
EECC550 - Shaaban #1 Final Review Summer 2001 8-10-2001 CPU Organization Datapath Design:...
88
EECC550 - Shaaban EECC550 - Shaaban #1 Final Review Summer 2001 8-10 CPU Organization CPU Organization • Datapath Design: – Capabilities & performance characteristics of principal Functional Units (FUs): – (e.g., Registers, ALU, Shifters, Logic Units, ...) – Ways in which these components are interconnected (buses connections, multiplexors, etc.). – How information flows between components. • Control Unit Design: – Logic and means by which such information flow is controlled. – Control and coordination of FUs operation to realize the targeted Instruction Set Architecture to be implemented (can either be implemented using a finite state machine or a microprogram). • Hardware description with a suitable language, possibly using Register Transfer Notation (RTN).
-
date post
21-Dec-2015 -
Category
Documents
-
view
217 -
download
0
Transcript of EECC550 - Shaaban #1 Final Review Summer 2001 8-10-2001 CPU Organization Datapath Design:...

EECC550 - ShaabanEECC550 - Shaaban#1 Final Review Summer 2001 8-10-2001
CPU OrganizationCPU Organization• Datapath Design:
– Capabilities & performance characteristics of principal Functional Units (FUs):
– (e.g., Registers, ALU, Shifters, Logic Units, ...)– Ways in which these components are interconnected (buses
connections, multiplexors, etc.).– How information flows between components.
• Control Unit Design:– Logic and means by which such information flow is controlled.– Control and coordination of FUs operation to realize the targeted
Instruction Set Architecture to be implemented (can either be implemented using a finite state machine or a microprogram).
• Hardware description with a suitable language, possibly using Register Transfer Notation (RTN).

EECC550 - ShaabanEECC550 - Shaaban#2 Final Review Summer 2001 8-10-2001
CPU Execution Time: The CPU EquationCPU Execution Time: The CPU Equation• A program is comprised of a number of instructions
– Measured in: instructions/program
• The average instruction takes a number of cycles per instruction (CPI) to be completed. – Measured in: cycles/instruction
• CPU has a fixed clock cycle time = 1/clock rate – Measured in: seconds/cycle
• CPU execution time is the product of the above three parameters as follows:
CPU time = Seconds = Instructions x Cycles x Seconds
Program Program Instruction Cycle
CPU time = Seconds = Instructions x Cycles x Seconds
Program Program Instruction Cycle

EECC550 - ShaabanEECC550 - Shaaban#3 Final Review Summer 2001 8-10-2001
Instruction Types & CPI: An ExampleInstruction Types & CPI: An Example• An instruction set has three instruction classes:
• Two code sequences have the following instruction counts:
• CPU cycles for sequence 1 = 2 x 1 + 1 x 2 + 2 x 3 = 10 cycles
CPI for sequence 1 = clock cycles / instruction count
= 10 /5 = 2
• CPU cycles for sequence 2 = 4 x 1 + 1 x 2 + 1 x 3 = 9 cycles
CPI for sequence 2 = 9 / 6 = 1.5
Instruction class CPI A 1 B 2 C 3
Instruction counts for instruction classCode Sequence A B C 1 2 1 2 2 4 1 1

EECC550 - ShaabanEECC550 - Shaaban#4 Final Review Summer 2001 8-10-2001
Instruction Frequency & CPIInstruction Frequency & CPI • Given a program with n types or classes of
instructions with the following characteristics:
Ci = Count of instructions of typei
CPIi = Average cycles per instruction of typei
Fi = Frequency of instruction typei
= Ci/ total instruction count
Then:
n
iii FCPICPI
1

EECC550 - ShaabanEECC550 - Shaaban#5 Final Review Summer 2001 8-10-2001
Instruction Type Frequency & CPI: Instruction Type Frequency & CPI: A RISC ExampleA RISC Example
Typical Mix
Base Machine (Reg / Reg)
Op Freq Cycles CPI(i) % Time
ALU 50% 1 .5 23%
Load 20% 5 1.0 45%
Store 10% 3 .3 14%
Branch 20% 2 .4 18%
CPI = .5 x 1 + .2 x 5 + .1 x 3 + .2 x 2 = 2.2
n
iii FCPICPI
1

EECC550 - ShaabanEECC550 - Shaaban#6 Final Review Summer 2001 8-10-2001
Performance Enhancement Calculations:Performance Enhancement Calculations: Amdahl's Law Amdahl's Law
• The performance enhancement possible due to a given design improvement is limited by the amount that the improved feature is used
• Amdahl’s Law:
Performance improvement or speedup due to enhancement E: Execution Time without E Performance with E Speedup(E) = -------------------------------------- = --------------------------------- Execution Time with E Performance without E
– Suppose that enhancement E accelerates a fraction F of the execution time by a factor S and the remainder of the time is unaffected then:
Execution Time with E = ((1-F) + F/S) X Execution Time without E
Hence speedup is given by:
Execution Time without E 1Speedup(E) = --------------------------------------------------------- = --------------------
((1 - F) + F/S) X Execution Time without E (1 - F) + F/SNote: All fractions here refer to original execution time.

EECC550 - ShaabanEECC550 - Shaaban#7 Final Review Summer 2001 8-10-2001
Pictorial Depiction of Amdahl’s LawPictorial Depiction of Amdahl’s Law
Before: Execution Time without enhancement E:
Unaffected, fraction: (1- F)
After: Execution Time with enhancement E:
Enhancement E accelerates fraction F of execution time by a factor of S
Affected fraction: F
Unaffected, fraction: (1- F) F/S
Unchanged
Execution Time without enhancement E 1Speedup(E) = ------------------------------------------------------ = ------------------ Execution Time with enhancement E (1 - F) + F/S

EECC550 - ShaabanEECC550 - Shaaban#8 Final Review Summer 2001 8-10-2001
Amdahl's Law With Multiple Enhancements: Amdahl's Law With Multiple Enhancements: ExampleExample
• Three CPU performance enhancements are proposed with the following speedups and percentage of the code execution time affected:
Speedup1 = S1 = 10 Percentage1 = F1 = 20%
Speedup2 = S2 = 15 Percentage1 = F2 = 15%
Speedup3 = S3 = 30 Percentage1 = F3 = 10%
• While all three enhancements are in place in the new design, each enhancement affects a different portion of the code and only one enhancement can be used at a time.
• What is the resulting overall speedup?
• Speedup = 1 / [(1 - .2 - .15 - .1) + .2/10 + .15/15 + .1/30)] = 1 / [ .55 + .0333 ] = 1 / .5833 = 1.71
i ii
ii S
FFSpeedup
)( )1
1
(

EECC550 - ShaabanEECC550 - Shaaban#9 Final Review Summer 2001 8-10-2001
A Single Cycle MIPS DatapathA Single Cycle MIPS Datapathim
m16
32
ALUctr
Clk
busW
RegWr
32
32
busA
32busB
55 5
Rw Ra Rb32 32-bitRegisters
Rs
Rt
Rt
RdRegDst
Exten
der
Mu
x
3216imm16
ALUSrcExtOp
Mu
x
MemtoReg
Clk
Data InWrEn32 Adr
DataMemory
MemWrA
LU
Equal
Instruction<31:0>
0
1
0
1
01
<21:25>
<16:20>
<11:15>
<0:15>
Imm16RdRtRs
=
Ad
der
Ad
der
PC
Clk
00
Mu
x
4
nPC_sel
PC
Ext
Adr
InstMemory
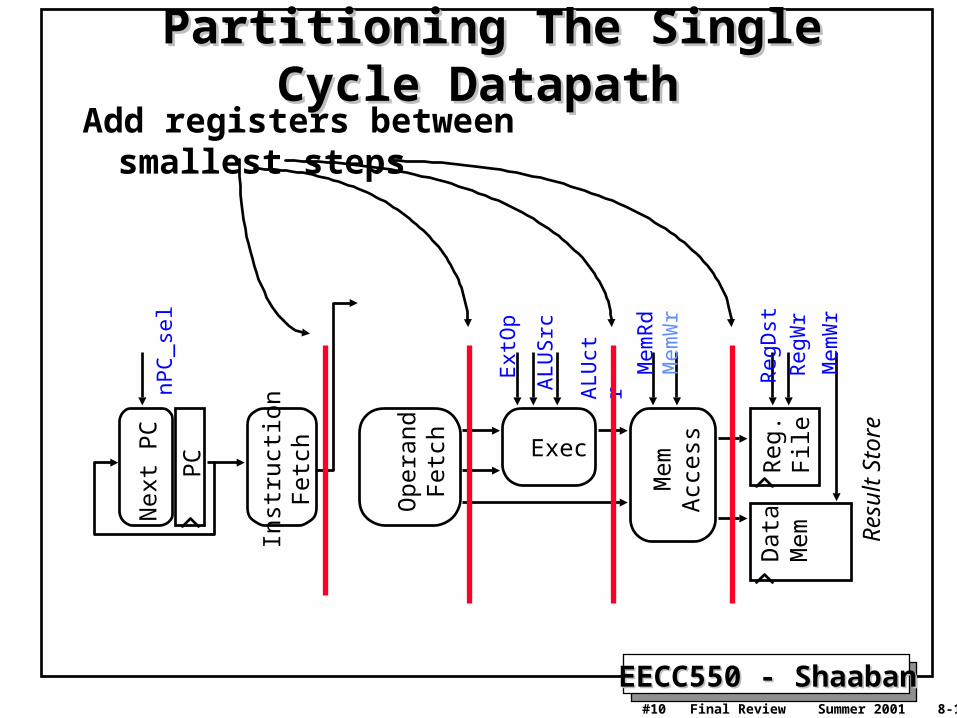
EECC550 - ShaabanEECC550 - Shaaban#10 Final Review Summer 2001 8-10-2001
Partitioning The Single Cycle DatapathPartitioning The Single Cycle Datapath Add registers between smallest steps
PC
Nex
t P
C
Ope
rand
Fet
ch Exec Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
Inst
ruct
ion
Fet
ch
Res
ult
Sto
re
AL
Uct
r
Reg
Dst
AL
US
rc
Ext
Op
Mem
Wr
nPC
_sel
Reg
Wr
Mem
Wr
Mem
Rd

EECC550 - ShaabanEECC550 - Shaaban#11 Final Review Summer 2001 8-10-2001
Example Multi-cycle DatapathExample Multi-cycle Datapath
PC
Nex
t P
C
Ope
rand
Fet
ch
Ext
ALU Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
Inst
ruct
ion
Fet
ch
Res
ult
Sto
re
AL
Uct
r
Reg
Dst
AL
US
rc
Ext
Op
nPC
_sel
Reg
Wr
Mem
Wr
Mem
Rd
IR
A
B
R
M
RegFile
Mem
ToR
eg
Equ
al
Registers added:
IR: Instruction registerA, B: Two registers to hold operands read from register file.R: or ALUOut, holds the output of the ALUM: or Memory data register (MDR) to hold data read from data memory

EECC550 - ShaabanEECC550 - Shaaban#12 Final Review Summer 2001 8-10-2001
Operations In Each CycleOperations In Each Cycle
Instruction Fetch
Instruction Decode
Execution
Memory
WriteBack
R-Type
IR Mem[PC]
A R[rs]
B R[rt]
R A + B
R[rd] R
PC PC + 4
Logic Immediate
IR Mem[PC]
A R[rs]
R A OR ZeroExt[imm16]
R[rt] R
PC PC + 4
Load
IR Mem[PC]
A R[rs]
R A + SignEx(Im16)
M Mem[R]
R[rd] M
PC PC + 4
Store
IR Mem[PC]
A R[rs]
B R[rt]
R A + SignEx(Im16)
Mem[R] B
PC PC + 4
Branch
IR Mem[PC]
A R[rs]
B R[rt]
If Equal = 1
PC PC + 4 +
(SignExt(imm16) x4)
else
PC PC + 4

EECC550 - ShaabanEECC550 - Shaaban#13 Final Review Summer 2001 8-10-2001
Mapping RTNs To Control Points ExamplesMapping RTNs To Control Points Examples& State Assignments& State Assignments
IR MEM[PC]
0000
R-type
A R[rs]B R[rt] 0001
R A fun B 0100
R[rd] RPC PC + 4
0101
R A or ZX 0110
R[rt] RPC PC + 4
0111
ORi
R A + SX 1000
R[rt] MPC PC + 4
1010
M MEM[S] 1001
LW
R A + SX 1011
MEM[S] BPC PC + 4 1100
BEQ & Equal
BEQ & ~Equal
PC PC + 4 0011
PC PC + SX || 00 0010
SW
“instruction fetch”
“decode / operand fetch”
Exe
cute
Mem
ory
Wri
te-b
ack
imem_rd, IRen
Aen, Ben
ALUfun, Sen
RegDst,RegWr,PCen To instruction fetch
state 0000
To instruction fetch state 0000To instruction fetch state 0000

EECC550 - ShaabanEECC550 - Shaaban#14 Final Review Summer 2001 8-10-2001
Alternative Multiple Cycle Datapath (In Textbook)
•Shared instruction/data memory unit• A single ALU shared among instructions• Shared units require additional or widened multiplexors• Temporary registers to hold data between clock cycles of the instruction:
• Additional registers: Instruction Register (IR), Memory Data Register (MDR), A, B, ALUOut

EECC550 - ShaabanEECC550 - Shaaban#15 Final Review Summer 2001 8-10-2001
Operations In Each CycleOperations In Each Cycle
Instruction Fetch
Instruction Decode
Execution
Memory
WriteBack
R-Type
IR Mem[PC]PC PC + 4
A R[rs]
B R[rt]
ALUout PC + (SignExt(imm16) x4)
ALUout A + B
R[rd] ALUout
Logic Immediate
IR Mem[PC]PC PC + 4
A R[rs]
B R[rt]
ALUout PC +
(SignExt(imm16) x4)
ALUout
A OR ZeroExt[imm16]
R[rt] ALUout
Load
IR Mem[PC]PC PC + 4
A R[rs]
B R[rt]
ALUout PC +
(SignExt(imm16) x4)
ALUout
A + SignEx(Im16)
M Mem[ALUout]
R[rd] Mem
Store
IR Mem[PC]PC PC + 4
A R[rs]
B R[rt]
ALUout PC +
(SignExt(imm16) x4)
ALUout
A + SignEx(Im16)
Mem[ALUout] B
Branch
IR Mem[PC]PC PC + 4
A R[rs]
B R[rt]
ALUout PC +
(SignExt(imm16) x4)
If Equal = 1
PC ALUout

EECC550 - ShaabanEECC550 - Shaaban#16 Final Review Summer 2001 8-10-2001
Finite State Machine (FSM) SpecificationFinite State Machine (FSM) SpecificationIR MEM[PC]
PC PC + 4
R-type
ALUout A fun B
R[rd] ALUout
ALUout A op ZX
R[rt] ALUout
ORiALUout
A + SX
R[rt] M
M MEM[ALUout]
LW
ALUout A + SX
MEM[ALUout] B
SW
“instruction fetch”
“decode”
Exe
cute
Mem
ory
Writ
e-ba
ck
0000
0001
0100
0101
0110
0111
1000
1001
1010
1011
1100
BEQ
0010
If A = B then PC ALUout
A R[rs]B R[rt]
ALUout PC +SX
To instruction fetch
To instruction fetchTo instruction fetch

EECC550 - ShaabanEECC550 - Shaaban#17 Final Review Summer 2001 8-10-2001
MIPS Multi-cycle Datapath MIPS Multi-cycle Datapath Performance EvaluationPerformance Evaluation
• What is the average CPI?– State diagram gives CPI for each instruction type
– Workload below gives frequency of each type
Type CPIi for type Frequency CPIi x freqIi
Arith/Logic 4 40% 1.6
Load 5 30% 1.5
Store 4 10% 0.4
branch 3 20% 0.6
Average CPI: 4.1
Better than CPI = 5 if all instructions took the same number of clock cycles (5).

EECC550 - ShaabanEECC550 - Shaaban#18 Final Review Summer 2001 8-10-2001
Types of “branching”• Set state to 0 (fetch)• Dispatch i (state 1)• Use incremented address (seq) state number 2
Opcode
State Reg
Microinstruction Address
Inputs
Outputs Control Signal Fields
Microprogram Storage
ROM/PLA
MulticycleDatapath
1
Address Select Logic
Adder
MicroprogramCounter, MicroPC
SequencingControlField
Microprogrammed Control UnitMicroprogrammed Control Unit

EECC550 - ShaabanEECC550 - Shaaban#19 Final Review Summer 2001 8-10-2001
Microprogram for The Control UnitMicroprogram for The Control UnitLabel ALU SRC1 SRC2 Dest. Memory Mem. Reg. PC Write Sequencing
Fetch: Add PC 4 Read PC IR ALU SeqAdd PC Extshft Dispatch
Lw: Add rs Extend Seq Read ALU Seq
rt MEM Fetch
Sw: Add rs Extend SeqWrite ALU Fetch
Rtype: Func rs rt Seqrd ALU Fetch
Beq: Subt. rs rt ALUoutCond. Fetch
Ori: Or rs Extend0 Seqrt ALU Fetch

EECC550 - ShaabanEECC550 - Shaaban#20 Final Review Summer 2001 8-10-2001
MIPS Integer ALU RequirementsMIPS Integer ALU Requirements
00 add
01 addU
02 sub
03 subU
04 and
05 or
06 xor
07 nor
12 slt
13 sltU
(1) Functional Specification:
inputs: 2 x 32-bit operands A, B, 4-bit modeoutputs: 32-bit result S, 1-bit carry, 1 bit overflow, 1 bit zerooperations: add, addu, sub, subu, and, or, xor, nor, slt, sltU
(2) Block Diagram:
ALUALUA B
movf
S
32 32
32
4c
10 operations thus 4 control bits
zero

EECC550 - ShaabanEECC550 - Shaaban#21 Final Review Summer 2001 8-10-2001
Building Block: 1-bit ALUBuilding Block: 1-bit ALU
A
B
Mu
x
CarryIn
Result
1-bitFull
Adder
CarryOut
add
and
or
invertBOperation
Performs: AND, OR, addition on A, B or A, B inverted

EECC550 - ShaabanEECC550 - Shaaban#22 Final Review Summer 2001 8-10-2001
32-Bit ALU Using 32 1-Bit ALUs32-Bit ALU Using 32 1-Bit ALUs
32-bit rippled-carry adder (operation/invertB lines not shown)
A31
B31
1-bitALU
Result31
A0
B0
1-bitALU
Result0
CarryIn0
CarryOut0
A1
B1
1-bitALU
Result1
CarryIn1
CarryOut1
A2
B2
1-bitALU
Result2
CarryIn2
CarryIn3
CarryOut31
::
CarryOut30CarryIn31
C
Addition/Subtraction Performance:
Assume gate delay = T
Total delay = 32 x (1-Bit ALU Delay) = 32 x 2 x gate delay = 64 x gate delay = 64 T

EECC550 - ShaabanEECC550 - Shaaban#23 Final Review Summer 2001 8-10-2001
MIPS ALU With SLT Support AddedMIPS ALU With SLT Support Added
A311-bitALU
B31 Result31
B0 1-bitALU
A0Result0
CarryIn0
CarryOut0
A1B1
1-bitALU
Result1
CarryIn1
CarryOut1
A2B2 1-bit
ALUResult2
CarryIn2
CarryIn3
CarryOut31
::
CarryOut30CarryIn31
C
::::
Zero
Overflow
Less = 0
Less = 0
Less = 0
Less

EECC550 - ShaabanEECC550 - Shaaban#24 Final Review Summer 2001 8-10-2001
Improving ALU Performance: Carry Look Ahead (CLA)
A B C-out0 0 0 “kill”0 1 C-in “propagate”1 0 C-in “propagate”1 1 1 “generate”
A0
B1
SGP
G = A and BP = A xor B
A
B
SGP
A
B
SGP
A
B
SGP
Cin
C1 =G0 + C0 P0
C2 = G1 + G0 P1 + C0 P0 P1
C3 = G2 + G1 C3 = G2 + G1 P2 + G0 P2 + G0 P1 P1 P2 + C0 P2 + C0 P0 P0 P1 P1 P2 P2
GP

EECC550 - ShaabanEECC550 - Shaaban#25 Final Review Summer 2001 8-10-2001
Cascaded Carry Look-ahead Cascaded Carry Look-ahead 16-Bit Example16-Bit ExampleC
LA
4-bitAdder
4-bitAdder
4-bitAdder
C1 =G0 + C0 P0
C2 = G1 + G0 P1 + C0 P0 P1
C3 = G2 + G1 P2 + G0 P1 P2 + C0 P0 P1 P2
GP
G0P0
C4 = . . .
C0
Delay = 2 + 2 + 1 = 5 gate delays = 5T
Assuming allgates haveequal delay T
{

EECC550 - ShaabanEECC550 - Shaaban#26 Final Review Summer 2001 8-10-2001
Unsigned Multiplication ExampleUnsigned Multiplication Example• Paper and pencil example (unsigned):
Multiplicand 1000 Multiplier 1001
1000 0000 0000
1000 Product 01001000
• m bits x n bits = m + n bit product, m = 32, n = 32, 64 bit product.
• The binary number system simplifies multiplication:
0 => place 0 ( 0 x multiplicand).
1 => place a copy ( 1 x multiplicand).
• We will examine 4 versions of multiplication hardware & algorithm:
–Successive refinement of design.

EECC550 - ShaabanEECC550 - Shaaban#27 Final Review Summer 2001 8-10-2001
Operation of Combinational MultiplierOperation of Combinational Multiplier
B0
A0A1A2A3
A0A1A2A3
A0A1A2A3
A0A1A2A3
B1
B2
B3
P0P1P2P3P4P5P6P7
0 0 0 00 0 0
• At each stage shift A left ( x 2).
• Use next bit of B to determine whether to add in shifted multiplicand.
• Accumulate 2n bit partial product at each stage.

EECC550 - ShaabanEECC550 - Shaaban#28 Final Review Summer 2001 8-10-2001
MULTIPLY HARDWARE Version 3MULTIPLY HARDWARE Version 3
Product (Multiplier)
Multiplicand
32-bit ALU
WriteControl
32 bits
64 bits
Shift Right
• Combine Multiplier register and Product register:
– 32-bit Multiplicand register.– 32 -bit ALU. – 64-bit Product register, (0-bit Multiplier register).

EECC550 - ShaabanEECC550 - Shaaban#29 Final Review Summer 2001 8-10-2001
Multiply Algorithm Multiply Algorithm Version 3Version 3
DoneYes: 32 repetitions
2. Shift the Product register right 1 bit.
No: < 32 repetitions
1. TestProduct0
Product0 = 0Product0 = 1
1a. Add multiplicand to the left half of product & place the result in the left half of Product register
32nd repetition?
Start

EECC550 - ShaabanEECC550 - Shaaban#30 Final Review Summer 2001 8-10-2001
Combinational Shifter from MUXesCombinational Shifter from MUXes
1 0sel
A B
D
Basic Building Block
8-bit right shifter
1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0
1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0
1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0
S2 S1 S0A0A1A2A3A4A5A6A7
R0R1R2R3R4R5R6R7
• What comes in the MSBs?
• How many levels for 32-bit shifter?

EECC550 - ShaabanEECC550 - Shaaban#31 Final Review Summer 2001 8-10-2001
DivisionDivision 1001 Quotient
Divisor 1000 1001010 Dividend–1000 10 101 1010 –1000 10 Remainder (or Modulo result)
• See how big a number can be subtracted, creating quotient bit on each step:
Binary => 1 * divisor or 0 * divisor
Dividend = Quotient x Divisor + Remainder => | Dividend | = | Quotient | + | Divisor |
• 3 versions of divide, successive refinement

EECC550 - ShaabanEECC550 - Shaaban#32 Final Review Summer 2001 8-10-2001
Remainder (Quotient)
Divisor
32-bit ALU
WriteControl
32 bits
64 bits
Shift Left“HI” “LO”
• 32-bit Divisor register.
• 32 -bit ALU.
• 64-bit Remainder regegister (0-bit Quotient register).
DIVIDE HARDWARE Version 3DIVIDE HARDWARE Version 3

EECC550 - ShaabanEECC550 - Shaaban#33 Final Review Summer 2001 8-10-2001
3b. Restore the original value by adding the Divisor register to the left half of the Remainderregister, &place the sum in the left half of the Remainder register. Also shift the Remainder register to the left, setting the new least significant bit to 0.
Test Remainder
Remainder < 0Remainder >= 0
2. Subtract the Divisor register from the left half of the Remainder register, & place the result in the left half of the Remainder register.
3a. Shift the Remainder register to the left setting the new rightmost bit to 1.
1. Shift the Remainder register left 1 bit.
Done. Shift left half of Remainder right 1 bit.
Yes: n repetitions (n = 4 here)
nthrepetition?
No: < n repetitions
Start: Place Dividend in RemainderDivide Algorithm Divide Algorithm Version 3Version 3

EECC550 - ShaabanEECC550 - Shaaban#34 Final Review Summer 2001 8-10-2001
Representation of Floating Point Numbers inRepresentation of Floating Point Numbers in
Single PrecisionSingle Precision IEEE 754 StandardIEEE 754 Standard
Example: 0 = 0 00000000 0 . . . 0 -1.5 = 1 01111111 10 . . . 0
Magnitude of numbers that can be represented is in the range: 2
-126(1.0) to 2
127(2 - 2-23 )
Which is approximately: 1.8 x 10- 38
to 3.40 x 10 38
0 E 255Actual exponent is: e = E - 127
1 8 23
sign
exponent:excess 127binary integeradded
mantissa:sign + magnitude, normalizedbinary significand with a hidden integer bit: 1.M
E MS
Value = N = (-1)S X 2 E-127 X (1.M)

EECC550 - ShaabanEECC550 - Shaaban#35 Final Review Summer 2001 8-10-2001
Floating Point Conversion ExampleFloating Point Conversion Example• The decimal number -2345.12510 is to be represented in the IEEE 754
32-bit single precision format:
-2345.12510 = -100100101001.0012 (converted to binary)
= -1.00100101001001 x 211 (normalized binary)
• The mantissa is negative so the sign S is given by:
S = 1
• The biased exponent E is given by E = e + 127
E = 11 + 127 = 13810 = 100010102
• Fractional part of mantissa M:
M = .00100101001001000000000 (in 23 bits)
The IEEE 754 single precision representation is given by:
1 10001010 00100101001001000000000
S E M
1 bit 8 bits 23 bits
Hidden

EECC550 - ShaabanEECC550 - Shaaban#36 Final Review Summer 2001 8-10-2001
Floating PointFloating Point AdditionAddition FlowchartFlowchart
Start
Normalize the sum, either shifting right andincrementing the exponent or shifting leftand decrementing the exponent
Compare the exponents of the two numbersshift the smaller number to the right until itsexponent matches the larger exponent
Round the significand to the appropriate number of bitsIf mantissa = 0, set exponent to 0
Add the significands (mantissas)
Done
Overflow orUnderflow ?
Generate exception or return error
(1)
(2)
(3)
(4)
(5)
Stillnormalized?
Yes
No
yes
No

EECC550 - ShaabanEECC550 - Shaaban#37 Final Review Summer 2001 8-10-2001
Floating Point Addition Hardware

EECC550 - ShaabanEECC550 - Shaaban#38 Final Review Summer 2001 8-10-2001
Overflow or Underflow?
Floating Point Floating Point Multiplication FlowchartMultiplication Flowchart
(1)
(2)
(3)
(5)
(6)
Start
Done
Is one/both operands =0?
Set the result to zero: exponent = 0
Multiply the mantissas
Compute sign of result: Xs XOR Ys
Round or truncate the result mantissa
Compute exponent: biased exp.(X) + biased exp.(Y) - bias
Generate exception or return error
Normalize mantissa if needed
(4)
StillNormalized?
(7)
Yes
NoNo
Yes

EECC550 - ShaabanEECC550 - Shaaban#39 Final Review Summer 2001 8-10-2001
Rounding DigitsRounding DigitsNormalized result, but some non-zero digits to the right of the significand --> the number should be rounded
E.g., B = 10, p = 3: 0 2 1.69
0 0 7.85
0 2 1.61
= 1.6900 * 10
= - .0785 * 10
= 1.6115 * 10
2-bias
2-bias
2-bias-
One round digit must be carried to the right of the guard digit so that after a normalizing left shift, the result can be rounded, accordingto the value of the round digit.
IEEE Standard: four rounding modes: round to nearest (default)
round towards plus infinityround towards minus infinityround towards 0
round to nearest: round digit < B/2 then truncate > B/2 then round up (add 1 to ULP: unit in last place) = B/2 then round to nearest even digit
it can be shown that this strategy minimizes the mean error introduced by rounding.

EECC550 - ShaabanEECC550 - Shaaban#40 Final Review Summer 2001 8-10-2001
Sticky BitSticky BitAdditional bit to the right of the round digit to better fine tune rounding
d0 . d1 d2 d3 . . . dp-1 0 0 0 0 . 0 0 X . . . X X X S X X S
Sticky bit: set to 1 if any 1 bits fall off the end of the round digit
d0 . d1 d2 d3 . . . dp-1 0 0 0 0 . 0 0 X . . . X X X 0
d0 . d1 d2 d3 . . . dp-1 0 0 0 0 . 0 0 X . . . X X X 1
generates a borrow
Rounding Summary:
Radix 2 minimizes wobble in precision.
Normal operations in +,-,*,/ require one carry/borrow bit + one guard digit.
One round digit needed for correct rounding.
Sticky bit needed when round digit is B/2 for max accuracy.
Rounding to nearest has mean error = 0 if uniform distribution of digitsare assumed.

EECC550 - ShaabanEECC550 - Shaaban#41 Final Review Summer 2001 8-10-2001
Pipelining: Design GoalsPipelining: Design Goals• The length of the machine clock cycle is determined by the time
required for the slowest pipeline stage.
• An important pipeline design consideration is to balance the length of each pipeline stage.
• If all stages are perfectly balanced, then the time per instruction on a pipelined machine (assuming ideal conditions with no stalls):
Time per instruction on unpipelined machine Number of pipe stages
• Under these ideal conditions:– Speedup from pipelining = the number of pipeline stages = k
– One instruction is completed every cycle: CPI = 1 .

EECC550 - ShaabanEECC550 - Shaaban#42 Final Review Summer 2001 8-10-2001
Pipelined Instruction ProcessingPipelined Instruction ProcessingRepresentationRepresentation
Clock cycle Number Time in clock cycles Instruction Number 1 2 3 4 5 6 7 8 9
Instruction I IF ID EX MEM WB
Instruction I+1 IF ID EX MEM WB
Instruction I+2 IF ID EX MEM WB
Instruction I+3 IF ID EX MEM WB
Instruction I +4 IF ID EX MEM WB
Time to fill the pipeline
Pipeline Stages:
IF = Instruction Fetch
ID = Instruction Decode
EX = Execution
MEM = Memory Access
WB = Write Back
First instruction, ICompleted
Last instruction, I+4 completed

EECC550 - ShaabanEECC550 - Shaaban#43 Final Review Summer 2001 8-10-2001
For 1000 instructions, execution time:
• Single Cycle Machine:
– 8 ns/cycle x 1 CPI x 1000 inst = 8000 ns
• Multicycle Machine:
– 2 ns/cycle x 4.6 CPI (due to inst mix) x 1000 inst = 9200 ns
• Ideal pipelined machine, 5-stages:
– 2 ns/cycle x (1 CPI x 1000 inst + 4 cycle fill) = 2008 ns
Single Cycle, Multi-Cycle, Pipeline:Single Cycle, Multi-Cycle, Pipeline:Performance Comparison ExamplePerformance Comparison Example

EECC550 - ShaabanEECC550 - Shaaban#44 Final Review Summer 2001 8-10-2001
Single Cycle, Multi-Cycle, Vs. PipelineSingle Cycle, Multi-Cycle, Vs. Pipeline
Clk
Cycle 1
Multiple Cycle Implementation:
IF ID EX MEM WB
Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Cycle 8 Cycle 9 Cycle 10
IF ID EX MEM
Load Store
Clk
Single Cycle Implementation:
Load Store Waste
IF
R-type
Load IF ID EX MEM WB
Pipeline Implementation:
IF ID EX MEM WBStore
IF ID EX MEM WBR-type
Cycle 1 Cycle 2
8 ns
2ns

EECC550 - ShaabanEECC550 - Shaaban#45 Final Review Summer 2001 8-10-2001
MIPS: A Pipelined DatapathMIPS: A Pipelined Datapath
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM MEM/WB
Mux
0
1
Add
PC
0
Address
Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
Datamemory
1
ALUresult
Mux
ALUZero
ID/EX
IF ID EX MEM WBInstruction Fetch Instruction Decode Execution Memory Write Back

EECC550 - ShaabanEECC550 - Shaaban#46 Final Review Summer 2001 8-10-2001
Pipeline ControlPipeline Control• Pass needed control signals along from one stage to the next as the instruction travels through the
pipeline just like the data
Execution/Address Calculation stage control lines
Memory access stage control lines
Write-back stage control
lines
InstructionReg Dst
ALU Op1
ALU Op0
ALU Src Branch
Mem Read
Mem Write
Reg write
Mem to Reg
R-format 1 1 0 0 0 0 0 1 0lw 0 0 0 1 0 1 0 1 1sw X 0 0 1 0 0 1 0 Xbeq X 0 1 0 1 0 0 0 X
Control
EX
M
WB
M
WB
WB
IF/ID ID/EX EX/MEM MEM/WB
Instruction

EECC550 - ShaabanEECC550 - Shaaban#47 Final Review Summer 2001 8-10-2001
Basic Performance Issues In Basic Performance Issues In PipeliningPipelining
• Pipelining increases the CPU instruction throughput: The number of instructions completed per unit time. Under ideal condition instruction throughput is one instruction per machine cycle, or CPI = 1
• Pipelining does not reduce the execution time of an individual instruction: The time needed to complete all processing steps of an instruction (also called instruction completion latency).
• It usually slightly increases the execution time of each instruction over unpipelined implementations due to the increased control overhead of the pipeline and pipeline stage registers delays.

EECC550 - ShaabanEECC550 - Shaaban#48 Final Review Summer 2001 8-10-2001
Pipelining Performance ExamplePipelining Performance Example• Example: For an unpipelined machine:
– Clock cycle = 10ns, 4 cycles for ALU operations and branches and 5 cycles for memory operations with instruction frequencies of 40%, 20% and 40%, respectively.
– If pipelining adds 1ns to the machine clock cycle then the speedup in instruction execution from pipelining is:
Non-pipelined Average instruction execution time = Clock cycle x Average CPI
= 10 ns x ((40% + 20%) x 4 + 40%x 5) = 10 ns x 4.4 = 44 ns
In the pipelined five implementation five stages are used with an average instruction execution time of: 10 ns + 1 ns = 11 ns
Speedup from pipelining = Instruction time unpipelined
Instruction time pipelined
= 44 ns / 11 ns = 4 times

EECC550 - ShaabanEECC550 - Shaaban#49 Final Review Summer 2001 8-10-2001
Pipeline HazardsPipeline Hazards• Hazards are situations in pipelining which prevent the next
instruction in the instruction stream from executing during the designated clock cycle resulting in one or more stall cycles.
• Hazards reduce the ideal speedup gained from pipelining and are classified into three classes:
– Structural hazards: Arise from hardware resource conflicts when the available hardware cannot support all possible combinations of instructions.
– Data hazards: Arise when an instruction depends on the results of a previous instruction in a way that is exposed by the overlapping of instructions in the pipeline.
– Control hazards: Arise from the pipelining of conditional branches and other instructions that change the PC.

EECC550 - ShaabanEECC550 - Shaaban#50 Final Review Summer 2001 8-10-2001
Structural hazard Example: Single Memory For Instructions & Data
Mem
Instr.
Order
Time (clock cycles)
Load
Instr 1
Instr 2
Instr 3
Instr 4A
LUMem Reg Mem Reg
AL
UMem Reg Mem Reg
AL
UMem Reg Mem Reg
AL
UReg Mem Reg
AL
UMem Reg Mem Reg
Detection is easy in this case (right half highlight means read, left half write)
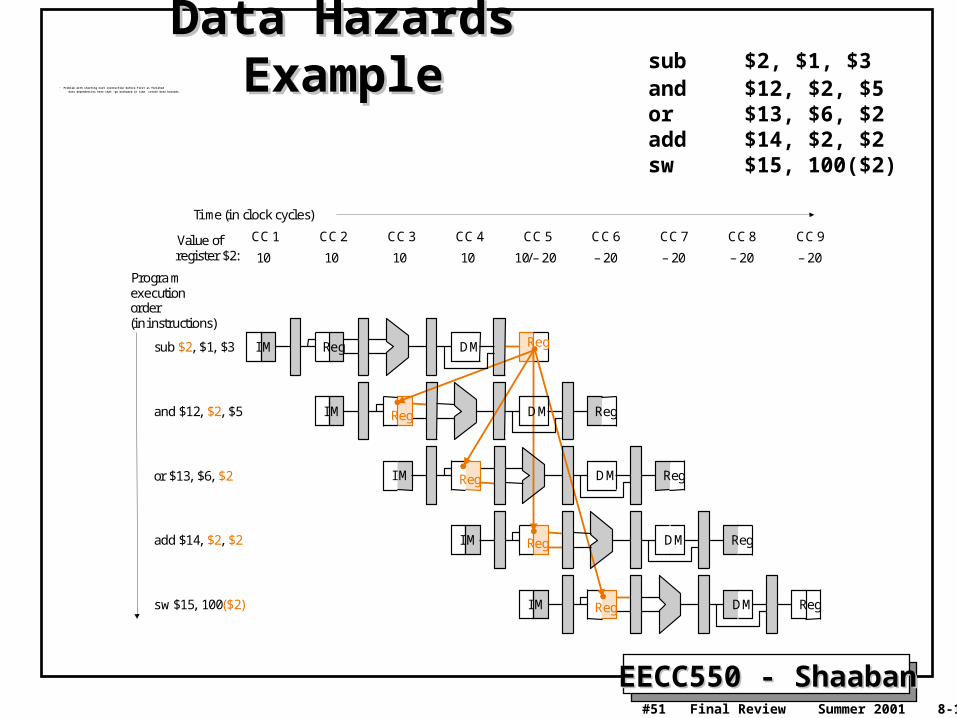
EECC550 - ShaabanEECC550 - Shaaban#51 Final Review Summer 2001 8-10-2001
Data Hazards ExampleData Hazards Example• Problem with starting next instruction before first is finished
– Data dependencies here that “go backward in time” create data hazards.
sub $2, $1, $3and $12, $2, $5or $13, $6, $2add $14, $2, $2sw $15, 100($2)
IM Reg
IM Reg
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6
Time (in clock cycles)
sub $2, $1, $3
Programexecutionorder(in instructions)
and $12, $2, $5
IM Reg DM Reg
IM DM Reg
IM DM Reg
CC 7 CC 8 CC 9
10 10 10 10 10/– 20 – 20 – 20 – 20 – 20
or $13, $6, $2
add $14, $2, $2
sw $15, 100($2)
Value of register $2:
DM Reg
Reg
Reg
Reg
DM

EECC550 - ShaabanEECC550 - Shaaban#52 Final Review Summer 2001 8-10-2001
Data Hazard Resolution: Stall Cycles Data Hazard Resolution: Stall Cycles Stall the pipeline by a number of cycles.The control unit must detect the need to insert stall cycles.
In this case two stall cycles are needed.
IM Reg
IM
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6
Time (in clock cycles)
sub $2, $1, $3
Programexecutionorder(in instructions)
and $12, $2, $5
CC 7 CC 8
10 10 10 10 10/– 20 – 20 – 20 – 20
CC 9
– 20
or $13, $6, $2
add $14, $2, $2
sw $15, 100($2)
Value of register $2:
DM Reg
Reg
IM Reg DM Reg
IM DM Reg
IM DM Reg
Reg
Reg
Reg
DMSTALL STALL
CC 10
– 20
CC 11
– 20
STALL STALL

EECC550 - ShaabanEECC550 - Shaaban#53 Final Review Summer 2001 8-10-2001
Performance of Pipelines with StallsPerformance of Pipelines with Stalls• Hazards in pipelines may make it necessary to stall the
pipeline by one or more cycles and thus degrading performance from the ideal CPI of 1.
CPI pipelined = Ideal CPI + Pipeline stall clock cycles per instruction
• If pipelining overhead is ignored and we assume that the stages are perfectly balanced then:
Speedup = CPI unpipelined / (1 + Pipeline stall cycles per instruction)
• When all instructions take the same number of cycles and is equal to the number of pipeline stages then:
Speedup = Pipeline depth / (1 + Pipeline stall cycles per instruction)

EECC550 - ShaabanEECC550 - Shaaban#54 Final Review Summer 2001 8-10-2001
Data Hazard Resolution: Forwarding Data Hazard Resolution: Forwarding – Register file forwarding to handle read/write to same register
– ALU forwarding

EECC550 - ShaabanEECC550 - Shaaban#55 Final Review Summer 2001 8-10-2001
Data Hazard Example With ForwardingData Hazard Example With Forwarding
IM Reg
IM Reg
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6
Time (in clock cycles)
sub $2, $1, $3
Programexecution order(in instructions)
and $12, $2, $5
IM Reg DM Reg
IM DM Reg
IM DM Reg
CC 7 CC 8 CC 9
10 10 10 10 10/– 20 – 20 – 20 – 20 – 20
or $13, $6, $2
add $14, $2, $2
sw $15, 100($2)
Value of register $2 :
DM Reg
Reg
Reg
Reg
X X X – 20 X X X X XValue of EX/MEM :X X X X – 20 X X X XValue of MEM/WB :
DM

EECC550 - ShaabanEECC550 - Shaaban#56 Final Review Summer 2001 8-10-2001
A Data Hazard Requiring A StallA Data Hazard Requiring A Stall
Reg
IM
Reg
Reg
IM
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6
Time (in clock cycles)
lw $2, 20($1)
Programexecutionorder(in instructions)
and $4, $2, $5
IM Reg DM Reg
IM DM Reg
IM DM Reg
CC 7 CC 8 CC 9
or $8, $2, $6
add $9, $4, $2
slt $1, $6, $7
DM Reg
Reg
Reg
DM
A load followed by an R-type instruction that uses the loaded value
Even with forwarding in place a stall cycle is neededThis condition must be detected by hardware

EECC550 - ShaabanEECC550 - Shaaban#57 Final Review Summer 2001 8-10-2001
Compiler Scheduling ExampleCompiler Scheduling Example• Reorder the instructions to avoid as many pipeline stalls as possible:
lw $15, 0($2)lw $16, 4($2)add $14, $5, $16sw $16, 4($2)
• The data hazard occurs on register $16 between the second lw and the add resulting in a stall cycle
• With forwarding we need to find only one independent instructions to place between them, swapping the lw instructions works:
lw $16, 4($2)lw $15, 0($2)nopadd $14, $5, $16 sw $16, 4($2)
• Without forwarding we need two independent instructions to place between them, so in addition a nop is added.
lw $16, 4($2)lw $15, 0($2)add $14, $5, $16sw $16, 4($2)

EECC550 - ShaabanEECC550 - Shaaban#58 Final Review Summer 2001 8-10-2001
Control Hazards: ExampleControl Hazards: Example• Three other instructions are in the pipeline before branch instruction target decision is made when BEQ is in MEM stage.
• In the above diagram, we are predicting “branch not taken”– Need to add hardware for flushing the three following instructions if we are wrong losing three cycles.
Reg
Reg
CC 1
Time (in clock cycles)
40 beq $1, $3, 7
Programexecutionorder(in instructions)
IM Reg
IM DM
IM DM
IM DM
DM
DM Reg
Reg Reg
Reg
Reg
RegIM
44 and $12, $2, $5
48 or $13, $6, $2
52 add $14, $2, $2
72 lw $4, 50($7)
CC 2 CC 3 CC 4 CC 5 CC 6 CC 7 CC 8 CC 9
Reg

EECC550 - ShaabanEECC550 - Shaaban#59 Final Review Summer 2001 8-10-2001
Reducing Delay of Taken BranchesReducing Delay of Taken Branches• Next PC of a branch known in MEM stage: Costs three lost cycles if taken.• If next PC is known in EX stage, one cycle is saved.• Branch address calculation can be moved to ID stage using a register comparator, costing
only one cycle if branch is taken.
PCInstruction
memory
4
Registers
Mux
Mux
Mux
ALU
EX
M
WB
M
WB
WB
ID/EX
0
EX/MEM
MEM/WB
Datamemory
Mux
Hazarddetection
unit
Forwardingunit
IF.Flush
IF/ID
Signextend
Control
Mux
=
Shiftleft 2
Mux

EECC550 - ShaabanEECC550 - Shaaban#60 Final Review Summer 2001 8-10-2001
Pipeline Performance ExamplePipeline Performance Example• Assume the following MIPS instruction mix:
• What is the resulting CPI for the pipelined MIPS with forwarding and branch address calculation in ID stage?
• CPI = Ideal CPI + Pipeline stall clock cycles per instruction
= 1 + stalls by loads + stalls by branches
= 1 + .3x.25x1 + .2 x .45x1
= 1 + .075 + .09
= 1.165
Type FrequencyArith/Logic 40%Load 30% of which 25% are followed immediately by an instruction using the loaded value Store 10%branch 20% of which 45% are taken

EECC550 - ShaabanEECC550 - Shaaban#61 Final Review Summer 2001 8-10-2001
Memory Hierarchy: MotivationMemory Hierarchy: MotivationProcessor-Memory (DRAM) Performance GapProcessor-Memory (DRAM) Performance Gap
µProc60%/yr.
DRAM7%/yr.
1
10
100
1000198
0198
1 198
3198
4198
5 198
6198
7198
8198
9199
0199
1 199
2199
3199
4199
5199
6199
7199
8 199
9200
0
DRAM
CPU
198
2
Processor-MemoryPerformance Gap:(grows 50% / year)
Per
form
ance

EECC550 - ShaabanEECC550 - Shaaban#62 Final Review Summer 2001 8-10-2001
Memory Hierarchy: MotivationMemory Hierarchy: Motivation
The Principle Of LocalityThe Principle Of Locality• Programs usually access a relatively small portion of their address
space (instructions/data) at any instant of time (program working set).
• Two Types of locality:
– Temporal Locality: If an item is referenced, it will tend to be referenced again soon.
– Spatial locality: If an item is referenced, items whose addresses are close will tend to be referenced soon.
• The presence of locality in program behavior, makes it possible to satisfy a large percentage of program access needs using memory levels with much less capacity than program address space.

EECC550 - ShaabanEECC550 - Shaaban#63 Final Review Summer 2001 8-10-2001
Levels of The Memory HierarchyLevels of The Memory HierarchyPart of The On-chip CPU Datapath 16-256 Registers
One or more levels (Static RAM):Level 1: On-chip 16-64K Level 2: On or Off-chip 128-512KLevel 3: Off-chip 128K-8M
Registers
Cache
Main Memory
Magnetic Disc
Optical Disk or Magnetic Tape
Farther away from The CPU
Lower Cost/Bit
Higher Capacity
Increased AccessTime/Latency
Lower ThroughputDynamic RAM (DRAM) 16M-16G
Interface:SCSI, RAID, IDE, 13944G-100G

EECC550 - ShaabanEECC550 - Shaaban#64 Final Review Summer 2001 8-10-2001
Cache Design & Operation IssuesCache Design & Operation Issues• Q1: Where can a block be placed cache?
(Block placement strategy & Cache organization)– Fully Associative, Set Associative, Direct Mapped
• Q2: How is a block found if it is in cache? (Block identification)– Tag/Block
• Q3: Which block should be replaced on a miss? (Block replacement)– Random, LRU
• Q4: What happens on a write? (Cache write policy)– Write through, write back

EECC550 - ShaabanEECC550 - Shaaban#65 Final Review Summer 2001 8-10-2001
Cache Organization & Placement StrategiesCache Organization & Placement StrategiesPlacement strategies or mapping of a main memory data block onto cache block frame addresses divide cache into three organizations:
1 Direct mapped cache: A block can be placed in one location only, given by:
(Block address) MOD (Number of blocks in cache)
2 Fully associative cache: A block can be placed anywhere in cache.
3 Set associative cache: A block can be placed in a restricted set of places, or cache block frames. A set is a group of block frames in the cache. A block is first mapped onto the set and then it can be placed anywhere within the set. The set in this case is chosen by:
(Block address) MOD (Number of sets in cache)
If there are n blocks in a set the cache placement is called n-way set-associative.

EECC550 - ShaabanEECC550 - Shaaban#66 Final Review Summer 2001 8-10-2001
Cache Organization ExampleCache Organization Example

EECC550 - ShaabanEECC550 - Shaaban#67 Final Review Summer 2001 8-10-2001
Locating A Data Block in CacheLocating A Data Block in Cache• Each block frame in cache has an address tag.
• The tags of every cache block that might contain the required data are checked or searched in parallel.
• A valid bit is added to the tag to indicate whether this entry contains a valid address.
• The address from the CPU to cache is divided into:
– A block address, further divided into:
• An index field to choose a block set in cache.
(no index field when fully associative).
• A tag field to search and match addresses in the selected set.
– A block offset to select the data from the block.
Block Address BlockOffsetTag Index

EECC550 - ShaabanEECC550 - Shaaban#68 Final Review Summer 2001 8-10-2001
Address Field SizesAddress Field Sizes
Block Address BlockOffsetTag Index
Block offset size = log2(block size)
Index size = log2(Total number of blocks/associativity)
Tag size = address size - index size - offset sizeTag size = address size - index size - offset size
Physical Address Generated by CPU

EECC550 - ShaabanEECC550 - Shaaban#69 Final Review Summer 2001 8-10-2001
Four-Way Set Associative Cache:Four-Way Set Associative Cache:MIPS Implementation ExampleMIPS Implementation Example
Ad dress
2 2 8
V TagIndex
0
1
2
253
254
255
D ata V Tag D ata V Tag D ata V Tag D ata
3 22 2
4 - to - 1 m ultip lexo r
H it D a ta
123891011123 031 0
IndexField
TagField
256 sets1024 block frames

EECC550 - ShaabanEECC550 - Shaaban#70 Final Review Summer 2001 8-10-2001
Cache Organization/Addressing ExampleCache Organization/Addressing Example
• Given the following:– A single-level L1 cache with 128 cache block frames
• Each block frame contains four words (16 bytes)
– 16-bit memory addresses to be cached (64K bytes main memory or 4096 memory blocks)
• Show the cache organization/mapping and cache address fields for:
• Fully Associative cache.
• Direct mapped cache.
• 2-way set-associative cache.

EECC550 - ShaabanEECC550 - Shaaban#71 Final Review Summer 2001 8-10-2001
Cache Example: Fully Associative CaseCache Example: Fully Associative Case
Block offset = 4 bits
Block Address = 12 bits
Tag = 12 bits
All 128 tags mustbe checked in parallelby hardware to locate a data block
V
V
V
Valid bit

EECC550 - ShaabanEECC550 - Shaaban#72 Final Review Summer 2001 8-10-2001
Cache Example: Direct Mapped CaseCache Example: Direct Mapped Case
Block offset = 4 bits
Block Address = 12 bits
Tag = 5 bits Index = 7 bits Main Memory
Only a single tag mustbe checked in parallelto locate a data block
V
Valid bit
V
V
V

EECC550 - ShaabanEECC550 - Shaaban#73 Final Review Summer 2001 8-10-2001
Block offset = 4 bits
Block Address = 12 bits
Tag = 6 bits Index = 6 bits
Cache Example: 2-Way Set-AssociativeCache Example: 2-Way Set-Associative
Main Memory
Two tags in a set mustbe checked in parallelto locate a data block
Valid bits not shown

EECC550 - ShaabanEECC550 - Shaaban#74 Final Review Summer 2001 8-10-2001
Calculating Number of Cache Bits NeededCalculating Number of Cache Bits Needed• How many total bits are needed for a direct- mapped cache with 64 KBytes of
data and one word blocks, assuming a 32-bit address?
– 64 Kbytes = 16 K words = 214 words = 214 blocks– Block size = 4 bytes => offset size = 2 bits, – #sets = #blocks = 214 => index size = 14 bits– Tag size = address size - index size - offset size = 32 - 14 - 2 = 16 bits – Bits/block = data bits + tag bits + valid bit = 32 + 16 + 1 = 49– Bits in cache = #blocks x bits/block = 214 x 49 = 98 Kbytes
• How many total bits would be needed for a 4-way set associative cache to store the same amount of data?
– Block size and #blocks does not change.– #sets = #blocks/4 = (214)/4 = 212 => index size = 12 bits– Tag size = address size - index size - offset = 32 - 12 - 2 = 18 bits– Bits/block = data bits + tag bits + valid bit = 32 + 18 + 1 = 51– Bits in cache = #blocks x bits/block = 214 x 51 = 102 Kbytes
• Increase associativity => increase bits in cache

EECC550 - ShaabanEECC550 - Shaaban#75 Final Review Summer 2001 8-10-2001
Cache Replacement PolicyCache Replacement Policy• When a cache miss occurs the cache controller may have to
select a block of cache data to be removed from a cache block frame and replaced with the requested data, such a block is selected by one of two methods:
– Random: • Any block is randomly selected for replacement providing
uniform allocation.
• Simple to build in hardware.
• The most widely used cache replacement strategy.
– Least-recently used (LRU): • Accesses to blocks are recorded and and the block
replaced is the one that was not used for the longest period of time.
• LRU is expensive to implement, as the number of blocks to be tracked increases, and is usually approximated.

EECC550 - ShaabanEECC550 - Shaaban#76 Final Review Summer 2001 8-10-2001
Miss Rates for Caches with Different Size, Miss Rates for Caches with Different Size, Associativity & Replacement AlgorithmAssociativity & Replacement Algorithm
Sample DataSample Data
Associativity: 2-way 4-way 8-way
Size LRU Random LRU Random LRURandom
16 KB 5.18% 5.69% 4.67% 5.29% 4.39% 4.96%
64 KB 1.88% 2.01% 1.54% 1.66% 1.39% 1.53%
256 KB 1.15% 1.17% 1.13% 1.13% 1.12% 1.12%

EECC550 - ShaabanEECC550 - Shaaban#77 Final Review Summer 2001 8-10-2001
Cache PerformanceCache PerformancePrinceton Memory ArchitecturePrinceton Memory Architecture
For a CPU with a single level (L1) of cache for both instructions
and data (Princeton memory architecture) and no stalls for
cache hits:
CPU time = (CPU execution clock cycles +
Memory stall clock cycles) x clock cycle time
Memory stall clock cycles = (Reads x Read miss rate x Read miss penalty) + (Writes x Write miss rate x Write miss penalty)
If write and read miss penalties are the same:
Memory stall clock cycles = Memory accesses x Miss rate x Miss penalty
With ideal memory

EECC550 - ShaabanEECC550 - Shaaban#78 Final Review Summer 2001 8-10-2001
Cache PerformanceCache PerformancePrinceton Memory ArchitecturePrinceton Memory Architecture
CPUtime = Instruction count x CPI x Clock cycle time
CPIexecution = CPI with ideal memory
CPI = CPIexecution + Mem Stall cycles per instruction
CPUtime = Instruction Count x (CPIexecution +
Mem Stall cycles per instruction) x Clock cycle time
Mem Stall cycles per instruction = Mem accesses per instruction x Miss rate x Miss penalty
CPUtime = IC x (CPIexecution + Mem accesses per instruction x
Miss rate x Miss penalty) x Clock cycle time
Misses per instruction = Memory accesses per instruction x Miss rate
CPUtime = IC x (CPIexecution + Misses per instruction x Miss penalty) x
Clock cycle time
EECC550 - ShaabanEECC550 - Shaaban#79 Final Review Summer 2001 8-10-2001
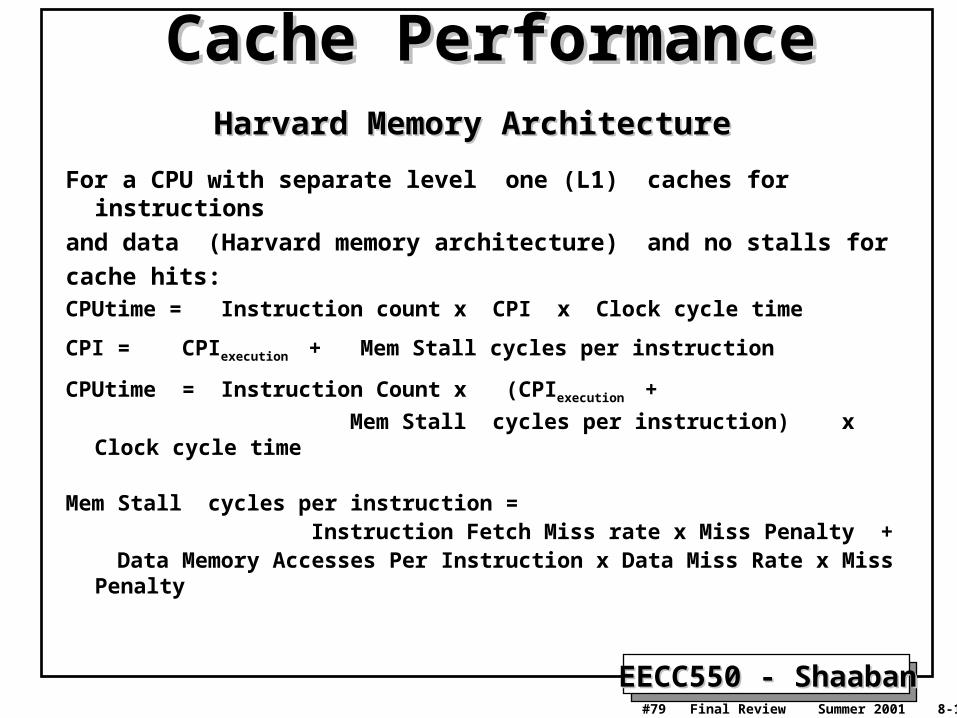
Cache PerformanceCache PerformanceHarvard Memory ArchitectureHarvard Memory Architecture
For a CPU with separate level one (L1) caches for instructions
and data (Harvard memory architecture) and no stalls for
cache hits:CPUtime = Instruction count x CPI x Clock cycle time
CPI = CPIexecution + Mem Stall cycles per instruction
CPUtime = Instruction Count x (CPIexecution +
Mem Stall cycles per instruction) x Clock cycle time
Mem Stall cycles per instruction = Instruction Fetch Miss rate x Miss Penalty + Data Memory Accesses Per Instruction x Data Miss Rate x Miss Penalty

EECC550 - ShaabanEECC550 - Shaaban#80 Final Review Summer 2001 8-10-2001
Cache Performance ExampleCache Performance Example• Suppose a CPU executes at Clock Rate = 200 MHz (5 ns per cycle) with a
single level of cache.
• CPIexecution = 1.1
• Instruction mix: 50% arith/logic, 30% load/store, 20% control• Assume a cache miss rate of 1.5% and a miss penalty of 50 cycles.
CPI = CPIexecution + mem stalls per instruction
Mem Stalls per instruction =
Mem accesses per instruction x Miss rate x Miss penalty
Mem accesses per instruction = 1 + .3 = 1.3
Mem Stalls per instruction = 1.3 x .015 x 50 = 0.975
CPI = 1.1 + .975 = 2.075
The ideal CPU with no misses is 2.075/1.1 = 1.88 times faster
Instruction fetch Load/store

EECC550 - ShaabanEECC550 - Shaaban#81 Final Review Summer 2001 8-10-2001
Cache Performance ExampleCache Performance Example• Suppose for the previous example we double the clock rate to
400 MHZ, how much faster is this machine, assuming similar miss rate, instruction mix?
• Since memory speed is not changed, the miss penalty takes more CPU cycles:
Miss penalty = 50 x 2 = 100 cycles.
CPI = 1.1 + 1.3 x .015 x 100 = 1.1 + 1.95 = 3.05
Speedup = (CPIold x Cold)/ (CPInew x Cnew)
= 2.075 x 2 / 3.05 = 1.36
The new machine is only 1.36 times faster rather than 2 times faster due to the increased effect of cache misses.
CPUs with higher clock rate, have more cycles per cache miss and more
memory impact on CPI

EECC550 - ShaabanEECC550 - Shaaban#82 Final Review Summer 2001 8-10-2001
2 Levels of Cache: L2 Levels of Cache: L11, L, L22
CPU
L1 Cache
L2 Cache
Main Memory
Hit Rate= H1, Hit time = 1 cycle (No Stall)
Hit Rate= H2, Hit time = T2 cycles
Memory access penalty, M

EECC550 - ShaabanEECC550 - Shaaban#83 Final Review Summer 2001 8-10-2001
2-Level Cache Performance 2-Level Cache Performance Memory Access TreeMemory Access Tree
CPU Stall Cycles Per Memory AccessCPU Stall Cycles Per Memory Access
CPU Memory Access
L1 Miss: % = (1-H1)
L1 Hit:Stalls= H1 x 0 = 0(No Stall)
L2 Miss: Stalls= (1-H1)(1-H2) x M
L2 Hit:(1-H1) x H2 x T2
Stall cycles per memory access = (1-H1) x H2 x T2 + (1-H1)(1-H2) x MCPUtime = IC x (CPIexecution + Mem Stall cycles per instruction) x C
Mem Stall cycles per instruction = Mem accesses per instruction x Stall cycles per access
L1
L2

EECC550 - ShaabanEECC550 - Shaaban#84 Final Review Summer 2001 8-10-2001
Two-Level Cache ExampleTwo-Level Cache Example• CPU with CPIexecution = 1.1 running at clock rate = 500 MHZ
• 1.3 memory accesses per instruction.• L1 cache operates at 500 MHZ with a miss rate of 5%
• L2 cache operates at 250 MHZ with miss rate 3%, (T2 = 2 cycles)
• Memory access penalty, M = 100 cycles. Find CPI.
CPI = CPIexecution + Mem Stall cycles per instruction
With No Cache, CPI = 1.1 + 1.3 x 100 = 131.1
With single L1, CPI = 1.1 + 1.3 x .05 x 100 = 7.6Mem Stall cycles per instruction = Mem accesses per instruction x Stall cycles per access
Stall cycles per memory access = (1-H1) x H2 x T2 + (1-H1)(1-H2) x M
= .05 x .97 x 2 + .05 x .03 x 100
= .097 + .15 = .247Mem Stall cycles per instruction = Mem accesses per instruction x Stall cycles per access
= .247 x 1.3 = .32
CPI = 1.1 + .32 = 1.42
Speedup = 7.6/1.42 = 5.35

EECC550 - ShaabanEECC550 - Shaaban#85 Final Review Summer 2001 8-10-2001
Memory Bandwidth Improvement TechniquesMemory Bandwidth Improvement Techniques
• Wider Main Memory: Memory width is increased to a number of words (usually the size of
a second level cache block). Memory bandwidth is proportional to memory width.
e.g Doubling the width of cache and memory doubles
memory bandwidth
• Simple Interleaved Memory: Memory is organized as a number of banks each one word wide.
– Simultaneous multiple word memory reads or writes are accomplished by sending memory addresses to several memory banks at once.
– Interleaving factor: Refers to the mapping of memory addressees to memory banks.
e.g. using 4 banks, bank 0 has all words whose address is:
(word address) (mod) 4 = 0

EECC550 - ShaabanEECC550 - Shaaban#86 Final Review Summer 2001 8-10-2001
Three examples of bus width, memory width, and memory interleaving to achieve higher memory bandwidth
Narrow busand cachewithinterleaved memory
Wider memory, busand cache
Simplest design:Everything is the width of one word

EECC550 - ShaabanEECC550 - Shaaban#87 Final Review Summer 2001 8-10-2001
Memory InterleavingMemory Interleaving

EECC550 - ShaabanEECC550 - Shaaban#88 Final Review Summer 2001 8-10-2001
Memory Width, Interleaving: An ExampleMemory Width, Interleaving: An ExampleGiven a base system with following parameters:
Cache Block size = 1 word, Memory bus width = 1 word, Miss rate = 3%
Miss penalty = 32 cycles, broken down as follows:
(4 cycles to send address, 24 cycles access time/word, 4 cycles to send a word)
Memory access/instruction = 1.2 Ideal execution CPI (ignoring cache misses) = 2
Miss rate (block size=2 word) = 2% Miss rate (block size=4 words) = 1%
• The CPI of the base machine with 1-word blocks = 2 + (1.2 x .03 x 32) = 3.15
• Increasing the block size to two words gives the following CPI:
– 32-bit bus and memory, no interleaving = 2 + (1.2 x .02 x 2 x 32) = 3.54
– 32-bit bus and memory, interleaved = 2 + (1.2 x .02 x (4 + 24 + 8) = 2.86
– 64-bit bus and memory, no interleaving = 2 + (1.2 x .02 x 1 x 32) = 2.77
• Increasing the block size to four words; resulting CPI:
– 32-bit bus and memory, no interleaving = 2 + (1.2 x 1% x 4 x 32) = 3.54
– 32-bit bus and memory, interleaved = 2 + (1.2 x 1% x (4 +24 + 16) = 2.53
– 64-bit bus and memory, no interleaving = 2 + (1.2 x 1% x 2 x 32) = 2.77


















