
EDMA3 Keystone SoC Devices. Agenda What is DMA? EDMA Architecture Definition of EDMA3 Terminology...
56
Multicore Training EDMA3 Keystone SoC Devices
-
Upload
godfrey-jennings -
Category
Documents
-
view
213 -
download
0
Transcript of EDMA3 Keystone SoC Devices. Agenda What is DMA? EDMA Architecture Definition of EDMA3 Terminology...

Multicore Training
EDMA3 Keystone SoC Devices

Multicore Training
Agenda• What is DMA?• EDMA Architecture• Definition of EDMA3 Terminology• Synchronization• Indexing• Example to Summarize• Trigger Mechanisms• Action Mechanisms• Linking• Chaining• QDMA• EDMA3 LLD Review

Multicore Training
What is DMA?• What is DMA?• EDMA Architecture• Definition of EDMA3 Terminology• Synchronization• Indexing• Example to Summarize• Trigger Mechanisms• Action Mechanisms• Linking• Chaining• QDMA• EDMA3 LLD Review

Multicore Training
Why Use DMA?
D0D1D2D3
buf_0
buf_1
• The primary function of DMA is to move data without direct CPU involvement.
• What information does a DMA controller need to perform a transfer? Source address Destination address Length (or size)
• What options might be useful to perform the transfer? Do you want to interrupt the CPU when the transfer is complete? Is this transfer synchronized to an event (like the McBSP RCV buffer is full)? How do the source and destination addresses update? (same, +1, -1, +4 ?)

Multicore Training
DMA in KeyStone DevicesThere are MANY forms of DMA (Direct Memory Access) in the KeyStone Architecture.
• EDMA3 – Enhanced DMA handles M DMA CHs and X QDMA CHs DMA – M Channels that can be triggered manually or by events/chaining QDMA – X channels of Quick DMA triggered by writing to a trigger word
• IDMA – 2 CHs of Internal DMA (Periph Cfg, Xfr L1 ↔ L2)
• Peripheral DMAs – Each master device hooked to the TeraNet has its own DMA (PktDMA) (e.g. SRIO, EMAC, etc.)
Ch0L1DL2 PERIPH Ch1L1 L2
IDMA
Q0Q1Q2Qn
TC0TC1TC2TCn
TeraNet
QDMA
EVTxChain
Manual
EDMA3
DMA
Trigger Word
Resourcesconnectedto TeraNet

Multicore Training
EDMA Architecture• What is DMA?• EDMA Architecture• Definition of EDMA3 Terminology• Synchronization• Indexing• Example to Summarize• Trigger Mechanisms• Action Mechanisms• Linking• Chaining• QDMA• EDMA3 LLD Review

Multicore Training
EDMA3 ArchitectureEvt Reg (ER)
Chain Evt Reg(CER)
Evt Enable Reg(EER)
Evt Set Reg(ESR)
Q0
Q1
Q2
Qm
QueuePSET 0PSET 1
PSET X
TRSubmit
CompletionDetection
Int Pending Reg – IPR
Int Enable Reg – IER
TC0
TC1
TC2
TCm
TCCC
..
. EarlyTCC
NormalTCC
E0E1EnD
ata TeraNet
Global Interrupt & Region
Interrupt (0-n)
Memory Protection

Multicore Training
Shadow Regions and Memory Protection
• Multi-level protection:
Regions restrict access to the channels from the peripheral masters.
Memory Protection provides restricted access to different memory
spaces within the device.
• Each region has a copy of the channel configuration registers to configure
the channels allocated to the specific region (DRAEn and DRAEHn, QRAEn).
• In addition to the shadow regions, there is a global region access to the
Channel Controller.
• Memory protection is provided by setting the privilege level, requestor, and
types of access allowed for each region (MPPAn and MPPAG).
• Each shadow region is also associated with a completion interrupt that can
be tied to different interrupt events.

Multicore Training
Shadow Region

Multicore Training
Definition of EDMA3 Terminology• What is DMA?• EDMA Architecture• Definition of EDMA3 Terminology• Synchronization• Indexing• Example to Summarize• Trigger Mechanisms• Action Mechanisms• Linking• Chaining• QDMA• EDMA3 LLD Review

Multicore Training
Direct Memory Access (DMA)• Copy from memory to memory – HARDWARE memcpy(dst, src, len);• Faster than CPU LD/ST. One INT per block vs. one INT per sample
• Import raw data from off-chip to on-chip before processing.• Export results from on-chip to off-chip afterward.
• Transfer Configuration (i.e., Parameter Set - aka PaRAM or PSET)• Transfer configuration primarily includes 8 control registers.
Goal :
Examples :
Controlled by :
Original DataBlock
Copied DataBlock
DMA
TransferConfiguration
SourceACNT
DestinationBCNTLength
Multicore Training
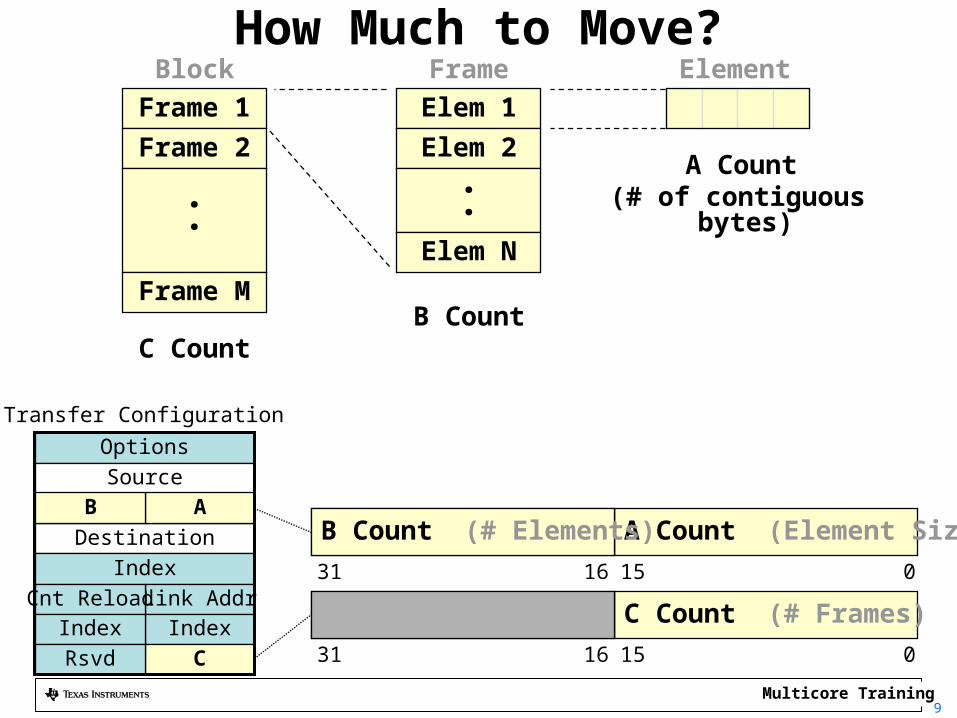
How Much to Move?Element
(# of contiguous bytes)
A Count (Element Size)015
OptionsSource
DestinationIndex
Link AddrCnt Reload
Transfer Count
A Count
1631
B Count (# Elements)
Elem 1Elem 2
Elem N
Frame
.
.
B Count
IndexIndexCRsvd
Frame 1Frame 2
Frame M
Block
..
C Count
C Count (# Frames)0151631
AB
Transfer Configuration
9
Multicore Training
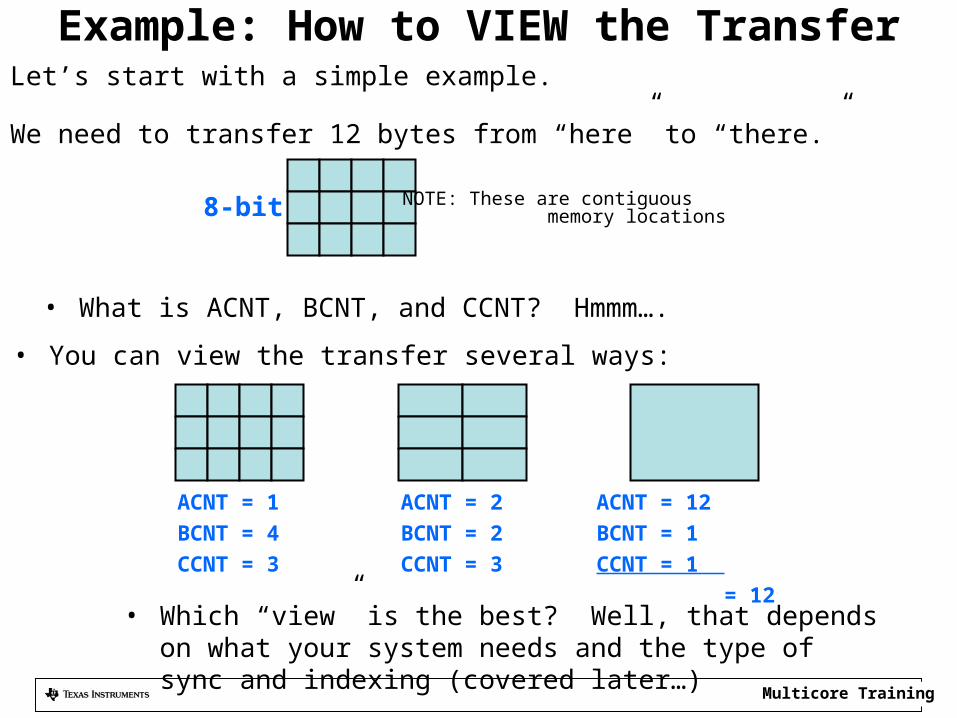
Example: How to VIEW the Transfer
ACNT = 2BCNT = 2 CCNT = 3
ACNT = 1BCNT = 4 CCNT = 3
ACNT = 12BCNT = 1 CCNT = 1 = 12
8-bit
• Let’s start with a simple example.
• We need to transfer 12 bytes from “here” to “there.”
• What is ACNT, BCNT, and CCNT? Hmmm….
• You can view the transfer several ways:
• Which “view” is the best? Well, that depends on what your system needs and the type of sync and indexing (covered later…)
NOTE: These are contiguous memory locations

Multicore Training
Synchronization• What is DMA?• EDMA Architecture• Definition of EDMA3 Terminology• Synchronization• Indexing• Example to Summarize• Trigger Mechanisms• Action Mechanisms• Linking• Chaining• QDMA• EDMA3 LLD Review
Multicore Training
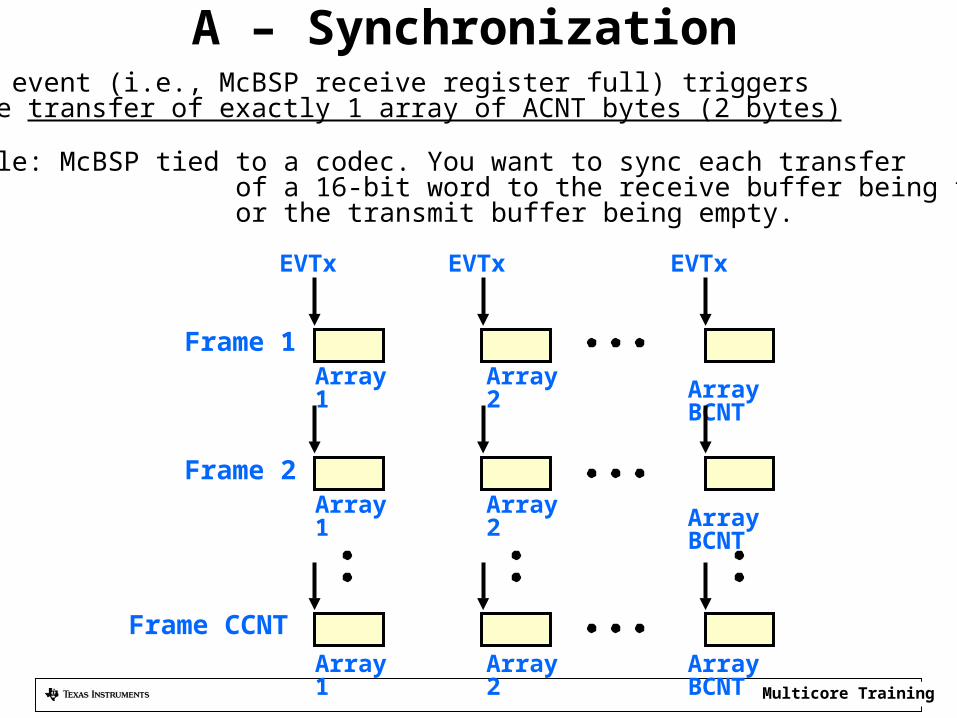
A – Synchronization • An event (i.e., McBSP receive register full) triggers
the transfer of exactly 1 array of ACNT bytes (2 bytes)
• Example: McBSP tied to a codec. You want to sync each transfer of a 16-bit word to the receive buffer being full or the transmit buffer being empty.
Frame 1Array1 Array2 Array BCNT
Frame 2Array1 Array2 Array BCNT
Frame CCNTArray1 Array2 Array BCNT
EVTx EVTx EVTx

Multicore Training
AB – Synchronization • An event triggers a two-dimensional transfer of BCNT arrays
of ACNT bytes (A*B).
• Example: Line of video pixels; Each line has BCNT pixels consisting of 3 bytes each – Y, Cb, Cr
Frame 1Array1 Array2 Array BCNT
Frame 2Array1 Array2 Array BCNT
Frame CCNTArray1 Array2 Array BCNT
EVTx

Multicore Training
Indexing• What is DMA?• EDMA Architecture• Definition of EDMA3 Terminology• Synchronization• Indexing• Example to Summarize• Trigger Mechanisms• Action Mechanisms• Linking• Chaining• QDMA• EDMA3 LLD Review

Multicore Training
Indexing: ‘BIDX, ‘CIDX • EDMA3 has two types of indexing: ‘BIDX and ‘CIDX
• Each index can be set separately for SRC and DST (next slide…)
• ‘BIDX = index in bytes between ACNT arrays (same for A-sync and AB-sync)
• ‘CIDX = index in bytes between BCNT frames (different for A-sync vs. AB-sync)
• ‘BIDX/’CIDX: signed 16-bit, -32768 to +32767
• CIDX distance is calculated from the starting address of the previouslytransferred block (array for A-sync, frame for AB-sync) to the next frame tobe transferred.
. .EVTx EVTx EVTx
. .
‘BIDX‘CIDXA
A-Sync
. .EVTx
. .
‘BIDXCIDXAB
AB-Sync

Multicore Training
Indexed Transfers
1 3
9 115 7
13 15
1 3
5 7
9 11
EDMA3 has 4 indexes allowing higher flexibility forcomplex transfers:• SRCBIDX = # bytes between arrays (Ex: SRCBIDX = 2)• SRCCIDX = # bytes between frames (Ex: SRCCIDXA = 2, SRCCIDXAB = 4)• Note: ‘CIDX depends on the synchronization used – “A” or “AB”• DSTBIDX = # bytes between arrays (Ex: DSTBIDX = 3)• DSTCIDX = # bytes between frames (Ex: DSTCIDXA = 5, DSTCIDXAB = 8)
SRC (8-bit)
DST (8-bit)
SRCBIDX
SRCCIDXA
DSTBIDX
DSTCIDXA
(contiguous)
(contiguous)

Multicore Training
Example: Using Indexing
ACNT = 2BCNT = 2 CCNT = 3
ACNT = 1BCNT = 4 CCNT = 3
ACNT = 12BCNT = 1 CCNT = 1
8-bit
• Remember this example? For each “view”, fillin the proper SOURCE index values:
• Which “view” is the best? Well, that depends on what you are transferring from/to and which sync mode is used.
‘BIDX = 1
‘CIDXA = 1
‘CIDXAB = 4
‘BIDX = 2
‘CIDXA = 2
‘CIDXAB = 4
‘BIDX = N/A
‘CIDXA = N/A
‘CIDXAB = N/A
NOTE: These are contiguous memory locations

Multicore Training
Example to Summarize• What is DMA?• EDMA Architecture• Definition of EDMA3 Terminology• Synchronization• Indexing• Example to Summarize• Trigger Mechanisms• Action Mechanisms• Linking• Chaining• QDMA• EDMA3 LLD Review

Multicore Training
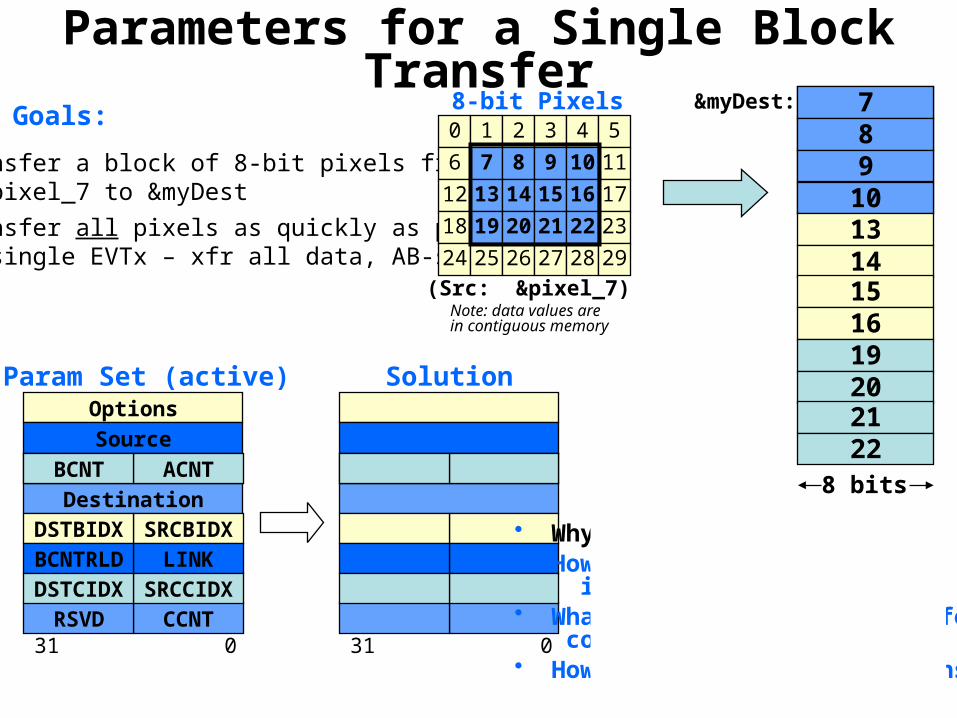
Parameters for a Single Block Transfer&myDest:
8 bits
89
1011
789
10• Transfer a block of 8-bit pixels from
&pixel_7 to &myDest• Transfer all pixels as quickly as possible
(single EVTx – xfr all data, AB-sync)
31 0
OptionsSource
Destination
CCNTRSVD
ACNTBCNT
SRCBIDXDSTBIDXLINKBCNTRLD
SRCCIDXDSTCIDX
1314151619202122
0 1 2 3 4 56 7 8 9 10 11
12 13 14 15 16 1718 19 20 21 22 2324 25 26 27 28 29
8-bit Pixels
(Src: &pixel_7)
Goals:
31 0
Options
&pixel_7
&myDest
1RSVD
43
640xFFFF (later)= BCNT
00
SolutionParam Set (active)
• Why can’t we use ACNT=1?• How does this transfer work
inside the EDMA?• What happens when the transfer
completes?• How do you program this transfer?
Note: data values arein contiguous memory
Multicore Training
Parameters for a Single Block Transfer&myDest:
8 bits
89
1011
789
10• Transfer a block of 8-bit pixels from
&pixel_7 to &myDest• Transfer all pixels as quickly as possible
(single EVTx – xfr all data, AB-sync)
31 0
OptionsSource
Destination
CCNTRSVD
ACNTBCNT
SRCBIDXDSTBIDXLINKBCNTRLD
SRCCIDXDSTCIDX
1314151619202122
0 1 2 3 4 56 7 8 9 10 11
12 13 14 15 16 1718 19 20 21 22 2324 25 26 27 28 29
8-bit Pixels
(Src: &pixel_7)
Goals:
31 0
SolutionParam Set (active)
• Why can’t we use ACNT=1?• How does this transfer work
inside the EDMA?• What happens when the transfer
completes?• How do you program this transfer?
Note: data values arein contiguous memory

Multicore Training
Parameters for a Single Block Transfer&myDest:
8 bits
89
1011
789
10• Transfer a block of 8-bit pixels from
&pixel_7 to &myDest• Transfer all pixels as quickly as possible
(single EVTx – xfr all data, AB-sync)
31 0
OptionsSource
Destination
CCNTRSVD
ACNTBCNT
SRCBIDXDSTBIDXLINKBCNTRLD
SRCCIDXDSTCIDX
1314151619202122
0 1 2 3 4 56 7 8 9 10 11
12 13 14 15 16 1718 19 20 21 22 2324 25 26 27 28 29
8-bit Pixels
(Src: &pixel_7)
Goals:
31 0
SolutionParam Set (active)
• Why can’t we use ACNT=1?• How does this transfer work
inside the EDMA?• What happens when the transfer
completes?• How do you program this transfer?
Note: data values arein contiguous memory

Multicore Training
Parameters for a Single Block Transfer&myDest:
8 bits
89
1011
789
10• Transfer a block of 8-bit pixels from
&pixel_7 to &myDest• Transfer all pixels as quickly as possible
(single EVTx – xfr all data, AB-sync)
31 0
OptionsSource
Destination
CCNTRSVD
ACNTBCNT
SRCBIDXDSTBIDXLINKBCNTRLD
SRCCIDXDSTCIDX
1314151619202122
0 1 2 3 4 56 7 8 9 10 11
12 13 14 15 16 1718 19 20 21 22 2324 25 26 27 28 29
8-bit Pixels
(Src: &pixel_7)
Goals:
31 0
AB-sync
1
43
SolutionParam Set (active)
• Why can’t we use ACNT=1?• How does this transfer work
inside the EDMA?• What happens when the transfer
completes?• How do you program this transfer?
Note: data values arein contiguous memory

Multicore Training
Parameters for a Single Block Transfer&myDest:
8 bits
89
1011
789
10• Transfer a block of 8-bit pixels from
&pixel_7 to &myDest• Transfer all pixels as quickly as possible
(single EVTx – xfr all data, AB-sync)
31 0
OptionsSource
Destination
CCNTRSVD
ACNTBCNT
SRCBIDXDSTBIDXLINKBCNTRLD
SRCCIDXDSTCIDX
1314151619202122
0 1 2 3 4 56 7 8 9 10 11
12 13 14 15 16 1718 19 20 21 22 2324 25 26 27 28 29
8-bit Pixels
(Src: &pixel_7)
Goals:
31 0
AB-sync
1
43
SolutionParam Set (active)
• Why can’t we use ACNT=1?• How does this transfer work
inside the EDMA?• What happens when the transfer
completes?• How do you program this transfer?
Note: data values arein contiguous memory

Multicore Training
Parameters for a Single Block Transfer&myDest:
8 bits
89
1011
789
10• Transfer a block of 8-bit pixels from
&pixel_7 to &myDest• Transfer all pixels as quickly as possible
(single EVTx – xfr all data, AB-sync)
31 0
OptionsSource
Destination
CCNTRSVD
ACNTBCNT
SRCBIDXDSTBIDXLINKBCNTRLD
SRCCIDXDSTCIDX
1314151619202122
0 1 2 3 4 56 7 8 9 10 11
12 13 14 15 16 1718 19 20 21 22 2324 25 26 27 28 29
8-bit Pixels
(Src: &pixel_7)
Goals:
31 0
AB-sync
43
SolutionParam Set (active)
• Why can’t we use ACNT=1?• How does this transfer work
inside the EDMA?• What happens when the transfer
completes?• How do you program this transfer?
Note: data values arein contiguous memory
1

Multicore Training
Parameters for a Single Block Transfer&myDest:
8 bits
89
1011
789
10• Transfer a block of 8-bit pixels from
&pixel_7 to &myDest• Transfer all pixels as quickly as possible
(single EVTx – xfr all data, AB-sync)
31 0
OptionsSource
Destination
CCNTRSVD
ACNTBCNT
SRCBIDXDSTBIDXLINKBCNTRLD
SRCCIDXDSTCIDX
1314151619202122
0 1 2 3 4 56 7 8 9 10 11
12 13 14 15 16 1718 19 20 21 22 2324 25 26 27 28 29
8-bit Pixels
(Src: &pixel_7)
Goals:
31 0
4
SolutionParam Set (active)
• Why can’t we use ACNT=1?• How does this transfer work
inside the EDMA?• What happens when the transfer
completes?• How do you program this transfer?
Note: data values arein contiguous memory
A-sync?

Multicore Training
Parameters for a Single Block Transfer&myDest:
8 bits
89
1011
789
10• Transfer a block of 8-bit pixels from
&pixel_7 to &myDest• Transfer all pixels as quickly as possible
(single EVTx – xfr all data, AB-sync)
31 0
OptionsSource
Destination
CCNTRSVD
ACNTBCNT
SRCBIDXDSTBIDXLINKBCNTRLD
SRCCIDXDSTCIDX
13 - 1114 - 1215 - 1316 - 1419 - 1520 - 1621 - 1722 - 18
0 1 2 3 4 56 7 8 9 10 11
12 13 14 15 16 1718 19 20 21 22 2324 25 26 27 28 29
8-bit Pixels
(Src: &pixel_7)
Goals:
31 0
12
SolutionParam Set (active)
• Why can’t we use ACNT=1?• How does this transfer work
inside the EDMA?• What happens when the transfer
completes?• How do you program this transfer?
Note: data values arein contiguous memory
A-sync?

Multicore Training
Parameters for a Single Block Transfer&myDest:
8 bits
89
1011
789
10• Transfer a block of 8-bit pixels from
&pixel_7 to &myDest• Transfer all pixels as quickly as possible
(single EVTx – xfr all data, AB-sync)
31 0
OptionsSource
Destination
CCNTRSVD
ACNTBCNT
SRCBIDXDSTBIDXLINKBCNTRLD
SRCCIDXDSTCIDX
1314151619202122
0 1 2 3 4 56 7 8 9 10 11
12 13 14 15 16 1718 19 20 21 22 2324 25 26 27 28 29
8-bit Pixels
(Src: &pixel_7)
Goals:
31 0
AB-sync
1
43
SolutionParam Set (active)
• Why can’t we use ACNT=1?• How does this transfer work
inside the EDMA?• What happens when the transfer
completes?• How do you program this transfer?
Note: data values arein contiguous memory
&pixel_7
&myDest

Multicore Training
Parameters for a Single Block Transfer&myDest:
8 bits
89
1011
789
10• Transfer a block of 8-bit pixels from
&pixel_7 to &myDest• Transfer all pixels as quickly as possible
(single EVTx – xfr all data, AB-sync)
31 0
OptionsSource
Destination
CCNTRSVD
ACNTBCNT
SRCBIDXDSTBIDXLINKBCNTRLD
SRCCIDXDSTCIDX
1314151619202122
0 1 2 3 4 56 7 8 9 10 11
12 13 14 15 16 1718 19 20 21 22 2324 25 26 27 28 29
8-bit Pixels
(Src: &pixel_7)
Goals:
31 0
AB-sync
1
43
SolutionParam Set (active)
• Why can’t we use ACNT=1?• How does this transfer work
inside the EDMA?• What happens when the transfer
completes?• How do you program this transfer?
Note: data values arein contiguous memory
&pixel_7
&myDest
6

Multicore Training
Parameters for a Single Block Transfer&myDest:
8 bits
89
1011
789
10• Transfer a block of 8-bit pixels from
&pixel_7 to &myDest• Transfer all pixels as quickly as possible
(single EVTx – xfr all data, AB-sync)
31 0
OptionsSource
Destination
CCNTRSVD
ACNTBCNT
SRCBIDXDSTBIDXLINKBCNTRLD
SRCCIDXDSTCIDX
1314151619202122
0 1 2 3 4 56 7 8 9 10 11
12 13 14 15 16 1718 19 20 21 22 2324 25 26 27 28 29
8-bit Pixels
(Src: &pixel_7)
Goals:
31 0
AB-sync
1
43
SolutionParam Set (active)
• Why can’t we use ACNT=1?• How does this transfer work
inside the EDMA?• What happens when the transfer
completes?• How do you program this transfer?
Note: data values arein contiguous memory
&pixel_7
&myDest64
Multicore Training
Parameters for a Single Block Transfer&myDest:
8 bits
89
1011
789
10• Transfer a block of 8-bit pixels from
&pixel_7 to &myDest• Transfer all pixels as quickly as possible
(single EVTx – xfr all data, AB-sync)
31 0
OptionsSource
Destination
CCNTRSVD
ACNTBCNT
SRCBIDXDSTBIDXLINKBCNTRLD
SRCCIDXDSTCIDX
1314151619202122
0 1 2 3 4 56 7 8 9 10 11
12 13 14 15 16 1718 19 20 21 22 2324 25 26 27 28 29
8-bit Pixels
(Src: &pixel_7)
Goals:
31 0
AB-sync
1
43
00
SolutionParam Set (active)
• Why can’t we use ACNT=1?• How does this transfer work
inside the EDMA?• What happens when the transfer
completes?• How do you program this transfer?
Note: data values arein contiguous memory
&pixel_7
&myDest64
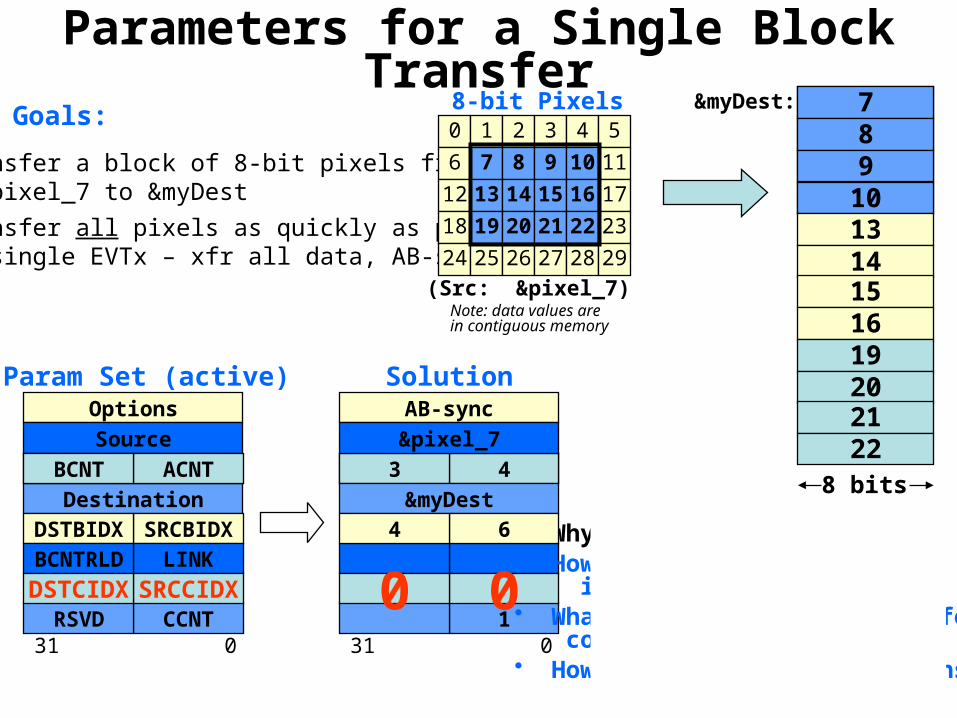
Multicore Training
Parameters for a Single Block Transfer&myDest:
8 bits
89
1011
789
10• Transfer a block of 8-bit pixels from
&pixel_7 to &myDest• Transfer all pixels as quickly as possible
(single EVTx – xfr all data, AB-sync)
31 0
OptionsSource
Destination
CCNTRSVD
ACNTBCNT
SRCBIDXDSTBIDXLINKBCNTRLD
SRCCIDXDSTCIDX
1314151619202122
0 1 2 3 4 56 7 8 9 10 11
12 13 14 15 16 1718 19 20 21 22 2324 25 26 27 28 29
8-bit Pixels
(Src: &pixel_7)
Goals:
31 0
AB-sync
1
43
BCNT or any00
SolutionParam Set (active)
• Why can’t we use ACNT=1?• How does this transfer work
inside the EDMA?• What happens when the transfer
completes?• How do you program this transfer?
Note: data values arein contiguous memory
&pixel_7
&myDest64

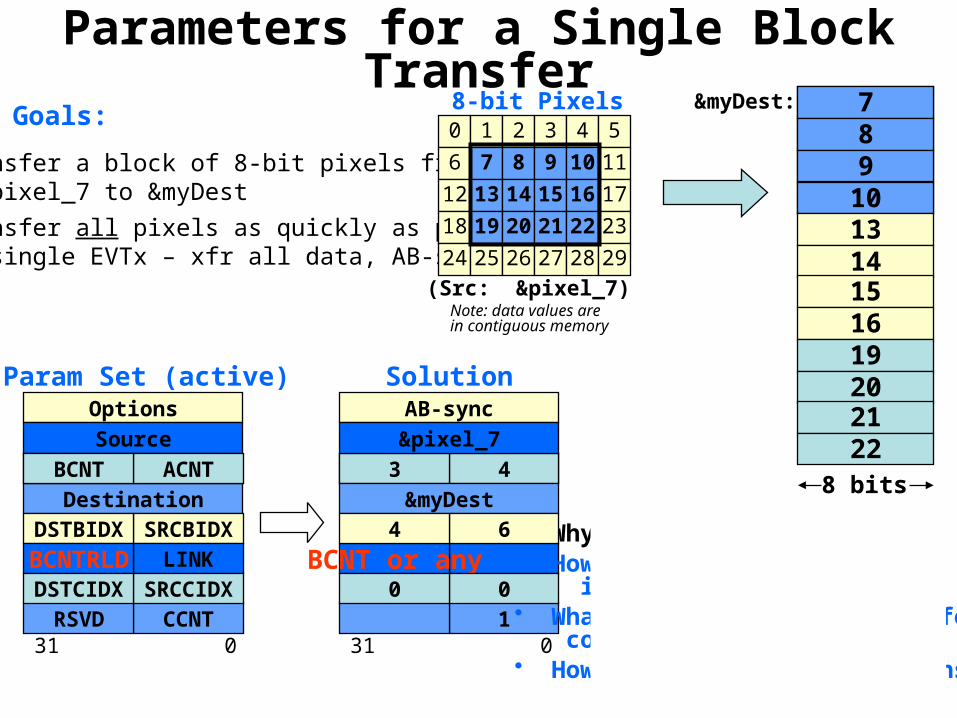
Multicore Training
Parameters for a Single Block Transfer&myDest:
8 bits
89
1011
789
10• Transfer a block of 8-bit pixels from
&pixel_7 to &myDest• Transfer all pixels as quickly as possible
(single EVTx – xfr all data, AB-sync)
31 0
OptionsSource
Destination
CCNTRSVD
ACNTBCNT
SRCBIDXDSTBIDX
LINKBCNTRLDSRCCIDXDSTCIDX
1314151619202122
0 1 2 3 4 56 7 8 9 10 11
12 13 14 15 16 1718 19 20 21 22 2324 25 26 27 28 29
8-bit Pixels
(Src: &pixel_7)
Goals:
31 0
AB-sync
1
43
0xffff300
SolutionParam Set (active)
• Why can’t we use ACNT=1?• How does this transfer work
inside the EDMA?• What happens when the transfer
completes?• How do you program this transfer?
Note: data values arein contiguous memory
&pixel_7
&myDest64

Multicore Training
Parameters for a Single Block Transfer&myDest:
8 bits
89
1011
789
10• Transfer a block of 8-bit pixels from
&pixel_7 to &myDest• Transfer all pixels as quickly as possible
(single EVTx – xfr all data, AB-sync)
31 0
OptionsSource
Destination
CCNTRSVD
ACNTBCNT
SRCBIDXDSTBIDXLINKBCNTRLD
SRCCIDXDSTCIDX
1314151619202122
0 1 2 3 4 56 7 8 9 10 11
12 13 14 15 16 1718 19 20 21 22 2324 25 26 27 28 29
8-bit Pixels
(Src: &pixel_7)
Goals:
31 0
AB-sync
1
43
0xffff300
SolutionParam Set (active)
• Why can’t we use ACNT=1?• How does this transfer work
inside the EDMA?• What happens when the transfer
completes?• How do you program this transfer?
Note: data values arein contiguous memory
&pixel_7
&myDest64

Multicore Training
Channel OPTions Register• The Options register contains bit fields that configure how the channel operates.• Each field has a corresponding description in the Param Setup code comments.
• TCC = Transfer Complete Code to signal completion
• SYNCDIM = A-sync or AB-sync
• PRIV = Privilege level of the host that can program the PSET
• PRIVID = Privilege ID of the host that program the PSET
• ITCCHEN = Intermediate Transfer Completion Chaining Enable
• TCCHEN = Transfer Completion Chaining Enable
• ITCINTEN = Intermediate Transfer Completion Interrupt Enable
• TCINTEN = Transfer Completion Interrupt Enable
• TCC = Transfer Completion Code
• TCCMODE = Point at which the transfer is considered to be complete.
• SAM = Source Address Mode
• DAM = Desitination Address Mode
• FWID = FIFO Width
• STATIC = Option to enable changing PSET

Multicore Training
Trigger Mechanisms• What is DMA?• EDMA Architecture• Definition of EDMA3 Terminology• Synchronization• Indexing• Example to Summarize• Trigger Mechanisms• Action Mechanisms• Linking• Chaining• QDMA• EDMA3 LLD Review

Multicore Training
EDMA3 Basics Revisited
• Event:Triggers the transfer to begin• Transfer: The transfer config describes the transfers to be executed when triggered.• Resulting Action: What do you want to happen after the transfer is complete?
• Count: How many items to move• A, B, and C counts
• Addresses: The source & destination addresses• Index: How far to increment the src/dst after each transfer
1 2 3 4 5 67 12
13 14 15 16 17 1819 20 21 22 23 2425 26 27 28 29 30
8 9 10 118 9 10 11
T(xfer config)
E(event)
Done
A(action)
OptionsSource
DestinationIndex
Link AddrCnt Reload
Transfer Count
IndexIndexCRsvd
AB
T(xfer config)

Multicore Training
How to TRIGGER a Transfer There are 3 ways to trigger an EDMA transfer:
1 Event Sync from peripheral
SPIREVTSPIXEVT
SPI EDMA3
ER EER Start Ch Xfr
2 Manually trigger the channel to run
Application Channel y
ESR Start Ch XfrSet Ch #y;
ER = Event Register (flag)EER = Event Enable Register (user)
ESR = Event Set Register (user)
3 Chain event from another channel (more details later…)
Channel x Channel y
CER Start Ch XfrTCCHEN_EN
TCC = Chy
TCCHEN = TC Chain Enable (OPT)
28

Multicore Training
Action Mechanisms• What is DMA?• EDMA Architecture• Definition of EDMA3 Terminology• Synchronization• Indexing• Example to Summarize• Trigger Mechanisms• Action Mechanisms• Linking• Chaining• QDMA• EDMA3 LLD Review
Multicore Training
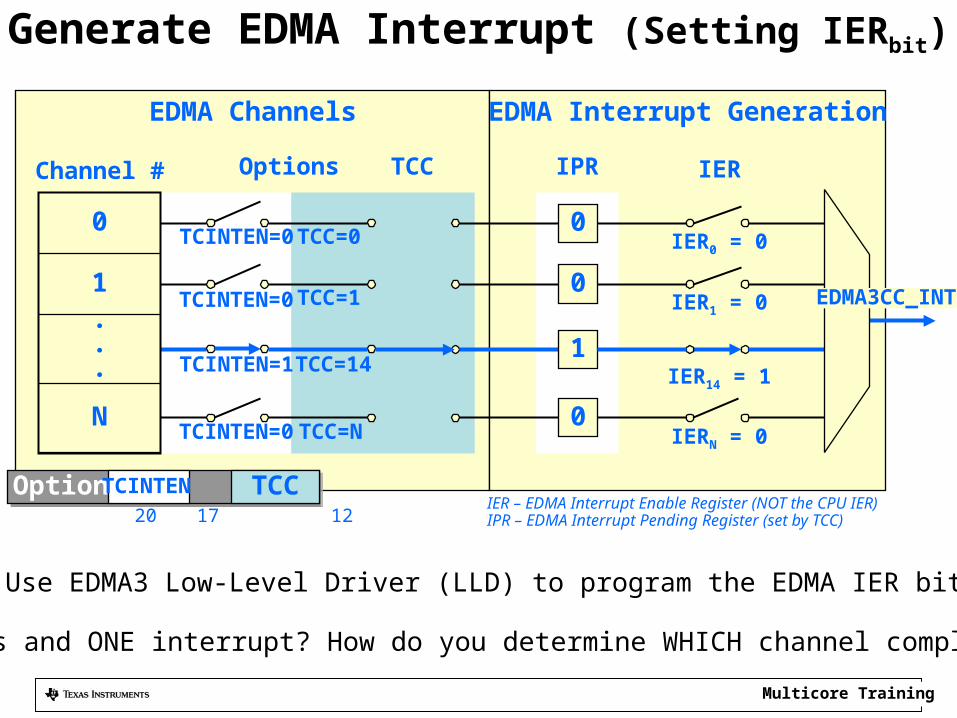
Generate EDMA Interrupt (Setting IERbit)
EDMA Channels
Channel #
TCINTEN=0
TCINTEN=0
TCINTEN=1
TCINTEN=0
TCC=0
TCC=1
TCC=14
TCC=NN
.
.
.
1
0
Options
OptionsOptions TCCTCINTEN20 17 12
EDMA Interrupt Generation
0
0
1
0
IPR
IER0 = 0
IER1 = 0
IER14 = 1
IERN = 0
IER
EDMA3CC_INT
TCC
• Use EDMA3 Low-Level Driver (LLD) to program the EDMA IER bits
IER – EDMA Interrupt Enable Register (NOT the CPU IER)IPR – EDMA Interrupt Pending Register (set by TCC)
N Channels and ONE interrupt? How do you determine WHICH channel completed?

Multicore Training
EDMA Interrupt DispatcherHere’s the interrupt chain from beginning to end:
Use EDMA3 LLD to program the proper callback fxn for this HWI.
EDMA3CC_GINT
2. Interrupt Selector
HWI_INT5
1. An interrupt occurs 3. HWI_INT5 Properties
4. EDMA Dispatcher Function
Read IPR bitsDetermine which one is setCall corresponding handler(ISR) in Fxn Table
5. ISR (interrupt handler)
void edma_rcv_isr (void)
{
SEM_post (&semaphore);
}
How does the ISR Fxn Table (in #4 above) get loaded with the proper handler Fxn names?

Multicore Training
Linking• What is DMA?• EDMA Architecture• Definition of EDMA3 Terminology• Synchronization• Indexing• Example to Summarize• Trigger Mechanisms• Action Mechanisms• Linking• Chaining• QDMA• EDMA3 LLD Review

Multicore Training
Linking – “Action” – Overview
T(xfer config)
E(event)
Done
A(action)
OptionsSource
DestinationIndex
Link AddrCnt Reload
Transfer Count
IndexIndexCRsvd
AB
T(xfer config)
• Need: auto-reload channel with new config Ex1: do the same transfer again Ex2: ping/pong system
• Solution: use linking to reload Ch config• Concept:
Linking two or more channels together allowsthe EDMA to auto-reload a new configurationwhen the current transfer is complete.
Linking still requires a “trigger” to start thetransfer (manual, chain, event).
You can link as many PSETs as you like – it is only limited by the #PSETs on a device.
How does linking work? User must specify the LINK field
in the config to link to another PSET. When the current xfr (0) is complete,
the EDMA auto reloads the newconfig (1) from the linked PSET.
1LINK
Config 0
NULLLINK
Config 1
reload
Alias: “Re-load” “Auto-init”
NOTE: Does NOT start transfer!!

Multicore Training
Chaining• What is DMA?• EDMA Architecture• Definition of EDMA3 Terminology• Synchronization• Indexing• Example to Summarize• Trigger Mechanisms• Action Mechanisms• Linking• Chaining• QDMA• EDMA3 LLD Review

Multicore Training
Triggering Transfers RevisitedThere are 3 ways to trigger an EDMA transfer:
1 Event sync from peripheral
RRDY
XRDY
McASP0 EDMA3
ER EER Start Ch Xfr
2 Manually trigger the channel to run
Application Channel y
ESR Start Ch XfrSet Ch #y;
ER = Event Register (flag)EER = Event Enable Register (user)
ESR = Event Set Register (user)
3 Chain event from another channel
Channel x Channel y
CER Start Ch XfrTCCHEN_EN
TCC = Chy
TCCHEN = TC Chain Enable (OPT)
Multicore Training
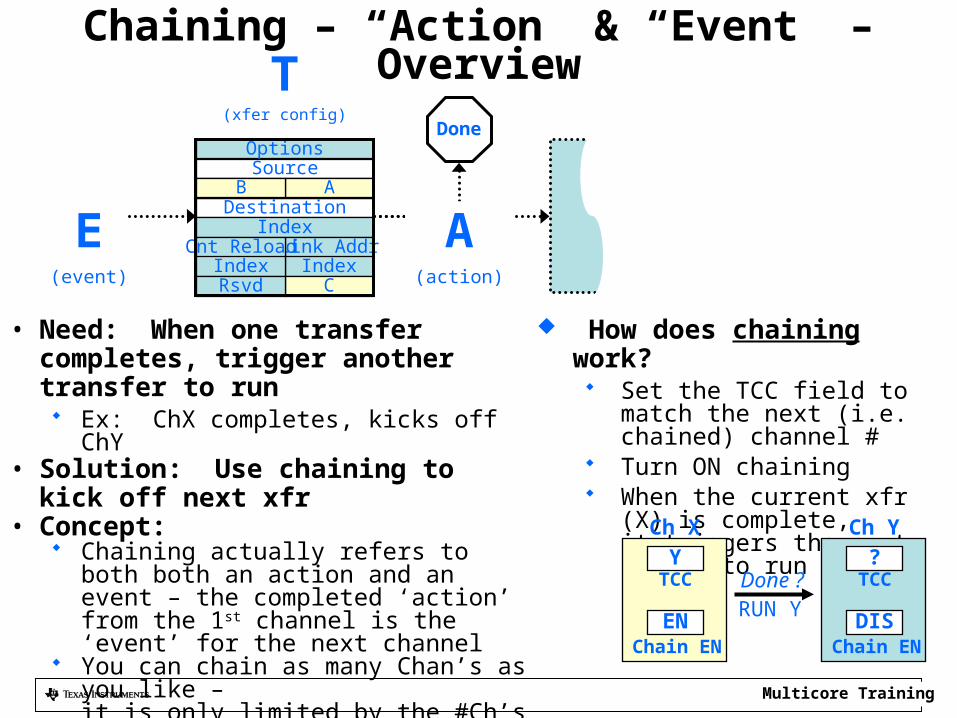
Chaining – “Action” & “Event” – Overview
T(xfer config)
E(event)
Done
A(action)
OptionsSource
DestinationIndex
Link AddrCnt Reload
Transfer Count
IndexIndexCRsvd
AB
T(xfer config)
• Need: When one transfer completes, trigger another transfer to run Ex: ChX completes, kicks off ChY
• Solution: Use chaining to kick off next xfr• Concept:
Chaining actually refers to both both an action and an event – the completed ‘action’ from the 1st channel is the ‘event’ for the next channel
You can chain as many Chan’s as you like – it is only limited by the #Ch’s on a device
Chaining does NOT reload current Chan config – that can only be accomplished by linking. It simply triggers another channel to run.
How does chaining work? Set the TCC field to match the
next (i.e. chained) channel # Turn ON chaining When the current xfr (X) is
complete,it triggers the next Ch (Y) to run
YTCC
Ch X
ENChain EN
?TCC
Ch Y
DISChain EN
Done ?RUN Y

Multicore Training
QDMA• What is DMA?• EDMA Architecture• Definition of EDMA3 Terminology• Synchronization• Indexing• Example to Summarize• Trigger Mechanisms• Action Mechanisms• Linking• Chaining• QDMA• EDMA3 LLD Review

Multicore Training
Quick DMA (QDMA)• QDMA is used for simple transfers where syncing to an event
is not required. Address/count updates and linking are notperformed. CCNT = 1 (single event transfer).
• A transfer can be triggered by two methods:(1) writing to a trigger word (2) using the EDMA3 LLD.
• It is “quick” because the CPU can initiate a transfer with asfew as ONE write to a channel register.
• How does it work?
QDMA channel is “auto-triggered” when CPU writes to the “trigger” word Eliminates the need to write to PSET and kick off transfer w/ separate write to ESR Selection of the trigger word allows CPU to modify only words of interest in a PSET Assumes OPT.STATIC = 1. Count and address updates and linking NOT performed.
• Example: If ACNT/BCNT/CCNT are typically static for a given algorithm, but SRC is different
for each transfer, then SRC could be defined as the trigger word. CPU can initiate atransfer with a single write to the SRC address for the specified PSET.

Multicore Training
QDMA Mapping

Multicore Training
EDMA3 LLD Review• What is DMA?• EDMA Architecture• Definition of EDMA3 Terminology• Synchronization• Indexing• Example to Summarize• Trigger Mechanisms• Action Mechanisms• Linking• Chaining• QDMA• EDMA3 LLD Review

Multicore Training
Programming EDMA3Low Level Driver (LLD) is optimal way to program EDMA3.• Implements synchronized DMA transfers• Consists of libraries to manage the EDMA3 peripheral:
Resource Manager (EDMA3 RM) manages all EDMA3 hardware resources and interrupts.
Driver (EDMA3 DRV) handles all EDMA3 configuration and allocating resources (via RM).
Application Code
(Drivers)
LLD
(DRV)Resource Mgr (RM)
EDMA3 Hardware

Multicore Training
Programming EDMA3• EDMA3_DRV_create(edma3InstanceId,
globalConfig&miscParam);
• hEdma = EDMA3_DRV_open (edma3InstanceId, (void *) &initCfg, &edma3Result);
• EDMA3_DRV_requestChannel (hEdma, nChannel, nTransferControl, ..);
• EDMA3_DRV_setSrcParams (hEdma, nChannel, Src Addr, Addrmode, width);
• EDMA3_DRV_setDestParams (hEdma, nChannel, DstAddr, Addrmode, width);
• EDMA3_DRV_setTransferParams (hEdma, nChannel, acnt, bcnt, ccnt, bbcntrld, syncType);
• EDMA3_DRV_enableTransfer (hEdma, nChannel, trgMode);

Multicore Training
Program Flow• Identify all the channels that are going to be used by
the application.
• Develop corresponding service routines for these events.
• Initialize all these ISR with the underlying OS.
• Initialize the Resource Manager to get all the available resources.
• Create and open the EDMA3 instance.
• Set the params for the transfers.
• Enable the transfer.

Multicore Training
For More Information
• Refer to the Enhanced Direct memory Access 3 (EDMA3) for KeyStone Devices User's Guide.
• Device-specific Data Manuals for the KeyStone SoCs can be found at TI.com/multicore.
• Multicore articles, tools, and software are available at Embedded Processors Wiki for the KeyStone Device Architecture.
• View the complete C66x Multicore SOC Online Training for KeyStone Devices, including details on the individual modules.
• For questions regarding topics covered in this training, visit the support forums at theTI E2E Community website.


















