
Energy-efficient Instruction Dispatch Buffer Design for Superscalar Processors* Gurhan Kucuk, Kanad...
23
Energy-efficient Instruction Dispatch Buffer Design for Superscalar Processors* Gurhan Kucuk, Kanad Ghose, Dmitry V. Ponomarev Department of Computer Science State University of New York Binghamton, NY 13902-6000 {gurhan, ghose, dima}@cs.binghamton.edu Peter M. Kogge Dept. of Computer Science and Engineering University of Notre Dame Notre Dame, IN 46556 [email protected] International Symposium on Low Power Electronics and Design (ISLPED’01) * supported in part by DARPA through the PAC-C program and NSF
-
Upload
leon-bickel -
Category
Documents
-
view
217 -
download
0
Transcript of Energy-efficient Instruction Dispatch Buffer Design for Superscalar Processors* Gurhan Kucuk, Kanad...

Energy-efficient Instruction Dispatch Buffer Design for Superscalar Processors*
Gurhan Kucuk, Kanad Ghose, Dmitry V. Ponomarev
Department of Computer Science
State University of New York
Binghamton, NY 13902-6000
{gurhan, ghose, dima}@cs.binghamton.edu
Peter M. Kogge
Dept. of Computer Science and Engineering
University of Notre Dame
Notre Dame, IN 46556
International Symposium on Low Power Electronics and Design (ISLPED’01)
* supported in part by DARPA through the PAC-C program and NSF

Motivation/GoalsCurrent Trends in Microarchitecture:
• Aggressive out-of-order execution, use of register renaming, multiple FUs, sizable on-chip caches, large register files, ROB etc.
Impact on Energy/Power Dissipation:
• Absolute power dissipation of processor is high
• Areal energy/power density of high-end superscalar processors is becoming an immediate, serious concern - will soon become comparable to that of nuclear reactors
Consequences:
• Intermittent and permanent failures on the die and serious challenges for the cooling facilities/packaging
Goal:
• Limit energy dissipation through technology independent techniques with no impact on performance

Typical Superscalar Datapath

The Dispatch Buffer• Instruction Dispatch Buffer (a.k.a. Issue Queue) is one of the major source of
power dissipation in modern superscalar processors: up to 22% of total chip power
• Major components of power dissipation in Dispatch Buffer are:
1. Dispatch (Entry Setup = Locating free entries + writing to them)
2. Issue (FU arbitration + Reading selected instr. From the DB)
3. Forwarding (Tag comparison + latching)
To function units (issue)
From Decode/Dispatch Stage
From function units (forwarding)
issue
forwarding
dispatch
SPECint 95 SPECfp 95
I50.1 %
I53.8 %
F28.9 %
D24.2 %
F25.7 %
D17.3 %

Main Results• 60% plus energy savings within the DB achieved using three
relatively independent techniques:
Replacing traditional comparators with dissipate-on-match comparator Not reading or writing leading zero bytes Using bit-line segmentation to reduce bit line capacitance and
dissipations during reads and writes
• No impact on cycle time
• Only 12% increase in layout area of DB – for 4 metal layer, 0.5 micron layout: smaller increase with additional metal layers

Low Power Comparator• Traditional comparators dissipate power on mismatches
• Only 5% of total comparisons matches
• This is a major source for power dissipation in Dispatch Buffer
Number of bits matching
% of total cases
2 LSBs
4 LSBs
6 LSBs
All 8 bits
Avg. SPECint 95
27.2 9.8 5.7 5.6
Avg. SPECfp 95
33.1 10.7 5.4 4.4
Avg. all SPEC 95
30.5 10.3 5.6 4.9LSB = least significant bits
Dispatch Buffer Comparator Statistics

Low Power Comparator• Traditional comparators dissipate power on mismatches
• Only 5% of total comparisons matches
• This is a major source for power dissipation in Dispatch Buffer
DB
X
XX
Forwarding Bus
XMatching slotWaiting slotInactive slot
Number of bits matching
% of total cases
2 LSBs
4 LSBs
6 LSBs
All 8 bits
Avg. SPECint 95
27.2 9.8 5.7 5.6
Avg. SPECfp 95
33.1 10.7 5.4 4.4
Avg. all SPEC 95
30.5 10.3 5.6 4.9LSB = least significant bits
Dispatch Buffer Comparator Statistics
8 bi
t phy
s. r
eg. n
umbe
r

Low Power ComparatorIdea: Design of a new comparator that dissipates power only on
matches
Number of bits matching
% of total cases
2 LSBs
4 LSBs
6 LSBs
All 8 bits
Avg. SPECint 95
27.2 9.8 5.7 5.6
Avg. SPECfp 95
33.1 10.7 5.4 4.4
Avg. all SPEC 95
30.5 10.3 5.6 4.9LSB = least significant bits
New dissipate-on-match comparator:Domino logic with pass-transistor at the front end
Dispatch Buffer Comparator Statistics

Zero-Byte EncodingObservation:• The simulated execution of the SPEC 95
benchmarks show that about half of the byte fields within operands are all zeros
Reasons:• Use of small integer literals (address offsets,
literal operands, flags, byte ops, etc.)• Consequence of byte packing and unpacking
operations and usage of the bit or byte masks to isolate parts of the operands
• Some floating point operands may not use all of the bits allowed in the mantissa field
• Use of lower-precision data may not make use of full datapath width
0
10
20
30
40
50
60
RF to DB DB to FU FU to DB
0s everywhere
Leading 0s
Leading 1s
32 and 64-bit Integer Operands(90%of all operands)

Zero-Byte EncodingIdea:
• Instead of driving byte with all-zeroes, encode it using the ZI (Zero Indicator) bit and only drive this bit, thus achieving power savings during writes.
Associated Circuit Techniques: Readout Logic

Zero-Byte Encoding• Stored ZI bit disables reading of associated byte- avoiding bitline
discharge and sense-amp dissipation
Associated Circuit Techniques: Readout Logic

Zero-Byte Encoding
Associated Circuit Techniques: Encoding Logic for bytes of all zeroes

Bitline Segmentation• The DB is essentially a Register File with additional associative
logic for data forwarding.
To function units (issue)
From Decode/Dispatch Stage
WRITE PORTS
READ PORTS
• For each instruction dispatched in a cycle a write port is needed for entry setup process
• For each instruction issued in a cycle a read port is needed to move the instruction from DB to FU.
• The bitlines associated with each read and write port present a high capacitive load, which consists of a component that varies linearly with the number of rows in the DB.
• This component is due to the wire capacitances of the bitlines and the diffusion capacitance of the pass transistors that connect the bitcells to the bitlines

Bitline SegmentationIdea: The DB is reconstructed into segments.• Capacitive loading on each segment is lowered: Each segment is connected
to only 16 pass devices• Wire capacitance is lowered: Wire length of the bitline segment is one
fourth of the original bitline
Bitline segmented DB

Evaluation Methodology• Used a true cycle-by-cycle register-level simulator for a
typical superscalar pipeline. Simplescalar has been substantially modified for this purpose to mimic real superscalar datapaths
• Simulated the execution of SPEC 95 benchmarks.
• Collected transition counts for each major datapath component
• Used SPICE measurements for the VLSI layout of dispatch buffer and reorder buffer in a 0.5 micron, 4-metal layer process to estimate the power dissipated for each type of transition within each major component (migrating to 0.18 micron soon!)

Evaluation Methodology
Datapath Power Estimator

ResultsTraditional vs. New Comparator
0
50
100
150
200
250
300
350
com
pre
ss
vo
rte
x
m8
8k
sim
gcc go
ijp
eg
lisp
pe
rl
turb
3d
fpp
pp
apsi
app
lu
hyd
ro2
d
mg
rid
su2
cor
swim
tom
catv
wav
e5
SP
EC
int
95
SP
EC
fp 9
5
SP
EC
95
Traditional
New
Power dissipation within the DB during forwarding
44%
49%
45%
mW
Pow
er D
issi
pat
ion

ResultsTraditional vs. New Comparator
0100200300400500600700800900
1000
com
pre
ss
vo
rte
x
m8
8k
sim
gcc go
ijp
eg
lisp
pe
rl
turb
3d
fpp
pp
apsi
app
lu
hyd
ro2
d
mg
rid
su2
cor
swim
tom
catv
wav
e5
SP
EC
int
95
SP
EC
fp 9
5
SP
EC
95
Traditional
New
Total power dissipation within the DB
11%
14%
12%
mW
Pow
er D
issi
pat
ion

ResultsZero-Byte Encoding and Bitline Segmentation
0
20
40
60
80
100
120
140
160
com
pre
ss
vo
rte
x
m8
8k
sim
gcc go
ijp
eg
lisp
pe
rl
turb
3d
fpp
pp
apsi
app
lu
hyd
ro2
d
mg
rid
su2
cor
swim
tom
catv
wav
e5
SP
EC
int
95
SP
EC
fp 9
5
SP
EC
95
BaseSeg.ZESeg + ZE
Power dissipation within the DB during instruction dispatch
mW
Pow
er D
issi
pat
ion
54%,26%,61%
53%,21%,59%
53%,23%,60%

ResultsZero-Byte Encoding and Bitline Segmentation
0
100
200
300
400
500
600
com
pre
ss
vo
rte
x
m8
8k
sim
gcc go
ijp
eg
lisp
pe
rl
turb
3d
fpp
pp
apsi
app
lu
hyd
ro2
d
mg
rid
su2
cor
swim
tom
catv
wav
e5
SP
EC
int
95
SP
EC
fp 9
5
SP
EC
95
BaseSeg.ZESeg + ZE
Power dissipation within the DB during instruction issue
mW
Pow
er D
issi
pat
ion
41%,32%,58%
41%,35%,60%
40%,41%,62%
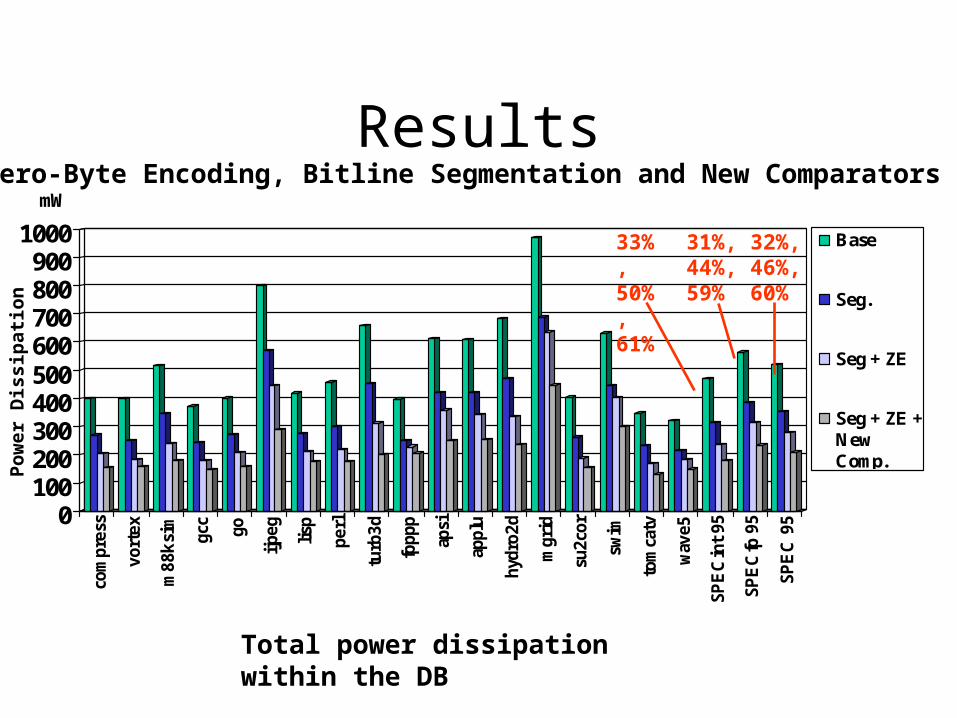
ResultsZero-Byte Encoding, Bitline Segmentation and New Comparators
0100200300400500600700800900
1000
com
pre
ss
vo
rte
x
m8
8k
sim
gcc go
ijp
eg
lisp
pe
rl
turb
3d
fpp
pp
apsi
app
lu
hyd
ro2
d
mg
rid
su2
cor
swim
tom
catv
wav
e5
SP
EC
int
95
SP
EC
fp 9
5
SP
EC
95
Base
Seg.
Seg + ZE
Seg + ZE +NewComp.
Total power dissipation within the DB
mW
Pow
er D
issi
pat
ion
31%,44%,59%
32%,46%,60%
33%,50%,61%

Related Work• Zero byte encoding of function unit results (Brooks and Martonosi,
1999)
• Zero-byte compression on buses, register files, DB and ROB in superscalar datapath (Ponomarev, Ghose, Kucuk, Kogge and Toomarian, 2000)
• Zero-byte compression for I-caches (Villa, Zhang, Asanovic, 2000)
• Zero-byte compression in simple scalar datapath (Canal, Gonzalez and Smith, 2000)
• Dynamic resizing of issue queue (Buyuktosunoglu, Albonesi, Schuster, Brooks, Bose and Cook, 2001 + Folegnani and Gonzalez, 2001)
• Dynamic resizing of dispatch buffer and reorder buffer (Ponomarev, Kucuk and Ghose, 2001)

Conclusion• We studied three relatively independent techniques to reduce the energy
dissipation in the instruction dispatch buffers of modern superscalar processors:
1. New comparators that dissipate the energy mainly on the tag matches
2. Zero-Byte encoding to reduce the number of bitlines that have to be driven during instruction dispatch and issue as well as during forwarding of the results to the waiting instructions in the DB
3. Bitline segmentation to reduce the length of bitlines (to reduce wire and diffusion capacitances)
1. Total power reduction is about 60%
• The DB power reductions are achieved without compromising the cycle time and only through a modest growth in the area of the DB (about 12%)
• Our studies also show that the use of all the techniques that reduce the DB power can also be used to achieve reductions of a similar scale in other datapath artifacts that use associative addressing (such as the Reorder Buffer and LOAD/STORE Queue.)


















