
Efficient Image Search and Retrieval using Compact Binary Codes Rob Fergus (NYU) Antonio Torralba...
38
Efficient Image Search and Retrieval using Compact Binary Codes Rob Fergus (NYU) Antonio Torralba (MIT) Yair Weiss (Hebrew U.)
-
Upload
david-perkins -
Category
Documents
-
view
222 -
download
1
Transcript of Efficient Image Search and Retrieval using Compact Binary Codes Rob Fergus (NYU) Antonio Torralba...

Efficient Image Search and Retrieval using Compact
Binary Codes
Rob Fergus (NYU)Antonio Torralba (MIT)Yair Weiss (Hebrew U.)

How can we search them, based on visual content?
Large scale image search
Internet contains many billions of images
The Challenge:– Need way of measuring similarity between images– Needs to scale to Internet

Existing approaches to Content-Based Image Retrieval
• Focus of scaling rather than understanding image• Variety of simple/hand-designed cues:– Color and/or Texture histograms, Shape, PCA, etc.
• Various distance metrics– Earth Movers Distance (Rubner et al. ‘98)
• Most recognition approaches slow (~1sec/image)

Our Approach
• Learn the metric from training data
DO BOTH TOGETHER
• Use compact binary codes for speed

Large scale image/video search• Representation must fit in memory (disk too slow)
• Facebook has ~10 billion images (1010)• PC has ~10 Gbytes of memory (1011 bits) Budget of 101 bits/image
• YouTube has ~ a trillion video frames (1012)• Big cluster of PCs has ~10 Tbytes (1014 bits) Budget of 102 bits/frame

Binary codes for images
• Want images with similar contentto have similar binary codes
• Use Hamming distance between codes– Number of bit flips– E.g.:
• Semantic Hashing [Salakhutdinov & Hinton, 2007]– Text documents
Ham_Dist(10001010,10001110)=1
Ham_Dist(10001010,11101110)=3
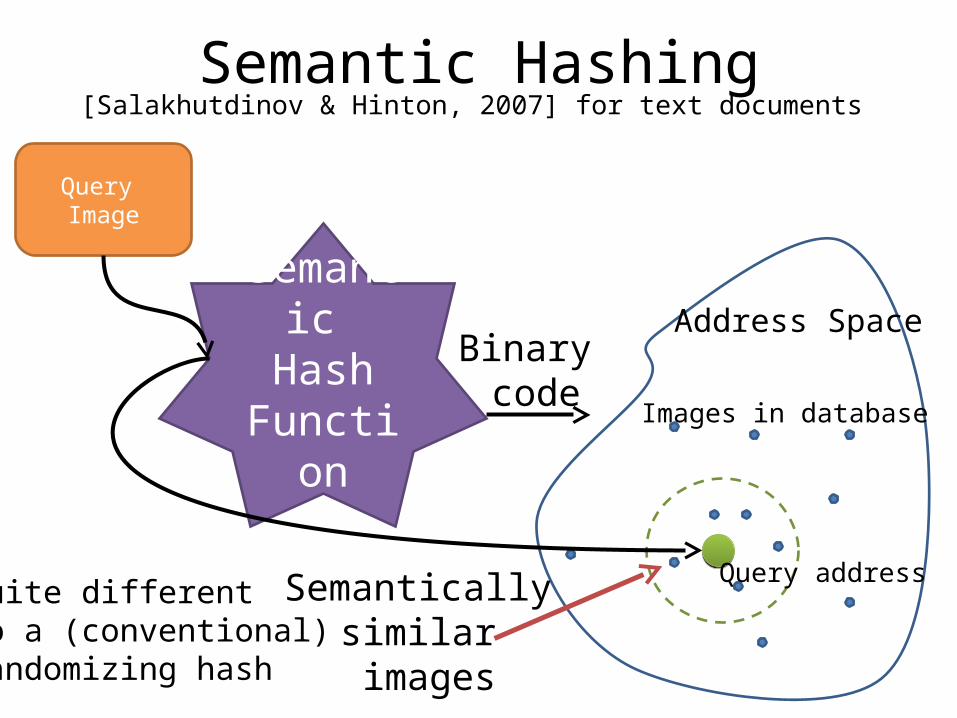
Semantic Hashing
Address Space
Semantically similar images
Query address
Semantic
HashFunction
Query Image
Binary code
Images in database
[Salakhutdinov & Hinton, 2007] for text documents
Quite differentto a (conventional)randomizing hash

Semantic Hashing
• Each image code is a memory address• Find neighbors by exploring Hamming
ball around query address Address Space
Query address
Images in database
ChooseCode length
Radius
• Lookup time is independentof # of data points
• Depends on radius of ball & length of code:

Code requirements
• Similar images Similar Codes• Very compact (<102 bits/image)• Fast to compute• Does NOT have to reconstruct image
Three approaches:1. Locality Sensitive Hashing (LSH)2. Boosting3. Restricted Boltzmann Machines (RBM’s)

Input Image representation: Gist vectors
• Pixels not a convenient representation• Use Gist descriptor instead (Oliva & Torralba,
2001)• 512 dimensions/image (real-valued 16,384 bits)• L2 distance btw. Gist vectors not bad substitute for
human perceptual distance
Oliva & Torralba, IJCV 2001
NO COLOR INFORMATION

1. Locality Sensitive Hashing• Gionis, A. & Indyk, P. & Motwani, R. (1999)• Take random projections of data• Quantize each projection with few bits
0
1
0
10
1
101
No learning involved
Gist descriptor

2. Boosting• Modified form of BoostSSC
[Shaknarovich, Viola & Darrell, 2003]• Positive examples are pairs of similar images• Negative examples are pairs of unrelated images
0
10
1
0 1
Learn threshold & dimension for each bit (weak classifier)

3. Restricted Boltzmann Machine (RBM)
Hidden units
Visible units
Symmetric weights
• Type of Deep Belief Network• Hinton & Salakhutdinov, Science 2006
SingleRBMlayer
• Attempts to reconstruct input at visible layer from activation of hidden layer
W
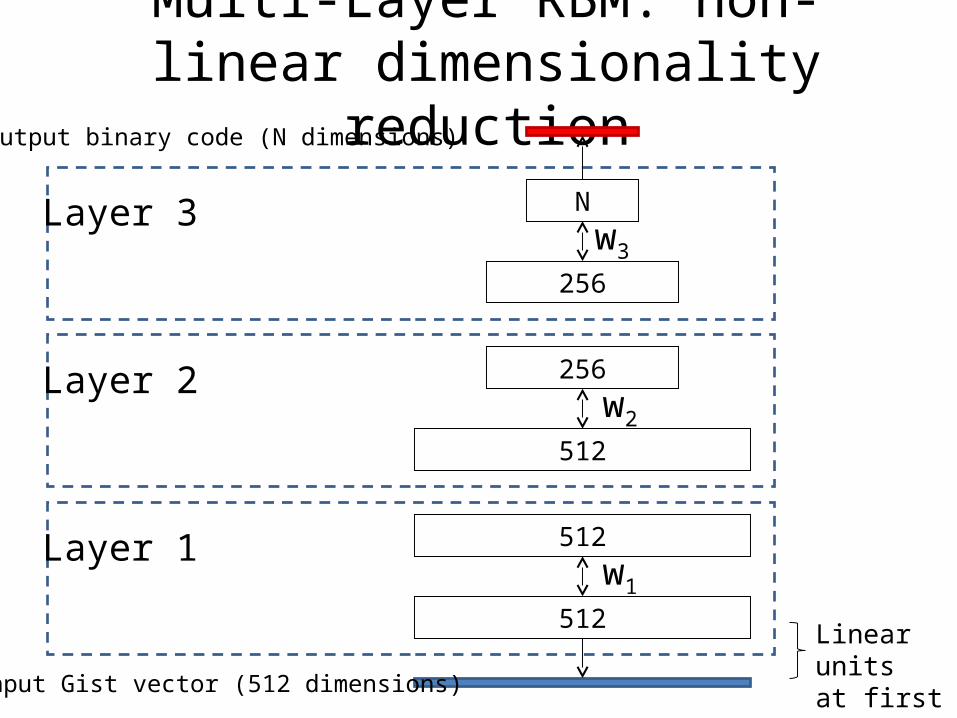
Multi-Layer RBM: non-linear dimensionality reduction
512
512w1
Input Gist vector (512 dimensions)
Layer 1
512
256w2
Layer 2
256
Nw3
Layer 3
Output binary code (N dimensions)
Linear units at first layer

Training RBM models
1st Phase: Pre-training
Unsupervised
Can use unlabeled data (unlimited quantity)
Learn parameters greedily per layer
Gets them to right ballpark
2nd Phase: Fine-tuning
Supervised
Requires labeled data(limited quantity)
Back propagate gradients of chosen error function
Moves parameters to local minimum

Greedy pre-training (Unsupervised)
512
512w1
Input Gist vector (512 real dimensions)
Layer 1

Greedy pre-training (Unsupervised)
Activations of hidden units from layer 1 (512 binary dimensions)
512
256w2
Layer 2

Greedy pre-training (Unsupervised)
Activations of hidden units from layer 2 (256 binary dimensions)
256
Nw3
Layer 3

Fine-tuning: back-propagation of Neighborhood Components Analysis objective
512
512
Input Gist vector (512 real dimensions)
Layer 1
512
256Layer 2
256
NLayer 3
Output binary code (N dimensions)
w1 + ∆ w1
w2 + ∆ w2
w3 + ∆w3 w3
w2
w1

Neighborhood Components Analysis• Goldberger, Roweis, Salakhutdinov & Hinton, NIPS 2004• Tries to preserve neighborhood structure of input space– Assumes this structure is given (will explain later)
Points in output space (coordinate is activation probability of unit)
Toy example with 2 classes & N=2 units at top of network:

Neighborhood Components Analysis• Adjust network parameters (weights and biases)
to move:– Points of SAME class closer
– Points of DIFFERENT class away

Neighborhood Components Analysis• Adjust network parameters (weights and biases)
to move:– Points of SAME class closer
– Points of DIFFERENT class away
Points close in input space (Gist) will be close in output code space

Simple Binarization Strategy
Set threshold- e.g. use median
0
1
0 1

Overall Query Scheme
Query Image
RBM
Compute Gist
Binary codeBinary code
Gist descriptor
Image 1
Semantic Hash
Retrieved images <1ms
~1ms (in Matlab)
<10μs

Retrieval Experiments

Test set 1: LabelMe
• 22,000 images (20,000 train | 2,000 test)• Ground truth segmentations for all• Can define ground truth distance btw. images
using these segmentations

Defining ground truth • Boosting and NCA back-propagation require
ground truth distance between images• Define this using labeled images from LabelMe

Defining ground truth • Pyramid Match (Lazebnik et al. 2006, Grauman & Darrell 2005)

Defining ground truth • Pyramid Match (Lazebnik et al. 2006, Grauman & Darrell 2005)
CarCar
Sky
Tree
Car
Road
Building
Car
Tree
Road
Building
CarCar
Sky
Tree
Car
Road
Building
Car
Tree
Road
Building
CarCar
Sky
Tree
Car
Road
Building
Car
Tree
Road
Building
Varying spatial resolution to capture approximate spatial correspondance

Examples of LabelMe retrieval• 12 closest neighbors under different distance metrics

LabelMe Retrieval
Size of retrieval set % o
f 50
true
nei
ghbo
rs in
retr
ieva
l set
0 2,000 10,000 20,0000
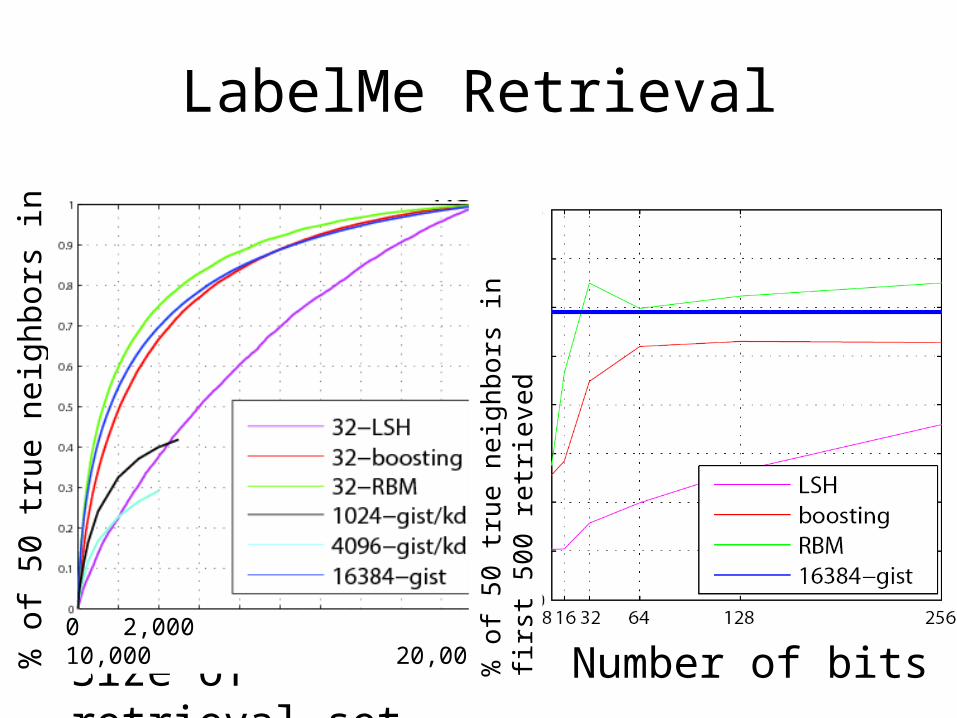
LabelMe Retrieval
Size of retrieval set % o
f 50
true
nei
ghbo
rs in
retr
ieva
l set
0 2,000 10,000 20,0000
Number of bits% o
f 50
true
nei
ghbo
rs in
firs
t 500
retr
ieve
d

Test set 2: Web images
• 12.9 million images• Collected from Internet• No labels, so use Euclidean distance between
Gist vectors as ground truth distance

Web images retrieval%
of 5
0 tr
ue n
eigh
bors
in re
trie
val s
et
Size of retrieval set

Web images retrieval
Size of retrieval set
% o
f 50
true
nei
ghbo
rs in
retr
ieva
l set
% o
f 50
true
nei
ghbo
rs in
retr
ieva
l set
Size of retrieval set

Examples of Web retrieval
• 12 neighbors using different distance metrics

Retrieval Timings

Summary
• Explored various approaches to learning binary codes for hashing-based retrieval– Very quick with performance comparable to complex
descriptors
• More recent work on binarization– Spectral Hashing (Weiss, Torralba, Fergus NIPS 2009)


















