
Efficient Multiple Kernel Learning Algorithms Using...
10
Research Article Efficient Multiple Kernel Learning Algorithms Using Low-Rank Representation Wenjia Niu, 1,2 Kewen Xia, 1,2 Baokai Zu, 1,2 and Jianchuan Bai 1,2 1 School of Electronic and Information Engineering, Hebei University of Technology, Tianjin 300401, China 2 Key Lab of Big Data Computation of Hebei Province, Tianjin 300401, China Correspondence should be addressed to Kewen Xia; [email protected] Received 23 February 2017; Revised 20 June 2017; Accepted 5 July 2017; Published 22 August 2017 Academic Editor: Cheng-Jian Lin Copyright © 2017 Wenjia Niu et al. is is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Unlike Support Vector Machine (SVM), Multiple Kernel Learning (MKL) allows datasets to be free to choose the useful kernels based on their distribution characteristics rather than a precise one. It has been shown in the literature that MKL holds superior recognition accuracy compared with SVM, however, at the expense of time consuming computations. is creates analytical and computational difficulties in solving MKL algorithms. To overcome this issue, we first develop a novel kernel approximation approach for MKL and then propose an efficient Low-Rank MKL (LR-MKL) algorithm by using the Low-Rank Representation (LRR). It is well-acknowledged that LRR can reduce dimension while retaining the data features under a global low-rank constraint. Furthermore, we redesign the binary-class MKL as the multiclass MKL based on pairwise strategy. Finally, the recognition effect and efficiency of LR-MKL are verified on the datasets Yale, ORL, LSVT, and Digit. Experimental results show that the proposed LR-MKL algorithm is an efficient kernel weights allocation method in MKL and boosts the performance of MKL largely. 1. Introduction Support Vector Machine (SVM) is an important machine learning method [1], which trains linear learner in feature space derived by the kernel function, and utilizes generaliza- tion theory to avoid overfitting phenomenon. Recently, Mul- tiple Kernel Learning (MKL) method has received intensive attention due to its more desirable recognition effect over the classical SVM [2, 3]. However, parameter optimization of multiple kernel introduces a high computing cost in search- ing the entire feature space and solving tremendous convex quadratic optimization problems. Hassan et al. [4] utilize the Genetic Algorithm (GA) to improve the search efficiency in MKL, but the availability of GA remains to be proved and its search direction is too complex to be determined. Besides, with the data volume increasing exponentially in the real world, it is intractable to solve large scale problems by using conventional optimal methods. erefore, many approaches have been put forward to improve MKL. For example, the Sequential Minimal Optimization (SMO) algorithm [5] is a typical decomposition approach that updates one or two Lagrange multipliers at every training step to get the iterative solutions. And some online algorithms [6, 7] refine predic- tors through online-to-batch conversion scheme, whereas it should be noted that the convergence rate of such decompo- sition approaches is unstable. Another approach is to approxi- mate the kernel matrix such as Cholesky decomposition [8, 9] which is used to reduce the computational cost, however, at the cost of giving up recognition accuracy due to lost information. Generally, when we set as sample size and as the number of kernels, the complexities of solving convex quadratic optimization problems in SVM and MKL are ( 3 ) and ( 3.5 ) [10], respectively. It can be observed that the computing scale depends on the size of training set rather than the kernel space dimension [8]. In this big data era, it is imperative to find an approach that can minimize the computing scale while capturing the global data structure to perfect SVM or MKL. Low-Rank Representation (LRR) [11] recently has attracted great interest in many research fields, such as image processing [12, 13], computer vision [14], and Hindawi Computational Intelligence and Neuroscience Volume 2017, Article ID 3678487, 9 pages https://doi.org/10.1155/2017/3678487
Transcript of Efficient Multiple Kernel Learning Algorithms Using...

Research ArticleEfficient Multiple Kernel Learning Algorithms UsingLow-Rank Representation
Wenjia Niu12 Kewen Xia12 Baokai Zu12 and Jianchuan Bai12
1School of Electronic and Information Engineering Hebei University of Technology Tianjin 300401 China2Key Lab of Big Data Computation of Hebei Province Tianjin 300401 China
Correspondence should be addressed to Kewen Xia kwxiahebuteducn
Received 23 February 2017 Revised 20 June 2017 Accepted 5 July 2017 Published 22 August 2017
Academic Editor Cheng-Jian Lin
Copyright copy 2017 Wenjia Niu et al This is an open access article distributed under the Creative Commons Attribution Licensewhich permits unrestricted use distribution and reproduction in any medium provided the original work is properly cited
Unlike Support Vector Machine (SVM) Multiple Kernel Learning (MKL) allows datasets to be free to choose the useful kernelsbased on their distribution characteristics rather than a precise one It has been shown in the literature that MKL holds superiorrecognition accuracy compared with SVM however at the expense of time consuming computations This creates analytical andcomputational difficulties in solving MKL algorithms To overcome this issue we first develop a novel kernel approximationapproach for MKL and then propose an efficient Low-Rank MKL (LR-MKL) algorithm by using the Low-Rank Representation(LRR) It is well-acknowledged that LRR can reduce dimension while retaining the data features under a global low-rank constraintFurthermore we redesign the binary-class MKL as the multiclass MKL based on pairwise strategy Finally the recognition effectand efficiency of LR-MKL are verified on the datasets Yale ORL LSVT and Digit Experimental results show that the proposedLR-MKL algorithm is an efficient kernel weights allocation method in MKL and boosts the performance of MKL largely
1 Introduction
Support Vector Machine (SVM) is an important machinelearning method [1] which trains linear learner in featurespace derived by the kernel function and utilizes generaliza-tion theory to avoid overfitting phenomenon Recently Mul-tiple Kernel Learning (MKL) method has received intensiveattention due to its more desirable recognition effect overthe classical SVM [2 3] However parameter optimization ofmultiple kernel introduces a high computing cost in search-ing the entire feature space and solving tremendous convexquadratic optimization problems Hassan et al [4] utilize theGenetic Algorithm (GA) to improve the search efficiency inMKL but the availability of GA remains to be proved and itssearch direction is too complex to be determined Besideswith the data volume increasing exponentially in the realworld it is intractable to solve large scale problems by usingconventional optimal methods Therefore many approacheshave been put forward to improve MKL For example theSequential Minimal Optimization (SMO) algorithm [5] isa typical decomposition approach that updates one or two
Lagrange multipliers at every training step to get the iterativesolutions And some online algorithms [6 7] refine predic-tors through online-to-batch conversion scheme whereas itshould be noted that the convergence rate of such decompo-sition approaches is unstable Another approach is to approxi-mate the kernelmatrix such as Cholesky decomposition [8 9]which is used to reduce the computational cost howeverat the cost of giving up recognition accuracy due to lostinformation
Generally when we set 119899 as sample size and 119873 asthe number of kernels the complexities of solving convexquadratic optimization problems in SVM andMKL are119874(1198993)and 119874(11987311989935) [10] respectively It can be observed that thecomputing scale depends on the size of training set ratherthan the kernel space dimension [8] In this big data erait is imperative to find an approach that can minimize thecomputing scale while capturing the global data structure toperfect SVM or MKL Low-Rank Representation (LRR) [11]recently has attracted great interest in many research fieldssuch as image processing [12 13] computer vision [14] and
HindawiComputational Intelligence and NeuroscienceVolume 2017 Article ID 3678487 9 pageshttpsdoiorg10115520173678487
2 Computational Intelligence and Neuroscience
data mining [15] LRR as a compressed sensing approachaims to find the lowest-rank linear combination of all trainingsamples for reconstructing test samples under a global low-rank constraint When the training samples are sufficientlycomplete the process of representing data with low-rank willaugment the similarities among the intraclass samples and thedifferences among the interclass samples Meanwhile if thedata is corrupted since the rank of coefficient matrix will belargely increased the lowest-rank criterion can enforce noisecorrection LRR integrates data clustering and noise correc-tion into a unified framework which can greatly improvethe recognition accuracy and robustness in the preprocessingstage In this sense the recognition of SVM or MKL canbe increasingly accurate and of high speed when they arecombined with LRR
In this paper combining LRR and MKL we will developa novel recognition approach so as to construct a Low-RankMKL (LR-MKL) algorithm In the proposed algorithm thecombined Low-Rank SVM (LR-SVM) will simultaneously beutilized as the reference We will conduct extensive experi-ments on public databases to show that our proposed LR-MKL algorithm can achieve better performance than originalSVM and MKL
The remainder of the paper is organized as follows Westart by a brief review on SVM in next section In Section 3 wedescribe some existing MKL algorithms and their structureframes Section 4 is devoted to introducing efficient MKLalgorithms using LRR which we present and call LR-MKLExperiments which demonstrate the utility of the suggestedalgorithm on real data are presented in Section 5 Section 6gives the conclusions
2 Overview of SVM
Given input space X sube R119863 and label vector Y XY meetsindependent and identically distributed conditions so thetraining set can be denoted as x119894 119910119894119899119894=1 (contains 119899 samples)According to the theory of structural risk minimization[1] SVM can find the classification hyperplane with themaximummargin in the mapping space R119875 Hence the SVMtraining with 1198971-norm softmargin is a quadratic optimizationproblem
min 12 ⟨ww⟩ + 119862 119899sum119894=1
120585119894st 119910119894 (⟨w x119894⟩ + 119887) ge 1 minus 120585119894
w isin R119875120585119894 isin R119899+119894 = 1 119899
(1)
Herew is the weight coefficient vector119862 is the penalty factor120585119894 is the slack variable and 119887 is the bias term of classificationhyperplane The optimization problem can be transformedinto its dual form by introducing Lagrangianmultiplier120572119894 120572119895
and the data X can be implicitly mapped to the feature spaceby utilizing the kernel function119870 so formula (1) changes into
min 12119899sum119894=1
119899sum119895=1
119910119894119910119895120572119894120572119895119870(x119894 x119895) minus 119899sum119894=1
120572119894
st119899sum119894=1
120572119894119910119894 = 0119862 ge 120572119894 ge 0119894 = 1 119899
(2)
Simplify the objective function of formula (2) into vectorform
min 12120572TQ120572 + 1T120572st yT120572 = 0
119862 ge 120572 ge 0(3)
where 120572 isin R119899 is the vector of Lagrangian multiplier y isin Y119899is the label vector 1 is a vector of 11015840s (119899 lowast 1-dimension)and Q119894119895 = 119910119894119910119895119870(x119894 x119895) If the solution of optimizationproblem is 120572lowast119894 119894 = 1 119899 the discriminant function canbe represented as
119891 (x) = 119899sum119894=1
120572lowast119894 119910119894119870(x119894 x) + 119887 (4)
The kernel functions commonly used in SVM are linearkernel polynomial kernel radial basis function kernel andsigmoid kernel respectively denoted as
119870LIN (x119894 x119895) = ⟨x119894 x119895⟩ 119870POL (x119894 x119895) = (120574 lowast ⟨x119894 x119895⟩ + 1)119902 119870RBF (x119894 x119895) = exp (minus120574 lowast 10038171003817100381710038171003817x119894 minus x119895
1003817100381710038171003817100381722) 119870SIG (x119894 x119895) = tanh (120574 lowast ⟨x119894 x119895⟩ + 1)
(5)
To obtain the high recognition accuracy in monokernelSVM we need to discern what kind of kernel distributioncharacteristics the test data will obey Nevertheless it isunpractical and wasteful of resources to try different distri-bution characteristics one by one In this sense we needMKLto allocate the kernel weights based on the data structureautomatically
3 Multiple Kernel Learning (MKL) Algorithms
To improve the universal applicability of SVM algorithmMKL is applied instead of one specific kernel function
119870120583 (x119894 x119895) = 119891120583 (119870119898 (x119894 x119895)119872119898=1 | 120583) (6)
Computational Intelligence and Neuroscience 3
where 119870119898 is the monokernel function The multiple kernel119870120583 can be obtained by function 119891120583 R119863 rarr R119875 combining119872 different119870119898 And 120583 is the proportion parameter of kernelThere are many different methods to assign kernel weights
Pavlidis et al [16] propose a simple combination modeusing an unweighted sum or product of heterogeneouskernelsThe combining function of this UnweightedMultipleKernel Learning (UMKL) method is
119870120583 (x119894 x119895) = 119872sum119898=1
119870119898 (x119894 x119895)
119870120583 (x119894 x119895) = 119872prod119898=1
119870119898 (x119894 x119895) (7)
In a follow-up study the distribution of 120583 in MKL becomesa vital limiting factor of availability Chapelle and Rako-tomamonjy [17] report that the optimization problem canbe solved by a project gradient method in two alternativesteps first solving a primal SVM with the given 120583 secondupdating 120583 through the gradient function with 120572 calculatedin the first step The kernel combining function objectivefunction and gradient function of this Alternative MultipleKernel Learning (AMKL) method are
119870120583 (x119894 x119895) = 119872sum119898=1
120583119898119870119898 (x119894 x119895)
119869 (120583) = 12119899sum119894=1
119899sum119895=1
119910119894119910119895120572119894120572119895( 119872sum119898=1
120583119898119870119898 (x119894 x119895))
minus 119899sum119894=1
120572119894120597119869 (120583)120597120583119898 = 12
119899sum119894=1
119899sum119895=1
119910119894119910119895120572119894120572119895119870120583 (x119894 x119895)120597120583119898= 12119899sum119894=1
119899sum119895=1
119910119894119910119895120572119894120572119895119870119898 (x119894 x119895) forall119898
(8)
The Generalized Multiple Kernel Learning (GMKL) method[18] also employs the gradient tool to approach solution but itregards kernel weights as a regularization item 119903(120583) which istaken as (12)(120583minus1119872)T(120583minus1119872) So the objective functionand gradient function can be transformed into
119869 (120583) = 12119899sum119894=1
119899sum119895=1
119910119894119910119895120572119894120572119895119870120583 (x119894 x119895) minus 119899sum119894=1
120572119894 minus 119903 (120583) 120597119869 (120583)120597120583119898 = 12
119899sum119894=1
119899sum119895=1
119910119894119910119895120572119894120572119895 120597119870120583 (x119894 x119895)120597120583119898 minus 120597119903 (120583)120597120583119898 forall119898
(9)
And the kernel combined function is
119870120583 (x119894 x119895) = 119872prod119898=1
exp (minus120583119898 (x119898119894 minus x119898119895 )2)
= exp( 119872sum119898=1
minus120583119898 (x119898119894 minus x119898119895 )2) (10)
There is another two-step alternate method using a gatingmodel called Localized Multiple Kernel Learning (LMKL)method [19] The formula of locally combined kernel isrepresented as
119870120583 (x119894 x119895) = 119872sum119898=1
120583119898 (x119894) ⟨Φ119898 (x119894) Φ119898 (x119895)⟩ 120583119898 (x119895) (11)
where Φ(x) is the mapping space of feature space To ensurenonnegativity kernels can be composed in competitive orcooperative mode by using softmax form and sigmoid form[25] respectively
softmax 120583119898 = exp (⟨k119898 x⟩ + V1198980)sum119872ℎ=1 exp (⟨kℎ x⟩ + Vℎ0) forall119898sigmoid 120583119898 = 1
exp (minus ⟨k119898 x⟩ + V1198980) forall119898(12)
where V = k119898 V1198980119872119898=1 denotes the parameter of gatingmodel On the other hand Qiu and Lane [20] quantify thefitness between kernel and accuracy in a Heuristic MultipleKernel Learning (HMKL) way by exploiting the relationshipbetween kernel matrixK and sample label y The relationshipcan be expressed by kernel alignment
119865 (K yyT) = ⟨K yyT⟩119865
radic⟨KK⟩119865 ⟨yyT yyT⟩119865= ⟨K yyT⟩
119865119899radic⟨KK⟩119865 (13)
where ⟨K yyT⟩119865 = sum119899119894=1sum119899119895=1119870(x119894 x119895)119910119894119895119910T119894119895 ⟨sdot sdot⟩119865 is the
Frobenius inner product Using kernel alignment weighs theproportion of multikernels
120583119898 = 119865 (119870119898 yyT)sum119872ℎ=1 119865 (119870ℎ yyT) forall119898 (14)
Then the concentration bound is added in kernel alignmentby Cortes et al [21] to form centering kernel
[119870119888]119894119895 = 119870119894119895 minus 1119899119899sum119894=1
119870119894119895 minus 1119899119899sum119895=1
119870119894119895 + 11198992119899sum119894119895=1
119870119894119895 (15)
Accordingly the multikernel weights of this Centering Mul-tiple Kernel Learning (CMKL) method are
120583 = Cminus1a1003817100381710038171003817Cminus1a10038171003817100381710038172 (16)
where C = ⟨119870119888119898 119870119888ℎ⟩119865119872119898ℎ=1 and a = ⟨119870119888119898 yyT⟩119865119872119898=1
4 Computational Intelligence and Neuroscience
Later Cortes et al [22] studied a Polynomial MultipleKernel Learning (PMKL) method which utilized the poly-nomial combination of the base kernels with higher degree(119889 ge 1) based on the Kernel Ridge Regression (KRR) theory
119870120583 (x119894 x119895) = sum12058311989611198962 sdotsdotsdot1198961198721198701 (x1119894 x1119895)1198961sdot 1198702 (x2119894 x2119895)1198962 sdot sdot sdot 119870119872 (x119872119894 x119872119895 )119896119872
119896119898 ge 0 sum (1198961 + 1198962 + sdot sdot sdot + 119896119872) le 119889 12058311989611198962 sdotsdotsdot119896119872 ge 0(17)
However the computing complex of coefficients 12058311989611198962 sdotsdotsdot119896119872 is119874(119872119889) which is too large to apply in practice So12058311989611198962 sdotsdotsdot119896119872 canbe simplified as a product form by nonnegative coefficients12058311989611 12058311989622 sdot sdot sdot 120583119896119872119872 and the special case (119889 = 2) can be expressedas
119870120583 (x119894 x119895) = 119872sum119898=1
119872sumℎ=1
120583119898120583ℎ119870119898 (x119898119894 x119898119895 )119870ℎ (xℎ119894 xℎ119895) (18)
Here the related optimization of learning 119870120583 can be formu-lated as the following min-max form
min120583isin120593
max120572isinR119899
minus120572T (119870120583 + 120582I) 120572 + 2120572Ty (19)
where 120593 is a positive bounded and convex set Two boundedsets 1198971-norm and 1198972-norm are the appropriate choices toconstruct 120593
1205931 = 120583 | 120583 ge 0 1003817100381710038171003817120583 minus 120583010038171003817100381710038171 le and 1205932 = 120583 | 120583 ge 0 1003817100381710038171003817120583 minus 120583010038171003817100381710038172 le and (20)
Here 1205830 and and are model parameters and 1205830 is generallyequal to 0 or 12058301205830 = 1
Other than approaches described above inspired bythe consistency between group Lasso and MKL [26] Xuet al [23] and Kloft et al [24] propose an MKL iterativemethod in a generalized 119897119901-norm (119901 ge 1) form They arecollectively called Arbitrary Norms Multiple Kernel Learn-ing (ANMKL) method On the basis of duality conditionw11989822 = 1205832119898sum119899119894=1sum119899119895=1 119910119894119910119895120572119894120572119895119870119898(x119898119894 x119898119895 ) the updatedformula of kernels weight is
120583119898 =1003817100381710038171003817w11989810038171003817100381710038172(119901+1)2
(sum119872ℎ=1 1003817100381710038171003817wℎ10038171003817100381710038172119901(119901+1)2 )1119901 forall119898 (21)
It can be seen from the formulas in this section that theoperation complexity of MKL is mainly decided by x119894 Sotrying to simplify the feature space is an efficient way toimprove the performance of MKLThrough the optimizationof basis vectors LRR can reduce dimension while retainingthe data features which is ideal for improving MKL
4 MKL Using Low-Rank Representation
41 Low-Rank Representation (LRR) The theoreticaladvances on LRR enable us to use latent low-rank structure
in data [27 28] And it simultaneously obtains therepresentation of all samples under a global low-rankconstraint Meantime the LRR procedure can operate in arelatively short time with guaranteed performance
Let the input samples space X be represented by a linearcombination in the dictionary A
X = AZ (22)
where Z = [z1 z2 z119899] is the coefficient matrix and each z119894is a representation coefficient vector of x119894 When the samplesare sufficient X serves as the dictionary A By consideringthe noise or tainted data in practical application LRR aims atapproximatingX intoAZ+E by themeans of minimizing therank of matrix A while reducing the 1198970-norm of E in whichA is a low-rank matrix and E is the associated sparse error Itcan be generally formulated as
minZE
rank (A) + 120582 E0 st X = AZ + E (23)
Here 120582 is used to balance the effect of low-rank and errorterm 1198970-norm as NP-hard problem can be substituted for1198971-norm or 11989721-norm We choose 11989721-norm as the errorterm measurement here which is defined as E21 =sum119899119895=1radicsum119899119895=1([E]119894119895)2 Meantime rank(A) can relax intonuclear-norm sdot lowast [29] Consequently the convex relaxationof formula (23) is
minZE
Zlowast + 120582 E21 st X = AZ + E (24)
The optimal solution Zlowast can be obtained via the AugmentedLagrange Multipliers (ALM) method [11]
42 Efficient SVM and MKL Using LRR Kernel matrixremarkably impacts the computational efficiency and accu-racy of SVM andMKL How to find an appropriate variant ofkernel matrix that contains both the initial label and the datageometry structure for recognition is a crucial task Since LRRhas been theoretically proved to be superior in the sequelwe adopt LRR to transform the kernel for augmenting thesimilarities among the intraclass samples and the differencesamong the interclass samples Moreover a representationof all samples under a global low-rank constraint can beattained which is more conducive to capturing the globaldata structure [30] So LR-SVM and LR-MKL are twoalternative techniques that we propose to use to improve theperformance of SVM and MKL
Firstly based on the LRR theory we improve the monok-ernel SVM as the reference item from which the improve-ment brought by LRR can be displayed visually The specificprocedure of efficient LR-SVM is presented in Algorithm 1
Algorithm 1 (efficient SVM using LRR (LR-SVM))
Input This includes the whole training set XY the featurespace of testing setX119878 = [x119899+1 x119899+2 x119899+119904] the parameters119905 120574 119862 119902 of SVM and the parameter 120582 of LRR
Computational Intelligence and Neuroscience 5
Step 1 Normalize XX119878Step 2 Perform (24) procedure on the normalized XX119878 toproject them on the coefficient feature space ZZ119878 respec-tively
Step 3 Plug Z and the label vector Y into SVM for trainingclassification model
Step 4 Utilize the obtained classificationmodel to classify thecoefficient feature Z119878 of testing set X119878 and the discriminantfunction is 119891(z) = sum119899119894=1 120572lowast119894 119910119894119870(z119894 z) + 119887Output Compare the actual label vector of test set Y119878 and theprediction label vector Y119875 to obtain the recognition results
It is well known that SVM suffers from instability forthe various data structures Thus MKL recognition becomesthe development trend Next we combine LRR and MKLalgorithms mentioned in the Section 3 and change binary-classification model into multiclassification model by pair-wise (one-versus-one) strategy through which a classifierbetween any two categories of samples (119896 is the number ofcategories) can be designed Then we adopt voting methodand assign sample to the category the most votes obtainedAll the combined algorithms can be summarized into a framewhich is given in Algorithm 2 and we refer to it collectively asLR-MKL
Algorithm 2 (efficient MKL using LRR (LR-MKL))
Input This includes the whole training set XY the featurespace of testing set X119878 = [x119899+1 x119899+2 x119899+119904] and theparameter 120582 of LRR
Step 1simStep 2 They are the same as the LR-SVM algorithm
Step 3 Plug Z and the label vector Y into MKL to train 119896(119896 minus1)2 classifiers with the pairwise strategy
Step 4 Utilize each one of the binary MKL classifiers toclassify the coefficient feature Z119878 of testing set X119878
Step 5 According to the prediction label vectorsY1198751 Y1198752 Y119875119896(119896minus1)2 vote for the category of each sample toget the multilabels Y119875
Output Compare the actual label vector of test set Y119878 and theprediction label vector Y119875 to obtain the recognition resultsand the kernel weight vector 1205835 Experiments and Analysis
In this section we conduct extensive experiments to examinethe efficiency of proposed LR-SVM and LR-MKL algorithmsThe operating environment is based on MATLAB (R2013a)under the Intel Core i5 CPU processor 253GHz frequencyparameters The SVM toolbox used in this paper is theLIBSVM [31] which can be easily applied and is shown to befast in large scale databases
The simulations are performed on diverse datasets toensure the universal recognition effectThe test datasets range
over the frequently used face databases and the standard testdata of UCI repository In the simulations all the samples arenormalized first
(1) Yale face database (httpvisionucsdeducontentyale-face-database) it contains 165 grayscale imagesof 15 individuals with different facial expression orconfiguration and each image is resized to 64 lowast 64pixels with 256 grey levels
(2) ORL face database (httpwwwclcamacukresearchdtgattarchivefacedatabasehtm) it contains 400images of 40 distinct subjects taken at different timesvarying light facial expressions and details Weresize them to 64 lowast 64 pixels with 256 grey levels perpixel
(3) LSVT Voice Rehabilitation dataset (httparchiveicsuciedumldatasetsLSVT+Voice+Rehabilitation)[32] it is composed of 126 speech signals from 14people with 309 features divided into two categories
(4) Multiple Features Digit dataset (httparchiveicsuciedumldatasetsMultiple+Features) it includes 2000digitized handwritten numerals 0ndash9 with 649 fea-tures
51 Experiments on LR-SVM In order to demonstrate therecognition performance of SVM improved by the presentedLR-SVM we carry out numerous experiments on the Yaleand ORL face database According to the different rate oftraining sample (20 30 40 50 60 70 and 80)we implement seven groups of experiments on each databaseTo ensure stable and reliable test each group has ten differentdivisions randomly and we average them as the final resultsThe kernel functions are 119870LIN 119870POL 119870RBF 119870SIG (119902 = 3) and120574 = 1119892 (119892 is the dimension of feature space)
The classification accuracy and run time of Yale databaseby using SVM and LR-SVM are shown in Figures 1 and 2respectively Similarly the classification accuracy and runtime of ORL database are shown in Figures 3 and 4The solidlines depict the result of SVM with different kernels whilethe patterned lines with the corresponding colour depictthat of LR-SVM As can be seen from the Figures 1 and3 the proposed LR-SVM method consistently achieves anobvious improvement in classification accuracy compared tothe original SVM method In most cases the classificationaccuracy increases with the rise in training sample rate It isshown that the more complete the training set the better theclassification accuracy But it is impossible for the trainingset to include so many samples in reality LR-MKL has ahigh accuracy even under the low training sample rate whichis suitable for the real applications Meanwhile Figures 2and 4 show that through LRR conversion the run timecan be reduced more than an order of magnitude which isreasonable for the real-time requirements of data processingin the big data era
52 Experiments on LR-MKL In this section we compare theperformance of the MKL algorithms involved in Section 3
6 Computational Intelligence and Neuroscience
45
50
55
60
65
70
75
80
85Ac
cura
cy (
)
30 40 50 60 70 8020Training sample rate ()
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 1 Classification accuracy of Yale by using SVM and LR-SVM
6040 50 70 803020Training sample rate ()
0
005
01
015
02
025
03
035
04
045
05
Run
time (
s)
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 2 Run time of Yale by using SVM and LR-SVM
and their corresponding LR-MKL algorithms The multik-ernel is composed of 119870LIN 119870POL 119870RBF 119870SIG (119902 = 3) Theproportion parameter vector of kernel is 120583 = [1205831 1205832 1205833 1205834]The comparative algorithms are listed below
(i) Unweighted MKL (UMKL) [16] and LR-UMKL (+)indicates sum form and (lowast) indicates product form
(ii) Alternative MKL (AMKL) [17] and LR-AMKL(iii) Generalized MKL (GMKL) [18] and LR-GMKL(iv) Localized MKL (LMKL) [19] and LR-LMKL (sof)
distribute 120583 into softmax mode and (sig) distribute120583 into sigmoid mode
30 40 50 60 70 8020Training sample rate ()
65
70
75
80
85
90
Accu
racy
()
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 3 Classification accuracy of ORL by using SVM and LR-SVM
0
05
1
15
2
25
3
Run
time (
s)
30 40 50 60 70 8020Training sample rate ()
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 4 Run time of ORL by using SVM and LR-SVM
(v) Heuristic MKL (HMKL) [20] and LR-HMKL(vi) Centering MKL (CMKL) [21] and LR-CMKL(vii) Polynomial MKL (PMKL) [22] and LR-PMKL (1)
adopts the bounded set 1205931 with 1198971-norm and (2)adopts the bounded set 1205932 with 1198972-norm
(viii) Arbitrary Norm MKL (ANMKL) [23 24] and LR-ANMKL (1) iterates 120583 with 1198971-norm and (2) iterates120583 with 1198972-norm
(ix) Besides the highest accuracy among the four monok-ernel SVM selected as the reference item which isreferred to as SVM(best)
Computational Intelligence and Neuroscience 7
Table1Th
eperform
anceso
fMKL
algorithm
sand
LR-M
KLalgorithm
sonthed
atasetsY
aleORL
LSV
TandDigit
Yale
ORL
LSVT
Digit
Acc
Time
Acc
Time
Acc
Time
Acc
Time
SVM(best)
6932
3102981
800002
16798
7619
0500142
959302
09195
LR-SVM(best)
79866
700109
870015
01575
776637
000
4396
330
4009
72UMKL
(+)[16]
875114
25981
93579
8182352
785714
00229
9735
7147412
LR-U
MKL
(+)
95893
6030
18834813
10817
738095
00152
9815
9520278
UMKL
(lowast)[16]
583248
27244
775022
205507
666935
00281
960904
71661
LR-U
MKL
(lowast)935739
026
3693406
321836
670033
00176
984618
363
92AMKL
[17]
857753
37236
938741
46854
809524
00452
974725
112138
LR-AMKL
94379
9038
6996
9417
045
9288
0952
000
8598
6952
688
04GMKL
[18]
862989
45330
962057
50070
857143
00565
9914
9980774
LR-G
MKL
958015
062
5398
5833
07761
88928
600183
99467
3459
72LM
KL(sof)[19]
879077
21540
55970003
2203122
850090
51989
99889
81667978
LR-LMKL
(sof)
979352
22720
498
9724
17379
186
742
911933
983591
9818
12LM
KL(sig)[19]
880145
1067552
970108
1070
911
887541
07238
9937
50485914
LR-LMKL
(sig)
98066
7159711
97997
911724
092
662
7045
9499
562
524
592
7HMKL
[20]
636037
924410
935109
1182340
805998
00915
976258
1035
59LR
-HMKL
919611
859
7298
689
310936
88516
2500352
98347
963959
CMKL
[21]
864166
950618
960308
1076
940
799503
00874
965014
106074
LR-C
MKL
94008
310638
098
479
9129746
939024
003
4798
9113
626
96PM
KL(1)[
22]
890035
61842
984901
69065
928571
01079
995881
248702
LR-PMKL
(1)99
1429
090
5399
5712
098
2895
938
6005
7310000
00129831
PMKL
(2)[22]
890261
53893
987533
65450
924662
01295
99504
62116
79LR
-PMKL
(2)98
896
8084
9499
582
8089
1195
5145
006
5199
794
1135108
ANMKL
(1)[2324]
867210
64856
984396
204564
919827
01167
980007
1039
79LR
-ANMKL
(1)96
866
7070
4199
464
328519
92224
700247
992850
690
70ANMKL
(2)[2324]
866998
7066
4982204
2116
15930035
0119
4980039
97753
LR-ANMKL
(2)972917
088
6399
2857
305
979253
91002
2499
249
750374
8 Computational Intelligence and Neuroscience
We conduct experiments on the test datasets YaleORL LSVTVoice Rehabilitation (LSVT for short) andMultiple FeaturesDigit (Digit for short)The 60 samples of dataset are drawnout randomly to train classification model and the remainingsamples serve as the test set Through the optimized resultsof 120574 and penalty factor 119862 by grid search method we findthat the classification accuracy varies not too much with 120574and 119862 ranging in a certain interval So there is no need tosearch the whole parameter space which inevitably increasesthe computational costThe penalty factor119862 can be given thattrying values 001 01 1 10 100 and 120574 are fixed on 1119892 Thenwe assign a value which has the highest average accuracyon the 5 lowast 2 cross validation sets to 119862 Each algorithm isconducted with 10 independent runs and we average them asthe final results The bold numbers represent the preferablerecognition effect between the original algorithms and theirLRR combined algorithmsThe numbers in italic font denotethe algorithms whose recognition precision is inferior tothe SVM(best) The recognition performance of algorithmsis measured by the classification accuracy and run timeillustrated by Table 1
In most cases our proposed LR-MKL methods consis-tently achieve superior results to the original MKL whichverifies the higher classification accuracy and shorter opera-tion time It is indicated that LRR can augment the similaritiesamong the intraclass samples and the differences among theinterclass samples while simplifying the kernel matrix Notethat UMKL(lowast) fails to achieve the ideal recognition effectsin many cases even less accurate than SVM(best) Howevercombiningwith LRR improves its effects to a large extentThisillustrates that simply combining kernels without accordingdata structure is infeasible and LRR can offset part of theconsequences of irrational distribution In general PMKLANMKL and their improved algorithms have the preferablerecognition effects especially the improved algorithms withthe accuracy over 90 percent all the time In terms of runtime it is clearly observed that the real-time performance ofMKL is much worse than SVM because MKL has a processof allocating kernel weights and the process can be very timeconsuming Among them LMKL is the worst and fails tosatisfy the real-time requirement Obviously our combinedLR-MKL can reduce the run time manifold even more thanone order of magnitude so it can speed high-precision MKLup to satisfy the real-time requirement In brief the proposedLR-MKL can boost the performance ofMKL to a great extent
6 Conclusion
The complexity of solving convex quadratic optimizationproblem in MKL is 119874(11987311989935) so it is infeasible to apply inlarge scale problems for its large computational cost Oureffort has beenmade on decreasing the dimension of trainingset Note that LRR just can capture the global structure ofdata in relatively few dimensions Therefore we have givena review of several existing MKL algorithms Based on thispoint we have proposed a novel combined LR-MKL whichlargely improves the performance ofMKL A large number ofexperiments have been carried on four real world datasets tocontrast the recognition effects of various kinds of MKL and
LR-MKL algorithms It has been shown that in most casesthe recognition effects of MKL algorithms are better thanSVM(best) except UMKL(lowast) And our proposed LR-MKLmethods have consistently achieved the superior results tothe original MKL Among them PMKL ANMKL and theirimproved algorithms have shown possessing the preferablerecognition effects
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
This work was supported by the National Natural ScienceFoundation of China (no 51208168) Hebei Province NaturalScience Foundation (no E2016202341) and Tianjin NaturalScience Foundation (no 13JCYBJC37700)
References
[1] V N Vapnik ldquoAn overview of statistical learning theoryrdquo IEEETransactions on Neural Networks vol 10 no 5 pp 988ndash9991999
[2] M Hu Y Chen and J T-Y Kwok ldquoBuilding sparse multiple-kernel SVM classifiersrdquo IEEE Transactions on Neural Networksvol 20 no 5 pp 827ndash839 2009
[3] X Wang X Liu N Japkowicz and S Matwin ldquoEnsemble ofmultiple kernel SVM classifiersrdquo Advances in Artificial Intelli-gence vol 8436 pp 239ndash250 2014
[4] E Hassan S Chaudhury N Yadav P Kalra and M GopalldquoOff-line handwritten input based identity determination usingmulti kernel feature combinationrdquo Pattern Recognition Lettersvol 35 no 1 pp 113ndash119 2014
[5] F Cai and V Cherkassky ldquoGeneralized SMO algorithm forSVM-based multitask learningrdquo IEEE Transactions on NeuralNetworks and Learning Systems vol 23 no 6 pp 997ndash10032012
[6] K Crammer O Dekel J Keshet S Shalev-Shwartz andY Singer ldquoOnline passive-aggressive algorithmsrdquo Journal ofMachine Learning Research vol 7 pp 551ndash585 2006
[7] N Cesa-Bianchi A Conconi and C Gentile ldquoOn the gen-eralization ability of on-line learning algorithmsrdquo Institute ofElectrical and Electronics Engineers Transactions on InformationTheory vol 50 no 9 pp 2050ndash2057 2004
[8] S Fine and K Scheinberg ldquoEfficient SVM training usinglow-rank kernel representationsrdquo Journal of Machine LearningResearch vol 2 no 2 pp 243ndash264 2002
[9] S Zhou ldquoSparse LSSVM in primal using cholesky factorizationfor large-scale problemsrdquo IEEETransactions onNeuralNetworksand Learning Systems vol 27 no 4 pp 783ndash795 2016
[10] L Jia S-Z Liao and L-Z Ding ldquoLearning with uncertainkernel matrix setrdquo Journal of Computer Science and Technologyvol 25 no 4 pp 709ndash727 2010
[11] G Liu Z Lin S Yan J Sun Y Yu and Y Ma ldquoRobust recov-ery of subspace structures by low-rank representationrdquo IEEETransactions on Pattern Analysis and Machine Intelligence vol35 no 1 pp 171ndash184 2013
[12] Y Peng A Ganesh J Wright W Xu and Y Ma ldquoRASL robustalignment by sparse and low-rank decomposition for linearly
Computational Intelligence and Neuroscience 9
correlated imagesrdquo IEEE Transactions on Pattern Analysis andMachine Intelligence vol 34 no 11 pp 2233ndash2246 2012
[13] B Cheng G Liu J Wang Z Huang and S Yan ldquoMulti-tasklow-rank affinity pursuit for image segmentationrdquo in Proceed-ings of the IEEE International Conference on Computer Vision(ICCV rsquo11) pp 2439ndash2446 IEEE Barcelona Spain November2011
[14] YMu JDongX Yuan and S Yan ldquoAccelerated low-rank visualrecovery by random projectionrdquo in Proceedings of the 2011 IEEEConference on Computer Vision and Pattern Recognition CVPR2011 pp 2609ndash2616 Colorado Springs Colo USA June 2011
[15] J Chen J Zhou and J Ye ldquoIntegrating low-rank and group-sparse structures for robust multi-task learningrdquo in Proceedingsof the 17th ACM SIGKDD International Conference on Knowl-edge Discovery and Data Mining KDDrsquo11 pp 42ndash50 San DiegoCalif USA August 2011
[16] P Pavlidis J Cai JWeston andWNGrundy ldquoGene functionalclassification fromheterogeneous datardquo inProceedings of the 5thAnnual Internatinal Conference on Computational Biology pp249ndash255 Montreal Canada May 2001
[17] O Chapelle and A Rakotomamonjy ldquoSecond order optimiza-tion of kernel parametersrdquo Nips Workshop on Kernel Learning2008
[18] M Varma and B R Babu ldquoMore generality in efficient mul-tiple kernel learningrdquo in Proceedings of the 26th InternationalConference On Machine Learning ICML 2009 pp 1065ndash1072Montreal Canada June 2009
[19] M Gonen and E Alpaydin ldquoLocalized multiple kernel learn-ingrdquo in Proceedings of the the 25th international conference pp352ndash359 Helsinki Finland July 2008
[20] S Qiu and T Lane ldquoA framework for multiple kernel supportvector regression and its applications to siRNA efficacy predic-tionrdquo IEEEACM Transactions on Computational Biology andBioinformatics vol 6 no 2 pp 190ndash199 2009
[21] CCortesMMohri andARostamizadeh ldquoTwo-stage learningkernel algorithmsrdquo in Proceedings of the 27th InternationalConference on Machine Learning ICML 2010 pp 239ndash246Haifa Israel June 2010
[22] C Cortes M Mohri and A Rostamizadeh ldquoLearning non-linear combinations of kernelsrdquo in Proceedings of the 23rdAnnual Conference on Neural Information Processing Systems(NIPS rsquo09) pp 396ndash404 December 2009
[23] Z Xu R Jin H Yang I King and M R Lyu ldquoSimple andefficient multiple kernel learning by group lassordquo in Proceedingsof the 27th International Conference onMachine Learning ICML2010 pp 1175ndash1182 Haifa Israel June 2010
[24] M Kloft U Brefeld S Sonnenburg and A Zien ldquoNon-sparseregularization and efficient training with multiple kernelsArxiv Preprint abs1003rdquo httpsarxivorgabs10030079
[25] M Gonen and E Alpaydın ldquoMultiple kernel learning algo-rithmsrdquo Journal of Machine Learning Research vol 12 pp 2211ndash2268 2011
[26] F R Bach ldquoConsistency of the group lasso and multiple kernellearningrdquo Journal ofMachine Learning Research vol 9 no 2 pp1179ndash1225 2008
[27] E J Candes X Li Y Ma and JWright ldquoRobust principal com-ponent analysisrdquo Journal of the ACM vol 58 no 3 2011
[28] C-F Chen C-P Wei and Y-C F Wang ldquoLow-rank matrixrecovery with structural incoherence for robust face recogni-tionrdquo in Proceedings of the 2012 IEEE Conference on ComputerVision and Pattern Recognition CVPR 2012 pp 2618ndash2625Providence RI USA June 2012
[29] J-F Cai E J Candes and Z Shen ldquoA singular value thresh-olding algorithm for matrix completionrdquo SIAM Journal onOptimization vol 20 no 4 pp 1956ndash1982 2010
[30] L Zhuang H Gao Z Lin Y Ma X Zhang and N Yu ldquoNon-negative low rank and sparse graph for semi-supervised learn-ingrdquo in Proceedings of the 2012 IEEE Conference on ComputerVision and Pattern Recognition CVPR 2012 pp 2328ndash2335 usaJune 2012
[31] C Chang and C Lin ldquoLIBSVM a Library for support vectormachinesrdquo ACM Transactions on Intelligent Systems and Tech-nology vol 2 no 3 article 27 2011
[32] A Tsanas M A Little C Fox and L O Ramig ldquoObjectiveautomatic assessment of rehabilitative speech treatment inparkinsonrsquos diseaserdquo IEEE Transactions on Neural Systems andRehabilitation Engineering vol 22 no 1 pp 181ndash190 2014
Submit your manuscripts athttpswwwhindawicom
Computer Games Technology
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
Advances in
FuzzySystems
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014
International Journal of
ReconfigurableComputing
Hindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
Applied Computational Intelligence and Soft Computing
thinspAdvancesthinspinthinsp
Artificial Intelligence
HindawithinspPublishingthinspCorporationhttpwwwhindawicom Volumethinsp2014
Advances inSoftware EngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporation
httpwwwhindawicom Volume 2014
Advances in
Multimedia
International Journal of
Biomedical Imaging
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational Intelligence and Neuroscience
Industrial EngineeringJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Human-ComputerInteraction
Advances in
Computer EngineeringAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014

2 Computational Intelligence and Neuroscience
data mining [15] LRR as a compressed sensing approachaims to find the lowest-rank linear combination of all trainingsamples for reconstructing test samples under a global low-rank constraint When the training samples are sufficientlycomplete the process of representing data with low-rank willaugment the similarities among the intraclass samples and thedifferences among the interclass samples Meanwhile if thedata is corrupted since the rank of coefficient matrix will belargely increased the lowest-rank criterion can enforce noisecorrection LRR integrates data clustering and noise correc-tion into a unified framework which can greatly improvethe recognition accuracy and robustness in the preprocessingstage In this sense the recognition of SVM or MKL canbe increasingly accurate and of high speed when they arecombined with LRR
In this paper combining LRR and MKL we will developa novel recognition approach so as to construct a Low-RankMKL (LR-MKL) algorithm In the proposed algorithm thecombined Low-Rank SVM (LR-SVM) will simultaneously beutilized as the reference We will conduct extensive experi-ments on public databases to show that our proposed LR-MKL algorithm can achieve better performance than originalSVM and MKL
The remainder of the paper is organized as follows Westart by a brief review on SVM in next section In Section 3 wedescribe some existing MKL algorithms and their structureframes Section 4 is devoted to introducing efficient MKLalgorithms using LRR which we present and call LR-MKLExperiments which demonstrate the utility of the suggestedalgorithm on real data are presented in Section 5 Section 6gives the conclusions
2 Overview of SVM
Given input space X sube R119863 and label vector Y XY meetsindependent and identically distributed conditions so thetraining set can be denoted as x119894 119910119894119899119894=1 (contains 119899 samples)According to the theory of structural risk minimization[1] SVM can find the classification hyperplane with themaximummargin in the mapping space R119875 Hence the SVMtraining with 1198971-norm softmargin is a quadratic optimizationproblem
min 12 ⟨ww⟩ + 119862 119899sum119894=1
120585119894st 119910119894 (⟨w x119894⟩ + 119887) ge 1 minus 120585119894
w isin R119875120585119894 isin R119899+119894 = 1 119899
(1)
Herew is the weight coefficient vector119862 is the penalty factor120585119894 is the slack variable and 119887 is the bias term of classificationhyperplane The optimization problem can be transformedinto its dual form by introducing Lagrangianmultiplier120572119894 120572119895
and the data X can be implicitly mapped to the feature spaceby utilizing the kernel function119870 so formula (1) changes into
min 12119899sum119894=1
119899sum119895=1
119910119894119910119895120572119894120572119895119870(x119894 x119895) minus 119899sum119894=1
120572119894
st119899sum119894=1
120572119894119910119894 = 0119862 ge 120572119894 ge 0119894 = 1 119899
(2)
Simplify the objective function of formula (2) into vectorform
min 12120572TQ120572 + 1T120572st yT120572 = 0
119862 ge 120572 ge 0(3)
where 120572 isin R119899 is the vector of Lagrangian multiplier y isin Y119899is the label vector 1 is a vector of 11015840s (119899 lowast 1-dimension)and Q119894119895 = 119910119894119910119895119870(x119894 x119895) If the solution of optimizationproblem is 120572lowast119894 119894 = 1 119899 the discriminant function canbe represented as
119891 (x) = 119899sum119894=1
120572lowast119894 119910119894119870(x119894 x) + 119887 (4)
The kernel functions commonly used in SVM are linearkernel polynomial kernel radial basis function kernel andsigmoid kernel respectively denoted as
119870LIN (x119894 x119895) = ⟨x119894 x119895⟩ 119870POL (x119894 x119895) = (120574 lowast ⟨x119894 x119895⟩ + 1)119902 119870RBF (x119894 x119895) = exp (minus120574 lowast 10038171003817100381710038171003817x119894 minus x119895
1003817100381710038171003817100381722) 119870SIG (x119894 x119895) = tanh (120574 lowast ⟨x119894 x119895⟩ + 1)
(5)
To obtain the high recognition accuracy in monokernelSVM we need to discern what kind of kernel distributioncharacteristics the test data will obey Nevertheless it isunpractical and wasteful of resources to try different distri-bution characteristics one by one In this sense we needMKLto allocate the kernel weights based on the data structureautomatically
3 Multiple Kernel Learning (MKL) Algorithms
To improve the universal applicability of SVM algorithmMKL is applied instead of one specific kernel function
119870120583 (x119894 x119895) = 119891120583 (119870119898 (x119894 x119895)119872119898=1 | 120583) (6)
Computational Intelligence and Neuroscience 3
where 119870119898 is the monokernel function The multiple kernel119870120583 can be obtained by function 119891120583 R119863 rarr R119875 combining119872 different119870119898 And 120583 is the proportion parameter of kernelThere are many different methods to assign kernel weights
Pavlidis et al [16] propose a simple combination modeusing an unweighted sum or product of heterogeneouskernelsThe combining function of this UnweightedMultipleKernel Learning (UMKL) method is
119870120583 (x119894 x119895) = 119872sum119898=1
119870119898 (x119894 x119895)
119870120583 (x119894 x119895) = 119872prod119898=1
119870119898 (x119894 x119895) (7)
In a follow-up study the distribution of 120583 in MKL becomesa vital limiting factor of availability Chapelle and Rako-tomamonjy [17] report that the optimization problem canbe solved by a project gradient method in two alternativesteps first solving a primal SVM with the given 120583 secondupdating 120583 through the gradient function with 120572 calculatedin the first step The kernel combining function objectivefunction and gradient function of this Alternative MultipleKernel Learning (AMKL) method are
119870120583 (x119894 x119895) = 119872sum119898=1
120583119898119870119898 (x119894 x119895)
119869 (120583) = 12119899sum119894=1
119899sum119895=1
119910119894119910119895120572119894120572119895( 119872sum119898=1
120583119898119870119898 (x119894 x119895))
minus 119899sum119894=1
120572119894120597119869 (120583)120597120583119898 = 12
119899sum119894=1
119899sum119895=1
119910119894119910119895120572119894120572119895119870120583 (x119894 x119895)120597120583119898= 12119899sum119894=1
119899sum119895=1
119910119894119910119895120572119894120572119895119870119898 (x119894 x119895) forall119898
(8)
The Generalized Multiple Kernel Learning (GMKL) method[18] also employs the gradient tool to approach solution but itregards kernel weights as a regularization item 119903(120583) which istaken as (12)(120583minus1119872)T(120583minus1119872) So the objective functionand gradient function can be transformed into
119869 (120583) = 12119899sum119894=1
119899sum119895=1
119910119894119910119895120572119894120572119895119870120583 (x119894 x119895) minus 119899sum119894=1
120572119894 minus 119903 (120583) 120597119869 (120583)120597120583119898 = 12
119899sum119894=1
119899sum119895=1
119910119894119910119895120572119894120572119895 120597119870120583 (x119894 x119895)120597120583119898 minus 120597119903 (120583)120597120583119898 forall119898
(9)
And the kernel combined function is
119870120583 (x119894 x119895) = 119872prod119898=1
exp (minus120583119898 (x119898119894 minus x119898119895 )2)
= exp( 119872sum119898=1
minus120583119898 (x119898119894 minus x119898119895 )2) (10)
There is another two-step alternate method using a gatingmodel called Localized Multiple Kernel Learning (LMKL)method [19] The formula of locally combined kernel isrepresented as
119870120583 (x119894 x119895) = 119872sum119898=1
120583119898 (x119894) ⟨Φ119898 (x119894) Φ119898 (x119895)⟩ 120583119898 (x119895) (11)
where Φ(x) is the mapping space of feature space To ensurenonnegativity kernels can be composed in competitive orcooperative mode by using softmax form and sigmoid form[25] respectively
softmax 120583119898 = exp (⟨k119898 x⟩ + V1198980)sum119872ℎ=1 exp (⟨kℎ x⟩ + Vℎ0) forall119898sigmoid 120583119898 = 1
exp (minus ⟨k119898 x⟩ + V1198980) forall119898(12)
where V = k119898 V1198980119872119898=1 denotes the parameter of gatingmodel On the other hand Qiu and Lane [20] quantify thefitness between kernel and accuracy in a Heuristic MultipleKernel Learning (HMKL) way by exploiting the relationshipbetween kernel matrixK and sample label y The relationshipcan be expressed by kernel alignment
119865 (K yyT) = ⟨K yyT⟩119865
radic⟨KK⟩119865 ⟨yyT yyT⟩119865= ⟨K yyT⟩
119865119899radic⟨KK⟩119865 (13)
where ⟨K yyT⟩119865 = sum119899119894=1sum119899119895=1119870(x119894 x119895)119910119894119895119910T119894119895 ⟨sdot sdot⟩119865 is the
Frobenius inner product Using kernel alignment weighs theproportion of multikernels
120583119898 = 119865 (119870119898 yyT)sum119872ℎ=1 119865 (119870ℎ yyT) forall119898 (14)
Then the concentration bound is added in kernel alignmentby Cortes et al [21] to form centering kernel
[119870119888]119894119895 = 119870119894119895 minus 1119899119899sum119894=1
119870119894119895 minus 1119899119899sum119895=1
119870119894119895 + 11198992119899sum119894119895=1
119870119894119895 (15)
Accordingly the multikernel weights of this Centering Mul-tiple Kernel Learning (CMKL) method are
120583 = Cminus1a1003817100381710038171003817Cminus1a10038171003817100381710038172 (16)
where C = ⟨119870119888119898 119870119888ℎ⟩119865119872119898ℎ=1 and a = ⟨119870119888119898 yyT⟩119865119872119898=1
4 Computational Intelligence and Neuroscience
Later Cortes et al [22] studied a Polynomial MultipleKernel Learning (PMKL) method which utilized the poly-nomial combination of the base kernels with higher degree(119889 ge 1) based on the Kernel Ridge Regression (KRR) theory
119870120583 (x119894 x119895) = sum12058311989611198962 sdotsdotsdot1198961198721198701 (x1119894 x1119895)1198961sdot 1198702 (x2119894 x2119895)1198962 sdot sdot sdot 119870119872 (x119872119894 x119872119895 )119896119872
119896119898 ge 0 sum (1198961 + 1198962 + sdot sdot sdot + 119896119872) le 119889 12058311989611198962 sdotsdotsdot119896119872 ge 0(17)
However the computing complex of coefficients 12058311989611198962 sdotsdotsdot119896119872 is119874(119872119889) which is too large to apply in practice So12058311989611198962 sdotsdotsdot119896119872 canbe simplified as a product form by nonnegative coefficients12058311989611 12058311989622 sdot sdot sdot 120583119896119872119872 and the special case (119889 = 2) can be expressedas
119870120583 (x119894 x119895) = 119872sum119898=1
119872sumℎ=1
120583119898120583ℎ119870119898 (x119898119894 x119898119895 )119870ℎ (xℎ119894 xℎ119895) (18)
Here the related optimization of learning 119870120583 can be formu-lated as the following min-max form
min120583isin120593
max120572isinR119899
minus120572T (119870120583 + 120582I) 120572 + 2120572Ty (19)
where 120593 is a positive bounded and convex set Two boundedsets 1198971-norm and 1198972-norm are the appropriate choices toconstruct 120593
1205931 = 120583 | 120583 ge 0 1003817100381710038171003817120583 minus 120583010038171003817100381710038171 le and 1205932 = 120583 | 120583 ge 0 1003817100381710038171003817120583 minus 120583010038171003817100381710038172 le and (20)
Here 1205830 and and are model parameters and 1205830 is generallyequal to 0 or 12058301205830 = 1
Other than approaches described above inspired bythe consistency between group Lasso and MKL [26] Xuet al [23] and Kloft et al [24] propose an MKL iterativemethod in a generalized 119897119901-norm (119901 ge 1) form They arecollectively called Arbitrary Norms Multiple Kernel Learn-ing (ANMKL) method On the basis of duality conditionw11989822 = 1205832119898sum119899119894=1sum119899119895=1 119910119894119910119895120572119894120572119895119870119898(x119898119894 x119898119895 ) the updatedformula of kernels weight is
120583119898 =1003817100381710038171003817w11989810038171003817100381710038172(119901+1)2
(sum119872ℎ=1 1003817100381710038171003817wℎ10038171003817100381710038172119901(119901+1)2 )1119901 forall119898 (21)
It can be seen from the formulas in this section that theoperation complexity of MKL is mainly decided by x119894 Sotrying to simplify the feature space is an efficient way toimprove the performance of MKLThrough the optimizationof basis vectors LRR can reduce dimension while retainingthe data features which is ideal for improving MKL
4 MKL Using Low-Rank Representation
41 Low-Rank Representation (LRR) The theoreticaladvances on LRR enable us to use latent low-rank structure
in data [27 28] And it simultaneously obtains therepresentation of all samples under a global low-rankconstraint Meantime the LRR procedure can operate in arelatively short time with guaranteed performance
Let the input samples space X be represented by a linearcombination in the dictionary A
X = AZ (22)
where Z = [z1 z2 z119899] is the coefficient matrix and each z119894is a representation coefficient vector of x119894 When the samplesare sufficient X serves as the dictionary A By consideringthe noise or tainted data in practical application LRR aims atapproximatingX intoAZ+E by themeans of minimizing therank of matrix A while reducing the 1198970-norm of E in whichA is a low-rank matrix and E is the associated sparse error Itcan be generally formulated as
minZE
rank (A) + 120582 E0 st X = AZ + E (23)
Here 120582 is used to balance the effect of low-rank and errorterm 1198970-norm as NP-hard problem can be substituted for1198971-norm or 11989721-norm We choose 11989721-norm as the errorterm measurement here which is defined as E21 =sum119899119895=1radicsum119899119895=1([E]119894119895)2 Meantime rank(A) can relax intonuclear-norm sdot lowast [29] Consequently the convex relaxationof formula (23) is
minZE
Zlowast + 120582 E21 st X = AZ + E (24)
The optimal solution Zlowast can be obtained via the AugmentedLagrange Multipliers (ALM) method [11]
42 Efficient SVM and MKL Using LRR Kernel matrixremarkably impacts the computational efficiency and accu-racy of SVM andMKL How to find an appropriate variant ofkernel matrix that contains both the initial label and the datageometry structure for recognition is a crucial task Since LRRhas been theoretically proved to be superior in the sequelwe adopt LRR to transform the kernel for augmenting thesimilarities among the intraclass samples and the differencesamong the interclass samples Moreover a representationof all samples under a global low-rank constraint can beattained which is more conducive to capturing the globaldata structure [30] So LR-SVM and LR-MKL are twoalternative techniques that we propose to use to improve theperformance of SVM and MKL
Firstly based on the LRR theory we improve the monok-ernel SVM as the reference item from which the improve-ment brought by LRR can be displayed visually The specificprocedure of efficient LR-SVM is presented in Algorithm 1
Algorithm 1 (efficient SVM using LRR (LR-SVM))
Input This includes the whole training set XY the featurespace of testing setX119878 = [x119899+1 x119899+2 x119899+119904] the parameters119905 120574 119862 119902 of SVM and the parameter 120582 of LRR
Computational Intelligence and Neuroscience 5
Step 1 Normalize XX119878Step 2 Perform (24) procedure on the normalized XX119878 toproject them on the coefficient feature space ZZ119878 respec-tively
Step 3 Plug Z and the label vector Y into SVM for trainingclassification model
Step 4 Utilize the obtained classificationmodel to classify thecoefficient feature Z119878 of testing set X119878 and the discriminantfunction is 119891(z) = sum119899119894=1 120572lowast119894 119910119894119870(z119894 z) + 119887Output Compare the actual label vector of test set Y119878 and theprediction label vector Y119875 to obtain the recognition results
It is well known that SVM suffers from instability forthe various data structures Thus MKL recognition becomesthe development trend Next we combine LRR and MKLalgorithms mentioned in the Section 3 and change binary-classification model into multiclassification model by pair-wise (one-versus-one) strategy through which a classifierbetween any two categories of samples (119896 is the number ofcategories) can be designed Then we adopt voting methodand assign sample to the category the most votes obtainedAll the combined algorithms can be summarized into a framewhich is given in Algorithm 2 and we refer to it collectively asLR-MKL
Algorithm 2 (efficient MKL using LRR (LR-MKL))
Input This includes the whole training set XY the featurespace of testing set X119878 = [x119899+1 x119899+2 x119899+119904] and theparameter 120582 of LRR
Step 1simStep 2 They are the same as the LR-SVM algorithm
Step 3 Plug Z and the label vector Y into MKL to train 119896(119896 minus1)2 classifiers with the pairwise strategy
Step 4 Utilize each one of the binary MKL classifiers toclassify the coefficient feature Z119878 of testing set X119878
Step 5 According to the prediction label vectorsY1198751 Y1198752 Y119875119896(119896minus1)2 vote for the category of each sample toget the multilabels Y119875
Output Compare the actual label vector of test set Y119878 and theprediction label vector Y119875 to obtain the recognition resultsand the kernel weight vector 1205835 Experiments and Analysis
In this section we conduct extensive experiments to examinethe efficiency of proposed LR-SVM and LR-MKL algorithmsThe operating environment is based on MATLAB (R2013a)under the Intel Core i5 CPU processor 253GHz frequencyparameters The SVM toolbox used in this paper is theLIBSVM [31] which can be easily applied and is shown to befast in large scale databases
The simulations are performed on diverse datasets toensure the universal recognition effectThe test datasets range
over the frequently used face databases and the standard testdata of UCI repository In the simulations all the samples arenormalized first
(1) Yale face database (httpvisionucsdeducontentyale-face-database) it contains 165 grayscale imagesof 15 individuals with different facial expression orconfiguration and each image is resized to 64 lowast 64pixels with 256 grey levels
(2) ORL face database (httpwwwclcamacukresearchdtgattarchivefacedatabasehtm) it contains 400images of 40 distinct subjects taken at different timesvarying light facial expressions and details Weresize them to 64 lowast 64 pixels with 256 grey levels perpixel
(3) LSVT Voice Rehabilitation dataset (httparchiveicsuciedumldatasetsLSVT+Voice+Rehabilitation)[32] it is composed of 126 speech signals from 14people with 309 features divided into two categories
(4) Multiple Features Digit dataset (httparchiveicsuciedumldatasetsMultiple+Features) it includes 2000digitized handwritten numerals 0ndash9 with 649 fea-tures
51 Experiments on LR-SVM In order to demonstrate therecognition performance of SVM improved by the presentedLR-SVM we carry out numerous experiments on the Yaleand ORL face database According to the different rate oftraining sample (20 30 40 50 60 70 and 80)we implement seven groups of experiments on each databaseTo ensure stable and reliable test each group has ten differentdivisions randomly and we average them as the final resultsThe kernel functions are 119870LIN 119870POL 119870RBF 119870SIG (119902 = 3) and120574 = 1119892 (119892 is the dimension of feature space)
The classification accuracy and run time of Yale databaseby using SVM and LR-SVM are shown in Figures 1 and 2respectively Similarly the classification accuracy and runtime of ORL database are shown in Figures 3 and 4The solidlines depict the result of SVM with different kernels whilethe patterned lines with the corresponding colour depictthat of LR-SVM As can be seen from the Figures 1 and3 the proposed LR-SVM method consistently achieves anobvious improvement in classification accuracy compared tothe original SVM method In most cases the classificationaccuracy increases with the rise in training sample rate It isshown that the more complete the training set the better theclassification accuracy But it is impossible for the trainingset to include so many samples in reality LR-MKL has ahigh accuracy even under the low training sample rate whichis suitable for the real applications Meanwhile Figures 2and 4 show that through LRR conversion the run timecan be reduced more than an order of magnitude which isreasonable for the real-time requirements of data processingin the big data era
52 Experiments on LR-MKL In this section we compare theperformance of the MKL algorithms involved in Section 3
6 Computational Intelligence and Neuroscience
45
50
55
60
65
70
75
80
85Ac
cura
cy (
)
30 40 50 60 70 8020Training sample rate ()
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 1 Classification accuracy of Yale by using SVM and LR-SVM
6040 50 70 803020Training sample rate ()
0
005
01
015
02
025
03
035
04
045
05
Run
time (
s)
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 2 Run time of Yale by using SVM and LR-SVM
and their corresponding LR-MKL algorithms The multik-ernel is composed of 119870LIN 119870POL 119870RBF 119870SIG (119902 = 3) Theproportion parameter vector of kernel is 120583 = [1205831 1205832 1205833 1205834]The comparative algorithms are listed below
(i) Unweighted MKL (UMKL) [16] and LR-UMKL (+)indicates sum form and (lowast) indicates product form
(ii) Alternative MKL (AMKL) [17] and LR-AMKL(iii) Generalized MKL (GMKL) [18] and LR-GMKL(iv) Localized MKL (LMKL) [19] and LR-LMKL (sof)
distribute 120583 into softmax mode and (sig) distribute120583 into sigmoid mode
30 40 50 60 70 8020Training sample rate ()
65
70
75
80
85
90
Accu
racy
()
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 3 Classification accuracy of ORL by using SVM and LR-SVM
0
05
1
15
2
25
3
Run
time (
s)
30 40 50 60 70 8020Training sample rate ()
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 4 Run time of ORL by using SVM and LR-SVM
(v) Heuristic MKL (HMKL) [20] and LR-HMKL(vi) Centering MKL (CMKL) [21] and LR-CMKL(vii) Polynomial MKL (PMKL) [22] and LR-PMKL (1)
adopts the bounded set 1205931 with 1198971-norm and (2)adopts the bounded set 1205932 with 1198972-norm
(viii) Arbitrary Norm MKL (ANMKL) [23 24] and LR-ANMKL (1) iterates 120583 with 1198971-norm and (2) iterates120583 with 1198972-norm
(ix) Besides the highest accuracy among the four monok-ernel SVM selected as the reference item which isreferred to as SVM(best)
Computational Intelligence and Neuroscience 7
Table1Th
eperform
anceso
fMKL
algorithm
sand
LR-M
KLalgorithm
sonthed
atasetsY
aleORL
LSV
TandDigit
Yale
ORL
LSVT
Digit
Acc
Time
Acc
Time
Acc
Time
Acc
Time
SVM(best)
6932
3102981
800002
16798
7619
0500142
959302
09195
LR-SVM(best)
79866
700109
870015
01575
776637
000
4396
330
4009
72UMKL
(+)[16]
875114
25981
93579
8182352
785714
00229
9735
7147412
LR-U
MKL
(+)
95893
6030
18834813
10817
738095
00152
9815
9520278
UMKL
(lowast)[16]
583248
27244
775022
205507
666935
00281
960904
71661
LR-U
MKL
(lowast)935739
026
3693406
321836
670033
00176
984618
363
92AMKL
[17]
857753
37236
938741
46854
809524
00452
974725
112138
LR-AMKL
94379
9038
6996
9417
045
9288
0952
000
8598
6952
688
04GMKL
[18]
862989
45330
962057
50070
857143
00565
9914
9980774
LR-G
MKL
958015
062
5398
5833
07761
88928
600183
99467
3459
72LM
KL(sof)[19]
879077
21540
55970003
2203122
850090
51989
99889
81667978
LR-LMKL
(sof)
979352
22720
498
9724
17379
186
742
911933
983591
9818
12LM
KL(sig)[19]
880145
1067552
970108
1070
911
887541
07238
9937
50485914
LR-LMKL
(sig)
98066
7159711
97997
911724
092
662
7045
9499
562
524
592
7HMKL
[20]
636037
924410
935109
1182340
805998
00915
976258
1035
59LR
-HMKL
919611
859
7298
689
310936
88516
2500352
98347
963959
CMKL
[21]
864166
950618
960308
1076
940
799503
00874
965014
106074
LR-C
MKL
94008
310638
098
479
9129746
939024
003
4798
9113
626
96PM
KL(1)[
22]
890035
61842
984901
69065
928571
01079
995881
248702
LR-PMKL
(1)99
1429
090
5399
5712
098
2895
938
6005
7310000
00129831
PMKL
(2)[22]
890261
53893
987533
65450
924662
01295
99504
62116
79LR
-PMKL
(2)98
896
8084
9499
582
8089
1195
5145
006
5199
794
1135108
ANMKL
(1)[2324]
867210
64856
984396
204564
919827
01167
980007
1039
79LR
-ANMKL
(1)96
866
7070
4199
464
328519
92224
700247
992850
690
70ANMKL
(2)[2324]
866998
7066
4982204
2116
15930035
0119
4980039
97753
LR-ANMKL
(2)972917
088
6399
2857
305
979253
91002
2499
249
750374
8 Computational Intelligence and Neuroscience
We conduct experiments on the test datasets YaleORL LSVTVoice Rehabilitation (LSVT for short) andMultiple FeaturesDigit (Digit for short)The 60 samples of dataset are drawnout randomly to train classification model and the remainingsamples serve as the test set Through the optimized resultsof 120574 and penalty factor 119862 by grid search method we findthat the classification accuracy varies not too much with 120574and 119862 ranging in a certain interval So there is no need tosearch the whole parameter space which inevitably increasesthe computational costThe penalty factor119862 can be given thattrying values 001 01 1 10 100 and 120574 are fixed on 1119892 Thenwe assign a value which has the highest average accuracyon the 5 lowast 2 cross validation sets to 119862 Each algorithm isconducted with 10 independent runs and we average them asthe final results The bold numbers represent the preferablerecognition effect between the original algorithms and theirLRR combined algorithmsThe numbers in italic font denotethe algorithms whose recognition precision is inferior tothe SVM(best) The recognition performance of algorithmsis measured by the classification accuracy and run timeillustrated by Table 1
In most cases our proposed LR-MKL methods consis-tently achieve superior results to the original MKL whichverifies the higher classification accuracy and shorter opera-tion time It is indicated that LRR can augment the similaritiesamong the intraclass samples and the differences among theinterclass samples while simplifying the kernel matrix Notethat UMKL(lowast) fails to achieve the ideal recognition effectsin many cases even less accurate than SVM(best) Howevercombiningwith LRR improves its effects to a large extentThisillustrates that simply combining kernels without accordingdata structure is infeasible and LRR can offset part of theconsequences of irrational distribution In general PMKLANMKL and their improved algorithms have the preferablerecognition effects especially the improved algorithms withthe accuracy over 90 percent all the time In terms of runtime it is clearly observed that the real-time performance ofMKL is much worse than SVM because MKL has a processof allocating kernel weights and the process can be very timeconsuming Among them LMKL is the worst and fails tosatisfy the real-time requirement Obviously our combinedLR-MKL can reduce the run time manifold even more thanone order of magnitude so it can speed high-precision MKLup to satisfy the real-time requirement In brief the proposedLR-MKL can boost the performance ofMKL to a great extent
6 Conclusion
The complexity of solving convex quadratic optimizationproblem in MKL is 119874(11987311989935) so it is infeasible to apply inlarge scale problems for its large computational cost Oureffort has beenmade on decreasing the dimension of trainingset Note that LRR just can capture the global structure ofdata in relatively few dimensions Therefore we have givena review of several existing MKL algorithms Based on thispoint we have proposed a novel combined LR-MKL whichlargely improves the performance ofMKL A large number ofexperiments have been carried on four real world datasets tocontrast the recognition effects of various kinds of MKL and
LR-MKL algorithms It has been shown that in most casesthe recognition effects of MKL algorithms are better thanSVM(best) except UMKL(lowast) And our proposed LR-MKLmethods have consistently achieved the superior results tothe original MKL Among them PMKL ANMKL and theirimproved algorithms have shown possessing the preferablerecognition effects
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
This work was supported by the National Natural ScienceFoundation of China (no 51208168) Hebei Province NaturalScience Foundation (no E2016202341) and Tianjin NaturalScience Foundation (no 13JCYBJC37700)
References
[1] V N Vapnik ldquoAn overview of statistical learning theoryrdquo IEEETransactions on Neural Networks vol 10 no 5 pp 988ndash9991999
[2] M Hu Y Chen and J T-Y Kwok ldquoBuilding sparse multiple-kernel SVM classifiersrdquo IEEE Transactions on Neural Networksvol 20 no 5 pp 827ndash839 2009
[3] X Wang X Liu N Japkowicz and S Matwin ldquoEnsemble ofmultiple kernel SVM classifiersrdquo Advances in Artificial Intelli-gence vol 8436 pp 239ndash250 2014
[4] E Hassan S Chaudhury N Yadav P Kalra and M GopalldquoOff-line handwritten input based identity determination usingmulti kernel feature combinationrdquo Pattern Recognition Lettersvol 35 no 1 pp 113ndash119 2014
[5] F Cai and V Cherkassky ldquoGeneralized SMO algorithm forSVM-based multitask learningrdquo IEEE Transactions on NeuralNetworks and Learning Systems vol 23 no 6 pp 997ndash10032012
[6] K Crammer O Dekel J Keshet S Shalev-Shwartz andY Singer ldquoOnline passive-aggressive algorithmsrdquo Journal ofMachine Learning Research vol 7 pp 551ndash585 2006
[7] N Cesa-Bianchi A Conconi and C Gentile ldquoOn the gen-eralization ability of on-line learning algorithmsrdquo Institute ofElectrical and Electronics Engineers Transactions on InformationTheory vol 50 no 9 pp 2050ndash2057 2004
[8] S Fine and K Scheinberg ldquoEfficient SVM training usinglow-rank kernel representationsrdquo Journal of Machine LearningResearch vol 2 no 2 pp 243ndash264 2002
[9] S Zhou ldquoSparse LSSVM in primal using cholesky factorizationfor large-scale problemsrdquo IEEETransactions onNeuralNetworksand Learning Systems vol 27 no 4 pp 783ndash795 2016
[10] L Jia S-Z Liao and L-Z Ding ldquoLearning with uncertainkernel matrix setrdquo Journal of Computer Science and Technologyvol 25 no 4 pp 709ndash727 2010
[11] G Liu Z Lin S Yan J Sun Y Yu and Y Ma ldquoRobust recov-ery of subspace structures by low-rank representationrdquo IEEETransactions on Pattern Analysis and Machine Intelligence vol35 no 1 pp 171ndash184 2013
[12] Y Peng A Ganesh J Wright W Xu and Y Ma ldquoRASL robustalignment by sparse and low-rank decomposition for linearly
Computational Intelligence and Neuroscience 9
correlated imagesrdquo IEEE Transactions on Pattern Analysis andMachine Intelligence vol 34 no 11 pp 2233ndash2246 2012
[13] B Cheng G Liu J Wang Z Huang and S Yan ldquoMulti-tasklow-rank affinity pursuit for image segmentationrdquo in Proceed-ings of the IEEE International Conference on Computer Vision(ICCV rsquo11) pp 2439ndash2446 IEEE Barcelona Spain November2011
[14] YMu JDongX Yuan and S Yan ldquoAccelerated low-rank visualrecovery by random projectionrdquo in Proceedings of the 2011 IEEEConference on Computer Vision and Pattern Recognition CVPR2011 pp 2609ndash2616 Colorado Springs Colo USA June 2011
[15] J Chen J Zhou and J Ye ldquoIntegrating low-rank and group-sparse structures for robust multi-task learningrdquo in Proceedingsof the 17th ACM SIGKDD International Conference on Knowl-edge Discovery and Data Mining KDDrsquo11 pp 42ndash50 San DiegoCalif USA August 2011
[16] P Pavlidis J Cai JWeston andWNGrundy ldquoGene functionalclassification fromheterogeneous datardquo inProceedings of the 5thAnnual Internatinal Conference on Computational Biology pp249ndash255 Montreal Canada May 2001
[17] O Chapelle and A Rakotomamonjy ldquoSecond order optimiza-tion of kernel parametersrdquo Nips Workshop on Kernel Learning2008
[18] M Varma and B R Babu ldquoMore generality in efficient mul-tiple kernel learningrdquo in Proceedings of the 26th InternationalConference On Machine Learning ICML 2009 pp 1065ndash1072Montreal Canada June 2009
[19] M Gonen and E Alpaydin ldquoLocalized multiple kernel learn-ingrdquo in Proceedings of the the 25th international conference pp352ndash359 Helsinki Finland July 2008
[20] S Qiu and T Lane ldquoA framework for multiple kernel supportvector regression and its applications to siRNA efficacy predic-tionrdquo IEEEACM Transactions on Computational Biology andBioinformatics vol 6 no 2 pp 190ndash199 2009
[21] CCortesMMohri andARostamizadeh ldquoTwo-stage learningkernel algorithmsrdquo in Proceedings of the 27th InternationalConference on Machine Learning ICML 2010 pp 239ndash246Haifa Israel June 2010
[22] C Cortes M Mohri and A Rostamizadeh ldquoLearning non-linear combinations of kernelsrdquo in Proceedings of the 23rdAnnual Conference on Neural Information Processing Systems(NIPS rsquo09) pp 396ndash404 December 2009
[23] Z Xu R Jin H Yang I King and M R Lyu ldquoSimple andefficient multiple kernel learning by group lassordquo in Proceedingsof the 27th International Conference onMachine Learning ICML2010 pp 1175ndash1182 Haifa Israel June 2010
[24] M Kloft U Brefeld S Sonnenburg and A Zien ldquoNon-sparseregularization and efficient training with multiple kernelsArxiv Preprint abs1003rdquo httpsarxivorgabs10030079
[25] M Gonen and E Alpaydın ldquoMultiple kernel learning algo-rithmsrdquo Journal of Machine Learning Research vol 12 pp 2211ndash2268 2011
[26] F R Bach ldquoConsistency of the group lasso and multiple kernellearningrdquo Journal ofMachine Learning Research vol 9 no 2 pp1179ndash1225 2008
[27] E J Candes X Li Y Ma and JWright ldquoRobust principal com-ponent analysisrdquo Journal of the ACM vol 58 no 3 2011
[28] C-F Chen C-P Wei and Y-C F Wang ldquoLow-rank matrixrecovery with structural incoherence for robust face recogni-tionrdquo in Proceedings of the 2012 IEEE Conference on ComputerVision and Pattern Recognition CVPR 2012 pp 2618ndash2625Providence RI USA June 2012
[29] J-F Cai E J Candes and Z Shen ldquoA singular value thresh-olding algorithm for matrix completionrdquo SIAM Journal onOptimization vol 20 no 4 pp 1956ndash1982 2010
[30] L Zhuang H Gao Z Lin Y Ma X Zhang and N Yu ldquoNon-negative low rank and sparse graph for semi-supervised learn-ingrdquo in Proceedings of the 2012 IEEE Conference on ComputerVision and Pattern Recognition CVPR 2012 pp 2328ndash2335 usaJune 2012
[31] C Chang and C Lin ldquoLIBSVM a Library for support vectormachinesrdquo ACM Transactions on Intelligent Systems and Tech-nology vol 2 no 3 article 27 2011
[32] A Tsanas M A Little C Fox and L O Ramig ldquoObjectiveautomatic assessment of rehabilitative speech treatment inparkinsonrsquos diseaserdquo IEEE Transactions on Neural Systems andRehabilitation Engineering vol 22 no 1 pp 181ndash190 2014
Submit your manuscripts athttpswwwhindawicom
Computer Games Technology
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
Advances in
FuzzySystems
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014
International Journal of
ReconfigurableComputing
Hindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
Applied Computational Intelligence and Soft Computing
thinspAdvancesthinspinthinsp
Artificial Intelligence
HindawithinspPublishingthinspCorporationhttpwwwhindawicom Volumethinsp2014
Advances inSoftware EngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporation
httpwwwhindawicom Volume 2014
Advances in
Multimedia
International Journal of
Biomedical Imaging
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational Intelligence and Neuroscience
Industrial EngineeringJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Human-ComputerInteraction
Advances in
Computer EngineeringAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014

Computational Intelligence and Neuroscience 3
where 119870119898 is the monokernel function The multiple kernel119870120583 can be obtained by function 119891120583 R119863 rarr R119875 combining119872 different119870119898 And 120583 is the proportion parameter of kernelThere are many different methods to assign kernel weights
Pavlidis et al [16] propose a simple combination modeusing an unweighted sum or product of heterogeneouskernelsThe combining function of this UnweightedMultipleKernel Learning (UMKL) method is
119870120583 (x119894 x119895) = 119872sum119898=1
119870119898 (x119894 x119895)
119870120583 (x119894 x119895) = 119872prod119898=1
119870119898 (x119894 x119895) (7)
In a follow-up study the distribution of 120583 in MKL becomesa vital limiting factor of availability Chapelle and Rako-tomamonjy [17] report that the optimization problem canbe solved by a project gradient method in two alternativesteps first solving a primal SVM with the given 120583 secondupdating 120583 through the gradient function with 120572 calculatedin the first step The kernel combining function objectivefunction and gradient function of this Alternative MultipleKernel Learning (AMKL) method are
119870120583 (x119894 x119895) = 119872sum119898=1
120583119898119870119898 (x119894 x119895)
119869 (120583) = 12119899sum119894=1
119899sum119895=1
119910119894119910119895120572119894120572119895( 119872sum119898=1
120583119898119870119898 (x119894 x119895))
minus 119899sum119894=1
120572119894120597119869 (120583)120597120583119898 = 12
119899sum119894=1
119899sum119895=1
119910119894119910119895120572119894120572119895119870120583 (x119894 x119895)120597120583119898= 12119899sum119894=1
119899sum119895=1
119910119894119910119895120572119894120572119895119870119898 (x119894 x119895) forall119898
(8)
The Generalized Multiple Kernel Learning (GMKL) method[18] also employs the gradient tool to approach solution but itregards kernel weights as a regularization item 119903(120583) which istaken as (12)(120583minus1119872)T(120583minus1119872) So the objective functionand gradient function can be transformed into
119869 (120583) = 12119899sum119894=1
119899sum119895=1
119910119894119910119895120572119894120572119895119870120583 (x119894 x119895) minus 119899sum119894=1
120572119894 minus 119903 (120583) 120597119869 (120583)120597120583119898 = 12
119899sum119894=1
119899sum119895=1
119910119894119910119895120572119894120572119895 120597119870120583 (x119894 x119895)120597120583119898 minus 120597119903 (120583)120597120583119898 forall119898
(9)
And the kernel combined function is
119870120583 (x119894 x119895) = 119872prod119898=1
exp (minus120583119898 (x119898119894 minus x119898119895 )2)
= exp( 119872sum119898=1
minus120583119898 (x119898119894 minus x119898119895 )2) (10)
There is another two-step alternate method using a gatingmodel called Localized Multiple Kernel Learning (LMKL)method [19] The formula of locally combined kernel isrepresented as
119870120583 (x119894 x119895) = 119872sum119898=1
120583119898 (x119894) ⟨Φ119898 (x119894) Φ119898 (x119895)⟩ 120583119898 (x119895) (11)
where Φ(x) is the mapping space of feature space To ensurenonnegativity kernels can be composed in competitive orcooperative mode by using softmax form and sigmoid form[25] respectively
softmax 120583119898 = exp (⟨k119898 x⟩ + V1198980)sum119872ℎ=1 exp (⟨kℎ x⟩ + Vℎ0) forall119898sigmoid 120583119898 = 1
exp (minus ⟨k119898 x⟩ + V1198980) forall119898(12)
where V = k119898 V1198980119872119898=1 denotes the parameter of gatingmodel On the other hand Qiu and Lane [20] quantify thefitness between kernel and accuracy in a Heuristic MultipleKernel Learning (HMKL) way by exploiting the relationshipbetween kernel matrixK and sample label y The relationshipcan be expressed by kernel alignment
119865 (K yyT) = ⟨K yyT⟩119865
radic⟨KK⟩119865 ⟨yyT yyT⟩119865= ⟨K yyT⟩
119865119899radic⟨KK⟩119865 (13)
where ⟨K yyT⟩119865 = sum119899119894=1sum119899119895=1119870(x119894 x119895)119910119894119895119910T119894119895 ⟨sdot sdot⟩119865 is the
Frobenius inner product Using kernel alignment weighs theproportion of multikernels
120583119898 = 119865 (119870119898 yyT)sum119872ℎ=1 119865 (119870ℎ yyT) forall119898 (14)
Then the concentration bound is added in kernel alignmentby Cortes et al [21] to form centering kernel
[119870119888]119894119895 = 119870119894119895 minus 1119899119899sum119894=1
119870119894119895 minus 1119899119899sum119895=1
119870119894119895 + 11198992119899sum119894119895=1
119870119894119895 (15)
Accordingly the multikernel weights of this Centering Mul-tiple Kernel Learning (CMKL) method are
120583 = Cminus1a1003817100381710038171003817Cminus1a10038171003817100381710038172 (16)
where C = ⟨119870119888119898 119870119888ℎ⟩119865119872119898ℎ=1 and a = ⟨119870119888119898 yyT⟩119865119872119898=1
4 Computational Intelligence and Neuroscience
Later Cortes et al [22] studied a Polynomial MultipleKernel Learning (PMKL) method which utilized the poly-nomial combination of the base kernels with higher degree(119889 ge 1) based on the Kernel Ridge Regression (KRR) theory
119870120583 (x119894 x119895) = sum12058311989611198962 sdotsdotsdot1198961198721198701 (x1119894 x1119895)1198961sdot 1198702 (x2119894 x2119895)1198962 sdot sdot sdot 119870119872 (x119872119894 x119872119895 )119896119872
119896119898 ge 0 sum (1198961 + 1198962 + sdot sdot sdot + 119896119872) le 119889 12058311989611198962 sdotsdotsdot119896119872 ge 0(17)
However the computing complex of coefficients 12058311989611198962 sdotsdotsdot119896119872 is119874(119872119889) which is too large to apply in practice So12058311989611198962 sdotsdotsdot119896119872 canbe simplified as a product form by nonnegative coefficients12058311989611 12058311989622 sdot sdot sdot 120583119896119872119872 and the special case (119889 = 2) can be expressedas
119870120583 (x119894 x119895) = 119872sum119898=1
119872sumℎ=1
120583119898120583ℎ119870119898 (x119898119894 x119898119895 )119870ℎ (xℎ119894 xℎ119895) (18)
Here the related optimization of learning 119870120583 can be formu-lated as the following min-max form
min120583isin120593
max120572isinR119899
minus120572T (119870120583 + 120582I) 120572 + 2120572Ty (19)
where 120593 is a positive bounded and convex set Two boundedsets 1198971-norm and 1198972-norm are the appropriate choices toconstruct 120593
1205931 = 120583 | 120583 ge 0 1003817100381710038171003817120583 minus 120583010038171003817100381710038171 le and 1205932 = 120583 | 120583 ge 0 1003817100381710038171003817120583 minus 120583010038171003817100381710038172 le and (20)
Here 1205830 and and are model parameters and 1205830 is generallyequal to 0 or 12058301205830 = 1
Other than approaches described above inspired bythe consistency between group Lasso and MKL [26] Xuet al [23] and Kloft et al [24] propose an MKL iterativemethod in a generalized 119897119901-norm (119901 ge 1) form They arecollectively called Arbitrary Norms Multiple Kernel Learn-ing (ANMKL) method On the basis of duality conditionw11989822 = 1205832119898sum119899119894=1sum119899119895=1 119910119894119910119895120572119894120572119895119870119898(x119898119894 x119898119895 ) the updatedformula of kernels weight is
120583119898 =1003817100381710038171003817w11989810038171003817100381710038172(119901+1)2
(sum119872ℎ=1 1003817100381710038171003817wℎ10038171003817100381710038172119901(119901+1)2 )1119901 forall119898 (21)
It can be seen from the formulas in this section that theoperation complexity of MKL is mainly decided by x119894 Sotrying to simplify the feature space is an efficient way toimprove the performance of MKLThrough the optimizationof basis vectors LRR can reduce dimension while retainingthe data features which is ideal for improving MKL
4 MKL Using Low-Rank Representation
41 Low-Rank Representation (LRR) The theoreticaladvances on LRR enable us to use latent low-rank structure
in data [27 28] And it simultaneously obtains therepresentation of all samples under a global low-rankconstraint Meantime the LRR procedure can operate in arelatively short time with guaranteed performance
Let the input samples space X be represented by a linearcombination in the dictionary A
X = AZ (22)
where Z = [z1 z2 z119899] is the coefficient matrix and each z119894is a representation coefficient vector of x119894 When the samplesare sufficient X serves as the dictionary A By consideringthe noise or tainted data in practical application LRR aims atapproximatingX intoAZ+E by themeans of minimizing therank of matrix A while reducing the 1198970-norm of E in whichA is a low-rank matrix and E is the associated sparse error Itcan be generally formulated as
minZE
rank (A) + 120582 E0 st X = AZ + E (23)
Here 120582 is used to balance the effect of low-rank and errorterm 1198970-norm as NP-hard problem can be substituted for1198971-norm or 11989721-norm We choose 11989721-norm as the errorterm measurement here which is defined as E21 =sum119899119895=1radicsum119899119895=1([E]119894119895)2 Meantime rank(A) can relax intonuclear-norm sdot lowast [29] Consequently the convex relaxationof formula (23) is
minZE
Zlowast + 120582 E21 st X = AZ + E (24)
The optimal solution Zlowast can be obtained via the AugmentedLagrange Multipliers (ALM) method [11]
42 Efficient SVM and MKL Using LRR Kernel matrixremarkably impacts the computational efficiency and accu-racy of SVM andMKL How to find an appropriate variant ofkernel matrix that contains both the initial label and the datageometry structure for recognition is a crucial task Since LRRhas been theoretically proved to be superior in the sequelwe adopt LRR to transform the kernel for augmenting thesimilarities among the intraclass samples and the differencesamong the interclass samples Moreover a representationof all samples under a global low-rank constraint can beattained which is more conducive to capturing the globaldata structure [30] So LR-SVM and LR-MKL are twoalternative techniques that we propose to use to improve theperformance of SVM and MKL
Firstly based on the LRR theory we improve the monok-ernel SVM as the reference item from which the improve-ment brought by LRR can be displayed visually The specificprocedure of efficient LR-SVM is presented in Algorithm 1
Algorithm 1 (efficient SVM using LRR (LR-SVM))
Input This includes the whole training set XY the featurespace of testing setX119878 = [x119899+1 x119899+2 x119899+119904] the parameters119905 120574 119862 119902 of SVM and the parameter 120582 of LRR
Computational Intelligence and Neuroscience 5
Step 1 Normalize XX119878Step 2 Perform (24) procedure on the normalized XX119878 toproject them on the coefficient feature space ZZ119878 respec-tively
Step 3 Plug Z and the label vector Y into SVM for trainingclassification model
Step 4 Utilize the obtained classificationmodel to classify thecoefficient feature Z119878 of testing set X119878 and the discriminantfunction is 119891(z) = sum119899119894=1 120572lowast119894 119910119894119870(z119894 z) + 119887Output Compare the actual label vector of test set Y119878 and theprediction label vector Y119875 to obtain the recognition results
It is well known that SVM suffers from instability forthe various data structures Thus MKL recognition becomesthe development trend Next we combine LRR and MKLalgorithms mentioned in the Section 3 and change binary-classification model into multiclassification model by pair-wise (one-versus-one) strategy through which a classifierbetween any two categories of samples (119896 is the number ofcategories) can be designed Then we adopt voting methodand assign sample to the category the most votes obtainedAll the combined algorithms can be summarized into a framewhich is given in Algorithm 2 and we refer to it collectively asLR-MKL
Algorithm 2 (efficient MKL using LRR (LR-MKL))
Input This includes the whole training set XY the featurespace of testing set X119878 = [x119899+1 x119899+2 x119899+119904] and theparameter 120582 of LRR
Step 1simStep 2 They are the same as the LR-SVM algorithm
Step 3 Plug Z and the label vector Y into MKL to train 119896(119896 minus1)2 classifiers with the pairwise strategy
Step 4 Utilize each one of the binary MKL classifiers toclassify the coefficient feature Z119878 of testing set X119878
Step 5 According to the prediction label vectorsY1198751 Y1198752 Y119875119896(119896minus1)2 vote for the category of each sample toget the multilabels Y119875
Output Compare the actual label vector of test set Y119878 and theprediction label vector Y119875 to obtain the recognition resultsand the kernel weight vector 1205835 Experiments and Analysis
In this section we conduct extensive experiments to examinethe efficiency of proposed LR-SVM and LR-MKL algorithmsThe operating environment is based on MATLAB (R2013a)under the Intel Core i5 CPU processor 253GHz frequencyparameters The SVM toolbox used in this paper is theLIBSVM [31] which can be easily applied and is shown to befast in large scale databases
The simulations are performed on diverse datasets toensure the universal recognition effectThe test datasets range
over the frequently used face databases and the standard testdata of UCI repository In the simulations all the samples arenormalized first
(1) Yale face database (httpvisionucsdeducontentyale-face-database) it contains 165 grayscale imagesof 15 individuals with different facial expression orconfiguration and each image is resized to 64 lowast 64pixels with 256 grey levels
(2) ORL face database (httpwwwclcamacukresearchdtgattarchivefacedatabasehtm) it contains 400images of 40 distinct subjects taken at different timesvarying light facial expressions and details Weresize them to 64 lowast 64 pixels with 256 grey levels perpixel
(3) LSVT Voice Rehabilitation dataset (httparchiveicsuciedumldatasetsLSVT+Voice+Rehabilitation)[32] it is composed of 126 speech signals from 14people with 309 features divided into two categories
(4) Multiple Features Digit dataset (httparchiveicsuciedumldatasetsMultiple+Features) it includes 2000digitized handwritten numerals 0ndash9 with 649 fea-tures
51 Experiments on LR-SVM In order to demonstrate therecognition performance of SVM improved by the presentedLR-SVM we carry out numerous experiments on the Yaleand ORL face database According to the different rate oftraining sample (20 30 40 50 60 70 and 80)we implement seven groups of experiments on each databaseTo ensure stable and reliable test each group has ten differentdivisions randomly and we average them as the final resultsThe kernel functions are 119870LIN 119870POL 119870RBF 119870SIG (119902 = 3) and120574 = 1119892 (119892 is the dimension of feature space)
The classification accuracy and run time of Yale databaseby using SVM and LR-SVM are shown in Figures 1 and 2respectively Similarly the classification accuracy and runtime of ORL database are shown in Figures 3 and 4The solidlines depict the result of SVM with different kernels whilethe patterned lines with the corresponding colour depictthat of LR-SVM As can be seen from the Figures 1 and3 the proposed LR-SVM method consistently achieves anobvious improvement in classification accuracy compared tothe original SVM method In most cases the classificationaccuracy increases with the rise in training sample rate It isshown that the more complete the training set the better theclassification accuracy But it is impossible for the trainingset to include so many samples in reality LR-MKL has ahigh accuracy even under the low training sample rate whichis suitable for the real applications Meanwhile Figures 2and 4 show that through LRR conversion the run timecan be reduced more than an order of magnitude which isreasonable for the real-time requirements of data processingin the big data era
52 Experiments on LR-MKL In this section we compare theperformance of the MKL algorithms involved in Section 3
6 Computational Intelligence and Neuroscience
45
50
55
60
65
70
75
80
85Ac
cura
cy (
)
30 40 50 60 70 8020Training sample rate ()
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 1 Classification accuracy of Yale by using SVM and LR-SVM
6040 50 70 803020Training sample rate ()
0
005
01
015
02
025
03
035
04
045
05
Run
time (
s)
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 2 Run time of Yale by using SVM and LR-SVM
and their corresponding LR-MKL algorithms The multik-ernel is composed of 119870LIN 119870POL 119870RBF 119870SIG (119902 = 3) Theproportion parameter vector of kernel is 120583 = [1205831 1205832 1205833 1205834]The comparative algorithms are listed below
(i) Unweighted MKL (UMKL) [16] and LR-UMKL (+)indicates sum form and (lowast) indicates product form
(ii) Alternative MKL (AMKL) [17] and LR-AMKL(iii) Generalized MKL (GMKL) [18] and LR-GMKL(iv) Localized MKL (LMKL) [19] and LR-LMKL (sof)
distribute 120583 into softmax mode and (sig) distribute120583 into sigmoid mode
30 40 50 60 70 8020Training sample rate ()
65
70
75
80
85
90
Accu
racy
()
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 3 Classification accuracy of ORL by using SVM and LR-SVM
0
05
1
15
2
25
3
Run
time (
s)
30 40 50 60 70 8020Training sample rate ()
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 4 Run time of ORL by using SVM and LR-SVM
(v) Heuristic MKL (HMKL) [20] and LR-HMKL(vi) Centering MKL (CMKL) [21] and LR-CMKL(vii) Polynomial MKL (PMKL) [22] and LR-PMKL (1)
adopts the bounded set 1205931 with 1198971-norm and (2)adopts the bounded set 1205932 with 1198972-norm
(viii) Arbitrary Norm MKL (ANMKL) [23 24] and LR-ANMKL (1) iterates 120583 with 1198971-norm and (2) iterates120583 with 1198972-norm
(ix) Besides the highest accuracy among the four monok-ernel SVM selected as the reference item which isreferred to as SVM(best)
Computational Intelligence and Neuroscience 7
Table1Th
eperform
anceso
fMKL
algorithm
sand
LR-M
KLalgorithm
sonthed
atasetsY
aleORL
LSV
TandDigit
Yale
ORL
LSVT
Digit
Acc
Time
Acc
Time
Acc
Time
Acc
Time
SVM(best)
6932
3102981
800002
16798
7619
0500142
959302
09195
LR-SVM(best)
79866
700109
870015
01575
776637
000
4396
330
4009
72UMKL
(+)[16]
875114
25981
93579
8182352
785714
00229
9735
7147412
LR-U
MKL
(+)
95893
6030
18834813
10817
738095
00152
9815
9520278
UMKL
(lowast)[16]
583248
27244
775022
205507
666935
00281
960904
71661
LR-U
MKL
(lowast)935739
026
3693406
321836
670033
00176
984618
363
92AMKL
[17]
857753
37236
938741
46854
809524
00452
974725
112138
LR-AMKL
94379
9038
6996
9417
045
9288
0952
000
8598
6952
688
04GMKL
[18]
862989
45330
962057
50070
857143
00565
9914
9980774
LR-G
MKL
958015
062
5398
5833
07761
88928
600183
99467
3459
72LM
KL(sof)[19]
879077
21540
55970003
2203122
850090
51989
99889
81667978
LR-LMKL
(sof)
979352
22720
498
9724
17379
186
742
911933
983591
9818
12LM
KL(sig)[19]
880145
1067552
970108
1070
911
887541
07238
9937
50485914
LR-LMKL
(sig)
98066
7159711
97997
911724
092
662
7045
9499
562
524
592
7HMKL
[20]
636037
924410
935109
1182340
805998
00915
976258
1035
59LR
-HMKL
919611
859
7298
689
310936
88516
2500352
98347
963959
CMKL
[21]
864166
950618
960308
1076
940
799503
00874
965014
106074
LR-C
MKL
94008
310638
098
479
9129746
939024
003
4798
9113
626
96PM
KL(1)[
22]
890035
61842
984901
69065
928571
01079
995881
248702
LR-PMKL
(1)99
1429
090
5399
5712
098
2895
938
6005
7310000
00129831
PMKL
(2)[22]
890261
53893
987533
65450
924662
01295
99504
62116
79LR
-PMKL
(2)98
896
8084
9499
582
8089
1195
5145
006
5199
794
1135108
ANMKL
(1)[2324]
867210
64856
984396
204564
919827
01167
980007
1039
79LR
-ANMKL
(1)96
866
7070
4199
464
328519
92224
700247
992850
690
70ANMKL
(2)[2324]
866998
7066
4982204
2116
15930035
0119
4980039
97753
LR-ANMKL
(2)972917
088
6399
2857
305
979253
91002
2499
249
750374
8 Computational Intelligence and Neuroscience
We conduct experiments on the test datasets YaleORL LSVTVoice Rehabilitation (LSVT for short) andMultiple FeaturesDigit (Digit for short)The 60 samples of dataset are drawnout randomly to train classification model and the remainingsamples serve as the test set Through the optimized resultsof 120574 and penalty factor 119862 by grid search method we findthat the classification accuracy varies not too much with 120574and 119862 ranging in a certain interval So there is no need tosearch the whole parameter space which inevitably increasesthe computational costThe penalty factor119862 can be given thattrying values 001 01 1 10 100 and 120574 are fixed on 1119892 Thenwe assign a value which has the highest average accuracyon the 5 lowast 2 cross validation sets to 119862 Each algorithm isconducted with 10 independent runs and we average them asthe final results The bold numbers represent the preferablerecognition effect between the original algorithms and theirLRR combined algorithmsThe numbers in italic font denotethe algorithms whose recognition precision is inferior tothe SVM(best) The recognition performance of algorithmsis measured by the classification accuracy and run timeillustrated by Table 1
In most cases our proposed LR-MKL methods consis-tently achieve superior results to the original MKL whichverifies the higher classification accuracy and shorter opera-tion time It is indicated that LRR can augment the similaritiesamong the intraclass samples and the differences among theinterclass samples while simplifying the kernel matrix Notethat UMKL(lowast) fails to achieve the ideal recognition effectsin many cases even less accurate than SVM(best) Howevercombiningwith LRR improves its effects to a large extentThisillustrates that simply combining kernels without accordingdata structure is infeasible and LRR can offset part of theconsequences of irrational distribution In general PMKLANMKL and their improved algorithms have the preferablerecognition effects especially the improved algorithms withthe accuracy over 90 percent all the time In terms of runtime it is clearly observed that the real-time performance ofMKL is much worse than SVM because MKL has a processof allocating kernel weights and the process can be very timeconsuming Among them LMKL is the worst and fails tosatisfy the real-time requirement Obviously our combinedLR-MKL can reduce the run time manifold even more thanone order of magnitude so it can speed high-precision MKLup to satisfy the real-time requirement In brief the proposedLR-MKL can boost the performance ofMKL to a great extent
6 Conclusion
The complexity of solving convex quadratic optimizationproblem in MKL is 119874(11987311989935) so it is infeasible to apply inlarge scale problems for its large computational cost Oureffort has beenmade on decreasing the dimension of trainingset Note that LRR just can capture the global structure ofdata in relatively few dimensions Therefore we have givena review of several existing MKL algorithms Based on thispoint we have proposed a novel combined LR-MKL whichlargely improves the performance ofMKL A large number ofexperiments have been carried on four real world datasets tocontrast the recognition effects of various kinds of MKL and
LR-MKL algorithms It has been shown that in most casesthe recognition effects of MKL algorithms are better thanSVM(best) except UMKL(lowast) And our proposed LR-MKLmethods have consistently achieved the superior results tothe original MKL Among them PMKL ANMKL and theirimproved algorithms have shown possessing the preferablerecognition effects
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
This work was supported by the National Natural ScienceFoundation of China (no 51208168) Hebei Province NaturalScience Foundation (no E2016202341) and Tianjin NaturalScience Foundation (no 13JCYBJC37700)
References
[1] V N Vapnik ldquoAn overview of statistical learning theoryrdquo IEEETransactions on Neural Networks vol 10 no 5 pp 988ndash9991999
[2] M Hu Y Chen and J T-Y Kwok ldquoBuilding sparse multiple-kernel SVM classifiersrdquo IEEE Transactions on Neural Networksvol 20 no 5 pp 827ndash839 2009
[3] X Wang X Liu N Japkowicz and S Matwin ldquoEnsemble ofmultiple kernel SVM classifiersrdquo Advances in Artificial Intelli-gence vol 8436 pp 239ndash250 2014
[4] E Hassan S Chaudhury N Yadav P Kalra and M GopalldquoOff-line handwritten input based identity determination usingmulti kernel feature combinationrdquo Pattern Recognition Lettersvol 35 no 1 pp 113ndash119 2014
[5] F Cai and V Cherkassky ldquoGeneralized SMO algorithm forSVM-based multitask learningrdquo IEEE Transactions on NeuralNetworks and Learning Systems vol 23 no 6 pp 997ndash10032012
[6] K Crammer O Dekel J Keshet S Shalev-Shwartz andY Singer ldquoOnline passive-aggressive algorithmsrdquo Journal ofMachine Learning Research vol 7 pp 551ndash585 2006
[7] N Cesa-Bianchi A Conconi and C Gentile ldquoOn the gen-eralization ability of on-line learning algorithmsrdquo Institute ofElectrical and Electronics Engineers Transactions on InformationTheory vol 50 no 9 pp 2050ndash2057 2004
[8] S Fine and K Scheinberg ldquoEfficient SVM training usinglow-rank kernel representationsrdquo Journal of Machine LearningResearch vol 2 no 2 pp 243ndash264 2002
[9] S Zhou ldquoSparse LSSVM in primal using cholesky factorizationfor large-scale problemsrdquo IEEETransactions onNeuralNetworksand Learning Systems vol 27 no 4 pp 783ndash795 2016
[10] L Jia S-Z Liao and L-Z Ding ldquoLearning with uncertainkernel matrix setrdquo Journal of Computer Science and Technologyvol 25 no 4 pp 709ndash727 2010
[11] G Liu Z Lin S Yan J Sun Y Yu and Y Ma ldquoRobust recov-ery of subspace structures by low-rank representationrdquo IEEETransactions on Pattern Analysis and Machine Intelligence vol35 no 1 pp 171ndash184 2013
[12] Y Peng A Ganesh J Wright W Xu and Y Ma ldquoRASL robustalignment by sparse and low-rank decomposition for linearly
Computational Intelligence and Neuroscience 9
correlated imagesrdquo IEEE Transactions on Pattern Analysis andMachine Intelligence vol 34 no 11 pp 2233ndash2246 2012
[13] B Cheng G Liu J Wang Z Huang and S Yan ldquoMulti-tasklow-rank affinity pursuit for image segmentationrdquo in Proceed-ings of the IEEE International Conference on Computer Vision(ICCV rsquo11) pp 2439ndash2446 IEEE Barcelona Spain November2011
[14] YMu JDongX Yuan and S Yan ldquoAccelerated low-rank visualrecovery by random projectionrdquo in Proceedings of the 2011 IEEEConference on Computer Vision and Pattern Recognition CVPR2011 pp 2609ndash2616 Colorado Springs Colo USA June 2011
[15] J Chen J Zhou and J Ye ldquoIntegrating low-rank and group-sparse structures for robust multi-task learningrdquo in Proceedingsof the 17th ACM SIGKDD International Conference on Knowl-edge Discovery and Data Mining KDDrsquo11 pp 42ndash50 San DiegoCalif USA August 2011
[16] P Pavlidis J Cai JWeston andWNGrundy ldquoGene functionalclassification fromheterogeneous datardquo inProceedings of the 5thAnnual Internatinal Conference on Computational Biology pp249ndash255 Montreal Canada May 2001
[17] O Chapelle and A Rakotomamonjy ldquoSecond order optimiza-tion of kernel parametersrdquo Nips Workshop on Kernel Learning2008
[18] M Varma and B R Babu ldquoMore generality in efficient mul-tiple kernel learningrdquo in Proceedings of the 26th InternationalConference On Machine Learning ICML 2009 pp 1065ndash1072Montreal Canada June 2009
[19] M Gonen and E Alpaydin ldquoLocalized multiple kernel learn-ingrdquo in Proceedings of the the 25th international conference pp352ndash359 Helsinki Finland July 2008
[20] S Qiu and T Lane ldquoA framework for multiple kernel supportvector regression and its applications to siRNA efficacy predic-tionrdquo IEEEACM Transactions on Computational Biology andBioinformatics vol 6 no 2 pp 190ndash199 2009
[21] CCortesMMohri andARostamizadeh ldquoTwo-stage learningkernel algorithmsrdquo in Proceedings of the 27th InternationalConference on Machine Learning ICML 2010 pp 239ndash246Haifa Israel June 2010
[22] C Cortes M Mohri and A Rostamizadeh ldquoLearning non-linear combinations of kernelsrdquo in Proceedings of the 23rdAnnual Conference on Neural Information Processing Systems(NIPS rsquo09) pp 396ndash404 December 2009
[23] Z Xu R Jin H Yang I King and M R Lyu ldquoSimple andefficient multiple kernel learning by group lassordquo in Proceedingsof the 27th International Conference onMachine Learning ICML2010 pp 1175ndash1182 Haifa Israel June 2010
[24] M Kloft U Brefeld S Sonnenburg and A Zien ldquoNon-sparseregularization and efficient training with multiple kernelsArxiv Preprint abs1003rdquo httpsarxivorgabs10030079
[25] M Gonen and E Alpaydın ldquoMultiple kernel learning algo-rithmsrdquo Journal of Machine Learning Research vol 12 pp 2211ndash2268 2011
[26] F R Bach ldquoConsistency of the group lasso and multiple kernellearningrdquo Journal ofMachine Learning Research vol 9 no 2 pp1179ndash1225 2008
[27] E J Candes X Li Y Ma and JWright ldquoRobust principal com-ponent analysisrdquo Journal of the ACM vol 58 no 3 2011
[28] C-F Chen C-P Wei and Y-C F Wang ldquoLow-rank matrixrecovery with structural incoherence for robust face recogni-tionrdquo in Proceedings of the 2012 IEEE Conference on ComputerVision and Pattern Recognition CVPR 2012 pp 2618ndash2625Providence RI USA June 2012
[29] J-F Cai E J Candes and Z Shen ldquoA singular value thresh-olding algorithm for matrix completionrdquo SIAM Journal onOptimization vol 20 no 4 pp 1956ndash1982 2010
[30] L Zhuang H Gao Z Lin Y Ma X Zhang and N Yu ldquoNon-negative low rank and sparse graph for semi-supervised learn-ingrdquo in Proceedings of the 2012 IEEE Conference on ComputerVision and Pattern Recognition CVPR 2012 pp 2328ndash2335 usaJune 2012
[31] C Chang and C Lin ldquoLIBSVM a Library for support vectormachinesrdquo ACM Transactions on Intelligent Systems and Tech-nology vol 2 no 3 article 27 2011
[32] A Tsanas M A Little C Fox and L O Ramig ldquoObjectiveautomatic assessment of rehabilitative speech treatment inparkinsonrsquos diseaserdquo IEEE Transactions on Neural Systems andRehabilitation Engineering vol 22 no 1 pp 181ndash190 2014
Submit your manuscripts athttpswwwhindawicom
Computer Games Technology
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
Advances in
FuzzySystems
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014
International Journal of
ReconfigurableComputing
Hindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
Applied Computational Intelligence and Soft Computing
thinspAdvancesthinspinthinsp
Artificial Intelligence
HindawithinspPublishingthinspCorporationhttpwwwhindawicom Volumethinsp2014
Advances inSoftware EngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporation
httpwwwhindawicom Volume 2014
Advances in
Multimedia
International Journal of
Biomedical Imaging
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational Intelligence and Neuroscience
Industrial EngineeringJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Human-ComputerInteraction
Advances in
Computer EngineeringAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014

4 Computational Intelligence and Neuroscience
Later Cortes et al [22] studied a Polynomial MultipleKernel Learning (PMKL) method which utilized the poly-nomial combination of the base kernels with higher degree(119889 ge 1) based on the Kernel Ridge Regression (KRR) theory
119870120583 (x119894 x119895) = sum12058311989611198962 sdotsdotsdot1198961198721198701 (x1119894 x1119895)1198961sdot 1198702 (x2119894 x2119895)1198962 sdot sdot sdot 119870119872 (x119872119894 x119872119895 )119896119872
119896119898 ge 0 sum (1198961 + 1198962 + sdot sdot sdot + 119896119872) le 119889 12058311989611198962 sdotsdotsdot119896119872 ge 0(17)
However the computing complex of coefficients 12058311989611198962 sdotsdotsdot119896119872 is119874(119872119889) which is too large to apply in practice So12058311989611198962 sdotsdotsdot119896119872 canbe simplified as a product form by nonnegative coefficients12058311989611 12058311989622 sdot sdot sdot 120583119896119872119872 and the special case (119889 = 2) can be expressedas
119870120583 (x119894 x119895) = 119872sum119898=1
119872sumℎ=1
120583119898120583ℎ119870119898 (x119898119894 x119898119895 )119870ℎ (xℎ119894 xℎ119895) (18)
Here the related optimization of learning 119870120583 can be formu-lated as the following min-max form
min120583isin120593
max120572isinR119899
minus120572T (119870120583 + 120582I) 120572 + 2120572Ty (19)
where 120593 is a positive bounded and convex set Two boundedsets 1198971-norm and 1198972-norm are the appropriate choices toconstruct 120593
1205931 = 120583 | 120583 ge 0 1003817100381710038171003817120583 minus 120583010038171003817100381710038171 le and 1205932 = 120583 | 120583 ge 0 1003817100381710038171003817120583 minus 120583010038171003817100381710038172 le and (20)
Here 1205830 and and are model parameters and 1205830 is generallyequal to 0 or 12058301205830 = 1
Other than approaches described above inspired bythe consistency between group Lasso and MKL [26] Xuet al [23] and Kloft et al [24] propose an MKL iterativemethod in a generalized 119897119901-norm (119901 ge 1) form They arecollectively called Arbitrary Norms Multiple Kernel Learn-ing (ANMKL) method On the basis of duality conditionw11989822 = 1205832119898sum119899119894=1sum119899119895=1 119910119894119910119895120572119894120572119895119870119898(x119898119894 x119898119895 ) the updatedformula of kernels weight is
120583119898 =1003817100381710038171003817w11989810038171003817100381710038172(119901+1)2
(sum119872ℎ=1 1003817100381710038171003817wℎ10038171003817100381710038172119901(119901+1)2 )1119901 forall119898 (21)
It can be seen from the formulas in this section that theoperation complexity of MKL is mainly decided by x119894 Sotrying to simplify the feature space is an efficient way toimprove the performance of MKLThrough the optimizationof basis vectors LRR can reduce dimension while retainingthe data features which is ideal for improving MKL
4 MKL Using Low-Rank Representation
41 Low-Rank Representation (LRR) The theoreticaladvances on LRR enable us to use latent low-rank structure
in data [27 28] And it simultaneously obtains therepresentation of all samples under a global low-rankconstraint Meantime the LRR procedure can operate in arelatively short time with guaranteed performance
Let the input samples space X be represented by a linearcombination in the dictionary A
X = AZ (22)
where Z = [z1 z2 z119899] is the coefficient matrix and each z119894is a representation coefficient vector of x119894 When the samplesare sufficient X serves as the dictionary A By consideringthe noise or tainted data in practical application LRR aims atapproximatingX intoAZ+E by themeans of minimizing therank of matrix A while reducing the 1198970-norm of E in whichA is a low-rank matrix and E is the associated sparse error Itcan be generally formulated as
minZE
rank (A) + 120582 E0 st X = AZ + E (23)
Here 120582 is used to balance the effect of low-rank and errorterm 1198970-norm as NP-hard problem can be substituted for1198971-norm or 11989721-norm We choose 11989721-norm as the errorterm measurement here which is defined as E21 =sum119899119895=1radicsum119899119895=1([E]119894119895)2 Meantime rank(A) can relax intonuclear-norm sdot lowast [29] Consequently the convex relaxationof formula (23) is
minZE
Zlowast + 120582 E21 st X = AZ + E (24)
The optimal solution Zlowast can be obtained via the AugmentedLagrange Multipliers (ALM) method [11]
42 Efficient SVM and MKL Using LRR Kernel matrixremarkably impacts the computational efficiency and accu-racy of SVM andMKL How to find an appropriate variant ofkernel matrix that contains both the initial label and the datageometry structure for recognition is a crucial task Since LRRhas been theoretically proved to be superior in the sequelwe adopt LRR to transform the kernel for augmenting thesimilarities among the intraclass samples and the differencesamong the interclass samples Moreover a representationof all samples under a global low-rank constraint can beattained which is more conducive to capturing the globaldata structure [30] So LR-SVM and LR-MKL are twoalternative techniques that we propose to use to improve theperformance of SVM and MKL
Firstly based on the LRR theory we improve the monok-ernel SVM as the reference item from which the improve-ment brought by LRR can be displayed visually The specificprocedure of efficient LR-SVM is presented in Algorithm 1
Algorithm 1 (efficient SVM using LRR (LR-SVM))
Input This includes the whole training set XY the featurespace of testing setX119878 = [x119899+1 x119899+2 x119899+119904] the parameters119905 120574 119862 119902 of SVM and the parameter 120582 of LRR
Computational Intelligence and Neuroscience 5
Step 1 Normalize XX119878Step 2 Perform (24) procedure on the normalized XX119878 toproject them on the coefficient feature space ZZ119878 respec-tively
Step 3 Plug Z and the label vector Y into SVM for trainingclassification model
Step 4 Utilize the obtained classificationmodel to classify thecoefficient feature Z119878 of testing set X119878 and the discriminantfunction is 119891(z) = sum119899119894=1 120572lowast119894 119910119894119870(z119894 z) + 119887Output Compare the actual label vector of test set Y119878 and theprediction label vector Y119875 to obtain the recognition results
It is well known that SVM suffers from instability forthe various data structures Thus MKL recognition becomesthe development trend Next we combine LRR and MKLalgorithms mentioned in the Section 3 and change binary-classification model into multiclassification model by pair-wise (one-versus-one) strategy through which a classifierbetween any two categories of samples (119896 is the number ofcategories) can be designed Then we adopt voting methodand assign sample to the category the most votes obtainedAll the combined algorithms can be summarized into a framewhich is given in Algorithm 2 and we refer to it collectively asLR-MKL
Algorithm 2 (efficient MKL using LRR (LR-MKL))
Input This includes the whole training set XY the featurespace of testing set X119878 = [x119899+1 x119899+2 x119899+119904] and theparameter 120582 of LRR
Step 1simStep 2 They are the same as the LR-SVM algorithm
Step 3 Plug Z and the label vector Y into MKL to train 119896(119896 minus1)2 classifiers with the pairwise strategy
Step 4 Utilize each one of the binary MKL classifiers toclassify the coefficient feature Z119878 of testing set X119878
Step 5 According to the prediction label vectorsY1198751 Y1198752 Y119875119896(119896minus1)2 vote for the category of each sample toget the multilabels Y119875
Output Compare the actual label vector of test set Y119878 and theprediction label vector Y119875 to obtain the recognition resultsand the kernel weight vector 1205835 Experiments and Analysis
In this section we conduct extensive experiments to examinethe efficiency of proposed LR-SVM and LR-MKL algorithmsThe operating environment is based on MATLAB (R2013a)under the Intel Core i5 CPU processor 253GHz frequencyparameters The SVM toolbox used in this paper is theLIBSVM [31] which can be easily applied and is shown to befast in large scale databases
The simulations are performed on diverse datasets toensure the universal recognition effectThe test datasets range
over the frequently used face databases and the standard testdata of UCI repository In the simulations all the samples arenormalized first
(1) Yale face database (httpvisionucsdeducontentyale-face-database) it contains 165 grayscale imagesof 15 individuals with different facial expression orconfiguration and each image is resized to 64 lowast 64pixels with 256 grey levels
(2) ORL face database (httpwwwclcamacukresearchdtgattarchivefacedatabasehtm) it contains 400images of 40 distinct subjects taken at different timesvarying light facial expressions and details Weresize them to 64 lowast 64 pixels with 256 grey levels perpixel
(3) LSVT Voice Rehabilitation dataset (httparchiveicsuciedumldatasetsLSVT+Voice+Rehabilitation)[32] it is composed of 126 speech signals from 14people with 309 features divided into two categories
(4) Multiple Features Digit dataset (httparchiveicsuciedumldatasetsMultiple+Features) it includes 2000digitized handwritten numerals 0ndash9 with 649 fea-tures
51 Experiments on LR-SVM In order to demonstrate therecognition performance of SVM improved by the presentedLR-SVM we carry out numerous experiments on the Yaleand ORL face database According to the different rate oftraining sample (20 30 40 50 60 70 and 80)we implement seven groups of experiments on each databaseTo ensure stable and reliable test each group has ten differentdivisions randomly and we average them as the final resultsThe kernel functions are 119870LIN 119870POL 119870RBF 119870SIG (119902 = 3) and120574 = 1119892 (119892 is the dimension of feature space)
The classification accuracy and run time of Yale databaseby using SVM and LR-SVM are shown in Figures 1 and 2respectively Similarly the classification accuracy and runtime of ORL database are shown in Figures 3 and 4The solidlines depict the result of SVM with different kernels whilethe patterned lines with the corresponding colour depictthat of LR-SVM As can be seen from the Figures 1 and3 the proposed LR-SVM method consistently achieves anobvious improvement in classification accuracy compared tothe original SVM method In most cases the classificationaccuracy increases with the rise in training sample rate It isshown that the more complete the training set the better theclassification accuracy But it is impossible for the trainingset to include so many samples in reality LR-MKL has ahigh accuracy even under the low training sample rate whichis suitable for the real applications Meanwhile Figures 2and 4 show that through LRR conversion the run timecan be reduced more than an order of magnitude which isreasonable for the real-time requirements of data processingin the big data era
52 Experiments on LR-MKL In this section we compare theperformance of the MKL algorithms involved in Section 3
6 Computational Intelligence and Neuroscience
45
50
55
60
65
70
75
80
85Ac
cura
cy (
)
30 40 50 60 70 8020Training sample rate ()
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 1 Classification accuracy of Yale by using SVM and LR-SVM
6040 50 70 803020Training sample rate ()
0
005
01
015
02
025
03
035
04
045
05
Run
time (
s)
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 2 Run time of Yale by using SVM and LR-SVM
and their corresponding LR-MKL algorithms The multik-ernel is composed of 119870LIN 119870POL 119870RBF 119870SIG (119902 = 3) Theproportion parameter vector of kernel is 120583 = [1205831 1205832 1205833 1205834]The comparative algorithms are listed below
(i) Unweighted MKL (UMKL) [16] and LR-UMKL (+)indicates sum form and (lowast) indicates product form
(ii) Alternative MKL (AMKL) [17] and LR-AMKL(iii) Generalized MKL (GMKL) [18] and LR-GMKL(iv) Localized MKL (LMKL) [19] and LR-LMKL (sof)
distribute 120583 into softmax mode and (sig) distribute120583 into sigmoid mode
30 40 50 60 70 8020Training sample rate ()
65
70
75
80
85
90
Accu
racy
()
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 3 Classification accuracy of ORL by using SVM and LR-SVM
0
05
1
15
2
25
3
Run
time (
s)
30 40 50 60 70 8020Training sample rate ()
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 4 Run time of ORL by using SVM and LR-SVM
(v) Heuristic MKL (HMKL) [20] and LR-HMKL(vi) Centering MKL (CMKL) [21] and LR-CMKL(vii) Polynomial MKL (PMKL) [22] and LR-PMKL (1)
adopts the bounded set 1205931 with 1198971-norm and (2)adopts the bounded set 1205932 with 1198972-norm
(viii) Arbitrary Norm MKL (ANMKL) [23 24] and LR-ANMKL (1) iterates 120583 with 1198971-norm and (2) iterates120583 with 1198972-norm
(ix) Besides the highest accuracy among the four monok-ernel SVM selected as the reference item which isreferred to as SVM(best)
Computational Intelligence and Neuroscience 7
Table1Th
eperform
anceso
fMKL
algorithm
sand
LR-M
KLalgorithm
sonthed
atasetsY
aleORL
LSV
TandDigit
Yale
ORL
LSVT
Digit
Acc
Time
Acc
Time
Acc
Time
Acc
Time
SVM(best)
6932
3102981
800002
16798
7619
0500142
959302
09195
LR-SVM(best)
79866
700109
870015
01575
776637
000
4396
330
4009
72UMKL
(+)[16]
875114
25981
93579
8182352
785714
00229
9735
7147412
LR-U
MKL
(+)
95893
6030
18834813
10817
738095
00152
9815
9520278
UMKL
(lowast)[16]
583248
27244
775022
205507
666935
00281
960904
71661
LR-U
MKL
(lowast)935739
026
3693406
321836
670033
00176
984618
363
92AMKL
[17]
857753
37236
938741
46854
809524
00452
974725
112138
LR-AMKL
94379
9038
6996
9417
045
9288
0952
000
8598
6952
688
04GMKL
[18]
862989
45330
962057
50070
857143
00565
9914
9980774
LR-G
MKL
958015
062
5398
5833
07761
88928
600183
99467
3459
72LM
KL(sof)[19]
879077
21540
55970003
2203122
850090
51989
99889
81667978
LR-LMKL
(sof)
979352
22720
498
9724
17379
186
742
911933
983591
9818
12LM
KL(sig)[19]
880145
1067552
970108
1070
911
887541
07238
9937
50485914
LR-LMKL
(sig)
98066
7159711
97997
911724
092
662
7045
9499
562
524
592
7HMKL
[20]
636037
924410
935109
1182340
805998
00915
976258
1035
59LR
-HMKL
919611
859
7298
689
310936
88516
2500352
98347
963959
CMKL
[21]
864166
950618
960308
1076
940
799503
00874
965014
106074
LR-C
MKL
94008
310638
098
479
9129746
939024
003
4798
9113
626
96PM
KL(1)[
22]
890035
61842
984901
69065
928571
01079
995881
248702
LR-PMKL
(1)99
1429
090
5399
5712
098
2895
938
6005
7310000
00129831
PMKL
(2)[22]
890261
53893
987533
65450
924662
01295
99504
62116
79LR
-PMKL
(2)98
896
8084
9499
582
8089
1195
5145
006
5199
794
1135108
ANMKL
(1)[2324]
867210
64856
984396
204564
919827
01167
980007
1039
79LR
-ANMKL
(1)96
866
7070
4199
464
328519
92224
700247
992850
690
70ANMKL
(2)[2324]
866998
7066
4982204
2116
15930035
0119
4980039
97753
LR-ANMKL
(2)972917
088
6399
2857
305
979253
91002
2499
249
750374
8 Computational Intelligence and Neuroscience
We conduct experiments on the test datasets YaleORL LSVTVoice Rehabilitation (LSVT for short) andMultiple FeaturesDigit (Digit for short)The 60 samples of dataset are drawnout randomly to train classification model and the remainingsamples serve as the test set Through the optimized resultsof 120574 and penalty factor 119862 by grid search method we findthat the classification accuracy varies not too much with 120574and 119862 ranging in a certain interval So there is no need tosearch the whole parameter space which inevitably increasesthe computational costThe penalty factor119862 can be given thattrying values 001 01 1 10 100 and 120574 are fixed on 1119892 Thenwe assign a value which has the highest average accuracyon the 5 lowast 2 cross validation sets to 119862 Each algorithm isconducted with 10 independent runs and we average them asthe final results The bold numbers represent the preferablerecognition effect between the original algorithms and theirLRR combined algorithmsThe numbers in italic font denotethe algorithms whose recognition precision is inferior tothe SVM(best) The recognition performance of algorithmsis measured by the classification accuracy and run timeillustrated by Table 1
In most cases our proposed LR-MKL methods consis-tently achieve superior results to the original MKL whichverifies the higher classification accuracy and shorter opera-tion time It is indicated that LRR can augment the similaritiesamong the intraclass samples and the differences among theinterclass samples while simplifying the kernel matrix Notethat UMKL(lowast) fails to achieve the ideal recognition effectsin many cases even less accurate than SVM(best) Howevercombiningwith LRR improves its effects to a large extentThisillustrates that simply combining kernels without accordingdata structure is infeasible and LRR can offset part of theconsequences of irrational distribution In general PMKLANMKL and their improved algorithms have the preferablerecognition effects especially the improved algorithms withthe accuracy over 90 percent all the time In terms of runtime it is clearly observed that the real-time performance ofMKL is much worse than SVM because MKL has a processof allocating kernel weights and the process can be very timeconsuming Among them LMKL is the worst and fails tosatisfy the real-time requirement Obviously our combinedLR-MKL can reduce the run time manifold even more thanone order of magnitude so it can speed high-precision MKLup to satisfy the real-time requirement In brief the proposedLR-MKL can boost the performance ofMKL to a great extent
6 Conclusion
The complexity of solving convex quadratic optimizationproblem in MKL is 119874(11987311989935) so it is infeasible to apply inlarge scale problems for its large computational cost Oureffort has beenmade on decreasing the dimension of trainingset Note that LRR just can capture the global structure ofdata in relatively few dimensions Therefore we have givena review of several existing MKL algorithms Based on thispoint we have proposed a novel combined LR-MKL whichlargely improves the performance ofMKL A large number ofexperiments have been carried on four real world datasets tocontrast the recognition effects of various kinds of MKL and
LR-MKL algorithms It has been shown that in most casesthe recognition effects of MKL algorithms are better thanSVM(best) except UMKL(lowast) And our proposed LR-MKLmethods have consistently achieved the superior results tothe original MKL Among them PMKL ANMKL and theirimproved algorithms have shown possessing the preferablerecognition effects
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
This work was supported by the National Natural ScienceFoundation of China (no 51208168) Hebei Province NaturalScience Foundation (no E2016202341) and Tianjin NaturalScience Foundation (no 13JCYBJC37700)
References
[1] V N Vapnik ldquoAn overview of statistical learning theoryrdquo IEEETransactions on Neural Networks vol 10 no 5 pp 988ndash9991999
[2] M Hu Y Chen and J T-Y Kwok ldquoBuilding sparse multiple-kernel SVM classifiersrdquo IEEE Transactions on Neural Networksvol 20 no 5 pp 827ndash839 2009
[3] X Wang X Liu N Japkowicz and S Matwin ldquoEnsemble ofmultiple kernel SVM classifiersrdquo Advances in Artificial Intelli-gence vol 8436 pp 239ndash250 2014
[4] E Hassan S Chaudhury N Yadav P Kalra and M GopalldquoOff-line handwritten input based identity determination usingmulti kernel feature combinationrdquo Pattern Recognition Lettersvol 35 no 1 pp 113ndash119 2014
[5] F Cai and V Cherkassky ldquoGeneralized SMO algorithm forSVM-based multitask learningrdquo IEEE Transactions on NeuralNetworks and Learning Systems vol 23 no 6 pp 997ndash10032012
[6] K Crammer O Dekel J Keshet S Shalev-Shwartz andY Singer ldquoOnline passive-aggressive algorithmsrdquo Journal ofMachine Learning Research vol 7 pp 551ndash585 2006
[7] N Cesa-Bianchi A Conconi and C Gentile ldquoOn the gen-eralization ability of on-line learning algorithmsrdquo Institute ofElectrical and Electronics Engineers Transactions on InformationTheory vol 50 no 9 pp 2050ndash2057 2004
[8] S Fine and K Scheinberg ldquoEfficient SVM training usinglow-rank kernel representationsrdquo Journal of Machine LearningResearch vol 2 no 2 pp 243ndash264 2002
[9] S Zhou ldquoSparse LSSVM in primal using cholesky factorizationfor large-scale problemsrdquo IEEETransactions onNeuralNetworksand Learning Systems vol 27 no 4 pp 783ndash795 2016
[10] L Jia S-Z Liao and L-Z Ding ldquoLearning with uncertainkernel matrix setrdquo Journal of Computer Science and Technologyvol 25 no 4 pp 709ndash727 2010
[11] G Liu Z Lin S Yan J Sun Y Yu and Y Ma ldquoRobust recov-ery of subspace structures by low-rank representationrdquo IEEETransactions on Pattern Analysis and Machine Intelligence vol35 no 1 pp 171ndash184 2013
[12] Y Peng A Ganesh J Wright W Xu and Y Ma ldquoRASL robustalignment by sparse and low-rank decomposition for linearly
Computational Intelligence and Neuroscience 9
correlated imagesrdquo IEEE Transactions on Pattern Analysis andMachine Intelligence vol 34 no 11 pp 2233ndash2246 2012
[13] B Cheng G Liu J Wang Z Huang and S Yan ldquoMulti-tasklow-rank affinity pursuit for image segmentationrdquo in Proceed-ings of the IEEE International Conference on Computer Vision(ICCV rsquo11) pp 2439ndash2446 IEEE Barcelona Spain November2011
[14] YMu JDongX Yuan and S Yan ldquoAccelerated low-rank visualrecovery by random projectionrdquo in Proceedings of the 2011 IEEEConference on Computer Vision and Pattern Recognition CVPR2011 pp 2609ndash2616 Colorado Springs Colo USA June 2011
[15] J Chen J Zhou and J Ye ldquoIntegrating low-rank and group-sparse structures for robust multi-task learningrdquo in Proceedingsof the 17th ACM SIGKDD International Conference on Knowl-edge Discovery and Data Mining KDDrsquo11 pp 42ndash50 San DiegoCalif USA August 2011
[16] P Pavlidis J Cai JWeston andWNGrundy ldquoGene functionalclassification fromheterogeneous datardquo inProceedings of the 5thAnnual Internatinal Conference on Computational Biology pp249ndash255 Montreal Canada May 2001
[17] O Chapelle and A Rakotomamonjy ldquoSecond order optimiza-tion of kernel parametersrdquo Nips Workshop on Kernel Learning2008
[18] M Varma and B R Babu ldquoMore generality in efficient mul-tiple kernel learningrdquo in Proceedings of the 26th InternationalConference On Machine Learning ICML 2009 pp 1065ndash1072Montreal Canada June 2009
[19] M Gonen and E Alpaydin ldquoLocalized multiple kernel learn-ingrdquo in Proceedings of the the 25th international conference pp352ndash359 Helsinki Finland July 2008
[20] S Qiu and T Lane ldquoA framework for multiple kernel supportvector regression and its applications to siRNA efficacy predic-tionrdquo IEEEACM Transactions on Computational Biology andBioinformatics vol 6 no 2 pp 190ndash199 2009
[21] CCortesMMohri andARostamizadeh ldquoTwo-stage learningkernel algorithmsrdquo in Proceedings of the 27th InternationalConference on Machine Learning ICML 2010 pp 239ndash246Haifa Israel June 2010
[22] C Cortes M Mohri and A Rostamizadeh ldquoLearning non-linear combinations of kernelsrdquo in Proceedings of the 23rdAnnual Conference on Neural Information Processing Systems(NIPS rsquo09) pp 396ndash404 December 2009
[23] Z Xu R Jin H Yang I King and M R Lyu ldquoSimple andefficient multiple kernel learning by group lassordquo in Proceedingsof the 27th International Conference onMachine Learning ICML2010 pp 1175ndash1182 Haifa Israel June 2010
[24] M Kloft U Brefeld S Sonnenburg and A Zien ldquoNon-sparseregularization and efficient training with multiple kernelsArxiv Preprint abs1003rdquo httpsarxivorgabs10030079
[25] M Gonen and E Alpaydın ldquoMultiple kernel learning algo-rithmsrdquo Journal of Machine Learning Research vol 12 pp 2211ndash2268 2011
[26] F R Bach ldquoConsistency of the group lasso and multiple kernellearningrdquo Journal ofMachine Learning Research vol 9 no 2 pp1179ndash1225 2008
[27] E J Candes X Li Y Ma and JWright ldquoRobust principal com-ponent analysisrdquo Journal of the ACM vol 58 no 3 2011
[28] C-F Chen C-P Wei and Y-C F Wang ldquoLow-rank matrixrecovery with structural incoherence for robust face recogni-tionrdquo in Proceedings of the 2012 IEEE Conference on ComputerVision and Pattern Recognition CVPR 2012 pp 2618ndash2625Providence RI USA June 2012
[29] J-F Cai E J Candes and Z Shen ldquoA singular value thresh-olding algorithm for matrix completionrdquo SIAM Journal onOptimization vol 20 no 4 pp 1956ndash1982 2010
[30] L Zhuang H Gao Z Lin Y Ma X Zhang and N Yu ldquoNon-negative low rank and sparse graph for semi-supervised learn-ingrdquo in Proceedings of the 2012 IEEE Conference on ComputerVision and Pattern Recognition CVPR 2012 pp 2328ndash2335 usaJune 2012
[31] C Chang and C Lin ldquoLIBSVM a Library for support vectormachinesrdquo ACM Transactions on Intelligent Systems and Tech-nology vol 2 no 3 article 27 2011
[32] A Tsanas M A Little C Fox and L O Ramig ldquoObjectiveautomatic assessment of rehabilitative speech treatment inparkinsonrsquos diseaserdquo IEEE Transactions on Neural Systems andRehabilitation Engineering vol 22 no 1 pp 181ndash190 2014
Submit your manuscripts athttpswwwhindawicom
Computer Games Technology
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
Advances in
FuzzySystems
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014
International Journal of
ReconfigurableComputing
Hindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
Applied Computational Intelligence and Soft Computing
thinspAdvancesthinspinthinsp
Artificial Intelligence
HindawithinspPublishingthinspCorporationhttpwwwhindawicom Volumethinsp2014
Advances inSoftware EngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporation
httpwwwhindawicom Volume 2014
Advances in
Multimedia
International Journal of
Biomedical Imaging
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational Intelligence and Neuroscience
Industrial EngineeringJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Human-ComputerInteraction
Advances in
Computer EngineeringAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014

Computational Intelligence and Neuroscience 5
Step 1 Normalize XX119878Step 2 Perform (24) procedure on the normalized XX119878 toproject them on the coefficient feature space ZZ119878 respec-tively
Step 3 Plug Z and the label vector Y into SVM for trainingclassification model
Step 4 Utilize the obtained classificationmodel to classify thecoefficient feature Z119878 of testing set X119878 and the discriminantfunction is 119891(z) = sum119899119894=1 120572lowast119894 119910119894119870(z119894 z) + 119887Output Compare the actual label vector of test set Y119878 and theprediction label vector Y119875 to obtain the recognition results
It is well known that SVM suffers from instability forthe various data structures Thus MKL recognition becomesthe development trend Next we combine LRR and MKLalgorithms mentioned in the Section 3 and change binary-classification model into multiclassification model by pair-wise (one-versus-one) strategy through which a classifierbetween any two categories of samples (119896 is the number ofcategories) can be designed Then we adopt voting methodand assign sample to the category the most votes obtainedAll the combined algorithms can be summarized into a framewhich is given in Algorithm 2 and we refer to it collectively asLR-MKL
Algorithm 2 (efficient MKL using LRR (LR-MKL))
Input This includes the whole training set XY the featurespace of testing set X119878 = [x119899+1 x119899+2 x119899+119904] and theparameter 120582 of LRR
Step 1simStep 2 They are the same as the LR-SVM algorithm
Step 3 Plug Z and the label vector Y into MKL to train 119896(119896 minus1)2 classifiers with the pairwise strategy
Step 4 Utilize each one of the binary MKL classifiers toclassify the coefficient feature Z119878 of testing set X119878
Step 5 According to the prediction label vectorsY1198751 Y1198752 Y119875119896(119896minus1)2 vote for the category of each sample toget the multilabels Y119875
Output Compare the actual label vector of test set Y119878 and theprediction label vector Y119875 to obtain the recognition resultsand the kernel weight vector 1205835 Experiments and Analysis
In this section we conduct extensive experiments to examinethe efficiency of proposed LR-SVM and LR-MKL algorithmsThe operating environment is based on MATLAB (R2013a)under the Intel Core i5 CPU processor 253GHz frequencyparameters The SVM toolbox used in this paper is theLIBSVM [31] which can be easily applied and is shown to befast in large scale databases
The simulations are performed on diverse datasets toensure the universal recognition effectThe test datasets range
over the frequently used face databases and the standard testdata of UCI repository In the simulations all the samples arenormalized first
(1) Yale face database (httpvisionucsdeducontentyale-face-database) it contains 165 grayscale imagesof 15 individuals with different facial expression orconfiguration and each image is resized to 64 lowast 64pixels with 256 grey levels
(2) ORL face database (httpwwwclcamacukresearchdtgattarchivefacedatabasehtm) it contains 400images of 40 distinct subjects taken at different timesvarying light facial expressions and details Weresize them to 64 lowast 64 pixels with 256 grey levels perpixel
(3) LSVT Voice Rehabilitation dataset (httparchiveicsuciedumldatasetsLSVT+Voice+Rehabilitation)[32] it is composed of 126 speech signals from 14people with 309 features divided into two categories
(4) Multiple Features Digit dataset (httparchiveicsuciedumldatasetsMultiple+Features) it includes 2000digitized handwritten numerals 0ndash9 with 649 fea-tures
51 Experiments on LR-SVM In order to demonstrate therecognition performance of SVM improved by the presentedLR-SVM we carry out numerous experiments on the Yaleand ORL face database According to the different rate oftraining sample (20 30 40 50 60 70 and 80)we implement seven groups of experiments on each databaseTo ensure stable and reliable test each group has ten differentdivisions randomly and we average them as the final resultsThe kernel functions are 119870LIN 119870POL 119870RBF 119870SIG (119902 = 3) and120574 = 1119892 (119892 is the dimension of feature space)
The classification accuracy and run time of Yale databaseby using SVM and LR-SVM are shown in Figures 1 and 2respectively Similarly the classification accuracy and runtime of ORL database are shown in Figures 3 and 4The solidlines depict the result of SVM with different kernels whilethe patterned lines with the corresponding colour depictthat of LR-SVM As can be seen from the Figures 1 and3 the proposed LR-SVM method consistently achieves anobvious improvement in classification accuracy compared tothe original SVM method In most cases the classificationaccuracy increases with the rise in training sample rate It isshown that the more complete the training set the better theclassification accuracy But it is impossible for the trainingset to include so many samples in reality LR-MKL has ahigh accuracy even under the low training sample rate whichis suitable for the real applications Meanwhile Figures 2and 4 show that through LRR conversion the run timecan be reduced more than an order of magnitude which isreasonable for the real-time requirements of data processingin the big data era
52 Experiments on LR-MKL In this section we compare theperformance of the MKL algorithms involved in Section 3
6 Computational Intelligence and Neuroscience
45
50
55
60
65
70
75
80
85Ac
cura
cy (
)
30 40 50 60 70 8020Training sample rate ()
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 1 Classification accuracy of Yale by using SVM and LR-SVM
6040 50 70 803020Training sample rate ()
0
005
01
015
02
025
03
035
04
045
05
Run
time (
s)
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 2 Run time of Yale by using SVM and LR-SVM
and their corresponding LR-MKL algorithms The multik-ernel is composed of 119870LIN 119870POL 119870RBF 119870SIG (119902 = 3) Theproportion parameter vector of kernel is 120583 = [1205831 1205832 1205833 1205834]The comparative algorithms are listed below
(i) Unweighted MKL (UMKL) [16] and LR-UMKL (+)indicates sum form and (lowast) indicates product form
(ii) Alternative MKL (AMKL) [17] and LR-AMKL(iii) Generalized MKL (GMKL) [18] and LR-GMKL(iv) Localized MKL (LMKL) [19] and LR-LMKL (sof)
distribute 120583 into softmax mode and (sig) distribute120583 into sigmoid mode
30 40 50 60 70 8020Training sample rate ()
65
70
75
80
85
90
Accu
racy
()
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 3 Classification accuracy of ORL by using SVM and LR-SVM
0
05
1
15
2
25
3
Run
time (
s)
30 40 50 60 70 8020Training sample rate ()
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 4 Run time of ORL by using SVM and LR-SVM
(v) Heuristic MKL (HMKL) [20] and LR-HMKL(vi) Centering MKL (CMKL) [21] and LR-CMKL(vii) Polynomial MKL (PMKL) [22] and LR-PMKL (1)
adopts the bounded set 1205931 with 1198971-norm and (2)adopts the bounded set 1205932 with 1198972-norm
(viii) Arbitrary Norm MKL (ANMKL) [23 24] and LR-ANMKL (1) iterates 120583 with 1198971-norm and (2) iterates120583 with 1198972-norm
(ix) Besides the highest accuracy among the four monok-ernel SVM selected as the reference item which isreferred to as SVM(best)
Computational Intelligence and Neuroscience 7
Table1Th
eperform
anceso
fMKL
algorithm
sand
LR-M
KLalgorithm
sonthed
atasetsY
aleORL
LSV
TandDigit
Yale
ORL
LSVT
Digit
Acc
Time
Acc
Time
Acc
Time
Acc
Time
SVM(best)
6932
3102981
800002
16798
7619
0500142
959302
09195
LR-SVM(best)
79866
700109
870015
01575
776637
000
4396
330
4009
72UMKL
(+)[16]
875114
25981
93579
8182352
785714
00229
9735
7147412
LR-U
MKL
(+)
95893
6030
18834813
10817
738095
00152
9815
9520278
UMKL
(lowast)[16]
583248
27244
775022
205507
666935
00281
960904
71661
LR-U
MKL
(lowast)935739
026
3693406
321836
670033
00176
984618
363
92AMKL
[17]
857753
37236
938741
46854
809524
00452
974725
112138
LR-AMKL
94379
9038
6996
9417
045
9288
0952
000
8598
6952
688
04GMKL
[18]
862989
45330
962057
50070
857143
00565
9914
9980774
LR-G
MKL
958015
062
5398
5833
07761
88928
600183
99467
3459
72LM
KL(sof)[19]
879077
21540
55970003
2203122
850090
51989
99889
81667978
LR-LMKL
(sof)
979352
22720
498
9724
17379
186
742
911933
983591
9818
12LM
KL(sig)[19]
880145
1067552
970108
1070
911
887541
07238
9937
50485914
LR-LMKL
(sig)
98066
7159711
97997
911724
092
662
7045
9499
562
524
592
7HMKL
[20]
636037
924410
935109
1182340
805998
00915
976258
1035
59LR
-HMKL
919611
859
7298
689
310936
88516
2500352
98347
963959
CMKL
[21]
864166
950618
960308
1076
940
799503
00874
965014
106074
LR-C
MKL
94008
310638
098
479
9129746
939024
003
4798
9113
626
96PM
KL(1)[
22]
890035
61842
984901
69065
928571
01079
995881
248702
LR-PMKL
(1)99
1429
090
5399
5712
098
2895
938
6005
7310000
00129831
PMKL
(2)[22]
890261
53893
987533
65450
924662
01295
99504
62116
79LR
-PMKL
(2)98
896
8084
9499
582
8089
1195
5145
006
5199
794
1135108
ANMKL
(1)[2324]
867210
64856
984396
204564
919827
01167
980007
1039
79LR
-ANMKL
(1)96
866
7070
4199
464
328519
92224
700247
992850
690
70ANMKL
(2)[2324]
866998
7066
4982204
2116
15930035
0119
4980039
97753
LR-ANMKL
(2)972917
088
6399
2857
305
979253
91002
2499
249
750374
8 Computational Intelligence and Neuroscience
We conduct experiments on the test datasets YaleORL LSVTVoice Rehabilitation (LSVT for short) andMultiple FeaturesDigit (Digit for short)The 60 samples of dataset are drawnout randomly to train classification model and the remainingsamples serve as the test set Through the optimized resultsof 120574 and penalty factor 119862 by grid search method we findthat the classification accuracy varies not too much with 120574and 119862 ranging in a certain interval So there is no need tosearch the whole parameter space which inevitably increasesthe computational costThe penalty factor119862 can be given thattrying values 001 01 1 10 100 and 120574 are fixed on 1119892 Thenwe assign a value which has the highest average accuracyon the 5 lowast 2 cross validation sets to 119862 Each algorithm isconducted with 10 independent runs and we average them asthe final results The bold numbers represent the preferablerecognition effect between the original algorithms and theirLRR combined algorithmsThe numbers in italic font denotethe algorithms whose recognition precision is inferior tothe SVM(best) The recognition performance of algorithmsis measured by the classification accuracy and run timeillustrated by Table 1
In most cases our proposed LR-MKL methods consis-tently achieve superior results to the original MKL whichverifies the higher classification accuracy and shorter opera-tion time It is indicated that LRR can augment the similaritiesamong the intraclass samples and the differences among theinterclass samples while simplifying the kernel matrix Notethat UMKL(lowast) fails to achieve the ideal recognition effectsin many cases even less accurate than SVM(best) Howevercombiningwith LRR improves its effects to a large extentThisillustrates that simply combining kernels without accordingdata structure is infeasible and LRR can offset part of theconsequences of irrational distribution In general PMKLANMKL and their improved algorithms have the preferablerecognition effects especially the improved algorithms withthe accuracy over 90 percent all the time In terms of runtime it is clearly observed that the real-time performance ofMKL is much worse than SVM because MKL has a processof allocating kernel weights and the process can be very timeconsuming Among them LMKL is the worst and fails tosatisfy the real-time requirement Obviously our combinedLR-MKL can reduce the run time manifold even more thanone order of magnitude so it can speed high-precision MKLup to satisfy the real-time requirement In brief the proposedLR-MKL can boost the performance ofMKL to a great extent
6 Conclusion
The complexity of solving convex quadratic optimizationproblem in MKL is 119874(11987311989935) so it is infeasible to apply inlarge scale problems for its large computational cost Oureffort has beenmade on decreasing the dimension of trainingset Note that LRR just can capture the global structure ofdata in relatively few dimensions Therefore we have givena review of several existing MKL algorithms Based on thispoint we have proposed a novel combined LR-MKL whichlargely improves the performance ofMKL A large number ofexperiments have been carried on four real world datasets tocontrast the recognition effects of various kinds of MKL and
LR-MKL algorithms It has been shown that in most casesthe recognition effects of MKL algorithms are better thanSVM(best) except UMKL(lowast) And our proposed LR-MKLmethods have consistently achieved the superior results tothe original MKL Among them PMKL ANMKL and theirimproved algorithms have shown possessing the preferablerecognition effects
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
This work was supported by the National Natural ScienceFoundation of China (no 51208168) Hebei Province NaturalScience Foundation (no E2016202341) and Tianjin NaturalScience Foundation (no 13JCYBJC37700)
References
[1] V N Vapnik ldquoAn overview of statistical learning theoryrdquo IEEETransactions on Neural Networks vol 10 no 5 pp 988ndash9991999
[2] M Hu Y Chen and J T-Y Kwok ldquoBuilding sparse multiple-kernel SVM classifiersrdquo IEEE Transactions on Neural Networksvol 20 no 5 pp 827ndash839 2009
[3] X Wang X Liu N Japkowicz and S Matwin ldquoEnsemble ofmultiple kernel SVM classifiersrdquo Advances in Artificial Intelli-gence vol 8436 pp 239ndash250 2014
[4] E Hassan S Chaudhury N Yadav P Kalra and M GopalldquoOff-line handwritten input based identity determination usingmulti kernel feature combinationrdquo Pattern Recognition Lettersvol 35 no 1 pp 113ndash119 2014
[5] F Cai and V Cherkassky ldquoGeneralized SMO algorithm forSVM-based multitask learningrdquo IEEE Transactions on NeuralNetworks and Learning Systems vol 23 no 6 pp 997ndash10032012
[6] K Crammer O Dekel J Keshet S Shalev-Shwartz andY Singer ldquoOnline passive-aggressive algorithmsrdquo Journal ofMachine Learning Research vol 7 pp 551ndash585 2006
[7] N Cesa-Bianchi A Conconi and C Gentile ldquoOn the gen-eralization ability of on-line learning algorithmsrdquo Institute ofElectrical and Electronics Engineers Transactions on InformationTheory vol 50 no 9 pp 2050ndash2057 2004
[8] S Fine and K Scheinberg ldquoEfficient SVM training usinglow-rank kernel representationsrdquo Journal of Machine LearningResearch vol 2 no 2 pp 243ndash264 2002
[9] S Zhou ldquoSparse LSSVM in primal using cholesky factorizationfor large-scale problemsrdquo IEEETransactions onNeuralNetworksand Learning Systems vol 27 no 4 pp 783ndash795 2016
[10] L Jia S-Z Liao and L-Z Ding ldquoLearning with uncertainkernel matrix setrdquo Journal of Computer Science and Technologyvol 25 no 4 pp 709ndash727 2010
[11] G Liu Z Lin S Yan J Sun Y Yu and Y Ma ldquoRobust recov-ery of subspace structures by low-rank representationrdquo IEEETransactions on Pattern Analysis and Machine Intelligence vol35 no 1 pp 171ndash184 2013
[12] Y Peng A Ganesh J Wright W Xu and Y Ma ldquoRASL robustalignment by sparse and low-rank decomposition for linearly
Computational Intelligence and Neuroscience 9
correlated imagesrdquo IEEE Transactions on Pattern Analysis andMachine Intelligence vol 34 no 11 pp 2233ndash2246 2012
[13] B Cheng G Liu J Wang Z Huang and S Yan ldquoMulti-tasklow-rank affinity pursuit for image segmentationrdquo in Proceed-ings of the IEEE International Conference on Computer Vision(ICCV rsquo11) pp 2439ndash2446 IEEE Barcelona Spain November2011
[14] YMu JDongX Yuan and S Yan ldquoAccelerated low-rank visualrecovery by random projectionrdquo in Proceedings of the 2011 IEEEConference on Computer Vision and Pattern Recognition CVPR2011 pp 2609ndash2616 Colorado Springs Colo USA June 2011
[15] J Chen J Zhou and J Ye ldquoIntegrating low-rank and group-sparse structures for robust multi-task learningrdquo in Proceedingsof the 17th ACM SIGKDD International Conference on Knowl-edge Discovery and Data Mining KDDrsquo11 pp 42ndash50 San DiegoCalif USA August 2011
[16] P Pavlidis J Cai JWeston andWNGrundy ldquoGene functionalclassification fromheterogeneous datardquo inProceedings of the 5thAnnual Internatinal Conference on Computational Biology pp249ndash255 Montreal Canada May 2001
[17] O Chapelle and A Rakotomamonjy ldquoSecond order optimiza-tion of kernel parametersrdquo Nips Workshop on Kernel Learning2008
[18] M Varma and B R Babu ldquoMore generality in efficient mul-tiple kernel learningrdquo in Proceedings of the 26th InternationalConference On Machine Learning ICML 2009 pp 1065ndash1072Montreal Canada June 2009
[19] M Gonen and E Alpaydin ldquoLocalized multiple kernel learn-ingrdquo in Proceedings of the the 25th international conference pp352ndash359 Helsinki Finland July 2008
[20] S Qiu and T Lane ldquoA framework for multiple kernel supportvector regression and its applications to siRNA efficacy predic-tionrdquo IEEEACM Transactions on Computational Biology andBioinformatics vol 6 no 2 pp 190ndash199 2009
[21] CCortesMMohri andARostamizadeh ldquoTwo-stage learningkernel algorithmsrdquo in Proceedings of the 27th InternationalConference on Machine Learning ICML 2010 pp 239ndash246Haifa Israel June 2010
[22] C Cortes M Mohri and A Rostamizadeh ldquoLearning non-linear combinations of kernelsrdquo in Proceedings of the 23rdAnnual Conference on Neural Information Processing Systems(NIPS rsquo09) pp 396ndash404 December 2009
[23] Z Xu R Jin H Yang I King and M R Lyu ldquoSimple andefficient multiple kernel learning by group lassordquo in Proceedingsof the 27th International Conference onMachine Learning ICML2010 pp 1175ndash1182 Haifa Israel June 2010
[24] M Kloft U Brefeld S Sonnenburg and A Zien ldquoNon-sparseregularization and efficient training with multiple kernelsArxiv Preprint abs1003rdquo httpsarxivorgabs10030079
[25] M Gonen and E Alpaydın ldquoMultiple kernel learning algo-rithmsrdquo Journal of Machine Learning Research vol 12 pp 2211ndash2268 2011
[26] F R Bach ldquoConsistency of the group lasso and multiple kernellearningrdquo Journal ofMachine Learning Research vol 9 no 2 pp1179ndash1225 2008
[27] E J Candes X Li Y Ma and JWright ldquoRobust principal com-ponent analysisrdquo Journal of the ACM vol 58 no 3 2011
[28] C-F Chen C-P Wei and Y-C F Wang ldquoLow-rank matrixrecovery with structural incoherence for robust face recogni-tionrdquo in Proceedings of the 2012 IEEE Conference on ComputerVision and Pattern Recognition CVPR 2012 pp 2618ndash2625Providence RI USA June 2012
[29] J-F Cai E J Candes and Z Shen ldquoA singular value thresh-olding algorithm for matrix completionrdquo SIAM Journal onOptimization vol 20 no 4 pp 1956ndash1982 2010
[30] L Zhuang H Gao Z Lin Y Ma X Zhang and N Yu ldquoNon-negative low rank and sparse graph for semi-supervised learn-ingrdquo in Proceedings of the 2012 IEEE Conference on ComputerVision and Pattern Recognition CVPR 2012 pp 2328ndash2335 usaJune 2012
[31] C Chang and C Lin ldquoLIBSVM a Library for support vectormachinesrdquo ACM Transactions on Intelligent Systems and Tech-nology vol 2 no 3 article 27 2011
[32] A Tsanas M A Little C Fox and L O Ramig ldquoObjectiveautomatic assessment of rehabilitative speech treatment inparkinsonrsquos diseaserdquo IEEE Transactions on Neural Systems andRehabilitation Engineering vol 22 no 1 pp 181ndash190 2014
Submit your manuscripts athttpswwwhindawicom
Computer Games Technology
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
Advances in
FuzzySystems
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014
International Journal of
ReconfigurableComputing
Hindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
Applied Computational Intelligence and Soft Computing
thinspAdvancesthinspinthinsp
Artificial Intelligence
HindawithinspPublishingthinspCorporationhttpwwwhindawicom Volumethinsp2014
Advances inSoftware EngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporation
httpwwwhindawicom Volume 2014
Advances in
Multimedia
International Journal of
Biomedical Imaging
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational Intelligence and Neuroscience
Industrial EngineeringJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Human-ComputerInteraction
Advances in
Computer EngineeringAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014

6 Computational Intelligence and Neuroscience
45
50
55
60
65
70
75
80
85Ac
cura
cy (
)
30 40 50 60 70 8020Training sample rate ()
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 1 Classification accuracy of Yale by using SVM and LR-SVM
6040 50 70 803020Training sample rate ()
0
005
01
015
02
025
03
035
04
045
05
Run
time (
s)
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 2 Run time of Yale by using SVM and LR-SVM
and their corresponding LR-MKL algorithms The multik-ernel is composed of 119870LIN 119870POL 119870RBF 119870SIG (119902 = 3) Theproportion parameter vector of kernel is 120583 = [1205831 1205832 1205833 1205834]The comparative algorithms are listed below
(i) Unweighted MKL (UMKL) [16] and LR-UMKL (+)indicates sum form and (lowast) indicates product form
(ii) Alternative MKL (AMKL) [17] and LR-AMKL(iii) Generalized MKL (GMKL) [18] and LR-GMKL(iv) Localized MKL (LMKL) [19] and LR-LMKL (sof)
distribute 120583 into softmax mode and (sig) distribute120583 into sigmoid mode
30 40 50 60 70 8020Training sample rate ()
65
70
75
80
85
90
Accu
racy
()
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 3 Classification accuracy of ORL by using SVM and LR-SVM
0
05
1
15
2
25
3
Run
time (
s)
30 40 50 60 70 8020Training sample rate ()
LINLR-LINRBFLR-RBF
POLLR-POLSIGLR-SIG
Figure 4 Run time of ORL by using SVM and LR-SVM
(v) Heuristic MKL (HMKL) [20] and LR-HMKL(vi) Centering MKL (CMKL) [21] and LR-CMKL(vii) Polynomial MKL (PMKL) [22] and LR-PMKL (1)
adopts the bounded set 1205931 with 1198971-norm and (2)adopts the bounded set 1205932 with 1198972-norm
(viii) Arbitrary Norm MKL (ANMKL) [23 24] and LR-ANMKL (1) iterates 120583 with 1198971-norm and (2) iterates120583 with 1198972-norm
(ix) Besides the highest accuracy among the four monok-ernel SVM selected as the reference item which isreferred to as SVM(best)
Computational Intelligence and Neuroscience 7
Table1Th
eperform
anceso
fMKL
algorithm
sand
LR-M
KLalgorithm
sonthed
atasetsY
aleORL
LSV
TandDigit
Yale
ORL
LSVT
Digit
Acc
Time
Acc
Time
Acc
Time
Acc
Time
SVM(best)
6932
3102981
800002
16798
7619
0500142
959302
09195
LR-SVM(best)
79866
700109
870015
01575
776637
000
4396
330
4009
72UMKL
(+)[16]
875114
25981
93579
8182352
785714
00229
9735
7147412
LR-U
MKL
(+)
95893
6030
18834813
10817
738095
00152
9815
9520278
UMKL
(lowast)[16]
583248
27244
775022
205507
666935
00281
960904
71661
LR-U
MKL
(lowast)935739
026
3693406
321836
670033
00176
984618
363
92AMKL
[17]
857753
37236
938741
46854
809524
00452
974725
112138
LR-AMKL
94379
9038
6996
9417
045
9288
0952
000
8598
6952
688
04GMKL
[18]
862989
45330
962057
50070
857143
00565
9914
9980774
LR-G
MKL
958015
062
5398
5833
07761
88928
600183
99467
3459
72LM
KL(sof)[19]
879077
21540
55970003
2203122
850090
51989
99889
81667978
LR-LMKL
(sof)
979352
22720
498
9724
17379
186
742
911933
983591
9818
12LM
KL(sig)[19]
880145
1067552
970108
1070
911
887541
07238
9937
50485914
LR-LMKL
(sig)
98066
7159711
97997
911724
092
662
7045
9499
562
524
592
7HMKL
[20]
636037
924410
935109
1182340
805998
00915
976258
1035
59LR
-HMKL
919611
859
7298
689
310936
88516
2500352
98347
963959
CMKL
[21]
864166
950618
960308
1076
940
799503
00874
965014
106074
LR-C
MKL
94008
310638
098
479
9129746
939024
003
4798
9113
626
96PM
KL(1)[
22]
890035
61842
984901
69065
928571
01079
995881
248702
LR-PMKL
(1)99
1429
090
5399
5712
098
2895
938
6005
7310000
00129831
PMKL
(2)[22]
890261
53893
987533
65450
924662
01295
99504
62116
79LR
-PMKL
(2)98
896
8084
9499
582
8089
1195
5145
006
5199
794
1135108
ANMKL
(1)[2324]
867210
64856
984396
204564
919827
01167
980007
1039
79LR
-ANMKL
(1)96
866
7070
4199
464
328519
92224
700247
992850
690
70ANMKL
(2)[2324]
866998
7066
4982204
2116
15930035
0119
4980039
97753
LR-ANMKL
(2)972917
088
6399
2857
305
979253
91002
2499
249
750374
8 Computational Intelligence and Neuroscience
We conduct experiments on the test datasets YaleORL LSVTVoice Rehabilitation (LSVT for short) andMultiple FeaturesDigit (Digit for short)The 60 samples of dataset are drawnout randomly to train classification model and the remainingsamples serve as the test set Through the optimized resultsof 120574 and penalty factor 119862 by grid search method we findthat the classification accuracy varies not too much with 120574and 119862 ranging in a certain interval So there is no need tosearch the whole parameter space which inevitably increasesthe computational costThe penalty factor119862 can be given thattrying values 001 01 1 10 100 and 120574 are fixed on 1119892 Thenwe assign a value which has the highest average accuracyon the 5 lowast 2 cross validation sets to 119862 Each algorithm isconducted with 10 independent runs and we average them asthe final results The bold numbers represent the preferablerecognition effect between the original algorithms and theirLRR combined algorithmsThe numbers in italic font denotethe algorithms whose recognition precision is inferior tothe SVM(best) The recognition performance of algorithmsis measured by the classification accuracy and run timeillustrated by Table 1
In most cases our proposed LR-MKL methods consis-tently achieve superior results to the original MKL whichverifies the higher classification accuracy and shorter opera-tion time It is indicated that LRR can augment the similaritiesamong the intraclass samples and the differences among theinterclass samples while simplifying the kernel matrix Notethat UMKL(lowast) fails to achieve the ideal recognition effectsin many cases even less accurate than SVM(best) Howevercombiningwith LRR improves its effects to a large extentThisillustrates that simply combining kernels without accordingdata structure is infeasible and LRR can offset part of theconsequences of irrational distribution In general PMKLANMKL and their improved algorithms have the preferablerecognition effects especially the improved algorithms withthe accuracy over 90 percent all the time In terms of runtime it is clearly observed that the real-time performance ofMKL is much worse than SVM because MKL has a processof allocating kernel weights and the process can be very timeconsuming Among them LMKL is the worst and fails tosatisfy the real-time requirement Obviously our combinedLR-MKL can reduce the run time manifold even more thanone order of magnitude so it can speed high-precision MKLup to satisfy the real-time requirement In brief the proposedLR-MKL can boost the performance ofMKL to a great extent
6 Conclusion
The complexity of solving convex quadratic optimizationproblem in MKL is 119874(11987311989935) so it is infeasible to apply inlarge scale problems for its large computational cost Oureffort has beenmade on decreasing the dimension of trainingset Note that LRR just can capture the global structure ofdata in relatively few dimensions Therefore we have givena review of several existing MKL algorithms Based on thispoint we have proposed a novel combined LR-MKL whichlargely improves the performance ofMKL A large number ofexperiments have been carried on four real world datasets tocontrast the recognition effects of various kinds of MKL and
LR-MKL algorithms It has been shown that in most casesthe recognition effects of MKL algorithms are better thanSVM(best) except UMKL(lowast) And our proposed LR-MKLmethods have consistently achieved the superior results tothe original MKL Among them PMKL ANMKL and theirimproved algorithms have shown possessing the preferablerecognition effects
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
This work was supported by the National Natural ScienceFoundation of China (no 51208168) Hebei Province NaturalScience Foundation (no E2016202341) and Tianjin NaturalScience Foundation (no 13JCYBJC37700)
References
[1] V N Vapnik ldquoAn overview of statistical learning theoryrdquo IEEETransactions on Neural Networks vol 10 no 5 pp 988ndash9991999
[2] M Hu Y Chen and J T-Y Kwok ldquoBuilding sparse multiple-kernel SVM classifiersrdquo IEEE Transactions on Neural Networksvol 20 no 5 pp 827ndash839 2009
[3] X Wang X Liu N Japkowicz and S Matwin ldquoEnsemble ofmultiple kernel SVM classifiersrdquo Advances in Artificial Intelli-gence vol 8436 pp 239ndash250 2014
[4] E Hassan S Chaudhury N Yadav P Kalra and M GopalldquoOff-line handwritten input based identity determination usingmulti kernel feature combinationrdquo Pattern Recognition Lettersvol 35 no 1 pp 113ndash119 2014
[5] F Cai and V Cherkassky ldquoGeneralized SMO algorithm forSVM-based multitask learningrdquo IEEE Transactions on NeuralNetworks and Learning Systems vol 23 no 6 pp 997ndash10032012
[6] K Crammer O Dekel J Keshet S Shalev-Shwartz andY Singer ldquoOnline passive-aggressive algorithmsrdquo Journal ofMachine Learning Research vol 7 pp 551ndash585 2006
[7] N Cesa-Bianchi A Conconi and C Gentile ldquoOn the gen-eralization ability of on-line learning algorithmsrdquo Institute ofElectrical and Electronics Engineers Transactions on InformationTheory vol 50 no 9 pp 2050ndash2057 2004
[8] S Fine and K Scheinberg ldquoEfficient SVM training usinglow-rank kernel representationsrdquo Journal of Machine LearningResearch vol 2 no 2 pp 243ndash264 2002
[9] S Zhou ldquoSparse LSSVM in primal using cholesky factorizationfor large-scale problemsrdquo IEEETransactions onNeuralNetworksand Learning Systems vol 27 no 4 pp 783ndash795 2016
[10] L Jia S-Z Liao and L-Z Ding ldquoLearning with uncertainkernel matrix setrdquo Journal of Computer Science and Technologyvol 25 no 4 pp 709ndash727 2010
[11] G Liu Z Lin S Yan J Sun Y Yu and Y Ma ldquoRobust recov-ery of subspace structures by low-rank representationrdquo IEEETransactions on Pattern Analysis and Machine Intelligence vol35 no 1 pp 171ndash184 2013
[12] Y Peng A Ganesh J Wright W Xu and Y Ma ldquoRASL robustalignment by sparse and low-rank decomposition for linearly
Computational Intelligence and Neuroscience 9
correlated imagesrdquo IEEE Transactions on Pattern Analysis andMachine Intelligence vol 34 no 11 pp 2233ndash2246 2012
[13] B Cheng G Liu J Wang Z Huang and S Yan ldquoMulti-tasklow-rank affinity pursuit for image segmentationrdquo in Proceed-ings of the IEEE International Conference on Computer Vision(ICCV rsquo11) pp 2439ndash2446 IEEE Barcelona Spain November2011
[14] YMu JDongX Yuan and S Yan ldquoAccelerated low-rank visualrecovery by random projectionrdquo in Proceedings of the 2011 IEEEConference on Computer Vision and Pattern Recognition CVPR2011 pp 2609ndash2616 Colorado Springs Colo USA June 2011
[15] J Chen J Zhou and J Ye ldquoIntegrating low-rank and group-sparse structures for robust multi-task learningrdquo in Proceedingsof the 17th ACM SIGKDD International Conference on Knowl-edge Discovery and Data Mining KDDrsquo11 pp 42ndash50 San DiegoCalif USA August 2011
[16] P Pavlidis J Cai JWeston andWNGrundy ldquoGene functionalclassification fromheterogeneous datardquo inProceedings of the 5thAnnual Internatinal Conference on Computational Biology pp249ndash255 Montreal Canada May 2001
[17] O Chapelle and A Rakotomamonjy ldquoSecond order optimiza-tion of kernel parametersrdquo Nips Workshop on Kernel Learning2008
[18] M Varma and B R Babu ldquoMore generality in efficient mul-tiple kernel learningrdquo in Proceedings of the 26th InternationalConference On Machine Learning ICML 2009 pp 1065ndash1072Montreal Canada June 2009
[19] M Gonen and E Alpaydin ldquoLocalized multiple kernel learn-ingrdquo in Proceedings of the the 25th international conference pp352ndash359 Helsinki Finland July 2008
[20] S Qiu and T Lane ldquoA framework for multiple kernel supportvector regression and its applications to siRNA efficacy predic-tionrdquo IEEEACM Transactions on Computational Biology andBioinformatics vol 6 no 2 pp 190ndash199 2009
[21] CCortesMMohri andARostamizadeh ldquoTwo-stage learningkernel algorithmsrdquo in Proceedings of the 27th InternationalConference on Machine Learning ICML 2010 pp 239ndash246Haifa Israel June 2010
[22] C Cortes M Mohri and A Rostamizadeh ldquoLearning non-linear combinations of kernelsrdquo in Proceedings of the 23rdAnnual Conference on Neural Information Processing Systems(NIPS rsquo09) pp 396ndash404 December 2009
[23] Z Xu R Jin H Yang I King and M R Lyu ldquoSimple andefficient multiple kernel learning by group lassordquo in Proceedingsof the 27th International Conference onMachine Learning ICML2010 pp 1175ndash1182 Haifa Israel June 2010
[24] M Kloft U Brefeld S Sonnenburg and A Zien ldquoNon-sparseregularization and efficient training with multiple kernelsArxiv Preprint abs1003rdquo httpsarxivorgabs10030079
[25] M Gonen and E Alpaydın ldquoMultiple kernel learning algo-rithmsrdquo Journal of Machine Learning Research vol 12 pp 2211ndash2268 2011
[26] F R Bach ldquoConsistency of the group lasso and multiple kernellearningrdquo Journal ofMachine Learning Research vol 9 no 2 pp1179ndash1225 2008
[27] E J Candes X Li Y Ma and JWright ldquoRobust principal com-ponent analysisrdquo Journal of the ACM vol 58 no 3 2011
[28] C-F Chen C-P Wei and Y-C F Wang ldquoLow-rank matrixrecovery with structural incoherence for robust face recogni-tionrdquo in Proceedings of the 2012 IEEE Conference on ComputerVision and Pattern Recognition CVPR 2012 pp 2618ndash2625Providence RI USA June 2012
[29] J-F Cai E J Candes and Z Shen ldquoA singular value thresh-olding algorithm for matrix completionrdquo SIAM Journal onOptimization vol 20 no 4 pp 1956ndash1982 2010
[30] L Zhuang H Gao Z Lin Y Ma X Zhang and N Yu ldquoNon-negative low rank and sparse graph for semi-supervised learn-ingrdquo in Proceedings of the 2012 IEEE Conference on ComputerVision and Pattern Recognition CVPR 2012 pp 2328ndash2335 usaJune 2012
[31] C Chang and C Lin ldquoLIBSVM a Library for support vectormachinesrdquo ACM Transactions on Intelligent Systems and Tech-nology vol 2 no 3 article 27 2011
[32] A Tsanas M A Little C Fox and L O Ramig ldquoObjectiveautomatic assessment of rehabilitative speech treatment inparkinsonrsquos diseaserdquo IEEE Transactions on Neural Systems andRehabilitation Engineering vol 22 no 1 pp 181ndash190 2014
Submit your manuscripts athttpswwwhindawicom
Computer Games Technology
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
Advances in
FuzzySystems
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014
International Journal of
ReconfigurableComputing
Hindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
Applied Computational Intelligence and Soft Computing
thinspAdvancesthinspinthinsp
Artificial Intelligence
HindawithinspPublishingthinspCorporationhttpwwwhindawicom Volumethinsp2014
Advances inSoftware EngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporation
httpwwwhindawicom Volume 2014
Advances in
Multimedia
International Journal of
Biomedical Imaging
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational Intelligence and Neuroscience
Industrial EngineeringJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Human-ComputerInteraction
Advances in
Computer EngineeringAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
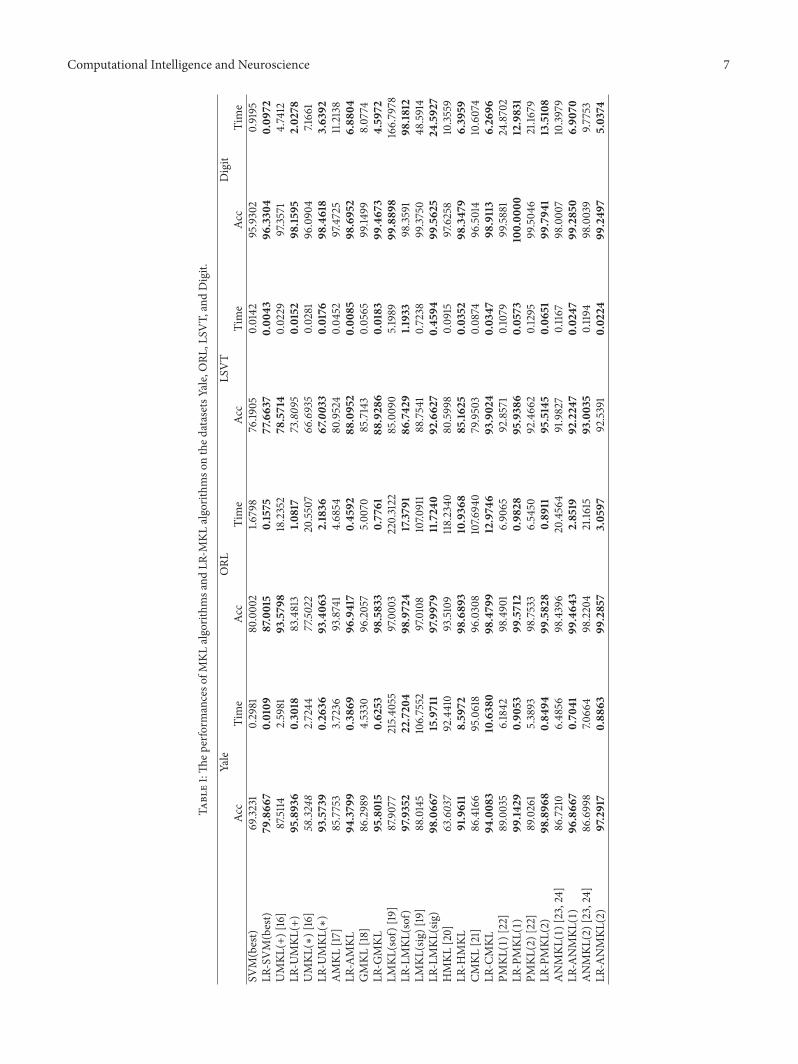
Computational Intelligence and Neuroscience 7
Table1Th
eperform
anceso
fMKL
algorithm
sand
LR-M
KLalgorithm
sonthed
atasetsY
aleORL
LSV
TandDigit
Yale
ORL
LSVT
Digit
Acc
Time
Acc
Time
Acc
Time
Acc
Time
SVM(best)
6932
3102981
800002
16798
7619
0500142
959302
09195
LR-SVM(best)
79866
700109
870015
01575
776637
000
4396
330
4009
72UMKL
(+)[16]
875114
25981
93579
8182352
785714
00229
9735
7147412
LR-U
MKL
(+)
95893
6030
18834813
10817
738095
00152
9815
9520278
UMKL
(lowast)[16]
583248
27244
775022
205507
666935
00281
960904
71661
LR-U
MKL
(lowast)935739
026
3693406
321836
670033
00176
984618
363
92AMKL
[17]
857753
37236
938741
46854
809524
00452
974725
112138
LR-AMKL
94379
9038
6996
9417
045
9288
0952
000
8598
6952
688
04GMKL
[18]
862989
45330
962057
50070
857143
00565
9914
9980774
LR-G
MKL
958015
062
5398
5833
07761
88928
600183
99467
3459
72LM
KL(sof)[19]
879077
21540
55970003
2203122
850090
51989
99889
81667978
LR-LMKL
(sof)
979352
22720
498
9724
17379
186
742
911933
983591
9818
12LM
KL(sig)[19]
880145
1067552
970108
1070
911
887541
07238
9937
50485914
LR-LMKL
(sig)
98066
7159711
97997
911724
092
662
7045
9499
562
524
592
7HMKL
[20]
636037
924410
935109
1182340
805998
00915
976258
1035
59LR
-HMKL
919611
859
7298
689
310936
88516
2500352
98347
963959
CMKL
[21]
864166
950618
960308
1076
940
799503
00874
965014
106074
LR-C
MKL
94008
310638
098
479
9129746
939024
003
4798
9113
626
96PM
KL(1)[
22]
890035
61842
984901
69065
928571
01079
995881
248702
LR-PMKL
(1)99
1429
090
5399
5712
098
2895
938
6005
7310000
00129831
PMKL
(2)[22]
890261
53893
987533
65450
924662
01295
99504
62116
79LR
-PMKL
(2)98
896
8084
9499
582
8089
1195
5145
006
5199
794
1135108
ANMKL
(1)[2324]
867210
64856
984396
204564
919827
01167
980007
1039
79LR
-ANMKL
(1)96
866
7070
4199
464
328519
92224
700247
992850
690
70ANMKL
(2)[2324]
866998
7066
4982204
2116
15930035
0119
4980039
97753
LR-ANMKL
(2)972917
088
6399
2857
305
979253
91002
2499
249
750374
8 Computational Intelligence and Neuroscience
We conduct experiments on the test datasets YaleORL LSVTVoice Rehabilitation (LSVT for short) andMultiple FeaturesDigit (Digit for short)The 60 samples of dataset are drawnout randomly to train classification model and the remainingsamples serve as the test set Through the optimized resultsof 120574 and penalty factor 119862 by grid search method we findthat the classification accuracy varies not too much with 120574and 119862 ranging in a certain interval So there is no need tosearch the whole parameter space which inevitably increasesthe computational costThe penalty factor119862 can be given thattrying values 001 01 1 10 100 and 120574 are fixed on 1119892 Thenwe assign a value which has the highest average accuracyon the 5 lowast 2 cross validation sets to 119862 Each algorithm isconducted with 10 independent runs and we average them asthe final results The bold numbers represent the preferablerecognition effect between the original algorithms and theirLRR combined algorithmsThe numbers in italic font denotethe algorithms whose recognition precision is inferior tothe SVM(best) The recognition performance of algorithmsis measured by the classification accuracy and run timeillustrated by Table 1
In most cases our proposed LR-MKL methods consis-tently achieve superior results to the original MKL whichverifies the higher classification accuracy and shorter opera-tion time It is indicated that LRR can augment the similaritiesamong the intraclass samples and the differences among theinterclass samples while simplifying the kernel matrix Notethat UMKL(lowast) fails to achieve the ideal recognition effectsin many cases even less accurate than SVM(best) Howevercombiningwith LRR improves its effects to a large extentThisillustrates that simply combining kernels without accordingdata structure is infeasible and LRR can offset part of theconsequences of irrational distribution In general PMKLANMKL and their improved algorithms have the preferablerecognition effects especially the improved algorithms withthe accuracy over 90 percent all the time In terms of runtime it is clearly observed that the real-time performance ofMKL is much worse than SVM because MKL has a processof allocating kernel weights and the process can be very timeconsuming Among them LMKL is the worst and fails tosatisfy the real-time requirement Obviously our combinedLR-MKL can reduce the run time manifold even more thanone order of magnitude so it can speed high-precision MKLup to satisfy the real-time requirement In brief the proposedLR-MKL can boost the performance ofMKL to a great extent
6 Conclusion
The complexity of solving convex quadratic optimizationproblem in MKL is 119874(11987311989935) so it is infeasible to apply inlarge scale problems for its large computational cost Oureffort has beenmade on decreasing the dimension of trainingset Note that LRR just can capture the global structure ofdata in relatively few dimensions Therefore we have givena review of several existing MKL algorithms Based on thispoint we have proposed a novel combined LR-MKL whichlargely improves the performance ofMKL A large number ofexperiments have been carried on four real world datasets tocontrast the recognition effects of various kinds of MKL and
LR-MKL algorithms It has been shown that in most casesthe recognition effects of MKL algorithms are better thanSVM(best) except UMKL(lowast) And our proposed LR-MKLmethods have consistently achieved the superior results tothe original MKL Among them PMKL ANMKL and theirimproved algorithms have shown possessing the preferablerecognition effects
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
This work was supported by the National Natural ScienceFoundation of China (no 51208168) Hebei Province NaturalScience Foundation (no E2016202341) and Tianjin NaturalScience Foundation (no 13JCYBJC37700)
References
[1] V N Vapnik ldquoAn overview of statistical learning theoryrdquo IEEETransactions on Neural Networks vol 10 no 5 pp 988ndash9991999
[2] M Hu Y Chen and J T-Y Kwok ldquoBuilding sparse multiple-kernel SVM classifiersrdquo IEEE Transactions on Neural Networksvol 20 no 5 pp 827ndash839 2009
[3] X Wang X Liu N Japkowicz and S Matwin ldquoEnsemble ofmultiple kernel SVM classifiersrdquo Advances in Artificial Intelli-gence vol 8436 pp 239ndash250 2014
[4] E Hassan S Chaudhury N Yadav P Kalra and M GopalldquoOff-line handwritten input based identity determination usingmulti kernel feature combinationrdquo Pattern Recognition Lettersvol 35 no 1 pp 113ndash119 2014
[5] F Cai and V Cherkassky ldquoGeneralized SMO algorithm forSVM-based multitask learningrdquo IEEE Transactions on NeuralNetworks and Learning Systems vol 23 no 6 pp 997ndash10032012
[6] K Crammer O Dekel J Keshet S Shalev-Shwartz andY Singer ldquoOnline passive-aggressive algorithmsrdquo Journal ofMachine Learning Research vol 7 pp 551ndash585 2006
[7] N Cesa-Bianchi A Conconi and C Gentile ldquoOn the gen-eralization ability of on-line learning algorithmsrdquo Institute ofElectrical and Electronics Engineers Transactions on InformationTheory vol 50 no 9 pp 2050ndash2057 2004
[8] S Fine and K Scheinberg ldquoEfficient SVM training usinglow-rank kernel representationsrdquo Journal of Machine LearningResearch vol 2 no 2 pp 243ndash264 2002
[9] S Zhou ldquoSparse LSSVM in primal using cholesky factorizationfor large-scale problemsrdquo IEEETransactions onNeuralNetworksand Learning Systems vol 27 no 4 pp 783ndash795 2016
[10] L Jia S-Z Liao and L-Z Ding ldquoLearning with uncertainkernel matrix setrdquo Journal of Computer Science and Technologyvol 25 no 4 pp 709ndash727 2010
[11] G Liu Z Lin S Yan J Sun Y Yu and Y Ma ldquoRobust recov-ery of subspace structures by low-rank representationrdquo IEEETransactions on Pattern Analysis and Machine Intelligence vol35 no 1 pp 171ndash184 2013
[12] Y Peng A Ganesh J Wright W Xu and Y Ma ldquoRASL robustalignment by sparse and low-rank decomposition for linearly
Computational Intelligence and Neuroscience 9
correlated imagesrdquo IEEE Transactions on Pattern Analysis andMachine Intelligence vol 34 no 11 pp 2233ndash2246 2012
[13] B Cheng G Liu J Wang Z Huang and S Yan ldquoMulti-tasklow-rank affinity pursuit for image segmentationrdquo in Proceed-ings of the IEEE International Conference on Computer Vision(ICCV rsquo11) pp 2439ndash2446 IEEE Barcelona Spain November2011
[14] YMu JDongX Yuan and S Yan ldquoAccelerated low-rank visualrecovery by random projectionrdquo in Proceedings of the 2011 IEEEConference on Computer Vision and Pattern Recognition CVPR2011 pp 2609ndash2616 Colorado Springs Colo USA June 2011
[15] J Chen J Zhou and J Ye ldquoIntegrating low-rank and group-sparse structures for robust multi-task learningrdquo in Proceedingsof the 17th ACM SIGKDD International Conference on Knowl-edge Discovery and Data Mining KDDrsquo11 pp 42ndash50 San DiegoCalif USA August 2011
[16] P Pavlidis J Cai JWeston andWNGrundy ldquoGene functionalclassification fromheterogeneous datardquo inProceedings of the 5thAnnual Internatinal Conference on Computational Biology pp249ndash255 Montreal Canada May 2001
[17] O Chapelle and A Rakotomamonjy ldquoSecond order optimiza-tion of kernel parametersrdquo Nips Workshop on Kernel Learning2008
[18] M Varma and B R Babu ldquoMore generality in efficient mul-tiple kernel learningrdquo in Proceedings of the 26th InternationalConference On Machine Learning ICML 2009 pp 1065ndash1072Montreal Canada June 2009
[19] M Gonen and E Alpaydin ldquoLocalized multiple kernel learn-ingrdquo in Proceedings of the the 25th international conference pp352ndash359 Helsinki Finland July 2008
[20] S Qiu and T Lane ldquoA framework for multiple kernel supportvector regression and its applications to siRNA efficacy predic-tionrdquo IEEEACM Transactions on Computational Biology andBioinformatics vol 6 no 2 pp 190ndash199 2009
[21] CCortesMMohri andARostamizadeh ldquoTwo-stage learningkernel algorithmsrdquo in Proceedings of the 27th InternationalConference on Machine Learning ICML 2010 pp 239ndash246Haifa Israel June 2010
[22] C Cortes M Mohri and A Rostamizadeh ldquoLearning non-linear combinations of kernelsrdquo in Proceedings of the 23rdAnnual Conference on Neural Information Processing Systems(NIPS rsquo09) pp 396ndash404 December 2009
[23] Z Xu R Jin H Yang I King and M R Lyu ldquoSimple andefficient multiple kernel learning by group lassordquo in Proceedingsof the 27th International Conference onMachine Learning ICML2010 pp 1175ndash1182 Haifa Israel June 2010
[24] M Kloft U Brefeld S Sonnenburg and A Zien ldquoNon-sparseregularization and efficient training with multiple kernelsArxiv Preprint abs1003rdquo httpsarxivorgabs10030079
[25] M Gonen and E Alpaydın ldquoMultiple kernel learning algo-rithmsrdquo Journal of Machine Learning Research vol 12 pp 2211ndash2268 2011
[26] F R Bach ldquoConsistency of the group lasso and multiple kernellearningrdquo Journal ofMachine Learning Research vol 9 no 2 pp1179ndash1225 2008
[27] E J Candes X Li Y Ma and JWright ldquoRobust principal com-ponent analysisrdquo Journal of the ACM vol 58 no 3 2011
[28] C-F Chen C-P Wei and Y-C F Wang ldquoLow-rank matrixrecovery with structural incoherence for robust face recogni-tionrdquo in Proceedings of the 2012 IEEE Conference on ComputerVision and Pattern Recognition CVPR 2012 pp 2618ndash2625Providence RI USA June 2012
[29] J-F Cai E J Candes and Z Shen ldquoA singular value thresh-olding algorithm for matrix completionrdquo SIAM Journal onOptimization vol 20 no 4 pp 1956ndash1982 2010
[30] L Zhuang H Gao Z Lin Y Ma X Zhang and N Yu ldquoNon-negative low rank and sparse graph for semi-supervised learn-ingrdquo in Proceedings of the 2012 IEEE Conference on ComputerVision and Pattern Recognition CVPR 2012 pp 2328ndash2335 usaJune 2012
[31] C Chang and C Lin ldquoLIBSVM a Library for support vectormachinesrdquo ACM Transactions on Intelligent Systems and Tech-nology vol 2 no 3 article 27 2011
[32] A Tsanas M A Little C Fox and L O Ramig ldquoObjectiveautomatic assessment of rehabilitative speech treatment inparkinsonrsquos diseaserdquo IEEE Transactions on Neural Systems andRehabilitation Engineering vol 22 no 1 pp 181ndash190 2014
Submit your manuscripts athttpswwwhindawicom
Computer Games Technology
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
Advances in
FuzzySystems
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014
International Journal of
ReconfigurableComputing
Hindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
Applied Computational Intelligence and Soft Computing
thinspAdvancesthinspinthinsp
Artificial Intelligence
HindawithinspPublishingthinspCorporationhttpwwwhindawicom Volumethinsp2014
Advances inSoftware EngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporation
httpwwwhindawicom Volume 2014
Advances in
Multimedia
International Journal of
Biomedical Imaging
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational Intelligence and Neuroscience
Industrial EngineeringJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Human-ComputerInteraction
Advances in
Computer EngineeringAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014

8 Computational Intelligence and Neuroscience
We conduct experiments on the test datasets YaleORL LSVTVoice Rehabilitation (LSVT for short) andMultiple FeaturesDigit (Digit for short)The 60 samples of dataset are drawnout randomly to train classification model and the remainingsamples serve as the test set Through the optimized resultsof 120574 and penalty factor 119862 by grid search method we findthat the classification accuracy varies not too much with 120574and 119862 ranging in a certain interval So there is no need tosearch the whole parameter space which inevitably increasesthe computational costThe penalty factor119862 can be given thattrying values 001 01 1 10 100 and 120574 are fixed on 1119892 Thenwe assign a value which has the highest average accuracyon the 5 lowast 2 cross validation sets to 119862 Each algorithm isconducted with 10 independent runs and we average them asthe final results The bold numbers represent the preferablerecognition effect between the original algorithms and theirLRR combined algorithmsThe numbers in italic font denotethe algorithms whose recognition precision is inferior tothe SVM(best) The recognition performance of algorithmsis measured by the classification accuracy and run timeillustrated by Table 1
In most cases our proposed LR-MKL methods consis-tently achieve superior results to the original MKL whichverifies the higher classification accuracy and shorter opera-tion time It is indicated that LRR can augment the similaritiesamong the intraclass samples and the differences among theinterclass samples while simplifying the kernel matrix Notethat UMKL(lowast) fails to achieve the ideal recognition effectsin many cases even less accurate than SVM(best) Howevercombiningwith LRR improves its effects to a large extentThisillustrates that simply combining kernels without accordingdata structure is infeasible and LRR can offset part of theconsequences of irrational distribution In general PMKLANMKL and their improved algorithms have the preferablerecognition effects especially the improved algorithms withthe accuracy over 90 percent all the time In terms of runtime it is clearly observed that the real-time performance ofMKL is much worse than SVM because MKL has a processof allocating kernel weights and the process can be very timeconsuming Among them LMKL is the worst and fails tosatisfy the real-time requirement Obviously our combinedLR-MKL can reduce the run time manifold even more thanone order of magnitude so it can speed high-precision MKLup to satisfy the real-time requirement In brief the proposedLR-MKL can boost the performance ofMKL to a great extent
6 Conclusion
The complexity of solving convex quadratic optimizationproblem in MKL is 119874(11987311989935) so it is infeasible to apply inlarge scale problems for its large computational cost Oureffort has beenmade on decreasing the dimension of trainingset Note that LRR just can capture the global structure ofdata in relatively few dimensions Therefore we have givena review of several existing MKL algorithms Based on thispoint we have proposed a novel combined LR-MKL whichlargely improves the performance ofMKL A large number ofexperiments have been carried on four real world datasets tocontrast the recognition effects of various kinds of MKL and
LR-MKL algorithms It has been shown that in most casesthe recognition effects of MKL algorithms are better thanSVM(best) except UMKL(lowast) And our proposed LR-MKLmethods have consistently achieved the superior results tothe original MKL Among them PMKL ANMKL and theirimproved algorithms have shown possessing the preferablerecognition effects
Conflicts of Interest
The authors declare that they have no conflicts of interest
Acknowledgments
This work was supported by the National Natural ScienceFoundation of China (no 51208168) Hebei Province NaturalScience Foundation (no E2016202341) and Tianjin NaturalScience Foundation (no 13JCYBJC37700)
References
[1] V N Vapnik ldquoAn overview of statistical learning theoryrdquo IEEETransactions on Neural Networks vol 10 no 5 pp 988ndash9991999
[2] M Hu Y Chen and J T-Y Kwok ldquoBuilding sparse multiple-kernel SVM classifiersrdquo IEEE Transactions on Neural Networksvol 20 no 5 pp 827ndash839 2009
[3] X Wang X Liu N Japkowicz and S Matwin ldquoEnsemble ofmultiple kernel SVM classifiersrdquo Advances in Artificial Intelli-gence vol 8436 pp 239ndash250 2014
[4] E Hassan S Chaudhury N Yadav P Kalra and M GopalldquoOff-line handwritten input based identity determination usingmulti kernel feature combinationrdquo Pattern Recognition Lettersvol 35 no 1 pp 113ndash119 2014
[5] F Cai and V Cherkassky ldquoGeneralized SMO algorithm forSVM-based multitask learningrdquo IEEE Transactions on NeuralNetworks and Learning Systems vol 23 no 6 pp 997ndash10032012
[6] K Crammer O Dekel J Keshet S Shalev-Shwartz andY Singer ldquoOnline passive-aggressive algorithmsrdquo Journal ofMachine Learning Research vol 7 pp 551ndash585 2006
[7] N Cesa-Bianchi A Conconi and C Gentile ldquoOn the gen-eralization ability of on-line learning algorithmsrdquo Institute ofElectrical and Electronics Engineers Transactions on InformationTheory vol 50 no 9 pp 2050ndash2057 2004
[8] S Fine and K Scheinberg ldquoEfficient SVM training usinglow-rank kernel representationsrdquo Journal of Machine LearningResearch vol 2 no 2 pp 243ndash264 2002
[9] S Zhou ldquoSparse LSSVM in primal using cholesky factorizationfor large-scale problemsrdquo IEEETransactions onNeuralNetworksand Learning Systems vol 27 no 4 pp 783ndash795 2016
[10] L Jia S-Z Liao and L-Z Ding ldquoLearning with uncertainkernel matrix setrdquo Journal of Computer Science and Technologyvol 25 no 4 pp 709ndash727 2010
[11] G Liu Z Lin S Yan J Sun Y Yu and Y Ma ldquoRobust recov-ery of subspace structures by low-rank representationrdquo IEEETransactions on Pattern Analysis and Machine Intelligence vol35 no 1 pp 171ndash184 2013
[12] Y Peng A Ganesh J Wright W Xu and Y Ma ldquoRASL robustalignment by sparse and low-rank decomposition for linearly
Computational Intelligence and Neuroscience 9
correlated imagesrdquo IEEE Transactions on Pattern Analysis andMachine Intelligence vol 34 no 11 pp 2233ndash2246 2012
[13] B Cheng G Liu J Wang Z Huang and S Yan ldquoMulti-tasklow-rank affinity pursuit for image segmentationrdquo in Proceed-ings of the IEEE International Conference on Computer Vision(ICCV rsquo11) pp 2439ndash2446 IEEE Barcelona Spain November2011
[14] YMu JDongX Yuan and S Yan ldquoAccelerated low-rank visualrecovery by random projectionrdquo in Proceedings of the 2011 IEEEConference on Computer Vision and Pattern Recognition CVPR2011 pp 2609ndash2616 Colorado Springs Colo USA June 2011
[15] J Chen J Zhou and J Ye ldquoIntegrating low-rank and group-sparse structures for robust multi-task learningrdquo in Proceedingsof the 17th ACM SIGKDD International Conference on Knowl-edge Discovery and Data Mining KDDrsquo11 pp 42ndash50 San DiegoCalif USA August 2011
[16] P Pavlidis J Cai JWeston andWNGrundy ldquoGene functionalclassification fromheterogeneous datardquo inProceedings of the 5thAnnual Internatinal Conference on Computational Biology pp249ndash255 Montreal Canada May 2001
[17] O Chapelle and A Rakotomamonjy ldquoSecond order optimiza-tion of kernel parametersrdquo Nips Workshop on Kernel Learning2008
[18] M Varma and B R Babu ldquoMore generality in efficient mul-tiple kernel learningrdquo in Proceedings of the 26th InternationalConference On Machine Learning ICML 2009 pp 1065ndash1072Montreal Canada June 2009
[19] M Gonen and E Alpaydin ldquoLocalized multiple kernel learn-ingrdquo in Proceedings of the the 25th international conference pp352ndash359 Helsinki Finland July 2008
[20] S Qiu and T Lane ldquoA framework for multiple kernel supportvector regression and its applications to siRNA efficacy predic-tionrdquo IEEEACM Transactions on Computational Biology andBioinformatics vol 6 no 2 pp 190ndash199 2009
[21] CCortesMMohri andARostamizadeh ldquoTwo-stage learningkernel algorithmsrdquo in Proceedings of the 27th InternationalConference on Machine Learning ICML 2010 pp 239ndash246Haifa Israel June 2010
[22] C Cortes M Mohri and A Rostamizadeh ldquoLearning non-linear combinations of kernelsrdquo in Proceedings of the 23rdAnnual Conference on Neural Information Processing Systems(NIPS rsquo09) pp 396ndash404 December 2009
[23] Z Xu R Jin H Yang I King and M R Lyu ldquoSimple andefficient multiple kernel learning by group lassordquo in Proceedingsof the 27th International Conference onMachine Learning ICML2010 pp 1175ndash1182 Haifa Israel June 2010
[24] M Kloft U Brefeld S Sonnenburg and A Zien ldquoNon-sparseregularization and efficient training with multiple kernelsArxiv Preprint abs1003rdquo httpsarxivorgabs10030079
[25] M Gonen and E Alpaydın ldquoMultiple kernel learning algo-rithmsrdquo Journal of Machine Learning Research vol 12 pp 2211ndash2268 2011
[26] F R Bach ldquoConsistency of the group lasso and multiple kernellearningrdquo Journal ofMachine Learning Research vol 9 no 2 pp1179ndash1225 2008
[27] E J Candes X Li Y Ma and JWright ldquoRobust principal com-ponent analysisrdquo Journal of the ACM vol 58 no 3 2011
[28] C-F Chen C-P Wei and Y-C F Wang ldquoLow-rank matrixrecovery with structural incoherence for robust face recogni-tionrdquo in Proceedings of the 2012 IEEE Conference on ComputerVision and Pattern Recognition CVPR 2012 pp 2618ndash2625Providence RI USA June 2012
[29] J-F Cai E J Candes and Z Shen ldquoA singular value thresh-olding algorithm for matrix completionrdquo SIAM Journal onOptimization vol 20 no 4 pp 1956ndash1982 2010
[30] L Zhuang H Gao Z Lin Y Ma X Zhang and N Yu ldquoNon-negative low rank and sparse graph for semi-supervised learn-ingrdquo in Proceedings of the 2012 IEEE Conference on ComputerVision and Pattern Recognition CVPR 2012 pp 2328ndash2335 usaJune 2012
[31] C Chang and C Lin ldquoLIBSVM a Library for support vectormachinesrdquo ACM Transactions on Intelligent Systems and Tech-nology vol 2 no 3 article 27 2011
[32] A Tsanas M A Little C Fox and L O Ramig ldquoObjectiveautomatic assessment of rehabilitative speech treatment inparkinsonrsquos diseaserdquo IEEE Transactions on Neural Systems andRehabilitation Engineering vol 22 no 1 pp 181ndash190 2014
Submit your manuscripts athttpswwwhindawicom
Computer Games Technology
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
Advances in
FuzzySystems
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014
International Journal of
ReconfigurableComputing
Hindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
Applied Computational Intelligence and Soft Computing
thinspAdvancesthinspinthinsp
Artificial Intelligence
HindawithinspPublishingthinspCorporationhttpwwwhindawicom Volumethinsp2014
Advances inSoftware EngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporation
httpwwwhindawicom Volume 2014
Advances in
Multimedia
International Journal of
Biomedical Imaging
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational Intelligence and Neuroscience
Industrial EngineeringJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Human-ComputerInteraction
Advances in
Computer EngineeringAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014

Computational Intelligence and Neuroscience 9
correlated imagesrdquo IEEE Transactions on Pattern Analysis andMachine Intelligence vol 34 no 11 pp 2233ndash2246 2012
[13] B Cheng G Liu J Wang Z Huang and S Yan ldquoMulti-tasklow-rank affinity pursuit for image segmentationrdquo in Proceed-ings of the IEEE International Conference on Computer Vision(ICCV rsquo11) pp 2439ndash2446 IEEE Barcelona Spain November2011
[14] YMu JDongX Yuan and S Yan ldquoAccelerated low-rank visualrecovery by random projectionrdquo in Proceedings of the 2011 IEEEConference on Computer Vision and Pattern Recognition CVPR2011 pp 2609ndash2616 Colorado Springs Colo USA June 2011
[15] J Chen J Zhou and J Ye ldquoIntegrating low-rank and group-sparse structures for robust multi-task learningrdquo in Proceedingsof the 17th ACM SIGKDD International Conference on Knowl-edge Discovery and Data Mining KDDrsquo11 pp 42ndash50 San DiegoCalif USA August 2011
[16] P Pavlidis J Cai JWeston andWNGrundy ldquoGene functionalclassification fromheterogeneous datardquo inProceedings of the 5thAnnual Internatinal Conference on Computational Biology pp249ndash255 Montreal Canada May 2001
[17] O Chapelle and A Rakotomamonjy ldquoSecond order optimiza-tion of kernel parametersrdquo Nips Workshop on Kernel Learning2008
[18] M Varma and B R Babu ldquoMore generality in efficient mul-tiple kernel learningrdquo in Proceedings of the 26th InternationalConference On Machine Learning ICML 2009 pp 1065ndash1072Montreal Canada June 2009
[19] M Gonen and E Alpaydin ldquoLocalized multiple kernel learn-ingrdquo in Proceedings of the the 25th international conference pp352ndash359 Helsinki Finland July 2008
[20] S Qiu and T Lane ldquoA framework for multiple kernel supportvector regression and its applications to siRNA efficacy predic-tionrdquo IEEEACM Transactions on Computational Biology andBioinformatics vol 6 no 2 pp 190ndash199 2009
[21] CCortesMMohri andARostamizadeh ldquoTwo-stage learningkernel algorithmsrdquo in Proceedings of the 27th InternationalConference on Machine Learning ICML 2010 pp 239ndash246Haifa Israel June 2010
[22] C Cortes M Mohri and A Rostamizadeh ldquoLearning non-linear combinations of kernelsrdquo in Proceedings of the 23rdAnnual Conference on Neural Information Processing Systems(NIPS rsquo09) pp 396ndash404 December 2009
[23] Z Xu R Jin H Yang I King and M R Lyu ldquoSimple andefficient multiple kernel learning by group lassordquo in Proceedingsof the 27th International Conference onMachine Learning ICML2010 pp 1175ndash1182 Haifa Israel June 2010
[24] M Kloft U Brefeld S Sonnenburg and A Zien ldquoNon-sparseregularization and efficient training with multiple kernelsArxiv Preprint abs1003rdquo httpsarxivorgabs10030079
[25] M Gonen and E Alpaydın ldquoMultiple kernel learning algo-rithmsrdquo Journal of Machine Learning Research vol 12 pp 2211ndash2268 2011
[26] F R Bach ldquoConsistency of the group lasso and multiple kernellearningrdquo Journal ofMachine Learning Research vol 9 no 2 pp1179ndash1225 2008
[27] E J Candes X Li Y Ma and JWright ldquoRobust principal com-ponent analysisrdquo Journal of the ACM vol 58 no 3 2011
[28] C-F Chen C-P Wei and Y-C F Wang ldquoLow-rank matrixrecovery with structural incoherence for robust face recogni-tionrdquo in Proceedings of the 2012 IEEE Conference on ComputerVision and Pattern Recognition CVPR 2012 pp 2618ndash2625Providence RI USA June 2012
[29] J-F Cai E J Candes and Z Shen ldquoA singular value thresh-olding algorithm for matrix completionrdquo SIAM Journal onOptimization vol 20 no 4 pp 1956ndash1982 2010
[30] L Zhuang H Gao Z Lin Y Ma X Zhang and N Yu ldquoNon-negative low rank and sparse graph for semi-supervised learn-ingrdquo in Proceedings of the 2012 IEEE Conference on ComputerVision and Pattern Recognition CVPR 2012 pp 2328ndash2335 usaJune 2012
[31] C Chang and C Lin ldquoLIBSVM a Library for support vectormachinesrdquo ACM Transactions on Intelligent Systems and Tech-nology vol 2 no 3 article 27 2011
[32] A Tsanas M A Little C Fox and L O Ramig ldquoObjectiveautomatic assessment of rehabilitative speech treatment inparkinsonrsquos diseaserdquo IEEE Transactions on Neural Systems andRehabilitation Engineering vol 22 no 1 pp 181ndash190 2014
Submit your manuscripts athttpswwwhindawicom
Computer Games Technology
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
Advances in
FuzzySystems
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014
International Journal of
ReconfigurableComputing
Hindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
Applied Computational Intelligence and Soft Computing
thinspAdvancesthinspinthinsp
Artificial Intelligence
HindawithinspPublishingthinspCorporationhttpwwwhindawicom Volumethinsp2014
Advances inSoftware EngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporation
httpwwwhindawicom Volume 2014
Advances in
Multimedia
International Journal of
Biomedical Imaging
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational Intelligence and Neuroscience
Industrial EngineeringJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Human-ComputerInteraction
Advances in
Computer EngineeringAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014

Submit your manuscripts athttpswwwhindawicom
Computer Games Technology
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Distributed Sensor Networks
International Journal of
Advances in
FuzzySystems
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014
International Journal of
ReconfigurableComputing
Hindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
Applied Computational Intelligence and Soft Computing
thinspAdvancesthinspinthinsp
Artificial Intelligence
HindawithinspPublishingthinspCorporationhttpwwwhindawicom Volumethinsp2014
Advances inSoftware EngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporation
httpwwwhindawicom Volume 2014
Advances in
Multimedia
International Journal of
Biomedical Imaging
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Advances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 201
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Computational Intelligence and Neuroscience
Industrial EngineeringJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Human-ComputerInteraction
Advances in
Computer EngineeringAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014


















