
EECS 570 Lecture 5 Applications - University of Michigan · •Process large data sets ... , BAAN,...
41
Lecture 5 Slide 1 EECS 570 EECS 570 Lecture 5 Applications Winter 2018 Prof. Satish Narayanasamy http://www.eecs.umich.edu/courses/eecs570/ Special thanks to Babak Falsafi (EPFL) for ecocloud slides Slides developed in part by Profs. Falsafi , Hardavellas , Nowatzyk , Mytkowicz and Wenisch of EPFL, Northwestern, CMU , Microsoft, U - M.
Transcript of EECS 570 Lecture 5 Applications - University of Michigan · •Process large data sets ... , BAAN,...

Lecture 5 Slide 1EECS 570
EECS570Lecture5ApplicationsWinter2018
Prof.SatishNarayanasamy
http://www.eecs.umich.edu/courses/eecs570/
SpecialthankstoBabak Falsafi (EPFL)forecocloud slides
Slides developed in part by Profs. Falsafi, Hardavellas, Nowatzyk, Mytkowiczand Wenisch of EPFL, Northwestern, CMU, Microsoft, U-M.

Lecture 5 Slide 2EECS 570
Announcements
ProjectproposaldueWednesdayviaCanvas
ProgrammingAssignment1dueFriday2/211:59pm• UploadzipinCanvas
Projectkick-offmeetings– signuptomeet

Lecture 5 Slide 3EECS 570
ReadingsForToday:
❒ P.Ranganathan,K.Gharachorloo,S.V.Adve,andL.A.Barroso,“PerformanceofDatabaseWorkloadsonShared-MemorySystemswithOut-of-OrderProcessors.”ASPLOS1998
❒ M.Ferdman,A.Adileh,O.Kocberber,S.Volos,M.Alisafaee,D.Jevdjic,C.Kaynak,A.Popescu,A.Ailamaki,B.Falsafi,ClearingtheClouds:AStudyofEmergingWorkloadsonModernHardware,ASPLOS 2012
ForFriday:❒ MichaelScott.Shared-MemorySynchronization.Morgan&
ClaypoolSynthesisLecturesonComputerArchitecture(Ch.1,4.0-4.3.3,5.0-5.2.5)
❒ AlainKagi,DougBurger,andJimGoodman.EfficientSynchronization:LetThemEatQOLB,Proc.24thInternationalSymposiumonComputerArchitecture(ISCA24),June,1997.

Lecture 5 Slide 4EECS 570
Applications

Lecture 5 Slide 5EECS 570
What is a “scientific application”Frequentcharacteristics:• Computeintensive,usuallyFPheavy(butnotalways,e.g.,logicsimulation,theoremproving,cryptography)
• Processlargedatasets• Singleproblem:wall-clocktimetoanswermatters• Corecodefootprintstendtobesmall
❒ Kernels– smallpiecesofcriticalcode;typicallyinnerloops
• Dataaccesspatternsoftenpredictable• Vectorization oftenworks

Lecture 5 Slide 6EECS 570
Traditional Server Software (a.k.a Scale-up)
• Historically,primarymarketformultiprocessorsystems• Examples:
❒ Databasesystems:Oracle,DB2,SQLServer,PostGres,MySQL❒ Businessapps:SAP,BAAN,PeopleSoft❒ Dataanalysis:largescalegraphprocessing❒ Web-servers
❍ Staticcontent❍ Dynamiccontent:databaseintegration+businesslogic❍ Web2.0:user-suppliedcontent
❒ Infrastructureapps:J2EE

Lecture 5 Slide 7EECS 570
Why study database apps?• Theyareeconomicallyimportant
• Theysharecharacteristicsofmanyotherapps(filesystems,websearch,etc.)
• Thevendorshavespentalotoftimeoptimizing(generally,theywon’thavesillybottlenecks)

Lecture 5 Slide 8EECS 570
Key characteristics• Large,complex,monolithicsoftwaresystems
• DesignedforMPsystems❒ Clusters(distributeddatabases)❒ SharedMemory
• SubsumesmanyOSfunctions❒ Filesystem❒ Schedulingandmulti-threading❒ Memorymanagement
• Designedforhighreliability(ACIDproperties)❒ Atomicity:atransactionhappensordoesn’t❒ Consistency:thestateoftheDBremainsconsistent❒ Isolation:transactionsareindependent❒ Durability:onceperformed,transactionsarepermanent❒ Aside:wewillseetheseideaspopupinarchitecturecontext
againwithtransactionalmemory

Lecture 5 Slide 9EECS 570
How are they different from Sci Apps?
• Requirestuning:knowledge-intensive,difficult• Competitivemarket:deliberateobfuscation/benchmarkgaming• Largeinstructionfootprints(I$matters)• Hugedatafootprints(TLBsmatter)• Weirdaccesstypes(cross-endian,non-cacheable,etc.)• Latency,notbandwidthbound• Dynamicmemoryallocation,sometimesgarbagecollection• Morepointer-chasing,fewerarrays• Nosingleobvious“workingset”
❒ multipleworkingsetswithvaryingtemporallocality• Unpredictablesharingpatterns• Data&lockcontention

Lecture 5 Slide 10EECS 570
DBMS Structure
Source: Silberschatz, Korth, Sudarshan. Database System Concepts
Lecture 5 Slide 11EECS 570
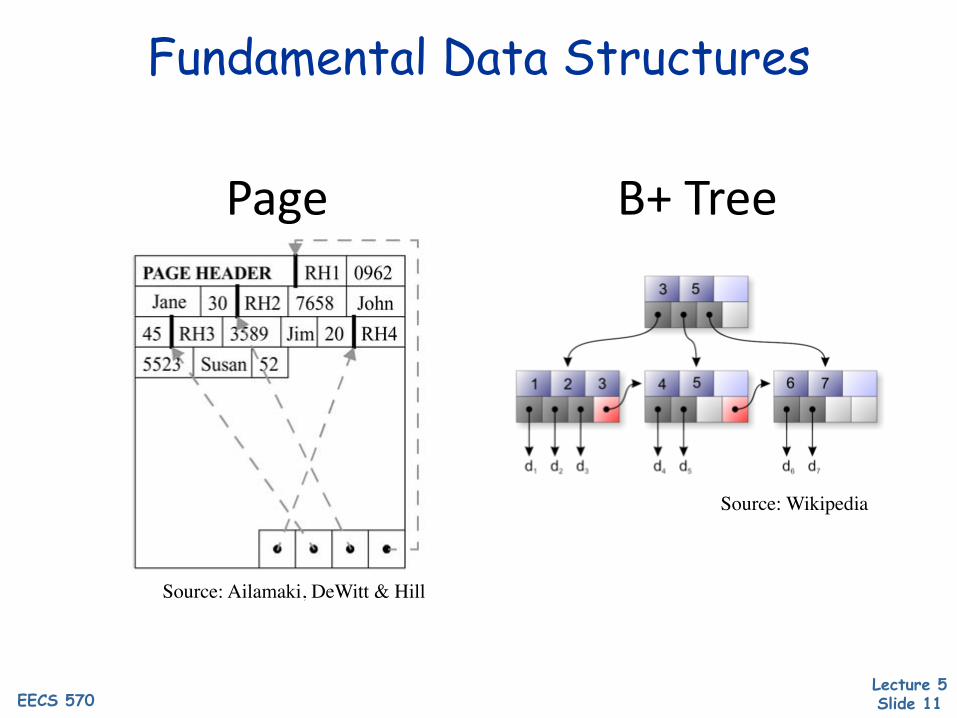
Fundamental Data Structures
B+TreePage
Source: Ailamaki, DeWitt & Hill
Source: Wikipedia

Lecture 5 Slide 12EECS 570
Where does time go: Microbenchmarks
• Computetime<50%oftotaltimeSource:Ailamaki etal– DBMSsonAModernProcessor:Wheredoestimego?– VLDB99

Lecture 5 Slide 13EECS 570
Where does time go:Memory stalls breakdown
• L1instructionandL2datastallsdominateSource:Ailamaki etal– DBMSsonAModernProcessor:Wheredoestimego?– VLDB99

Lecture 5 Slide 14EECS 570
Standardized Benchmarks
• TransactionProcessingCouncil(TPC)❒ Strictscaling,disclosure,auditingrules❒ Runningtheseforrealishard:bighardware,20-50engineers,
monthsofeffort❒ Runningtheminsimulationsisalsohard:scaling,non-determinism
• Twoflavorsofbenchmark❒ Online transactionprocessing(OLTP):TPC-C
❒ Lotsofsmalltransactions❒ Lotsoflocking,concurrency,I/O;memory-latencybound
❒ Decisionsupportsystem(DSS):TPC-H❒ Large,complexread-onlyqueries❒ Oftencomputebound(givenenoughdisks)❒ Highlyparallel
❒ Datapartitioning❒ Paralleloperators

Lecture 5 Slide 15EECS 570
Performance of DB Workloads on Shared Memory with OoO CPUs
[Ranganathan et al - ISCA 98]
ExaminesimpactofILPandmultiprocessingonDSS&OLTP• Basedonextensivesimulations• Explores:
❒ Multipleissue❒ Out-of-order(includingwindowsize)❒ Numberofoutstandingmisses❒ Instruction/branchpredictioneffects❒ Impactofmultiprocessing&memoryconsistency❒ Waystomitigateinstruction&coherencemisses

Lecture 5 Slide 16EECS 570
• LotsofILP•Multipleissuehelps,butOoO helpsmore• L2hitsaccountformostdatastalls•Multipleoutstandingmissesarecritical
DSS – Impact of ILP

Lecture 5 Slide 17EECS 570
• Instructioncachemisses&syncharenowissues• LessILP,but2-waystillhelpsalot• Coherence(dirty)&DTLBmissescausemostreadstalls• 2outstandingmissesiscritical,butmoredoesn’thelp
OLTP – Impact of ILP

Lecture 5 Slide 18EECS 570
Impact of Multiprocessing
• Coherencemisses&syncaredramaticinOLTP
OLTP DSS

Lecture 5 Slide 19EECS 570
Impact of Memory Consistency
• SC=sequentialconsistency• PC=asystemwithawritebuffer(loadsbypassstores)• RC=waitonlyatsynchronizationinstructions•Massiveperformancedifference!
❒ Wewillrevisitthislaterinthecourse…
OLTP DSS

Lecture 5 Slide 20EECS 570
Cloud Computing Software(scale-out)

© 2011 Babak Falsafi
Whatabout“cloudcomputing”software?[Ferdman etal- ASPLOS2012]
Emergingworkloads:• Scaleout• Oftendataintensive• Likeconventionalserverworkloads
DifferentfromCPUbenchmarksuites:• UseofFP• Donotexercisethememoryhierarchy• Similartoconventionalserverworkloads[CIDR’07]

© 2011 Babak Falsafi
CloudSuite:ABenchmarkSuiteofEmergingScale-OutWorkloads
PubliclyreleasedAlphaversion:• Analytics(Classification)• Dataserving(YCSB)• Simulation(Cloud9)• Streaming(Darwin)• Webfrontend(Cloudstone)• Websearch(Nutch)

© 2011 Babak Falsafi
RanExperimentsonNehalemBladesHardware Specifications
Processor IntelXeon5670,6cores,[email protected]
CMPSize 6OoO cores
Superscalarwidth 4-wideissue
Reorderbuffer 128entries
Load/Storebuffer 48/32entries
Reservationstations 36entries
L1Cache splitI/D,32KB,4-cyclesaccesslatency
L2Cache 6-coreCMP:256KBpercore,12-cyclesaccesslatency
LLC(L3)cache 12MB,cycles39-cyclesaccesslatency
Memory 24GB,180/280cyclesaccesslatencylocal/remoteDRAM
Wheredoestimego?

© 2011 Babak Falsafi
ExecutionBreakdown
• Unlikedesktop/RMSapps,memorystallsdominate• Designshouldbecenteredaroundmemory

© 2011 Babak Falsafi
Front-EndInefficiencies
0%
25%
50%
75%
100%C
ore
stal
l tim
e
Frontend Backend
• Instruction fetch: 10-60% of total stalls• Next-line prefetch. (in the CPU) not efficient

© 2011 Babak Falsafi
CoreInefficiencies
• Low IPC & MLP despite 4-wide OoO core• Using SMT doubles MLP• But, SMT achieves only 30% performance gain
• Threads compete for core resources• Intel’s SMT fetch not effective
0
1
2
Data S
ervin
g
MapRed
uce
Media
Simula
tion
Web
Fro
ntend
Web
Sea
rch
Ap
plic
atio
n IP
C
Base SMT
0
1
2
3
4
Data S
ervin
g
MapRed
uce
Media
Simula
tion
Web
Fro
ntend
Web
Sea
rch
App
licat
ion
MLP
Base SMT

© 2011 Babak Falsafi
CacheCapacity(LLC)Inefficiencies
• Large LLC consumes area, but has diminishing returns• Results (not shown) indicate much LLC accesses are
instructions

© 2011 Babak Falsafi
DataPrefetchingInefficiencies
0
20
40
60
80
100
L2 H
it ra
tio (%
)
0
20
40
60
80
100
LLC
Hit
ratio
(%)
Base Adjacent disabled Stride disabled
• Existing prefetchers are ineffective• Pointer-intensive patterns [Wenisch 2005]
© 2011 Babak Falsafi
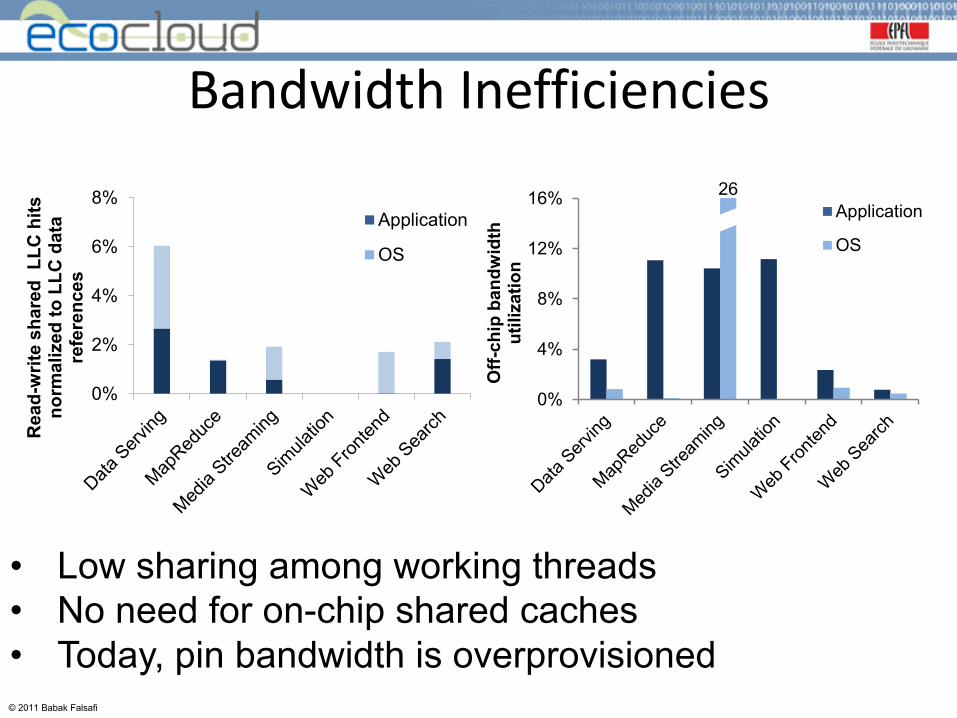
BandwidthInefficiencies
0%
2%
4%
6%
8%
Rea
d-w
rite
shar
ed L
LC h
its
norm
aliz
ed to
LLC
dat
a re
fere
nces
Application
OS
• Low sharing among working threads• No need for on-chip shared caches• Today, pin bandwidth is overprovisioned
0%
4%
8%
12%
16%
Off-
chip
ban
dwid
th
utili
zatio
n
26Application
OS

© 2011 Babak Falsafi
CloudSuiteConclusions
Corroboratepriorfindings[CIDR’07]Scale-outworkloadsneed:• Simple(multithreaded)cores• Partitionedcaches(nosharing)• Largeon-chipinstructionfootprints• Advancedprefetchers

Sirius: An Open End-to-End Voice and Vision Personal Assistant and Its Implications for Future Warehouse Scale ComputersJohann Hauswald, Michael A. Laurenzano, Yunqi Zhang, Cheng Li, Austin Rovinski, Arjun Khurana, Ron Dreslinski, Trevor Mudge, Vinicius Petrucci, Lingjia Tang, Jason Mars
University of Michigan — Ann Arbor, MI

DjiNN and Tonic: DNN as a Service 32
• Sirius: full end-to-end with inputs, pre-trained models, and databases• Sirius-suite: 7 kernels with inputs to study each service individually
32
Answer
Question-Answering
Search Database
Question
ActionExecute
Action
Mob
ile
Ser
ver
DisplayAnswer
ImageDatabase
Image Matching
Image
Image D
ataVoice Question
orAction
Query Classifier
AutomaticSpeech-Recognition
Users
Sirius: An Open End-to-End Voice and Vision Personal Assistant
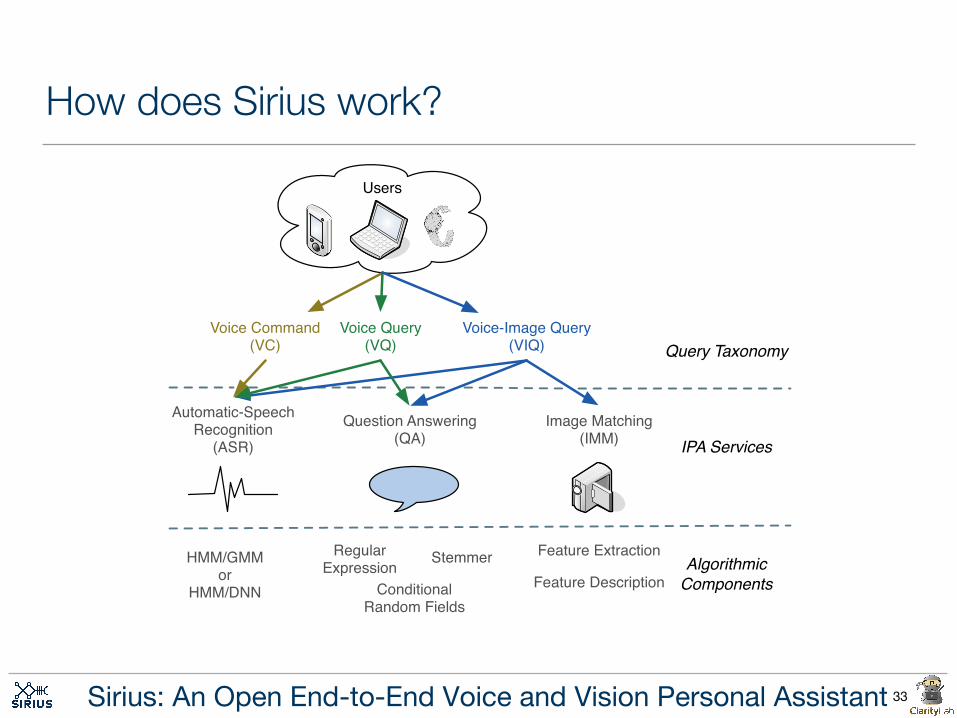
How does Sirius work?
33
Users
Voice Command(VC)
Voice Query(VQ)
Voice-Image Query(VIQ) Query Taxonomy
IPA Services
AlgorithmicComponents
HMM/GMMor
HMM/DNN
Automatic-Speech Recognition
(ASR)
StemmerRegularExpression
ConditionalRandom Fields
Question Answering(QA)
Feature Extraction
Feature Description
Image Matching(IMM)

DjiNN and Tonic: DNN as a Service
Sirius-suite
34
GMM (85%)DNN (78%)
Stemmer (46%)Regex (22%)CRF (17%)
FE (41%)FD (56%)
7 kernels: 92% total execution of Sirius
Suite entirely written in C/C++/CUDA
Release includes inputs and models
Users
Voice Command(VC)
Voice Query(VQ)
Voice-Image Query(VIQ) Query Taxonomy
IPA Services
AlgorithmicComponents
HMM/GMMor
HMM/DNN
Automatic-Speech Recognition
(ASR)
StemmerRegularExpression
ConditionalRandom Fields
Question Answering(QA)
Feature Extraction
Feature Description
Image Matching(IMM)

DjiNN and Tonic: DNN as a Service
Upgrading Datacenters with COTS Systems
35
Platform Model Clock Threads
Multicore CPU Intel Xeon E3-1240 V3 3.40 GHz 8
GPU NVIDIA GTX 770 1.05 GHz 12288
Intel Phi Phi 5110P 1.05 GHz 240
FPGA Xilinx Virtex-6 ML605 400 MHz N/A

DjiNN and Tonic: DNN as a Service
Upgrading Datacenters with COTS Systems
36
Platform Advantage Disadvantage
Multicore CPU Minor SW changes Limited speedup
GPU Many threads Programability
Intel Phi Manycore Limited compiler support
FPGA Flexible New implementation

DjiNN and Tonic: DNN as a Service
Acceleration Overview
37
Platform GMM DNN Stemmer Regex CRF FE FD
CMP 3.5 6.0 4.0 3.9 3.7 5.2 5.9
GPU 70.0 54.7 6.2 48.0* 3.8* 10.5 120.5
Intel Phi 1.1 11.2 5.6 1.1 4.7 2.5 12.7
FPGA 169.0 110.5* 30.0 168.2* 7.5* 34.6* 75.5*

DjiNN and Tonic: DNN as a Service and Its Implications for Future Warehouse Scale Computers
Johann Hauswald, Yiping Kang, Michael A. Laurenzano, Quan Chen, Cheng Li, Trevor Mudge, Ronald G. Dreslinski, Jason Mars, Lingjia Tang
University of Michigan — Ann Arbor, MI
DjiNN and Tonic: DNN as a Service
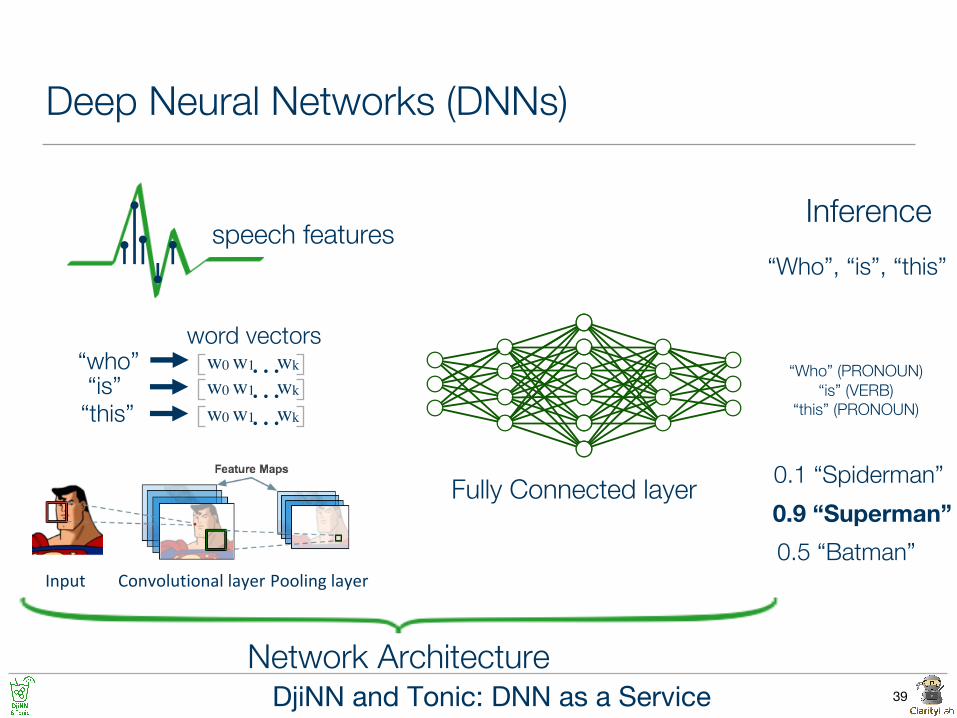
Deep Neural Networks (DNNs)
39
Inference
0.9 “Superman”
speech features
Network Architecture
0.5 “Batman”
0.1 “Spiderman”
word vectors“who” wkw0 w1…
wkw0 w1…wkw0 w1…
“is”“this”
Convolutionallayer PoolinglayerInput
Fully Connected layer
“Who”, “is”, “this”
“Who” (PRONOUN)“is” (VERB)
“this” (PRONOUN)

DjiNN and Tonic: DNN as a Service 40
Users
DNN Architecture
IMC DIG FACE ASR
POS CHK NER
Trained Models
DjiNN DNN Service
Natural Language Processing Task
POS “business” (noun) “Superman” (P. noun)
CHK “It’s” (VP, B-NP)“business” (NP, I-NP)
NER “Superman” (PERSON)
IMCImage Task
FACEDIG
Speech Recognition (ASR) Task
“It’s business, Superman”
Tonic Suite Applications

DjiNN and Tonic: DNN as a Service
DNN as a Service
41
Image Classification
Digit Recognition
Facial Recognition
Speech Recognition
Natural LanguageProcessing
Unified, highly optimized appliance
for DNN


















