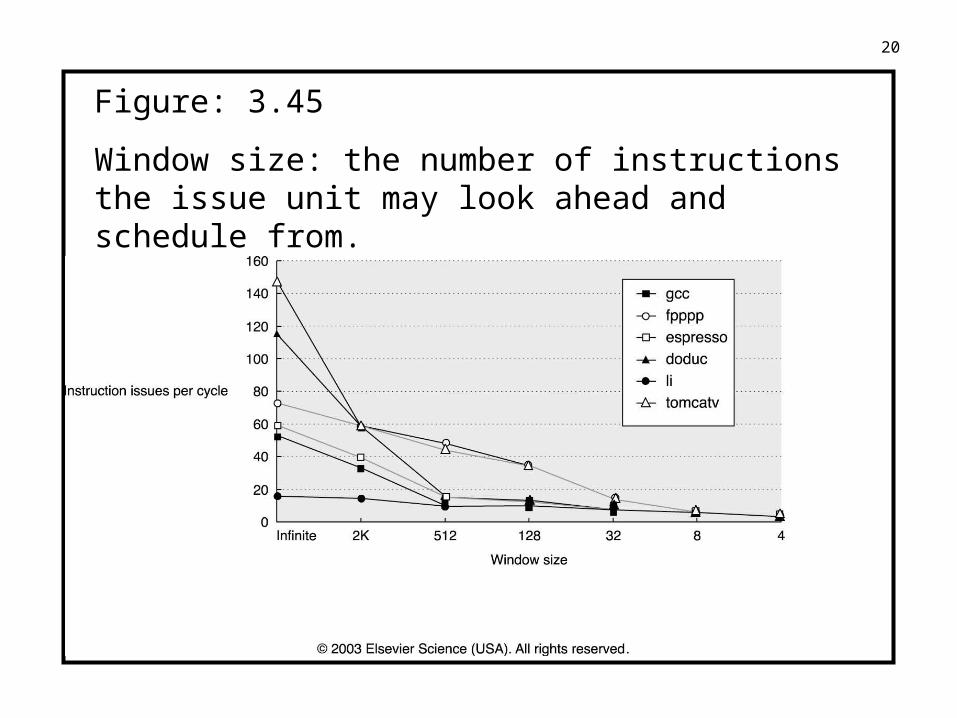
20
Figure: 3.45
Window size: the number of instructions the issue unit may look ahead and schedule from.

ENGS 116 Lecture 11 21
ILP: Software Approaches 2
22
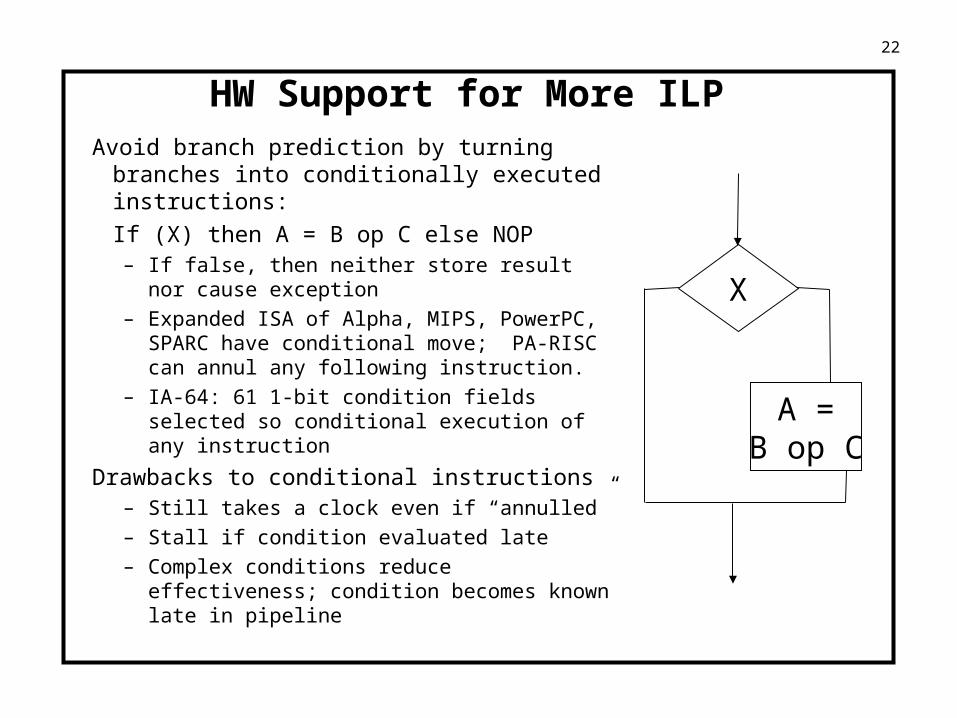
HW Support for More ILP
Avoid branch prediction by turning branches into conditionally executed instructions:
If (X) then A = B op C else NOP– If false, then neither store result nor cause
exception
– Expanded ISA of Alpha, MIPS, PowerPC, SPARC have conditional move; PA-RISC can annul any following instruction.
– IA-64: 61 1-bit condition fields selected so conditional execution of any instruction
Drawbacks to conditional instructions– Still takes a clock even if “annulled”
– Stall if condition evaluated late
– Complex conditions reduce effectiveness; condition becomes known late in pipeline
X
A =B op C
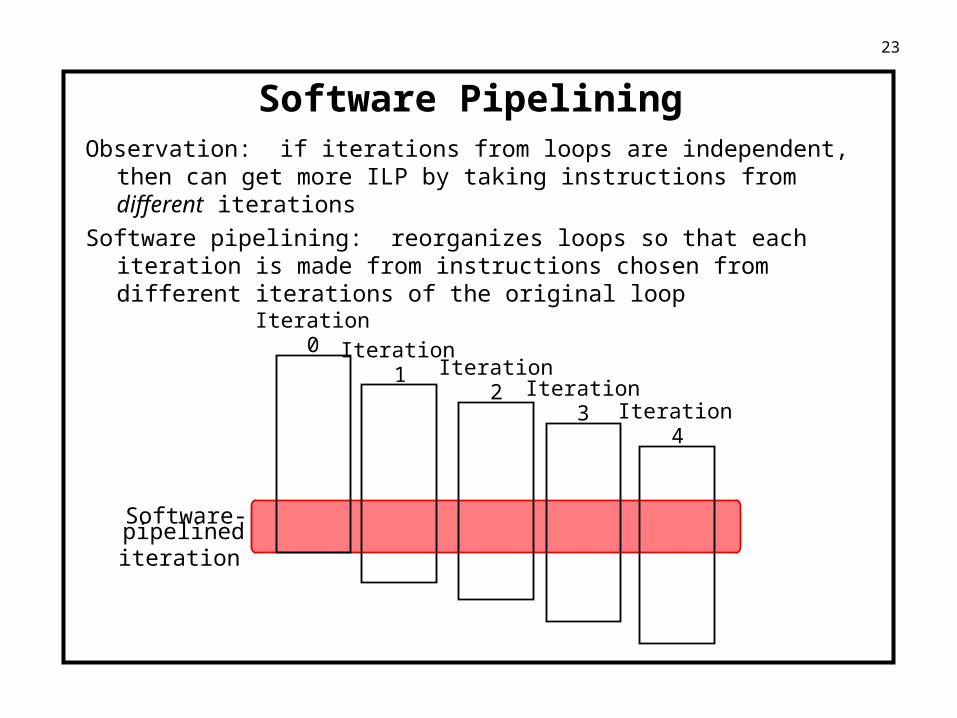
23
Software PipeliningObservation: if iterations from loops are independent, then can get more
ILP by taking instructions from different iterations
Software pipelining: reorganizes loops so that each iteration is made from instructions chosen from different iterations of the original loop
Software-
Iteration0 Iteration
1 Iteration2 Iteration
3 Iteration4
pipelinediteration
24
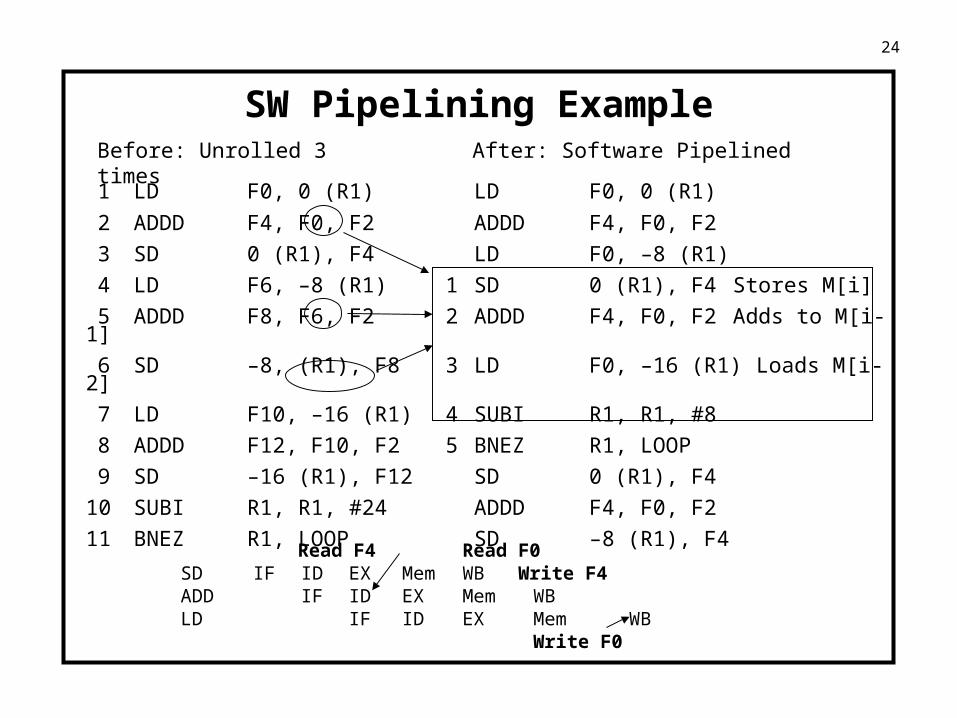
SW Pipelining Example
1 LD F0, 0 (R1) LD F0, 0 (R1)
2 ADDD F4, F0, F2 ADDD F4, F0, F2
3 SD 0 (R1), F4 LD F0, –8 (R1)
4 LD F6, –8 (R1) 1 SD 0 (R1), F4 Stores M[i]
5 ADDD F8, F6, F2 2 ADDD F4, F0, F2 Adds to M[i-1]
6 SD –8, (R1), F8 3 LD F0, –16 (R1) Loads M[i-2]
7 LD F10, –16 (R1) 4 SUBI R1, R1, #8
8 ADDD F12, F10, F2 5 BNEZ R1, LOOP
9 SD –16 (R1), F12 SD 0 (R1), F4
10 SUBI R1, R1, #24 ADDD F4, F0, F2
11 BNEZ R1, LOOP SD –8 (R1), F4
Read F4 Read F0SD IF ID EX Mem WB Write F4ADD IF ID EX Mem WBLD IF ID EX Mem WB
Write F0
Before: Unrolled 3 times After: Software Pipelined
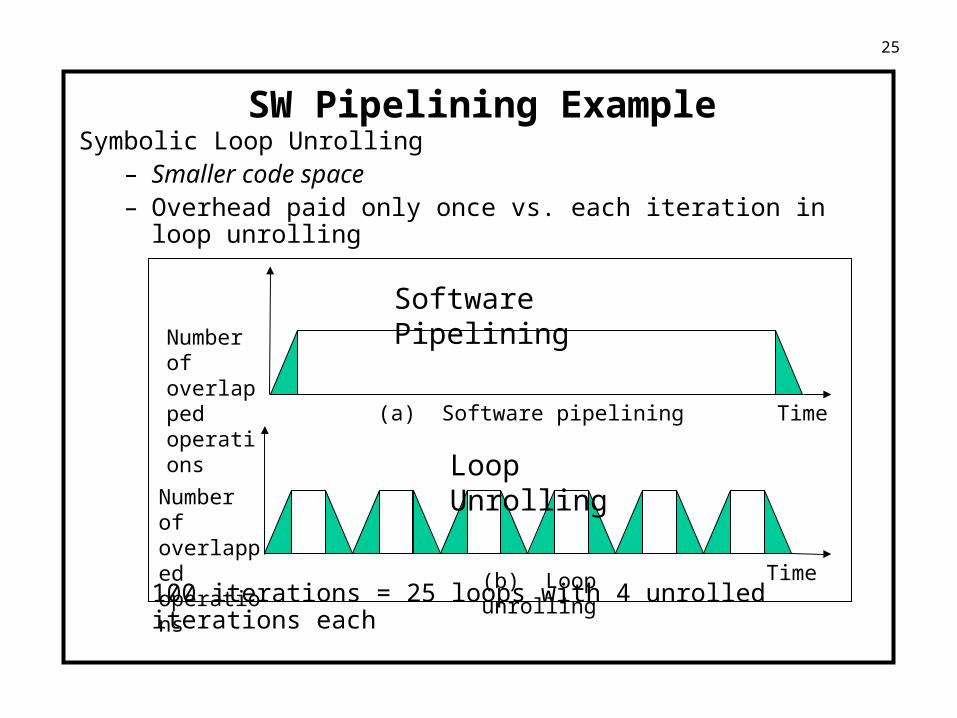
25
SW Pipelining ExampleSymbolic Loop Unrolling
– Smaller code space– Overhead paid only once vs. each iteration in loop unrolling
100 iterations = 25 loops with 4 unrolled iterations each
Number of overlapped operations
Software Pipelining
(a) Software pipelining Time
Loop Unrolling
(b) Loop unrolling Time
Number of overlapped operations

26
Trace Scheduling
Focus on critical path (trace selection)
– Compiler has to decide what the critical path (the trace) is
– Most likely basic blocks are put in the trace
– Loops are unrolled in the trace
Now speed it up (trace compaction)
– Focus on limiting instruction count
– Branches are seen as jumps into or out of the trace
Problem:
– Significant overhead for parts that are not in the trace
– Unclear if it is feasible in practice

27
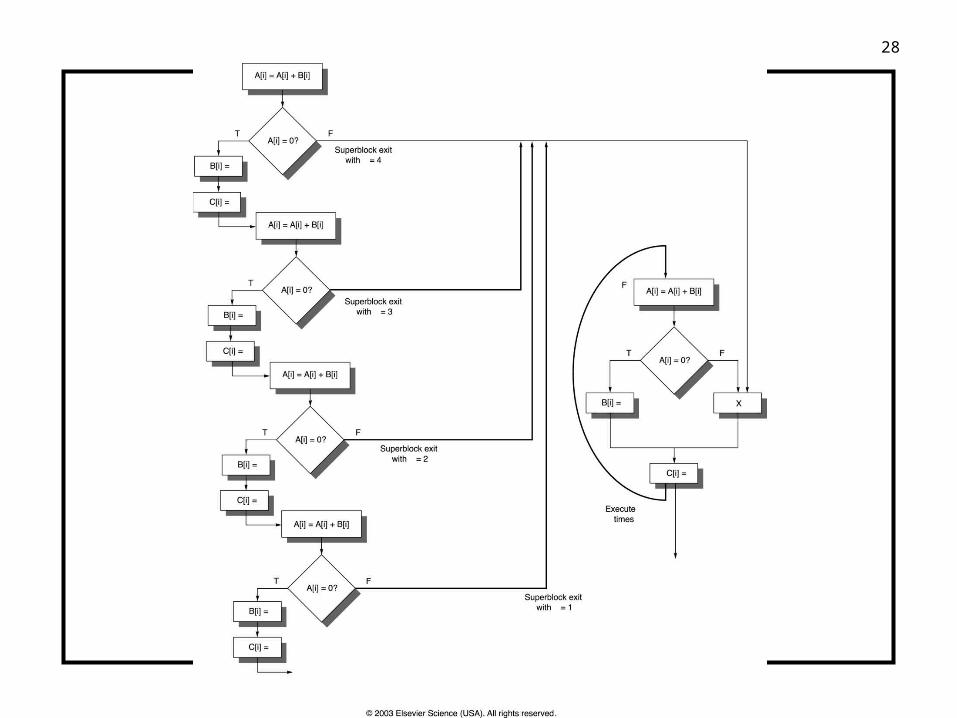
Superblocks
Similar to Trace Scheduling but:
– Single entrance, multiple exits
Tail duplication:
– Handle cases that exited the superblock
– Residual loop handling
– Could in itself be a superblock
Problem:
– Code size
– Worth the hassle?
28

29
Conditional instructions
Instruction that is executed depending on one of its arguments:
Instruction is executed but results are not always written.
Should only be used for very small sequences, else use normal branch.
BNEZ R1, L
ADDU R2, R3, R0
L:
CMOVZ R2, R3, R1

30
Speculation
Compiler moves instructions before branch if:– Data flow is not affected (optionally with use of renaming)– Preserve exception behavior– Avoid load/store address conflicts (no renaming for memory loc.)
Preserving exception behavior– Mechanism to indicate an instruction is speculative– Poison bit: raise exception when value is used– Using Conditional instructions:
• Requires In-Order instruction commit• Register renaming• Writeback at commit• Forwarding• Raise exceptions at commit
31
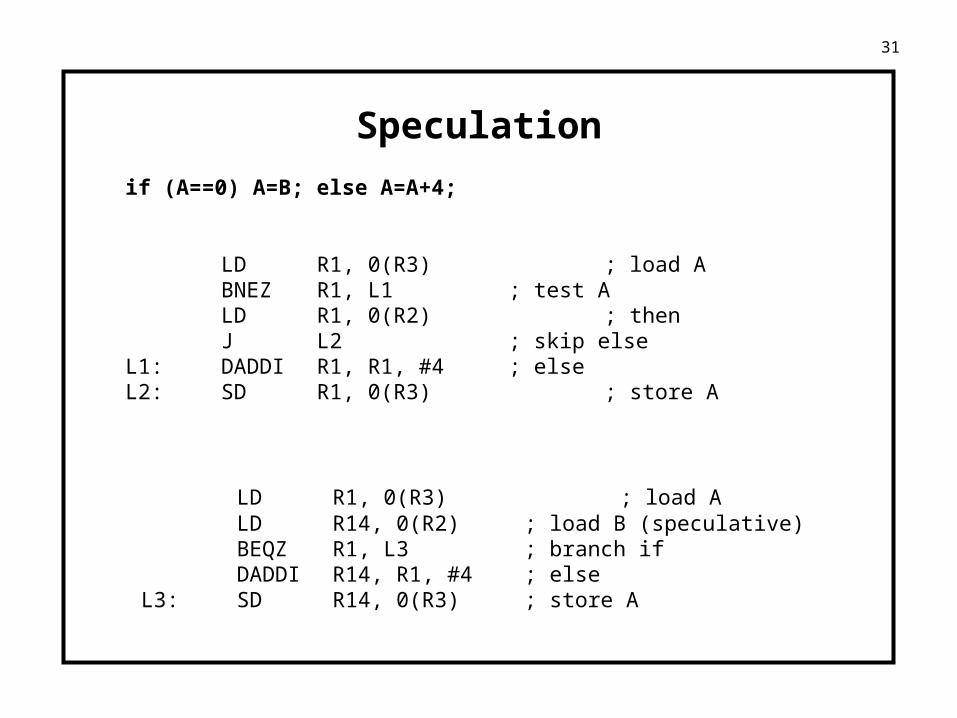
Speculation
if (A==0) A=B; else A=A+4;
LD R1, 0(R3) ; load ABNEZ R1, L1 ; test ALD R1, 0(R2) ; thenJ L2 ; skip else
L1: DADDI R1, R1, #4 ; elseL2: SD R1, 0(R3) ; store A
LD R1, 0(R3) ; load ALD R14, 0(R2) ; load B (speculative)BEQZ R1, L3 ; branch ifDADDI R14, R1, #4 ; else
L3: SD R14, 0(R3) ; store A


















